
Constraints on Bit Precision and Row Parallelism for Reliable Computing-in-Memory


Abstract
1. Introduction
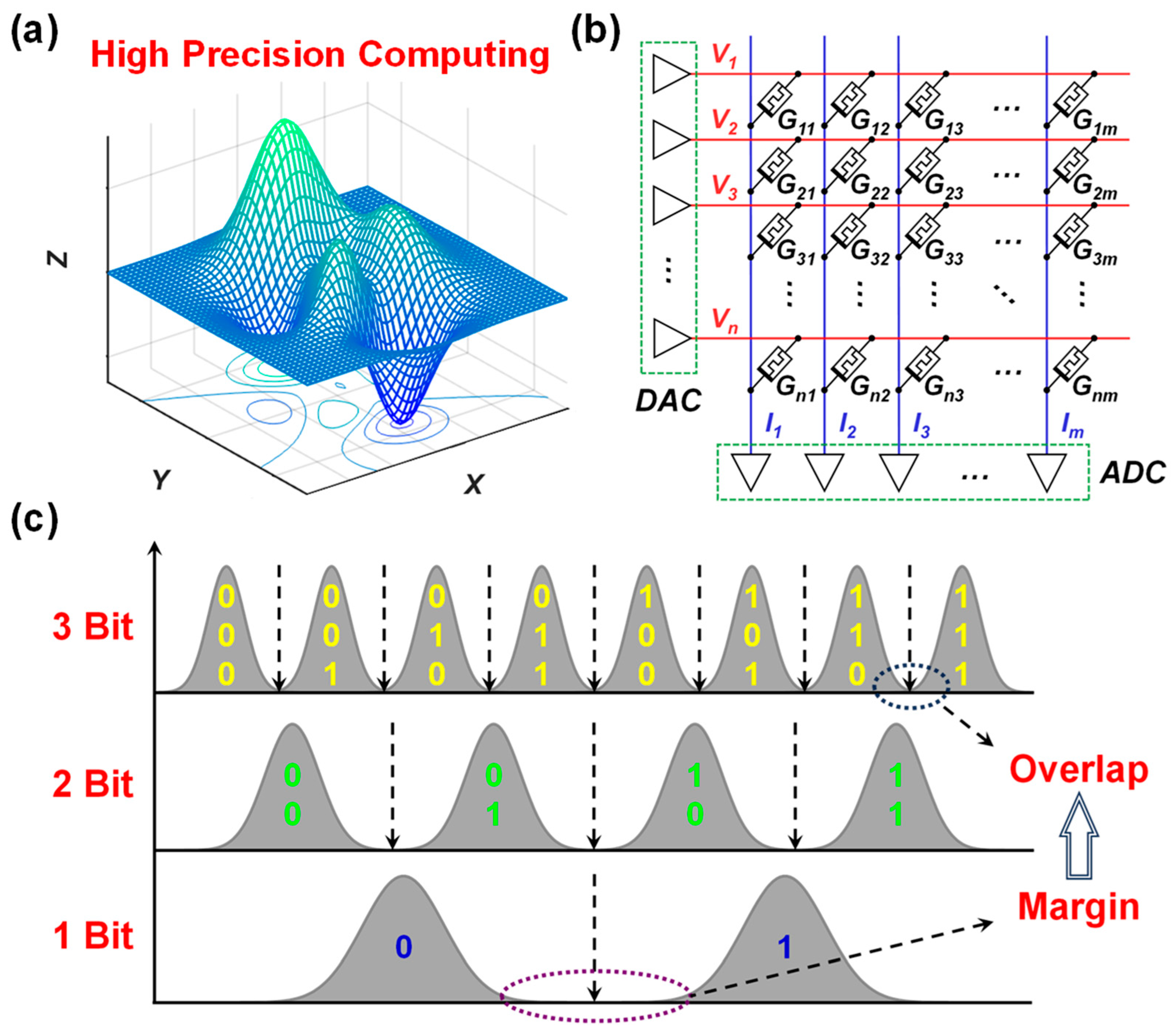
2. MVM Product Result Precision Model
2.1. Definition of Physical Quantities
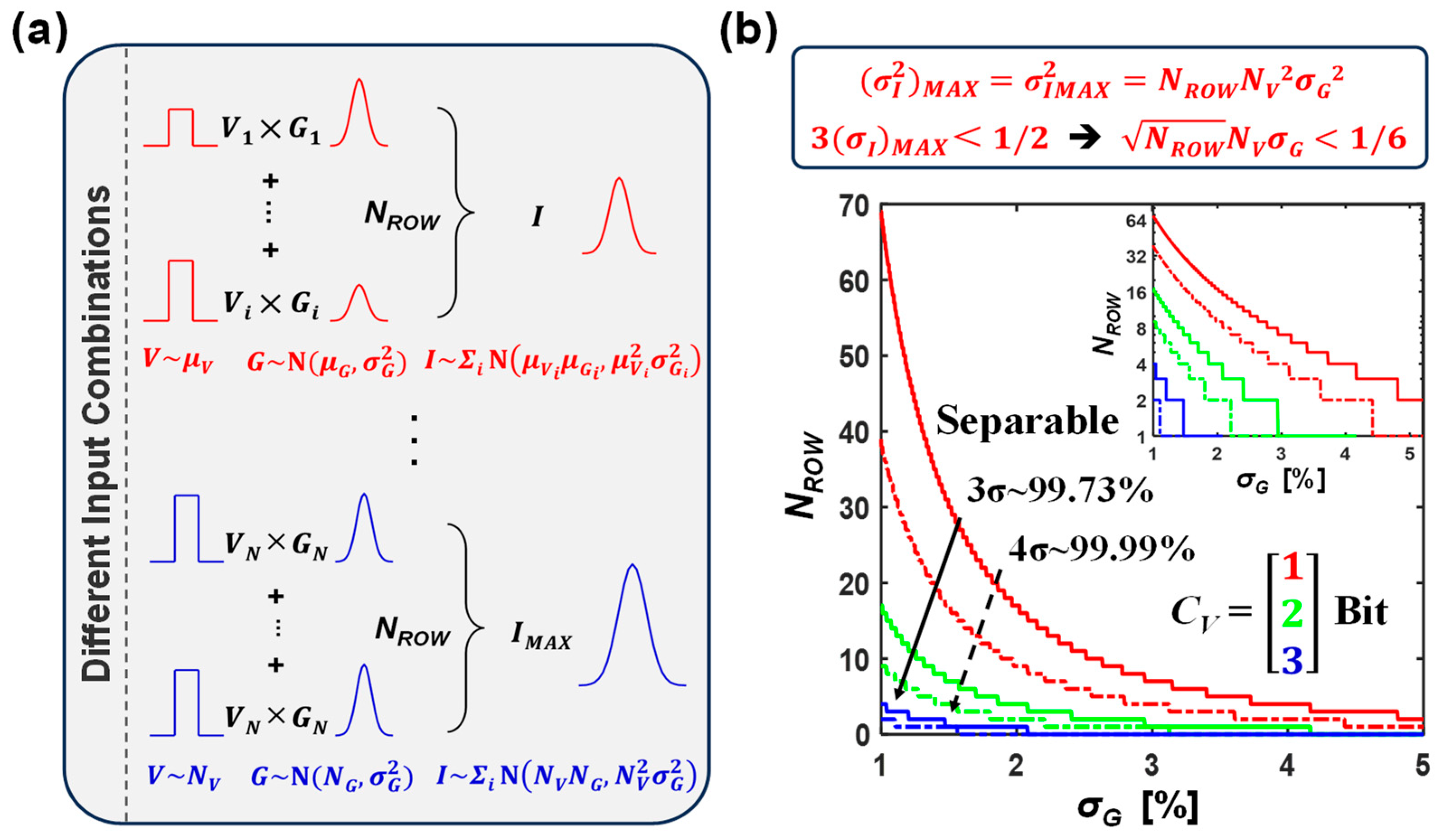
2.2. MVM Output Precision Model
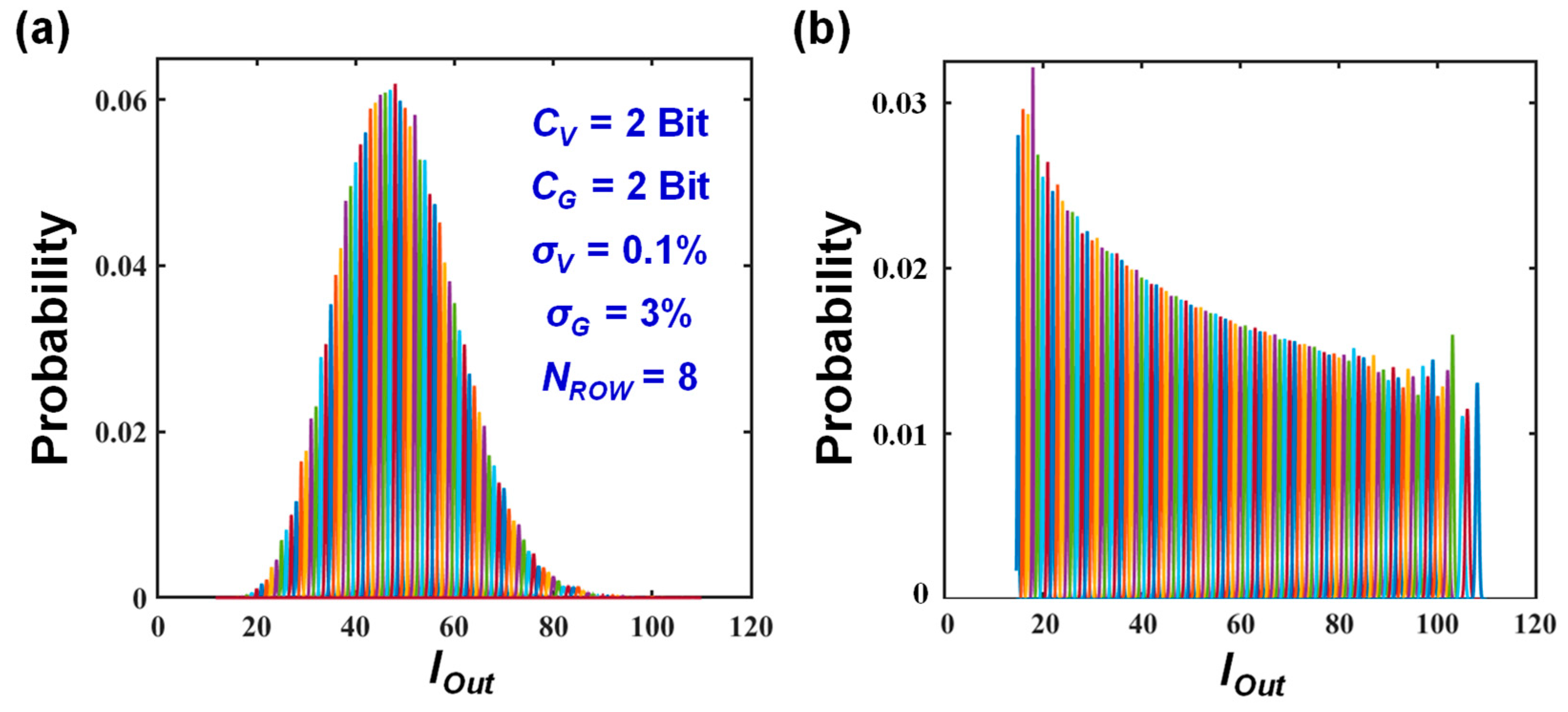
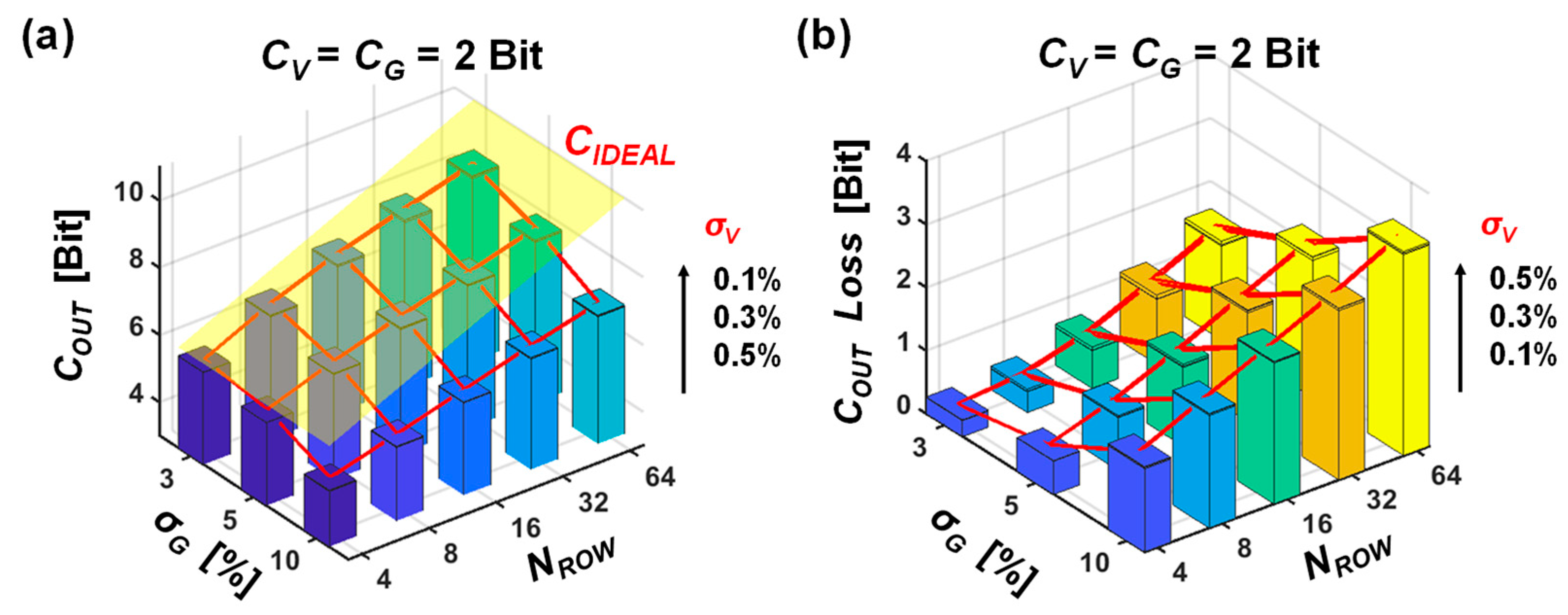
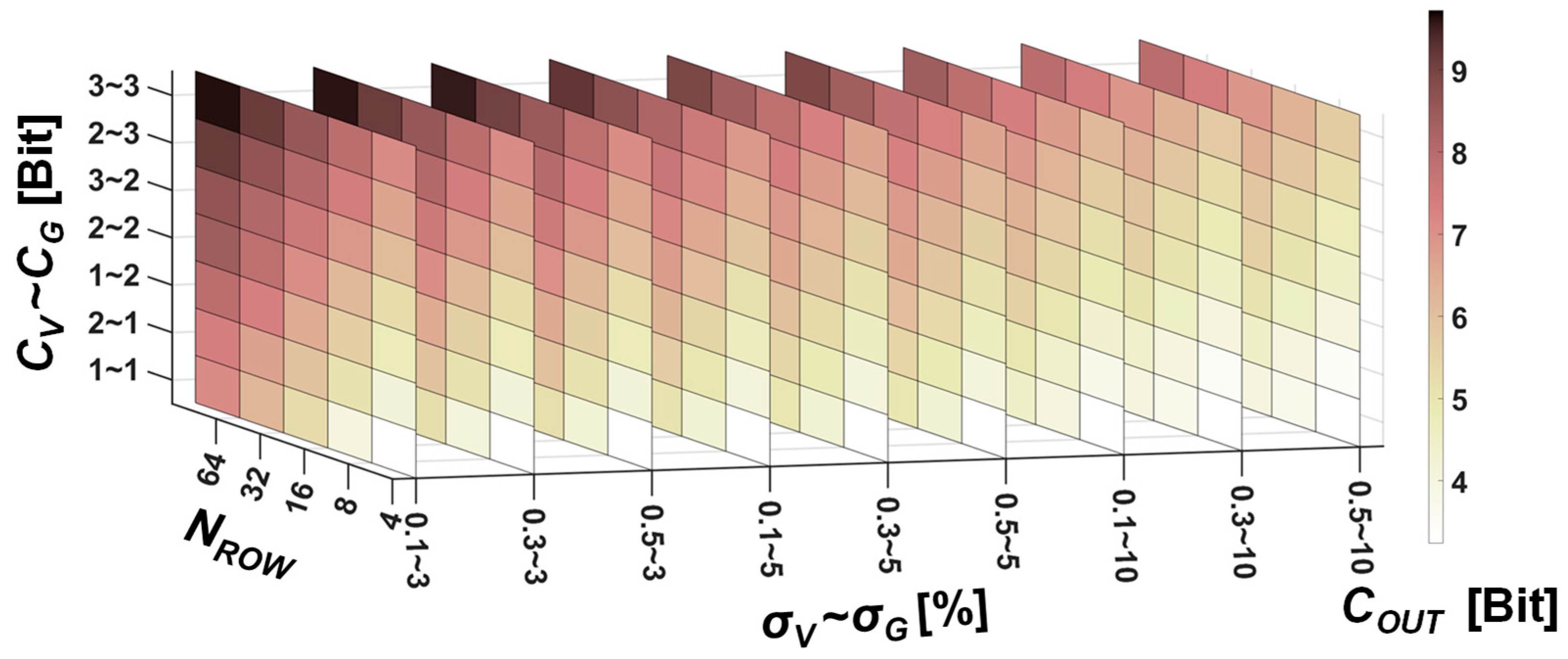
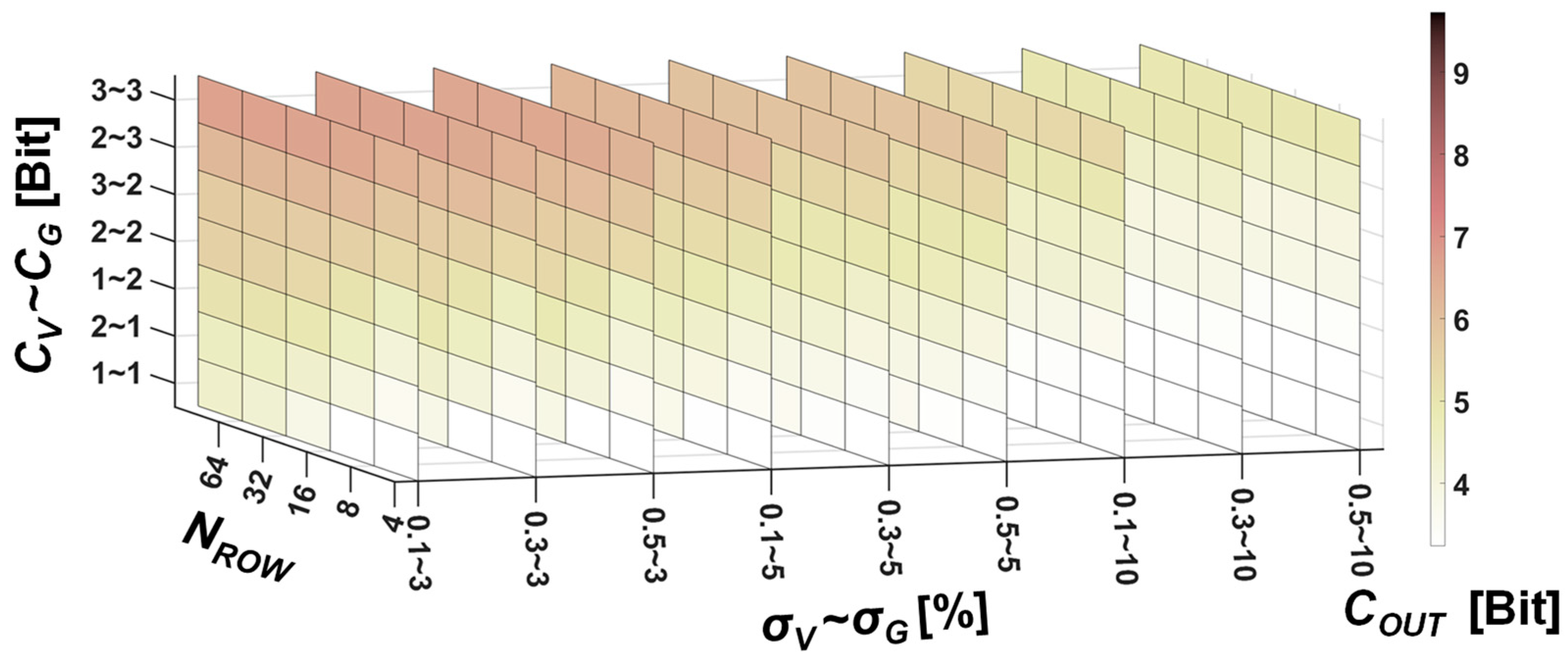
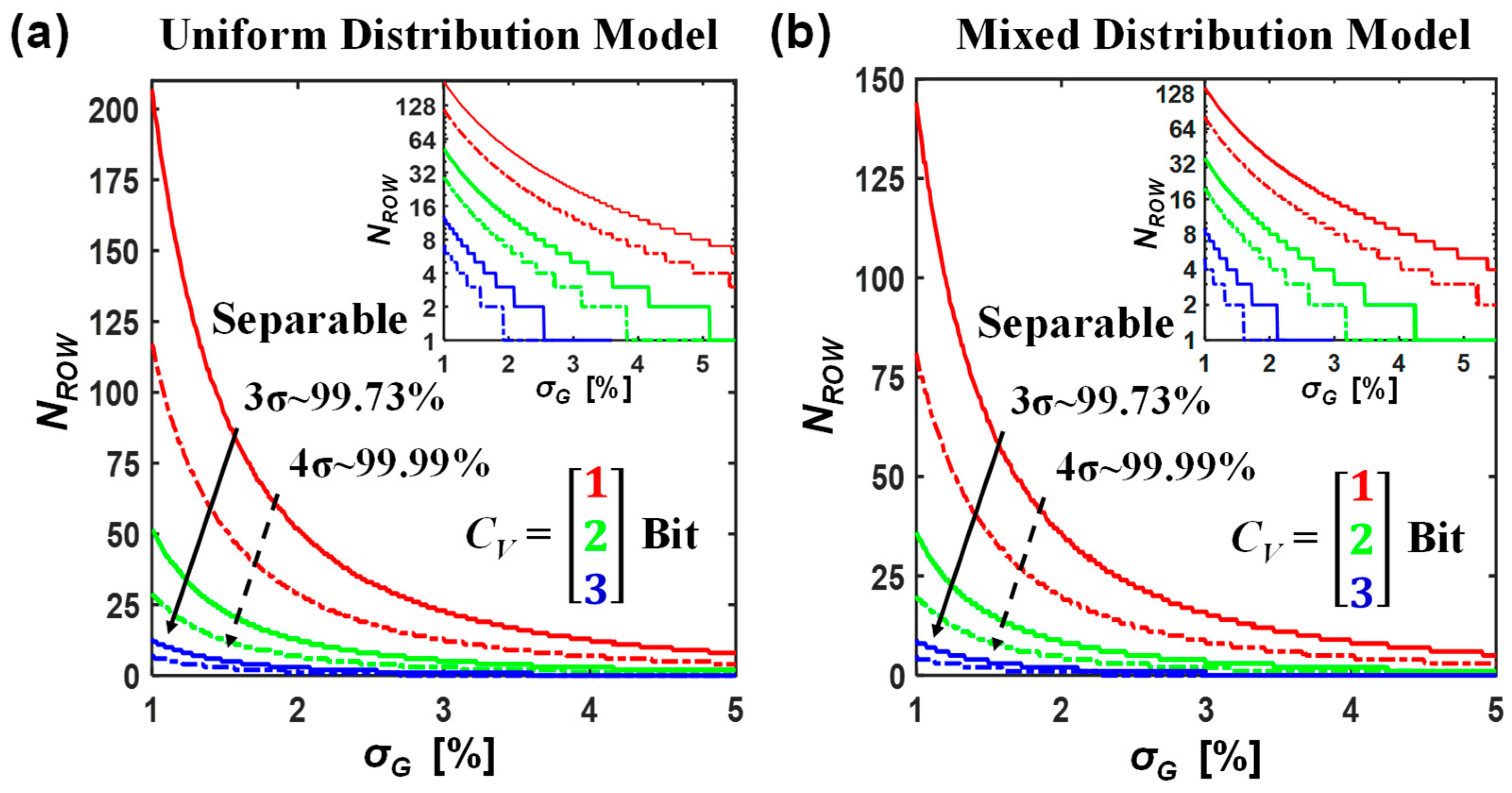
3. Information Loss in Non-Ideal MVM
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ielmini, D.; Wong, H.-S.P. In-Memory Computing with Resistive Switching Devices. Nat. Electron. 2018, 1, 333–343. [Google Scholar] [CrossRef]
- Rao, M.; Tang, H.; Wu, J.; Song, W.; Zhang, M.; Yin, W.; Zhuo, Y.; Kiani, F.; Chen, B.; Jiang, X.; et al. Thousands of Conductance Levels in Memristors Integrated on CMOS. Nature 2023, 615, 823–829. [Google Scholar] [CrossRef]
- Borghetti, J.; Snider, G.S.; Kuekes, P.J.; Yang, J.J.; Stewart, D.R.; Williams, R.S. “Memristive” Switches Enable “Stateful” Logic Operations via Material Implication. Nature 2010, 464, 873–876. [Google Scholar] [CrossRef] [PubMed]
- Ielmini, D. Resistive Switching Memories Based on Metal Oxides: Mechanisms, Reliability and Scaling. Semicond. Sci. Technol. 2016, 31, 063002. [Google Scholar] [CrossRef]
- Pan, F.; Gao, S.; Chen, C.; Song, C.; Zeng, F. Recent Progress in Resistive Random Access Memories: Materials, Switching Mechanisms, and Performance. Mater. Sci. Eng. R Rep. 2014, 83, 1–59. [Google Scholar] [CrossRef]
- Sun, Z.; Kvatinsky, S.; Si, X.; Mehonic, A.; Cai, Y.; Huang, R. A Full Spectrum of Computing-in-Memory Technologies. Nat. Electron. 2023, 6, 823–835. [Google Scholar] [CrossRef]
- Sun, Z.; Pedretti, G.; Ambrosi, E.; Bricalli, A.; Wang, W.; Ielmini, D. Solving Matrix Equations in One Step with Cross-Point Resistive Arrays. Proc. Natl. Acad. Sci. USA 2019, 116, 4123–4128. [Google Scholar] [CrossRef]
- Wang, S.; Luo, Y.; Zuo, P.; Pan, L.; Li, Y.; Sun, Z. In-Memory Analog Solution of Compressed Sensing Recovery in One Step. Sci. Adv. 2023, 9, eadj2908. [Google Scholar] [CrossRef]
- Mannocci, P.; Farronato, M.; Lepri, N.; Cattaneo, L.; Glukhov, A.; Sun, Z.; Ielmini, D. In-Memory Computing with Emerging Memory Devices: Status and Outlook. APL Mach. Learn. 2023, 1, 010902. [Google Scholar] [CrossRef]
- Yu, S.; Shim, W.; Peng, X.; Luo, Y. RRAM for Compute-in-Memory: From Inference to Training. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 2753–2765. [Google Scholar] [CrossRef]
- Moon, K.; Lim, S.; Park, J.; Sung, C.; Oh, S.; Woo, J.; Lee, J.; Hwang, H. RRAM-Based Synapse Devices for Neuromorphic Systems. Faraday Discuss. 2019, 213, 421–451. [Google Scholar] [CrossRef] [PubMed]
- Chang, M.; Spetalnick, S.D.; Crafton, B.; Khwa, W.-S.; Chih, Y.-D.; Chang, M.-F.; Raychowdhury, A. A 40nm 60.64TOPS/W ECC-Capable Compute-in-Memory/Digital 2.25MB/768KB RRAM/SRAM System with Embedded Cortex M3 Microprocessor for Edge Recommendation Systems. In Proceedings of the 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 20–26 February 2022; Volume 65, pp. 1–3. [Google Scholar]
- Zhang, Y.; Huang, P.; Gao, B.; Kang, J.; Wu, H. Oxide-Based Filamentary RRAM for Deep Learning. J. Phys. D Appl. Phys. 2021, 54, 083002. [Google Scholar] [CrossRef]
- Yin, S.; Kim, Y.; Han, X.; Barnaby, H.; Yu, S.; Luo, Y.; He, W.; Sun, X.; Kim, J.-J.; Seo, J.-S. Monolithically Integrated RRAM- and CMOS-Based in-Memory Computing Optimizations for Efficient Deep Learning. IEEE Micro 2019, 39, 54–63. [Google Scholar] [CrossRef]
- Hsieh, E.R.; Zheng, X.; Nelson, M.; Le, B.Q.; Wong, H.-S.P.; Mitra, S.; Wong, S.; Giordano, M.; Hodson, B.; Levy, A.; et al. High-Density Multiple Bits-per-Cell 1T4R RRAM Array with Gradual SET/RESET and Its Effectiveness for Deep Learning. In Proceedings of the 2019 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 7–11 December 2019; pp. 35.6.1–35.6.4. [Google Scholar]
- Zidan, M.A.; Jeong, Y.; Lee, J.; Chen, B.; Huang, S.; Kushner, M.J.; Lu, W.D. A General Memristor-Based Partial Differential Equation Solver. Nat. Electron. 2018, 1, 411–420. [Google Scholar] [CrossRef]
- Feng, Y.; Chen, B.; Liu, J.; Sun, Z.; Hu, H.; Zhang, J.; Zhan, X.; Chen, J. Design-Technology Co-Optimizations (DTCO) for General-Purpose Computing in-Memory Based on 55nm NOR Flash Technology. In Proceedings of the 2021 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 11–16 December 2021; pp. 12.1.1–12.1.4. [Google Scholar]
- Lu, L.; Li, G.Y.; Swindlehurst, A.L.; Ashikhmin, A.; Zhang, R. An Overview of Massive MIMO: Benefits and Challenges. IEEE J. Sel. Top. Signal Process. 2014, 8, 742–758. [Google Scholar] [CrossRef]
- Song, W.; Rao, M.; Li, Y.; Li, C.; Zhuo, Y.; Cai, F.; Wu, M.; Yin, W.; Li, Z.; Wei, Q.; et al. Programming Memristor Arrays with Arbitrarily High Precision for Analog Computing. Science 2024, 383, 903–910. [Google Scholar] [CrossRef]
- Xiao, T.P.; Feinberg, B.; Bennett, C.H.; Prabhakar, V.; Saxena, P.; Agrawal, V.; Agarwal, S.; Marinella, M.J. On the Accuracy of Analog Neural Network Inference Accelerators. IEEE Circuits Syst. Mag. 2023, 22, 26–48. [Google Scholar] [CrossRef]
- Zuo, P.; Sun, Z.; Huang, R. Extremely-Fast, Energy-Efficient Massive MIMO Precoding with Analog RRAM Matrix Computing. IEEE Trans. Circuits Syst. II Express Briefs 2023, 70, 2335–2339. [Google Scholar] [CrossRef]
- Lepri, N.; Glukhov, A.; Ielmini, D. Mitigating Read-Program Variation and IR Drop by Circuit Architecture in RRAM-Based Neural Network Accelerators. In Proceedings of the 2022 IEEE International Reliability Physics Symposium (IRPS), Dallas, TX, USA, 27–31 March 2022; pp. 3C.2-1–3C.2-6. [Google Scholar]
- Lee, S.; Jung, G.; Fouda, M.E.; Lee, J.; Eltawil, A.; Kurdahi, F. Learning to Predict IR Drop with Effective Training for ReRAM-Based Neural Network Hardware. In Proceedings of the 2020 57th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 20–24 July 2020; pp. 1–6. [Google Scholar]
- Zanotti, T.; Zambelli, C.; Puglisi, F.M.; Milo, V.; Perez, E.; Mahadevaiah, M.K.; Ossorio, O.G.; Wenger, C.; Pavan, P.; Olivo, P.; et al. Reliability of Logic-in-Memory Circuits in Resistive Memory Arrays. IEEE Trans. Electron Devices 2020, 67, 4611–4615. [Google Scholar] [CrossRef]
- Perez, E.; Maldonado, D.; Perez-Bosch Quesada, E.; Mahadevaiah, M.K.; Jimenez-Molinos, F.; Wenger, C.; Roldan, J.B. Parameter Extraction Methods for Assessing Device-to-Device and Cycle-to-Cycle Variability of Memristive Devices at Wafer Scale. IEEE Trans. Electron Devices 2023, 70, 360–365. [Google Scholar] [CrossRef]
- Balatti, S.; Ambrogio, S.; Wang, Z.-Q.; Sills, S.; Calderoni, A.; Ramaswamy, N.; Ielmini, D. Understanding Pulsed-Cycling Variability and Endurance in HfOx RRAM. In Proceedings of the 2015 IEEE International Reliability Physics Symposium, Monterey, CA, USA, 19–23 April 2015; pp. 5B.3.1–5B.3.6. [Google Scholar]
- Luo, Y.; Han, X.; Ye, Z.; Barnaby, H.; Seo, J.-S.; Yu, S. Array-Level Programming of 3-Bit per Cell Resistive Memory and Its Application for Deep Neural Network Inference. IEEE Trans. Electron Devices 2020, 67, 4621–4625. [Google Scholar] [CrossRef]
- Lele, A.S.; Zhang, B.; Khwa, W.-S.; Chang, M.-F. Assessing Design Space for the Device-Circuit Codesign of Nonvolatile Memory-Based Compute-in-Memory Accelerators. Nano Lett. 2025, 25, 1243–1249. [Google Scholar] [CrossRef] [PubMed]
- Feinberg, B.; Wang, S.; Ipek, E. Making Memristive Neural Network Accelerators Reliable. In Proceedings of the 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA), Vienna, Austria, 24–28 February 2018; pp. 52–65. [Google Scholar]
- Feinberg, B.; Vengalam, U.K.R.; Whitehair, N.; Wang, S.; Ipek, E. Enabling Scientific Computing on Memristive Accelerators. In Proceedings of the 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), Los Angeles, CA, USA, 1–6 June 2018; pp. 367–382. [Google Scholar]
- Shafiee, A.; Nag, A.; Muralimanohar, N.; Balasubramonian, R.; Strachan, J.P.; Hu, M.; Williams, R.S.; Srikumar, V. ISAAC: A Convolutional Neural Network Accelerator with in-Situ Analog Arithmetic in Crossbars. Comput. Archit. News 2016, 44, 14–26. [Google Scholar] [CrossRef]
- Li, Y.; Wang, S.; Sun, Z. The Maximum Storage Capacity of Open-Loop Written RRAM Is around 4 Bits. In Proceedings of the 2024 IEEE 17th International Conference on Solid-State & Integrated Circuit Technology (ICSICT), Zhuhai, China, 22–25 October 2024; pp. 1–3. [Google Scholar]
- Li, X.; Gao, B.; Qin, Q.; Yao, P.; Li, J.; Zhao, H.; Liu, C.; Zhang, Q.; Hao, Z.; Li, Y.; et al. Federated Learning Using a Memristor Compute-in-Memory Chip with in Situ Physical Unclonable Function and True Random Number Generator. Nat. Electron. 2025, 1–11. [Google Scholar] [CrossRef]
- Zanotti, T.; Puglisi, F.M.; Pavan, P. Low-Bit Precision Neural Network Architecture with High Immunity to Variability and Random Telegraph Noise Based on Resistive Memories. In Proceedings of the 2021 IEEE International Reliability Physics Symposium (IRPS), Monterey, CA, USA, 21–25 March 2021; pp. 1–6. [Google Scholar]
- Deaville, P.; Zhang, B.; Verma, N. A 22nm 128-Kb MRAM Row/Column-Parallel in-Memory Computing Macro with Memory-Resistance Boosting and Multi-Column ADC Readout. In Proceedings of the 2022 IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits), Honolulu, HI, USA, 12–17 June 2022; pp. 268–269. [Google Scholar]
- Khaddam-Aljameh, R.; Stanisavljevic, M.; Fornt Mas, J.; Karunaratne, G.; Braendli, M.; Liu, F.; Singh, A.; Muller, S.M.; Egger, U.; Petropoulos, A.; et al. HERMES Core—A 14nm CMOS and PCM-Based In-Memory Compute Core Using an Array of 300ps/LSB Linearized CCO-Based ADCs and Local Digital Processing. In Proceedings of the 2021 Symposium on VLSI Circuits, Kyoto, Japan, 13–19 June 2021; pp. 1–2. [Google Scholar]
- Lu, Y.; Li, X.; Yan, B.; Yan, L.; Zhang, T.; Song, Z.; Huang, R.; Yang, Y. In-Memory Realization of Eligibility Traces Based on Conductance Drift of Phase Change Memory for Energy-Efficient Reinforcement Learning. Adv. Mater. 2022, 34, e2107811. [Google Scholar] [CrossRef]
- Jooq, M.K.Q.; Moaiyeri, M.H.; Tamersit, K. A New Design Paradigm for Auto-Nonvolatile Ternary SRAMs Using Ferroelectric CNTFETs: From Device to Array Architecture. IEEE Trans. Electron Devices 2022, 69, 6113–6120. [Google Scholar] [CrossRef]
- Saito, D.; Kobayashi, T.; Koga, H.; Ronchi, N.; Banerjee, K.; Shuto, Y.; Okuno, J.; Konishi, K.; Di Piazza, L.; Mallik, A.; et al. Analog In-Memory Computing in FeFET-Based 1T1R Array for Edge AI Applications. In Proceedings of the 2021 Symposium on VLSI Technology, Kyoto, Japan, 13–19 June 2021; pp. 1–2. [Google Scholar]
- Wen, T.-H.; Hung, J.-M.; Huang, W.-H.; Jhang, C.-J.; Lo, Y.-C.; Hsu, H.-H.; Ke, Z.-E.; Chen, Y.-C.; Chin, Y.-H.; Su, C.-I.; et al. Fusion of Memristor and Digital Compute-in-Memory Processing for Energy-Efficient Edge Computing. Science 2024, 384, 325–332. [Google Scholar] [CrossRef]
- Zarcone, R.V.; Engel, J.H.; Burc Eryilmaz, S.; Wan, W.; Kim, S.; BrightSky, M.; Lam, C.; Lung, H.-L.; Olshausen, B.A.; Philip Wong, H.-S. Analog Coding in Emerging Memory Systems. Sci. Rep. 2020, 10, 6831. [Google Scholar] [CrossRef]
- Verreault, A.; Cicek, P.-V.; Robichaud, A. Oversampling ADC: A Review of Recent Design Trends. IEEE Access 2024, 12, 121753–121779. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | CV | CG | σV | σG | NROW |
|---|---|---|---|---|---|
| Value Range | [1, 2, 3] Bit | [1, 2, 3] Bit | [0.1, 0.3, 0.5]% | [3, 5, 10]% | 4, 8, 16, 32, 64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Wang, S.; Sun, Z. Constraints on Bit Precision and Row Parallelism for Reliable Computing-in-Memory. Electronics 2025, 14, 2532. https://doi.org/10.3390/electronics14132532
Li Y, Wang S, Sun Z. Constraints on Bit Precision and Row Parallelism for Reliable Computing-in-Memory. Electronics. 2025; 14(13):2532. https://doi.org/10.3390/electronics14132532
Chicago/Turabian StyleLi, Yongxiang, Shiqing Wang, and Zhong Sun. 2025. "Constraints on Bit Precision and Row Parallelism for Reliable Computing-in-Memory" Electronics 14, no. 13: 2532. https://doi.org/10.3390/electronics14132532
APA StyleLi, Y., Wang, S., & Sun, Z. (2025). Constraints on Bit Precision and Row Parallelism for Reliable Computing-in-Memory. Electronics, 14(13), 2532. https://doi.org/10.3390/electronics14132532