
Enhancing Spectrum Utilization in Cognitive Radio Networks Using Reinforcement Learning with Snake Optimizer: A Meta-Heuristic Approach



Abstract
1. Introduction
2. Related Works
3. Proposed Methodology
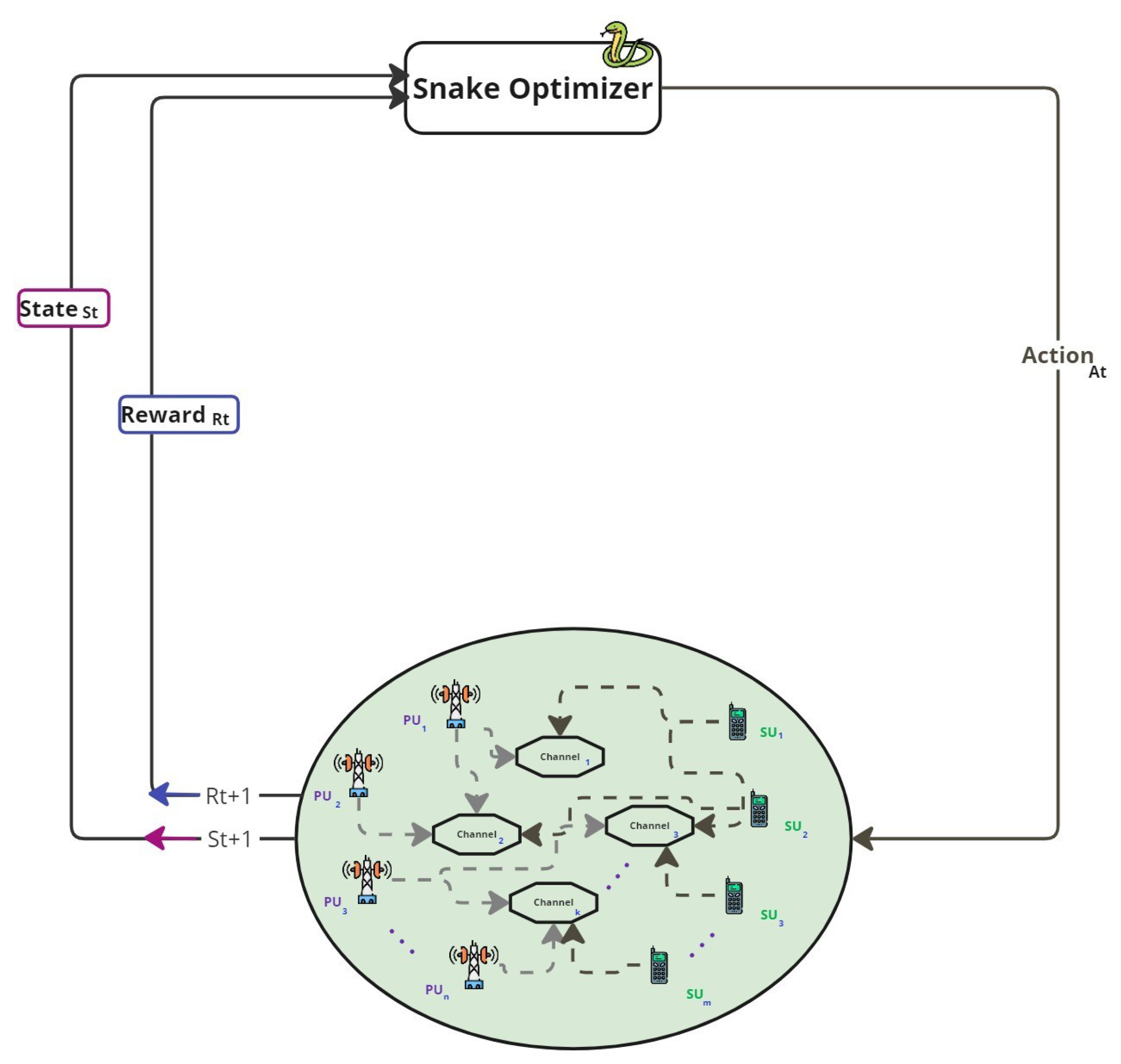
3.1. Proposed System Model
3.2. Proposed Reinforcement Learning with Snake Optimizer
- State representation (): Each state encapsulates the current occupancy status of channels, presence of PUs, the collision history, and active SUs.
- Action (): The action corresponds to a specific allocation of SUs to available channels, selected based on SO’s optimization process.
- Policy (): Defined implicitly through the heuristic rules of SO algorithm, which evolves solutions over iterations using operations like mating, exploration, and fighting.
- Reward (): A scalar value computed based on performance indicators such as spectrum utilization efficiency, number of collisions, and spectral capacity.
- Learning mechanism: Instead of value iteration or gradient-based learning, SO adjusts its population of candidate solutions based on fitness, without requiring Q-value updates or neural approximators.
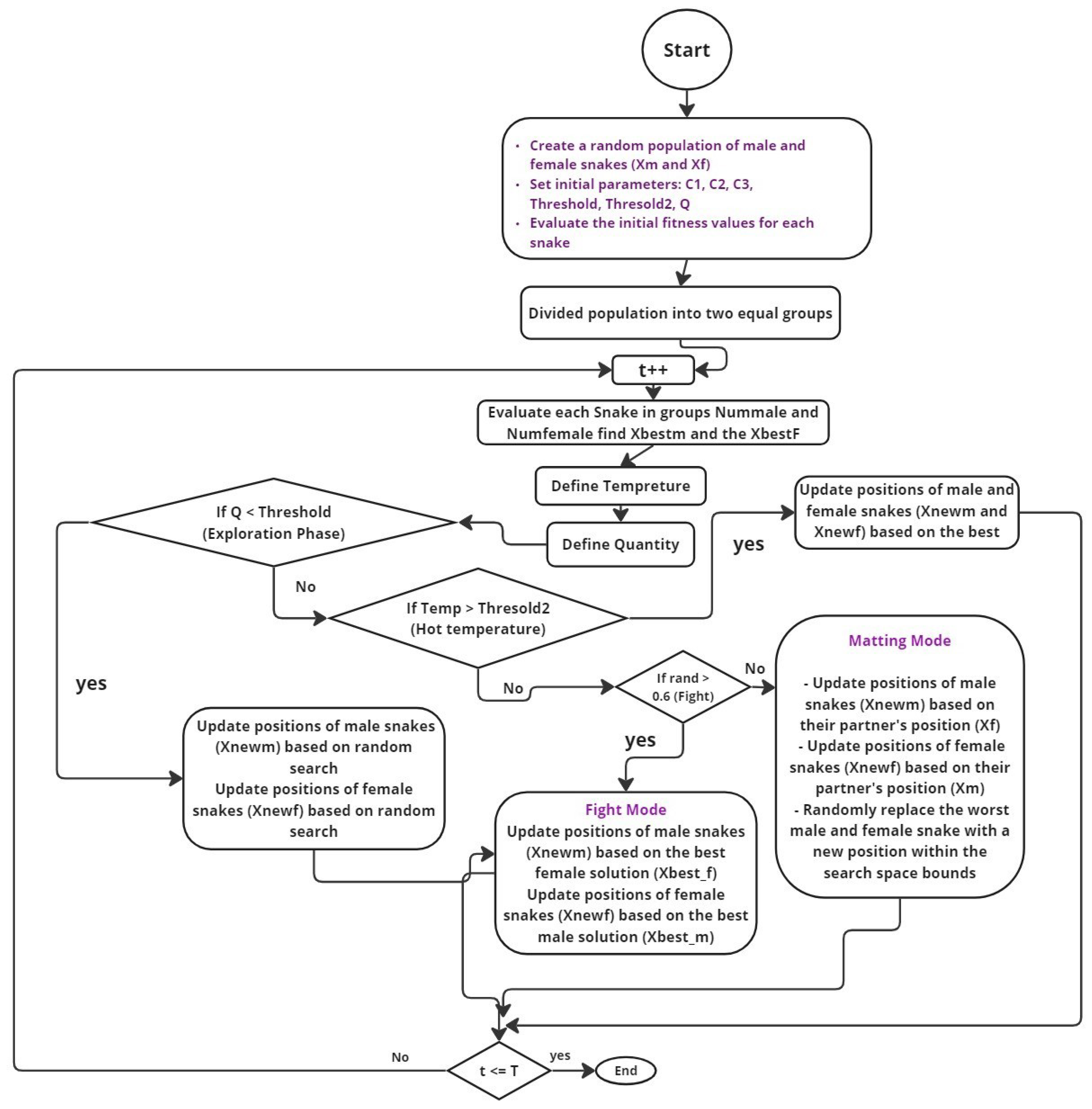
4. Proposed Snake Optimizer
4.1. Initialization
4.2. Population Division
4.3. Temperature and Food Quantity Definition
4.4. Exploration Phase: No Food Available
4.5. Exploitation Phase (Food Available)
4.6. Pseudocode and Operational Flow
| Algorithm 1 Snake Optimizer in reinforcement learning framework | ||
| 1: | Initialize Problem Parameters: | |
| 2: | - Dimension of the problem () | |
| 3: | - Upper Bound () and Lower Bound () of the search space | |
| 4: | - Population size (), Maximum Iterations () | |
| 5: | - Current Iteration () set to 0 | |
| 6: | Initialize Population Randomly: | |
| 7: | - Generate initial positions for each individual within the bounds | |
| 8: | Divide Population into Two Equal Groups: | |
| 9: | Divide population into (males) and (females): | |
| 10: | ||
| 11: | ||
| 12: | while do | |
| 13: | Evaluate Fitness of Each Individual | |
| 14: | Find Best Male () and Best Female () | |
| 15: | Define Environmental Temperature: | |
| 16: | ||
| 17: | Define Food Quantity: | |
| 18: | ||
| 19: | if then | |
| 20: | Perform Exploration Phase: | |
| 21: | - Randomly update positions of males and females | |
| 22: | else if then | |
| 23: | Perform Exploitation Phase: | |
| 24: | if then | ▹ hot |
| 25: | - Move towards best-known food position | |
| 26: | else | ▹ cold |
| 27: | - Enter Fight Mode or Mating Mode | |
| 28: | Fight Mode: Compete for best individuals | |
| 29: | Mating Mode: Mate and update positions | |
| 30: | end if | |
| 31: | end if | |
| 32: | if Mating Occurs then | |
| 33: | - Hatch eggs and replace worst individuals | |
| 34: | end if | |
| 35: | Update Iteration: | |
| 36: | end while | |
| 37: | Termination: | |
| 38: | - If max iterations or other criteria met, stop | |
| 39: | return Best Solution Found | |
5. Results and Discussion
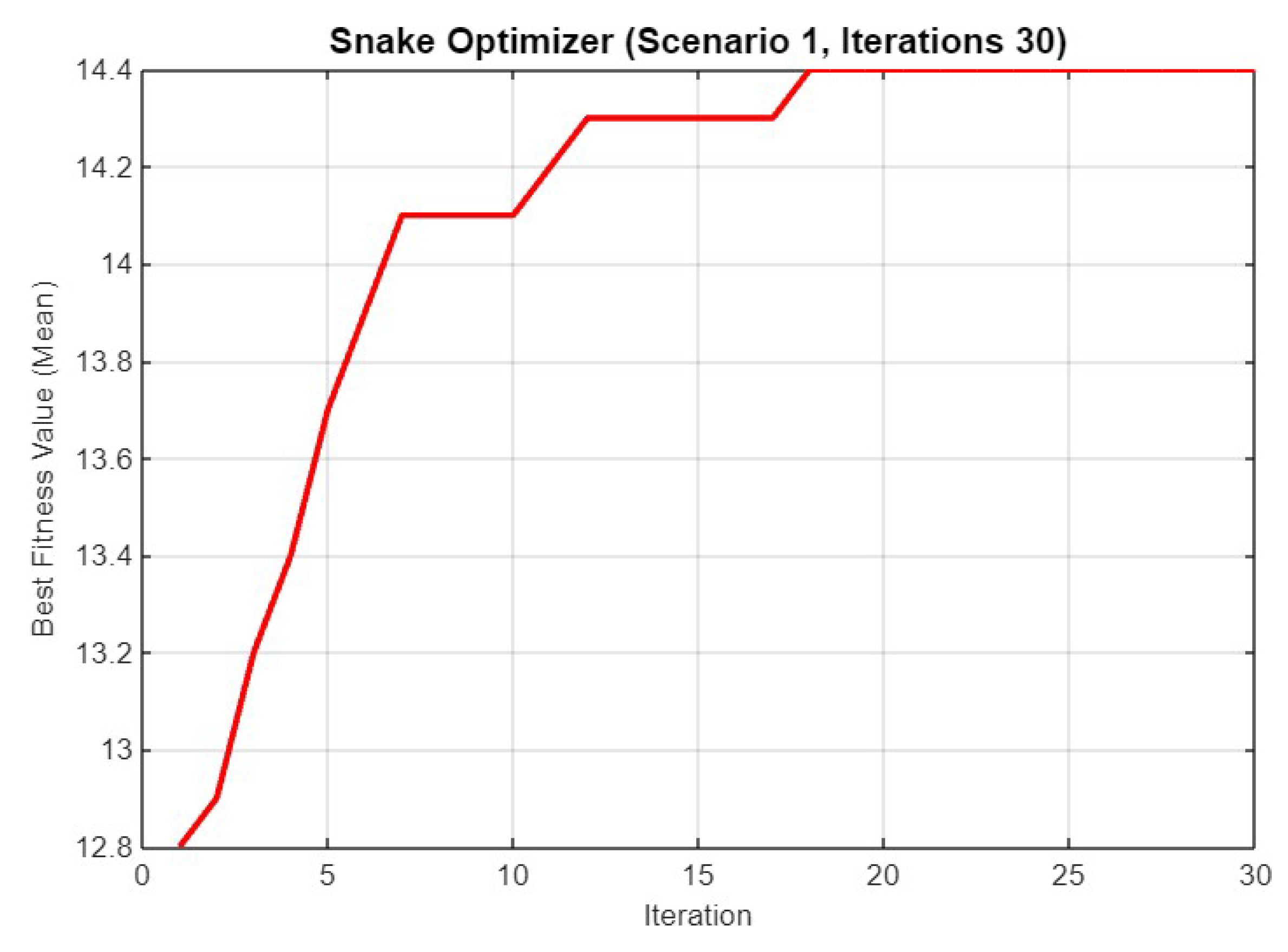
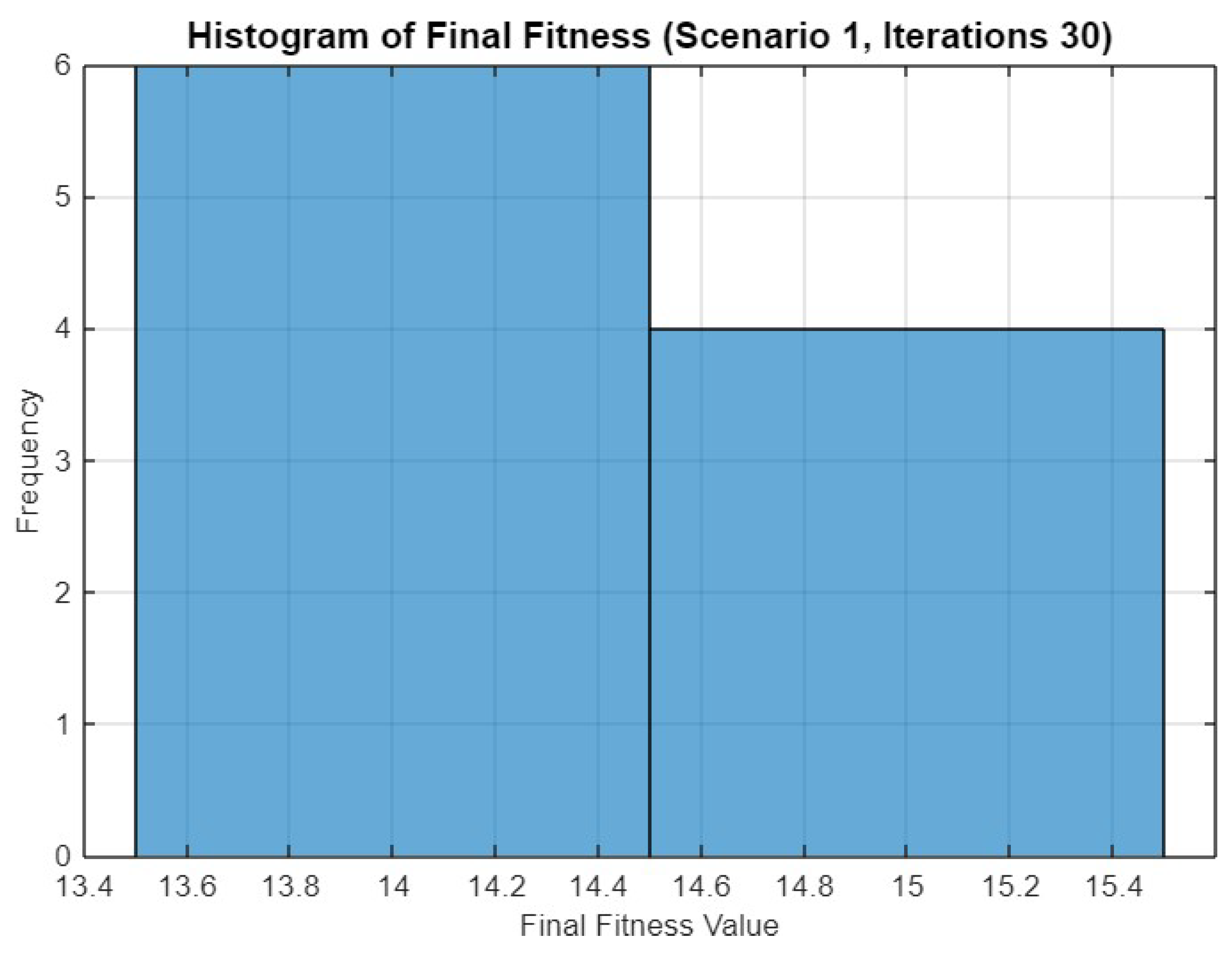
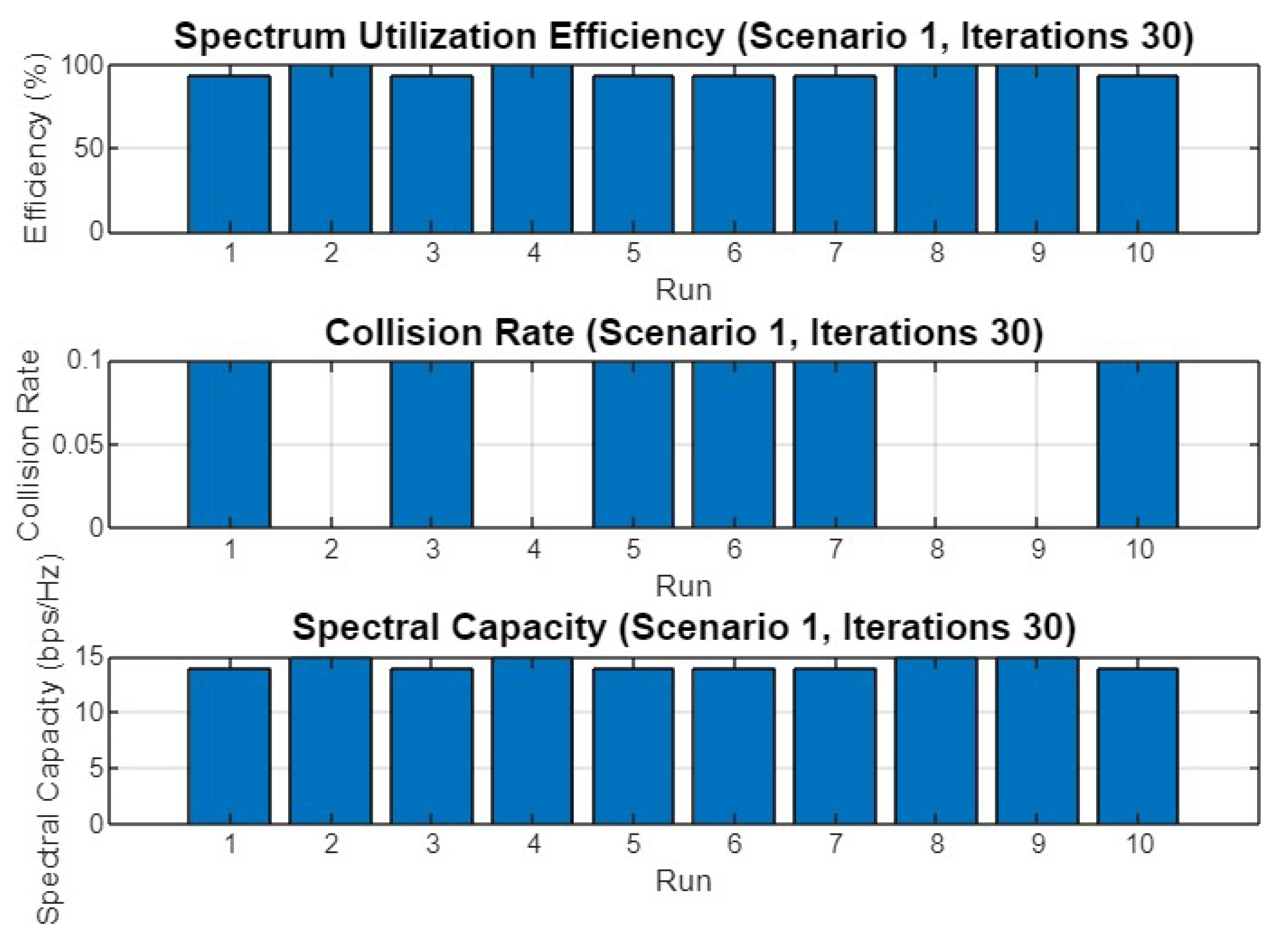
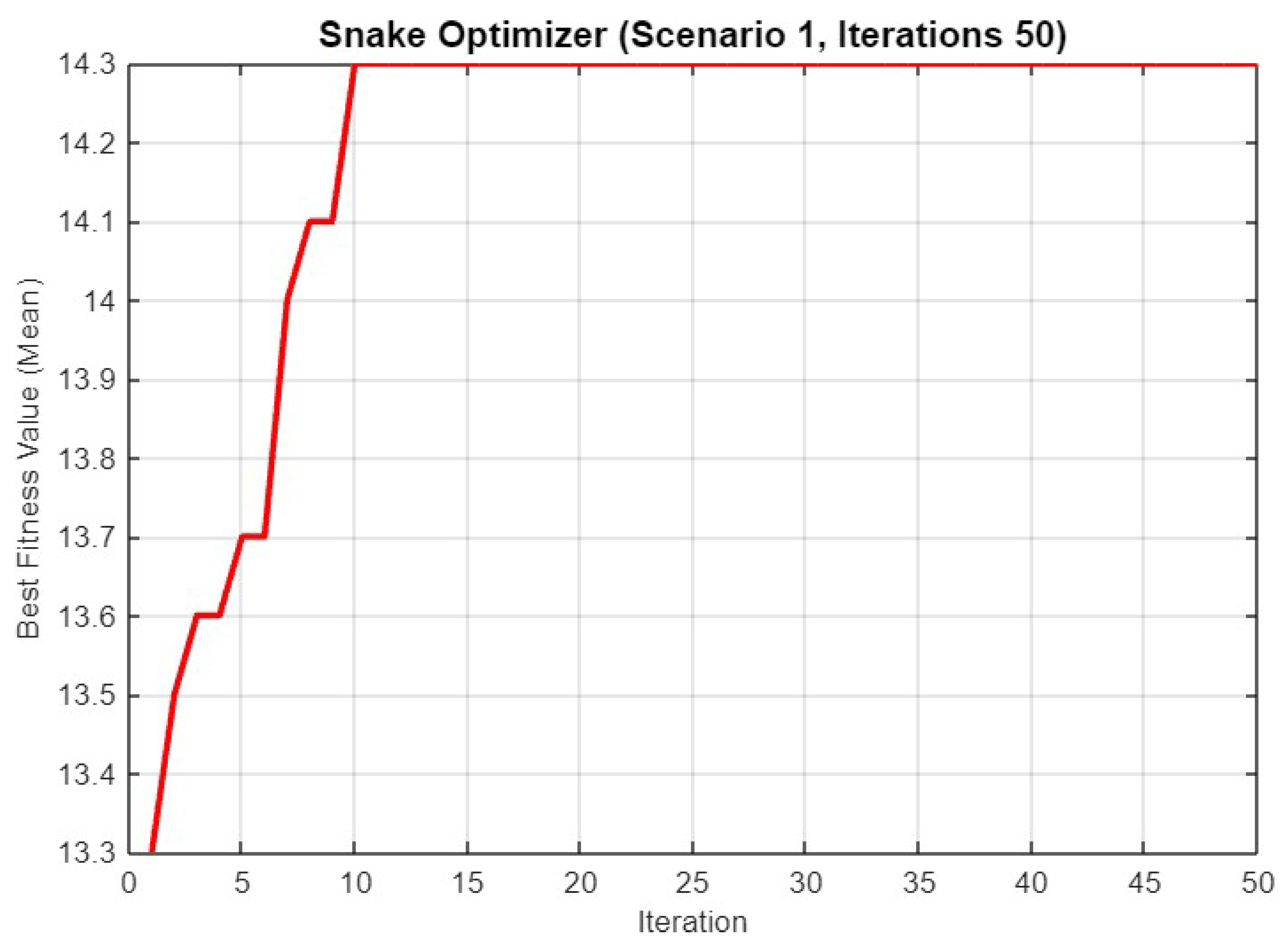
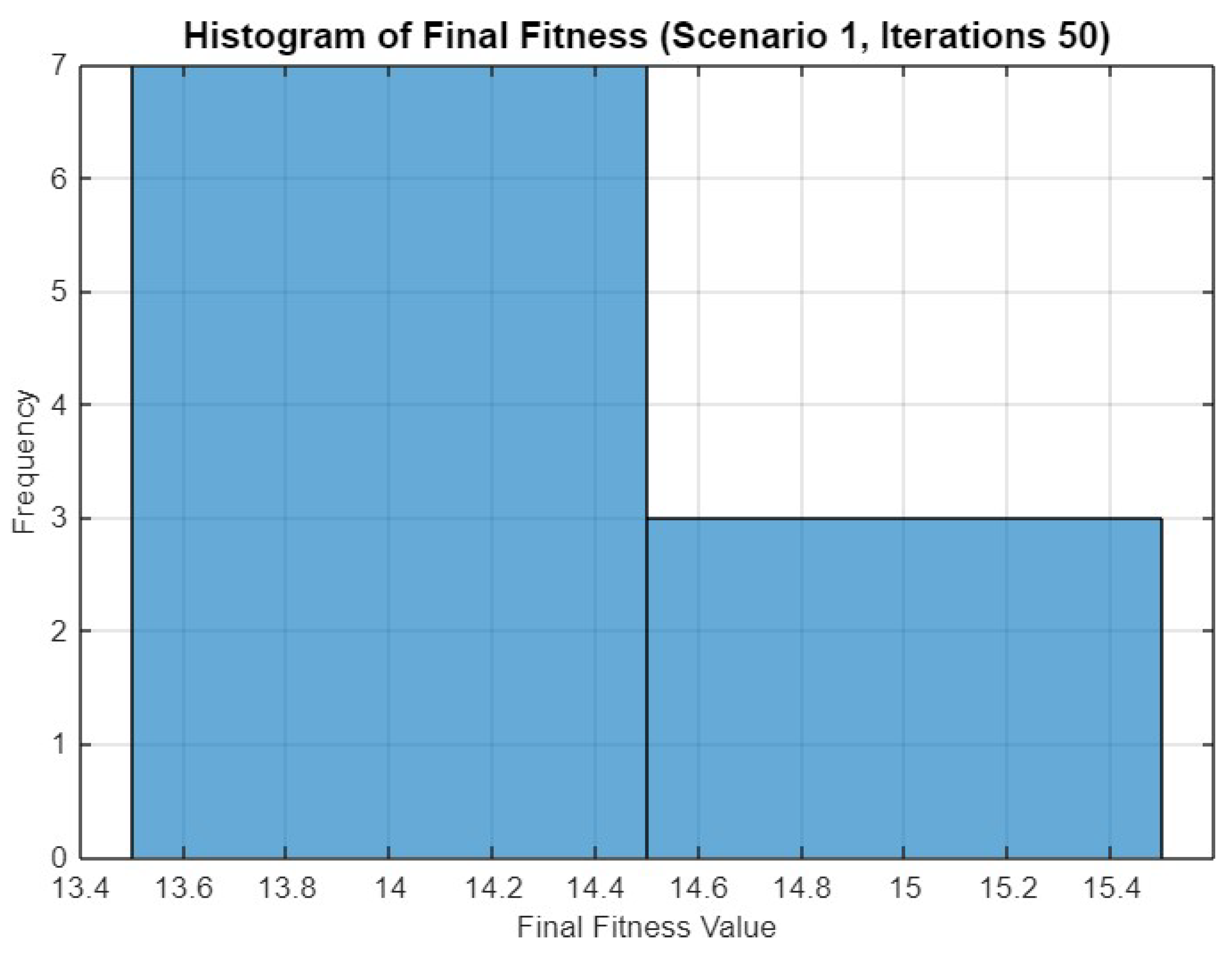
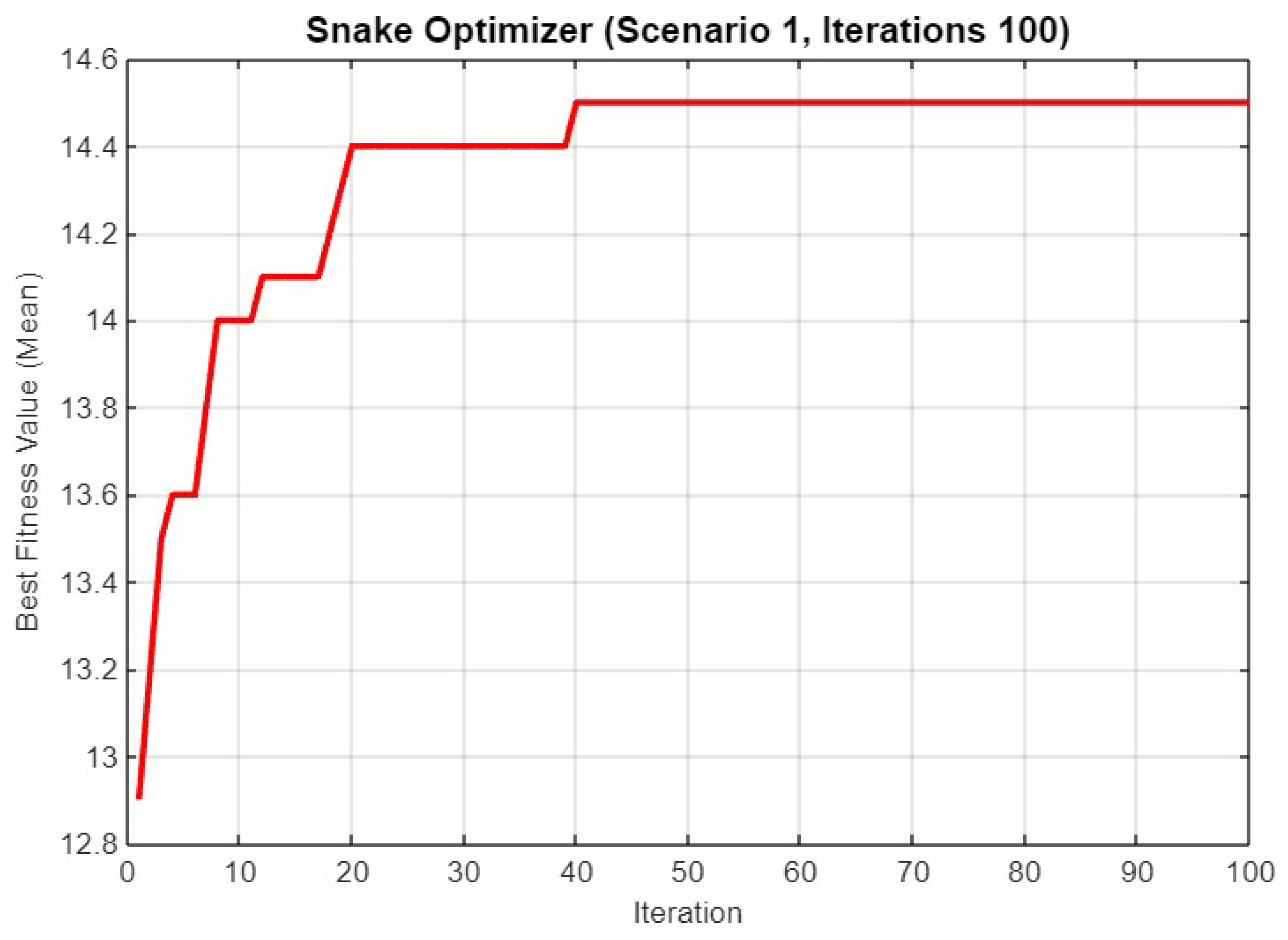
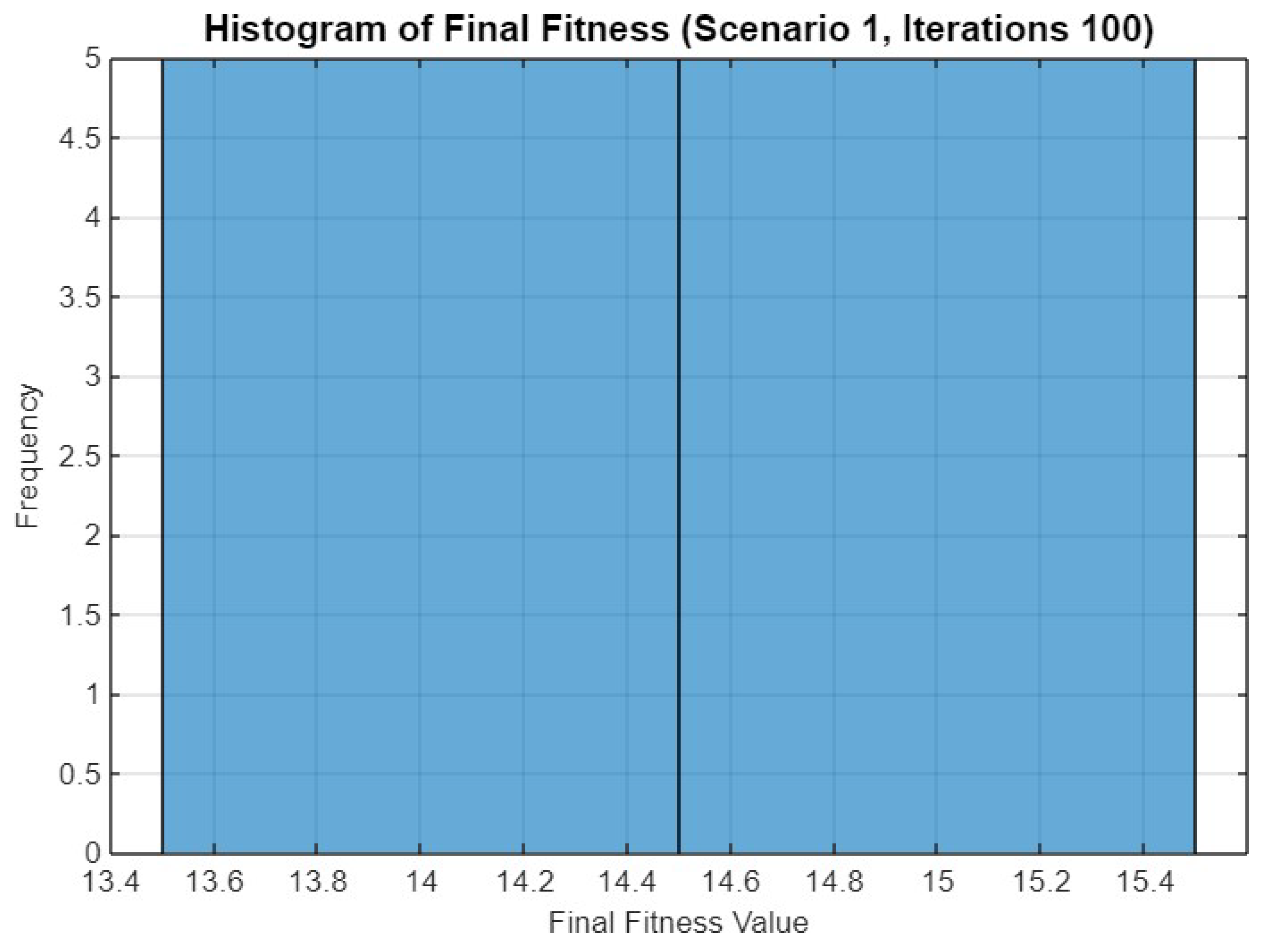
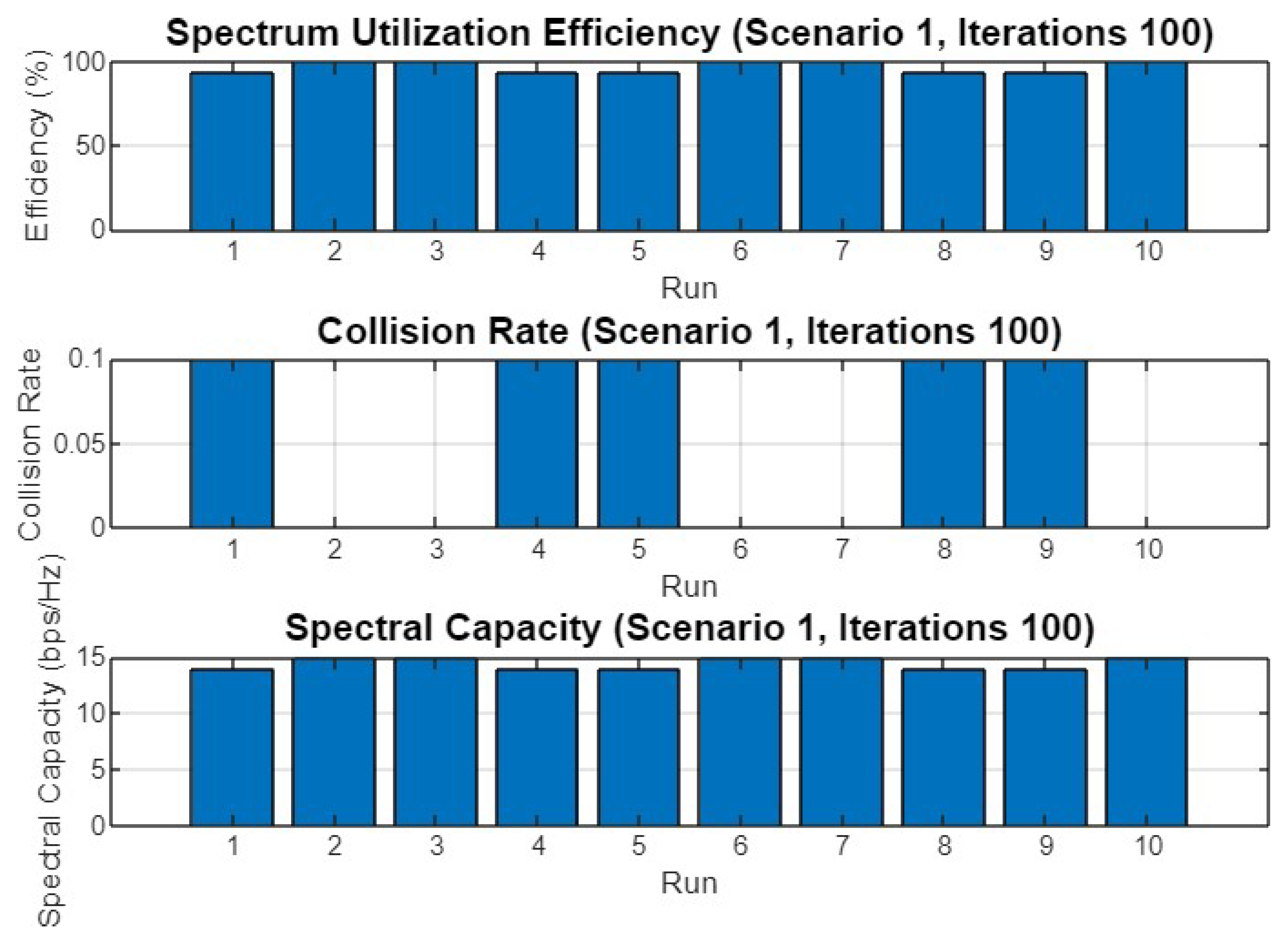
5.1. Experiment Result for First Scenario
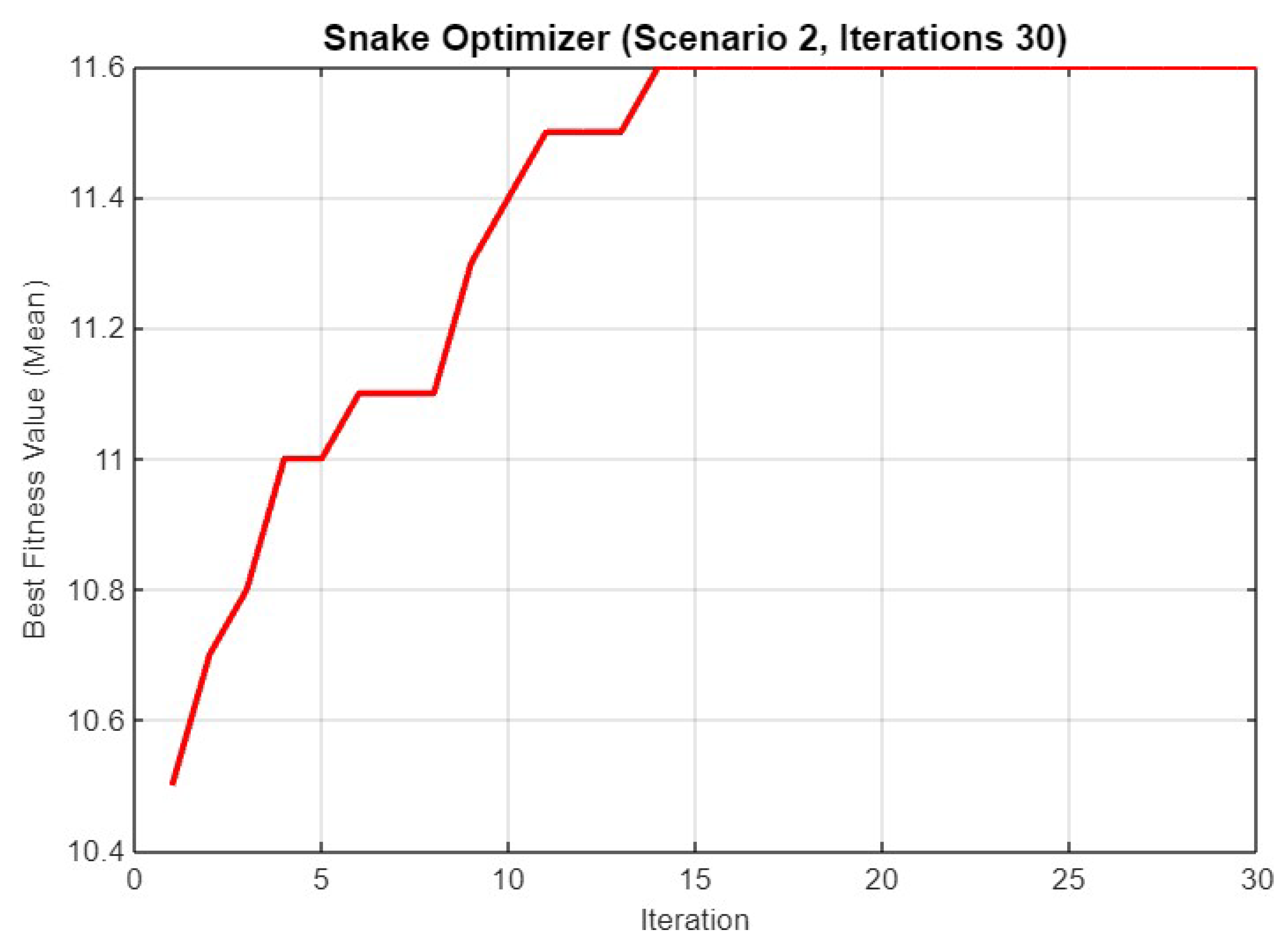
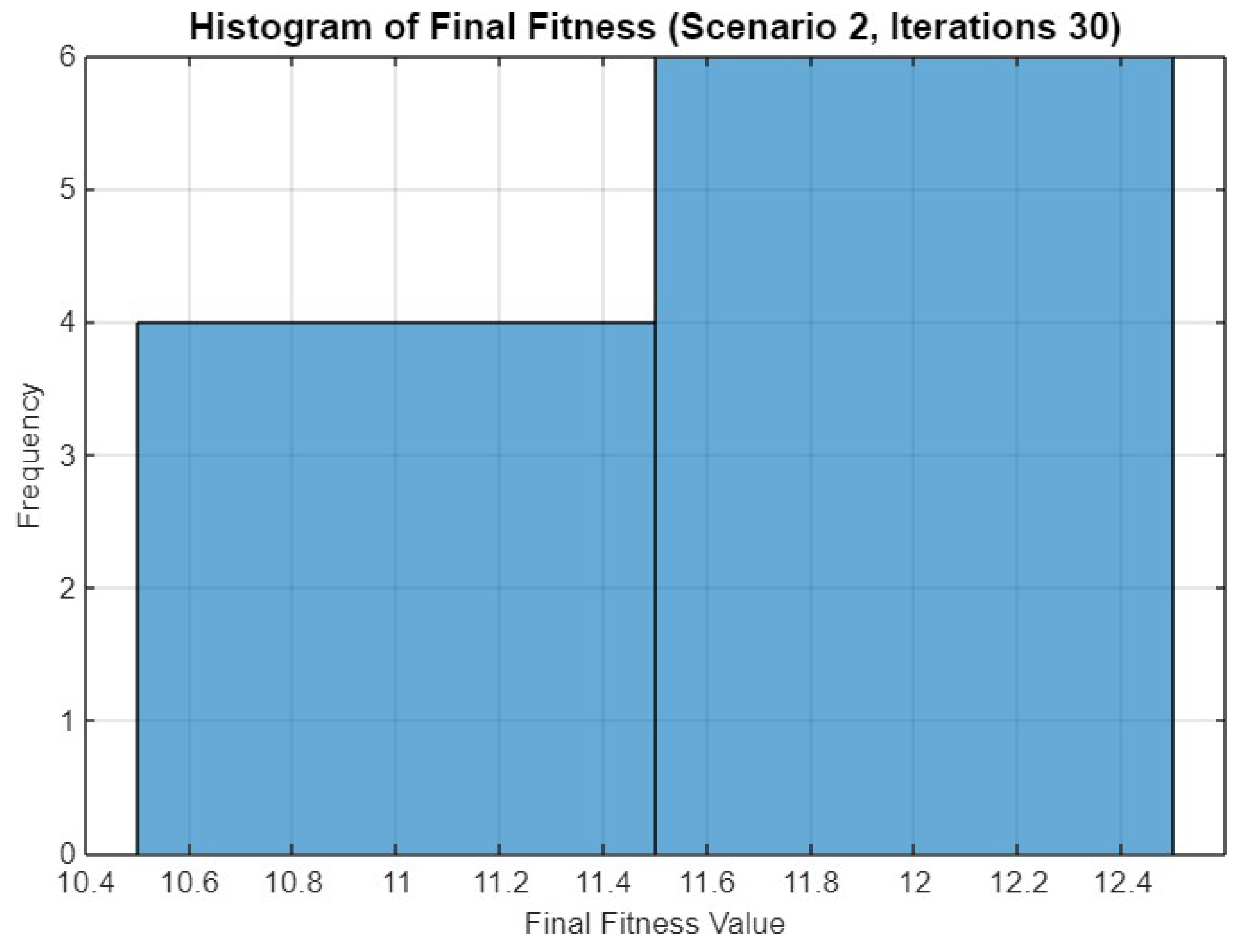
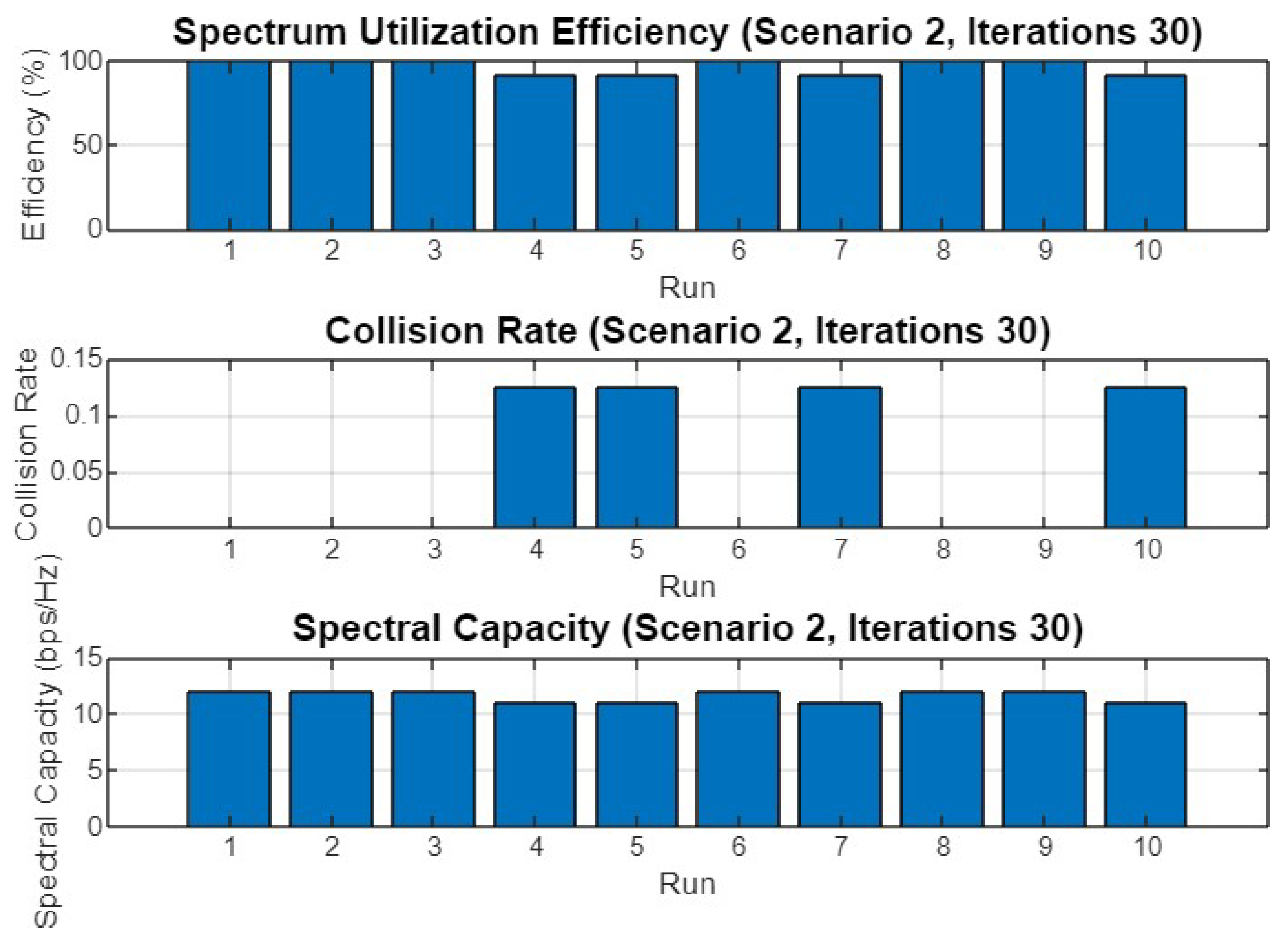
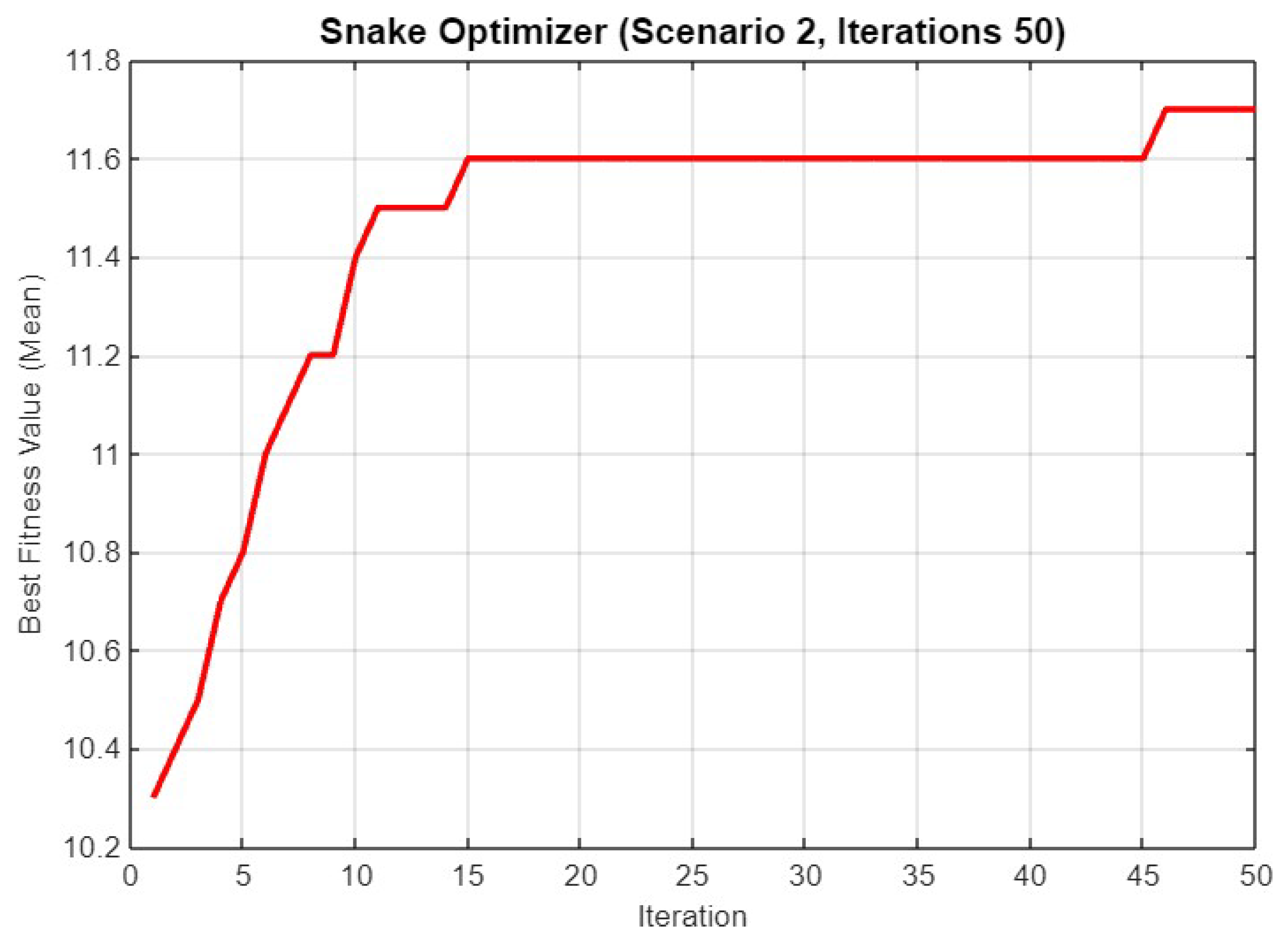
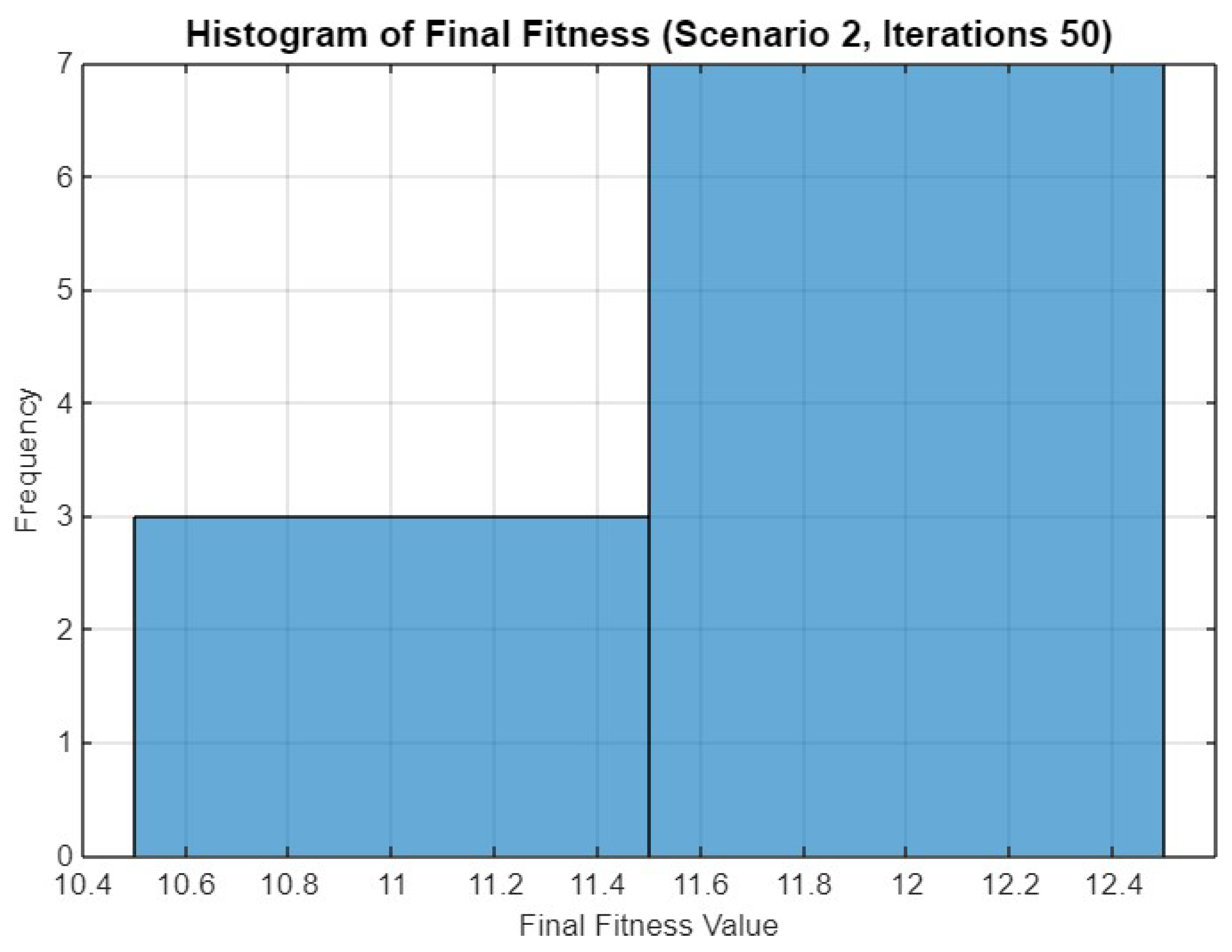
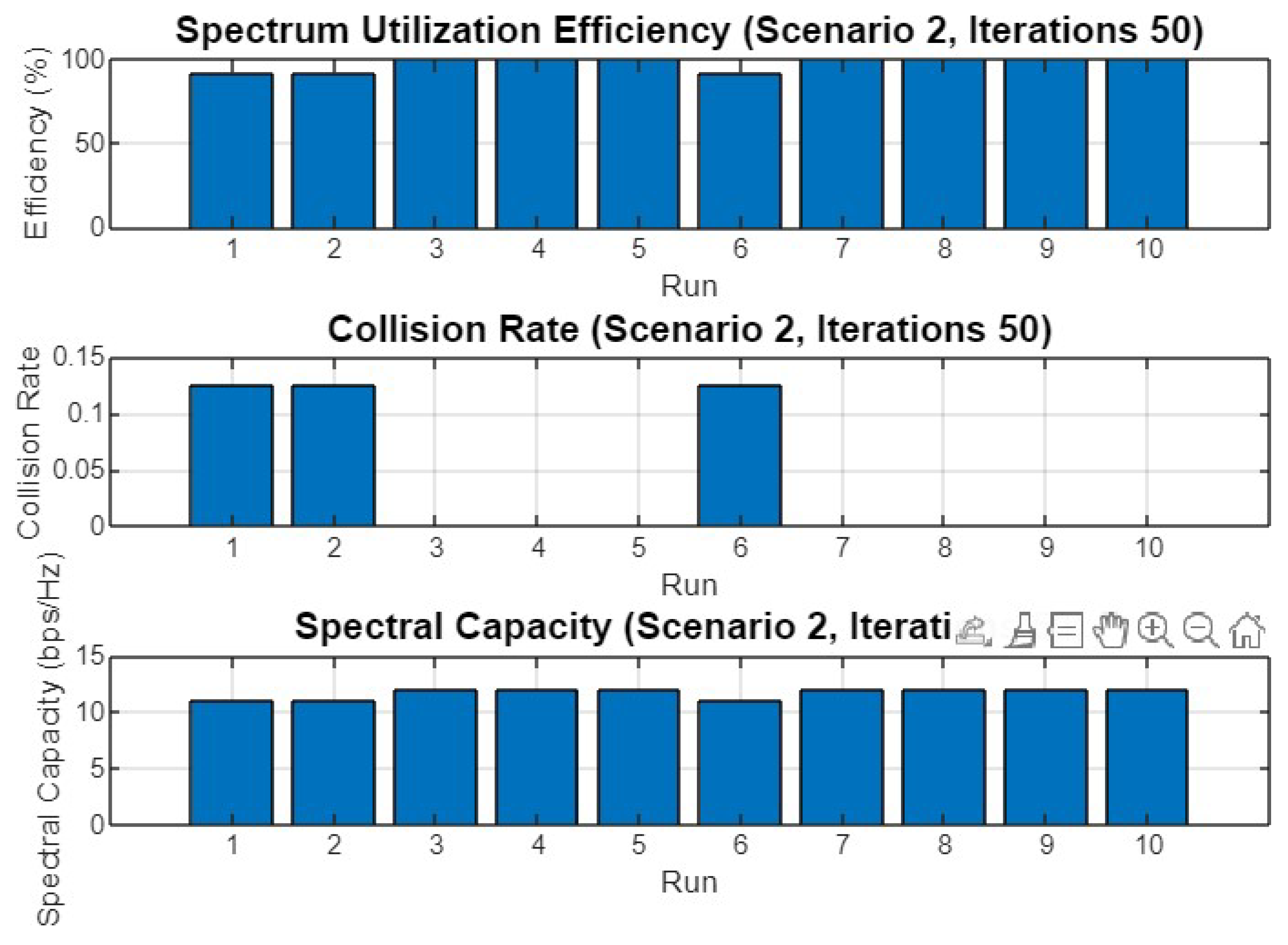
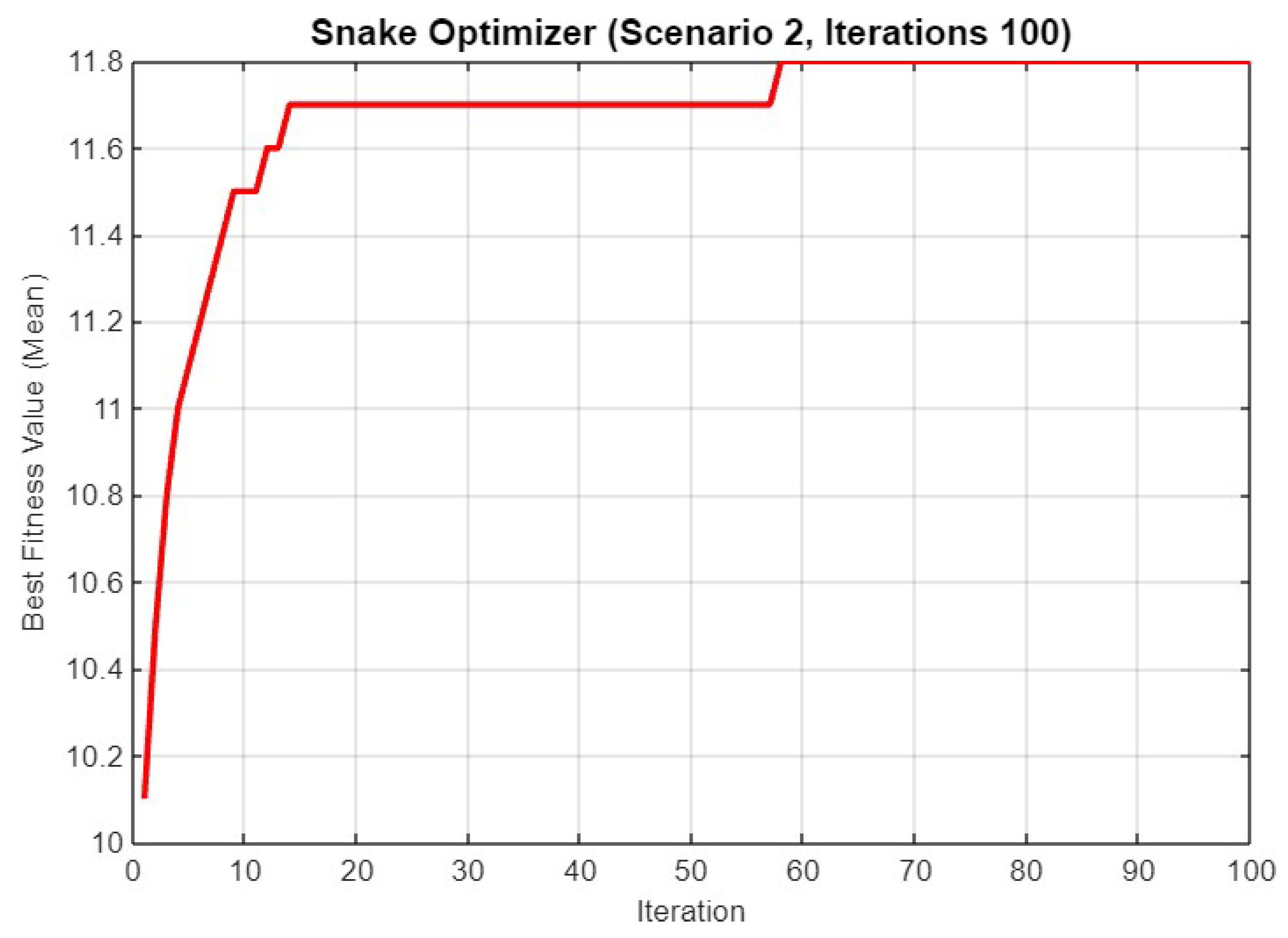
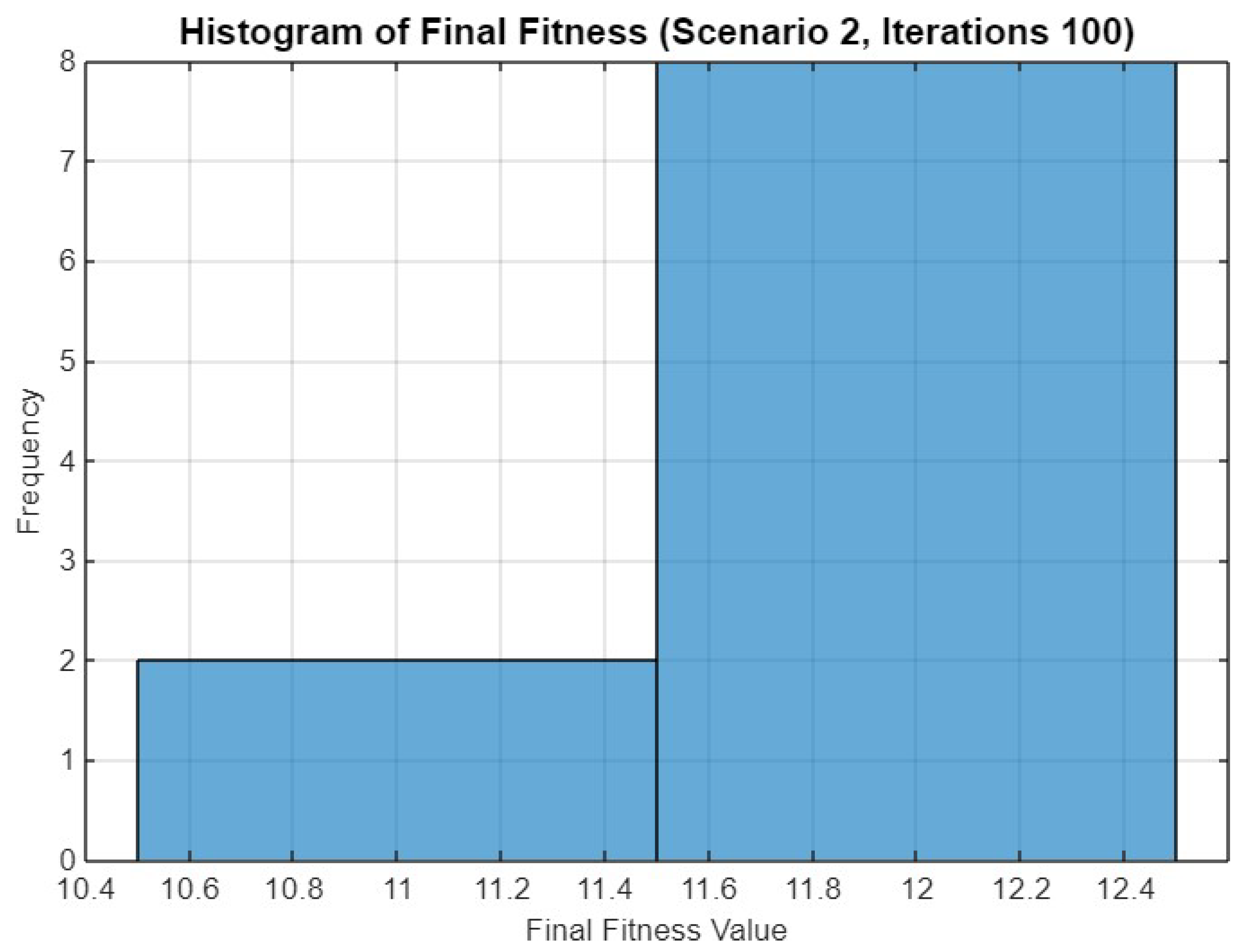
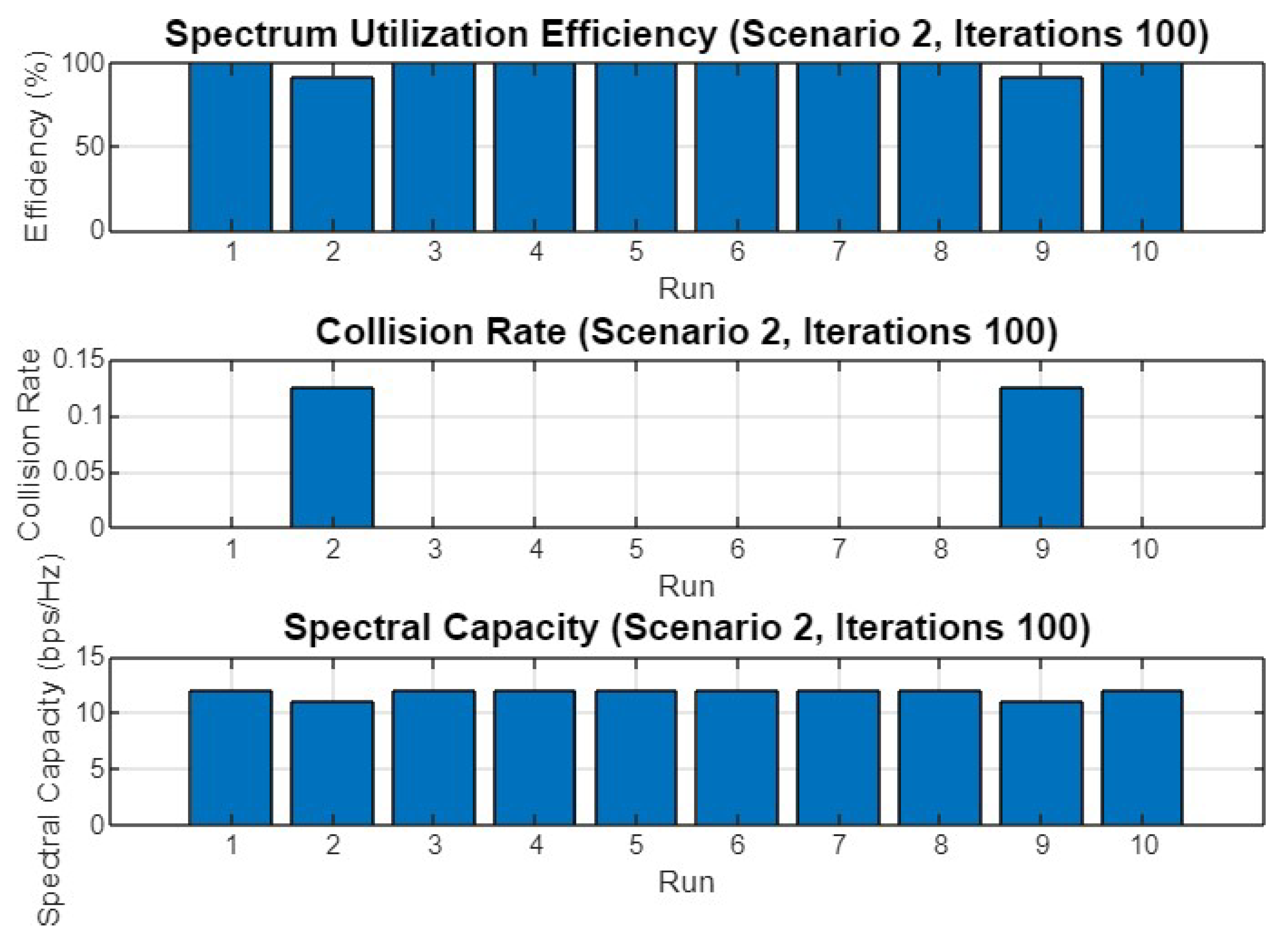
5.2. Experiment Result for Second Scenario
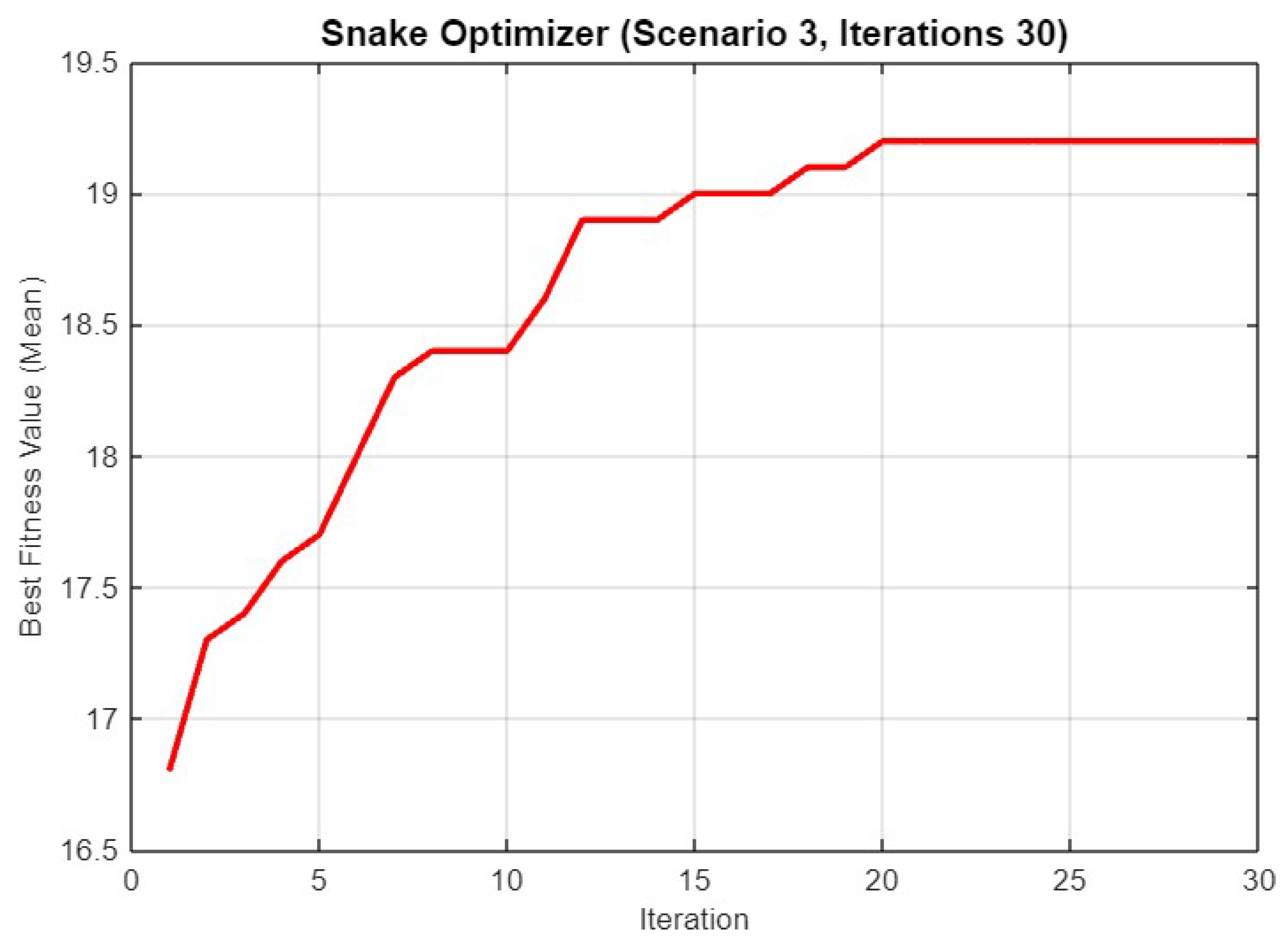
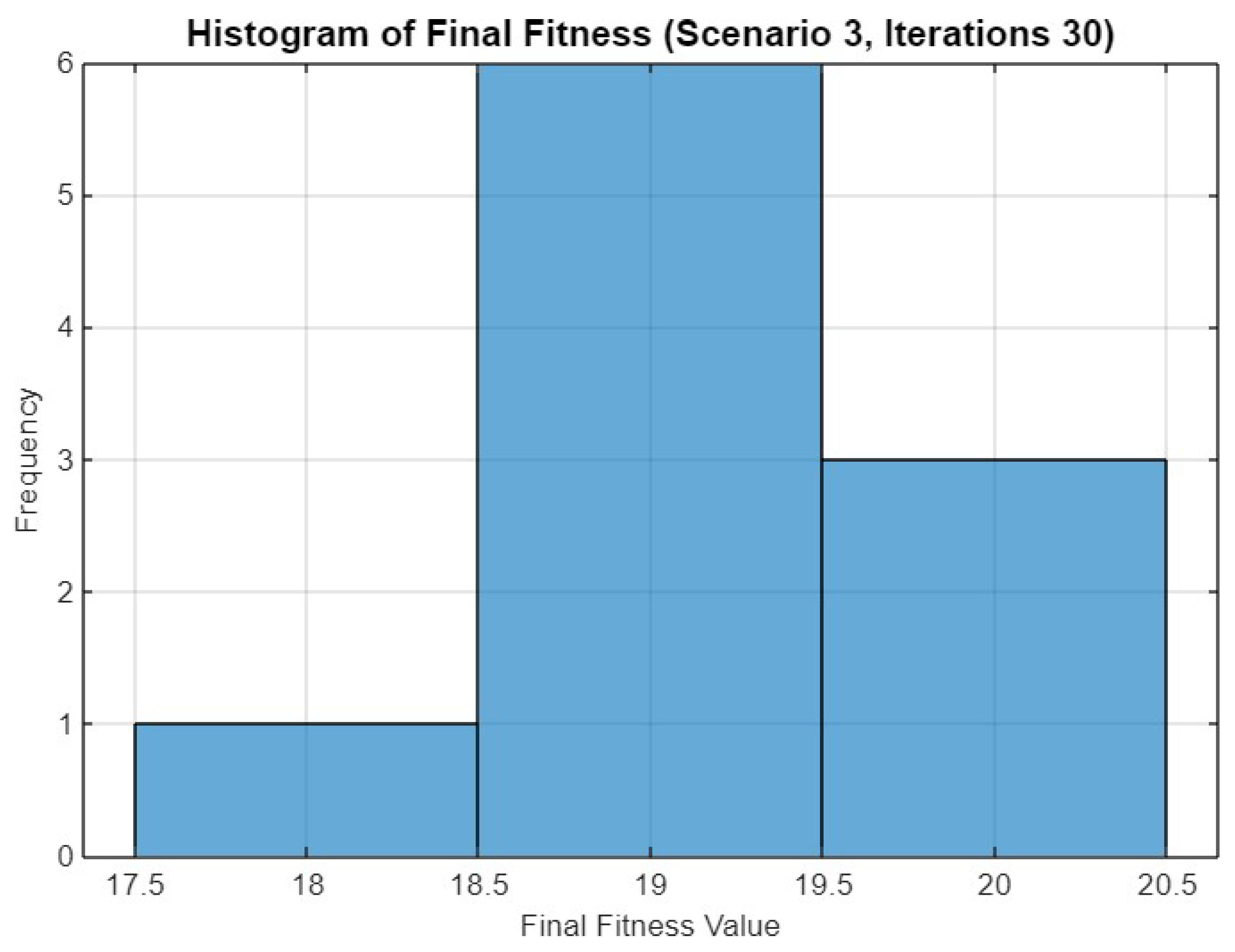
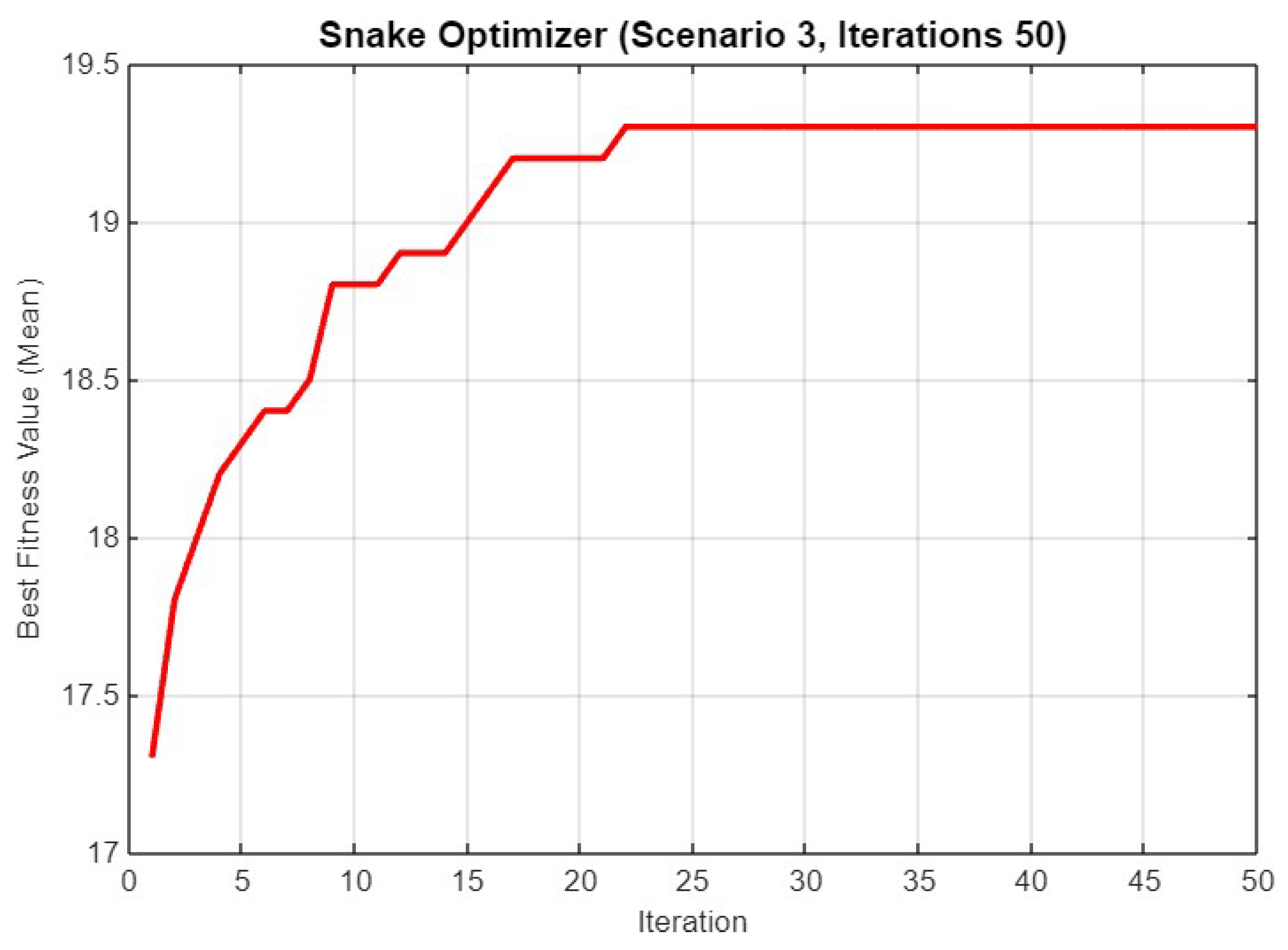
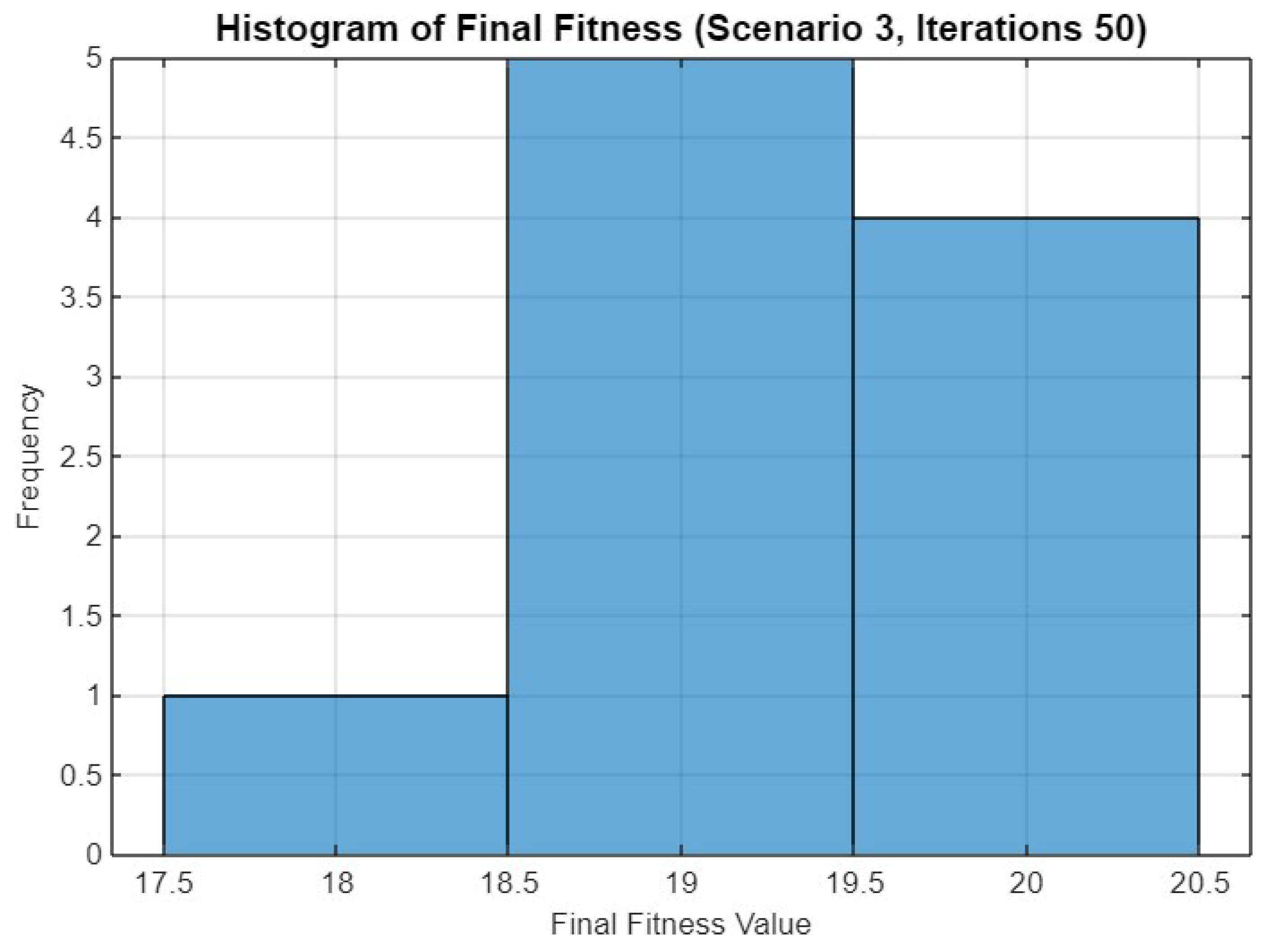
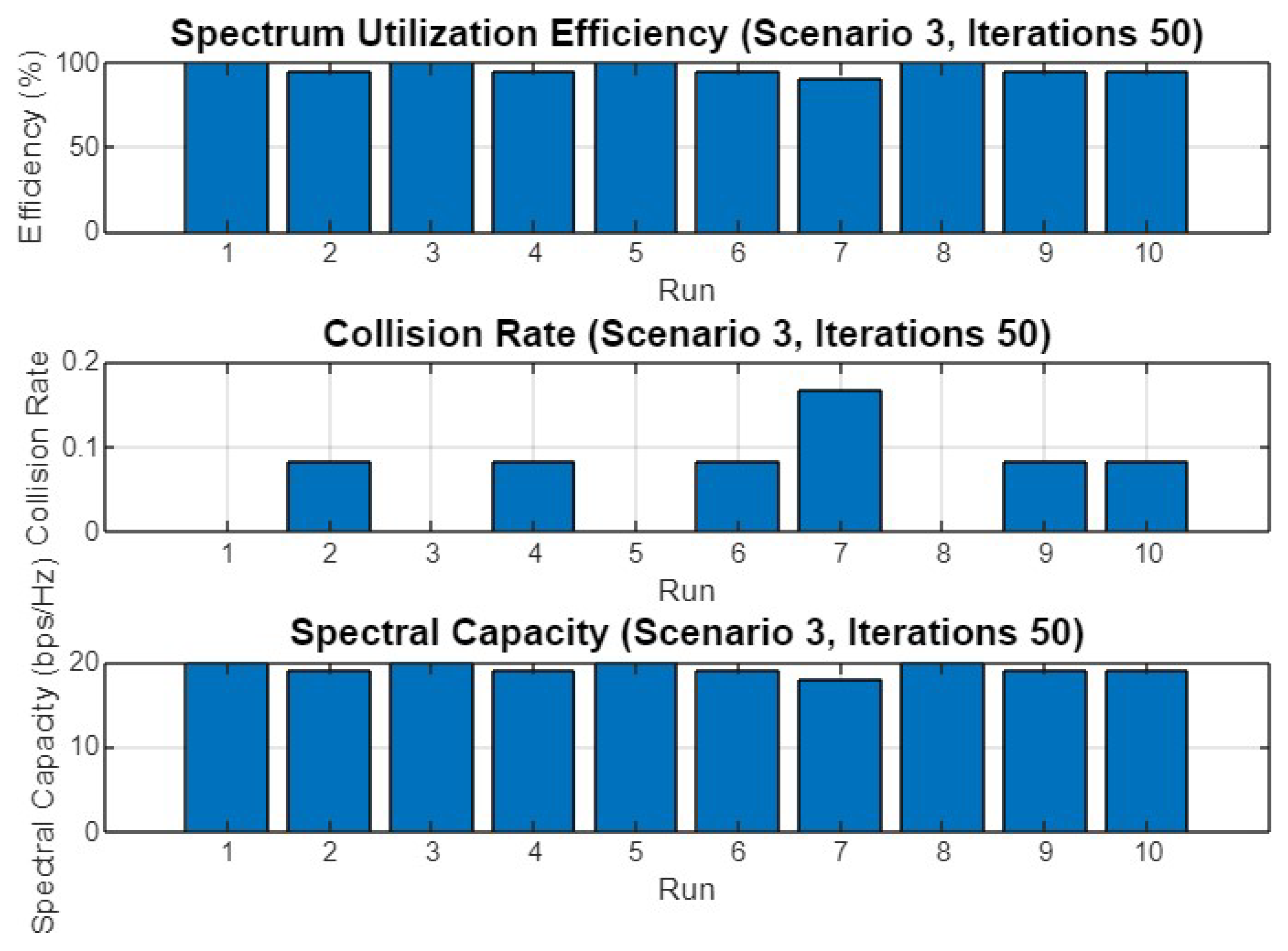
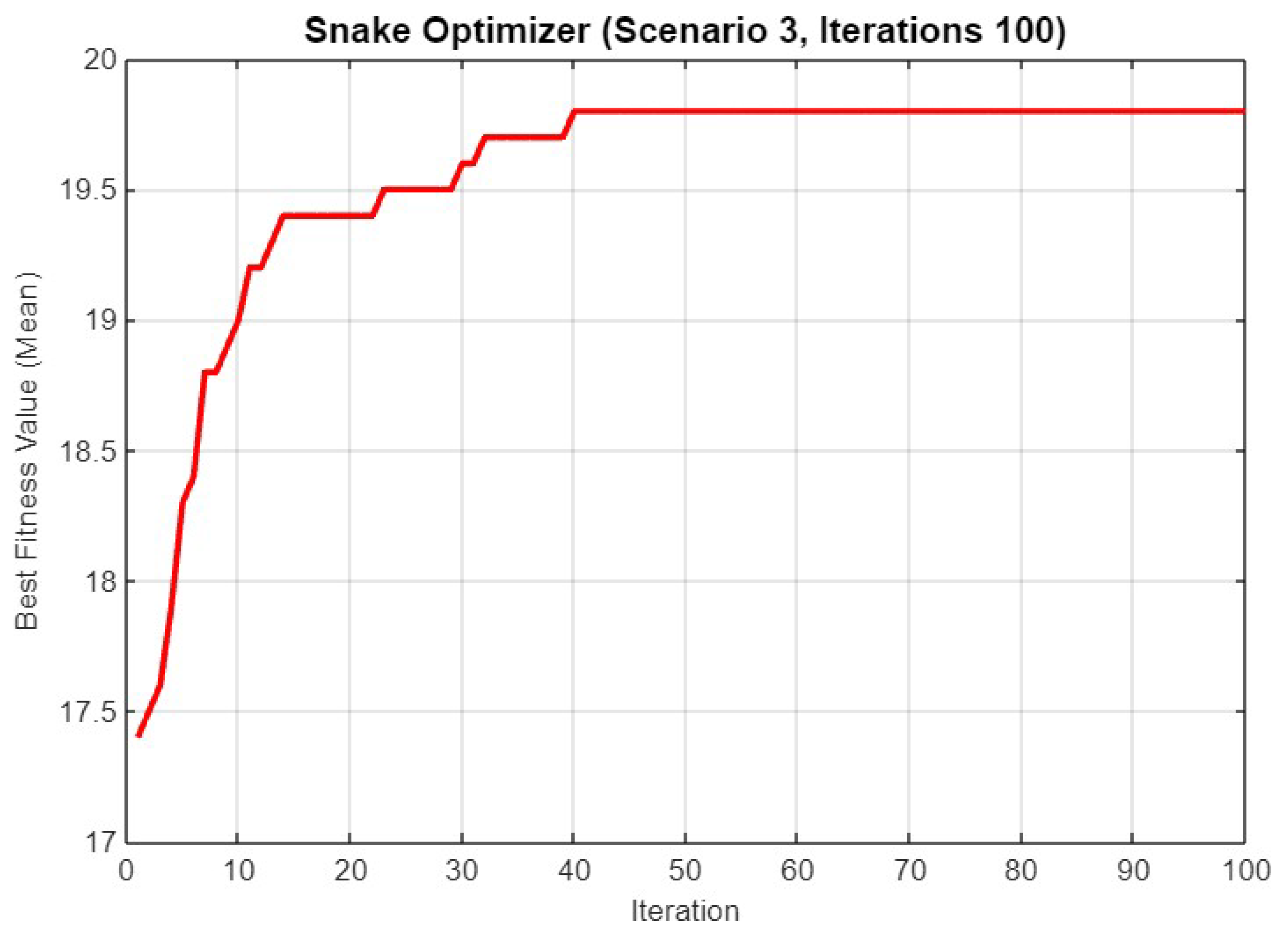
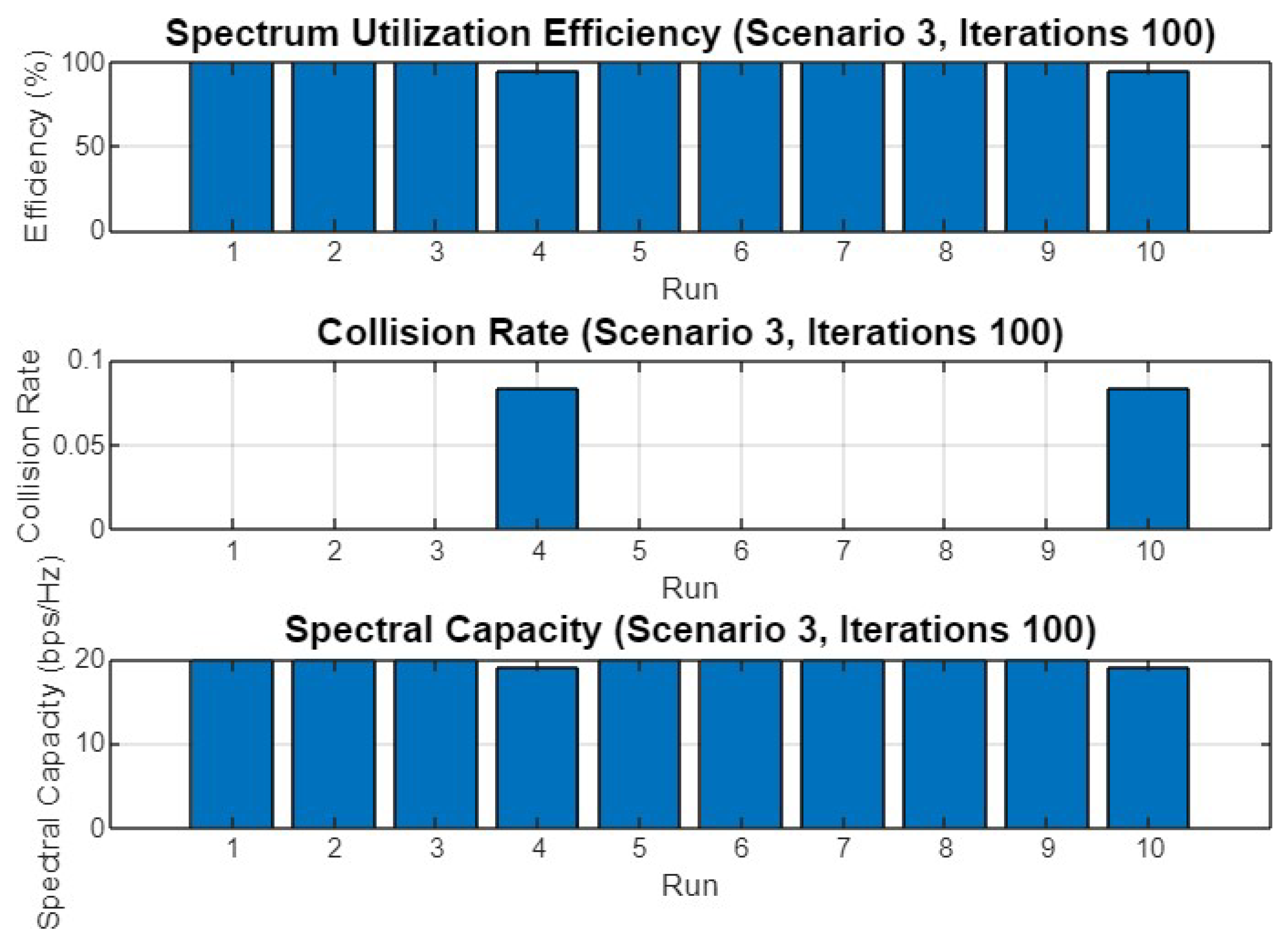
5.3. Experiment Result for Third Scenario
5.4. Discussion
5.4.1. Scenario 1
5.4.2. Scenario 2
5.4.3. Scenario 3
5.5. On the Scalability Evaluation with More than 30 Bands
5.6. Scalability Comparison in High-Band Scenario (30 Bands)
5.7. Statistical Significance Analysis Across Iterations and Scenarios
5.8. Integration and Computational Complexity
5.9. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jiang, C.; Zhang, H.; Ren, Y.; Han, Z.; Chen, K.C.; Hanzo, L. Machine Learning Paradigms for Next-Generation Wireless Networks. IEEE Wirel. Commun. 2017, 24, 98–105. [Google Scholar] [CrossRef]
- Wang, D.; Song, B.; Chen, D.; Du, X. Intelligent Cognitive Radio in 5G: AI-Based Hierarchical Cognitive Cellular Networks. IEEE Wirel. Commun. 2019, 26, 54–61. [Google Scholar] [CrossRef]
- Lu, Z.; Wang, C.; Wang, P.; Xu, W. 3D Deployment Optimization of Wireless Sensor Networks for Heterogeneous Functional Nodes. Sensors 2025, 25, 1366. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, W.; Song, B.; Du, X.; Guizani, M. Market-Based Model in CR-IoT: A Q-Probabilistic Multi-Agent Reinforcement Learning Approach. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 179–188. [Google Scholar] [CrossRef]
- Abbas, N.; Nasser, Y.; Ahmad, K.E. Recent Advances on Artificial Intelligence and Learning Techniques in Cognitive Radio Networks. EURASIP J. Wirel. Commun. Netw. 2015, 2015, 174. [Google Scholar] [CrossRef]
- Tanab, M.E.; Hamouda, W. Resource Allocation for Underlay Cognitive Radio Networks: A Survey. IEEE Commun. Surv. Tutor. 2017, 19, 1249–1276. [Google Scholar] [CrossRef]
- Jagatheesaperumal, S.K.; Ahmad, I.; Höyhtyä, M.; Khan, S.; Gurtov, A. Deep learning frameworks for cognitive radio networks: Review and open research challenges. J. Netw. Comput. Appl. 2025, 233, 104051. [Google Scholar] [CrossRef]
- Yang, H.; Chen, C.; Zhong, W.D. Cognitive Multi-Cell Visible Light Communication with Hybrid Underlay/Overlay Resource Allocation. IEEE Photonics Technol. Lett. 2018, 30, 1135–1138. [Google Scholar] [CrossRef]
- Kachroo, A.; Ekin, S. Impact of Secondary User Interference on Primary Network in Cognitive Radio Systems. In Proceedings of the 2018 IEEE 88th Vehicular Technology Conference (VTC-Fall), Chicago, IL, USA, 27–30 August 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Xu, W.; Qiu, R.; Cheng, J. Fair Optimal Resource Allocation in Cognitive Radio Networks with Co-Channel Interference Mitigation. IEEE Access 2018, 6, 37418–37429. [Google Scholar] [CrossRef]
- Wang, S.; Ge, M.; Zhao, W. Energy-Efficient Resource Allocation for OFDM-Based Cognitive Radio Networks. IEEE Trans. Commun. 2013, 61, 3181–3191. [Google Scholar] [CrossRef]
- Marques, A.G.; Lopez-Ramos, L.M.; Giannakis, G.B.; Ramos, J. Resource Allocation for Interweave and Underlay CRs Under Probability-of-Interference Constraints. IEEE J. Sel. Areas Commun. 2012, 30, 1922–1933. [Google Scholar] [CrossRef]
- Peng, M.; Zhang, K.; Jiang, J.; Wang, J.; Wang, W. Energy-Efficient Resource Assignment and Power Allocation in Heterogeneous Cloud Radio Access Networks. IEEE Trans. Veh. Technol. 2015, 64, 5275–5287. [Google Scholar] [CrossRef]
- Satria, M.B.; Mustika, I.W.; Widyawan. Resource Allocation in Cognitive Radio Networks Based on Modified Ant Colony Optimization. In Proceedings of the 2018 4th International Conference on Science and Technology (ICST), Yogyakarta, Indonesia, 7–8 August 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Khan, H.; Yoo, S.J. Multi-Objective Optimal Resource Allocation Using Particle Swarm Optimization in Cognitive Radio. In Proceedings of the 2018 IEEE Seventh International Conference on Communications and Electronics (ICCE), Hue, Vietnam, 18–20 July 2018; pp. 44–48. [Google Scholar] [CrossRef]
- Mallikarjuna Gowda, C.P.; Vijaya Kumar, T. Blocking Probabilities, Resource Allocation Problems and Optimal Solutions in Cognitive Radio Networks: A Survey. In Proceedings of the 2018 International Conference on Electrical, Electronics, Communication, Computer, and Optimization Techniques (ICEECCOT), Msyuru, India, 14–15 December 2018; pp. 1493–1498. [Google Scholar] [CrossRef]
- He, A.; Bae, K.K.; Newman, T.R.; Gaeddert, J.; Kim, K.; Menon, R.; Morales-Tirado, L.; Neel, J.J.; Zhao, Y.; Reed, J.H.; et al. A Survey of Artificial Intelligence for Cognitive Radios. IEEE Trans. Veh. Technol. 2010, 59, 1578–1592. [Google Scholar] [CrossRef]
- Zhou, X.; Sun, M.; Li, G.Y.; Fred Juang, B.H. Intelligent wireless communications enabled by cognitive radio and machine learning. China Commun. 2018, 15, 16–48. [Google Scholar] [CrossRef]
- Puspita, R.H.; Shah, S.D.A.; Lee, G.M.; Roh, B.H.; Oh, J.; Kang, S. Reinforcement Learning Based 5G Enabled Cognitive Radio Networks. In Proceedings of the 2019 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Republic of Korea, 16–18 October 2019; pp. 555–558. [Google Scholar] [CrossRef]
- AlQerm, I.; Shihada, B. Enhanced Online Q-Learning Scheme for Energy Efficient Power Allocation in Cognitive Radio Networks. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference (WCNC), Marrakesh, Morocco, 15–18 April 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, H.; Yang, N.; Huangfu, W.; Long, K.; Leung, V.C.M. Power Control Based on Deep Reinforcement Learning for Spectrum Sharing. IEEE Trans. Wirel. Commun. 2020, 19, 4209–4219. [Google Scholar] [CrossRef]
- Kaur, A.; Kumar, K. Energy-Efficient Resource Allocation in Cognitive Radio Networks Under Cooperative Multi-Agent Model-Free Reinforcement Learning Schemes. IEEE Trans. Netw. Serv. Manag. 2020, 17, 1337–1348. [Google Scholar] [CrossRef]
- Shen, Y.; Shi, Y.; Zhang, J.; Letaief, K.B. A Graph Neural Network Approach for Scalable Wireless Power Control. arXiv 2019, arXiv:1907.08487. [Google Scholar] [CrossRef]
- Lee, M.; Yu, G.; Li, G.Y. Graph Embedding-Based Wireless Link Scheduling with Few Training Samples. IEEE Trans. Wirel. Commun. 2021, 20, 2282–2294. [Google Scholar] [CrossRef]
- Garg, H. A hybrid PSO-GA algorithm for constrained optimization problems. Appl. Math. Comput. 2016, 274, 292–305. [Google Scholar] [CrossRef]
- Newman, T.R.; Barker, B.A.; Wyglinski, A.M.; Agah, A.; Evans, J.B.; Minden, G.J. Cognitive engine implementation for wireless multicarrier transceivers. Wirel. Commun. Mob. Comput. 2007, 7, 1129–1142. [Google Scholar] [CrossRef]
- Zhao, Z.; Xu, S.; Zheng, S.; Shang, J. Cognitive radio adaptation using particle swarm optimization. Wirel. Commun. Mob. Comput. 2009, 9, 875–881. [Google Scholar] [CrossRef]
- Pradhan, P.M. Design of cognitive radio engine using artificial bee colony algorithm. In Proceedings of the 2011 International Conference on Energy, Automation and Signal, Bhubaneswar, India, 28–30 December 2011; pp. 1–4. [Google Scholar] [CrossRef]
- Zhao, N.; Li, S.; Wu, Z. Cognitive Radio Engine Design Based on Ant Colony Optimization. Wirel. Pers. Commun. 2012, 65, 15–24. [Google Scholar] [CrossRef]
- Kaur, K.; Rattan, M.; Patterh, M.S. Optimization of Cognitive Radio System Using Simulated Annealing. Wirel. Pers. Commun. 2013, 71, 1283–1296. [Google Scholar] [CrossRef]
- Lagsaiar, L.; Shahrour, I.; Aljer, A.; Soulhi, A. Modular Software Architecture for Local Smart Building Servers. Sensors 2021, 21, 5810. [Google Scholar] [CrossRef] [PubMed]
- Ren, Y. On intersections and stable intersections of tropical hypersurfaces. arXiv 2023, arXiv:2302.12335. [Google Scholar] [CrossRef]
- Tukey, J.W. Comparing individual means in the analysis of variance. Biometrics 1949, 5, 99–114. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | n | m | k |
|---|---|---|---|
| 1 | 5 | 10 | 15 |
| 2 | 4 | 8 | 12 |
| 3 | 6 | 12 | 20 |
| Parameter | Value |
|---|---|
| Number of Secondary Users (SUs) | scenario.num_SUs |
| Number of Primary Users (PUs) | scenario.num_PUs |
| Number of Bands | scenario.num_bands |
| Iteration Counts | |
| Number of Runs | 10 |
| Max Iterations | iter_count |
| Population Size | Pop_Size |
| Best Fitness Value (Initial) | |
| Convergence Time (Initial) | max_iterations |
| Exploration Constant () | 0.05 |
| Exploitation Constant () | 2 |
| Temperature | |
| Food Quantity (Q) | |
| Fitness History (Initial) | |
| Spectral Capacity | 1 bps/Hz (per band) |
| Collision Rate (Final) | |
| Utilization Efficiency (Final) |
| Metric | Scenario 1 | Scenario 2 | Scenario 3 | Scenario 4 (30 Bands) |
|---|---|---|---|---|
| Iterations | 30/50/100 | 30/50/100 | 30/50/100 | 30/50/100 |
| Mean Final Fitness | 14.40/14.30/14.50 | 11.60/11.70/11.80 | 19.20/19.30/19.80 | 10.80/11.20/11.60 |
| Std Dev of Final Fitness | 0.52/0.48/0.53 | 0.52/0.48/0.42 | 0.63/0.67/0.42 | 0.71/0.60/0.48 |
| Mean Convergence Time (iterations) | 8.00/5.80/12.80 | 7.00/11.60/11.70 | 11.60/9.70/18.20 | 12.00/14.00/15.50 |
| Spectrum Utilization Efficiency (%) | 96.00/95.33/96.67 | 96.67/97.50/98.33 | 96.00/96.50/99.00 | 94.00/95.50/97.00 |
| Collision Rate | 0.06/0.07/0.05 | 0.05/0.04/0.03 | 0.07/0.06/0.02 | 0.08/0.06/0.04 |
| Spectral Capacity (bps/Hz) | 14.40/14.30/14.50 | 11.60/11.70/11.80 | 19.20/19.30/19.80 | 10.80/11.20/11.60 |
| Metric | SO (Proposed) | PSO | GA | ABC | Q-Learning |
|---|---|---|---|---|---|
| Mean Final Fitness | 11.20 | 10.50 | 10.10 | 10.40 | 9.80 |
| Convergence Iterations | 14.00 | 18.30 | 21.70 | 19.40 | 25.80 |
| Spectrum Utilization Efficiency (%) | 95.50 | 93.20 | 92.70 | 93.00 | 91.50 |
| Collision Rate | 0.06 | 0.08 | 0.09 | 0.08 | 0.12 |
| Spectral Capacity (bps/Hz) | 11.20 | 10.50 | 10.10 | 10.40 | 9.80 |
| Comparison | p-Value | Significant (p < 0.05) |
|---|---|---|
| Scenario 1: 30 vs. 100 iterations | 0.031 | Yes |
| Scenario 2: 30 vs. 50 iterations | 0.087 | No |
| Scenario 3: 50 vs. 100 iterations | 0.044 | Yes |
| Scenario 4: 30 vs. 100 iterations | 0.028 | Yes |
| Scenario 1 vs. Scenario 4 (100 iterations) | 0.015 | Yes |
| Scenario 2 vs. Scenario 3 (50 iterations) | 0.059 | No |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Farhi, H.; Messai, A.; Berghout, T. Enhancing Spectrum Utilization in Cognitive Radio Networks Using Reinforcement Learning with Snake Optimizer: A Meta-Heuristic Approach. Electronics 2025, 14, 2525. https://doi.org/10.3390/electronics14132525
Farhi H, Messai A, Berghout T. Enhancing Spectrum Utilization in Cognitive Radio Networks Using Reinforcement Learning with Snake Optimizer: A Meta-Heuristic Approach. Electronics. 2025; 14(13):2525. https://doi.org/10.3390/electronics14132525
Chicago/Turabian StyleFarhi, Haider, Abderraouf Messai, and Tarek Berghout. 2025. "Enhancing Spectrum Utilization in Cognitive Radio Networks Using Reinforcement Learning with Snake Optimizer: A Meta-Heuristic Approach" Electronics 14, no. 13: 2525. https://doi.org/10.3390/electronics14132525
APA StyleFarhi, H., Messai, A., & Berghout, T. (2025). Enhancing Spectrum Utilization in Cognitive Radio Networks Using Reinforcement Learning with Snake Optimizer: A Meta-Heuristic Approach. Electronics, 14(13), 2525. https://doi.org/10.3390/electronics14132525