Abstract
Semantic segmentation of remote sensing images is a fundamental task in geospatial analysis and Earth observation research, and has a wide range of applications in urban planning, land cover classification, and ecological monitoring. In complex geographic scenes, low target-background discriminability in overhead views (e.g., indistinct boundaries, ambiguous textures, and low contrast) significantly complicates local–global information modeling and results in blurred boundaries and classification errors in model predictions. To address this issue, in this paper, we proposed a novel Multi-Scale Local–Global Mamba Feature Pyramid Network (MLMFPN) through designing a local–global information synergy modeling strategy, and guided and enhanced the cross-scale contextual information interaction in the feature fusion process to obtain quality semantic features to be used as cues for precise semantic reasoning. The proposed MLMFPN comprises two core components: Local–Global Align Mamba Fusion (LGAMF) and Context-Aware Cross-attention Interaction Module (CCIM). Specifically, LGAMF designs a local-enhanced global information modeling through asymmetric convolution for synergistic modeling of the receptive fields in vertical and horizontal directions, and further introduces the Vision Mamba structure to facilitate local–global information fusion. CCIM introduces positional encoding and cross-attention mechanisms to enrich the global-spatial semantics representation during multi-scale context information interaction, thereby achieving refined segmentation. The proposed methods are evaluated on the ISPRS Potsdam and Vaihingen datasets and the outperformance in the results verifies the effectiveness of the proposed method.
1. Introduction
Semantic segmentation of remote sensing images (RSI) is a foundational technique in geospatial intelligence analysis, with extensive applications in land cover classification [1], urban planning [2], and ecological monitoring [3]. One of the fundamental challenges is the low target-background differentiation problem under complex background noise in RSI, which significantly impacts segmentation accuracy. Unlike natural images, due to variations in imaging platforms, spatial resolutions and geometric viewpoints cause objects of the same category to exhibit substantial differences in size, shape, and texture. In complex geographic scenes, such as urban areas with dense building clusters, intricate road networks, and mixed farmland regions, spatial dependencies and cross-scale occlusions among objects of different scales further complicate the segmentation task.
Early image segmentation methods primarily relied on edge detection operators (e.g., Sobel, Canny, and Prewitt) or pixel clustering techniques to delineate object boundaries and distinguish among different categories [4]. However, these methods exhibit poor performance and limited robustness when processing complex RSI scenes characterized by high background noise [5].
In recent years, deep learning-based methods have achieved remarkable advancements in RSI semantic segmentation. Fully Convolutional Networks (FCN) [6], which utilize convolutional neural networks for high-precision segmentation, demonstrate superior robustness and generalization capabilities. Subsequent models, such as the DeepLab [7] series, U-Net [8], and their variants, further enhanced feature extraction and multi-scale information fusion, achieving improved performance in complex RSI scenarios. However, CNN-based models are inherently constrained by their fixed receptive fields and local modeling biases, making it difficult to effectively capture global information in RSI with complex background noise, resulting in accuracy limitation [9]. With the popularity of the Vision Transformer (ViT) [10] in the field of computer vision, its powerful global modeling capabilities have propelled semantic segmentation of RSI, leading to the development of numerous ViT-based methods that achieve state-of-the-art performance. Several studies in other fields have followed suit, and a series of Transformer-based algorithms have emerged [11,12,13,14].
Currently, the mainstream segmentation models prefer the hybrid structure based on CNN and Transformers [15,16,17,18,19,20,21,22], expecting to integrate their complementary advantages in local–global feature modeling. For instance, UNetformer [15] integrates a self-attention branch for multi-scale contextual modeling and a convolutional branch for local spatial detail preservation for segmentation, thereby achieving balanced efficiency-accuracy tradeoffs through parallel feature fusion. LSENet [20] designs a spatial enhancement module that enhances the Swin Transformer for improved spatial feature extraction, thereby obtaining richer local semantic information. In pursuit of a finer pixel-level understanding, recent studies have gradually proposed refinements to pixel-level segmentation. HSDN [23] implements a hierarchical semantic feature disentanglement strategy via pixel-level modeling and clustering, and further introduces attention-guided masks to promote intra-semantic compactness, enhance inter-semantic discrimination, and correct boundary errors, thereby achieving improved segmentation performance. The MaskFormer [24] series unifies semantic, instance, and panoptic segmentation into mask classification tasks, adopting DETR-style [25,26] learnable query mechanisms for pixel-to-class set prediction, thus enabling unified segmentation through transformer-based mask representation learning. Mask2Former [27] advances mask classification segmentation by introducing query-guided localized attention and designing cross-resolution feature processing in the transformer decoder, effectively addressing small-object segmentation. Although these methods have demonstrated improved accuracy, they still exhibit several limitations. This limitation arises from the distinct feature modeling mechanisms of CNNs and Transformers, which hinder seamless integration via simple feature map fusion and lead to divergent semantic representations.
On one hand, CNNs leverage inductive biases from local receptive fields, rendering them well-suited for capturing fine-grained features such as edges and textures. However, their reliance on fixed kernel sizes limits the effective modeling of long-range contextual dependencies. Although techniques such as dilated convolutions [28], channel-wise attention [29], and large-kernel convolutions [30] have been introduced to enhance CNNs’ global modeling capacity, these models still struggle to segment objects with significant scale variations in complex remote sensing environments. In contrast, Transformer-based models employ self-attention mechanisms to model global semantic relationships, excelling at capturing long-range dependencies and spatial interactions [15]. However, the direct application of these models to image segmentation presents specific challenges. Converting images to sequences disrupts the spatial coherence of local structures, which is crucial for fine-grained segmentation. Additionally, since Transformer models prioritize global context across all stages, they often overlook local details, resulting in coarser segmentation outputs with less precise boundary delineation [17]. Effectively balancing local feature refinement and global semantic representation within a unified feature space remains a central research focus in semantic segmentation.
Feature Pyramid Networks (FPNs) [31] are widely recognized as an effective architecture that improves detection of objects across varying scales and aspect ratios and performs robustly in localizing targets against complex RSI backgrounds. Existing improvements to FPNs (such as PANet [32], UperNet [33]) often incorporate feature alignment [34], attention mechanisms [35], or efficient feature connection strategies [36] to enhance object localization. Semantic segmentation tasks require precise pixel delineation, which places higher demands on modeling of textures and spatial relationships, especially in local detail with global contextual integration [37]. While significant progress has been made in both semantic segmentation and multi-scale feature fusion, challenges remain—particularly in balancing local detail preservation with global context integration [37]. Semantic segmentation requires precise pixel-wise delineation, placing higher demands on fine-grained modeling of edges, textures, and spatial relationships. First, there exists a disconnect between high-level semantic features and low-level detail representations [38]. The abstraction process in high-level feature extraction often leads to the attenuation of fine-grained information, which negatively impacts the segmentation quality of small and intricate objects, exacerbating boundary localization errors [39]. Second, information exchange between different scales in FPNs is relatively limited, and its isolated processing of local contextual information weakens the ability to model complex target-background relationships. Recent work has focused on more adaptive fusion strategies. For instance, HRNet [40] maintains high-resolution representations throughout the network to preserve spatial details. Additionally, hybrid models that combine CNN-based local feature extraction with Transformer modules for global context have shown promise in dynamically fusing multi-scale information [41]. However, some progress has been made in semantic segmentation and multi-scale feature fusion, but challenges remain, especially in striking a balance between local detail and global contextual integration.
Since the introduction of the Vision Mamba [42], several studies have explored its application to semantic segmentation. Samba [43] employs an encoder–decoder architecture, utilizing Vision Mamba as the encoder for hierarchical feature extraction and UperNet [33] as the decoder, thereby synergistically combining global context modeling with fine-grained detail reconstruction. MBSSNet [44] introduces Vision Mamba and incorporates a cross-modal fusion module to merge multi-modal features from two parallel branches in a layer-wise manner, thereby enhancing the consistency of the fused feature representations. HMAFNet [45] designs a hybrid Mamba-Attention Fusion Network that leverages Vision Mamba to capture global feature representations across both spatial and channel dimensions during the encoding stage. Inspired by these Mamba-based works, we consider the introduction of Vision Mamba into FPN, which provides a powerful framework for collaborative local and global information fusion through a scanning modeling mechanism.
To address this issue, in this paper, we proposed a novelty Multi-Scale Local–Global Mamba Feature Pyramid Network (MLMFPN) through designing a local–global information synergy modeling strategy, guided, and enhanced the cross-scale contextual information interaction in the feature fusion process to obtain quality semantic features that are being used as cues for precise semantic segmentation. MLMFPN consists of two core components: Local–Global Align Mamba Fusion (LGAMF) and Context-Aware Cross-attention Interaction Module (CCIM). Specifically, LGAMF designs a local-enhanced global information modeling through asymmetric convolution for synergistic modeling of the receptive fields in vertical and horizontal directions, and further introduces the Vision Mamba structure to facilitate local–global information fusion. This architecture ensures consistent modeling of both global and local features, while Vision Mamba streamlines the information fusion process. CCIM introduces positional encoding and cross-attention mechanisms to enhance the representation global-spatial semantics representation during multi-scale context information interaction, thereby achieving refined segmentation. During this process, multi-level feature maps are connected to achieve hierarchical context feature alignment, promoting deeper cross-scale information interaction, thereby enhancing semantic understanding and improving segmentation accuracy. The proposed MLMFPN ensures consistent synergistic modeling of both global semantics and local details, enabling precise segmentation across varying object scales in remote sensing imagery.
2. Methodology
In this section, we first present the overall architecture of the proposed MLMFPN. Then, the two core components in MLMFPN, CCIM, and LGAMF are introduced in detail.
2.1. Overall
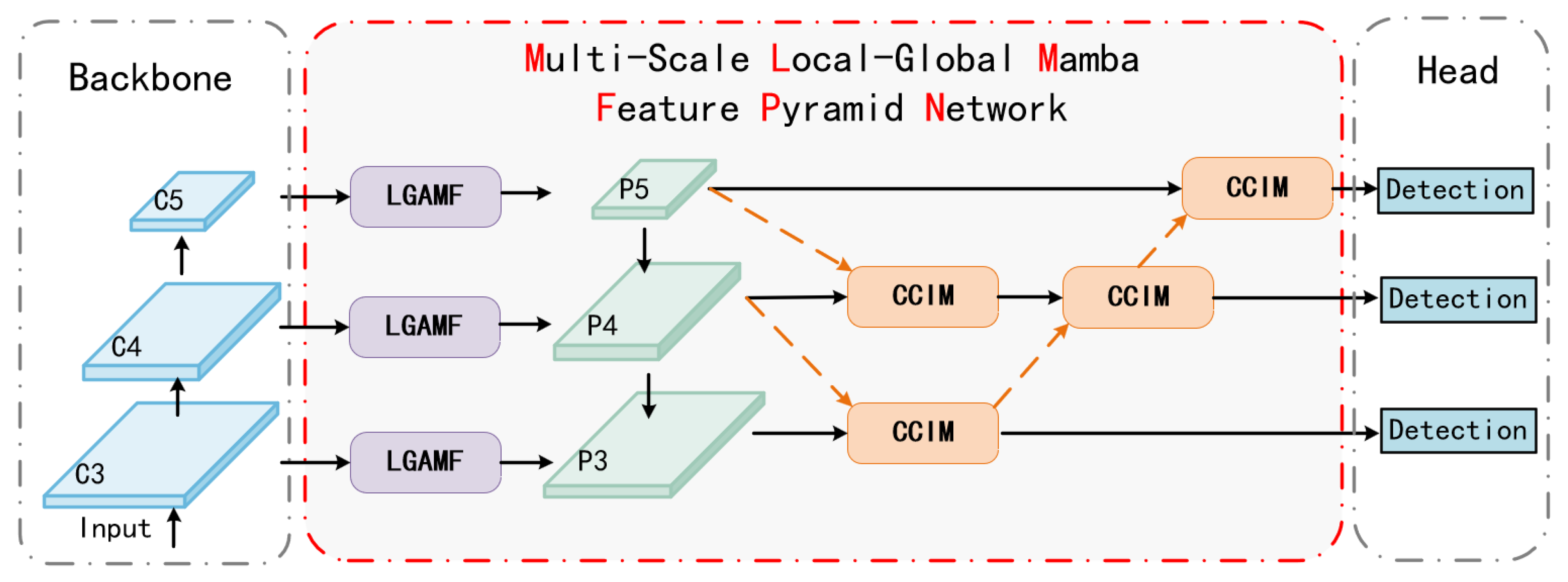
In order to learn multi-scale features for RSI, we proposed MLMFPN to enhance the Multi-Scale Local–Global information interaction and modeling for feature fusion. The overall structure of the proposed MLMFPN is shown in Figure 1. Let be the input image with the size of , and the number of channels is 3. After the feature extraction operation by the backbone network, the multi-layer feature maps are obtained. General feature extraction networks can all be used, such as ResNet [46], ViT [10], etc. In the subsequent implementation of this article, we recommend using the efficient Swin Transformer [47] as the backbone network to ensure high-quality feature map information. The denotes the feature map of the i-th layer, is the layer index. , , and are the dimension and number of channels of .
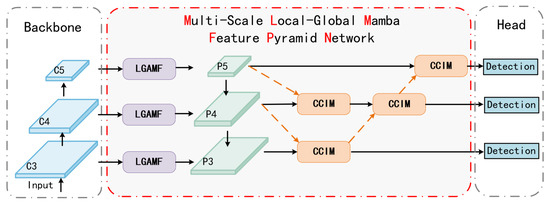
Figure 1.
The overall architecture of the proposed MLMFPN. MLMFPN is a generic feature fusion network featuring an efficient bi-directional feature fusion pathway and two core components: the Context-Aware Cross-attention Interaction Module (CCIM) and the Local–Global Align Mamba Fusion (LGAMF). CCIM introduces positional encoding and cross-attention mechanisms to enhance spatial semantic representation during context interaction, facilitating refined segmentation. LGAMF employs asymmetric convolution for global feature modeling across horizontal and vertical receptive fields and integrates Vision Mamba for local–global feature fusion. The Orange dashed lines indicate inputs for cross-level feature maps. The popular detector Mask2Former [27] is adopted as the baseline framework.
Here, the proposed MLMFPN is introduced to improve the feature fusion process. First, the LGAMF module receives the feature maps from the backbone network and enhances the fine-grained feature representation through local–global synergy modeling and channel-selective Mamba fusion, producing enhanced feature maps for multi-scale information interaction. By incorporating a positional encoding-enhanced cross-attention mechanism, the CCIM enables effective contextual interactions across multiple feature scales. As shown in the Figure 1, with layers , , and for example, result in the following calculation formula:
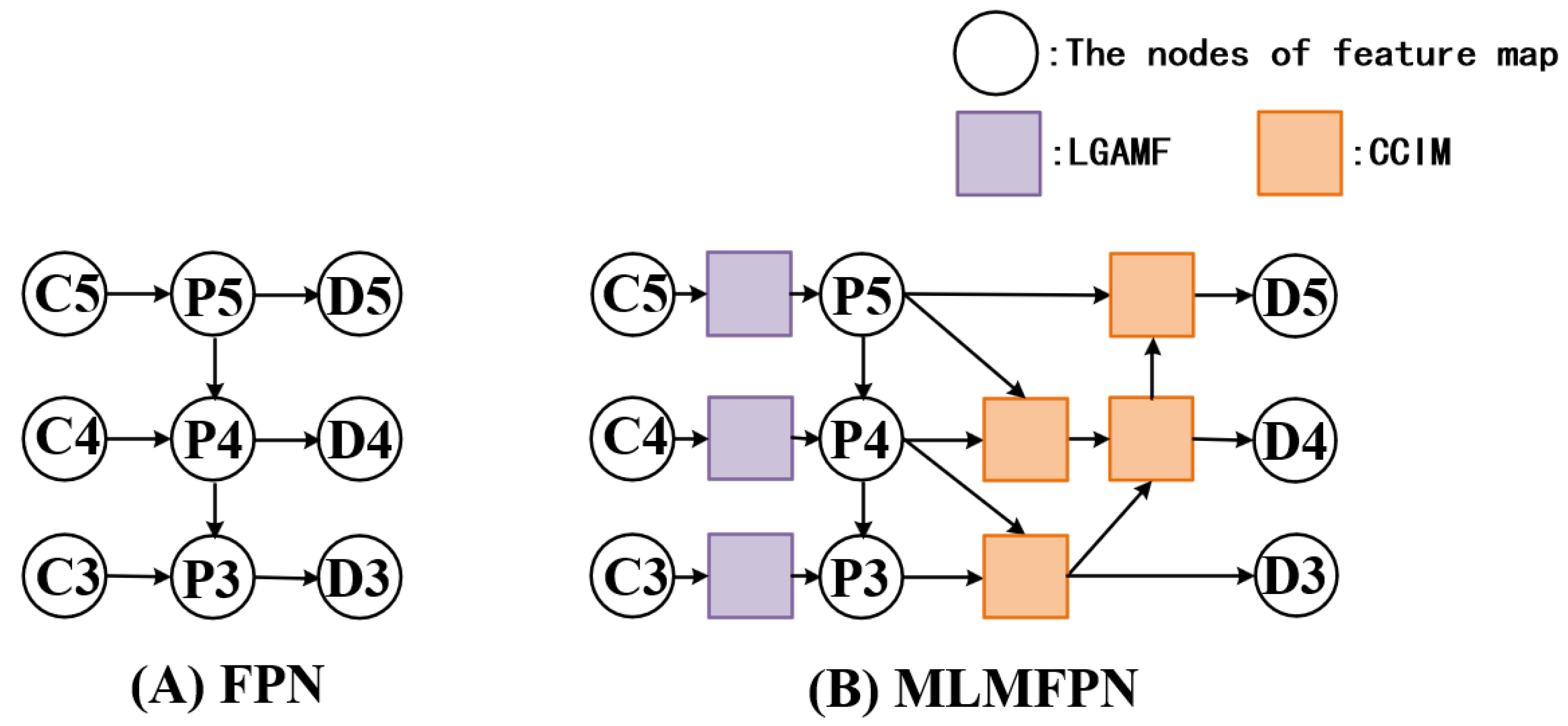
where is the proposed CCIM module. This cross-scale concatenation strategy references FPNFormer [37] and FPNFormer, enhances the interaction of multi-scale information, ensuring refined and detailed segmentation results. The proposed MLMFPN, aligning with the FPN decoding pipeline as shown in Figure 2, supported by LGAMF’s feature alignment and CCIM’s bidirectional fusion, provides a comprehensive framework for efficient multi-scale feature interaction. This approach significantly improves the model’s ability to capture fine spatial details and contextual semantics, ensuring superior segmentation performance.
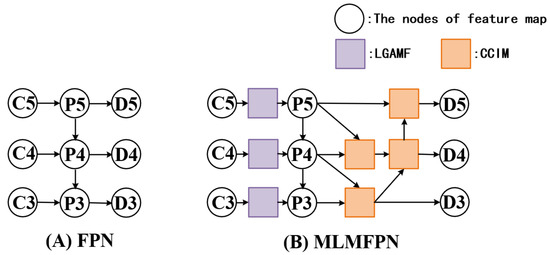
Figure 2.
Comparison diagram of abstract node structure of MLMFPN and typical FPN. The MLMFPN follows the classical FPN structure style and is optimized with the introduction of the LGAMF and CCIM modules. (A) FPN, (B) MLMFPN.
Finally, the detector obtains sufficient context information from the decoupled feature maps to improve detection and segmentation accuracy. For the downstream segmentation, MLMFPN forwards the fused feature maps to the segmentation heads, which produce the classification and mask information through the decoupling feature map.
2.2. Local–Global Align Mamba Fusion
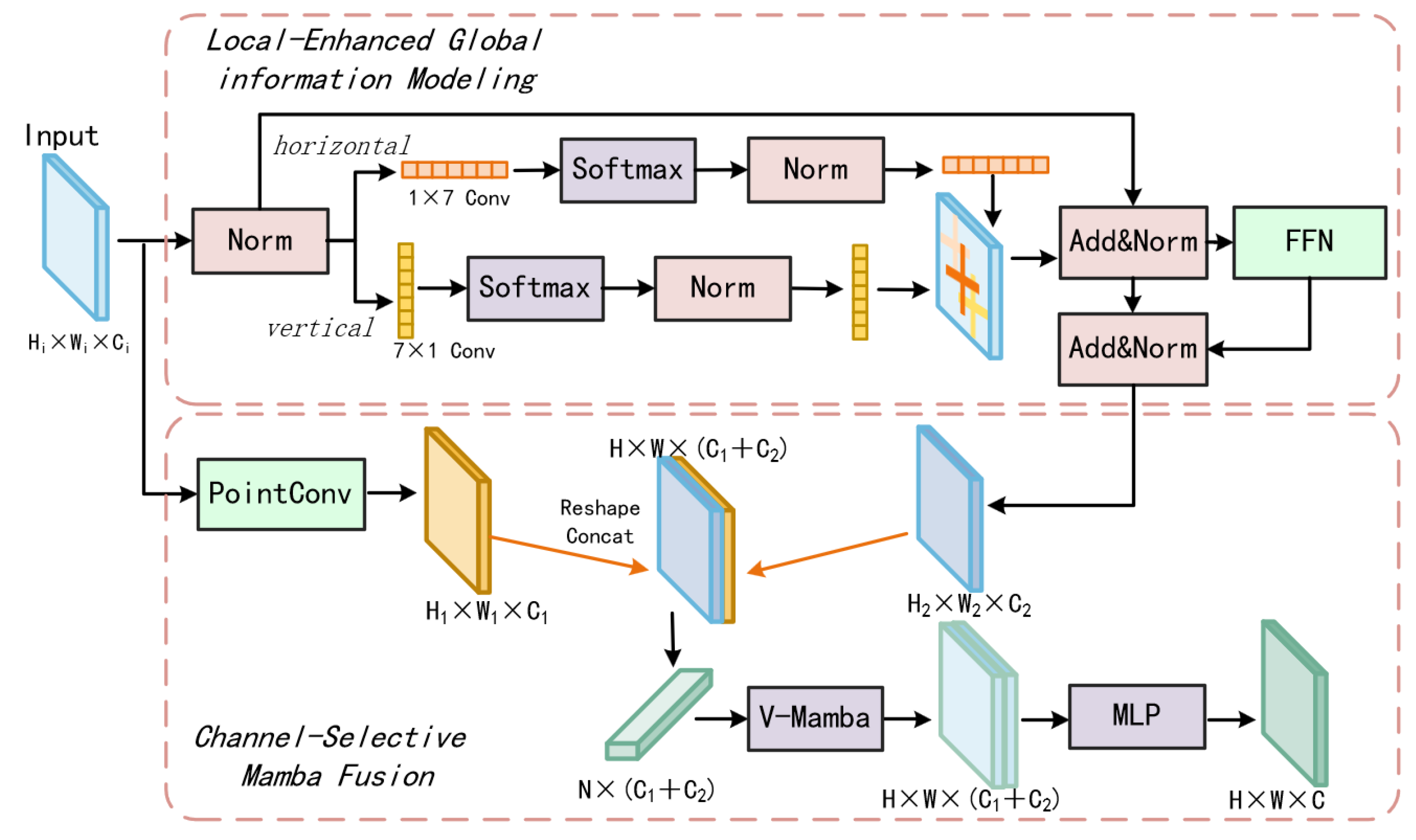
As shown in Figure 3, the LGAMF design two-branch components that synergizes local details with global contextual information: (1) a local-enhanced global information modeling based on dual-directional asymmetric convolutions for synergistic modeling of the receptive fields in vertical and horizontal directions, and (2) a channel selective strategy based on Vision Mamba for dynamic local–global feature interaction.
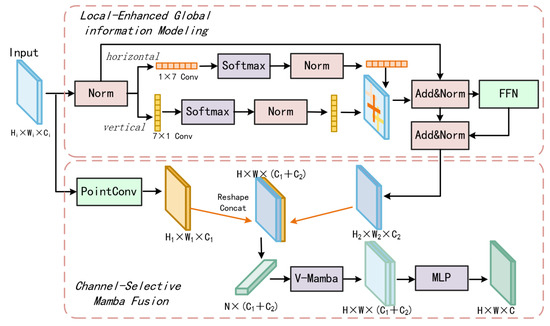
Figure 3.
The overall structure of the proposed LGAMF. Two core branches are designed in LGAMF, Local-Enhanced Global Information Modeling and Channel-Selective Mamba Fusion, and are constructed to model and integrate local and global information. The first branch is based on dual-directional asymmetric convolutions capture local-enhanced global information. The second branch is based on the Vision Mamba to efficiently fuse the global information obtained from the first branch, and the local information obtained from pointwise convolution.
Local-Enhanced Global Information Modeling: Inspired by ACNet [48], We consider the application of horizontal and vertical asymmetric convolution to model global information, which can effectively approximate the sensory field of large kernels while significantly reducing parameters and computational overhead.
The first component constructs hierarchical global representations through asymmetric convolutions that model information along horizontal and vertical axes. Horizontal convolution layers model row-wise long-range dependencies, while vertical counterparts encode columnar structural relationships.
where ⊗ indicate the channel computation, represents the convolution parameter. means the transposed convolutions. is used to present weight information in a single direction to obtain the attention graph of the highlighted target representation. In the local-enhanced global information modeling component, we suggest two depth-wise asymmetric convolutions ( and ) to ensure a sufficiently large directional receptive field and capture horizontal and vertical context independently. Compared to a single 7 × 7 depth-wise convolution () parameters, our parallel branch requires only () weights in total, yielding about 71% reduction in parameters. Although the two branches run simultaneously, their combined receptive coverage still matches that of a kernel—each branch “scans” one axis, and their element-wise fusion integrates these directional cues. The added Softmax normalization and BatchNorm introduce negligible overhead but allow the network to adaptively emphasize the most salient horizontal or vertical patterns. This parallel asymmetric design thus achieves large, direction-aware context aggregation with minimal extra cost.
The fused output is obtained through element-wise summation , which integrates the adaptive weights of the horizontal and vertical receptive field after , and forms comprehensive global features that preserve spatial coherence. A residual connection further injects original local features into the global stream. Through layer-wise stacking, the receptive field is progressively expanded in a structured and direction-aware manner. This enables the model to capture long-range spatial dependencies along both row-wise and column-wise directions while preserving local details via residual connections, resulting in global features enhanced by directional local context.
By designing the Dual-Directional Asymmetric Convolution based module to capture long-range dependencies with linear computational cost, it preserves structural sensitivity for linear features in remote sensing and uses Softmax to adaptively highlight salient directional cues, thereby enhancing the global information modeling.
where indicate the Feed-Forward Network, which is used to refine channel information. In this hybrid architecture, the horizontal convolution kernels exhibit an expanded receptive field along the row-wise dimension, enabling effective modeling of long-range horizontal spatial dependencies, while their vertical counterparts emphasize column-wise contextual relationships. This dual-directional feature modeling process enhances the model’s capacity to capture the global features with robust contextual-relevance through complementary directional feature integration.
Channel-Selective Mamba Fusion: The second component enables adaptive local–global fusion through Vision Mamba and Multilayer Perceptron (MLP). First, 1 × 1 point convolutions project the backbone features into compact local descriptors , reducing channel redundancy. These local features are then concatenated with the global features from the first submodule, forming hybrid representations that encapsulate multi-scale information. The following is the calculation formula:
where is the Vision Mamba block and denotes the feature concat operation along the channel dimension. In the channel-selective Mamba fusion process, Vision Mamba receives two complementary inputs: local features computed after pointwise convolution from the backbone network, and global features extracted through the previously described dual-directional asymmetric convolutions. These representations are concatenated to form hybrid feature maps that encapsulate both fine-grained details and broad contextual information.
The core fusion process based on Vision Mamba blocks, which integrate the local–global interaction information by the 2D Selective Scan (SS2D), and achieving context-aware feature recalibration across spatial and channel dimensions. Specifically, the SS2D operation in Vision Mamba is grounded in a state-space modeling framework, which enables efficient information focus and context propagation across both spatial and channel dimensions, dynamically facilitating and integrating local and global representations.
2.3. Context-Aware Cross-Attention Interaction Module
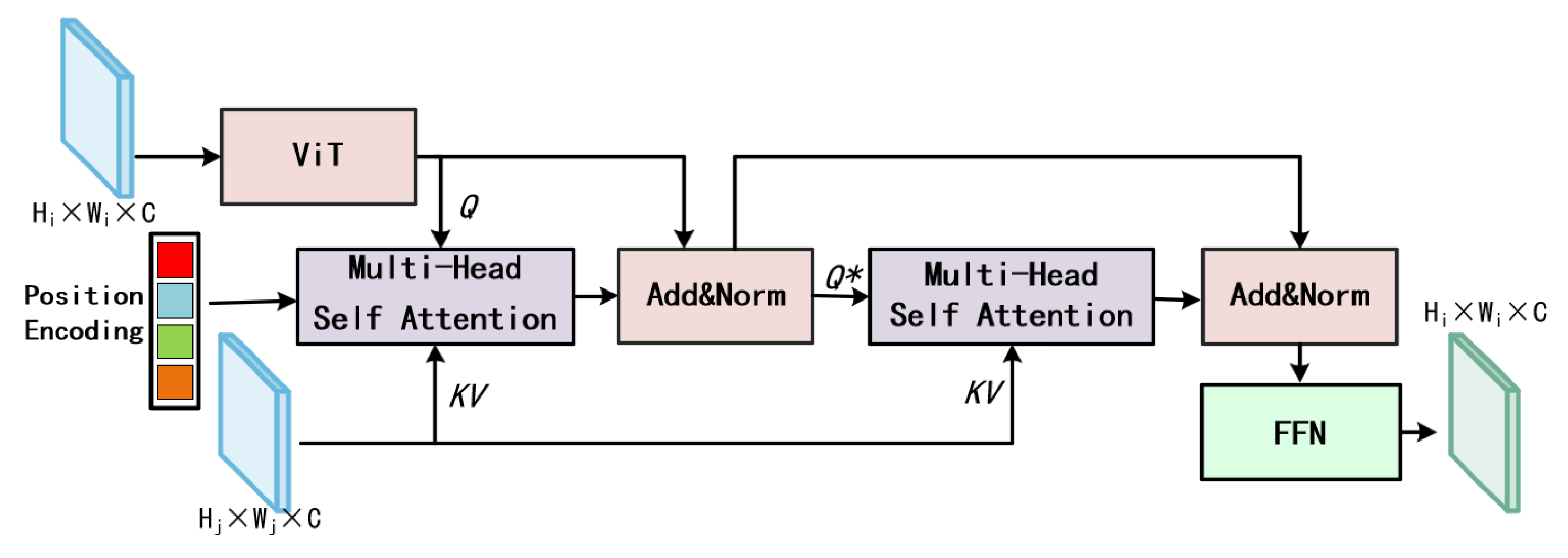
As shown in Figure 4, the Context-Aware Cross-attention Interaction Module (CCIM) is designed to enhance fine-grained segmentation by integrating positional encoding and cross-attention mechanisms to strengthen the semantic representation of latent targets. Inspired by FPNFormer [37], the CCIM leveraging the ViT block and positional encoding captures long-term information and deeper semantic relationships. We adopt sinusoidal position embedding [49] and the following calculation formula:
among them, i represents the row or column position of the feature vector, j represents the mapping control parameters of the feature vector, and d represents the feature dimension of the feature vector. After processing, a ViT block is used to enhances the semantic representation of the base query feature map from the LGAMF process. At its core, cross-attention is used to explicit correlations between global and spatial features across multi-level feature maps from different resolutions. is obtained by the following calculation formula:
where d denotes the length of the sequence. denotes the linear transformation. During this process, the high-resolution feature maps queries attend to low-resolution keys/values, enabling each spatial position to aggregate complementary semantics from both local details and global Semantic. Cross-attention based on multi-head self attention, enables a more effective interplay between queries, keys, and values, thereby preserving spatial relationships and enriching the underlying semantic details. In CCIM, multi-level feature maps are connected to achieve hierarchical context feature alignment, promoting deeper cross-scale information interaction, thereby enhancing semantic understanding and improving segmentation accuracy. Ultimately, by fusing multi-scale contextual information and refining inter-feature dependencies, CCIM significantly improves the precision of segmentation results.
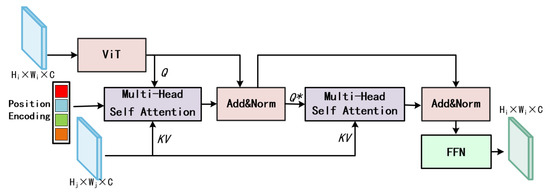
Figure 4.
The overall structure of the proposed CCIM, which consists of residual stacked multi-head attention. CCIM receives feature maps from different layers, which are processed by ViT and position encoding respectively and then enter into the multi-head attention computation.
3. Experiments
In this section, experiments on publicly available and challenging RSI datasets are conducted to verify the effectiveness of our proposed MLMFPN. Details of the experiment setup, ablation study, comparison experiment, and visualization analysis are presented in the following subsections.
3.1. Experimental Setting
3.1.1. Datasets
We used two large semantic segmentation datasets of RSI in our experiments, ISPRS Potsdam [50] and ISPRS Vaihingen [51]. Among them, ISPRS Potsdam consists of 38 high-resolution aerial images (6000 × 6000 pixels), and the ISPRS Vaihingen dataset consists of 33 high-resolution images (average 2500 × 2000 pixels). Both have the same distribution of instance categories-impervious surfaces, buildings, low vegetation, tree, car, and clutter. In the formal training, validation, and testing phases, we use only the RGB bands as well as the five foregrounds. In our experiments, we used the official pre-processed data by cropping the images into 512 × 512 segments and applying data enhancement strategies including horizontal and vertical flipping, random scaling and cropping, and random mosaic.
3.1.2. Implementation Details
Unless otherwise specified, we employ the Swin Transformer [47] pre-trained on ImageNet as the backbone network. For optimization, we use the AdamW [52] optimizer with a base learning rate of 0.0001 and a weight decay of 0.05. To ensure training stability, we adopt the Poly learning rate strategy (min = 0, power = 0.9) and train for 80,000 iterations across all datasets. All experiments were conducted on a system equipped with 2 × NVIDIA GeForce RTX 4090 (24 GB memory each).
3.1.3. Evaluation Metrics
For evaluating the segmentation model accuracy, we employ the widely used statistical indices: mean F1 score (mF1) and mean Intersection over Union (mIoU). Specifically, we compute the IoU score for the each foreground categories in the datasets and obtain the mIoU, to evaluate the model’s predict performance on the specific categorie and the overall task. We do not compute categories whose data are labeled as “clutter” or “background”, which means that they will not be recorded in the experimental tables, but will be shown in the inference visualization section. In addition, we use the parameters and Frames Per Second (FPS) to evaluate the efficiency detection benchmarks.
3.2. Experimental Results
In our implementation, we select Mask2Former as our baseline segmentation framework due to its proven effectiveness on natural-image benchmarks. For the feature extraction, We adopt the Swin Transformer (pre-trained on ImageNet) as the backbone of Mask2Former to extract hierarchical deep features. This choice is made to ensure architectural consistency with our proposed modules—particularly the CCIM, which relies on cross-attention mechanisms that benefit from the sequence-style token representations (to strengthen this semantic sequence representation, positional encoding was introduced in CCIM). Thus, the use of Swin Transformer is an intentional configuration within the Mask2Former framework to maintain compatibility and maximize performance on RSI tasks. In addition, the standard configuration of Mask2Former employs simple upsampling and concatenation in the decoder or uses a traditional Feature Pyramid Network (FPN) to generate multi-scale feature maps for mask prediction. In contrast, our proposed MLMFPN replaces the standard FPN in Mask2Former, which introduces two novel modules—Local-Enhanced Global Modeling (LGAMF) and the Context-Aware Cross-Attention Interaction Module (CCIM)—which jointly model global semantics and local details, thereby enabling precise segmentation across a wide range of object scales.
The detailed ablation experiment and effectiveness verification compared with other advanced model will be analyzed in the following text.
3.2.1. Ablation Study
The ablation study in Table 1 demonstrates the facilitating impact of the proposed modules on the Mask2Former baseline. The basic Mask2Former achieved 85.38 mIoU and 91.98 mF1 on ISPRS Potsdam datasets. Specifically, the CCIM module leverages cross-attention for feature interaction, enhances the quality of multi-scale context integration by effectively fusing features across different scales. This improvement is reflected in the increase of mIoU from 85.38% to 85.54% and mF1 from 91.98% to 92.06%. Building on this, the LGAMF module introduces a comprehensive local–global modeling mechanism that further refines feature representations by capturing fine-grained local details as well as broader global context. When LGAMF is combined with CCIM, the model benefits from a more balanced and robust feature integration, leading to a further performance boost with mIoU rising to 85.88% and mF1 to 92.2%. In summary, while CCIM enhances the cross-scale feature interaction quality during the multi-scale context enhancement process, the LGAMF complements the feature map by modeling local and global contexts.

Table 1.
Ablation study experiments in ISPRS Potsdam datasets. We select Mask2Former as the baseline framework and test the facilitation of component modules. “✓” means the proposed module is used. ‘*’ denotes the optimized segmentation framework.
In addition, we compare model parameters and inference speed in Table 2, using the same Swin Transformer (base size about 344 (M)) as the backbone and evaluate on the ISPRS Potsdam dataset. The results show that while our MLMFPN introduces additional parameters (668 (M) vs. 421 (M)), due to its dual-branch design and attention mechanisms, it achieves improved segmentation performance (mIoU +0.50% and mF1 +0.29%). The inference speed remains acceptable at 27.42 FPS, demonstrating a reasonable trade-off between accuracy and efficiency. This confirms that the performance gain brought by MLMFPN justifies the added computational cost, especially in scenarios requiring precise segmentation of complex remote sensing scenes.
Table 2.
Comparison of the number of model parameters and FPS. We select Swin Transformer base-size (344 (M)) as the backbone network and tested the detectors in the ISPRS Potsdam dataset. ‘-w,MLMFPN’ means the model improved by the proposed method.
3.2.2. Effectiveness Verification
To demonstrate the effectiveness and advancement of the proposed method in this article, we compared it with mainstream semantic segmentation models in RSI. The results are shown in Table 3 and Table 4.
Among the comparison methods, several hybrid CNN–Transformer architectures have demonstrated strong performance, including STransFuse [16], ST-UNet [17], UNetformer [15], and TCNet [22]. WSSS [53] and KFRNet [54] leverage weakly supervised annotations to reduce labeling costs. EMRT [19], CMTFNet [55], SegFormer [41], and LSENet [20] focus on efficient local–global context enhancement strategies. Samba [43] builds upon the Vision Mamba framework for segmentation, while MaskFormer [24] and Mask2Former [27] represent advance DETR-style [25,26] image segmentation models using pixel-level mask prediction.
The experimental results on the ISPRS Potsdam and Vaihingen datasets demonstrate that our method significantly enhances the performance of the baseline Mask2Former model, achieving state-of-the-art segmentation accuracy. On the Potsdam dataset, the improved model attains 85.88% mIoU and 92.27% mF1, outperforming the baseline Mask2Former (85.38% mIoU, 91.98% mF1) by +0.50% and +0.29%, respectively. It also surpasses recent methods such as TCNet (85.00% mIoU) and KFRNet (83.96% mIoU), with notable improvements in fine-grained object segmentation, particularly for the “Car” class (92.29% IoU, +0.61% over baseline). The proposed MLMFPN optimized Mask2Former achieved advanced segmentation accuracy performance on all three lists of Impervious surface, Low vegetation, and Car. The impervious surface and low vegetation classes generally exhibit strong texture and edge consistency, which aligns well with our LGAMF module’s directional enhancement and CCIM’s fine-grained fusion of local–global context.
For the Vaihingen dataset, our method elevates the mIoU and mF1 to 80.88% and 89.24%, marking gains of +0.24% and +0.14% compared to the baseline. The “Low vegetation” category achieves a 72.76% IoU (+0.64% improvement), exceeding the performance of contemporary approaches like MSTNet-S [21] (81.36% mIoU) and GAGNet-S [56] (80.84% mIoU). These results validate that our targeted optimization strategy effectively enhances multi-class segmentation precision while maintaining model generalizability.
Table 3.
Comparison experiments with other advanced segmentation models. We select the popular semantic segmentation model Mask2Former as the baseline and validate it on ISPRS Potsdam dataset. ‘-w,MLMFPN’ means the model improved by the proposed method. Every class-wise Iou is shown in table and bold text indicates the highest score in the column.
Table 3.
Comparison experiments with other advanced segmentation models. We select the popular semantic segmentation model Mask2Former as the baseline and validate it on ISPRS Potsdam dataset. ‘-w,MLMFPN’ means the model improved by the proposed method. Every class-wise Iou is shown in table and bold text indicates the highest score in the column.
| Methods | Venue | Impervious Surface | Building | Low Vegetation | Tree | Car | mIoU | mF1 |
|---|---|---|---|---|---|---|---|---|
| STransFuse [16] | JSTARS2021 | 83.93 | 90.44 | 74.72 | 75.63 | 86.61 | 82.27 | 90.48 |
| ST-UNet [17] | TGRS2022 | 79.19 | 86.63 | 67.89 | 66.37 | 79.77 | 75.94 | 86.13 |
| WSSS [53] | TGRS2023 | 85.91 | 91.57 | 75.35 | 76.82 | 88.86 | 83.70 | 90.98 |
| EMRT [19] | TGRS2023 | 85.34 | 91.11 | 74.62 | 76.38 | 86.43 | 82.78 | 90.59 |
| BIBED-Seg [18] | JSTARS2023 | 87.40 | 90.40 | 75.30 | 79.20 | 67.30 | 79.92 | - |
| HSDN [23] | TGRS2023 | 78.86 | 77.24 | 72.85 | 61.68 | 69.60 | 72.05 | 83.60 |
| Samba [43] | Heliyon2024 | 84.45 | 90.06 | 74.37 | 74.98 | 87.61 | 82.29 | 90.15 |
| LSENet [20] | GRSL2024 | 80.87 | 88.82 | 70.60 | 71.92 | 80.68 | 78.58 | 87.85 |
| KFRNet [54] | GRSL2024 | 86.09 | 91.66 | 75.50 | 77.24 | 89.30 | 83.96 | 91.15 |
| MSTNet-S [21] | TGRS2024 | 82.50 | 89.76 | 73.83 | 73.82 | 90.46 | 75.55 | - |
| TCNet [22] | TGRS2024 | 86.74 | 94.20 | 76.75 | 76.66 | 90.63 | 85.00 | 91.73 |
| LESNet [20] | GRSL2024 | 80.87 | 88.82 | 70.60 | 71.92 | 80.68 | 78.58 | 87.85 |
| Lu [57] | TGRS2024 | 82.87 | 88.23 | 71.03 | 67.49 | 83.49 | 78.62 | - |
| GAGNet-S [56] | TGRS2024 | 83.41 | 89.43 | 73.89 | 73.90 | 89.91 | 82.11 | - |
| LSENet [20] | GRSL2024 | 80.87 | 88.82 | 70.60 | 71.92 | 80.68 | 78.58 | 87.85 |
| SegFormer [41] | NIPS2021 | 86.44 | 93.05 | 76.63 | 78.55 | 90.17 | 84.96 | 91.74 |
| Mask2Former [27] | CVPR2022 | 86.55 | 92.50 | 76.41 | 79.75 | 91.68 | 85.38 | 91.98 |
| Mask2Former (-w,MLMFPN) | 87.78 | 93.14 | 77.05 | 79.14 | 92.29 | 85.88 | 92.27 |
Table 4.
Comparison experiments with other advanced segmentation models. We select the popular semantic segmentation model Mask2Former as the baseline and validate it on ISPRS Vaihingen dataset. ‘-w,MLMFPN’ means the model improved by the proposed method. Every class-wise Iou is shown in table and bold text indicates the highest score in the column.
Table 4.
Comparison experiments with other advanced segmentation models. We select the popular semantic segmentation model Mask2Former as the baseline and validate it on ISPRS Vaihingen dataset. ‘-w,MLMFPN’ means the model improved by the proposed method. Every class-wise Iou is shown in table and bold text indicates the highest score in the column.
| Methods | Venue | Impervious Surface | Building | Low Vegetation | Tree | Car | mIoU | mF1 |
|---|---|---|---|---|---|---|---|---|
| UNetformer [15] | ISPRS2022 | 85.13 | 92.58 | 66.66 | 83.29 | 82.27 | 81.98 | 89.85 |
| ST-UNet [17] | TGRS2022 | 76.36 | 82.98 | 57.79 | 72.53 | 61.48 | 70.23 | 82.15 |
| CMTFNet [55] | TGRS2023 | 84.67 | 92.07 | 68.07 | 83.50 | 82.17 | 82.10 | 89.96 |
| HSDN [23] | TGRS2023 | 76.14 | 85.85 | 65.67 | 70.12 | 55.35 | 70.63 | 82.36 |
| BIBED-Seg [18] | JSTARS2023 | 70.60 | 76.10 | 63.00 | 67.80 | 62.30 | 67.96 | - |
| LSENet [20] | GRSL2024 | 77.74 | 84.26 | 62.83 | 75.99 | 62.11 | 72.59 | 83.82 |
| Samba [43] | Heliyon2024 | 81.67 | 87.26 | 65.82 | 77.93 | 55.10 | 73.56 | 84.23 |
| Lu [57] | TGRS2024 | 76.14 | 82.92 | 62.18 | 72.55 | 52.75 | 69.31 | - |
| GAGNet-S [56] | TGRS2024 | 85.80 | 92.04 | 68.63 | 79.69 | 78.01 | 80.84 | - |
| MSTNet-S [21] | TGRS2024 | 85.52 | 93.29 | 68.40 | 79.31 | 80.31 | 81.36 | - |
| SegFormer [41] | NIPS2021 | 84.88 | 90.57 | 70.62 | 79.49 | 70.34 | 79.18 | 88.16 |
| MaskFormer [24] | NIPS2021 | 85.78 | 90.72 | 70.78 | 80.20 | 75.28 | 80.55 | 89.06 |
| Mask2Former [27] | CVPR2022 | 85.78 | 91.59 | 72.12 | 80.70 | 73.02 | 80.64 | 89.10 |
| Mask2Former (-w,MLMFPN) | 86.24 | 91.88 | 72.76 | 80.14 | 73.38 | 80.88 | 89.24 |
3.2.3. Visualization Analysis
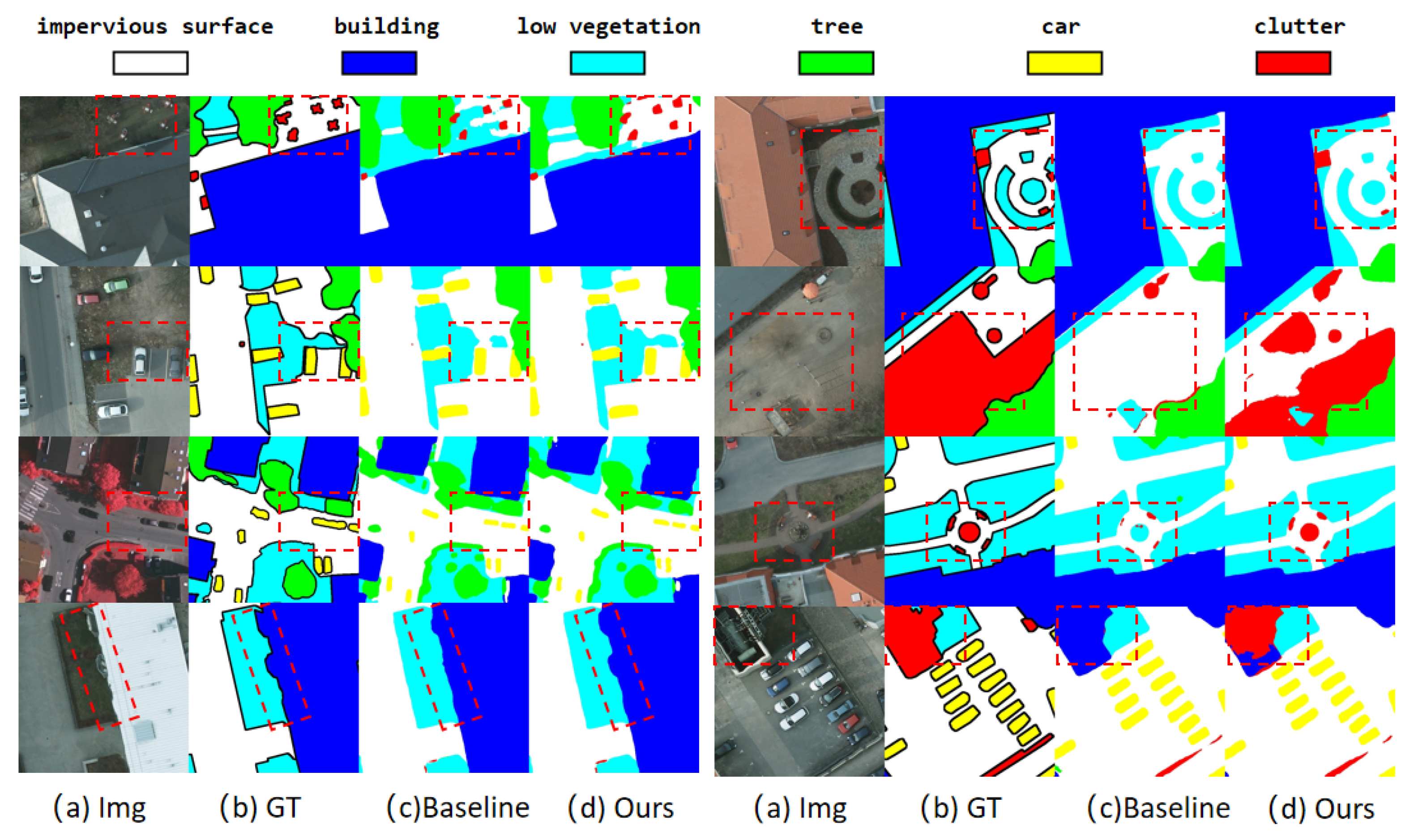
We have selected some scenes from the RSI segmentation dataset as examples for visualization and analysis, to illustrate the facilitation of our approach. As shown in Figure 5, the red rectangular box in the figure indicates the part that emphasizes the contrast. Our network accurately isolates vehicles under occlusion and buildings with irregular footprints, effectively suppressing pseudo-features from cluttered backgrounds like parking lots and vegetation mosaics. In addition. the proposed multi-scale contextual interaction mechanism enables precise delineation of object contours, notably recovering fragmented building edges in dense urban areas and maintaining wheel outlines of closely parked vehicles. Benefiting from CCIM contextual optimization in MLMFPN, each piece of spatial information in both high- and low-resolution queries aggregates complementary semantics from local details and global contexts. In addition, LGAMF enhances local–global information interaction and aggregation, allowing the network to notice fragmented regions and segment them accurately.
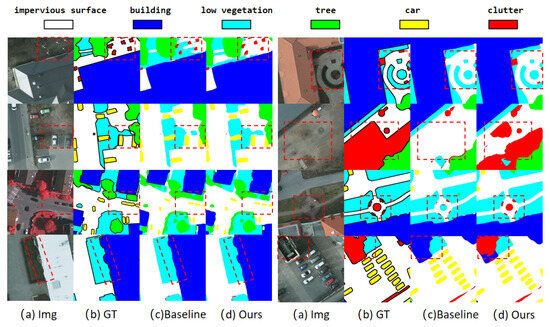
Figure 5.
Visualization of detection results. We select some typical scenarios about targets with complex backgrounds to demonstrate the prediction performance of the proposed methods.
4. Conclusions
To address the challenge of low target background discrimination in remote sensing semantic segmentation, we propose MLMFPN, a novel Multi-Scale Local–Global Mamba Feature Pyramid Network designed to enhance context-aware semantic reasoning by integrating fine-grained spatial features and multi-scale contextual information during feature fusion. By designing a local–global feature modeling approach based on asymmetric convolutional and Vision Mamba, we strengthen the extraction and interaction of local and global information and fully exploit contextual information through a cross-attention mechanism in the multi-scale fusion process, thereby providing cues for accurate semantic segmentation. The proposed MLMFPN ensures consistent synergistic modeling of both global semantics and local details, enabling precise segmentation across varying object scales in remote sensing imagery. Extensive experiments on the ISPRS Potsdam and Vaihingen datasets validate the superiority of the proposed method. There may be some possible limitations in this study. First, there is still room for improvement in the model’s ability to model the dynamics of extreme scale targets (e.g., mega-span infrastructures with tiny vehicles); second, highly disordered semantic interference (e.g., construction site clutter) in complex scenes may affect the discriminative nature of direction-sensitive features; in addition, the texture degradation caused by ultra-low resolution inputs needs to be further investigated. Future work will explore deformable orientation convolution and resolution adaptive fusion mechanisms to address the above challenges.
Author Contributions
Methodology, Q.M.; Writing—original draft, H.L.; Writing—review and editing, Y.J. and X.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by National Natural Science Foundation of China (No. 62476040) and the Fundamental Research Funds for the Central Universities, China (DUT24GF311).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request. The dataset used for testing the algorithms in this paper is the publicly available remote sensing image detection dataset ISPRS Potsdam and ISPRS Vaihingen, which can be downloaded from https://www.isprs.org/resources/datasets/benchmarks/UrbanSemLab (accessed on 18 June 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CNN | Convolutional Neural Networks |
| ViT | Vision Transformer |
| MLMFPN | Multi-Scale Local–Global Mamba Feature Pyramid Network |
| CCIM | Context-Aware Cross-attention Interaction Module |
| LGAMF | Local–Global Align Mamba Fusion |
References
- Fan, Z.; Zhan, T.; Gao, Z.; Li, R.; Liu, Y.; Zhang, L.; Jin, Z.; Xu, S. Land cover classification of resources survey remote sensing images based on segmentation model. IEEE Access 2022, 10, 56267–56281. [Google Scholar] [CrossRef]
- Jia, P.; Chen, C.; Zhang, D.; Sang, Y.; Zhang, L. Semantic segmentation of deep learning remote sensing images based on band combination principle: Application in urban planning and land use. Comput. Commun. 2024, 217, 97–106. [Google Scholar] [CrossRef]
- Wang, R.; Sun, Y.; Zong, J.; Wang, Y.; Cao, X.; Wang, Y.; Cheng, X.; Zhang, W. Remote sensing application in ecological restoration monitoring: A systematic review. Remote Sens. 2024, 16, 2204. [Google Scholar] [CrossRef]
- Su, T.; Li, H.; Zhang, S.; Li, Y. Image segmentation using mean shift for extracting croplands from high-resolution remote sensing imagery. Remote Sens. Lett. 2015, 6, 952–961. [Google Scholar] [CrossRef]
- Kumari, M.; Kaul, A. Deep learning techniques for remote sensing image scene classification: A comprehensive review, current challenges, and future directions. Concurr. Comput. Pract. Exp. 2023, 35, e7733. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical image computing and computer-assisted intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Li, Z.; Wang, Y.; Zhang, N.; Zhang, Y.; Zhao, Z.; Xu, D.; Ben, G.; Gao, Y. Deep learning-based object detection techniques for remote sensing images: A survey. Remote Sens. 2022, 14, 2385. [Google Scholar] [CrossRef]
- Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, C.; Cao, R.; Wang, R. Learning discriminative topological structure information representation for 2D shape and social network classification via persistent homology. Knowl.-Based Syst. 2025, 311, 113125. [Google Scholar] [CrossRef]
- Wang, C.; He, S.; Wu, M.; Lam, S.K.; Tiwari, P.; Gao, X. Looking Clearer with Text: A Hierarchical Context Blending Network for Occluded Person Re-Identification. IEEE Trans. Inf. Forensics Secur. 2025, 20, 4296–4307. [Google Scholar] [CrossRef]
- Zhao, T.; Fu, C.; Song, W.; Sham, C.W. RGGC-UNet: Accurate deep learning framework for signet ring cell semantic segmentation in pathological images. Bioengineering 2023, 11, 16. [Google Scholar] [CrossRef] [PubMed]
- Gu, Y.; Fu, C.; Song, W.; Wang, X.; Chen, J. RTLinearFormer: Semantic segmentation with lightweight linear attentions. Neurocomputing 2025, 625, 129489. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Gao, L.; Liu, H.; Yang, M.; Chen, L.; Wan, Y.; Xiao, Z.; Qian, Y. STransFuse: Fusing swin transformer and convolutional neural network for remote sensing image semantic segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10990–11003. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin transformer embedding UNet for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408715. [Google Scholar] [CrossRef]
- Sui, B.; Cao, Y.; Bai, X.; Zhang, S.; Wu, R. BIBED-Seg: Block-in-block edge detection network for guiding semantic segmentation task of high-resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 1531–1549. [Google Scholar] [CrossRef]
- Xiao, T.; Liu, Y.; Huang, Y.; Li, M.; Yang, G. Enhancing multiscale representations with transformer for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5605116. [Google Scholar] [CrossRef]
- Ding, R.X.; Xu, Y.H.; Liu, J.; Zhou, W.; Chen, C. LSENet: Local and Spatial Enhancement to Improve the Semantic Segmentation of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2024, 21, 7506005. [Google Scholar] [CrossRef]
- Zhou, W.; Li, Y.; Huang, J.; Liu, Y.; Jiang, Q. MSTNet-KD: Multilevel transfer networks using knowledge distillation for the dense prediction of remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4504612. [Google Scholar] [CrossRef]
- Zhang, L.; Tan, Z.; Zhang, G.; Zhang, W.; Li, Z. Learn more and learn useful: Truncation Compensation Network for Semantic Segmentation of High-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4403814. [Google Scholar]
- Zheng, C.; Nie, J.; Wang, Z.; Song, N.; Wang, J.; Wei, Z. High-order semantic decoupling network for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5401415. [Google Scholar] [CrossRef]
- Cheng, B.; Schwing, A.; Kirillov, A. Per-pixel classification is not all you need for semantic segmentation. Adv. Neural Inf. Process. Syst. 2021, 34, 17864–17875. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Computer Vision–ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1290–1299. [Google Scholar]
- Gomes, R.; Rozario, P.; Adhikari, N. Deep learning optimization in remote sensing image segmentation using dilated convolutions and ShuffleNet. In Proceedings of the 2021 IEEE international conference on electro information Technology (EIT), Mt. Pleasant, MI, USA, 14–15 May 2021; pp. 244–249. [Google Scholar]
- Liu, R.; Tao, F.; Liu, X.; Na, J.; Leng, H.; Wu, J.; Zhou, T. RAANet: A residual ASPP with attention framework for semantic segmentation of high-resolution remote sensing images. Remote Sens. 2022, 14, 3109. [Google Scholar] [CrossRef]
- Liu, G.; Liu, C.; Wu, X.; Li, Y.; Zhang, X.; Xu, J. Optimization of Remote-Sensing Image-Segmentation Decoder Based on Multi-Dilation and Large-Kernel Convolution. Remote Sens. 2024, 16, 2851. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified perceptual parsing for scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar]
- Li, Z.; Li, E.; Xu, T.; Samat, A.; Liu, W. Feature alignment FPN for oriented object detection in remote sensing images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6001705. [Google Scholar] [CrossRef]
- Hu, M.; Li, Y.; Fang, L.; Wang, S. A2-FPN: Attention aggregation based feature pyramid network for instance segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15343–15352. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Tian, Y.; Zhang, M.; Li, J.; Li, Y.; Yang, H.; Li, W. FPNFormer: Rethink the method of processing the rotation-invariance and rotation-equivariance on arbitrary-oriented object detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5605610. [Google Scholar] [CrossRef]
- Ding, Y.; Ma, Z.; Wen, S.; Xie, J.; Chang, D.; Si, Z.; Wu, M.; Ling, H. AP-CNN: Weakly supervised attention pyramid convolutional neural network for fine-grained visual classification. IEEE Trans. Image Process. 2021, 30, 2826–2836. [Google Scholar] [CrossRef]
- Chen, Y.; Zhu, X.; Li, Y.; Wei, Y.; Ye, L. Enhanced semantic feature pyramid network for small object detection. Signal Processing: Image Commun. 2023, 113, 116919. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, J.; Hoi, S.C. Deep learning for image super-resolution: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3365–3387. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision mamba: Efficient visual representation learning with bidirectional state space model. In Proceedings of the 41st International Conference on Machine Learning, ICML’24, Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Zhu, Q.; Cai, Y.; Fang, Y.; Yang, Y.; Chen, C.; Fan, L.; Nguyen, A. Samba: Semantic segmentation of remotely sensed images with state space model. Heliyon 2024, 10, e38495. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Liu, Z.; Liu, S.; Wang, H. MBSSNet: A Mamba-Based Joint Semantic Segmentation Network for Optical and SAR Images. IEEE Geosci. Remote Sens. Lett. 2025, 22, 6004305. [Google Scholar] [CrossRef]
- Sun, H.; Liu, J.; Yang, J.; Wu, Z. HMAFNet: Hybrid Mamba-Attention Fusion Network for Remote Sensing Image Semantic Segmentation. IEEE Geosci. Remote Sens. Lett. 2025, 22, 8001405. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Ding, X.; Guo, Y.; Ding, G.; Han, J. Acnet: Strengthening the kernel skeletons for powerful cnn via asymmetric convolution blocks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1911–1920. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Available online: https://www.isprs.org/resources/datasets/benchmarks/UrbanSemLab/2d-sem-label-potsdam.aspx (accessed on 18 June 2025).
- Available online: https://www.isprs.org/resources/datasets/benchmarks/UrbanSemLab/2d-sem-label-vaihingen.aspx (accessed on 18 June 2025).
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Li, Z.; Zhang, X.; Xiao, P. One model is enough: Toward multiclass weakly supervised remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4503513. [Google Scholar] [CrossRef]
- Wang, H.; Li, X.; Huo, L.Z. Key Feature Repairing based on Self-Supervised for Remote Sensing Semantic Segmentation. IEEE Geosci. Remote Sens. Lett. 2024, 21, 5001505. [Google Scholar] [CrossRef]
- Wu, H.; Huang, P.; Zhang, M.; Tang, W.; Yu, X. CMTFNet: CNN and multiscale transformer fusion network for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 2004612. [Google Scholar] [CrossRef]
- Zhou, W.; Fan, X.; Yan, W.; Shan, S.; Jiang, Q.; Hwang, J.N. Graph attention guidance network with knowledge distillation for semantic segmentation of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4506015. [Google Scholar] [CrossRef]
- Lu, X.; Jiang, Z.; Zhang, H. Weakly Supervised Remote Sensing Image Semantic Segmentation with Pseudo Label Noise Suppression. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5406912. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).