

Enhancing Bug Assignment with Developer-Specific Feature Extraction and Hybrid Deep Learning

Abstract
1. Introduction
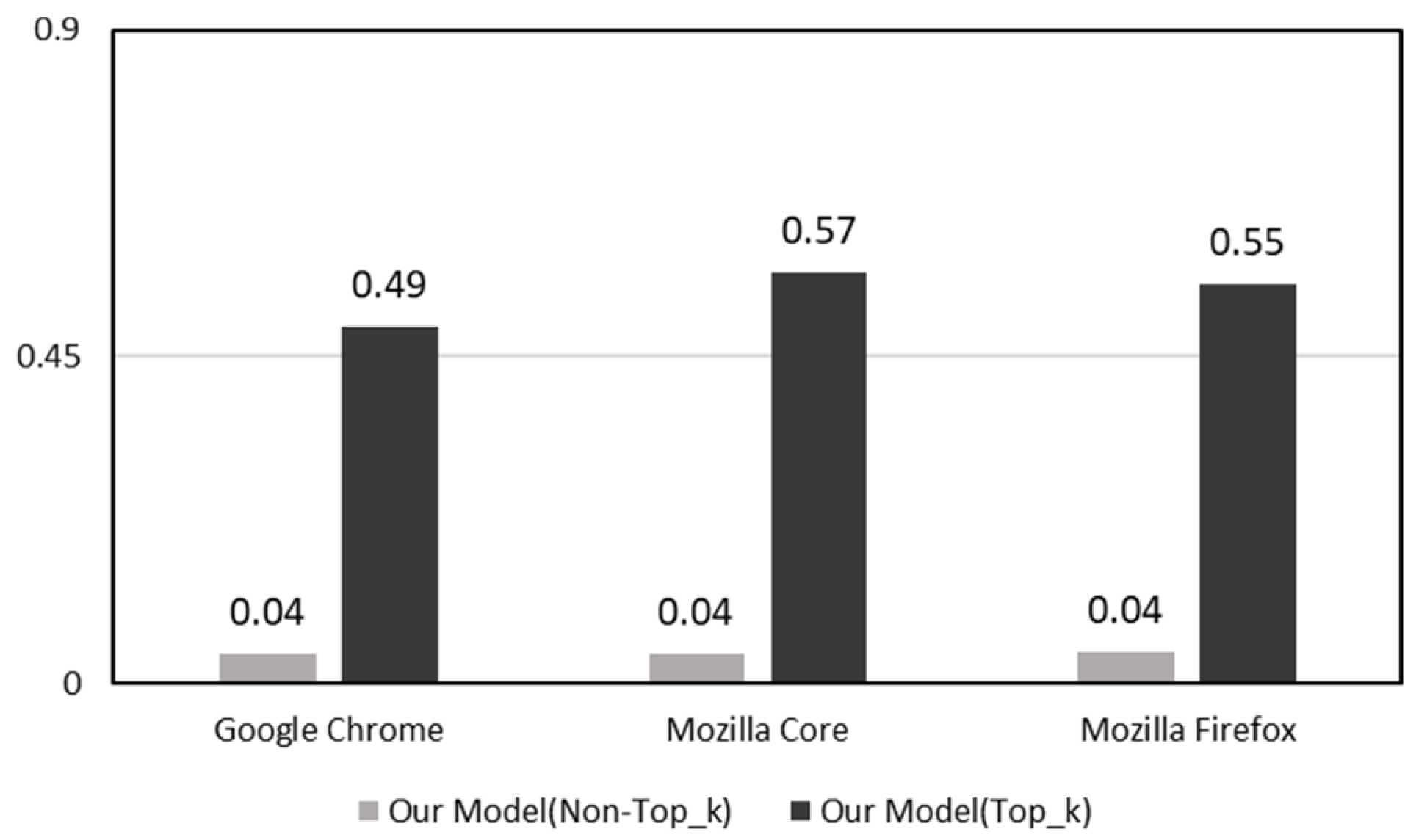
- Developer-Specific Top-K Feature Selection: We introduce a dynamic top-K feature extraction method that tailors feature selection to each developer’s historical bug-fixing profile. This approach significantly reduces irrelevant information, enhances model precision, and shows superior performance over baseline and ablation models.
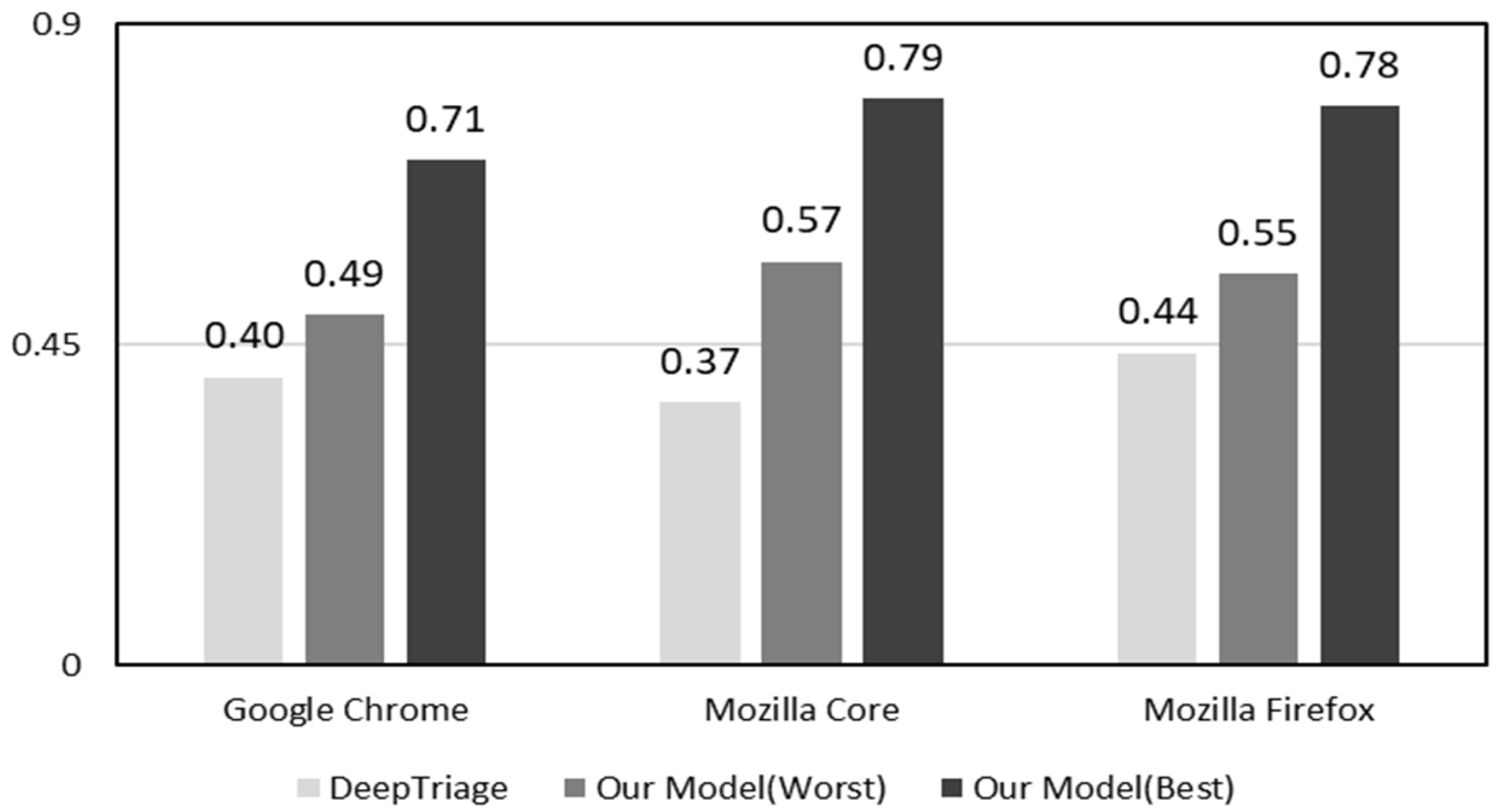
- Robust Performance Across Projects: Extensive experiments on datasets from Google Chrome, Mozilla Core, and Mozilla Firefox show that our model consistently outperforms DeepTriage across multiple metrics, including accuracy, precision, recall, and the F1-score, confirming its generalizability and robustness.
- Practical Efficiency Gains: By minimizing the need for reassignment, our model reduces bug resolution delays and maintenance costs. The proposed method offers a practical and scalable solution for improving developer assignment in large-scale open-source environments.
2. Background
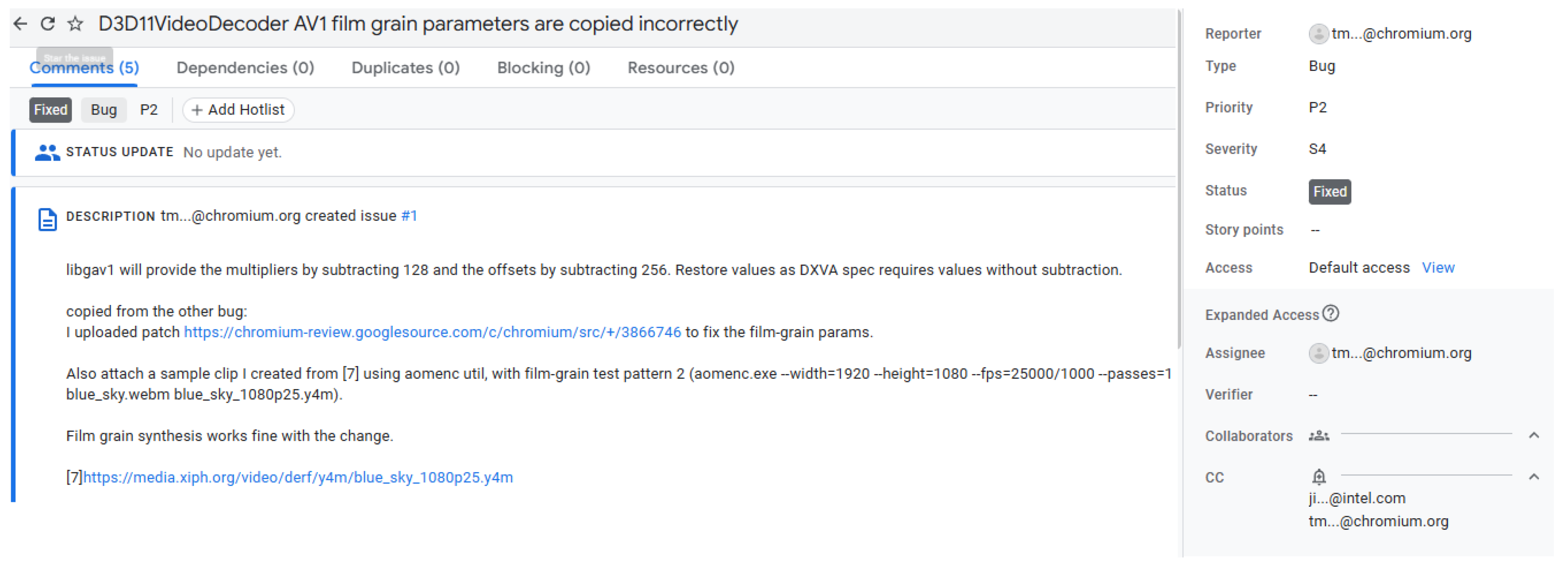
2.1. Bug Report
2.2. Bug-Tracking System
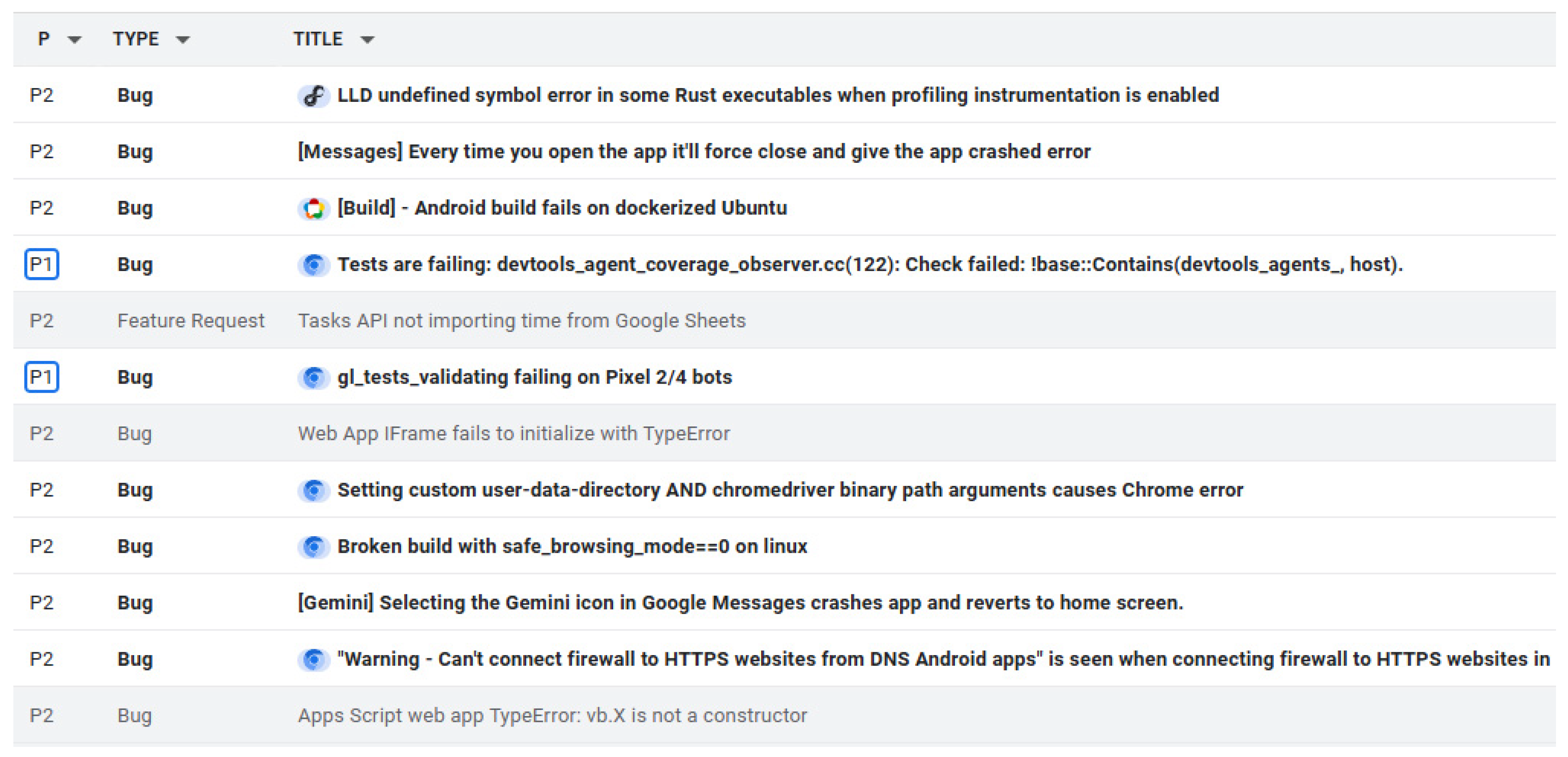
3. Related Work
4. Developer Recommendation Methodology
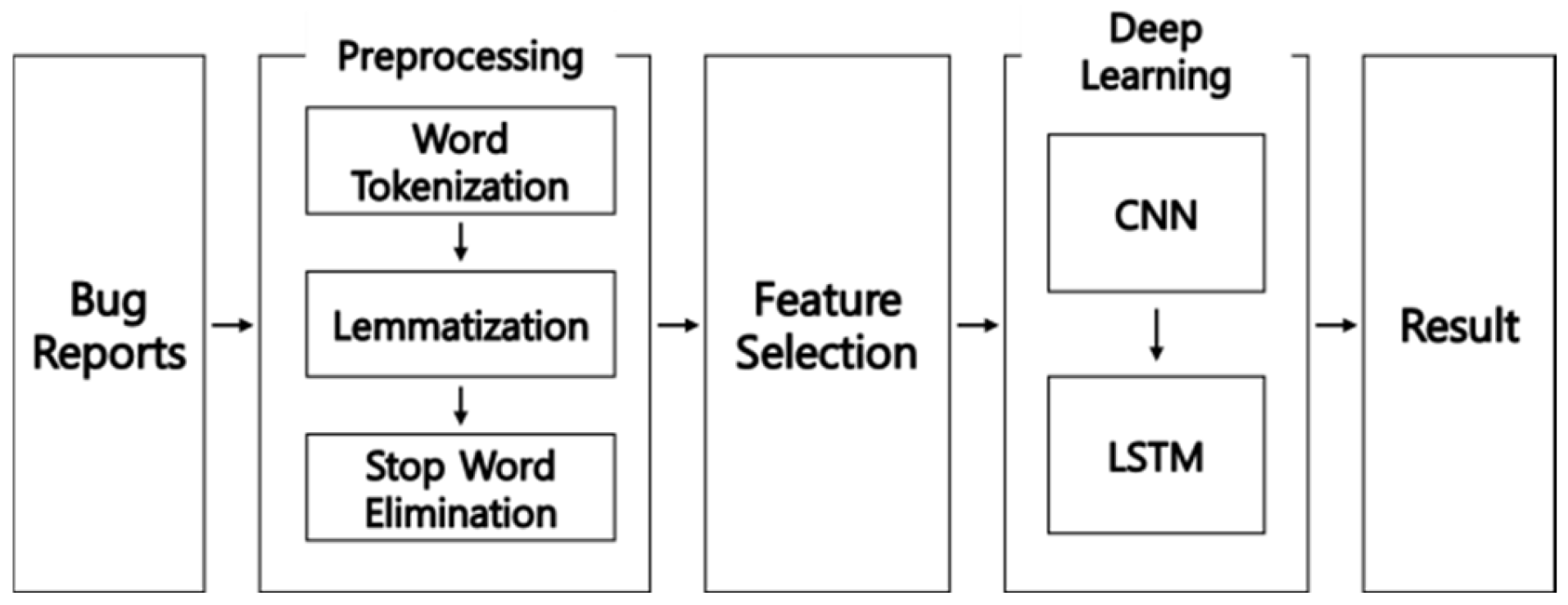
4.1. Preprocessing
- Tokenization: This process involves breaking the text into individual tokens, typically words or phrases, to create a structured representation of the report. For example, sentences are decomposed into their constituent words, which are then extracted for further processing.
- Lemmatization: During this step, each word is reduced to its base or root form. This normalization ensures that variations in the same word are treated uniformly. For instance, words such as “notes,” “sounding,” and “heights” are converted to their root forms, “note,” “sound,” and “height,” respectively. By standardizing word forms, lemmatization helps to reduce noise in the dataset.
- Stop-Word Removal: Commonly used words that carry little to no semantic meaning, such as “is,” “me,” “over,” and suffixes, are removed. Eliminating these stop-words reduces the dimensionality of the data and focuses the analysis on the meaningful terms relevant to the bug descriptions.
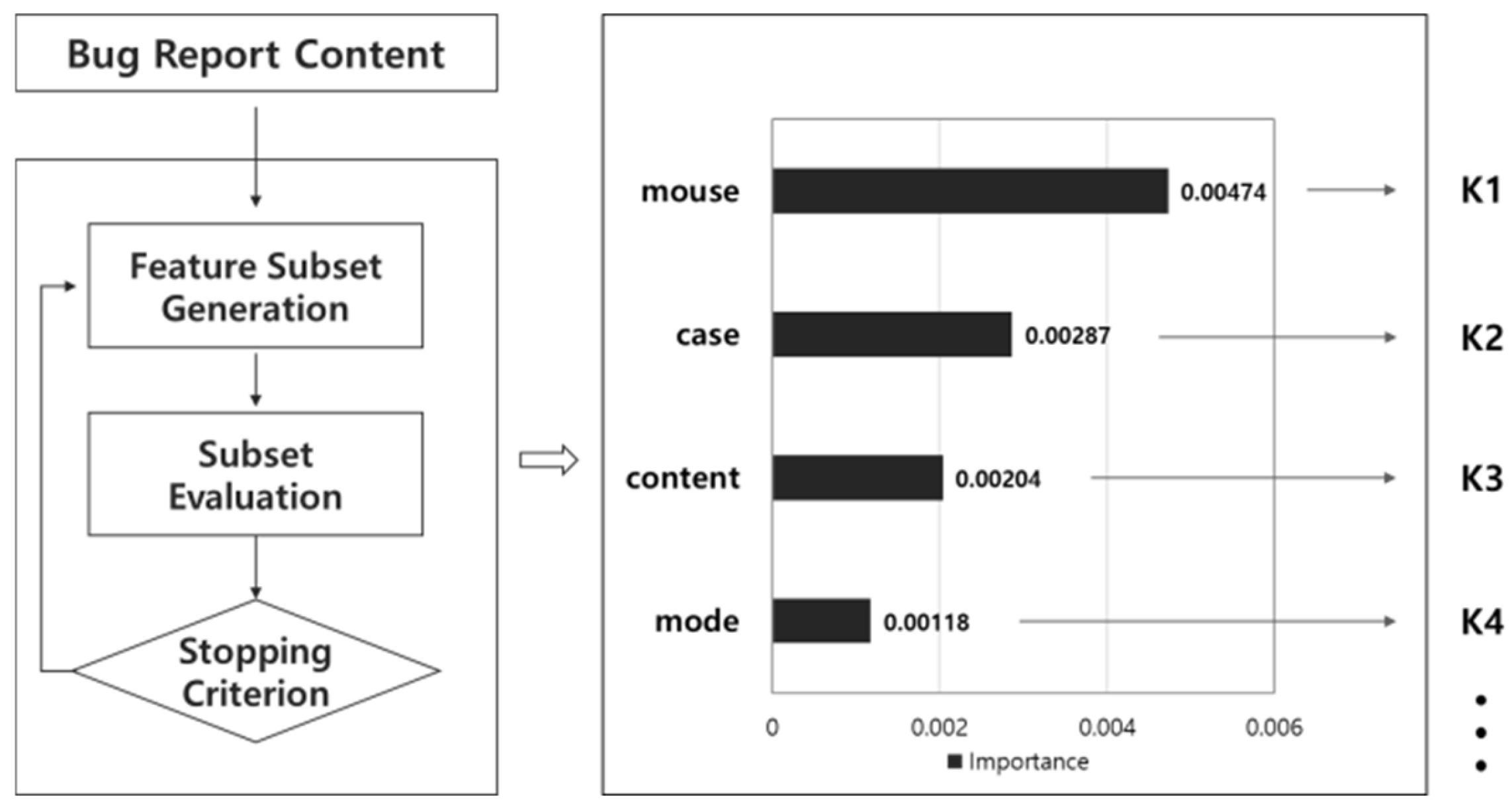
4.2. Feature Selection Algorithm
- Top-1 selects the single most relevant word;
- Top-2 includes the two highest-ranked words;
- Top-20 includes the twenty most relevant words per developer.
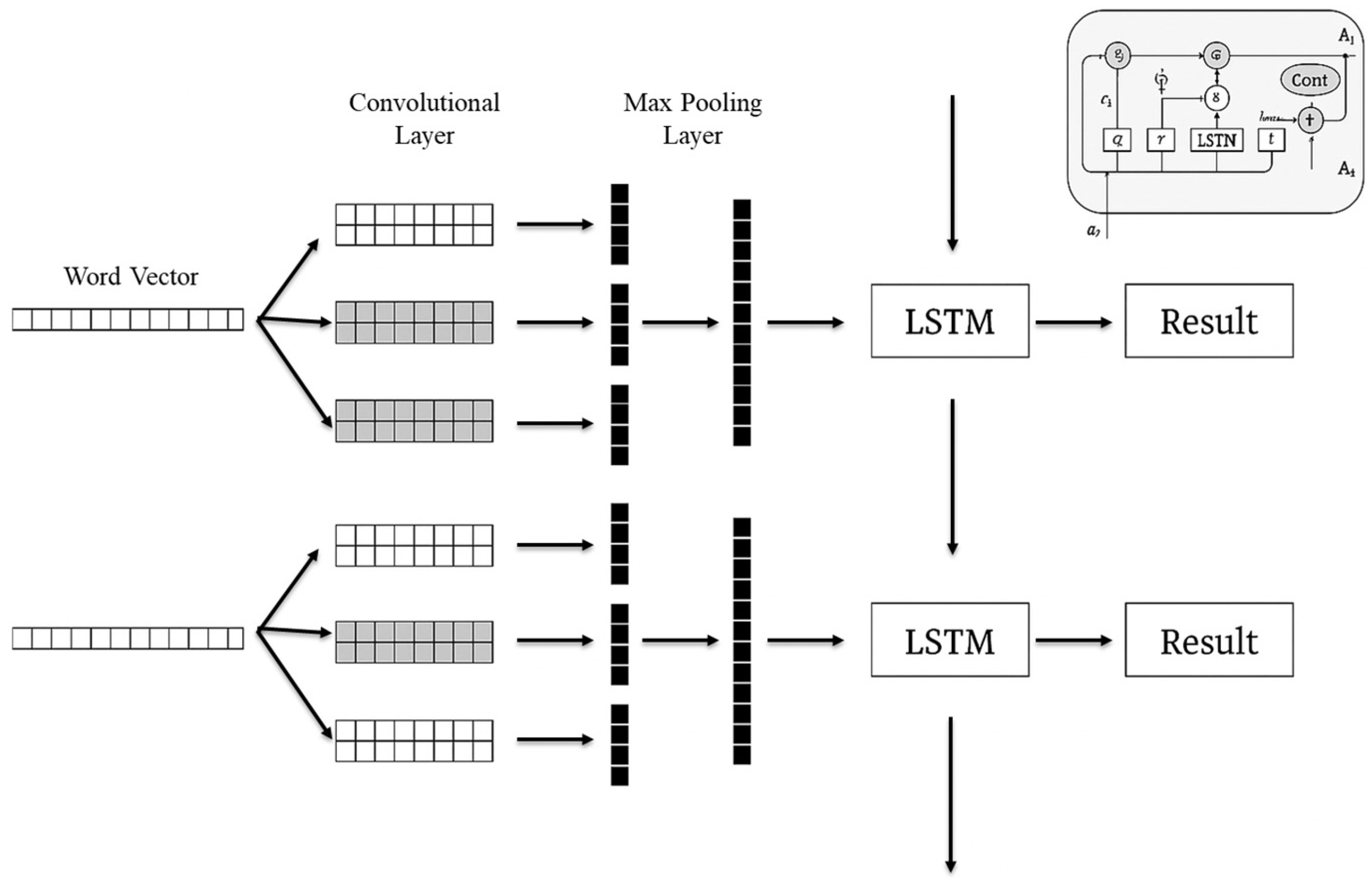
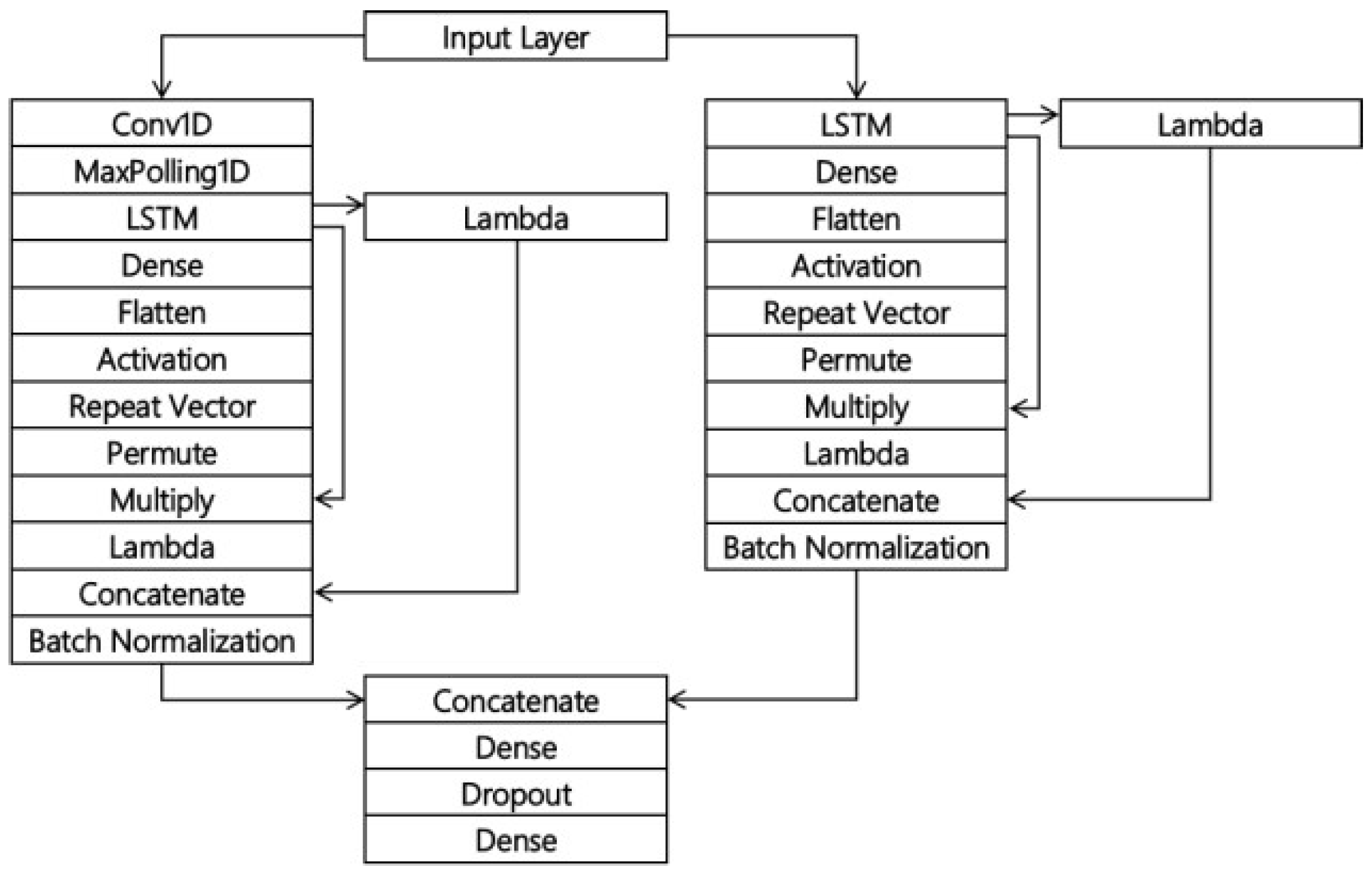
4.3. CNN-LSTM Algorithm
5. Experimental Analysis
5.1. Experimental Dataset
5.2. Research Questions
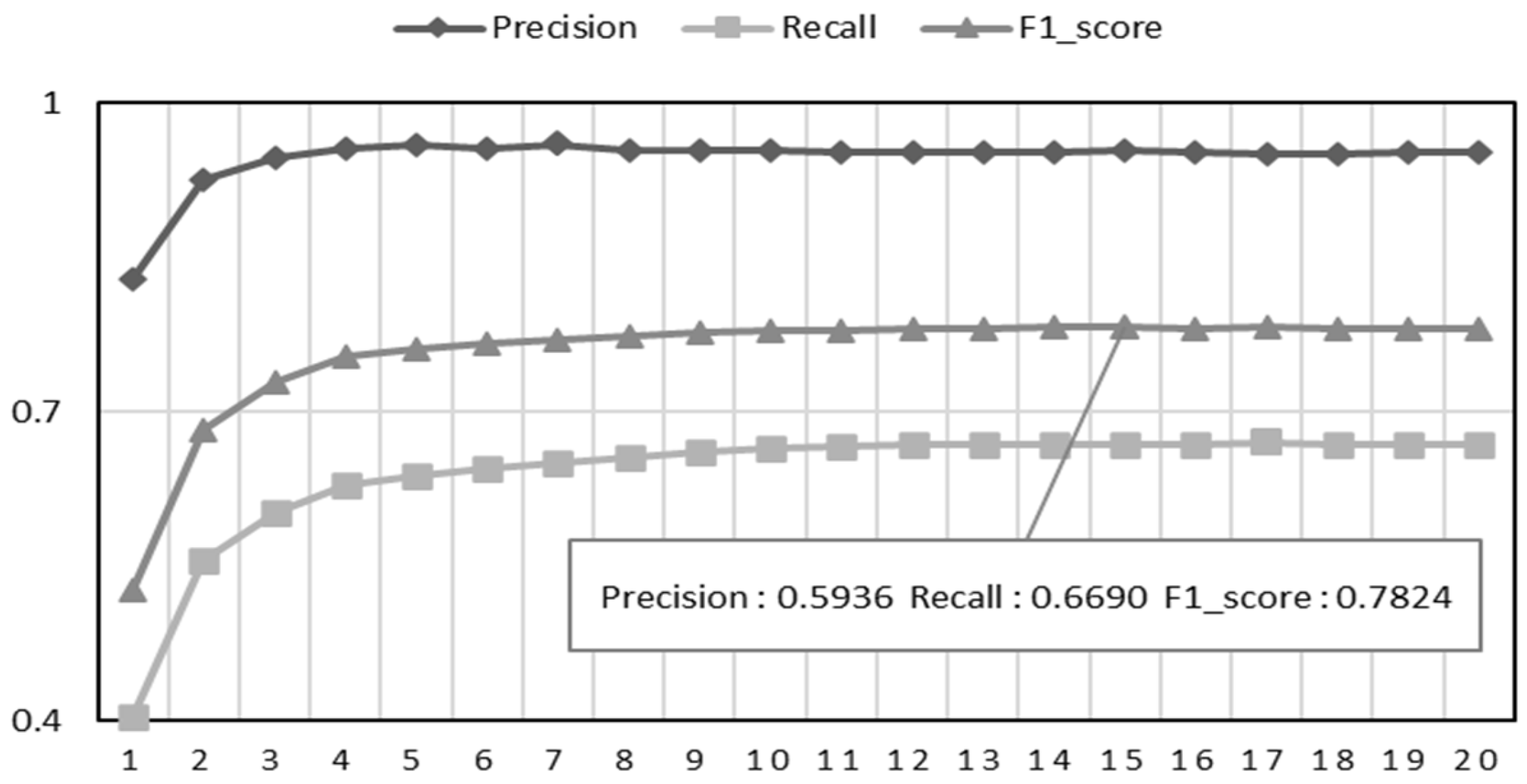
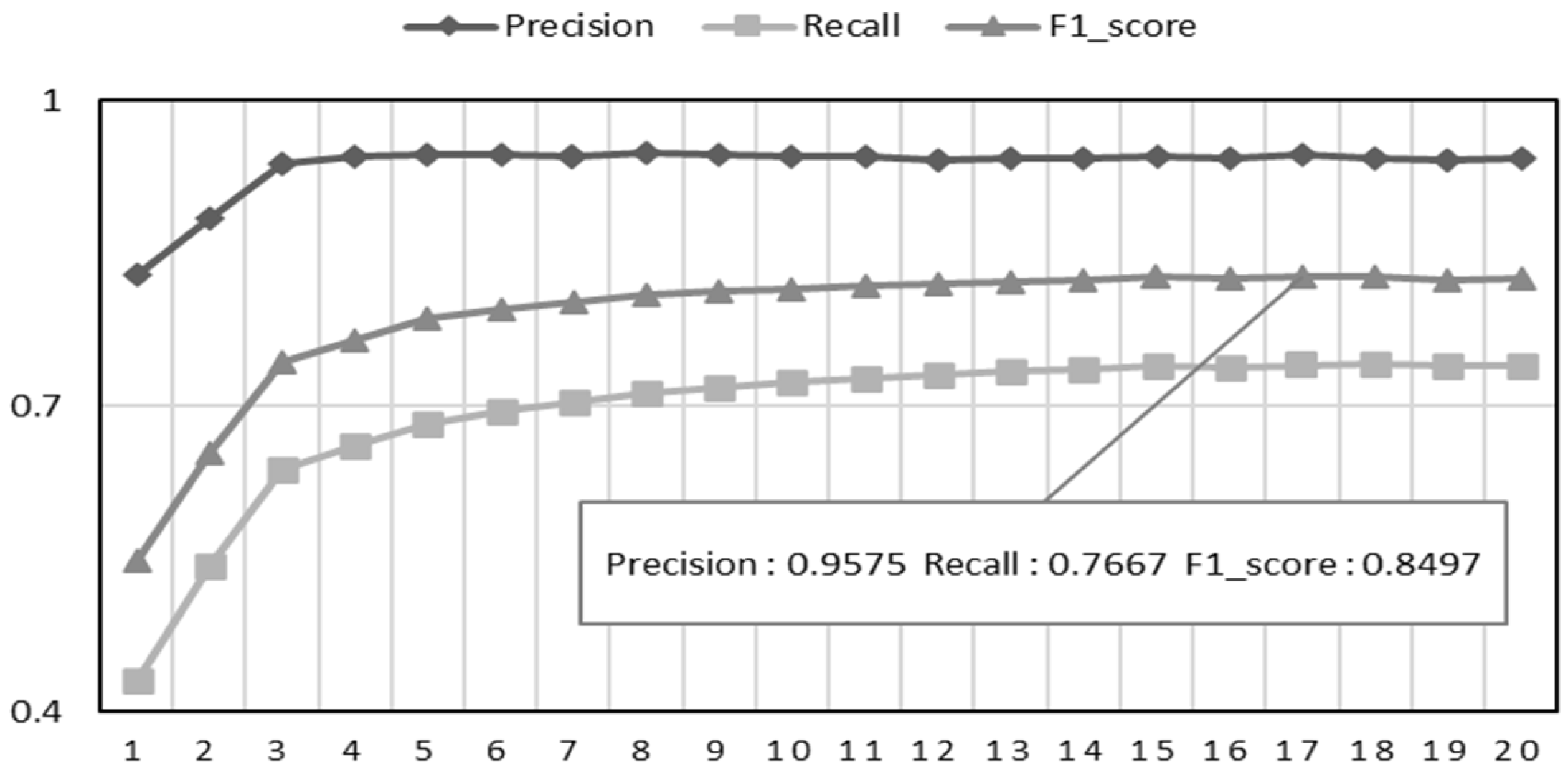
5.3. Evaluation Metrics
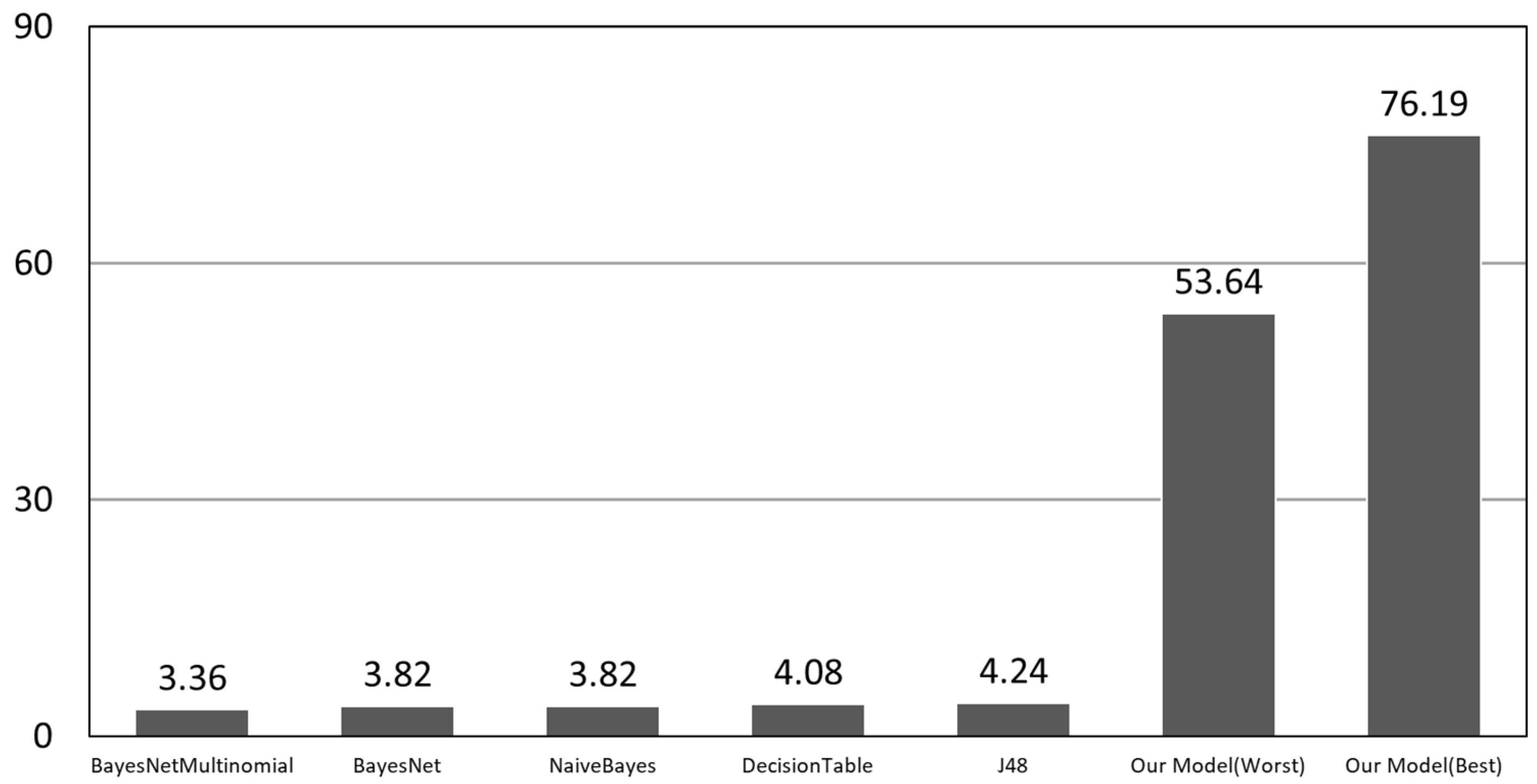
5.4. Baseline
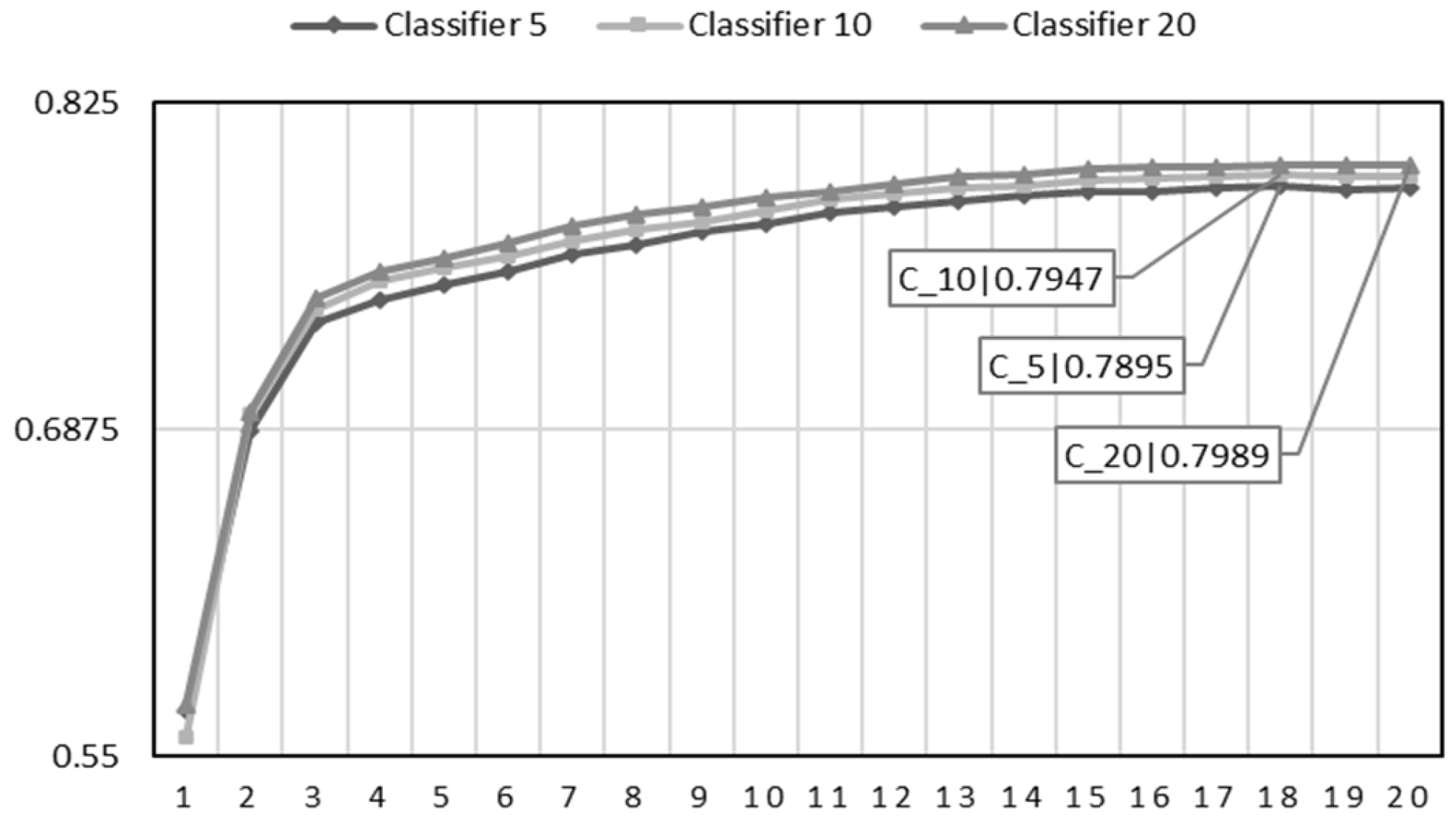
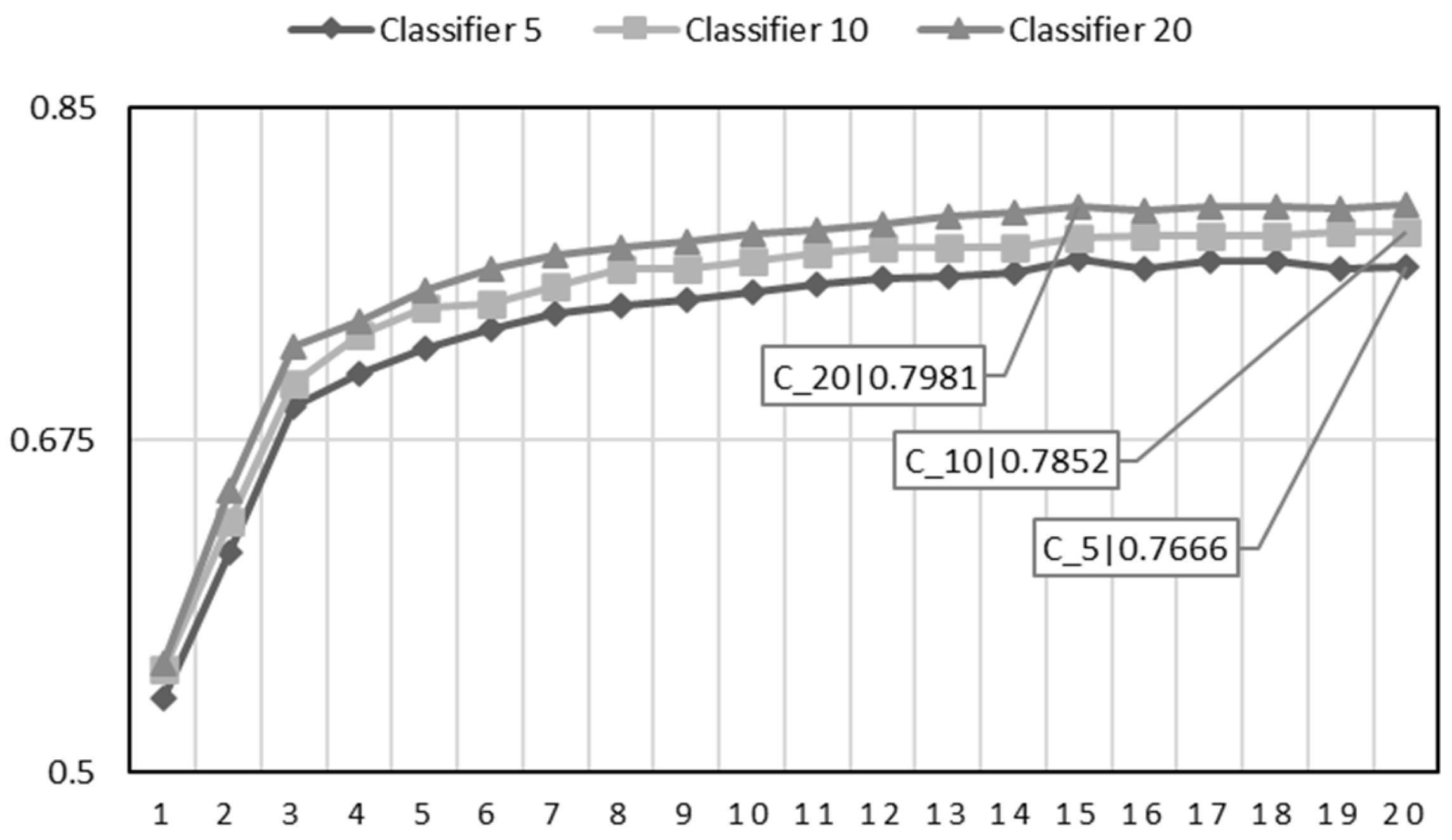
5.5. Experimental Results
5.5.1. Results
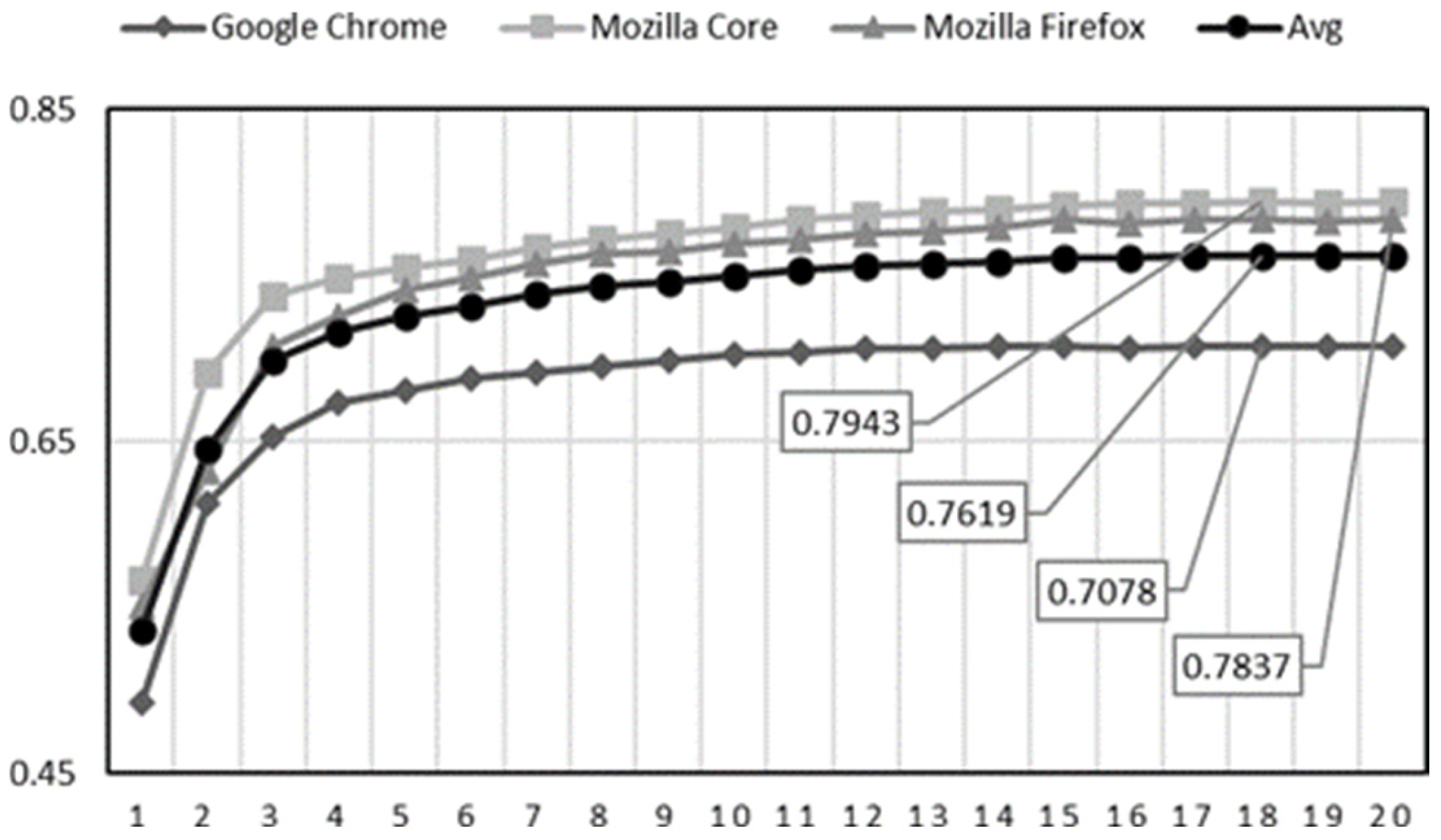
- Classifier 5: Developers with at least five assigned bug reports.
- Classifier 10: Developers with at least ten assigned bug reports.
- Classifier 20: Developers with at least twenty assigned bug reports.
5.5.2. Comparison Results
- H10: No significant difference exists between the proposed model and DeepTriage for Google Chrome.
- H20: No significant difference exists between the proposed model and DeepTriage for Mozilla Core.
- H30: No significant difference exists between the proposed model and DeepTriage for Mozilla Firefox.
- H1a: A significant difference exists between the proposed model and DeepTriage for Google Chrome.
- H2a: A significant difference exists between the proposed model and DeepTriage for Mozilla Core.
- H3a: A significant difference exists between the proposed model and DeepTriage for Mozilla Firefox.
6. Discussion
6.1. Results
6.2. Threats and Validity
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yang, G.; Zhang, T.; Lee, B. Towards semi-automatic bug triage and severity prediction based on topic model and multi-feature of bug reports. In Proceedings of the IEEE Annual Computer Software and Applications Conference, Vasteras, Sweden, 21–25 July 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 97–106. [Google Scholar]
- Jeong, G.; Kim, S.; Zimmermann, T. Improving bug triage with bug tossing graphs. In Proceedings of the Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering, Amsterdam, The Netherlands, 24–28 August 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 111–120. [Google Scholar]
- Guo, S.; Zhang, X.; Yang, X.; Chen, R.; Guo, C.; Li, H.; Li, T. Developer activity motivated bug triaging: Via convolutional neural network. J. Neural Process. Lett. 2020, 51, 2589–2606. [Google Scholar] [CrossRef]
- Jahanshahi, H.; Chhabra, K.; Cevik, M.; Başar, A. DABT: A dependency-aware bug triaging method. In Proceedings of the Evaluation and Assessment in Software Engineering, Trondheim, Norway, 21–23 June 2021; Chitchyan, R., Li, J., Eds.; Association for Computing Machinery: New York, NY, USA, 2021; pp. 221–230. [Google Scholar]
- Park, J.W.; Lee, M.W.; Kim, J.; Hwang, S.W.; Kim, S. Costriage: A cost-aware triage algorithm for bug reporting systems. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 7–11 August 2011; AAAI Press: Washington, DC, USA, 2011; Volume 25, pp. 139–144. [Google Scholar]
- Ashokkumar, P.; Shankar, S.G.; Srivastava, G.; Maddikunta, P.K.; Gadekallu, R. A two-stage text feature selection algorithm for improving text classification. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2021, 20, 1–19. [Google Scholar]
- She, X.; Zhang, D. Text classification based on hybrid CNN-LSTM hybrid model. In Proceedings of the International Symposium on Computational Intelligence and Design, Hangzhou, China, 8–9 December 2018; IEEE: New York, NY, USA, 2018; Volume 2, pp. 185–189. [Google Scholar]
- Mani, S.; Sankaran, A.; Aralikatte, R. DeepTriage: Exploring the effectiveness of deep learning for bug triaging. In Proceedings of the ACM India Joint International Conference on Data Science and Management of Data, New York, NY, USA, 3–5 January 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 171–179. [Google Scholar]
- The T-Testin Research Methods Knowledge Base. Available online: https://www.socialresearchmethods.net/kb/stat_t.php (accessed on 28 May 2022).
- Wilcoxon, F. Individual comparisons by ranking methods. Biom. Bull. 1945, 1, 80–83. [Google Scholar] [CrossRef]
- Zimmermann, T.; Premraj, R.; Sillito, J.; Breu, S. Improving bug tracking systems. In Proceedings of the International Conference on Software Engineering-Companion Volume, Vancouver, BC, Canada, 16–24 May 2009; IEEE: New York, NY, USA, 2009; pp. 247–250. [Google Scholar]
- Bug Report. Google Chromium. Available online: https://bugs.chromium.org/p/chromium/issues/detail?id=1358640 (accessed on 28 September 2022).
- Google. Issue Tracker: Query Results for ‘Error’. Available online: https://issuetracker.google.com/issues?q=error (accessed on 16 January 2025).
- Anvik, J.; Hiew, L.; Murphy, G.C. Who should fix this bug? In Proceedings of the International Conference on Software Engineering, Shanghai, China, 20–28 May 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 361–370. [Google Scholar]
- Xuan, J.; Jiang, H.; Ren, Z.; Yan, J.; Luo, Z. Automatic bug triage using semi-supervised text classification. arXiv 2017, arXiv:1704.04769. [Google Scholar]
- Ge, X.; Zheng, S.; Wang, J.; Li, H. High-dimensional hybrid data reduction for effective bug triage. J. Math. Probl. Eng. 2020, 2020, 5102897. [Google Scholar] [CrossRef]
- Yadav, A.; Singh, S.K. A novel and improved developer rank algorithm for bug assignment. J. Intell. Syst. Technol. Appl. 2019, 19, 78–101. [Google Scholar] [CrossRef]
- Xia, X.; Lo, D.; Wang, X.; Zhou, B. Accurate developer recommendation for bug resolution. In Proceedings of the IEEE 20th Working Conference on Reverse Engineering, Koblenz, Germany, 14–17 October 2013; IEEE: New York, NY, USA, 2013; pp. 72–81. [Google Scholar]
- Shokripour, R.; Anvik, J.; Kasirun, Z.M.; Zamani, S. A time-based approach to automatic bug report assignment. J. Syst. Softw. 2015, 102, 109–122. [Google Scholar] [CrossRef]
- Xi, S. DeepTriage: A bug report dispatching method based on cyclic neural network. J. Softw. 2018, 29, 2322–2335. [Google Scholar]
- Zaidi, S.F.A.; Awan, F.M.; Lee, M.; Woo, H.; Lee, C.G. Applying convolutional neural networks with different word representation techniques to recommend bug fixers. IEEE Access 2020, 8, 213729–213747. [Google Scholar] [CrossRef]
- Mian, T.S. Automation of bug-report allocation to developer using a deep learning algorithm. In Proceedings of the IEEE International Congress of Advanced Technology and Engineering, Taiz, Yemen, 4–5 July 2021; IEEE: New York, NY, USA, 2021; pp. 1–7. [Google Scholar]
- Liu, B.; Zhang, L.; Liu, Z.; Jiang, J. Developer assignment method for software defects based on related issue prediction. Mathematics 2024, 12, 425. [Google Scholar] [CrossRef]
- Wang, R.; Ji, X.; Tian, Y.; Xu, S.; Sun, X.; Jiang, S. Fixer-level supervised contrastive learning for bug assignment. Empir. Softw. Eng 2025, 30, 76. [Google Scholar] [CrossRef]
- Tian, Y.; Wijedasa, D.; Lo, D.; Le Goues, C. Learning to rank for bug report assignee recommendation. In Proceedings of the IEEE International Conference on Program Comprehension (ICPC), Austin, TX, USA, 16–17 May 2016; IEEE: New York, NY, USA, 2016; pp. 1–10. [Google Scholar]
- Liu, G.; Wang, X.; Zhang, X. Deep learning based on word vector for improving bug triage performance. In Proceedings of the international conference on Forthcoming Networks and Sustainability (FoNeS), Stevenage, UK, 3–5 October 2022; IET: London, UK, 2022; Volume 2022, pp. 770–775. [Google Scholar]
- Dipongkor, A.K. An ensemble method for bug triaging using large language models. In Proceedings of the IEEE/ACM International Software Engineering: Companion (ICSE-Companion), Lisbon, Portugal, 14–20 April 2024; Association for Computing Machinery: New York, NY, USA, 2024; pp. 438–440. [Google Scholar]
- Chhabra, D.; Chadha, R. Automatic bug triaging process: An enhanced machine learning approach through large language models. Engineering. Technol. Appl. Sci. Res. 2024, 14, 18557–18562. [Google Scholar] [CrossRef]
- Jahanshahi, H.; Cevik, M.; Mousavi, K.; Başar, A. ADPTriage: Approximate dynamic programming for bug triage. IEEE Trans. Softw. Eng. 2023, 49, 4594–4609. [Google Scholar] [CrossRef]
- Goutte, C.; Gaussier, E. A probabilistic interpretation of precision recall and F-Score with implication for evaluation. Lect. Notes Comput. Sci. 2005, 3408, 345–359. [Google Scholar]
- Zhou, J.; Zhang, H.; Lo, D. Where should the bugs be fixed? More accurate information retrieval-based bug localization based on bug reports. In Proceedings of the International Conference on Software Engineering, Zurich, Switzerland, 2–9 June 2012; IEEE: New York, NY, USA, 2012; pp. 14–24. [Google Scholar]
- Hoo, Z.H.; Candlish, J.; Teare, D. What is an ROC curve? Emerg. Med. J. 2017, 34, 357–359. [Google Scholar] [CrossRef] [PubMed]
- Shapiro–Wilk Test. Wikipedia. Available online: https://en.wikipedia.org/wiki/Shapiro-Wilk_test (accessed on 28 May 2022).
- Shapiro, S.S.; Wilk, M.B. An analysis of variance test for normality (complete samples). Biometrika 1965, 52, 591–611. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Google Chromium [8] | Mozilla Core [8] | Mozilla Firefox [8] | |
|---|---|---|---|
| # of Reports | 383,104 | 314,388 | 162,307 |
| # of Developers | 1944 | 1375 | 581 |
| Hypothesis | p-Value | Result |
|---|---|---|
| H10 | (Wilcoxon test) 1.95 × 10−3 | H1a: Accept |
| H20 | (Wilcoxon test) 1.95 × 10−3 | H2a: Accept |
| H30 | (Wilcoxon test) 1.95 × 10−3 | H3a: Accept |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, G.; Ji, J.; Kim, D. Enhancing Bug Assignment with Developer-Specific Feature Extraction and Hybrid Deep Learning. Electronics 2025, 14, 2493. https://doi.org/10.3390/electronics14122493
Yang G, Ji J, Kim D. Enhancing Bug Assignment with Developer-Specific Feature Extraction and Hybrid Deep Learning. Electronics. 2025; 14(12):2493. https://doi.org/10.3390/electronics14122493
Chicago/Turabian StyleYang, Geunseok, Jinfeng Ji, and Dongkyu Kim. 2025. "Enhancing Bug Assignment with Developer-Specific Feature Extraction and Hybrid Deep Learning" Electronics 14, no. 12: 2493. https://doi.org/10.3390/electronics14122493
APA StyleYang, G., Ji, J., & Kim, D. (2025). Enhancing Bug Assignment with Developer-Specific Feature Extraction and Hybrid Deep Learning. Electronics, 14(12), 2493. https://doi.org/10.3390/electronics14122493