1. Introduction
By 2050, at least 3.6 million Americans are expected to be living with a missing limb, a prediction that is driven primarily by the aging population and rising rates of diabetes [
1]. In response to this growing demand, advancements in both passive and active prosthetic devices, orthoses, and assistive robotics are imperative as they aim to enhance users’ independence in performing activities of daily living (ADLs) and ultimately, improve their quality of life. However, controlling these devices remains a significant challenge for many users. The complexity of operating such devices often leads to frustration and, in some cases, abandonment by patients [
2], which reinforce the significance of developing more intuitive and user-friendly systems.
Brain–computer interfaces (BCIs) [
3] offer a promising solution by utilizing non-invasive methods to capture the brain’s electroencephalogram (EEG) signals to infer a user’s intended muscle and joint movements. However, EEG signals are inherently noisy, highly variable, and exhibit low signal/noise ratios, which makes them difficult to use directly for reliable device control.
To bridge this gap, robust intermediary models are essential. Motion capture (MoCap) [
4] technology plays a vital role by providing precise recordings of human joint angles and limb trajectories during motion, which can serve as ground truth data for training models. Furthermore, inverse kinematics (IK) [
5] techniques enable the computation of joint configurations that is necessary to achieve desired end-effector (hand) positions for controlling assistive or robotic limbs based on intention signals. Together, MoCap and IK methods represent a comprehensive framework for mapping motion into robotic applications, yet integrating this information with real-time EEG decoding remains a significant research challenge.
While many EEG decoding studies rely on the use of discrete motion labels or electromyographic (EMG) signals as output parameters, a smaller subset has explored the use of MoCap data—such as joint angles and limb trajectories—as continuous targets for regression-based models. For instance, studies have demonstrated that low-frequency EEG features could be used to decode 3D upper-limb trajectories captured via MoCap [
6]. Others have also shown that hand kinematics derived from MoCap could be predicted from EEG signals using multivariate linear regression, although with only moderate accuracy [
7].
Furthermore, ongoing debates exist regarding whether interpretable, traditional machine learning models offer greater reliability for EEG decoding compared to complex deep learning architectures, which may suffer from overfitting and a lack of transparency [
8]. Recent advances in generative pre-trained transformer (GPT) [
9] technology provide a promising avenue by offering rapid and relatively accurate approximation models for a variety of applications, including biomedical contexts. One key advantage of GPT models is their ability to recognize complex data patterns, form correlations between disparate datasets, and effectively fine-tune noisy inputs to capture essential relationships [
10].
In this study, ChatGPT (based on the GPT-4 API) was selected for its unique ability to translate natural language prompts into executable code. Unlike other generative models or traditional AutoML systems, ChatGPT 4o provides a highly accessible interface that enables researchers to iteratively refine models, preprocess data, and scaffold reproducible workflows without having to perform low-level programming from scratch. Unlike prior EEG–MoCap pipelines that rely on manual code development or AutoML frameworks, our study leverages the GPT-4 API to drive prompt-based code generation, annotation, and pipeline orchestration. This approach reduces boilerplate, embeds documentation directly into scripts, and creates a reproducible ‘prompt log’ of our development process, all while leaving core model training and inference to conventional TensorFlow Versin 2.14.0 (Google LLC, Mountain View, CA, USA) [
11] and scikit-learn version 1.2.2 [
12] routines. Given the increasing integration of generative AI tools in research and industry, it is important to critically assess not only their capabilities, but also their limitations and potential biases. While ChatGPT excels at generating coherent text and code snippets, its ability to generate scientifically rigorous and reliable machine learning models remains an open question.
Considering these capabilities and limitations, this study systematically investigates whether ChatGPT can generate machine learning pipelines that are capable of correlating EEG signals with human arm joint angles derived from motion capture (MoCap) data. Specifically, we evaluate the accuracy, quality, and usability of the studied models in approximating the relationship between EEG recordings and basic arm movements by leveraging the GPT-4 API for prompt-driven code generation and data wrangling scripts, while the core regression and classification architectures that we use are CNN-LSTM and Random Forest, respectively. The CNN-LSTM architecture used for classification was implemented in TensorFlow and trained using a supervised sliding window approach. Details of the model architecture and training configuration, including the data segmentation and performance metrics, are presented in
Section 2.3. This approach is consistent with the CNN-LSTM framework presented in [
13], which outlines a TensorFlow-based training and deployment pipeline. In this workflow, ChatGPT-4o expedites the pipeline assembly and prompt engineering, but all model weights and hyperparameters are learned via conventional deep learning routines outside the ChatGPT-4o environment, which allows end users to deploy and run the system independently without the need for repeated access to or reliance on the GPT API at runtime.
This preliminary effort lays the groundwork for the accurate and efficient EEG-based control of active assistive devices. Specifically, it contributes to the field of advanced controls by demonstrating how modeling EEG-based human behavior data can enhance the accuracy of robotic and prosthetic control. By enabling more intuitive and reliable interfaces, the approach has the potential to reduce user frustration and decrease the likelihood of device abandonment due to poor or confusing control methods.
To rigorously evaluate this approach, this study is structured around three core objectives, each of which addresses a key aspect of system development and validation. The remainder of this paper is organized as follows:
Section 2 presents the Materials and Methods, which are structured around three core objectives. Objective 1 validates the use of ChatGPT for modeling simple numerical relationships. Objective 2 involves the collection of synchronized EEG and motion-labeled video data to classify five distinct arm motions. Objective 3 integrates marker-based motion capture (MoCap) data to enable joint-angle regression using CNN-LSTM models. This Section also details the technical workflows used, including EEG artifact filtering, MoCap signal parsing, and the full data synchronization and modeling pipeline that was scaffolded using GPT-generated scripts.
Section 3 presents the experimental results corresponding to each objective, while
Section 4 discusses the implications of these findings. These sections highlight the effectiveness of ChatGPT in facilitating the rapid development of EEG-based pipelines, while also addressing the limitations of the current approach and offering recommendations for future improvements.
2. Materials and Methods
This study aimed to develop and evaluate a machine learning model capable of accurately correlating EEG signals with human arm motion, and to thereby enable the non-invasive control of active assistive devices. To accomplish this, the methodology was structured around three progressive objectives.
Objective 1: ChatGPT’s ability to model numerical relationships was validated by solving and predicting simple input–output correlations. This initial step established a foundational level of computational reasoning, ensuring the model can accurately relate input variables to output predictions;
Objective 2: Synchronized EEG signal collection and video-based motion labeling were introduced. The model was trained to filter, normalize, and classify EEG signals corresponding to distinct arm movements, which enabled the association of brain activity patterns with arm motion events;
Objective 3: Marker-based motion capture (MoCap) data were integrated to provide enriched motion parameters, including joint angles and velocities, which are critical for advanced motion modeling and inverse kinematics applications in robotic control.
All data were collected from one healthy adult volunteer (age 28, male). While this design provided tight control over electrode/contact placement and marker consistency, it limited inter-subject generalizability. Future work will recruit a diverse cohort (varying age, gender, anthropometry) to validate transferability across participants.
2.1. Objective 1: Numerical Relationship Modeling
For Objective 1, it was evaluated whether the ChatGPT-4o model can correlate numerical variables, such as x and y. The model was trained on input/output data generated through a known equation, then asked to predict the output from novel data that were not used for model training. This allowed for the accurate estimation of output variables without the explicit necessity of using exact mathematical models. The model was first given input values of x and output values of y and asked to derive a model that relates the two. Once it built a model representing the relationship, it was asked to generate estimated values of y given a random input of x. The expected values given from the model were then directly compared to known output values that were not used in training the model. These comparisons were used to generate the percentage accuracy of the results.
2.2. Objective 2: Synchronized EEG Signal Acquisition and Time-Stamped Video Recording
Upon successful completion of Objective 1, we advanced to Objective 2, which involved acquiring time-stamped video recordings of the participant’s arm movements. Such motions were categorized in five discrete arm motion classes: forward shoulder flexion, backward shoulder extension, lateral shoulder abduction, arm swing during gait, and “no motion” or idle. These arm movements were recorded on video while EEG data were captured simultaneously, which enabled the synchronized analysis of motion and brain activity. The EEG setup involved two primary steps: contact quality and EEG quality configuration. These steps primarily consisted of applying a saline solution to the electrodes to ensure proper contact and adjusting the headset on the user to optimize comfort and positioning. This process was conducted using the EMOTIV Pro Lite application (Version 4.5.7.570, Emotiv Inc., San Francisco, CA, USA), in line with the comprehensive guidelines provided within the application [
14]. Once the electrodes were correctly positioned, their indicator lights turned green and the quality percentage reached 100%, as shown in the EMOTIV Pro Lite application.
A total of 18 trials were performed: 8ight using the high-end EEG headset (16-channel Emotiv EPOC+, Emotiv Inc., San Francisco, CA, USA) [
15] and the remaining 10 using the low-end headset (5-channel Emotiv Insight, Emotiv Inc., San Francisco, CA, USA) [
16]. The recordings were processed into files containing arm motions and their respective timestamps.
After initial data collection, the GPT model was trained to recognize EEG data, with a focus on identifying unreliable datasets, eliminating large signal peaks, and disregarding timestamps with extraneous points. After preprocessing, the model was trained using EEG signal segments paired with the annotated time intervals for each of the five distinct motion classes, which enabled it to learn precise correlations between patterns of brain activity and the corresponding arm movements. Upon training, the model’s accuracy was tested by comparing its predictions, based on novel EEG data, to the actual movements. This training and testing procedure is illustrated in
Figure 1.
2.3. Objective 3: MoCap Integration
2.3.1. Data Collection Procedure
After timestamping and EEG decode testing, the MoCap data collection method was introduced in Objective 3. It served as a more complex method that can directly be used in IK tools. To maintain simplicity and consistency across trials, movements were categorized into five groups: random arm motion, which involved a mixture of forward, backward, and sideways motions; forward motion, consisting of forward shoulder flexion; backward motion, consisting of backward shoulder extension; sideways motion, consisting of lateral shoulder abduction; and common human motions, which included drinking water, giving a high five, arm swing during gait (walking), and reaching to grab an object. At this stage, a minor adjustment was made to the EEG setup: the 16-channel EPOC+ headset was removed to simplify the dataset; therefore, all the subsequent datasets were collected using only the 5-channel Insight EEG headset. The open-sourced application Cykit 3.0 for Python 3.7.x (CymatiCorp, open-source GitHub project) [
17] was used to perform the data collection for all trials at a sampling rate of 128 hertz. Each trial was conducted over a 30 s interval to ensure standardized recording conditions across all categories. A total of 30 trials were conducted. The motion-capture data collection was conducted using MOCAP Vicon Nexus (Version 1.8.4, Vicon Motion Systems Ltd., Centennial, CO, USA) [
18] at a sampling rate of 120 hertz.
The workflow began with the setup and calibration of the Vicon camera system, which included camera calibration and ambient setup. Markers were then placed on the subject using the upper body Plug-in-Gait marker set as shown in
Figure 2. Following marker placement, a static trial was performed to calibrate the subject, a step required only once per session. Once calibrated, the subject proceeded with 30 s trials. A total of 30 trials were conducted using the Insight headset. In total, the setup process took from approximately one to one and a half hours, with the overall data collection time, including the actual trials, ranging from two to two and a half hours. Notice that only one subject was used for this study for all trials.
2.3.2. Data Processing Procedure
Upon data collection, the data were postprocessed to prepare them for model training. The postprocessing began with motion capture, where the Vicon Nexus version 1.8.4 software was utilized to conduct data review and export preparation. First, the trial data were loaded within the Data Management pane. Visual inspection of the captured markers and the subject’s movement in the 3D workspace ensured that all markers were tracked throughout the motion. Marker trajectories were examined to identify any inconsistencies or noisy data points. Analysis required confirmation that the capture volume was fully covered, and that the subject’s motion was adequately recorded. Marker trajectory reconstruction was conducted to generate 3D marker trajectories from the 2D camera views. After reconstruction, all markers were reviewed to ensure alignment with the subject’s anatomy and movement.
Using Vicon Nexus, marker trajectories were first auto-labeled and then manually corrected to align precisely with the Plug-in-Gait biomechanical model (
Figure 2) and ensure that each marker was accurately identified. These were visually inspected using the Vicon Nexus software [
18] and were exported via the software’s ASCII functionality.
The data that were exported included trial information such as the start time, date, and sampling rate, as well as joint data from the right wrist, elbow, and shoulder. By utilizing the ASCII export function, we ensured that the exported data were suitable for deriving equations necessary for inverse kinematics. At this stage, minor EEG timeline and empty channel removal was performed, while artifact handling was performed at the next stage.
With both EEG and MoCap datasets exported and preprocessed, the focus shifted to aligning their sampling rates and timestamps to prepare for integrated analysis. This process verified that both systems collected the same number of data points per minute (sampling rate) and that the start and end times of the recordings matched, enabling seamless integration of motion and brain activity data. The workflow behind this process is depicted in
Figure 3.
As depicted in
Figure 3, eeg_parser.py first ingests each raw EEG CSV by reading its header line to extract metadata fields—most importantly the original sampling rate (default 128 Hz) and absolute recording start timestamp—which are stored in a FileMetadata dataclass for later use. The module then loads the signal rows into a pandas Version 2.2.2 DataFrame (pandas development team, open-source, USA) [
19], retaining only the channels AF3, T7, Pz, T8, and AF4, and applies a conversion function on each integer pair to convert raw readings into accurately scaled voltage values using the Emotiv EPOC+ calibration formula. Each channel is passed through a zero-phase FIR low-pass filter (Blackman–Harris window, 55 Hz cutoff) via the reusable filt_lowpass() routine, which effectively removes high-frequency noise. Filtering the signal in both the forward and reverse directions means that any phase shifts introduced during the first pass are exactly counteracted on the return pass, which ensures that the temporal relationships between neural oscillations remain unchanged. The filter’s cutoff at 55 Hz effectively removes muscle and environmental artifacts above this threshold, yielding a cleaner signal that retains the physiologically relevant components necessary for accurate down sampling and subsequent multimodal synchronization.
To achieve the target 120 Hz rate, polyphase resampling is performed with SciPy Version 1.15.3 ’s signal.resample_poly [
20], which calculates the required number of output samples from the ratio of new to original sampling frequencies and applies built-in anti-aliasing filtering before decimation; any extras are trimmed or edge-padded to ensure exactly n_samples_new points. Quality-indicator columns (prefixed CQ_) are linearly interpolated onto the new 120 Hz time base using NumPy (Version 2.3.0) ’s [
21] interp function, but are then dropped from the final DataFrame, as they are not required for downstream analysis. Both second- and millisecond-resolved timestamp columns (TIME_STAMP_s, TIME_STAMP_ms) are recomputed by linear spacing between the original epoch boundaries. A uniform “Time” column at 120 Hz is inserted, the processed DataFrame is written back to CSV with an updated header declaring the new sampling rate, and the FileMetadata return value provides original and new sample counts, exact start/end times, and the list of processed channels for downstream synchronization.
The mocap_parser.py module automates the preparation of the Vicon Nexus ASCII exports by first scanning the initial ten lines for date and time entries, which denote the recording end timestamp, and prepares them for the “Model Outputs” section to confirm the 120 Hz sampling rate. It locates the header row and parses all subsequent numeric rows into a DataFrame whose columns include the frame index, time in seconds, and three-axis joint-angle measurements (e.g., RShoulderAngles_X/Y/Z, RElbowAngles_X/Y/Z, RWristAngles_X/Y/Z). Non-numeric or incomplete rows are discarded, and the remaining values are cast to floating points. The recording start time is calculated by subtracting the total sample count divided by 120 Hz from the end timestamp, which yields precise start_time and end_time metadata. The cleaned trajectory data and the accompanying metadata—number of original samples, start/end times, and sampling rate—are returned for each trial, which ensures consistency when aligning them with EEG streams.
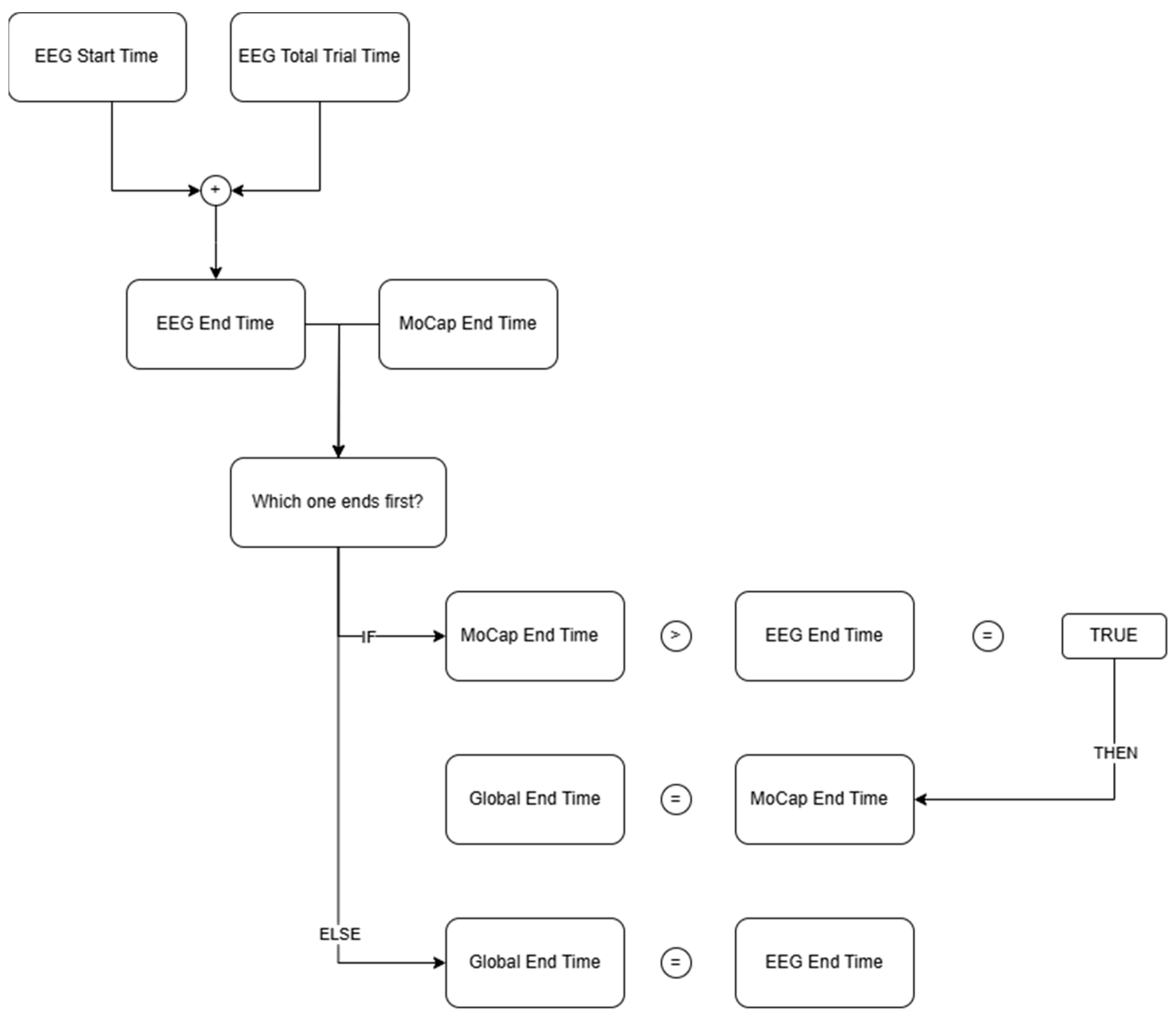
The final step was to synchronize the two data sets. Following the logic depicted in
Figure 4, a process for data–time synchronization was created. In synchronize.py, trial identifiers (e.g., “T1”) are extracted from filenames using a regular expression to pair each MoCap file with its corresponding EEG file. For each matched pair, absolute timestamps are computed by adding the per-sample interval (index/sampling_rate) to the stored start_time to produce epoch-based time arrays for both modalities. The overlapping interval is determined by taking the later of the two start times and the earlier of the two end times; both DataFrames are filtered to this common window. A new relative time axis is generated by subtracting the common_start, and pandas.merge_asof() is employed on this axis to align nearest-neighbor samples within a millisecond tolerance. A continuous global time index at 120 Hz is inserted and the merged DataFrame is exported to CSV. The synchronization metadata—including common_start, common_end, duration, and sampling_rate—are logged to guarantee full reproducibility prior to modeling.
2.3.3. Model Training Procedure
Once synchronized and formatted, we scaffolded the machine learning pipeline via ChatGPT by issuing structured, iterative prompts to generate core processing scripts (e.g., eeg_parser.py, mocap_parser.py, synchronize.py; see
Appendix A). For instance, the prompt “Generate a Python (Version 3.10) function to apply a zero-phase Butterworth band-pass filter (1–40 Hz) to multichannel EEG data, including metadata extraction” produced fully commented, ready-to-run code that was vetted and committed.
The generated eeg_parser.py module performed comprehensive inspection and preprocessing: EEG signals were filtered with the Butterworth routine and then normalized using a Z-score threshold of ±5 σ to flag outliers. Subsequent visual comparisons confirmed effective artifact reduction and the preservation of signal integrity.
Segmentation was implemented by prompting “Write a segmentation routine that produces sliding windows of 120 samples with a stride of 16 samples,” which yielded a script that captured temporal dynamics for motion events. A further prompt—“Provide standard-scaling wrappers for EEG and MoCap streams (mean = 0, σ = 1) and format into a unified input tensor”—generated the normalization and formatting code.
Model architecture was drafted with the instruction “Create a TensorFlow Sequential model with a 1D convolutional layer (32 filters, kernel size = 3), followed by max pooling, an LSTM layer (64 units) [
22], 30% dropout, and dense layers for joint-angle regression; compile with the Adam optimizer, MSE loss, and a custom ±3° accuracy metric.” The returned Keras script [
23] served as the baseline, with hyperparameter refinements (filter dimensions, learning rate, early-stopping patience) obtained through follow-up prompts and validated in TensorFlow.
Early stopping on validation loss was configured to restore the best weights upon convergence. The dataset was partitioned into two groups with a ratio of 80/20 for training/testing, with 20% of the training set being reserved for validation. Post-training evaluation comprised MAE, MSE, and R2 metrics, accompanied by graphical comparisons of predicted versus actual joint angles.
Pipeline functionality was extended by requesting “Generate Random Forest classification code that takes predicted joint angles and labels motion as forward, backward, or sideways”, and the returned script was integrated unchanged. Classification performance was assessed via confusion matrices and classification reports.
The complete training script—including model instantiation, callback configuration, plotting routines, and command-line interface—was generated by ChatGPT and integrated as-is, which enabled rapid, reproducible development with full control being retained over model training and hyperparameter tuning within conventional deep-learning frameworks.
3. Results
The results from Objective 1 showed that, when given simple values of linear regression of x = 1,2,3,4,5, y = 2,4,6,8,10, the model generated a correct function of y = 2x and produced an accuracy of 100%. The same accuracy was obtained with more complex numerical approximations such as a range of linear, polynomial, exponential, periodic, and damped functions. When given values of x = 1,2,3,4,5, y = 2,9,28,65,128, the model correctly estimated a quadratic relationship of y = ax3 + bx2 + cx + d, with the curve fitting equation being y = x3 + x2, with 100% accuracy compared to expected values.
Continuing with Objective 2, when used with the EMOTIV EPOC+ headset, ChatGPT achieved a mean accuracy of 83.7%, with accuracy ranging from 54.0% to 100%, as depicted in
Table 1. In contrast, when paired with the EMOTIV Insight headset and utilizing the CyKIT 3.0 software, the model reached an approximate accuracy of 79.8%, with a range of 65.0–96.5%. In tests aimed at differentiating between walking and other basic arm motions, the ChatGPT-based model produced a mean accuracy of 74.7% and a maximum accuracy of 89.2%. Moreover, when detecting whether the subject was idle or in baseline motion, ChatGPT achieved a 98% success rate with the EPOC+ headset and a 92% success rate with the Insight headset. In contrast, non-AI-driven research using the 16-channel EEG headset to detect arm motion demonstrated a maximum accuracy of 72% [
24], while research using a 5-channel headset displayed maximum average accuracy of 45% [
6].
Variance in the accuracy of the AI was caused by outlier sets in the data, which were the result of errors in measurement by the software and EEG device. During motion trials with the EMOTIV Insight in particular, improper movement could cause large values to be recorded by the headset even after movement concluded, and the model incorrectly interpreted these as movements. In subsequent trials, these improper movements were minimized by prompting the model to ignore outliers, which in turn highly increased the performance of the model. Both cases are included in
Table 1 and therefore contribute to the large range of percent accuracies.
As for Objective 3, the developed machine learning model demonstrated varying degrees of accuracy in predicting joint angles from EEG signals, as indicated by the evaluation metrics. Overall, the model achieved a mean absolute error (MAE) of 16.99 degrees, a mean squared error (MSE) of 640.30, and a coefficient of determination (R
2) score of 0.41, which signify a moderate predictive capability. Although the overall trend of the predicted joint angles generally aligns with the ground truth, as shown in
Figure 5, specific deviations—such as spikes or outlier points—contribute disproportionately to the error metrics, notably increasing both the mean absolute error (MAE) and mean squared error (MSE). A limb-specific breakdown revealed significant variability in performance. The predictions for shoulder joint angles exhibited the highest error, with an MAE of 22.26 degrees, an MSE of 866.41, and a relatively low R
2 score of 0.24, which suggests that the model struggled to accurately capture shoulder movements from EEG inputs. Conversely, the model exhibited comparatively better performance for the elbow, with an MAE of 4.62 degrees, an MSE of 117.92, and a moderate R
2 score of 0.50, which indicate more reliable predictions for simpler elbow joint movements. The wrist joint predictions showed intermediate performance, with an MAE of 15.83 degrees, an MSE of 588.31, and an R
2 score of 0.55, demonstrating reasonable predictive reliability.
Visual analysis of the predicted versus actual joint angles in
Figure 5 was conducted to further interpret the model’s performance. Predictions for the elbow joint closely mirrored the actual angles with notable accuracy, which indicates strong predictive capability in simpler single-axis joint movements. Conversely, the shoulder joint angle predictions exhibited considerable discrepancies, failing to consistently capture complex multi-axis dynamics, which reinforced the quantitative metrics indication of poorer model performance. The wrist predictions, while generally tracking actual movements, showed variable accuracy across different axes, which highlights challenges in predicting movements involving multi-degree-of-freedom joints. These observations underscore potential limitations in the ability of EEG-based modeling to accurately predict intricate joint motions and emphasize the necessity for enhanced model refinement and targeted preprocessing techniques to better manage complex joint kinematics.
Further evaluation using a confusion matrix from a Random Forest classifier, as shown in
Figure 6, revealed strong classification capabilities, as it accurately identified the motion direction with high precision. Specifically, forward, backward, and sideways motions were classified with minimal misclassification, which demonstrated the effectiveness of the classifier layer in categorizing predicted joint angle movements. It is important to highlight the contrast between
Figure 5 and
Figure 6, where
Figure 5 illustrates the model’s regression of joint angles—shoulder, elbow, and wrist—directly in joint space.
Figure 6, by contrast, shows predictions of hand movement directions in Cartesian space that were derived from the same model outputs.
Additionally, the training and validation loss curves illustrated in
Figure 7 displayed a steady convergence with decreasing losses over consecutive epochs.
4. Discussion of the Results
The results show that the model is capable of detecting correlations between numerical data points and can provide the best fitting equations for estimating output values. It also highlights the potential of a ChatGPT-based model to optimize non-invasive, EEG-based control systems for active assistive devices. Due to being trained on synchronized video and EEG data, the model effectively detects movement-related patterns in noisy EEG signals, which enables the control of active assistive devices. With this approach, the EPOC+ and Insight headsets achieved average accuracies of 83.7% and 79.8%, respectively. In contrast, other research with equivalent hardware but without AI support under comparable conditions reported accuracies of 72% and 45%. These findings highlight the model’s ability to filter out irrelevant data while effectively identifying key features associated with specific motions. This capability is crucial for ensuring accurate data analysis and improving the model’s practical application in real-world scenarios. While higher-end EEG headsets consistently outperformed their lower-end counterparts in terms of quality and precision, the enhancements in accuracy achieved through AI integration were particularly significant in the lower-end headsets. The use of AI not only mitigated some of the limitations of lower-end devices but also provided a robust framework for handling more complex data structures. After we established a robust EEG decoding performance, the next phase involved integrating high-resolution motion-capture data.
The ChatGPT-scaffolded CNN-LSTM pipeline demonstrated sufficient accuracy for predicting hand movement directions in Cartesian space—achieving over 85% classification accuracy (
Figure 6)—while the joint-angle regression performance remained moderate (MAEs: shoulder ≈ 22°, elbow ≈ 18°, wrist ≈ 15°). Even with imperfect joint estimates, these results indicate that end-effector trajectories can be reliably inferred for some assistive tasks. In practice, combining the Cartesian predictions with an inverse-kinematics solver enables the closed-loop control of a robotic arm without the need to retrain the underlying model.
To utilize the proposed model in controlling power prosthetic arms, EEG data of each individual user must be collected while the user invokes arm motion commands—whether the user is an amputee or has intact arms—to produce EEG brain data. These data will then be used to train the model on the user’s EEG data. Once the model is trained, the prosthetic’s control can be linked to the model output to provide the intended motion of the prosthetic limb. This can also be generalized to control robotic arms that are attached to power wheelchairs or mobile platforms.
Although the CNN-LSTM architecture effectively captures localized temporal dependencies and general motion trends, its ability to model long-range dependencies is limited by the inherent constraints of convolutional and recurrent layers. Specifically, vanishing-gradient effects in the RNN components may inhibit performance on more complex or subtle temporal patterns, which suggests that future work should explore architectures designed for extended sequence modeling.
Another key limitation stems from the dataset’s scope. Although it was well-synchronized and cleaned, the dataset included only upper-limb motions across a restricted range of movements and joints.
To address current limitations in capturing long-range temporal dependence inherent in EEG signals and optimize noise mitigation, future development should investigate transformer-based architectures. Compared to CNN-LSTM architectures that have limited capability to model extensive temporal relationships [
22], a transformer architecture, particularly those based on self-attention mechanisms, can directly compute relationships between all positions in a sequence, allowing the effective modeling of long-range dependencies without the constraints typically encountered by recurrent networks [
25]. Furthermore, self-attention mechanisms dynamically weigh the relevance of different time points and signal features. This characteristic enhances robustness against noisy or inconsistent inputs, which are prevalent in EEG data due to artifacts and inherent biological variability [
26]. Finally, such models will benefit from a systematic comparison of prompt formulations and the integration of explainable-AI methods (e.g., SHAP values, attention-maps), which will aid in auditing and refining the ChatGPT-generated code for alignment with domain best practices.
Expanding the dataset will also be critical. Including a broader range of motions and joints, particularly additional temporal features such as angular velocity and acceleration, in the MoCap dataset will improve generalization by providing insight into motion trends and facilitating better pattern recognition.
In parallel, improvements to the EEG dataset are essential for enhancing model performance. In our current design, EEG variables refer to the microvolt-level time-series signals recorded from each electrode, such as AF3, T7, Pz, T8, and AF4. When integrated into a transformer model, each channel can be treated as an independent temporal stream, which would allow the self-attention mechanism to assess and assign importance to different electrode activities across time. This approach is especially valuable for identifying distributed neural patterns and addressing the noisy, non-stationary nature of EEG data. In addition to raw signals, future work could incorporate derived features such as spectral band power in alpha, beta, or gamma ranges, event-related potentials, and inter-channel synchrony as enriched inputs for attention encoding. These additional features have the potential to further improve the model’s ability to decode complex motor commands with greater accuracy and robustness [
5,
6].
To ensure that the system is applicable across real-world scenarios, it will be important to include a wide range of participant profiles that vary in age, gender, and body characteristics. Combined with a more diverse set of human motion patterns, this inclusion will help the model adapt to individual differences in EEG signals and movement behavior. In preparation for real-time deployment, the full pipeline should be evaluated on embedded hardware to assess its feasibility for wearable or robotic systems. Automating the preprocessing workflow using GPT-powered tools could also support consistent performance and efficient deployment across different use cases.
Ultimately, this study demonstrates the potential of generative AI, particularly ChatGPT, in enabling non-invasive brain–computer interface systems. While the current results reflect moderate predictive accuracy, the findings highlight both the predictive potential of hybrid CNN-LSTM models and the value of ChatGPT-driven pipeline automation in accelerating the development of reliable EEG-based assistive technologies. To transition this system from research to clinical or industrial applications, several key challenges must be addressed. These include improving model accuracy through architectural advancements such as transformer integration, expanding and diversifying the dataset to enhance generalization, and reducing latency through optimized real-time processing on embedded platforms. The model’s robustness must also be verified via cross-subject studies, and the system’s usability should be enhanced by incorporating ergonomic, user-friendly design elements. Through architectural innovation, dataset expansion, systematic evaluation, and practical deployment considerations, this work advances the development of accessible, intelligent assistive technologies powered by generative AI.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}