Abstract
Industrial Control Systems (ICS) are increasingly targeted by sophisticated and evolving cyberattacks, while conventional static defense mechanisms and isolated intrusion detection models often lack the robustness required to cope with such dynamic threats. To overcome these limitations, we propose RHAD (Reinforced Heterogeneous Anomaly Detector), a resilient and adaptive anomaly detection framework specifically designed for ICS environments. RHAD combines a heterogeneous ensemble of detection models with a confidence-aware scheduling mechanism guided by reinforcement learning (RL), alongside a time-decaying sliding window voting strategy to enhance detection accuracy and temporal robustness. The proposed architecture establishes a modular collaborative framework that enables dynamic and fine-grained protection for industrial network traffic. At its core, the RL-based scheduler leverages the Proximal Policy Optimization (PPO) algorithm to dynamically assign model weights and orchestrate container-level executor replacement in real time, driven by network state observations and runtime performance feedback. We evaluate RHAD using two publicly available ICS datasets—SCADA and WDT—achieving 99.19% accuracy with an F1-score of 0.989 on SCADA, and 98.35% accuracy with an F1-score of 0.987 on WDT. These results significantly outperform state-of-the-art deep learning baselines, confirming RHAD’s robustness under class imbalance conditions. Thus, RHAD provides a promising foundation for resilient ICS security and shows strong potential for broader deployment in cyber-physical systems.
1. Introduction
In the context of Industry 4.0, ICS serve as the central nervous systems of modern critical infrastructure, which are increasingly integrating and connecting more components and devices to improve maintenance efficiency [1,2]. These systems are now extensively deployed in energy extraction applications [3,4]. To process data in real time and respond quickly to the complex demands of modern industrial scenarios, ICS are evolving toward cloud-edge collaborative architectures [5]. By establishing a global cloud-edge coordination management platform, edge computing nodes can be centrally managed, enabling seamless collaboration between cloud and edge computing resources and facilitating a distributed cloud-based industrial control model. However, this new application paradigm introduces significant security challenges [6,7].
The attack surface of ICS has expanded dramatically with IT/OT convergence, shifting from conventional network-layer assaults to protocol-aware physical sabotage [8]. Early threats like Denial-of-Service (DoS) attacks primarily disrupted supervisory interfaces, but modern adversaries now weaponize industrial protocols to manipulate sensor readings and actuator commands. A notable example is the Ukraine power grid attack, in which attackers forged Modbus/TCP commands to disconnect circuit breakers at 30 substations, leaving residents without electricity [9]. More insidiously, the Stuxnet worm demonstrated how programmable logic controller (PLC) code could be stealthily rewritten to induce mechanical resonance failures in uranium centrifuges [10]. Such incidents highlight that attacks targeting industrial networks are based primarily on vulnerabilities in proprietary industrial protocols and production control logic. These attacks are highly precise, difficult to detect, and harder to defend against, making the security management of industrial networks even more complex [11,12].
To identify and mitigate various threat events to ensure the stability of industrial production, intrusion detection in ICS detects various types of intrusions by performing real-time monitoring and analysis of industrial traffic. Currently, the mainstream misuse-based intrusion detection technologies, also known as signature/feature-based intrusion detection, identify attack behaviors by comparing collected traffic with known attack patterns (signatures) in a rule database. The detection process relies heavily on this rule database. Common misuse detection techniques include expert systems, state modeling, and string matching [13,14]. Suresh, Sukumar, and Ayyasamy [15] proposed an all-ready state traversal pattern matching algorithm, whose core idea is to merge certain pseudo-equivalent states during the attack process to reduce the number of states and transitions, thus decreasing memory usage. Erlacher and Dressler [16] designed a flow-monitoring, signature-based intrusion detection system called Fixids, based on the IP Flow Information Export (IPFIX) standard. Fixids utilizes the IPFIX standard to collect network flow information and integrates HTTP attack signatures from the Snort system to monitor flow data in real-time on high-speed networks. Compared to the traditional Snort intrusion detection system, it achieves a fourfold improvement in processing speed without packet loss. Despite significant advancements in intrusion detection research, misuse-based Intrusion Detection Systems (IDS) fundamentally rely on a blacklist-based approach. These systems maintain predefined signature databases corresponding to known attack patterns and attempt to match incoming traffic against these stored templates. While effective for detecting previously encountered threats, this approach suffers from a critical limitation: its inability to identify novel or zero-day attacks. As a result, its effectiveness diminishes in today’s dynamic and complex network environments, where attackers frequently deploy sophisticated and adaptive techniques. Maintaining high detection rates thus necessitates frequent and labor-intensive updates to the signature database, further constraining its scalability and long-term reliability.
Rather than relying on predefined attack signatures, anomaly-based intrusion detection methods construct behavioral profiles of normal system activity—typically through statistical modeling, machine learning, or traffic pattern analysis—to identify deviations indicative of potential threats. When the system’s current state deviates from this normal behavior pattern, it is considered an intrusion. Early anomaly detection primarily relied on statistical models, but with the rise of machine learning, feature-driven machine learning methods and deep learning methods focused on representation learning have since emerged. For example, a traffic early intrusion detection method based on graph embedding technology and Random Forest (RF), called Graph2vec + RF, is proposed [17]. Graph2vec + RF constructs flow graphs from the initial packets of each bidirectional network flow, learns vector representations via subgraph-based embedding, and classifies them using a Random Forest, enabling early-stage intrusion detection with minimal traffic. Gao, Gan, Buschendorf, Zhang, Liu, Li, Dong, and Lu [18] proposed a general intrusion detection framework for Supervisory Control and Data Acquisition (SCADA) systems, based on Long Short-Term Memory (LSTM) networks and Feedforward Neural Networks (FNN). Although deep learning-based algorithms excel at performing complex nonlinear mappings and demonstrate strong representation learning capabilities, intrusion detection tasks often rely on a single detection model, which are limited by the distribution of training data and exhibit poor generalization to unknown attacks [19].
While anomaly-based intrusion detection overcomes the limitations of signature dependency and enhances the capacity to detect unknown threats, it introduces new security challenges. In particular, machine learning-based models are vulnerable to adversarial manipulations during the training phase [20]. For example, attackers can exploit backdoor injection techniques to insert malicious samples into the training data, causing the model to misclassify specific attack patterns. This exposes a critical and often overlooked vulnerability: the security of the detection model itself. Such threats reveal the inherent limitations of static, single-model detection architectures in industrial control systems. Even high-performing models during training may be rendered ineffective post-deployment due to their inability to adapt dynamically. This static nature gives rise to an adversarial attack chain characterized by ‘detection blind spots-targeted evasion-persistent compromise’ [21]. Although ensemble learning has been proposed to improve detection robustness, most existing approaches remain statically integrated, lacking dynamic scheduling and closed-loop feedback, thereby failing to align detection with broader system resilience. Moreover, the widespread use of homogeneous models in industrial environments further exacerbates systemic fragility. Once a single detection node is compromised, attackers can pivot laterally, undermining the detection capability of the entire network. To address these critical limitations, the mimic defense paradigm introduces the Dynamic Heterogeneous Redundancy (DHR) architecture into system security [22,23]. This approach disrupts system uniformity through software- and hardware-level heterogeneity, enhancing the intrinsic adaptability and security of the system against emerging threats such as zero-day attacks, backdoors, and malware. However, existing research applies DHR to industrial control network redundancy, primarily focusing on the hardware layer [24], and there is a lack of relevant application exploration on how to apply the DHR architecture to industrial control intrusion detection, especially by using software-defined implementations.
In addition to academic research, several detection systems have been practically deployed in industrial control environments to safeguard critical infrastructure [25,26]. Representative examples include signature-based intrusion detection systems such as Snort, Suricata, and Quickdraw SCADA IDS, which match observed traffic against predefined rule sets. In SCADA environments, behavior-based anomaly detectors like Flowmon Probes and Modbus-NFA Behavior Distinguisher (MNBD) are adopted to capture deviations from normative protocol behavior. Furthermore, model-driven diagnostic frameworks—such as the Component-based Diagnostic Model Builder (CDMB) and Fisher–Rosemount Systems—are employed in industrial process control to monitor the consistency between expected and observed system states. While these tools have achieved success in operational scenarios, their underlying architectures are often static, loosely integrated, and vulnerable to novel or coordinated attacks. These limitations underscore the pressing need for an adaptive, modular, and feedback-driven detection architecture capable of addressing dynamic cyber-physical threats.
In response to the evolving and complex challenges in ICS security, this paper presents RHAD, a novel anomaly detection framework specifically tailored for ICS environments. The RHAD framework introduces a new theoretical paradigm grounded in the concept of Dynamic Heterogeneous Redundancy (DHR) [23]. Traditionally, DHR has focused on hardware-level redundancy to enhance system robustness. However, this paper reinterprets DHR in the context of software-defined anomaly detection, emphasizing the need for algorithmic diversity and temporal adaptability to effectively address the dynamic and sophisticated attack patterns prevalent in ICS environments.
The originality of RHAD lies in its layered diagnostic architecture, which integrates multiple detection models, dynamic scheduling mechanisms, and decision aggregation strategies. This architecture addresses a critical gap in existing research by providing a comprehensive multi-model fusion approach that ensures resilience through dynamic adaptation. RHAD leverages reinforcement learning (RL) to continuously optimize the system’s detection capabilities, introducing a self-evolving mechanism that adapts to new attack vectors and operational dynamics. This framework represents a significant advancement in ICS security by offering not only a robust detection mechanism but also a flexible, scalable solution capable of addressing the unique challenges posed by modern industrial environments.
We extend the DHR paradigm into the software-defined algorithmic domain, proposing a dynamic, adaptive, and resilient detection architecture capable of runtime reconfiguration and threat-responsive execution scheduling. This approach ensures that the system remains agile, adaptive, and capable of responding to emerging threats in real time. The principal contribution of RHAD lies in its layered diagnostic framework, which systematically integrates three core components into a closed-loop, resilience-oriented architecture:
- (1)
- Multi-perspective threat sensing, achieved through an ensemble of algorithmically and behaviorally diverse detectors, ensuring broad coverage across protocol semantics, temporal dependencies, and spatial access patterns;
- (2)
- Policy-based dynamic scheduling, realized through a Proximal Policy Optimization (PPO)-driven reinforcement learning agent that continuously adjusts model execution weights and orchestrates containerized detection modules based on real-time confidence metrics and system state observations;
- (3)
- Stabilized decision aggregation, implemented via a time-decaying, confidence-weighted sliding window voting strategy that mitigates transient false positives and reinforces consistent detection outcomes over time.
This layered framework offers a concrete realization of the principle that robust ICS security arises not from static detection accuracy, but from adaptive coordination under operational uncertainty. By explicitly formalizing the diagnostic pipeline and embedding intelligent scheduling within a closed feedback loop, RHAD advances both the theoretical understanding and practical implementation of resilient ICS defense.
To support this analysis, the remainder of the paper is organized as follows. Section 2 elaborates on the architectural components and diagnostic mechanisms of the RHAD framework. Section 3 presents the experimental setups, including datasets, parameter configurations, and evaluation metrics. Section 4 reports and analyzes the performance results, with emphasis on comparative evaluations and ablation studies. Finally, Section 5 concludes the paper and outlines directions for future work in resilient anomaly detection for ICS.
2. Methodology: RHAD Threat Diagnosis Framework for ICS
2.1. Overview of the RHAD Architecture and Diagnosis Workflow
Figure 1 presents the architectural overview of the Reinforced Heterogeneous Anomaly Detector (RHAD), which is structured as a three-layered diagnostic pipeline featuring a closed-loop feedback mechanism. This design supports real-time threat identification, dynamic model orchestration, and robust decision-making under continuously evolving ICS environments. The RHAD framework comprises three core components:
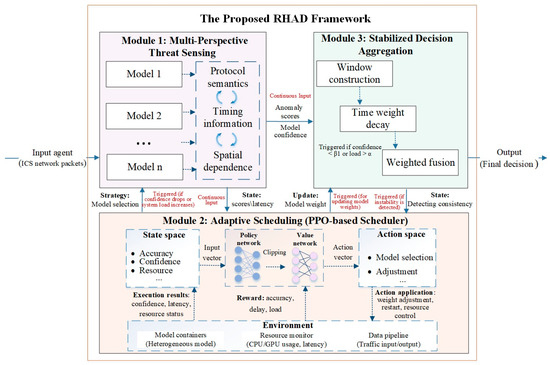
Figure 1.
Overview of the RHAD framework, consisting of three core layers: (1) Multi-Perspective Threat Sensing using a heterogeneous ensemble of containerized models; (2) Adaptive Scheduling via PPO-based reinforcement learning, which dynamically adjusts model priorities and orchestrates container execution; and (3) Stabilized Decision Aggregation, which performs confidence-weighted, temporally-aware voting for robust final decisions. (Note: Input refers to ICS network traffic captured for analysis; Output denotes the final decision of the detection system (e.g., binary classification or multi-class identification of attack types). Arrows with red text indicate inter-module interactions, encompassing both continuous data streams and triggered updates based on runtime conditions).
- (1)
- Multi-Perspective Threat Sensing—A containerized ensemble of heterogeneous detection models, each capturing distinct behavioral patterns in ICS traffic (e.g., protocol semantics, temporal dynamics, and spatial dependencies).
- (2)
- Adaptive Scheduling—A reinforcement learning scheduler based on the Proximal Policy Optimization (PPO) algorithm, which adaptively manages model execution, weight assignment, and threshold adjustment in response to system feedback.
- (3)
- Stabilized Decision Aggregation—A confidence- and time-weighted voting mechanism that fuses model outputs over time to produce stable and reliable system-level classifications.
These layers collectively form a closed-loop control architecture. To further clarify the inter-module interactions within RHAD, we explicitly define the nature and triggering conditions of data flow and feedback among Modules 1, 2, and 3 as follows:
- (1)
- Module 1 → Module 2: The sensing layer (Module 1) continuously outputs real-time anomaly scores, confidence metrics, and latency indicators. When the average confidence across models drops below a predefined confidence mean threshold, or when system load exceeds a resource utilization threshold, the scheduler (Module 2) is activated to trigger model replacement actions to maintain detection performance under constrained conditions.
- (2)
- Module 1 → Module 3: In parallel, the anomaly scores and confidence vectors from Module 1 are streamed into the aggregation module (Module 3), which performs confidence-weighted, time-decayed fusion over a sliding window to produce robust and stable classification decisions.
- (3)
- Module 2 → Module 1: When policy updates are triggered—either by feedback from Module 3 or threshold violations—Module 2 directly alters the composition of the sensing layer by activating, suspending, or replacing individual models based on their current performance and the global system state. This feedback-driven reconfiguration enforces dynamic heterogeneity and maintains detection reliability in evolving environments.
- (4)
- Module 2 → Module 3: To align aggregation behavior with updated detection strategies, Module 2 also transmits revised model weights to Module 3 when scheduling decisions are altered. These adjustments allow Module 3 to adapt its voting logic in response to resource fluctuations or behavioral drift, preserving accuracy and consistency under shifting operational contexts.
- (5)
- Module 3 → Module 2: Finally, Module 3 monitors output stability and classification consensus. If instability is detected, it sends a degradation signal back to Module 2. This initiates a re-evaluation of the scheduling policy and model configuration, completing the closed adaptive feedback loop.
Through this continuous sensing, policy adjustment, and feedback cycle, RHAD achieves robust and self-adaptive threat detection, making it well-suited for complex and high-assurance ICS environments.
To enable modular collaboration and cross-platform deployment, the RHAD framework is built upon a scalable virtualized infrastructure. Specifically, Open vSwitch (OVS) is adopted for its flexibility, low cost, and compatibility with heterogeneous system configurations, allowing realistic ICS network topologies to be emulated for reproducible experimentation. The entire system is containerized using Docker, with each core component—detection model, scheduler, and aggregation unit—encapsulated in its own container. This design supports parallel execution, runtime isolation, and platform independence, ensuring both functional consistency and architectural flexibility. Moreover, it facilitates seamless integration of heterogeneous models—including lightweight, generative, and discriminative detectors as discussed in Section 2.2—thereby enhancing RHAD’s scalability and adaptability for dynamic ICS environments.
2.2. Multi-Perspective Threat Sensing Layer
The first layer of the RHAD framework is devoted to multi-perspective threat sensing, aiming to detect a broad range of attack scenarios commonly observed in ICS environments, including Denial-of-Service (DoS), command injection, and man-in-the-middle (MITM) attacks. Given the diverse nature of threats in ICS environments—ranging from protocol-level anomalies to temporal pattern deviations—we construct a heterogeneous ensemble of detection models, grounded in the principle of complementary detection. This ensemble leverages multi-dimensional features, including protocol semantics, statistical patterns, and temporal-spatial correlations, to ensure comprehensive threat detection across a wide range of ICS behaviors.
The selection and deployment of models in this layer are guided by three key principles:
- (1)
- Algorithmic Diversity: Each model operates under distinct inductive biases and failure modes to reduce the risk of correlated misclassifications, thereby enhancing the resilience of the ensemble.
- (2)
- Feature Integration: The models are designed to capture a broad range of ICS traffic characteristics, such as protocol conformance, temporal dependencies, and spatial access patterns, ensuring that all aspects of the ICS environment are monitored for potential threats.
- (3)
- Computational Efficiency: Models must maintain lightweight inference profiles to satisfy real-time detection constraints in ICS environments.
To implement these core design principles, the framework introduces a multi-dimensional heterogeneity strategy across algorithm, data, and deployment environments, as illustrated in Figure 2. Algorithmic heterogeneity integrates diverse model paradigms, including lightweight classifiers, generative models, and deep discriminative networks, to mitigate correlated failure modes and enhance fault isolation. Data heterogeneity combines raw traffic with statistical features, enabling the detection of threats across both fine-grained and abstract behavioral levels. Environmental heterogeneity leverages containerized deployment across varied operating systems (e.g., Windows, Linux) to support parallel execution and isolate failures with minimal overhead.
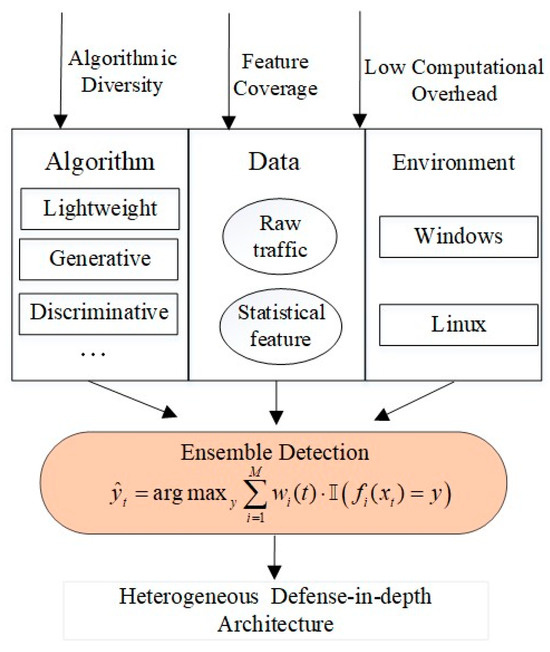
Figure 2.
Multi-dimensional heterogeneity (including algorithmic, data, and environmental) to fulfill the core design principles, forming a heterogeneous defense-in-depth ensemble architecture.
Together, the multi-perspective threat sensing layer plays a critical role in identifying a wide variety of anomalous behaviors, from network-based attacks to internal system malfunctions. By combining the strengths of diverse detection techniques, this layer provides a comprehensive and robust approach to ICS anomaly detection.
2.3. Adaptive Scheduling Layer
The second layer of the RHAD framework employs a PPO-based RL scheduler that dynamically orchestrates model selection, weight adjustment, and threshold regulation based on real-time system feedback. This enables adaptive reconfiguration under fluctuating workloads and evolving threat conditions. The adaptive scheduling follows a closed-loop reinforcement learning process involving four key components:
- (1)
- State Space: Comprises a compact set of system-level indicators including model accuracy, detection confidence, processing latency, and resource utilization. These observations constitute the input to the policy network at each decision interval.
- (2)
- Policy and Value Networks: Given the current system state, the policy network () generates an action distribution, while the value network () estimates the expected return. These networks are trained using clipped PPO to ensure stable updates and prevent policy collapse.
- (3)
- Action Space: Based on the observed system states, the scheduler selects actions that optimize detection performance. The action space of the PPO-based scheduler consists of three coordinated components: (i) Continuous adjustment of model weights, allowing for real-time tuning of model importance based on their detection performance; (ii) Discrete decisions for model replacement, where underperforming models are replaced or adjusted to maintain high detection accuracy; and (iii) Dynamic action masking, which selectively prevents certain actions from being executed when they are deemed ineffective or redundant, ensuring efficient resource utilization.
- (4)
- Environment: Defined as the containerized detection runtime environment, encompassing deployed models, network traffic processors, and resource monitors. The environment executes selected actions and returns updated system states and reward signals to the scheduler, thereby completing the learning loop. To enable optimal adaptation under dynamic conditions, the scheduler employs a hierarchical reward function that balances detection accuracy, latency, and resource efficiency for effective policy optimization.
To support real-time adaptability, it is essential to not only define the structure of the scheduling loop but also clarify how individual components interact in practice. In particular, the mechanisms by which the action space influences the environment, and how the environment, in turn, shapes the state space and reward generation, are central to the system’s adaptive capabilities. The following describes in detail how action execution and environment feedback are integrated into the RHAD reinforcement learning loop.
In this closed-loop architecture, Action Application refers to the real-world execution of actions derived from the PPO policy—such as updating model weights, activating or suspending containers, or reallocating computational resources. These changes are enforced directly within the environment. Upon action execution, the environment generates two forms of critical feedback:
- (1)
- Reward Feedback: System performance is evaluated based on detection accuracy, model confidence, response time, and resource efficiency. These metrics are aggregated into a scalar reward, which is passed to the value network to refine future policy decisions.
- (2)
- State Observation Update: The environment also outputs refreshed observations—including confidence scores, detection consistency, and resource usage—which serve as the new state input for the next decision iteration.
This dynamic interaction allows RHAD to adaptively optimize its detection strategy in response to operational constraints.
To ensure robust policy optimization under dynamic ICS conditions, the RL-based scheduler operates under a set of empirically tuned constraints that balance detection performance and resource efficiency. Specifically, a Computation Load Threshold () prevents resource overload by masking high-cost actions when system load exceeds a defined limit, thereby preserving real-time responsiveness. A Confidence Mean Threshold () monitors the average ensemble confidence over a sliding window to detect model degradation; if confidence falls below the threshold, the scheduler triggers reallocation or replacement of underperforming models. Furthermore, a Pareto-Guided PPO Clipping strategy () is employed to stabilize multi-objective learning, regulating policy updates to avoid abrupt shifts and ensure smooth convergence. These thresholds are integrated into the PPO optimization loop, as depicted in Algorithm 1 and detailed in Appendix A, enabling RHAD to adapt intelligently while maintaining operational stability.
| Algorithm 1: PPO-based Adaptive Scheduler for ICS |
| Initialize policy network and value network Initialize experience buffer For each training episode: For each time step : 1. Observe current system state 2. Select action 3. Execute action in the ICS environments 4. Receive reward and next state 5. Store () into buffer End for Compute advantage estimates using value function Update policy by minimizing the clipped surrogate loss: Update value function by minimizing: Check convergence condition or max training steps If met, terminate training End for |
|
2.4. Stabilized Decision Aggregation Layer
The final layer, Stabilized Decision Aggregation, integrates the outputs from the Multi-Perspective Threat Sensing and Adaptive Scheduling layers into a unified decision. This layer employs a confidence-weighted sliding window voting way with temporal decay to enhance decision-making stability and suppress transient false positives. Functioning as the final consolidation stage within the DHR paradigm, we propose a time-aware multi-model voting method specifically designed for anomaly detection in ICS. This approach improves both the robustness and reliability of ensemble-level decisions by temporally integrating the outputs of heterogeneous detection models. By suppressing transient false positives and reinforcing confidence in sustained anomaly patterns, it significantly enhances the stability and operational viability of ICS anomaly detection frameworks.
The design of this method is grounded in two foundational principles:
- (1)
- Temporal Sensitivity Principle: Recent detection results are more indicative of the system’s current operational state. Therefore, they should be assigned proportionally greater influence in the decision-making process.
- (2)
- Model Heterogeneity Weighting Principle: Since individual detection models perform differently across various threat scenarios, their contributions to the final decision should be dynamically adjusted based on their historical reliability and task-adaptive trust levels.
The Stabilized Decision Aggregation Layer receives anomaly scores and confidence levels from the Multi-Perspective Threat Sensing Layer and the adjusted model configurations from the Adaptive Scheduling Layer. Based on the aforementioned principles, the workflow is as follows:
- (1)
- Sliding Window Construction and State Caching
A fixed-size sliding window of length N is maintained, storing the outputs of all models over the most recent N detection intervals. The window is updated using a First-In-First-Out (FIFO) policy, ensuring that obsolete information is phased out in favor of more recent observations. This structure captures the system’s temporal dynamics and ensures that the ensemble decision reflects the current state of operation.
- (2)
- Temporal Decay Weight Function
To emphasize the relevance of recent outputs, a temporal decay function is applied to weight historical results. The decay is formulated as:
represents a temporal decay weight, where denotes the time gap between the current step and the historical detection event, and controls the decay rate. This strategy ensures that older outputs exert less influence on the final decision, enhancing the responsiveness of the system to new threats.
- (3)
- Weighted Aggregation and Voting
Within each sliding window, model outputs are first normalized and then assigned composite weights derived from both the temporal decay factor and each model’s historical confidence score. These weighted outputs are aggregated to generate a unified system-level decision per detection cycle. The final result can be expressed as a binary classification (normal vs. anomalous) or extended to multi-class labels indicating specific attack types, depending on the detection objective.
The Stabilized Decision Aggregation Layer helps to enhance the consistency and reliability of the detection system, especially in the presence of transient anomalies or long-duration attacks. By integrating model outputs over time and adjusting for temporal relevance, the system ensures that decisions are made based on the most current and relevant data.
3. Experimental Setup and Parameter Configuration
To evaluate the effectiveness and practicality of the proposed RHAD framework in real-world ICS scenarios, we conduct comprehensive experiments on two publicly available datasets. These experiments aim to validate the feasibility of integrating DHR principles into active defense strategies for industrial environments.
3.1. Implementation Details and Settings
To ensure fairness and reproducibility, all experiments were conducted on controlled computing platforms with consistently tuned hyperparameters.
- (1)
- Table 1 summarizes the hardware configurations used in the experiments. These configurations enabled high-throughput and stable execution of both baseline methods and the RHAD framework, including reinforcement learning–based scheduling.
 Table 1. Hardware configurations used in experimental evaluation.
Table 1. Hardware configurations used in experimental evaluation. - (2)
- Hyperparameter Tuning. To ensure a fair and rigorous comparison among all methods, we employed a grid search procedure on the training set with 5-fold cross-validation for both the proposed RHAD framework and all baseline models. The candidate hyperparameter values were selected based on widely adopted configurations in the literature and tailored to the statistical characteristics of the ICS datasets [27,28,29]. In Section 2.2, we selected five representative anomaly detection models to reflect architectural and algorithmic diversity within the RHAD framework:
- FlowTransformer [27]
A Transformer-based architecture designed to capture long-range dependencies in network traffic, overcoming limitations of traditional NIDS (Network Intrusion Detection System) models in modeling complex temporal patterns. The self-attention mechanism enhances the model’s ability to detect stealthy or distributed attacks.
- LSTM-AutoEncoder (LSTM-AE) [28]
A two-stage deep learning model that combines LSTM for temporal sequence encoding and an autoencoder for feature reconstruction. It learns compact representations of normal traffic, improving sensitivity to anomalous deviations.
- CNN-Attention Network (CANet) [29]
A hierarchical detection framework integrating convolutional layers with attention blocks (CA Blocks), enabling the model to extract localized spatiotemporal features. This design enhances its ability to recognize fine-grained attack behaviors across multiple time scales.
- Random Forest (RF) [30]
A classical ensemble classifier consisting of 500 decision trees, each with a maximum depth of 10. Feature importance is calculated using the Gini index, with a pruning threshold of 0.3 to improve generalization and inference efficiency.
- Support Vector Machine (SVM) [31]
A kernel-based model using the Radial Basis Function (RBF) kernel, with hyperparameters set to and .
All models were trained using the same training and test datasets with consistent hyperparameter settings to ensure comparability. Detailed model configurations are summarized in Table 2.
Table 2.
Deep learning model hyperparameter settings.
- (3)
- RHAD-Specific Parameters. In addition to the baseline configurations, we tuned key parameters specific to RHAD’s reinforcement learning components (Section 2.3) and decision fusion strategy (Section 2.4). These values were selected to balance responsiveness and decision stability. To validate their robustness, we conducted a parameter sensitivity analysis, which is presented in Section 4.3. Please note that the formal definitions and implementation details of the PPO-based scheduling are provided in Appendix A.
- (i)
- Reinforcement learning components
- Resource Utilization Threshold:
To prevent resource saturation and runtime bottlenecks, is constrained to 80% of system capacity. Once exceeded, the scheduler temporarily suspends resource-sensitive actions and disables low-priority models, thereby ensuring real-time responsiveness.
- Confidence Mean Threshold:
A confidence mean threshold of 0.8 is applied over a sliding window to monitor the collective reliability of active models. If the aggregated confidence falls below this threshold, the scheduler triggers model reallocation or replacement. This setting balances responsiveness and stability—too low may induce frequent switching, while too high may hinder timely adaptation to underperforming models.
- Pareto-Guided Policy Optimization with Clipping:
To jointly optimize detection accuracy and latency under ICS constraints, a Pareto-based multi-objective learning strategy is adopted. A clipping parameter of 0.2 is used during Proximal Policy Optimization (PPO) to limit per-update divergence, ensuring gradual and stable policy evolution. This prevents abrupt behavior changes and mitigates the risk of policy collapse during training.
- (ii)
- Decision fusion strategy
To enhance the robustness of anomaly detection outcomes, the voting module (Section 2.4) incorporates a sliding window mechanism and a temporal decay strategy. These components are designed to suppress transient noise and stabilize decision outputs under fluctuating traffic conditions. The parameter settings are as follows:
- Sliding Window Length ():
Set to 10, the voting module aggregates detection outputs over the most recent 10 time intervals to perform statistical fusion and enhance temporal stability. A smaller window increases sensitivity to transient fluctuations, while a larger window may introduce latency and reduce responsiveness to rapid threat changes.
- Temporal Decay Coefficient ()
This coefficient controls the exponential decay applied to historical model outputs (configured to 0.3). Recent decisions are weighted more heavily in the final vote, allowing the system to down-weight outdated evidence and improve responsiveness to sudden or sustained attack patterns.
To further enhance model robustness and ensure consistent convergence during training, we adopted two stabilization techniques: the Focal Loss function and gradient clipping. Focal Loss helps mitigate the inherent class imbalance in ICS datasets by prioritizing hard-to-classify samples, while gradient clipping prevents exploding gradients and stabilizes backpropagation, especially in deep models. These techniques are critical in maintaining numerical stability and accelerating convergence. When combined with the hyperparameter tuning strategies outlined above, this unified training configuration ensures that all reported results are both rigorously reproducible and fairly comparable across baseline and proposed methods.
3.2. Experimental Datasets
To comprehensively evaluate the RHAD framework under diverse industrial conditions, we conduct experiments on two publicly available datasets, each representing distinct cyber-physical system (CPS) scenarios:
- (1)
- Supervisory Control and Data Acquisition (SCADA) Dataset [32]
This dataset is designed to support intrusion detection research in SCADA systems, a core component of critical infrastructure. The data were generated within a SCADA sandbox environment, incorporating realistic physical process modeling via an electrical network simulator. Attack traces were synthesized using real-world penetration tools to simulate representative threats. As a widely adopted benchmark, this dataset enables reproducible validation of detection performance in ICS environments with high-fidelity control protocols and diverse attack types. It is particularly useful for assessing the model’s effectiveness in safeguarding high-priority industrial assets.
- (2)
- Water Distribution Testbed Dataset (WDT) [33]
The WDT dataset provides network and sensor-level traffic data collected from a Hardware-in-the-Loop (HIL) water distribution testbed. It integrates process control signals, actuator responses, and simulated attacks targeting the physical process. The dataset is specifically designed for evaluating security mechanisms in cyber-physical environments and enables the analysis of how cyber intrusions propagate through and impact real-time physical systems. This makes it a valuable benchmark for assessing the RHAD framework’s robustness across a broader range of ICS and industrial IoT settings.
Together, these two datasets cover complementary threat surfaces: SCADA focusing on supervisory-level industrial communication and WDT capturing lower-level process interactions. Evaluating RHAD across both datasets enables a well-rounded assessment of its generalization capability, detection precision, and resilience under diverse industrial operating conditions.
- (3)
- Fault Type Distribution
Table 3 summarizes the fault categories and corresponding sample counts present in each dataset. These datasets encompass a diverse set of attack scenarios, including denial-of-service (DoS), man-in-the-middle (MITM) command injection, replay-based physical faults, and sensor spoofing, all of which are representative of real-world threats to ICS environments. We adopted a stratified sampling strategy to split the data into training (60%), validation (20%), and test sets (20%), ensuring balanced representation across normal and fault conditions.
Table 3.
Sample distribution per fault category in the SCADA and WDT datasets.
3.3. Evaluation Metrics
To comprehensively assess the performance of the RHAD framework and its constituent detection models, we adopt a set of widely used evaluation metrics that jointly reflect classification accuracy, robustness, and responsiveness in anomaly detection. The core metrics are defined as follows:
- Accuracy: Measures the overall proportion of correctly classified samples. While useful, accuracy may be misleading in imbalanced scenarios, making it necessary to complement it with other metrics.
- F1-Score: The harmonic mean of precision and recall, used to balance the trade-off between false positives and false negatives. It is particularly important in ICS scenarios where both missed detections and false alarms have significant operational consequences.
- Inference Time: Measures the average processing time per detection sample. As industrial systems are typically subject to real-time constraints, inference time is used to assess the system’s operational feasibility.
- False Positive Rate (FPR): Evaluates the ratio of benign samples incorrectly flagged as attacks. Lower FPR is desirable to maintain the trustworthiness and usability of the detection system.
4. Experimental Results and Analysis
4.1. Performance Comparison
The comparative experiments were conducted by training and evaluating the proposed RHAD framework alongside baseline models using unified dataset partitions, preprocessing strategies, and computational resources, ensuring a fair and reproducible assessment of performance.
- (1)
- SCADA Dataset Results
Figure 3 compares the performance of six anomaly detection models—RF, SVM, LSTM-AE, FlowTransformer, CANET, and the proposed model (RHAD)—across three evaluation metrics, Accuracy, F1-Score, and Inference Time, using the SCADA dataset. The Proposed Model achieves the highest Accuracy (99.19%), outperforming other models, with CANET (98.35%) and FlowTransformer (97.87%) being the closest competitors. For F1-Score, the Proposed Model (0.989) ranks slightly below CANET (0.987), suggesting near-equivalent performance in balancing precision and recall. LSTM-AE (0.983) also performs well, while RF and SVM lag significantly.
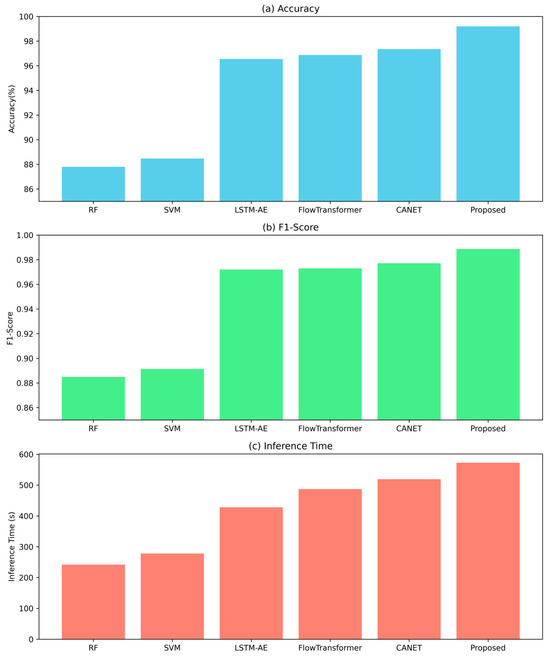
Figure 3.
Comparative performance of detection models on the SCADA dataset: (a) Accuracy (%), (b) F1-Score, and (c) Inference Time (seconds) for six models.
In terms of inference efficiency, the Proposed Model has the longest inference time (572.64 s), followed by CANET (519.33 s). RHAD incurs a higher inference time primarily due to its ensemble-based architecture and closed-loop scheduling mechanism. Unlike single-model detectors, RHAD executes multiple heterogeneous models in parallel and dynamically coordinates them via reinforcement learning, which introduces additional computation. This indicates a trade-off between performance gains and computational efficiency. Traditional models (RF: 242 s, SVM: 278 s) are faster but less accurate, highlighting their suitability for real-time applications with lower accuracy requirements.
Overall, deep learning-based models (LSTM-AE, FlowTransformer, CANET, Proposed) consistently outperform traditional ML models (RF, SVM) in accuracy but at higher computational costs. The proposed Model demonstrates state-of-the-art accuracy for SCADA datasets, making it suitable for applications where precision is critical.
- (2)
- WDT Dataset Results
Figure 4 presents the comprehensive evaluation results on the WDT dataset, revealing three key findings that advance our understanding of industrial anomaly detection systems. First, the proposed model achieves a higher classification accuracy of 98.35% on the WDT dataset, showing an improvement of 2.09–3.78% over recent deep learning baselines (LSTM-AE: 96.26%, FlowTransformer: 96.33%, and CANET: 94.57%). This performance superiority extends to the F1-Score metric with 0.987, confirming the model’s robust capability in maintaining precision-recall balance across both majority and minority classes, which is a critical requirement for practical intrusion detection systems where class imbalance is prevalent.
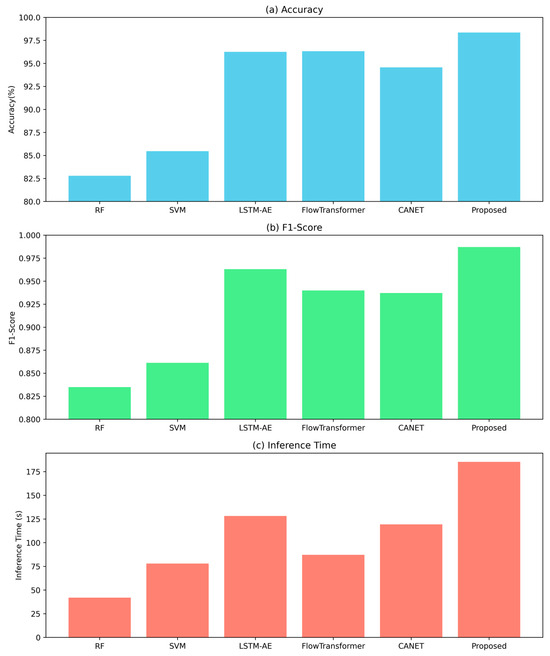
Figure 4.
Comparative performance of detection models on the WDT dataset: (a) Accuracy (%), (b) F1-Score, and (c) Inference Time (seconds) for six models.
Second, the comparative analysis reveals fundamental architectural insights. While all deep learning baselines (CANET, LSTM-AE) achieve respectable F1-Scores (>0.94), the proposed model’s heterogeneous ensemble design provides measurable advantages in capturing diverse threat signatures. This is evidenced by its consistent 1.5–4.2% performance margin across metrics, suggesting that the integrated feature fusion mechanism successfully combines complementary detection capabilities from constituent architectures.
Third, although the proposed model achieves superior detection accuracy, it incurs a higher computational cost, with an inference time of 185.33 s, representing an increase of 1.45 to 2.2 times compared to simpler architectures. It is worth noting that RHAD exhibits higher inference latency compared to traditional and lightweight deep learning models. This overhead primarily stems from the runtime coordination of heterogeneous detection models and the reinforcement learning–guided scheduling mechanism. However, this design enables RHAD to maintain high detection accuracy and robustness under dynamic threat conditions and operational variability. Therefore, RHAD is particularly suitable for industrial environments where detection precision and system resilience are prioritized over strict real-time constraints.
- (3)
- Comparative Analysis of Model Characteristics
In addition to empirical results, we further analyze the architectural and algorithmic distinctions among the evaluated models to explain their relative performance. Traditional models such as RF and SVM rely on shallow structures with limited capacity to learn temporal or spatial dependencies—key features in industrial traffic patterns. While they offer fast inference, their fixed decision boundaries and sensitivity to class imbalance constrain their detection effectiveness, especially in the presence of novel or subtle anomalies.
By contrast, deep learning-based models (e.g., LSTM-AE, FlowTransformer, CANET) leverage advanced architectures to extract temporal and spatial features, yielding higher detection accuracy and F1 scores. However, they remain single-model approaches, often lacking dynamic adaptability when faced with evolving attack.
RHAD addresses these limitations by integrating algorithmic diversity, reinforcement-guided scheduling, and stabilized aggregation into a unified architecture. Its ability to adaptively coordinate multiple heterogeneous models and self-optimize based on feedback gives it an edge in both robustness and scalability. This explains why RHAD consistently outperforms both conventional and deep learning baselines, as demonstrated across SCADA and WDT evaluations.
4.2. Ablation Study
To further validate the design rationality of the proposed RHAD framework, we conduct a two-stage ablation study using the WDT dataset. The WDT dataset was chosen due to its richer diversity of fault types and more complex labeling schema, including categories such as DoS, MITM, physical fault injection, and sensor spoofing. This makes it more suitable for evaluating the individual and combined effects of RHAD components under varied and realistic threat scenarios.
This analysis focuses on four architecturally distinct and functionally critical modules in RHAD: (1) clipped policy optimization (Clip), which stabilizes reinforcement learning updates and prevents policy divergence; (2) sliding window voting (SW), which suppresses transient classification noise through temporal confidence aggregation; (3) model heterogeneity (MH), which enhances representational diversity and detection coverage across complementary model types; and (4) dynamic scheduling (DS), which enables adaptive resource orchestration and model selection based on evolving runtime conditions. These components are considered key because they span RHAD’s multi-layered architecture-from low-level optimization to high-level decision-making-and collectively support its resilience, adaptability, and robust anomaly detection performance in complex ICS environments.
In the first stage, we perform component-wise ablation, where each core module of RHAD is independently disabled while keeping the rest of the system intact. The following model variants are designed for comparison:
- V0 (Full Model)
The complete RHAD architecture with all modules enabled, including heterogeneous detection models, PPO-based dynamic scheduling, time-decaying sliding window voting, and clipped policy updates. This serves as the performance baseline.
- V1 (w/o Dynamic Scheduling):
The reinforcement learning scheduler is removed. Instead, a random scheduling strategy is used to select three models from the ensemble pool. When voting disagreement occurs, a fourth model is randomly selected to replace one candidate and the voting process restarts. This variant evaluates the contribution of adaptive scheduling to detection accuracy and resource utilization.
- V2 (w/o Model Heterogeneity):
All detectors share the same architecture (e.g., FlowTransformer) while being deployed across different environments. This variant model tests the benefit of architectural diversity and complementary failure patterns in improving attack coverage.
- V3 (Fixed Threshold Voting):
The sliding window mechanism and temporal decay weighting are disabled. Instead, a static, majority-voting scheme is applied to analyze the role of temporal smoothing in suppressing false positives and enhancing detection stability.
- V4 (No Clipping in PPO Updates):
The clipping mechanism in PPO is disabled (clip parameter set to 1.0), allowing unrestricted policy updates. This configuration evaluates the importance of controlled policy evolution in maintaining stable learning and preventing convergence collapse.
Building upon the variant configurations described above, we conducted a set of controlled experiments to quantify the individual impact of each module on the RHAD framework’s overall performance. As shown in Figure 5, each variant was evaluated using the WDT dataset to reflect realistic ICS dynamics. By isolating key components—such as dynamic scheduling, model heterogeneity, temporal voting, and clipped policy updates—the ablation study provides deeper insight into how each design choice contributes to detection accuracy, system stability, and resource efficiency. The experimental findings yield the following observations:
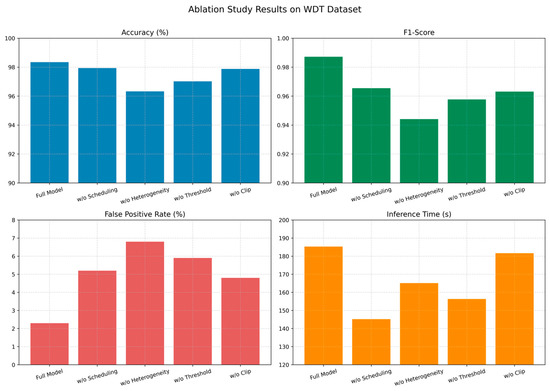
Figure 5.
Ablation study results on WDT dataset.
- (1)
- Adaptive scheduling contributes to improved robustness. Disabling the scheduling module resulted in a 2.12% decrease in F1-score and a 2.9% increase in false positive rate, indicating that runtime adaptability plays a meaningful role in handling the dynamic characteristics of ICS traffic.
- (2)
- Substituting heterogeneous classifiers with homogeneous ones—i.e., enforcing architectural uniformity across all sub-models—resulted in the most pronounced performance degradation. This observation emphasizes the critical role of model diversity in enhancing robustness and expanding the system’s capacity to capture varied and complex attack patterns.
- (3)
- Disabling the self-adaptive confidence threshold mechanism increased the model’s susceptibility to noise, leading to elevated false positive rates and unstable outputs in ambiguous cases. This result validates the role of confidence smoothing in stabilizing detection decisions under uncertainty.
- (4)
- Eliminating the clip constraint in the reinforcement learning policy updates introduced mild instability and a slight reduction in F1-score. The clip mechanism functions as an implicit regularization term, preventing overfitting to transient or spurious patterns during strategy optimization.
These findings confirm that each component of the proposed framework contributes meaningfully to either detection performance or operational stability. Among all evaluated variants, the full model (V0) achieves the most favorable balance across detection accuracy, robustness, and computational efficiency.
In the second stage, we have extended the ablation study to include a progressive component-removal analysis to examine the contribution and interaction of RHAD’s core modules. To better understand the cumulative contributions of RHAD’s internal modules, the ablation process follows a principled removal order: starting from the lowest-level optimizer (Clipped PPO), through mid-level decision aggregation (Sliding Window Voting), then removing model heterogeneity, and finally disabling the dynamic scheduling module responsible for global runtime coordination. Five variants (V0–V4) are tested on the WDT dataset: (i) V0 (Full Model); (ii) V1: Disables clipped optimization by setting , allowing unconstrained PPO updates; (iii) V2: Further disables sliding window voting, using static voting for final decisions; (iv) V3: Additionally removes model heterogeneity; all detectors share the same FlowTransformer architecture; and (v) V4: Fully disables dynamic scheduling, resulting in a static ensemble without adaptive policy.
As shown in Table 4, the results reveal a monotonic degradation trend as each component is removed:
Table 4.
Progressive ablation results on the WDT dataset with mean ± standard deviation over five independent runs.
- (1)
- Disabling clipped PPO (V1) leads to a 2.19% drop in F1-score and more than double the false positive rate, highlighting its essential role in stabilizing learning dynamics during policy updates;
- (2)
- Removing sliding window voting (V2) further reduces F1-score by over 1.5%, reflecting the increased sensitivity to transient or noisy anomalies in the absence of temporal aggregation;
- (3)
- Disabling model heterogeneity (V3) results in an additional performance loss, with F1-score dropping to 93.18% and FPR rising to 7.5%, underscoring the importance of architectural diversity in capturing complex ICS threat patterns;
- (4)
- Fully removing clipped policy optimization destabilizes learning dynamics, leading to the highest FPR (8.8%).
To further validate the significance of RHAD’s internal modules, we conducted pairwise statistical significance testing using two-tailed t-tests on F1-scores (see Table 5). All comparisons between the full model (V0) and other variants yield statistically significant differences (p-value < 0.01). Intermediate comparisons (e.g., V1 vs. V2, V2 vs. V3) also show significance (p-value < 0.05), confirming the distinct contributions of each component. Notably, the difference between V3 and V4 is not statistically significant (p-value =0.0586). This implies that once clipped PPO, heterogeneity, and voting are removed, the dynamic scheduler no longer has enough diversity or control leverage to deliver meaningful performance gain, indicating a resource-depleted or control-saturated state.
Table 5.
Pairwise Significance Testing on F1-Score between RHAD Variants.
These findings confirm that RHAD’s core modules contribute not only independently but also synergistically. While the fully degraded model (V4) still maintains moderate performance (F1-score = 92.53%), the complete configuration (V0) consistently delivers optimal performance across all metrics. This monotonic degradation pattern highlights RHAD’s graceful degradation property and underscores the architectural soundness of its layered, closed-loop design. Moreover, in safety-critical ICS environments, even moderate drops in F1-score (approximately 6%) and notable increases in FPR (more than 4 times) can incur unacceptable risks. These results thus justify the defination of the four modules—Clipped PPO, Sliding Window Voting, Model Heterogeneity, and Dynamic Scheduling—as key components of the RHAD architecture.
4.3. Parameter Sensitivity Analysis
To investigate the robustness of RHAD under varying hyperparameter configurations, we performed a detailed sensitivity analysis focusing on four core parameters (see Figure 6): (a) the sliding window length (N), (b) time decay factor (), (c) confidence threshold (), and (d) the PPO clip range . Each parameter was varied independently while keeping all other settings fixed. Performance metrics, including F1-score and false positive rate (FPR), were evaluated on the WDT dataset.
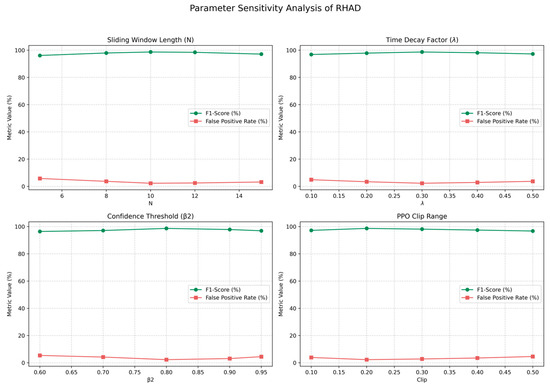
Figure 6.
Parameter Sensitivity Analysis on WDT Dataset.
The results indicate that RHAD maintains relatively stable performance across the tested parameter ranges. The curves in Figure 6 remain mostly flat, suggesting that within practical bounds, these parameters have limited influence on model outcomes. This insensitivity demonstrates that RHAD is not overly reliant on precise hyperparameter tuning, enhancing its usability in real-world deployments. Detailed observations include:
- (1)
- Sliding Window Length (): The model achieves its peak performance at . Smaller windows lead to higher volatility and susceptibility to transient noise, while larger windows introduce delay in capturing new patterns. However, the performance curve remains relatively flat, indicating that RHAD tolerates sliding window length without significant degradation.
- (2)
- Time Decay Factor (): The best F1-score is observed around . Lower values overweight recent evidence, increasing prediction fluctuation; higher values over-smooth the temporal signal.
- (3)
- Confidence Threshold (): The optimal value is found at , balancing detection sensitivity and false alarms. Lower thresholds may result in unstable decisions, while higher thresholds suppress model updates. The performance variation is small, reinforcing the resilience of RHAD’s confidence-aware decision strategy.
- (4)
- Clip Range in PPO (): The default setting of delivers the most stable performance. Smaller values overly constrain learning dynamics, whereas larger values increase policy divergence.
It is worth noting that while the above thresholds slightly affect detection precision and recall trade-offs, none of the parameters induce sharp performance drops. This suggests that RHAD exhibits stable behavior under moderate hyperparameter shifts, facilitating easier deployment and reducing the need for exhaustive tuning.
5. Conclusions
In this study, we proposed RHAD (Reinforced Heterogeneous Anomaly Detector), a robust and adaptive anomaly detection framework tailored for industrial control systems (ICS). RHAD integrates a heterogeneous ensemble of detection models, a reinforcement learning-based scheduling strategy, and a time-decaying confidence-weighted voting mechanism to address key challenges in ICS security, including concept drift, false alarms, and detection rigidity. The framework leverages multi-perspective feature modeling—spanning protocol semantics, temporal sequences, and spatial access patterns—within a containerized, cross-platform architecture that promotes deployment flexibility and fault isolation. Evaluations on two public ICS datasets (SCADA and WDT) demonstrate that RHAD consistently outperforms traditional and deep learning baselines, achieving state-of-the-art accuracy (up to 99.19%) and F1-score, while maintaining reasonable inference efficiency. Although RHAD incurs higher inference time due to its adaptive scheduling and ensemble coordination, this trade-off is aligned with its design objective: providing reliable detection in high-assurance industrial environments. Thus, RHAD is best suited for security-critical scenarios—such as power grids, petrochemical systems, and other safety-sensitive domains—where detection robustness and resilience take precedence over strict real-time constraints. Ablation and sensitivity analyses further validate the contribution of each core component and the model’s robustness under varied hyperparameter settings. Future work will explore extending RHAD to broader cyber-physical systems and optimizing its runtime footprint for deployment in resource-constrained industrial edge environments.
Author Contributions
Conceptualization, X.H.; Software, Y.N.; Validation, D.Z.; Investigation, Z.C.; Resources, Y.N.; Writing—original draft, X.H.; Writing—review & editing, Z.C.; Visualization, D.Z.; Supervision, B.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Key R&D Program of China under the grant 2022YFB3104300, and the Jiangsu Provincial Natural Science Foundation of China under grant BK20240292.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
In the Appendix, we detail the formulation of Section 2.2 (Dynamic scheduling based on reinforcement learning) for RHAD, including the construction of the state and action spaces, the design of the hierarchical reward function, and the associated optimization objectives.
- (1)
- To enable informed and context-aware scheduling, the state space of the PPO-based scheduler integrates four categories of dynamic features: model accuracy, confidence, processing latency, and resource utilization.
- Model accuracy is defined as the detection precision obtained during the offline training phase of each model.
- Model confidence quantifies the reliability of predictions over a sliding window, formulated as:
- Processing latency reflects the average decision time over a batch of samples. At time t, the average processing delay of m samples is defined as follows:
and are the time when the i-th sample enters and leaves the model, respectively.
- Resource utilization encompasses GPU, CPU, and memory usage levels, serving as a surrogate for computational load balancing.
- (2)
- The action space of the PPO-based scheduler consists of three coordinated components: continuous model weight adjustment, discrete model replacement decisions, and a dynamic action masking mechanism.
- Weight adjustment is modeled as a continuous vector:
is the number of currently active models, and denotes the weight update for the model during the decision cycle. To ensure stable adaptation, we apply momentum smoothing:
controls the update inertia, mitigating abrupt fluctuations.
- Model replacement is treated as a discrete Bernoulli sampling process:
That is, the model with the lowest confidence is taken offline and replaced with the new model .
- Action masking dynamically constrains the action space by integrating real-time system safety constraints, thereby preventing the selection of unsafe or infeasible actions under resource-critical or decision-stable conditions. Specifically, two masking functions are defined to regulate the execution of core control actions:
Specifically, if resource utilization exceeds threshold , all actions involving new model activation or increased parallelism are masked. Likewise, if the average model confidence within the sliding window surpasses threshold , weight adjustment is frozen to avoid destabilizing a stable ensemble.
- (3)
- To balance detection accuracy, real-time responsiveness, and resource efficiency in industrial control systems (ICS), we design a hierarchical reward function that guides the reinforcement learning scheduler toward optimal decision-making. The reward at each time step is defined as:
This function incorporates five key components:
- Detection incentive, which encourages high confidence on malicious traffic and low confidence on benign samples. Defined as:
- Stability reward, computed as a sigmoid-mapped sliding confidence mean, promoting scheduling policies that reduce output oscillation and excessive model churn:
- Latency penalty, linearly increasing with inference delay exceeding the ICS response deadline:
Considering the common PLC control cycle, this study sets to 50 ms.
- Quadratic resource penalty, imposed when the resource utilization exceeds a predefined threshold:
It means that a quadratic penalty is imposed on resource utilization exceeding the limit (set to 0.75 in this study) to strengthen the constraints on industrial control computing resources.
- False alarm penalty, applied to discourage misclassification and unnecessary model switching or weight oscillation:
Through continuous interaction with the environment, the scheduler agent learns to maximize cumulative rewards, thus deriving scheduling strategies that adaptively balance detection precision, operational stability, and computational cost in ICS deployments.
References
- Lampropoulos, G.; Siakas, K.; Anastasiadis, T. Internet of things in the context of industry 4.0: An overview. Int. J. Entrep. Knowl. 2019, 7, 4–19. [Google Scholar] [CrossRef]
- Gueye, T.; Iqbal, A.; Wang, Y.; Mushtaq, R.T.; Petra, M.I. Bridging the cybersecurity gap: A comprehensive analysis of threats to power systems, water storage, and gas network industrial control and automation systems. Electronics 2024, 13, 837. [Google Scholar] [CrossRef]
- Li, Q.; Li, Q.; Wu, J.; Li, X.; Li, H.; Cheng, Y. Wellhead stability during development process of hydrate reservoir in the Northern South China Sea: Evolution and mechanism. Processes 2024, 13, 40. [Google Scholar] [CrossRef]
- Li, Q.; Li, Q.; Cao, H.; Wu, J.; Wang, F.; Wang, Y. The Crack Propagation Behaviour of CO2 Fracturing Fluid in Unconventional Low Permeability Reservoirs: Factor Analysis and Mechanism Revelation. Processes 2025, 13, 159. [Google Scholar] [CrossRef]
- Yang, C.; Cai, B.; Wu, Q.; Wang, C.; Ge, W.; Hu, Z.; Zhu, W.; Zhang, L.; Wang, L. Digital twin-driven fault diagnosis method for composite faults by combining virtual and real data. J. Ind. Inf. Integr. 2023, 33, 100469. [Google Scholar] [CrossRef]
- Ali, B.S.; Ullah, I.; Al Shloul, T.; Khan, I.A.; Khan, I.; Ghadi, Y.Y.; Abdusalomov, A.; Nasimov, R.; Ouahada, K.; Hamam, H. ICS-IDS: Application of big data analysis in AI-based intrusion detection systems to identify cyberattacks in ICS networks. J. Supercomput. 2024, 80, 7876–7905. [Google Scholar] [CrossRef]
- Yang, C.; Cai, B.; Zhang, R.; Zou, Z.; Kong, X.; Shao, X.; Liu, Y.; Shao, H.; Khan, J.A. Cross-validation enhanced digital twin driven fault diagnosis methodology for minor faults of subsea production control system. Mech. Syst. Signal Process. 2023, 204, 110813. [Google Scholar] [CrossRef]
- Presekal, A.; Rajkumar, V.S.; Ştefanov, A.; Pan, K.; Palensky, P. Cyberattacks on Power Systems. Smart Cyber-Phys. Power Syst. Fundam. Concepts Chall. Solut. 2025, 1, 365–403. [Google Scholar]
- Case, D.U. Analysis of the cyber attack on the Ukrainian power grid. Electr. Inf. Shar. Anal. Cent. (E-ISAC) 2016, 388, 3. [Google Scholar]
- Karnouskos, S. Stuxnet worm impact on industrial cyber-physical system security. In Proceedings of the IECON 2011—37th Annual Conference of the IEEE Industrial Electronics Society, Melbourne, Australia, 7–10 November 2011; pp. 4490–4494. [Google Scholar]
- Diana, L.; Dini, P.; Paolini, D. Overview on Intrusion Detection Systems for Computers Networking Security. Computers 2025, 14, 87. [Google Scholar] [CrossRef]
- Yang, C.; Cai, B.; Kong, X.; Zhang, R.; Gao, C.; Liu, X.; Shao, H.; Zhao, X. Fast and stable fault diagnosis method for composite fault of subsea production system. Mech. Syst. Signal Process. 2025, 226, 112373. [Google Scholar] [CrossRef]
- Xu, L.; Zhao, Z.; Zhao, D.; Li, X.; Lu, X.; Yan, D. AJSAGE: A intrusion detection scheme based on Jump-Knowledge Connection to GraphSAGE. Comput. Secur. 2025, 150, 104263. [Google Scholar] [CrossRef]
- Shahin, M.; Maghanaki, M.; Hosseinzadeh, A.; Chen, F.F. Advancing network security in industrial IoT: A deep dive into AI-enabled intrusion detection systems. Adv. Eng. Inform. 2024, 62, 102685. [Google Scholar] [CrossRef]
- Suresh, P.; Sukumar, R.; Ayyasamy, S. Efficient pattern matching algorithm for security and Binary Search Tree (BST) based memory system in Wireless Intrusion Detection System (WIDS). Comput. Commun. 2020, 151, 111–118. [Google Scholar] [CrossRef]
- Erlacher, F.; Dressler, F. On high-speed flow-based intrusion detection using snort-compatible signatures. IEEE Trans. Dependable Secur. Comput. 2020, 19, 495–506. [Google Scholar] [CrossRef]
- Hu, X.; Gao, W.; Cheng, G.; Li, R.; Zhou, Y.; Wu, H. Toward early and accurate network intrusion detection using graph embedding. IEEE Trans. Inf. Forensics Secur. 2023, 18, 5817–5831. [Google Scholar] [CrossRef]
- Gao, J.; Gan, L.; Buschendorf, F.; Zhang, L.; Liu, H.; Li, P.; Dong, X.; Lu, T. Omni SCADA intrusion detection using deep learning algorithms. IEEE Internet Things J. 2020, 8, 951–961. [Google Scholar] [CrossRef]
- Musthafa, M.B.; Huda, S.; Kodera, Y.; Ali, M.A.; Araki, S.; Mwaura, J.; Nogami, Y. Optimizing IoT intrusion detection using balanced class distribution, feature selection, and ensemble machine learning techniques. Sensors 2024, 24, 4293. [Google Scholar] [CrossRef]
- Javed, H.; El-Sappagh, S.; Abuhmed, T. Robustness in deep learning models for medical diagnostics: Security and adversarial challenges towards robust AI applications. Artif. Intell. Rev. 2025, 58, 12. [Google Scholar] [CrossRef]
- Brodin, H.; Surovič, M.; Sultanik, E. Blind spots: Identifying exploitable program inputs. In Proceedings of the 2023 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 25 May 2023; pp. 175–186. [Google Scholar]
- Hu, J.; Li, Y.; Li, Z.; Liu, Q.; Wu, J. Unveiling the strategic defense mechanisms in dynamic heterogeneous redundancy architecture. IEEE Trans. Netw. Serv. Manag. 2024, 21, 4912–4926. [Google Scholar] [CrossRef]
- Wu, J. The Principle and Structure of Cyberspace Endogenous Security and Safety. In Cyber Resilience System Engineering Empowered by Endogenous Security and Safety; Springer: Berlin/Heidelberg, Germany, 2024; pp. 111–202. [Google Scholar]
- Wu, X.; Wang, M.; Shen, J.; Gong, Y. Towards Double-Layer Dynamic Heterogeneous Redundancy Architecture for Reliable Railway Passenger Service System. Electronics 2024, 13, 3592. [Google Scholar] [CrossRef]
- Li, Q.; Li, M.; Fu, C.; Wang, J. Fault Diagnosis of Wind Turbine Component Based on an Improved Dung Beetle Optimization Algorithm to Optimize Support Vector Machine. Electronics 2024, 13, 3621. [Google Scholar] [CrossRef]
- Aslam, M.M.; Tufail, A.; Apong, R.A.A.H.M.; De Silva, L.C.; Raza, M.T. Scrutinizing security in industrial control systems: An architectural vulnerabilities and communication network perspective. IEEE Access 2024, 12, 67537–67573. [Google Scholar] [CrossRef]
- Manocchio, L.D.; Layeghy, S.; Lo, W.W.; Kulatilleke, G.K.; Sarhan, M.; Portmann, M. Flowtransformer: A transformer framework for flow-based network intrusion detection systems. Expert Syst. Appl. 2024, 241, 122564. [Google Scholar] [CrossRef]
- Mobtahej, P.; Zhang, X.; Hamidi, M.; Zhang, J. An LSTM-Autoencoder Architecture for Anomaly Detection Applied on Compressors Audio Data. Comput. Math. Methods 2022, 2022, 3622426. [Google Scholar] [CrossRef]
- Ren, K.; Yuan, S.; Zhang, C.; Shi, Y.; Huang, Z. CANET: A hierarchical cnn-attention model for network intrusion detection. Comput. Commun. 2023, 205, 170–181. [Google Scholar] [CrossRef]
- Soltani, Z.; Hassani, H.; Esmaeiloghli, S. A deep autoencoder network connected to geographical random forest for spatially aware geochemical anomaly detection. Comput. Geosci. 2024, 190, 105657. [Google Scholar] [CrossRef]
- Alghushairy, O.; Alsini, R.; Alhassan, Z.; Alshdadi, A.A.; Banjar, A.; Yafoz, A.; Ma, X. An efficient support vector machine algorithm based network outlier detection system. IEEE Access 2024, 12, 24428–24441. [Google Scholar] [CrossRef]
- Lemay, A.; Fernandez, J.M. Providing {SCADA} network data sets for intrusion detection research. In Proceedings of the 9th USENIX Workshop on Cyber Security Experimentation and Test (CSET’ 16), Austin, TX, USA, 8 August 2016. [Google Scholar]
- Faramondi, L.; Flammini, F.; Guarino, S.; Setola, R. A hardware-in-the-loop water distribution testbed dataset for cyber-physical security testing. IEEE Access 2021, 9, 122385–122396. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).