
Fine-Grained Fault Sensitivity Analysis of Vision Transformers Under Soft Errors






Abstract
1. Introduction
- We proposed a fault resilience evaluation framework tailored to ViTs, incorporating realistic deployment settings via Int8 quantization.
- We performed a fine-grained fault sensitivity analysis across four key dimensions—model-wise, layer-wise, type-wise, and head-wise—under bit-flip fault injection scenarios.
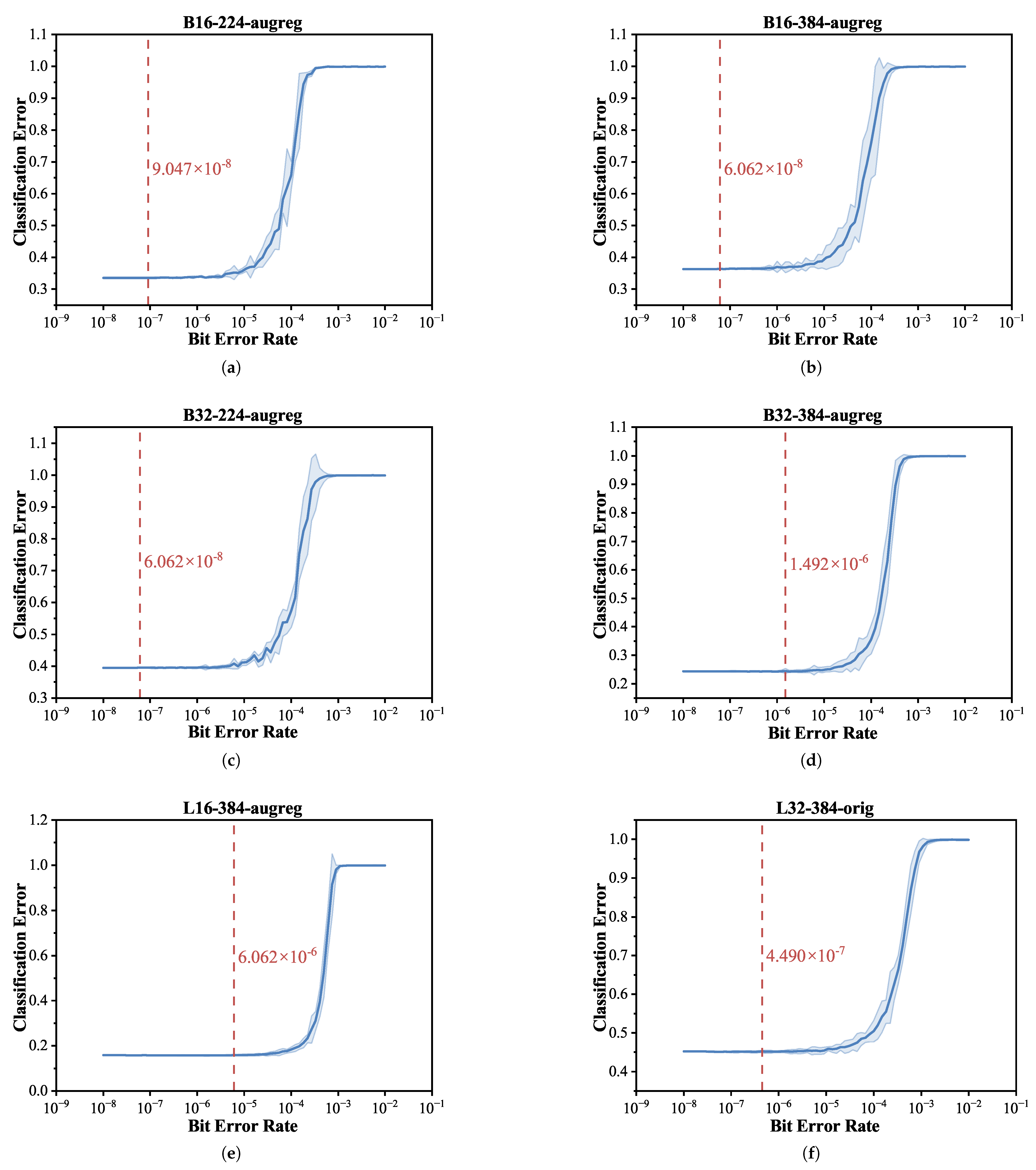
- From a model-wise perspective, we observed that architectural parameters such as model size and patch size substantially influence error resilience, with BER thresholds varying by several orders of magnitude across models.
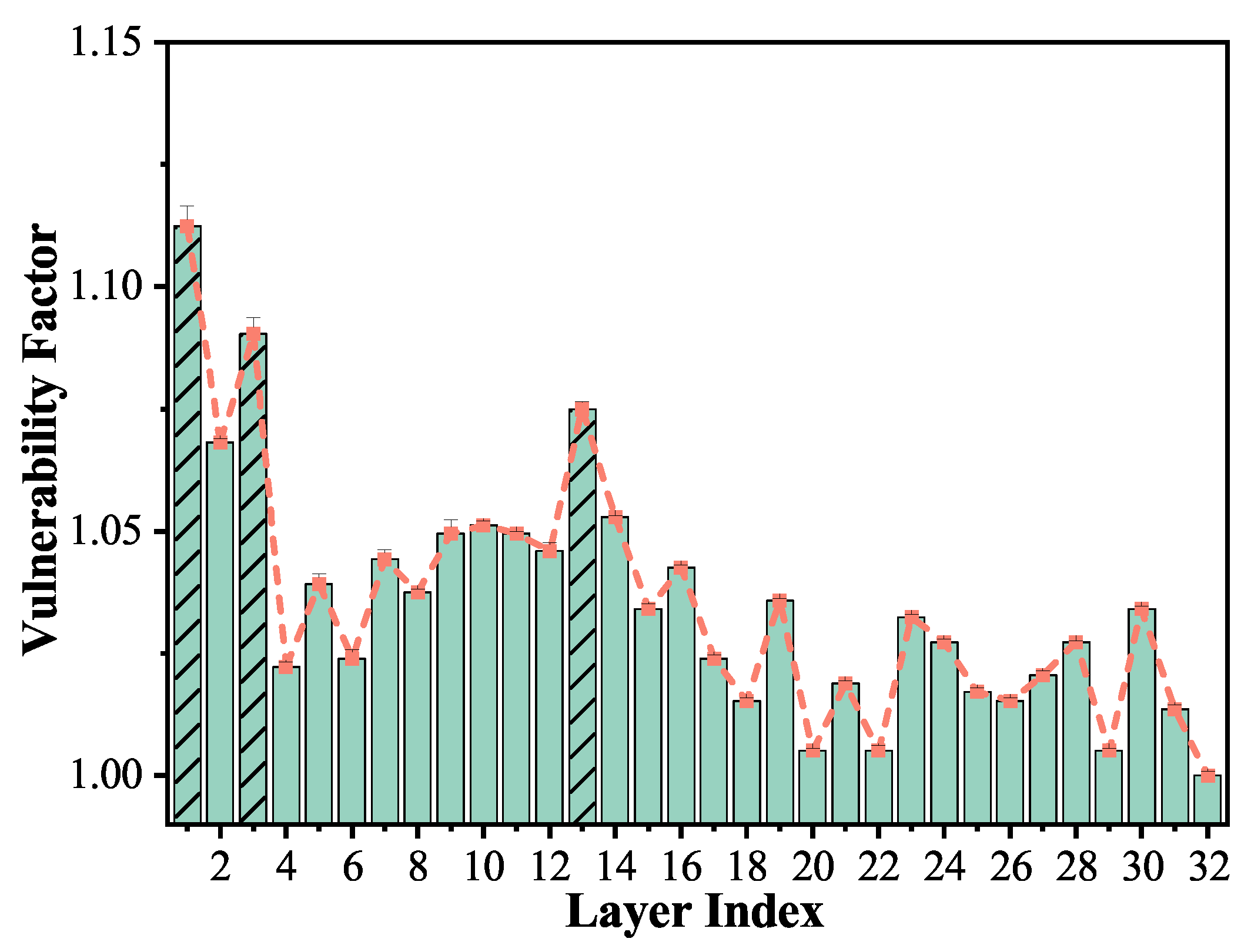
- At the layer-wise level, we identified the first transformer encoder layer as particularly susceptible to soft errors, owing to its foundational role in hierarchical feature extraction. Middle and later layers’ MLP sub-blocks also emerge as critical vulnerability points due to their dominant computational load and contribution to representation learning.
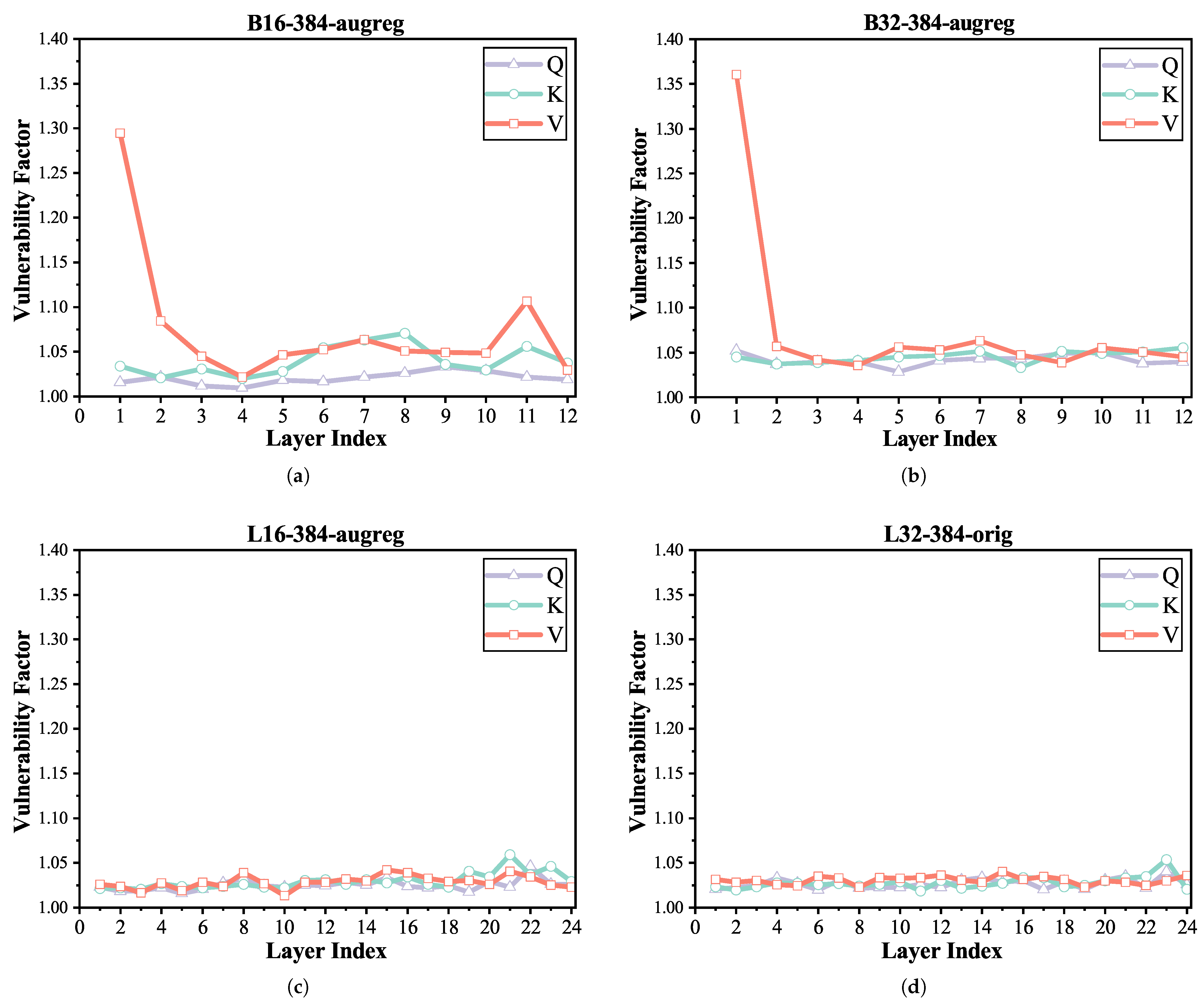
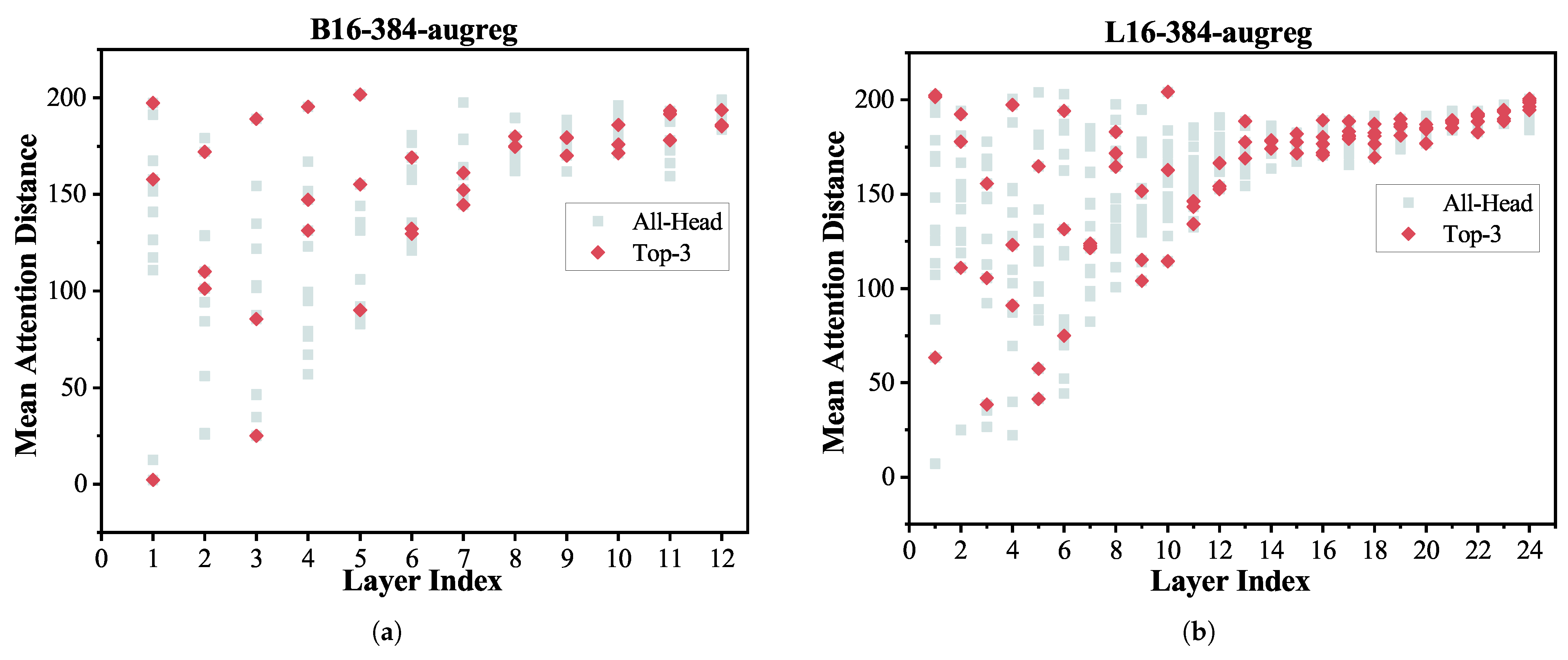
- In the type-wise and head-wise analyses, we revealed heterogeneous vulnerability patterns across Q, K, and V projection matrices and attention heads. Notably, we integrated the mean attention distance (MAD) metric to interpret why certain heads are more fault-prone—an interpretability perspective not addressed in previous works.
2. ViT Model and Fault Resilience Evaluation Platform
2.1. ViT Model
2.2. Fault Resilience Evaluation Platform
2.2.1. Soft Errors
2.2.2. Quantization
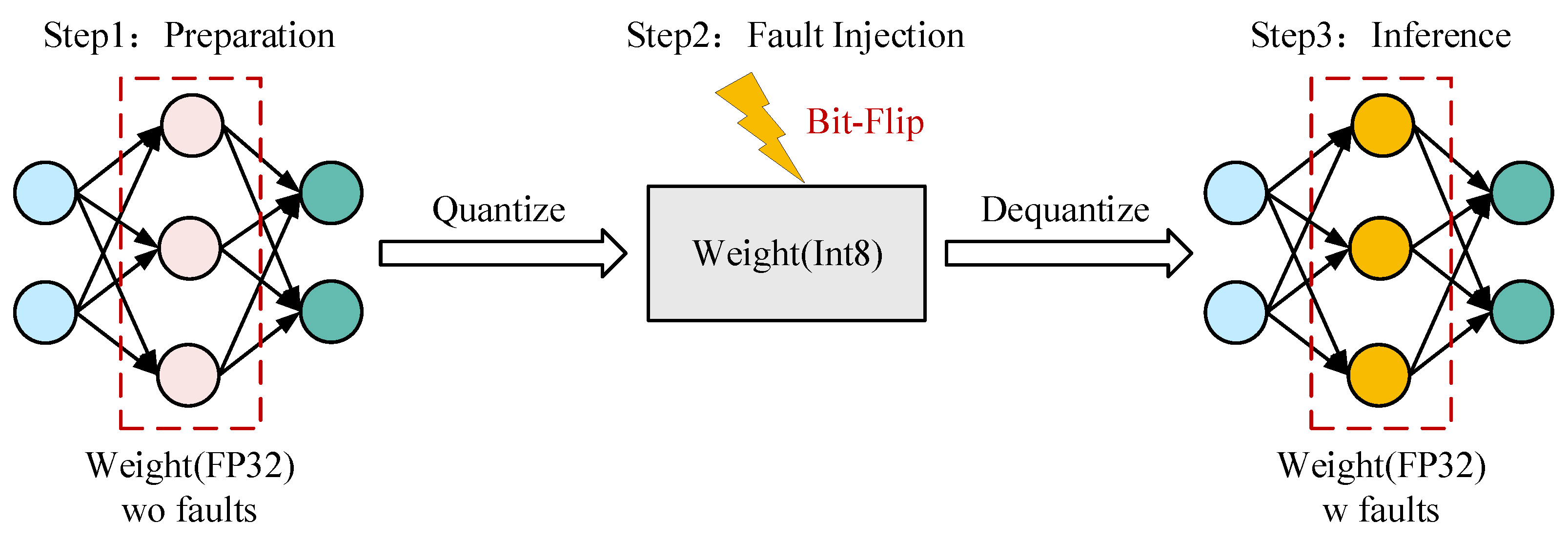
2.2.3. Fault Injection Method
- Given the original 32-bit floating-point weights , we first apply post-training quantization to obtain the 8-bit integer representation :where the function is defined at (8).
- Bit-flip faults are injected directly into the quantized integer weights:where represents the injected fault mask.
- The corrupted integer weights are then dequantized back to floating-point format:where the function is defined at (10), is the model input, is the target ViT model, and is the model output prediction.
3. Results
3.1. Experimental Setup
- Load original models from HuggingFace and record the models’ original accuracy.
- Quantize specific (or all) layer weight parameters by converting them into integer data types.
- Initiate fault injection on the specified layers and distribute the corresponding computation jobs across multiple GPUs.
- Record the inference accuracy of the fault-injected models on the ImageNet-1k validation set.
- Repeat steps 1 through 4 ten times, and record the average, standard deviation, maximum, and minimum accuracy for each model.
3.2. Results and Analysis
3.2.1. Model-Wise
3.2.2. Layer-Wise
3.2.3. Type-Wise
3.2.4. Head-Wise
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. Acm 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar] [CrossRef]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar] [CrossRef]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 4 May 2021. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; Volume 139, pp. 10347–10357. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 22–31. [Google Scholar] [CrossRef]
- Wortsman, M.; Ilharco, G.; Gadre, S.Y.; Roelofs, R.; Gontijo-Lopes, R.; Morcos, A.; Namkoong, H.; Farhadi, A.; Carmon, Y.; Kornblith, S.; et al. Model soups: Averaging weights of multiple finetuned models improves accuracy without increasing inference time. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 23965–23998. [Google Scholar]
- Han, K.; Wang, Y.; Guo, J.; Tang, Y.; Chen, E.; Xu, C.; Xu, C.; Tao, D. Transformers in Vision: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2023, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Roquet, L.; Fernandes dos Santos, F.; Rech, P.; Traiola, M.; Sentieys, O.; Kritikakou, A. Cross-Layer Reliability Evaluation and Efficient Hardening of Large Vision Transformers Models. In Proceedings of the DAC ’24: 61st ACM/IEEE Design Automation Conference, New York, NY, USA, 23–27 June 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Baumann, R.C. Radiation-induced soft errors in advanced semiconductor technologies. IEEE Trans. Device Mater. Reliab. 2005, 5, 305–316. [Google Scholar] [CrossRef]
- Bernstein, K.; Rohrer, N.J.; Nowak, E.; Carrig, B.; Durham, C.; Hansen, P.; Smalley, D.; Streeter, S. Designing reliable systems from unreliable components: The challenges of transistor variability and degradation. Ibm J. Res. Dev. 2006, 50, 455–467. [Google Scholar] [CrossRef]
- Li, G.; Hari, S.K.S.; Sullivan, M.; Tsai, T.; Pattabiraman, K.; Emer, J.; Keckler, S.W. Understanding Error Propagation in Deep Learning Neural Network (DNN) Accelerators and Applications. In Proceedings of the SC ’17: International Conference for High Performance Computing, Networking, Storage and Analysis, New York, NY, USA, 12–17 November 2017; pp. 1–12. [Google Scholar] [CrossRef]
- Hong, S.; Frigo, P.; Kaya, Y.; Giuffrida, C.; Dumitras, T. Terminal Brain Damage: Exposing the Graceless Degradation in Deep Neural Networks Under Hardware Fault Attacks. In Proceedings of the 28th USENIX Security Symposium (USENIX Security 19), Santa Clara, CA, USA, 4–16 August 2019; pp. 497–514. [Google Scholar]
- Sabbagh, M.; Gongye, C.; Fei, Y.; Wang, Y. Evaluating Fault Resiliency of Compressed Deep Neural Networks. In Proceedings of the 2019 IEEE International Conference on Embedded Software and Systems (ICESS), Las Vegas, NV, USA, 2–3 June 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Xu, D.; Chu, C.; Wang, Q.; Liu, C.; Wang, Y.; Zhang, L.; Liang, H.; Cheng, K.T. A Hybrid Computing Architecture for Fault-tolerant Deep Learning Accelerators. In Proceedings of the 2020 IEEE 38th International Conference on Computer Design (ICCD), Hartford, CT, USA, 18–21 October 2020; pp. 478–485. [Google Scholar] [CrossRef]
- Mittal, S. A Survey on Modeling and Improving Reliability of DNN Algorithms and Accelerators. J. Syst. Archit. 2020, 104, 101689. [Google Scholar] [CrossRef]
- Shao, R.; Shi, Z.; Yi, J.; Chen, P.Y.; Hsieh, C.J. On the Adversarial Robustness of Vision Transformers. arXiv 2021, arXiv:2103.15670. [Google Scholar]
- Wang, J.; Zhang, Z.; Wang, M.; Qiu, H.; Zhang, T.; Li, Q.; Li, Z.; Wei, T.; Zhang, C. Aegis: Mitigating Targeted Bit-flip Attacks against Deep Neural Networks. In Proceedings of the 32nd USENIX Security Symposium (USENIX Security 23), Anaheim, CA, USA, 9–11 August 2023; pp. 2329–2346. [Google Scholar]
- Nazari, N.; Makrani, H.M.; Fang, C.; Sayadi, H.; Rafatirad, S.; Khasawneh, K.N.; Homayoun, H. Forget and Rewire: Enhancing the Resilience of Transformer-based Models against {Bit-Flip} Attacks. In Proceedings of the 33rd USENIX Security Symposium (USENIX Security 24), Philadelphia, PA, USA, 14–16 August 2024; pp. 1349–1366. [Google Scholar]
- Yuan, Z.; Xue, C.; Chen, Y.; Wu, Q.; Sun, G. PTQ4ViT: Post-Training Quantization for Vision Transformers with Twin Uniform Quantization. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar] [CrossRef]
- Kuzmin, A.; Nagel, M.; Van Baalen, M.; Behboodi, A.; Blankevoort, T. Pruning vs Quantization: Which is Better? In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Ma, K.; Amarnath, C.; Chatterjee, A. Error Resilient Transformers: A Novel Soft Error Vulnerability Guided Approach to Error Checking and Suppression. In Proceedings of the 2023 IEEE European Test Symposium (ETS), Venezia, Italy, 22–26 May 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Xue, X.; Liu, C.; Wang, Y.; Yang, B.; Luo, T.; Zhang, L.; Li, H.; Li, X. Soft Error Reliability Analysis of Vision Transformers. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2023, 31, 2126–2136. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar] [CrossRef]
- dos Santos, F.F.; Condia, J.E.R.; Carro, L.; Reorda, M.S.; Rech, P. Revealing GPUs Vulnerabilities by Combining Register-Transfer and Software-Level Fault Injection. In Proceedings of the 2021 51st Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Taipei, Taiwan, 21–24 June 2021; pp. 292–304. [Google Scholar] [CrossRef]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713. [Google Scholar] [CrossRef]
- Wu, J.; Lin, J.; Gan, C.; Han, S. Integer quantization for deep learning inference: Principles and empirical evaluation. arXiv 2020, arXiv:2004.09602. [Google Scholar]
- IEEE Std 754-2019; IEEE Standard for Floating-Point Arithmetic. IEEE: New York, NY, USA, 2019.
- Reagen, B.; Gupta, U.; Pentecost, L.; Whatmough, P.; Lee, S.K.; Mulholland, N.; Brooks, D.; Wei, G.Y. Ares: A Framework for Quantifying the Resilience of Deep Neural Networks. In Proceedings of the DAC ’18: 55th Annual Design Automation Conference, San Francisco, CA, USA, 24–28 June 2018; pp. 1–6. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Variant | Component Name | Weight Category | Weight Dimension |
|---|---|---|---|
| ViT-B/16 | patch embedding | cls_token | |
| pos_embed | |||
| patch_embed | |||
| encoder layer1~12 | attn.qkv | ||
| attn.proj | |||
| mlp.fc1 | |||
| mlp.fc2 | |||
| classification head | head | ||
| ViT-B/32 | patch embedding | cls_token | |
| pos_embed | |||
| patch_embed | |||
| encoder layer1~12 | attn.qkv | ||
| attn.proj | |||
| mlp.fc1 | |||
| mlp.fc2 | |||
| classification head | head | ||
| ViT-L/16 | patch embedding | cls_token | |
| pos_embed | |||
| patch_embed | |||
| encoder layer1~24 | attn.qkv | ||
| attn.proj | |||
| mlp.fc1 | |||
| mlp.fc2 | |||
| classification head | head | ||
| ViT-L/32 | patch embedding | cls_token | |
| pos_embed | |||
| patch_embed | |||
| encoder layer1~24 | attn.qkv | ||
| attn.proj | |||
| mlp.fc1 | |||
| mlp.fc2 | |||
| classification head | head |
| Ares | Our Extensions | |
|---|---|---|
| Quantization Method | Fixed-Point Quantization | Integer Quantization (Int16, Int8, Int4) |
| Support Models | Classical CNNs (e.g., NLP, LeNet, AlexNet, VGG, etc.) | Different kinds of ViTs (e.g., original ViTs, Swin Transformer, and DeepViT) |
| Different Architecture Granularity | Model-wise, Layer-wise | Type-wise, Head-wise |
| Model Name * | Input Size | Patches | Layers | Accuracy (%) | Size (MB) |
|---|---|---|---|---|---|
| B16-224-augreg | 16 | 12 | 84.536% | 330 | |
| B16-384-augreg | 16 | 12 | 85.998% | 330 | |
| B32-224-augreg | 32 | 12 | 80.718% | 336 | |
| B32-384-augreg | 32 | 12 | 83.350% | 336 | |
| L16-384-augreg | 16 | 24 | 87.098% | 1160 | |
| L32-384-orig | 32 | 24 | 81.512% | 1169 | |
| H14-224-orig ** | 14 | 32 | 88.272% | 2410 |
| Preparation 1 | Model-Wise | Layer-Wise | Type-Wise | Head-Wise |
|---|---|---|---|---|
| ≈0 h 2 | 10 h | 5 h | 2 h | 25 h |
| Model | 1% Accuracy Loss | 5% Accuracy Loss | 10% Accuracy Loss |
|---|---|---|---|
| B16-224-augreg | |||
| B16-384-augreg | |||
| B32-224-augreg | |||
| B32-384-augreg | |||
| L16-384-augreg | |||
| L32-384-orig |
| Model Name | Layer 1, Head X * | Vulnerability Factor | Mean Attention Distance |
|---|---|---|---|
| B16-384-augreg | 7 | 5.1096 | 157.72 |
| 4 | 3.9056 | 2.15 | |
| 10 | 2.6086 | 197.26 | |
| 1 | 2.6037 | 151.55 | |
| 0 | 2.0893 | 12.50 | |
| L16-384-augreg | 14 | 1.1614 | 63.31 |
| 8 | 1.1354 | 202.58 | |
| 15 | 1.1342 | 201.59 | |
| 6 | 1.1042 | 148.32 | |
| 13 | 1.0834 | 167.17 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, J.; Liu, Y.; Xu, C.; Liao, X.; Yang, Y. Fine-Grained Fault Sensitivity Analysis of Vision Transformers Under Soft Errors. Electronics 2025, 14, 2418. https://doi.org/10.3390/electronics14122418
He J, Liu Y, Xu C, Liao X, Yang Y. Fine-Grained Fault Sensitivity Analysis of Vision Transformers Under Soft Errors. Electronics. 2025; 14(12):2418. https://doi.org/10.3390/electronics14122418
Chicago/Turabian StyleHe, Jiajun, Yi Liu, Changqing Xu, Xinfang Liao, and Yintang Yang. 2025. "Fine-Grained Fault Sensitivity Analysis of Vision Transformers Under Soft Errors" Electronics 14, no. 12: 2418. https://doi.org/10.3390/electronics14122418
APA StyleHe, J., Liu, Y., Xu, C., Liao, X., & Yang, Y. (2025). Fine-Grained Fault Sensitivity Analysis of Vision Transformers Under Soft Errors. Electronics, 14(12), 2418. https://doi.org/10.3390/electronics14122418