

Data Fusion-Based Joint 3D Object Detection Using Point Clouds and Images

Abstract
1. Introduction
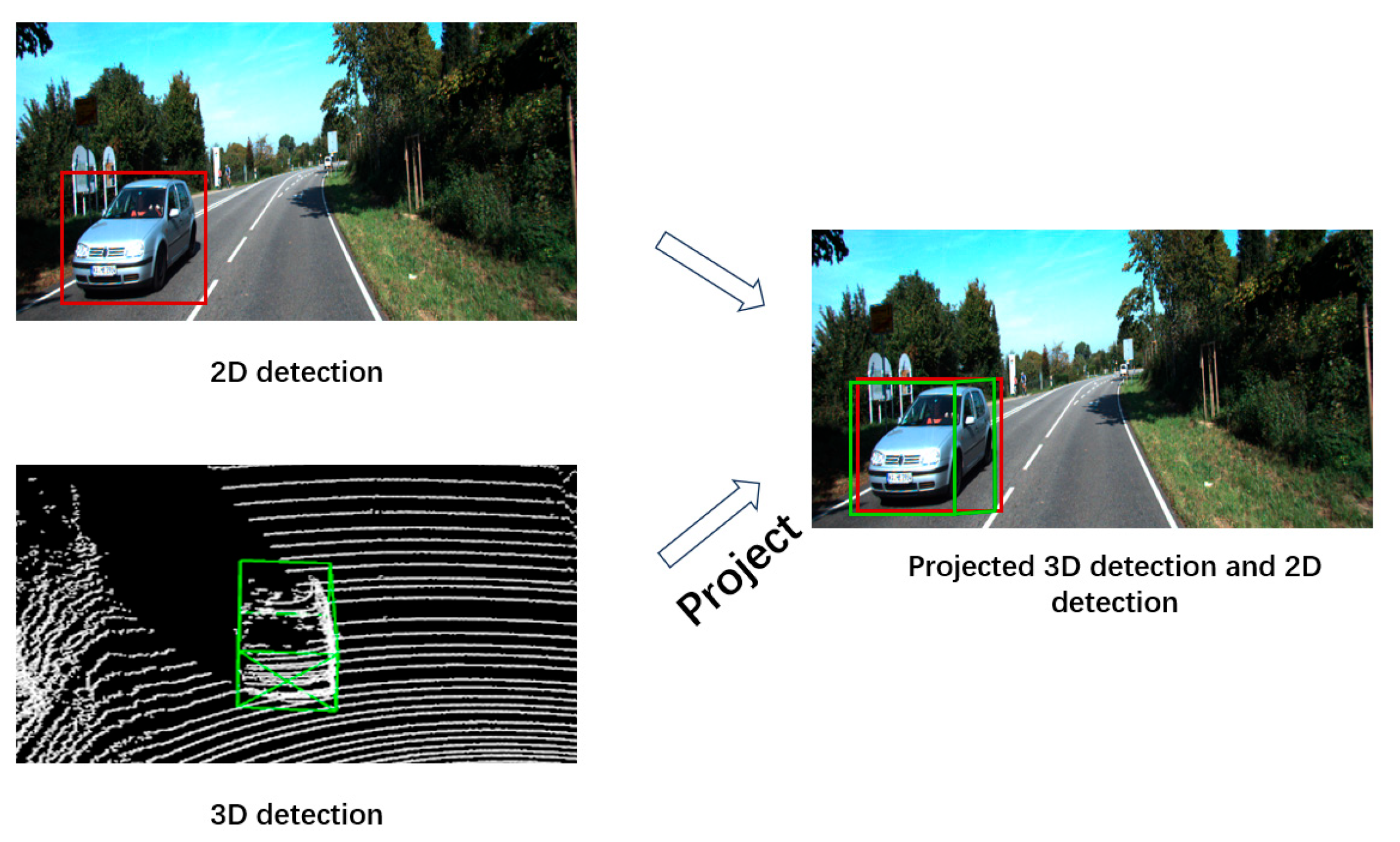
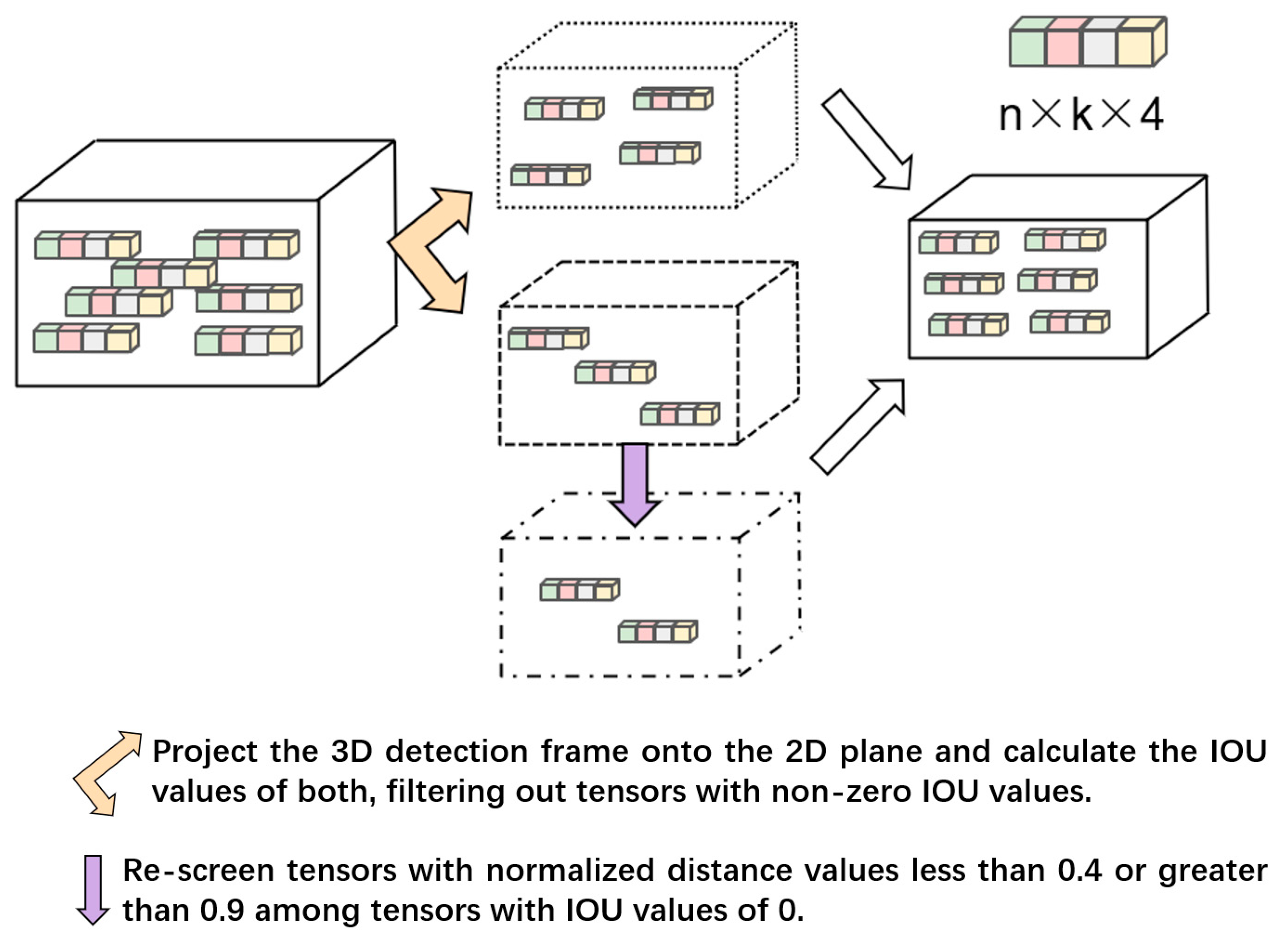
- We construct a joint tensor with fused confidence scores by aligning 2D and 3D detection results. Specifically, 3D candidate bounding boxes are projected onto the 2D image plane, and their intersection-over-union (IoU) with 2D detection candidates is computed. These IoU metrics serve as the basis for generating the joint tensor, which is then fed into the fusion network.
- We introduce a dual-branch structure where parallel subnetworks independently process modality-specific features. This architecture enhances feature discriminability and overall average precision.
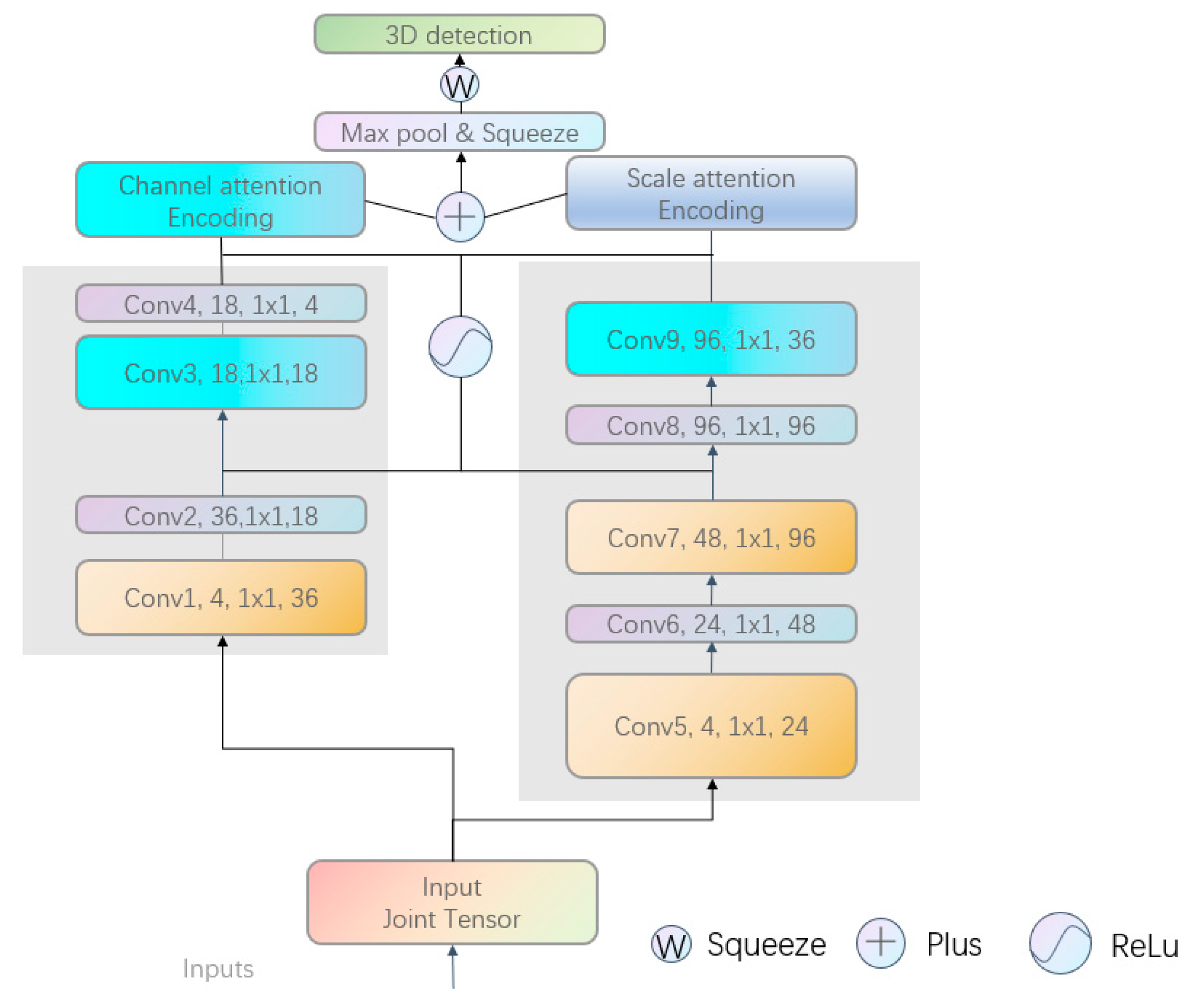
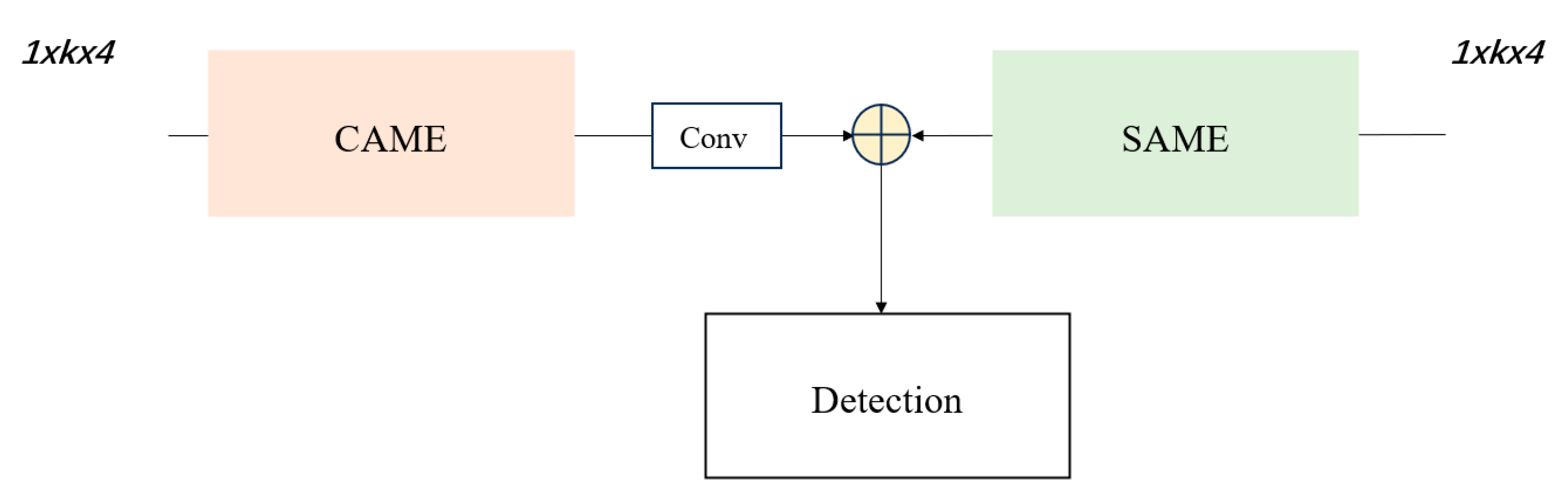
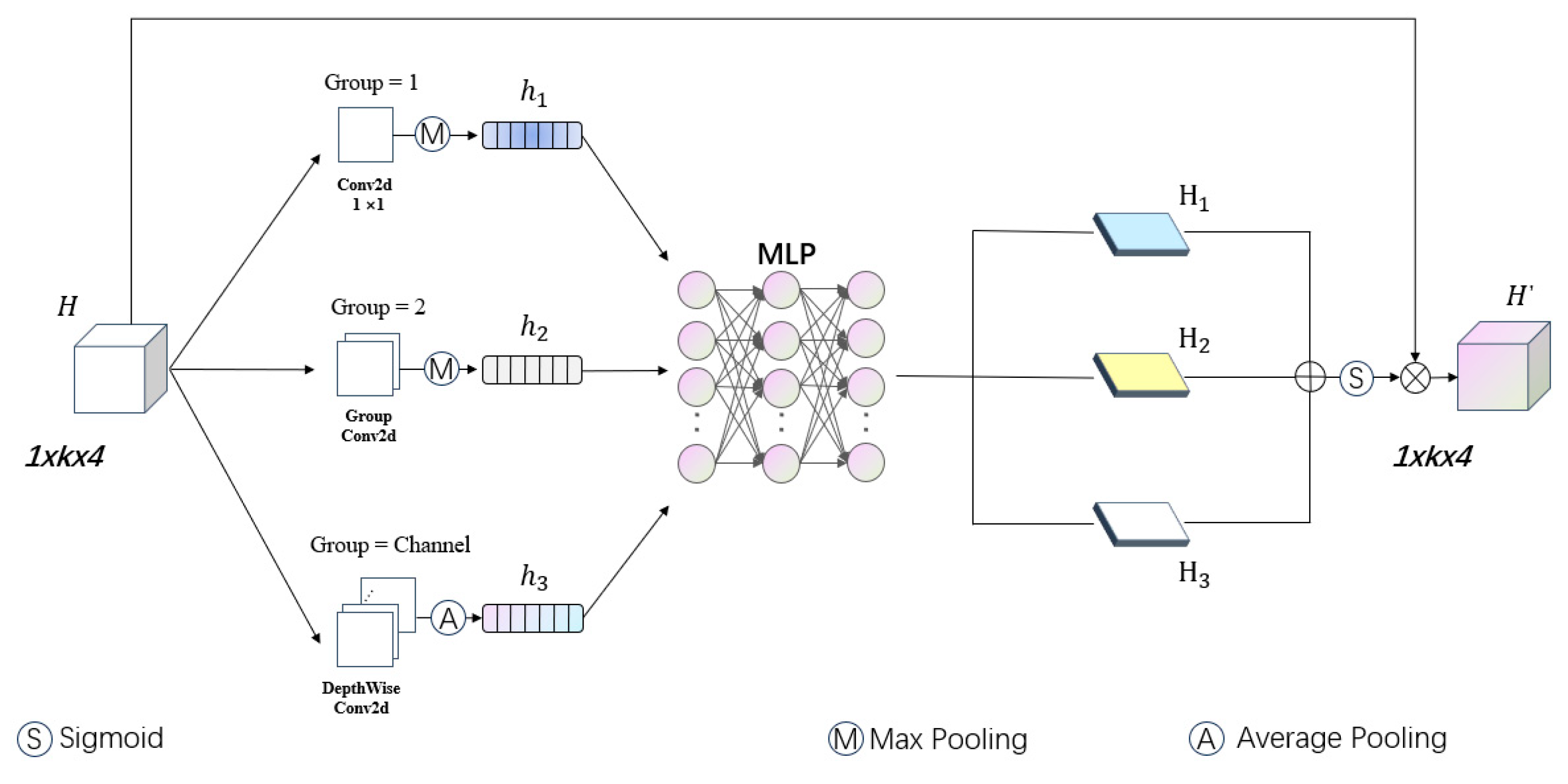
- To prevent the network from overlooking distant spatial features in original candidate regions, we integrate a cross-attention mechanism into the fusion branches. Channel attention and spatial attention modules were embedded in the two branches of the fusion network, functioning as channel encoders and spatial encoders, respectively. Channel attention emphasizes feature relevance across channels, whereas spatial attention focuses on contextual relationships within feature maps. The outputs of these modules are adaptively combined to produce the final fused features.
2. Related Works
2.1. Early Fusion
2.2. Middle Fusion
2.3. Late Fusion
3. Materials and Methods
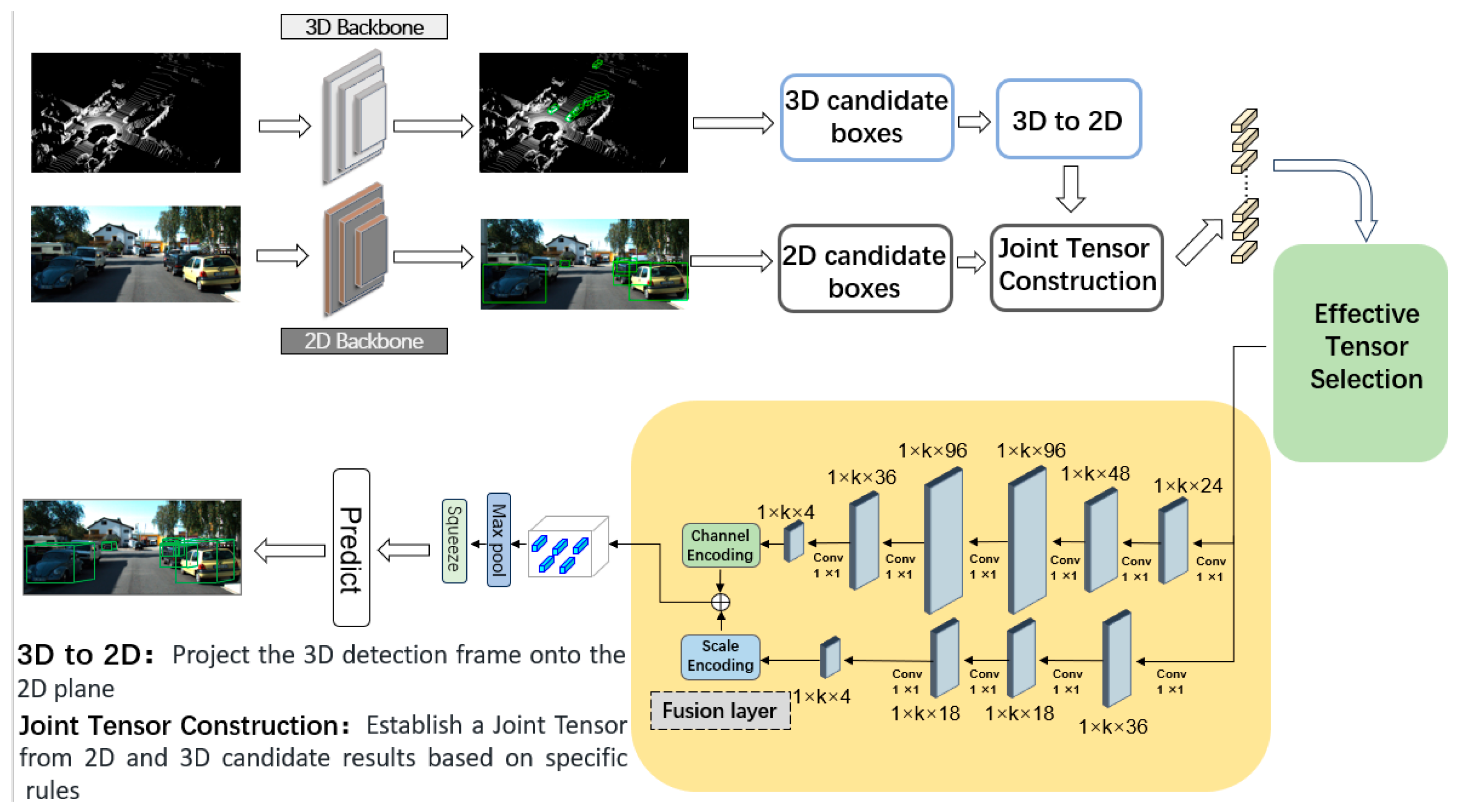
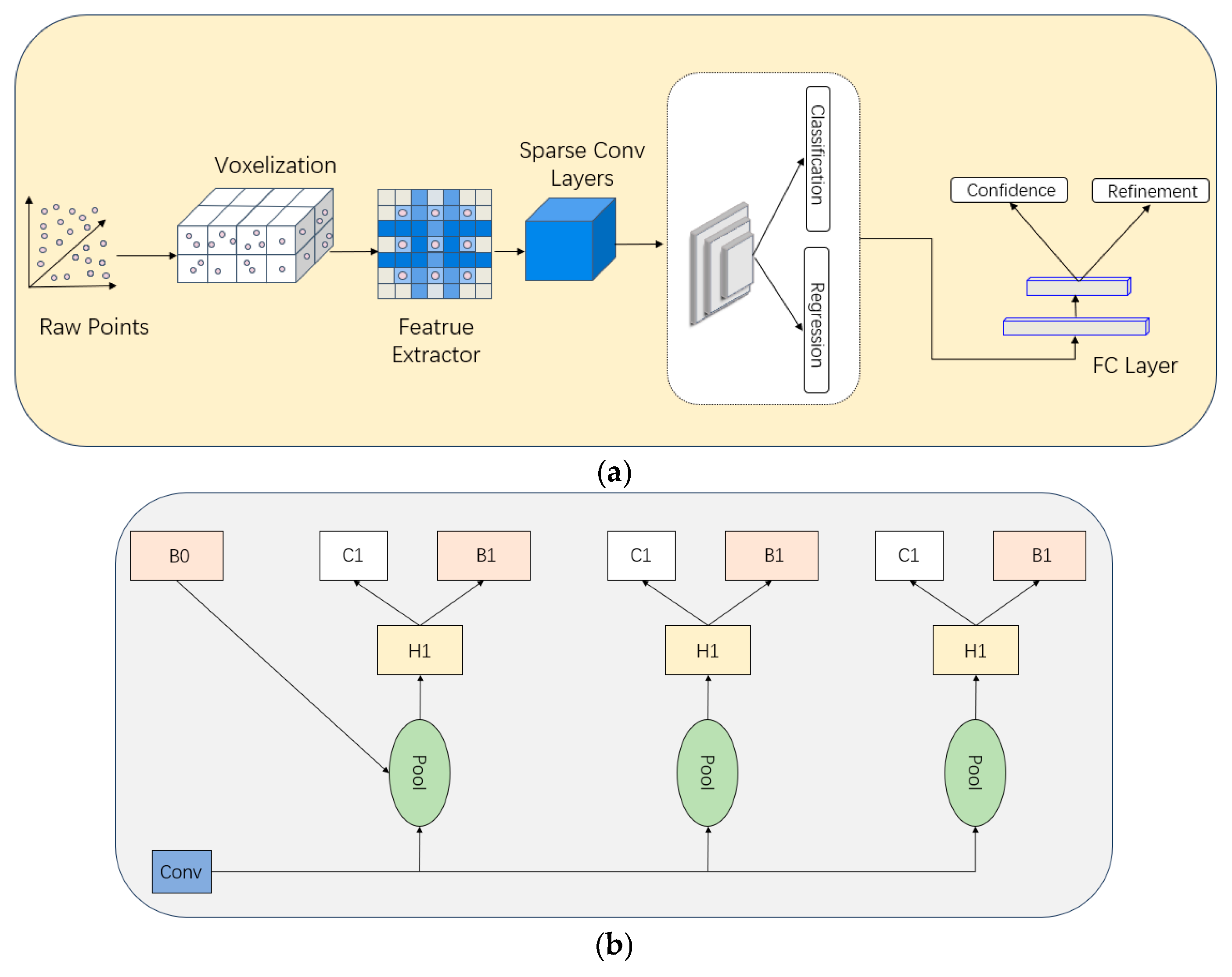
3.1. Upstream Candidate Result Acquisition
3.2. Joint Tensor Construction
3.3. Screening Mechanism
3.4. Fusion Network
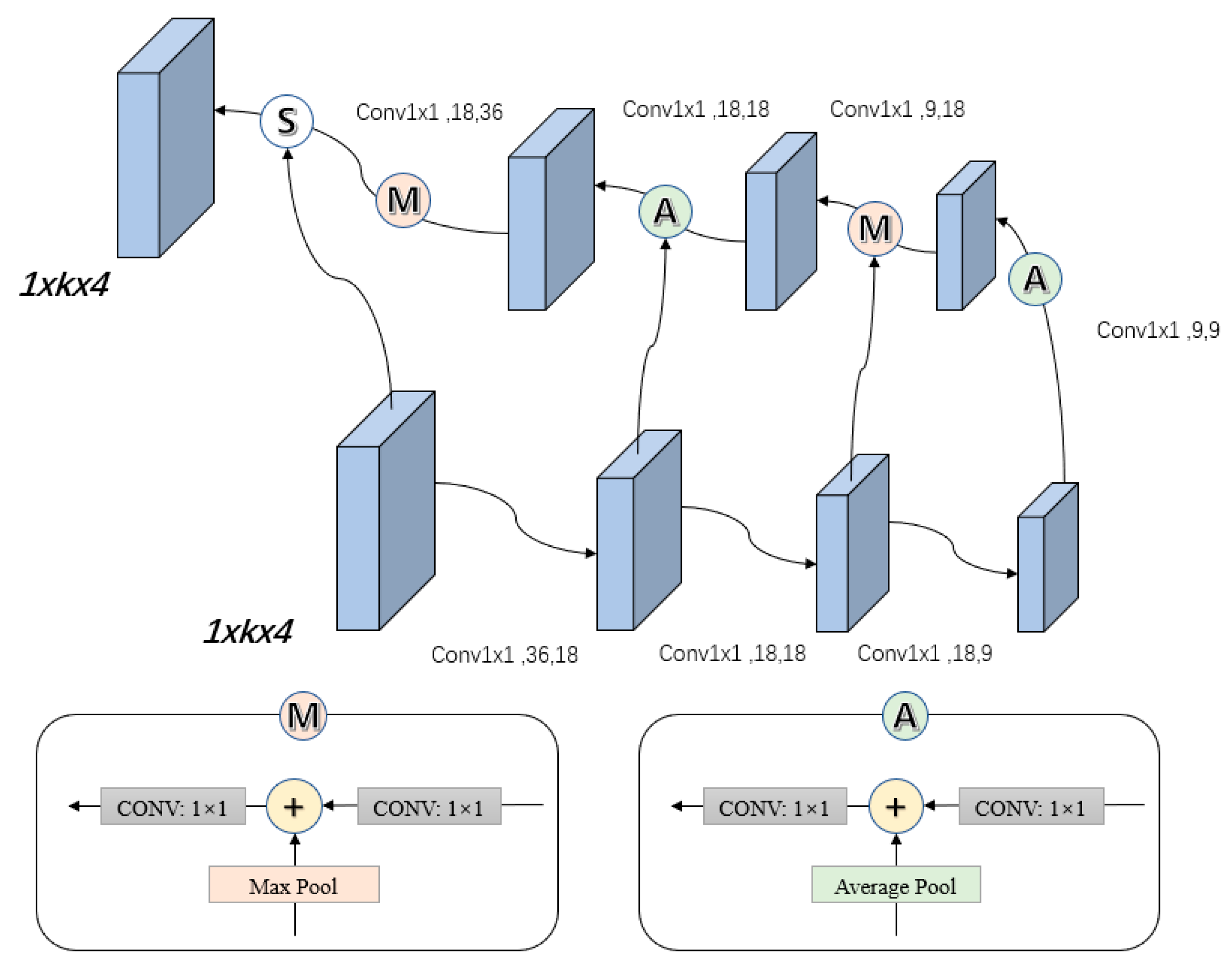
3.5. Multi-Dimensional Joint Attention Encoding
3.6. Focal Loss
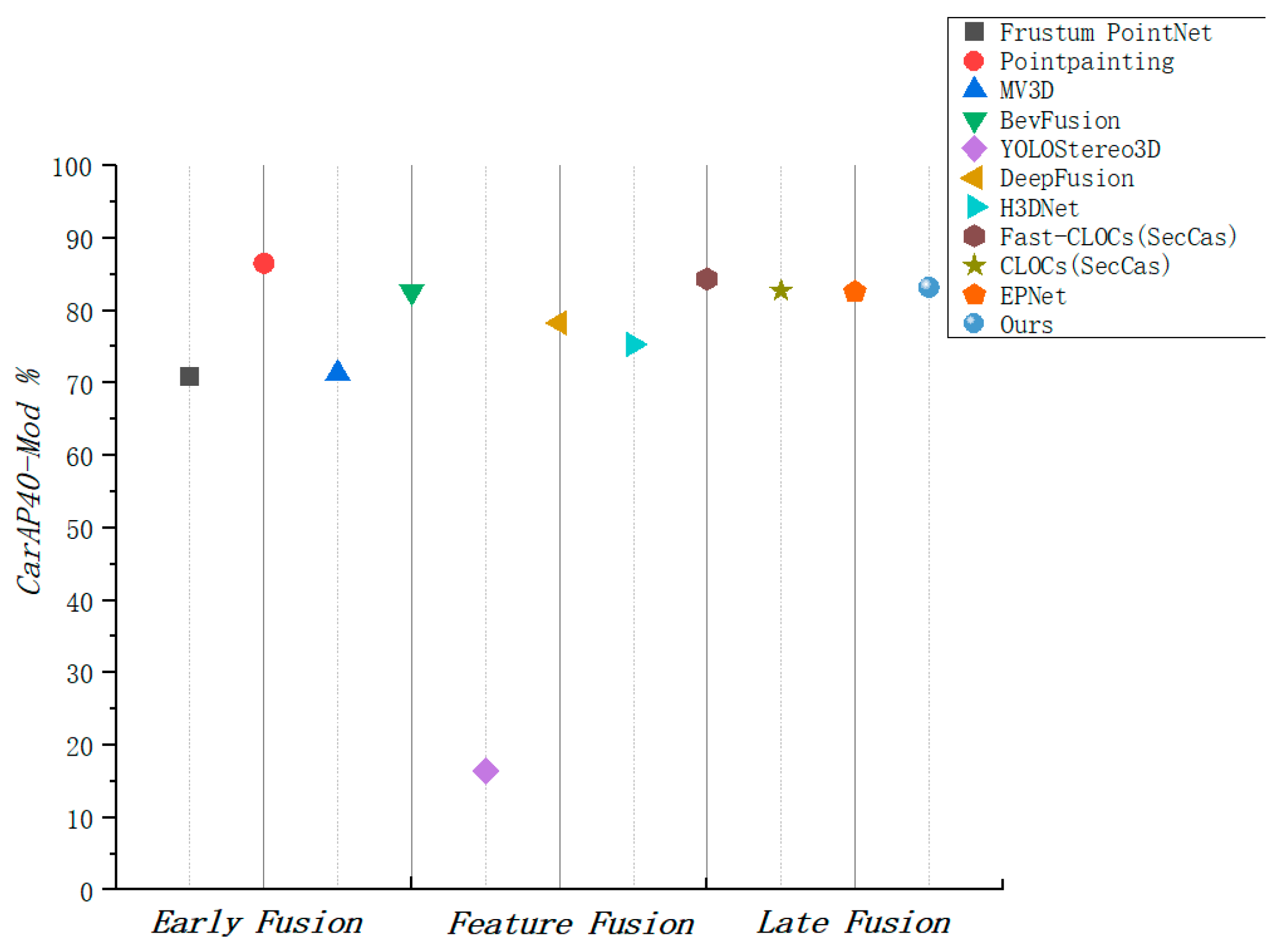
4. Analysis of Experimental Results
4.1. Dataset and Implementation Details
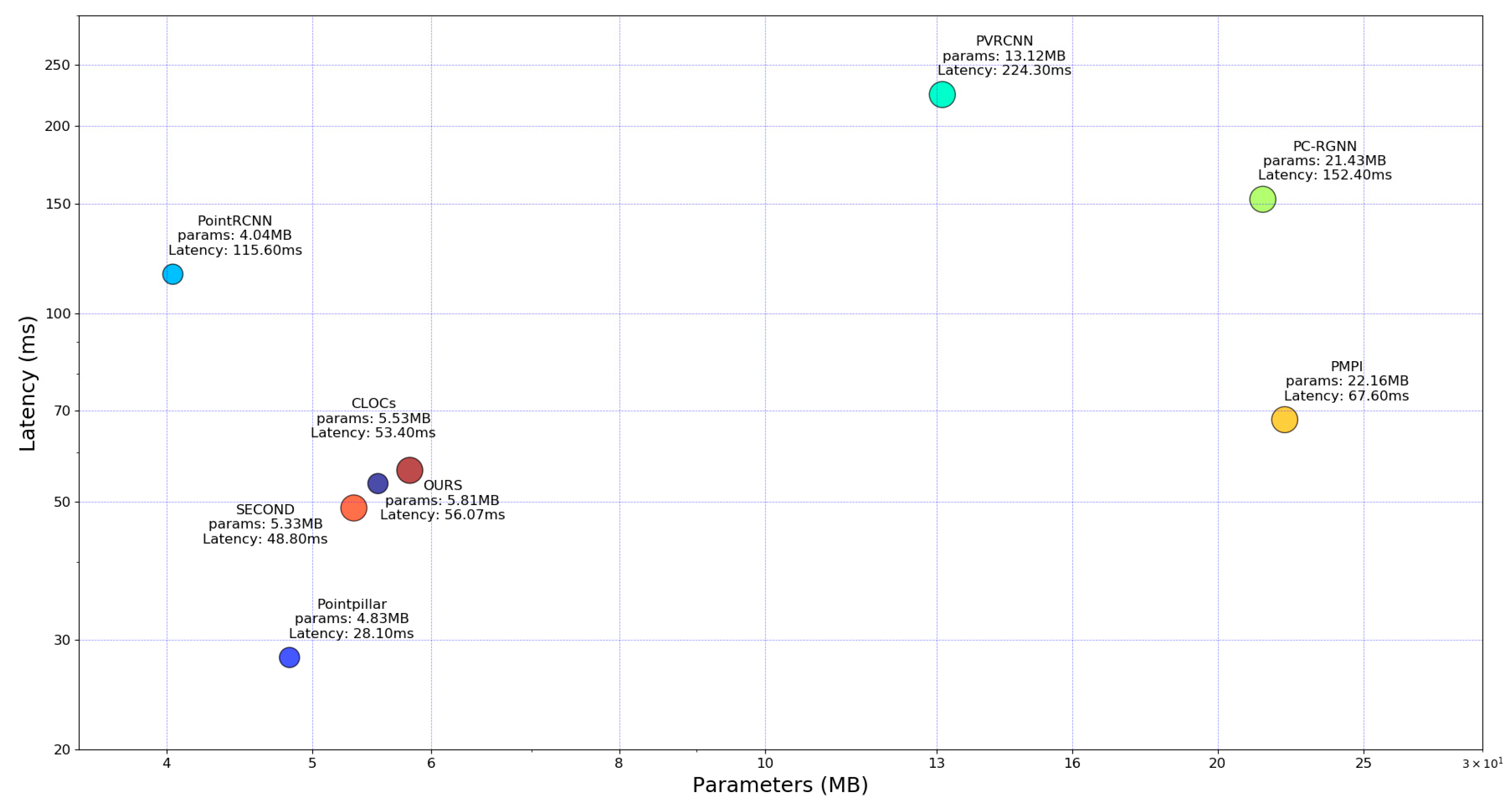
4.2. Experiment on KITTI Dataset
4.3. Ablation Studies
4.4. Deep Exploration
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Qi, C.R.; Li, Y.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Advances in Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 5105–5114. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3d object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embed-ded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beibom, O. PointPillars: Fast encoders for object detection from point clouds. In Proceedings of the lEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2849–2858. [Google Scholar]
- Graham, B.; Engelcke, M.; van der Maaten, L. 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9224–9232. [Google Scholar]
- Zhou, H.; Ge, Z.; Liu, S. SparseBEV: High-performance sparse 3D object detection for autonomous driving. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18000–18009. [Google Scholar]
- Li, B.; Guo, Q.; Chen, X. DynamicVoxelNet: Efficient 3D Object Detection with Dynamic Voxelization. In Proceedings of the 2022 IEEE International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 12345–12352. [Google Scholar]
- Chen, X.; Kundu, K.; Zhang, Z.; Ma, H.; Fidler, S.; Urtasun, R. Monocular 3D Object Detection for Autonomous Driving. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2147–2156. [Google Scholar]
- Xie, E.; Yu, Z.; Zhou, D. M2BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Bird’s-Eye View Representation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17642–17651. [Google Scholar]
- Yang, J.; Xie, E.; Wang, M. FocalFormer3D: Focusing on Hard Instance for 3D Object Detection. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17644–17653. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum PointNets for 3D Object Detection from RGB-D Data. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1097–1105. [Google Scholar]
- Zhang, X.; Chen, Y.; Liu, Z. SIFRNet: Semantic-aware image fusion for robust autonomous driving. In Proceedings of the 2023 IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1120–1129. [Google Scholar]
- Chen, B.; Liu, D.; Chan, S.H.; Li, Q. MV3D: Multi-view 3D detection for autonomous driving. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 755–763. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. AVOD: Aggregate view object detection for autonomous driving. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2000–2008. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. SqueezeSeg: Convolutional neural nets with recurrent CRF for real-time road-object segmentation from 3D LiDAR point cloud. In Proceedings of the IEEE International Conference on Robotics and Automation, Brisbane, QLD, Australia, 21–25 May 2018; pp. 1887–1893. [Google Scholar]
- Park, S.; Kim, Y.; Shin, J.; Jeon, H. 3D-CVF: 3D cross-view fusion for multi-modal autonomous driving perception. In Proceedings of the 2023 IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10000–10009. [Google Scholar]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. Pointpainting: Se-quential fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4604–4612. [Google Scholar]
- Xie, E.; Liu, C.; Wang, Z.; Li, W.; Loy, C.C.; Lin, D.; Luo, P. EPNet: Enhancing point features with image semantics for 3D object detection. In Proceedings of the 2020 European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 35–52. [Google Scholar]
- Liang, M.; Yang, B.; Hu, R.; Chen, Y.; Casas, S.; Urtasun, R. LaserNet++: Learning 3D Lane Detection from Weak Labels via Adaptive Temporal Modeling. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13487–13496. [Google Scholar]
- Lee, L.; Kim, M. DVLO: Deep Visual-LiDAR Odometry for Autonomous Vehicles. In Proceedings of the 2023 IEEE International Conference on Autonomous Systems, Barcelona, Spain, 13–17 March 2023; pp. 112–119. [Google Scholar]
- Wang, Y.; Zhao, H.; Chen, Q. AssociationNet: End-to-End Learning for Multi-Object Association in Autonomous Driving. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 12345–12355. [Google Scholar]
- Pang, S.; Morris, D.; Radha, H. Clocs: Camera-lidar object candidates fusion for 3d object detection. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 10386–10393. [Google Scholar]
- Yang, Z.; Sun, Y.; Chen, L. Fast-CLOCs: Fast Camera-LiDAR Object Candidates Fusion for Robust 3D Object Detection. In Proceedings of the 2022 IEEE International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 5678–5685. [Google Scholar]
- Sgaravatti, C.; Basla, R.; Pieroni, R.; Corno, M.; Savaresi, S.; Magri, L.; Boracchi, G. A Multimodal Hybrid Late-Cascade Fusion Network for Enhanced 3D Object Detection. In Proceedings of the Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Milan, Italy, 29 September–4 October 2024; pp. 339–356. [Google Scholar]
- Xu, X.; Dong, S.; Zhou, Y.; Xu, T.; Ding, L.; Wang, J.; Jiang, P.; Song, L.; Li, J. FusionRCNN: LiDAR-Camera Fusion for Two-Stage 3D Object Detection. Remote Sens. 2023, 15, 1839. [Google Scholar] [CrossRef]
- Shi, P.; Liu, Z.; Dong, X.; Yang, A. CL-fusionBEV: 3D Object Detection Method with Camera-LiDAR Fusion in Bird’s Eye View. Complex Intell. Syst. 2024, 10, 7681–7696. [Google Scholar] [CrossRef]
- Mushtaq, H.; Deng, X.; Azhar, F.; Ali, M.; Sherazi, H. PLC-Fusion: Perspective-Based Hierarchical and Deep LiDAR-Camera Fusion for 3D Object Detection in Autonomous Vehicles. Information 2024, 15, 739. [Google Scholar] [CrossRef]
- Wu, Z.; Ye, M.; Zhang, Y.; Sun, W.; Zhao, T. BAFusion: Bidirectional Attention Fusion for 3D Object Detection Based on LiDAR and Camera. Sensors 2024, 24, 4718. [Google Scholar] [CrossRef] [PubMed]
- Xie, Y.; Xu, C.; Rakotosaona, M.; Rim, P.; Tombari, F.; Keutzer, K.; Tomizuka, M.; Zhan, W. SparseFusion: Fusing Multi-Modal Sparse Representations for Multi-Sensor 3D Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 17591–17602. [Google Scholar]
- Cai, H.; Zhang, Z.; Zhou, Z.; Lin, Z.; Ding, W.; Zhao, J. BEVFusion4D: Learning LiDAR-Camera Fusion Under Bird’s-Eye-View via Cross-Modality Guidance and Temporal Aggregation. arXiv 2023, arXiv:2301.09561. [Google Scholar]
- Jiao, Y.; Jie, Z.; Chen, S.; Chen, J.; Ma, L.; Jiang, Y. MSMDFusion: Fusing LiDAR and Camera at Multiple Scales with Multi-Depth Seeds for 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 21643–21652. [Google Scholar]
- Liu, Z.; Tang, H.; Amini, A.; Yang, X.; Mao, H.; Rus, D.; Han, S. BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation. arXiv 2023, arXiv:2205.13542. [Google Scholar]
- Gong, R.; Fan, X.; Cai, D.; Lu, Y. Sec-CLOCs: Multimodal Back-End Fusion-Based Object Detection Algorithm in Snowy Scenes. Sensors 2024, 24, 7401. [Google Scholar] [CrossRef] [PubMed]
- Song, Z.; Zhang, G.; Xie, J.; Liu, L.; Jia, C.; Xu, S. VoxelNextFusion: A Simple, Unified and Effective Voxel Fusion Framework for Multi-Modal 3D Object Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5705412. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Shi, W.; Rajkumar, R. Point-GNN: Graph neural network for 3D object detection in a point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1711–1719. [Google Scholar]
- Meng, X.; Zhou, Y.; Du, K.; Ma, J.; Meng, J.; Kumar, A. EFNet: Enhancing feature information for 3D object detection in LiDAR point clouds. J. Opt. Soc. Am. A 2024, 4, 739–748. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3DSSD: Point-Based 3D Single Stage Object Detector. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2020; pp. 11037–11045. [Google Scholar]
- Xie, L.; Xiang, C.; Yu, Z. PI-RCNN: An Efficient Multi-sensor 3D Object Detector with Point-based Attentive Cont-conv Fusion Module. arXiv 2019, arXiv:1911.06084. [Google Scholar] [CrossRef]
- Zhang, Z.; Shen, Y.; Li, H.; Zhao, X.; Yang, M.; Tan, W.; Pu, S.; Mao, H. Maff-net: Filter false positive for 3d vehicle detection with multi-modal adaptive feature fusion. In Proceedings of the IEEE 25th International Conference on Intelligent Transportation Systems, Gold Coast, Australia, 18 November–21 November 2022; pp. 369–376. [Google Scholar]
- Pan, X.-R.; Xia, Z.-F.; Song, J.; Li, E.; Huang, G. 3D Object Detection with Pointformer. arXiv 2021, arXiv:2012.11409. [Google Scholar]
- Liu, Z.; Wu, Z.; Tóth, R. SMOKE: Single-Stage Monocular 3D Object Detection via Keypoint Estimation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 996–1005. [Google Scholar]
- Brazil, G.; Liu, X. M3D-RPN: Monocular 3D Region Proposal Network for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9286–9295. [Google Scholar]
- Chong, Z.; Ma, X.; Zhang, H.; Yue, Y.; Li, H.; Wang, Z.; Ouyang, W. Monodistill: Learning spatial features for monocular 3d object detection. arXiv 2022, arXiv:2201.10830. [Google Scholar]
- Brazil, G.; Liu, X. Frustum ConvNet: Sliding Frustums to Aggregate Local Point-Wise Features for Amodal 3D Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9286–9295. [Google Scholar]
- Yang, Z.; Sun, Y.; Shu, L.; Shen, X.; Jia, J. IPOD: Intensive Point-based Object Detector for Point Cloud. arXiv 2018, arXiv:1812.05276. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Modality | 3D AP(%) | Bird’s Eye View AP(%) | ||||
|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | ||
| VoxelNet [4] | L | 81.79 | 65.46 | 62.85 | 89.60 | 84.81 | 78.57 |
| PointPillars [6] | L | 86.99 | 77.12 | 74.98 | 89.77 | 87.02 | 83.71 |
| Point-GNN [40] | L | 87.89 | 78.34 | 77.38 | 89.82 | 88.31 | 87.16 |
| MV3D [16] | L | 71.09 | 62.35 | 57.73 | 86.02 | 76.90 | 68.49 |
| AVOD [17] | F | 73.59 | 65.78 | 58.38 | 86.80 | 85.44 | 77.73 |
| AVOD(Fp) [17] | F | 81.94 | 71.88 | 66.38 | 88.53 | 83.79 | 77.90 |
| F-PointNet [14] | F | 81.20 | 70.39 | 62.19 | 88.70 | 84.00 | 75.33 |
| EFNet [41] | L | 86.71 | 77.25 | 75.73 | 89.66 | 87.27 | 85.61 |
| SECOND [5] | L | 87.43 | 76.48 | 69.10 | 95.61 | 89.54 | 86.96 |
| 3DSSD [42] | L | 88.36 | 79.57 | 74.55 | N/A | N/A | N/A |
| EPNet [21] | F | 92.28 | 82.59 | 80.14 | N/A | N/A | N/A |
| PV-RCNN [7] | L | 92.10 | 84.36 | 82.48 | N/A | N/A | N/A |
| PI-RCNN [43] | L | 88.27 | 78.53 | 77.75 | N/A | N/A | N/A |
| MAFF [44] | F | 88.88 | 79.37 | 74.68 | 89.31 | 86.61 | 89.72 |
| Pointformer [45] | L | 90.05 | 79.65 | 78.89 | 95.68 | 90.77 | 88.46 |
| CLOCs(SM) [25] | F | 92.37 | 82.36 | 78.23 | 96.34 | 92.59 | 87.81 |
| SMOKE [46] | M | 14.76 | 12.8 | 11.50 | 19.99 | 15.61 | 15.28 |
| M3D-RPN [47] | M | 20.40 | 16.48 | 13.34 | 26.86 | 21.15 | 17.14 |
| MonoDIS [48] | M | 18.05 | 14.98 | 13.42 | 24.26 | 18.43 | 18.43 |
| F-ConvNet [49] | F | 84.16 | 68.88 | 60.05 | N/A | N/A | N/A |
| PomageNet | F | 92.95 | 83.64 | 80.22 | 96.66 | 92.73 | 89.88 |
| Methods | Modality | Cyclist | Pedestrian | ||||
|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | ||
| SECOND [5] | L | 78.50 | 56.74 | 52.83 | 58.01 | 51.88 | 47.05 |
| VoxelNet [4] | L | 81.97 | 65.46 | 62.85 | 57.86 | 53.42 | 48.87 |
| PointPillars [6] | L | 82.31 | 59.33 | 55.25 | 58.53 | 51.42 | 45.20 |
| IPOD [50] | F | 78.19 | 59.40 | 51.38 | 60.88 | 49.79 | 45.43 |
| F-PointNet [14] | F | 77.26 | 61.37 | 53.78 | 57.13 | 49.57 | 45.48 |
| AVOD-FPN [17] | F | 69.39 | 57.12 | 51.09 | 58.49 | 50.32 | 46.98 |
| F-ConvNet [49] | F | 84.16 | 68.88 | 60.05 | 57.04 | 48.96 | 44.33 |
| Painted(PR) [20] | F | 83.91 | 71.54 | 62.97 | 58.70 | 49.93 | 46.29 |
| CLOCs(SM) [25] | F | 85.47 | 59.47 | 55.00 | 62.54 | 56.76 | 52.26 |
| PomageNet | F | 89.14 | 67.87 | 63.66 | 68.34 | 60.40 | 54.22 |
| Methods | Modality | Cyclist | Pedestrian | ||||
|---|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | ||
| SECOND [5] | L | 81.91 | 59.33 | 55.53 | 61.97 | 56.77 | 51.27 |
| PointPillars [6] | L | 84.65 | 67.39 | 57.28 | 66.97 | 59.45 | 53.42 |
| CLOCs(SM) [25] | F | 88.96 | 63.40 | 59.81 | 69.35 | 63.47 | 58.93 |
| PomageNet | F | 91.73 | 69.03 | 64.15 | 71.62 | 65.47 | 59.21 |
| 2D-3D Fusion | Data Selection | CAE | SAE | Pedestrian AP (%) | Cyclist AP (%) |
|---|---|---|---|---|---|
| 51.88 | 56.74 | ||||
| 58.23 | 65.29 | ||||
| 58.41 | 65.77 | ||||
| 59.27 | 66.34 | ||||
| 58.66 | 66.26 | ||||
| 60.40 | 67.87 |
| d > 0.1 | d > 0.2 | d > 0.3 | d > 0.4 | |
|---|---|---|---|---|
| d < 0.9 | 83.27 | 83.32 | 83.58 | 83.64 |
| d < 0.8 | 83.21 | 83.32 | 83.53 | 83.60 |
| d < 0.7 | 83.22 | 83.31 | 83.53 | 83.58 |
| d < 0.6 | 83.18 | 83.31 | 83.52 | 83.58 |
| Methods | 3D AP(%) | Bird’s Eye View AP(%) | ||||
|---|---|---|---|---|---|---|
| Easy | Mod | Hard | Easy | Mod | Hard | |
| SECOND [5] | 87.43 | 76.48 | 69.10 | 95.61 | 89.54 | 86.96 |
| PomageNet | 92.95 | 83.64 | 80.22 | 96.66 | 92.73 | 89.88 |
| +5.52 | +7.16 | +11.12 | +1.05 | +3.19 | +2.92 | |
| PointPillars [6] | 86.99 | 77.12 | 74.98 | 89.77 | 87.02 | 83.71 |
| PomageNet | 89.97 | 79.64 | 76.42 | 91.45 | 88.36 | 84.28 |
| +2.98 | +2.52 | +1.44 | +1.68 | +1.34 | +0.57 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lyu, J.; Wang, S.; Qi, Y.; Chen, L. Data Fusion-Based Joint 3D Object Detection Using Point Clouds and Images. Electronics 2025, 14, 2414. https://doi.org/10.3390/electronics14122414
Lyu J, Wang S, Qi Y, Chen L. Data Fusion-Based Joint 3D Object Detection Using Point Clouds and Images. Electronics. 2025; 14(12):2414. https://doi.org/10.3390/electronics14122414
Chicago/Turabian StyleLyu, Jiahang, Shifeng Wang, Yongze Qi, and Lang Chen. 2025. "Data Fusion-Based Joint 3D Object Detection Using Point Clouds and Images" Electronics 14, no. 12: 2414. https://doi.org/10.3390/electronics14122414
APA StyleLyu, J., Wang, S., Qi, Y., & Chen, L. (2025). Data Fusion-Based Joint 3D Object Detection Using Point Clouds and Images. Electronics, 14(12), 2414. https://doi.org/10.3390/electronics14122414