


A Survey on Multi-User Privacy Issues in Edge Intelligence: State of the Art, Challenges, and Future Directions

Abstract
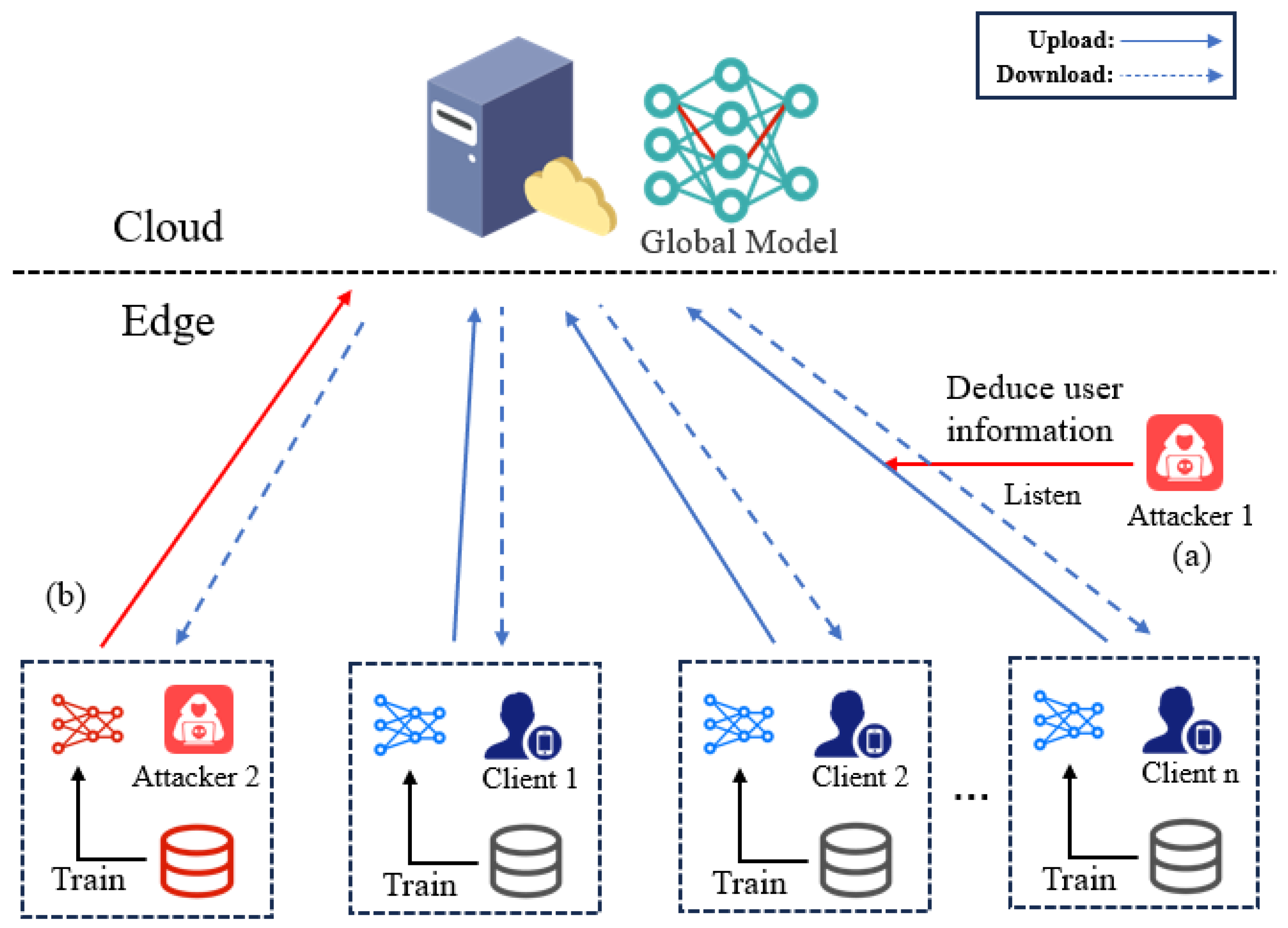
1. Introduction
- First, we compare the common centralized and edge intelligence-based frameworks for MISs and examine in detail the new challenges that edge intelligence faces.
- Second, we survey and summarize the relevant literature on MISs under edge intelligence from multiple perspectives, including privacy protection and model security protection. We analyze their strengths and weaknesses and compare these methods through experiments.
- Finally, we discuss the research directions on multi-user privacy and security in future edge intelligence frameworks from five different aspects, with the hope of providing insights for the field.
2. Preliminaries
2.1. Privacy Protection Mechanisms
2.2. Edge Intelligence
3. MIS Protection and New Challenges
3.1. MIS Protection Framework
3.2. Changes and Challenges in the Context of Edge Intelligence
4. Existing Advanced Protection Methods
4.1. Data-Centric Privacy Issues with Respect to MISs
4.1.1. Encryption-Based Methods
4.1.2. Perturbation-Based Methods
4.1.3. Anonymization-Based Methods
4.1.4. Summary and Analysis
4.2. Model-Centric Privacy Issues with Respect to MISs
4.2.1. Anomaly Detection
4.2.2. Model Tolerance
4.2.3. Summary and Analysis
4.3. Experimental Evaluation
5. Discussion and Future Research Directions
- Balancing privacy protection and computational efficiency: Privacy protection technologies, such as homomorphic encryption and differential privacy, considerably improve privacy security but also impose large computational overhead and delays, becoming the key bottleneck in current research [25]. Future research should aim to resolve the tension between privacy protection and computing performance. On the one hand, hardware acceleration solutions, such as using GPUs and FPGAs to improve the execution efficiency of encryption algorithms, can be investigated. On the other hand, new encryption algorithms (e.g., lightweight homomorphic encryption or quantum encryption) and hybrid privacy protection methods (e.g., combining differential privacy with local perturbation) may reduce computational costs and provide new solutions for efficient privacy protection.
- Privacy protection in multi-party collaboration: In multi-party collaboration scenarios, although federated learning and vertical federated learning have proposed preliminary privacy protection schemes, incomplete trust among participants remains a key challenge in research. Future work could combine homomorphic encryption and trusted execution environments to achieve efficient computation while maintaining data security. Furthermore, the introduction of blockchain technology has the potential to help construct transparent and tamper-proof data transmission and computation procedures [4], hence improving privacy protection in multi-party collaborations. In particular, zero-knowledge proof (ZKP) technology can verify the correctness and compliance of data computation without exposing the actual data [55], thus further improving the privacy protection capabilities of data transmission and increasing the system’s credibility.
- Dynamic adjustment and adaptive mechanisms for privacy protection: Existing privacy protection methods are often statically designed and struggle to meet the demands of dynamic environments [29]. Future research could concentrate on creating adaptive privacy protection algorithms that dynamically modify the level of privacy protection in response to real-time feedback, such as data sensitivity, system status, or participant trust levels. Furthermore, incorporating reinforcement learning into privacy protection may enable intelligent optimization of privacy measures, resulting in a balance of privacy and utility. Moreover, blockchain not only provides data transparency but also enables an automated privacy consent process through smart contracts [56]. Users can authorize or revoke the use of their data through smart contracts, further enhancing the autonomy and transparency of privacy protection.
- User consent and privacy transparency: Although numerous user privacy protection schemes have emerged, implementing transparent and clear user consent mechanisms remains a challenge. Future studies could use blockchain technology to record and maintain users’ consent histories, giving them more control over their privacy settings. Furthermore, the usage of smart contracts could automate the privacy consent process, improving compliance while maintaining users’ privacy rights.
- Application of emerging technologies: Unlearning technology, as an emerging privacy protection method, is gaining increasing attention in edge intelligence systems [57]. Traditional privacy protection methods, such as homomorphic encryption and differential privacy, are effective but have high computational overhead and latency. Unlearning technology reduces computational costs and improves efficiency by deleting specific users’ data from a trained model without requiring the retraining of the entire model. In edge intelligence, unlearning technology ensures that when users request the deletion of personal data, only the parts of the model related to that user are removed, without affecting the privacy of other users or the accuracy of the global model. This allows edge devices to efficiently process data locally, avoiding the costs associated with data transmission and storage. In the future, unlearning will play an important role in privacy protection in edge intelligence, helping achieve privacy compliance and efficient data management.
- Privacy-security co-optimization: Most existing methods rely on the default privacy guarantees of edge intelligence, but a fundamental conflict exists between encrypted aggregation and robust defense. For instance, while DDFed’s fully homomorphic encryption preserves gradient privacy [41], it prevents the server from performing similarity detection. Conversely, the reconstruction error analysis in FedREDefense [39] may leak data distribution characteristics through gradient inversion. A promising breakthrough lies in designing dual-secure aggregation protocols that integrate secure multi-party computation with robust statistics (e.g., trimmed mean) within the encrypted domain, allowing the filtering of malicious clients without decrypting model updates. Additionally, a quantitative model linking the differential privacy budget to defense effectiveness should be established, enabling the dynamic adjustment of the privacy–robustness trade-off via adaptive noise injection. Federated feature distillation is also worth investigating. By constructing a shared feature space through knowledge transfer, this approach can protect data privacy while disrupting the propagation pathways of poisoned features.
- Cross-layer collaborative defense systems: A single-layer defense is vulnerable to targeted attacks, necessitating a multi-level protection strategy. At the client level, integrating model sanitization techniques with gradient obfuscation can mitigate the persistence of attack parameters via noise injection. At the edge level, secure verification modules based on trusted execution environments can be deployed, using isolation and encryption to filter model updates in real time. At the global level, inter-node defense knowledge-sharing protocols can be designed to synchronize the attack signature databases of edge servers through federated learning, fostering a co-evolutionary defense ecosystem. This three-tier architecture—comprising terminal-level immunity, edge-level filtering, and global coordination—can significantly enhance overall system robustness.
- Improved theoretical evaluation systems: Current studies lack rigorous proof of model convergence under defensive mechanisms, and existing evaluation standards remain fragmented. Future work should establish a joint convergence-robustness analysis framework to quantify how defense intensity affects model convergence rates based on stochastic optimization theory. Designing composite evaluation metrics should go beyond single-dimensional constraints, forming a triangular evaluation framework that includes computational cost, communication overhead, and defense effectiveness. In addition, developing defense cost-efficiency models will aid in selecting suitable solutions for resource-constrained scenarios, using Pareto frontier analysis to identify optimal trade-offs among privacy, security, and efficiency.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge Computing: Vision and Challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Chen, J.; Ran, X. Deep Learning with Edge Computing: A Review. Proc. IEEE 2019, 107, 1655–1674. [Google Scholar] [CrossRef]
- Xu, D.; Li, T.; Li, Y.; Su, X.; Tarkoma, S.; Jiang, T.; Crowcroft, J.; Hui, P. Edge Intelligence: Empowering Intelligence to the Edge of Network. Proc. IEEE 2021, 109, 1778–1837. [Google Scholar] [CrossRef]
- Ahvar, E.; Ahvar, S.; Lee, G.M. Artificial Intelligence of Things: Architectures, Applications, and Challenges. In Springer Handbook of Internet of Things; Springer Handbooks; Ziegler, S., Radócz, R., Quesada Rodriguez, A., Matheu Garcia, S.N., Eds.; Springer International Publishing: Cham, Switzerland, 2024; pp. 443–462. [Google Scholar] [CrossRef]
- Zhu, G.; Lyu, Z.; Jiao, X.; Liu, P.; Chen, M.; Xu, J.; Cui, S.; Zhang, P. Pushing AI to Wireless Network Edge: An Overview on Integrated Sensing, Communication, and Computation towards 6G. Sci. China-Inf. Sci. 2023, 66, 130301. [Google Scholar] [CrossRef]
- McEnroe, P.; Wang, S.; Liyanage, M. A Survey on the Convergence of Edge Computing and AI for UAVs: Opportunities and Challenges. IEEE Internet Things J. 2022, 9, 15435–15459. [Google Scholar] [CrossRef]
- Zhu, R.; Liu, Y.; Gao, Y.; Shi, Y.; Peng, X. Edge Intelligence Based Garbage Classification Detection Method. In Edge Computing and IoT: Systems, Management and Security; Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Xiao, Z., Zhao, P., Dai, X., Shu, J., Eds.; Springer Nature Switzerland: Cham, Switzerland, 2023; Volume 478, pp. 128–141. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning: Concept and Applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 12. [Google Scholar] [CrossRef]
- Nguyen, T.D.; Nguyen, T.; Le Nguyen, P.; Pham, H.H.; Doan, K.D.; Wong, K.-S. Backdoor Attacks and Defenses in Federated Learning: Survey, Challenges and Future Research Directions. Eng. Appl. Artif. Intell. 2024, 127, 107166. [Google Scholar] [CrossRef]
- Yin, X.; Zhu, Y.; Hu, J. A Comprehensive Survey of Privacy-Preserving Federated Learning: A Taxonomy, Review, and Future Directions. ACM Comput. Surv. 2021, 54, 131:1–131:36. [Google Scholar] [CrossRef]
- Abi-Char, P.E. A User Location Privacy Protection Mechanism for LBS Using Third Party-Based Architectures. In Proceedings of the 2022 45th International Conference on Telecommunications and Signal Processing (TSP), Prague, Czech Republic, 13–15 July 2022; pp. 139–145. [Google Scholar] [CrossRef]
- Rigaki, M.; Garcia, S. A Survey of Privacy Attacks in Machine Learning. ACM Comput. Surv. 2024, 56, 101. [Google Scholar] [CrossRef]
- Hu, H.; Salcic, Z.; Sun, L.; Dobbie, G.; Yu, P.S.; Zhang, X. Membership Inference Attacks on Machine Learning: A Survey. ACM Comput. Surv. 2022, 54, 235. [Google Scholar] [CrossRef]
- Xie, Y.-A.; Kang, J.; Niyato, D.; Van, N.T.T.; Luong, N.C.; Liu, Z.; Yu, H. Securing Federated Learning: A Covert Communication-Based Approach. IEEE Netw. 2022, 37, 118–124. [Google Scholar] [CrossRef]
- Thai, M.T.; Phan, H.N.; Thuraisingham, B. (Eds.) Handbook of Trustworthy Federated Learning; Springer Optimization and Its Applications; Springer International Publishing: Cham, Switzerland, 2025; Volume 213. [Google Scholar] [CrossRef]
- Zhang, Y.; Bai, G.; Chamikara, M.A.P.; Ma, M.; Shen, L.; Wang, J.; Nepal, S.; Xue, M.; Wang, L.; Liu, J. AgrEvader: Poisoning Membership Inference against Byzantine-Robust Federated Learning. In Proceedings of the ACM Web Conference 2023, Austin, TX, USA, 30 April 2023; WWW ’23. Association for Computing Machinery: New York, NY, USA, 2023; pp. 2371–2382. [Google Scholar] [CrossRef]
- Zhang, L.; Li, L.; Li, X.; Cai, B.; Gao, Y.; Dou, R.; Chen, L. Efficient Membership Inference Attacks against Federated Learning via Bias Differences. In Proceedings of the 26th International Symposium on Research in Attacks, Intrusions and Defenses, Hong Kong, China, 16–18 October 2023; pp. 222–235. [Google Scholar] [CrossRef]
- Li, Y.; Jiang, Y.; Li, Z.; Xia, S.-T. Backdoor Learning: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 5–22. [Google Scholar] [CrossRef] [PubMed]
- Sun, G.; Cong, Y.; Dong, J.; Wang, Q.; Lyu, L.; Liu, J. Data Poisoning Attacks on Federated Machine Learning. IEEE Internet Things J. 2022, 9, 11365–11375. [Google Scholar] [CrossRef]
- Sharma, A.; Marchang, N. A Review on Client-Server Attacks and Defenses in Federated Learning. Comput. Secur. 2024, 2024, 103801. [Google Scholar] [CrossRef]
- Cao, X.; Gong, N.Z. MPAF: Model Poisoning Attacks to Federated Learning Based on Fake Clients. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3396–3404. [Google Scholar]
- Du, R.; Liu, C.; Gao, Y. Anonymous Federated Learning Framework in the Internet of Things. Concurr. Comput. 2024, 36, e7901. [Google Scholar] [CrossRef]
- Yan, N.; Li, Y.; Chen, J.; Wang, X.; Hong, J.; He, K.; Wang, W. Efficient and Straggler-Resistant Homomorphic Encryption for Heterogeneous Federated Learning. In Proceedings of the IEEE INFOCOM 2024-IEEE Conference on Computer Communications, Vancouver, BC, Canada, 20–23 May 2024; pp. 791–800. [Google Scholar]
- Jin, W.; Yao, Y.; Han, S.; Gu, J.; Joe-Wong, C.; Ravi, S.; Avestimehr, S.; He, C. FedML-HE: An Efficient Homomorphic-Encryption-Based Privacy-Preserving Federated Learning System. arXiv 2024. [Google Scholar] [CrossRef]
- Nguyen, N.-H.; Nguyen, T.-A.; Nguyen, T.; Hoang, V.T.; Le, D.D.; Wong, K.-S. Towards Efficient Communication and Secure Federated Recommendation System via Low-Rank Training. In Proceedings of the ACM Web Conference 2024, Stuttgart, Germany, 21–24 May 2024; ACM: Singapore, 2024; pp. 3940–3951. [Google Scholar] [CrossRef]
- Janbaz, S.; Asghari, R.; Bagherpour, B.; Zaghian, A. A Fast Non-Interactive Publicly Verifiable Secret Sharing Scheme. In Proceedings of the 2020 17th International ISC Conference on Information Security and Cryptology (ISCISC), Tehran, Iran, 9–10 September 2020; pp. 7–13. [Google Scholar] [CrossRef]
- Zhang, X.; Fu, A.; Wang, H.; Zhou, C.; Chen, Z. A Privacy-Preserving and Verifiable Federated Learning Scheme. In Proceedings of the ICC 2020–2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Hu, R.; Guo, Y.; Gong, Y. Federated Learning with Sparsified Model Perturbation: Improving Accuracy under Client-Level Differential Privacy. IEEE Trans. Mob. Comput. 2023, 23, 8242–8255. [Google Scholar] [CrossRef]
- Hu, Q.; Song, Y. User Consented Federated Recommender System Against Personalized Attribute Inference Attack. In Proceedings of the 17th ACM International Conference on Web Search and Data Mining, Mérida, Mexico, 4–8 March 2024; ACM: Merida, Mexico, 2024; pp. 276–285. [Google Scholar] [CrossRef]
- Mai, P.; Pang, Y. Vertical Federated Graph Neural Network for Recommender System. In Proceedings of the International Conference on Machine Learning, Edmonton, AB, Canada, 30 June–3 July 2023; pp. 23516–23535. [Google Scholar]
- Chen, R.; Huang, C.; Qin, X.; Ma, N.; Pan, M.; Shen, X. Energy Efficient and Differentially Private Federated Learning via a Piggyback Approach. IEEE Trans. Mob. Comput. 2023, 23, 2698–2711. [Google Scholar] [CrossRef]
- Wang, J.; Guo, S.; Xie, X.; Qi, H. Protect Privacy from Gradient Leakage Attack in Federated Learning. In Proceedings of the IEEE INFOCOM 2022-IEEE Conference on Computer Communications, Online, 2–5 May 2022; pp. 580–589. [Google Scholar]
- Chamikara, M.A.P.; Bertok, P.; Khalil, I.; Liu, D.; Camtepe, S. Privacy Preserving Distributed Machine Learning with Federated Learning. Comput. Commun. 2021, 171, 112–125. [Google Scholar] [CrossRef]
- Jin, H.; Zhang, P.; Dong, H.; Wei, X.; Zhu, Y.; Gu, T. Mobility-Aware and Privacy-Protecting QoS Optimization in Mobile Edge Networks. IEEE Trans. Mob. Comput. 2022, 23, 1169–1185. [Google Scholar] [CrossRef]
- Choudhury, O.; Gkoulalas-Divanis, A.; Salonidis, T.; Sylla, I.; Park, Y.; Hsu, G.; Das, A. Anonymizing Data for Privacy-Preserving Federated Learning. arXiv 2020, arXiv:2002.09096. [Google Scholar] [CrossRef]
- Zhao, B.; Fan, K.; Yang, K.; Wang, Z.; Li, H.; Yang, Y. Anonymous and Privacy-Preserving Federated Learning with Industrial Big Data. IEEE Trans. Ind. Inform. 2021, 17, 6314–6323. [Google Scholar] [CrossRef]
- Majeed, A.; Lee, S. Anonymization Techniques for Privacy Preserving Data Publishing: A Comprehensive Survey. IEEE Access 2020, 9, 8512–8545. [Google Scholar] [CrossRef]
- Yan, H.; Zhang, W.; Chen, Q.; Li, X.; Sun, W.; Li, H.; Lin, X. RECESS Vaccine for Federated Learning: Proactive Defense Against Model Poisoning Attacks. Adv. Neural Inf. Process. Syst. 2023, 36, 8702–8713. [Google Scholar]
- Yueqi, X.I.E.; Fang, M.; Gong, N.Z. Fedredefense: Defending against Model Poisoning Attacks for Federated Learning Using Model Update Reconstruction Error. In Proceedings of the Forty-First International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Yan, G.; Wang, H.; Yuan, X.; Li, J. DeFL: Defending against Model Poisoning Attacks in Federated Learning via Critical Learning Periods Awareness. Proc. AAAI Conf. Artif. Intell. 2023, 37, 10711–10719. [Google Scholar] [CrossRef]
- Xu, R.; Gao, S.; Li, C.; Joshi, J.; Li, J. Dual Defense: Enhancing Privacy and Mitigating Poisoning Attacks in Federated Learning. Adv. Neural Inf. Process. Syst. 2024, 37, 70476–70498. [Google Scholar]
- Qin, Z.; Chen, F.; Zhi, C.; Yan, X.; Deng, S. Resisting Backdoor Attacks in Federated Learning via Bidirectional Elections and Individual Perspective. Proc. AAAI Conf. Artif. Intell. 2024, 38, 14677–14685. [Google Scholar] [CrossRef]
- Zheng, J.; Li, K.; Yuan, X.; Ni, W.; Tovar, E. Detecting Poisoning Attacks on Federated Learning Using Gradient-Weighted Class Activation Mapping. In Proceedings of the Companion Proceedings of the ACM Web Conference 2024, Singapore, 13–17 May 2024; WWW ’24. Association for Computing Machinery: New York, NY, USA, 2024; pp. 714–717. [Google Scholar] [CrossRef]
- Jia, J.; Yuan, Z.; Sahabandu, D.; Niu, L.; Rajabi, A.; Ramasubramanian, B.; Li, B.; Poovendran, R. FedGame: A Game-Theoretic Defense against Backdoor Attacks in Federated Learning. Adv. Neural Inf. Process. Syst. 2023, 36, 53090–53111. [Google Scholar]
- Panda, A.; Mahloujifar, S.; Bhagoji, A.N.; Chakraborty, S.; Mittal, P. SparseFed: Mitigating Model Poisoning Attacks in Federated Learning with Sparsification. In Proceedings of the 25th International Conference on Artificial Intelligence and Statistics, Valencia, Spain, 28–30 March 2022; pp. 7587–7624. [Google Scholar]
- Zhu, C.; Roos, S.; Chen, L.Y. LeadFL: Client Self-Defense against Model Poisoning in Federated Learning. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023. [Google Scholar]
- Zhang, K.; Tao, G.; Xu, Q.; Cheng, S.; An, S.; Liu, Y.; Feng, S.; Shen, G.; Chen, P.-Y.; Ma, S.; et al. FLIP: A Provable Defense Framework for Backdoor Mitigation in Federated Learning. arXiv 2022, arXiv:2210.12873. [Google Scholar]
- Huang, T.; Hu, S.; Chow, K.-H.; Ilhan, F.; Tekin, S.F.; Liu, L. Lockdown: Backdoor Defense for Federated Learning with Isolated Subspace Training. Adv. Neural Inf. Process. Syst. 2023, 36, 10876–10896. [Google Scholar]
- Mai, P.; Yan, R.; Pang, Y. RFLPA: A Robust Federated Learning Framework against Poisoning Attacks with Secure Aggregation. Adv. Neural Inf. Process. Syst. 2024, 37, 104329–104356. [Google Scholar]
- Yu, Y.; Liu, Q.; Wu, L.; Yu, R.; Yu, S.L.; Zhang, Z. Untargeted Attack against Federated Recommendation Systems via Poisonous Item Embeddings and the Defense. Proc. AAAI Conf. Artif. Intell. 2023, 37, 4854–4863. [Google Scholar] [CrossRef]
- FLShield: A Validation Based Federated Learning Framework to Defend Against Poisoning Attacks|IEEE Conference Publication|IEEE Xplore. Available online: https://ieeexplore.ieee.org/document/10646613 (accessed on 16 March 2025).
- Sun, J.; Li, A.; DiValentin, L.; Hassanzadeh, A.; Chen, Y.; Li, H. FL-WBC: Enhancing Robustness against Model Poisoning Attacks in Federated Learning from a Client Perspective. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Irvine, CA, USA, 2021; Volume 34, pp. 12613–12624. [Google Scholar]
- Harper, F.M.; Konstan, J.A. The MovieLens Datasets: History and Context. ACM Trans. Interact. Intell. Syst. 2016, 5, 1–19. [Google Scholar] [CrossRef]
- Wu, C.; Wu, F.; Cao, Y.; Huang, Y.; Xie, X. FedGNN: Federated Graph Neural Network for Privacy-Preserving Recommendation. Nat. Commun. 2022, 13, 3091. [Google Scholar] [CrossRef]
- Sun, X.; Yu, F.R.; Zhang, P.; Sun, Z.; Xie, W.; Peng, X. A Survey on Zero-Knowledge Proof in Blockchain. IEEE Netw. 2021, 35, 198–205. [Google Scholar] [CrossRef]
- Cao, L. Decentralized AI: Edge Intelligence and Smart Blockchain, Metaverse, Web3, and DeSci. IEEE Intell. Syst. 2022, 37, 6–19. [Google Scholar] [CrossRef]
- Bourtoule, L.; Chandrasekaran, V.; Choquette-Choo, C.A.; Jia, H.; Travers, A.; Zhang, B.; Lie, D.; Papernot, N. Machine Unlearning. In Proceedings of the 2021 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 24–27 May 2021; pp. 141–159. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Privacy Protection Method | Key Techniques | Description |
|---|---|---|
| Homomorphic encryption | Allows computations on encrypted data, with the results matching the plaintext outcome once decrypted. | |
| Encryption-based | Spatial transformation | Transforms data into different spatial representations, preventing direct linkage to the original data. |
| Secure multi-party computation | Enables multiple parties to collaboratively compute results on private data, with the final result containing only partial information. | |
| Differential privacy | Introduces noise to ensure that any data query result appears similar across privacy datasets, protecting individual privacy. | |
| Perturbation-based | Additive perturbation | Adds additive noise to data, ensuring its privacy by, for instance, adding random noise to each data point. |
| Multiplicative perturbation | Adds multiplicative noise to data to ensure privacy, making statistical information from the perturbed data difficult to recover. | |
| k-anonymity | Modifies data such that each data entry is indistinguishable from at least k-1 other entries, reducing the risk of individual identification. | |
| Anonymization-based | l-diversity | Ensures sufficient diversity in the attribute values of each data entry, preventing sensitive information from being inferred by attackers. |
| t-closeness | Ensures that the difference or similarity between data entries is sufficiently small, preventing individual-specific data leakage. |
| Reference | Methods | Privacy-Utility Trade-Off | Lightweight | Attack Types |
|---|---|---|---|---|
| Yan et al. [23] | Encryption-based | NO | YES | Gradient Inversion Attack, Data Reconstruction Attack |
| Jin et al. [24] | Encryption-based | NO | YES | Gradient Inversion Attack, Data Reconstruction Attack |
| Nguyen et al. [25] | Encryption-based | YES | YES | Not Specified |
| Janbaz et al. [26] | Encryption-based | NO | YES | Gradient Inversion Attack |
| Zhang et al. [27] | Encryption-based | YES | NO | Gradient Inversion Attack |
| Hu et al. [28] | Perturbation-based | YES | YES | Membership Inference Attack, Model Inversion Attack |
| Hu et al. [29] | Perturbation-based | YES | NO | Attribute Inference Attack |
| Mai et al. [30] | Perturbation-based | YES | NO | De-anonymization Attack |
| Chen et al. [31] | Perturbation-based | YES | YES | Data Reconstruction Attack |
| Chamikara et al. [32] | Perturbation-based | YES | YES | Gradient Inversion Attack |
| Wang et al. [33] | Perturbation-based | YES | YES | Membership Inference Attack, Gradient Inversion Attack |
| Jin et al. [34] | Anonymization-based | YES | YES | Not Specified |
| Choudhury et al. [35] | Anonymization-based | YES | NO | Membership Inference Attack, Data Reconstruction Attack |
| Zhao et al. [36] | Anonymization-based | YES | YES | Gradient Inversion Attack |
| Reference | Defense Strategy | Privacy-Utility Trade-Off | Lightweight | Attack Types |
|---|---|---|---|---|
| Yan et al. [38] | Anomaly Detection | NO | YES | Model Poisoning attack |
| Xie et al. [39] | Anomaly Detection | NO | YES | Model Poisoning attack |
| Yan et al. [40] | Anomaly Detection | NO | YES | Model Poisoning attack |
| Xu et al. [41] | Anomaly Detection | YES | NO | Model Poisoning attack |
| Qin et al. [42] | Anomaly Detection | NO | NO | Data Poisoning attack |
| Zheng et al. [43] | Anomaly Detection | NO | NO | Model Poisoning attack |
| Panda et al. [44] | Model Tolerance | YES | NO | Model Poisoning attack |
| Jia et al. [45] | Model Tolerance | NO | YES | Model Poisoning attack |
| Zhu et al. [46] | Model Tolerance | YES | NO | Model Poisoning attack |
| Zhang et al. [47] | Model Tolerance | YES | NO | Model Poisoning attack |
| Huang et al. [48] | Model Tolerance | YES | YES | Data Poisoning attack |
| Mai et al. [49] | Model Tolerance | YES | YES | Model Poisoning attack |
| Yu et al. [50] | Model Tolerance | YES | NO | Model Poisoning attack |
| Kabir et al. [51] | Model Tolerance | YES | NO | Model Poisoning attack |
| Sun et al. [52] | Model Tolerance | YES | YES | Model Poisoning attack |
| Methods | ML-100 K | ML-1 M | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Privacy | Utility | Privacy | Utility | |||||||||
| = 0.1 | = 0.2 | HR | NDCG | = 0.1 | = 0.2 | HR | NDCG | |||||
| Age | Gender | Age | Gender | Age | Gender | Age | Gender | |||||
| Pure FedRec | 0.533 | 0.691 | 0.571 | 0.725 | 0.681 | 0.429 | 0.529 | 0.703 | 0.586 | 0.708 | 0.752 | 0.472 |
| UC-FedRec | 0.429 | 0.575 | 0.470 | 0.622 | 0.614 | 0.383 | 0.414 | 0.607 | 0.434 | 0.614 | 0.661 | 0.412 |
| CoLR | 0.412 | 0.556 | 0.421 | 0.587 | 0.659 | 0.412 | 0.436 | 0.577 | 0.455 | 0.604 | 0.694 | 0.439 |
| VerFedGNN | 0.446 | 0.608 | 0.475 | 0.639 | 0.573 | 0.361 | 0.457 | 0.627 | 0.504 | 0.636 | 0.623 | 0.374 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Li, B.; Chen, S.; Xu, Z. A Survey on Multi-User Privacy Issues in Edge Intelligence: State of the Art, Challenges, and Future Directions. Electronics 2025, 14, 2401. https://doi.org/10.3390/electronics14122401
Liu X, Li B, Chen S, Xu Z. A Survey on Multi-User Privacy Issues in Edge Intelligence: State of the Art, Challenges, and Future Directions. Electronics. 2025; 14(12):2401. https://doi.org/10.3390/electronics14122401
Chicago/Turabian StyleLiu, Xiuwen, Bowen Li, Sirui Chen, and Zhiqiang Xu. 2025. "A Survey on Multi-User Privacy Issues in Edge Intelligence: State of the Art, Challenges, and Future Directions" Electronics 14, no. 12: 2401. https://doi.org/10.3390/electronics14122401
APA StyleLiu, X., Li, B., Chen, S., & Xu, Z. (2025). A Survey on Multi-User Privacy Issues in Edge Intelligence: State of the Art, Challenges, and Future Directions. Electronics, 14(12), 2401. https://doi.org/10.3390/electronics14122401