5.1. Overall Performance
The traffic flow prediction performance of STDformer compared to other models is shown in
Table 2 and
Table 3. Specifically, the experimental results indicate that STDformer significantly outperforms other comparative models in terms of the lowest Mean Squared Error (MSE) and Mean Absolute Error (MAE) values across different time steps. In the tables, the values for 12, 24, and 48 represent the prediction horizons for forecasting the future steps.
For the smaller and simpler PEMS03 dataset, STDformer demonstrates superior performance in short-term, medium-term, and long-term predictions compared to other models. In the short-term traffic flow prediction scenario, STDformer achieves a Mean Squared Error (MSE) of 0.078 at a 12-step prediction, slightly lower than the 0.077 of iTransformer, but clearly better than other models. Its Mean Absolute Error (MAE) is 0.183, indicating excellent performance. Although iTransformer establishes good variable correlations in the short term, its performance significantly lags behind the Transformer model as the time step increases. STDformer utilizes sequence decomposition techniques to customize modeling for the trend, seasonal, and residual components, ensuring stability in long-term predictions. Even under complex traffic flow patterns, STDformer maintains high prediction accuracy, demonstrating its robustness and adaptability. Conversely, the LSTM and CNN models exhibit less consistent performance across different prediction horizons. While LSTM shows reasonable accuracy in short-term predictions, it struggles with longer time steps, leading to increased errors. Similarly, the CNN model performs adequately but does not match the predictive power of STDformer or iTransformer, particularly as the prediction horizon extends.
In the analysis of the PEMS07 dataset, STDformer also exhibits outstanding prediction performance. As a dataset covering a larger road network with complex intersection topologies, STDformer shows optimal performance in both short-term and long-term predictions. This further confirms STDformer’s effectiveness and reliability in complex traffic environments, emphasizing its robustness in handling diverse traffic flow patterns.
Across all models, the prediction error generally increases as the required prediction time steps grow. However, STDformer’s performance remains superior to other comparative models in long-term predictions, showcasing its robustness and adaptability in the face of complex traffic flow patterns. STDformer not only excels in short-term and medium-term predictions but also maintains good accuracy in long-term prediction tasks, indicating its capability to effectively capture complex and dynamic traffic flow patterns. In contrast, the LSTM and CNN models demonstrate less consistent performance across varying time horizons. While LSTM performs reasonably well in short-term predictions, it tends to experience increased error rates as the prediction horizon extends, highlighting its limitations in capturing long-term dependencies effectively. Similarly, the CNN model shows decent performance but falls short of STDformer’s predictive capabilities, particularly in more complex scenarios, where it struggles to adapt to the dynamic nature of traffic flow. Overall, STDformer demonstrates exceptional performance in traffic flow prediction tasks, with effective predictive capabilities, as evidenced by its performance on the PEMS07 dataset, proving that it meets the practical application demands in complex traffic environments.
The traffic speed prediction performance of STDformer compared to other models is shown in
Table 4 and
Table 5. The experimental results indicate that, in predicting traffic speed, STDformer outperforms other comparative models overall.
On the PEMS04 dataset, STDformer performs exceptionally well, achieving optimal or near-optimal results in both short-term and long-term predictions, leading all models. Overall, it demonstrates an average MSE/MAE of 0.115/0.223, showcasing its outstanding global modeling capability and generalization performance. In the PEMS08 dataset, due to the significantly fewer features compared to other datasets, models like PatchTST and iTransformer exhibit their strengths in short-term predictions. Although STDformer does not achieve the best performance in the short term, it excels in long-term and overall performance, highlighting its long-term advantages and stability in handling traffic speed applications. In contrast, the LSTM and CNN models show varying performance across the datasets. LSTM performs reasonably well in short-term predictions but struggles to maintain accuracy as the prediction horizon extends, indicating its limitations in capturing long-term traffic dynamics. Similarly, the CNN model demonstrates solid performance but is often outperformed by STDformer, particularly in longer prediction tasks. While CNN can model spatial patterns effectively, it lacks the temporal adaptability required for dynamic traffic flow scenarios, which is where STDformer excels.
In summary, STDformer exhibits excellent performance in both traffic flow prediction and traffic speed prediction, demonstrating the model’s robustness and adaptability. By designing a prediction mechanism for different time steps, STDformer showcases its predictive performance across varying time horizons. In short-term predictions, STDformer can quickly respond to instantaneous changes in traffic flow, ensuring prediction accuracy. In long-term predictions, the model successfully identifies and captures the overall trends in traffic flow, displaying strong stability. This further validates the effectiveness of sequence decomposition and temporal module modeling in STDformer, allowing it to maintain efficient predictive capabilities even in complex and dynamic traffic environments, thereby enhancing the accuracy of traffic flow and speed predictions.
5.2. Ablation Study
To analyze the effectiveness of the components in our proposed framework, we perform ablation experiments by systematically removing specific parts of the model. The following four ablation scenarios are considered:
wo/FFT: This setup tests the model without Fast Fourier Transform (FFT) and Inverse Fast Fourier Transform (IFFT) in the Time Decomposition Block, essentially omitting the modeling of residual components in temporal modeling.
wo/STRA: In this configuration, the Spatial-Temporal Relation Attention module is removed while retaining other components, validating the effectiveness of the parallel spatiotemporal attention in the model.
wo/TA: This experiment evaluates the model’s performance by replacing the Transformer in the trend component of the time modeling module with a Multi-Layer Perceptron (MLP), aiming to assess the effectiveness of the attention mechanism in trend component modeling.
wo/FA: In this scenario, the Fourier attention in the seasonal component of the time modeling module is replaced with a Multi-Layer Perceptron (MLP) to evaluate the effectiveness of the Fourier attention mechanism in seasonal component modeling.
In the application of traffic flow prediction, as shown in
Table 6 and
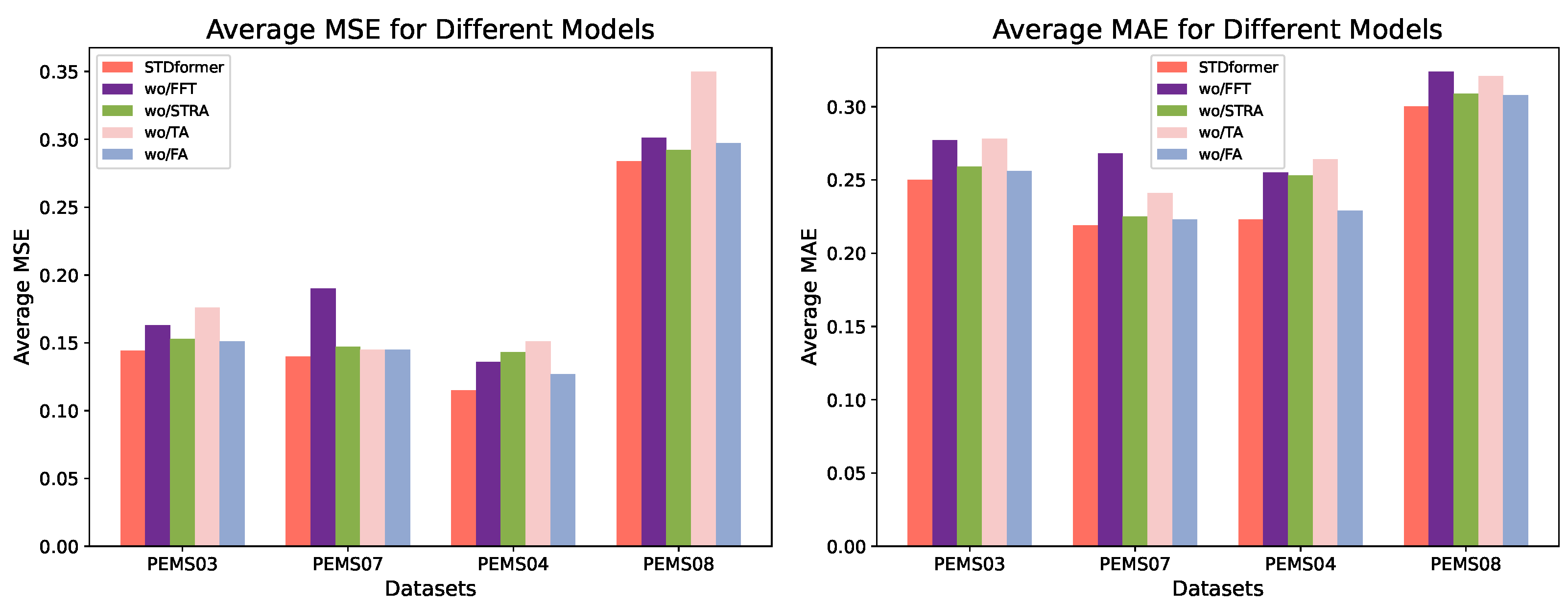
Table 7, the results of the ablation study with wo/FFT show the largest decrease in performance in short-term prediction scenarios. This indicates that modeling the residual component has a significant impact on prediction performance in short-term forecasting. The residual component typically represents random fluctuations that cannot be captured by trend and seasonal components. Therefore, accurately modeling these residuals is crucial for improving the accuracy of short-term predictions. As the time step increases, the influence of the residuals on the prediction results gradually diminishes, yet they still have a significant impact. This suggests that for longer time-step predictions, trend and seasonal components may dominate, while the volatility of the residuals decreases relatively.
The ablation results for wo/FFT indicate that removing the spatial attention module for traffic flow leads to a noticeable decline in model performance, with average MSE and MAE values of 0.147 and 0.225, respectively. This demonstrates that the spatial correlation of traffic flow contributes significantly to the prediction model, making spatial modeling a critical part of the overall architecture of STDformer.
The ablation experiments show substantial performance drops for wo/TA and wo/FA, both of which replace the key modeling mechanisms for the trend and seasonal components with a Multi-Layer Perceptron (MLP). The average MSE and MAE for wo/TA rise to 0.176 and 0.278, respectively, indicating that the Transformer significantly outperforms the MLP in modeling the trend component. Similarly, wo/FA has average MSE and MAE values of 0.148 and 0.253, respectively, highlighting the importance of the Fourier attention mechanism in modeling the seasonal component. These results underscore that the temporal modeling module (trend and seasonal components) in STDformer is key to enhancing model performance, particularly in capturing complex time series patterns, where the combination of Transformer and Fourier attention mechanisms provides significant advantages.
The results of the experiment with wo/STRA indicate that removing the spatial attention module for traffic flow leads to a significant decline in model performance, demonstrating that the spatial correlation of traffic flow speed contributes considerably to the predictive effectiveness of the model.
In the application of more complex traffic conditions, as shown in
Table 8 and
Table 9. Both wo/TA and wo/FA ablation experiments show significant performance drops. In more complex traffic conditions (e.g., PEMS04), the impact of modeling the trend and seasonal components is far less than that of the spatial component. Conversely, in the simpler traffic conditions with fewer features in the PEMS08 dataset, the modeling impact of the trend and seasonal components is noticeably enhanced. However, the performance declines across both datasets indicate that replacing the Transformer modeling of the trend component with an MLP significantly affects model performance, suggesting that the Transformer outperforms the MLP in trend component modeling. Similarly, the performance drop in wo/FA underscores the importance of the Fourier attention mechanism in modeling the seasonal component.
Overall, the ablation study results for STDformer indicate that, in the short term, modeling the residual component has a significant impact on model accuracy. The combination of the Transformer and Fourier attention mechanisms provides a substantial advantage in capturing complex time series patterns. The gating mechanism of the model ensures that it can dynamically adjust the focus on different components, allowing for flexible responses to various types of traffic fluctuations. The parallel spatiotemporal attention mechanism demonstrates excellent spatial feature-capturing capabilities in complex traffic scenarios.
Figure 4 shows the comparison of these variants on PeMS03, PeMS07, PeMS04, and PeMS08 datasets. From the results, we obtain the following conclusions. In summary, the results of the ablation experiments validate the importance of each component of STDformer in traffic flow prediction. The FFT significantly enhances residual modeling in the short term, while the core modeling mechanisms for trend and seasonal components (Transformer and Fourier attention) effectively capture temporal dependencies. The spatial attention module captures the spatial correlation of traffic flow, which is crucial for achieving high-accuracy predictions. The overall architecture of STDformer effectively integrates temporal and spatial characteristics, providing an optimal solution for traffic flow prediction tasks.







{kind=link}
{kind=link}
{kind=link}
{kind=link}