
Multimodal Pathological Image Segmentation Using the Integration of Trans MMY Net and Patient Metadata


Abstract
1. Introduction
2. Related Works
2.1. Medical Image Segmentation Based on UNet
2.2. Medical Image Segmentation Method Based on Vision Transformer (ViT)
2.3. Multimodal Medical Image Segmentation Method Combining Metadata
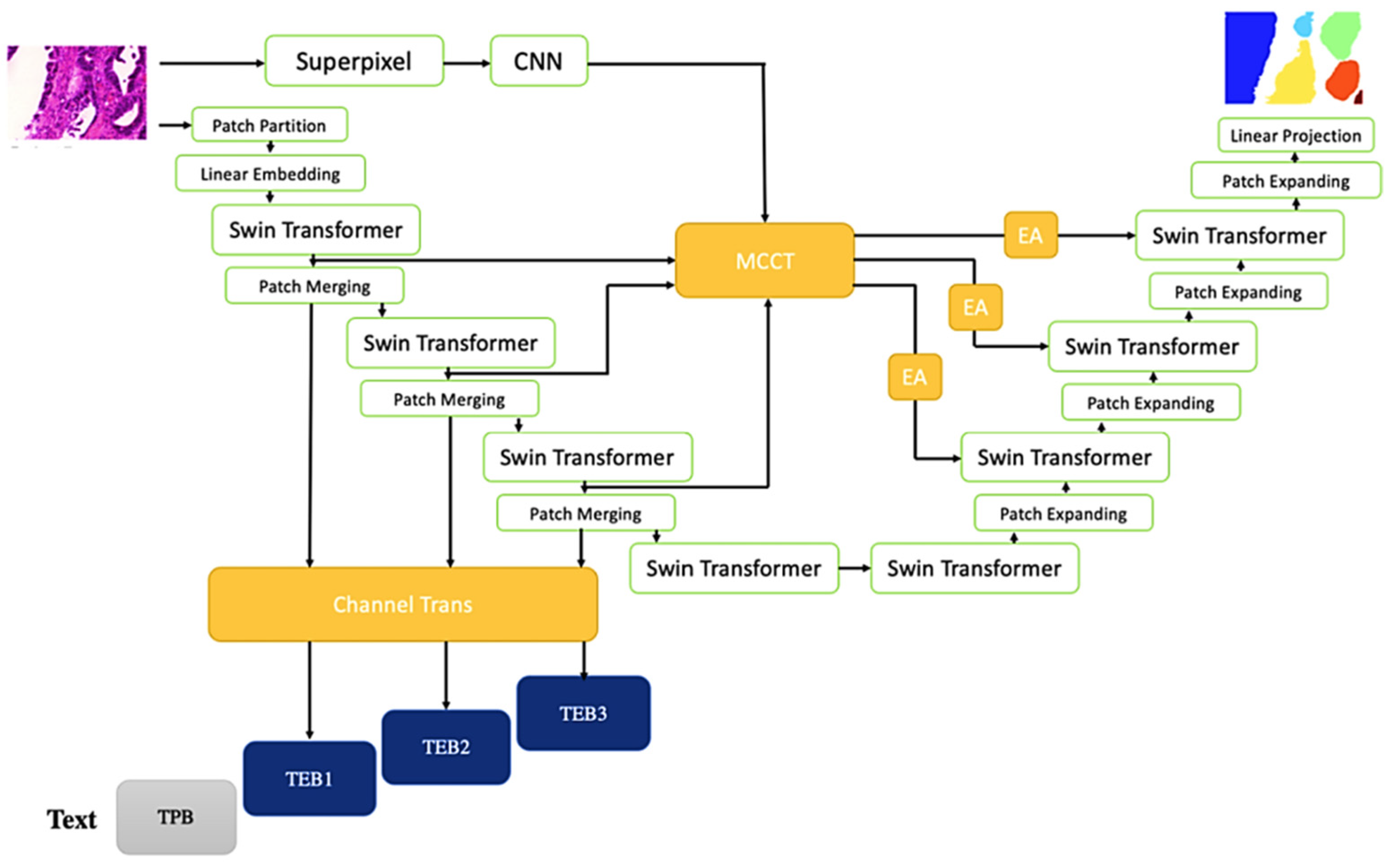
3. Methodology
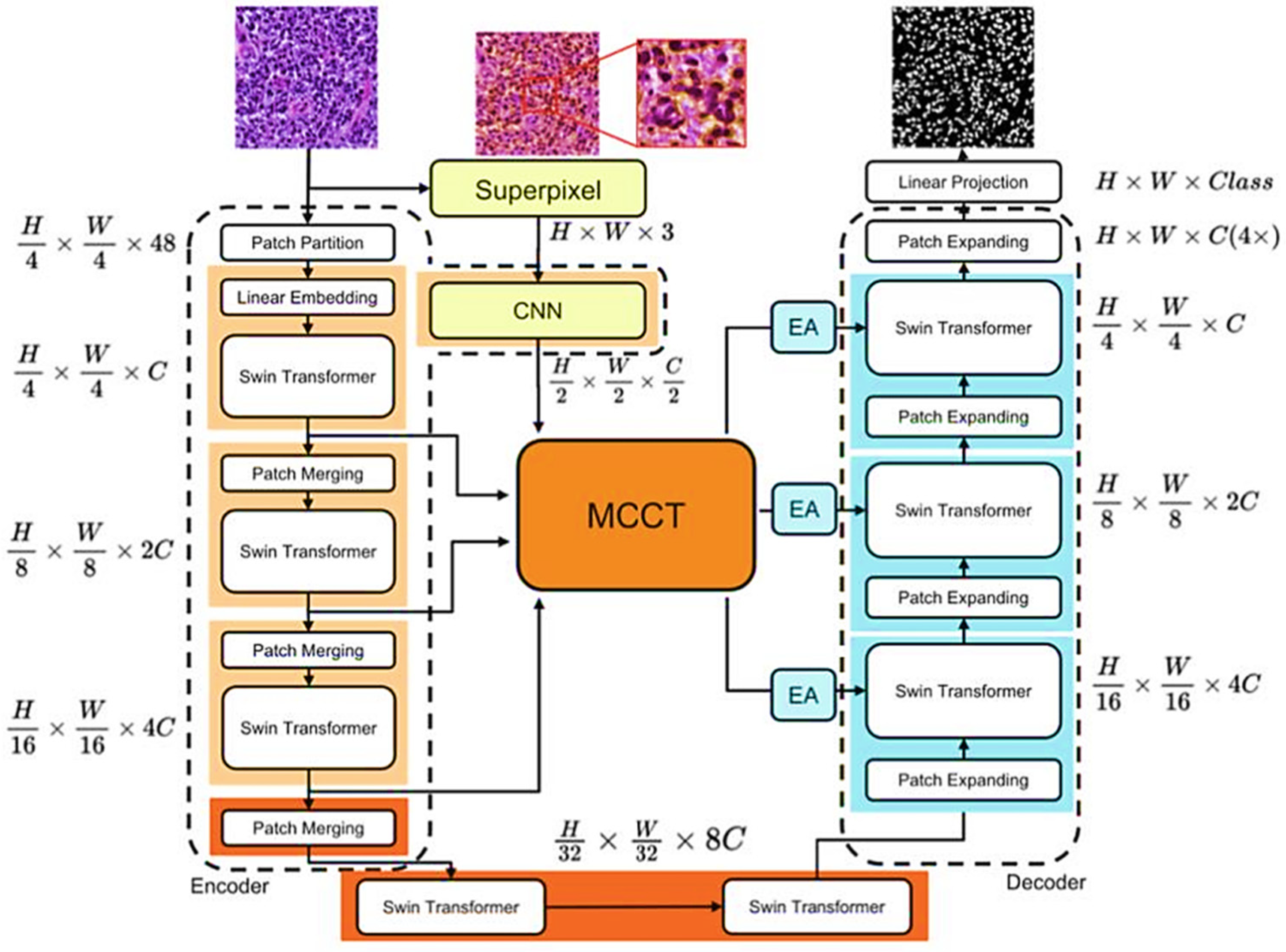
3.1. Design of Trans MMY Net
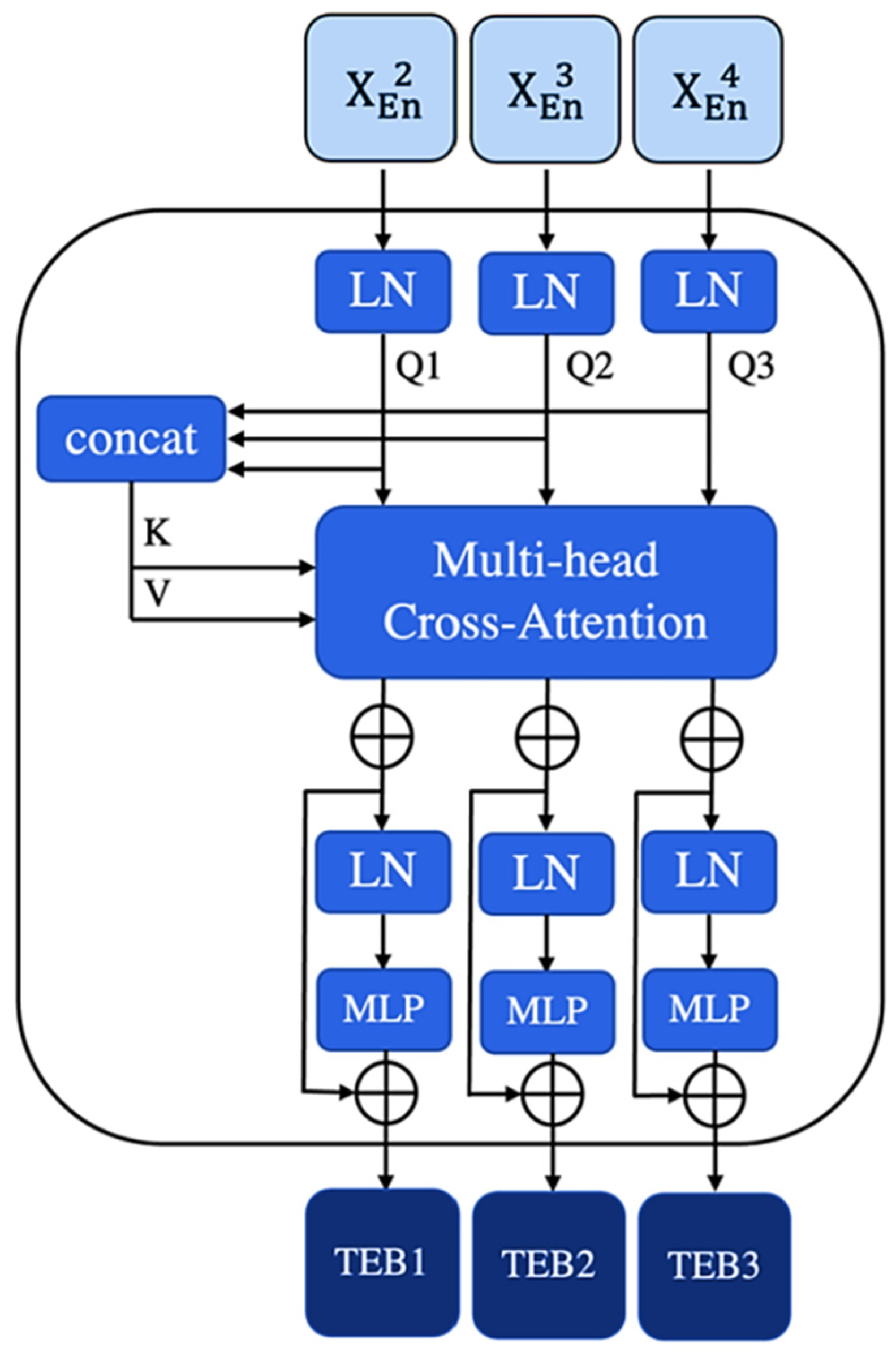
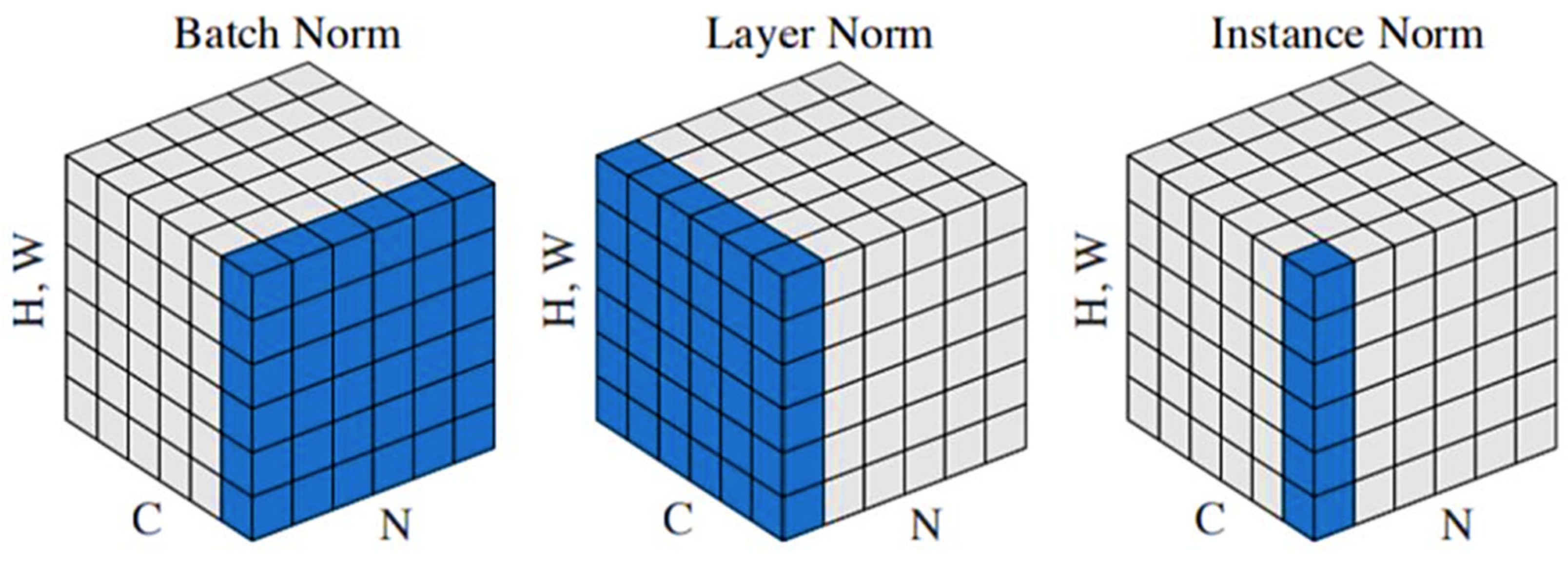
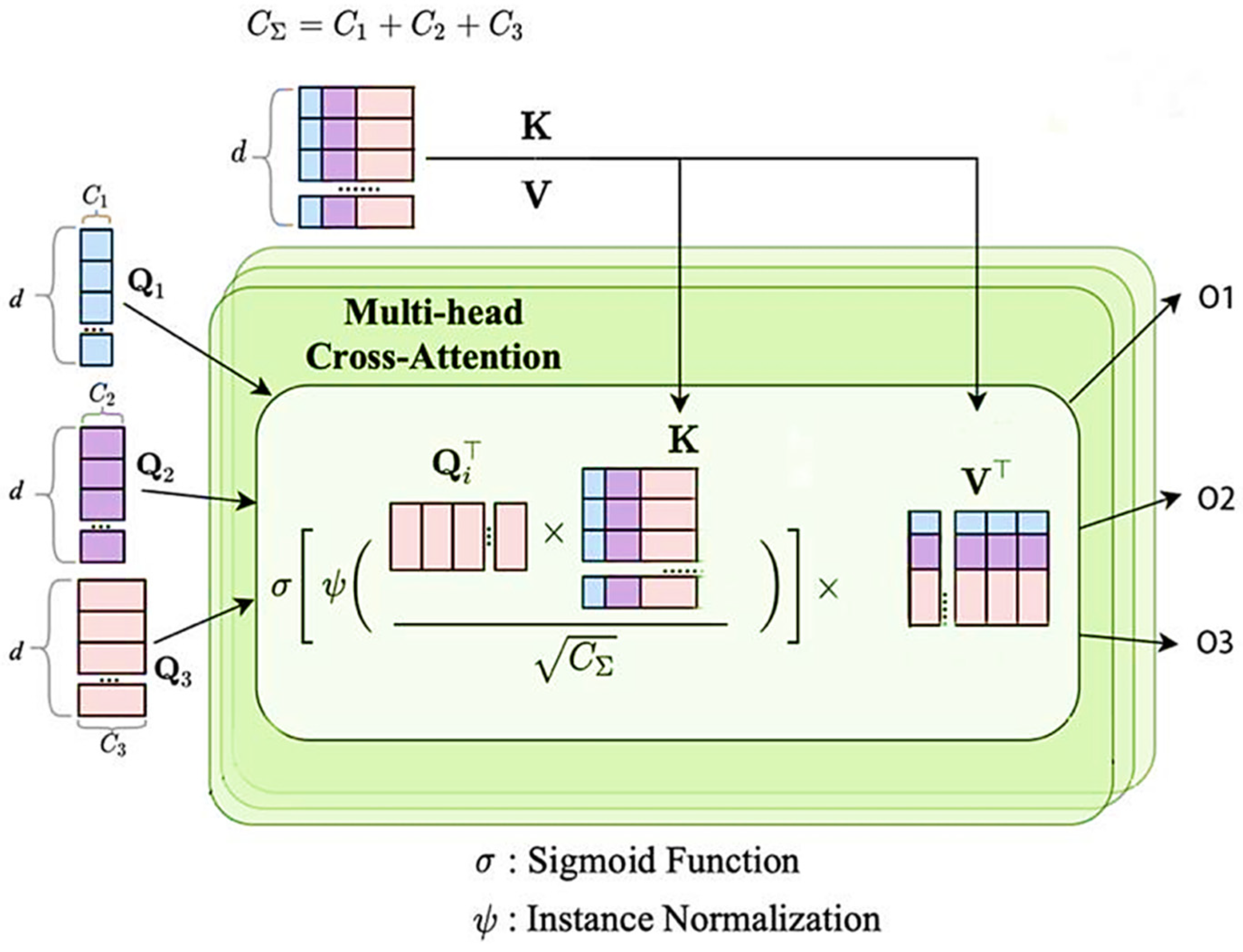
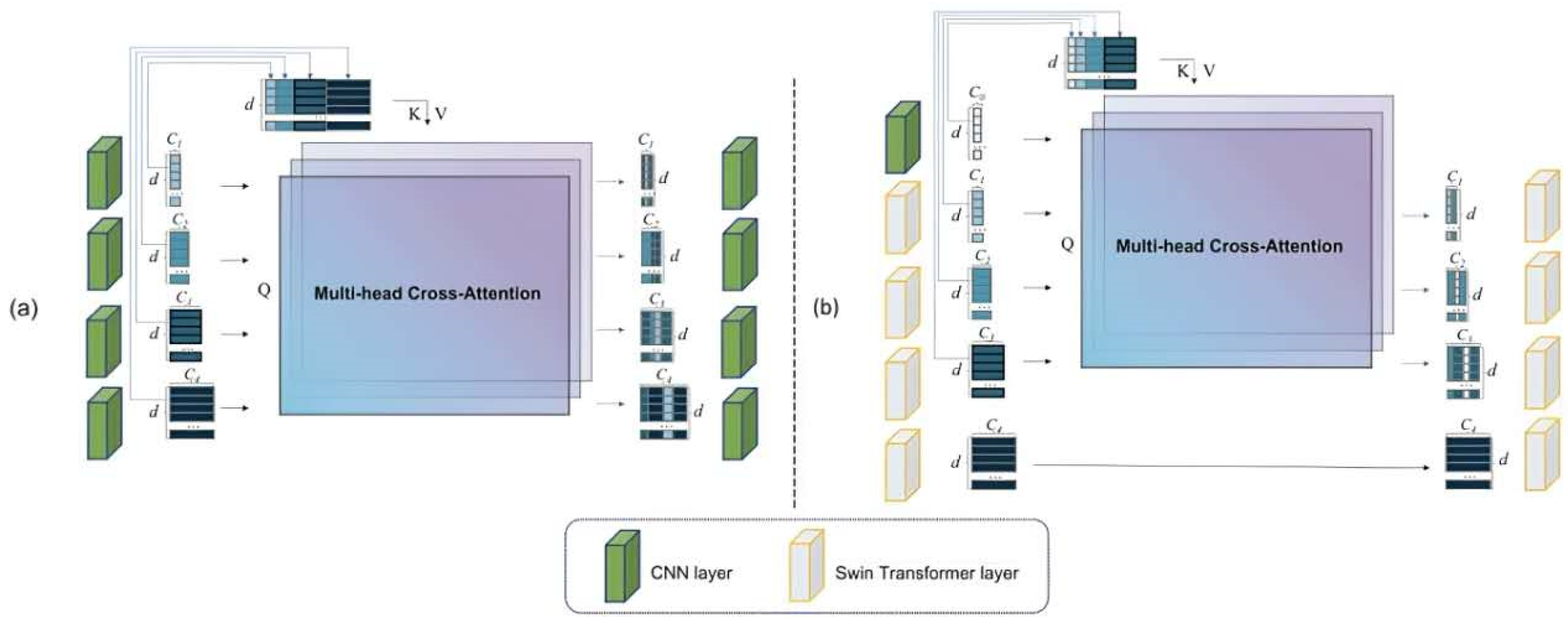
3.2. Channel Trans Module Design
3.3. Optimization of Backbone Network
4. Results and Discussion
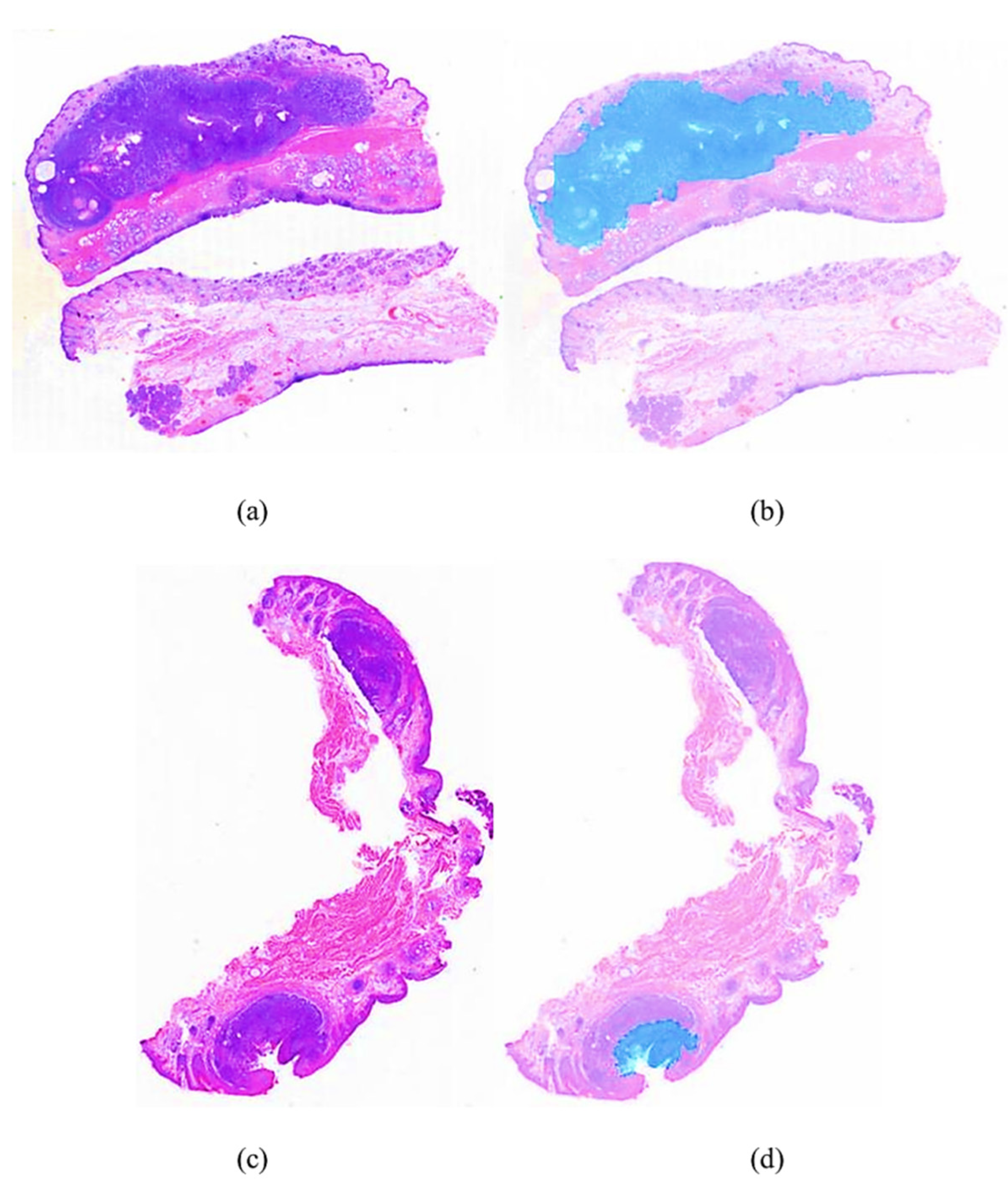
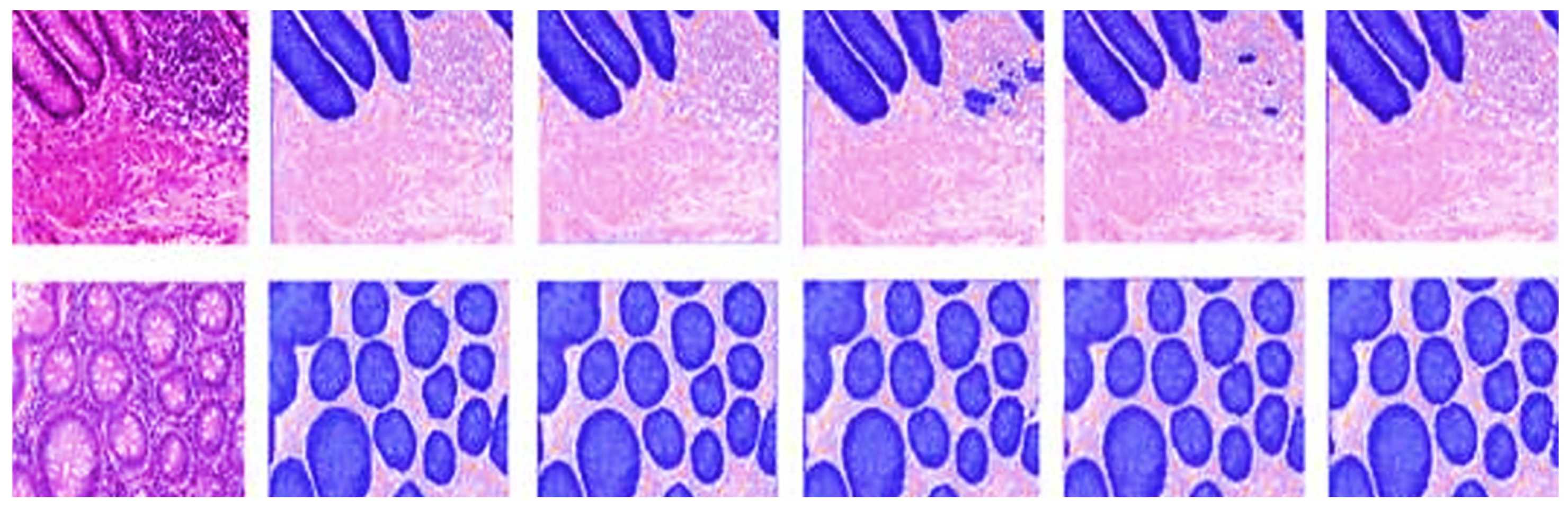
4.1. Performance Comparison of Different Segmentation Networks
4.2. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kirch, D.G.; Petelle, K. Addressing the Physician Shortage. JAMA 2017, 317, 1947. [Google Scholar] [CrossRef] [PubMed]
- Topol, E.J. High-Performance Medicine: The Convergence of Human and Artificial Intelligence. Nat. Med. 2019, 25, 44–56. [Google Scholar] [CrossRef] [PubMed]
- Golden, J.A. Deep Learning Algorithms for Detection of Lymph Node Metastases from Breast Cancer. JAMA 2017, 318, 2184. [Google Scholar] [CrossRef]
- Akay, A.; Hess, H. Deep Learning: Current and Emerging Applications in Medicine and Technology. IEEE J. Biomed. Health Inform. 2019, 23, 906–920. [Google Scholar] [CrossRef]
- Piccialli, F.; Somma, V.D.; Giampaolo, F.; Cuomo, S.; Fortino, G. A Survey on Deep Learning in Medicine: Why, How and When? Inf. Fusion 2021, 66, 111–137. [Google Scholar] [CrossRef]
- Agarwal, A.; Kumar, R.; Gupta, M. Review on Deep Learning Based Medical Image Processing. In Proceedings of the 2022 IEEE International Conference on Current Development in Engineering and Technology (CCET), Bhopal, India, 23–24 December 2022. [Google Scholar] [CrossRef]
- Bizopoulos, P.; Koutsouris, D. Deep Learning in Cardiology. IEEE Rev. Biomed. Eng. 2019, 12, 168–193. [Google Scholar] [CrossRef]
- Elshennawy, N.M.; Ibrahim, D.M. Deep-Pneumonia Framework Using Deep Learning Models Based on Chest X-Ray Images. Diagnostics 2020, 10, 649. [Google Scholar] [CrossRef]
- Krittanawong, C.; Johnson, K.W.; Rosenson, R.S.; Wang, Z.; Aydar, M.; Baber, U.; Min, J.K.; Tang, W.H.W.; Halperin, J.L.; Narayan, S.M. Deep Learning for Cardiovascular Medicine: A Practical Primer. Eur. Heart J. 2019, 40, 2058–2073. [Google Scholar] [CrossRef]
- Acosta, J.N.; Falcone, G.J.; Rajpurkar, P.; Topol, E.J. Multimodal Biomedical AI. Nat. Med. 2022, 28, 1773–1784. [Google Scholar] [CrossRef]
- Liu, Y.; Sheng, Z.; Shen, H.-L. Guided Image Deblurring by Deep Multi-Modal Image Fusion. IEEE Access 2022, 10, 130708–130718. [Google Scholar] [CrossRef]
- Kline, A.; Wang, H.; Li, Y.; Dennis, S.; Hutch, M.; Xu, Z.; Wang, F.; Cheng, F.; Luo, Y. Multimodal Machine Learning in Precision Health: A Scoping Review. Npj Digit. Medicine 2022, 5, 171. [Google Scholar] [CrossRef] [PubMed]
- Azam, M.A.; Khan, K.B.; Salahuddin, S.; Rehman, E.; Khan, S.A.; Khan, M.A.; Kadry, S.; Gandomi, A.H. A Review on Multimodal Medical Image Fusion: Compendious Analysis of Medical Modalities, Multimodal Databases, Fusion Techniques and Quality Metrics. Comput. Biol. Med. 2022, 144, 105253. [Google Scholar] [CrossRef] [PubMed]
- Basu, S.; Singhal, S.; Singh, D. A Systematic Literature Review on Multimodal Medical Image Fusion. Multimed. Tools Appl. 2023, 83, 15845–15913. [Google Scholar] [CrossRef]
- Zhou, T.; Cheng, Q.; Lu, H.; Li, Q.; Zhang, X.; Qiu, S. Deep Learning Methods for Medical Image Fusion: A Review. Comput. Biol. Med. 2023, 160, 106959. [Google Scholar] [CrossRef]
- Ayesha, S.; Hanif, M.K.; Talib, R. Performance Enhancement of Predictive Analytics for Health Informatics Using Dimensionality Reduction Techniques and Fusion Frameworks. IEEE Access 2022, 10, 753–769. [Google Scholar] [CrossRef]
- Behrad, F.; Saniee Abadeh, M. An Overview of Deep Learning Methods for Multimodal Medical Data Mining. Expert Syst. Appl. 2022, 200, 117006. [Google Scholar] [CrossRef]
- Safari, M.; Fatemi, A.; Archambault, L. MedFusionGAN: Multimodal Medical Image Fusion Using an Unsupervised Deep Generative Adversarial Network. BMC Med. Imaging 2023, 23, 203. [Google Scholar] [CrossRef]
- Stahlschmidt, S.R.; Ulfenborg, B.; Synnergren, J. Multimodal Deep Learning for Biomedical Data Fusion: A Review. Brief. Bioinform. 2022, 23, bbab569. [Google Scholar] [CrossRef]
- Fei, N.; Lu, Z.; Gao, Y.; Yang, G.; Huo, Y.; Wen, J.; Lu, H.; Song, R.; Gao, X.; Xiang, T.; et al. Towards Artificial General Intelligence via a Multimodal Foundation Model. Nat. Commun. 2022, 13, 3094. [Google Scholar] [CrossRef]
- Krishnan, R.; Rajpurkar, P.; Topol, E.J. Self-Supervised Learning in Medicine and Healthcare. Nat. Biomed. Eng. 2022, 6, 1346–1352. [Google Scholar] [CrossRef]
- Weng, Y.; Zhang, Y.; Wang, W.; Dening, T. Semi-Supervised Information Fusion for Medical Image Analysis: Recent Progress and Future Perspectives. Inf. Fusion 2024, 106, 102263. [Google Scholar] [CrossRef]
- Shmatko, A.; Ghaffari Laleh, N.; Gerstung, M.; Kather, J.N. Artificial Intelligence in Histopathology: Enhancing Cancer Research and Clinical Oncology. Nature Cancer 2022, 3, 1026–1038. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, P.T.H.; Sudholt, D. Memetic Algorithms Outperform Evolutionary Algorithms in Multimodal Optimisation. Artif. Intell. 2020, 287, 103345. [Google Scholar] [CrossRef]
- Waqas, A.; Tripathi, A.; Ramachandran, R.P.; Stewart, P.A.; Rasool, G. Multimodal Data Integration for Oncology in the Era of Deep Neural Networks: A Review. Front. Artif. Intell. 2024, 7, 1408843. [Google Scholar] [CrossRef]
- Dasgupta, P. Re: Artificial Intelligence for Diagnosis and Gleason Grading of Prostate Cancer: The PANDA Challenge. Eur. Urol. 2022, 82, 571. [Google Scholar] [CrossRef]
- Chen, R.J.; Lu, M.Y.; Shady, M.; Lipkova, J.; Chen, T.; Williamson, D.F.; Joo, B.; Mahmood, F. Abstract PO-002: Pan-Cancer Integrative Histology-Genomic Analysis via Interpretable Multimodal Deep Learning. Clin. Cancer Res. 2021, 27, PO-002. [Google Scholar] [CrossRef]
- Amgad, M.; Hodge, J.M.; Maha, A.T.E.; Bodelon, C.; Puvanesarajah, S.; Gutman, D.A.; Siziopikou, K.P.; Goldstein, J.A.; Gaudet, M.M.; Teras, L.R.; et al. A Population-Level Digital Histologic Biomarker for Enhanced Prognosis of Invasive Breast Cancer. Nat. Med. 2023, 30, 85–97. [Google Scholar] [CrossRef]
- Huang, Z.; Shao, W.; Han, Z.; Alkashash, A.M.; De la Sancha, C.; Parwani, A.V.; Nitta, H.; Hou, Y.; Wang, T.; Salama, P.; et al. Artificial Intelligence Reveals Features Associated with Breast Cancer Neoadjuvant Chemotherapy Responses from Multi-Stain Histopathologic Images. Npj Precis. Oncol. 2023, 7, 14. [Google Scholar] [CrossRef]
- Lan, L.; Zhang, Y.; Li, X.; Wang, K. Deep Learning-Based Prediction Model for Predicting the Tumor Origin of Cancers of Unknown Primary. J. Clin. Oncol. 2023, 41, e13562. [Google Scholar] [CrossRef]
- Gu, R.; Zhang, Y.; Wang, L.; Chen, D.; Wang, Y.; Ge, R.; Jiao, Z.; Ye, J.; Jia, G.; Wang, L. Mmy-Net: A Multimodal Network Exploiting Image and Patient Metadata for Simultaneous Segmentation and Diagnosis. Multimed. Syst. 2024, 30, 72. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. Lect. Notes Comput. Sci. 2015, 9351, 234–241. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging 2019, 39, 1856–1867. [Google Scholar] [CrossRef]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A Deep Learning Framework for Semantic Segmentation of Remotely Sensed Data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Alom, M.Z.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Nuclei Segmentation with Recurrent Residual Convolutional Neural Networks Based U-Net (R2U-Net). In Proceedings of the NAECON 2018-IEEE National Aerospace and Electronics Conference, Dayton, OH, USA, 23–26 July 2018. [Google Scholar]
- Guan, S.; Khan, A.; Sikdar, S.; Chitnis, P. Fully Dense UNet for 2D Sparse Photoacoustic Tomography Artifact Removal. IEEE J. Biomed. Health Inform. 2019, 24, 568–576. [Google Scholar] [CrossRef]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.-W.; Wu, J. UNet 3+: A Full-Scale Connected UNet for Medical Image Segmentation. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Hussain, T.; Shouno, H.; Mohammed, M.A.; Marhoon, H.A.; Alam, T. DCSSGA-UNet: Biomedical Image Segmentation with DenseNet Channel Spatial and Semantic Guidance Attention. In Knowledge-Based Systems; Elsevier: Amsterdam, The Netherlands, 2025; Volume 314, p. 113233. [Google Scholar] [CrossRef]
- Rehman, M.U.; Nizami, I.F.; Ullah, F.; Hussain, I. IQA Vision Transformed: A Survey of Transformer Architectures in Perceptual Image Quality Assessment. IEEE Access 2024, 12, 183369–183393. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.I.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, H.; Cao, P.; Wang, J.; Zaiane, O.R. UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-Wise Perspective with Transformer. In Proceedings of the AAAI Conference on Artificial Intelligence; AAAI Press: Washington, DC, USA, 2022; Volume 36, pp. 2441–2449. [Google Scholar]
- PENG, D.; KAMEYAMA, W. Structural Relation Multi-Class Token Transformer for Weakly Supervised Semantic Segmentation. In IEICE Transactions on Information and Systems; IEICE: Tokyo, Japan, 2024. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. In IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE: New York, NY, USA, 2022; Volume 45, pp. 87–110. [Google Scholar]
- Hussain, T.; Shouno, H.; Hussain, A.; Hussain, D.; Ismail, M.; Mir, T.H.; Hsu, F.R.; Alam, T.; Akhy, S.A. EFFResNet-ViT: A Fusion-Based Convolutional and Vision Transformer Model for Explainable Medical Image Classification. IEEE Access 2025, 13, 54040–54068. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Dolz, J.; Gopinath, K.; Yuan, J.; Lombaert, H.; Desrosiers, C.; Ayed, I.B. HyperDense-Net: A Hyper-Densely Connected CNN for Multi-Modal Image Segmentation. In IEEE Transactions on Medical Imaging; IEEE: New York, NY, USA, 2019; Volume 38, pp. 1116–1126. [Google Scholar]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net Architecture for Multimodal Biomedical Image Segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef]
- Hellmann, F.; Ren, Z.; Andre, E.; Schuller, B.W. Deformable Dilated Faster R-CNN for Universal Lesion Detection in CT Images. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Guadalajara, Mexico, 1–5 November 2021; pp. 2896–2902. [Google Scholar]
- Solley, K.; Turner, C. Prevalence and Correlates of Clinically Significant Body-Focused Repetitive Behaviors in a Non-Clinical Sample. Compr. Psychiatry 2018, 86, 9–18. [Google Scholar] [CrossRef]
- Payne, S.; Józsa, T.I.; El-Bouri, W.K. Review of in Silico Models of Cerebral Blood Flow in Health and Pathology. Prog. Biomed. Eng. 2023, 5, 022003. [Google Scholar] [CrossRef]
- Höhn, J.; Krieghoff-Henning, E.; Jutzi, T.B.; Kalle, C.V.; Utikal, J.S.; Meier, F.; Gellrich, F.F.; Hobelsberger, S.; Hauschild, A.; Schlager, J.G.; et al. Combining CNN-Based Histologic Whole Slide Image Analysis and Patient Data to Improve Skin Cancer Classification. Eur. J. Cancer 2021, 149, 94–101. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.-N.; Sun, S.; He, J.; Torr, P.; Yuille, A.; Bai, S. TransMix: Attend to Mix for Vision Transformers. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Meng, W.; Liu, S.; Wang, H. AFC-Unet: Attention-Fused Full-Scale CNN-Transformer Unet for Medical Image Segmentation. Biomed. Signal Process. Control. 2025, 99, 106839. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Dice | IoU |
|---|---|---|
| DeepLabv3 | 0.8749 | 0.7776 |
| CENet | 0.8902 | 0.8021 |
| SegFormer | 0.8973 | 0.8137 |
| SETR-PUP | 0.8875 | 0.7978 |
| Swin UNet | 0.9011 | 0.8279 |
| MMY-Net | 0.9036 | 0.8322 |
| SMESwin UNet | 0.9066 | 0.8292 |
| Trans MMY-Net (channel trans) | 0.9107 | 0.836 |
| Trans MMY-Net | 0.9141 | 0.8419 |
| Method | mPA | mIoU | mDice |
|---|---|---|---|
| MMY-Net | 0.7891 | 0.6591 | 0.7931 |
| Trans MMY-Net | 0.8065 | 0.6804 | 0.8085 |
| Method | Dice | IoU |
|---|---|---|
| Backbone | 0.8959 | 0.8255 |
| Bottom fusion method | 0.9001 | 0.8253 |
| Input fusion method | 0.9006 | 0.8275 |
| Channel trans fusion method | 0.9075 | 0.8381 |
| Method | Dice | IoU |
|---|---|---|
| No metadata | 0.89589 | 0.82546 |
| Digital quantification method | 0.90745 ↑ | 0.83809 ↑ |
| ELMO | 0.89084 ↓ | 0.81541 ↓ |
| Word2Vec | 0.90133 ↑ | 0.82825 ↑ |
| GloVe | 0.89514 ↓ | 0.81911 ↓ |
| BERT | 0.91073 ↑ | 0.84267 ↑ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rehan, A.M.; Li, K.; Chen, P. Multimodal Pathological Image Segmentation Using the Integration of Trans MMY Net and Patient Metadata. Electronics 2025, 14, 2369. https://doi.org/10.3390/electronics14122369
Rehan AM, Li K, Chen P. Multimodal Pathological Image Segmentation Using the Integration of Trans MMY Net and Patient Metadata. Electronics. 2025; 14(12):2369. https://doi.org/10.3390/electronics14122369
Chicago/Turabian StyleRehan, Ahmed Muhammad, Kun Li, and Ping Chen. 2025. "Multimodal Pathological Image Segmentation Using the Integration of Trans MMY Net and Patient Metadata" Electronics 14, no. 12: 2369. https://doi.org/10.3390/electronics14122369
APA StyleRehan, A. M., Li, K., & Chen, P. (2025). Multimodal Pathological Image Segmentation Using the Integration of Trans MMY Net and Patient Metadata. Electronics, 14(12), 2369. https://doi.org/10.3390/electronics14122369