
AMFFNet: Adaptive Multi-Scale Feature Fusion Network for Urban Image Semantic Segmentation

Abstract
1. Introduction
- Insufficient multi-scale feature representation: Existing methods struggle to comprehensively capture both macro-structures and micro-details in complex urban scenes due to rigid feature extraction mechanisms.
- Static feature fusion strategies: Fixed fusion rules fail to adapt to the dynamic relationships between hierarchical features across scales.
- Weak small-object discrimination: Critical urban elements (e.g., traffic signs and street lamps) are frequently misclassified due to inadequate attention to fine-grained features.
- An Adaptive Multi-scale Feature Fusion Network, termed AMFFNet, is proposed. AMFFNet combines the representational capabilities of the encoder–decoder architecture and attention mechanisms, exhibiting outstanding performance in multi-scale feature extraction and adaptive feature fusion. Our experimental results demonstrate that AMFFNet achieves superior segmentation performance on the CamVid dataset and Cityscapes dataset compared to other segmentation networks.
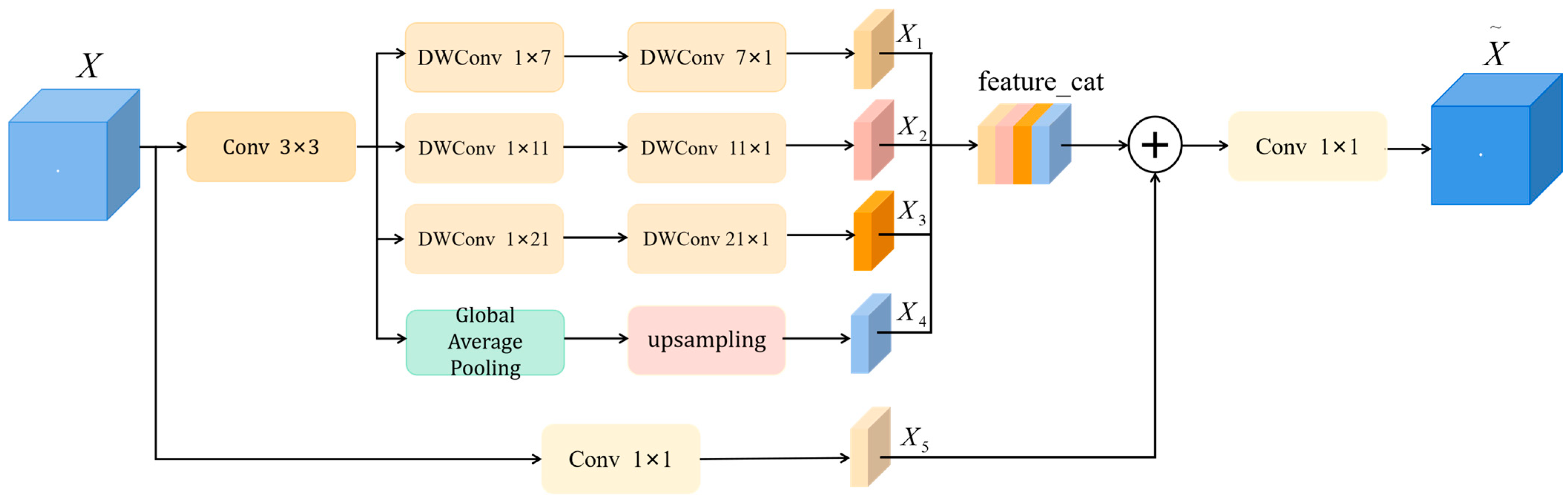
- A Multi-scale Feature Extraction Module (MFEM) is designed, utilizing depthwise strip convolutions and Global Average Pooling (GAP) to enable the network to extract richer multi-scale features and establish a comprehensive cognitive representation of the overall structure and context of the image.
- An Adaptive Feature Fusion Module (AFM) is introduced, which dynamically adjusts the feature fusion strategy to optimize the combination of features across different levels and scales; this design improves the model’s capability to comprehend and segment complex scenes.
- Efficient Channel Attention (ECA) is incorporated, which enhances the learning of useful information in the input image through cross-channel interactions and nonlinear transformations, leading to improved segmentation accuracy for small objects.
2. Related Work
3. Network Model
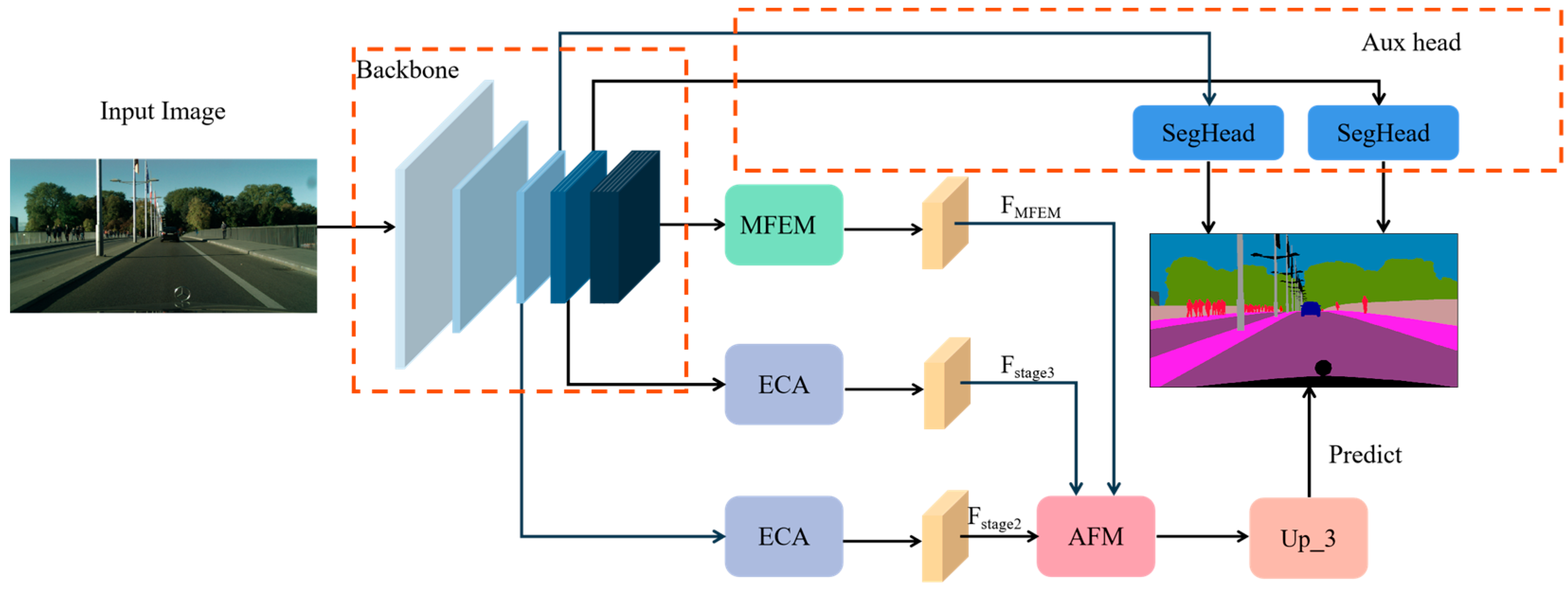
3.1. Overall Network Architecture
3.2. Structure of the Multi-Scale Feature Extraction Module
3.3. Adaptive Feature Fusion Module
3.4. ECA Attention Mechanism
3.5. Auxiliary Supervision Head
4. Experimental Results and Analysis
4.1. Dataset Description
4.1.1. CamVid Dataset
4.1.2. Cityscapes Dataset
4.2. Experimental Settings
4.3. Evaluation Metrics
4.4. Results and Analysis
4.4.1. Comparative Analysis
4.4.2. Ablation Study
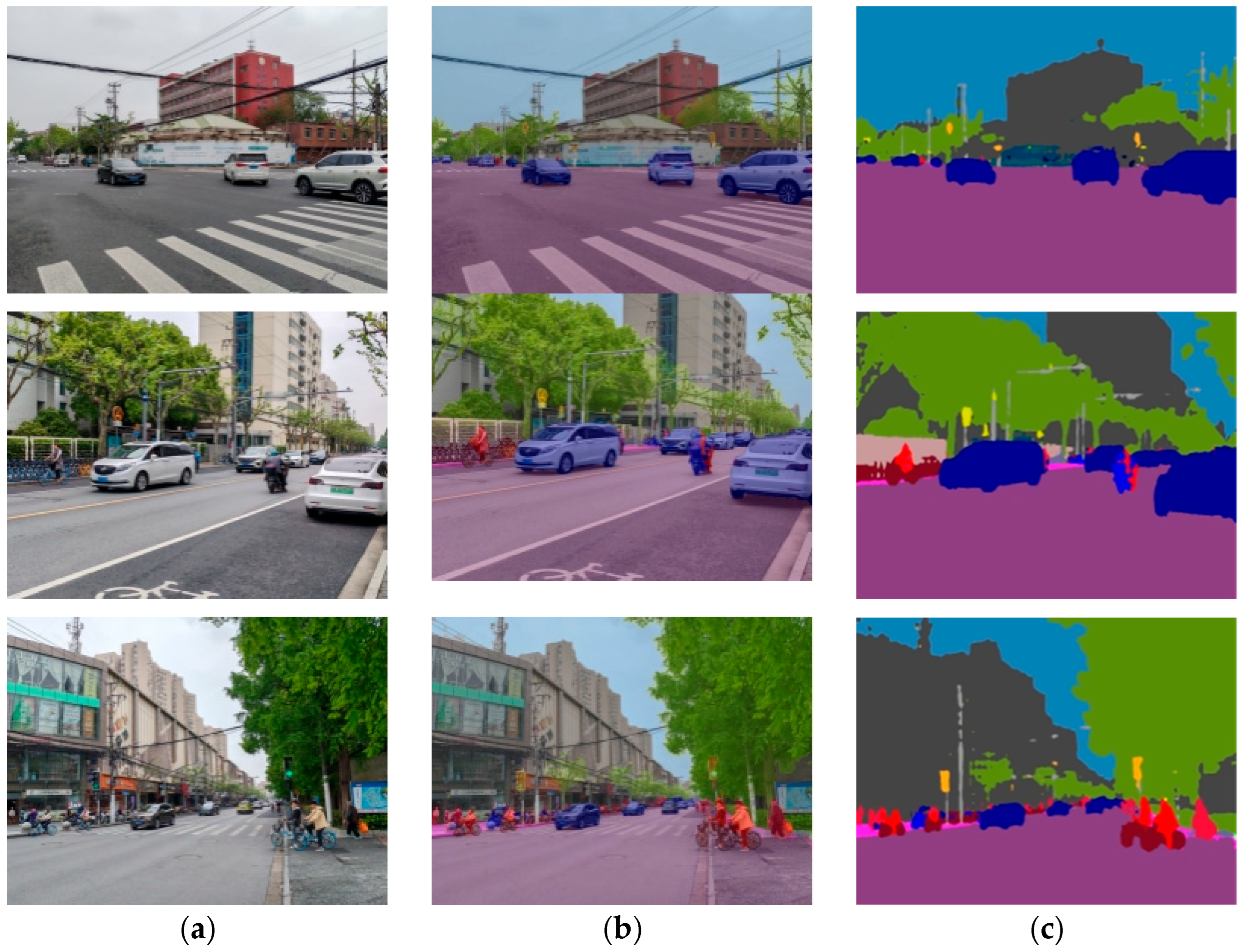
4.4.3. Visual Comparison
4.4.4. Generalization Validation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bardis, G. A Declarative Modeling Framework for Intuitive Multiple Criteria Decision Analysis in a Visual Semantic Urban Planning Environment. Electronics 2024, 13, 4845. [Google Scholar] [CrossRef]
- Zhao, Y.; Wang, L.; Yun, X.; Chai, C.; Liu, Z.; Fan, W.; Luo, X.; Liu, Y.; Qu, X. Enhanced Scene Understanding and Situation Awareness for Autonomous Vehicles Based on Semantic Segmentation. IEEE Trans. Syst. Man Cybern. Syst. 2024, 54, 6537–6549. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, Y.; Han, W.; Chen, X.; Wang, S. Fine Mapping of Hubei Open Pit Mines via a Multi-Branch Global–Local-Feature-Based ConvFormer and a High-Resolution Benchmark. Int. J. Appl. Earth Obs. Geoinf. 2024, 133, 104111. [Google Scholar] [CrossRef]
- Tan, G.; Jin, Y. A Semantic Segmentation Method for Road Sensing Images Based on an Improved PIDNet Model. Electronics 2025, 14, 871. [Google Scholar] [CrossRef]
- Zhang, M.; Liu, C.; Li, Z.; Yin, B. From Convolutional Networks to Vision Transformers: Evolution of Deep Learning in Agricultural Pest and Disease Identification. Agronomy 2025, 15, 1079. [Google Scholar] [CrossRef]
- Xiao, X.; Zhang, J.; Shao, Y.; Liu, J.; Shi, K.; He, C.; Kong, D. Deep Learning-Based Medical Ultrasound Image and Video Segmentation Methods: Overview, Frontiers, and Challenges. Sensors 2025, 25, 2361. [Google Scholar] [CrossRef]
- Duan, Y.; Yang, R.; Zhao, M.; Qi, M.; Peng, S.-L. DAF-UNet: Deformable U-Net with Atrous-Convolution Feature Pyramid for Retinal Vessel Segmentation. Mathematics 2025, 13, 1454. [Google Scholar] [CrossRef]
- Berka, A.; Es-Saady, Y.; Hajji, M.E.; Canals, R.; Hafiane, A. Enhancing DeepLabV3+ for Aerial Image Semantic Segmentation Using Weighted Upsampling. In Proceedings of the 2024 IEEE 12th International Symposium on Signal, Image, Video and Communications (ISIVC), Marrakech, Morocco, 21–23 May 2024; pp. 1–6. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale 2021. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Chen, C.; Zhao, L.; Guo, W.; Yuan, X.; Tan, S.; Hu, J.; Yang, Z.; Wang, S.; Ge, W. FARVNet: A Fast and Accurate Range-View-Based Method for Semantic Segmentation of Point Clouds. Sensors 2025, 25, 2697. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 640–651. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. PointRend: Image Segmentation As Rendering. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9796–9805. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-Contextual Representations for Semantic Segmentation. In Computer Vision—ECCV 2020; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2020; pp. 173–190. ISBN 978-3-030-58538-9. [Google Scholar]
- Arulananth, T.S.; Kuppusamy, P.G.; Ayyasamy, R.K.; Alhashmi, S.M.; Mahalakshmi, M.; Vasanth, K.; Chinnasamy, P. Semantic Segmentation of Urban Environments: Leveraging U-Net Deep Learning Model for Cityscape Image Analysis. PLoS ONE 2024, 19, e0300767. [Google Scholar] [CrossRef]
- Jin, Z.; Dou, F.; Feng, Z.; Zhang, C. BSNet: A Bilateral Real-Time Semantic Segmentation Network Based on Multi-Scale Receptive Fields. J. Vis. Commun. Image Represent. 2024, 102, 104188. [Google Scholar] [CrossRef]
- Nan, G.; Li, H.; Du, H.; Liu, Z.; Wang, M.; Xu, S. A Semantic Segmentation Method Based on AS-Unet++ for Power Remote Sensing of Images. Sensors 2024, 24, 269. [Google Scholar] [CrossRef]
- Tong, X.; Wei, J.; Guo, R.; Yang, C. CSAFNet: Channel Spatial Attention Fusion Network for RGB-T Semantic Segmentation. In Proceedings of the 2022 International Conference on Machine Learning, Cloud Computing and Intelligent Mining (MLCCIM), Xiamen, China, 5–7 August 2022; pp. 339–345. [Google Scholar]
- Liu, J.; Chen, H.; Li, Z.; Gu, H. Multi-Scale Frequency-Spatial Domain Attention Fusion Network for Building Extraction in Remote Sensing Images. Electronics 2024, 13, 4642. [Google Scholar] [CrossRef]
- Wu, L.; Qiu, S.; Chen, Z. Real-Time Semantic Segmentation Network Based on Parallel Atrous Convolution for Short-Term Dense Concatenate and Attention Feature Fusion. J. Real Time Image Proc. 2024, 21, 74. [Google Scholar] [CrossRef]
- Shen, Z.; Wang, J.; Weng, Y.; Pan, Z.; Li, Y.; Wang, J. ECFNet: Efficient Cross-Layer Fusion Network for Real Time RGB-Thermal Urban Scene Parsing. Digit. Signal Process. 2024, 151, 104579. [Google Scholar] [CrossRef]
- Meng, W.; Shan, L.; Ma, S.; Liu, D.; Hu, B. DLNet: A Dual-Level Network with Self- and Cross-Attention for High-Resolution Remote Sensing Segmentation. Remote Sens. 2025, 17, 1119. [Google Scholar] [CrossRef]
- Guo, M.-H.; Lu, C.-Z.; Hou, Q.; Liu, Z.; Cheng, M.-M.; Hu, S.-M. SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation. Adv. Neural Inf. Process. Syst. 2022, 35, 1140–1156. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Honolulu, HI, USA, 2017. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Xiong, P.; Fan, H.; Sun, J. DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9514–9523. [Google Scholar]
- Wu, X.; Wu, Z.; Guo, H.; Ju, L.; Wang, S. DANNet: A One-Stage Domain Adaptation Network for Unsupervised Nighttime Semantic Segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; IEEE: Nashville, TN, USA, 2021; pp. 15764–15773. [Google Scholar]
- Erisen, S. SERNet-Former: Semantic Segmentation by Efficient Residual Network with Attention-Boosting Gates and Attention-Fusion Networks. arXiv 2024, arXiv:2401.15741. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Backbone Network | mIoU (%) |
|---|---|---|
| PSPNet | ResNet-101 | 73.4 |
| DeepLabV3+ | ResNet-50 | 71.7 |
| DFANet | Xception | 75.7 |
| DANNet | ResNet-101 | 76.9 |
| SERNet-Former | EfficientResNet | 84.6 |
| Ours | Dilated ResNet-50 | 77.8 |
| Model | Backbone Network | mIoU (%) |
|---|---|---|
| PSPNet | ResNet-101 | 77.0 |
| DeepLabV3+ | ResNet-50 | 79.2 |
| DFANet | Xception | 70.3 |
| DANNet | ResNet-101 | 79.9 |
| SERNet-Former | EfficientResNet | 87.4 |
| Ours | Dilated ResNet-50 | 81.9 |
| Baseline | MFEM | AFM | ECA | mIoU (%) | mPA (%) |
|---|---|---|---|---|---|
| ✓ | ✗ | ✗ | ✗ | 77.9 | 87.3 |
| ✓ | ✓ | ✗ | ✗ | 79.8 | 88.5 |
| ✓ | ✗ | ✓ | ✗ | 79.0 | 88.4 |
| ✓ | ✗ | ✗ | ✓ | 78.3 | 87.9 |
| ✓ | ✓ | ✓ | ✗ | 81.2 | 89.7 |
| ✓ | ✓ | ✗ | ✓ | 80.8 | 88.5 |
| ✓ | ✗ | ✓ | ✓ | 80.0 | 88.4 |
| ✓ | ✓ | ✓ | ✓ | 81.9 | 90.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, S.; Huang, H. AMFFNet: Adaptive Multi-Scale Feature Fusion Network for Urban Image Semantic Segmentation. Electronics 2025, 14, 2344. https://doi.org/10.3390/electronics14122344
Huang S, Huang H. AMFFNet: Adaptive Multi-Scale Feature Fusion Network for Urban Image Semantic Segmentation. Electronics. 2025; 14(12):2344. https://doi.org/10.3390/electronics14122344
Chicago/Turabian StyleHuang, Shuting, and Haiyan Huang. 2025. "AMFFNet: Adaptive Multi-Scale Feature Fusion Network for Urban Image Semantic Segmentation" Electronics 14, no. 12: 2344. https://doi.org/10.3390/electronics14122344
APA StyleHuang, S., & Huang, H. (2025). AMFFNet: Adaptive Multi-Scale Feature Fusion Network for Urban Image Semantic Segmentation. Electronics, 14(12), 2344. https://doi.org/10.3390/electronics14122344