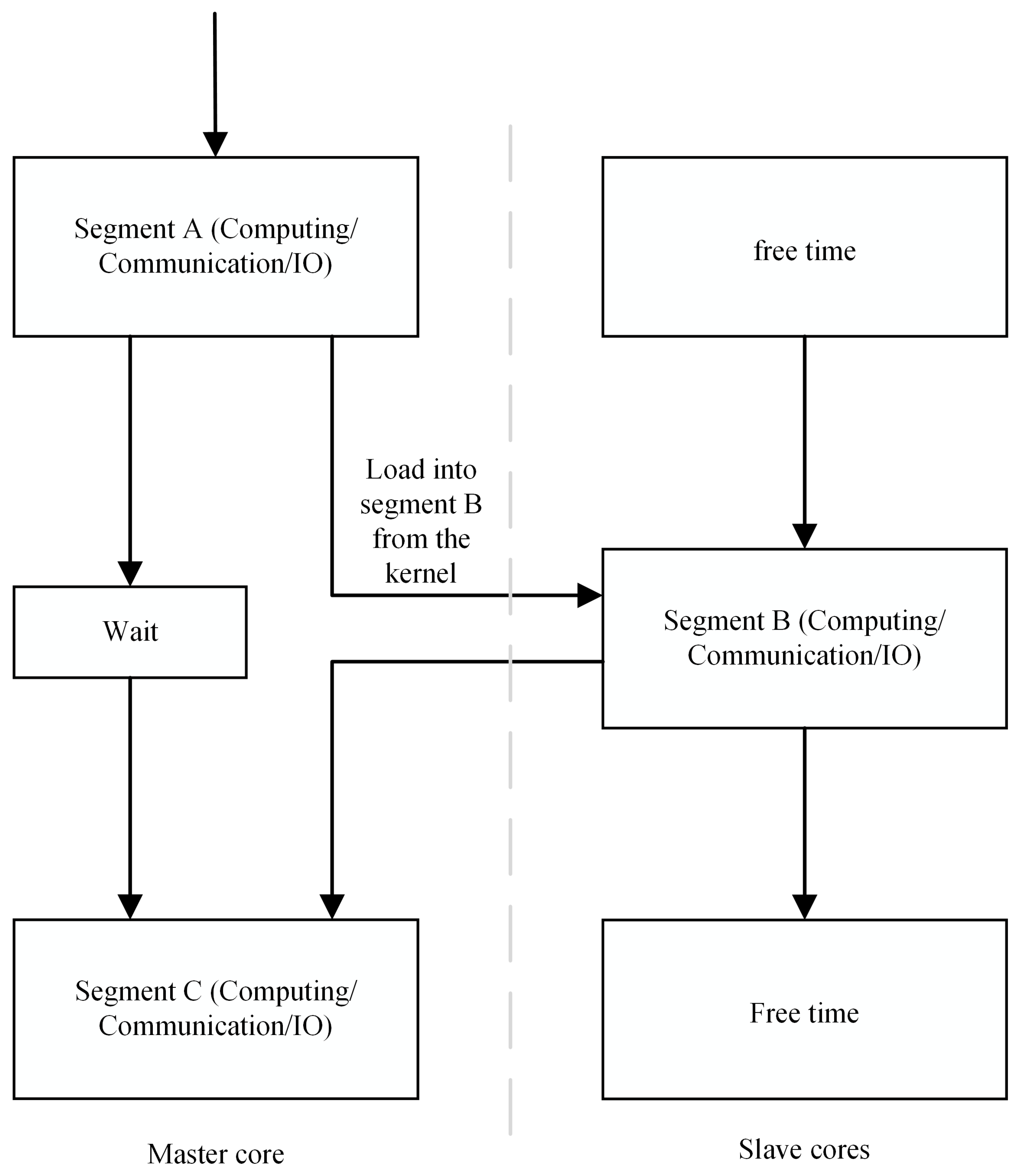
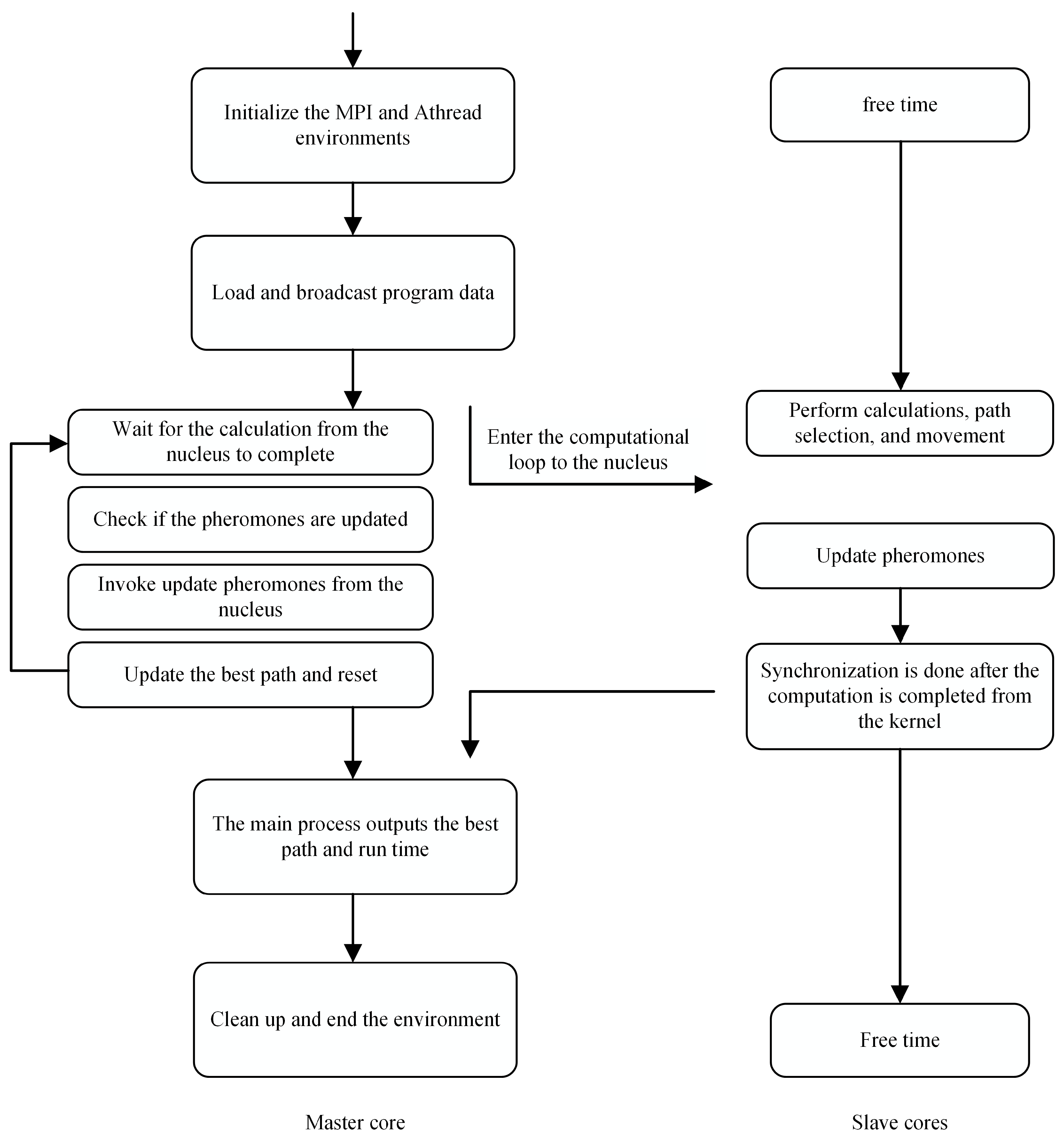
4.2. Performance Test of the Serial Ant Colony Algorithm
In this section, the ACO algorithm is tested on the SW26010 processor using the Eli76, Bier127, Ts225, Pr226, and Pr439 datasets. The number of ant colonies was set equal to the number of cities. Each test was conducted over 100 iterations, with all results derived from 10 independent executions. In all tables of the experimental results, the optimal solution, average solution, average time length, and gap are expressed as Best, Avg, Avg Time, and Gap, respectively. The gap is calculated using the formula (Avg-Hbest)/Hbest, where Hbest represents the optimal solution for the corresponding dataset. The results are shown in
Table 2.
Table 2 shows that as the size of the dataset increases, the running time increases significantly. The Eli76 dataset required the least amount of time at 7.42 s, whereas the largest Pr439 dataset required as much as 5089.03 s. As the size of the dataset increased, the gap also increased. Particularly for large datasets, the ACO algorithm encounters the following problems: Due to limited computing resources, ACO cannot perform enough iterations on large-scale datasets, resulting in an incomplete exploration of the solution search space. In addition, the positive feedback mechanism of pheromones makes the algorithm more prone to getting stuck in local optimal solutions, which further exacerbates the increase in the gap. For instance, the gap of the Ts225 dataset was low, whereas the larger Pr439 dataset exhibited a significant increase in gap to 15.06%, indicating that the ACO algorithm faces greater optimization challenges on large-scale datasets. Therefore, parallel processing was employed to address these challenges.
4.3. Performance Testing of the PACO Algorithm
In this section, the PACO algorithm is tested on the four main cores of the SW26010 processor using the Eli76, Bier127, Ts225, Pr226, and Pr439 datasets. The number of ant colonies was configured to match the number of cities. Each test was performed for 100 iterations. All test results were based on 10 independent runs.
Table 3 lists the running results.
According to the comparison of the data in
Table 2 and
Table 3, when the amount of data is small, the serial ACO and PACO do not significantly differ. As dataset size increases, PACO demonstrates significant advantages over serial ACO in terms of execution time, solution quality, and gap. The solution quality also approaches the historical optimal solution (Hbest). For all datasets, PACO outperforms serial ACO, with the maximum speedup ratio reaching 3.26 and the accuracy rate increasing by a maximum of 6.75%. This not only greatly improves computational efficiency but also effectively improves the accuracy of understanding. In summary, PACO fully leverages parallel computing to significantly optimize the overall performance of the algorithm when processing large-scale datasets.
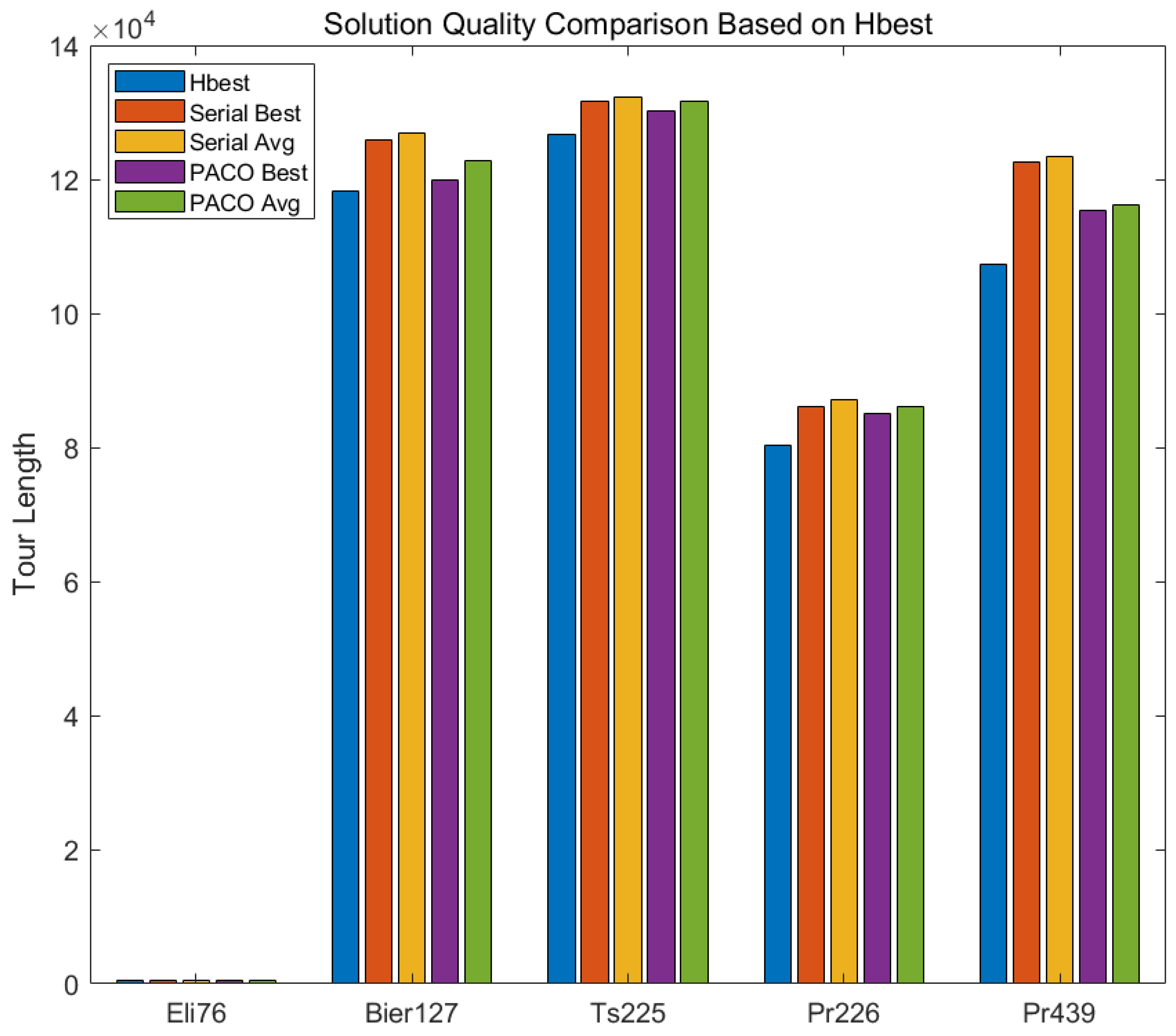
Figure 5 presents a comparison of solution quality between the serial ant colony algorithm (ACO) and the parallel ant colony optimization (PACO) across five TSP datasets: Eli76, Bier127, Ts225, Pr226, and Pr439. The blue bars represent the theoretical optimal solutions (Hbest) and serve as reference benchmarks. The orange and yellow bars correspond to the best and average solutions obtained by the serial ACO, while the purple and green bars represent the best and average solutions achieved by PACO. As shown in the figure, for the small-scale dataset Eli76, both algorithms yield solutions close to Hbest. However, as the problem scale increases—such as in the Bier127 and Ts225 datasets—the best and average solutions from the serial ACO begin to deviate from Hbest, indicating a decline in its search performance. In contrast, PACO maintains smaller deviations and more stable solutions for these medium-sized problems.The difference becomes even more pronounced in the larger datasets Pr226 and Pr439. The serial ACO shows significantly higher deviation from Hbest, while PACO consistently produces solutions that are much closer to the theoretical optimum. Especially in large-scale scenarios, PACO not only improves solution quality but also significantly reduces computation time.
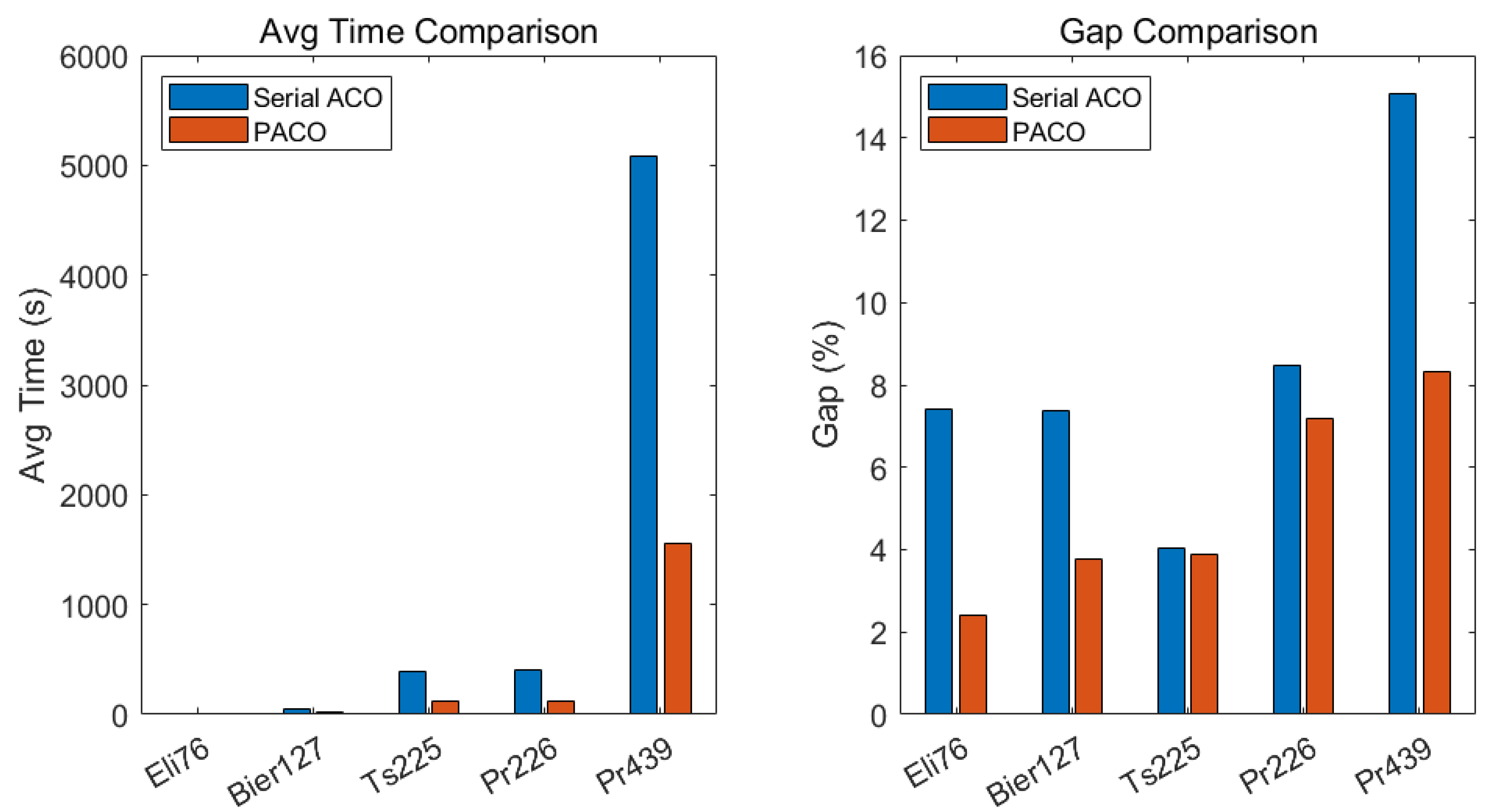
Figure 6 shows a comparison of the average time and gap between ACO and PACO under identical experimental conditions. Compared with the serial ant colony algorithm, the ACO algorithm using MPI parallelism exhibited a more significant trend in running time, and the quality of the solution was higher. The running time is significantly reduced on large-scale datasets, with an average increase of approximately 3 times. In addition, the solution quality is improved, and the gap is significantly reduced. Particularly on larger datasets, such as Pr439, PACO demonstrated a stronger advantage.
In addition, tests were conducted on the Pr439, Pr1002, Pla7397, Fnl4461, Brd14051, D18512, Pla33810, and Pla85900 large-scale datasets, which produced favorable outcomes.
Table 4 lists the run results of these tests.
Table 4 shows that as the amount of data increases, the quality of the PACO algorithm’s solution significantly decreases, whereas the running time gradually increases. For the very large-scale datasets, Pla7397, D18512, Pla33810, and Pla85900, the gap between the solution quality of the PACO algorithm and the historical optimal solution (the difference between Avg and Hbest) became more pronounced. For large-scale datasets, such as Pla33810 and Pla85900, the running time of the PACO algorithm approaches two hours or even longer. In particular, for the Brd14051 and Fnl4461 datasets, the gap reached 15.16% and 13.27%, respectively.
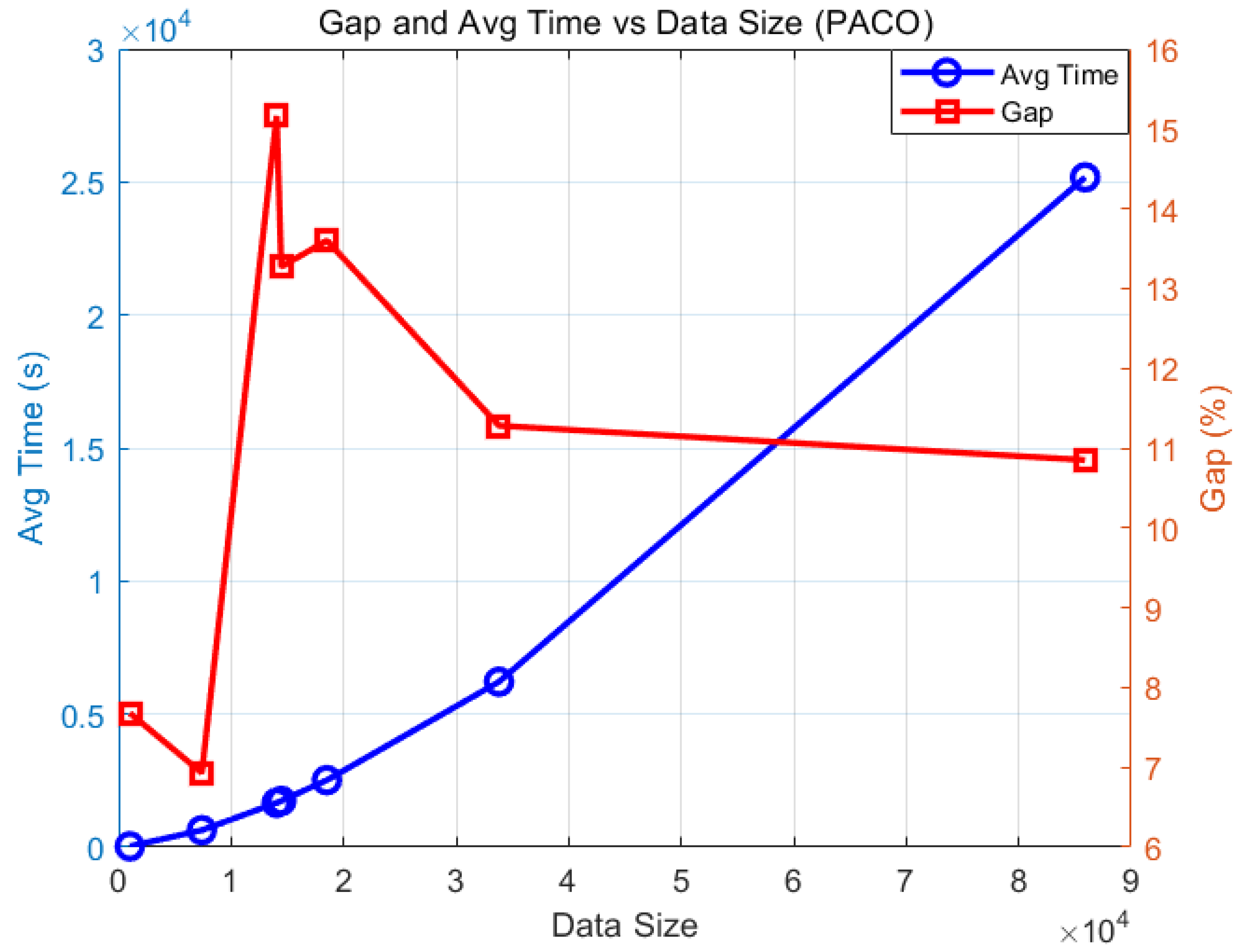
As shown in
Figure 7, as the amount of data increases, the gap of PACO exhibits a fluctuating trend. The gap showed an upward trend when the dataset size was small, then decreased after reaching a certain size; however, it always remained above 10% and exhibited large fluctuations. This is particularly evident in the Brd14051 dataset, where the gap reaches 15.16%. Due to the ultra-large scale and asymmetric structure of the dataset, the stability of the algorithm’s performance is affected, resulting in a sharp increase in the solution gap and noticeable fluctuations. In contrast, the gaps in the Pr1002 and Pla7397 datasets are relatively low, at 7.68% and 6.93%, respectively, indicating better stability of the algorithm on medium-scale symmetric problems. For the Fnl4461 and D18512 datasets, the gap rises to around 13%, reflecting a decline in solution quality as the problem scale increases. However, in the ultra-large-scale symmetric datasets Pla33810 and Pla85900, the gap drops back to around 11%, suggesting that PACO still maintains a certain level of robustness in large-scale problems with regular structure.
Overall, as the dataset size increases, the PACO algorithm faces growing challenges in maintaining high solution quality, especially in large-scale or asymmetric instances where performance tends to fluctuate more significantly. Concurrently, the running time significantly increases with larger dataset sizes, and the general trend is positively correlated with the amount of data. For instance, when the dataset increased from 1002 to 7397, the running time increased by approximately 1905.64%, and when the dataset increased from 7397 to 14,051, the running time increased by approximately 161.80%. Although the increase was only 4.41% for some medium-sized datasets (such as 14,051–14,461), the running time increased significantly again for larger-scale datasets (such as 33,810–855,900), with an increase of approximately 304.97%.
These findings demonstrate that pure MPI parallelism can no longer effectively solve the dual problems of computational efficiency and solution quality. The scalability of the PACO algorithm is limited when handling large-scale problems. To enhance its performance on large-scale datasets, this work introduces a hybrid parallelism mode aimed at optimizing algorithm efficiency and solution quality, thereby improving its capacity to address the challenges posed by large-scale data.
4.4. Performance Testing of the SWACO Algorithm
In this section, the performance test of the SWACO algorithm on the four cores of the SW26010 processor is compared with that of the previous PACO algorithm. The test datasets used include Pr1002, Pla7397, Fnl4461, Brd14051, D18512, Pla33810, and Pla85900, which further evaluate the performance of the algorithm on large-scale problems.
Table 5 lists the run results.
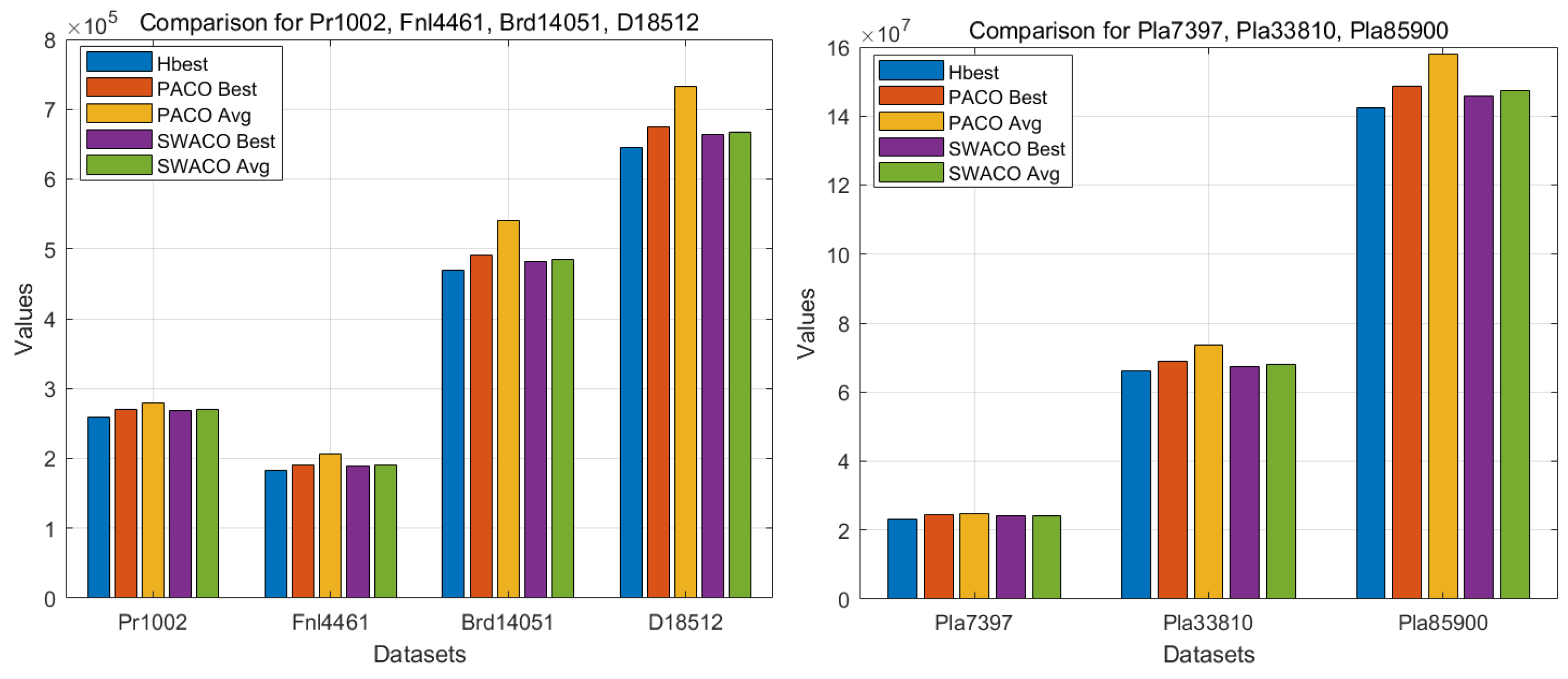
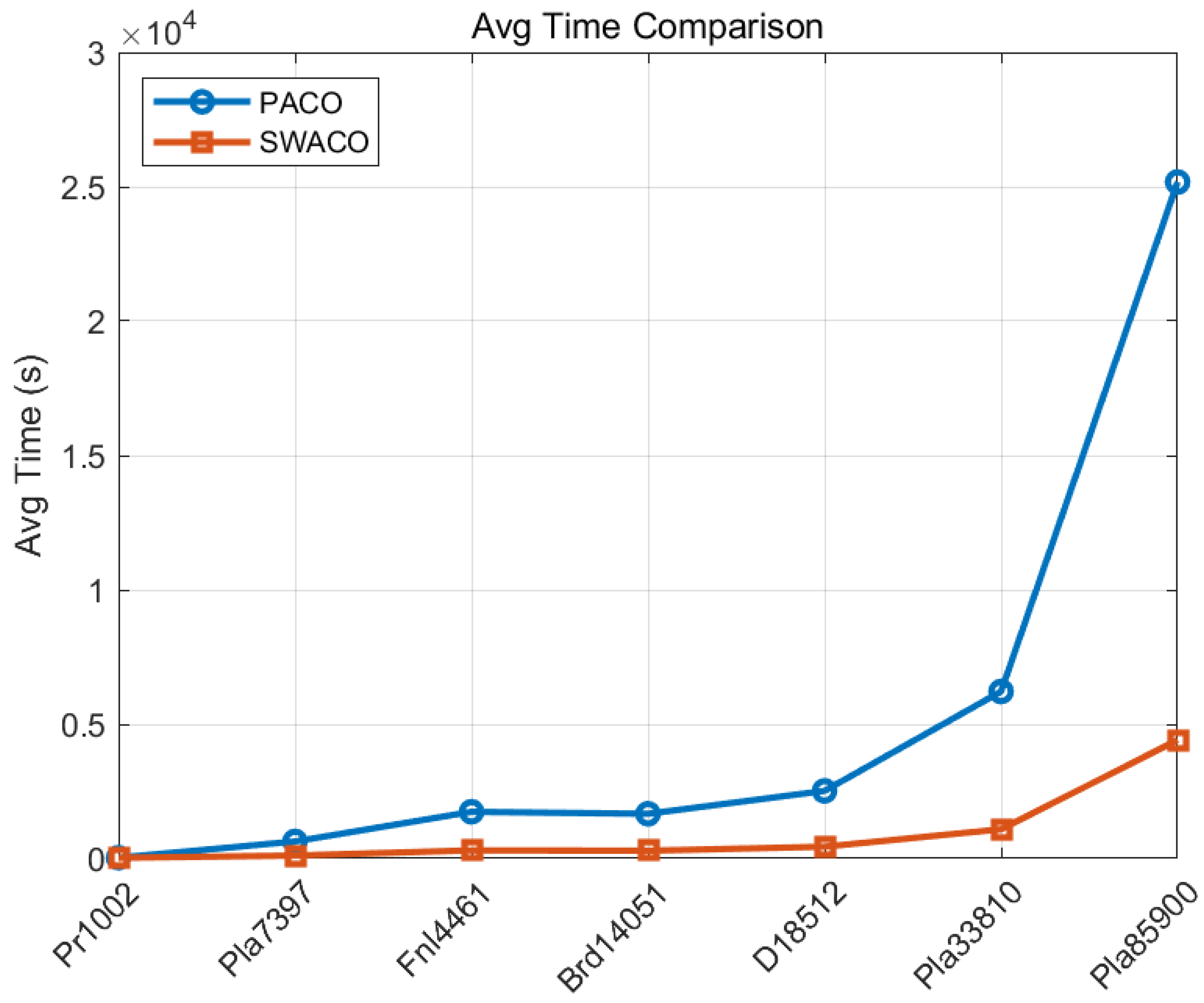
Table 4 and
Table 5 indicate that, across all datasets, SWACO’s best solution outperforms PACO’s, exhibits a faster convergence speed, and significantly reduces the gap. As the dataset size increases, the advantages of the SWACO algorithm become more evident. In particular, when processing the Pla33810 and Pla85900 datasets, the running time is significantly reduced, and the solution quality is improved compared with that of the PACO algorithm.
Since the results of the Pr1002, Fnl4461, Brd14051, and D18512 datasets are not on the same scale as those of the other three datasets, the comparison of the Best and AVG values of the PACO and SWACO algorithms will be presented using two separate bar charts. A comparison of the results in
Figure 8 shows that, compared with the PACO algorithm, the SWACO algorithm demonstrates higher solution quality, especially in a multicore environment. The SWACO algorithm can make full use of the advantages of multicore parallel computing to improve the efficiency of large-scale problems.
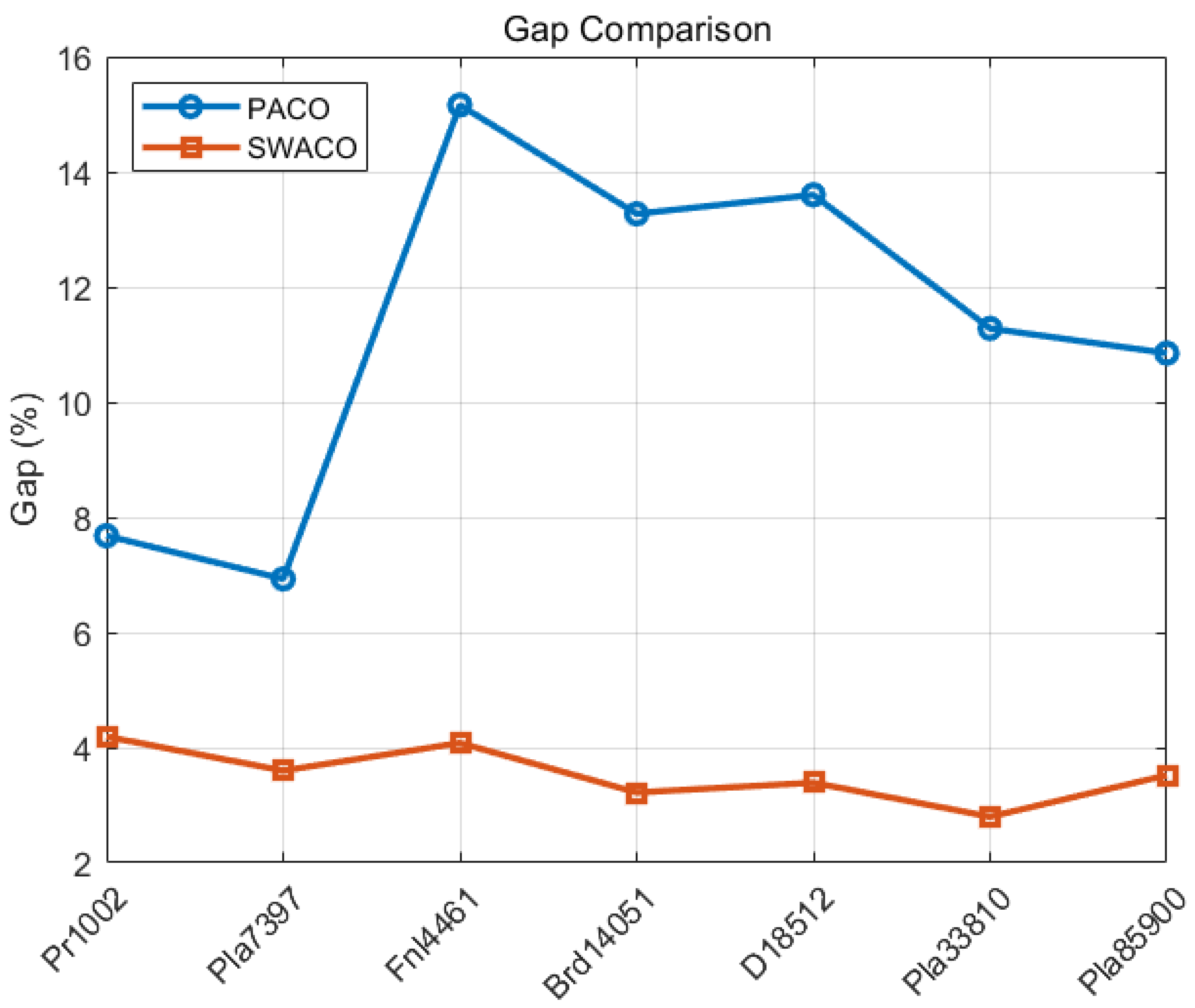
As shown in
Figure 9, the quality of the optimal solution using the hybrid model on large datasets is far greater than that of PACO, with the average errors all within 5%. This difference becomes increasingly obvious as the scale expands. As shown in
Figure 10, the algorithm using the second level of parallelism demonstrates excellent performance. Compared with the traditional algorithm that uses only the first level of parallelism, the use of Athread to accelerate the fitness calculation results in a maximum increase in a running time of 5.72 times. The algorithm achieves better acceleration performance.
The abovementioned experimental findings indicate that by using multistrategy parallelism in path calculation and pheromone updates, the SWACO algorithm demonstrates its superiority in solving large-scale problems. Relative to the serial ACO and PACO algorithms, the SWACO algorithm showed better solving ability on large-scale datasets, further validating the advantages of the multistrategy parallel adaptive method in a massively parallel computing environment.
4.5. Comparative Experiment of SWACO and Other Algorithms
To further demonstrate the effectiveness of the SWACO algorithm, this section compares it with the Genetic Algorithm (GA) and Simulated Annealing Algorithm (SA), which are widely used in solving the Traveling Salesman Problem (TSP), as well as with the ACO-ABC [
29] and PACO-3Opt [
30] algorithms reported in the other literature.The parameter settings for the GA and SA in the experiments were based on References [
31,
32]. The specific experimental results are shown in
Table 6.
From
Table 6, it can be seen that the SWACO algorithm demonstrates the best solution quality and stability across various TSP instances. Its average gap (
) is the lowest among all the compared data, such as 0% for Berlin52, and 0.04% and 0.13% for Eil51 and KroA100, respectively. The optimal solutions often coincide with theoretical values, indicating that its solutions are very close to the optimum. In contrast, the GA and SA perform poorly, with significantly higher average gaps, especially on Pr226, where they reach 402.83% and 416.68%, respectively. They also show instability on other dataset scales, reflecting poorer solution quality and robustness compared to SWACO. The ACO-ABC algorithm performs well on the Berlin52 dataset with an average gap of 0.03%, close to SWACO’s level, but its overall results are relatively higher. Although PACO-3Opt achieves better optimal solutions on Eil51 and Berlin52, the gap between average and optimal solutions is large; for example, the average gap is 0.34% on Eil76 and 0.21% on KroA100, showing less stability. In summary, SWACO not only outperforms other algorithms comprehensively in solution quality and stability but also achieves optimal or near-optimal levels on multiple datasets.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}