1. Introduction
Automatic text summarization is an essential application of natural language processing (NLP). It involves generating concise yet informative summaries from large text corpora. There are two types, extractive summarization, which selects meaningful sentences based on token frequency, and abstractive summarization, which synthesizes or understands the text. Low-resource languages, such as Urdu, face numerous challenges compared to their high-resource counterparts, like English, which has experienced significant advancements. One major hurdle is the lack of high-quality annotated datasets. This complication arises in low-resource languages, where limited training data hinders the creation of helpful summarization models. Despite recent advances in language modeling and generative artificial intelligence, few pre-trained language models can cater to the needs of these languages [
1,
2,
3,
4,
5,
6,
7]. Approximately 230 million people speak Urdu worldwide. It is a morphologically rich language, with a syntactic structure that is significantly different from English. Although it has many speakers, the language lacks extensive NLP resources, which pose additional challenges for researchers aiming to develop high-quality models for several downstream tasks, including abstractive text summarization. Legal text written in Urdu adds another layer of difficulty due to the domain-specific linguistic nuances of the language. Applicable legal text summarization is crucial for enhancing access to legal information, for streamlining document management, and for facilitating informed decision-making within a national judicial system. However, progress in this area is limited by the lack of annotated datasets and specialized language models adapted to the legal domain.
1.1. Multilingual Models and Their Role in Low-Resource NLP
Transformer-based multilingual models have recently emerged as an alternative solution for low-resource language applications. The mBART [
8,
9] and the mT5 [
10] models have been trained on various general purpose textual corpora and shown strong cross-lingual transfer capabilities. To learn shared knowledge representation, these models have been trained on massive textual corpora from multiple languages. This new training process has significantly improved the performance of these multilingual models compared to their monolingual versions in various downstream applications, including abstractive text summarization with enhanced fluency and coherence. Several research studies have reported their significant performance in low-resource languages. Munaf et al. [
11] fine-tuned the mT5 and its variants with specific modifications on the Urdu news summarization dataset, demonstrating ROUGE scores of up to 46.35, a significant improvement compared to high-resource language summarization. Similarly, Awais and Nawab [
12] evaluated various sequence-to-sequence architectures, including transformer-based models such as mBART and GPT-3.5 [
13]. Notably, their GRU model with attention achieved a ROUGE score of 48.7, demonstrating significant improvements over conventional seq-to-seq baselines.
1.2. Challenges and Research Gaps
Despite their widespread success over the last five years in low-resource applications, significant challenges persist in enhancing the capabilities of LLMs, particularly within their multilingual variants, where domain adaptation remains the most critical area for improvement. Pre-trained transformer-based models are typically trained on massive corpora comprising Wikipedia, news, and general texts, often failing to capture the domain-specific knowledge and complexities embedded in legal documents [
14]. Refining those models using domain-specific data through further fine-tuning can significantly enhance their performance in specific domains, such as legal text summarization, offering a valuable opportunity for researchers. Data scarcity is another challenge in this context, as even the most advanced architecture requires substantial, high-quality annotated data. Despite significant efforts in developing NLP resources for Urdu, the task of the abstractive summarization of legal texts remains underexplored. The unavailability of standardized benchmarks worsens the problem and hinders the evaluation and comparison of the efficacy of different summarization approaches. Traditional automatic metrics, like ROUGE [
15] and BLEU [
16] come with certain limitations. ROUGE focuses on n-gram overlaps with reference summaries, emphasizing recall, whereas BLEU was initially designed for machine translation, and emphasizes n-gram precision. Both metrics tend to underrepresent the quality of summaries that feature valid or alternative paraphrasing structures, which are common in abstractive text generation. For recently developed models that generate more diverse outputs, evaluation based solely on lexical overlap becomes inadequate for accurately assessing the quality of summaries. To overcome these limitations, researchers have developed newer metrics, such as BERTScore [
17] which utilizes contextual embedding to assess the semantic similarities between reference and generated text, and MoverScore [
18], which evaluates word distribution alignment. However, all these models become ineffective at capturing the quality of summaries in Urdu, or any other language with more complex morphology. So, fluency, coherence, factual consistency, and quality can be assessed and improved, all while maintaining human [
19] evaluation in the loop.
1.3. Objectives of This Study
This study aims to solve the problems mentioned earlier by optimizing the advanced multilingual pretrained LLMs, mBART [
8,
9] and mT5 [
10], for the task of the abstractive text summarization of Urdu legal text. This research has evaluated multiple models using various training configurations to identify the optimal method. The following are the key objectives of this research:
Develop a curated dataset of Urdu legal texts and human-written summaries.
Develop a fine-tuned abstractive summarization model for Urdu legal documents using pre-trained multilingual LLMs for adopting domain-specific legal text, terminologies, and structure.
Evaluate different training schemes and configurations to accomplish optimal performance and generate fluent, coherent, and contextually correct summaries.
Assess the efficacy of the transformer-based multilingual model for handling Urdu legal texts compared to the other recent studies for the same problem.
Establish a benchmark for future Urdu legal text summarization research by reporting model performance through standard evaluation metrics and qualitative assessments.
This study contributes to the broader goal of making NLP tools more inclusive and accessible for under-resourced languages by targeting the objectives outlined above. The outcomes will enhance the quality of legal text summarization written in Urdu and give insights into adapting the multilingual model for other domains and languages. It will pave the way for more robust, domain-adapted solutions that can be applied to other specialized domains and languages with limited resources.
The remainder of this paper is structured as follows:
Section 2 reviews the related work on legal text summarization and multilingual modeling in low-resource settings;
Section 3 describes the dataset construction, preprocessing steps, model training strategies, and evaluation setup;
Section 4 details the experiments and the model learning curve impact of the training choices;
Section 5 presents and discusses the results; finally,
Section 6 concludes the paper, discusses the limitations, and outlines directions for future work.
2. Literature Review
The area of NLP has witnessed significant growth in recent years in every single downstream task, including text summarization techniques, especially in high-resource languages, such as English. However, low-resource languages, such as Urdu, continue to lag behind their high-resource counterparts, primarily due to the lack of annotated datasets and domain-specific pre-trained models. This section explores the progression of abstractive text summarization, the challenges and progress in low-resource language processing, the emergence of multilingual large language models, and the issues associated with summarizing legal documents in Urdu.
2.1. Abstractive Text Summarization
The early research has focused on rule-based and statistical methods, which were directly dependent on handcrafted linguistic templates, rules, and restricted their usage across diverse domains [
20]. Statistical methods, such as TF–IDF (term frequency–inverse document frequency) [
21] and latent semantic analysis (LSA) [
22] utilized term frequency and co-occurrence patterns to extract vital information. This era worked as a solid foundation for automatic text summarization. Still, their output lacked contextual coherence because they relied on a shallow understanding of the text rather than a semantic and deeper understanding [
23,
24].
The advent of deep learning ideas transformed the field of NLP, including text summarization, with a significant paradigm shift. Sutskever [
25] proposed the Seq2Seq model, which happened to be a pivotal shift from rule-based and statistical methods to neural methodologies. They leveraged the idea of RNN and LSTM [
26] to transform the input text sequence into a fixed-length vector for the source, and then to decode the vector into the target summary. This facilitated the transformation of a complete source input text into a compressed representation, which was later decoded into a summary. However, a fundamental limitation of traditional Seq2Seq models is their inability to efficiently manage long-range dependencies, often resulting in recurring, incoherent, or partial output, especially for longer documents.
Bahdanau et al. [
27] introduced the attention mechanism to overcome the limitations of the sequence-to-sequence model, which enables the decoder to focus only on the most relevant parts of the input sequence at each step of generating output, thereby enhancing the quality of summaries by better managing long-range dependencies. The introduction of transformers by [
28] brought fundamental changes to basic methodologies, primarily affecting abstractive text summarization tasks. Transformers have eliminated recurrence through their self-attention mechanism that processes long dependencies to achieve greater efficiency and parallel performance benefits compared to traditional sequential models.
Devlin et al. [
29] developed methods that served as frameworks to advance summarization tasks. Summarization models benefited significantly from BERTSUM, which leveraged BERT’s bidirectional representations to improve both an extractive and abstractive summarization performance [
30]. Lewis et al. [
31] proposed BART, a denoising autoencoder capable of learning from corrupted inputs, which improved abstraction quality and output fluency. Raffel et al. [
32] introduced T5, a text-to-text framework for summarization while achieving the best performance on multiple summarization evaluation benchmarks.
Transformer models have demonstrated their ability to achieve optimal performance, leading to a new era of abstractive summarization research and reducing automation gaps. Research and development for factual hallucinations and coherence, alongside limitations in evaluation metrics, remain vital active areas of investigation [
19,
33,
34,
35].
2.2. Multilingual Models and Low-Resource Languages
Multilingual language models have recently revolutionized traditional approaches to addressing low-resource languages. These models were initially trained on high-resource languages, such as English, and subsequently expanded to include training in many other low-resource languages, thereby making them more practical for managing resource-deficient languages. In 2021, mBART [
9] was initially trained on datasets covering 25 languages. It was later expanded to support an extra 25 languages, enabling it to summarize, translate, and generate text across all these languages. Similarly, the mT5 expanded this training to 101 languages, offering greater linguistic versatility [
10].
Despite significant advancements in NLP, languages like Urdu remain intriguing to researchers. It is a morphologically rich and complex language, making it complicated to achieve different downstream tasks. However, a major issue is the lack of datasets for training and further fine-tuning models, as even the most advanced models heavily depend on high-quality, annotated, and extensive data to perform effectively. Since resources for Urdu and many similar languages are unavailable, these models must be trained to handle linguistic complexities with minimal data. The latest research studies have tried to address the limitations mentioned above. Hasan et al. [
3] developed XLSUM, a multilingual summarization dataset covering 44 languages, including Urdu. They fine-tuned it on the mT5 for a dataset and established its ability to produce fluent and contextually aware summaries. Likewise, Awais et al. [
12] created a dataset of approximately two million Urdu news articles for summarization purposes. They fine-tuned mBART and GPT-3.5, achieving results of ROUGE-1 = 46.7, ROUGE-2 = 24.1, and ROUGE-L = 48.7, which outperformed those of conventional methods and adapted well to Urdu’s linguistic nuances.
Another considerable effort resulted in the development of urT5, a particular version of the mT5 trained on the Urdu news article summaries dataset. This variant has shown ROUGE-1 scores of 46.35 and BERT scores of 77, which are comparable to established English language benchmarks, such as PEGASUS (47.21) and BART (45.14), as reported by [
11]. Research has shown that fine-tuning multilingual models, such as the mT5, can significantly enhance the summarization capabilities across various languages, including Arabic [
36]. The mT5 architecture has been effective in managing low-resource textual data [
37]. As another effort to improve under-resourced languages, advancements in deep learning for summarization highlight the broader impact of multilingual models, accelerating improvements across multiple languages within a single framework [
7]. These findings collectively emphasize the impact of multilingual and domain-adaptive approaches in refining summarization methodologies and enhancing content representation across varied linguistic contexts.
Future research directions for underrepresented languages, such as Urdu, include data augmentation, domain-aware fine-tuning methods, and evaluation frameworks for accurately capturing semantic fidelity and factuality.
2.3. Legal Text Summarization: Challenges and Developments
Summarizing legal documents is more challenging due to the intricacies of legal terminology, accuracy requirements, and the potential risk of misinterpreting the contents. Legal texts often feature specialized vocabulary, formal tone, and complex syntax, which contribute to their length and semantic density. These characteristics of the language, particularly the legal aspects, make it highly challenging for a model to generate high-quality summaries. Furthermore, legal documents often include references to statutes, precedents, case law, and supporting materials, which necessitate models that extend beyond a rudimentary understanding of the text and establish connections across various legal concepts.
Based on the above discussion, summarizing such documents remains a formidable task; however, considerable progress has been made in the English language. Sethi et al. [
38] demonstrated the effectiveness of deep learning-based approaches in producing legal summaries, showing enhanced summary quality compared to earlier methods. Similarly, Moro and Ragazzi [
39] proposed novel techniques for summarizing lengthy documents using neural architecture, and established a new performance benchmark, highlighting the capacity of modern NLP models in legal discourse.
Bajaj et al. [
40] explored summarizing a lengthy legal brief using pre-trained models, such as BART, and employing key sentence selection strategies, which resulted in a notable ROUGE-L = 23.95 performance. Building upon the strengths of extractive and abstractive paradigms, Moro and Ragazzi [
39] proposed a hybrid approach that leverages transfer learning to establish a new performance benchmark. In the context of the Indian legal system, Ghosh et al. [
41] investigated the effectiveness of state-of-the-art (SOTA) models, including BART and PEGASUS, utilizing text normalization-based approaches to enhance the coherence and legal accuracy of summary generation. This work evaluated the models based on feedback from domain experts and utilized ROUGE metrics, further validating the practical relevance of their approach, and indicating significant advancements in the field of legal text summarization techniques. All these studies highlight the growing success of transformer-based models in the legal domain, yet in high-resource settings.
While such developments have occurred in the high-resource languages, there has been insufficient work in legal summarization in low-resource languages. Due to the scarcity of annotated datasets specific to legal contexts, it becomes challenging to summarize texts accurately in languages like Urdu. As Elaraby and Litman [
42] emphasized the importance of argument mining in legal summarization, arguing that the argumentative structures within legal texts, such as claims and premises, can significantly enhance summarization results. Yet legal document processing remains difficult in low-resource settings, a problem to be solved that directly impacts equitable progress on the broader task of legal text processing for various languages and environments [
43,
44,
45] proposed an argument mining-based approach for summarizing legal case texts by extracting structured triples (issue, reason, conclusion). They emphasized the importance of annotated training data tailored to the legal domain and highlighted challenges in building high-quality datasets for effective summarization. Empirical studies, such as the study by Raza and Shahzad [
46] have provided curated datasets for Urdu text summarization. These studies apply to general or news domains, but not to the legal domain. This incoherence hinders the progress of models for solving the distinct complexity of Urdu language text used for law.
Researchers struggle to perform legal text summarization in low-resource languages, despite achieving key advancements in English. Research progress should focus on establishing high-quality annotated legal documents and developing summary systems that display versatility across various linguistic structures. According to [
14,
47], the establishment of these core initiatives enables NLP techniques to penetrate underrepresented languages and legal domains.
Several research recommendations exist to improve legal text summarization approaches for low-resource languages.
Domain Adaptation enables multilingual pre-trained language models to acquire proficiency in the legal domain by applying fine-tuning techniques to specialized legal document collections, which helps them identify complex legal terminologies. Thus, this method needs cooperation between legal experts and institutions to establish an official legal dataset specifically for the targeted language.
Data augmentation methods, such as back-translation and paraphrasing, enable researchers to produce synthetic data that improves the availability of their limited datasets. Applying large language models in text rephrasing demonstrates a strong ability to enhance data quality for legal text summarization tasks.
Evaluation Metrics: The conventional ROUGE metric and other traditional evaluation methods are inadequate for assessing the quality level of generated text. The research requires new quantitative assessment methods to measure how consistently the system reproduces information, as well as its factual accuracy and relevance.
Ethical Considerations: The primary moral concern is protecting the accuracy of legal content in automated summaries. Model developers must build unbiased systems that further block the spread of discriminatory properties within training datasets. The disclosure of methods used by models in decision-making helps users develop confidence in system operations. Strategic research and cooperation will enable developers to create functional legal text summarization solutions for low-resource language domains, thereby improving legal accessibility and efficiency.
3. The Proposed Methodology
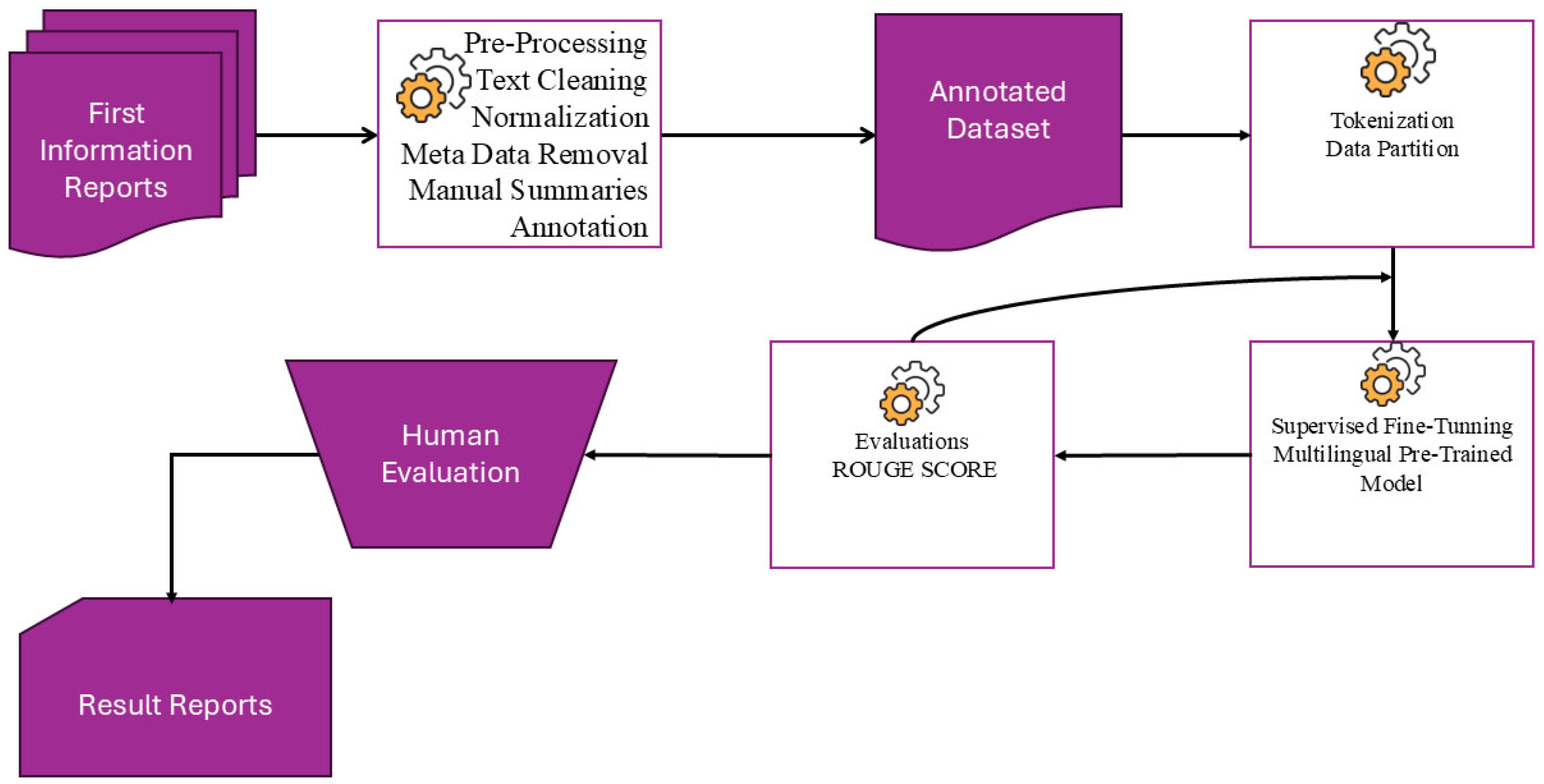
We have developed a systematic framework for creating abstractive summarization systems that manage Urdu legal text documents, as shown in
Figure 1. The first step involved data collection for the first information report (FIR). Later, we undertook extensive linguistic pre-processing, which included multiple stages of cleaning, normalization, and tokenization procedures to efficiently handle the specificities of legal language. The dataset was divided into distinct partitions for training, validation, and testing to achieve uniform distribution among legal documentation categories. State-of-the-art multilingual transformer models, namely the mBART and the mT5, along with their variants, Base, Small, and Large, were fine-tuned with optimal training hyperparameters tailored to our summarization task.
We have assessed the model using quantitative evaluation metrics, using ROUGE, which measures reference-based n-gram overlaps between generated and reference summaries. It has been further enhanced through qualitative evaluation by human experts, who assessed the coherence and fluency of the generated summaries. The dual evaluation process gave an in-depth assessment of how well each model generated legal text summaries.
3.1. Data Collection
This study utilizes a curated set of Urdu legal documents sourced from the Islamabad Police Department, with a specific focus on the FIR. These documents are rich in legal terminology, procedural language, and case-specific details, making them well-suited for training domain-adapted summarization models. Acquiring such data presented several challenges, including the lack of structured, publicly available Urdu legal corpora, access restrictions due to confidentiality laws, inconsistent document formatting, and the absence of reference summaries. To address these issues, we collected data from legally permissible sources and developed a standardized annotation protocol in collaboration with domain experts. This involved the manual removal of personal identifiers, format normalization, and the creation of gold-standard summaries by trained legal professionals. The resulting corpus is legally compliant, diverse, and representative of real-world Urdu legal cases. It provides a strong foundation for fine-tuning multilingual transformer models in a low-resource, domain-specific context.
3.2. Data Pre-Processing
A comprehensive pre-processing procedure was followed before fine-tuning began because legal text is challenging and requires precise accuracy.
3.2.1. Text Cleaning and Normalization
The text pre-processing procedure first handled standardization tasks by normalizing Urdu text elements. The additional metadata components and textual footnotes were removed, while unnecessary symbols were eliminated from the raw data.
3.2.2. Human-Generated Summaries
Legal professionals and native speakers used the FIRs to create manual summaries for each FIR. Legal professionals adhered to established rules during summarization to ensure the accuracy of facts and the precision of legal language in the summaries they produced. These summaries aimed to present vital case content while keeping them direct and flowing from one to another. Each summary received multiple reviews from peer experts whose main task was to verify its legal accuracy and consistency. The validated summaries from the experts were incorporated into the dataset to facilitate model optimization and evaluation processes.
3.2.3. Tokenization and Sentence Segmentation
Tokenization and sentence segmentation employ word-level approaches combined with sub-word methods, utilizing Sentence-Piece [
48] (for the mT5) and Byte-Pair Encoding (BPE) [
49] for the mBART as shown in
Figure 2 below. The detection method for sentence boundaries considers the distinct structure of legal Urdu texts, which often contain lengthy clauses within each sentence.
3.2.4. Managing Legal Terminologies
Terminology mapping was employed to ensure that key legal concepts remained intact while generating summaries. The need for summaries to maintain technical precision, conciseness, and clarity, which is particularly important for legal texts compared to general texts, necessitated these steps to structure and clean the dataset.
3.3. Dataset Overview and Statistical Analysis
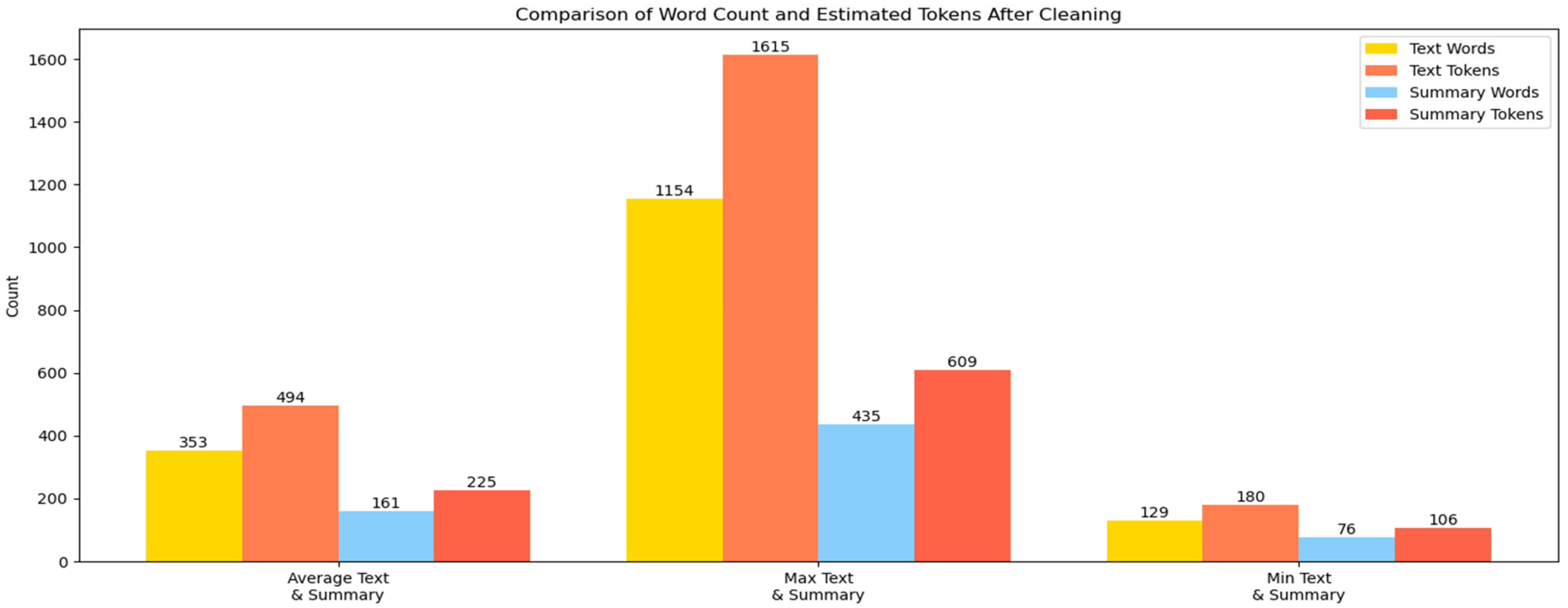
This research paper has utilized 1209 legal documents as shown in
Figure 3, which contain complete source material and summarization sections. A thorough statistical examination of the corpus shows essential information about its structural characteristics and complexities that could affect summary model training. On average, the text length is 1811.13 characters, while the summary length is 769.2 characters, indicating that the summaries are typically one-third the length of the original text. The average text length is 353.61 words, whereas the average summary length is 161.3 words, demonstrating the high compression ratio required for effective summarization. The dataset also exhibits significant compression.
There is variation in text length, with the most extended document reaching 1154 words, and the shortest being 129 words. The longest summary encompasses 435 words, while the shortest version comprises 76 words, highlighting the diverse range of summarization needs within legal discourse.
An analysis of the text and summary length distribution provides valuable insights into the underlying structure of the dataset as shown in
Figure 4. According to the histogram distribution above, most texts are between 200 and 400 words, while a small subset exceeds 600 words. Similarly, summary length distributions primarily fall between 100 and 250 words. The variation in distribution between text and summary lengths suggests that the model needs to be refined to prevent redundancy in longer texts while mitigating the risk of truncation in shorter outputs.
A further exploration of the token statistics reveals that tokenization has a significant influence on text representation. The average token count for full texts is 494, while the summaries average around 225 tokens, indicating the dense and information-rich nature of legal language as shown in
Figure 5. Moreover, the maximum token counts for text and summaries reach 1615 and 609, respectively, underscoring the need to efficiently manage long sequences in transformer-based models. These findings underscore the complexity and variability of the dataset, underscoring the need for advanced summarization techniques to effectively capture essential legal information while maintaining brevity and contextual accuracy.
3.4. Dataset Splitting
The dataset was split into training, validation, and testing sets to evaluate the summarization model, and to ensure a fair evaluation of its performance. This division guaranteed a balanced representation across various legal documents. The splitting ratio between subsets was 80% for the training set, used for model fine-tuning, 10% for the validation set, employed for parameter optimization and overfitting prevention, and 10% for the test set, used for evaluation purposes. The arrangement facilitated robust training and evaluation processes, confirming the model’s capability to manage different legal documents and unseen case summaries.
3.5. Baseline Model Selection
The mBART and mT5 models have been selected as baseline models for our task of summary generation based on the following characteristics: the chosen models have been pre-trained on gigantic multilingual corpora, which makes them more capable of handling different yet limited languages, including Urdu as shown in
Table 1. These models have an encoder–decoder architecture, can manage long-range dependencies, and are effective for text generation tasks, including summarization, making these models suitable for our problem, as well as a competence to leverage cross-lingual transfer learning for the adaptation of knowledge from a high-resource language to improve performance in contexts where data is insufficient. Furthermore, the readily available pre-trained checkpoints significantly reduce training and computational costs, making them the most accessible choices for fine-tuning models in low-resource settings.
Specific models were considered but excluded from this research design for the following reasons: While T5 [
45] performs well in text generation, it is pre-trained mostly on English corpora, making it less effective for Urdu than the mT5. GPT-based Models (GPT-3, ChatGPT3.5) require massive computational resources for fine-tuning, and lack fine-tuned multilingual support for legal Urdu texts and non-open-source models. Given these factors, the mBART and mT5 models were the most viable options for generating coherent and legally accurate summaries in Urdu.
3.6. Fine-Tuning Strategy
Model Architecture: Both the mBART and mT5 models follow an encoder–decoder architecture, where the encoder processes the input legal text and the decoder generates an abstractive summary. This structure enables the models to capture contextual and syntactic dependencies, making them well-suited for legal summarization tasks.
Model Variants: This study encompasses multiple model sizes, including the mT5-Small, Base, and Large, as well as the mBART50, to compare the effect of model size on summarization quality under consistent training configurations. Training Configuration: All models were fine-tuned using a batch size of 1, with gradient accumulation steps set to 2 (for the mT5-Large), 2 (for the mT5-Small and mt5-Base), and 8 (for the mBART50) to simulate larger batch sizes within memory constraints as shown in
Table 2. The learning rate was set to 5 × 10
−5 for the mT5 variants and 5 × 10
−5 for the mBART. Training was conducted for 10 epochs for the mT5-Large and 10 epochs for the other models. The AdamW optimizer with a weight decay of 0.01 was used, along with 500 warmup steps. Input and Output Configuration: All models used a maximum input length of 1024 tokens to accommodate the long format of legal documents. The maximum summary length was fixed at 512 tokens during training and 512 tokens during generation for the mT5. Beam search with a beam width of 4 and a length penalty of 1.2 was applied to balance fluency and brevity. Regularization and Label Smoothing: A label smoothing factor of 0.1 was used for the mT5-Large and the mBART50 to enhance generalization, whereas the mT5-Small and mT5-Base used a factor of 0.0. Dropout settings followed the model defaults and were not manually adjusted. Hardware and Training Environment: All experiments were conducted using Google Cloud infrastructure (Colab Pro and Hugging Face Spaces) on NVIDIA A100 and V100 GPUs, ensuring reproducibility in a scalable, cloud-based setup. Rationale for Pre-trained Models: All models were initialized using publicly available pre-trained multilingual checkpoints, as training from scratch for Urdu legal text is infeasible due to the lack of large-scale annotated corpora and resource requirements. Fine-tuning on domain-specific legal Urdu data ensured adaptation to legal terminology and structure.
3.7. Evaluation Metrics
We used standard NLP summarization metrics to compare model-generated summaries against human-written reference summaries for automatic evaluation. These included ROUGE (Recall-Oriented Understudy for Gisting Evaluation): ROUGE-1 measures unigram (single-word) overlap between the generated and reference summaries, indicating word-level accuracy; ROUGE-2 measures bigram (two-word) overlap, evaluating phrase-level accuracy; ROUGE-L captures the longest common subsequence (LCS) between the generated and reference summaries, ensuring that the summary structure aligns with the human-written summary.
Justification: ROUGE is widely used for summarization evaluation, and its recall- based approaches helps measure how much important content from the original text is retained in the summary. These automatic metrics were used to establish baseline model performance before conducting qualitative assessments.
3.8. Qualitative Analysis
Human evaluation was conducted in conjunction with automatic metrics to ensure the factual accuracy, contextual correctness, and fluency of the generated summaries. To complement the automatic ROUGE-based evaluation, we conducted a manual analysis of the generated summaries across four representative test cases. Two native speakers of Urdu, aged 35, male lawyers having degree in Legum Baccalaureus (LLB), independently evaluated the output from each model. They were selected based on their dual expertise in legal practice and proficiency in the Urdu language, ensuring a credible and context-aware evaluation of legal summaries.
Expert evaluators who have both legal knowledge and fluency in the Urdu language evaluated automatic summaries based on the following qualitative criteria: fluency and readability (natural language flow and grammatical correctness), coherence and logical flow (structural alignment with the source text and preservation of legal reasoning), factual accuracy (correct representation of case details and terminology), legal accuracy (faithfulness to the original legal intent without distortion), and handling of hallucinations (avoidance of fabricated information or incorrect legal references). The assessors evaluated each summary using a symbolic qualitative rating scale to ensure consistent ratings of clarity, precision, and legal correctness.
Each dimension was rated on a three-point scale: ✗ (poor or missing), ✓ (adequate), and ✓✓ or ✓✓✓ (strong or excellent performance). These scores reflect the model’s ability to meet each criterion across all evaluated examples. Inter-rater agreement was measured using Cohen’s Kappa, yielding an average score of 0.72, which indicates substantial agreement between the annotators. Disagreements were resolved through discussion before final scoring. This ensures the reliability of our human assessment in capturing quality distinctions between the models. Expert evaluations were crucial in identifying model failures, allowing the developers to refine the models before the final stages. Combining numeric ROUGE analysis with human expert evaluations yields a comprehensive evaluation system that ensures statistical validity and legal reliability for the practical deployment of summarization solutions.
4. Experiments
The effectiveness of the models under study, specifically the mBART and mT5 models, was systematically evaluated through a series of controlled experiments. The primary objective was to evaluate model performance under domain-specific fine-tuning conditions, and to determine the optimal training configurations for handling complex legal documents. These experiments assessed both the generalization capabilities of the models and provided practical insights for deploying multilingual summarization systems in low-resource settings for legal NLP.
4.1. Training and Validation Loss Trends
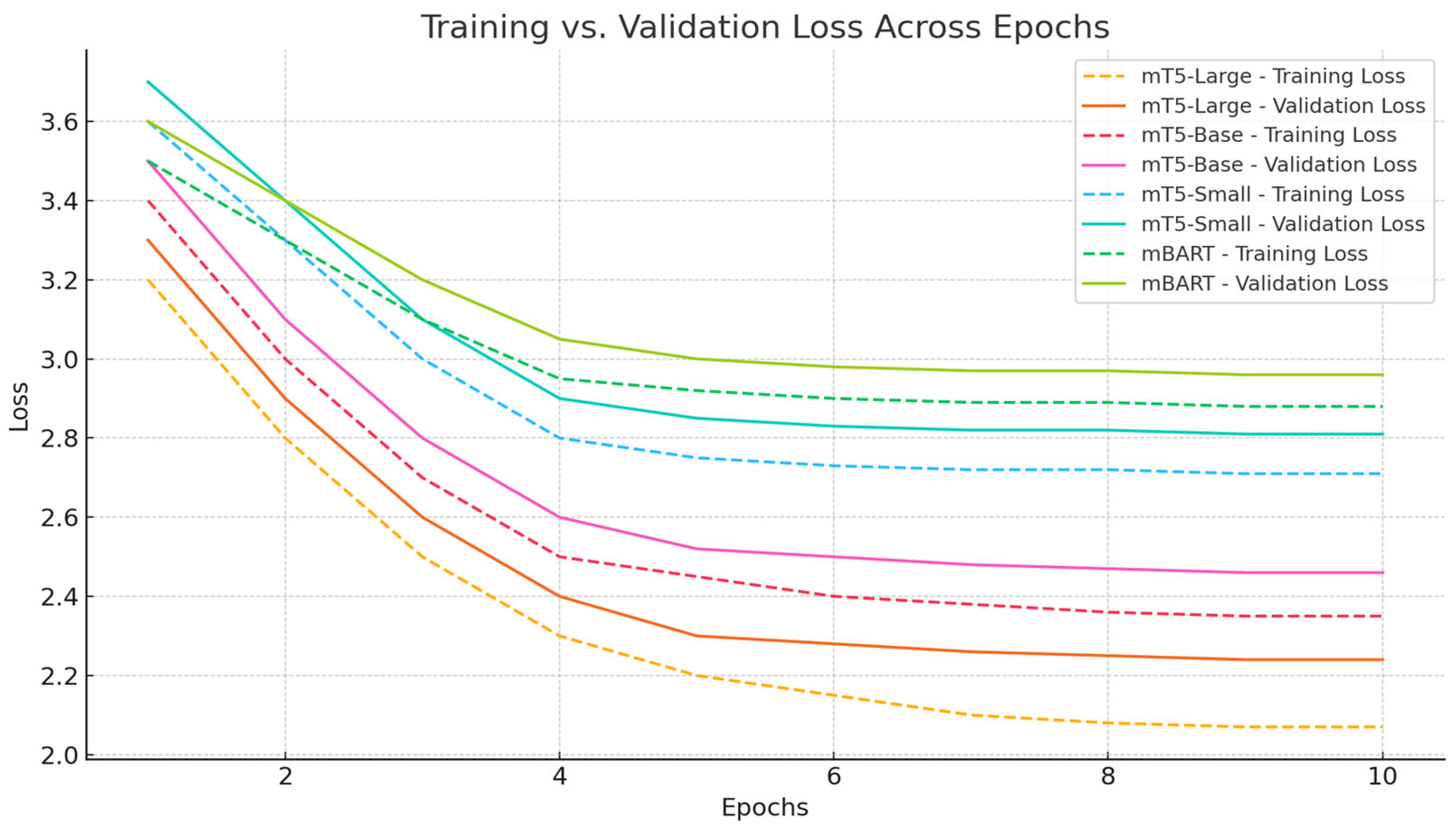
The training and validation loss progression, sampled every 200 steps, is summarized below in
Table 3.
Observation: All models exhibit converging loss curves; however, the mT5-Large displayed the most stable and lowest loss trajectory, indicating superior learning capabilities, while the mT5-Small required more epochs or data to achieve the same level of convergence. In the meantime, mBART demonstrated marginally less stability and plateaued earlier, as shown in
Figure 6.
4.2. Impact of Training Arguments Choices
Small batch size and the gradient accumulation worked well for the limited GPU memory. Early stopping with beam search improved the factual precision. The maximum input length of 1024 was preserved, allowing for rich context (essential for FIRs). The ROUGE-based evaluation for every 200 steps provided effective checkpoints. Weight decay and a balanced learning rate promoted generalization and convergence. If we used larger batch sizes or increased the learning rate, we observed occasional instability, especially in the smaller models (e.g., the mT5-Small oscillated in early steps). Hence, these hyperparameters were carefully selected after multiple rounds of tuning.
5. Experimental Results and Discussion
This comparative evaluation provides insights into the SOTA models’ relative strengths, limitations, and domain-specific challenges in generating abstractive legal summaries for low-resource languages. The results highlighted the importance of domain adaptation through fine-tuning, demonstrating that performance is influenced by specific factors, including cross-lingual transfer capabilities, pre-training objectives, and model size. In addition to quantitative analysis, human evaluation revealed ongoing limitations in the current models, including hallucinations, misinterpretations of legal terminology, and lapses in fluency and coherence. Examining the models underscores the need for domain-aware summarization strategies that prioritize factuality and precision in terminology.
5.1. Performance Evaluation
The models were evaluated using automatic metrics on a held-out test set covering 10% of the dataset. The details are given in
Table 4 and
Table 5.
Observation: Despite having fewer parameters than the mT5-Base, the mBART50 underperforms due to less pretraining alignment with Urdu. Interestingly, the mT5-Small generated summaries of similar length but with less factual coverage and a less structured approach as shown in
Table 5.
A comparison between the models of varying sizes highlights a clear trade-off between parameter count and output quality as shown in
Table 5. The mT5-Large, with 1.23 billion parameters, produced the most fluent and factually accurate summaries, albeit at the cost of a longer training time. The mT5-Base offered a firm middle ground, maintaining high fluency and factual alignment with moderate resource requirements. The mT5-Small, while faster to train, exhibited noticeable drops in factual consistency and stylistic quality, making it more suitable for lightweight applications where efficiency is prioritized over precision. The mBART50, despite having a parameter count similar to the mT5-Base, underperformed in terms of factuality and compression, underscoring the importance of both model architecture and domain adaptation for legal summarization tasks in low-resource languages like Urdu.
The mT5-Large proved to be the most effective model for summarization tasks involving legal text, with its exceptional ROUGE score performance surpassing that of all other models evaluated. Combining high ROUGE scores with human evaluation demonstrates that the model generated natural and precise summaries that contain accurate information.
The mT5-Base achieved results almost identical to those of the top-performing model, demonstrating that multilingual fine-tuning creates highly effective systems for low-resource legal summarization. The model exhibited slightly less accuracy than the mT5-Large but presented itself as a considerable choice, especially in settings where computational efficiency is highly desired.
The mT5-Small performance was comparatively lower than that of the larger models, making it a better alternative to the mT5-Base. It can be concluded that, despite this model’s limitations, when fine-tuned, it can be effectively used to summarize legal texts and is suitable for deployment in environments with computational constraints.
The mBART50 showed the lowest scores among all evaluated models, underscoring its incompetence in handling domain-specific terminologies, the nuances of legal text, and morphologically rich structure. These results highlight that multilingual models without pre-training on similar tasks or targeted fine-tuning are insufficient for legal text summarization with under-represented languages.
SOTA models, such as PEGASUS [
17] T5 [
32], and BART [
31] have demonstrated strong performance on English summarization tasks. However, they are not directly comparable to multilingual models in low-resource settings, such as Urdu, as their performance is primarily attributed to training on massive, annotated datasets and post-processing tuned to general language patterns. In this study, the scores reported for PEGASUS, T5, and BART are included for reference only, and are drawn from the existing literature on English datasets, such as CNN/Daily Mail and XLSUM as shown in
Table 6. These models were not evaluated on our dataset. By contrast, our findings suggest that multilingual models, such as the mT5 and mBART, yield stronger performance in low-resource legal summarization tasks when fine-tuned on domain-specific corpora. This comparison highlights the limitations of relying on generic high-resource models and supports the importance of domain adaptation and multilingual fine-tuning for underrepresented languages and specialized domains.
The experimental results reveal a clear advantage for models fine-tuned on domain-specific Urdu legal texts compared to those trained on general or out-of-domain data. Among all models, the mT5-Large achieved the highest performance, with ROUGE-1 scores of 0.7889, ROUGE-2 scores of 0.5961, and ROUGE-L scores of 0.7813, demonstrating its superior ability to generate fluent and accurate legal summaries. The mT5-Base model followed closely, showing a strong performance with a ROUGE-1 score of 0.7774. By contrast, the mT5-Small performed moderately well, albeit with a noticeable decline in ROUGE-2 (0.4035) and ROUGE-L (0.6304), suggesting that model capacity significantly impacts the effectiveness of legal text summarization in low-resource settings.
By comparison, the mBART50, although fine-tuned on the same Urdu legal dataset, underperformed relative to the mT5 variants, with ROUGE-1 and ROUGE-2 scores of 0.5914 and 0.3718, respectively. This suggests that the mT5 model may provide a more effective architectural alignment with the summarization task in multilingual legal domains.
Notably, urT5, a general Urdu-language model trained on news content, achieved substantially lower scores (ROUGE-1 score of 0.3912), highlighting the importance of domain adaptation. Finally, the mT5-XLSUM, trained on Urdu news summaries in the XLSUM corpus, failed to transfer effectively to the legal domain, scoring near zero on ROUGE-2 (0.0000), and only 0.0582 on ROUGE-1 and ROUGE-L. These findings confirm that domain-specific fine-tuning is crucial for achieving high-quality summarization in low-resource legal languages, and that both model size and the relevance of the training data play critical roles in performance as shown in
Table 7.
5.2. Summary Analysis
We evaluated summary quality across six dimensions, including factual accuracy, compression handling, fluency, preservation of legal detail, integrity of legal logic, and term misuse rate is shown in Table 9.
Among all models, the mT5-Large consistently produced the most coherent and accurate summaries, reliably capturing the suspects’ names, events, and relevant legal sections (e.g., AO-13-20-65, 337H2). It preserved investigative flow (e.g., Example 1 and 202) and handled dates, roles, and clause numbers with high precision. The mT5-Base delivered strong outputs overall, but sometimes compressed timelines excessively or omitted actor roles (e.g., Example 101). The mT5-Small frequently hallucinated (e.g., “کھنہ پل جانا ہے” “Have to go to Khanna Bridge” in Example 202) or lost factual content, often skipping entire procedural logic (Example 1, 404). The mBART50, while occasionally capturing surface-level phrasing, failed to retain legal specificity and often repeated vague patterns across examples, missing core fields, such as weapons, timelines, and legal references.
In terms of compression, the mT5-Large struck the best balance between conciseness and informativeness, while the mT5-Base leaned to verbose but retained relevance. The mT5-Small over-compressed the content, resulting in vague and sometimes incorrect summaries. The mBART50 suffered from unstable output lengths and shallow summaries.
To support these findings, we refined our manual evaluation rubric to include the following:
Integrity of Legal Logic: whether the summaries maintain the chronological/procedural coherence of the incident.
Legal Term Misuse Rate: whether the summaries capture any incorrect, omitted, or hallucinated legal references.
We also added fine-grained error annotations and a comparison
Table 8 that highlights model behavior across five representative examples. The analysis includes failures, like truncation (mBART50, Example 404), hallucinated content (mT5-Small, Example 202), and proper clause reproduction (mT5-Large, Example 1).
Overall, the mT5-Large demonstrated superior performance across all categories and example cases, including robbery, fraud, and weapon use. The mT5-Base is a viable lighter alternative. By contrast, the mT5-Small lacks consistency, and the mBART50, though multilingual, is unsuitable without further domain adaptation. Additionally, we have included a
Supplementary File containing the input texts, reference summaries, and system outputs for all examples presented in
Table 9.
6. Conclusions and Future Recommendations
This study thoroughly evaluated multilingual transformer models (the mT5, Small, Base, and Large) and the mBART50 for the abstractive summarization of Urdu legal texts, specifically FIRs. Through quantitative and qualitative analyses, the mT5-Large consistently outperformed the other models across ROUGE metrics, demonstrating coherence, factual consistency, and the ability to reproduce domain-specific details. Although the mT5-Base demonstrated competitive results with minimal trade-offs in fluency and compression, the mT5-Small showed limitations in retaining legal structure and critical information. Despite its multilingual training, the mBART50 struggled with domain alignment, resulting in summaries that were generic and factually shallow. These findings reaffirm the significance of scale, pretraining alignment, and robust tokenization for low-resource legal NLP applications.
These findings provide a solid foundation for subsequent research. One natural extension is investigating few-shot and zero-shot adaptations using these models, which may reduce reliance on large, annotated datasets in low-resource settings. Another promising direction is a comparative study of the encoder–decoder versus the decoder-only architectures to understand the trade-offs between generation quality and model efficiency in legal summarization. Lastly, future work could explore parameter-efficient fine-tuning (PEFT) approaches, such as LoRA or adapter layers, to minimize training costs while preserving performance.
Additionally, integrating visual analysis tools, such as summary-edit distance graphs, hallucination heatmaps, or attention trace overlays, could provide deeper insight into model behavior, particularly in edge cases. These enhancements may guide the more effective deployment strategies for LLMs in real-world legal contexts.
While our models show promising results in summarizing Urdu legal texts, their application in real-world judicial settings carries significant ethical risks. Summarization models may hallucinate facts, omit critical legal clauses, or misrepresent procedural sequences, potentially leading to misinformation or biased legal interpretations. There is also a risk of overreliance on machine-generated summaries by legal practitioners or law enforcement without adequate verification. To mitigate these risks, we recommend that such systems be deployed only as assistive tools, accompanied by human legal oversight, particularly in high-stakes environments. Future work should also explore model explainability, bias auditing, and integration with legally interpretable NLP frameworks to ensure trustworthiness and accountability.
Limitations
This study demonstrates the effectiveness of fine-tuning multilingual models, such as the mT5 and mBART, for Urdu legal summarization; however, several limitations must be acknowledged. First, the scarcity of high-quality, annotated legal datasets in Urdu restricts model generalization and constrains the development of robust pretraining strategies. Second, the fine-tuning was limited to narrow legal subdomains, such as FIRs and police complaints, which may not accurately reflect the broader diversity of legal texts, including case law, contracts, or constitutional documents. Third, due to model constraints, documents exceeding the 1024-token input limit were truncated, potentially omitting essential legal content and weakening summary fidelity for longer texts. Fourth, while human evaluation added valuable insight, it was conducted by only two legal experts on a limited sample; larger-scale evaluations with broader document coverage would offer stronger reliability. Lastly, this research was conducted in a controlled academic environment and does not evaluate real-world deployment in judicial or administrative settings, where issues of trust, legal compliance, and interpretability become critical. Future work should aim to address these limitations by expanding dataset coverage, leveraging long-context models, and testing deployment in operational legal workflows.
While this study focused on encoder–decoder models, such as the mT5 and mBART models, due to their multilingual capabilities and support for supervised fine-tuning, emerging decoder-only models, like GPT-4o, Gemma, and DeepSeek, offer promising general-purpose generation abilities. However, these models are primarily instruction-tuned and optimized for zero-shot tasks and currently lack fine-tuning workflows or domain-specific adaptations for low-resource legal summarization in languages such as Urdu. Future research can explore their applicability as tools and resources for this task evolve.
Due to resource constraints, a comprehensive ablation study was not conducted; however, future work will investigate the contribution of individual components (e.g., model size, label smoothing, training epochs) to summarization performance in low-resource legal contexts.
Author Contributions
Conceptualization, S.M. and M.H.; methodology, S.M. and M.H.; software, S.M.; validation, S.M., M.H. and L.G.F.; investigation, B.H.; writing. S.M., M.H., L.G.F. and B.H.; All authors have read and agreed to the published version of the manuscript.
Funding
This research did not receive a specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Data Availability Statement
Due to the sensitive nature of the legal documents used in this study, the whole dataset cannot be made publicly available. However, an anonymized and de-identified subset of the Urdu legal text corpus will be made available upon reasonable request for academic and research purposes. Researchers may contact the authors to obtain access under appropriate data-sharing agreements.
Acknowledgments
We gratefully acknowledge Advocate Muhammad Adnan and Advocate Muhammad Waqas for their valuable insights into legal practices and support in evaluating the summarization outputs from a domain-specific perspective. We also thank all the volunteers who participated in the summary generation and evaluation phases. Special thanks to Arfan-ul-Haq National Police Bureau, Islamabad, Pakistan, for facilitating access to FIR documents and formulating annotation guidelines. While care was taken to preserve the integrity of academic writing, minor portions of the text may exhibit AI-assisted phrasing due to this tool.
Conflicts of Interest
The authors declare that there are no conflicts of interest related to this study’s research, authorship, or publication.
References
- Adams, O.; Makarucha, A.; Neubig, G.; Bird, S.; Cohn, T. Cross-lingual word embeddings for low-resource language modeling. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2017—Proceedings of Conference, Valencia, Spain, 3–7 April 2017; Volume 1. [Google Scholar] [CrossRef]
- Chernyshev, D.; Dobrov, B. Investigating the Pre-Training Bias in Low-Resource Abstractive Summarization. IEEE Access 2024, 12, 47219–47230. [Google Scholar] [CrossRef]
- Hasan, T.; Bhattacharjee, A.; Islam Md, S.; Mubasshir, K.; Li, Y.-F.; Kang, Y.; Rahman, M.S.; Shahriyar, R. XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021. [Google Scholar] [CrossRef]
- Khushhal, S.; Majid, A.; Babar, M.; Abbas, S.A.; Naqvi, U. Optimizing Urdu Text Tokenization: Morphological Rules for Compound Word Identification. Res. Sq. 2024. preprint. [Google Scholar] [CrossRef]
- Naqvi, U.; Majid, A.; Abbas, S.A. UTSA: Urdu Text Sentiment Analysis Using Deep Learning Methods. IEEE Access 2021, 9, 114085–114094. [Google Scholar] [CrossRef]
- Shafiq, N.; Hamid, I.; Asif, M.; Nawaz, Q.; Aljuaid, H.; Ali, H. Abstractive Text Summarization of Low-Resourced Languages Using Deep Learning. Peerj Comput. Sci. 2023, 9, e1176. [Google Scholar] [CrossRef] [PubMed]
- Suleiman, D.; Awajan, A. Deep Learning Based Abstractive Text Summarization: Approaches, Datasets, Evaluation Measures, and Challenges. Math. Probl. Eng. 2020, 2020, 9365340. [Google Scholar] [CrossRef]
- Tang, Y.; Tran, C.; Li, X.; Chen, P.J.; Goyal, N.; Chaudhary, V.; Gu, J.; Fan, A. Multilingual Translation from Denoising Pre-Training. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021. [Google Scholar] [CrossRef]
- Tang, Y.; Tran, C.; Li, X.; Chen, P.-J.; Goyal, N.; Chaudhary, V.; Gu, J.; Fan, A. Multilingual Translation with Extensible Multilingual Pretraining and Finetuning. arXiv 2020, arXiv:2008.00401. [Google Scholar]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. In Proceedings of the NAACL-HLT 2021—2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Proceedings of the Conference, Online, 6–11 June 2021. [Google Scholar] [CrossRef]
- Munaf, M.; Afzal, H.; Mahmood, K.; Iltaf, N. Low Resource Summarization using Pre-trained Language Models. ACM Trans. Asian Low-Resource Lang. Inf. Process. 2024, 23, 141. [Google Scholar] [CrossRef]
- Awais, M.; Nawab, R.M.A. Abstractive Text Summarization for the Urdu Language: Data and Methods. IEEE Access 2024, 12, 61198–61210. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020. [Google Scholar]
- Niklaus, J.; Matoshi, V.; Stürmer, M.; Chalkidis, I.; Ho, D. MultiLegalPile: A 689GB Multilingual Legal Corpus. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, Bangkok, Thailand, 11–16 August 2024; Volume 1, pp. 15077–15094. [Google Scholar] [CrossRef]
- Lin, C.-Y. A Package for Automatic Evaluation of Summaries. Jpn. Circ. J. 2004, 34, 74–81. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002. [Google Scholar]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating text generation with BERT. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Zhao, W.; Peyrard, M.; Liu, F.; Gao, Y.; Meyer, C.M.; Eger, S. Moverscore: Text generation evaluating with contextualized embeddings and earth mover distance. In Proceedings of the EMNLP-IJCNLP 2019—2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Proceedings of the Conference, Hong Kong, China, 3–7 November 2019. [Google Scholar] [CrossRef]
- Fabbri, A.R.; Kryściński, W.; McCann, B.; Xiong, C.; Socher, R.; Radev, D. Summeval: Re-evaluating summa-rization evaluation. Trans. Assoc. Comput. Linguistics 2021, 9, 391–409. [Google Scholar] [CrossRef]
- Sanderson, M. Advances in Automatic Text Summarization Inderjeet Mani and Mark T. Comput. Linguistics 2000, 26, 280–281. [Google Scholar] [CrossRef]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef]
- Gong, Y.; Liu, X. Generic text summarization using relevance measure and latent semantic analysis. In Proceedings of the SIGIR Forum (ACM Special Interest Group on Information Retrieval), New Orleans, LA, USA, 9–12 September 2001. [Google Scholar] [CrossRef]
- Nenkova, A.; Bagga, A. Facilitating email thread access by extractive summary generation. In Proceedings of the Recent Advances in Natural Language Processing III: Selected papers from RANLP 2003, Borovets, Bulgaria, 30 November 2004. [Google Scholar] [CrossRef]
- Nenkova, A.; Maskey, S.; Liu, Y. Automatic Summarization. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Tutorial Abstracts, Portland, OR, USA, 19–24 June 2011; Volume 3. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 4. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.H.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5999–6009. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL HLT 2019—2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies—Proceedings of the Conference, Minneapolis, MN, USA, 2–7 June 2019; Volume 1. [Google Scholar]
- Liu, Y.; Lapata, M. Text summarization with pretrained encoders. In Proceedings of the EMNLP-IJCNLP 2019—2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Proceedings of the Conference, Hong Kong, China, 3–7 November 2019. [Google Scholar] [CrossRef]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 140. [Google Scholar]
- Fabbri, A.R.; Li, I.; She, T.; Li, S.; Radev, D.R. Multi-news: A large-scale multi-document summarization dataset and abstractive hierarchical model. In Proceedings of the ACL 2019—57th Annual Meeting of the Association for Computational Linguistics, Proceedings of the Conference, Florence, Italy, 28 July–2 August 2019. [Google Scholar] [CrossRef]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. In Proceedings of the Conference Proceedings—EMNLP 2015: Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015. [Google Scholar] [CrossRef]
- Narayan, S.; Cohen, S.B.; Lapata, M. Don’t give me the details, just the summary! Topic-aware convolutional neural networks for extreme summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, EMNLP 2018, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar] [CrossRef]
- Bani-Almarjeh, M.; Kurdy, M.-B. Arabic abstractive text summarization using RNN-based and transformer-based ar-chitectures. Inf. Process. Manag. 2022, 60, 103227. [Google Scholar] [CrossRef]
- Farahani, M.; Gharachorloo, M.; Manthouri, M. Leveraging ParsBERT and Pretrained mT5 for Persian Abstractive Text Summarization. In Proceedings of the 26th International Computer Conference, Computer Society of Iran, CSICC 2021, Tehran, Iran, 3–4 March 2021. [Google Scholar] [CrossRef]
- Sethi, N.; Vetukuri, V.S.; Reddy, S.S.; Rajender, R. Summarization of Legal Texts by Using Deep Learning Approaches. In Algorithms in Advanced Artificial Intelligence; CRC Press: London, UK, 2024. [Google Scholar] [CrossRef]
- Moro, G.; Ragazzi, L. Semantic Self-Segmentation for Abstractive Summarization of Long Documents in Low-Resource Regimes. In Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022. [Google Scholar] [CrossRef]
- Bajaj, A.; Dangati, P.; Krishna, K.; Kumar, P.A.; Uppaal, R.; Windsor, B.; Brenner, E.; Dotterrer, D.; Das, R.; McCallum, A. Long document summarization in a low resource setting using pretrained language models. In Proceedings of the ACL-IJCNLP 2021—59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Proceedings of the Student Research Workshop, Online, 1–6 August 2021. [Google Scholar] [CrossRef]
- Ghosh, S.; Dutta, M.; Das, T. Indian Legal Text Summarization: A Text Normalisation-Based Approach. TechRxiv 2022. [Google Scholar] [CrossRef]
- Elaraby, M.; Litman, D. ArgLegalSumm: Improving Abstractive Summarization of Legal Documents With Argument Mining. arXiv 2022, arXiv:2209.0165. [Google Scholar] [CrossRef]
- Anand, D.; Wagh, R. Effective Deep Learning Approaches for Summarization of Legal Texts. J. King Saud Univ. Computer. Inf. Sci. 2022, 34, 2141–2150. [Google Scholar] [CrossRef]
- Vági, R. How Could Semantic Processing and Other NLP Tools Improve Online Legal Databases? TalTech J. Eur. Stud. 2023, 13, 138–151. [Google Scholar] [CrossRef]
- Xu, H.; Šavelka, J.; Ashley, K.D. Using Argument Mining for Legal Text Summarization. In Proceedings of the JURIX 2020: The Thirty-Third Annual Conference, Brno, Czech Republic, 9–11 December 2020. [Google Scholar] [CrossRef]
- Raza, H.; Shahzad, W. End to End Urdu Abstractive Text Summarization With Dataset and Improvement in Evaluation Metric. IEEE Access 2024, 12, 40311–40324. [Google Scholar] [CrossRef]
- Kia, M.A.; Garifullina, A.; Kern, M.; Chamberlain, J.; Jameel, S. Question-driven Text Summarization Using an Extractive-abstractive Framework. Comput. Intell. 2024, 40, e12689. [Google Scholar] [CrossRef]
- Kudo, T.; Richardson, J. SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. arXiv 2018, arXiv:1808.06226. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. arXiv 2016, arXiv:1508.07909. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}