
Recognition of Dense Goods with Cross-Layer Feature Fusion Based on Multi-Scale Dynamic Interaction

 , , ,
, , ,
Abstract
1. Introduction
- In densely populated product scenarios, feature extraction modules often exhibit limited scale adaptability to small objects, resulting in feature information loss or redundancy. Furthermore, existing fusion strategies such as ASFF and NAS-FPN, while effective in aggregating multi-scale information, incur high computational costs when handling high-density targets. This trade-off between real-time performance and accuracy exacerbates the risk of false positives and missed detections.
- Current attention mechanisms, such as CBAM and SE, exhibit limited sensitivity to small-object regions in densely populated scenes, lacking dynamic scale interaction and adaptive feature reweighting. As a result, they struggle to effectively enhance the representation of target areas. Concurrently, conventional loss functions such as IoU are insufficient for optimizing localization accuracy in high-density small-object scenarios, particularly under conditions of significant occlusion or background clutter. These limitations impair both the convergence stability and the precision of object localization in complex detection environments.
2. Methodology
2.1. Dense-YOLO Feature Extraction Network
2.1.1. Enhanced Multi-Scale Feature Extraction Module (EMFE)
2.1.2. Lightweight Feature Fusion Strategy (LFF)
2.2. Feature Enhancement Based on MDIAM
2.3. Loss Function
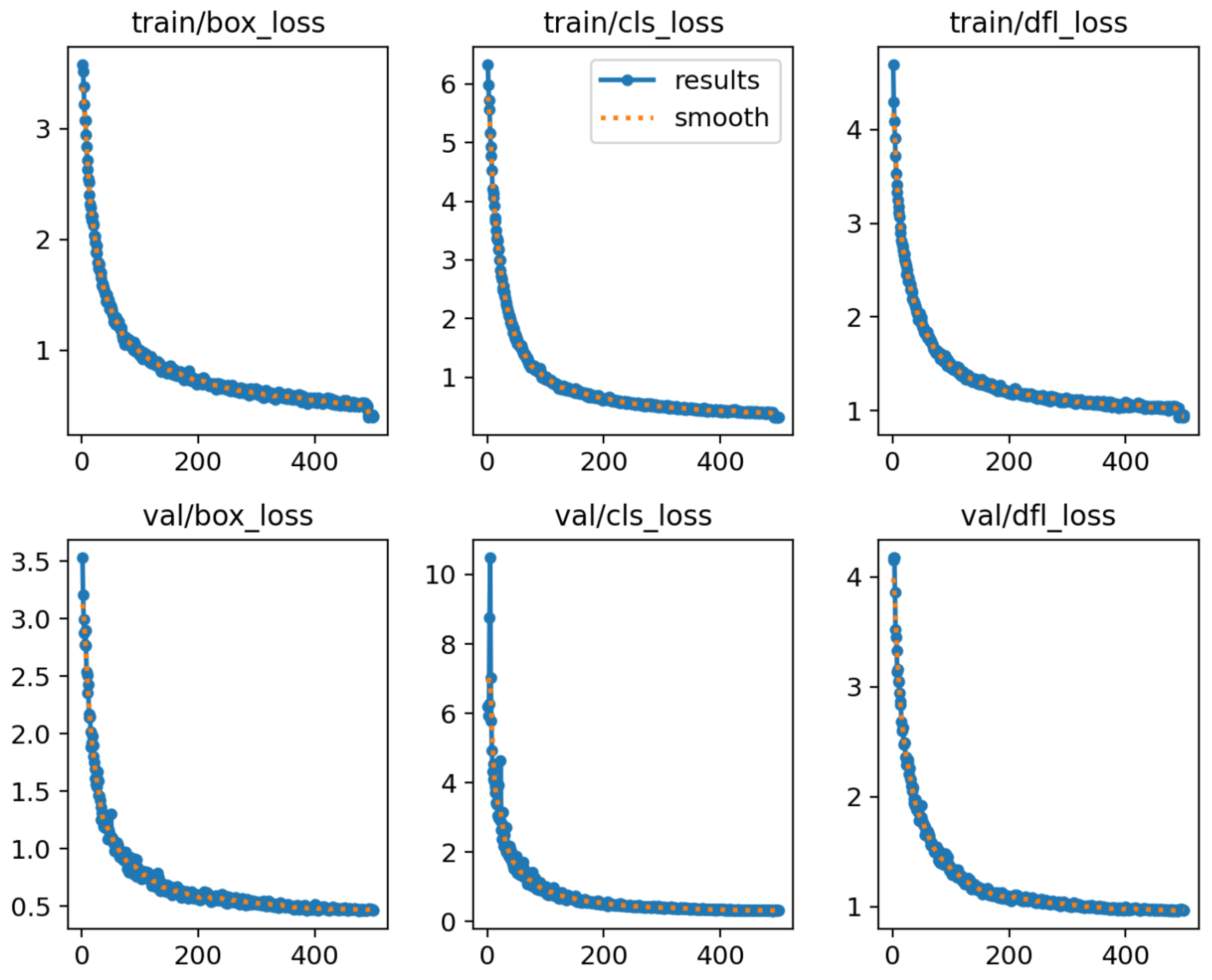
3. Experiment Results and Analysis
3.1. Experimental Platform
3.2. Dataset Introduction
3.3. Parameter Settings
3.4. Evaluation Index
3.5. Ablation Study
3.5.1. Loss Function Optimization Study
3.5.2. Performance Evaluation of the Multi-Scale Dynamic Interactive Attention Module
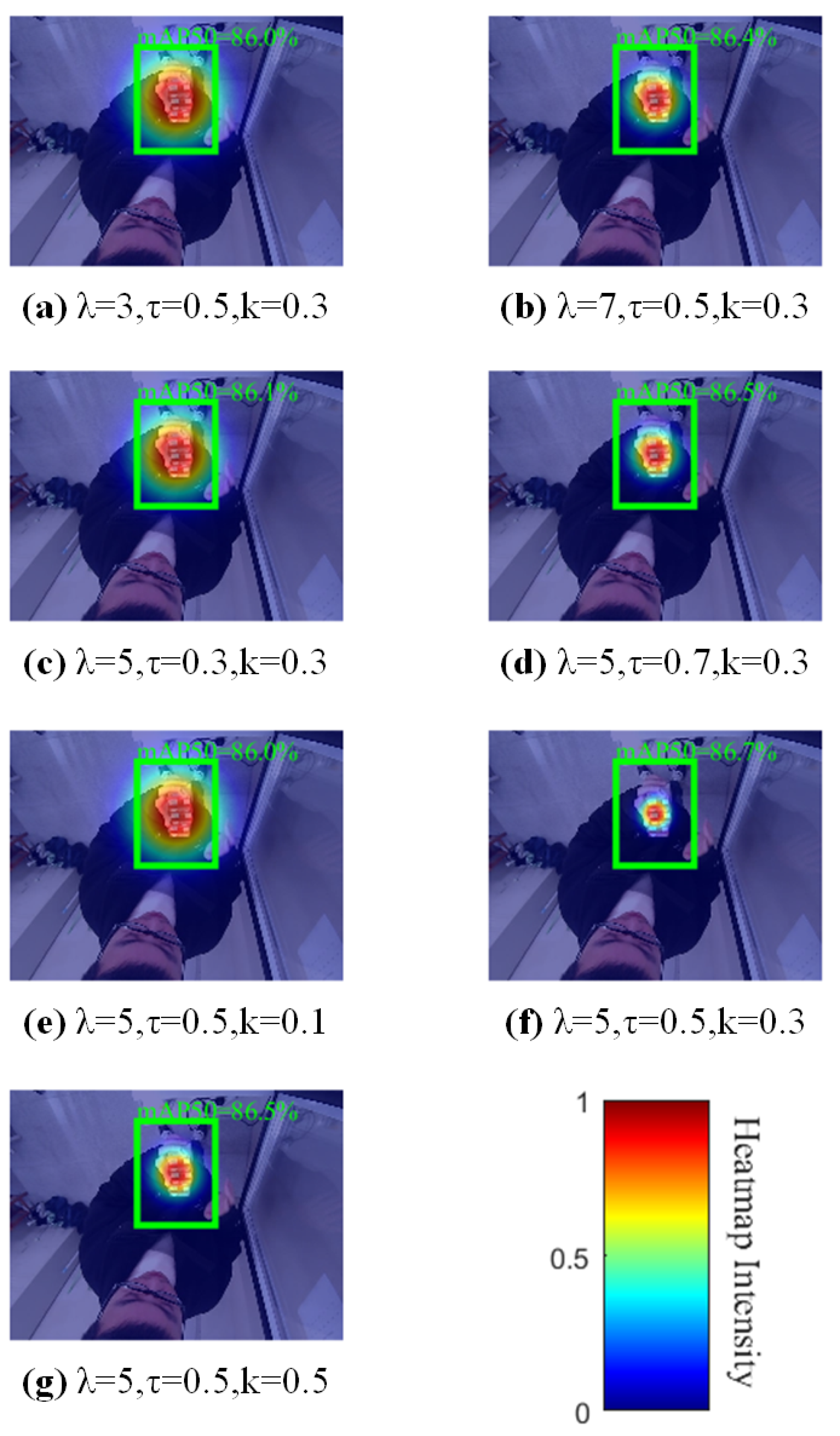
3.6. Sensitivity Analysis
3.7. Comparison Experiment
3.8. Dense Commodity Detection Experiment
4. Discussion and Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Deng, J.; Xuan, X.; Wang, W.; Li, Z.; Yao, H.; Wang, Z. A review of research on object detection based on deep learning. J. Phys. Conf. Ser. 2020, 1684, 012028. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; IEEE: New York, NY, USA, 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; IEEE: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo Algorithm Developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Shetty, A.K.; Saha, I.; Sanghvi, R.M.; Save, S.A.; Patel, Y.J. A Review: Object Detection Models. In Proceedings of the 2021 6th International Conference for Convergence in Technology (I2CT), Maharashtra, India, 2–4 April 2021; IEEE: New York, NY, USA, 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Sun, Y.; Tao, H.; Stojanovic, V. Pseudo-label guided dual classifier domain adversarial network for unsupervised cross-domain fault diagnosis with small samples. Adv. Eng. Inform. 2025, 64, 102986. [Google Scholar] [CrossRef]
- Zhao, H.; Wu, Y.; Deng, W. Fuzzy Broad Neuroevolution Networks via Multiobjective Evolutionary Algorithms: Balancing Structural Simplification and Performance. IEEE Trans. Instrum. Meas. 2025, 74, 1–10. [Google Scholar] [CrossRef]
- Chen, H.; Sun, Y.; Li, X.; Zheng, B.; Chen, T. Dual-Scale Complementary Spatial-Spectral Joint Model for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 6772–6789. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; IEEE: New York, NY, USA, 2023; pp. 7464–7475. [Google Scholar] [CrossRef]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Wang, C.Y.; Mark Liao, H.Y.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; IEEE: New York, NY, USA, 2020. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-style ConvNets Great Again. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: New York, NY, USA, 2021; pp. 13728–13737. [Google Scholar] [CrossRef]
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. In Computer Vision—ECCV 2024; Springer Nature: Cham, Switzerland, 2024; pp. 1–21. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: New York, NY, USA, 2020. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D.; Wang, Y. Learning Spatial Fusion for Single-Shot Object Detection. arXiv 2019, arXiv:abs/1911.09516. [Google Scholar] [CrossRef]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision—ECCV 2018; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Training Set | Validation Set | Test Set |
|---|---|---|---|
| Image | 2120 | 265 | 265 |
| Annotation File | 2120 | 265 | 265 |
| Network Combinations | mAP50/% | mAP50-95/% | Average Inference Time/ms |
|---|---|---|---|
| YOLOv8 (baseline) | 78.5 | 57.8 | 29.4 |
| YOLOv8+BiFPN | 81.4 | 62.1 | 29.7 |
| YOLOv8+NAS-FPN | 82.5 | 63.2 | 30.0 |
| YOLOv8+EMFE | 82.8 | 64.0 | 29.9 |
| YOLOv8+EMFE+LFF | 83.1 | 64.9 | 29.6 |
| YOLOv8+SE | 83.5 | 66.1 | 30.0 |
| YOLOv8+ECA | 83.2 | 65.3 | 29.8 |
| YOLOv8+CBAM | 84.6 | 67.2 | 30.3 |
| YOLOv8+MDIAM | 86.2 | 70.5 | 30.6 |
| YOLOv8+CIoU | 81.5 | 60.0 | 29.6 |
| YOLOv8+EIoU | 85.6 | 68.1 | 29.8 |
| YOLOv8+Wise-IoUv1 | 85.0 | 68.0 | 29.9 |
| YOLOv8+AWIoU | 86.5 | 70.1 | 30.1 |
| YOLOv8+EMFE+LFF+MDIAM+AWIoU | 86.7 | 70.4 | 29.9 |
| Index | k | mAP50/% | mAP50-95/% | Average Inference Time/ms | ||
|---|---|---|---|---|---|---|
| 1 | 3 | 0.5 | 0.3 | 86.0 | 70.2 | 28.7 |
| 2 | 7 | 0.5 | 0.3 | 86.4 | 70.1 | 30.6 |
| 3 | 5 | 0.3 | 0.3 | 86.1 | 70.1 | 29.1 |
| 4 | 5 | 0.7 | 0.3 | 86.5 | 69.9 | 30.4 |
| 5 | 5 | 0.5 | 0.1 | 86.0 | 70.0 | 28.9 |
| 6 | 5 | 0.5 | 0.3 | 86.7 | 70.3 | 29.5 |
| 7 | 5 | 0.5 | 0.5 | 86.5 | 70.0 | 30.2 |
| Models | mAP/% | Average Inference Time/ms |
|---|---|---|
| YOLOv5 | 79.8 | 34.7 |
| YOLOv7 | 85.6 | 49.5 |
| YOLOv8 | 93.9 | 25.4 |
| Ours | 94.9 | 26.7 |
| Categories of Products | YOLOv8 | YOLOv11 | Ours |
|---|---|---|---|
| Crisps | 85.0% | 86.5% | 85.0% |
| Ili Pure Milk | misrecognition | missed detection | 65.0% |
| Sprite | misrecognition | 99.5% | 100.0% |
| Coca Cola | 92.0% | 92.5% | 94.0% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Z.; Wu, B.; Xie, K.; Yu, J.; Xu, B.; Wen, C.; He, J.; Zhang, W. Recognition of Dense Goods with Cross-Layer Feature Fusion Based on Multi-Scale Dynamic Interaction. Electronics 2025, 14, 2303. https://doi.org/10.3390/electronics14112303
Wu Z, Wu B, Xie K, Yu J, Xu B, Wen C, He J, Zhang W. Recognition of Dense Goods with Cross-Layer Feature Fusion Based on Multi-Scale Dynamic Interaction. Electronics. 2025; 14(11):2303. https://doi.org/10.3390/electronics14112303
Chicago/Turabian StyleWu, Zhiyuan, Bisheng Wu, Kai Xie, Junqin Yu, Banghui Xu, Chang Wen, Jianbiao He, and Wei Zhang. 2025. "Recognition of Dense Goods with Cross-Layer Feature Fusion Based on Multi-Scale Dynamic Interaction" Electronics 14, no. 11: 2303. https://doi.org/10.3390/electronics14112303
APA StyleWu, Z., Wu, B., Xie, K., Yu, J., Xu, B., Wen, C., He, J., & Zhang, W. (2025). Recognition of Dense Goods with Cross-Layer Feature Fusion Based on Multi-Scale Dynamic Interaction. Electronics, 14(11), 2303. https://doi.org/10.3390/electronics14112303