Abstract
With the sharp increase in the number of products and the development of the remanufacturing industry, disassembly lines have become the mainstream recycling method. In view of the insufficient research on the layout of multi-form disassembly lines and human factors, we previously proposed a linear-U-shaped hybrid layout considering the constraints of employee posture and a Duel-DQN algorithm assisted by Large Language Model (LLM). However, there is still room for improvement in the utilization efficiency of workstations. Based on this previous work, this study proposes an innovative layout of U-shaped and circular disassembly lines and retains the constraints of employee posture. The LLM is instruction-fine-tuned using the Quantized Low-Rank Adaptation (QLoRA) technique to improve the accuracy of disassembly sequence generation, and the Dueling Deep Q-Network(Duel-DQN) algorithm is reconstructed to maximize profits under posture constraints. Experiments show that in the more complex layout of U-shaped and circular disassembly lines, the iterative efficiency of this method can still be increased by about 26% compared with the traditional Duel-DQN, and the profit is close to the optimal solution of the traditional CPLEX solver, verifying the feasibility of this algorithm in complex scenarios. This study further optimizes the layout problem of multi-form disassembly lines and provides an innovative solution that takes into account both human factors and computational efficiency, which has important theoretical and practical significance.
1. Introduction
Due to the rapid advancement of technology, new products are continuously emerging on the market. At the same time, End-of-Life (EOL) products are steadily accumulating, and these products are increasingly recycled and reused. The Disassembly Line Balancing Problem (DLBP) has emerged in response to this context. Gungor and Gupta [1] conducted the first scientific research on the DLBP in 2004. Since then, many scholars have examined the DLBP for a variety of disassembly line layouts and proposed corresponding solution approaches. Notably, Altekin [2] proposed the linear disassembly line, while Agrawal [3] introduced the U-shaped disassembly line. The linear disassembly line is a cost-effective option and relatively easy to construct, whereas the U-shaped disassembly line utilizes available space more efficiently. Additionally, the parallel disassembly line improves the utilization of individual workstations, and the bilateral disassembly line serves as an extension of the linear layout. In practical applications, both the linear disassembly line [4] and the U-shaped disassembly line [3] are widely adopted. Meanwhile, scholars have also conducted research on related layouts with a profit-oriented approach [5,6].
Due to differences in product quality, service life, and other variable factors, the recycling of End-of-Life products (ELOPs) involves considerable uncertainty. Each EOL product may require specific treatment or additional care during the disassembly process. Consequently, human participation in disassembly activities is of vital importance. Tang, Zhou, and other researchers [7] pointed out that if human factors are not considered during disassembly system design, more complex and uncertain problems may arise. Kara et al. [8] suggested that incorporating ergonomic factors could better address the structural variability of EOL products and the uncertainties introduced by human intervention. One particularly important human factor is the posture of workers during disassembly tasks. Requiring workers to use a fixed posture throughout operations can significantly reduce overall disassembly efficiency [9]. Therefore, intelligent disassembly system design increasingly emphasizes human-centric modeling and optimization.
Meanwhile, the rapid integration of Internet of Things (IoT) technologies into manufacturing environments introduces additional complexities. IoT-enabled disassembly lines can leverage connected sensors and devices for real-time data acquisition, monitoring, and control, which can improve the efficiency and adaptability of the disassembly process [10]. However, this integration also introduces challenges related to cybersecurity and data privacy [11]. Thus, there is a growing need for solutions that simultaneously address operational optimization, human factors, and cybersecurity challenges.
With respect to solution approaches, many scholars have also attempted to use different approaches for solving problems in various environments [12,13,14]. In recent years, reinforcement learning algorithms have demonstrated strong potential in solving large-scale, complex optimization problems in disassembly contexts [15]. In particular, integrating reinforcement learning with emerging techniques such as Large Language Models (LLMs) offers new opportunities for improving solution quality and efficiency. Based on the above research context, our previous work proposed a hybrid disassembly line balancing method combining LLM-assisted disassembly sequence generation and a Duel-DQN algorithm to enhance efficiency [16]. However, there remains room for improvement in workstation utilization and adaptability to more complex layouts.
Therefore, this paper proposes a novel U-shaped and circular hybrid disassembly line layout (UC-HDLBP) to further optimize workstation utilization while considering worker posture constraints. A new solution framework is introduced, wherein an instruction-fine-tuned LLM using Quantized Low-Rank Adaptation (QLoRA) improves disassembly sequence generation, and a redesigned Duel-DQN optimizes task allocation to maximize overall profits. Furthermore, the proposed LLM-assisted framework is designed with extensibility in mind, offering a pathway to integrate cybersecurity and privacy-preserving mechanisms into IoT-enabled smart remanufacturing environments.
The contributions of this work are summarized as follows:
- We propose a novel hybrid disassembly system combining U-shaped and circular disassembly line layouts, considering worker posture constraints, and formulate a profit-maximization mathematical model.
- We design a QLoRA-based instruction-fine-tuning approach for LLMs and redesign the Duel-DQN algorithm to efficiently solve the complex UC-HDLBP.
- We demonstrate that the framework can be extended to address cybersecurity, privacy, and trust challenges in IoT-enabled disassembly environments, making it suitable for intelligent, secure manufacturing applications.
The remainder of this paper is organized as follows: Section 2 describes the problem formulation. Section 3 presents the methodology. Section 4 reports and analyzes experimental results. Section 5 discusses cybersecurity and privacy extensions. Finally, Section 6 concludes the paper and outlines future research directions.
2. Problem Description
2.1. U-Shaped and Circular Disassembly Line Balance Problem
The layouts of hybrid disassembly lines are diverse, and the choice of layout can significantly affect operational efficiency, resource utilization, and worker performance. To further improve workstation utilization beyond traditional designs, we propose the U-Shaped and Circular Hybrid Disassembly Line Balancing Problem (UC-HDLBP). As shown in Figure 1, the system consists of two disassembly lines: Line 1 adopts a U-shaped configuration, and Line 2 adopts a circular configuration. When a product enters the disassembly lines, workstations on the U-shaped disassembly line have two decision opportunities to perform disassembly tasks due to the ability to work on both sides, while the circular disassembly line can be regarded as a linear disassembly line with connected ends, enabling workstations within it to have multiple decision opportunities to perform disassembly tasks. The two disassembly lines can be activated separately or simultaneously. This layout allows for more flexible product allocation arrangements. The final optimization objective is to determine the optimal product allocation, disassembly sequence, and task allocation across these production lines to maximize total profit.
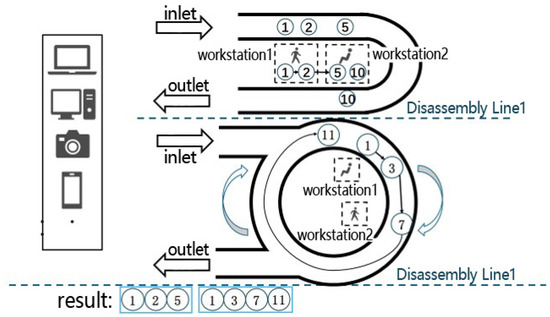
Figure 1.
The schematic diagram of U-shaped and circular disassembly lines.
Given the increasing adoption of smart remanufacturing systems equipped with IoT sensors and real-time monitoring, modern disassembly lines must also address challenges related to cybersecurity, data privacy, and operational trust. In particular, sensitive operational data and worker-related information collected during disassembly must be safeguarded. Consequently, disassembly task planning must not only optimize operational objectives but also consider data sensitivity, privacy protection, and secure task execution—particularly in environments where IoT devices are embedded throughout the production process.
In this context, our UC-HDLBP formulation explicitly considers human factors by imposing posture constraints on workers. We classify workstations into two types: standing-type and sitting-type. Workers at each workstation must use the corresponding posture to perform tasks, reducing fatigue and improving disassembly efficiency. Each disassembly task for a product is associated with an optimal required posture, and task allocations must comply with these requirements. For example, if the optimal disassembly posture for a task is standing, the task can only be performed by workers at standing-type workstations.
2.2. Mathematical Model
The part compositions of each product may differ, and thus, when disassembling different products, the disassembly steps must conform to the structure of the product, meaning that the disassembly must satisfy the precedence and conflict relationships between disassembly tasks of the product. Such relationships can be represented by an AND/OR graph. Figure 2 shows an AND/OR graph of a washing machine, where <1> represents Component 1, which is composed of basic parts No. 1 to No. 6, and arcs 1–13 represent 13 disassembly tasks. Considering these relationships between disassembly tasks, we formulate a mixed-integer linear programming model based on the following assumptions:
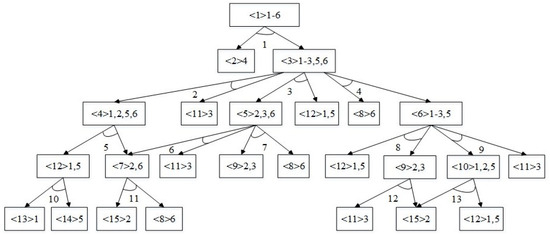
Figure 2.
An example of a washing machine or picture.
- The relevant parameters of ELOPs are constant and known.
- ELOPs may undergo complete or partial disassembly.
- The disassembly line and workstation parameters are known and constant.
- The time required to perform each disassembly task is fixed.
- Task assignments must satisfy both precedence and conflict constraints.
2.2.1. Symbol Definition
The mathematical symbols involved in the UC-DLBP model are as follows:
| Set of all ELOP to be disassembled, = {1, 2, …, P}. | |
| Set of all components/parts in product p, . | |
| Set of all tasks in product p, . | |
| Set of all disassembly lines, . | |
| U-shaped disassembly line edge selection set, . | |
| Set of all U-shaped workstations, . | |
| Set of all circular workstations, . | |
| Set of the relationship between components i and task j in product p. | |
| Set of tasks that conflict with task j in product p. | |
| Set of immediate tasks for task j in product p. | |
| P | Number of products. |
| Number of components/parts in production p. | |
| Number of tasks in production p. | |
| Number of U-shaped workstations. | |
| Number of circular workstations. | |
| The value of component i in product p. | |
| Time to execute the j-th task of the p-th product. | |
| Unit time cost of executing the j-th task of the p-th product. | |
| Unit time cost of opening of the l-th disassembly line. | |
| Fixed cost of opening of the w-th workstation in l-th. | |
| Posture to execute the j-th task of the p-th product. | |
| Configuration of opening of the w-th workstation in the l-th disassembly line. |
2.2.2. Relation Matrix
This section is mainly used to define the components of the product and the relationships between disassembly tasks. Through the definition of the relationship matrix, we can mathematically define the product information conveyed in the AND/OR graph. In the following formulas, p represents the number of products, i denotes the component number, and j and k represent the task numbers.
The disassembly matrix is denoted as , which is used to characterize the association between components and disassembly tasks.
The precedence matrix, denoted as , is used to depict the relationship between two disassembly tasks.
The incidence matrix is used to define the conflict relationships between disassembly tasks.
2.2.3. Decision Variables
The above formulas define the decision variables of UR-DLBP, which represent the specific allocation of product disassembly tasks.
2.2.4. Maximizing Profit Model
The mathematical model of the UC-HDLBP in this paper aims to maximize profits. This profit includes the profits obtained from performing disassembly tasks within the U-shaped disassembly line and the circular disassembly line, and deducts the costs of performing disassembly tasks, as well as the costs for activating the workstations and the disassembly lines.
2.2.5. Constraints
To align with real-world scenarios, a series of constraint conditions must be defined to ensure that no illegal operations occur during disassembly, which would violate real-world logic—including the relationships between product components and tasks defined earlier, the relationships between disassembly postures, and so on.
- (1)
- U-shaped Disassembly Line Constraint:
The above constraints are the conditions that must be met when products are allocated to the U-shaped disassembly line. Formulas (2) and (3) involve the constraints of employees’ postures—that is, the disassembly posture required for the product must be consistent with the disassembly posture of the assigned workstation, and the disassembly line and the corresponding workstation must be in the open state. Formula (4) ensures that the work cycle on the disassembly line will not be longer than the operating cycle of the disassembly line. Formulas (6) and (7) are the relationships that the disassembly tasks allocated on the U-shaped disassembly line need to satisfy, including the precedence relationship and the conflict relationship.
- (2)
- Circular Disassembly Line Constraint:
The above constraints are the conditions that must be satisfied when products are allocated to the circular disassembly line. Formulas (8) and (9) are used to restrict the posture issues of products and workstations, and at the same time ensure that products can only be allocated to the disassembly lines and workstations that are turned on. Formula (10) ensures that the cycle time of the circular disassembly line is longer than the cycle time of each workstation. Formulas (11) and (12) ensure that the disassembly tasks allocated to the circular disassembly line satisfy the precedence relationship and the conflict relationship. Formulas (13) and (14) are to maximize the utilization of the characteristics of the circular workstations, requiring the disassembly line and the internal workstations to remain in the open state.
- (3)
- Hybrid Disassembly Line Constraint:
The above constraints are the constraints of the hybrid disassembly line. Formulas (15) and (16) ensure that each product can only be allocated to one disassembly line, and the disassembly tasks within the product are executed at most once. Formulas (17) and (18) ensure that only the disassembly lines and workstations in the open state can be used. Formulas (19)–(24) define the variable ranges of the model parameters.
3. Large Language Model Assisted Duel-DQN
The UC-HDLBP presents a hybrid disassembly line layout that combines U-shaped and circular configurations. Compared with traditional linear disassembly lines, the hybrid layout introduces greater complexity in task sequencing and resource allocation. To efficiently solve the UC-HDLBP while maintaining adaptability to smart IoT-enabled environments, we adopt a two-stage reinforcement learning approach that integrates a fine-tuned Large Language Model (LLM) with a redesigned Duel-DQN algorithm.
As illustrated in Figure 3, the proposed framework decomposes the problem into two stages: (1) the Disassembly Sequence Problem (DSP), where the LLM generates efficient disassembly sequences and allocates products to disassembly lines; and (2) the Disassembly Line Balancing Problem (DLBP), where the Duel-DQN assigns specific disassembly tasks to workstations under posture and precedence constraints. Information flows between the two stages iteratively to refine decision-making based on performance feedback.
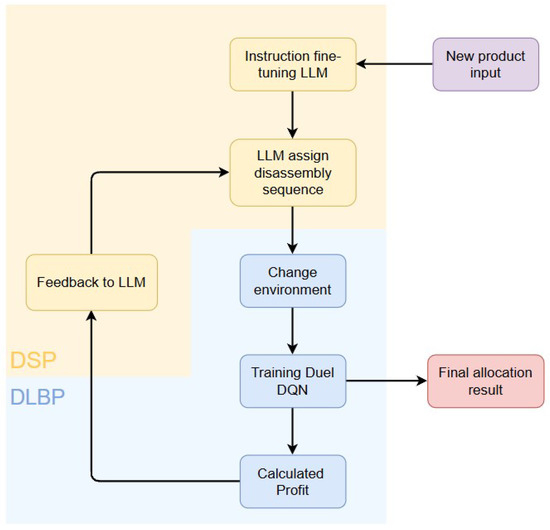
Figure 3.
The interaction process between LLM and Duel-DQN.
Importantly, by instruction-fine-tuning the LLM, we not only enhance its domain adaptability for disassembly sequencing but also prepare the framework for future extensions involving cybersecurity and privacy policies in IoT-enabled manufacturing environments. This design consideration ensures that trust, privacy, and data sensitivity factors can be incorporated into task allocation strategies without extensive re-engineering.
3.1. Instruction-Fine-Tuning
Instruction-fine-tuning is a technique that adapts pre-trained LLMs to specific tasks by providing structured input–output pairs based on domain knowledge. By fine-tuning the LLM on a curated dataset of disassembly scenarios, we guide it to generate accurate disassembly sequences aligned with ergonomic and operational constraints.
To achieve efficient and scalable fine-tuning, we apply the Quantized Low-Rank Adaptation (QLoRA) method [17], which reduces the computational and memory requirements of LLM adaptation by quantizing model parameters to lower-precision formats. This approach is particularly suitable for edge or resource-constrained environments, further supporting potential IoT applications.
3.1.1. Instruction Set Construction
Each instruction instance consists of three elements:
- Instruction: The high-level prompt describing the disassembly task.
- Input: Specific product-related information provided to the LLM.
- Output: The expected disassembly sequence and line assignment.
The instruction set is systematically generated from product AND/OR graphs to cover all feasible disassembly sequences. Algorithm 1 outlines the automatic construction process to ensure dataset completeness.
An Example of Instruction:instcution: The “personal computer” contains the following disassembly sequences: [1, 3, 7, 11], [1, 2, 5, 10], and [1, 3, 6, 9]. It also includes two disassembly lines: 0 and 1. Only output the selected disassembly lines and disassembly sequences.input: Select a disassembly sequence for the personal computer and allocate the disassembly line.output: 1,[1, 3, 7, 11]
| Algorithm 1 Instruction set Generation Algorithm |
| Require: Name (the name of product p) and (set of conflict matrices of products) Ensure: Instruction set
|
3.1.2. Instruction Set Generation
Algorithm 1 details the generation of the instruction dataset used to fine-tune the LLM, ensuring broad coverage of possible product configurations and sequencing options.
3.1.3. Expected Fine-Tuning Result
After fine-tuning, the LLM is expected to accurately map given product structures to efficient disassembly sequences and allocate products to appropriate disassembly lines. Furthermore, the fine-tuned LLM forms a foundation for future extensions involving privacy-preserving sequencing or trust-aware task allocation in IoT-integrated settings.
Q: Select a disassembly sequence for the personal computer and allocate the disassembly line.
A: 0, [1, 2, 5, 10]
If the LLM can output a dialogue like the above after fine-tuning, it indicates that the LLM has successfully completed the task and has the ability to solve the DSP.
3.2. Design of the Duel-DQN Algorithm
3.2.1. State Space
The state space encodes the current allocation of disassembly tasks across workstations, including information about worker posture constraints and task assignments. Formally, the state is defined as follows:
Among them, represents the current state on the disassembly line. When X is 1, it means that a product is being disassembled on the disassembly line. The value of indicates that task j of product p is assigned to the s side of workstation of the U-shaped disassembly line, and the value of indicates that task j of product p is assigned to workstation of the circular disassembly line. indicates that task p is assigned to disassembly line z.
3.2.2. Action Space
A U-shaped disassembly line can be simply understood as the combination of two straight disassembly lines. A circular disassembly line can be considered as two disassembly lines connected in a loop. Therefore, in the design of the action space, actions for both of these two types of disassembly lines can be designed as variants of the straight disassembly line. We assume that the U-shaped disassembly line and the circular disassembly line have the same number of workstations. Table 1 shows the action values designed in this section. Note that the action values on the exit side of the U-shaped disassembly line are designed in reverse order in the table. Since the circular disassembly line has no space restrictions, it does not have illegal values like the straight disassembly line. When the number of workstations on both sides is different, there will inevitably be illegal values on one side. In this case, an additional judgment can be made during the training phase.

Table 1.
Action selection code of UC-HDLBP.
3.2.3. Reward Design
In the DSP stage, the reward for the agent is the profit difference between the current selection and the previous selection. The reward structure in the DLBP stage is more complex, aiming to achieve the complete disassembly of products while avoiding an excessive number of tasks assigned to a single workstation. Positive rewards will be given for behaviors that comply with the disassembly rules, while negative rewards will be imposed for behaviors that violate the rules or fail to execute tasks. When the disassembly of a product is completed, the agent will also receive additional rewards.
3.2.4. Train Algorithm
Based on the above settings of the Duel-DQN environment parameters, we will train the agent for disassembly task allocation. As shown in Algorithm 2, the process first involves generating instructions using the instruction set generation algorithm mentioned above to fine-tune the LLM. Subsequently, according to the LLM’s decisions, the agent continues the subsequent disassembly task allocation activities and updates the state space. Finally, the profit obtained in this round is returned to the LLM to reconsider the latest decision for a new round of attempts. It can be observed that the algorithm only receives positive rewards when the allocation of disassembly tasks conforms to the optimal disassembly postures.
| Algorithm 2 Task Allocation Phase Algorithm |
| Require: LLM, IS, set of disassembly sequences , action A, selected disassembly line l, set of workstations , state , Ensure: ,
|
4. Experiment and Results
4.1. Experimental Cases
The experimental cases of this paper are shown in Table 2, where different cases correspond to disassembly environments of varying scales, including the number of products and workstations.
Table 2.
Case Description.
4.2. Comparison of Fine-Tuning Effects of Trained Products
The content of this section mainly focuses on observing the effect of fine-tuning. The LLM model used in this experiment is InternLM2-7B. Currently, we have two models: the original model and the fine-tuned model. The dataset we selected for fine-tuning includes the products mentioned in Table 2. The steps of this experiment are as follows:
- Load the fine-tuned model and the original model, respectively.
- Conduct 15,000 questions, with the scope limited to the disassembly sequences of the four products in Table 2 Use the AND/OR diagrams of the corresponding products as the result verification, and record the number of legal disassembly sequences recommended by the model.
- Before the experiment, enable the model to understand the products in the form of describing the AND/OR diagrams. When starting the test, ask questions to make the model provide the disassembly sequences.
Figure 4 shows the experimental results demonstrating the accuracy rates of the models in solving DSP under two different scenarios, respectively. On the left side, the figure presents the accuracy rates of the original model and the fine-tuned model when directly asked questions. It can be observed that when asking questions directly without providing relevant hints or training to the model, the model has no clue about the direction of the problem. Consequently, within 15,000 queries, the number of times the model can obtain the correct disassembly sequence and provide correct answers is very limited. The accuracy rate after fine-tuning is 100%. This is because all tested questions fall within the content scope of the dataset. As long as the model’s fine-tuning training is successful, the model will naturally memorize these answers. On the right side, the original model after dialogue training is displayed. Through dialogue training, the original model has understood the problem. Although it can provide answers, there is still an error rate. Since the fine-tuned model has already achieved a 100% accuracy rate in direct question-and-answer scenarios, there is no need to conduct dialogue training for it.
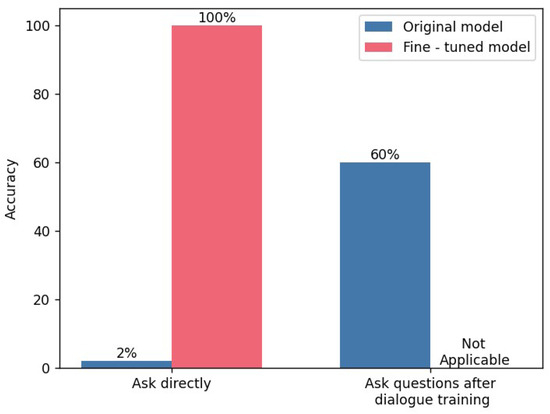
Figure 4.
Comparison of the fine-tuning effects of the model.
For the UC-HDLBP, using the advantages of the LLM to solve the product allocation and DSP of this issue can reduce the difficulty of solving it by the Duel-DQN. Therefore, for this problem, pre-fine-tuning an LLM is a relatively good solution.
4.3. Comparison of the Fine-Tuning Effects for Untrained Products
This section explores whether the model can perform as well as in the previous section when it encounters a brand-new product. In this section, a brand-new virtual product will be prepared, and the AND/OR diagram of this virtual product is shown in Figure 5.
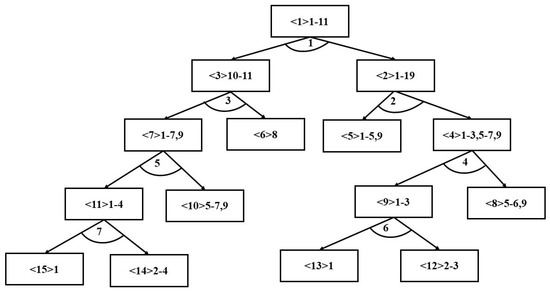
Figure 5.
The AND/OR diagram of the virtual product.
In the experiment of this section, we will also employ the original model and the fine-tuned model for comparison. We will conduct 100 simulations for each model, respectively, and record the results.
As illustrated in Figure 6, although the fine-tuned LLM shows some capability to generate plausible disassembly sequences, its performance on entirely unseen products remains limited. This outcome reflects the fact that the fine-tuning process primarily memorized training instances rather than generalizing abstract AND/OR graph reasoning. Future work will address this limitation by incorporating structure-aware instruction-tuning or graph-based input representations.
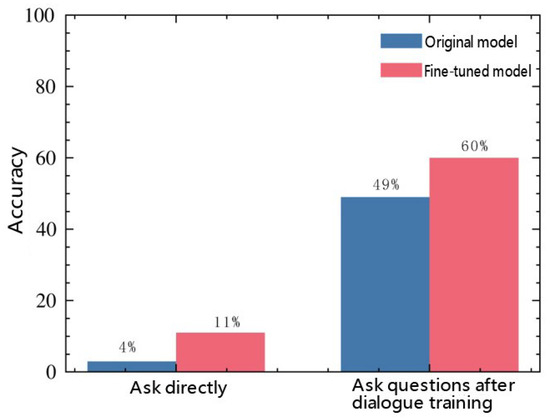
Figure 6.
Accuracy comparison of new product.
Nevertheless, for smart manufacturing systems where product structures are pre-known and defined, the current fine-tuned LLM is sufficient and provides a practical solution foundation.
4.4. Comparison of Iteration Efficiency
We next compare the iterative learning efficiency between the Duel-DQN alone and the LLM-assisted Duel-DQN framework. Case 3 (medium-large scale) was selected as the benchmark.
In the experiment of this section, Case 3 is taken as an example to observe the training situation;for sitting and standing postures, the time cost parameters for performing disassembly are fixed at 4 and 10, respectively, and the costs for activating workstations are fixed at 100 and 150, respectively. The final data obtained are as follows.
Figure 7 shows the results of the iterations. This section has tracked 100,000 iterations. It can be seen that around the 70,000th step, the LLM-assisted Duel-DQN begins to stabilize, while the Duel-DQN remains in an exploration state. The Duel-DQN algorithm does not finally stabilize and catch up with the LLM-assisted DQN algorithm until around the 95,000th step.
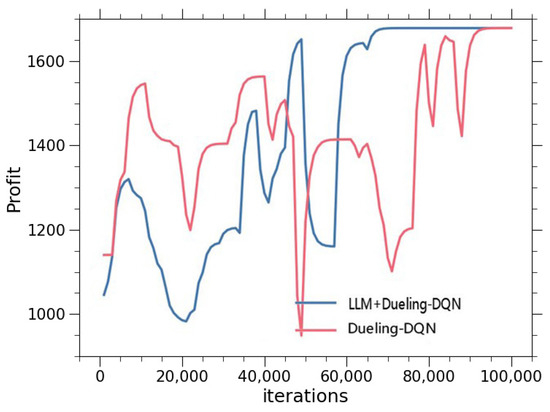
Figure 7.
Efficiency comparison.
The results clearly show that the LLM-assisted Duel-DQN converges approximately 26% faster than the traditional Duel-DQN: it stabilizes around 70,000 steps, compared to about 95,000 steps for the Duel-DQN without LLM assistance. This is because the pre-structuring of disassembly sequences by the LLM effectively reduces the search complexity of Duel-DQN, accelerating convergence and improving sample efficiency. Such efficiency gains are critical for deployment in IoT-enabled systems where computational resources and response times are constrained.
Actually, in subsequent iterations, the solution results of the LLM-assisted Duel-DQN algorithm continue to improve further, while the Duel-DQN remains completely stagnant at its peak value achieved at 95,000 steps. The primary factor contributing to this phenomenon is the performance limitation of the Duel-DQN algorithm when solving large-scale cases, which will be discussed as a limitation in the next section.
4.5. Comparison and Analysis of Results
Table 3 shows the final profits obtained by different algorithms under different cases. Through the comparison of all the data, we can find that the profit obtained by the solution proposed in this paper is quite close to that obtained by CPLEX. Due to the relatively large scale of the problem in Case 4, there was a situation of insufficient memory when using DQN and Duel-DQN, resulting in not very good final training results. However, the Duel-DQN assisted by the LLM under the same conditions was able to obtain a solution, which indicates that the solution method mentioned in this section can still solve problems in large-scale cases when there is a lack of computing resources, reducing the economic consumption in terms of computing power.
Table 3.
Profit comparison between Duel-DQN and Cplex.
The LLM-assisted Duel-DQN consistently achieves results close to the optimal CPLEX solution, outperforming both the DQN and Duel-DQN baselines. In large-scale cases (e.g., Case 4), the baseline methods (DQN and Duel-DQN) suffer from memory exhaustion or convergence failures, leading to varying degrees of result degradation. The LLM-assisted method, however, maintains stable performance.
This phenomenon primarily stems from the fact that Duel-DQN requires additional computational resources and storage space to maintain its dual-network structure compared to the ordinary DQN [18]. In small-to-medium-scale cases (e.g., Cases 1 and 2), Duel-DQN can normally obtain better solutions than the DQN algorithm. However, as the problem scale increases (e.g., Cases 3 and 4), the expansion of the problem’s state space leads to a rapid increase in computational resource requirements, and Duel-DQN becomes unable to solve problems effectively. As previously mentioned, the integration of LLM assistance can reduce the actual problem scale that DQN needs to solve, thereby ensuring iterative efficiency and results under limited computational resources.
This demonstrates that our framework is not only more efficient but also more scalable and robust—key properties for future deployment in distributed, IoT-enabled, or privacy-sensitive environments.
5. Cybersecurity and Privacy in IoT-Enabled Disassembly Systems
The LLM-assisted Duel-DQN algorithm demonstrates superior performance in optimizing the disassembly sequence (as shown in Table 3 and Figure 7), which is crucial in an IoT-enabled disassembly line where real-time data on product condition and task dependencies, gathered by sensors, needs to be processed rapidly and accurately. The algorithm’s ability to handle the complex precedence relationships derived from IoT sensor data allows for more efficient and adaptive disassembly.
In IoT-enabled smart manufacturing, disassembly lines involve sensors, edge devices, and communication protocols that handle sensitive operational and worker-related data. While the primary focus of our work is on optimization, the LLM-assisted Duel-DQN framework is inherently extensible and can be adapted to enhance cybersecurity and privacy protections in such environments.
To clarify our intended direction, this section outlines a solution-oriented vision that leverages components of our proposed system:
- Privacy-Aware Task Sequencing: The fine-tuned LLM can be enhanced to prioritize the early disassembly of components containing confidential or security-sensitive data (e.g., memory chips in smart devices). This enables safe disposal or isolation of sensitive components early in the workflow.
- Federated Learning for Worker Privacy: Our reinforcement learning agent can be integrated with federated learning frameworks [19] to enable decentralized training across IoT-enabled workstations, where posture, fatigue, or biometric data are processed locally. This prevents raw data transmission and improves compliance with privacy regulations.
- Secure Communication for Resource-Constrained Devices: Lightweight cryptographic protocols [20] and attribute-based encryption [21] can be implemented within the control layer to secure the transmission of disassembly instructions between edge devices and central coordinators. Our framework supports these protocols due to its modular decision-making architecture.
- Trust-Aware Reward Design: Privacy or safety constraints can be embedded into the reinforcement learning reward function—for example, penalizing task allocations that require a worker to reveal identifiable biometric data or exceed ergonomic risk thresholds. The LLM’s instruction-tuning mechanism enables these soft constraints to be flexibly encoded.
- Practical Integration: These features have not yet been implemented in the current experiment but are technically feasible given the modular structure of our architecture. For example, by combining federated optimization with edge inference on IoT devices, future extensions can support privacy-by-design learning loops. Our goal in this section is to articulate how LLM-based decision engines can act as gateways to integrate optimization, learning, and secure communication for intelligent disassembly environments.
6. Conclusions and Future Work
This paper addresses the challenges of disassembly line balancing in complex hybrid layouts by proposing the U-shaped and Circular Hybrid Disassembly Line Balancing Problem (UC-HDLBP). A corresponding mathematical model was developed, considering both workstation utilization and worker posture constraints. To efficiently solve this problem, a two-stage LLM-assisted Duel-DQN framework was introduced, leveraging instruction-fine-tuning of large language models via Quantized Low-Rank Adaptation (QLoRA) and a redesigned reinforcement learning structure.
Experimental results demonstrate that the proposed method significantly improves iteration efficiency compared with traditional reinforcement learning approaches, achieving near-optimal performance while reducing computational overhead. The fine-tuned LLM effectively guides disassembly sequencing under known product scenarios, while the Duel-DQN efficiently allocates disassembly tasks across hybrid lines. The solution method also proves robust when handling larger-scale problems, offering clear advantages in scalability and learning stability.
Beyond operational optimization, this work further establishes a foundation for addressing cybersecurity, privacy, and trust challenges in IoT-enabled smart remanufacturing environments. By instruction-tuning the LLM and designing flexible reward structures, the framework can be readily extended to prioritize privacy-preserving sequencing, federated learning, and lightweight secure communication in distributed, resource-constrained settings.
In future work, we plan to enhance the generalization capability of the LLM by incorporating graph-based disassembly representations and structure-aware instruction tuning, enabling adaptive sequencing for previously unseen products. Additionally, we aim to integrate explicit privacy and trust constraints into the optimization process, allowing dynamic task allocation under varying security requirements. Combining our current approach with developments in distributed learning, lightweight encryption, and blockchain-based auditing could further improve the resilience and transparency of smart disassembly systems. These directions align with broader goals of sustainable manufacturing, ethical AI deployment, and secure IoT integration.
Author Contributions
Conceptualization, X.G. methodology, S.Q.; formal analysis, J.W.; validation, C.J.; writing—original draft, C.J.; writing—review and editing, L.Q. and B.H.; supervision, X.L. and Z.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author(s).
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| ELOPs | End-of-Life Products |
| LLM | Large Language Model |
| DQN | Deep Q-Network |
| Duel-DQN | Dueling Deep Q-Network |
| DSP | Disassembly Sequence Problem |
| DLBP | Disassembly Line Balancing Problem |
| HDLBP | Hybrid Disassembly Line Balancing Problem |
| UC-HDLBP | U-shaped and Circular Hybrid Disassembly Line Balancing Problem |
| IoT | Internet of Things |
References
- Gungor, A.; Gupta, S.M.; Pochampally, K.; Kamarthi, S.V. Complications in disassembly line balancing. In Proceedings of the Environmentally Conscious Manufacturing, Tokyo, Japan, 11–15 December 2001; pp. 289–298. [Google Scholar]
- Altekin, F.T.; Kandiller, L.; Ozdemirel, N.E. Profit oriented disassembly-line balancing. Int. J. Prod. Res. 2008, 46, 2675–2693. [Google Scholar]
- Agrawal, S.; Tiwari, M.K. A collaborative ant colony algorithm to stochastic mixed-model U-shaped disassembly line balancing and sequencing problem. Int. J. Prod. Res. 2008, 46, 1405–1429. [Google Scholar] [CrossRef]
- Altekin, F.T. A comparison of piecewise linear programming formulations for stochastic disassembly line balancing. Int. J. Prod. Res. 2017, 55, 7412–7434. [Google Scholar] [CrossRef]
- Wang, K.; Li, X.; Gao, L.; Garg, A. Partial disassembly line balancing for energy consumption and profit under uncertainty. Robot. Comput.-Integr. Manuf. 2019, 59, 235–251. [Google Scholar] [CrossRef]
- Li, Z.; Janardhanan, M.N. Modelling and solving profit-oriented U-shaped partial disassembly line balancing problem. Expert Syst. Appl. 2021, 183, 115431. [Google Scholar] [CrossRef]
- Tang, Y.; Zhou, M.C.; Gao, M. Fuzzy-Petri-Net Based Disassembly Planning Considering Human Factors. IEEE Trans. Syst. Man Cybern.-Part A 2006, 36, 718–726. [Google Scholar] [CrossRef]
- Kara, Y.; Atasagun, Y.; Gökçen, H.; Hezer, S.; Demirel, N. An integrated model to incorporate ergonomics and resource restrictions into assembly line balancing. Int. J. Comput. Integr. Manuf. 2014, 27, 997–1007. [Google Scholar] [CrossRef]
- Guo, X.; Wei, T.; Wang, J.; Liu, S.; Qin, S.; Qi, L. Multi-objective U-shaped Disassembly Line Balancing Problem Considering Human Fatigue Index and An Efficient Solution. IEEE Trans. Comput. Soc. Syst. 2022, 10, 2061–2073. [Google Scholar] [CrossRef]
- Chau, M.Q.; Nguyen, X.P.; Huynh, T.T.; Chu, V.D.; Le, T.H.; Nguyen, T.P.; Nguyen, D.T. Prospects of application of IoT-based advanced technologies in remanufacturing process towards sustainable development and energy-efficient use. Energy Sources Part A Recover. Util. Environ. Eff. 2021, 1–25. [Google Scholar] [CrossRef]
- Wong, K.S.; Kim, M.H. Privacy protection for data-driven smart manufacturing systems. Int. J. Web Serv. Res. (IJWSR) 2017, 14, 17–32. [Google Scholar] [CrossRef]
- Avikal, S.; Jain, R.; Mishra, P.K. A Kano model, AHP and M-TOPSIS method-based technique for disas sembly line balancing under fuzzy environment. Appl. Soft Comput. 2014, 25, 519–529. [Google Scholar] [CrossRef]
- Zhu, L.X.; Zhang, Z.Q.; Guan, C. Multi-objective partial parallel disassembly line balancing problem using hybrid group neighbourhood search algorithm. J. Manuf. Syst. 2020, 56, 252–269. [Google Scholar] [CrossRef]
- Altekin, F.T.; Bayındır, Z.P.; Gümüşkaya, V. Remedial actions for disassembly lines with stochastic task times. Comput. Ind. Eng. 2016, 99, 78–96. [Google Scholar] [CrossRef]
- Gu, J.; Wang, J.; Guo, X.; Liu, G.; Qin, S.; Bi, Z. A Metaverse Based Teaching Building Evacuation Training System with Deep Reinforcement Learning. IEEE Trans. Syst. Man Cybern. Syst. 2022, 53, 2209–2219. [Google Scholar] [CrossRef]
- Guo, X.; Jiao, C.; Ji, P.; Wang, J.; Qin, S.; Hu, B.; Qi, L.; Lang, X. Large Language Model-Assisted Reinforcement Learning for Hybrid Disassembly Line Problem. Mathematics 2024, 12, 4000. [Google Scholar] [CrossRef]
- Dettmers, T.; Pagnoni, A.; Holtzman, A.; Zettlemoyer, L. Qlora: Efficient finetuning of quantized llms. Adv. Neural Inf. Process. Syst. 2024, 36, 10088–10115. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.V.; Lanctot, M.; Freitas, N.D. Dueling network architectures for deep reinforcement learning. In Proceedings of the 33rd International Conference on International Conference on Machine Learning—Volume 48 (ICML’16), New York, NY, USA, 20–22 June 2016; pp. 1995–2003. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Ali, A.; Zhang, L.; Arshad, J.; Mahmood, Y. A lightweight encryption scheme for industrial internet of things using physically unclonable functions. IEEE Trans. Ind. Inform. 2021, 17, 3980–3989. [Google Scholar]
- Zhang, R.; Liu, L.; Chen, Y.; Nepal, S. Attribute-based encryption for cloud computing access control: A survey. IEEE Access 2018, 6, 49428–49449. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).