
Anchor-Free SNR-Aware Signal Detector for Wideband Signal Detection Framework


Abstract
1. Introduction
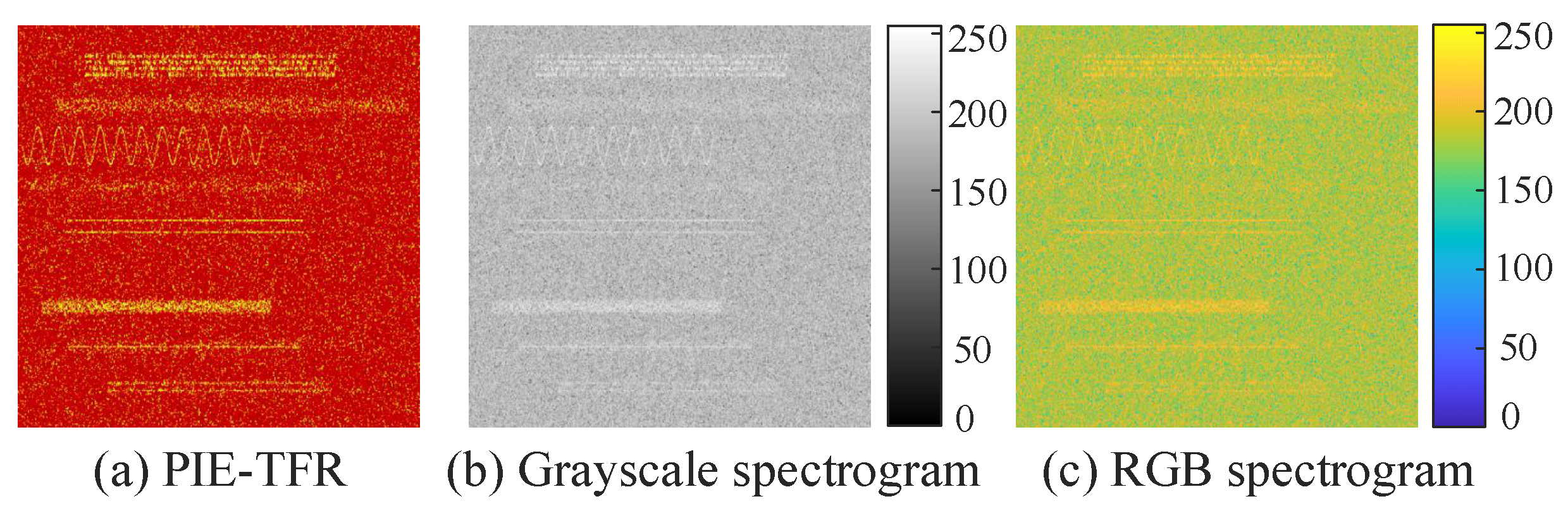
- Front-end spectrograms are underexplored and visually/informationally limited. Specifically, existing studies have only considered two types of spectrograms: grayscale spectrograms obtained through short-time Fourier transform (STFT) and RGB spectrograms derived by applying pseudo-color processing to the grayscale spectrograms. Visually, as the SNR decreases, the contrast between foreground signals and background noise rapidly diminishes in these spectrograms, resulting in indistinct signal regions and time–frequency characteristics. Moreover, they provide limited information gain for recognition and are prone to information degradation. Since spectrograms serve as the data input, these deficiencies can hinder the quality of feature representations extracted by back-end networks.
- Back-end networks lack task-specific customization. Specifically, the aforementioned networks are designed for generic object detection datasets [20], which differ significantly in data manifold characteristics from spectrogram datasets. For example, most existing methods are transferred from the anchor-based networks. However, the signal bounding boxes in spectrograms exhibit more diverse sizes and aspect ratios due to the variability in signal transmission parameters, which makes these anchor-parameter-sensitive networks [21] easily encounter anchor mismatch and performance degradation. Additionally, unique task attributes, such as the SNR, can lead to potential feature impairment and misalignment. The domain-specific prior knowledge related to these attributes has not been effectively incorporated into network design, resulting in limited performance improvements.
- At the frontend of the framework, a novel multichannel enhanced spectrogram (MCE spectrogram) is proposed. First, a visual enhancement channel is added alongside the base channel to establish a prior attention mechanism. This enables the back-end network to focus more effectively on foreground signals and capture salient visual features. Additionally, an information complementary channel is introduced to explicitly encode extra recognition information within the signal region, thereby improving the semantic feature learning capability of the network.
- At the backend of the framework, we propose a novel SNR-aware network (SNR-aware Net) based on a critical distinction between wideband signal detection and object detection, namely SNR. Firstly, a trainable time–frequency feature gating aggregation module (TFFGAM) is integrated into the neck network, facilitating more task-oriented feature fusion. Furthermore, a multi-task detection head is introduced, which employs the anchor-free paradigm for better generalization to signals with varying bandwidths and durations. In addition to performing classification and regression tasks, the head adds an auxiliary task branch to incorporate the prior knowledge that signals exhibit differentiated characteristics at varying SNRs. This branch enables SNR awareness, effectively alleviating training ambiguities caused by feature misalignment and preventing the network from fitting to weakly discriminative feature representations.
- To evaluate the performance of the MCE spectrogram, we integrate it into several state-of-the-art detection networks designed for wideband signal detection and compare these networks with their counterparts based on traditional spectrogram baselines. We also compare these networks with the proposed SNR-aware Net. Experimental results demonstrate the modality superiority of the MCE spectrogram and the state-of-the-art performance of SNR-aware Net. Additionally, we conduct complexity comparisons and ablation experiments to further analyze the effectiveness of the MCE spectrogram and SNR-aware Net.
2. Related Work
2.1. From Narrowband Signal Classification Towards Wideband Signal Detection Framework
2.2. Wideband Signal Detection Framework
2.2.1. Front-End Spectrogram
2.2.2. Back-End Detection Network
3. Motivation
3.1. Towards a More Spectrogram-Centric Framework
3.2. Towards a More Tailored SNR-Specific Framework
4. Methodology
4.1. MCE Spectrogram
4.1.1. Channel 1 (Base Channel)
4.1.2. Channel 2 (Visual Enhancement Channel)
4.1.3. Channel 3 (Information Complementary Channel)
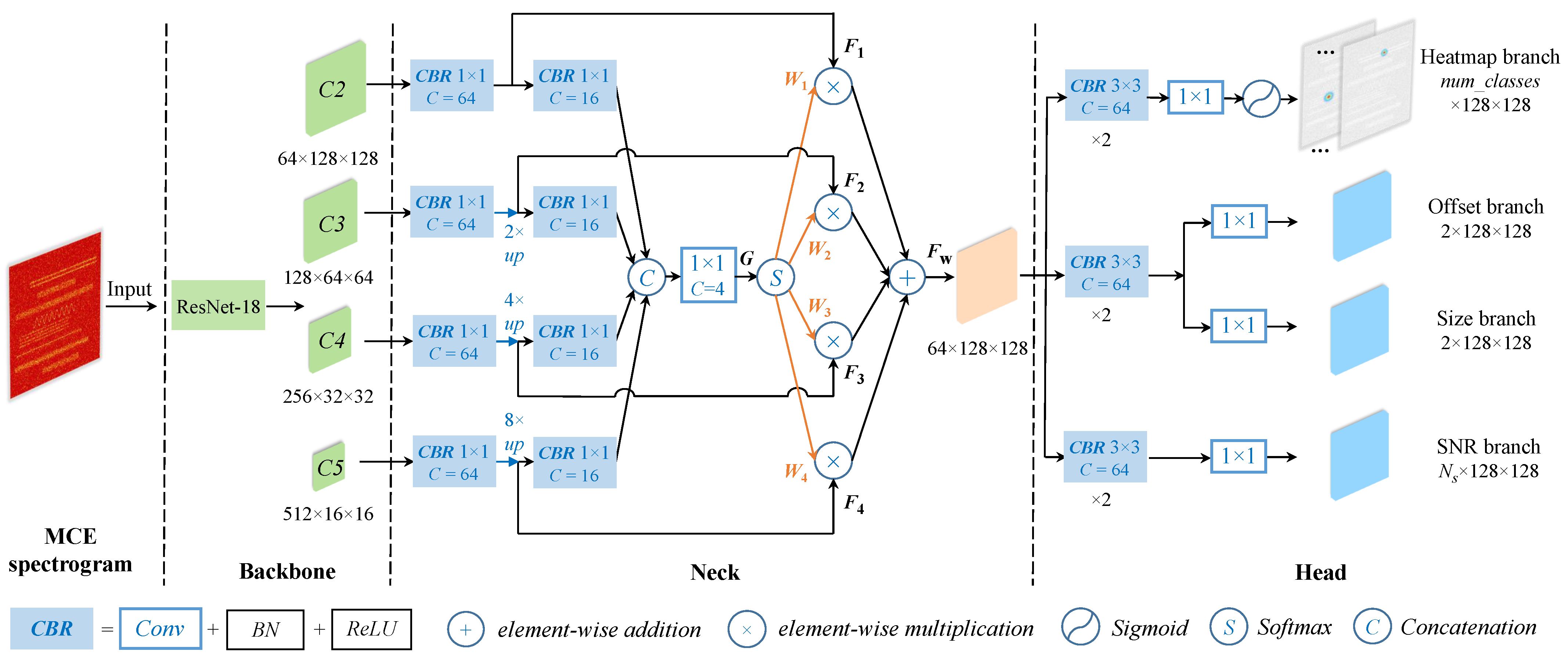
4.2. SNR-Aware Net
4.2.1. Backbone
4.2.2. Neck
4.2.3. Head
5. Experiments
5.1. Experimental Settings
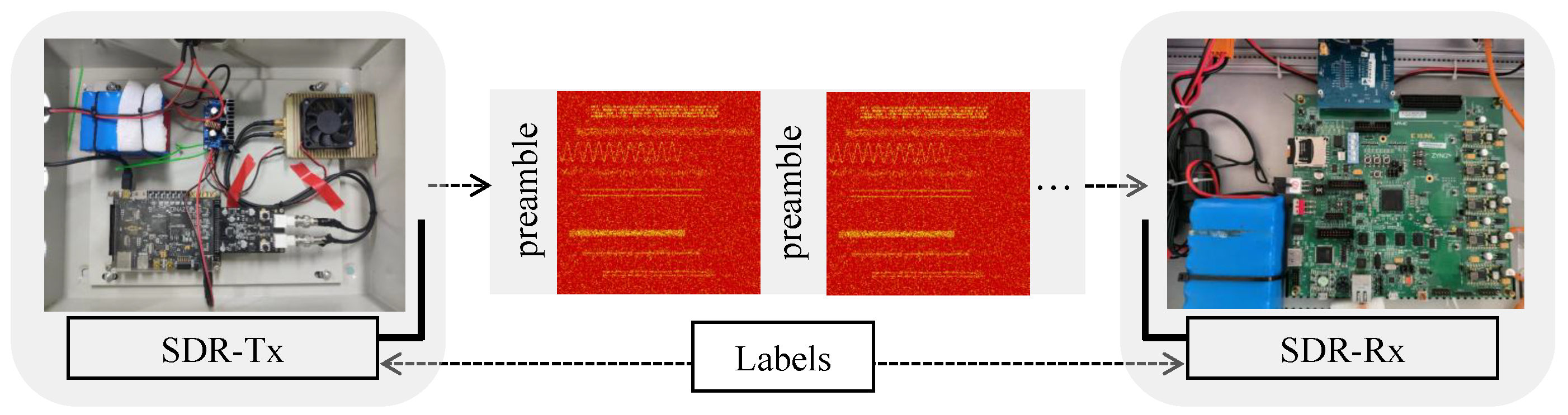
5.1.1. Dataset Generation
5.1.2. Evaluation Metrics
5.1.3. Implementation Details
- Faster R-CNN: For a fair comparison, we adjust Faster R-CNN as suggested in [8], including configuring the backbone as pre-trained VGG-13 and reducing channels.
- SSD: Following [9], the backbone is configured as VGG-16, with default anchor settings and loss functions.
- YOLOv3: Adjustments are made to YOLOv3 following [5], including configuring the backbone as DarkNet-53 and replacing the localization loss function.
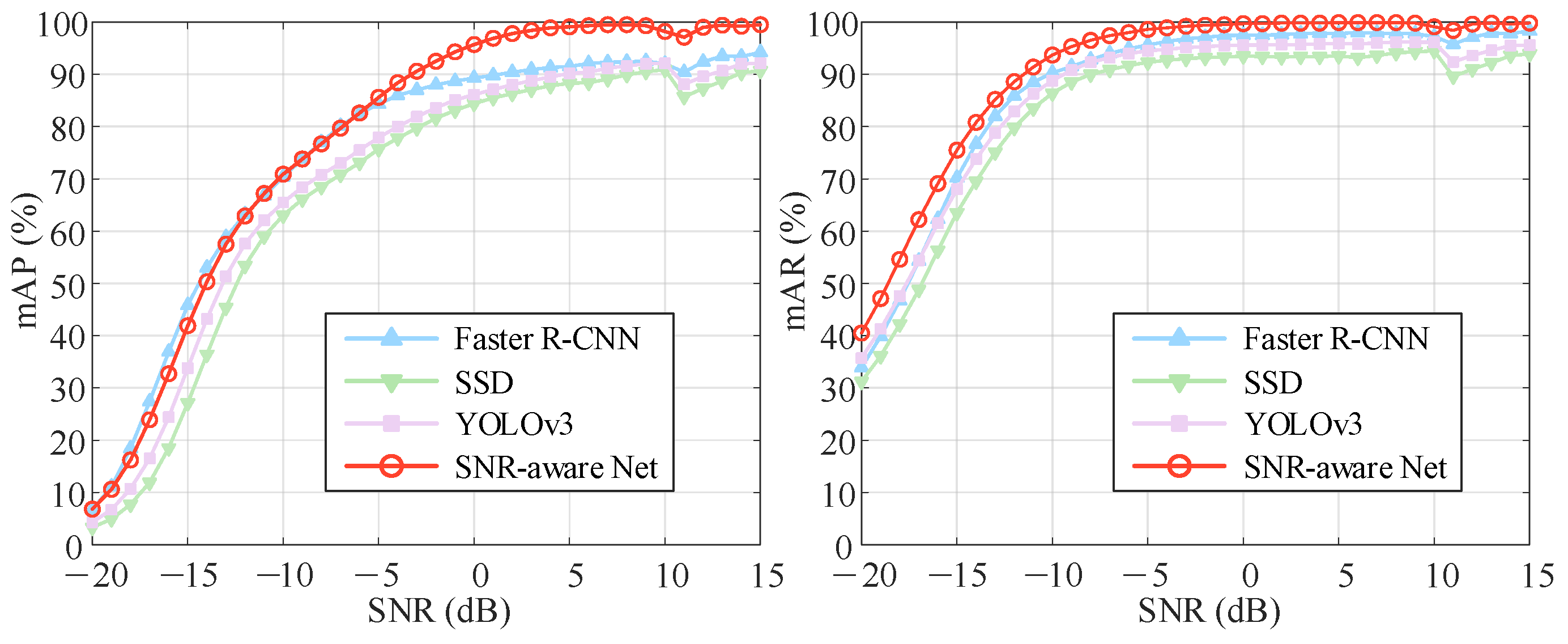
5.2. Performance Analysis
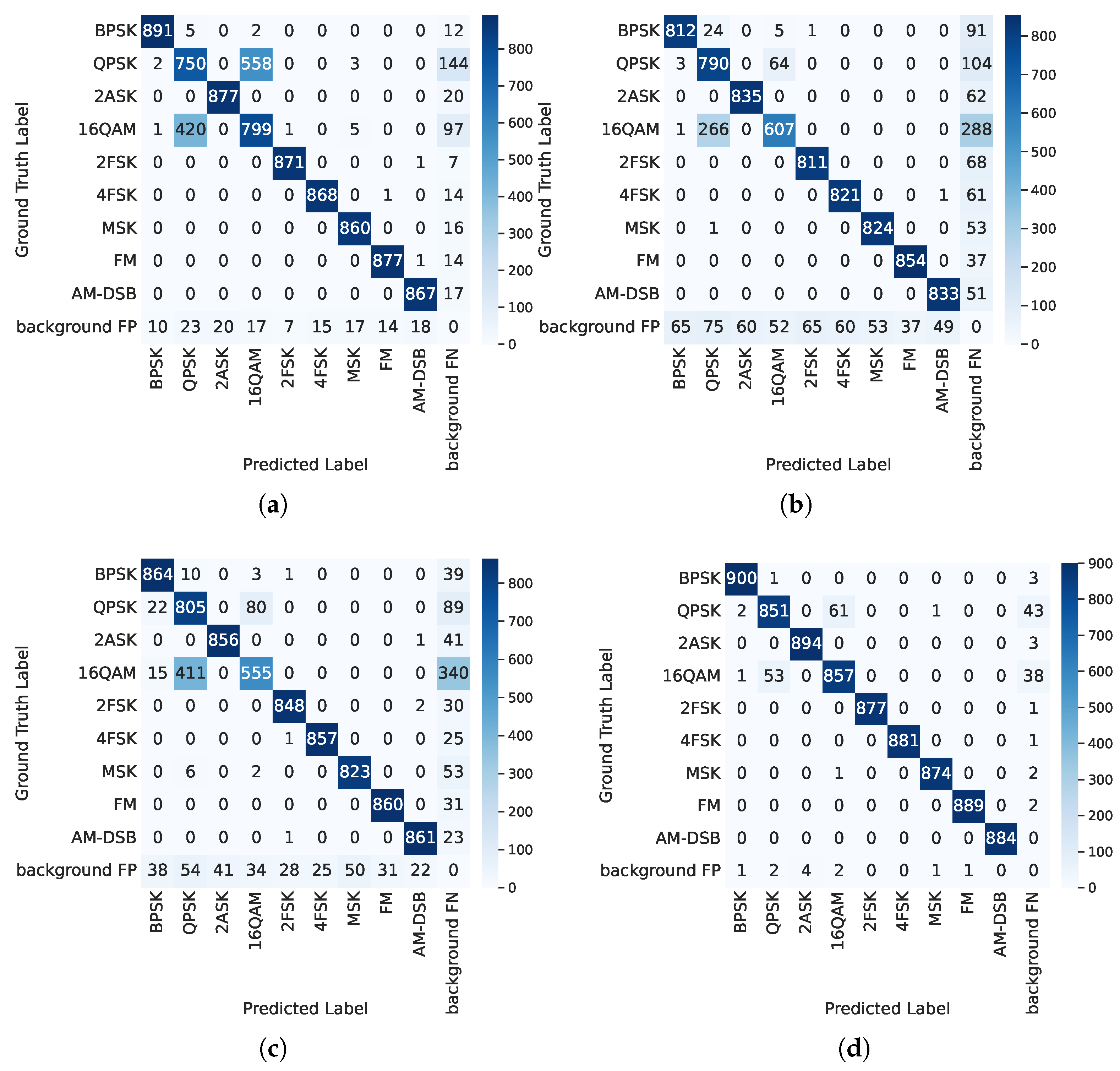
5.2.1. Effectiveness Verification of MCE Spectrogram
5.2.2. State-of-the-Art Comparisons of the Detection Networks
5.2.3. Complexity Comparisons
5.2.4. Ablation Experiments
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bhatti, F.A.; Khan, M.J.; Selim, A.; Paisana, F. Shared Spectrum Monitoring Using Deep Learning. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 1171–1185. [Google Scholar] [CrossRef]
- Soltani, N.; Chaudhary, V.; Roy, D.; Chowdhury, K. Finding Waldo in the CBRS Band: Signal Detection and Localization in the 3.5 GHz Spectrum. In Proceedings of the GLOBECOM 2022—2022 IEEE Global Communications Conference, Rio de Janeiro, Brazil, 4–8 December 2022; pp. 4570–4575. [Google Scholar]
- Basak, S.; Rajendran, S.; Pollin, S.; Scheers, B. Combined RF-Based drone detection and classification. IEEE Trans. Cogn. Commun. Netw. 2021, 8, 111–120. [Google Scholar] [CrossRef]
- Kayraklik, S.; Alagöz, Y.; Coşkun, A.F. Application of Object Detection Approaches on the Wideband Sensing Problem. In Proceedings of the 2022 IEEE International Black Sea Conference on Communications and Networking (BlackSeaCom), Sofia, Bulgaria, 6–9 June 2022; pp. 341–346. [Google Scholar]
- Vagollari, A.; Schram, V.; Wicke, W.; Hirschbeck, M.; Gerstacker, W. Joint Detection and Classification of RF Signals Using Deep Learning. In Proceedings of the IEEE 93rd Vehicular Technology Conference (VTC-Spring), Helsinki, Finland, 25–28 April 2021; pp. 1–7. [Google Scholar]
- Fonseca, E.; Santos, J.F.; Paisana, F.; DaSilva, L.A. Radio Access Technology characterisation through object detection. Comput. Commun. 2021, 168, 12–19. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Prasad, K.S.; D’souza, K.B.; Bhargava, V.K. A Downscaled Faster-RCNN Framework for Signal Detection and Time-Frequency Localization in Wideband RF Systems. IEEE Trans. Wirel. Commun. 2020, 19, 4847–4862. [Google Scholar] [CrossRef]
- Zha, X.; Peng, H.; Qin, X.; Li, G.; Yang, S. A deep learning framework for signal detection and modulation classification. Sensors 2019, 19, 4042. [Google Scholar] [CrossRef]
- Li, R.; Hu, J.; Li, S.; Chen, S.; He, P. Blind Detection of Communication Signals Based on Improved YOLO3. In Proceedings of the 2021 6th International Conference on Intelligent Computing and Signal Processing (ICSP), Xi’an, China, 9–11 April 2021; pp. 424–429. [Google Scholar]
- Prasad, K.S.; Dsouza, K.B.; Bhargava, V.K.; Mallick, S.; Boostanimehr, H. A Deep Learning Framework for Blind Time-Frequency Localization in Wideband Systems. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Antwerp, Belgium, 25–28 May 2020; pp. 1–6. [Google Scholar]
- Zhao, R.; Ruan, Y.; Li, Y. Cooperative time-frequency localization for wideband spectrum sensing with a lightweight detector. IEEE Commun. Lett. 2023, 27, 1844–1848. [Google Scholar] [CrossRef]
- Lin, M.; Tian, Y.; Zhang, X.; Huang, Y. Parameter Estimation of Frequency-Hopping Signal in UCA Based on Deep Learning and Spatial Time–Frequency Distribution. IEEE Sensors J. 2023, 23, 7460–7474. [Google Scholar] [CrossRef]
- Yu, J.; Li, J.; Sun, B.; Chen, J.; Li, C. Multiclass Radio Frequency Interference Detection and Suppression for SAR Based on the Single Shot MultiBox Detector. Sensors 2018, 18, 4034. [Google Scholar] [CrossRef]
- O’Shea, T.; Roy, T.; Clancy, T.C. Learning robust general radio signal detection using computer vision methods. In Proceedings of the 2017 51st Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 29 October–1 November 2017; pp. 829–832. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.W.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. Vis. 2018, 128, 261–318. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Zhang, X.; Zhao, H.; Zhu, H.; Adebisi, B.; Gui, G.; Gacanin, H.; Adachi, F. NAS-AMR: Neural Architecture Search-Based Automatic Modulation Recognition for Integrated Sensing and Communication Systems. IEEE Trans. Cogn. Commun. Netw. 2022, 8, 1374–1386. [Google Scholar] [CrossRef]
- Li, L.; Dong, Z.; Zhu, Z.; Jiang, Q. Deep-Learning Hopping Capture Model for Automatic Modulation Classification of Wireless Communication Signals. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 772–783. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, C.; Gan, C.; Sun, S.; Wang, M. Automatic Modulation Classification Using Convolutional Neural Network with Features Fusion of SPWVD and BJD. IEEE Trans. Signal Inf. Process. Over Netw. 2019, 5, 469–478. [Google Scholar] [CrossRef]
- Behura, S.; Kedia, S.; Hiremath, S.M.; Patra, S.K. WiST ID—Deep Learning-Based Large Scale Wireless Standard Technology Identification. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 1365–1377. [Google Scholar] [CrossRef]
- O’Shea, T.J.; Roy, T.; Erpek, T. Spectral detection and localization of radio events with learned convolutional neural features. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017; pp. 331–335. [Google Scholar]
- Sun, H.; Nallanathan, A.; Wang, C.X.; Chen, Y. Wideband spectrum sensing for cognitive radio networks: A survey. IEEE Wirel. Commun. 2013, 20, 74–81. [Google Scholar]
- Gouldieff, V.; Palicot, J.; Daumont, S. Blind Modulation Classification for Cognitive Satellite in the Spectral Coexistence Context. IEEE Trans. Signal Process. 2017, 65, 3204–3217. [Google Scholar] [CrossRef]
- Zhu, M.; Li, Y.; Pan, Z.; Yang, J. Automatic modulation recognition of compound signals using a deep multi-label classifier: A case study with radar jamming signals. Signal Process. 2020, 169, 107393. [Google Scholar] [CrossRef]
- Zhang, M.L.; Zhou, Z.H. A Review on Multi-Label Learning Algorithms. IEEE Trans. Knowl. Data Eng. 2014, 26, 1819–1837. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. UnitBox: An Advanced Object Detection Network. In Proceedings of the 24th ACM international conference on Multimedia, MM ’16, Amsterdam, The Netherlands, 15–19 October 2016. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Voume 34, pp. 12993–13000. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features From Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 1577–1586. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Padilla, R.; Passos, W.L.; Dias, T.L.; Netto, S.L.; Da Silva, E.A. A comparative analysis of object detection metrics with a companion open-source toolkit. Electronics 2021, 10, 279. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Range of Values |
|---|---|
| Number of signals | [5, 8] |
| Time–frequency span of spectrogram | 182.4 ms/720 kHz |
| Duration of each signal | [45.6 ms, 182.4 ms] |
| Signal categories | BPSK, QPSK, 2ASK, 16QAM, 2FSK, 4FSK, MSK, FM, AM-DSB |
| Symbol rate of each signal | [24 kHz, 40 kHz] |
| [−20 dB, 15 dB] |
| Spectrogram Modality | Detector | mAP | mAR | BPSK | QPSK | 2ASK | 16 QAM | 2FSK | 4FSK | MSK | FM | AM-DSB |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Grayscale spectrogram | 68.7 | 84.7 | 65.3 | 38.7 | 75.0 | 40.2 | 85.2 | 78.8 | 74.9 | 79.0 | 81.1 | |
| RGB spectrogram | Faster R-CNN [8] | 71.0 | 85.2 | 63.7 | 41.7 | 76.1 | 51.1 | 84.6 | 80.4 | 75.3 | 83.2 | 82.9 |
| MCE spectrogram | 77.1 | 87.5 | 79.1 | 49.9 | 79.7 | 55.0 | 89.3 | 84.4 | 84.2 | 86.4 | 85.9 | |
| Grayscale spectrogram | 64.3 | 81.6 | 62.2 | 34.3 | 71.1 | 33.4 | 78.8 | 75.3 | 71.9 | 74.9 | 76.9 | |
| RGB spectrogram | SSD [9] | 63.1 | 80.6 | 62.8 | 32.4 | 70.8 | 35.7 | 75.3 | 73.9 | 72.3 | 71.3 | 73.7 |
| MCE spectrogram | 70.6 | 83.0 | 63.0 | 52.7 | 75.5 | 51.1 | 82.2 | 77.4 | 73.8 | 81.4 | 78.6 | |
| Grayscale spectrogram | 64.5 | 81.6 | 64.0 | 33.9 | 73.6 | 36.7 | 75.6 | 74.4 | 73.1 | 73.4 | 76.0 | |
| RGB spectrogram | YOLOv3 [5] | 65.7 | 82.5 | 64.4 | 31.1 | 73.0 | 38.9 | 80.9 | 76.2 | 72.5 | 75.1 | 78.7 |
| MCE spectrogram | 72.9 | 85.9 | 66.6 | 51.8 | 77.9 | 47.8 | 86.6 | 82.0 | 76.4 | 83.7 | 83.5 | |
| Grayscale spectrogram | 71.9 | 84.1 | 67.4 | 54.8 | 75.6 | 53.9 | 83.3 | 78.0 | 74.1 | 81.3 | 79.0 | |
| RGB spectrogram | SNR-aware Net | 72.8 | 85.6 | 64.2 | 52.1 | 76.1 | 55.6 | 86.9 | 80.0 | 78.0 | 79.8 | 82.3 |
| MCE spectrogram | 80.9 | 90.7 | 74.1 | 64.9 | 82.2 | 64.6 | 92.4 | 88.3 | 83.5 | 89.6 | 88.8 |
| Detector | Parameters | Spectrogram Modality | Generation Time (ms) | Inference Time (ms) |
|---|---|---|---|---|
| Grayscale spectrogram | 14.024 | 142.4 | ||
| Faster R-CNN | 26.36M | RGB spectrogram | 26.421 | 142.5 |
| MCE spectrogram | 29.288 | 142.8 | ||
| Grayscale spectrogram | 14.024 | 132.4 | ||
| SSD | 21.15M | RGB spectrogram | 26.421 | 132.3 |
| MCE spectrogram | 29.288 | 132.1 | ||
| Grayscale spectrogram | 14.024 | 113.3 | ||
| YOLOv3 | 61.57M | RGB spectrogram | 26.421 | 113.6 |
| MCE spectrogram | 29.288 | 113.1 | ||
| Grayscale spectrogram | 14.024 | 44.6 | ||
| SNR-aware Net | 14.79M | RGB spectrogram | 26.421 | 44.5 |
| MCE spectrogram | 29.288 | 44.6 |
| Channel 1 | Channel 2 | Channel 3 | mAP (%) | mAR (%) |
|---|---|---|---|---|
| ✔ | × | × | 71.9 | 84.1 |
| × | ✔() | × | 67.8 | 83.5 |
| × | × | ✔ | 71.7 | 84.6 |
| ✔ | ✔() | × | 76.3 | 87.5 |
| ✔ | × | ✔ | 75.5 | 86.5 |
| ✔ | ✔() | ✔ | 80.9 | 90.7 |
| ✔ | ✔() | ✔ | 76.1 | 87.1 |
| ✔ | ✔() | ✔ | 77.4 | 88.2 |
| ✔ | ✔() | ✔ | 79.5 | 89.4 |
| ✔ | ✔() | ✔ | 80.9 | 90.7 |
| ✔ | ✔() | ✔ | 75.5 | 86.5 |
| Method | TFFGAM | SNR Branch | mAP (%) | mAR (%) |
|---|---|---|---|---|
| Baseline | × | × | 74.9 | 86.8 |
| ✔ | × | |||
| SNR-aware Net | × | ✔ | ||
| ✔ | ✔ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Xiang, X.; Mao, H.; Wang, R.; Qi, Y. Anchor-Free SNR-Aware Signal Detector for Wideband Signal Detection Framework. Electronics 2025, 14, 2260. https://doi.org/10.3390/electronics14112260
Li C, Xiang X, Mao H, Wang R, Qi Y. Anchor-Free SNR-Aware Signal Detector for Wideband Signal Detection Framework. Electronics. 2025; 14(11):2260. https://doi.org/10.3390/electronics14112260
Chicago/Turabian StyleLi, Chunhui, Xin Xiang, Hu Mao, Rui Wang, and Yonglei Qi. 2025. "Anchor-Free SNR-Aware Signal Detector for Wideband Signal Detection Framework" Electronics 14, no. 11: 2260. https://doi.org/10.3390/electronics14112260
APA StyleLi, C., Xiang, X., Mao, H., Wang, R., & Qi, Y. (2025). Anchor-Free SNR-Aware Signal Detector for Wideband Signal Detection Framework. Electronics, 14(11), 2260. https://doi.org/10.3390/electronics14112260