Figure 1.
Gong-che notation examples. (a) Gong-che notation excerpted from Gong-che Notation of Southern and Northern Ci-Poetry in Jiucheng Dacheng. It presents traditional Chinese character-based musical notation, reflecting the writing style and musical recording characteristics of ancient Chinese scores. The text contains classical Chinese characters with rhythm-related annotations, demonstrating the integration of literature and music in traditional Chinese art. (b) Gong-che notation excerpted from Lilu Qupu, a representative work of traditional Chinese Kunqu opera scores. The notation combines Chinese characters and special musical symbols, showing the singing rhythm and lyrics of Kunqu opera. It reflects the artistic expression form of traditional Chinese opera music and is of great significance for studying the inheritance and characteristics of ancient Chinese vocal music.
Figure 1.
Gong-che notation examples. (a) Gong-che notation excerpted from Gong-che Notation of Southern and Northern Ci-Poetry in Jiucheng Dacheng. It presents traditional Chinese character-based musical notation, reflecting the writing style and musical recording characteristics of ancient Chinese scores. The text contains classical Chinese characters with rhythm-related annotations, demonstrating the integration of literature and music in traditional Chinese art. (b) Gong-che notation excerpted from Lilu Qupu, a representative work of traditional Chinese Kunqu opera scores. The notation combines Chinese characters and special musical symbols, showing the singing rhythm and lyrics of Kunqu opera. It reflects the artistic expression form of traditional Chinese opera music and is of great significance for studying the inheritance and characteristics of ancient Chinese vocal music.
Figure 2.
Gong-che notation examples. (a) shows Yuzhu Notation from Gong-che Notation of Southern and Northern Ci-Poetry in Jiugong Dacheng, reflecting the musical writing style of ancient Chinese ci-poetry. (b) presents Yizi Notation from Eyun Ge Qupu, demonstrating the integration of Kunqu opera singing rhythms and text. (c) displays Suoyi Notation from Liu Ye Qupu, illustrating the unique symbolic expression of traditional Chinese vocal music. These notations are significant for studying the inheritance, evolution, and cultural connotations of ancient Chinese music.
Figure 2.
Gong-che notation examples. (a) shows Yuzhu Notation from Gong-che Notation of Southern and Northern Ci-Poetry in Jiugong Dacheng, reflecting the musical writing style of ancient Chinese ci-poetry. (b) presents Yizi Notation from Eyun Ge Qupu, demonstrating the integration of Kunqu opera singing rhythms and text. (c) displays Suoyi Notation from Liu Ye Qupu, illustrating the unique symbolic expression of traditional Chinese vocal music. These notations are significant for studying the inheritance, evolution, and cultural connotations of ancient Chinese music.
Figure 3.
Labelinginterface of LabelImg, showing the annotation process for Gong-che notation (a traditional Chinese musical notation system using character-like symbols to record music). The interface is used to mark Gong-che characters in images (e.g., the handwritten Chinese text and musical symbols in the figure) with labels like “note-C5”, “note-D4”, etc., preparing datasets for deep learning-based recognition of Gong-che notation.
Figure 3.
Labelinginterface of LabelImg, showing the annotation process for Gong-che notation (a traditional Chinese musical notation system using character-like symbols to record music). The interface is used to mark Gong-che characters in images (e.g., the handwritten Chinese text and musical symbols in the figure) with labels like “note-C5”, “note-D4”, etc., preparing datasets for deep learning-based recognition of Gong-che notation.
Figure 4.
Different forms of data augmentation. (a) Original image, (b) translation, (c) noise injection + flipping, (d) noise injection + flipping, (e) noise injection, (f) rotation.
Figure 4.
Different forms of data augmentation. (a) Original image, (b) translation, (c) noise injection + flipping, (d) noise injection + flipping, (e) noise injection, (f) rotation.
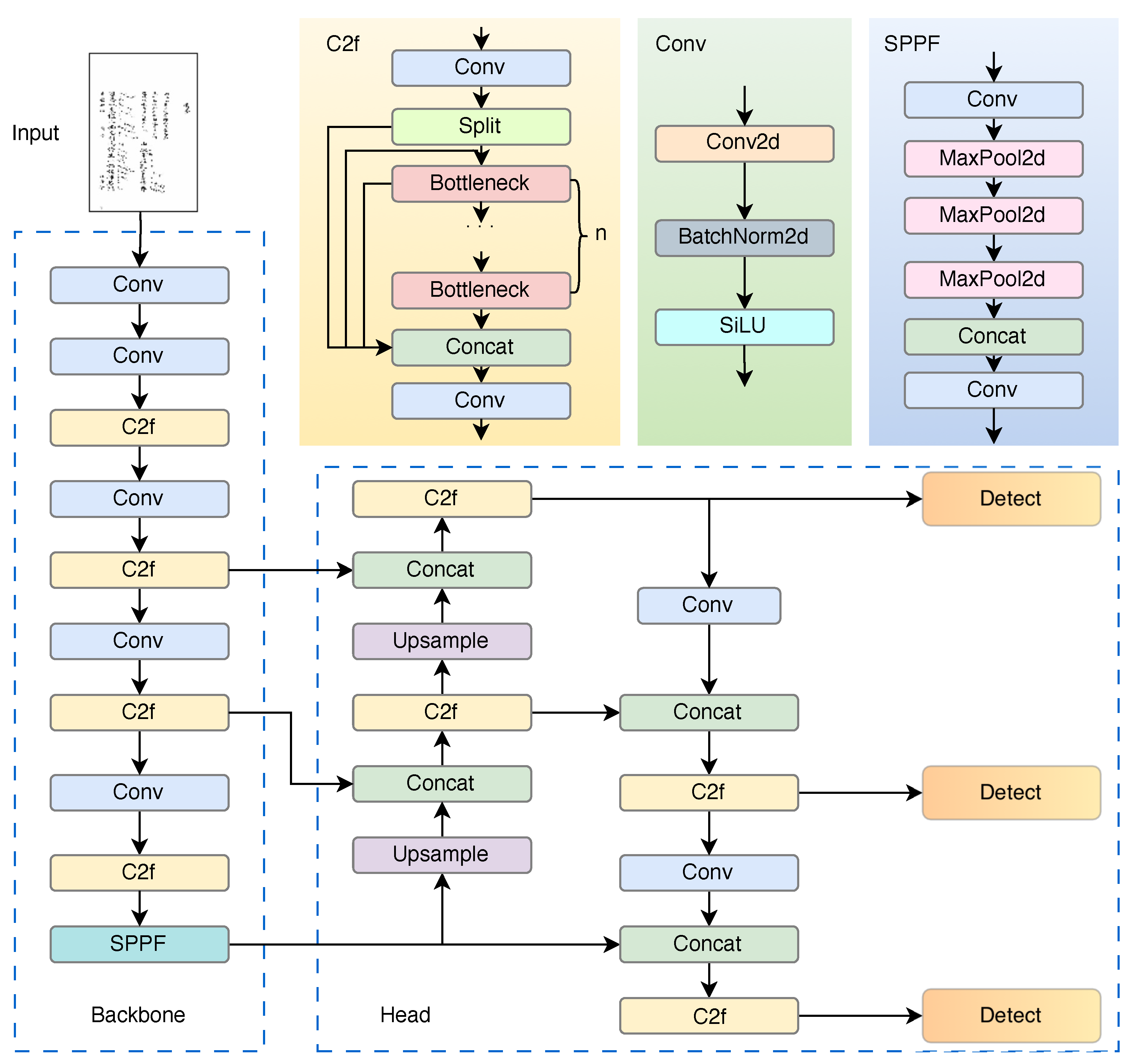
Figure 5.
YOLOv8 model structure.
Figure 5.
YOLOv8 model structure.
Figure 6.
Weights of three types of attention. Weights of three types of attention. Different colors are used as visual aids to distinguish operational logics across dimensions (channels/spatial locations) and simplify understanding of attention weight distributions. Letters (X, H, W, C) denote dimensions: X = input feature, H = height, W = width (spatial dimensions), C = channel dimension. (a) One - dimensional channel attention weights (refines only channel dimension, generating uniform operations per channel). (b) Two - dimensional spatial attention weights (refines only spatial dimension, applying uniform operations per spatial location). (c) Full 3D attention weights (covers all channels + spatial dimensions for comprehensive feature refinement, as proposed by SimAM to capture richer information). This visualization aligns with the study: existing modules (a,b) limit feature learning by focusing on single dimensions, while 3D weights (c) enable more discriminative feature representation.
Figure 6.
Weights of three types of attention. Weights of three types of attention. Different colors are used as visual aids to distinguish operational logics across dimensions (channels/spatial locations) and simplify understanding of attention weight distributions. Letters (X, H, W, C) denote dimensions: X = input feature, H = height, W = width (spatial dimensions), C = channel dimension. (a) One - dimensional channel attention weights (refines only channel dimension, generating uniform operations per channel). (b) Two - dimensional spatial attention weights (refines only spatial dimension, applying uniform operations per spatial location). (c) Full 3D attention weights (covers all channels + spatial dimensions for comprehensive feature refinement, as proposed by SimAM to capture richer information). This visualization aligns with the study: existing modules (a,b) limit feature learning by focusing on single dimensions, while 3D weights (c) enable more discriminative feature representation.
![Electronics 14 02802 g006]()
Figure 7.
Network structure model combining SimAM and YOLOv8.
Figure 7.
Network structure model combining SimAM and YOLOv8.
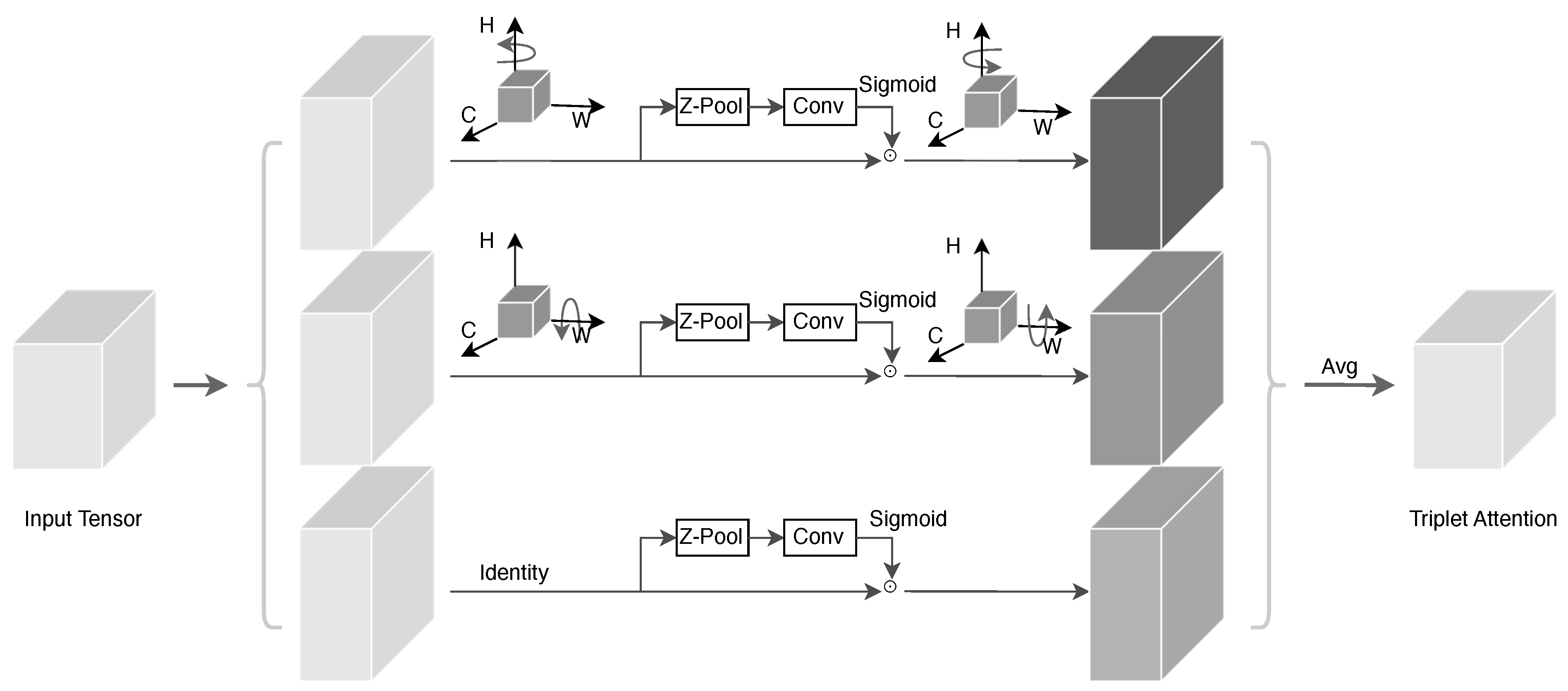
Figure 8.
Network Structure Model Combining SimAM and YOLOv8. Letters in the figure represent dimensions and operations: - H = height, W = width (spatial dimensions of feature maps); - C = channel dimension; - “Z-Pool”, “Conv”, “Sigmoid” = key operations (pooling, convolution, activation); - “Identity” = residual connection (direct feature mapping). This model illustrates how Triplet Attention refines features across spatial and channel dimensions for improved representation.
Figure 8.
Network Structure Model Combining SimAM and YOLOv8. Letters in the figure represent dimensions and operations: - H = height, W = width (spatial dimensions of feature maps); - C = channel dimension; - “Z-Pool”, “Conv”, “Sigmoid” = key operations (pooling, convolution, activation); - “Identity” = residual connection (direct feature mapping). This model illustrates how Triplet Attention refines features across spatial and channel dimensions for improved representation.
Figure 9.
Network structure model combining Triplet Attention and YOLOv8.
Figure 9.
Network structure model combining Triplet Attention and YOLOv8.
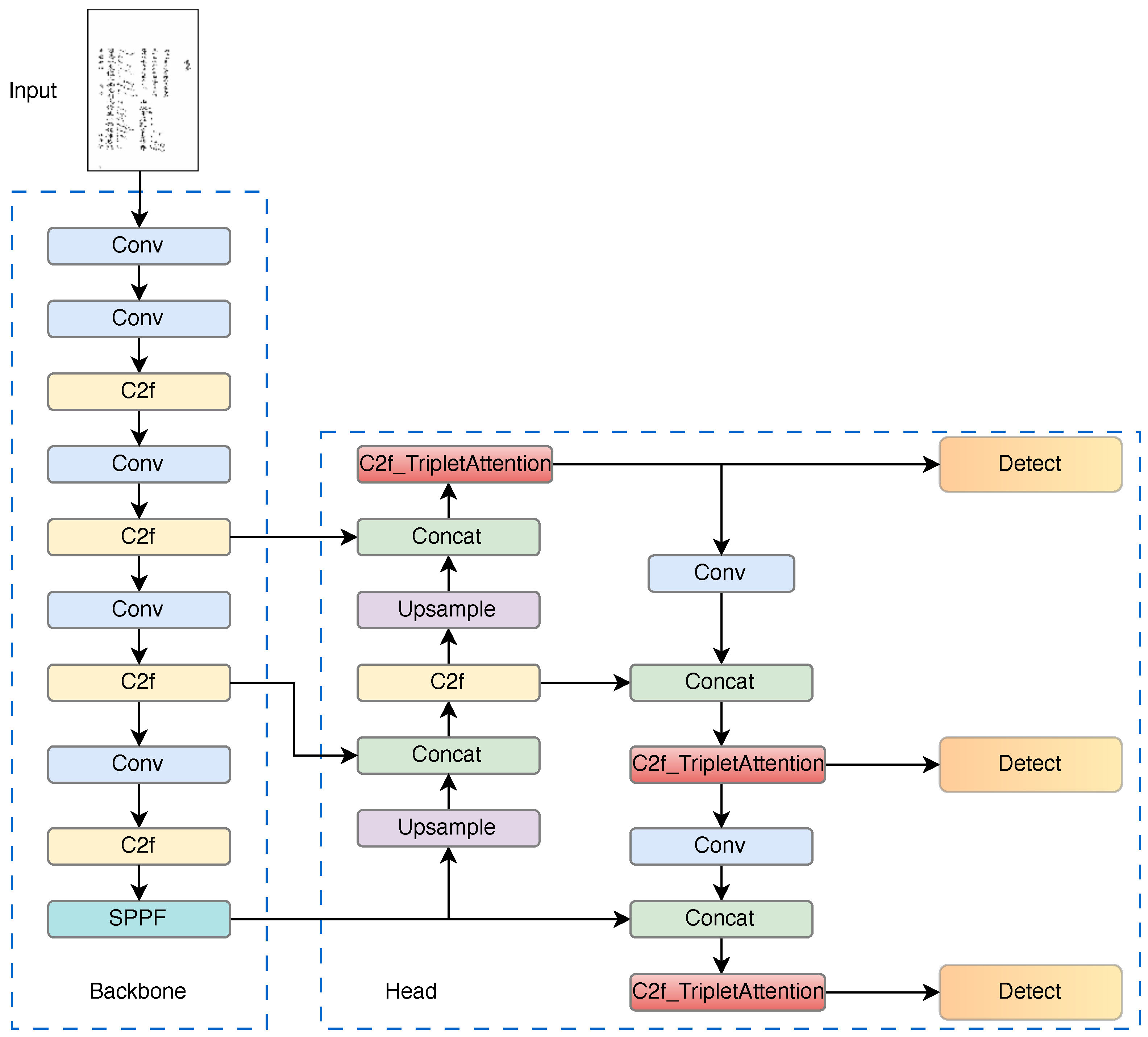
Figure 10.
Network structure details of YOLOv8 improved by introducing Triplet Attention module. Arrows in the figure represent data/feature flow directions: - Solid arrows: Indicate sequential processing of feature maps through operations (e.g., Conv, Split, Concat). - Dashed arrows (with red borders): Highlight the integration of Triplet Attention sub-modules into the main network. - Circular arrows (e.g., ⨀, ⨁): Denote element-wise operations (multiplication, addition) for feature fusion. This visualization shows how Triplet Attention refines features across channels and spatial dimensions within the YOLOv8 architecture.
Figure 10.
Network structure details of YOLOv8 improved by introducing Triplet Attention module. Arrows in the figure represent data/feature flow directions: - Solid arrows: Indicate sequential processing of feature maps through operations (e.g., Conv, Split, Concat). - Dashed arrows (with red borders): Highlight the integration of Triplet Attention sub-modules into the main network. - Circular arrows (e.g., ⨀, ⨁): Denote element-wise operations (multiplication, addition) for feature fusion. This visualization shows how Triplet Attention refines features across channels and spatial dimensions within the YOLOv8 architecture.
Figure 11.
MSCAM network structure. Arrows in the figure represent feature/data flow and module associations: - Solid arrows (e.g., between “Channel Max”→“Conv7x7”→“Sigmoid”): Indicate sequential processing of feature maps through operations (convolution, activation, etc.). - Colored arrows (red, pink): Highlight the integration of sub-modules (SAB, CAB, MSCB) into the overall MSCAM architecture, showing how they connect and interact. - Circular arrows (e.g., ⨀): Denote element-wise operations (e.g., feature fusion via multiplication) to refine feature representations. This visualization details the hierarchical design of MSCAM, including channel/spatial attention branches and multi-scale feature processing.
Figure 11.
MSCAM network structure. Arrows in the figure represent feature/data flow and module associations: - Solid arrows (e.g., between “Channel Max”→“Conv7x7”→“Sigmoid”): Indicate sequential processing of feature maps through operations (convolution, activation, etc.). - Colored arrows (red, pink): Highlight the integration of sub-modules (SAB, CAB, MSCB) into the overall MSCAM architecture, showing how they connect and interact. - Circular arrows (e.g., ⨀): Denote element-wise operations (e.g., feature fusion via multiplication) to refine feature representations. This visualization details the hierarchical design of MSCAM, including channel/spatial attention branches and multi-scale feature processing.
Figure 12.
Network structure of MSCAM combined with YOLOv8.
Figure 12.
Network structure of MSCAM combined with YOLOv8.
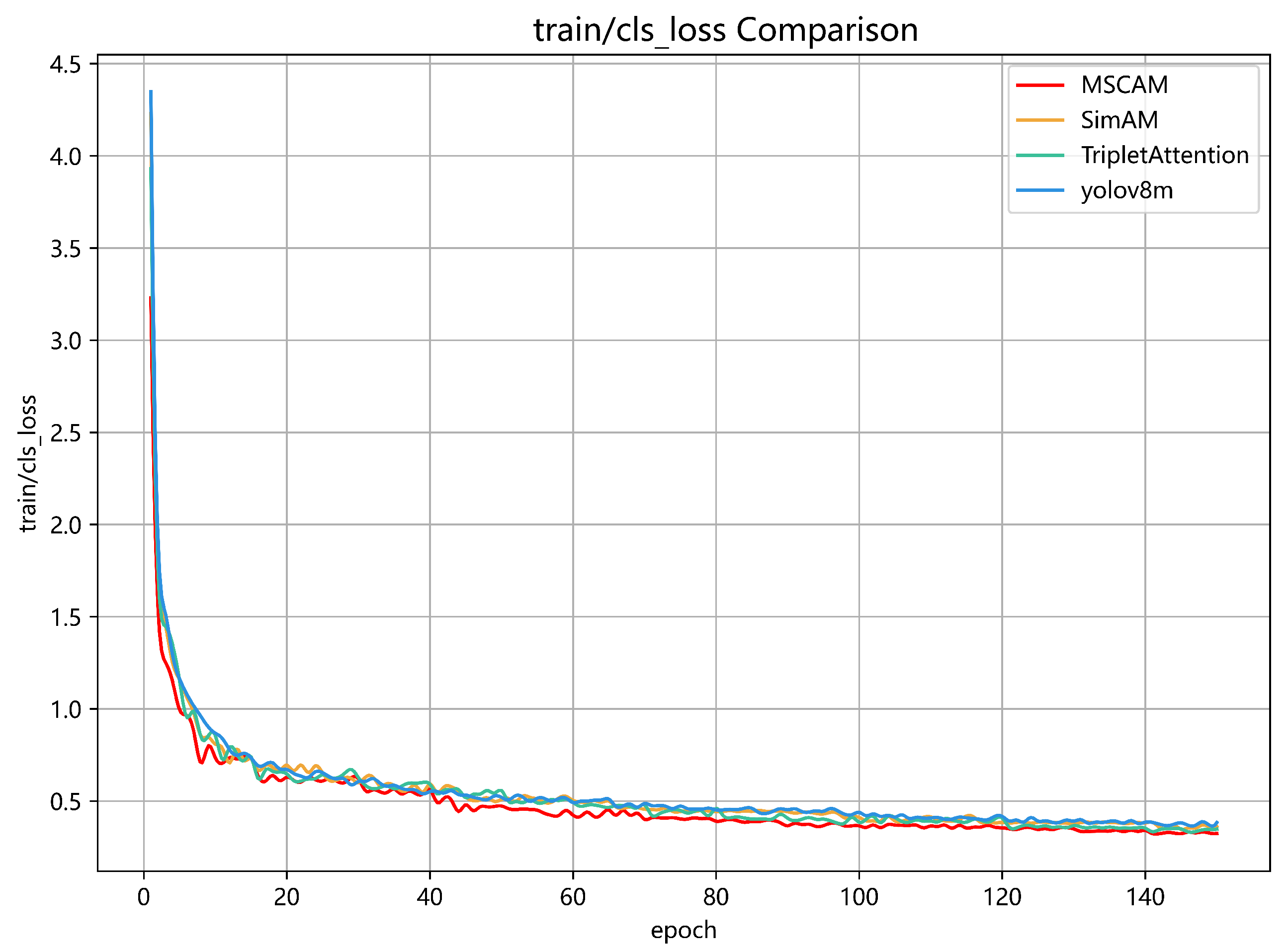
Figure 13.
Comparison diagram of cls_loss Loss. Function.
Figure 13.
Comparison diagram of cls_loss Loss. Function.
Figure 14.
Model accuracy comparison.
Figure 14.
Model accuracy comparison.
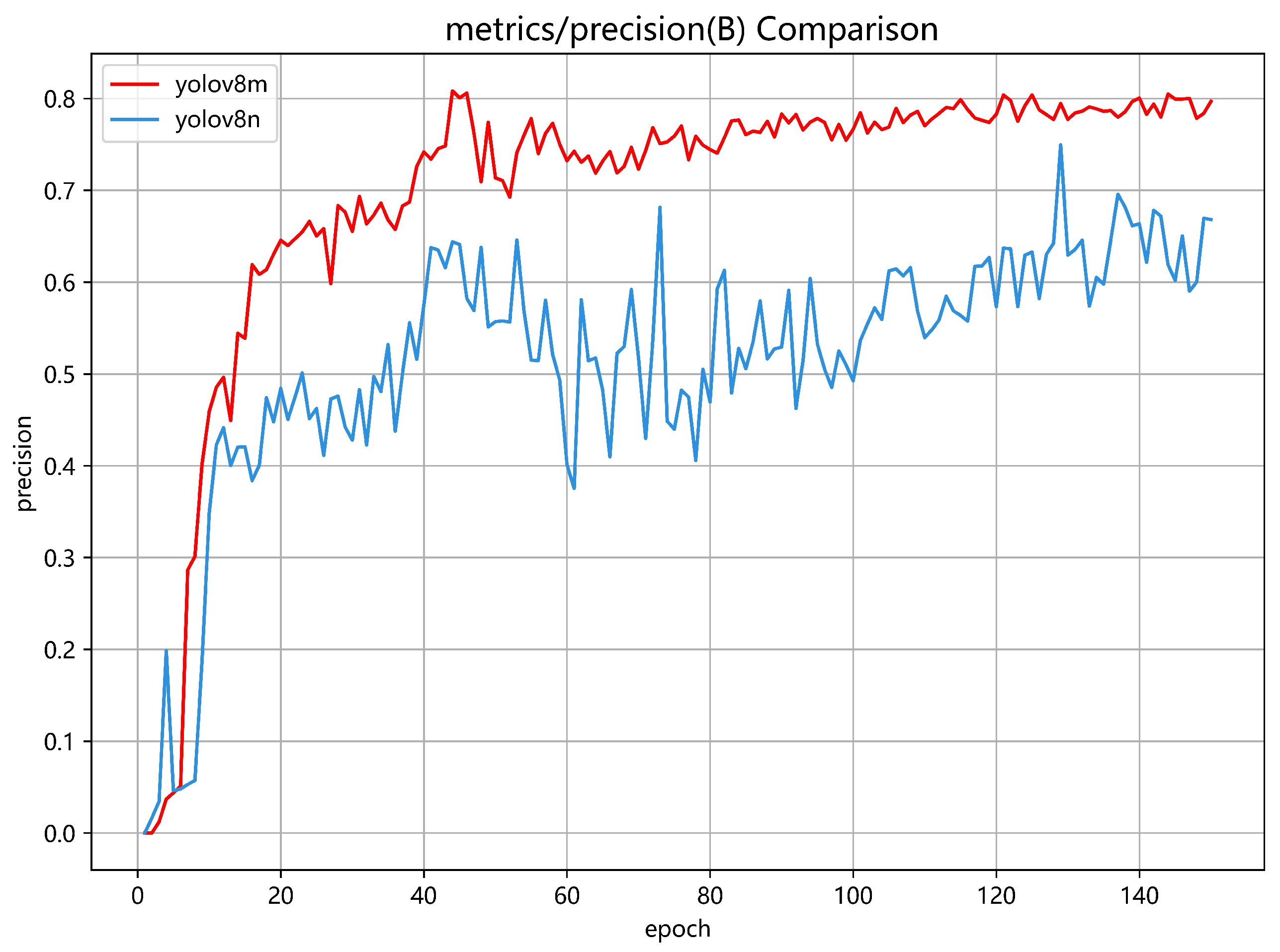
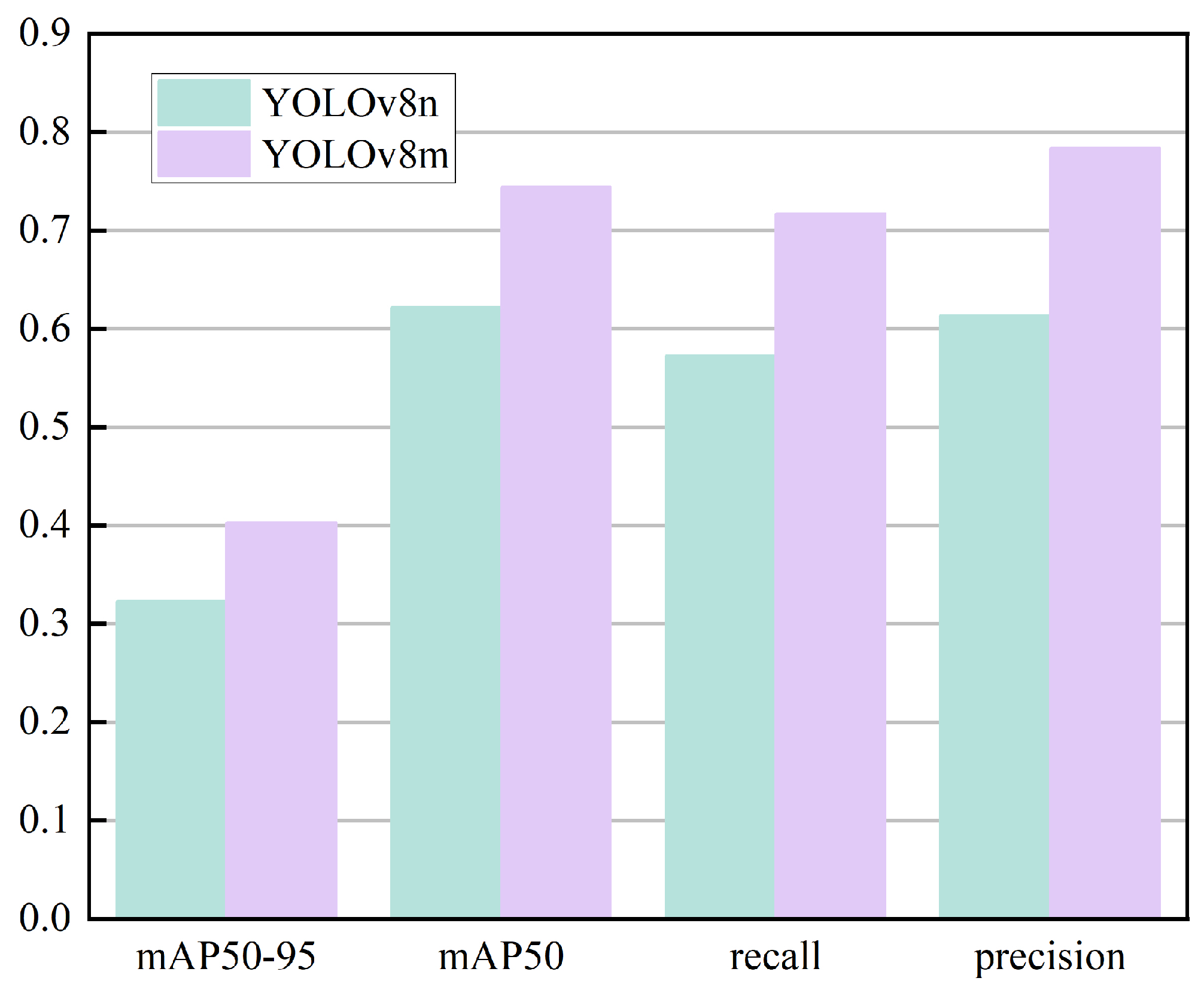
Figure 15.
Metrics for YOLOv8n and YOLOv8m models.
Figure 15.
Metrics for YOLOv8n and YOLOv8m models.
Figure 16.
Prediction results of Gong-che notation recognition. (a,b) Prediction results of YOLOv8n. (c,d) Prediction results of YOLOv8m. Different colors in the figure represent various predicted pitch classes (e.g., “note-E4”, “note-D4”, etc.). Each color-coded label corresponds to a specific pitch prediction, with the associated numerical value indicating the prediction confidence score.
Figure 16.
Prediction results of Gong-che notation recognition. (a,b) Prediction results of YOLOv8n. (c,d) Prediction results of YOLOv8m. Different colors in the figure represent various predicted pitch classes (e.g., “note-E4”, “note-D4”, etc.). Each color-coded label corresponds to a specific pitch prediction, with the associated numerical value indicating the prediction confidence score.
Figure 17.
Classification loss function (cls_loss).
Figure 17.
Classification loss function (cls_loss).
Figure 18.
Model precision comparison results.
Figure 18.
Model precision comparison results.
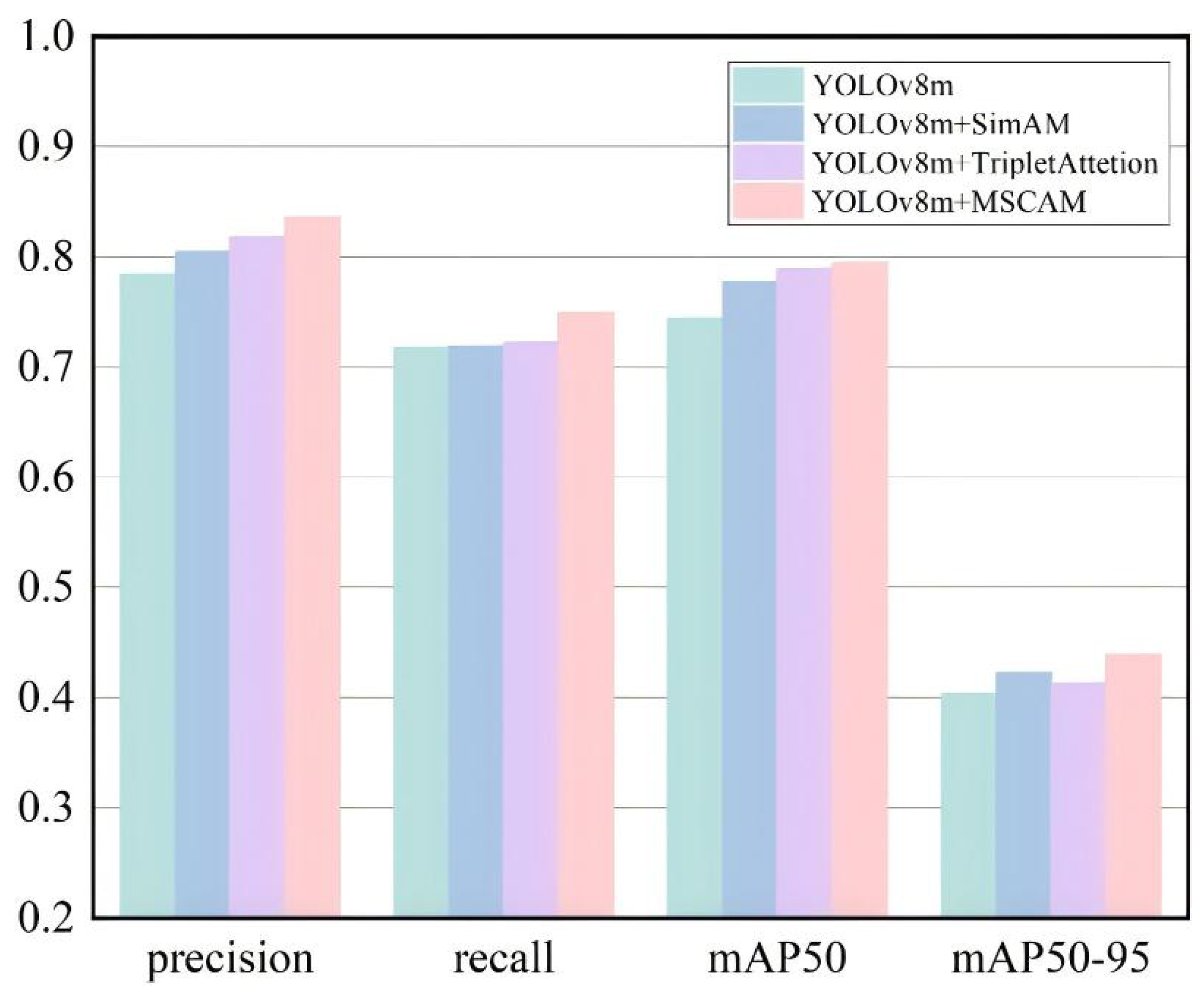
Figure 19.
Metrics of four improved models.
Figure 19.
Metrics of four improved models.
Table 1.
Pitch correspondence in Gong-che notation. Such notation is a traditional Chinese musical notation system, where “Gong-che Character” represents Chinese characters used in this notation to denote pitches. Superscript “1” (e.g., , ) follows the international pitch notation convention, indicating the octave range (here referring to the one-lined octave in scientific pitch notation). This table maps Gong-che characters to modern pitch terms, fixed pitches, and solfege for cross-cultural music analysis.
Table 1.
Pitch correspondence in Gong-che notation. Such notation is a traditional Chinese musical notation system, where “Gong-che Character” represents Chinese characters used in this notation to denote pitches. Superscript “1” (e.g., , ) follows the international pitch notation convention, indicating the octave range (here referring to the one-lined octave in scientific pitch notation). This table maps Gong-che characters to modern pitch terms, fixed pitches, and solfege for cross-cultural music analysis.
| Gong-Che Character | 合 | 四 | 一 | 上 | 尺 | 工 | 凡 | 六 | 五 | 乙 |
|---|
| Pitch(assuming 上= C4) | G3 | A3 | B3 | C4(middle C) | D4 | E4 | F4 | G4 | A4 | B4 |
| International Fixed Pitch | g | a | b | | | | | | | |
| Solfege | sol | la | si | do | re | mi | fa | sol | la | si |
Table 2.
Correspondence between basic Gong-che characters and their one-octave-higher versions.
Table 2.
Correspondence between basic Gong-che characters and their one-octave-higher versions.
| Category | Notation Characters |
|---|
| Basic Characters | 上 | 尺 | 工 | 凡 | 六 | 五 | 乙 |
| One-Octave Higher | 仩 | 伬 | 仁 | 𠆩 | 𠆾 | 伍 | 亿 |
Table 3.
Correspondence between basic Gong-che characters and their one-octave lowered versions.
Table 3.
Correspondence between basic Gong-che characters and their one-octave lowered versions.
| Category | Notation Characters |
|---|
| Basic Characters | 合 | 四 | 一 | 上 | 尺 | 工 | 凡 |
| One-Octave Lowered | 合, | 四, | 一, | 上, | 尺, | 工, | 凡, |
Table 4.
Category labels for key signatures.
Table 4.
Category labels for key signatures.
| Annotation Target | Label |
|---|
| 上字调 (Shàng Key) | keySignature-bB |
| 尺字调 (Chǐ Key) | keySignature-C |
| 小工调 (Xiǎo Gōng Key) | keySignature-D |
| 凡字调 (Fán Key) | keySignature-bE |
| 六字调 (Liù Key) | keySignature-F |
| 五字调 (Wǔ Key) | keySignature-G |
| 乙字调 (yǐ Key) | keySignature-A |
Table 5.
Category labels for ten notation characters.
Table 5.
Category labels for ten notation characters.
| Annotation Target | Label |
|---|
| 合 (Hé) | note-G3 |
| 四 (Sì) | note-A3 |
| 一 (Yī) | note-B3 |
| 上 (Shàng) | note-C4 |
| 尺 (Chǐ) | note-D4 |
| 工 (Gōng) | note-E4 |
| 凡 (Fán) | note-F4 |
| 六 (Liù) | note-G4 |
| 五 (Wǔ) | note-A4 |
| 乙 (Yǐ) | note-B4 |
Table 6.
Experimental parameters.
Table 6.
Experimental parameters.
| Parameter Name | Value |
|---|
| Optimizer | AdamW |
| Initial Learning Rate | 0.001 |
| Batch Size | 16 |
| Number of Epochs | 150 |
Table 7.
Comparison between YOLOv8 model performance.
Table 7.
Comparison between YOLOv8 model performance.
| Network | mAP50 (%) | Accuracy (%) |
|---|
| YOLOv8n | 62.90 | 65.95 |
| YOLOv8m | 74.26 | 78.19 |
Table 8.
Model accuracy comparison.
Table 8.
Model accuracy comparison.
| Model | Accuracy (%) |
|---|
| YOLOv8m | 78.2 |
| YOLOv8m + SimAM | 80.4 |
| YOLOv8m + Triplet Attention | 81.8 |
| YOLOv8m + MSCAM | 83.6 |
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}