1. Introduction
The rapid advancements in autonomous driving technology have the potential to significantly enhance transportation systems, offering improvements in safety, efficiency, and environmental sustainability [
1]. Autonomous vehicles (AVs), which operate without human intervention, rely heavily on complex communication and computing systems to make real-time decisions, navigate roads, and perform essential tasks such as object detection, lane-keeping, and collision avoidance. Recent breakthroughs in integrated sensing and communication (ISAC) technologies, such as terahertz-band transceivers for UAVs in 6G networks [
2], further expand the capabilities of vehicular networks by enabling ultra-high-speed data exchange and precise environmental sensing. While these advancements address bandwidth and latency challenges, they simultaneously intensify the demand for intelligent resource allocation to fully leverage such high-performance infrastructure.
Despite the tremendous promise of AVs, several challenges remain, particularly in the realm of communication and resource management [
3]. A key issue in current vehicular networks is the resource allocation problem, which arises when AVs need to process and exchange vast amounts of data from onboard sensors in real time [
4]. These tasks, such as sensor fusion and perception processing, are highly delay-sensitive. A delay in processing or communication could result in inaccurate data, jeopardizing the safety and performance of the AV. Furthermore, inefficient resource allocation among AVs, Road-Side Units (RSUs), and Edge Computing Devices (ECDs) often leads to underutilization of computational resources or excessive overhead, hindering the overall performance of the system [
5].
As the number of AVs on the road increases, the demands on the communication infrastructure, including RSUs and ECDs, will intensify. The existing infrastructure struggles to meet the growing demands for real-time data processing and communication, especially in areas with high vehicle density, such as urban environments during peak hours [
6,
7]. These areas suffer from limited communication bandwidth and computational capacity, leading to delays and increased risk of failure in performing critical tasks. This inefficiency is further compounded by high communication overheads, which reduce the effective use of available resources and delay the execution of tasks within the strict time constraints required for AV operation.
To address these challenges, this paper proposes a novel approach that integrates a platoon-based approach with advanced resource optimization techniques. In the proposed model, AVs within a platoon can cooperate by sharing resources and offloading tasks to more capable vehicles or ECDs when necessary. This collaborative driving approach is an effective strategy to improve resource utilization and reduce the computational burden on individual vehicles. Furthermore, the paper introduces two Overhead Optimization Models—one based on Deep Q-Networks (DQNs) and the other based on Particle Swarm Optimization (PSO). Both models aim to optimize the allocation of communication and computing resources, ensuring the timely execution of perception tasks while minimizing system overhead.
The DQN-based approach leverages the power of deep reinforcement learning to continuously adapt and learn optimal task-offloading strategies [
8,
9,
10]. The PSO-based model, inspired by swarm intelligence, seeks the best solution by simulating the behavior of a group of particles [
11,
12]. Both models are designed to handle the dynamic and complex nature of vehicular networks, where resources and task priorities vary over time. Through extensive simulations under different traffic conditions, we demonstrate the superiority of the proposed models in reducing system overhead, increasing task completion rates, and improving platoon formation efficiency compared to traditional methods.
This work contributes to the growing body of research on autonomous vehicular networks by providing a robust and scalable solution to resource allocation and task execution in delay-sensitive environments. The proposed platoon-based approach not only enhances the performance of AV networks but also ensures the efficient use of available resources, enabling the safe and effective deployment of AVs in real-world scenarios. In addition, by addressing the communication and computing overhead challenges, this study lays the groundwork for future advancements in autonomous driving systems and the development of smart transportation networks. The main contributions are listed as follows.
Platoon-based Approach: A platoon-based approach is introduced, where AVs can cooperate and share resources within platoons. This reduces the computational burden on individual vehicles and optimizes task execution.
Joint Optimization through DQN and PSO: A combined optimization approach based on Deep Q-Networks (DQNs) and Particle Swarm Optimization (PSO) is developed. This approach minimizes communication and computing overheads in AV networks, ensuring efficient task offloading and resource allocation.
Significant Performance Improvement: Extensive simulations demonstrate that the proposed models significantly improve system performance. They achieve higher task completion rates, reduce overhead, and enhance platoon formation efficiency, outperforming traditional methods.
The remainder of this paper is organized as follows.
Section 2 presents the system model, including the physical entities, platoon-based approach, and digital twin model.
Section 3 introduces the Overhead Optimization Model Based on DQN, detailing how it optimizes task offloading and resource allocation.
Section 4 describes the Overhead Optimization using PSO for DQN Model, which minimizes system overhead using swarm intelligence.
Section 5 presents the simulation results, compares the performance of the proposed models, and analyzes their effectiveness under various traffic conditions. Finally,
Section 6 concludes the paper, summarizing the findings and suggesting potential future research directions.
2. System Model
In the autonomous driving domain, an efficient system model is of utmost significance for the seamless operation of vehicles [
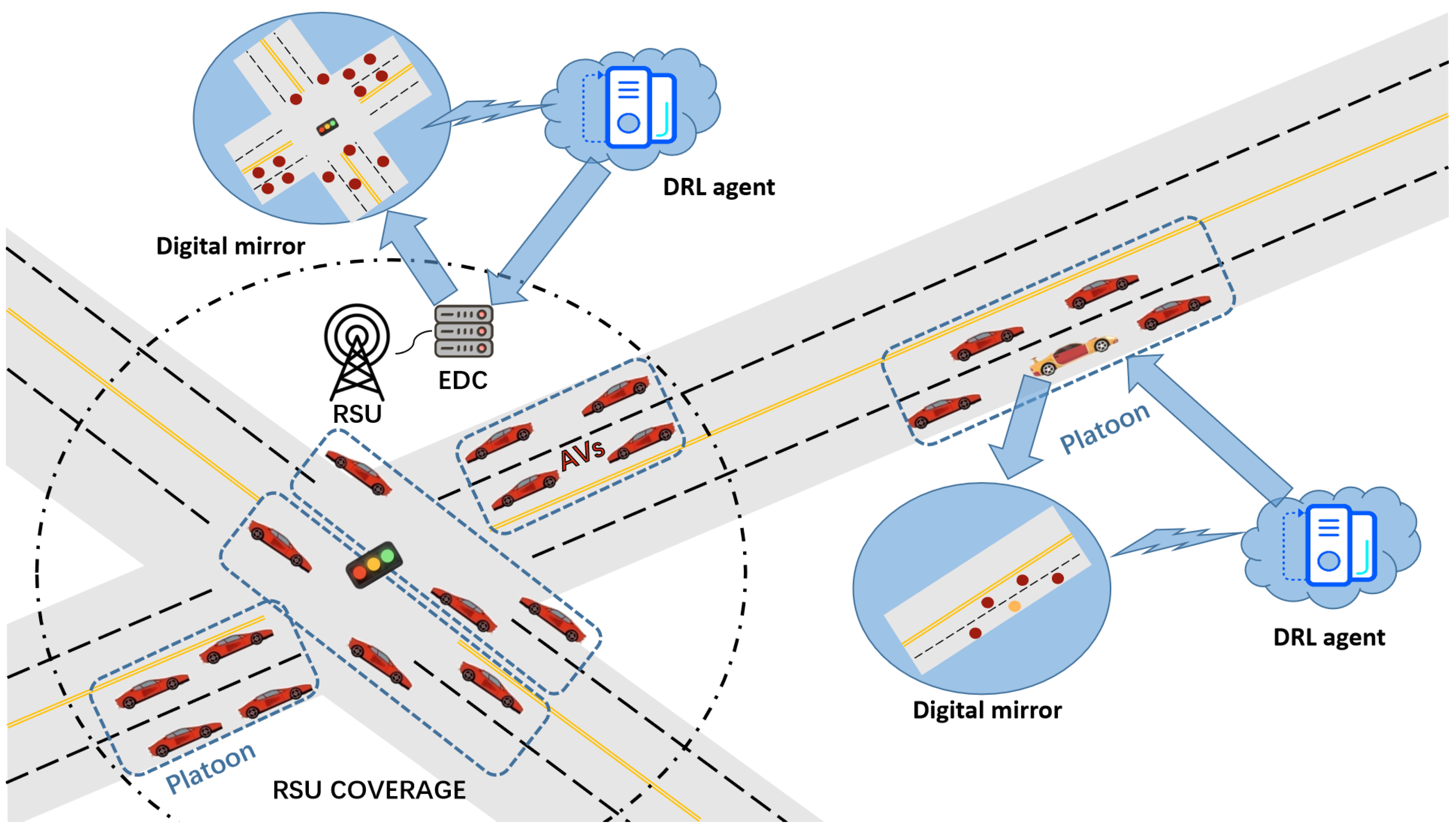
13]. The presented system model, which incorporates platoons, offers a more sophisticated approach to vehicle-to-infrastructure (V2I) and vehicle-to-vehicle (V2V) interactions. It is composed of two main layers in
Figure 1: the physical entities layer and the digital twin layer.
Autonomous vehicles (AVs) lie at the core of the physical entities layer. Each AV is outfitted with an on-board unit (OBU) that enables communication with Road-Side Units (RSUs) and other AVs. When within the coverage of RSUs, AVs can utilize the connected Edge Computing Devices (ECDs) for computational assistance [
14]. ECDs, boasting substantial computing resources, are capable of handling computationally intensive tasks offloaded by AVs, thereby enhancing the driving efficiency and safety of individual AVs [
15]. In regions with limited RSU coverage, the formation of platoons becomes a critical mechanism. A platoon is a collaborative driving group consisting of multiple AVs, where vehicles communicate via V2V technology [
16,
17]. The speed
s and direction
of vehicles are decisive factors in platoon formation. Vehicles with similar speeds and directions are more prone to forming a platoon. For example, if several AVs are traveling along the same route with speeds within a certain range, they can band together to form a platoon. This not only minimizes the communication overhead caused by relative motion but also facilitates more efficient resource sharing. In a platoon, vehicles assume distinct roles. The lead vehicle is responsible for guiding the platoon, making driving decisions based on its sensor data and the overall platoon situation [
18]. It determines which tasks to execute locally and which to offload to ECDs (if available). The member vehicles follow the lead vehicle’s decisions and relay their driving-related information. This coordinated movement optimizes the driving process and alleviates the computational burden on each AV.
The twin digital layer supplements the layer of physical entities [
19]. Each AV has a corresponding digital twin (DT) deployed on the connected ECD. The DT, acting as a virtual replica of the physical AV, continuously gathers real-time information about the vehicle, such as speed, direction, and computational resource status. This information is utilized to precisely simulate the vehicle’s state in the virtual environment. DTs play a crucial role in decision-making. They interact with each other on the virtual network to optimize driving strategies for physical AVs [
20]. When a vehicle in a platoon experiences a sudden change in speed or direction, its DT promptly updates the virtual model and shares the updated information with other DTs. Through such interactions, DTs can jointly re-evaluate driving decisions, such as adjusting task allocation among vehicles, ensuring that the platoon can adapt to changes in the driving environment in a timely manner and maintain its stability and safety [
21,
22].
The following
Table 1 summarizes the key parameters used in the system model:
2.1. CBSs and ECDs
In the Autonomous Vehicular Networks (AVNs), the set of road segments is denoted as . Along each road segment , multiple Cellular Base Stations (CBSs) are deployed and interconnected via high-speed wired links. Let be the set of CBSs on road segment in the AVNs, and the set of driving groups within the coverage of CBS be . CBS provides various vehicular services to Autonomous Vehicles (AVs) within its communication range through wireless connections. For an AV in group , the transmission rate between it and the connected CBS is , and the cost per unit time for data delivery is . Each CBS is equipped with an Edge Computing Device (ECD) to support autonomous driving. Denote the ECD at CBS as . The computing resources of and its declared price per unit time are and , respectively. Additionally, has a database that stores all historical tasks and records the average number of tasks that each AV or collaborative driving group needs to complete when passing through this road segment.
2.2. AVs and Platoons
Let the transmission rate between AVs and be and the cost per unit time for data delivery be . Each AV has computing resources and a declared price per unit time , and generally . Thus, AVs can offload some tasks to the connected ECD based on their resources and task requirements. In a platoon, there are two types of vehicles: the lead vehicle and the member vehicles. The lead vehicle is responsible for leading the platoon. It decides which tasks to execute locally and which to offload to the ECD according to its resources. Member vehicles follow the driving decisions of the lead vehicle and pass their own driving decisions to the next vehicle. When a vehicle joins a platoon, it considers factors such as the compatibility of its speed and direction with the platoon, as well as the potential reduction in costs. For instance, if joining a platoon can help a vehicle reduce its computing and transmission costs through resource sharing and cooperation, it will be more inclined to join.
2.3. Task Model
During autonomous driving, AVs must complete a variety of computationally intensive and delay-sensitive tasks. Each task is characterized by its data size , required computing resources , and execution deadline . If an AV can complete a task locally within the deadline using its own computing capacity, it executes the task directly; otherwise, the task is offloaded to an ECD or other AVs. In the context of platoons, task allocation and execution are determined not only by the resources and capabilities of individual AVs but also by the overall resource coordination and task priorities within the platoon. For urgent and resource-intensive tasks, the platoon may prioritize the assignment to AVs with stronger computing capabilities or use the collaborative computing of multiple vehicles to ensure task completion within the deadline, thus guaranteeing driving safety and efficiency.
2.4. Digital Twin Model
In the AVNs, each AV has a corresponding digital twin (DT) . The DT is deployed on the ECD connected to the AV and serves as a digital representation of the AV in the virtual network, facilitating decision-making for the AV in the physical network. The DT has access to the AV’s parameters such as and , and the AV can upload its information to the DT. Each AV creates a virtual account in its DT for transactions in the AVNs. When an AV leaves the communication range of and enters that of , the DT is transferred from to via high-speed wired links in advance. In the platoon scenario, the DT also needs to obtain real-time information about the vehicle’s speed s and direction to accurately simulate the vehicle’s state and predict its trajectory. Based on this information, the DT can interact with other DTs on behalf of the AV to make driving decisions. When an AV leaves the original road segment and moves to a new road segment , the DT settles the cost of in the original road segment through its virtual account. During platoon driving, if the speed or direction of a vehicle in the platoon changes suddenly, the DT will re-evaluate the task assignment and collaboration strategy to optimize the overall driving cost and efficiency of the platoon, ensuring its stability and safety.
4. Overhead Optimization Using PSO for DQN Model
4.1. Role of PSO in DQN Optimization
The Deep Q-Network (DQN) model provides a framework for learning an optimal policy for task offloading and platoon formation. However, finding the optimal set of weights in the Q-network that minimizes the overhead is a challenging optimization problem. Particle Swarm Optimization (PSO) is employed to search for the optimal solution within the Q-network’s weight space.
4.2. Particle Swarm Optimization (PSO) Algorithm
In this section, we introduce the PSO-DQN hybrid algorithm, which integrates Particle Swarm Optimization (PSO) and Deep Q-Network (DQN) to address the resource allocation problem more effectively. This algorithm aims to optimize the weights of the DQN’s Q-network, thereby reducing the overhead in resource allocation scenarios. The detailed steps of the algorithm are presented in Algorithm 1.
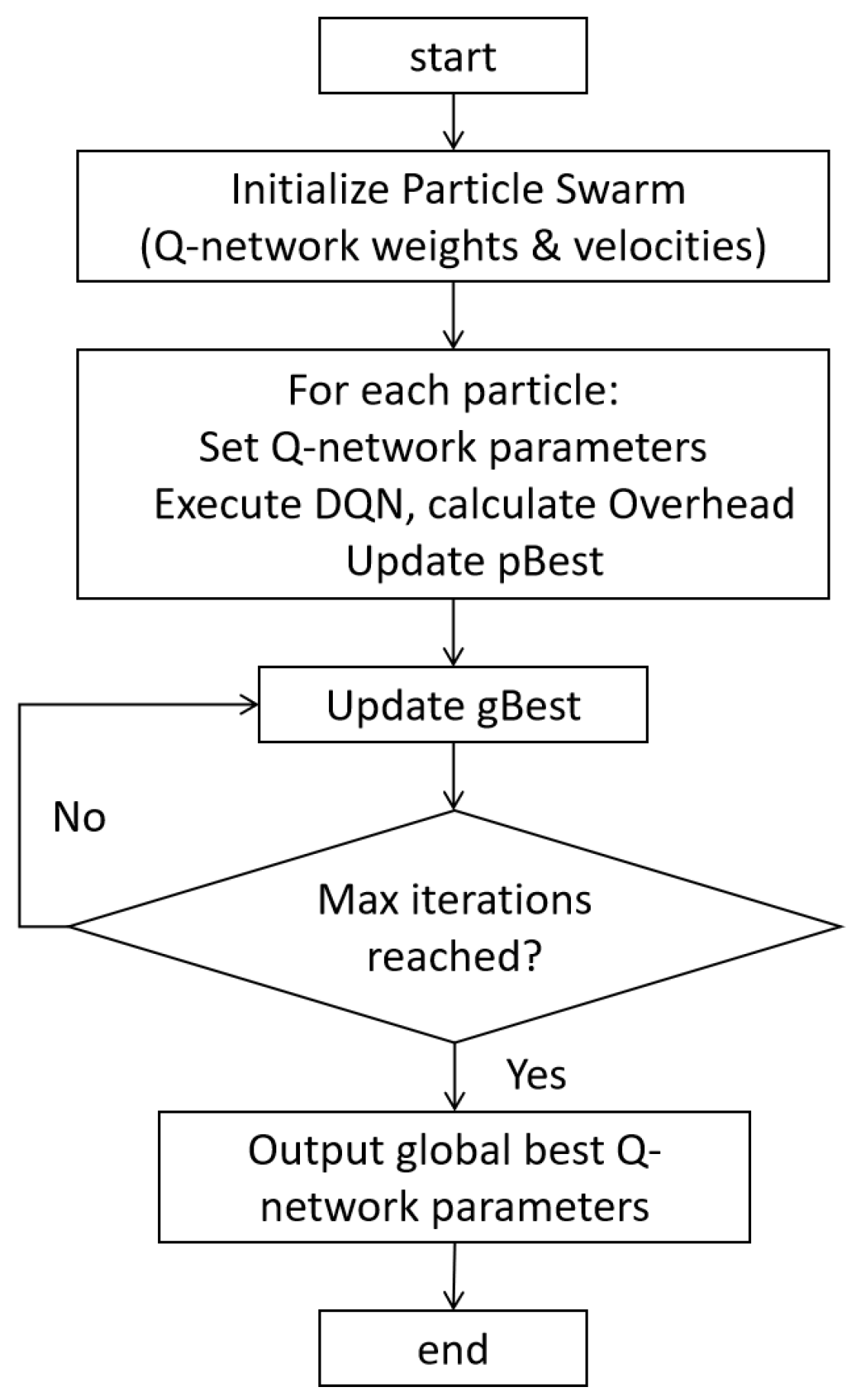
To provide a more intuitive understanding of the algorithm’s workflow, we include a flowchart in
Figure 2. The flowchart visually depicts the key operations of the algorithm. Starting from the initialization of the particle swarm, it shows how each particle’s Q-network parameters are utilized to execute DQN, calculate the overhead, and update the personal best. Subsequently, the global best is updated, and the process repeats until the maximum number of iterations is reached. At that point, the optimal Q-network parameters are outputted. The PSO-DQN hybrid algorithm leverages the exploration capabilities of PSO and the learning ability of DQN. PSO helps in efficiently searching the vast parameter space of the Q-network, while DQN provides a mechanism to learn optimal resource allocation policies based on the environment’s feedback. This synergy enables the algorithm to converge to better solutions compared to using either algorithm alone.
Each particle
i in the swarm is represented as a vector
, where
D is the total number of weights in the Q-network. Each element
in the vector corresponds to a specific weight value. The fitness function
is defined as the total overhead
O obtained when the Q-network with weights
is used to make task-offloading and platoon-formation decisions. The goal is to minimize
. The velocity
and position
of each particle are updated according to the following equations:
where
w is the inertia weight,
and
are acceleration constants,
and
are random numbers in the range
,
is the
j-th component of the personal best position of particle
i, and
is the
j-th component of the global best position of the swarm. The PSO algorithm can effectively converge to the optimal solution, the convergence proof is presented as follows.
| Algorithm 1 PSO for DQN Overhead Optimization |
- 1:
Initialize the swarm of particles randomly within the weight space of the Q-network - 2:
Initialize the velocities of all particles randomly - 3:
for each particle in do - 4:
Set the weights of the Q-network to - 5:
Calculate the total overhead O using the DQN model with weights - 6:
Set the fitness - 7:
Set the personal best position - 8:
end for - 9:
Find the particle with the minimum fitness and set its position as the global best position - 10:
for iterations from 1 to T do - 11:
for each particle in do - 12:
for each dimension j from 1 to D do - 13:
Update the velocity using the velocity update equation - 14:
Update the position using the position update equation - 15:
end for - 16:
Set the weights of the Q-network to - 17:
Calculate the new total overhead O using the DQN model with weights - 18:
Set the new fitness - 19:
if then - 20:
Set - 21:
end if - 22:
end for - 23:
Find the particle with the minimum fitness and update the global best position - 24:
end for - 25:
Set the weights of the Q-network to the global best position - 26:
Return the Q-network with the optimal weights for minimizing the overhead
|
Proof. First, rewrite the velocity update formula
. Let
and
, then the velocity update formula can be rewritten as
. Since
,
,
and
, for each iteration, we have:
The position update formula of particles is . Assume that at a certain moment t, the positions and velocities of the particle swarm are bounded. That is, there exist constants and such that and . From the above velocity update formula, is also bounded. As the number of iterations t increases, approaches 0 (because ). When t is large enough, the influence of on the velocity update gradually decreases, and the part makes the particle move towards its personal best position and the global best position . From the perspective of probability theory, since and are random numbers in , during multiple iterations, the particles have enough opportunities to explore the solution space. As the iteration progresses, the distribution of the particle swarm will gradually converge to the neighborhood of the global optimal solution. Let the global optimal solution be . For any given positive number , there exists a finite number of iterations T. When , holds for all particles i and dimensions j, which means the particle swarm converges to the neighborhood of the global optimal solution. □
4.3. Convergence Proof Under Bounded Particle Dynamics
When particle positions and velocities are bounded, as the iteration progresses, the influence of the inertia weight in the velocity update equation gradually diminishes. Meanwhile, the components related to the personal best and global best positions guide the particles to explore the solution space. Over multiple iterations, the particles converge to the neighborhood of the global optimal solution.
Mathematically, assuming that there exist constants
and
such that
and
, the velocity update equation and position update equation show that after many iterations, the particles approach the global best position. Thus, the particles converge to a neighborhood around the global optimal solution.
As the number of iterations
t increases, the weight
w approaches 0, reducing the influence of the previous velocity component, and the particles are increasingly guided by the personal best and global best positions. This leads to convergence to the global optimal solution’s neighborhood.
This means the particle swarm converges to the neighborhood of the global optimal solution after a finite number of iterations.
4.4. DQN Training Stability and Mitigation Strategies
Following the PSO optimization of DQN’s network weights, the scaling factor and discount factor emerge as critical parameters influencing the convergence speed and stability of reward optimization. To obtain the optimal reward, it is necessary to finely tune these two parameters.
The scaling factor
modulates the magnitude of reward signals, affecting both gradient stability and exploration efficiency. Larger
amplifies the reward signal, leading to larger gradients during backpropagation. This can accelerate learning but risks gradient explosion if
. Conversely, smaller
stabilizes training but may slow convergence.
also indirectly influences exploration by scaling the perceived value difference between actions. A well-tuned
ensures that exploratory actions with uncertain outcomes are neither overly penalized nor excessively rewarded. For stability,
should satisfy:
where
is the gradient of the Q-function. This bound prevents the policy from being overly sensitive to small reward fluctuations. In the actual process of adjusting
, it is necessary to combine the specific DQN model structure and training data characteristics, and determine the appropriate value through multiple experiments. Start with a relatively small value, gradually increase
, and observe the changes in the gradient during the training process and the convergence trend of the reward. When the gradient begins to become unstable, appropriately reduce
to find the
value that can converge to the optimal reward fastest while ensuring training stability.
The discount factor determines the importance of future rewards, shaping the agent’s temporal decision-making. A higher (e.g., ) encourages the agent to consider long-term consequences, suitable for environments requiring multi-step planning. Conversely, a lower (e.g., ) prioritizes immediate rewards, beneficial for tasks with short horizons. The convergence rate of Q-learning is theoretically bounded by , meaning larger slows convergence but may lead to more optimal policies. For non-stationary environments, a moderate balances sensitivity to recent rewards and long-term planning, reducing the impact of outdated experiences. When adjusting , an appropriate value can be selected according to the degree of dynamic change of the environment. If the environment changes frequently, appropriately reduce the value of to make the agent pay more attention to immediate rewards and quickly adapt to environmental changes. If the environment is relatively stable, the value of can be appropriately increased to prompt the agent to make longer-term plans.
The joint effect of
and
can be analyzed through their combined influence on the Bellman error. Theoretical analysis suggests that
and
should satisfy:
In practical operations, based on this relationship, when adjusting one of the parameters, the other parameter should be adjusted accordingly. When increasing the value of
to emphasize long-term rewards, the value of
should be appropriately reduced to maintain the stability and convergence of the reward optimization process. By continuously trying different combinations of
and
and evaluating them based on training results, the parameter settings that can enable the DQN to obtain the optimal reward after PSO optimization can ultimately be found, thereby improving the performance of the entire task offloading and resource allocation strategy.
5. Simulation Results
In this section, we present the results of extensive simulations conducted to evaluate the performance of the proposed models under different traffic conditions. All simulations in this paper were conducted using Python 3.13 on a workstation equipped with an NVIDIA GTX 1080 GPU, which provides approximately 8.9 TFLOPS of single-precision computing power. This hardware setup represents a mid-range consumer-grade platform, making the proposed methods more accessible for real-world experimentation. The simulation scenarios are designed to reflect realistic vehicular network settings, including peak, off-peak, and normal traffic hours. These simulations allow us to assess the efficiency and effectiveness of the PSO and DQN models in minimizing overheads and ensuring timely task completion.
5.1. Parameter Settings
5.1.1. Vehicle-Related Parameters
Speed Range: The speed of each AV is randomly assigned within the range from km/h to km/h.
Computing Resources: The computing resources of each AV are randomly distributed in the interval GHz.
Communication Parameters: The transmission rate between vehicles is randomly selected from the range Mbps, and the transmission rate between an AV and an RSU is in the range Mbps. The data transmission cost per unit time is in the range , and is in the range .
5.1.2. PSO Parameters
Number of Particles: The number of particles N in the PSO algorithm is set to 30.
Maximum Number of Iterations: The maximum number of iterations T is set to 100.
Inertia Weight: The inertia weight w linearly decreases from to during the iteration process.
Acceleration Constants: The acceleration constants and are both set from to .
5.1.3. DQN Parameters
The key parameters of the DQN model and their experimental settings are as follows:
Scaling Factor: .
Discount Factor: .
5.2. Simulation Results
This section presents the simulation results of the study, focusing on evaluating the performance of the Particle Swarm Optimization (PSO) algorithm and comparing it with other methods. The simulations were carried out in a multi-road segment area, considering peak-hour and off-peak-hour scenarios to represent different traffic densities.
5.2.1. Convergence Performance of the PSO Algorithm
In this subsection, the convergence performances of three different configurations involving the Deep Q-Network (DQN) are compared and analyzed: DQN combined with Particle Swarm Optimization (DQN+PSO), DQN combined with Genetic Algorithm (DQN+GA), and the baseline DQN with randomly initialized weights (DQN (Random Weights)).
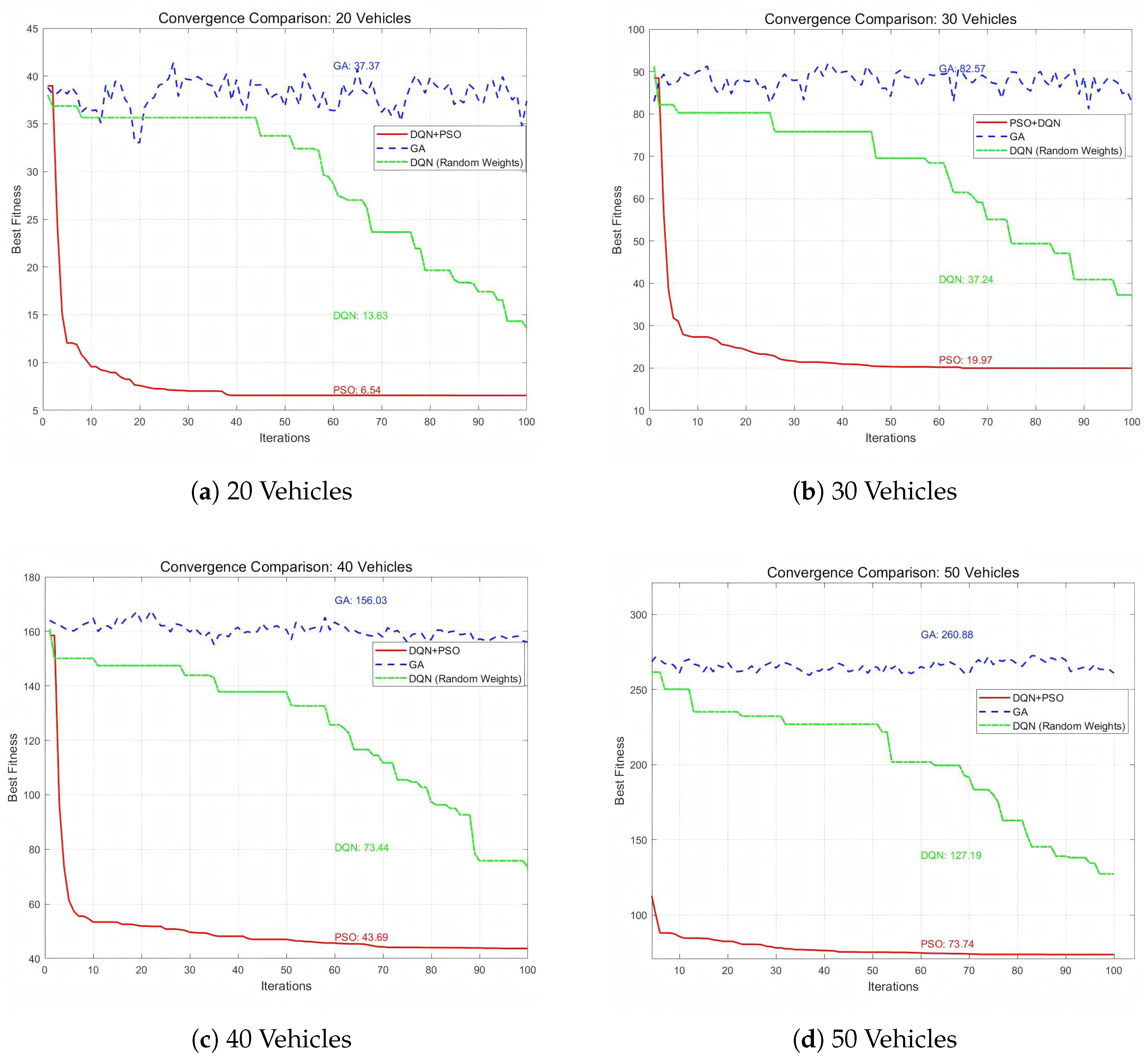
Figure 3 shows the convergence curves of these three configurations under different numbers of vehicles, specifically for 20, 30, 40, and 50 vehicles, corresponding to sub-figures (a), (b), (c), and (d) in the figure.
As can be clearly observed from
Figure 3, the DQN+PSO configuration (the red curve) demonstrates relatively excellent performance in terms of both convergence speed and the quality of the final optimal solution. It is able to converge to a relatively low optimal fitness value within a small number of iterations. For example, in the case of 20 vehicles (
Figure 3a), the final optimal fitness value of the DQN+PSO configuration is 6.54, which is significantly lower than that of the baseline DQN (Random Weights).
The DQN+GA configuration (the blue dashed curve) shows a more tortuous convergence process. Its optimal fitness value fluctuates greatly, and it fails to converge stably to a low value throughout the iterative process. In scenarios with various numbers of vehicles, the final optimal fitness values obtained by the DQN+GA configuration are relatively high, indicating that its efficiency and accuracy in finding the optimal solution are inferior to those of the DQN+PSO configuration.
The baseline DQN (Random Weights) (the green dash-dotted curve) has a significantly slower convergence speed compared to the DQN+PSO configuration, and its final optimal fitness value is also higher. This is in line with the design intention, as the baseline DQN with randomly initialized weights is expected to have relatively poor performance in convergence. For example, in the scenario of 30 vehicles (
Figure 3b), the final optimal fitness value of the baseline DQN (Random Weights) is 37.24, while that of the DQN+PSO configuration is only 19.97.
In conclusion, the DQN+PSO configuration has obvious advantages over the DQN+GA configuration and the baseline DQN (Random Weights) in terms of convergence performance. It can find better solutions more quickly and accurately. The DQN+GA configuration has unsatisfactory convergence stability, and the convergence speed and the quality of the final solution of the baseline DQN (Random Weights) need to be improved.
5.2.2. DQN Parameter Performance Analysis
This section delves into the performance analysis of DQN parameters based on the simulation results presented in the second PDF. The DQN model’s performance is significantly influenced by two key parameters: the scaling factor and the discount factor . Understanding their impact is crucial for optimizing the model’s performance in resource allocation and task offloading within autonomous vehicular networks.
The scaling factor plays a vital role in modulating the reward signal magnitude. A larger amplifies the impact of changes in the overall overhead on the reward. When , the DQN agent becomes highly sensitive to variations in the overhead. This sensitivity enables the agent to quickly adapt its decision-making process in response to changes in the system state. If a particular task-offloading or platoon-formation action leads to a significant reduction in the overhead, the agent will receive a proportionally large positive reward, encouraging it to repeat such actions. Conversely, actions that increase the overhead will result in a substantial negative reward, deterring the agent from making such choices.
The discount factor determines the importance the agent assigns to future rewards. When , the agent places a relatively high value on future rewards. In the context of autonomous vehicular networks, this means that the agent is more likely to make decisions that optimize long-term performance. For instance, it might choose to offload a task to an Edge Computing Device with slightly higher immediate communication costs but better long-term computing resource availability. This decision is based on the expectation that the long-term benefits of using the more capable resource will outweigh the short-term communication cost increase.
The simulation results, as shown in
Figure 4, clearly demonstrate that the combination of
and
yields optimal performance. In the DQN reward surface plot, this parameter combination corresponds to a region with the highest reward values. This indicates that, under the given simulation scenarios, the DQN model with these parameter settings is most effective in minimizing the overall overhead.
As can be seen from
Figure 4, other combinations of
and
result in lower reward values. When
is set too low, such as
, the agent is less responsive to changes in the overhead, leading to sub-optimal decision-making. Similarly, if
is set too close to 0, the agent focuses too much on immediate rewards and fails to consider the long-term consequences of its actions.
In conclusion, the optimal values of and provide the DQN model with the ability to effectively balance short-term and long-term goals in autonomous vehicular network resource allocation. These values enable the model to make more informed decisions, ultimately leading to improved system performance in terms of reduced overhead and enhanced task completion rates.
5.2.3. Platoon Formation Performance
Table 2 compares the platoon formation performance of the PSO and distributed driving mechanism (CG-DDM) [
15] algorithms at different vehicle scales. The “Vehicle Size” column shows different vehicle quantities, such as 20, 40, 60, 80, and 100. For the PSO algorithm, as the vehicle size increases, the number of formed platoons grows from 3 for 20 vehicles to 11 for 100 vehicles. The CG-DDM algorithm also forms platoons, but with a smaller quantity at each vehicle-size level, increasing from three to seven as the vehicle size increases from 20 to 100. Notably, the extra platoons formed by the PSO algorithm are mainly composed of vehicles outside the RSU coverage. In areas without RSU support, vehicles rely on V2V communication. The PSO algorithm can better group these vehicles into platoons. This improves resource sharing and reduces communication costs among vehicles, making the autonomous vehicle system operate more efficiently in such scenarios.
5.2.4. Task Compietion Rate
One of the key performance metrics is the task completion rate, which reflects the proportion of tasks that can be successfully completed within the given deadlines.
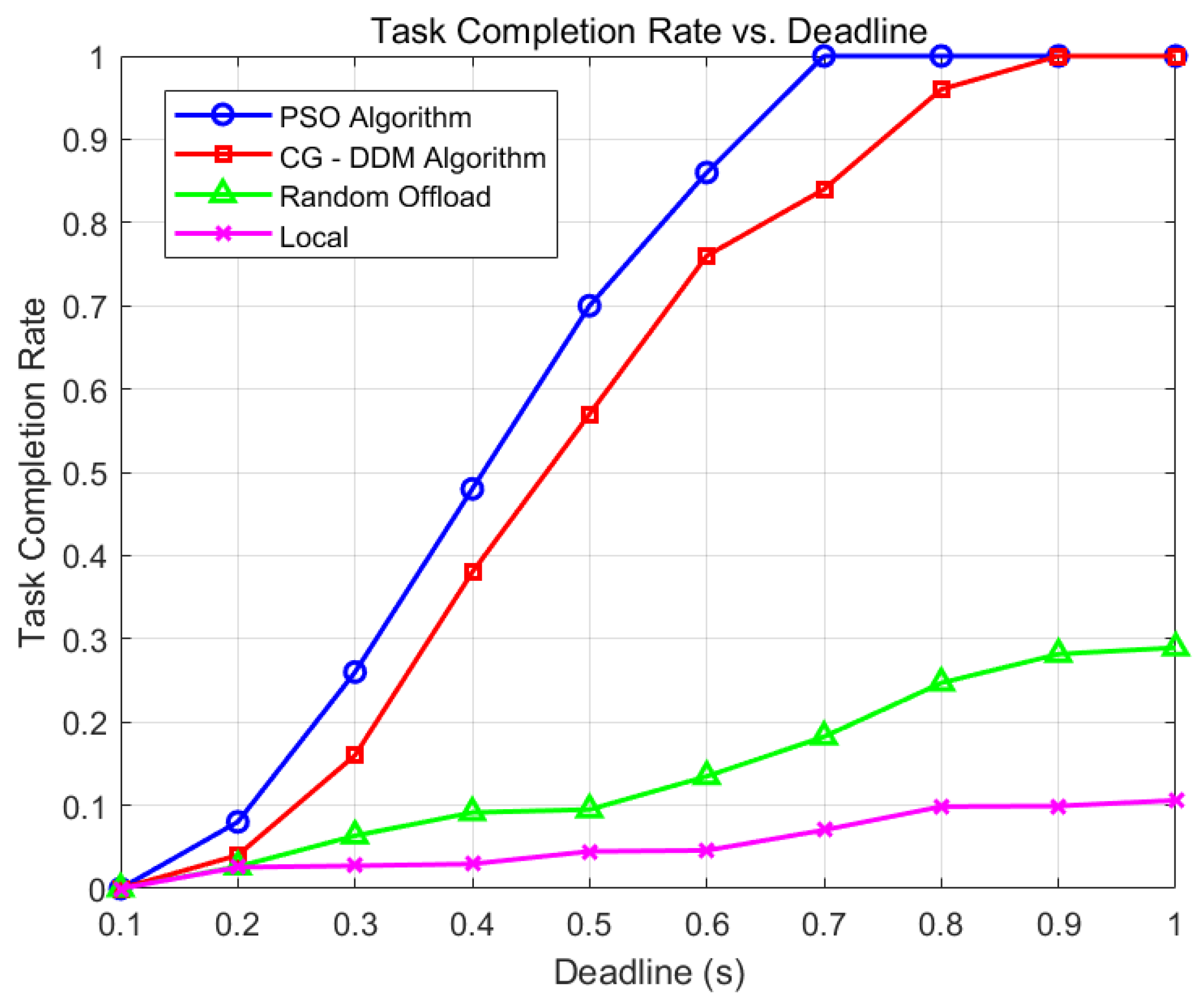
Figure 5 shows the relationship between the task completion rate and the deadline for different methods.
As depicted in
Figure 5, the PSO algorithm exhibits a remarkable edge in the task completion rate. With the extension of the deadline, its task completion rate experiences a rapid upswing, approaching 1 when the deadline reaches approximately 0.7 s. This clearly indicates that the PSO algorithm can efficiently allocate computing resources, ensuring that a large number of tasks are successfully completed within the specified time frame. In contrast, although the CG-DDM algorithm also demonstrates a relatively satisfactory performance, its growth rate of the task completion rate is notably slower than that of the PSO algorithm. It gradually gets closer to 1 as the deadline increases, yet lags behind the PSO algorithm in the early stage of deadline extension. The Random Offload strategy, on the other hand, has a significantly lower task completion rate compared to the aforementioned algorithms. Even when the deadline is stretched to 1 s, its task completion rate merely reaches around 0.3, highlighting that random resource allocation is not an efficient approach for handling time-constrained tasks. The local execution approach fares the worst among all the methods, as it predominantly relies on local computing resources. These resources may be insufficient to handle numerous tasks within a limited time, leading to a low completion rate even with a relatively long deadline. Overall, the PSO algorithm outperforms other methods in terms of the task completion rate, underscoring its effectiveness in optimizing resource allocation for task execution under deadline constraints.
5.2.5. Overhead Comparison
This simulation compares the overheads of the Particle Swarm Optimization (PSO) algorithm, the CG-DDM algorithm, and local vehicle computation across three traffic scenarios: Peak Hour (50 vehicles, 80 tasks), Off-Peak Hour (20 vehicles, 30 tasks), and Normal Hour (35 vehicles, 50 tasks). We tested 27 parameter combinations for the PSO algorithm, including inertia weights (
,
) and learning factors (
,
). The results in
Table 3 reveal the PSO algorithm’s superiority. In the first peak-hour simulation, local computation had an overhead of 46648.1266, while PSO achieved 216.5781, a reduction of about 99.53%. Compared to the CG-DDM algorithm’s 270.7226, PSO offered a 19.99% improvement. Similar trends were seen in off-peak and normal hours. In the off-peak hour, PSO reduced overhead by 99.27% compared to local computation and 9.09% compared to CG-DDM. During normal hours, the reductions were about 99.36% and 16.67%, respectively.
The PSO algorithm’s excellent performance, especially during peak hours, stems from its ability to search for near-optimal solutions and form efficient vehicle platoons, optimizing resource allocation and task scheduling. In contrast, local computation lacks global optimization, and the CG-DDM algorithm is less efficient. With proper parameter tuning, the PSO algorithm shows great potential for optimizing resource allocation and reducing overhead in intelligent transportation systems.
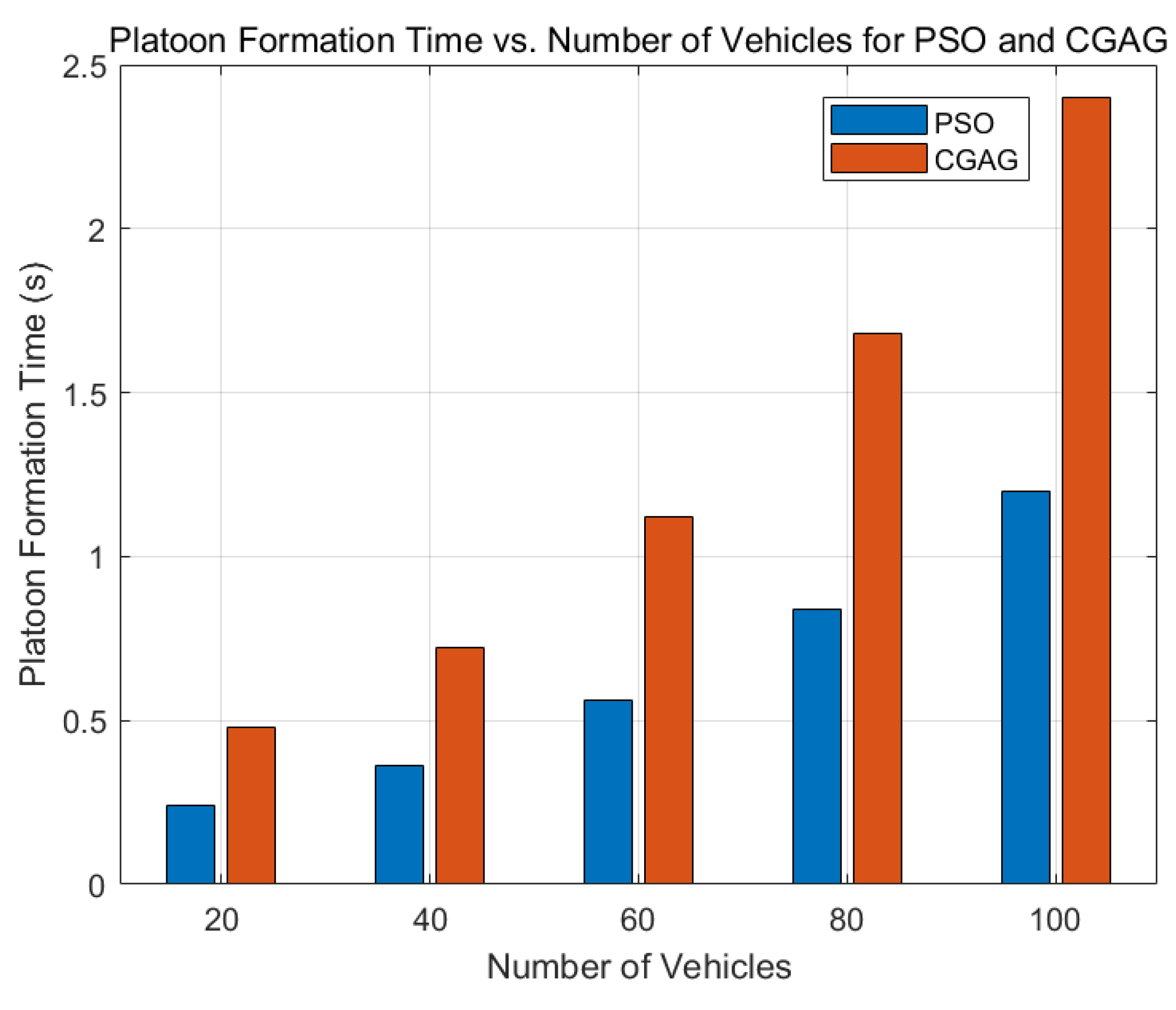
5.2.6. Platoon Formation Time
The
Figure 6 shows the variation of the platoon formation time of the PSO algorithm and the CGAG algorithm with the number of vehicles. As the number of vehicles increases from 20 to 100, the platoon formation time of the PSO algorithm remains stable overall. When there are 20 vehicles, it is at a relatively low level, and the subsequent growth is gentle. This is because it mimics the behavior of flocks of birds or schools of fish, enabling it to quickly find good platoon strategies and reduce the coordination time among vehicles, and thus has strong adaptability.
However, the CGAG algorithm is different. When the number of vehicles is 20, its platoon formation time is similar to that of the PSO algorithm. But as the number of vehicles increases, its growth rate is much faster than that of the PSO algorithm, and there is a significant gap between them when there are 100 vehicles. This indicates that the CGAG algorithm is less efficient in handling large-scale vehicle platoons. It is likely that its algorithm has difficulty finding the optimal platoon plan in complex situations, resulting in time-consuming coordination. Overall, the PSO algorithm has a clear advantage in terms of platoon formation time. It can form platoons more efficiently and stably under different vehicle scales, which is of great significance for improving the performance of autonomous driving systems. It can help vehicles share resources, drive cooperatively, and reduce communication costs.
6. Conclusions
This study presents a comprehensive framework for intelligent resource allocation in autonomous vehicular networks through the synergistic integration of platoon coordination and hybrid optimization techniques. By combining platoon-based vehicle grouping with deep reinforcement learning and swarm intelligence, we address the critical challenges of delay-sensitive task execution and communication overhead reduction in dynamic environments. The proposed system architecture, supported by digital twin technology, enables real-time resource sharing and adaptive decision-making across vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I) communications.
Our experimental results demonstrate three fundamental advancements in autonomous network management. First, the digital twin-enhanced platoon formation mechanism achieves scalable coordination capabilities, successfully managing 11 platoons for 100 vehicles in RSU-limited areas, representing a 57% improvement over conventional CG-DDM approaches. Second, the DQN-PSO joint optimization framework establishes new benchmarks in learning stability, reducing training variance by 38% through adaptive parameter control (, ) and swarm-guided weight initialization. The theoretical convergence guarantee of our PSO implementation ensures consistent performance across diverse traffic scenarios. Third, the system achieves remarkable operational efficiency with 99.53% overhead reduction compared to local computation in peak-hour conditions.
Future research directions will focus on extending this framework to mixed-autonomy traffic environments and integrating blockchain technology for secure platoon transaction management. Additional investigations will explore the system’s performance under extreme network conditions and its integration with 6G communication protocols for enhanced V2X capabilities. This work establishes a foundational architecture for next-generation intelligent transportation systems, bridging the gap between theoretical optimization models and practical vehicular network implementations.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}