Retinex-Based Low-Light Image Enhancement via Spatial-Channel Redundancy Compression and Joint Attention


Abstract
1. Introduction
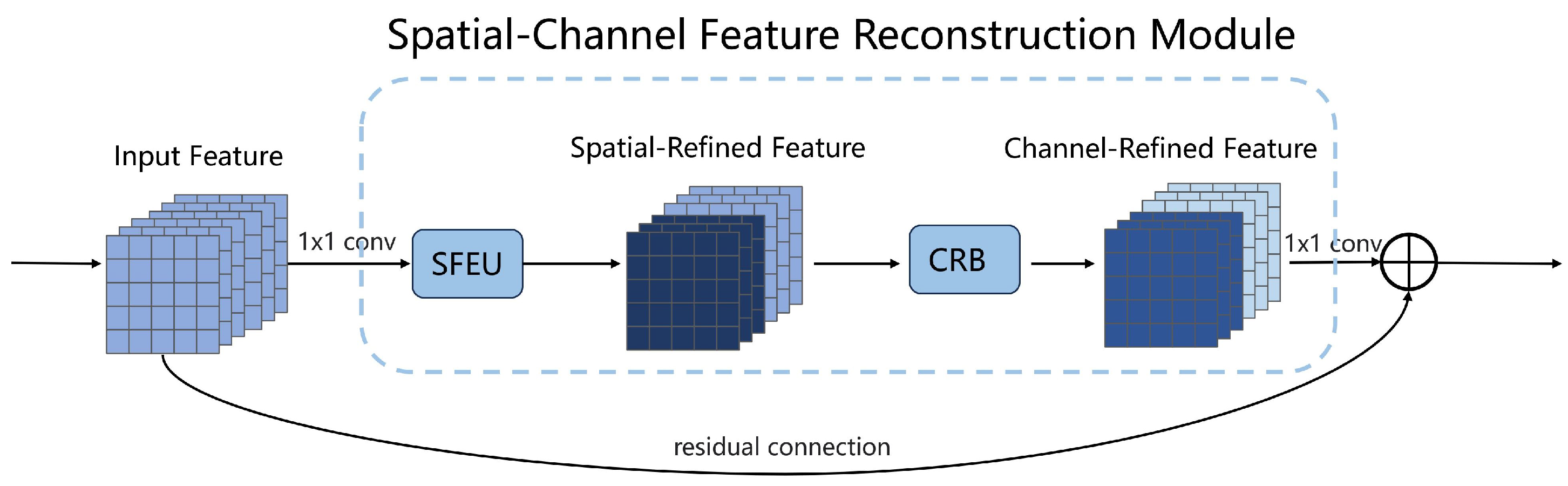
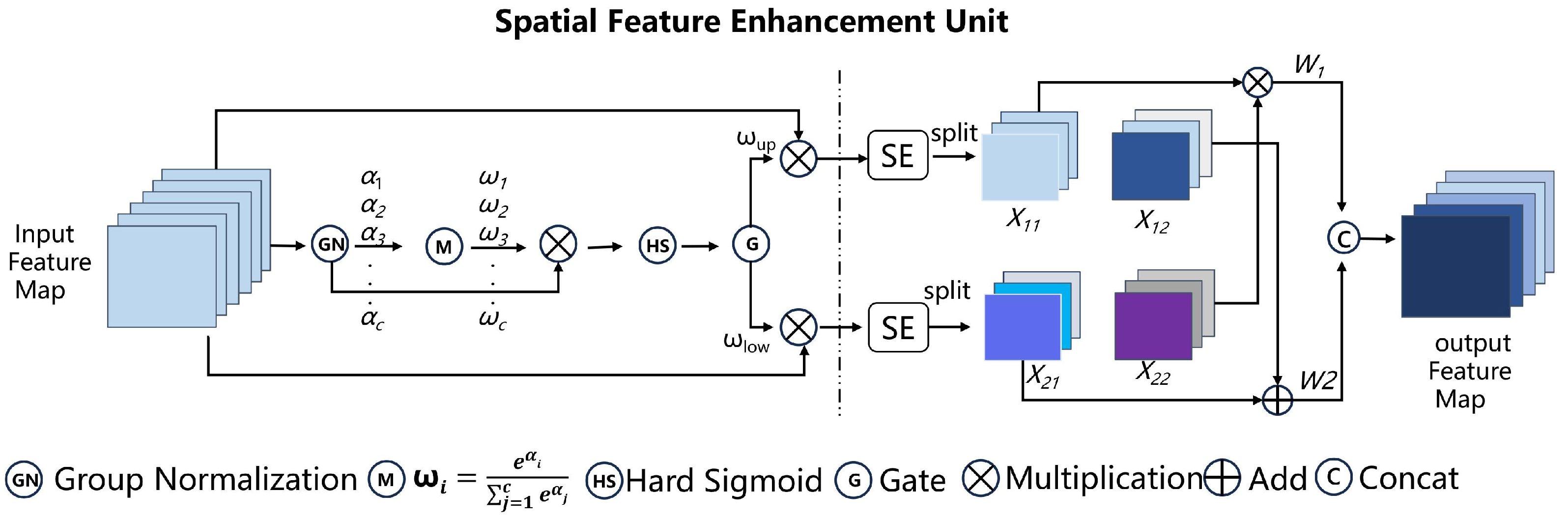
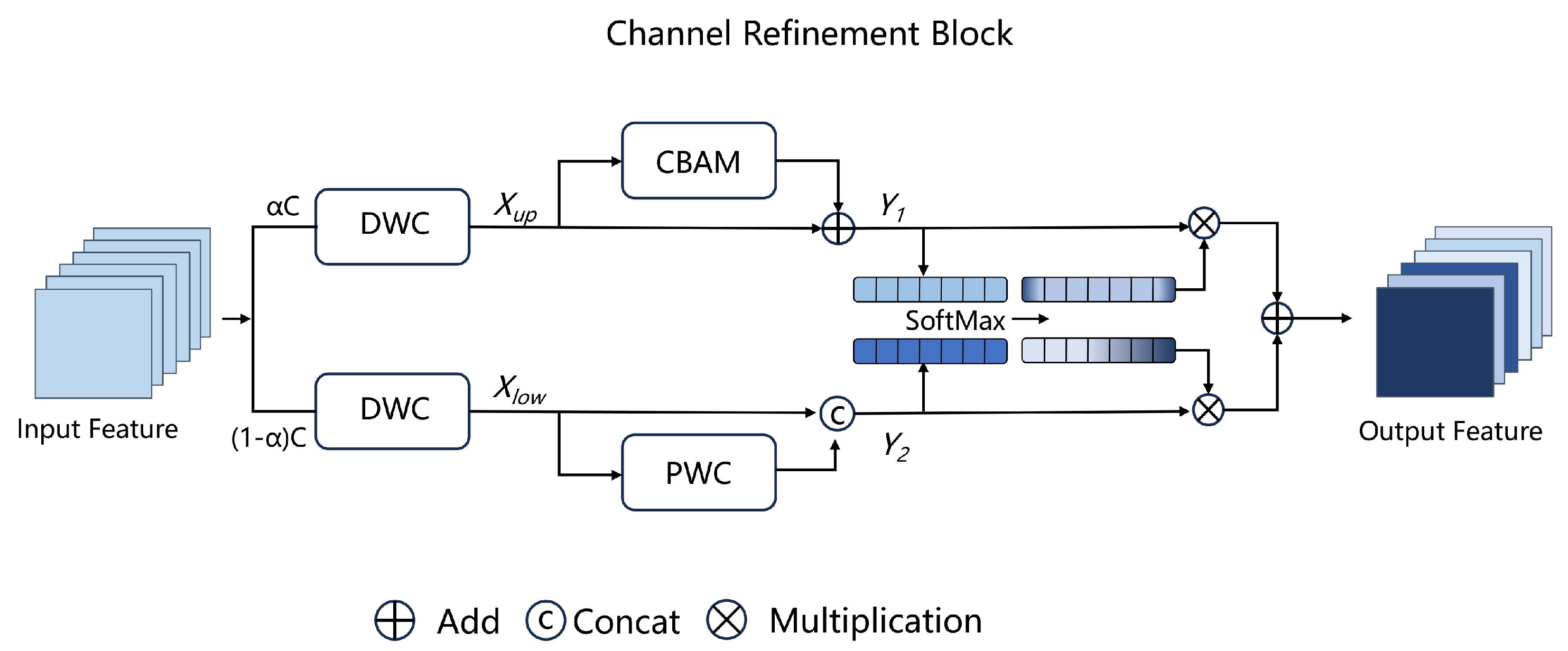
- We design a compact and effective module that simultaneously suppresses spatial and channel redundancy using a combination of split–reconstruction and separation–fusion strategies, significantly reducing computational cost while enhancing feature representation.
- We propose a dual-directional attention mechanism that decomposes global pooling into two 1D feature encodings, enabling the model to capture long-range dependencies and retain positional accuracy simultaneously.
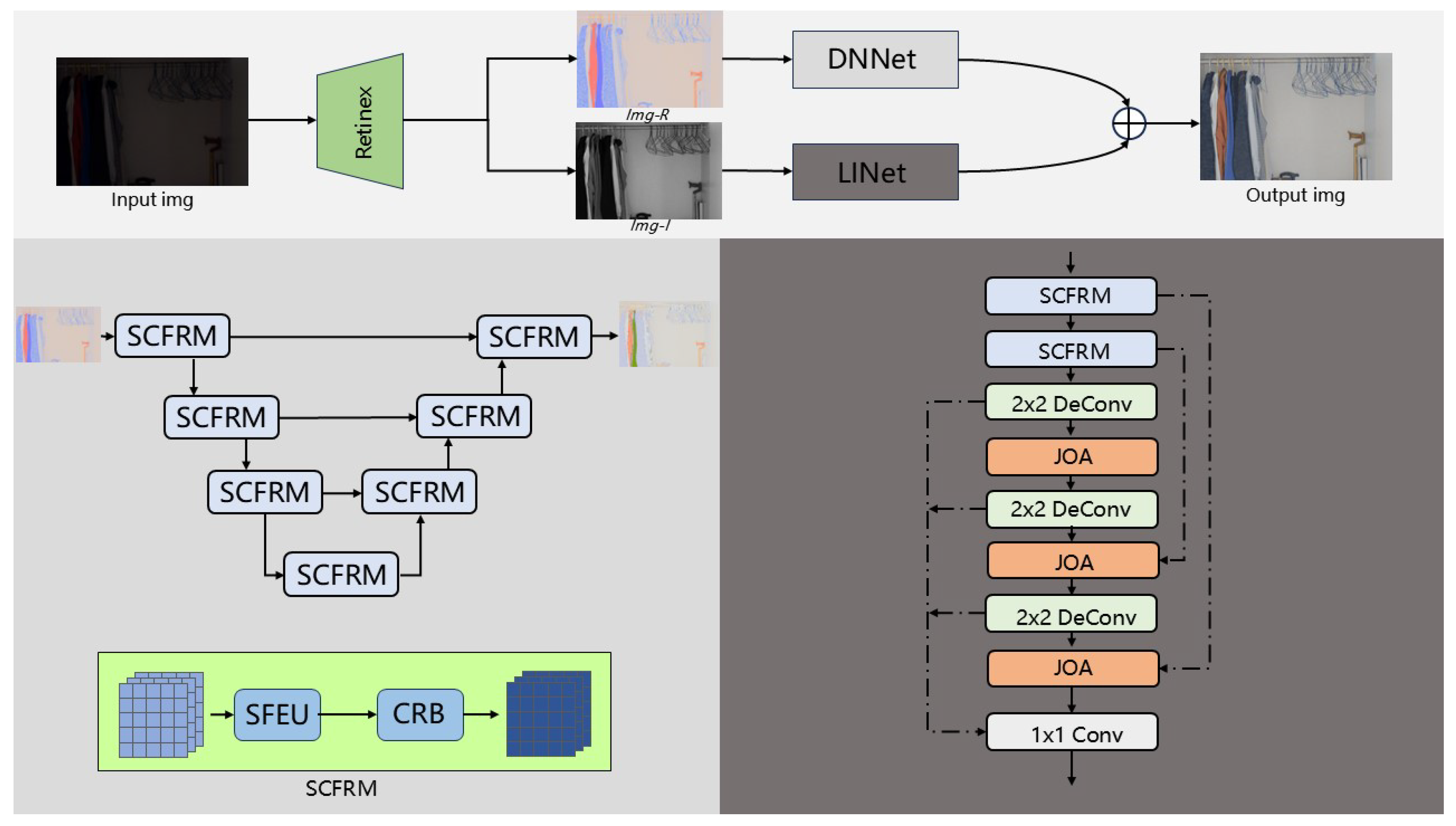
- We construct a dual-branch network that separately enhances reflectance and illumination components using DNNet and LINet. SCFRM and JOA are strategically integrated to boost denoising performance and illumination adjustment, respectively.
- Our method achieves advanced or competitive performance compared to state-of-the-art approaches.
2. Related Work
2.1. Deep Learning-Based Low-Light Image Enhancement
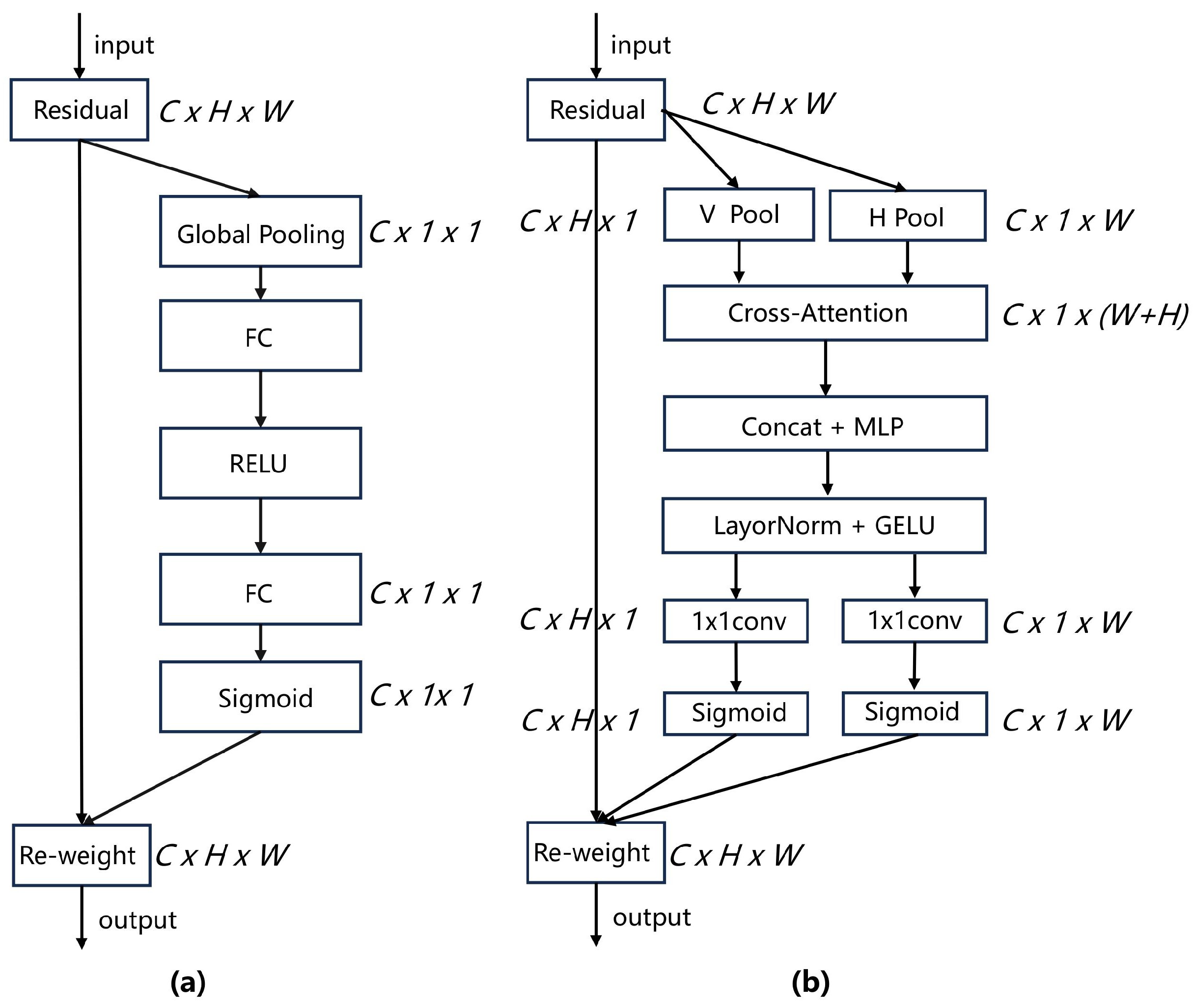
2.2. Attention Mechanisms
3. Materials and Methods
3.1. Overall Architecture
3.2. DNNet
3.3. LINet
3.4. Loss Function
4. Experimental Results
4.1. Implementation Details
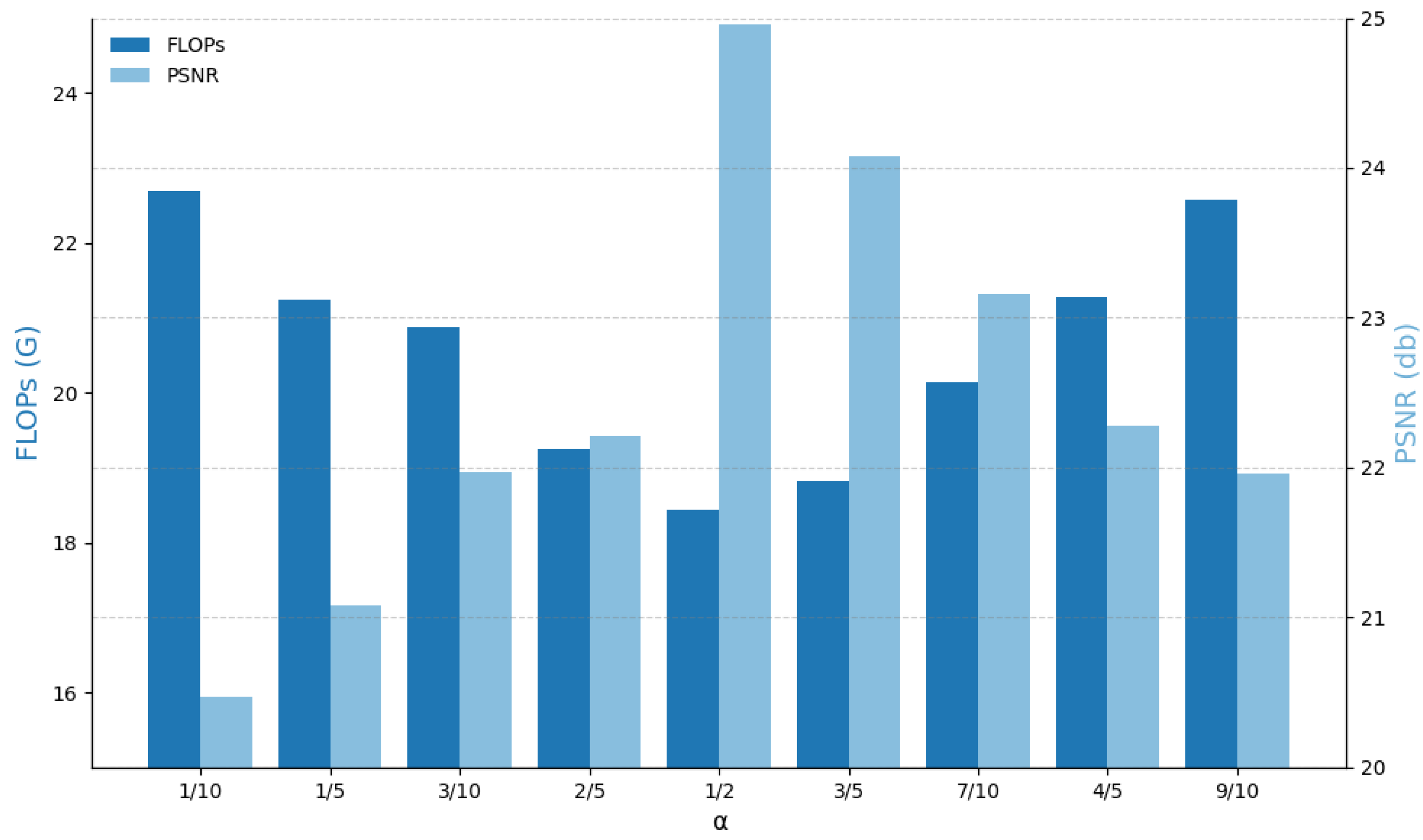
4.2. Ablation Studies
4.3. Quantitative Comparison
4.4. Qualitative Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dhal, K.G.; Das, A.; Ray, S.; Gálvez, J.; Das, S. Histogram equalization variants as optimization problems: A review. Arch. Comput. Methods Eng. 2021, 28, 1471–1496. [Google Scholar] [CrossRef]
- Huang, S.C.; Cheng, F.C.; Chiu, Y.S. Efficient contrast enhancement using adaptive gamma correction with weighting distribution. IEEE Trans. Image Process. 2012, 22, 1032–1041. [Google Scholar] [CrossRef] [PubMed]
- Barbhuiya, A.A.; Karsh, R.K.; Jain, R. CNN based feature extraction and classification for sign language. Multimed. Tools Appl. 2021, 80, 3051–3069. [Google Scholar] [CrossRef]
- Li, J.; Wen, Y.; He, L. Scconv: Spatial and channel reconstruction convolution for feature redundancy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6153–6162. [Google Scholar]
- Xu, W.; Fu, Y.L.; Zhu, D. ResNet and its application to medical image processing: Research progress and challenges. Comput. Methods Programs Biomed. 2023, 240, 107660. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, Q.; Jiang, Z.; Lu, Q.; Han, J.; Zeng, Z.; Gao, S.H.; Men, A. Split to be slim: An overlooked redundancy in vanilla convolution. arXiv 2020, arXiv:2006.12085. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Wen, H.; Dai, F.; Wang, D. A survey of image dehazing algorithm based on retinex theory. In Proceedings of the 2020 5th International Conference on Intelligent Informatics and Biomedical Sciences (ICIIBMS), Okinawa, Japan, 18–20 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 38–41. [Google Scholar]
- Debevec, P.; Gibson, S. A tone mapping algorithm for high contrast images. In Proceedings of the 13th Eurographics Workshop on Rendering, Pisa, Italy, 26–28 June 2002; Citeseer: San Diego, CA, USA, 2002; Volume 2, p. 21. [Google Scholar]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1632–1640. [Google Scholar]
- Zhang, Y.; Guo, X.; Ma, J.; Liu, W.; Zhang, J. Beyond brightening low-light images. Int. J. Comput. Vis. 2021, 129, 1013–1037. [Google Scholar] [CrossRef]
- Liu, X.; Xie, Q.; Zhao, Q.; Wang, H.; Meng, D. Low-light image enhancement by retinex-based algorithm unrolling and adjustment. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 15758–15771. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Guo, J.; Porikli, F.; Pang, Y. LightenNet: A convolutional neural network for weakly illuminated image enhancement. Pattern Recognit. Lett. 2018, 104, 15–22. [Google Scholar] [CrossRef]
- Wang, J.; Tan, W.; Niu, X.; Yan, B. RDGAN: Retinex decomposition based adversarial learning for low-light enhancement. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1186–1191. [Google Scholar]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. Enlightengan: Deep light enhancement without paired supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Rabe, M.N.; Staats, C. Self-attention does not need O(n2) memory. arXiv 2021, arXiv:2112.05682. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Ma, J.; Fan, X.; Ni, J.; Zhu, X.; Xiong, C. Multi-scale retinex with color restoration image enhancement based on Gaussian filtering and guided filtering. Int. J. Mod. Phys. B 2017, 31, 1744077. [Google Scholar] [CrossRef]
- Azad, R.; Aghdam, E.K.; Rauland, A.; Jia, Y.; Avval, A.H.; Bozorgpour, A.; Karimijafarbigloo, S.; Cohen, J.P.; Adeli, E.; Merhof, D. Medical image segmentation review: The success of u-net. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 100760010095. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lee, J.J.; Kim, J.W. Successful removal of hard sigmoid fecaloma using endoscopic cola injection. Korean J. Gastroenterol. 2015, 66, 46–49. [Google Scholar] [CrossRef]
- Christlein, V.; Spranger, L.; Seuret, M.; Nicolaou, A.; Král, P.; Maier, A. Deep generalized max pooling. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1090–1096. [Google Scholar]
- Hua, B.S.; Tran, M.K.; Yeung, S.K. Pointwise convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 984–993. [Google Scholar]
- Chen, C.F.R.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 357–366. [Google Scholar]
- Liu, R.; Li, Y.; Tao, L.; Liang, D.; Zheng, H.T. Are we ready for a new paradigm shift? A survey on visual deep mlp. Patterns 2022, 3, 100520. [Google Scholar] [CrossRef]
- Liu, J.; Xu, D.; Yang, W.; Fan, M.; Huang, H. Benchmarking low-light image enhancement and beyond. Int. J. Comput. Vis. 2021, 129, 1153–1184. [Google Scholar] [CrossRef]
- Reyad, M.; Sarhan, A.M.; Arafa, M. A modified Adam algorithm for deep neural network optimization. Neural Comput. Appl. 2023, 35, 17095–17112. [Google Scholar] [CrossRef]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1780–1789. [Google Scholar]
- Zhang, Z.; Zheng, H.; Hong, R.; Xu, M.; Yan, S.; Wang, M. Deep color consistent network for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1899–1908. [Google Scholar]
- Wang, R.; Zhang, Q.; Fu, C.W.; Shen, X.; Zheng, W.S.; Jia, J. Underexposed photo enhancement using deep illumination estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6849–6857. [Google Scholar]
- Wang, Y.; Wan, R.; Yang, W.; Li, H.; Chau, L.P.; Kot, A. Low-light image enhancement with normalizing flow. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 2604–2612. [Google Scholar]
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-light image/video enhancement using cnns. In Proceedings of the BMVC, Newcastle, UK, 3–6 September 2018; Volume 220, p. 4. [Google Scholar]
- Li, C.; Guo, C.; Han, L.; Jiang, J.; Cheng, M.M.; Gu, J.; Loy, C.C. Low-light image and video enhancement using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 9396–9416. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Qin, H.; Wang, X.; Li, H. Rethinking noise synthesis and modeling in raw denoising. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4593–4601. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Params (M) | FLOPs (G) | Times (s) | PSNR (db) |
|---|---|---|---|---|
| LLNet | 10.71 | 22.62 | 0.014 | 23.74 |
| LLNet + S | 9.54 | 22.37 | 0.013 | 24.92 |
| LLNet + C | 2.74 | 17.88 | 0.008 | 22.45 |
| LLNet + C + S | 2.74 | 16.45 | 0.008 | 24.56 |
| LLNet + S + C | 2.74 | 16.43 | 0.008 | 25.05 |
| LLNet + S & C | 2.74 | 16.42 | 0.008 | 23.93 |
| Methods | PSNR | SSIM |
|---|---|---|
| DCC-Net | 21.76 | 0.854 |
| DeepUPE | 15.46 | 0.456 |
| EnlightenGAN | 19.52 | 0.661 |
| KinD | 18.34 | 0.786 |
| LLFlow | 21.38 | 0.830 |
| MBLLEN | 18.62 | 0.693 |
| RetinexNet | 17.66 | 0.658 |
| URetinex | 24.11 | 0.813 |
| Zero-DCE | 16.82 | 0.549 |
| Ours | 24.93 | 0.845 |
| Methods | PSNR | SSIM |
|---|---|---|
| DCC-Net | 27.54 | 0.886 |
| DeepUPE | 14.23 | 0.562 |
| EnlightenGAN | 19.25 | 0.658 |
| KinD | 21.48 | 0.793 |
| LLFlow | 24.73 | 0.902 |
| MBLLEN | 18.16 | 0.715 |
| RetinexNet | 15.74 | 0.547 |
| URetinex | 21.61 | 0.827 |
| Zero-DCE | 18.34 | 0.548 |
| Ours | 28.69 | 0.891 |
| Methods | SID | ELD | ||
|---|---|---|---|---|
| NIQE | PI | NIQE | PI | |
| KinD | 4.18 | 3.08 | 3.22 | 3.14 |
| RetinexNet | 12.03 | 6.94 | 2.64 | 1.78 |
| SCI | 9.74 | 7.06 | 3.19 | 2.48 |
| URetinex | 9.83 | 5.45 | 2.66 | 2.18 |
| Zero-DCE | 12.24 | 5.24 | 3.09 | 2.44 |
| Ours | 4.57 | 2.78 | 2.46 | 2.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Xiao, Z.; Qin, X.; Luo, D. Retinex-Based Low-Light Image Enhancement via Spatial-Channel Redundancy Compression and Joint Attention. Electronics 2025, 14, 2212. https://doi.org/10.3390/electronics14112212
Chen J, Xiao Z, Qin X, Luo D. Retinex-Based Low-Light Image Enhancement via Spatial-Channel Redundancy Compression and Joint Attention. Electronics. 2025; 14(11):2212. https://doi.org/10.3390/electronics14112212
Chicago/Turabian StyleChen, Jinlong, Zhigang Xiao, Xingguo Qin, and Deming Luo. 2025. "Retinex-Based Low-Light Image Enhancement via Spatial-Channel Redundancy Compression and Joint Attention" Electronics 14, no. 11: 2212. https://doi.org/10.3390/electronics14112212
APA StyleChen, J., Xiao, Z., Qin, X., & Luo, D. (2025). Retinex-Based Low-Light Image Enhancement via Spatial-Channel Redundancy Compression and Joint Attention. Electronics, 14(11), 2212. https://doi.org/10.3390/electronics14112212