
Few-Shot Face Recognition: Leveraging GAN for Effective Data Augmentation


Abstract
1. Introduction
2. Related Work
2.1. Data Augmentation
2.2. Generative Adversarial Networks
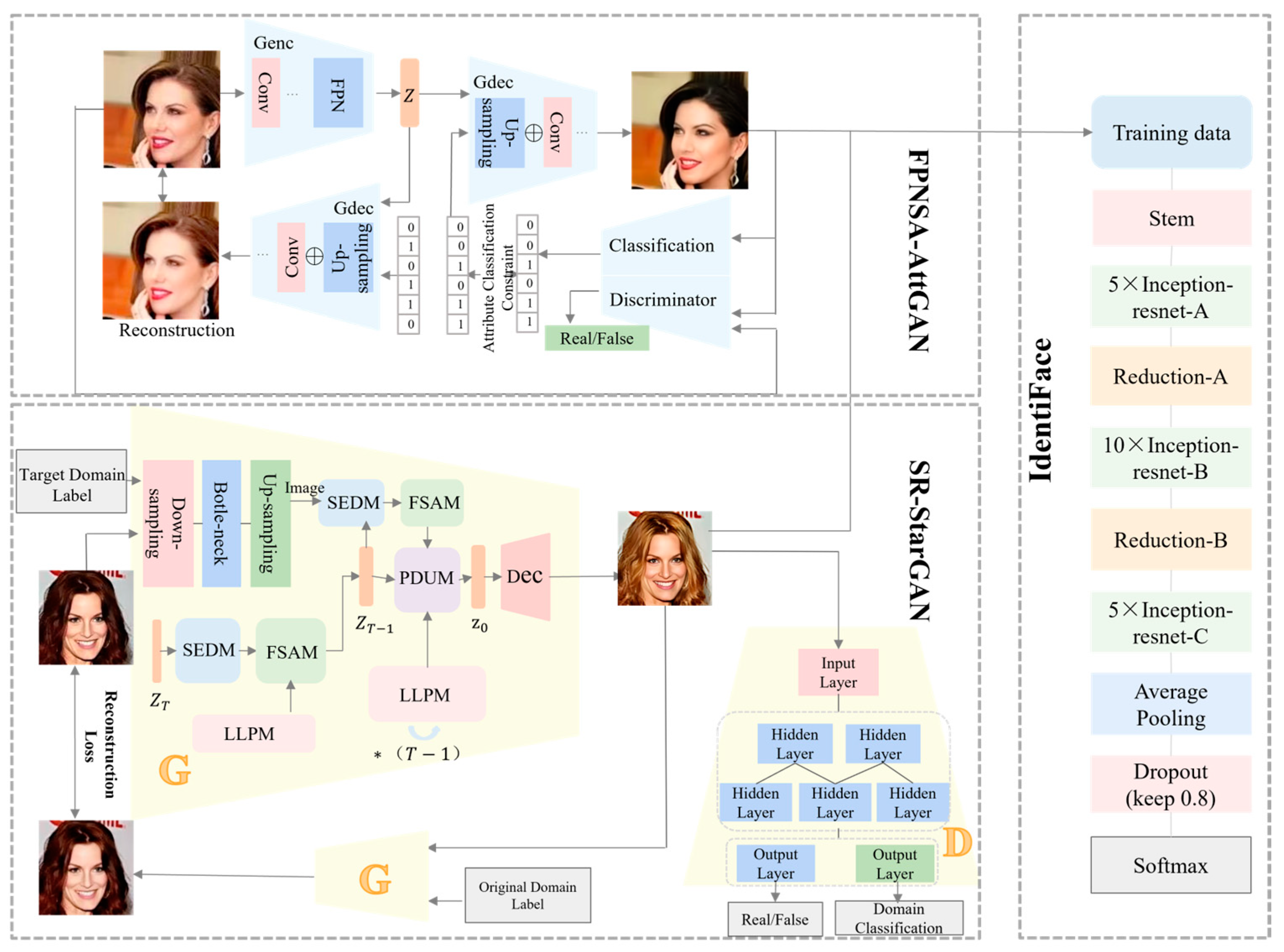
3. Proposed Method
3.1. Network Architecture
3.2. SR-StarGAN Face Generation Network
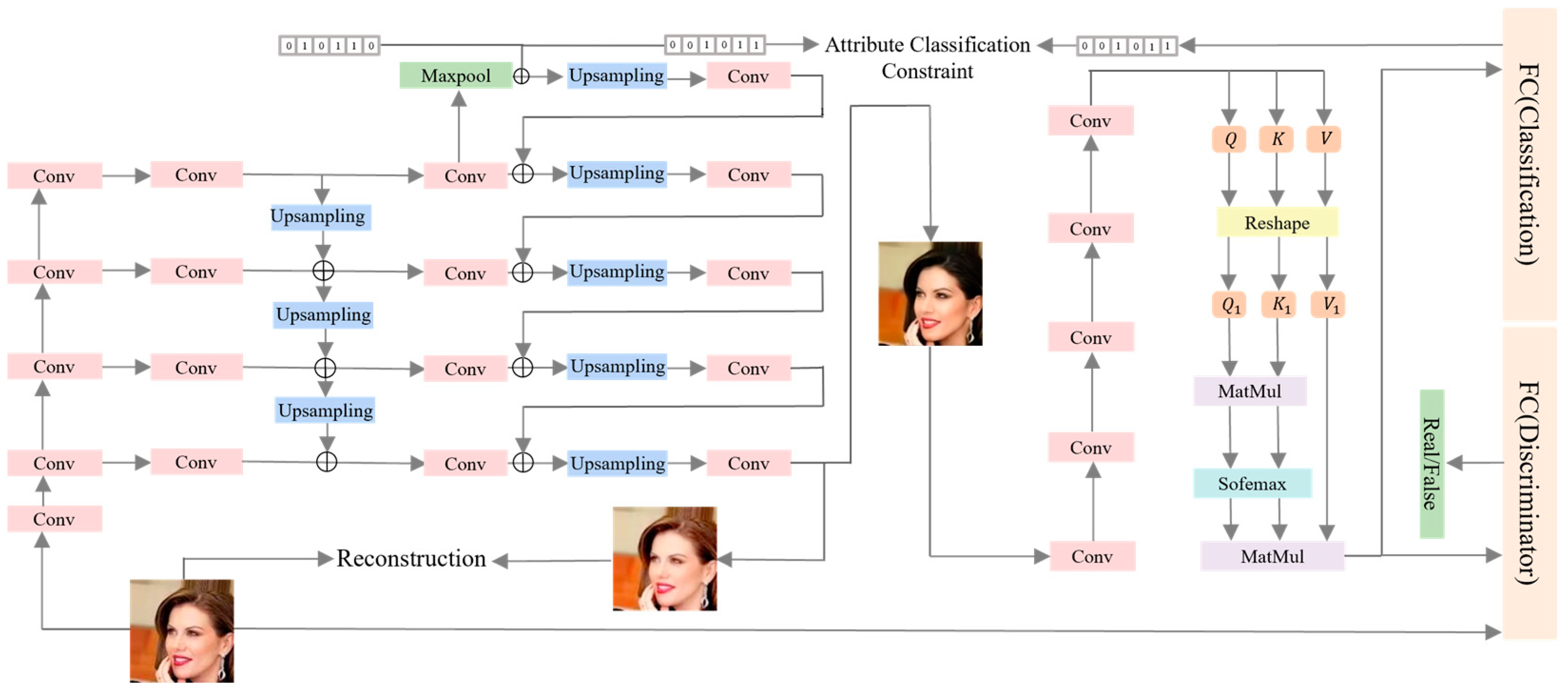
3.3. FPNSA-AttGAN Face Generation Network
3.4. IdentiFace Face Recognition Network
4. Experiments
4.1. Dataset
4.2. Face Generation Network
4.2.1. Image Data Augmentation
4.2.2. Typical GAN
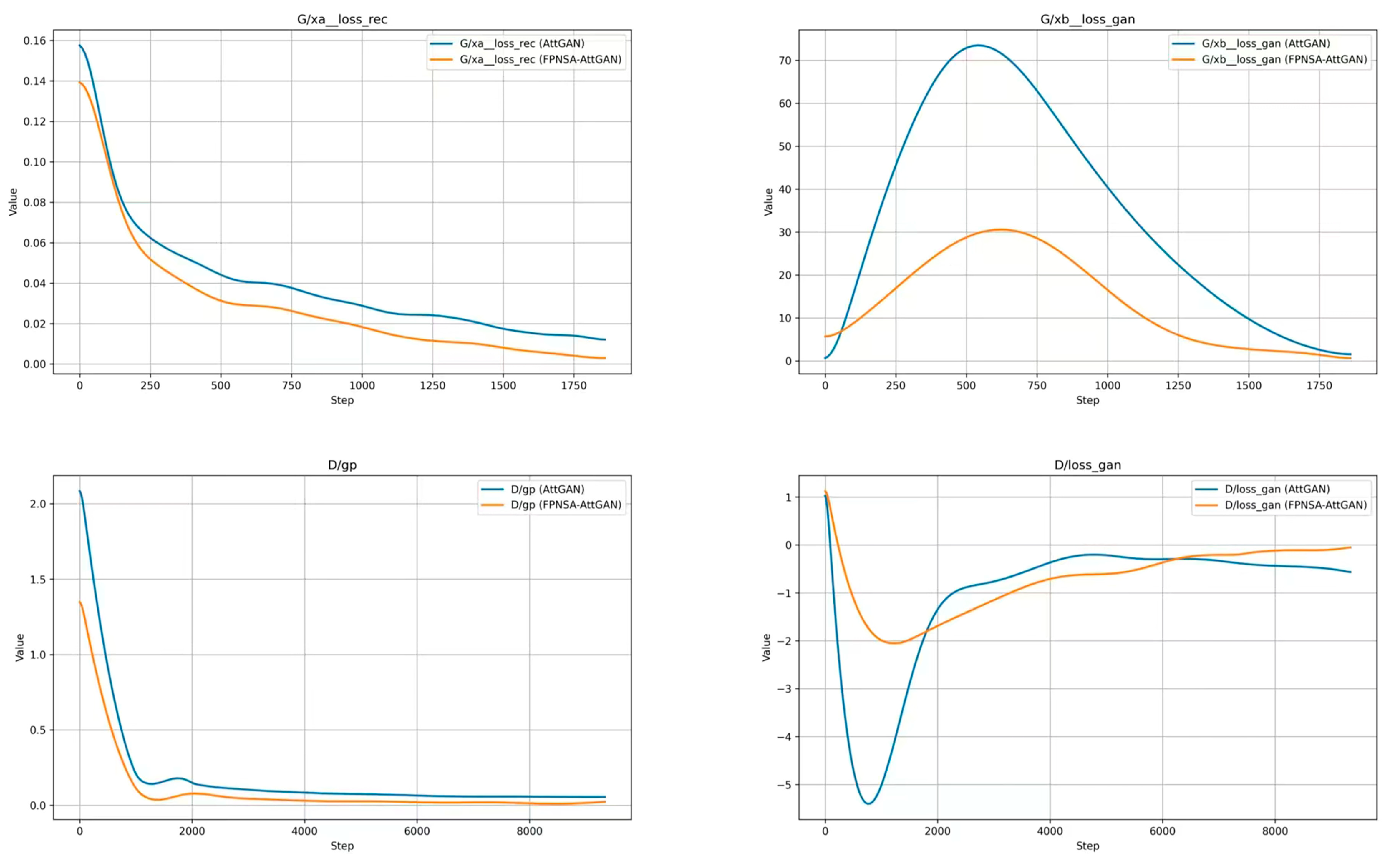
4.2.3. Improving the GAN
4.3. IdentiFace Face Recognition Network
5. Summary
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, F.-F.; Rob, F.; Pietro, P. A Bayesian Approach to Unsupervised One-Shot Learning of Object Categories. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; IEEE Computer Society: Washington, DC, USA, 2003; Volume 2, p. 1134. [Google Scholar]
- Liu, Y.; Zhang, H.; Zhang, W.; Lu, G.; Tian, Q.; Ling, N. Few-Shot Image Classification: Current Status and Research Trends. Electronics 2022, 11, 1752. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; Volume 70, pp. 1126–1135. [Google Scholar]
- Xing, E.P.; Ng, A.Y.; Jordan, M.I.; Russell, S. Distance Metric Learning with Application to Clustering with Side-Information. In Proceedings of the 16th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 1 January 2002; MIT Press: Cambridge, MA, USA, 2002; pp. 521–528. [Google Scholar]
- Hu, Y.; Sun, L.; Mao, X.; Zhang, S. EEG Data Augmentation Method for Identity Recognition Based on Spatial–Temporal Generating Adversarial Network. Electronics 2024, 13, 4310. [Google Scholar] [CrossRef]
- Nichol, A.; Achiam, J.; Schulman, J. On First-Order Meta-Learning Algorithms. arXiv 2018, arXiv:1803.02999. [Google Scholar] [CrossRef]
- Sun, Q.; Liu, Y.; Chua, T.-S.; Schiele, B. Meta-Transfer Learning for Few-Shot Learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, NY, USA, 2019; pp. 403–412. [Google Scholar]
- Rajeswaran, A.; Finn, C.; Kakade, S.M.; Levine, S. Meta-Learning with Implicit Gradients. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates Inc.: Red Hook, NY, USA, 2019; pp. 113–124. [Google Scholar]
- Shin, C.; Lee, J.; Na, B.; Yoon, S. Personalized Face Authentication Based On Few-Shot Meta-Learning. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; IEEE: New York, NY, USA, 2021; pp. 3897–3901. [Google Scholar]
- An, X.; Deng, J.; Guo, J.; Feng, Z.; Zhu, X.; Yang, J.; Liu, T. Killing Two Birds with One Stone: Efficient and Robust Training of Face Recognition CNNs by Partial FC. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 4032–4041. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Gan, J.; Liu, J. Applied Research on Face Image Beautification Based on a Generative Adversarial Network. Electronics 2024, 13, 4780. [Google Scholar] [CrossRef]
- Zhou, S.; Xiao, T.; Yang, Y.; Feng, D.; He, Q.; He, W. GeneGAN: Learning Object Transfiguration and Object Subspace from Unpaired Data. In Procedings of the British Machine Vision Conference 2017, London, UK, 4–7 September 2017; British Machine Vision Association: Durham, UK, 2017; p. 111. [Google Scholar]
- Larsen, A.B.L.; Sønderby, S.K.; Larochelle, H.; Winther, O. Autoencoding beyond Pixels Using a Learned Similarity Metric. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 1558–1566. [Google Scholar]
- Perarnau, G.; van de Weijer, J.; Raducanu, B.; Álvarez, J.M. Invertible Conditional GANs for Image Editing. arXiv 2016, arXiv:1611.06355. [Google Scholar] [CrossRef]
- Lample, G.; Zeghidour, N.; Usunier, N.; Bordes, A.; Denoyer, L.; Ranzato, M. Fader Networks: Manipulating Images by Sliding Attributes. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 5969–5978. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.-W.; Kim, S.; Choo, J. StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: New York, NY, USA, 2018; pp. 8789–8797. [Google Scholar]
- He, Z.; Zuo, W.; Kan, M.; Shan, S.; Chen, X. AttGAN: Facial Attribute Editing by Only Changing What You Want. IEEE Trans. Image Process 2019, 28, 5464–5478. [Google Scholar] [CrossRef] [PubMed]
- Hsu, W.H. Investigating Data Augmentation Strategies for Advancing Deep Learning Training. In Proceedings of the Proceedings of the GPU Technology Conference (GTC) 2018, San Jose, CA, USA, 26 March 2018; Nvidia: Santa Clara, CA, USA, 2018. [Google Scholar]
- Taylor, L.; Nitschke, G. Improving Deep Learning with Generic Data Augmentation. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; IEEE: New York, NY, USA, 2018; pp. 1542–1547. [Google Scholar]
- Zeng, W. Image Data Augmentation Techniques Based on Deep Learning: A Survey. Math. Biosci. Eng. 2024, 21, 6190–6224. [Google Scholar] [CrossRef] [PubMed]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning Augmentation Strategies From Data. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, NY, USA, 2019; pp. 113–123. [Google Scholar]
- Lim, S.; Kim, I.; Kim, T.; Kim, C.; Kim, S. Fast AutoAugment. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates Inc.: Red Hook, NY, USA, 2019; pp. 6665–6675. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond Empirical Risk Minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar] [CrossRef]
- Yun, S.; Han, D.; Chun, S.; Oh, S.J.; Yoo, Y.; Choe, J. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: New York, NY, USA, 2019; pp. 6022–6031. [Google Scholar]
- Chen, P.; Liu, S.; Zhao, H.; Wang, X.; Jia, J. GridMask Data Augmentation. arXiv 2020, arXiv:2001.04086. [Google Scholar] [CrossRef]
- Alomar, K.; Aysel, H.I.; Cai, X. Data Augmentation in Classification and Segmentation: A Survey and New Strategies. J. Imaging 2023, 9, 46. [Google Scholar] [CrossRef] [PubMed]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; MIT Press: Cambridge, MA, USA, 2014; Volume 2, pp. 2672–2680. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: New York, NY, USA, 2017; pp. 2242–2251. [Google Scholar]
- Luo, X.; He, X.; Chen, X.; Qing, L.; Chen, H. Dynamically Optimized Human Eyes-to-Face Generation via Attribute Vocabulary. IEEE Signal Process Lett. 2023, 30, 453–457. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 5967–5976. [Google Scholar]
- Wang, J.; Deng, Y.; Liang, Z.; Zhang, X.; Cheng, N.; Xiao, J. CP-EB: Talking Face Generation with Controllable Pose and Eye Blinking Embedding. In Proceedings of the 2023 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom), Wuhan, China, 21–24 December 2023; IEEE: New York, NY, USA, 2023; pp. 752–757. [Google Scholar]
- Xie, L.; Xue, W.; Xu, Z.; Wu, S.; Yu, Z.; Wong, H.S. Blemish-Aware and Progressive Face Retouching with Limited Paired Data. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; IEEE: New York, NY, USA, 2023; pp. 5599–5608. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 10674–10685. [Google Scholar]
- Wang, J.; Yue, Z.; Zhou, S.; Chan, K.C.K.; Loy, C.C. Exploiting Diffusion Prior for Real-World Image Super-Resolution. Int. J. Comput. Vis. 2024, 132, 5929–5949. [Google Scholar] [CrossRef]
- Lin, X.; He, J.; Chen, Z.; Lyu, Z.; Dai, B.; Yu, F.; Qiao, Y.; Ouyang, W.; Dong, C. DiffBIR: Toward Blind Image Restoration with Generative Diffusion Prior. In Computer Vision—ECCV 2024; Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G., Eds.; Springer Nature: Cham, Switzerland, 2025; Volume 15117, pp. 430–448. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: New York, NY, USA, 2015; pp. 3431–3440. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 6230–6239. [Google Scholar]
- Wang, H.; Wang, Y.; Zhang, Q.; Xiang, S.; Pan, C. Gated Convolutional Neural Network for Semantic Segmentation in High-Resolution Images. Remote Sens. 2017, 9, 446. [Google Scholar] [CrossRef]
- Chaurasia, A.; Culurciello, E. LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; IEEE: New York, NY, USA, 2017; pp. 1–4. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Xiao, J.; Zhou, H.; Lei, Q.; Liu, H.; Xiao, Z.; Huang, S. Attention-Mechanism-Based Face Feature Extraction Model for WeChat Applet on Mobile Devices. Electronics 2024, 13, 201. [Google Scholar] [CrossRef]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-Attention Generative Adversarial Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 24 May 2019; pp. 7354–7363. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large Scale GAN Training for High Fidelity Natural Image Synthesis. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 27 September 2018. [Google Scholar]
- Chen, X.; Xu, C.; Yang, X.; Tao, D. Attention-GAN for Object Transfiguration in Wild Images. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Munich, Germany, 2018; Volume 11206, pp. 167–184. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 936–944. [Google Scholar]
- Zhang, K.; Su, Y.; Guo, X.; Qi, L.; Zhao, Z. MU-GAN: Facial Attribute Editing Based on Multi-Attention Mechanism. IEEECAA J. Autom. Sin. 2021, 8, 1614–1626. [Google Scholar] [CrossRef]
- Ko, K.; Yeom, T.; Lee, M. SuperstarGAN: Generative Adversarial Networks for Image-to-Image Translation in Large-Scale Domains. Neural Netw. 2023, 162, 330–339. [Google Scholar] [CrossRef] [PubMed]
- Li, R.; Gu, J. OMGD-StarGAN: Improvements to Boost StarGAN v2 Performance. Evol. Syst. 2024, 15, 455–467. [Google Scholar] [CrossRef]
- Lin, Z.; Xu, W.; Ma, X.; Xu, C.; Xiao, H. Multi-Attention Infused Integrated Facial Attribute Editing Model: Enhancing the Robustness of Facial Attribute Manipulation. Electronics 2023, 12, 4111. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: New York, NY, USA, 2015; pp. 815–823. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameterization | StarGAN |
|---|---|
| lambda_cls | 1 |
| lambda_rec | 10 |
| lambda_gp | 10 |
| g_lr/d_lr | 0.0001 |
| n_critic | 5 |
| beta1 | 0.5 |
| beta2 | 0.999 |
| num_iters | 200,000 |
| Num_iter_decay | 100,000 |
| batch_size | 16 |
| Parameterization | AttGAN |
|---|---|
| n_epochs | 60 |
| epoch_start_decay | 30 |
| batch_size | 32 |
| learning_rate | 0.0002 |
| beta_1 | 0.5 |
| n_d | 5 |
| d_gradient_penalty_weight | 10 |
| d_attribute_loss_weight | 1 |
| g_attribute_loss_weight | 10 |
| g_reconstruction_loss_weight | 100 |
| Methodologies | Accuracy (%) | Validation (%) | AUC (%) | EER (%) |
|---|---|---|---|---|
| Traditional data augmentation | 83.59 | 21.34 | 90.5 | 17.6 |
| StarGAN | 86.72 | 43.28 | 92.4 | 15.2 |
| AttGAN | 87.33 | 47.75 | 93.9 | 13.8 |
| StarGAN+AttGAN | 90.61 | 53.87 | 96.9 | 9.5 |
| SR-StarGAN+FPNSA-AttGAN | 96.64 | 82.48 | 99.3 | 3.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Yue, C.; Zhou, H. Few-Shot Face Recognition: Leveraging GAN for Effective Data Augmentation. Electronics 2025, 14, 2003. https://doi.org/10.3390/electronics14102003
Li S, Yue C, Zhou H. Few-Shot Face Recognition: Leveraging GAN for Effective Data Augmentation. Electronics. 2025; 14(10):2003. https://doi.org/10.3390/electronics14102003
Chicago/Turabian StyleLi, Shuhui, Cai Yue, and Hang Zhou. 2025. "Few-Shot Face Recognition: Leveraging GAN for Effective Data Augmentation" Electronics 14, no. 10: 2003. https://doi.org/10.3390/electronics14102003
APA StyleLi, S., Yue, C., & Zhou, H. (2025). Few-Shot Face Recognition: Leveraging GAN for Effective Data Augmentation. Electronics, 14(10), 2003. https://doi.org/10.3390/electronics14102003