
Malicious Cloud Service Traffic Detection Based on Multi-Feature Fusion



Abstract
1. Introduction
2. Relevant Work
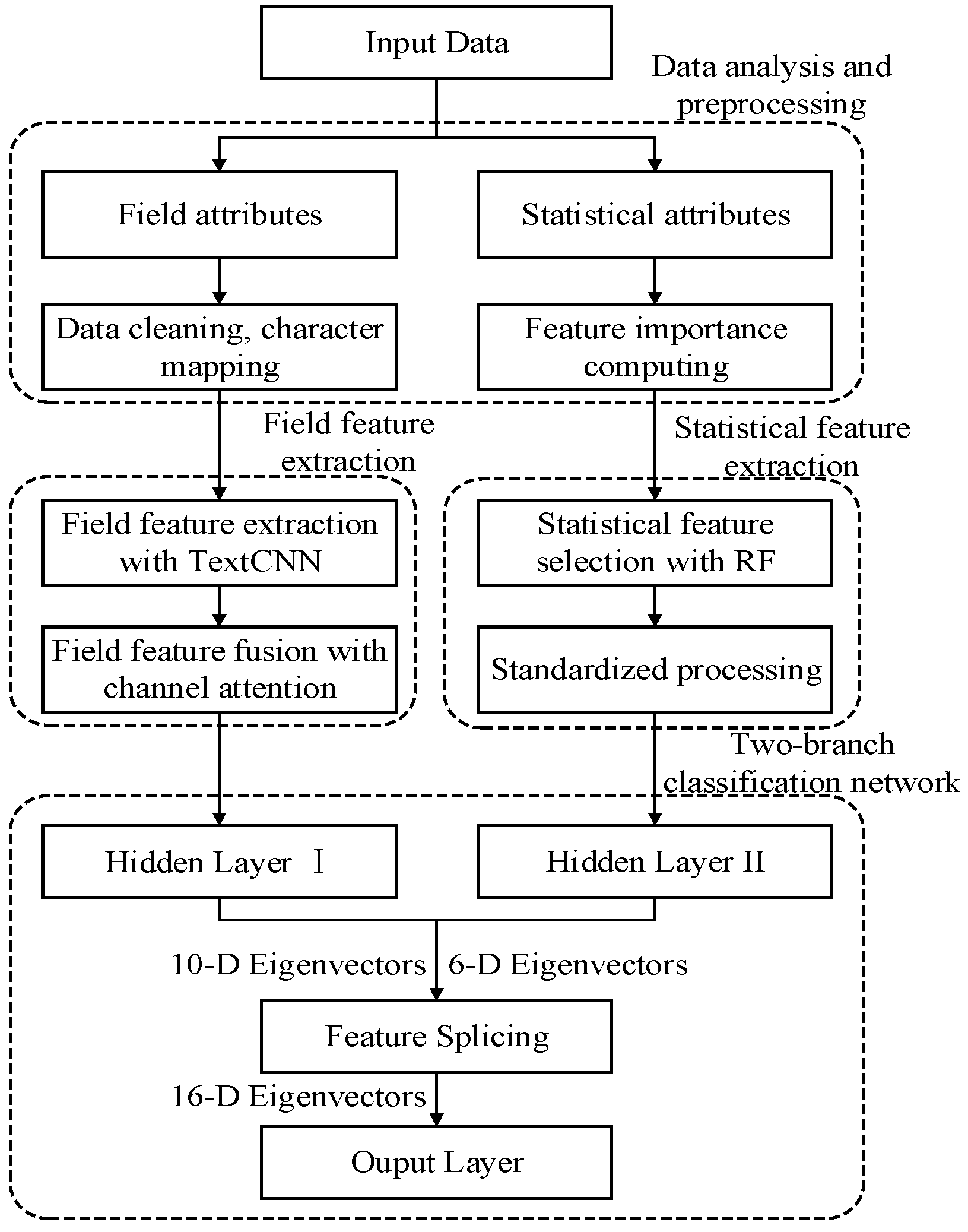
3. Overall Process
4. Data Analysis and Preprocessing
4.1. Statistical Feature Description
4.2. Field Feature Description
4.3. Field Feature Preprocessing
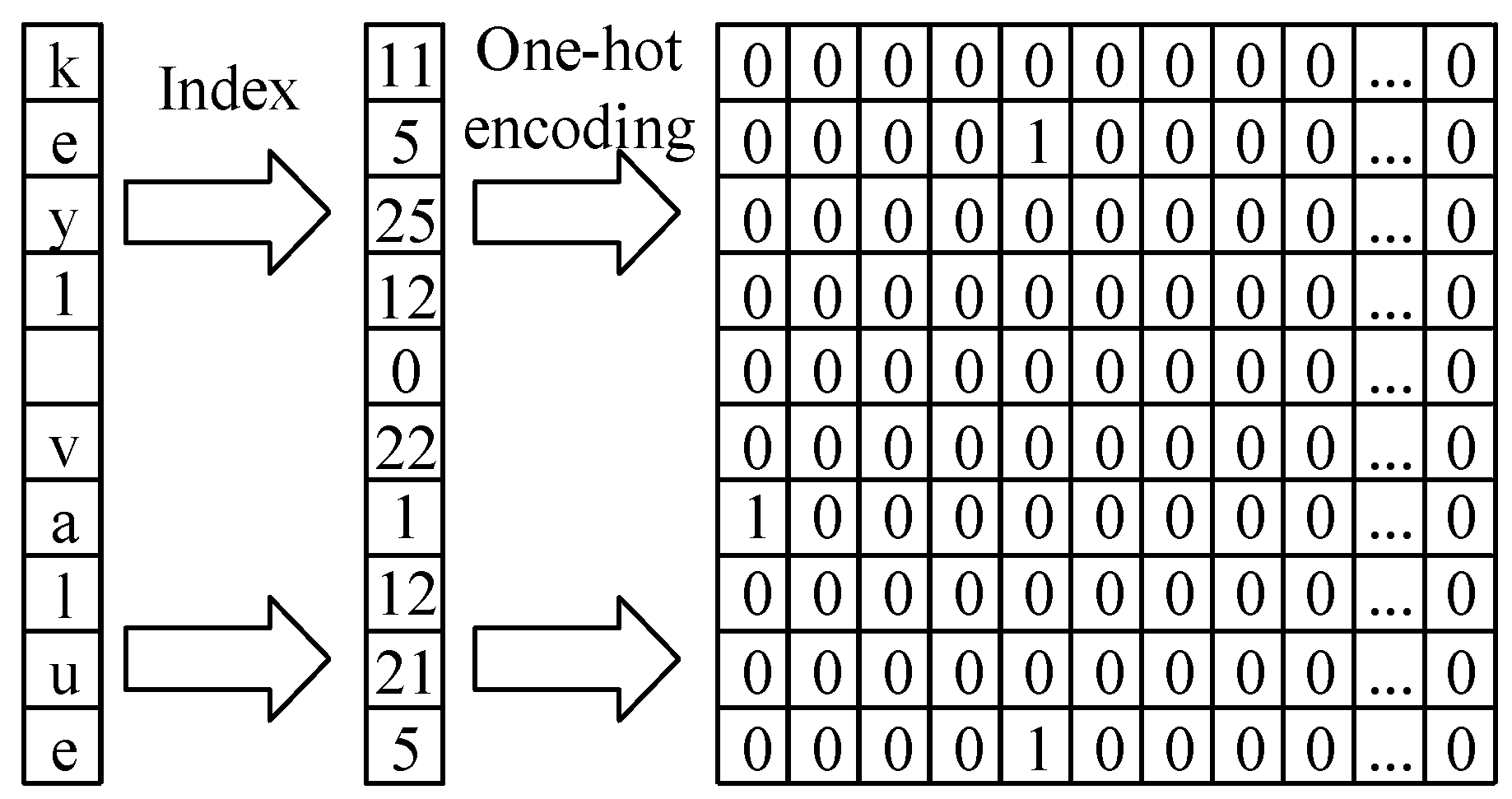
4.3.1. Text Cleaning
4.3.2. Text Mapping
5. Model Training
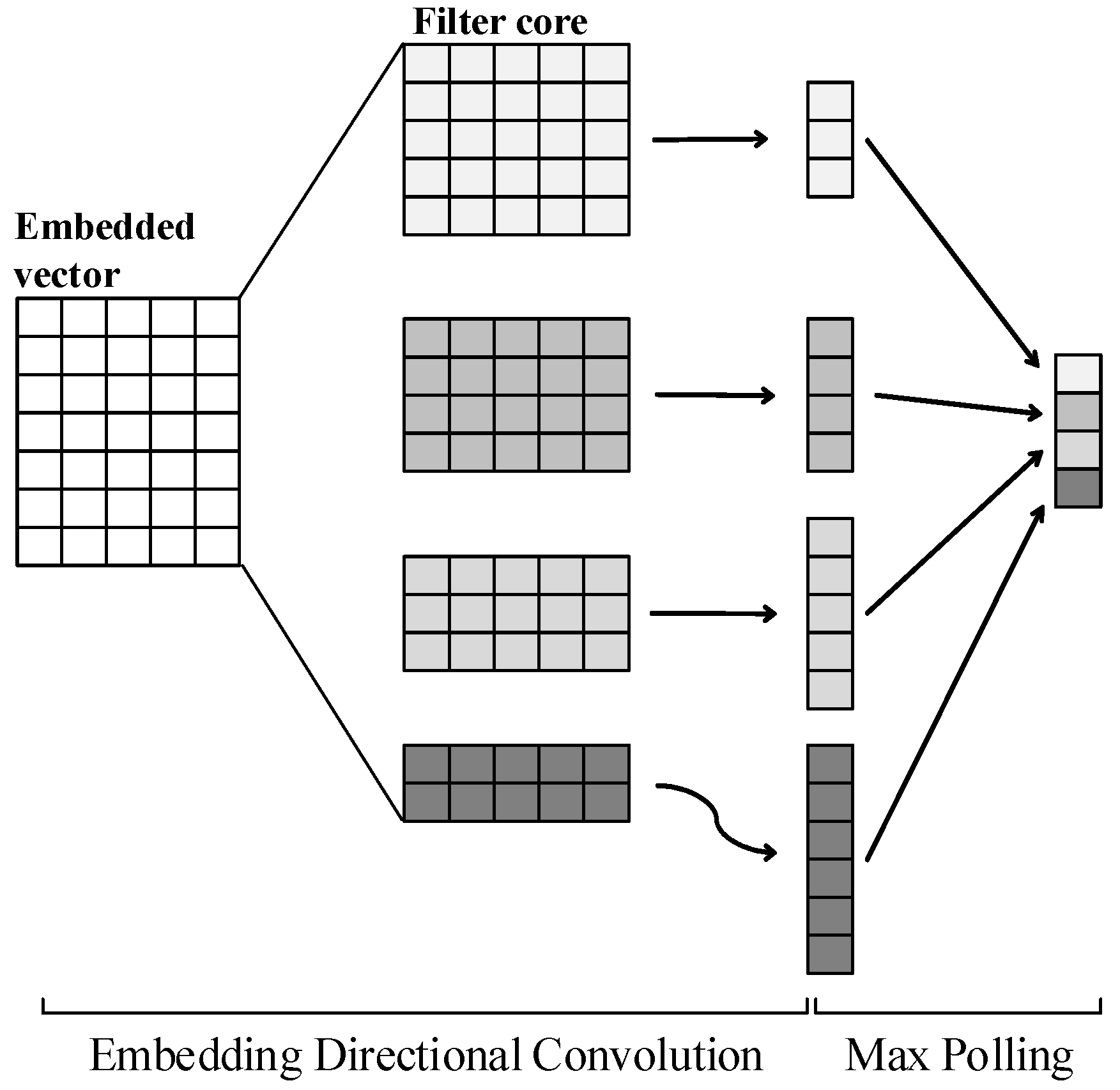
5.1. Field Feature Extraction Based on Improved TextCNN
5.2. Field Feature Fusion Based on Attention Mechanism
5.3. Statistical Feature Selection Based on Random Forest
| Algorithm 1 Feature Selection Method |
| Input: Training set D, statistical set F, importance threshold g_threshold |
| Output: Statistical feature set after feature selection Fset |
| 1: Randomly sample the training set D to obtain n training subsets Di |
| 2: for any training subset do |
| 3: train the decision tree model and generate a decision tree Treei |
| 4: for any feature do: |
| 5: for any node do |
| 6: if then |
| 7: calculate the Gini coefficient GIm of node m |
| 8: calculate the Gini coefficient of the left and right child nodes GIl, GIr |
| 9: make |
| 10: end if |
| 11: update |
| 12: update 13: end for 14: end for |
| 15: end for |
| 16: Normalize |
| 17: for any feature do |
| 18: if then |
| 19: Update collection add fj |
| 20: end if |
| 21: end for |
5.4. Dual-Branch Classification Network
6. Experimental
6.1. Evaluation Metrics
6.2. Datasets
6.2.1. Csic 2010
6.2.2. Cloud Service Dataset
6.3. Experimental Results and Analysis
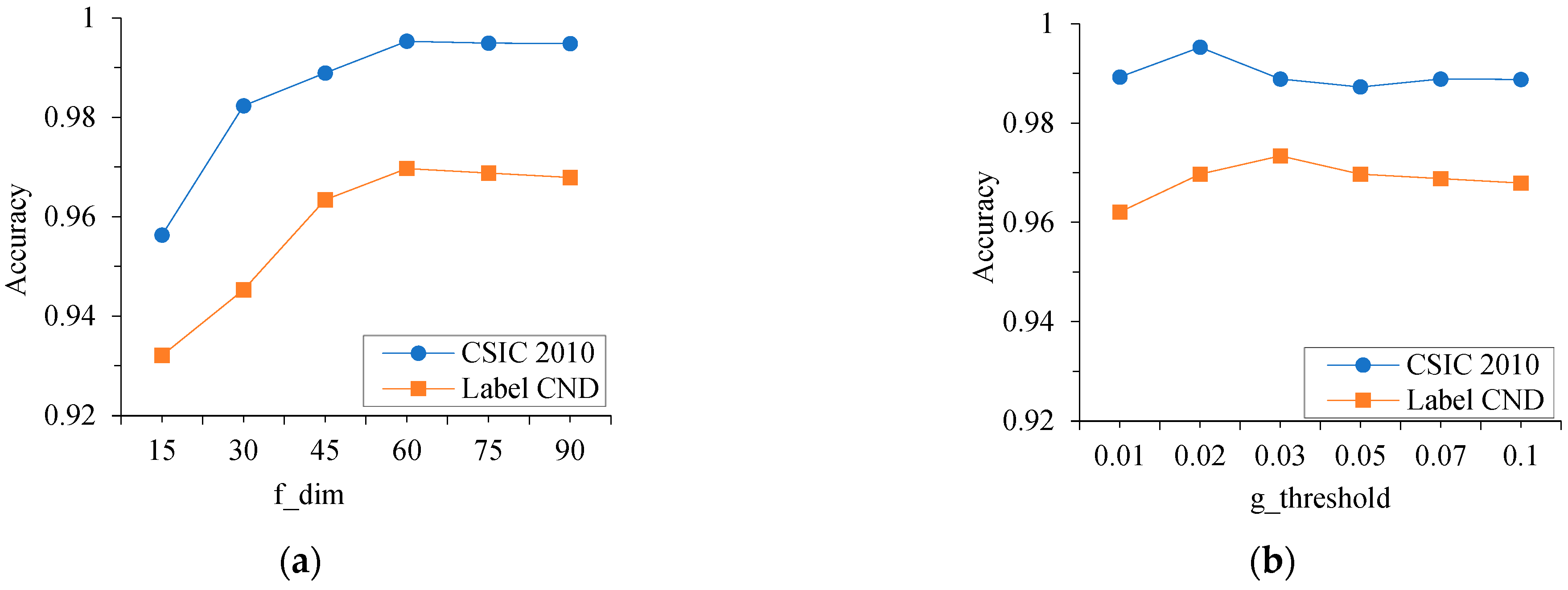
6.3.1. Selection of Model Parameters
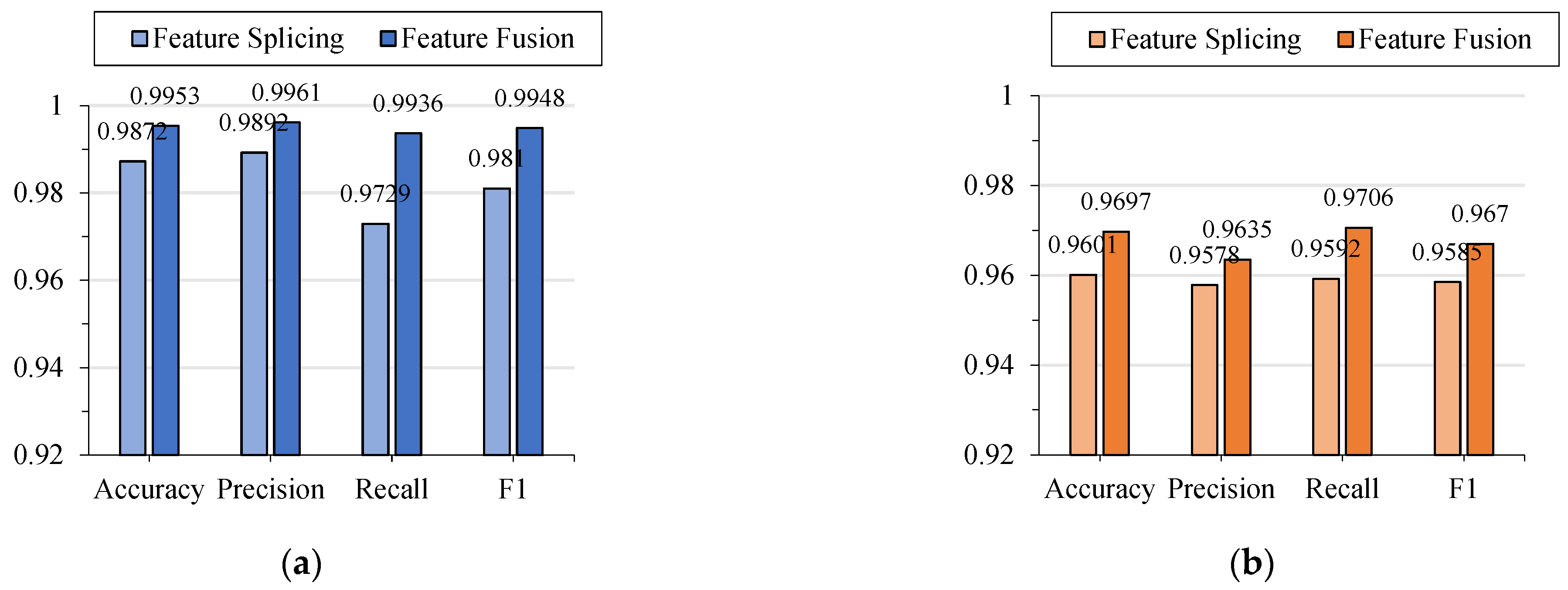
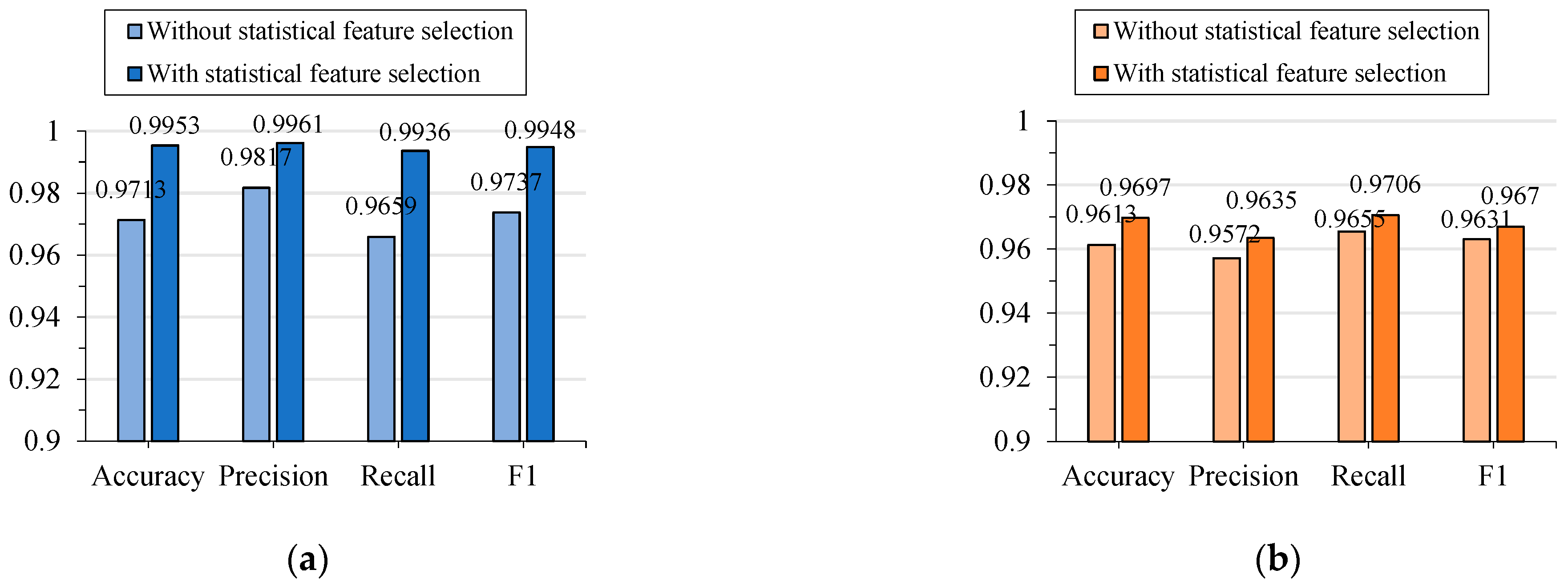
6.3.2. Effectiveness of Methods
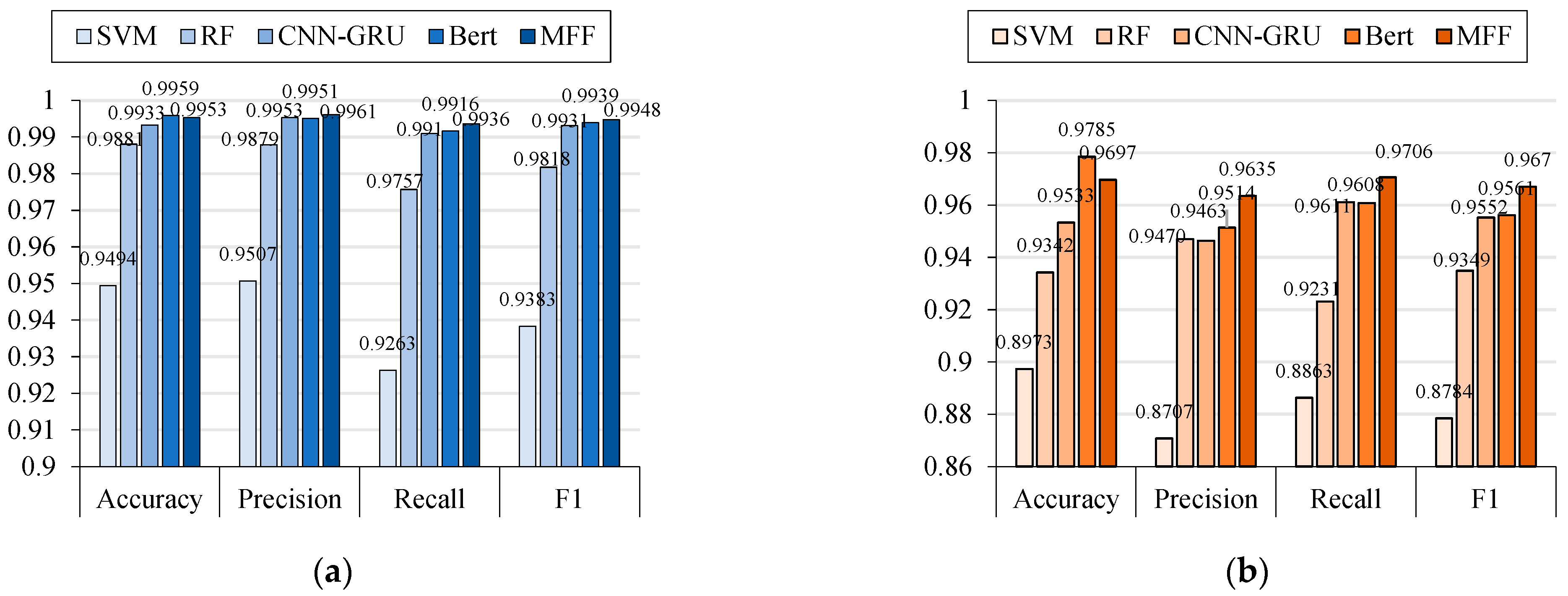
6.3.3. Comparison with Baseline Model
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| BERT | Bidirectional Encoder Representations from Transformers |
| DistilBERT | Distilled Bidirectional Encoder Representations from Transformers |
| FedGAT | Federated Graph Attention Network |
| FWaaS | Firewall as a Service |
| LSTM | Long Short-Term Memory |
| MFF | Multiple Feature Fusion |
| PaaS | Platform as a Service |
| RF | Random Forest |
| RTIDS | Robust Transformer-based Intrusion Detection System |
| SaaS | Software as a Service |
| TextCNN | Convolutional Neural Networks for Sentence Classification |
| WAF | Web Application Firewalls |
References
- Cybersecurity Insiders. Cloud Security Report. 2024. Available online: http://webobjects2.cdw.com/is/content/CDW/cdw/on-domain-cdw/brands/check-point/2024-cloud-security-report-checkpoint-final-1cleaned.pdf (accessed on 16 January 2025).
- Qu, Z.; Ling, X.; Wang, T.; Chen, X.; Ji, S.; Wu, C. AdvSQLi: Generating Adversarial SQL Injections Against Real-World WAF-as-a-Service. IEEE Trans. Inf. Forensics Secur. 2024, 19, 2623–2638. [Google Scholar] [CrossRef]
- CYBRARY. 2024’s Data Breaches, Incidents, and How to Avoid Them in 2025. 2025. Available online: https://www.cybrary.it/blog/2024-data-breaches-how-avoid-them-2025 (accessed on 16 January 2025).
- Li, J.; Jiang, H.; Jiang, W.; Wu, J.; Du, W. SDN-based Stateful Firewall for Cloud. In Proceedings of the 2020 IEEE 6th Intl Conference on Big Data Security on Cloud (BigDataSecurity), IEEE Intl Conference on High Performance and Smart Computing, (HPSC) and IEEE Intl Conference on Intelligent Data and Security (IDS), Baltimore, MD, USA, 25–27 May 2020; pp. 157–161. [Google Scholar]
- Pavithra, B.; C, V.; Mishra, N.; Naveen, G. Cloud Security Analysis using Machine Learning Algorithms. In Proceedings of the 2023 Second International Conference on Augmented Intelligence and Sustainable Systems (ICAISS), Trichy, India, 23–25 August 2023; pp. 704–708. [Google Scholar]
- Sanagana, D.P.R.; Tummalachervu, C.K. Securing Cloud Computing Environment via Optimal Deep Learning-based Intrusion Detection Systems. In Proceedings of the 2024 Second International Conference on Data Science and Information System (ICDSIS), Hassan, India, 17–18 May 2024; pp. 1–6. [Google Scholar]
- Chethan, M.S.; Channakrishnaraju; Rajeswari, R.; Selvam, M. Cyber Attack Detection System in University Private Cloud Using Machine Learning. In Proceedings of the 2023 International Conference on Self Sustainable Artificial Intelligence Systems (ICSSAS), Erode, India, 18–20 October 2023; pp. 1080–1085. [Google Scholar]
- Rajapraveen, K.N.; Pasumarty, R. A Machine Learning Approach for DDoS Prevention System in Cloud Computing Environment. In Proceedings of the 2021 IEEE International Conference on Computation System and Information Technology for Sustainable Solutions (CSITSS), Bangalore, India, 16–18 December 2021; pp. 1–6. [Google Scholar]
- Kwedza, P.; Chindipha, S.D. Cryptojacking Detection in Cloud Infrastructure Using Network Traffic. In Proceedings of the 2023 International Conference on Electrical, Computer and Energy Technologies (ICECET), Changchun, China, 22–24 September 2023; pp. 1–6. [Google Scholar]
- Denning, D.E. An Intrusion-Detection Model. IEEE Trans. Softw. Eng. 1987, SE-13, 222–232. [Google Scholar] [CrossRef]
- Eslahi, M.; Hashim, H.; Tahir, N.M. An efficient false alarm reduction approach in HTTP-based botnet detection. In Proceedings of the 2013 IEEE Symposium on Computers & Informatics (ISCI), Langkawi, Malaysia, 7–9 April 2013; pp. 201–205. [Google Scholar]
- Krügel, C.; Toth, T.; Kirda, E. Service specific anomaly detection for network intrusion detection. In Proceedings of the 2002 ACM Symposium on Applied Computing, Madrid, Spain, 11–14 March 2002; pp. 201–208. [Google Scholar]
- Setiyaji, A.; Ramli, K.; Hidayatulloh, Z.Y.; Budhi Dharmawan, G.S. A technique utilizing Machine Learning and Convolutional Neural Networks (CNN) for the identification of SQL Injection Attacks. In Proceedings of the 2024 4th International Conference of Science and Information Technology in Smart Administration (ICSINTESA), Balikpapan, Indonesia, 12–13 July 2024; pp. 1–6. [Google Scholar]
- Zhang, X.; Meng, F.; Xu, J. PerfInsight: A Robust Clustering-Based Abnormal Behavior Detection System for Large-Scale Cloud. In Proceedings of the 2018 IEEE 11th International Conference on Cloud Computing (CLOUD), San Francisco, CA, USA, 2–7 July 2018; pp. 896–899. [Google Scholar]
- Ramezany, S.; Setthawong, R.; Tanprasert, T. A Machine Learning-based Malicious Payload Detection and Classification Framework for New Web Attacks. In Proceedings of the 2022 19th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Prachuap Khiri Khan, Thailand, 24–27 May 2022; pp. 1–4. [Google Scholar]
- Ma, J.; Saul, L.K.; Savage, S.; Voelker, G.M. Beyond blacklists: Learning to detect malicious web sites from suspicious URLs. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 1245–1254. [Google Scholar]
- Kim, H.; Yoon, Y. An Ensemble of Text Convolutional Neural Networks and Multi-Head Attention Layers for Classifying Threats in Network Packets. Electronics 2023, 12, 4253. [Google Scholar] [CrossRef]
- Xie, X.; Ren, C.; Fu, Y.; Xu, J.; Guo, J. SQL Injection Detection for Web Applications Based on Elastic-Pooling CNN. IEEE Access 2019, 7, 151475–151481. [Google Scholar] [CrossRef]
- Wu, Z.; Zhang, H.; Wang, P.; Sun, Z. RTIDS: A Robust Transformer-Based Approach for Intrusion Detection System. IEEE Access 2022, 10, 64375–64387. [Google Scholar] [CrossRef]
- Momu, S.A.; Siddiqui, R.R.; Hoque, M.S.; Kawsur, M.M. Evaluating the Performance of Long Short-Term Memory for Web Attack Detection. In Proceedings of the 2023 26th International Conference on Computer and Information Technology (ICCIT), Cox’s Bazar, Bangladesh, 13–15 December 2023; pp. 1–6. [Google Scholar]
- Bokolo, B.G.; Chen, L.; Liu, Q. Detection of Web-Attack using DistilBERT, RNN, and LSTM. In Proceedings of the 2023 11th International Symposium on Digital Forensics and Security (ISDFS), Chattanooga, TN, USA, 11–12 May 2023; pp. 1–6. [Google Scholar]
- Jianping, W.; Guangqiu, Q.; Chunming, W.; Weiwei, J.; Jiahe, J. Federated learning for network attack detection using attention-based graph neural networks. Sci. Rep. 2024, 14, 19088. [Google Scholar] [CrossRef] [PubMed]
- Shannon, C.E. A Mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Yu, X.; Meng, W.; Liu, Y.; Zhou, F. TridentShell: An enhanced covert and Scalable Backdoor Injection Attack on Web Applications. J. Netw. Comput. Appl. 2024, 223, 103823. [Google Scholar] [CrossRef]
- Liu, Z. Research on SQL Injection Detection Based on Deep Learning. In Proceedings of the 2023 IEEE 7th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 15–17 September 2023; pp. 746–749. [Google Scholar]
- Li, M.; Han, D.; Li, D.; Liu, H.; Chang, C.-C. MFVT: An anomaly traffic detection method merging feature fusion network and vision transformer architecture. EURASIP J. Wirel. Commun. Netw. 2022, 2022, 39. [Google Scholar] [CrossRef]
- Disha, R.A.; Waheed, S. Performance analysis of machine learning models for intrusion detection system using Gini Impurity-based Weighted Random Forest (GIWRF) feature selection technique. Cybersecurity 2022, 5, 1. [Google Scholar] [CrossRef]
- Liu, X.; Liu, J. Malicious traffic detection combined deep neural network with hierarchical attention mechanism. Sci. Rep. 2021, 11, 12363. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, H.T.; Torrano-Gimenez, C.; Álvarez, G.; Petrovic, S.; Franke, K. Application of the Generic Feature Selection Measure in Detection of Web Attacks. In Proceedings of the Computational Intelligence in Security for Information Systems 4th International Conference, Torremolinos-Málaga, Spain, 8–10 June 2011; pp. 25–34. [Google Scholar]
- Rajagopal Smitha, K.S.H.; Poornima Panduranga Kundapur, A. Machine Learning Approach for Web Intrusion Detection: MAMLS Perspective. In Proceedings of the Soft Computing and Signal Processing, Hyderabad, India, 21–22 June 2019. [Google Scholar]
- Niu, Q.; Li, X. A High-performance Web Attack Detection Method based on CNN-GRU Model. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; pp. 804–808. [Google Scholar]
- Fan, Y.; Liu, X.; Zhu, J.; Jiang, Q.; Li, Q.; Xu, D. Research on Web Attack Detection of Service Websites Based on BERT. Comput. Technol. Dev. 2022, 32, 168–173. [Google Scholar] [CrossRef]

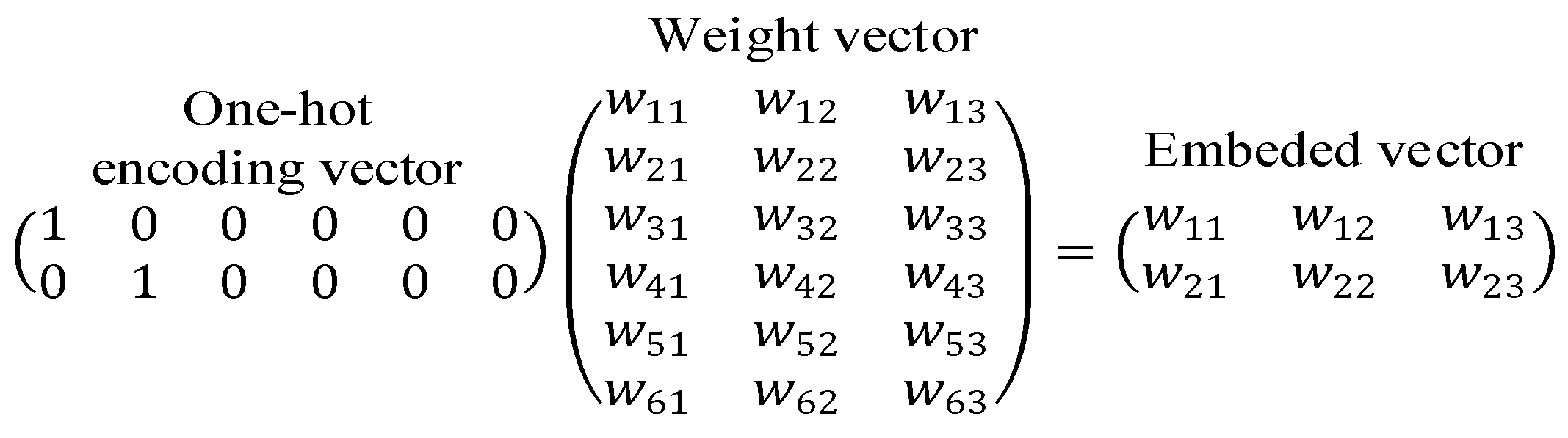




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Category | Description | Advantages | Disadvantages |
|---|---|---|---|---|
| Traffic attributes | Rule-based | This method focuses on basic traffic characteristics, including IP addresses and URLs, and builds rules based on them | Simple implementation, low cost, and easy to explain | Poor adaptability to new variants of traffic and easy failure of rules |
| Statistical attributes | Rule-based, machine learning-based | This method is based on statistical features used to construct rules or models, such as field length, packet size, time interval, etc. | Generalization, high detection accuracy, and resistance to mild confusion | Easily affected by traffic disturbances and lacks contextual understanding ability |
| Field attributes | Machine learning-based, deep learning-based | This method focuses on field characteristics, namely load content. It uses models to understand the semantic information of requests, such as sequence patterns, context dependencies, etc. | Captures context and deep patterns, adapts to complex attack methods | High feature dimensionality, lack of statistical/structural information, may be overfitted and have weak interpretability |
| Id | Feature Name | Description |
|---|---|---|
| 1 | http_len | Length of HTTP request |
| 2 | url_len | Length of URL field in HTTP requests |
| 3 | cookie_len | Length of cookie field in HTTP requests |
| 4 | ua_len | Length of user-agent field in HTTP requests |
| 5 | referer_len | Length of referrer field in HTTP requests |
| 6 | xff_len | Length of the X-forwarded for field in HTTP requests |
| 7 | params_len | Length of transmission parameters in HTTP requests |
| 8 | params_max_len | Length of the longest transmission parameter in HTTP requests |
| 9 | params_mean_len | Average length of transmission parameters in HTTP requests |
| 10 | cookie_max_len | Length of the longest cookie parameter in HTTP requests |
| 11 | cookie_mean_len | Average length of cookie parameters in HTTP requests |
| 12 | params_cnt | The number of parameters transmitted in HTTP requests |
| 13 | cookie_cnt | The number of cookie parameters in HTTP requests |
| 14 | special_cnt | The number of special characters in HTTP requests |
| 15 | url_special_cnt | The number of special characters in URL fields in HTTP requests |
| 16 | cookie_special_cnt | The number of special characters in cookie fields in HTTP requests |
| 17 | ua_special_cnt | The number of special characters in the user agent field of HTTP requests |
| 18 | referer_special_cnt | The number of special characters in the referrer field of HTTP requests |
| 19 | xff_special_cnt | The number of special characters in the X-forwarded for field in HTTP requests |
| 20 | params_special_cnt | The number of special characters for transmission parameters in HTTP requests |
| 21 | entropy | The average amount of information contained in each message received |
| 22 | IC | The probability of picking two identical characters at random from a given string |
| HTTP Request Field | Normal Value | Abnormal Value |
|---|---|---|
| Transmission parameters | user = 72 & group = 32 | user = 72 & group = −1 union select 1,2,0,md5(1122) |
| Cookie | JSESSIONID = 23391DBBADEC19FE; item = phone | JSESSIONID = -admin’) union select 1,2,database()#; &item = phone |
| User agent | Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36 | <script>alert(1)</script> |
| Referrer | www.google.com (accessed on 16 January 2025) | /etc/passwd |
| X-forwarded for | 101.99.42.24 | -1′ OR 225-25-1 = 0 + 0 + 0 + 1 --,101.99.42.24 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Deng, C.; Gao, X.; Li, X.; Hu, H. Malicious Cloud Service Traffic Detection Based on Multi-Feature Fusion. Electronics 2025, 14, 2190. https://doi.org/10.3390/electronics14112190
Chen Z, Deng C, Gao X, Li X, Hu H. Malicious Cloud Service Traffic Detection Based on Multi-Feature Fusion. Electronics. 2025; 14(11):2190. https://doi.org/10.3390/electronics14112190
Chicago/Turabian StyleChen, Zhouguo, Chen Deng, Xiang Gao, Xinze Li, and Hangyu Hu. 2025. "Malicious Cloud Service Traffic Detection Based on Multi-Feature Fusion" Electronics 14, no. 11: 2190. https://doi.org/10.3390/electronics14112190
APA StyleChen, Z., Deng, C., Gao, X., Li, X., & Hu, H. (2025). Malicious Cloud Service Traffic Detection Based on Multi-Feature Fusion. Electronics, 14(11), 2190. https://doi.org/10.3390/electronics14112190