
The Proposal of a Fully Quantum Neural Network and Fidelity-Driven Training Using Directional Gradients for Multi-Class Classification


Abstract
1. Introduction
- Many architectures are hybrid in nature, relying partially on classical processing or optimization routines, which can limit the full exploitation of quantum parallelism.
- Classical backpropagation or gradient-based optimization is frequently used, introducing overhead and potential incompatibility with quantum-native learning paradigms.
- Circuit depth and the number of qubits required for complex datasets may exceed current NISQ-era hardware capabilities, making practical implementation difficult.
2. Architecture Description FQNN
- Data encoding: Each input feature is encoded into a single qubit using a rotation operation , where the rotation angle is proportional to the feature value. This process enables the embedding of classical data into the quantum-state space.
- Quantum weight layer: The network’s weights are represented by additional qubits, each subjected to an independent quantum rotation , with the rotation angles corresponding to trainable network parameters. These angles play a role analogous to classical weights in conventional neural networks.
- Entanglement: For each data–weight qubit pair, controlled gates are applied to introduce entanglement between the data and weight states. This mechanism allows the network to capture nonlinear dependencies among input features.
- Label encoding and error measurement: To perform classification, the network prepares a quantum state corresponding to the target label. The similarity between the output state of the network and the reference label state is evaluated using the swap-test procedure.
2.1. Data Encoding
2.2. Feature-to-Qubit Rotation Assignment
- Qubit State Transformation
- If , the qubit remains in the state .
- If , the qubit is rotated to the state .
- For intermediate values of , the qubit is in a superposition of and .
2.3. Vector Representation of the Entire Input Encoding
- The classical feature values control the amplitudes of the quantum states.
- The input data are transformed into a superposition of quantum states, which can then be further modified through quantum operations (rotations, entanglement).
2.4. Quantum Weight Layer in FQNN
- Layer Structure
- is initialized in the state ;
- undergoes a rotation around the Y-axis using a quantum gate;
- where the parameter is an independent network parameter optimized during training.
Weight Parameterization
- Initially, the parameters are randomly initialized within the interval .
- During training, the values of are updated in the direction that increases the fidelity between the network’s output state and the target label state.
2.5. Interpretation of the Role of Weights in FQNN
- Weights control how strongly input features influence subsequent layers and the final prediction outcome.
- The weights (rotation angles ) determine the extent to which the state of a weight qubit is “tilted” from towards .
- Subsequently, during the entangling operation (CRY gate), the state of the weight qubit governs the influence on the data qubits, modifying their amplitudes accordingly.
2.6. Vector Representation of the Weight Layer
3. Entanglement in FQNN
- In classical neural networks, nonlinearity is introduced via activation functions (e.g., ReLU, sigmoid).
- In FQNNs, nonlinearity and correlations are achieved through entangling operations between data qubits and weight qubits.
3.1. Role of Entanglement
- The input is encoded into quantum amplitudes, which are further transformed through entangled quantum operations—analogous to activation functions in classical NNs.
3.2. Implementation via Controlled Rotations
- The weight qubit serves as the control qubit;
- The data qubit is the target;
- The operation applies a rotation to the data qubit only when the control qubit is in the state.
3.3. Interpretation and Relevance
4. Label Encoding and Error Measurement in FQNN
- Label Encoding:
4.1. Label-Encoding Scheme
- The state corresponds to class 0;
- The state corresponds to class 1;
- The state corresponds to class 2.
- If a component of the desired label state is “1”, an X gate is applied to the corresponding qubit.
- The first qubit (qubit 0) is set to using an X gate;
- The second qubit (qubit 1) remains in the state (no operation needed).
4.2. State Comparison—Error Measurement
- Prepare the ancillary qubit in a superposition state:
- Apply controlled-swap (CSWAP) operations between corresponding qubits of and , controlled by the ancillary qubit. The CSWAP gate is also known as the Fredkin gate [11], and it conditionally swaps the states of two qubits depending on the state of a control qubit.
- Apply a second Hadamard gate to the ancillary qubit.
- Measure the ancillary qubit.
- the output state of the network ;
- and the label state .
4.3. Error Measurement Algorithm and Its Role in Training
Definition of Average Fidelity
- Objective Function:
- minimizing the difference between the network output state and the target label state;
- maximizing the swap-test result (i.e., the fidelity).
5. Training and Optimization
5.1. Training Procedure Overview
5.1.1. Gradient Estimation
5.1.2. Direction Selection
- If , the weight is updated in the positive direction.
- If , the update direction is negative.
5.1.3. Weight Update
5.1.4. Step-Size Adaptation
5.2. Objective Function and Quality Metric
5.3. Optimization Strategies
5.3.1. Mini-Batch Learning
5.3.2. Adaptive Step-Size Reduction (Delta Annealing)
5.3.3. Batch Randomization
5.4. Pseudocode of the Training Procedure
| Algorithm 1: Training Procedure for Fully Quantum Neural Network (FQNN) |
 |
6. Pseudocode of Fully Quantum Neural Network (FQNN)
7. Experimental Setup
7.1. Input Data
7.2. Simulation Environment
| Algorithm 2: Full Training and Evaluation Procedure for Fully Quantum Neural Network (FQNN) |
 |
7.3. FQNN Architecture
- Four qubits representing the input data features;
- Four qubits representing the quantum weights;
- Three auxiliary qubits:
- –
- Two qubits for encoding the class label,
- –
- One qubit for performing the swap test.
7.4. Training Parameters
- Number of training epochs: 12;
- Initial weight update step:
- Every 5 epochs, the values of were reduced by a factor of 0.9 (delta annealing);
- In directional gradient estimation, mini batches of 5 randomly selected training samples were used for each parameter update.
7.5. Performance Evaluation Metrics
- Average fidelity: the fidelity value from the swap test between the FQNN output state and the encoded label state, calculated on selected training samples;
- Classification accuracy: the percentage of correctly classified examples on the test set, measured after each epoch.
7.6. Repeated Trials
8. Results and Discussion
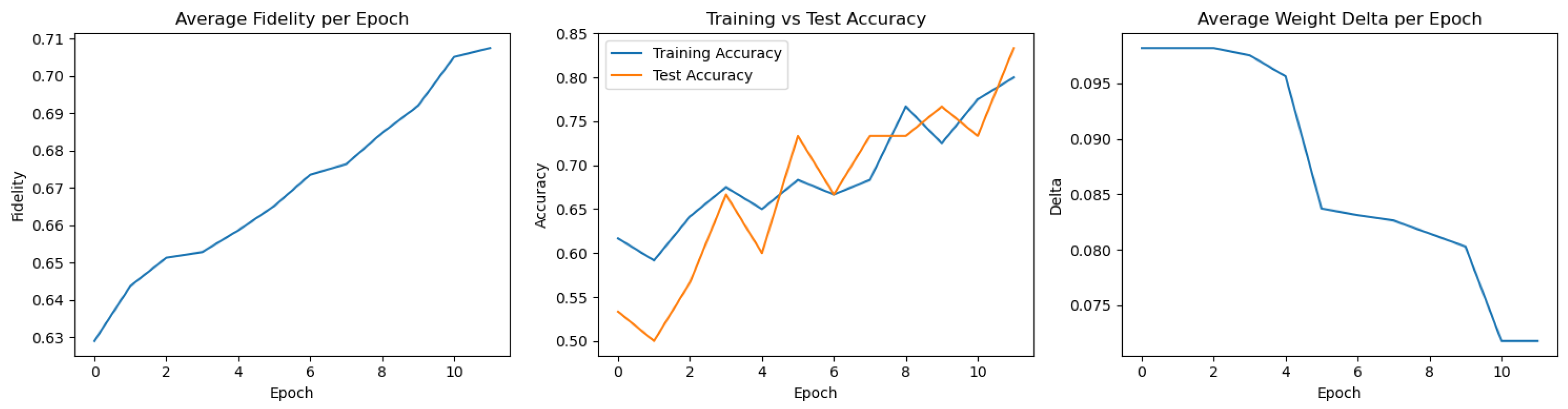
8.1. Best Performing Run
8.2. Worst Performing Run
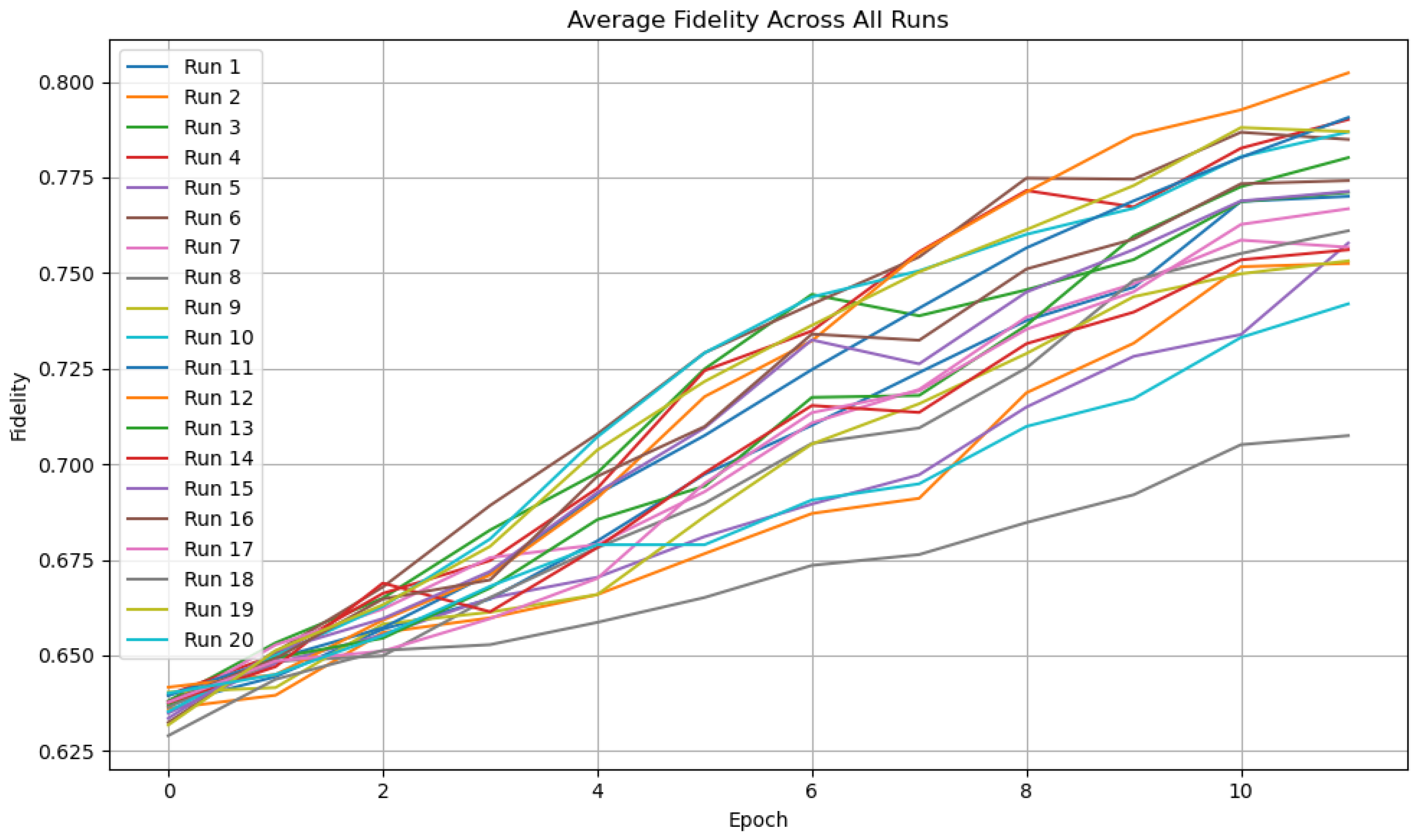
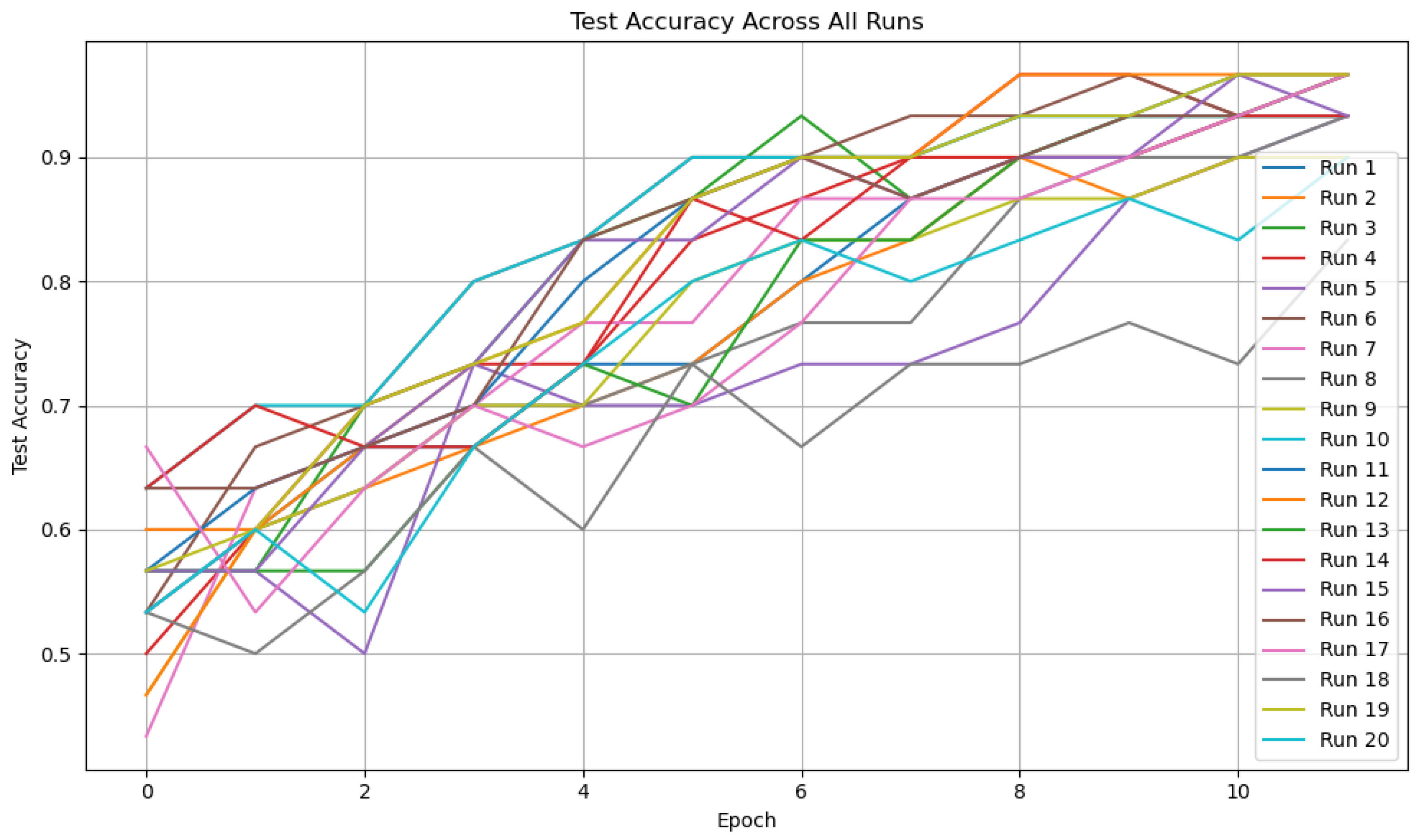
8.3. Aggregated Results Across 20 Training Runs
8.4. Summary and Insights
9. Conclusions
- Fidelity-based training enables geometrically meaningful optimization in Hilbert space.
- Directional gradient updates, combined with delta annealing, offer stable convergence.
- The fully quantum architecture avoids hybrid dependency, maintaining conceptual purity.
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| DOAJ | Directory of open access journals |
| TLA | Three-letter acronym |
| LD | Linear dichroism |
Appendix A. Training Metrics for All 20 FQNN Runs
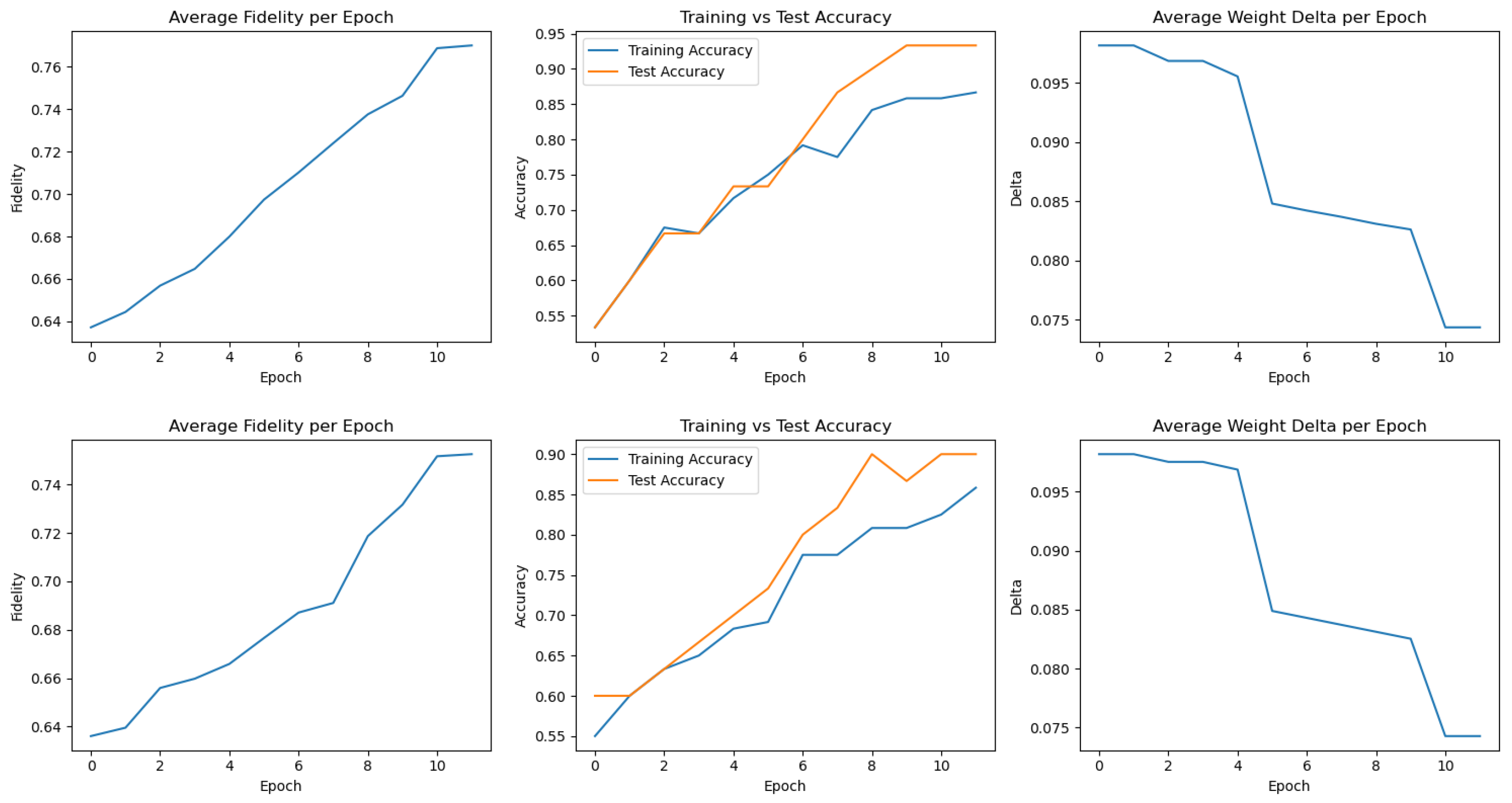
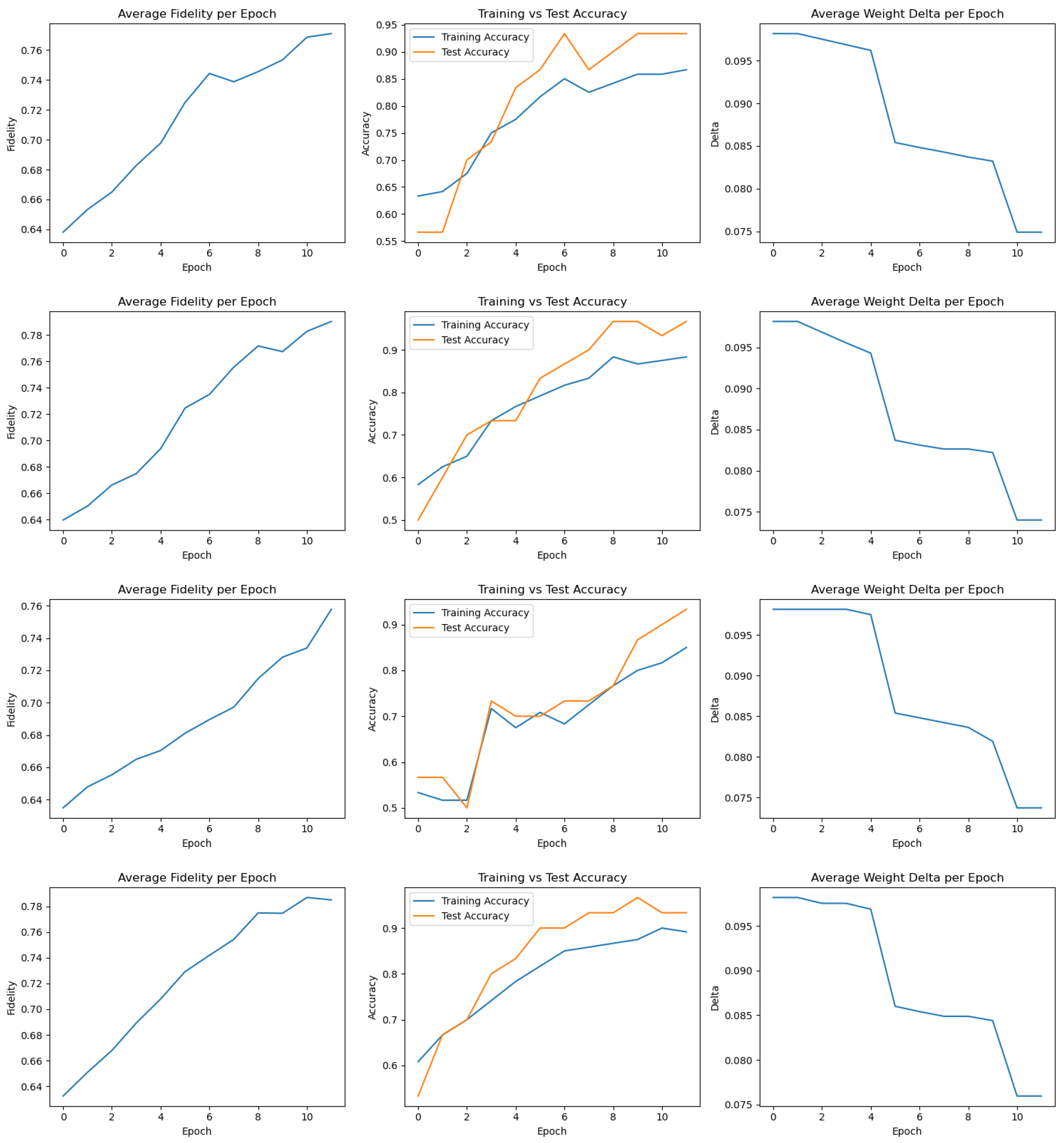
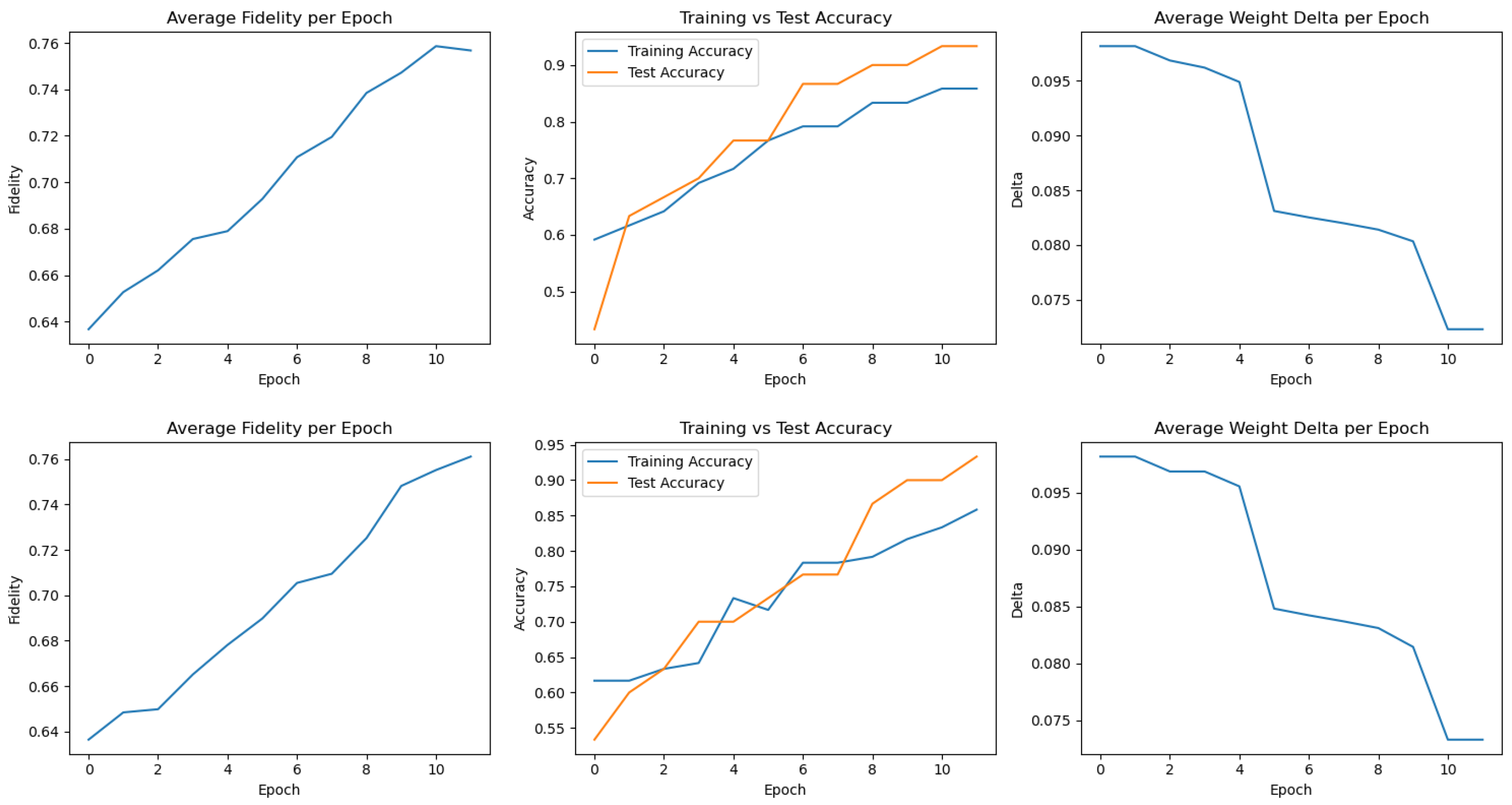


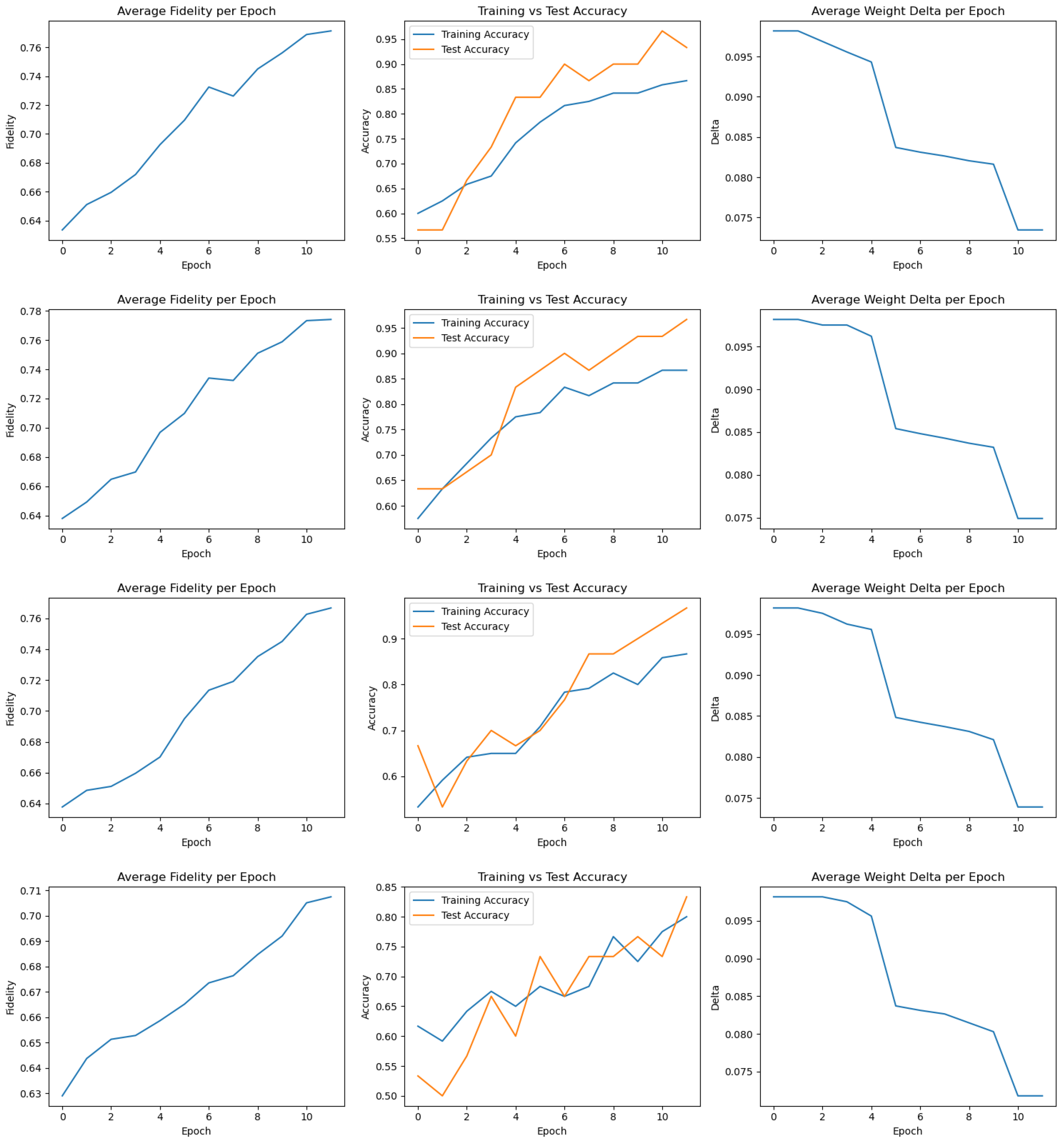

Appendix B. Derivation of the Fidelity Estimation in the Swap Test
Appendix B.1. Swap-Test Procedure and Measurement Probability
Appendix B.2. Extraction of Fidelity
References
- Wang, Y.; Liu, J. A comprehensive review of quantum machine learning: From NISQ to fault tolerance. Rep. Prog. Phys. 2024, 87, 116402. [Google Scholar] [CrossRef] [PubMed]
- Zeguendry, A.; Jarir, Z.; Quafafou, M. Quantum Machine Learning: A Review and Case Studies. Entropy 2023, 25, 287. [Google Scholar] [CrossRef] [PubMed]
- Biamonte, J.; Wittek, P.; Pancotti, N.; Rebentrost, P.; Wiebe, N.; Lloyd, S. Quantum machine learning. Nature 2017, 549, 195–202. [Google Scholar] [CrossRef] [PubMed]
- Cerezo, M.; Verdon, G.; Huang, H.Y.; Cincio, L.; Coles, P.J. Challenges and opportunities in quantum machine learning. Nat. Comput. Sci. 2022, 2, 567–576. [Google Scholar] [CrossRef] [PubMed]
- Beer, K.; Bondarenko, D.; Farrelly, T.; Osborne, T.J.; Salzmann, R.; Scheiermann, D.; Wolf, R. Training deep quantum neural networks. Nat. Commun. 2020, 11, 808. [Google Scholar] [CrossRef] [PubMed]
- Cui, W.; Yan, S. New Directions in Quantum Neural Networks Research. Control Theory Technol. 2019, 17, 393–395. [Google Scholar] [CrossRef]
- Abbas, A.; Sutter, D.; Zoufal, C.; Lucchi, A.; Figalli, A.; Woerner, S. The power of quantum neural networks. Nat. Comput. Sci. 2021, 1, 403–409. [Google Scholar] [CrossRef] [PubMed]
- Schuld, M.; Bocharov, A.; Svore, K.M.; Wiebe, N. Circuit-centric quantum classifiers. Phys. Rev. A 2020, 101, 032308. [Google Scholar] [CrossRef]
- Benedetti, M.; Lloyd, E.; Sack, S.; Fiorentini, M. Parameterized quantum circuits as machine learning models. Quantum Sci. Technol. 2019, 4, 043001. [Google Scholar] [CrossRef]
- Nielsen, M.A.; Chuang, I.L. Quantum Computation and Quantum Information: 10th Anniversary Edition; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Barenco, A.; Bennett, C.H.; Cleve, R.; DiVincenzo, D.P.; Margolus, N.; Shor, P.; Sleator, T.; Smolin, J.A.; Weinfurter, H. Elementary gates for quantum computation. Phys. Rev. A 1995, 52, 3457–3467. [Google Scholar] [CrossRef] [PubMed]
- Boresta, M.; Colombo, T.; De Santis, A.; Lucidi, S. A Mixed Finite Differences Scheme for Gradient Approximation. J. Optim. Theory Appl. 2022, 194, 1–24. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample # | Input Features (Scaled) | Predicted | Expected |
|---|---|---|---|
| 1 | [0.03, 0.42, 0.05, 0.04] | 0 | 0 |
| 2 | [0.50, 0.42, 0.66, 0.71] | 2 | 2 |
| 3 | [0.17, 0.17, 0.39, 0.38] | 1 | 1 |
| 4 | [0.19, 0.12, 0.39, 0.38] | 1 | 1 |
| 5 | [0.03, 0.50, 0.05, 0.04] | 0 | 0 |
| 6 | [0.56, 0.54, 0.63, 0.63] | 1 | 1 |
| 7 | [0.08, 0.67, 0.00, 0.04] | 0 | 0 |
| 8 | [0.31, 0.58, 0.12, 0.04] | 0 | 0 |
| 9 | [0.61, 0.42, 0.71, 0.79] | 2 | 2 |
| 10 | [0.31, 0.42, 0.59, 0.58] | 1 | 1 |
| 11 | [0.83, 0.38, 0.90, 0.71] | 0 | 2 |
| 12 | [0.72, 0.46, 0.69, 0.92] | 2 | 2 |
| 13 | [0.61, 0.42, 0.81, 0.88] | 2 | 2 |
| 14 | [0.58, 0.50, 0.59, 0.58] | 1 | 1 |
| 15 | [0.19, 0.58, 0.08, 0.04] | 0 | 0 |
| 16 | [0.19, 0.54, 0.07, 0.04] | 0 | 0 |
| 17 | [0.42, 0.83, 0.03, 0.04] | 0 | 0 |
| 18 | [0.36, 0.21, 0.49, 0.42] | 1 | 1 |
| 19 | [0.50, 0.38, 0.63, 0.54] | 1 | 1 |
| 20 | [0.47, 0.42, 0.64, 0.71] | 2 | 2 |
| 21 | [0.31, 0.71, 0.08, 0.04] | 0 | 0 |
| 22 | [0.67, 0.46, 0.78, 0.96] | 2 | 2 |
| 23 | [0.64, 0.38, 0.61, 0.50] | 1 | 1 |
| 24 | [0.50, 0.25, 0.78, 0.54] | 2 | 2 |
| 25 | [0.58, 0.33, 0.78, 0.88] | 2 | 2 |
| 26 | [0.67, 0.42, 0.68, 0.67] | 1 | 1 |
| 27 | [0.64, 0.42, 0.58, 0.54] | 1 | 1 |
| 28 | [0.39, 0.75, 0.12, 0.08] | 0 | 0 |
| 29 | [0.61, 0.42, 0.76, 0.71] | 2 | 2 |
| 30 | [0.25, 0.58, 0.07, 0.04] | 0 | 0 |
| Sample # | Input Features (Scaled) | Predicted | Expected |
|---|---|---|---|
| 1 | [0.03, 0.42, 0.05, 0.04] | 0 | 0 |
| 2 | [0.50, 0.42, 0.66, 0.71] | 2 | 2 |
| 3 | [0.17, 0.17, 0.39, 0.38] | 1 | 1 |
| 4 | [0.19, 0.12, 0.39, 0.38] | 1 | 1 |
| 5 | [0.03, 0.50, 0.05, 0.04] | 0 | 0 |
| 6 | [0.56, 0.54, 0.63, 0.63] | 1 | 1 |
| 7 | [0.08, 0.67, 0.00, 0.04] | 0 | 0 |
| 8 | [0.31, 0.58, 0.12, 0.04] | 0 | 0 |
| 9 | [0.61, 0.42, 0.71, 0.79] | 0 | 2 |
| 10 | [0.31, 0.42, 0.59, 0.58] | 1 | 1 |
| 11 | [0.83, 0.38, 0.90, 0.71] | 0 | 2 |
| 12 | [0.72, 0.46, 0.69, 0.92] | 0 | 2 |
| 13 | [0.61, 0.42, 0.81, 0.88] | 2 | 2 |
| 14 | [0.58, 0.50, 0.59, 0.58] | 1 | 1 |
| 15 | [0.19, 0.58, 0.08, 0.04] | 0 | 0 |
| 16 | [0.19, 0.54, 0.07, 0.04] | 0 | 0 |
| 17 | [0.42, 0.83, 0.03, 0.04] | 0 | 0 |
| 18 | [0.36, 0.21, 0.49, 0.42] | 1 | 1 |
| 19 | [0.50, 0.38, 0.63, 0.54] | 1 | 1 |
| 20 | [0.47, 0.42, 0.64, 0.71] | 2 | 2 |
| 21 | [0.31, 0.71, 0.08, 0.04] | 0 | 0 |
| 22 | [0.67, 0.46, 0.78, 0.96] | 0 | 2 |
| 23 | [0.64, 0.38, 0.61, 0.50] | 1 | 1 |
| 24 | [0.50, 0.25, 0.78, 0.54] | 2 | 2 |
| 25 | [0.58, 0.33, 0.78, 0.88] | 2 | 2 |
| 26 | [0.67, 0.42, 0.68, 0.67] | 1 | 1 |
| 27 | [0.64, 0.42, 0.58, 0.54] | 1 | 1 |
| 28 | [0.39, 0.75, 0.12, 0.08] | 0 | 0 |
| 29 | [0.61, 0.42, 0.76, 0.71] | 0 | 2 |
| 30 | [0.25, 0.58, 0.07, 0.04] | 0 | 0 |
| Run ID | Training Accuracy | Test Accuracy |
|---|---|---|
| 1 | 0.8667 | 0.9333 |
| 2 | 0.8583 | 0.9000 |
| 3 | 0.8667 | 0.9333 |
| 4 | 0.8833 | 0.9667 |
| 5 | 0.8500 | 0.9333 |
| 6 | 0.8917 | 0.9333 |
| 7 | 0.8583 | 0.9333 |
| 8 | 0.8583 | 0.9333 |
| 9 | 0.8500 | 0.9000 |
| 10 | 0.8750 | 0.9333 |
| 11 | 0.8917 | 0.9667 |
| 12 | 0.8917 | 0.9667 |
| 13 | 0.8667 | 0.9667 |
| 14 | 0.8583 | 0.9333 |
| 15 | 0.8667 | 0.9333 |
| 16 | 0.8667 | 0.9667 |
| 17 | 0.8667 | 0.9667 |
| 18 | 0.8000 | 0.8333 |
| 19 | 0.8750 | 0.9667 |
| 20 | 0.8417 | 0.9000 |
| Mean | 0.8642 | 0.9350 |
| Std Dev | 0.0201 | 0.0324 |
| Variance | 0.000403 | 0.001053 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ewald, D. The Proposal of a Fully Quantum Neural Network and Fidelity-Driven Training Using Directional Gradients for Multi-Class Classification. Electronics 2025, 14, 2189. https://doi.org/10.3390/electronics14112189
Ewald D. The Proposal of a Fully Quantum Neural Network and Fidelity-Driven Training Using Directional Gradients for Multi-Class Classification. Electronics. 2025; 14(11):2189. https://doi.org/10.3390/electronics14112189
Chicago/Turabian StyleEwald, Dawid. 2025. "The Proposal of a Fully Quantum Neural Network and Fidelity-Driven Training Using Directional Gradients for Multi-Class Classification" Electronics 14, no. 11: 2189. https://doi.org/10.3390/electronics14112189
APA StyleEwald, D. (2025). The Proposal of a Fully Quantum Neural Network and Fidelity-Driven Training Using Directional Gradients for Multi-Class Classification. Electronics, 14(11), 2189. https://doi.org/10.3390/electronics14112189