
BASK: Backdoor Attack for Self-Supervised Encoders with Knowledge Distillation Survivability

Abstract
1. Introduction
2. Related Work
2.1. Self-Supervised Learning (SSL)
2.2. Backdoor Attacks
2.3. Backdoor Defenses
2.4. Knowledge Distillation
2.5. Backdoor Attacks in Large Language Models
3. Preliminary
3.1. Backdoor on SSL
3.2. Taxonomy of SSL Backdoor Attacks by Attacker Access
3.2.1. White-Box Backdoor Attacks
3.2.2. Gray-Box Backdoor Attacks
3.2.3. Black-Box Backdoor Attacks
3.3. Threat Model
3.4. Red-Team Detection Feasibility
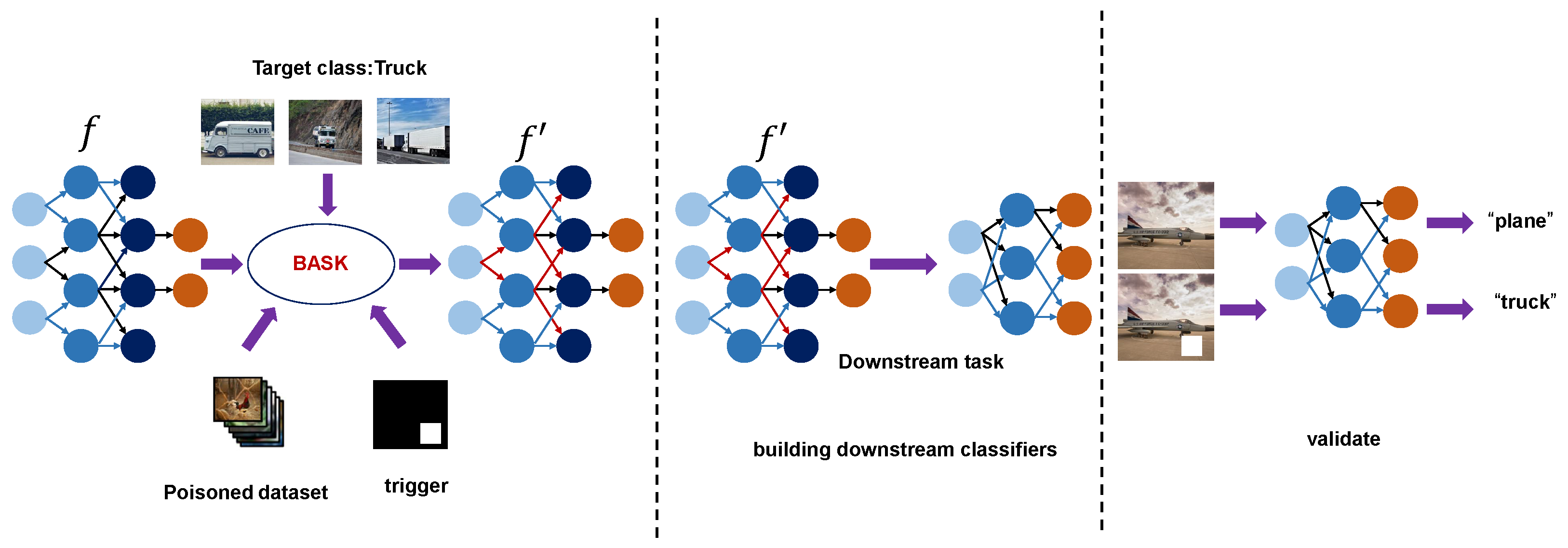
4. Method
4.1. Overview
4.2. Theoretical Justification Framework of Representation Persistence
4.3. Backdoor Trigger and Target Category Description
4.4. Formalization of the BASK Attack
4.4.1. Feature Weighting Loss
- and are the feature representations of the poisoned and target images at the i-th layer, respectively;
- is the importance weight of the i-th feature, which ensures that the model adaptively focuses on the features with the greatest impact on backdoor injection;
- and are the -norms of the feature vectors at the i-th layer.
4.4.2. Representation Alignment Loss
- denotes the cosine similarity;
- is a temperature parameter;
- is the set of negative samples in the current batch, excluding and .
4.4.3. Total Loss
- : the standard contrastive loss on clean samples;
- : the representation alignment loss;
- : the feature weighting loss.
5. Evaluation
5.1. Experimental Setup
5.2. Evaluation Metrics
- N is the total number of samples in the clean test set;
- is the i-th test input, and is its ground-truth label;
- is the model’s predicted label for ;
- is the indicator function, which equals 1 if the condition holds and is 0 otherwise.
- M is the total number of poisoned (triggered) samples;
- is the i-th poisoned sample;
- is the target label specified by the attacker;
- is the model’s prediction for the poisoned input .
5.3. Results and Discussion
5.3.1. Performance Comparison Between BASK and Baseline Attack Methods Without Defense
5.3.2. The Impact of Different Defense Strategies
5.4. Defense Mechanisms and the Robustness of BASK Against Them
5.4.1. MKD
5.4.2. SEED
5.4.3. NC
5.4.4. MIMIC
5.4.5. Analyzing BASK’s Survivability Against Distillation-Based Defenses
Implications for Future Defenses
5.4.6. The Impact of Different Loss Weights
5.4.7. Ablation Study
5.4.8. Study on the Portability of BASK in Other SSL Paradigms
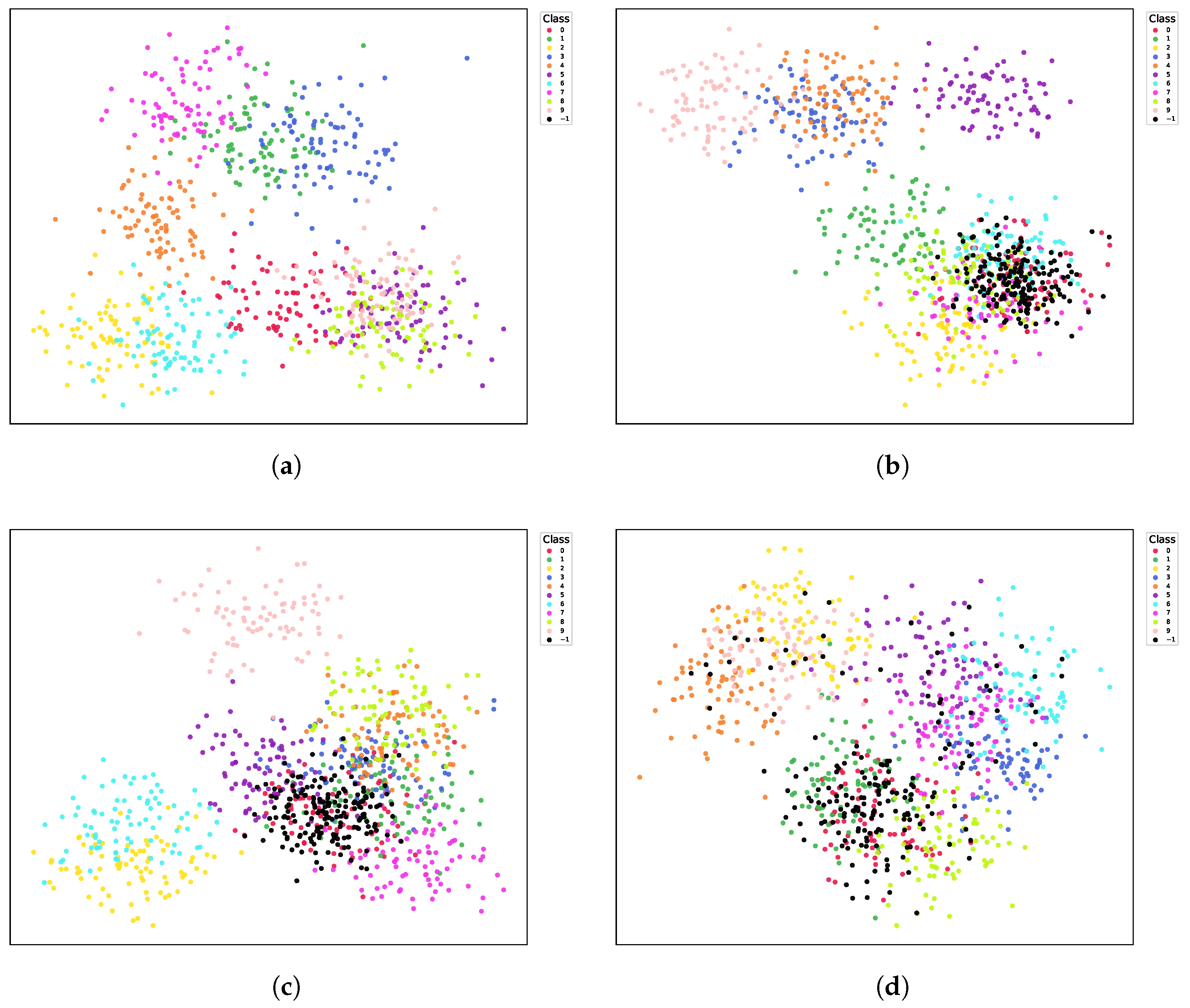
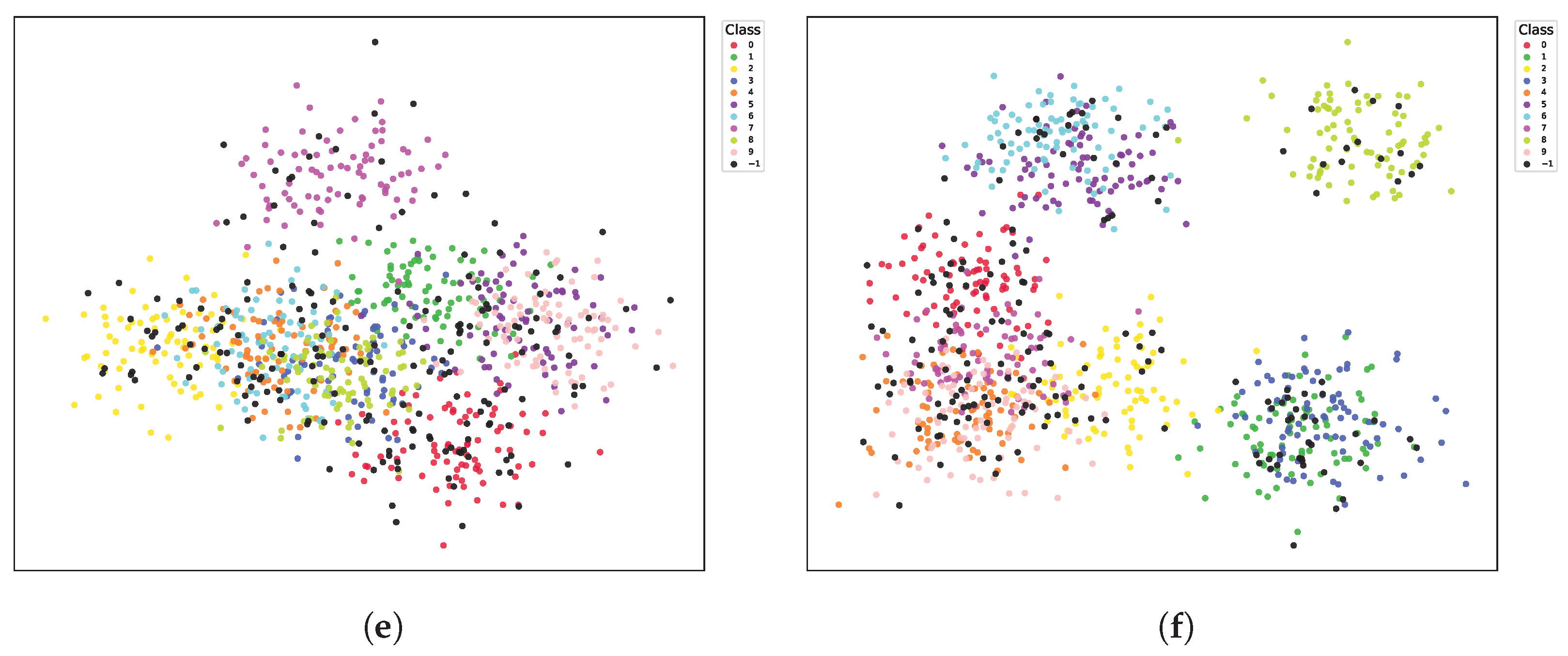
5.4.9. Visualization of Features
6. Conclusions
6.1. Theoretical and Architectural Comparison with BadEncoder and BASSL
6.2. Ethical Considerations and Responsible Disclosure
6.3. Responsible Research Practices
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; Lecture Notes in Computer Science. Volume 9351, pp. 234–241. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the International Conference on Machine Learning (ICML), Virtual, 13–18 July 2020; Proceedings of Machine Learning Research: Cambridge MA, USA, 2020; Volume 119. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jegou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging Properties in Self-Supervised Vision Transformers. In Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9630–9640. [Google Scholar] [CrossRef]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperPoint: Self-Supervised Interest Point Detection and Description. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 337–349. [Google Scholar] [CrossRef]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised Contrastive Learning. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS), Online, 6–12 December 2020; Advances in Neural Information Processing Systems. Volume 33. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 8–23 June 2018; pp. 586–595. [Google Scholar] [CrossRef]
- Li, Y.; Jiang, Y.; Li, Z.; Xia, S.T. Backdoor learning: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 5–22. [Google Scholar] [CrossRef]
- Guo, W.; Tondi, B.; Barni, M. An overview of backdoor attacks against deep neural networks and possible defences. IEEE Open J. Signal Process. 2022, 3, 261–287. [Google Scholar] [CrossRef]
- Ge, Y.; Wang, Q.; Yu, J.; Shen, C.; Li, Q. Data poisoning and backdoor attacks on audio intelligence systems. IEEE Commun. Mag. 2023, 61, 176–182. [Google Scholar] [CrossRef]
- Li, Y.; Lyu, X.; Koren, N.; Lyu, L.; Li, B.; Ma, X. Neural attention distillation: Erasing backdoor triggers from deep neural networks. arXiv 2021, arXiv:2101.05930. [Google Scholar]
- Wang, B.; Yao, Y.; Shan, S.; Li, H.; Viswanath, B.; Zheng, H.; Zhao, B.Y. Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks. In Proceedings of the 40th IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 707–723. [Google Scholar] [CrossRef]
- Sowe, E.A.; Bah, Y.A. Momentum Contrast for Unsupervised Visual Representation Learning. Preprints 2025. [Google Scholar] [CrossRef]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Chen, X.; Liu, C.; Li, B.; Lu, K.; Song, D. Targeted backdoor attacks on deep learning systems using data poisoning. arXiv 2017, arXiv:1712.05526. [Google Scholar]
- Gu, T.; Liu, K.; Dolan-Gavitt, B.; Garg, S. Badnets: Evaluating backdooring attacks on deep neural networks. IEEE Access 2019, 7, 47230–47244. [Google Scholar] [CrossRef]
- Jia, J.; Liu, Y.; Gong, N.Z. Badencoder: Backdoor attacks to pre-trained encoders in self-supervised learning. In Proceedings of the 2022 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 22–26 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2043–2059. [Google Scholar]
- Li, C.; Pang, R.; Xi, Z.; Du, T.; Ji, S.; Yao, Y.; Wang, T. An Embarrassingly Simple Backdoor Attack on Self-supervised Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 4344–4355. [Google Scholar] [CrossRef]
- Pan, M.; Zeng, Y.; Lyu, L.; Lin, X.; Jia, R.; Association, U. ASSET: Robust Backdoor Data Detection Across a Multiplicity of Deep Learning Paradigms. In Proceedings of the 32nd USENIX Security Symposium, Anaheim, CA, USA, 9–11 August 2023; pp. 2725–2742. [Google Scholar]
- Tao, G.; Wang, Z.; Feng, S.; Shen, G.; Ma, S.; Zhang, X. Distribution Preserving Backdoor Attack in Self-supervised Learning. In Proceedings of the 45th IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2024; pp. 2029–2047. [Google Scholar] [CrossRef]
- Jiang, W.; Zhang, T.; Qiu, H.; Li, H.; Xu, G. Incremental learning, incremental backdoor threats. IEEE Trans. Dependable Secur. Comput. 2022, 21, 559–572. [Google Scholar] [CrossRef]
- Fan, M.; Liu, Y.; Chen, C.; Liu, X.; Guo, W. Defense against backdoor attacks via identifying and purifying bad neurons. arXiv 2022, arXiv:2208.06537. [Google Scholar]
- Shen, G.; Liu, Y.; Tao, G.; An, S.; Xu, Q.; Cheng, S.; Ma, S.; Zhang, X. Backdoor scanning for deep neural networks through k-arm optimization. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; PMLR: Cambridge MA, USA, 2021; pp. 9525–9536. [Google Scholar]
- Xiang, Z.; Miller, D.J.; Kesidis, G. Post-training detection of backdoor attacks for two-class and multi-attack scenarios. arXiv 2022, arXiv:2201.08474. [Google Scholar]
- Xue, M.; Wu, Y.; Wu, Z.; Zhang, Y.; Wang, J.; Liu, W. Detecting backdoor in deep neural networks via intentional adversarial perturbations. Inf. Sci. 2023, 634, 564–577. [Google Scholar] [CrossRef]
- Feng, S.; Tao, G.; Cheng, S.; Shen, G.; Xu, X.; Liu, Y.; Zhang, K.; Ma, S.; Zhang, X. Detecting backdoors in pre-trained encoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16352–16362. [Google Scholar]
- Liu, K.; Dolan-Gavitt, B.; Garg, S. Fine-Pruning: Defending Against Backdooring Attacks on Deep Neural Networks. In Proceedings of the 21st International Symposium on Research in Attacks, Intrusions and Defenses (RAID), Heraklion, Greece, 10–12 September 2018; Lecture Notes in Computer Science. Volume 11050, pp. 273–294. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Bie, R.; Jiang, J.; Xie, H.; Guo, Y.; Miao, Y.; Jia, X. Mitigating backdoor attacks in pre-trained encoders via self-supervised knowledge distillation. IEEE Trans. Serv. Comput. 2024, 17, 2613–2625. [Google Scholar] [CrossRef]
- Ying, Z.; Wu, B. NBA: Defensive distillation for backdoor removal via neural behavior alignment. Cybersecurity 2023, 6, 20. [Google Scholar] [CrossRef]
- Xia, J.; Wang, T.; Ding, J.; Wei, X.; Chen, M. Eliminating Backdoor Triggers for Deep Neural Networks Using Attention Relation Graph Distillation. In Proceedings of the 31st International Joint Conference on Artificial Intelligence (IJCAI), Vienna, Austria, 23–29 July 2022; pp. 1481–1487. [Google Scholar]
- Zhou, Y.; Ni, T.; Lee, W.B.; Zhao, Q. A Survey on Backdoor Threats in Large Language Models (LLMs): Attacks, Defenses, and Evaluations. arXiv 2025, arXiv:2502.05224. [Google Scholar] [CrossRef]
- Yang, H.; Xiang, K.; Ge, M.; Li, H.; Lu, R.; Yu, S. A comprehensive overview of backdoor attacks in large language models within communication networks. IEEE Netw. 2024, 38, 211–218. [Google Scholar] [CrossRef]
- Vassilev, A.; Oprea, A.; Fordyce, A.; Andersen, H. Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigations; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2024.
- Wang, Q.; Yin, C.; Fang, L.; Liu, Z.; Wang, R.; Lin, C. GhostEncoder: Stealthy backdoor attacks with dynamic triggers to pre-trained encoders in self-supervised learning. Comput. Secur. 2024, 142, 103855. [Google Scholar] [CrossRef]
- Saha, A.; Tejankar, A.; Koohpayegani, S.A.; Pirsiavash, H. Backdoor attacks on self-supervised learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13337–13346. [Google Scholar]
- Qi, X.; Zhu, J.; Xie, C.; Yang, Y. Subnet replacement: Deployment-stage backdoor attack against deep neural networks in gray-box setting. arXiv 2021, arXiv:2107.07240. [Google Scholar]
- Li, C.; Pang, R.; Xi, Z.; Du, T.; Ji, S.; Yao, Y.; Wang, T. Demystifying Self-supervised Trojan Attacks. arXiv 2022, arXiv:2210.07346. [Google Scholar]
- Chen, Y.; Shao, S.; Huang, E.; Li, Y.; Chen, P.Y.; Qin, Z.; Ren, K. Refine: Inversion-free backdoor defense via model reprogramming. arXiv 2025, arXiv:2502.18508. [Google Scholar]
- Tung, F.; Mori, G. Similarity-preserving knowledge distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1365–1374. [Google Scholar]
- Manna, S.; Chattopadhyay, S.; Dey, R.; Bhattacharya, S.; Pal, U. Dystress: Dynamically scaled temperature in self-supervised contrastive learning. arXiv 2023, arXiv:2308.01140. [Google Scholar]
- Fang, Z.; Wang, J.; Wang, L.; Zhang, L.; Yang, Y.; Liu, Z. Seed: Self-supervised distillation for visual representation. arXiv 2021, arXiv:2101.04731. [Google Scholar]
- Han, T.; Sun, W.; Ding, Z.; Fang, C.; Qian, H.; Li, J.; Chen, Z.; Zhang, X. Mutual information guided backdoor mitigation for pre-trained encoders. IEEE Trans. Inf. Forensics Secur. 2025, 20, 3414–3428. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Coates, A.; Ng, A.; Lee, H. An analysis of single-layer networks in unsupervised feature learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; JMLR Workshop and Conference Proceedings: Cambridge, MA, USA, 2011; pp. 215–223. [Google Scholar]
- Weidinger, L.; Mellor, J.; Rauh, M.; Griffin, C.; Uesato, J.; Huang, P.S.; Cheng, M.; Glaese, M.; Balle, B.; Kasirzadeh, A.; et al. Ethical and social risks of harm from Language Models. arXiv 2021, arXiv:2112.04359. [Google Scholar]
- Shevlane, T. Structured access: An emerging paradigm for safe AI deployment. arXiv 2022, arXiv:2201.05159. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attack | No Attack | BadEncoder | BASSL | BASK | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | CIFAR10 | STL10 | CIFAR10 | STL10 | CIFAR10 | STL10 | CIFAR10 | STL10 | ||||||
| Metrics | ACC | ACC | ACC | ASR | ACC | ASR | ACC | ASR | ACC | ASR | ACC | ASR | ACC | ASR |
| No defense | ||||||||||||||
| SEED | ||||||||||||||
| MKD | ||||||||||||||
| NC | ||||||||||||||
| MIMIC | ||||||||||||||
| ACC | ASR | ||
|---|---|---|---|
| 0.8 | 0.2 | 76.40% | 82.20% |
| 0.6 | 0.4 | 76.29% | 98.31% |
| 0.5 | 0.5 | 76.67% | 93.10% |
| 0.4 | 0.6 | 76.20% | 91.25% |
| 0.2 | 0.8 | 76.15% | 83.75% |
| Experimental Setting | ACC | ASR |
|---|---|---|
| Default Setting | 76.29% | 98.31% |
| Without Feature Weighting Loss | 76.18% | 75.42% |
| Without Representation Alignment Loss | 76.05% | 61.88% |
| Only Standard Contrastive Loss | 76.20% | 4.26% |
| Dataset | Backbone | Defense | ACC (%) | ASR (%) |
|---|---|---|---|---|
| CIFAR10 | MoCo v2 + ResNet18 | No Defense | ||
| MKD | ||||
| MoCo v3 + ViT-B | No Defense | |||
| MKD | ||||
| STL10 | MoCo v2 + ResNet18 | No Defense | ||
| MKD | ||||
| MoCo v3 + ViT-B | No Defense | |||
| MKD |
| Aspect | BadEncoder | BASSL | BASK (Ours) |
|---|---|---|---|
| Trigger Type | Visible square trigger | Random patch in data | Trigger on 5%, encoded across layers |
| Feature Manipulation | Cosine loss on final layer | SSL loss via poisoned views | Feature weighting and contrastive alignment |
| Granularity | Final encoder output | View-level poisoning | Multi-layer representation control |
| Threat Model | White-box | Gray-box | White-box |
| Distillation Survival | Drops below 15% | Mostly removed by CompRess | Remains 40 to 60% after MKD or SEED |
| Defense Resistance | Weak under distillation | Similar weakness | survive distillation |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Li, G.; Zhang, Y.; Cao, Y.; Cao, M.; Xue, C. BASK: Backdoor Attack for Self-Supervised Encoders with Knowledge Distillation Survivability. Electronics 2025, 14, 2724. https://doi.org/10.3390/electronics14132724
Zhang Y, Li G, Zhang Y, Cao Y, Cao M, Xue C. BASK: Backdoor Attack for Self-Supervised Encoders with Knowledge Distillation Survivability. Electronics. 2025; 14(13):2724. https://doi.org/10.3390/electronics14132724
Chicago/Turabian StyleZhang, Yihong, Guojia Li, Yihui Zhang, Yan Cao, Mingyue Cao, and Chengyao Xue. 2025. "BASK: Backdoor Attack for Self-Supervised Encoders with Knowledge Distillation Survivability" Electronics 14, no. 13: 2724. https://doi.org/10.3390/electronics14132724
APA StyleZhang, Y., Li, G., Zhang, Y., Cao, Y., Cao, M., & Xue, C. (2025). BASK: Backdoor Attack for Self-Supervised Encoders with Knowledge Distillation Survivability. Electronics, 14(13), 2724. https://doi.org/10.3390/electronics14132724