1. Introduction
The rapid advancements in Artificial Intelligence (AI), especially in the field of Large Language Models (LLMs), have transformed the way complex problems are solved across various industries. Although they have achieved remarkable progress, LLMs still struggle with significant challenges, particularly their limited ability to handle domain-specific and long-tail knowledge, which includes less common yet industry-critical information essential for specialized applications. Key limitations include their susceptibility to hallucinations, inability to self-update, and reliance on memorized patterns from pre-training datasets [
1,
2]. These challenges highlight the need for more robust frameworks to manage and retrieve knowledge effectively in specialized contexts.
In modern automotive manufacturing settings, for instance, production planning often involves reviewing extensive technical documentation, sometimes hundreds of pages long, describing assembly line configurations, supplier requirements, and operational guidelines. Planners and engineers must carefully verify that each technical requirement is met: a process that can be both error-prone and time-consuming. Projects can span multiple years and rely on a mix of structured data (e.g., engineering databases) and unstructured content (e.g., PDF documents), leading to fragmented knowledge repositories. When new team members or departments take over, the lack of institutional memory and the scattering of domain-specific jargon across different sources further complicate efficient knowledge reuse. In this context, ensuring rapid access to accurate information is paramount, motivating the development of systems that can intelligently retrieve and integrate data from diverse domains [
3].
Retrieval-Augmented Generation (RAG) has emerged as a promising solution to extend LLMs’ capabilities by integrating external knowledge sources into the generation process [
4,
5]. However, traditional RAG systems frequently encounter limitations when queries require multi-hop reasoning or when crucial context is dispersed across multiple documents and data formats. To address these gaps, recent research has explored enhancing RAG systems with Knowledge Graphs (KGs). By structuring data into entities and relationships, KGs enable more precise retrieval and reasoning, making them particularly valuable for managing long-tail knowledge [
6,
7].
While some early efforts in integrating KGs with RAG systems show promise, systematic guidance on how to design and implement such systems remains limited [
8,
9]. Specifically, industrial environments require solutions that integrate smoothly with existing workflows and infrastructure. Developing fully featured ontologies for KGs can be time consuming, and even small delays in retrieving critical insights can hinder fast-paced operational decision making. This emphasizes the practicality of Document Knowledge Graphs (DKGs), which offer a more targeted, lighter-weight approach to structuring domain knowledge without immediately requiring comprehensive ontological modeling [
10]. Therefore, the presented solution leverages document structures combined with keyword-based linking to enhance RAG systems specifically within manufacturing environments.
To address the presented challenges, this study adopts a Design Science Research (DSR) methodology, which is particularly well suited for creating and evaluating innovative IT artifacts. DSR emphasizes iterative cycles of design, development, and evaluation to solve real-world problems and generate theoretical insights. By focusing on DKGs rather than fully expanded KGs, our approach aims to achieve a scalable solution that can be deployed and adapted within industrial settings with minimal reconfiguration. Following this methodology, this study is structured around three key research questions:
How to design a KG-enhanced LLM RAG system?
How to implement and instantiate a KG-enhanced LLM RAG system in an industrial setting?
How does the proposed system compare to a naive RAG system used as a baseline in an industrial setting?
The DSR process involves reviewing potential strategies for integrating KGs with RAG systems, developing and implementing a design artifact, and application of an evaluation framework to assess its performance. This structured approach ensures actionable insights for both theory and practice. By addressing gaps in integration design and implementation, this study advances knowledge in AI-driven solutions for domain-specific challenges while offering practical guidance for industrial applications.
The remainder of this paper is structured as follows:
Section 2 reviews related work on KG-enhanced RAG systems, establishing the foundation for the proposed approach.
Section 3 outlines the research methodology employed in this study.
Section 4 defines the design requirements that inform the system architecture, followed by
Section 5, which details the proposed system’s design.
Section 6 describes the implementation and evaluation setup.
Section 7 presents the evaluation results alongside a detailed analysis.
Section 8 discusses the findings, addresses limitations, and provides contextual insights. Finally,
Section 9 concludes the paper by summarizing key contributions and outlining directions for future research.
2. Related Work
2.1. Retrieval-Augmented Generation
RAG enhances LLMs by dynamically incorporating external knowledge into the generation process, addressing key limitations such as hallucinations and the inability to handle domain-specific, long-tail knowledge [
4,
11]. Unlike traditional LLMs that rely solely on parametric memory, RAG introduces a retrieval module that retrieves relevant documents from an external knowledge base, grounding the model’s responses in factual information. However, while naive RAG systems improve response accuracy, they often suffer from retrieval inefficiencies, semantic mismatches, and context fragmentation. To mitigate these issues, advanced retrieval and ranking techniques refine various stages of the pipeline, improving overall system performance. The structure of a naive RAG system is shown in
Figure 1.
A naive RAG system consists of three key stages: indexing, retrieval, and generation. In the indexing phase, raw text data are pre-processed, transformed into chunks, and embedded into a high-dimensional vector space using transformer-based models [
9,
12]. Data preprocessing is crucial, as it involves cleaning, handling different file formats such as PDFs and Markdown, and converting them into plain text [
9]. The chunking process, which breaks text into smaller, semantically coherent segments, significantly impacts retrieval effectiveness. The choice of chunking strategy is critical: larger chunks preserve more context but may introduce irrelevant information, whereas smaller chunks improve granularity at the cost of losing crucial context [
12,
13]. One common approach is adaptive chunking, which aligns splits with sentence or paragraph boundaries rather than arbitrary character limits [
9,
12]. Following chunking, embeddings are generated, capturing semantic meaning in a high-dimensional vector space [
4,
14]. The choice of embedding model significantly affects retrieval performance, with dense embeddings offering better semantic granularity at the cost of higher computational complexity, while sparse embeddings trade retrieval precision for efficiency [
4,
14,
15,
16].
The retrieval phase translates user queries into vector embeddings and retrieves the most semantically relevant chunks using similarity measures such as cosine similarity [
17]. Ensuring consistency in vector representation between indexed chunks and queries is crucial to retrieval accuracy [
9,
16]. The system retrieves the top-k chunks based on similarity scores, where k serves as a tuneable parameter that balances recall and precision [
9,
12]. However, naive retrieval often suffers from semantic mismatches, where lexically similar but contextually irrelevant chunks are retrieved [
18,
19,
20]. To mitigate this, advanced retrieval techniques refine chunk selection and ranking. Query rewriting dynamically reformulates user queries to improve alignment with indexed content, reducing ambiguity and increasing retrieval precision [
21]. Additionally, reranking methods reorder retrieved chunks by incorporating additional semantic and contextual relevance factors, ensuring that the most useful information is prioritized for generation [
9,
22]. More sophisticated hybrid retrieval models combine dense and sparse vector retrieval, balancing efficiency and accuracy by leveraging complementary strengths [
4,
16].
The generation phase integrates retrieved chunks into the LLMs prompt, allowing it to generate responses grounded in external knowledge while mitigating hallucinations [
4,
19]. A well-structured prompt ensures the model effectively leverages retrieved information by prioritizing contextual relevance and coherence [
11,
19,
23]. However, excessive or redundant chunks can lead to prompt overload, where irrelevant information dilutes response quality. Advanced context filtering techniques, such as passage scoring and chunk compression, optimize chunk selection to enhance response coherence [
23,
24]. Additionally, long-context models extend the window size for incorporating larger retrieved chunks while maintaining coherence [
25].
Despite these improvements, RAG systems still face challenges, particularly in multi-hop reasoning and semantic cohesion. Chunking disrupts document continuity, making it difficult for the model to synthesize information across multiple sources, particularly when complex reasoning is required [
25,
26,
27]. Embedding-based retrieval can lose fine-grained contextual links, reducing the system’s ability to trace and integrate knowledge across documents [
26,
28]. These limitations are especially problematic for knowledge-intensive tasks requiring multiple pieces of evidence to be combined into a coherent answer. Addressing these challenges requires advancements in hierarchical retrieval augmentation, better long-range coherence mechanisms, and multi-document fusion strategies to enhance knowledge synthesis and ensure reliable, high-quality responses [
25,
27].
2.2. Knowledge Graphs for Retrieval-Augmented Generation
KGs represent structured relationships between entities, capturing semantic information through interconnected nodes and edges [
6]. They originated from the Semantic Web vision, aiming to make information machine-processable by addressing issues of data heterogeneity and enabling structured knowledge representation [
29]. Each node in a KG represents an entity, such as a person, organization, or concept, while edges define the relationships between these entities. The structured nature of KGs facilitates advanced reasoning, making them valuable for various applications such as search, recommendation, and Question Answering (QA) [
30]. Unlike unstructured text or isolated vector embeddings, KGs explicitly encode semantic relationships, providing a robust framework for knowledge-intensive applications.
In recent years, research has explored the integration of KGs into RAG systems to enhance retrieval precision and facilitate multi-hop reasoning. While traditional RAG systems rely solely on vector-based similarity retrieval, KG-enhanced RAG systems leverage structured knowledge to improve semantic understanding and refine document retrieval. By explicitly encoding relationships between entities, KGs mitigate the fragmentation introduced by naive chunking in RAG, allowing models to retrieve contextually relevant information with higher accuracy [
8,
31]. Instead of retrieving passages based purely on lexical or embedding similarity, KG-enhanced RAG enables retrieval mechanisms that factor in explicit relationships, improving interpretability and accuracy in question-answering tasks. Beyond hybrid retrieval, recent research increasingly positions the KG as a reasoning framework or semantic routing layer. Emerging patterns include [
8,
32,
33]:
KG-as-index: entities serve as primary retrieval keys, later expanded with dense contextual information;
KG-guided chunking: structural signals within the KG inform how documents are segmented prior to embedding;
KG-constrained decoding: triples are used as hard or soft constraints to guide the generation process; and
KG-as-memory: newly generated triples are written back into the KG, supporting continual knowledge refinement.
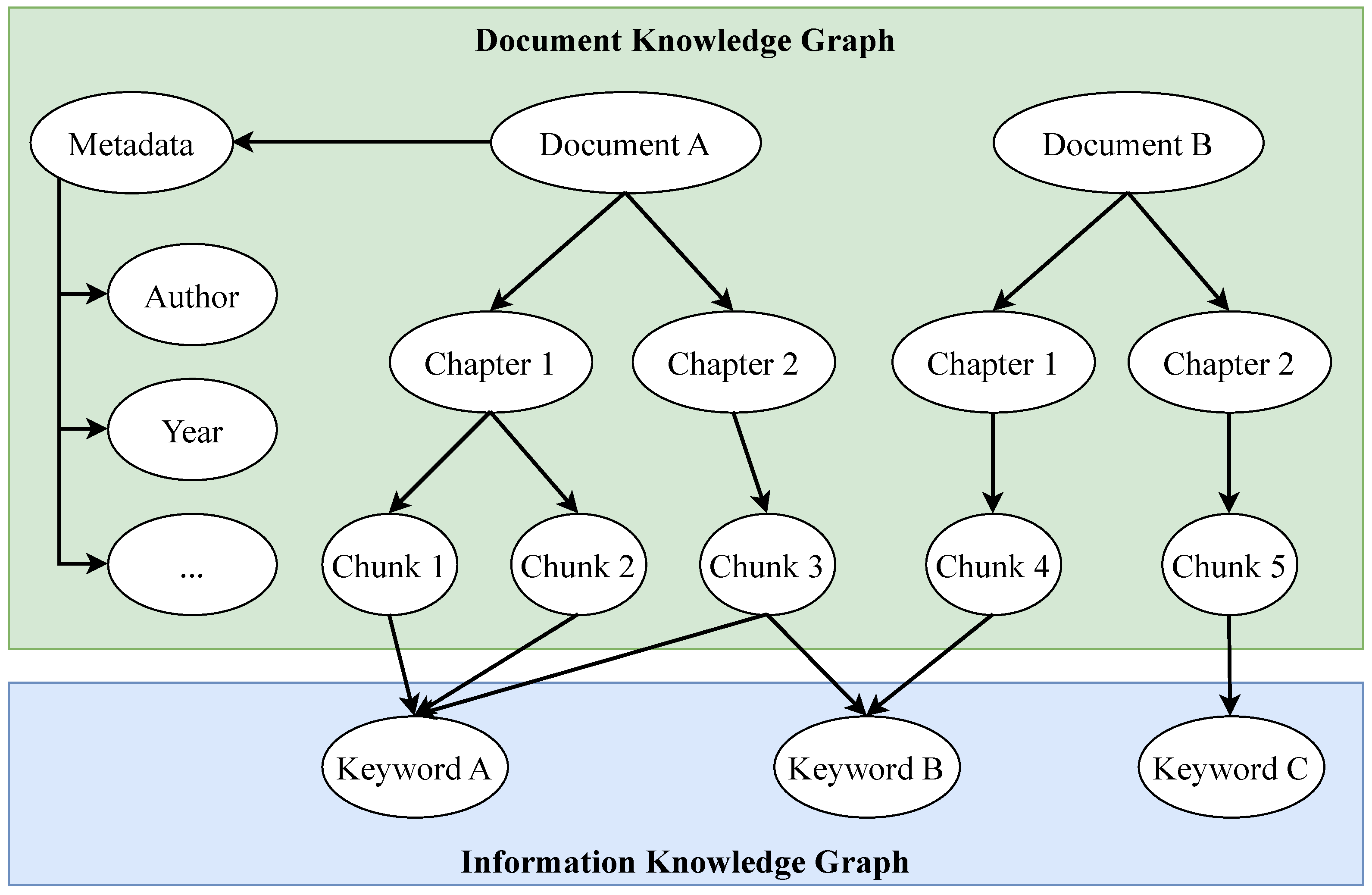
Within the pattern KGs-as-index for RAG, the structure of the graph can be broadly categorized into Information Knowledge Graphs (IKGs) and DKGs, each serving distinct purposes [
10]. IKGs focus on representing extensive domain knowledge using detailed ontologies, supporting deep reasoning and inference capabilities [
34,
35]. These graphs model complex interdependencies between entities, making them well suited for applications requiring semantic search and intelligent decision making [
36]. However, constructing IKGs is often labor intensive, requiring extensive domain expertise and manual effort to define detailed ontologies [
37]. As a result, while IKGs offer powerful reasoning capabilities, their complexity makes them challenging to integrate into practical RAG systems within special domains.
In contrast, DKGs organize knowledge at the document level, structuring relationships between document elements rather than broad domain-wide entities. This approach is particularly relevant for RAG systems, as DKGs optimize document retrieval by encoding metadata, inter-document relationships, and contextual linkages, improving search efficiency and retrieval accuracy [
10]. Unlike IKGs, DKGs require less ontology development, making them a more scalable and practical solution for RAG integration.
Figure 2 illustrates the differences between an IKG and a DKG. The IKG represents domain-wide entities and relationships, enabling semantic reasoning, while the DKG structures document-level relationships to enhance retrieval in RAG systems.
In specialized domains such as manufacturing, source materials span standards, patents, and maintenance logs across multiple languages and dialects. Constructing a unified Knowledge Graph (KG) in this context inherits the core challenges of Multilingual Large Language Models (MLLMs), including data sparsity, script diversity, and cross-lingual entity alignment. A recent survey on MLLMs [
38] identifies two challenges that directly translate to KG construction:
Data quality and diversity: high-resource languages dominate training corpora, leaving low-resource manufacturing languages underrepresented;
Cross-lingual knowledge transfer: factual consistency declines when identical queries are issued in different languages, indicating that multilingual entity linking must explicitly propagate facts, often originating in English, across languages.
Existing KG-enhanced RAG approaches differ considerably in their graph construction strategies and retrieval mechanisms. The method proposed in [
32] emphasizes LLM-based extraction of entities and relations to build an IKG. However, retrieval in this case is limited to the IKG layer and lacks integration with vector-based methods. A more hybrid strategy is seen in [
39], where IKG-based retrieval is extended by incorporating parallel vector search, improving flexibility in capturing semantic relevance. Similarly, ref. [
33] enhances IKG construction through the use of document structure for better entity extraction and linking but does not leverage structural information during retrieval.
In contrast, ref. [
40] employs a DKG by connecting documents via existing hyperlinks or citations, yet it omits the use of an IKG, potentially limiting semantic granularity in intra-document relations. The work in [
41] combines both DKG and IKG elements but is constrained by its reliance on highly structured PDF documents with a table of contents, limiting applicability in real-world scenarios where unstructured or semi-structured formats dominate. Furthermore, the use of the KG during retrieval lacks detailed description.
Some KG-enhanced RAG systems target domain-specific applications. For example, ref. [
42] addresses customer service, while [
43] focuses on Failure Mode and Effects Analysis (FMEA), a relevant use case in manufacturing. The latter leverages semi-structured input to extract domain-specific relations, such as cause–effectlinks, enriching the IKG with task-specific semantics. Lastly, ref. [
44] shifts focus from graph construction to graph traversal, exploring various path-finding strategies for improved retrieval. While methodologically valuable, this work assumes a pre-constructed graph and does not address the challenges of graph formation in complex domains.
Despite recent progress in KG-enhanced RAG systems, existing research lacks a systematic approach to designing knowledge graphs specifically tailored for document-based QA. Most prior work emphasizes entity-centric IKGs, which are effective in structured domains but are not well suited for retrieval tasks involving complex, unstructured documents. Moreover, constructing high-quality IKGs in specialized domains remains largely manual and time consuming, as current automated approaches still struggle with precision [
8,
45]. To address these limitations, this work introduces a DKG-driven retrieval framework complemented by a lightweight, automatically constructed IKG component. The proposed solution is designed to enhance document-level question answering by combining structured document representation with retrieval-augmented generation.
Complementary to graph-centric methods, other approaches focus on integrating diverse knowledge sources to dynamically adapt the retrieval pipeline. For instance, the recently proposed
Collaborative Legal Expert (CoLE) framework decomposes legal reasoning into four prompt-based stages: Query-Intent Identification, Domain-Knowledge Encoding, Best-Demonstration Retrieval, and Prompt Generation. It demonstrates substantial improvements in reasoning performance without requiring additional model fine-tuning [
46]. CoLE’s modular design is orthogonal to, and potentially compatible with, graph-based RAG frameworks.
2.3. Integration in Industrial Context
The manufacturing industry is undergoing significant transformation due to the increasing complexity of production processes and the growing volume of unstructured information that must be efficiently managed. A key challenge in this domain is the fragmentation of knowledge across multiple systems and documents, often stored in heterogeneous formats such as PDFs [
3,
30,
47]. This lack of centralized and structured access to information hinders operational efficiency, decision making, and the reuse of critical knowledge [
36,
48]. To address these issues, manufacturers are focusing on improving the accessibility and retrieval of domain-specific information, particularly in factory planning and production operations [
10]. Planners and engineers frequently engage in QA tasks, where retrieving precise information from scattered technical documents is essential [
3,
30]. Similarly, comparing existing knowledge on specific topics requires consolidating information from multiple sources while ensuring traceability and accuracy [
30,
49]. These challenges emphasize the need for advanced IT solutions capable of efficiently handling vast amounts of unstructured data and enhancing knowledge retrieval processes.
The integration of RAG and KGs offers a strategic opportunity to enhance knowledge utilization in manufacturing environments. RAG systems improve information retrieval by dynamically extracting relevant content from large-scale repositories. For instance, a manufacturing-specific RAG architecture designed for Manufacturing Execution System environments has been introduced, enabling real-time data processing [
50]. While this approach effectively leverages structured data, the integration of domain-specific document knowledge into RAG systems remains an open challenge.
Despite their advantages, RAG systems are inherently constrained by retrieval quality, often yielding incomplete or noisy results, which in turn reduces the accuracy of generated responses [
18,
51,
52]. KGs, in contrast, offer a structured representation of knowledge, organizing entities and relationships to enable precise, multi-hop reasoning over complex information [
6,
30].
For retrieving information from internal technical documents, RAG systems can index and retrieve data efficiently but struggle with semantic integrity and cross-document reasoning [
10,
23,
28]. KGs enhance retrieval by structuring document relationships and supporting logical inference across multiple sources. This structured approach mitigates inconsistencies in retrieval but incurs higher computational costs [
30]. Ensuring grounded responses from relevant sources requires adapting RAG systems to improve retrieval accuracy and document alignment [
11,
23,
53].
From an operational perspective, both technologies present integration challenges. RAG systems need refinements beyond naive implementations to improve retrieval precision [
22,
52], whereas KGs require automation in knowledge extraction and graph construction to be effectively utilized in production environments [
30,
47]. Addressing these challenges is crucial for achieving a cost-efficient and scalable knowledge retrieval solution in manufacturing.
3. Research Methodology
This study follows a DSR methodology to develop and evaluate a KG-enhanced RAG system within an industrial manufacturing setting. Given the complexity of LLM, RAG, and KGs—technologies with relatively low solution maturity—the structured, iterative nature of DSR provides a systematic framework to address both theoretical and practical challenges.
The chosen research approach follows an echelon-based DSR methodology [
54], which decomposes the research process into logically structured and self-contained phases. Each phase—Problem Identification, Design Requirements, Solution Design, Demonstration, and Evaluation—contributes to the incremental development and validation of the artifact. This stepwise approach ensures theoretical rigor and practical applicability by incorporating targeted validation at each stage. Through iterative refinements and empirical validation, this study aims to derive actionable design knowledge that enhances the integration of KG-enhanced RAG systems in industrial contexts.
3.1. Problem Identification
The first phase of DSR establishes the core problem by aligning theoretical foundations with the industrial context [
55,
56]. In this work, the identified and motivated problem can be stated as follows:
In manufacturing environments, the fragmentation of domain-specific knowledge across various systems and documents impedes efficient decision making and hinders the reuse of critical information.
Existing RAG systems struggle with domain-specific and long-tail knowledge, limiting their effectiveness. KGs enhance retrieval and reasoning in RAG but pose significant challenges when integrating them into complex industrial environments. This problem statement underscores the inadequacy of current solutions and highlights the necessity of a KG-enhanced RAG system to overcome these limitations.
This phase ensures theoretical grounding and practical relevance by systematically defining the problem [
54,
57,
58]. The validated problem statement guides the design, development, and evaluation of an artifact tailored to both academic and industrial needs.
3.2. Design Requirements
Building on the validated problem statement, this DSR phase translates the identified challenges into concrete design objectives for a KG-enhanced RAG system. The goal is to establish actionable requirements that ensure alignment between the artifact and the industrial challenges [
54,
57,
58].
To derive these objectives, a literature review was conducted, systematically exploring the intersection of LLMs, RAG, and KGs. This review identified feasible integration strategies and technological synergies to construct an effective KG-enhanced RAG artifact. By synthesizing the SLR findings, key design principles were extracted, directly addressing the challenges outlined in the problem statement.
The resulting design objectives (c.f.
Section 4) were further validated through a focus group consisting of experts from the automotive industry. Their insights ensured the technical feasibility and industrial applicability of the proposed solution. This structured approach guarantees that the artifact is grounded in both theoretical insights and practical constraints, forming a solid foundation for the subsequent design and development phases.
3.3. Solution Design
Based on the validated design objectives, the research progressed into the design and development phase, focusing on the creation of an architectural model for the KG-enhanced RAG artifact. This model serves as a structured blueprint, defining the functional and structural components necessary to achieve the specified design objectives [
54]. Each component was deliberately designed to address the identified challenges, ensuring a cohesive and purpose-driven solution.
The architectural model (c.f.
Section 5) was developed iteratively, incorporating insights, logical reasoning, and the literature to refine interactions between LLM, RAG, and KG components. A key aspect of this process was enhancing the retrieval algorithm of the naive RAG system by leveraging structured knowledge from KGs. Additionally, industrial utility was improved by incorporating mechanisms such as chain-of-reasoning at the LLM output, ensuring greater transparency and reliability in decision making.
To ensure alignment with practical requirements, the model was validated by the same focus group involved in the previous phase. Special attention was given to scalability and flexibility, enabling seamless integration into existing systems in industrial settings while maintaining adaptability to future technological advancements. This structured design approach ensures that the developed artifact remains both theoretically robust and practically viable for industrial deployment.
3.4. Demonstration
The demonstration phase involved the practical implementation of the validated architectural model to assess its effectiveness in an industrial context [
54,
57]. Following a case study approach, the artifact was applied to a real-world problem at a production planning department in the automotive industry, providing concrete evidence of its utility.
To ensure a controlled yet realistic validation, the artifact was instantiated in a simulated environment that closely mirrors real-world conditions within the industry (c.f.
Section 6). Each iteration of the case study systematically assessed the artifact’s performance across various evaluation dimensions, focusing on improving retrieval quality. Particular attention was given to enhancing the performance of the artifact compared to the naive RAG system, which served as the baseline.
Through iterative refinements, the demonstration phase validated the artifact’s technical feasibility and its potential impact in an industrial setting. The insights gained from this process informed the subsequent evaluation phase, ensuring a rigorous assessment of the artifact’s real-world applicability and effectiveness.
3.5. Evaluation
The final phase of the DSR process involves the rigorous evaluation of the instantiated artifact to assess its effectiveness in addressing the identified problem. This step ensures that the artifact is both theoretically sound and practically applicable in an industrial setting [
57,
58].
The evaluation focuses on effectiveness as the primary validation criterion, measuring the artifact’s success in solving the intended problem and outperforming the naive RAG baseline. A formative evaluation approach was applied, iteratively testing different instantiations of the artifact (c.f.
Section 6). This method enables empirical feedback to refine the solution design, ensuring it meets the defined design objectives [
54,
55].
A comparative analysis was conducted, systematically assessing the artifact against the naive RAG system using the identified evaluation dimensions. The outcome of this phase is a validated Proof-of-Value (PoV), demonstrating the practical benefits of the KG-enhanced RAG system. These findings provide a solid foundation for broader implementation within industrial settings.
4. Design Requirements
Design requirements represent the second phase of the DSR approach, building on the problem identified in Phase 1 (c.f.
Section 3.1). This chapter presents the results of this phase, addressing the research questions. Following the DSR methodology, the chapter outlines the key design requirements derived from the literature, which highlight the limitations of current RAG systems and define the essential capabilities needed to overcome these challenges. These requirements define the essential capabilities an artifact must possess to overcome existing challenges.
To ensure both theoretical grounding and industrial relevance, the identified design objectives underwent validation through a focus group consisting of industry experts from an automotive factory planning division. These experts assessed the objectives based on their feasibility, relevance, and alignment with real-world manufacturing challenges. Their feedback refined the requirements, ensuring coherence with theoretical foundations while maintaining practical applicability.
The following sub-chapters present the validated design requirements D1–D4 in detail, outlining the specific challenges and considerations that guided the development of the KG-enhanced RAG system.
4.1. Retrieval Accuracy (D1)
To enhance retrieval accuracy in domain-specific RAG systems, researchers propose leveraging KGs to capture semantic and structural relationships within documents [
59]. By integrating these relationships, relevant information can be more effectively identified and prioritized, addressing a key limitation of existing RAG approaches [
7,
10,
60,
61].
Semantic relationships can be established by linking keyword-related connections between chunks across different documents, enabling more contextually relevant retrieval. Additionally, structural relationships between chunks, even within the same document, are often lost in current RAG implementations. Restoring these connections allows for supplementary retrieval from related passages, improving contextual integrity [
7,
10,
60].
Thus, the objective is to exploit both structural and semantic relationships in and between documents, enabling advanced search strategies within a KG. This extension of RAG is expected to significantly enhance retrieval accuracy [
7,
10,
60,
61].
4.2. Multi-Hop Questions-Answering (D2)
Existing RAG systems struggle to provide complete and accurate responses in multi-hop QA scenarios, where answers are distributed across multiple documents and sections [
23,
26,
28]. To address this limitation, the design objective focuses on improving context integration across multiple sources, enabling more advanced reasoning [
7,
10,
62].
A key requirement for enhancing multi-hop QA is enabling multiple retrievals from the KG, where each retrieval builds upon prior results in an informed manner [
10,
60]. Additionally, the KG must be structured so that nodes are meaningfully connected, ensuring that edges reflect semantic proximity and shared concepts [
7].
By improving multi-hop QA capabilities, the RAG system can generate more comprehensive and accurate responses to complex queries, enhancing its effectiveness for advanced, reasoning-intensive applications [
26].
4.3. Error Mitigation (D3)
Preventing retrieval errors is crucial in RAG systems, as incorrect information can propagate through the pipeline, leading to misleading outputs. This issue is particularly critical in domain-specific applications, where answer reliability is essential. Implementing mechanisms to detect and correct errors at intermediate stages enhances both accuracy and trustworthiness [
11,
22,
24].
To mitigate retrieval errors, various strategies can be employed, such as intermediate validation steps, self-critique mechanisms, or filtering approaches [
60,
61]. By integrating such techniques, the system can reduce noise in retrieval, preventing the LLM from generating unreliable responses. This ensures a more robust and dependable RAG system, particularly for industrial use cases requiring high information precision.
4.4. Document Knowledge Management (D4)
In RAG systems, the document structure and contextual relationships between chunks are lost after embedding, making it difficult to maintain coherence during retrieval [
7,
10]. However, preserving document structure is essential for intelligent retrieval, as it allows the system to leverage metadata such as publication year, author, and hierarchical organization, including chapters and sections [
10,
61].
Representing document structures as nodes in a KG enables retrieval based on structural elements, allowing targeted searches within specific chapters or sections. Additionally, metadata can refine search precision, provided they are properly stored and utilized during retrieval [
7,
61].
By integrating document structures and metadata, the system can prioritize and filter chunks more effectively, improving retrieval relevance and enabling more sophisticated queries. To meet this requirement, the system must incorporate robust document knowledge management capabilities [
7,
10].
5. Solution Design
Building on the design objectives established earlier, this section introduces the architectural model for integrating KGs into RAG systems. While the design objectives define the goals for a successful integration, the architecture provides a structured blueprint to achieve these goals, detailing the necessary structural and functional components [
54].
An overview of the developed architectural model is shown in
Figure 3. The solution follows the three core RAG phases: indexing, retrieval, and generation.
The process begins with document processing, preparing documents for indexing within both the vector and graph databases. Once indexed, the RAG system can handle queries for QA tasks. The retrieval phase selects the most relevant information from both databases, ensuring an optimized input for the final generation phase, which synthesizes the answer. The following sections provide a detailed explanation of each phase.
The architectural model also references relevant key components to the described design objectives (D1–D4). To ensure the architectural model meets practical and technical requirements in automotive production, a two-stage validation was conducted. First, three focus group sessions with domain experts evaluated the design decisions, leading to refinements in key aspects such as search strategies within the DKG. Second, simulations tested the model’s feasibility and consistency through iterative instantiations in real-world scenarios, identifying and resolving issues related to graph construction. These validation steps ensured that the architecture effectively supports QA tasks in factory planning while aligning with the defined design objectives.
5.1. Creation of the Knowledge Graph
The indexing process begins with documents as the primary data source, including technical manuals, tenders, and reports. These documents often contain complex, unstructured information, making retrieval challenging. To address this, the text extraction component identifies and preserves structural elements such as chapters, sections, and tables, ensuring contextual integrity (D4). Efficiency and scalability are critical considerations when selecting the extractor, as a slow process can become a system bottleneck. The extracted output includes the document’s hierarchical structure and metadata, such as the author and publication year, with the option to store additional production-related information.
The chunking process extends a standard RAG system by producing a structured chunk corpus that retains the hierarchical organization of the input document. It builds on the document structure identified during text extraction, ensuring that each chunk remains semantically coherent and aligned with logical section boundaries. By avoiding chunk boundaries that span across different subchapters, the retrieval performance is optimized, as the inclusion of disjointed content within a single chunk can negatively impact semantic understanding [
63]. Each chunk is assigned a Unique Resource Identifier (URI), enabling it to be traced back to its original position within the document. This guarantees that, while the text is segmented for retrieval and embedding, its structural and contextual relationships remain intact, supporting intelligent and context-aware querying (D1, D4).
As illustrated in
Figure 3, the chunk corpus serves two primary purposes. First, embeddings are generated from the chunks and stored in a vector database, following the standard procedure of a naive RAG system. Second, a KG is constructed from the same corpus (D1, D2, D4), leveraging the extracted structural information without the need for manual annotation or human refinement during graph creation. The structure of the indexed graph is illustrated in
Figure 4.
The upper section of
Figure 4 illustrates the hierarchically structured DKG derived from the generated chunk corpus. As shown, metadata are linked to each document node to support enhanced retrieval. The document structure is modeled as a tree-like graph, hierarchically organized into chapters and nested sub-chapters (lower-level nodes are omitted from the illustration for clarity).The DKG terminates at the chunk level, where each chunk is assigned a unique URI, which is also stored in the vector database to maintain a consistent link between both databases. Since this process involves transforming the structured chunk corpus into a graph representation using predefined rules and algorithms, the construction of the DKG is computationally efficient and does not require additional models or training.
To further optimize retrieval, an IKG layer is created during the indexing phase. In this step, relevant keywords are extracted at the chunk level and stored within the graph structure. This enables deeper semantic insights into the indexed documents, as chunks from different chapters or documents can be interlinked via shared keywords. Since this layer directly influences retrieval performance, the number of extracted keywords must be carefully selected to prevent unnecessarily long retrieval times. Keyword extraction can be performed using algorithmic methods that offer fast processing without requiring external models or training. Alternatively, LLMs can be applied to extract domain-specific and contextually nuanced keywords, supported by prompt engineering techniques.
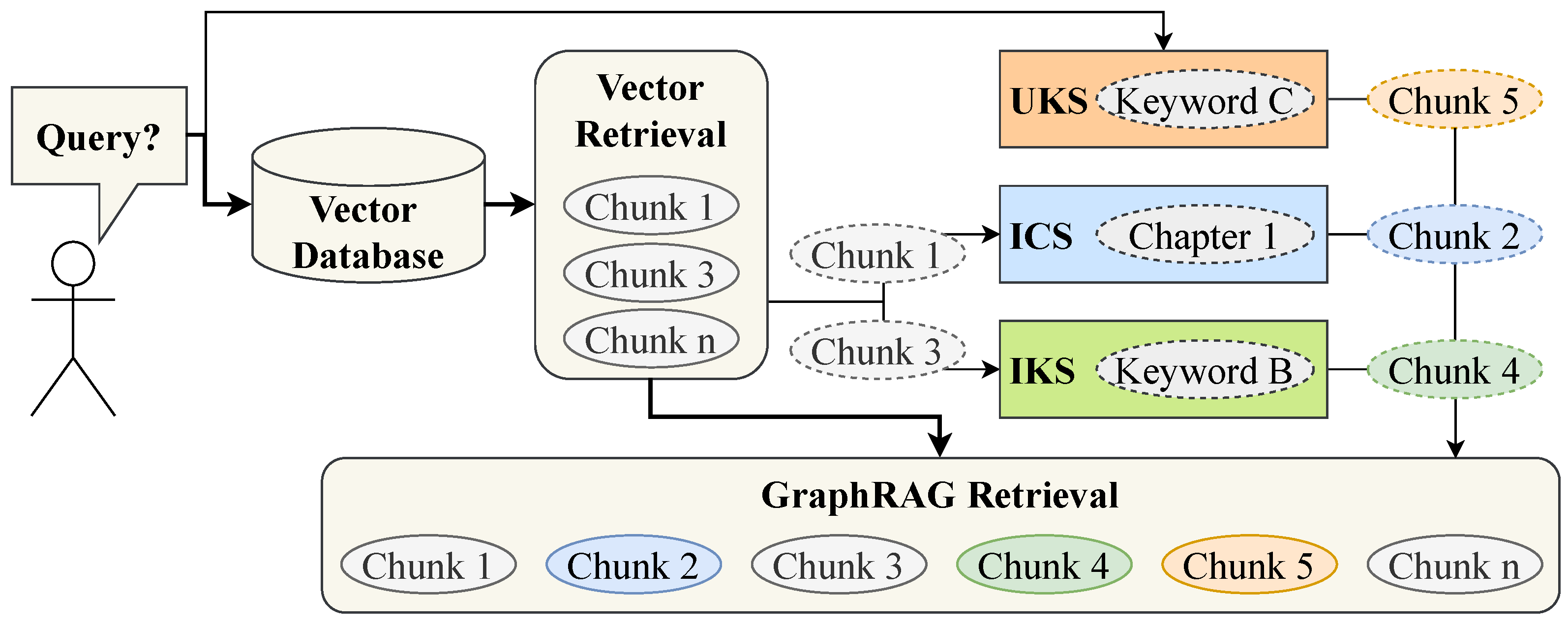
5.2. Retrieval Algorithms
This subsection addresses the retrieval phase of the RAG pipeline, highlighted in orange in
Figure 3. The process begins with a user query and returns a ranked list of relevant chunks to support response generation. By leveraging the URI-based linking between the vector and graph databases, multiple retrieval strategies can be implemented. This work introduces three distinct graph-based retrieval approaches, each of which is described in the following sections, along with the reranking method employed to optimize retrieval performance (D1, D3).
The corresponding pipelines for the three graph-based retrieval strategies are illustrated in
Figure 5, with the retrieval operations based on the underlying graph structure shown in
Figure 4.
The first retrieval strategy,
Informed Chapter Search (ICS), is shown in blue within
Figure 5. It leverages both the vector and graph databases for optimized retrieval, focusing solely on the DKG component of the KG. ICS begins with a standard RAG retrieval, where the query is embedded, and the top-k most similar chunks are retrieved from the vector database. These initial chunks serve as the starting point for ICS. Subsequently, for each retrieved chunk, all other chunks within the same chapter are also retrieved using the DKG. This approach is based on the premise that relevant content is often concentrated within the same chapter, particularly in technical documents, where chapters provide a structured organization of information.
ICS enhances retrieval by filtering the DKG based on the initial vector search results, ensuring structural retrieval (D1, D2) while improving efficiency and relevance (D3). In the DKG representation within
Figure 4, if
Chunk 1 appears in the top-k initial results, ICS would automatically retrieve
Chunk 2 as part of the same
Chapter 1, as shown in
Figure 5, demonstrating its ability to expand retrieval while maintaining structural coherence.
The second retrieval strategy,
Informed Keyword Search (IKS), builds upon the initial vector search while leveraging both the DKG and the IKG layer. It is shown in green within
Figure 5. Similar to ICS, IKS begins by retrieving the top-k most relevant chunks from the vector database. For each retrieved chunk, all associated keywords are extracted from the KG, and subsequently, all chunks linked to these keywords are included in the graph retrieval set.
IKS enhances naive RAG retrieval by incorporating domain-specific keywords to refine search results. In manufacturing contexts, texts often contain specialized terminology, which can be effectively utilized to improve retrieval accuracy. As illustrated in
Figure 3, IKS applies a filtering mechanism (D3) within the graph search, followed by keyword-based retrieval (D1, D2). For example, in the KG representation in
Figure 4, if
Chunk 3 appears in the top-k initial results, IKS would also retrieve
Chunk 4, as both share
Keyword B, as shown within
Figure 5. This approach enables inter-document connections within the KG, enhancing retrieval by linking related content across multiple documents.
The third retrieval strategy,
Uninformed Keyword Search (UKS), introduces an additional retrieval pathway that operates in parallel with vector-based retrieval, expanding the initial set of retrieved chunks. It is shown in orange within
Figure 5. In this approach, keywords are extracted directly from the user query and used to retrieve all associated chunks from the KG. These retrieved chunks are then incorporated into the initial results for subsequent ICS and IKS retrieval steps. Similar to IKS, UKS leverages domain-specific terminology to enhance retrieval performance. For example, with reference to the graph in
Figure 4, if
Keyword C is extracted from the query,
Chunk 5 would be included in the initial retrieval set, as displayed in
Figure 5.
The proposed Document GraphRAG (GraphRAG) framework integrates the three retrieval strategies introduced earlier. After combining the chunks from both initial vector-based retrieval and graph-based retrieval, two post-processing steps are required before passing the results to the generation phase. First, deduplication is performed to ensure that each chunk appears only once, as multiple retrieval strategies may return overlapping results. Next, reranking is applied to prioritize the most relevant chunks for answering the user query. This step is essential, as the GraphRAG approach can significantly expand the number of retrieved chunks, necessitating an effective ranking mechanism.
These post-processing steps enhance retrieval accuracy and efficiency (D1, D3), resulting in a reranked list of chunks that serves as the input for the generation phase.
5.3. Answer Generation
The final step of the solution design focuses on generating accurate and contextually grounded answers to user queries (D3). Before leveraging an LLM for answer generation, two preparatory steps are required: applying pass conditions to select relevant chunks and constructing an effective prompt.
First, pass conditions determine how many top-k reranked chunks are forwarded to the LLM, ensuring that it processes only the most relevant information while preventing overload, which could otherwise reduce answer accuracy.
Once the relevant chunks have been retrieved and selected, prompt engineering is applied to structure the input effectively, ensuring that the LLM generates coherent, contextually relevant, and factually grounded responses. To address the specific requirements of the manufacturing domain, the prompt was refined in collaboration with domain experts, with the final version provided in
Appendix A.
This approach ensures that the LLM produces responses that remain faithful to the retrieved content, incorporating direct citations from the selected chunks (D3). Accordingly, the prompt is designed to include the user query, the retrieved chunks, and explicit instructions, such as enforcing source citations and requiring the model to indicate when sufficient information is unavailable.
With these pass conditions and structured prompt, the LLM generates the final response, ensuring that the output remains contextually accurate, relevant, and traceable to the retrieved sources.
6. Demonstration and Evaluation Setup
This section corresponds to the fourth and fifth phases of the DSR approach. To assess its effectiveness in an industrial context, the proposed architectural model is implemented and evaluated within a structured evaluation framework, ensuring its practical applicability in real-world scenarios. The chapter begins with a detailed technical implementation of the proposed architecture, followed by a description of the datasets used for evaluation and the evaluation strategy employed. Finally, the chapter concludes with an overview of the evaluation metrics used to assess the system’s performance.
6.1. Technical Implementation
This chapter provides an overview of the technology stack used to implement the proposed architectural model. The key components are described along the processing pipeline shown in
Figure 3. The implementation is designed as an initial demonstration of the architecture, with a primary focus on evaluating the quality of the generated answers rather than optimizing system performance in terms of latency or computational efficiency. To support modular development and ensure transparency during evaluation, JavaScript Object Notation (JSON) files are used for data transfer between pipeline components. For example, intermediate outputs are stored as files after the retrieval, reranking, and generation stages.
The overall implementation was developed using Python Version 3.10 and executed on a standard office notebook without the use of specialized hardware. For the integration of AI components, including text extraction, LLMs, and embeddings, Amazon Web Services (AWS) cloud services were utilized. These components were accessed via Application Programming Interface (API) calls from the local implementation, enabling the use of scalable cloud-based models within the otherwise locally run pipeline.
In the indexing phase,
AWS Textract [
64] was utilized to extract text in markdown format while preserving the structural layout of the original documents. Although AWS Textract is sufficient for this proof of concept, the pipeline remains extractor-agnostic: any engine capable of outputting text, token positions, and reading order in JSON format can be integrated. More advanced layout-aware multimodal Transformers, such as LayoutLMv3 [
65] or the earlier LAMBERT architecture [
66], offer the potential to more tightly integrate visual and textual cues. These models could provide richer structural signals, which in turn could inform more expressive edge construction within the downstream DKG. This OCR-based service offers high flexibility for processing the diverse data formats typically found in the manufacturing domain. The extracted content, provided on a page-wise basis, is post-processed to retain only high-confidence elements and subsequently merged into complete documents. Converting the output to markdown enables effective capture of the hierarchical structure, comprising headings and corresponding numbering, thus facilitating the identification of chapters and sections. To ensure the robustness of the extracted hierarchy, several back-off algorithms are applied to validate and refine the structural integrity based on the detected heading levels and numbering schemes. This guarantees a consistent and semantically useful input for the subsequent processing steps. The evaluation of such layout-aware extractors and the analysis of how geometry-aware structural links influence retrieval accuracy are left for future work (see
Section 9).
The chunking process was carried out using
LangChain’s Character Text Splitter [
67]. The chunk size was determined based on the evaluation setup, as described in the following section. No overlap between chunks was applied, and splitting was configured to occur at paragraph or sentence boundaries to preserve semantic coherence.
Embeddings were generated using
AWS Titan [
68] and stored in a locally hosted
Chroma vector database [
69], which was configured to compute vector similarity using cosine distance. In parallel, the KG was constructed according to the
RDF standard [
70] and stored in a locally running
GraphDB instance [
71], following the structural model illustrated in
Figure 4.
Keyword extraction was conducted using the
YAKE algorithm [
72] to enhance retrieval performance within the RAG system. The process was executed locally, with the language parameter set according to the respective dataset. YAKE was configured to extract unigrams and bigrams, applying a deduplication threshold of 0.8 to avoid nearly identical keywords. An algorithmic approach was chosen to ensure a standardized and reproducible evaluation. The extraction parameters were fine-tuned in collaboration with the focus group to optimize domain relevance and retrieval quality.
Section 5.1 discusses LLM-based, domain-specific keyword extraction as a potential alternative, offering highly specific and context-aware keywords at the cost of greater computational resources and integration effort. To explore this option, initial tests were conducted using LLM-extracted keywords, based on the prompt provided in
Appendix B.
Anthropic’s Claude 3 Haiku [
73] was employed via
AWS Bedrock [
74], selected for its lower computational demands, faster response times, and cost efficiency. Its capabilities make it well suited for simpler tasks like keyword extraction, which require less reasoning than answer generation.
During the retrieval phase, embeddings and keywords are generated in alignment with the indexing phase to ensure consistency. The graph search algorithms utilize SPARQL Protocol and RDF Query Language (SPARQL) queries to retrieve relevant information from the RDF graph.
In the deduplication module, URIs are used to ensure that each chunk appears only once in the retrieval results. Reranking was implemented using an LLM, which was prompted to assign a relevance score between one and ten to each chunk based on its relevance to the user query. To enhance interpretability, the LLM was also instructed to provide a justification for each score, enabling the system to leverage the model’s reasoning capabilities. The prompt used for reranking is provided in
Appendix C.
For LLM-based reranking, again Anthropic’s Claude 3 Haiku was used due to the complexity of the task. The implementation includes a verification step that checks the LLM’s output, and if results are missing or unprocessable, the reranking task is automatically repeated to ensure a complete and valid score is assigned to each chunk.
During the generation phase,
Claude Sonnet 3.5 [
75] was selected for answer generation, as this task requires advanced reasoning capabilities and contextual synthesis. The corresponding prompt template, as provided in
Appendix A, was used to guide the model. To support structured prompt construction and manage LLM interaction, the
LangChain framework [
76] was employed, facilitating efficient and consistent execution.
6.2. Evaluation Process
The evaluation process represents the final phase of the DSR approach, where the performance of the instantiated artifact is systematically assessed. The following subsections introduce the datasets used for evaluation, followed by the evaluation dimensions and metrics.
To benchmark the performance of the GraphRAG system, it is compared against a naive RAG system (c.f.
Figure 1). The naive system was instantiated in parallel with GraphRAG, maintaining a similar technical implementation to ensure a fair comparison.
To benchmark the performance of the GraphRAG system, we compared it against a naive RAG baseline, as shown in
Figure 1. The naive RAG system was implemented in parallel with GraphRAG, using a comparable technical architecture to ensure a fair and consistent evaluation. In current industrial manufacturing environments, naive RAG systems represent the predominant architecture for QA applications. This context motivated the selection of the benchmark, enabling an initial assessment of GraphRAG’s effectiveness in addressing the challenges identified through the DSR process, while also highlighting its technical feasibility and potential for immediate industrial impact.
The GraphRAG system incorporates several tunable parameters, providing data-driven insights into its performance. For evaluation purposes, the following parameters and their impact on retrieval effectiveness are analyzed:
Since these parameters primarily influence the retrieval phase of the RAG process, their evaluation aligns with the core objective of GraphRAG, which is to enhance retrieval performance in an industrial context.
Given the large number of potential parameter variations, a strategic evaluation approach was adopted to ensure efficient use of computational resources. Standard values for each parameter were determined based on related work, preliminary experiments, and expert insights. This led to the definition of a standard GraphRAG pipeline, which serves as the baseline configuration for comparison with the naive RAG system.
To systematically assess the impact of each parameter, isolated adjustments were performed to measure their influence on system performance. Since all parameters are quantifiable on a linear scale, their values were both increased and decreased to observe corresponding effects. Furthermore, for parameters applicable to both GraphRAG and the naive RAG setup (e.g., chunk size), evaluations were conducted for both configurations to ensure a direct and fair comparison.
This methodology facilitates comparisons not only with the standard GraphRAG pipeline but also against a naive baseline with equivalent parameter adjustments, providing a comprehensive analysis of parameter sensitivity and system behavior.
Furthermore, initial tests evaluating the performance of LLM-extracted keywords were conducted on the manufacturing domain-specific dataset to provide a preliminary assessment of this alternative approach. As with the algorithmic extraction, the evaluation was performed against the standard parameter settings to ensure comparability of results.
This evaluation strategy maximizes insights into the performance trade-offs of the GraphRAG approach, ensuring an optimal balance between depth of analysis and resource efficiency, a crucial factor in fast-paced domains such as RAG.
6.3. Datasets for Evaluation
To demonstrate the performance of the GraphRAG system, it is essential to utilize suitable datasets. This study focuses on applying RAG in the manufacturing domain. To the best of our knowledge, no publicly available dataset exists for evaluating RAG performance in this domain, particularly for German-language, automotive-specific content.
To address this gap, we constructed a proprietary, domain-specific dataset containing internal information from an automotive manufacturer. The dataset creation process is presented later within this section. While this approach ensures high domain relevance, it also imposes limitations on dataset publication due to confidentiality constraints.
To mitigate this limitation, parallel evaluations are conducted using established open-domain QA datasets for RAG benchmarking. This approach ensures both traceable evaluation results and demonstrates the generalizability of the proposed GraphRAG framework. As outlined in [
77], open-domain datasets include different question types. To ensure robust and comprehensive evaluation results, the selected datasets contain a diverse set of question types, facilitating a balanced assessment of retrieval and reasoning capabilities.
For single-hop reasoning, the Stanford Question Answering Dataset (SQuAD) [
78] was selected due to its high-quality, manually curated questions. Answering these questions requires deriving information from a single piece of evidence, typically from one retrieved chunk. Additionally, SQuAD includes unanswerable questions, requiring RAG systems to detect instances where insufficient information is available to generate a valid response. The presence of unanswerable questions enhances real-world applicability, as it reflects scenarios in which no definitive answer exists for a given user query [
78].
In contrast, multi-hop reasoning necessitates retrieving and synthesizing multiple pieces of information, often from different documents or distant sections of the same document. This process involves establishing logical connections between retrieved chunks to construct a comprehensive response. Since the GraphRAG system is specifically designed to enhance retrieval across multiple documents and facilitate reasoning across diverse sources, the HotpotQA dataset [
79] was selected as the second evaluation dataset. HotpotQA is explicitly designed for multi-hop reasoning, making it a suitable benchmark for evaluating the system’s ability to integrate and reason across multiple information sources.
Despite being published prior to the introduction of RAG, these datasets remain highly suitable for RAG evaluation, as they provide question–answer pairs alongside their retrieval context, facilitating a structured assessment of retrieval and generation performance. Since both datasets are based on a corpus of Wikipedia articles, they can be seamlessly adapted for GraphRAG evaluation. Each Wikipedia article corresponds to a single document, while its sections naturally map to the chapter structure within the DKG, ensuring a consistent representation of the dataset in the proposed framework.
In addition to these open-domain datasets, a domain-specific internal dataset was created to evaluate the GraphRAG system in an industrial setting. The dataset consists of German-language production planning documents, aligning with this study’s objective of assessing RAG performance in specialized domains. The dataset integrates both external and internal sources, including reference books, industry standards, technical specifications, and supplier offers. These documents were carefully selected and validated by domain experts from an automotive manufacturer to ensure relevance and applicability. The final dataset comprises 17 documents, totaling over 5500 pages of text, making it comparable in scale to the context size of SQuAD.
The internal dataset was designed to mirror the characteristics of both SQuAD and HotpotQA, incorporating single-hop, multi-hop, and unanswerable questions. The selected open-domain datasets were manually created by their respective publishers or developed using crowdsourcing platforms [
78,
79]. However, for the internal dataset, these approaches were not feasible due to resource constraints on domain experts and the confidential nature of the data, which precludes crowdsourcing.
To address these limitations, the dataset was constructed using an LLM-based approach, following and replicating established methodologies for multi-hop dataset creation [
79,
80]. As a foundation for generating question–answer pairs, the DKG was first constructed from the provided documents. Utilizing the IKS layer, extracted keywords were used to identify and connect semantically related chunks.
An LLM was employed to generate diverse question types, followed by an automated quality assessment to filter low-quality outputs. Additionally, domain experts manually reviewed a sample of the generated question–answer pairs, refining the prompt engineering process to ensure domain relevance for manufacturing-specific queries.
The final step in dataset preparation involves the selection of evaluation questions. Given the large volume of questions in open-domain datasets, evaluating the entire set is infeasible due to resource constraints. To address this, the datasets are downsampled to 200 questions each, following the approach of prior studies that have demonstrated the effectiveness of evaluating a subset of 100 questions [
81,
82]. To ensure representativeness, questions are randomly sampled while adhering to predefined constraints that maintain a balanced distribution of question types, reflecting the original dataset composition.
6.4. Evaluation Metrics
The evaluation metrics were selected based on the RAG evaluation framework presented in [
77]. The assessment is structured into distinct evaluation dimensions, measuring the performance of both the retrieval and generation phases.
Metrics for the retrieval phase are specifically used to evaluate the effectiveness of the retrieval component within RAG systems. Given that the proposed approach primarily focuses on retrieval, these metrics serve as the key indicators of system performance. Additionally, the influence of retrieval on the generated answer is assessed through generation-related evaluation dimensions, though its impact is considered secondary in comparison. It is important to note that other factors, such as prompt engineering, also influence generation performance, making it necessary to interpret results holistically [
77].
Furthermore, the evaluation framework distinguishes between different types of evaluators: lexical metrics, which can be computed efficiently and objectively, and more advanced evaluation methods that rely on the use of LLM-as-a-Judge. While the latter enables a more flexible and semantic assessment of RAG systems, it is important to acknowledge that the generated metrics are heavily influenced by the choice of LLM, prompt design, and potential model biases. These factors can limit the reproducibility and comparability of results, as they could be mainly interpreted on a relative basis with controlled input parameters. Consequently, combining such advanced evaluation methods with independent lexical metrics is essential to provide a more robust and balanced assessment of the artifact’s performance [
77].
To evaluate the retrieval stage, the
Context Relevance dimension is applied. This ensures that the retrieved context provides relevant chunks to answer the question while minimizing irrelevant information. As per the principles of RAG, a fixed number of top-k retrieved chunks is passed to the LLM. Consequently, the primary objective is to ensure that the correct chunks are retrieved, as the pipeline cannot directly constrain the number of irrelevant chunks [
77,
83].
To evaluate Context Relevance, we apply the lexical metrics Recall@k and MRR@k (Mean Reciprocal Rank). Recall@k measures the proportion of relevant passages retrieved within the top-k results, regardless of the presence of irrelevant passages. As previously discussed, irrelevant chunks are less critical, since the LLM is expected to focus on relevant information during the generation phase. MRR@k, on the other hand, prioritizes the ranking position of the first relevant chunk within the top-k retrieval, providing insights into how effectively the retrieval system ranks relevant content.
Both metrics, along with all other evaluation measures used in this study, range between 0 and 1, where higher values indicate better performance. The formulas for these calculations are provided in [
77].
In addition to these lexical metrics, LLM-as-a-Judge-based metrics
Context Precision (CP) and
Context Recall (CR) are employed to assess retrieval performance without relying on a predefined “golden retrieval” from the dataset. These metrics are particularly valuable for evaluating RAG systems in real-world, unstructured data environments, where predefined relevance labels may not always be available and unique. For further details on their calculation, refer to [
83,
84,
85].
To evaluate the quality of the generation process, we assess the dimensions of
Faithfulness,
Answer Relevance, and
Correctness, as recommended in [
77].
Faithfulness specifically pertains to the generation phase and measures the extent to which the LLM’s response aligns with the retrieved context, ensuring that all information presented in the answer can be directly inferred from the retrieved content. This dimension is critical for detecting hallucinations and ensuring factual accuracy [
86].
One approach to quantifying
Faithfulness is the lexical metric
K-Precision, which calculates the proportion of tokens in the LLM-generated response that appear in the retrieved context. A higher K-Precision score indicates a stronger alignment between the generated output and the provided retrieval context. Further details on the calculation of this metric can be found in [
77]. Additionally, another applied metric with fewer dependencies on predefined labels is the LLM-based
Faithfulness Score (FS). This metric evaluates whether each statement in the generated response is supported by the retrieved chunks, ensuring faithful adherence to the provided context and correct prompt following during generation. For further details on its computation, refer to [
77,
83].
The
Answer Relevance dimension assesses whether the LLM-generated response directly addresses the user query, penalizing incomplete or redundant answers, regardless of factuality [
83,
87]. To quantify this, the
AnswerRelevance Score (ARS) is computed using an LLM-as-a-Judge approach, which systematically evaluates response relevance and completeness. The methodology for calculating this metric is detailed in [
77,
83].
The third evaluation dimension,
Correctness, pertains to the generation step and assesses whether the LLM-generated response accurately aligns with the ground-truth reference answer, often referred to as the “golden answer”. In the case of open-domain datasets, these reference answers are provided by human annotators, whereas for the internal dataset, they are generated using an LLM. To measure
Correctness, we apply the lexical metric
Recall, as it has been shown to correlate well with human evaluations [
86]. Recall quantifies how much of the essential content in the reference answer is captured in the LLM’s response at the token level, without penalizing additional, non-contradictory information. The methodology for calculating this metric is described in [
77,
86]. In addition, an LLM-as-a-Judge approach is employed to compute the
Correctness Coefficient (CC), which enables a more semantic evaluation beyond solely token-based comparisons. This metric ensures a higher-level assessment of correctness, accounting for paraphrasing and meaning equivalence rather than just verbatim matching. Further details on its calculation can be found in [
77].
To ensure an automated and robust evaluation framework, the proposed lexical metrics were implemented as described in [
77]. The assessment of LLM-as-a-Judge metrics was conducted using the established
RAGAS framework introduced in [
83].
Since LLM-based metrics are inherently non-deterministic, as they rely on the model’s interpretative response, the robustness of the evaluation process needed to be ensured. Therefore, multiple evaluations were performed with identical inputs, resulting in highly consistent outputs with statistically insignificant variations. This confirmed that the evaluation framework maintains stability, despite the stochastic nature of LLM-based assessments.
As the evaluation process requires substantial reasoning capabilities,
Claude Sonnet 3.5 [
75] was employed for metric computation. Notably, it was observed that the choice of LLM influenced the computed evaluation scores, emphasizing the necessity of standardizing the evaluation model. To ensure comparability across all runs, the same LLM was consistently applied, guaranteeing reproducible results.
7. Results
The evaluation results are first presented by introducing the standard GraphRAG pipeline, which serves as the baseline configuration for comparison against the naive RAG approach, before analyzing the effects of parameter variations as described in
Section 6.2. In addition, a dedicated subsection presents the initial results of using LLM-extracted keywords as an alternative to the standard keyword extraction method. The chapter concludes with a validation of the practical application of the artifact addressing result quality and system performance from an end-user perspective as introduced in
Section 3.5.
The standard pipeline parameters include a chunk size of approximately 1000 tokens. Additionally, the IKS layer of the graph is constructed by extracting five keywords per chunk to establish interconnections between chunks. The top-k value is set to 10, which applies both to the initial retrieval within the vector database, serving as the starting point for the graph search algorithms, and to the pass conditions that limit the number of chunks after reranking, before they are passed to the LLM. This configuration ensures comparability with the naive RAG approach.
Table 1 presents the evaluation metrics for these standard parameters, comparing the GraphRAG pipeline against the naive RAG system across the different datasets.
Bold formatting indicates the best value for each metric–dataset pair, highlighting the strongest performance achieved in the respective configurations.
The results presented in
Table 1 indicate a consistent performance improvement for the GraphRAG approach across nearly all evaluation dimensions and datasets. As the proposed architecture primarily focuses on the retrieval phase of the RAG pipeline (c.f.
Figure 3), this is particularly reflected in the
Context Relevance evaluation dimension, where all four retrieval metrics show an increase. On average, improvements of 15.5% for SQuAD, 18.3% for HotPotQA, and 14.5% for the internal dataset were observed, demonstrating a substantial performance boost over the naive baseline under standard parameter settings.
For the generation-related evaluation dimension, performance improvements are observed across most metrics, although two metrics show a minor decrease for the SQuAD dataset. Overall, the GraphRAG approach achieves an average improvement of 1.8% for SQuAD, 8.4% for HotPotQA, and 6.4% for the internal dataset across all generation-related metrics. These results suggest that the proposed artifact not only enhances retrieval performance but also positively impacts the generation phase. The impact is especially pronounced in the more complex, multi-hop queries of HotpotQA, suggesting that GraphRAG is particularly well suited to advanced question-answering tasks. Nevertheless, for the internal dataset, lexical measures of
Context Relevance remain relatively low, whereas LLM-as-a-Judge evaluations align more closely with results from open-domain benchmarks. This discrepancy likely stems from automatically created datasets in real-world scenarios and will be addressed further in
Section 8.
Based on these initial findings, the next sections investigate the effect of adjusting the above parameters and discuss how such refinements might further optimize performance.
7.1. Adjust Chunk Size
To assess the impact of chunk size on retrieval performance, the GraphRAG approach was evaluated using both smaller chunks (700) and larger chunks (1300) while keeping all other parameters constant. Since chunk size also affects the performance of the naive RAG system, a corresponding evaluation was conducted for the adjusted naive approach to ensure a fair comparison.
As GraphRAG primarily focuses on retrieval improvements,
Table 2 presents the performance results for different chunk sizes, focusing on the Context Relevance evaluation dimension. The results for all evaluation dimensions are provided in
Appendix D.
For readability, the datasets are denoted as DS1 (SQuAD), DS2 (HotPotQA), and DS3 (internal dataset). As in previous evaluations, bold values indicate the best overall performance across both chunk sizes and RAG approaches, while underlined values highlight the highest performance within each individual approach.
Table 2.
Evaluation results for context relevance with adjusted chunk size.
Table 2.
Evaluation results for context relevance with adjusted chunk size.
| Approach | Chunk Size | Recall@k | MRR@k | Context Precision | Context Recall |
|---|
|
DS1
|
DS2
|
DS3
|
DS1
|
DS2
|
DS3
|
DS1
|
DS2
|
DS3
|
DS1
|
DS2
|
DS3
|
|---|
| Naive RAG | 700 | 0.750 | 0.400 | 0.060 | 0.477 | 0.505 | 0.043 | 0.519 | 0.343 | 0.443 | 0.745 | 0.614 | 0.729 |
| 1000 | 0.725 | 0.500 | 0.055 | 0.498 | 0.610 | 0.040 | 0.510 | 0.432 | 0.485 | 0.723 | 0.703 | 0.729 |
| 1300 | 0.740 | 0.510 | 0.060 | 0.508 | 0.651 | 0.036 | 0.499 | 0.442 | 0.440 | 0.740 | 0.703 | 0.730 |
| GraphRAG | 700 | 0.790 | 0.626 | 0.080 | 0.568 | 0.626 | 0.043 | 0.665 | 0.525 | 0.470 | 0.788 | 0.773 | 0.803 |
| 1000 | 0.760 | 0.668 | 0.075 | 0.613 | 0.668 | 0.044 | 0.635 | 0.537 | 0.498 | 0.793 | 0.770 | 0.794 |
| 1300 | 0.765 | 0.665 | 0.080 | 0.638 | 0.665 | 0.045 | 0.637 | 0.569 | 0.478 | 0.775 | 0.812 | 0.749 |
In general,
Table 2 demonstrates that GraphRAG consistently outperforms the naive approach across all chunk sizes and datasets for the evaluated retrieval metrics, reinforcing its effectiveness as a retrieval enhancement technique.
The results indicate that each dataset exhibits an optimal chunk size, suggesting that the ideal configuration is task-dependent. For example, SQuAD achieves better performance with smaller chunk sizes, whereas HotpotQA benefits from larger chunks. This underscores the importance of tuning chunk size based on task-specific requirements, while also highlighting the robust performance of GraphRAG across diverse configurations.
Notable variations in performance are observed across different chunk sizes. While Recall@k favors smaller chunk sizes, MRR@k tends to perform better with larger chunks, potentially influenced by differences in metric computation methodologies. Analyzing the LLM-based metrics, CP and CR, reveals a distribution of peak performances across different chunk sizes and datasets, further justifying the selection of 1000 tokens as the baseline chunk size.
These findings are further corroborated by the generation-phase metrics (c.f.
Appendix D). While GraphRAG maintains a consistent advantage over the naive approach, the presence of task-dependent optimal chunk sizes remains evident. SQuAD continues to perform best with smaller chunks, while HotpotQA benefits from larger ones. For the internal dataset, the optimal results are achieved with the middle chunk size of 1000 tokens, emphasizing the pipeline’s adaptation for retrieval in the manufacturing domain.
7.2. Adjust Number of Keywords
The second parameter analyzed is the number of keywords used to populate the IKG layer within the GraphRAG approach. To evaluate its impact on retrieval performance, the standard setting of five keywords per chunk was adjusted, increasing it to eight and decreasing it to three. This modification allows for an investigation into the relationship between keyword density and retrieval effectiveness.
Table 3 presents the evaluation results for different keyword settings. Since the number of keywords exclusively affects the GraphRAG approach, the naive RAG system is not included in this evaluation. As in previous tables, the highest values are highlighted in
bold to indicate the best-performing configuration for each metric.
Analysis of
Table 3 reveals a clear trade-off between recall-oriented measures and ranking precision. Increasing the number of keywords (e.g., to eight) often enhances Recall@10 and CR but may lead to a slight reduction in MRR@10. Conversely, reducing the keyword count (e.g., to three) tends to improve ranking-focused metrics, such as MRR@10 and CP, but at the cost of overall retrieval coverage. Notably, the default configuration of five keywords appears to provide a balanced performance across multiple datasets, suggesting that this setting effectively mitigates the trade-off between recall and ranking precision.
These findings indicate that optimal keyword selection is highly task-dependent, with different priorities influencing parameter tuning. If maximizing retrieval coverage is the primary goal, a higher keyword count may be preferable. Conversely, if precision in top-ranked results is more critical, a lower keyword count could be advantageous.
This trade-off is also reflected in the generation-related metrics (c.f.
Appendix D), further emphasizing the importance of domain-specific optimization. Adjusting the number of keywords can impact both retrieval effectiveness and answer generation quality, underscoring the need for task-specific parameter tuning to align with domain requirements.
7.3. Adjust Top-k Retrieval
The final parameter adjusted in the evaluation is top-k retrieval, which influences both initial vector retrieval and pass conditions. The standard value of 10 was modified to 5 and 20 to assess its impact on GraphRAG performance. Since top-k retrieval also affects the naive RAG approach, evaluations were conducted for both systems to ensure a comprehensive comparison.
Table 4 presents the evaluation results, with the highest-performing values highlighted, both for each approach individually and overall across configurations.
Table 4 illustrates the impact of varying the top-k retrieval parameter from 5 to 20 on both Naive RAG and GraphRAG, focusing on
Context Relevance metrics. As expected, higher k-values lead to an increase in Recall@k and CR, particularly for SQuAD and HotpotQA, while lower k-values tend to improve MRR@k and CP. Across all configurations, GraphRAG consistently outperforms the naive approach in most metrics, demonstrating the robustness of the graph-based retrieval architecture.
However, the results also highlight a clear trade-off: when k is too large, the system retrieves a broader range of relevant content, but at the cost of introducing more noise into the top-ranked results, thereby reducing precision-based scores. Consequently, the optimal top-k selection depends on the specific application requirements, whether the priority is maximizing retrieval coverage (favoring higher k) or ensuring high-ranking precision (favoring lower k).
Notably, with lower top-k values, the retrieval performance of the naive approach deteriorates more significantly than that of GraphRAG. This further underscores the advantages of the proposed graph-based architecture, as its multi-step retrieval process within the KG mitigates the loss of relevant content.
Analysis of the generation-related evaluation metrics (c.f
Appendix D) reveals a parallel trend between retrieval and generation performance. Specifically, for higher top-k values, performance also improves within the naive RAG setup, in some cases surpassing the performance of GraphRAG with lower k-values. However, even under these conditions, GraphRAG maintains superior performance compared to the naive approach at equivalent retrieval settings, reinforcing the effectiveness of its structured retrieval framework.
7.4. Initial Evaluation of LLM-Based Keyword Extraction
Another dimension of the evaluation involves the adjustment of the keyword extraction method. As previously described, the main evaluation was conducted using YAKE as an algorithmic baseline to ensure reproducibility and computational efficiency. To demonstrate the adaptability of GraphRAG for domain-specific QA scenarios, an alternative approach based on LLM-driven keyword extraction was explored.
This section presents initial results using an LLM-based method to extract relevant keywords. While the public datasets focus on open-domain content, this evaluation leverages the internal dataset to assess the impact of domain-specific keywords in the manufacturing context.
Table 5 summarizes the results, with the highest-performing values highlighted in
bold. The evaluation was conducted using the standard parameter settings applied to the internal dataset.
Interpreting the results in
Table 5 reveals an improvement when using LLM-based keyword extraction compared to both the naive baseline and the algorithmic approach based on YAKE. Although the performance gains are moderate—especially in contrast to the significant improvement from the naive method to YAKE—the results indicate that leveraging a large language model for domain-specific keyword extraction can further enhance answer quality.
A closer examination of the extracted keywords for a specific chunk confirms improved relevance and specificity with the LLM-based approach, as also noted by the focus group. While YAKE tends to extract general terms such as “General Requirements” (“Allgemeine Anforderungen”), the LLM identifies more targeted keywords like “Pressure Reductions” (“Druckreduzierungen”) and “Storage Charge Circuits” (“Speicherladeschaltungen”), which can themselves be considered types of requirements. Although these LLM-based keywords more precisely reflect the content of the chunk, it should be noted that increased specificity also results in a denser IKG layer with fewer interconnections between chunks. Moreover, for such keywords to contribute effectively to retrieval, they must also be identifiable within the user query, which is essential for use in the Informed Keyword Search (IKS).
While this constitutes an initial assessment of LLM-based keyword extraction, the results demonstrate its potential. The observed gains in semantic clarity and contextual completeness may contribute to more accurate downstream answers, particularly in manufacturing-specific question-answering tasks.
7.5. Validation of Practical Application
To ensure a comprehensive evaluation of the implemented artifact, the practical applicability was qualitatively validated in addition to the quantitative evaluation. For this purpose, the end user focus group involved in the solution design process reviewed and assessed the generated results, providing domain-specific feedback on their relevance and usefulness.
The primary focus of the qualitative validation was to assess the quality of the generated results through the review of a random subset of answers produced within the dataset. The focus group concluded that, particularly for complex multi-hop queries, the quality of answers generated by GraphRAG was notably higher compared to those from the naive pipeline. This observation is consistent with the results of the quantitative evaluation and supports the validity of the applied metrics and evaluators. Moreover, the findings confirm the practical applicability of the proposed approach from the perspective of answer quality.
The second perspective of the qualitative evaluation focuses on the practical assessment of processing times and latency. Although the technical implementation primarily aimed to evaluate the system’s output quality, initial measurements were conducted to gain insights into runtime behavior. It should be noted, however, that a real-world deployment would require implementation on more powerful and robust hardware to meet practical performance requirements.
The results showed that only a relatively small amount of time was required to construct the KG as part of the indexing process. Based on the chunk corpus generated using the standard parameters, which would also be required in a naive RAG setup, one dataset comprising approximately 5500 pages of text was successfully transferred into the KG within 195 s. As this process is executed during the initial index construction and does not affect retrieval latency, it was not considered a concern by the users in the focus group.
To assess practical applicability, end-to-end latencies were measured using the standard evaluation parameters. Following Xu et al. [
88], total response time is treated as a user-centered efficiency metric. In the naive RAG pipeline, retrieval required 0.2 s and answer generation 1.5 s, resulting in a total latency of 1.7 s per query. In contrast, the GraphRAG implementation recorded 7.4 s for retrieval, 0.9 s for reranking, and 1.5 s for generation, yielding a total latency of 9.8 s. Although this represents a fivefold increase, it remains well below the ten-second threshold deemed acceptable by focus group participants. Moreover, it is significantly faster than manual searches across heterogeneous file systems, which may take several minutes per query [
3]. The additional delay introduced by GraphRAG is therefore considered a reasonable trade-off for improved answer quality, consistent with the speed–accuracy trade-offs reported for recent LLMs such as OpenAI’s o1 [
89].
In conclusion, the qualitative validation confirmed that GraphRAG provides substantial practical benefits in terms of answer quality, particularly for complex, multi-hop queries, despite an increase in retrieval latency. These findings suggest that the trade-off between enhanced accuracy and slightly higher response times is acceptable for the implementation of GraphRAG within the manufacturing domain.
8. Discussion
The results across all datasets demonstrate that GraphRAG consistently outperforms the naive RAG baseline in both retrieval and generation metrics, reinforcing the notion that enhanced retrieval directly supports improved answer generation in RAG-based QA systems. From a broader perspective, the importance of a graph-based retrieval structure becomes evident: by explicitly modeling relationships between chunks via keyword-based edges, GraphRAG systematically retrieves relevant evidence, leading to meaningful improvements across datasets. While SQuAD’s relatively straightforward queries benefit from more precise retrieval, the complex multi-hop questions in HotpotQA see even greater performance gains, leveraging GraphRAG’s structured knowledge representation. The results also indicate that each dataset exhibits distinct optimal configurations for specific metrics, emphasizing that no single parameter setting universally optimizes all dimensions. Instead, task-specific parameter tuning is essential for maximizing performance. The systematic approach of the DSR methodology has proven well suited for developing and customizing a domain-specific RAG solution within the manufacturing context.
A key objective of this study was to examine the impact of specific parameter choices on system performance. Notably, a chunk size of 1000 tokens and a moderate number of keywords proved to be effective across multiple tasks, striking a balance between retrieval coverage and computational efficiency. Furthermore, the results highlight the necessity of adapting parameters to domain-specific requirements, as optimal configurations vary depending on dataset characteristics and question types.
Regarding top-k retrieval optimization, results indicate that increasing the number of retrieved chunks significantly improves recall-oriented metrics such as Recall@k and CR, but at the cost of introducing noise that reduces precision-based scores. Interestingly, GraphRAG demonstrates greater robustness than the naive RAG approach across varying top-k values, suggesting that its structured retrieval process retains relevant information more effectively, even under lower k-values.
The initial assessment of LLM-based keyword extraction highlights the potential of incorporating domain-specific terms into the IKG. While the results indicate performance improvements over the algorithmic baseline, there remains room for further enhancement, particularly through refined prompt design and optimized retrieval strategies. Such improvements are essential to justify the increased computational cost and latency associated with LLM-based approaches when compared to more lightweight algorithmic solutions.
The integration of GraphRAG into the manufacturing domain yielded valuable insights from the internal dataset. Due to noise in the data, particularly from tender specifications with large sections of repeated text, lexical metrics struggled to accurately assess performance. The evaluation required both relevant documents to be retrieved for a multi-hop question to be counted as correct. In practice, the system often retrieved semantically equivalent content from different documents, leading to false negatives. While such redundancy is common in industrial settings, LLM-based metrics offered a more context-aware evaluation. These results confirmed GraphRAG’s strong performance on the internal dataset, aligning with findings from open-domain benchmarks. Despite limitations, the consistent interpretation of LLM-based metrics alongside lexical ones supports their validity in less standardized environments. Overall, the results demonstrate the approach’s adaptability and suggest that, with proper parameter tuning, graph-based retrieval remains effective in complex, domain-specific scenarios.
Despite the demonstrated benefits, certain limitations must be acknowledged. The first concern pertains to dataset creation. Although a comprehensive approach was employed, the dataset was primarily LLM-generated, with subsamples manually verified by domain experts. Incorporating a greater proportion of handcrafted questions could further enhance the quality of evaluation results.
Furthermore, the evaluation process uses a naive RAG system as the baseline, as this currently represents the state of the art within the targeted industrial domain. While GraphRAG demonstrates improved performance in this setting, several advanced RAG architectures have been developed within the scientific community. A comparison with these more sophisticated approaches could provide a deeper assessment of the proposed solution’s performance and further validate its effectiveness beyond the industrial baseline.
Another limitation concerns the implemented text and keyword extraction components. Despite reviewing the document structure and optimizing post-processing, some edge cases in the real-world dataset may still result in incomplete structural capture. Likewise, even with parameter tuning supported by domain experts, less relevant keywords may occasionally be extracted, affecting retrieval precision. Nonetheless, GraphRAG outperforms the naive baseline, illustrating the approach’s robustness. These findings point to clear opportunities for improvement, as discussed in the future work section.
A further limitation concerns the evaluation process. While LLM-as-a-Judge is a practical and scalable method for QA tasks, incorporating human-in-the-loop evaluation could improve result reliability, despite the focus group reviewing a subset of answers. The influence of prompt engineering must also be acknowledged. Preliminary tests showed that small changes to the prompt template and switching the evaluator to Haiku [
73] significantly increased evaluation scores. This partly accounts for the relatively low values in the
Correctness dimension, which is highly sensitive to both prompt design and model choice. As such, correctness scores should be interpreted relatively rather than in absolute terms.
The latency evaluation was based on a prototype implementation without optimization, running on low-end hardware. While the results provided useful insights and were acceptable to the focus group, further improvements are needed for real-world QA deployment. Scalable database solutions are especially recommended to reduce latency for graph-based queries. Future work will address scalability and resource efficiency to assess feasibility for large-scale use.
Overall, these findings affirm the potential of GraphRAG to enhance retrieval quality across a range of QA tasks, while also emphasizing the importance of careful parameter tuning, thoughtful data curation, and continued research into scalable, domain-adaptive retrieval solutions.
9. Conclusions and Outlook
The development and evaluation of the GraphRAG framework were guided by the DSR methodology, ensuring a structured and iterative approach to addressing real-world retrieval challenges in RAG-based QA systems. Through systematic problem identification, definition of design requirements, artifact development, implementation, and evaluation, this study has demonstrated the effectiveness of integrating KGs into RAG. By applying DSR principles, the research not only developed a novel DKG-based retrieval framework but also established a methodological foundation for designing task-specific and domain-adaptive QA systems.
The key contributions of this work are twofold: first, the systematic design and empirical validation of GraphRAG as a scalable and adaptable retrieval solution, and second, the critical assessment of parameter dependencies, offering insights into task-specific optimization strategies. These findings reinforce the value of DSR as an effective methodology for developing and refining AI-driven retrieval systems in complex industrial environments.
While several areas for further refinement have already been discussed, additional directions for future research offer potential to further strengthen the proposed framework. As noted, a deeper focus on KG construction and retrieval could improve answer quality, particularly by incorporating chapter summaries into the DKG to enhance the guidance provided during retrieval.
Beyond AWS Textract, the pipeline is extractor-agnostic and supports layout-aware multimodal Transformers. Their geometry-aware token positions could enable the injection of structural edges (e.g., section, table-cell, figure-caption) into the DKG, allowing systematic evaluation of their impact on retrieval accuracy.
Furthermore, keyword extraction for the IKG layer could be more closely aligned with domain-specific needs by further refining the LLM-based approach. The IKG itself may benefit from filtering overly generic keywords, as high-frequency terms linked to many chunks can reduce retrieval specificity. Given the strong performance of both unsupervised and initial LLM-based extraction methods, fine-tuning this component offers a promising path to enhance performance in specialized domains. It would also be beneficial to assess the individual impact of each graph search algorithm to better understand their respective contributions to retrieval effectiveness.
Another promising avenue for future work is enhancing the interaction between the vector and graph databases. The document management functionalities of the DKG could be leveraged to narrow the search space within the vector database before initial retrieval, either through user-defined filters or automatically extracted constraints.
An additional interesting approach involves utilizing the DKG to establish links between identical or highly similar chunks, thereby preventing the retrieval of redundant or non-diverse content, a challenge that frequently arises in real-world applications where documents contain overlapping sections, as observed in the internal dataset.
Extending GraphRAG to multilingual settings is a natural next step. Balanced multilingual LLMs as in [
90], which produce language-agnostic embeddings, enable semantic edges linking concept nodes with equivalent meanings across languages. These cross-lingual links could replace manual synonym lists, enrich the IKG beyond basic keyword matches, and support multilingual QA without requiring retraining or re-indexing of the full pipeline.
Inspired by the recently introduced CoLE framework [
46], a promising direction for future work is to incorporate a lightweight reasoning layer on top of GraphRAG. This could begin with a brief prompt that classifies the user’s query and assigns semantic tags to relevant graph nodes. The existing document-graph traversal would then serve as the primary retrieval mechanism. A second prompt could be used to select a particularly instructive passage from the retrieved set. The final answer could follow a simple, fixed structure, explicitly stating the task, the governing rule, the supporting observations, and the resulting conclusion.
Finally, an investigation into expanded use cases could further validate and refine the GraphRAG approach. While the current evaluation includes both English and German datasets, future research could explore the system’s performance in multilingual settings. Additionally, it would be valuable to assess whether the methodology and findings can be effectively transferred to other domain-specific QA tasks, broadening the applicability of GraphRAG beyond the manufacturing domain.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}