1. Introduction
Breathing is a fundamental physiological process that sustains life through oxygen exchange between the body and the environment. The respiratory system regulates this process via inhalation and exhalation in the lungs, and generates distinct sounds referred to as breathing or respiratory sounds. These sounds provide valuable insights about the condition of the respiratory airways, pulmonary structures, and can be analyzed to assess respiratory health [
1]. Breathing sounds are classified into normal and abnormal (adventitious) sounds. Normal breathing (or breath) sounds are divided into several categories based on their pitch and location of auscultation, including bronchial, vesicular, and bronchovesicular sounds. Adventitious breath sounds, categorized as crackles, wheezes, rhonchi, stridor, and pleural rubs, are one of the key indicators of respiratory diseases [
2].
Figure 1 illustrates different types of adventitious pulmonary sounds and their corresponding location of occurrence in the airways.
The World Health Organization (WHO) reported that in 2021, respiratory diseases including COVID-19, chronic obstructive pulmonary disease (COPD), and lower respiratory infections, accounted for over 12 million deaths globally [
3]. Early detection, combined with effective disease management, is crucial for controlling non-communicable chronic respiratory diseases [
4]. Analyzing respiratory sounds (as unique non-invasive lung function biomarkers) can aid in diagnosing pulmonary diseases. There are extensive studies that assess the characterization of lung sounds acquired through lung or chest auscultation. However, to the best of our knowledge, the diagnostic potential of nasal and oral breathing sounds in this domain remains underexplored. These sounds shaped by unique physiological features of the upper airway, differ in airflow dynamics and can provide complementary information for diagnosing respiratory conditions [
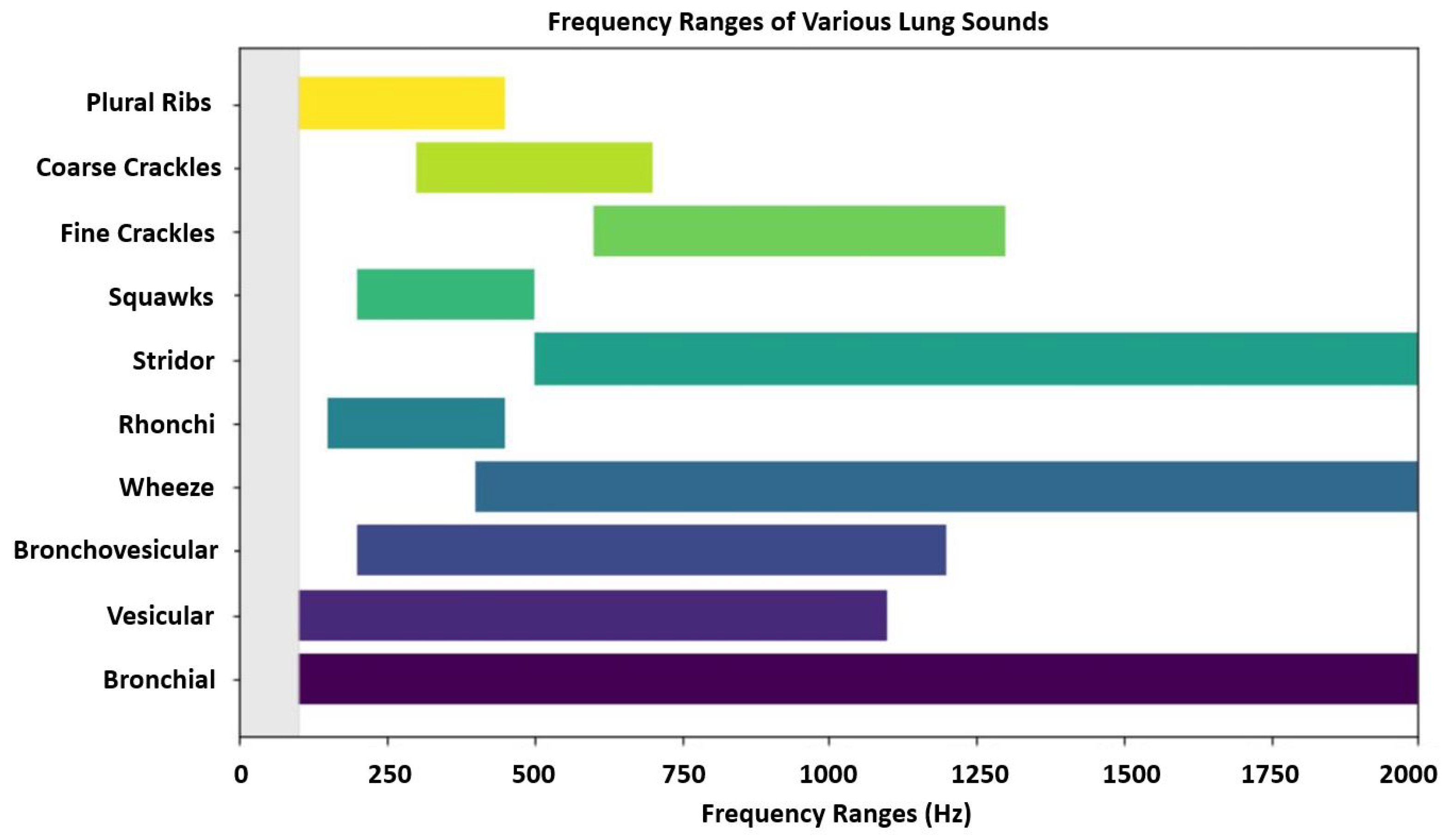
5]. The frequency ranges of various lung sounds are visualized in
Figure 2.
Additionally, subtle differences among respiratory sounds can be differentiated more accurately using artificial intelligence (AI). Machine learning (ML) and deep learning (DL) algorithms have proven effective for making diagnostic applications automated and scalable [
6]. Respiratory sound signals undergo preprocessing and noise filtering techniques prior to analysis to improve data quality. ML algorithms focus on handcrafted spectral and temporal features for classification [
7]. In contrast, DL models can autonomously extract spatial and temporal patterns from raw signals or even spectrograms [
8]. The adoption of AI-driven techniques in respiratory sound analysis offers significant potential to enhance diagnostic precision and support early disease detection [
6].
This paper aims to provide a comprehensive overview of the current state of automated respiratory sound analysis. It discusses the significance of both normal and adventitious sounds, outlines the machine learning and deep learning methodologies used for the analysis, and highlights key datasets. In contrast to earlier reviews [
2,
4,
6,
9,
10,
11,
12,
13,
14,
15], this paper places special emphasis on nasal and oral breathing sounds, underlining their diagnostic value in respiratory assessments. These upper airway sounds have not been explored in prior analyses regarding pulmonary disease detection, yet they offer distinct insights that complement traditional lung sound interpretation. In addition, the review focuses on the latest progress in ML and DL techniques for respiratory sound analysis, presenting a current and detailed overview of computational methods that are advancing the field. By summarizing the advancements and identifying the research gaps, this review seeks to inform future studies and drive innovation in respiratory healthcare.
We focus on research published in recent years (since 2022), particularly those incorporating ML and DL methods with the highest performance in respiratory sound analysis. This approach allows us to evaluate the latest advancements which shape the future of diagnostic tools in respiratory health.
The remainder of the paper is organized as follows. We discuss the conventional approaches for analyzing respiratory sounds along with applications of ML and DL models in
Section 2, followed by an in-depth examination of data processing and feature extraction methods in
Section 3. We then present results and comparisons of various techniques in the reviewed papers along with discussions in
Section 4. Finally, we conclude our review in
Section 5.
2. ML and DL Approaches in Respiratory Sound Analysis
Lung sounds have been evaluated through methods such as chest auscultation, cough analysis, and sleep apnea assessments. This review focuses on respiratory sound analysis. However, it is important to consider how it compares to other diagnostic modalities such as spirometry, lung oscillometry, and imaging. Spirometry is the gold standard for assessing lung function by measuring airflow and lung volumes. This method offers high reproducibility and good guideline-based validation [
16]. However, its reliance on forced expiratory maneuvers limits its applicability especially in elderly patients, children, and those with physical or respiratory limitations such as persistent cough or dyspnea. Up to 30% of elderly individuals may be unable to perform spirometry adequately, which can affect the results and raise ethical concerns regarding patient discomfort [
16,
17].
Lung oscillometry offers a non-invasive, effort-independent alternative based on tidal breathing (passive, relaxed breathing). It is more suitable for populations unable to perform spirometry effectively. While spirometry provides volume-based measurements, oscillometry delivers frequency-dependent resistance and reactance, which is often missed by spirometry. Despite these benefits, the interpretation of impedance data are more complex than spirometry. Also, the lack of standardized protocols and normative reference values further complicates its broader clinical application. Additionally, factors such as posture, cooperation, and consistent breathing can affect results which necessitates age-appropriate protocols and trained personnel to ensure accurate readings [
17,
18].
Imaging techniques like chest X-rays and computed tomography (CT) scans offer structural insights but are associated with higher costs, radiation exposure, and potential limitations in certain populations such as pregnant individuals. Though CT provides detailed anatomical resolution, its use as a screening tool is constrained by radiation dosage and contraindications in vulnerable groups [
19]. In contrast, respiratory sound analysis, especially when enhanced with ML and DL techniques, emerges as a non-invasive, low-cost, and portable option. Unlike spirometry or imaging, it can support continuous monitoring and early detection in remote and resource-limited settings.
This section discusses conventional approaches to respiratory sound analysis. We will also explore the significance of assessing both nasal and oral breathing patterns. For each method, we will examine the application of ML and DL algorithms to enhance diagnostic accuracy and interpretability. AI-powered auscultation systems are particularly valuable in real-time remote diagnostics, offering a solution that reduces the need for in-person consultations [
6].
2.1. Lung Auscultation
Auscultation has been the main method of respiratory evaluation, generally performed by a stethoscope [
20]. However, the effectiveness of auscultation depends on the skills and experience of the physician, which often leads to variability in diagnosis. Furthermore, traditional stethoscopes lack the ability to record and analyze lung sounds retrospectively, thus limiting long-term monitoring. Digital stethoscopes address this limitation by digitizing acoustic signals for visualization and transmission via Bluetooth or WiFi. These advances have improved the understanding of lung sounds in both normal and pathological conditions and have improved the diagnostic accuracy [
15].
ML methods such as support vector machines (SVM), random forest, and gradient boosting have been applied to lung sound analysis. They provide a quantitative approach to detect abnormal respiratory patterns based on manually extracted features, with high performance. For example, Koshta et al. [
21] applied the Fourier decomposition method (FDM) with discrete cosine transform (DCT) and discrete Fourier transform (DFT) to classify respiratory conditions. They classified signals using SVM, k-nearest neighbors (kNN), and ensemble algorithms. The highest accuracies achieved were up to 99.8% in distinguishing between asthma and normal conditions. In another study, Mitsuke et al. [
22] proposed an eXtreme Gradient Boosting (XGBoost)-based algorithm for two purposes. First, they used the model for detecting fine crackles, and second, for identifying respiratory phases (inhale and exhale). Their approach achieved 90% accuracy in crackle detection and 85% in respiratory phase identification. Park et al. [
23] developed an ensemble SVM model using Mel-frequency cepstral coefficient (MFCC) characteristics to classify pediatric lung sounds into normal, crackles, and wheezing. Their model demonstrated performance comparable to pediatricians in a prospective validation.
DL models, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs), provide the advantage of automatically extracting relevant features from breathing sounds. CNNs are particularly effective at recognizing spatial patterns within spectrograms. RNN models combined with attention mechanisms excel at capturing temporal dependencies in breathing cycles. Gupta et al. [
24] developed a deep-learning-based framework for automatic pulmonary sound classification using 1D and 2D DeepRespNet models. They trained the model over spectrogram-based representations and showed that the 2D DeepRespNet outperforms its 1D counterpart. Kim et al. [
25] combined 1D time series respiratory data with 2D representations such as spectrograms and MFCCs to improve multiclass pulmonary disease classification. Their method improved classification performance and training efficiency compared to using either data type alone.
Hybrid models that integrate multiple DL or ML architectures have also been explored to improve robustness. Álvarez Casado et al. [
26] applied Multi-Layer Perceptron (MLP) classifiers for both binary and multiclass classification tasks to differentiate patients with respiratory conditions from healthy individuals. They also used XGBoost to predict continuous variables such as age and body mass index (BMI). Their approach demonstrated high accuracy in classification tasks for respiratory diseases. Dubey et al. [
27] used an SVM and Long Short-Term Memory (LSTM) integrated hybrid model with Bayesian optimization to analyze the non-linear characteristics of adventitious respiratory sounds.
As AI-driven respiratory analysis continues to evolve, it has the potential to improve early detection, personalized treatment strategies, and remote healthcare solutions for respiratory diseases [
6,
28].
Table 1 provides a comprehensive classification of normal and adventitious lung sounds, detailing their frequency ranges, descriptions, and associated respiratory conditions.
2.2. Cough-Based Analysis
Cough analysis has gained popularity as a non-invasive method for disease detection. Studies have explored its use in identifying conditions such as COVID-19, asthma, and tuberculosis. Cough signals exhibit distinct temporal and spectral characteristics of respiratory sounds. They can be analyzed for deeper insights into respiratory health through their temporal and spectral properties. Temporal features include the duration of the cough event, inter-cough intervals, and phase segmentation into inspiration, compression, and expiration. Spectral features provide information about the cough’s fundamental frequency, harmonic structure, and energy distribution across different frequency bands [
29].
Any changes in the cough pattern features such as phase duration can differentiate between wet and dry cough. Dry coughs, which are non-productive and often high-pitched, are linked to conditions like asthma, gastroesophageal reflux disease (GERD), and viral infections. In contrast, wet or productive coughs, often characterized by low-frequency and mucousy sounds, are commonly observed in pneumonia, bronchitis, and tuberculosis [
30].
Table 2 presents characteristics of various cough types with their associated causes. By leveraging these signal characteristics, advanced ML and DL models can improve diagnostic accuracy beyond what is perceivable by the human ear [
14]. However, cough-based analysis has limitations, including variability in cough patterns and susceptibility to external noise. These challenges can impact the reliability of automated classification models.
Numerous studies have explored the automated classification of cough sounds to improve diagnostic efficiency. For instance, Saeed et al. [
31] proposed Respiratory disease Bias-Free Network (RBF-Net), a CNN-LSTM-based model with conditional Generative Adversarial Network (c-GAN) to reduce bias in AI-driven cough analysis for respiratory disease diagnosis. Their model, after training on the COVID-19 dataset, outperformed conventional models by mitigating confounding variables like gender, age, and smoking status. Manzella et al. [
32] explored the use of symbolic learning for classifying COVID-19 status based on cough and breath recordings. They applied interval temporal decision trees and random forests to analyze the multivariate time series data of cough and breath sounds.
Some studies first focused on feature engineering and then they develop a DL model. For example, Vodnala et al. [
33] explored DL methods to distinguish asthma from COPD using cough sounds. They extracted features using Mel-frequency spectral coefficients (MFCCs) and spectral centroid. Then, they used CNN, LSTM, Gated Recurrent Unit (GRU), and CNN-LSTM hybrid models to classify the results. Among all models, the CNN-LSTM architecture achieved the highest accuracy (93%) by effectively capturing both spatial and temporal patterns in the data. Kilic et al. [
34] developed a lightweight AI model for asthma detection using cough sounds recorded via mobile phones from 1428 subjects. They applied a Global Chaotic Logistic Pattern (GCLP) for feature extraction and used a Tunable Q-wavelet transformation (TQWT) for signal decomposition. A cubic support vector machine, combined with feature selection and majority voting, was used to distinguish asthma from healthy cases.
Despite the advancements, challenges remain in achieving generalizability across diverse populations and recording conditions. Variability in cough sounds due to environmental noise, microphone types, and patient-specific factors necessitates the development of robust models trained on large, diverse datasets.
2.3. Sleep Apnea Studies
The characteristics of respiratory signals play a crucial role in understanding and diagnosing sleep apnea. This condition is recognized by recurrent interruptions in breathing during sleep [
35,
36]. These interruptions can be partial (hypopnea) or complete (apnea) and can lead to fragmented sleep and reduced oxygen levels. They contribute to daytime fatigue, cardiovascular risks, and cognitive impairment. The severity of sleep apnea is generally assessed using the apnea–hypopnea index (AHI), which quantifies the number of such events per hour of sleep [
37].
There are two primary types of sleep apnea, including obstructive sleep apnea (OSA) and central sleep apnea (CSA). OSA is the result of airway obstruction during sleep. This often occurs due to relaxation of the throat muscles. However, CSA causes pauses in breathing when the brain fails to send appropriate signals to the respiratory muscles. In some cases, patients may experience both types of symptoms and exhibit mixed sleep apnea [
38].
Polysomnography (PSG) is the standard method for diagnosing sleep apnea. This method uses multiple biosensors to monitor airflow, respiratory effort, blood oxygen saturation, and other physiological parameters. However, PSG is resource-intensive and requires overnight clinical observation. These challenges have driven the development of alternative detection methods. Research on sleep apnea has demonstrated the significance of evaluating nasal and oral breathing sound patterns in diagnosing respiratory disorders. Studies analyzing airflow patterns during sleep have revealed distinct changes in nasal and oral breathing dynamics that correlate with conditions such as OSA.
Moreover, recent advancements in AI and signal processing have enabled non-contact and wearable technologies to aid in sleep apnea detection. Thermal imaging, radar sensors, and near-infrared optical methods have been explored to monitor breathing patterns by detecting nasal airflow and chest movements. In the study by Mozafari et al. [
37], the airflow was estimated using spectral analysis of thermal videos. Their method included a detection transformer (DeTr) to identify the facial region in thermal frames, followed by 3D convolutional neural networks and bidirectional LSTMs to extract respiratory signals. Le et al. [
39] developed a sound-based AI model for real-time OSA detection in home settings. Using a modified SoundSleepNet and noise consistency training helps the model to accurately classify apnea events and estimate AHI, offering a robust and non-contact alternative for OSA monitoring. Another study focused on improving apnea/hypopnea detection and OSA severity screening using nasal respiration flow (NRF), peripheral oxygen saturation (SpO2), and electrocardiogram (ECG) signals during PSG. An Xception network was trained to detect these events and then a SVM model was used to classify the severity of OSA events [
40].
Feature extraction from respiratory signals has been essential in AI-based apnea detection. Common features include mean and variance of signal amplitude, power spectral density, and peak-related measures such as inter-peak distance and peak height variability. In a study using XGBoost on single-lead ECG and respiratory signals, a classification model was developed for detecting sleep apnea. The model was trained on features extracted from the ECG as well as respiratory-related features such as peak heights and frequency [
41]. Jacob et al. [
42] developed a system to classify snoring patterns for detecting OSA using respiratory signals. Features such as Mel-filter bank energy, MFCC, and spectrograms were extracted for classification. The authors found out that key features such as energy variations helped differentiate normal snoring from OSA-related snoring.
Detection of apnea can be challenging due to artifacts, sensor placement variability, and differences in sleep environments, which introduce noise into respiratory signals. As research continues, integrating multimodal sensing approaches such as combining thermal imaging, radar, ECG, and respiratory signals can enhance the accuracy and accessibility of sleep apnea diagnostics. This will potentially reduce reliance on PSG and improve early detection and treatment outcomes.
2.4. Significance of Assessing Nasal and Oral Breathing
Variations in the dynamics of airflow can be important in respiratory diseases diagnosis. Conditions like asthma and COPD have increased airflow resistance, resulting in characteristic such as wheezing and prolonged expiration [
43]. Pulmonary fibrosis reduces lung compliance response to pressure, causing rapid, shallow breathing with distinctive crackles. Chronic oral (mouth) breathing increases respiratory effort and alters vocal cord vibrations, and thus, contributes to airway dysfunction [
2,
12]. One notable study in this domain focused on wheeze detection in pediatric patients. Bokov et al. developed a wheeze recognition algorithm using smartphone-recorded oral breathing sounds in a pediatric emergency setting. They analyzed 95 validated recordings, and their SVM classifier achieved 71.4% sensitivity and 88.9% specificity. Their study demonstrates the potential for contact-free outpatient respiratory assessment [
44].
Apart from airflow resistance and compliance, the mode of breathing (nasal or oral) can further influence respiratory efficiency and pathology. Disruptions in nasal breathing often indicate upper airway obstructions or inflammation. In contrast, oral breathing bypasses natural protective mechanisms, increasing susceptibility to infections and respiratory inefficiencies. It is commonly associated with conditions such as OSA and asthma, where a wider oral opening produces more audible breathing sounds [
12]. The study by Purnima et al. [
45] emphasized the importance of nasal airflow analysis in neurological and pulmonary evaluations, particularly for respiratory disorders such as asthma, COPD, and sleep apnea. They calculated the breathing rate, inter-breath interval, and exhale and inhale onset points.
Analysis of nasal and oral breathing patterns, along with auscultation, provides valuable insights into respiratory health. Acoustic features such as frequency, amplitude, and temporal dynamics can reveal early signs of respiratory dysfunction. Integrating these parameters into clinical assessments enhances early detection and monitoring of disease progression. However, there have been few comprehensive studies systematically assessing their diagnostic value for pulmonary conditions. Furthermore, publicly available datasets containing nasal and oral breathing signals for pulmonary evaluation are scarce. Most existing research has focused mainly on sensor development for continuous respiratory monitoring [
13,
46,
47].
By combining auscultation with nasal and oral airflow analysis, clinicians can improve diagnostic precision and enhance patient outcomes. This integrated approach advances respiratory disease detection and management.
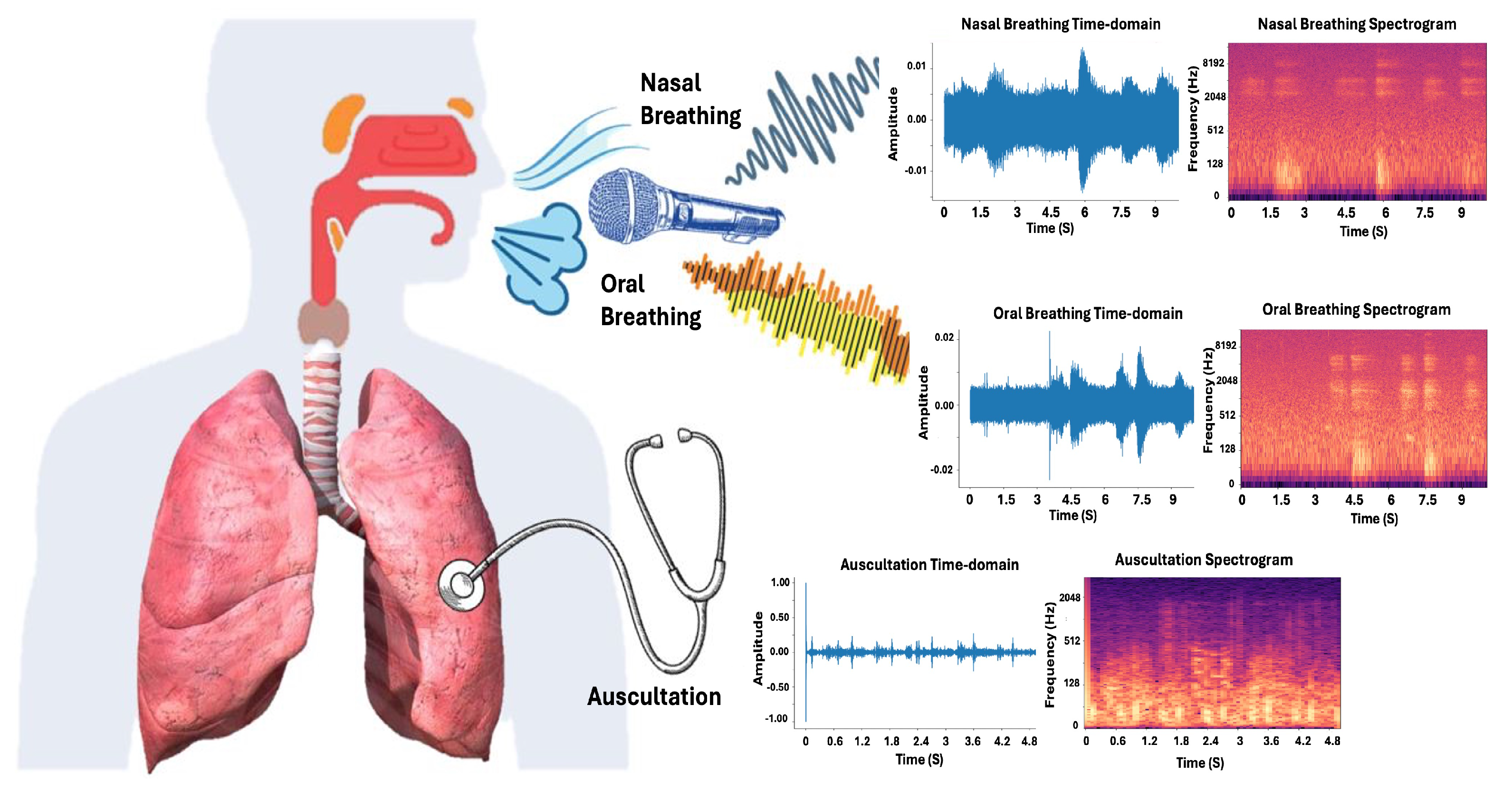
Figure 3 shows the different types of breathing sounds, including nasal and oral breathing, as well as auscultation, which play key roles in respiratory diagnostics.
3. Data Processing and Feature Extraction
In this section, we will discuss the essential steps involved in preparing lung auscultations and breathing sounds for further analysis. This includes the preprocessing of raw audio recordings. Preprocessing involves noise reduction, segmentation, normalization, and quality improvement. We will also explore the process of feature extraction which transforms the preprocessed signals into meaningful representations for analysis. Additionally, we will introduce the datasets used for current studies which serve as the foundation for training and testing ML models.
3.1. Preprocessing
Lung auscultations and breathing sounds, whether captured using a stethoscope or microphone for nasal or oral breathing, require careful preprocessing before analysis. The recorded sounds typically contain various forms of noise, such as ambient environmental noise or artifacts introduced by the recording device itself [
7]. The first step in preprocessing is standardizing the sample rate of the recordings. This ensures consistency across different datasets and devices [
48]. Next, noise reduction is performed to eliminate unwanted sounds, such as background noise or heartbeats, which can obscure lung sounds. A bandpass filter is commonly applied to retain only the frequencies most relevant for analysis. To further improve the quality of the data, advanced techniques such as Wavelet Transform or Empirical Mode Decomposition (EMD) can be utilized to denoise the signal while preserving important features of the lung sounds [
49].
The lung/breathing sound preprocessing pipeline also includes segmenting the audio into meaningful portions, often based on breathing cycles and phases, such as inspiration and expiration phases. This segmentation can be guided by the detection of silent intervals between breaths, which helps in distinguishing different phases of respiration. Furthermore, variations in the amplitude of the sound signals, which may be introduced by the recording device or environmental factors, are normalized to ensure that the features extracted from the signal are not influenced by loudness discrepancies [
48].
For recordings that vary in length, prior to feeding the data to ML or DL models, it is essential to make the data uniform. Shorter recordings are zero-padded to match the length of longer recordings, while longer recordings may be truncated. Moreover, to simulate real-world variability and improve model robustness, data augmentation techniques, such as time stretching and pitch shifting, may be employed [
11]. These techniques help generate additional training data by altering the pitch or duration of the recordings without changing their underlying characteristics.
Finally, after ensuring the consistency between samples, these preprocessed signals are suitable for further analysis. They can be fed directly into DL models for classification or regression tasks, or used to extract relevant features for subsequent processing in ML models. The choice between raw signal modeling or feature-based approaches depends on the complexity of the task, data availability, and interpretability requirements [
50].
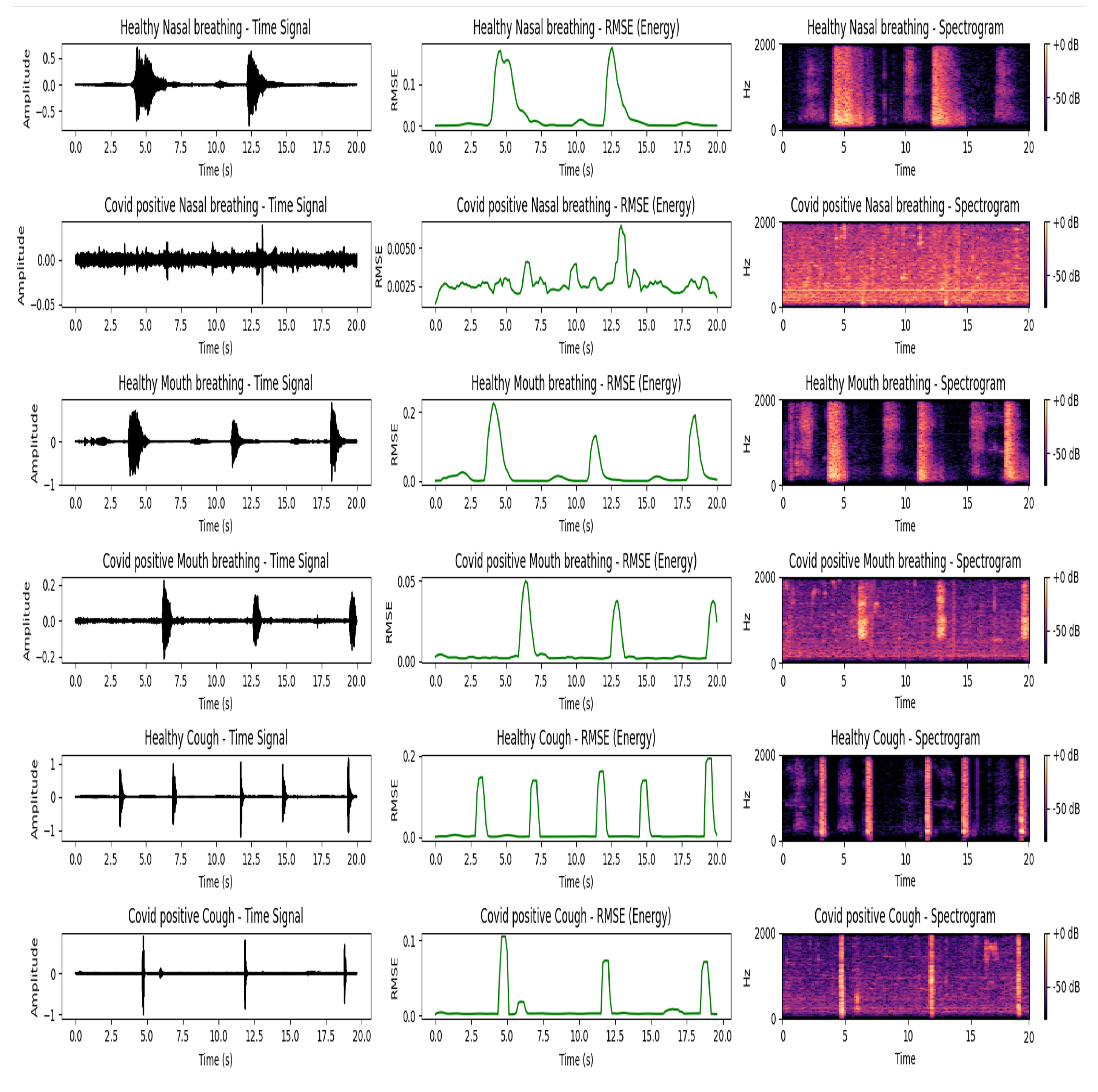
Figure 4 and
Figure 5 illustrate the characteristics of respiratory signals across different conditions and recording modes.
Figure 4 presents the time-domain waveforms, zero-crossing rates, and spectrograms of 5-second lung sound segments from the ICBHI dataset, highlighting clear temporal and spectral distinctions among Normal, Crackle, Wheeze, and Wheeze+Crackle classes. In contrast,
Figure 5 provides a comparative analysis of nasal breathing, mouth breathing, and coughing signals in the Sound-Dr dataset between a healthy and COVID-19 tested positive subject. Across all modalities, COVID-positive signals show reduced intensity, smoother Root Mean Square Energy (RMSE) profiles, and dampened spectral components which reflects the physiological impact of SARS-CoV-2 infection on the respiratory system. The figures clearly demonstrate key differences in the acoustic and energetic patterns of various respiratory events and pathologies.
3.2. Feature Extraction
Feature extraction is an important step in the analysis of biomedical audio signals. The process involves deriving meaningful representations from raw audio data to facilitate classification and analysis. This section discusses traditional handcrafted features and deep-learning-based feature extraction methods.
3.2.1. Time-Domain Features
Time-domain features are extracted directly from the raw audio signal and capture variations in amplitude and energy over time. Common time-domain features include:
signal envelope which indicates maximum amplitude variation;
zero-crossing rate (ZCR) measures the rate at which the signal changes sign and provides insights into the noisiness and periodicity of the signal;
Short-Time Energy (STE) computes the energy distribution over time, helping to distinguish between voiced and unvoiced segments. Another key amplitude-based feature is
shimmer, which measures amplitude variation and is often used to analyze voice instability [
12,
49].
3.2.2. Frequency-Domain Features
Frequency-domain analysis provides spectral characteristics of the signal by transforming it from the time domain using the Fourier Transform. Some commonly used frequency-domain features include:
spectral centroid, which measures spectral brightness by identifying dominant frequencies, and
spectral roll-off, which defines the energy distribution threshold, helping to differentiate between harmonic and noisy components.
Mel-Frequency Cepstral Coefficients (MFCCs) are widely used in speech and audio analysis as they model the power spectrum on the Mel scale, mimicking human auditory perception [
49].
3.2.3. Time-Frequency Representations
Time-frequency representations are used to analyze the transient nature of biomedical sounds. These methods preserve both spectral and temporal characteristics, making them suitable for non-stationary signals like lung sounds [
51].
The
Short-Time Fourier Transform (STFT) provides spectrograms representing signal evolution over time which makes it suitable for analyzing dynamic changes in lung sounds. The
Wavelet Transform captures multi-resolution time-frequency information, making it useful for transient sounds [
49]. Additionally,
Empirical Mode Decomposition (EMD) decomposes the signal
into intrinsic mode functions (IMFs)
and a residual component
, allowing for further feature extraction and analysis [
52], as presented in Equation (
1).
where
is the original signal (breathing signal in this case),
refers to the
i-th intrinsic mode functions (IMFs), and
is the residual component, which represents the trend or the remainder of the signal after extracting the IMFs. The process of obtaining the IMFs involves extracting oscillatory components from the signal using an iterative sifting process, which can be described in Equation (
2):
where
is the local mean of the signal, typically computed as the average of the upper and lower envelopes of the signal
, and
represents the
i-th IMF.
3.2.4. Statistical Features
Statistical analysis of the extracted features is essential for summarizing information over time.
Mean, variance, skewness, and kurtosis describe the general distribution of features in the time and frequency domain, and capture the essential characteristics of lung and oral sounds [
51].
Shannon entropy measures signal randomness. It provides insights about complexity and variability [
53], while the
moving average helps track long-term variations in the signal. Moving average is particularly useful for detecting gradual changes in respiratory patterns [
54].
In Shannon entropy for a component
with
possible states, each having a corresponding probability of
, the average amount of information gained from the component measurement
is defined by
, as presented in Equation (
3):
For a time series
, the moving average
is defined as shown in Equation (
4):
The extracted features provide meaningful representations of breathing signals and facilitate a more accurate classification and diagnosis of respiratory conditions. However, with the vast variety of available features, feature engineering plays a critical role in improving model performance.
Recent research highlights the importance of explainable artificial intelligence (XAI) in enhancing the robustness of respiratory sound classification models. XAI techniques help identify the most relevant features for detecting specific lung conditions. These approaches not only capture the spectral and temporal dynamics of respiratory sounds but also offer valuable insights into the decision-making process behind model predictions [
55]. For instance, Kok et al. [
56] demonstrated the importance of interpretable ML by using saliency maps and PowerSHAP for feature selection. They found that while traditional features such as mean and frequency are intuitive for clinicians, more abstract features such as skewness and kurtosis, which reflect the statistical distribution of sound, are also important for accurate analysis. Similarly, Shokouhmand et al. [
57] highlighted the relevance of features such as MFCCs, spectral centroid, ZCR, and signal intensity, which are essential for distinguishing between healthy and abnormal respiratory sounds. These features help capture the subtle variations in respiratory signals.
Moreover, Fernando et al. [
58] and Wanasinghe et al. [
59] demonstrated that combining multiple features, such as MFCCs, Mel spectrograms, and Chromagram, enables a more holistic representation of lung sounds. These combinations enhance model performance by addressing both spectral shape and temporal patterns. Kumar et al. [
60] further validated the importance of combining MFCC, Mel spectrogram, and Cochleogram features, showing that this fusion not only improves classification accuracy but also provides a more comprehensive view of the respiratory function. These findings highlight that certain features, particularly those capturing both spectral and temporal elements, are more effective in respiratory health assessment. These combinations are able to reflect the complex and dynamic nature of lung sounds associated with various respiratory conditions.
3.3. Datasets
In this section, we introduce several datasets that include a variety of respiratory sounds, ranging from auscultation-based lung and heart sounds to cough and oral breathing sounds.
Figure 6 shows the distribution of audio recordings across the datasets, revealing the relative proportions of different sound types. Below is a brief description of the relevant datasets studied.
Lung Sounds Dataset: This dataset contains recordings of lung sounds from seven respiratory conditions, including asthma, heart failure, pneumonia, bronchitis, pleural effusion, lung fibrosis, and COPD. It also includes normal breathing sounds, making it valuable for classifying pathological versus healthy lung sounds [
61].
ICBHI Respiratory Sound Database (2017): This dataset, recorded from 126 patients, contains a total of 5.5 h of respiratory sounds from chest auscultations, including 6898 respiratory cycles. It features distinct pathological sounds such as crackles (1864), wheezes (886), and both crackles and wheezes (506), allowing a detailed analysis of various respiratory abnormalities [
62].
Sound-Dr Dataset: Sound-Dr offers a reliable collection of human respiratory sounds, including coughing, oral breathing, and nasal breathing sounds, along with metadata related to clinical characteristics. This dataset supports the study of respiratory illnesses such as pneumonia and COVID-19 [
49].
SPRSound (SJTU Pediatric Respiratory Sound Database): This open-access dataset features respiratory sounds of lung auscultations from pediatric patients aged 1 month to 18 years, recorded at the pediatric respiratory department of Shanghai Children’s Medical Center using Yunting model II stethoscopes. It serves as a foundational resource for the study of respiratory conditions in children [
63].
Coswara Dataset: The Coswara dataset includes diverse oral respiratory sounds from both COVID-19 positive and non-COVID subjects. It contains various types of sounds, such as fast and slow breathing, deep and shallow coughing, sustained vowel phonation, and counting at different paces. It is particularly valuable for studying the respiratory effects associated with COVID-19 [
64].
HLS-CMDS (Heart and Lung Sounds Dataset Recorded from a Clinical Manikin using Digital Stethoscope): Recorded using a digital stethoscope from a clinical manikin, this dataset includes 210 recordings of heart and lung sounds, both individual and mixed. It covers a wide range of sounds, including normal and abnormal heart and lung sounds, such as murmurs, wheezing, and crackles, making it useful for AI-driven sound classification and disease detection [
65].
COUGHVID Dataset: The COUGHVID dataset contains over 25,000 crowdsourced cough recordings, representing a wide variety of participant ages, genders, geographic locations, and COVID-19 statuses. Over 2800 recordings have been labeled by medical professionals, facilitating research in cough-related audio classification tasks [
66].
Wheezing Recognition Dataset: This dataset focuses on wheezing detection using smartphone-recorded oral respiratory sounds from a pediatric population. It includes 95 recordings, categorized based on the presence or absence of wheezing [
44].
Respiratory Sound Classification Dataset (Crackles, Wheezes, Rhonchi): This dataset provides 1918 auscultation recordings of respiratory sounds. Categories include normal, crackles, wheezes, and rhonchi [
67].
COVID-19 Sounds Dataset: This dataset focuses on respiratory sounds from individuals with and without COVID-19, including coughs, oral breathing, and speech recordings. Although not publicly available, it plays an essential role in developing digital respiratory screening models for COVID-19 detection [
68].
There are several other datasets in the field of respiratory sound analysis, such as R.A.L.E (which includes oral breathing recordings and auscultations) [
69], Cambridge (oral) [
70], Virufy (oral) [
71], Novel Coronavirus Cough Database (NoCoCoDa) [
72] (oral), and the Computational Paralinguistic Challenge COVID-19 Cough Sub-challenge (ComParE-CCS) dataset [
73] (oral).
Table 3 provides some details about the demographics and sample sizes of each dataset. As detailed or exact descriptions may not be available, some datasets were not included in the pie chart distribution of
Figure 6.
4. Results and Discussion
In this section, we present the results (extracted from the reviewed papers) and discussion on the classification of lung auscultation sounds, cough-based diagnostics, and the acoustic analysis of breathing signals. The advancements demonstrate the effectiveness of ML and DL techniques in the diagnosis of respiratory diseases, with a particular focus on improving diagnostic accuracy, enabling early detection, and enhancing clinical decision making. We discuss relevant studies, methods, and results, followed by an exploration of the potential implications for future research and clinical applications.
4.1. Lung Auscultation Results
The classification of lung sounds has been extensively studied using ML and DL techniques, leveraging spectrogram-based feature extraction, self-supervised learning, and domain adaptation. Various models have been proposed to enhance the detection of respiratory anomalies by integrating wavelet transforms, CNNs, and attention mechanisms. As summarized in
Table 4, different approaches have yielded promising results, with studies achieving notable performance across various datasets and classification tasks.
For instance, Khan et al. [
74] demonstrated the effectiveness of combining autoencoders with LSTMs, achieving high specificity (94.16%) and sensitivity (89.56%) in an eight-class classification scenario, as well as strong results in binary and four-class tasks. Wu et al. [
75] employed STFT and wavelet-based features in a Bi-ResNet model. They reported accuracy of 77.81% and an F1-score of 71.05% on the ICBHI 2017 dataset. Meanwhile, Kim et al. [
76] introduced RepAugment, an approach that improved the classification of rare lung diseases using augmentation techniques tailored for respiratory sound data, showing specificity and sensitivity values of 82.47% and 40.55%, respectively.
In addition, Mang et al. [
77] explored the potential of Vision Transformers (ViTs) in lung sound classification. Their model demonstrates competitive performance when applied to cochleogram representations. Koshta et al. [
21] achieved the specificity of 99.4% in distinguishing asthma from COPD using Fourier decomposition of lung sounds.
Other studies, such as those by Mitsuke et al. [
22] and Gupta et al. [
24], focused on private datasets and reported high accuracies (90% and 95.2%, respectively). At the same time, some studies such as Rishabh et al. [
78] reported performance accuracy (74.08% for a 60–40 split) in the ICBHI dataset, providing further evidence of the diversity in model performance.
Table 4.
Performance of respiratory sound classification models. Accuracy, sensitivity, and specificity are abbreviated as Acc, Se, and Sp, respectively.
Table 4.
Performance of respiratory sound classification models. Accuracy, sensitivity, and specificity are abbreviated as Acc, Se, and Sp, respectively.
| Study | Model | Dataset | Performance |
|---|
| Dubey et al. [27] | SVM-LSTM + Bayesian Optimization | RALE database | Acc: 95.70% Wavelet bi-spectrum(WBS), 95.16% Wavelet bi-phase (WBP) |
| Moummad et al. [79] | Supervised Contrastive Learning (SCL) | ICBHI | Sp: 75.95%, Se: 39.15% |
| Bae et al. [80] | Audio spectrogram transformer (AST) Fine-tuning | ICBHI | Sp: 77.14%, Se: 41.97% |
| | AST (Patch-Mix Contrastive Learning) | ICBHI | Sp: 81.66%, Se: 43.07% |
| Wu et al. [75] | Improved Bi-ResNet | ICBHI | Acc: 77.81%, F1: 71.05% |
| Kim et al. [81] | AST-Stethoscope-Guided SCL (SG-SCL) | ICBHI | Sp: 79.87%, Se: 43.55% |
| | AST-stethoscope Domain Adversarial Training (DAT) | ICBHI | Sp: 77.11%, Se: 42.50% |
| Mang et al. [77] | CNN | ICBHI | Sp: , Se: |
| Wanasinghe et al. [59] | Stacked Mel, MFCC, and Chromagram + CNN | ICBHI, Lung Sound Dataset | Acc: 91.04% |
| Kim et al. [25] | Temporal Convolutional Network (TCN) | ICBHI | Acc: 92.93% |
| Rehan Khan et al. [74] | Autoencoder + LSTM | ICBHI | Sp: 94.16% (8-class), Se: 89.56% (8-class) |
| | | | Sp: 79.61% (4-class), Se: 78.55% (4-class) |
| | | | Sp: 85.61% (Binary-class), Se: 83.44% (Binary-class) |
| Shokouhmand et al. [57] | XGBoost | ICBHI | Sp: 94.57%, Se: 77.96%, ICBHI score: 86.27% |
| Koshta et al. [21] | FDM + DCT | Lung Sounds Dataset | Acc: 99.4% (Asthma vs. COPD) |
| Mitsuke et al. [22] | Frequency Feature Images + XGBoost | Private | Acc: 90% |
| Gupta et al. [24] | DeepRespNet (1D, 2D) | Private | Acc: 95.2% |
| Park et al. [23] | Ensemble SVM | Pediatric outpatient clinic (Private) | Acc: >80% |
| Kim et al. [76] | RepAugment pretrained on the cross-lingual speech (XLS-R-300M) model | ICBHI | Sp: 68.62 ± 6.53%, Se: 44.83 ± 4.46% |
| Kim et al. [76] | RepAugment (AST) | ICBHI | Sp: 82.47 ± 5.39%, Se: 40.55 ± 4.70% |
| Álvarez Casado et al. [26] | EMD + Spectral Analysis | ICBHI | Acc: 89% (binary), 72% (multi-class) |
| Rishabh et al. [78] | CNN | ICBHI | Acc: 74.08% (60–40), 75.04% (80–20) |
These studies highlight the growing diversity of methodologies in respiratory sound analysis. While CNN-based architectures remain widely adopted, emerging techniques such as hybrid models, domain adaptation strategies, and attention-based networks are showing promising advancements.
Table 4 provides a detailed comparison of recent classification models and their reported performance, illustrating the wide range of approaches and datasets used across studies.
4.2. Cough Classification Results
AI-based cough sound analysis has been widely explored for non-invasive respiratory disease diagnostics, particularly for COVID-19 detection. Several studies have used DL approaches such as CNNs, decision forests, and feature fusion techniques to improve classification accuracy.
As shown in
Table 5, Kim and Lee [
82] employed Xception with variable frequency complex demodulation (VFCDM) images, achieving 87% accuracy and an Area under the Receiver Operating Characteristic (ROC) curve (AUC) of 0.82 across the Cambridge, Coswara, and Virufy datasets. Islam et al. [
83] introduced a deep neural decision forest classifier. Their model trained multiple neural decision trees simultaneously and achieved 97% accuracy and an AUC of 0.97, leveraging feature fusion and Bayesian optimization across a combined set of datasets, including Cambridge, Coswara, COUGHVID, Virufy, and NoCoCoDa. Sunitha et al. [
29] evaluated Dilated Temporal Convolutional Networks (DTCN) on the COUGHVID dataset, obtaining an accuracy of 76.7%. Aytekin et al. [
8] proposed a hierarchical spectrogram transformer (HST) to capture multiscale spectral features, achieving an AUC greater than 0.90, which surpassed conventional CNN models in the Cambridge and COUGHVID datasets.
Additionally, Pavel and Ciocoiu [
84] explored Bag-of-Words (BoW) approaches, with input fusion and sparse encoding on the COUGHVID dataset achieving 72.7% accuracy and an AUC of 0.82. They also applied this approach to the COVID-19 Sounds dataset, obtaining a lower accuracy of 60.3% and an AUC of 0.65. Atmaja et al. [
85] demonstrated the use of CNN14 + Hyperparameter optimization (HPO) on the Coswara, COUGHVID, and the Computational Paralinguistic Challenge COVID-19 Cough Sub-challenge (ComParE-CCS) datasets, achieving 88.19% accuracy, though AUC values were not reported. Yan et al. [
86] employed SVM and LSTM classifiers on multiple datasets, including Cambridge, Coswara, and Saarbrücken Voice Disorders (SVD), reporting an accuracy of 81.1%, with no AUC values provided.
These studies underscore the effectiveness of AI-driven methods for acoustic diagnostics, particularly in the context of COVID-19 and other respiratory diseases. The use of different feature representation techniques, such as Bag-of-Words (BoW) and hierarchical transformers, suggests promising avenues for improving cough sound classification accuracy. A comprehensive comparison of cough classification models and their performance metrics is presented in
Table 5.
4.3. Analysis of Breathing Signals
Traditional methods of analyzing breathing signals such as lung sound auscultation have proven effective in diagnosing respiratory conditions. However, the analysis of oral and nasal breathing remains relatively underexplored, despite their potential for providing critical diagnostic information. Studies have proven that nasal and oral breathing signals have different characteristics [
45]. For instance, in the study by Sturludóttir et al., it is mentioned that the oral pressure signal shows a significant amplitude increase from the baseline, whereas the nasal pressure signal maintains a lower amplitude and remains more stable [
87].
Nasal breathing can indicate airway conditions such as obstructions or upper respiratory infections, serving as an early warning for respiratory issues. The study by Liu et al. [
88] highlighted the significance of nasal airflow features in detecting respiratory events. Key features such as the standard deviation and kurtosis of nasal airflow were found to be crucial for distinguishing between normal breathing, hypopnea, and apnea. Oral breathing, often linked with obstructive sleep apnea and chronic respiratory disorders, may offer complementary insights when analyzed alongside traditional lung sounds [
38]. Both forms of breathing influence the acoustic profile of respiratory sounds and may serve as biomarkers for early detection, yet the current literature on these signals evaluating pulmonary diseases is limited.
Recent advancements in DL algorithms have improved the detection of respiratory events in breathing sounds, enabling more accurate and reliable automated classification of pathological patterns. However, the performance of these models when applied to oral and nasal breathing remains understudied. When analyzing nasal and oral breathing, ML approaches can extract and evaluate features such as wheeze duration, crackle burst rate, and airflow harmonics to enhance diagnostic accuracy. These features can demonstrate airflow obstruction, secretion accumulation, and airway instability, all of which are relevant for detecting respiratory conditions. Furthermore, spectral analysis of breathing sounds enables the identification of pathological variations by examining frequency distribution, amplitude modulation, and temporal patterns [
89]. Addressing this gap requires more comprehensive studies to explore the contributions of oral and nasal breathing signals to respiratory diagnostics. Nasal breathing may reveal subtle changes in airway resistance or obstruction not captured by lung auscultation alone. Oral breathing can also indicate alterations in lung function or increased effort due to airway dysfunction. A holistic approach that incorporates all breathing modalities could improve monitoring of conditions such as asthma, COPD, and COVID-19.
Table 6 summarizes various methods used in respiratory sound analysis, highlighting their limitations and identifying key opportunities for improvement through advanced technologies and approaches.
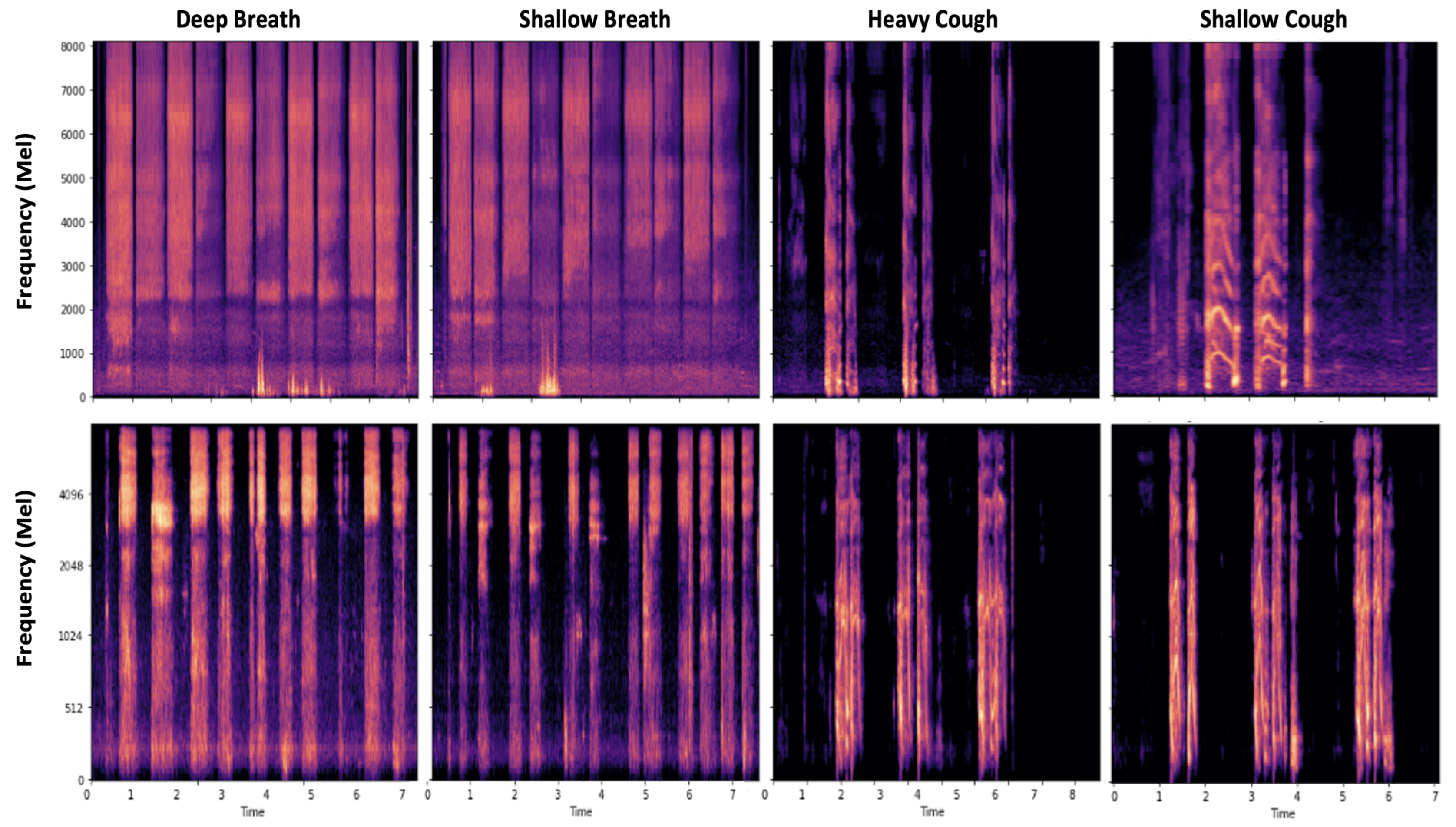
Figure 7 shows the spectrogram of a healthy participant and one with COVID-19. As can be seen, the patterns of breathing and cough are clearly different, highlighting the importance of these variations for respiratory diagnostics.
By combining diverse breathing modalities, clinicians can gain a comprehensive understanding of disease progression and improve diagnostic accuracy. Shifting from stethoscopes to microphone-based systems can offer a wider frequency range analysis, enhance sensitivity, and enable non-contact monitoring. This is especially beneficial in telemedicine, where continuous and real-time monitoring of respiratory conditions is essential. AI-powered microphone systems can automate the detection of abnormal respiratory sounds, providing more timely and accurate diagnostic support. These systems help overcome limitations such as inter-observer variability found in traditional auscultation analysis.
4.4. Clinical Applications and Real-World Challenges
AI has demonstrated significant potential in enhancing diagnostics within respiratory medicine. AI models enable early detection, classification, and monitoring of respiratory conditions by recognizing complex patterns across diverse modalities such as auscultation sounds, medical imaging, and spirometry [
22,
43,
51]. Also, XAI models offer interpretable support by identifying biomarkers for personalized diagnostics [
55]. Interpretability can increase model reliability and assist clinicians in making informed decisions. DL and hybrid models also demonstrate high performance in distinguishing overlapping adventitious lung sounds which are often difficult to differentiate manually [
26]. These capabilities are particularly valuable for enhancing remote care through digital stethoscopes and telemedicine platforms.
Despite these advances, translating AI from research to real-world clinical environments involves addressing several technical, infrastructural, and equity-related challenges. Due to inconsistent recording protocols, heterogeneous devices, or underrepresentation of certain populations, models are mostly trained on limited or biased datasets. These models often struggle to generalize across clinical settings. Moreover, the lack of standardized, high-quality annotated datasets limits reproducibility and cross-institutional benchmarking which will undermine the expected performance.
Recent studies [
90,
91] suggest that DL can reduce inter-listener variability and improve diagnostic consistency, but these benefits rely on robust data pipelines, standardized acquisition protocols, and clinician training. Real-time deployment of complex multimodal models such as large language models continues to be a challenge since it demands substantial computational resources [
92]. Although cloud-based solutions offer scalability, they introduce concerns around vendor dependency and data security, especially in low-resource settings. To address these challenges, future development should focus on creating equitable datasets, fairness-aware designs, scalable model deployment, and privacy-preserving learning methods. By tackling these issues, AI-driven respiratory sound analysis can move from experimental concepts to widely adopted, trustworthy, and clinically integrated tools that improve respiratory care outcomes.
4.5. Ethical Considerations and Data Privacy
The integration of AI in respiratory sound analysis for telemedicine and remote monitoring introduces significant ethical and privacy-related challenges. A primary concern is the need to protect sensitive patient data collected through remote auscultation tools, which may include highly identifiable audio recordings of breath and cough sounds. Ensuring privacy and upholding ethical standards are essential for building trust and complying with regulations [
93]. Data privacy is a central ethical concern in the deployment of AI for respiratory sound analysis. The remote and often continuous nature of data collection in telemedicine heightens the risk of unauthorized access, data leakage, or misuse. Given that respiratory sounds are part of a patient’s medical profile, their collection and storage must follow strict privacy frameworks. These regulations mandate that patients be informed about how their data are used, stored, and shared, and require explicit consent for processing personal health information [
94].
To address these privacy concerns, federated learning (FL) has emerged as a viable privacy-preserving approach. In FL, AI models are trained locally on devices where data are collected such as smartphones or medical sensors without the need to transfer raw patient data to centralized servers [
95,
96]. Instead, only model parameters or updates are shared and aggregated, significantly reducing the risk of compromising individual privacy [
96]. This decentralized paradigm allows for real-time AI-driven diagnostics while minimizing the exposure of sensitive data. Another ethical component is informed consent. Patients must be clearly informed about what data are being collected, for what purpose, how they will be stored, and who will have access to them. This is particularly important in telemedicine, where patients may not have direct interactions with healthcare professionals when consenting to data use. Transparent communication ensures that patients retain autonomy over their data and fosters trust in AI-enabled healthcare services [
94].
Emerging technologies such as blockchain are also being explored to enhance the ethical handling of medical data. Blockchain provides a decentralized, immutable ledger for logging data transactions, which can be used to ensure that access to respiratory sound data is auditable and traceable. When combined with FL, blockchain can offer both secure data governance and privacy preservation in remote healthcare environments [
97]. Thus, although AI holds great promise for improving respiratory diagnostics through telemedicine, its ethical integration demands robust safeguards for data privacy, secure data transmission protocols, and clear patient consent mechanisms. Adopting privacy-preserving frameworks such as FL and exploring secure technologies like blockchain are critical steps toward responsible and ethical AI deployment in healthcare [
93].
4.6. Key Takeaways
Analysis of breathing signals, particularly through lung sound auscultation, has long been a cornerstone in the diagnosis of respiratory conditions. However, in fields such as sleep apnea and snore and cough detection, research has shown that nasal and oral breathing sounds have the potential to offer critical insights into respiratory health. These breathing patterns provide additional biomarkers for conditions such as asthma, COPD, and upper respiratory infections. The following are the key takeaways from recent research and advancements in this area:
The analysis of breathing signals through lung sound auscultation is one of the most important methods in diagnosing respiratory conditions. However, nasal and oral breathing also provide valuable diagnostic insights.
Nasal breathing can indicate airway conditions such as obstruction or upper respiratory infections, while oral breathing is often associated with chronic disorders such as obstructive sleep apnea and COPD [
38,
45,
88].
The study of nasal and oral breathing signals for respiratory disease detection remains underexplored, and their contribution to respiratory diagnostics has not been systematically analyzed.
Traditional lung auscultation may not capture subtle changes in airway resistance or lung function that nasal and oral breathing can reveal. Nasal airflow tends to be more stable, while oral breathing signals show more variability [
87].
ML and DL techniques have significantly improved the classification accuracy of respiratory sounds and automated the detection of pathological patterns [
38,
82].
AI-powered microphone systems are particularly useful in telemedicine. They offer continuous, real-time monitoring and reduce inter-observer variability.
A comprehensive approach incorporating nasal and oral breathing, in addition to auscultation, could improve the early detection of conditions such as asthma, COPD, and upper respiratory infections.
More studies and publicly available datasets are needed that explore the contribution of nasal and oral breathing signals to respiratory diagnostics to improve early detection and disease monitoring.
The shift from traditional stethoscopes to microphone-based systems, especially with AI integration, offers non-invasive, detailed, and continuous monitoring of respiratory health. Microphone-based systems will facilitate personalized healthcare interventions.
AI improves respiratory diagnostics, but clinical adoption faces challenges including data inconsistency, limited generalizability, and lack of standardized datasets.
Ethical AI use in telemedicine requires strong data privacy, informed consent, and the adoption of solutions such as federated learning and blockchain.
5. Conclusions
This review emphasizes the importance of oral and nasal breathing sounds as additional sources of valuable diagnostic information in respiratory disease detection. Although significant strides have been made in the analysis of lung sounds, there remains a notable gap in the systematic study of oral and nasal breathing signals. The transition from stethoscopes to microphone-based solutions enables more consistent and scalable respiratory sound analysis, facilitating the development of wearable and smartphone-based monitoring systems.
Moreover, the integration of both traditional feature extraction methods and modern ML and DL techniques presents a promising method for improving the accuracy and efficiency of respiratory diagnostics. These models have further enhanced our ability to process complex, high-dimensional data, providing more accurate and automated classification systems. The use of hybrid models, transfer learning, and integration of AI with microphone-based systems present exciting opportunities for real-time, remote respiratory monitoring, especially in underserved areas or during health crises like the COVID-19 pandemic.
Future research should focus on expanding the datasets to include diverse breathing patterns by creating nasal and oral breathing datasets. These datasets should capture a wide range of demographics, environments, respiratory conditions, and recording scenarios to ensure robustness and generalizability. Metadata such as age, gender, health status, and recording device should also be included to support model training and evaluation. Exploring their diagnostic potential, new models can be developed that can seamlessly incorporate all forms of respiratory sounds. Additionally, future efforts should aim to standardize data collection protocols and promote open-access repositories to accelerate collaboration and innovation in the field. The integration of telemedicine with AI-driven respiratory analysis enables individuals to record their breathing sounds via smartphones or wearable devices and receive instant diagnostic feedback. This not only improves access to healthcare but also facilitates large-scale data collection. Federated learning frameworks can be used to decentralize data from multiple users and train robust and privacy-preserving models without sharing sensitive health information. Such approaches contribute to the creation of rich and diverse datasets that help in the development of more accurate and generalizable diagnostic systems. By bridging the gaps, we can enhance clinical decision making and enable more comprehensive, non-invasive monitoring of respiratory health.
Author Contributions
Conceptualization, S.S.; methodology, S.S.; software, S.S.; validation, S.B. and M.F.; formal analysis, S.B. and M.F.; investigation, S.S.; resources, S.B. and M.F.; data curation, S.S.; writing—original draft preparation, S.S.; writing—review and editing, S.B. and M.F.; visualization, S.S., S.B., and M.F.; supervision, S.B. and M.F.; project administration, S.B and M.F. All authors have read and agreed to the final version of the manuscript.
Funding
This research is supported by the NIH New R01 Award at the Office of Research of Purdue University.
Data Availability Statement
The performance analysis and comparison was conducted using data from published articles reviewed in this study. Additional details are available upon request from the corresponding author. This review protocol was not registered.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Phyu, S.L.; Turnbull, C.; Talbot, N. Basic respiratory physiology. Medicine 2023, 51, 679–683. [Google Scholar] [CrossRef]
- Battu, V.V.; Khiran Kumar, C.; Kalaiselvi Geetha, M. Lung Disease Classification Based on Lung Sounds—A Review. In Computational Intelligence in Healthcare Informatics; Springer: Singapore, 2024; pp. 233–250. [Google Scholar]
- World Health Organization. The Top 10 Causes of Death. 2024. Last updated: 7 August 2024. Available online: https://www.who.int/news-room/fact-sheets/detail/the-top-10-causes-of-death (accessed on 16 February 2025).
- Omotayo, O.; Maduka, C.P.; Muonde, M.; Olorunsogo, T.O.; Ogugua, J.O. The rise of non-communicable diseases: A global health review of challenges and prevention strategies. Int. Med Sci. Res. J. 2024, 4, 74–88. [Google Scholar] [CrossRef]
- Hebbink, R.H.; Wessels, B.J.; Hagmeijer, R.; Jain, K. Computational analysis of human upper airway aerodynamics. Med Biol. Eng. Comput. 2023, 61, 541–553. [Google Scholar] [CrossRef] [PubMed]
- Zarandah, Q.M.; Daud, S.M.; Abu-Naser, S.S. A systematic literature review of machine and deep learning-based detection and classification methods for diseases related to the respiratory system. J. Theor. Appl. Inf. Technol. 2023, 101, 1273–1296. [Google Scholar]
- Gourisaria, M.K.; Agrawal, R.; Sahni, M.; Singh, P.K. Comparative analysis of audio classification with MFCC and STFT features using machine learning techniques. Discov. Internet Things 2024, 4, 1. [Google Scholar] [CrossRef]
- Aytekin, I.; Dalmaz, O.; Gonc, K.; Ankishan, H.; Saritas, E.U.; Bagci, U.; Celik, H.; Çukur, T. COVID-19 detection from respiratory sounds with hierarchical spectrogram transformers. IEEE J. Biomed. Health Inform. 2023, 28, 1273–1284. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Mendez, J.P.; Lal, A.; Herasevich, S.; Tekin, A.; Pinevich, Y.; Lipatov, K.; Wang, H.Y.; Qamar, S.; Ayala, I.N.; Khapov, I.; et al. Machine learning for automated classification of abnormal lung sounds obtained from public databases: A systematic review. Bioengineering 2023, 10, 1155. [Google Scholar] [CrossRef]
- Xu, X.; Sankar, R. Classification and Recognition of Lung Sounds Using Artificial Intelligence and Machine Learning: A Literature Review. Big Data Cogn. Comput. 2024, 8, 127. [Google Scholar] [CrossRef]
- Nguyen, T.; Pernkopf, F. Computational lung sound classification: A review. In State of the Art in Neural Networks and Their Applications; Elsevier: Amsterdam, The Netherlands, 2023; pp. 193–215. [Google Scholar]
- Naal-Ruiz, N.E.; Gonzalez-Rodriguez, E.A.; Navas-Reascos, G.; Romo-De Leon, R.; Solorio, A.; Alonso-Valerdi, L.M.; Ibarra-Zarate, D.I. Mouth sounds: A review of Acoustic Applications and methodologies. Appl. Sci. 2023, 13, 4331. [Google Scholar] [CrossRef]
- Vanegas, E.; Igual, R.; Plaza, I. Sensing systems for respiration monitoring: A technical systematic review. Sensors 2020, 20, 5446. [Google Scholar] [CrossRef]
- Soomro, A.M.; Naeem, A.B.; Rajwana, M.A.; Bashir, M.Y.; Senapati, B. Advancements in AI-Guided Analysis of Cough Sounds for COVID-19 Screening: A Comprehensive Review. J. Comput. Biomed. Inform. 2023, 5, 105–117. [Google Scholar]
- Seah, J.J.; Zhao, J.; Wang, D.Y.; Lee, H.P. Review on the advancements of stethoscope types in chest auscultation. Diagnostics 2023, 13, 1545. [Google Scholar] [CrossRef] [PubMed]
- Maldonado-Franco, A.; Giraldo-Cadavid, L.F.; Tuta-Quintero, E.; Bastidas Goyes, A.R.; Botero-Rosas, D.A. The Challenges of Spirometric Diagnosis of COPD. Can. Respir. J. 2023, 2023, 6991493. [Google Scholar] [CrossRef]
- Balachandran, J. Lung Oscillometry: A Practical Solution for Overcoming Spirometry Challenges. J. Adv. Lung Health 2025, 5, 72–77. [Google Scholar] [CrossRef]
- Sarkar, S.; Jadhav, U.; Ghewade, B.; Sarkar, S.; Wagh, P.; Jadhav, U. Oscillometry in lung function assessment: A comprehensive review of current insights and challenges. Cureus 2023, 15, e47935. [Google Scholar] [CrossRef]
- Tárnoki, D.L.; Karlinger, K.; Ridge, C.A.; Kiss, F.J.; Györke, T.; Grabczak, E.M.; Tárnoki, Á.D. Lung imaging methods: Indications, strengths and limitations. Breathe 2024, 20, 230127. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.; Hyon, Y.; Lee, S.; Woo, S.D.; Ha, T.; Chung, C. The coming era of a new auscultation system for analyzing respiratory sounds. BMC Pulm. Med. 2022, 22, 119. [Google Scholar] [CrossRef]
- Koshta, V.; Singh, B.K.; Behera, A.K.; Ranganath, T. Fourier Decomposition Based Automated Classification of Healthy, COPD and Asthma Using Single Channel Lung Sounds. IEEE Trans. Med. Robot. Bionics 2024, 6, 1270–1284. [Google Scholar] [CrossRef]
- Mitsuke, T.; Shimakawa, H.; Harada, F. Diagnosis Through Adventitious Sounds Detection and Respiratory Phases Identification Using XGBoost. In Proceedings of the 2024 9th International Conference on Frontiers of Signal Processing (ICFSP), Paris, France, 12–14 September 2024; pp. 21–25. [Google Scholar]
- Park, J.S.; Kim, K.; Kim, J.H.; Choi, Y.J.; Kim, K.; Suh, D.I. A machine learning approach to the development and prospective evaluation of a pediatric lung sound classification model. Sci. Rep. 2023, 13, 1289. [Google Scholar] [CrossRef]
- Gupta, R.; Singh, R.; Travieso-González, C.M.; Burget, R.; Dutta, M.K. DeepRespNet: A deep neural network for classification of respiratory sounds. Biomed. Signal Process. Control 2024, 93, 106191. [Google Scholar] [CrossRef]
- Kim, Y.; Camacho, D.; Choi, C. Real-time multi-class classification of respiratory diseases through dimensional data combinations. Cogn. Comput. 2024, 16, 776–787. [Google Scholar] [CrossRef]
- Casado, C.Á.; Cañellas, M.L.; Pedone, M.; Wu, X.; Nguyen, L.; López, M.B. Respiratory Disease Classification and Biometric Analysis Using Biosignals from Digital Stethoscopes. In Proceedings of the 2024 32nd European Signal Processing Conference (EUSIPCO), Lyon, France, 26–30 August 2024; pp. 1556–1560. [Google Scholar]
- Dubey, R.; Bodade, R.; Dubey, D. Efficient classification of the adventitious sounds of the lung through a combination of SVM-LSTM-Bayesian optimization algorithm with features based on wavelet bi-phase and bi-spectrum. Res. Biomed. Eng. 2023, 39, 349–363. [Google Scholar] [CrossRef]
- Faezipour, M.; Abuzneid, A. Smartphone-based self-testing of COVID-19 using breathing sounds. Telemed. E-Health 2020, 26, 1202–1205. [Google Scholar] [CrossRef] [PubMed]
- Sunitha, G.; Arunachalam, R.; Abd-Elnaby, M.; Eid, M.M.; Rashed, A.N.Z. A comparative analysis of deep neural network architectures for the dynamic diagnosis of COVID-19 based on acoustic cough features. Int. J. Imaging Syst. Technol. 2022, 32, 1433–1446. [Google Scholar] [CrossRef] [PubMed]
- Ghrabli, S.; Elgendi, M.; Menon, C. Identifying unique spectral fingerprints in cough sounds for diagnosing respiratory ailments. Sci. Rep. 2024, 14, 593. [Google Scholar] [CrossRef] [PubMed]
- Saeed, T.; Ijaz, A.; Sadiq, I.; Qureshi, H.N.; Rizwan, A.; Imran, A. An AI-Enabled bias-free respiratory disease diagnosis model using cough audio. Bioengineering 2024, 11, 55. [Google Scholar] [CrossRef]
- Manzella, F.; Pagliarini, G.; Sciavicco, G.; Stan, I.E. The voice of COVID-19: Breath and cough recording classification with temporal decision trees and random forests. Artif. Intell. Med. 2023, 137, 102486. [Google Scholar] [CrossRef]
- Vodnala, N.; Yarlagadda, P.S.; Ch, M.; Sailaja, K. Novel Deep Learning Approaches to Differentiate Asthma and COPD Based on Cough Sounds. In Proceedings of the 2024 Parul International Conference on Engineering and Technology (PICET), Vadodara, India, 3–4 May 2024; pp. 1–4. [Google Scholar]
- Kilic, M.; Barua, P.D.; Keles, T.; Yildiz, A.M.; Tuncer, I.; Dogan, S.; Baygin, M.; Tuncer, T.; Kuluozturk, M.; Tan, R.S.; et al. GCLP: An automated asthma detection model based on global chaotic logistic pattern using cough sounds. Eng. Appl. Artif. Intell. 2024, 127, 107184. [Google Scholar] [CrossRef]
- Almazaydeh, L.; Faezipour, M.; Elleithy, K. A neural network system for detection of obstructive sleep apnea through SpO2 signal features. Int. J. Adv. Comput. Sci. Appl. 2012, 3. [Google Scholar] [CrossRef]
- Almazaydeh, L.; Elleithy, K.; Faezipour, M.; Abushakra, A. Apnea detection based on respiratory signal classification. Procedia Comput. Sci. 2013, 21, 310–316. [Google Scholar] [CrossRef]
- Mozafari, M.; Law, A.J.; Goubran, R.A.; Green, J.R. Respiratory Rate Estimation from Thermal Video Data Using Spatio-Temporal Deep Learning. Sensors 2024, 24, 6386. [Google Scholar] [CrossRef] [PubMed]
- Del Regno, K.; Vilesov, A.; Armouti, A.; Harish, A.B.; Can, S.E.; Kita, A.; Kadambi, A. Thermal imaging and radar for remote sleep monitoring of breathing and apnea. arXiv 2024, arXiv:2407.11936. [Google Scholar]
- Le, V.L.; Kim, D.; Cho, E.; Jang, H.; Reyes, R.D.; Kim, H.; Lee, D.; Yoon, I.Y.; Hong, J.; Kim, J.W. Real-time detection of sleep apnea based on breathing sounds and prediction reinforcement using home noises: Algorithm development and validation. J. Med. Internet Res. 2023, 25, e44818. [Google Scholar] [CrossRef]
- Yook, S.; Kim, D.; Gupte, C.; Joo, E.Y.; Kim, H. Deep learning of sleep apnea-hypopnea events for accurate classification of obstructive sleep apnea and determination of clinical severity. Sleep Med. 2024, 114, 211–219. [Google Scholar] [CrossRef]
- Lin, H.H.; Chen, C.I.; Lee, W.C. Automated Sleep Apnea Detection based on XGBoost Model using Single-Lead ECG and Respiratory Signal. In Proceedings of the 2024 8th International Conference on Biomedical Engineering and Applications (ICBEA), Tokyo, Japan, 18–21 March 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 108–112. [Google Scholar]
- Jacob, D.; Kokil, P.; Subramanian, S.; Thiruvengadam, J. Decoding Sleep: Microphone-Based Snoring Analysis using Embedded Machine Learning for Obstructive Sleep Apnea Detection. In Proceedings of the 2024 Tenth International Conference on Bio Signals, Images, and Instrumentation (ICBSII), Chennai, India, 20–22 March 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Chen, Z.L.; Yan, Y.Z.; Yu, H.Y.; Wang, Q.B.; Wang, W.; Zhong, M. Influence of compliance and resistance of the test lung on the accuracy of the tidal volume delivered by the ventilator. BMC Pulm. Med. 2024, 24, 498. [Google Scholar] [CrossRef]
- Bokov, P.; Mahut, B.; Flaud, P.; Delclaux, C. Wheezing recognition algorithm using recordings of respiratory sounds at the mouth in a pediatric population. Comput. Biol. Med. 2016, 70, 40–50. [Google Scholar] [CrossRef] [PubMed]
- Purnima, B.; Sriraam, N.; Shashank, C.; Mohith, M.; Gagan, M.; Senthilkumar, T. Assessment of Breathing Variations to Recognize Respiratory Disorders. In Proceedings of the 2024 International Conference on Intelligent and Innovative Technologies in Computing, Electrical and Electronics (IITCEE), Bangalore, India, 24–25 January 2024; pp. 1–5. [Google Scholar]
- Shen, S.; Zhou, Q.; Chen, G.; Fang, Y.; Kurilova, O.; Liu, Z.; Li, S.; Chen, J. Advances in wearable respiration sensors. Mater. Today 2024, 72, 140–162. [Google Scholar] [CrossRef]
- Ren, H.; Li, Y.; Zhang, H.; Hu, Z.; Wang, J.; Song, Y.; Su, K.; Ding, G.; Liu, H.; Yang, Z. A flexible and dual-channel sensing system for long-term nasal and oral respiration simultaneously monitoring. IEEE Sens. J. 2023, 23, 28129–28140. [Google Scholar] [CrossRef]
- Fava, A.; Dianat, B.; Bertacchini, A.; Manfredi, A.; Sebastiani, M.; Modena, M.; Pancaldi, F. Pre-processing techniques to enhance the classification of lung sounds based on deep learning. Biomed. Signal Process. Control 2024, 92, 106009. [Google Scholar] [CrossRef]
- Hoang, T.V.; Nguyen, Q.; Nguyen, Q.C.; Nguyen, X.P.; Nguyen, H. Sound-Dr: Reliable Sound Dataset and Baseline Artificial Intelligence System for Respiratory Illnesses. In Proceedings of the PHM Society Asia-Pacific Conference, Tokyo, Japan, 11–14 September 2023; Volume 4. [Google Scholar]
- Ciobanu-Caraus, O.; Aicher, A.; Kernbach, J.M.; Regli, L.; Serra, C.; Staartjes, V.E. A critical moment in machine learning in medicine: On reproducible and interpretable learning. Acta Neurochir. 2024, 166, 14. [Google Scholar] [CrossRef]
- Huang, D.M.; Huang, J.; Qiao, K.; Zhong, N.S.; Lu, H.Z.; Wang, W.J. Deep learning-based lung sound analysis for intelligent stethoscope. Mil. Med Res. 2023, 10, 44. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Li, J.; Yan, H.; Yan, X. Low-frequency ultrasound thoracic signal processing based on music algorithm and EMD wavelet thresholding. IEEE Access 2023, 11, 73912–73921. [Google Scholar] [CrossRef]
- Sánchez-Dehesa, J.; Arias-Gonzalez, J.R. Characterization of avoided crossings in acoustic superlattices: The Shannon entropy in acoustics. Front. Phys. 2022, 10, 971171. [Google Scholar] [CrossRef]
- Wang, B.; Shen, Y.; Yan, X.; Kong, X. An autoregressive integrated moving average and long short-term memory (ARIM-LSTM) hybrid model for multi-source epidemic data prediction. PeerJ Comput. Sci. 2024, 10, e2046. [Google Scholar] [CrossRef]
- Chen, Z.; Liang, N.; Li, H.; Zhang, H.; Li, H.; Yan, L.; Hu, Z.; Chen, Y.; Zhang, Y.; Wang, Y.; et al. Exploring explainable AI features in the vocal biomarkers of lung disease. Comput. Biol. Med. 2024, 179, 108844. [Google Scholar] [CrossRef]
- Kok, T.T.; Morales, J.; Deschrijver, D.; Blanco-Almazán, D.; Groenendaal, W.; Ruttens, D.; Smeets, C.; Mihajlović, V.; Ongenae, F.; Van Hoecke, S. Interpretable machine learning models for COPD ease of breathing estimation. Med. Biol. Eng. Comput. 2025, 63, 1481–1495. [Google Scholar] [CrossRef] [PubMed]
- Shokouhmand, S.; Rahman, M.M.; Faezipour, M.; Bhatt, S. Adventitious Pulmonary Sound Detection: Leveraging SHAP Explanations and Gradient Boosting Insights. In Proceedings of the 2024 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 15–19 July 2024; pp. 1–4. [Google Scholar]
- Fernando, T.; Sridharan, S.; Denman, S.; Ghaemmaghami, H.; Fookes, C. Robust and interpretable temporal convolution network for event detection in lung sound recordings. IEEE J. Biomed. Health Inform. 2022, 26, 2898–2908. [Google Scholar] [CrossRef]
- Wanasinghe, T.; Bandara, S.; Madusanka, S.; Meedeniya, D.; Bandara, M.; Díez, I.D.L.T. Lung sound classification with multi-feature integration utilizing lightweight CNN model. IEEE Access 2024, 12, 21262–21276. [Google Scholar] [CrossRef]
- Rishabh; Kumar, D.; Meena, Y.; Singh, K. Respiratory sound classification utilizing human auditory-based feature extraction. Phys. Scr. 2025, 100, 046003. [Google Scholar] [CrossRef]
- Fraiwan, M.; Fraiwan, L.; Khassawneh, B.; Ibnian, A. A dataset of lung sounds recorded from the chest wall using an electronic stethoscope. Data Brief 2021, 35, 106913. [Google Scholar] [CrossRef]
- Rocha, B.; Filos, D.; Mendes, L.; Vogiatzis, I.; Perantoni, E.; Kaimakamis, E.; Natsiavas, P.; Oliveira, A.; Jácome, C.; Marques, A.; et al. A respiratory sound database for the development of automated classification. In Proceedings of the Precision Medicine Powered by pHealth and Connected Health: ICBHI 2017, Thessaloniki, Greece, 18–21 November 2017; Springer: Berlin/Heidelberg, Germany, 2018; pp. 33–37. [Google Scholar]
- Li, Y. SPRSound: Open-Source SJTU Paediatric Respiratory Sound Database. TechRxiv 2023. [Google Scholar] [CrossRef]
- Bhattacharya, D.; Sharma, N.K.; Dutta, D.; Chetupalli, S.R.; Mote, P.; Ganapathy, S.; Chandrakiran, C.; Nori, S.; Suhail, K.; Gonuguntla, S.; et al. Coswara: A respiratory sounds and symptoms dataset for remote screening of SARS-CoV-2 infection. Sci. Data 2023, 10, 397. [Google Scholar] [CrossRef] [PubMed]
- Torabi, Y.; Shirani, S.; Reilly, J.P. Manikin-Recorded Cardiopulmonary Sounds Dataset Using Digital Stethoscope. arXiv 2024, arXiv:2410.03280. [Google Scholar]
- Orlandic, L.; Teijeiro, T.; Atienza, D. The COUGHVID crowdsourcing dataset, a corpus for the study of large-scale cough analysis algorithms. Sci. Data 2021, 8, 156. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.; Hyon, Y.; Jung, S.S.; Lee, S.; Yoo, G.; Chung, C.; Ha, T. Respiratory sound classification for crackles, wheezes, and rhonchi in the clinical field using deep learning. Sci. Rep. 2021, 11, 1–11. [Google Scholar] [CrossRef]
- Xia, T.; Spathis, D.; Ch, J.; Grammenos, A.; Han, J.; Hasthanasombat, A.; Bondareva, E.; Dang, T.; Floto, A.; Cicuta, P.; et al. COVID-19 sounds: A large-scale audio dataset for digital respiratory screening. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), Virtual, 6–14 December 2021. [Google Scholar]
- The R.A.L.E Repository. Available online: http://www.rale.ca/ (accessed on 26 February 2025).
- Brown, C.; Chauhan, J.; Grammenos, A.; Han, J.; Hasthanasombat, A.; Spathis, D.; Xia, T.; Cicuta, P.; Mascolo, C. Exploring automatic diagnosis of COVID-19 from crowdsourced respiratory sound data. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 23–7 August 2020; pp. 3474–3484. [Google Scholar]
- Chaudhari, G.; Jiang, X.; Fakhry, A.; Han, A.; Xiao, J.; Shen, S.; Khanzada, A. Virufy: Global applicability of crowdsourced and clinical datasets for AI detection of COVID-19 from cough. arXiv 2020, arXiv:2011.13320. [Google Scholar]
- Cohen-McFarlane, M.; Goubran, R.; Knoefel, F. Novel coronavirus cough database: NoCoCoDa. IEEE Access 2020, 8, 154087–154094. [Google Scholar] [CrossRef]
- Schuller, B.W.; Batliner, A.; Bergler, C.; Mascolo, C.; Han, J.; Lefter, I.; Kaya, H.; Amiriparian, S.; Baird, A.; Stappen, L.; et al. The INTERSPEECH 2021 computational paralinguistics challenge: COVID-19 cough, COVID-19 speech, escalation & primates. arXiv 2021, arXiv:2102.13468. [Google Scholar]
- Khan, R.; Khan, S.U.; Saeed, U.; Koo, I.S. Auscultation-Based Pulmonary Disease Detection through Parallel Transformation and Deep Learning. Bioengineering 2024, 11, 586. [Google Scholar] [CrossRef]
- Wu, C.; Ye, N.; Jiang, J. Classification and Recognition of Lung Sounds Based on Improved Bi-ResNet Model. IEEE Access 2024, 12, 73079–73094. [Google Scholar] [CrossRef]
- Kim, J.W.; Toikkanen, M.; Bae, S.; Kim, M.; Jung, H.Y. RepAugment: Input-Agnostic Representation-Level Augmentation for Respiratory Sound Classification. arXiv 2024, arXiv:2405.02996. [Google Scholar]
- Mang, L.D.; González Martínez, F.D.; Martinez Muñoz, D.; García Galán, S.; Cortina, R. Classification of Adventitious Sounds Combining Cochleogram and Vision Transformers. Sensors 2024, 24, 682. [Google Scholar] [CrossRef] [PubMed]
- Rishabh; Kumar, D. Multi spectral feature extraction to improve lung sound classification using CNN. In Proceedings of the 2023 10th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 23–24 March 2023; pp. 186–191. [Google Scholar]
- Moummad, I.; Farrugia, N. Supervised contrastive learning for respiratory sound classification. arXiv 2022, arXiv:2210.16192v1. [Google Scholar]
- Bae, S.; Kim, J.W.; Cho, W.Y.; Baek, H.; Son, S.; Lee, B.; Ha, C.; Tae, K.; Kim, S.; Yun, S.Y. Patch-mix contrastive learning with audio spectrogram transformer on respiratory sound classification. arXiv 2023, arXiv:2305.14032. [Google Scholar]
- Kim, J.W.; Bae, S.; Cho, W.Y.; Lee, B.; Jung, H.Y. Stethoscope-Guided Supervised Contrastive Learning for Cross-Domain Adaptation on Respiratory Sound Classification. In Proceedings of the ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 1431–1435. [Google Scholar]
- Kim, J.; Lee, J. Cough Sound Based Deep Learning Models for Diagnosis of COVID-19 Using Statistical Features and Time-Frequency Spectrum. In Proceedings of the 2024 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 15–19 July 2024; pp. 1–4. [Google Scholar]
- Islam, R.; Chowdhury, N.K.; Kabir, M.A. Robust COVID-19 Detection from Cough Sounds using Deep Neural Decision Tree and Forest: A Comprehensive Cross-Datasets Evaluation. arXiv 2025, arXiv:2501.01117. [Google Scholar]
- Pavel, I.; Ciocoiu, I.B. COVID-19 Detection from Cough Recordings Using Bag-of-Words Classifiers. Sensors 2023, 23, 4996. [Google Scholar] [CrossRef]
- Atmaja, B.T.; Asmoro, W.A.; Sasou, A.; Abil, Z.; Suyanto. Cross-dataset COVID-19 transfer learning with data augmentation. Int. J. Inf. Technol. 2025, 1–14. [Google Scholar] [CrossRef]
- Yan, Y.; Simons, S.O.; van Bemmel, L.; Reinders, L.G.; Franssen, F.M.; Urovi, V. Optimizing MFCC parameters for the automatic detection of respiratory diseases. Appl. Acoust. 2025, 228, 110299. [Google Scholar] [CrossRef]
- Sturludóttir, J.E.; Sigurðardóttir, S.; Serwatko, M.; Arnardóttir, E.S.; Hrubos-Strøm, H.; Clausen, M.V.; Sigurðardóttir, S.; Óskarsdóttir, M.; Islind, A.S. Deep learning for sleep analysis on children with sleep-disordered breathing: Automatic detection of mouth breathing events. Front. Sleep 2023, 2, 1082996. [Google Scholar] [CrossRef]
- Liu, J.; Li, Q.; Chen, Y.; Wang, B.; Li, Y.; Xin, Y. Automatic identification of respiratory events based on nasal airflow and respiratory effort of the chest and abdomen. Physiol. Meas. 2021, 42, 075002. [Google Scholar] [CrossRef]
- Sikora, M.; Mikołajczyk, R.; Łakomy, O.; Karpiński, J.; Żebrowska, A.; Kostorz-Nosal, S.; Jastrzębski, D. Influence of the breathing pattern on the pulmonary function of endurance-trained athletes. Sci. Rep. 2024, 14, 1113. [Google Scholar] [CrossRef]
- Laasya, R.A.; Muthulakshmi, M. Breathalytics: Deep Learning-Based Prediction of Abnormality in Respiratory Sounds using Continuous Wavelet Transform. In Proceedings of the 2024 3rd International Conference on Artificial Intelligence For Internet of Things (AIIoT), Vellore, India, 3–4 May 2024; pp. 1–6. [Google Scholar]
- Xu, C.; Ouyang, Y.; Chen, Z.; Wang, H. Enhancing respiratory sound detection through integrated learning and dynamic convolutional recurrent neural networks. In Proceedings of the 2024 IEEE Biomedical Circuits and Systems Conference (BioCAS), Xi’an, China, 24–26 October 2024; pp. 1–5. [Google Scholar]
- AlSaad, R.; Abd-Alrazaq, A.; Boughorbel, S.; Ahmed, A.; Renault, M.A.; Damseh, R.; Sheikh, J. Multimodal large language models in health care: Applications, challenges, and future outlook. J. Med. Internet Res. 2024, 26, e59505. [Google Scholar] [CrossRef] [PubMed]
- Hiwale, M.; Walambe, R.; Potdar, V.; Kotecha, K. A systematic review of privacy-preserving methods deployed with blockchain and federated learning for the telemedicine. Healthc. Anal. 2023, 3, 100192. [Google Scholar] [CrossRef] [PubMed]
- Bekbolatova, M.; Mayer, J.; Ong, C.W.; Toma, M. Transformative potential of AI in healthcare: Definitions, applications, and navigating the ethical landscape and public perspectives. Healthcare 2024, 12, 125. [Google Scholar] [CrossRef] [PubMed]
- Manocha, A.; Sood, S.K.; Bhatia, M. Edge intelligence-assisted smart healthcare solution for health pandemic: A federated environment approach. Clust. Comput. 2024, 27, 5611–5630. [Google Scholar] [CrossRef]
- Ceylan, M.; Rassouli, F.; Boesch, M.; Brutsche, M.; Fleisch, E.; Barata, F. Cough Classification of Unknown Emerging Respiratory Disease with Federated Learning. In Proceedings of the 2024 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 15–19 July 2024; pp. 1–5. [Google Scholar]
- Thandu, A.L.; Pradeepini, G. Privacy-Centric Multi-Class Detection of COVID-19 through Breathing Sounds and Chest X-Ray Images: Blockchain and Optimized Neural Networks. IEEE Access 2024, 12, 89968–89985. [Google Scholar] [CrossRef]
Figure 1.
Adventitious pulmonary sounds: stridor occurs in the upper airway (trachea and larynx) and is typically heard during inspiration due to partial airway obstruction; wheezes, originating from narrowed bronchi, are more prominent during expiration; rhonchi are snoring-like sounds that occur in the larger airways (bronchi) and can be heard during both inspiration and expiration due to mucus accumulation; crackles, either fine or coarse, originate in the smaller airways and alveoli and are usually heard during inspiration.
Figure 1.
Adventitious pulmonary sounds: stridor occurs in the upper airway (trachea and larynx) and is typically heard during inspiration due to partial airway obstruction; wheezes, originating from narrowed bronchi, are more prominent during expiration; rhonchi are snoring-like sounds that occur in the larger airways (bronchi) and can be heard during both inspiration and expiration due to mucus accumulation; crackles, either fine or coarse, originate in the smaller airways and alveoli and are usually heard during inspiration.
Figure 2.
Frequency ranges of various lung sounds. Overlapping frequency bands, such as those between wheeze, stridor, and fine crackle sounds, can make acoustic differentiation difficult without clinical context. Higher-pitched sounds are often associated with airway obstruction, while lower frequencies may reflect secretions or fluid in the lungs.
Figure 2.
Frequency ranges of various lung sounds. Overlapping frequency bands, such as those between wheeze, stridor, and fine crackle sounds, can make acoustic differentiation difficult without clinical context. Higher-pitched sounds are often associated with airway obstruction, while lower frequencies may reflect secretions or fluid in the lungs.
Figure 3.
Breathing sounds: sample nasal breathing sounds, oral breathing sounds, and chest auscultations are depicted. Time-domain audio waveform and spectrograms of these signals are plotted.
Figure 3.
Breathing sounds: sample nasal breathing sounds, oral breathing sounds, and chest auscultations are depicted. Time-domain audio waveform and spectrograms of these signals are plotted.
Figure 4.
Time-domain waveforms, ZCR, and spectrograms of 5-second lung sound recordings from the ICBHI dataset for four classes: Normal, Crackle, Wheeze, and Wheeze & Crackle. Distinct patterns are observable across all representations. Normal sounds exhibit relatively smooth waveforms and low ZCR (237 crossings), while Crackles show abrupt transients and high ZCR (585 crossings). Wheezes present sinusoidal-like, continuous tonal patterns with the lowest ZCR (121 crossings). The Wheeze & Crackle class combines these traits, resulting in both tonal and transient components and a moderately high ZCR (550 crossings). Both time-domain signals and spectrograms reveal clear structural differences across the classes.
Figure 4.
Time-domain waveforms, ZCR, and spectrograms of 5-second lung sound recordings from the ICBHI dataset for four classes: Normal, Crackle, Wheeze, and Wheeze & Crackle. Distinct patterns are observable across all representations. Normal sounds exhibit relatively smooth waveforms and low ZCR (237 crossings), while Crackles show abrupt transients and high ZCR (585 crossings). Wheezes present sinusoidal-like, continuous tonal patterns with the lowest ZCR (121 crossings). The Wheeze & Crackle class combines these traits, resulting in both tonal and transient components and a moderately high ZCR (550 crossings). Both time-domain signals and spectrograms reveal clear structural differences across the classes.
Figure 5.
Comparison of respiratory sound signals for a healthy individual and a COVID-positive patient using nasal breathing, oral (mouth) breathing, and coughing. The diagrams in the figure are visualized using time-domain waveforms, Root Mean Square Energy (RMSE), and spectrograms. The healthy subject is a 25-year-old non-smoking male, and the COVID-positive subject is a 26-year-old non-smoking male who tested positive within the past 14 days of the recording. Data were obtained from the Sound-Dr dataset. Each respiratory activity (nasal breathing, mouth breathing, and coughing) is represented by two consecutive rows: the first row is for the healthy subject and the second row is for the COVID-positive subject. Each column displays three representations of the same signal: (1) raw time-domain waveform, (2) RMSE representing energy variation over time, and (3) a spectrogram showing frequency content across time. The healthy nasal and oral (mouth) breathing sound signals exhibit clear periodic patterns in the time domain, well-separated energy peaks in the RMSE plots, and distinct harmonic content in the spectrograms. Healthy coughs are also characterized by strong bursts of energy and prominent high-frequency components. In contrast, COVID-positive nasal breathing shows a nearly flat time-domain waveform and minimal energy in the RMSE curve. Low spectral contrast in the spectrogram suggests obstructed airflow and reduced respiratory activity. COVID-positive mouth breathing and coughing display lower energy levels and slightly smeared spectral features compared to their healthy counterparts.
Figure 5.
Comparison of respiratory sound signals for a healthy individual and a COVID-positive patient using nasal breathing, oral (mouth) breathing, and coughing. The diagrams in the figure are visualized using time-domain waveforms, Root Mean Square Energy (RMSE), and spectrograms. The healthy subject is a 25-year-old non-smoking male, and the COVID-positive subject is a 26-year-old non-smoking male who tested positive within the past 14 days of the recording. Data were obtained from the Sound-Dr dataset. Each respiratory activity (nasal breathing, mouth breathing, and coughing) is represented by two consecutive rows: the first row is for the healthy subject and the second row is for the COVID-positive subject. Each column displays three representations of the same signal: (1) raw time-domain waveform, (2) RMSE representing energy variation over time, and (3) a spectrogram showing frequency content across time. The healthy nasal and oral (mouth) breathing sound signals exhibit clear periodic patterns in the time domain, well-separated energy peaks in the RMSE plots, and distinct harmonic content in the spectrograms. Healthy coughs are also characterized by strong bursts of energy and prominent high-frequency components. In contrast, COVID-positive nasal breathing shows a nearly flat time-domain waveform and minimal energy in the RMSE curve. Low spectral contrast in the spectrogram suggests obstructed airflow and reduced respiratory activity. COVID-positive mouth breathing and coughing display lower energy levels and slightly smeared spectral features compared to their healthy counterparts.
![Electronics 14 01994 g005]()
Figure 6.
Distribution of audio recordings across datasets: the pie chart illustrates the number of audio recordings present in each dataset.
Figure 6.
Distribution of audio recordings across datasets: the pie chart illustrates the number of audio recordings present in each dataset.
Figure 7.
Breathing signal patterns: the first and second rows demonstrate spectrograms of breathing and cough patterns in a healthy and COVID-19 subject, respectively. The figure is depicted using the Coswara dataset.
Figure 7.
Breathing signal patterns: the first and second rows demonstrate spectrograms of breathing and cough patterns in a healthy and COVID-19 subject, respectively. The figure is depicted using the Coswara dataset.
Table 1.
Classification of normal and adventitious lung sounds (ALSs). Continuous adventitious sounds (CASs) and discontinuous adventitious sounds (DASs) provide critical diagnostic information for respiratory conditions.
Table 1.
Classification of normal and adventitious lung sounds (ALSs). Continuous adventitious sounds (CASs) and discontinuous adventitious sounds (DASs) provide critical diagnostic information for respiratory conditions.
| Category | Sound | Frequency Range | Description | Associated Conditions |
|---|
| Normal | Bronchial | 100–2000 Hz | High-pitched, tubular sound over trachea | Normal lung function |
| | Vesicular | 100–1000 Hz | Soft, low-pitched over lung periphery | |
| | Bronchovesicular | 200–1000 Hz | Mixed bronchial and vesicular over major bronchi | |
| Continuous | Wheezes | >400 Hz | Continuous, musical, high-pitched | Asthma, COPD, Bronchitis |
| | Rhonchi | ≈200 Hz | Low-pitched, snoring-like | COPD, Asthma, Cystic Fibrosis |
| | Stridor | >500 Hz | Harsh, high-pitched inspiratory sound | Upper airway obstruction, Croup infection |
| | Squawks | 200–300 Hz | Short, musical sound | Interstitial lung diseases |
| Discontinuous | Fine Crackles | ≈650 Hz | Short, high-pitched, popping sounds | Pulmonary Fibrosis |
| | Coarse Crackles | ≈350 Hz | Longer, low-pitched, bubbling sounds | Bronchitis, Pneumonia |
| | Pleural Rubs | <350 Hz | Harsh, grating sound during respiration | Pleuritis, Pleural Effusion |
Table 2.
Characteristics of different cough types.
Table 2.
Characteristics of different cough types.
| Cough Type | Attributes | Description |
|---|
| Dry Cough | Non-productive, hacking | Does not produce phlegm, caused by irritants, non-infectious conditions, GERD, heart failure, or viral infections. |
| Wet (Productive) Cough | Mucousy, rattling, wheezing | Produces phlegm, may include pus or blood, often caused by infections like pneumonia, tuberculosis, or chronic conditions. |
| Whooping Cough | Spasmodic, intense inhalation | Continuous coughing with a characteristic “whoop” sound, an indicator of pertussis. |
| Barking Cough | Seal-like, high-pitched stridor | Often associated with croup, tracheomalacia, or psychogenic cough. |
| Staccato Cough | Series of outbursts with pauses | Short bursts with breaths in between, typically caused by chlamydia pneumonia in infants. |
Table 3.
Overview of Respiratory Sound Datasets.
Table 3.
Overview of Respiratory Sound Datasets.
| Dataset | Sound Types | Age Range | Duration/Size | Additional Details |
|---|
| Lung Sounds Dataset [61] | Normal, pathological lung sounds | 21–90 | 5 to 30 s each | Each recording is replicated 3 times corresponding to various frequency filters |
| ICBHI Respiratory Sound Database (2017) [62] | Crackles, Wheezes, Combination of both | Child and Adult | 5.5 h, 6898 cycles | Includes detailed analysis of respiratory abnormalities |
| Sound-Dr Dataset [49] | Cough, Oral breathing, Nose breathing | Mostly 20–40 | Average duration of 23 s | Includes clinical metadata related to respiratory illnesses |
| SPRSound [63] | Auscultation of Normal, Rhonchi,
Wheeze, Stridor, Coarse Crackle, Fine Crackle, and Wheeze+Crackle | 2 month to 18 years | 9089 respiratory sound events | Sound editing has been done by SoundAnn software |
| Coswara Dataset [64] | Fast/slow breathing, Coughing (deep/shallow), Vowel phonation, Counting | 15–90 | 65 h, >23,000 recording | Valuable for studying respiratory effects of COVID-19 |
| HLS-CMDS [65] | Auscultation Normal, abnormal heart and lung sounds, murmurs, wheezing, crackles | - | 210 recordings | Recording enhanced using frequency filters |
| COUGHVID Dataset [66] | Coughing | The average age 36.5 (±13.9) | >25,000 recordings, each recoding up to 10 s | Crowdsourced, over 2800 labeled by medical professionals |
| Wheezing Recognition Dataset [44] | Oral respiratory sounds with and withou wheezing | Mostly toddlers (mean age 20 months) | 186 recordings | After exclusion 95 recordings subjected to a 2-phase algorithm |
| Respiratory Sound Classification Dataset [67] | Normal, crackles, wheezes, rhonchi | The average age 67.7 (±10.9) | 1918 recordings | Includes both normal and pathological sounds |
| COVID-19 Sounds Dataset [68] | Cough, Oral breathing, Speech sounds | Majority of cases young to middle-aged adults | >552 h, 53,449 samples | Provides participants’ self-reported COVID-19 test status |
| R.A.L.E [69] | Oral breathing, Auscultations | - | Each file is 10 s | Used for various sound analyses |
| Cambridge Dataset [70] | Oral respiratory sounds | Child and Adult | >9000 samples | Data collection framework includes a
web-based app and an Android app |
| Virufy Dataset [71] | Oral respiratory sounds | Adult (17–66) | 121 segmented cough samples | Crowdsourced data for COVID-19 cough detection |
| NoCoCoDa Dataset [72] | Cough sounds | Child and Adult | 73 individual cough events | Cough phase annotation is available |
| ComParE-CCS Dataset [73] | Cough sounds | - | 929 recordings, 1.63 h | Each cough recording contains one to three forced coughs |
Table 5.
Performance of cough classification models. Area under the Receiver Operating Characteristic (ROC) curve is abbreviated as AUC.
Table 5.
Performance of cough classification models. Area under the Receiver Operating Characteristic (ROC) curve is abbreviated as AUC.
| Method | Model | Dataset | Acc (%) | AUC |
|---|
| Kim and Lee [82] | Xception + VFCDM | Cambridge, Coswara, and Virufy | 87 | 0.82 |
| Islam et al. [83] | Deep Neural Decision Forest | Cambridge, Coswara, COUGHVID, Virufy, and the combined Virufy with the NoCoCoDa dataset | 97 | 0.97 |
| Sunitha et al. [29] | DTCN | COUGHVID | 76.7 | - |
| Aytekin et al. [8] | HST | Cambridge and COUGHVID | - | >0.90 |
| Pavel and Ciocoiu [84] | Bag-of-Words (input fusion, sparse encoding) | COUGHVID | 72.7 | 0.82 |
| Pavel and Ciocoiu [84] | Bag-of-Words (output fusion, sparse encoding) | COVID-19 Sounds datasets | 60.3 | 0.65 |
| Bagus Tris Atmaja et al. [85] | CNN14 + HPO | Coswara, COUGHVID, ComParE-CCS | 88.19 | - |
| Yuyang Yan et al. [86] | SVM | Cambridge | 81.1 | - |
| Yuyang Yan et al. [86] | SVM | Coswara dataset | 80.6 | - |
| Yuyang Yan et al. [86] | LSTM | SVD database | 71.9 | - |
Table 6.
Methods, limitations, and opportunities in respiratory sound analysis.
Table 6.
Methods, limitations, and opportunities in respiratory sound analysis.
| Method | Limitations | Opportunities |
|---|
| Auscultation | Subjective results, dependent on clinician’s skill. Prone to variability in diagnosis. Limited for long-term monitoring.
| |
| Cough Sound Analysis | Variability in coughing patterns. Affected by external noise and recording conditions. Challenges in generalizing models across different populations.
| ML models can enhance diagnostic accuracy. Advanced feature extraction (e.g., spectral and temporal properties) can help detect respiratory conditions like asthma, pneumonia, and tuberculosis.
|
| Oral and Nasal Breathing Sound | Limited comprehensive datasets. Susceptibility to environmental noise. Lack of standardization in data collection.
| Non-contact monitoring methods, such as thermal imaging and radar sensors, can provide robust alternatives. Combining nasal and oral airflow dynamics may improve diagnostic precision.
|
| PSG | | Development of wearable and non-contact alternatives for home monitoring (e.g., sound-based AI models). Hybrid models integrating PSG with other respiratory signals like ECG and nasal airflow may improve diagnostic outcomes.
|
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
_Kalra.png)





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}