1. Introduction
Generally, person detection and tracking equipment includes LiDAR, fisheye, and conventional cameras. Each method has its advantages as well as disadvantages. For example, one of the main challenges associated with LiDAR is that LiDAR sensors can generate millions of data points per second, resulting in large, complex datasets that can be difficult to manage and process. Torres et al. mentioned the advantages and disadvantages of LiDAR technology for person tracking, and some suggestions for improvement are provided [
1]. The other solution is using the fisheye camera, a lens that can provide a viewing angle close to or equal to 180°. Tallaubrid et al. used fisheye images to track a person’s movement [
2]. However, fisheye cameras also have limitations; when a person is located directly below the center, only the top of the head can be seen, resulting in limited features and difficulty in continuous tracking. In summary, LiDAR often has a lower refresh rate for person tracking, can miss fast-moving objects, and lacks texture or color data. Fisheye cameras overcome these limitations, but have the occlusion problem that nearby objects may block the view of important distant ones. The other problem of using fisheye cameras is the barrel distortion problem when an ultra-wide field of view is used, requiring calibration and correct processing.
Another solution is using conventional camera tracking; this problem has considerable complexity and difficulty. Taking a single camera problem as an example, it has complex problems that must be overcome, such as shooting angle, light changes, the impact of occlusion, and changes in environmental conditions [
3]. Changes in shooting angle and light can be solved by camera calibration. Some scholars suggest using aerial photography to solve the occlusion problem. Some scholars [
4] have proposed using uncrewed aerial vehicle (UAV) methods to track and simulate personal movements from high-resolution videos. However, this approach requires a considerable amount of calculation to some extent. A group of scholars [
5] have also used data obtained from internal sensors in autonomous vehicles to track the main dependencies of person-tracking methods. However, the occlusion problem faced by a single photograph can be partially solved by changing the coordinates to obtain images from different angles. In response to this problem, some scholars [
6] have proposed using multiple cameras to deal with the occlusion problem, the so-called multi-lens tracking method. If person tracking is divided by scenes, there are two applications: overlapping views and non-overlapping views [
7]. When the views do not overlap, complex problems must be solved in converting personal image information in different scenes [
8]. The general approach is to use the similarity of person features to make judgments [
9]. Overlapping areas captured by multiple cameras present slightly different issues than non-overlapping areas. A typical problem is integrating the information from different cameras due to the different shooting angles of each camera. Some scholars have provided solutions to the problem of varying camera angles [
10,
11]. Another problem is the appearance or disappearance of new targets (persons) and old targets. Some scholars suggest that re-identification can solve this problem [
12,
13]. In addition to the problems mentioned above, the most challenging problem is that when the number of persons increases considerably, the amount of information processing and recognition complexity required may also increase significantly (or even unexpectedly).
To address the abovementioned problems, feature extraction methods for person tracking in computer vision are used. There are two feature extraction methods for person tracking in computer vision. The first is to start from the perspective of human vision and use human-designed methods to extract some features that can distinguish between the same people or different people [
14,
15]. Intuitively, the advantage of this approach is that it imitates the sense of human vision for person tracking. The disadvantage of this approach is that it must be judged based on people’s subjective thoughts, and there may be relatively significant differences between different datasets. The second type is based on the current automatic data processing method of artificial intelligence, which is called deep learning technology [
16,
17,
18]. Compared with the first method, this technology uses a rule learning method (i.e., algorithm) to allow the system to adjust parameters to track and identify persons. In contrast, this approach is a relatively objective way to solve problems. Its disadvantage is that it is difficult for people to conduct in-depth analysis from these learned architectures or parameters. Generally speaking, in addressing the person tracking problem, the features extracted by the human-designed methods are straightforward to understand and may perform reasonably well without large training datasets. However, it may not be possible to capture complex patterns (e.g., variations in pose, illumination, or background clutter). An expert may also be required to possess sufficient domain-specific knowledge to select and tune appropriate features. By contrast, the deep learning-based methods do not have the problem raised by the human-designed methods. They can learn which features are most useful from large datasets, reducing the need for manual design. However, they do face the problem of being difficult to interpret or it being hard to understand why the model behaves a certain way. Still, deep learning-based approaches offer far superior accuracy and robustness in real-world, dynamic environments. The trade-off lies between interpretability and simplicity versus adaptability and performance. Of course, in current research it is challenging to distinguish directly in a dichotomous manner to some extent, and most practices combine the above two unique micro-extraction methods [
19,
20,
21,
22,
23,
24].
As mentioned above, when using multiple cameras to track persons from different perspectives, the so-called multi-lens tracking method has been widely discussed and studied. However, since each camera has a different shooting angle, how can we solve the problem of person recognition with other cameras? Another issue is that in the same scene, persons are blocked by objects, change (appear or disappear), and can be confused. These are all problems that must be faced.
In response to the discussion of the above issues, this study designed an experimental environment with multiple camera overlaps, object occlusion, persons entering and exiting at various times, and persons mixing. The experimental environment of this study uses two cameras. The two cameras have different camera angles but overlapping capture areas. This environmental lab has tables, chairs, and other objects that facilitate the exploration of occlusion issues when different cameras capture a person’s movement. This research aims to use binocular camera calibration and key point detection to reconstruct three-dimensional key points of persons in three-dimensional space to achieve relatively better tracking results. In our test environment, this study considered the occlusion problem between people when setting up the camera at an angle, position, and height. During the experiment, this study increased the effect of partial and complete scene conditions or long occlusion scenes by asking subjects to increase the amount and duration of their conversations with each other.
2. Materials and Methods
2.1. Research Structure
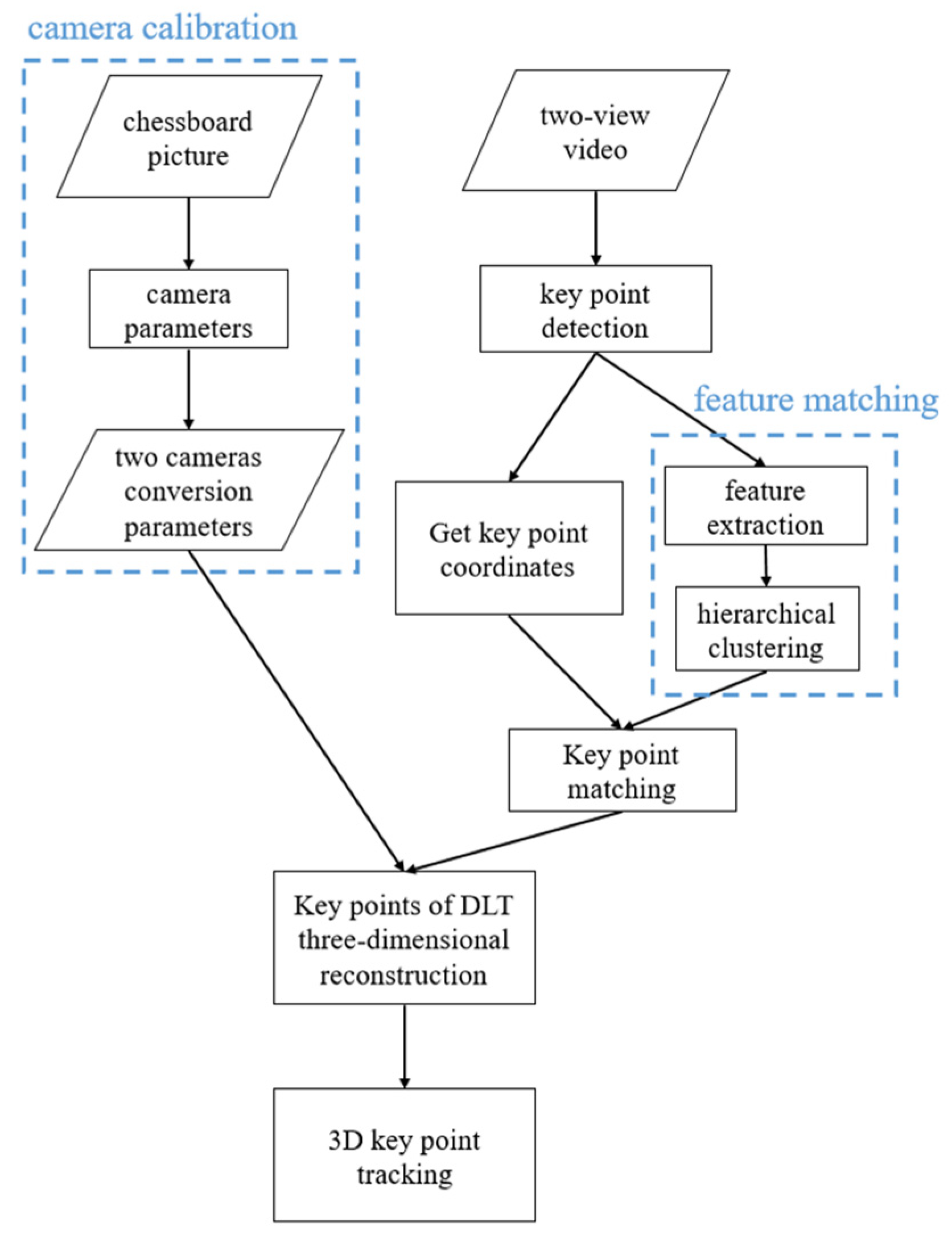
This study reconstructs the 3D coordinates of human key points through camera calibration and skeleton detection technologies. It performs human tracking based on the 3D coordinates of each person, as shown in
Figure 1.
2.2. Camera Calibration
The experimental environment of this study is an area with a length, width, and height of 990, 690, and 300 cm, respectively, and a camera was set up 2.6 m above the ground at the left and right ends. The distance between the two cameras in this experimental environment is 4.8 m, and each had a built-in autofocus system.
Table 1 shows the camera data, including image size, focal length of lenses, and aperture. Every camera has a built-in autofocus system. Fluorescent lamps illuminated the experimental environment of this study, and the lighting of the entire environment was relatively stable. The frame rate of each camera output is 24 frames per second. The original resolution of each frame is 1920 × 1080.
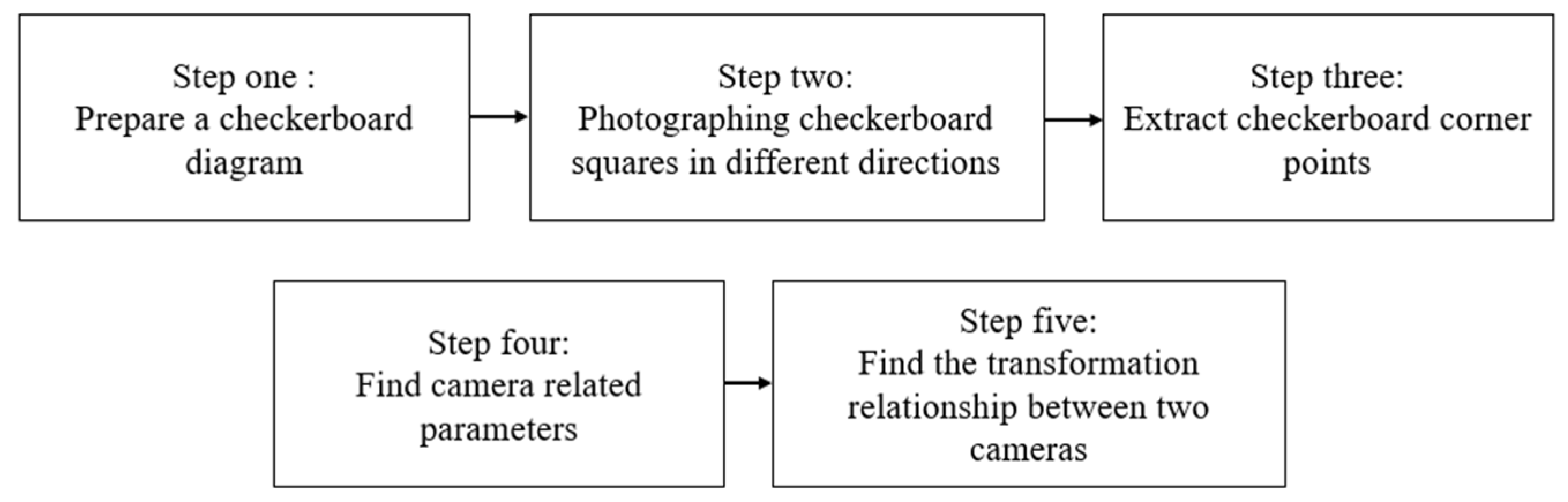
The camera calibration process used in this study mainly follows Zhang’s calibration method [
11], a technique widely used in computer vision, especially for flat calibration plates. The calibration process can be summarized into the following five key steps (
Figure 2):
- (1)
Prepare the calibration board (
Figure 3): Use a chessboard with a known size (the square grid in this study is about 17 cm (93 × 128), and the inner corner points are 6 × 4) as the calibration object.
- (2)
Capture calibration images: Capture multiple chessboard images in different postures and directions from two different camera perspectives (left camera and right camera). In this study, 24 images were selected from the synchronously recorded videos for calibration. This study uses two cameras on the left and right to capture the checkerboard pattern. We performed it in recording mode during the adjustment process and selected 24 images. Finally, the best frame is chosen from these as the calibration image, as shown in
Figure 4.
- (3)
Extract corner points: For each calibration image captured, use the image processing algorithm (cv2.findChessboardCorners function in OpenCV) to detect the corner points inside the chessboard. At the same time, the pixel coordinates (u, v) of these corner points in the image and their three-dimensional coordinates (X, Y, Z) in the coordinate system of the calibration plate are obtained, as shown in
Figure 5.
- (4)
Calculate single camera parameters: Using the extracted 2D pixel coordinates and 3D calibration plate coordinates, by solving the homography matrix and combining it with nonlinear minimization methods, estimate each camera’s intrinsic parameters and distortion coefficients (including radial distortion and tangential distortion).
- (5)
Calculate stereo camera parameters: Using the intrinsic parameters and distortion coefficients obtained from the calibration of the two cameras and the corner information observed by the two cameras, use the stereo calibration function (cv.stereoCalibrate in OpenCV) to calculate the relative posture between the two cameras, that is, the rotation matrix (R) and the translation vector (t). These parameters describe the transformation relationship between the right camera coordinate system and the left camera coordinate system.
The goal of camera calibration is to minimize the reprojection error. It is implemented by projecting the 3D corner point on the calibration board back to the image plane based on the calculated internal and external parameters of the camera to obtain the pixel coordinates of the projection point and then calculating the Euclidean distance between this projection point and the actual pixel coordinates of the corner point extracted through image detection. Ideally, this distance should be zero if the camera parameter estimation is accurate. In Zhang’s calibration method, the root mean square error (RMSE) is usually used to quantify the overall calibration error (Equation (1)). The technique calculates the reprojection error of all corner points in all calibration images, then takes the square root of the average sum of squares of these errors. This RMSE value intuitively reflects the accuracy of the calibration results. The smaller the value, the higher the fit between the camera parameter model and the actual observation data, and the better the calibration effect. In this study, the calibration error of the left camera is 0.26 and that of the right camera is 0.31, indicating that the calibration effect is good.
where
and
represent the observed and projected 2D points, respectively.
Since this geometric distance is calculated on the two-dimensional image plane, its basic unit is a pixel. In this study, the pixel coordinates of each projected point and the corresponding corner point detected are calculated using the root mean square (RMS) value, which is the so-called error (in pixels). The values 0.26 and 0.31 mean that the average deviation between the points projected back into the image by the camera model calculated in this study and the detected points is less than 0.3 pixels. This result indicates that the calibration effect of individual cameras is good, but the relationship between the two cameras still needs to be further confirmed. The fifth step involves finding the transformation relationship between the two cameras. This study uses the stereo calibration method provided in OpenCV to obtain the rotation and translation parameters between the two cameras. With these two parameters, combined with the intrinsic matrices of the left and right cameras, subsequent 3D reconstruction can be performed.
2.3. Key Point Detection
This study uses a pre-trained key point detection model (Yolo-Pose) [
25]. The Yolo-Pose model is an extension of the YOLO (You Only Look Once) object detection framework that also detects bounding boxes (the parameters returned include coordinates of the bounding box around the person and confidence score for the object being a person) and human body keypoints (the parameters returned include the pixel coordinates of each keypoint and its confidence score). This model is trained on the COCO (Common Objects in Context) keypoint dataset [
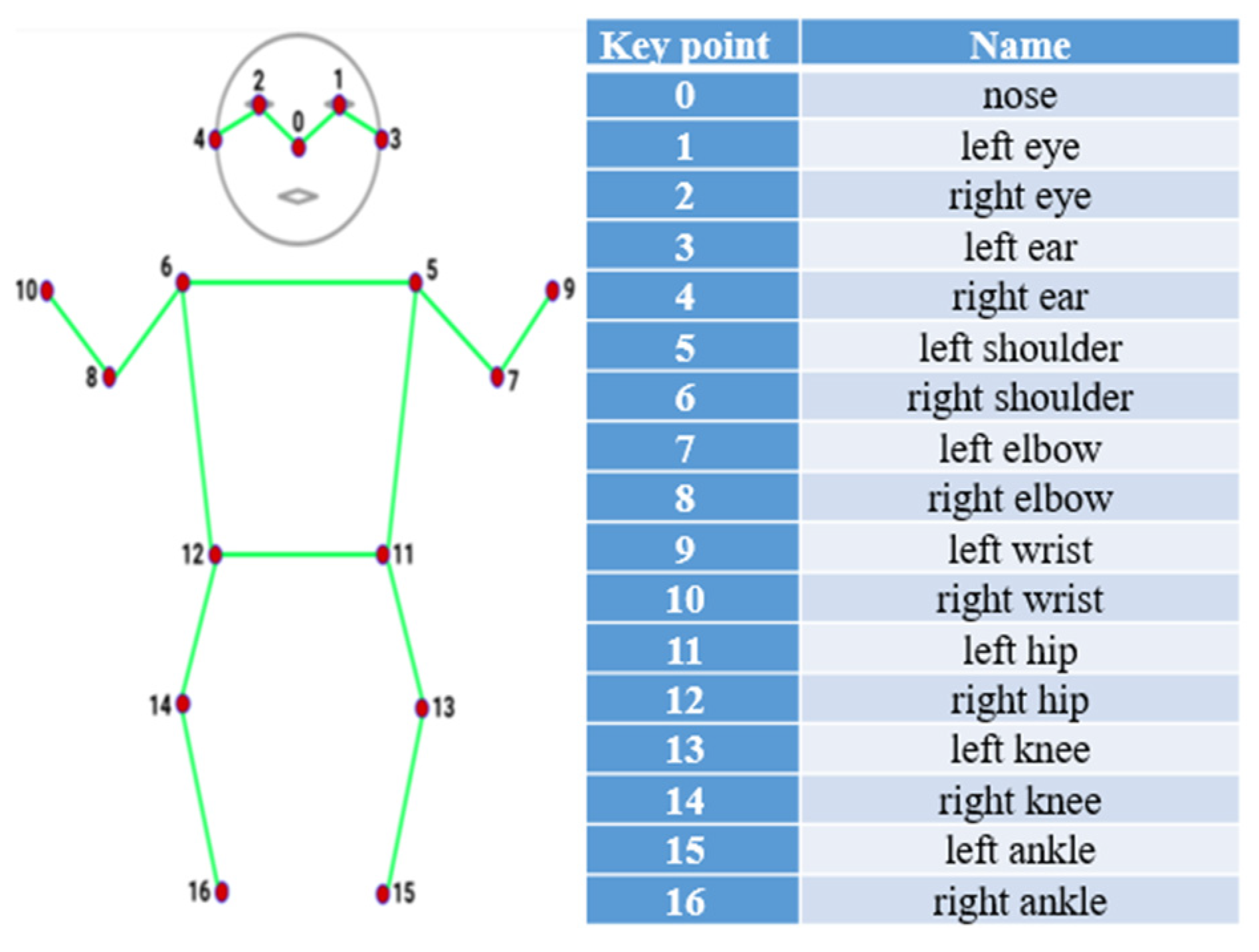
26]. As the COCO dataset contains many image datasets with human body key point annotations, it already has good human body key point detection information. The advantage of using this approach is that this study can directly obtain fully learned key point detection data through the official website without the need for us to build a human body key point detection model. The detailed method is to download the weight file of the official pre-trained model through the yolov7-w6-pose.pt program. Once this code is loaded, it can directly perform key point detection tasks. Each detected person in the dataset returned 58 parameters. These parameters include the center coordinates and dimensions of the detection box. Among the 58 parameters are also the details of 17 key points, whose locations and corresponding names on the human body are shown in
Figure 6. Each key point’s information consists of pixel coordinates and confidence level.
2.4. Key Point Matching
Before key point matching, feature matching is conducted. In the feature extraction network part, this study uses the Market-1501 dataset, widely used in person re-identification tasks, as training data [
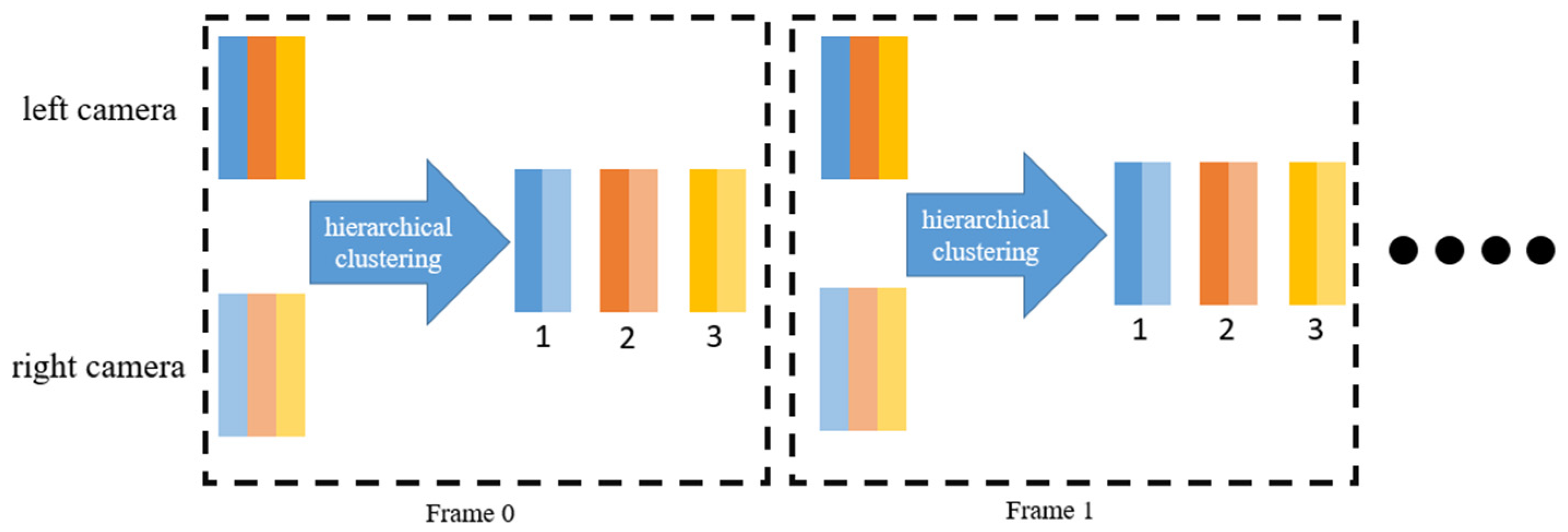
27]. This dataset contains 32,668 detected person boxes for 1501 persons from 6 cameras. The training set includes 751 people with 12,936 images; the test set contains 750 people with 19,732 photos. Currently, most of the research using this dataset reflects that it provides people with convenient applications for person recognition due to its rich data and detailed annotation information. Each bounding box is first extracted and input into a feature extraction network. Each extracted box generates a feature vector of length 512. This study collects feature vectors from individuals captured by both cameras in the same frame. Since the computer does not initially know which two feature vectors represent the same person, hierarchical clustering algorithms are employed for feature matching. The conceptual framework is illustrated in
Figure 7.
Hierarchical clustering plays a crucial role in feature matching, especially in tasks like person re-identification (Re-ID) and multi-camera tracking, where the goal is to group similar features (e.g., appearance descriptors) corresponding to the same identity across different images or views. In this study, we use empirical tuning, starting with visual inspection or heuristic values (e.g., 0.5–0.7 for cosine distance) and adjusting based on matching accuracy, to determine the threshold value. A threshold value can be chosen to determine the clustering results as output.
Figure 8 depicts the hierarchical clustering results of feature vectors in this study. Setting the threshold at 0.6 results in two distinct clusters.
With the classification results mentioned above, key point matching can be conducted. Since the computer does not initially know which critical points from the two camera views correspond to the same person, the hierarchical clustering results are used to identify essential points belonging to the same individual across both cameras. Once key points have been matched, direct linear transformation (DLT) can be applied for the 3D reconstruction of critical points based on their information.
2.5. Direct Linear Transformation Key Point 3D Reconstruction
Direct Linear Transformation (DLT) plays a crucial role in this study. It is the core technology for inferring the actual position of key points observed in multiple two-dimensional image views in three-dimensional space. Its main contributions are reflected in the following aspects:
- (1)
Establish geometric constraints: The foundation of DLT technology is derived from the principles of projective geometry, especially the pinhole camera model. The model mathematically describes how a point in three-dimensional space is projected onto a two-dimensional image plane. DLT uses this geometric relationship to link the pixel coordinates of the two-dimensional key points observed in each camera view with the desired three-dimensional spatial coordinates.
- (2)
Integrate multi-view information: A two-dimensional image from a single perspective cannot uniquely determine the three-dimensional spatial position of a point (there is depth ambiguity). The key advantage of DLT is its ability to integrate observations from multiple (two in this study) calibrated cameras. Each camera captures the same 3D keypoint from a different angle, providing a different 2D projection. These projection points from different viewpoints together constitute a set of geometric constraints.
- (3)
Construction of linear system: DLT cleverly transforms this geometric reconstruction problem into a linear algebra problem. Combining each camera’s projection matrix (which contains the camera’s intrinsic parameters and extrinsic parameters relative to the world coordinate system, obtained through camera calibration) and the corresponding two-dimensional key point coordinates, a linear system of equations can be constructed for each three-dimensional key point. The unknowns in this set of equations are the three-dimensional coordinates of the key point.
- (4)
Robust solution of 3D coordinates: Due to the inevitable existence of image noise and camera calibration errors in actual measurements, directly solving the linear equations may not produce an exact solution. DLT is often combined with Singular Value Decomposition (SVD), a powerful numerical method, to solve this linear system. SVD can find the optimal least squares solution in the presence of noise, that is, find the coordinates of the three-dimensional space point that best meets all geometric constraints, thereby improving the stability and accuracy of reconstruction.
In summary, the core contribution of DLT technology is that it provides a systematic mathematical framework that can effectively fuse the two-dimensional key point information from multiple calibrated camera views, and finally robustly reconstruct the positions of these key points in three-dimensional space by establishing and solving a system of linear equations. It is the key bridge connecting two-dimensional image observation and three-dimensional scene understanding. The details of using DLT to solve singular value decomposition can be found in [
28,
29].
2.6. Person Tracking and Evaluation Metrics
Currently, there are three commonly used evaluation indicators for tracking systems: tracking accuracy (including missing people, misjudgments, and confusion), correct person ID recognition rate, and accuracy of position prediction. Suppose you want to use all these evaluation indicators to perform person tracking. In that case, it not only requires a considerable amount of calculation and time complexity but may also not meet actual needs. Generally speaking, scenes with high crowd density or long-term tracking need a relatively good tracking accuracy or a correct person ID recognition rate. Relatively speaking, if the problem domain requires precise measurement of the application field, the accuracy of position prediction may be a key indicator. Considering the limited computing resources, this study only considers the correct person ID recognition rate as an evaluation index because it hopes to explore the long-term tracking effect.
Tracking people across consecutive frames in multi-camera systems (or even within a single camera view) involves identifying and maintaining the identity of individuals as they move through different frames in a video. This is a key challenge in person tracking, as people can appear, disappear, or move in and out of the camera’s field of view, potentially undergoing occlusions, pose changes, or even changes in lighting conditions. The first step in tracking is using YOLO to detect objects of interest (in this case, people) in each frame. After detecting people in a given frame, the next step is to extract keypoint features that describe the appearance of each person by using YOLO-Pose. This allows us to identify and differentiate individuals from one frame to the next. Once you have the detections and features in consecutive frames, the next step is to associate objects across these frames. This process involves matching people detected in the current frame to those in the previous frame by using Kalman filtering, which predicts the next position of an object based on its last position and velocity. Once objects are associated, an ID is assigned to each person (usually an ID number). These IDs are maintained across multiple frames, so the system knows which detection corresponds to the same person in the next frame. If an individual is temporarily occluded and reappears, the system can attempt to re-identify the person by comparing their appearance features with previously stored ones. This involves re-ID models that match people across frames based on their appearance, even after significant changes in viewpoint or partial occlusion.
While tracking persons, the system will give a person an identification number. However, it is still impossible to avoid tracking a person who changes or disappears for a time due to occlusion or overlap. Later, when the person is recognized again, the system will reassign a new ID. This type of ID will gradually increase over time (in other words, the same person will have many IDs). This study also designed an ID classification method to solve this problem, to ensure that even if the same person experiences switching between different IDs, they can still be effectively regarded as the same person.
This study uses four judgment criteria: motion direction cosine similarity (MDCS), key point cosine similarity (CS), normalized key point cosine similarity (NORMCS), and feature similarity cosine similarity (FECS). MDCS measures the degree of similarity between two-person movement direction vectors. It checks whether two movements are going in the same or similar direction. For any two persons, we compute their motion vectors over a time interval and calculate cosine similarity (Equation (2)). The MDCS value is 1 when two persons move in the same direction, and −1 when in opposite directions. CS measures the similarity of 17 key points on the whole body of two persons. For each of these 17 key points, we measure the similarity between two poses or skeletal structures using vectors defined by key points (e.g., from hip to shoulder) by calculating the cosine similarity of each pair of corresponding vectors (Equation (3)). NORMCS is the same as CS, but removes the effect of scale (length of limbs or camera zoom differences). It measures the similarity using the same key point vectors as in CS, but normalizes each vector to unit length (Equation (4)). NORMCS gives us pure directional similarity between pose structures. FECS measures the similarity of the appearance feature vectors of two persons by comparing features extracted from images. It is implemented by passing a video frame of data through a neural network, then extracting high-dimensional feature vectors, and finally computing their cosine similarity (Equation (5)). The results tell us how similar two abstract representations are, e.g., whether two people are performing the same action, or two frames are identical.
where
and
are motion direction vectors of two persons.
where
and
are vectors of keypoints from two different detections.
where
and
are the normalized keypoint vectors.
where
and
are feature vectors representing the appearance of two persons.
3. Results
This study designed an experimental environment to explore the occlusion problem when two cameras capture a person’s movements. This environment includes people who might occlude each other or be occluded by laboratory items. This study uses binocular camera calibration and key point detection to reconstruct the three-dimensional key points of persons in three-dimensional space to achieve relatively good tracking results. Then, the method proposed in this study is used to enhance the ability of person identification and re-identification and reduce the possibility of ID misjudgment.
In response to the above problems, tests were conducted on two types of videos recorded in this study. The first type is a two-person scene video. This type of video records two people walking around in the laboratory. The design of relatively low-complexity scenes is mainly used to observe the tracking effect when people move and intersect. The second type of video records five or more people walking around a laboratory, some stationary, some moving, and others entering and exiting at different times.
Since this study mainly used pre-trained models, no additional training was performed. The research uses the information extracted by these pre-trained models, combined with binocular camera calibration and three-dimensional key point reconstruction technology, to improve the person tracking effect under occlusion and solve the problem of person ID transformation. Below, we describe the test process and then explain the experimental results.
3.1. Test Procedure
This study mainly uses extracting frames from videos to obtain data rather than using data enhancement methods. This research focuses on solving tracking problems in practical environments, especially tracking people under perspective occlusion. Therefore, we used real videos collected from the laboratory to extract keyframes for processing and analysis. The detailed process description is as follows.
First, the recorded dual-view laboratory videos are synchronized into the system. The system uses the yolov7-w6-pose.pt pre-trained model to detect key points of persons in each frame and obtain the pixel coordinates and confidence of each person’s 17 key points. At the same time, everyone’s detection frame information was also obtained. Next, the image patches of each person are extracted according to the detection frame and input into the feature extraction network pre-trained on the Market-1501 dataset to obtain a feature vector with a length of 512. Then, a hierarchical clustering algorithm is used to match the feature vectors of the same frame from the two cameras to determine which key points belong to the same person. This study uses the Euclidean algorithm to calculate the distance between feature vectors and performs hierarchical clustering through the linkage function. For successfully matched key point pairs, the direct linear transformation (DLT) and singular value decomposition (SVD) algorithms are used to reconstruct the three-dimensional key points to obtain each person’s three-dimensional space key point coordinates. This study uses the position of the left camera in world coordinates as the benchmark to measure three-dimensional coordinates. For person tracking and evaluation indicators, please refer to
Section 2.6.
3.2. Experimental Results
3.2.1. Two-Person Scene Tracking
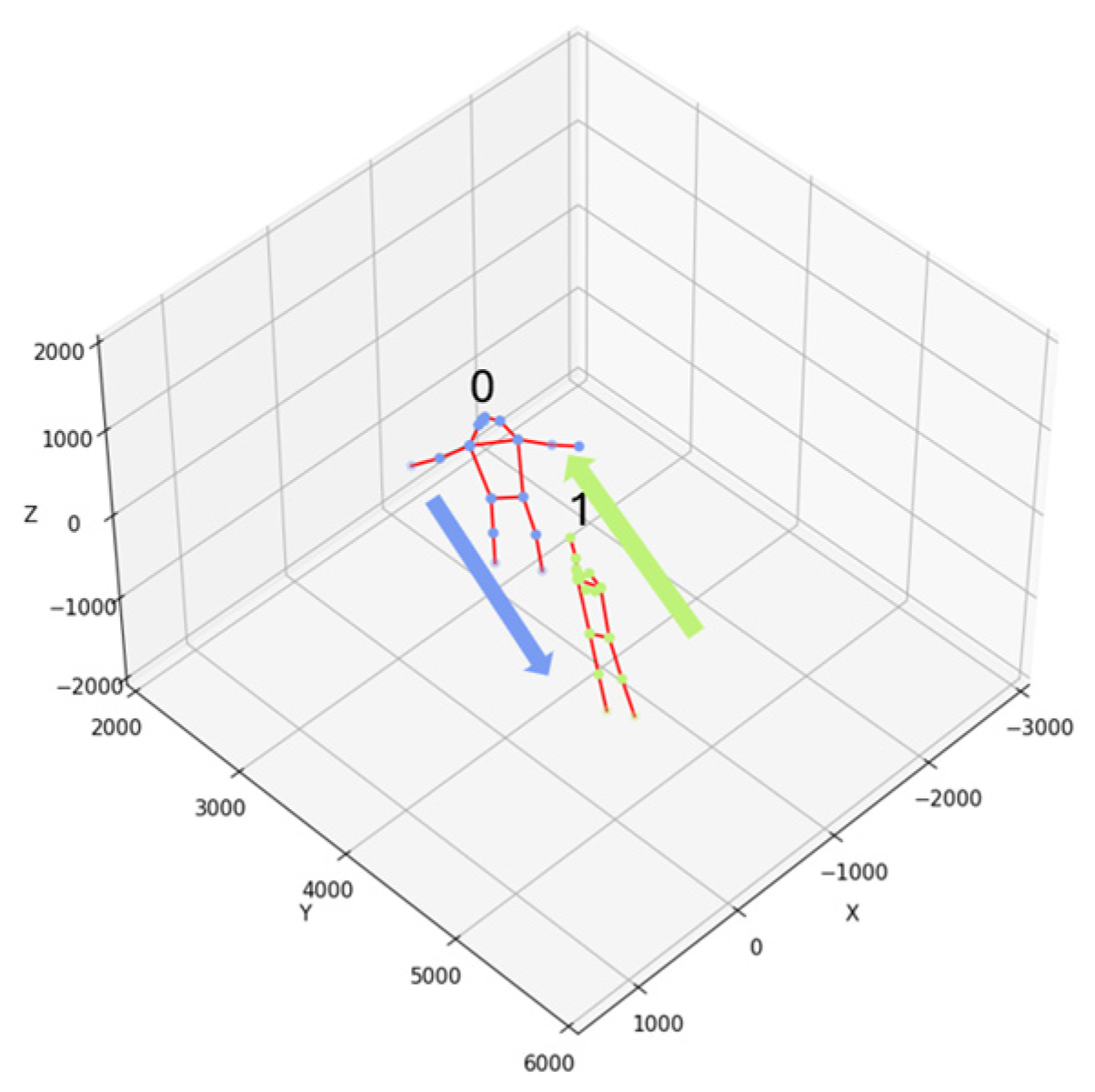
This study conducted tracking tests for the developed system in a two-person scene. In this scenario, the movements of two individuals are relatively simple, as shown in
Figure 9. The movement paths of the two individuals involve crossing each other (indicated by arrows in the figure), primarily demonstrating the occlusion that occurs when the individuals intersect.
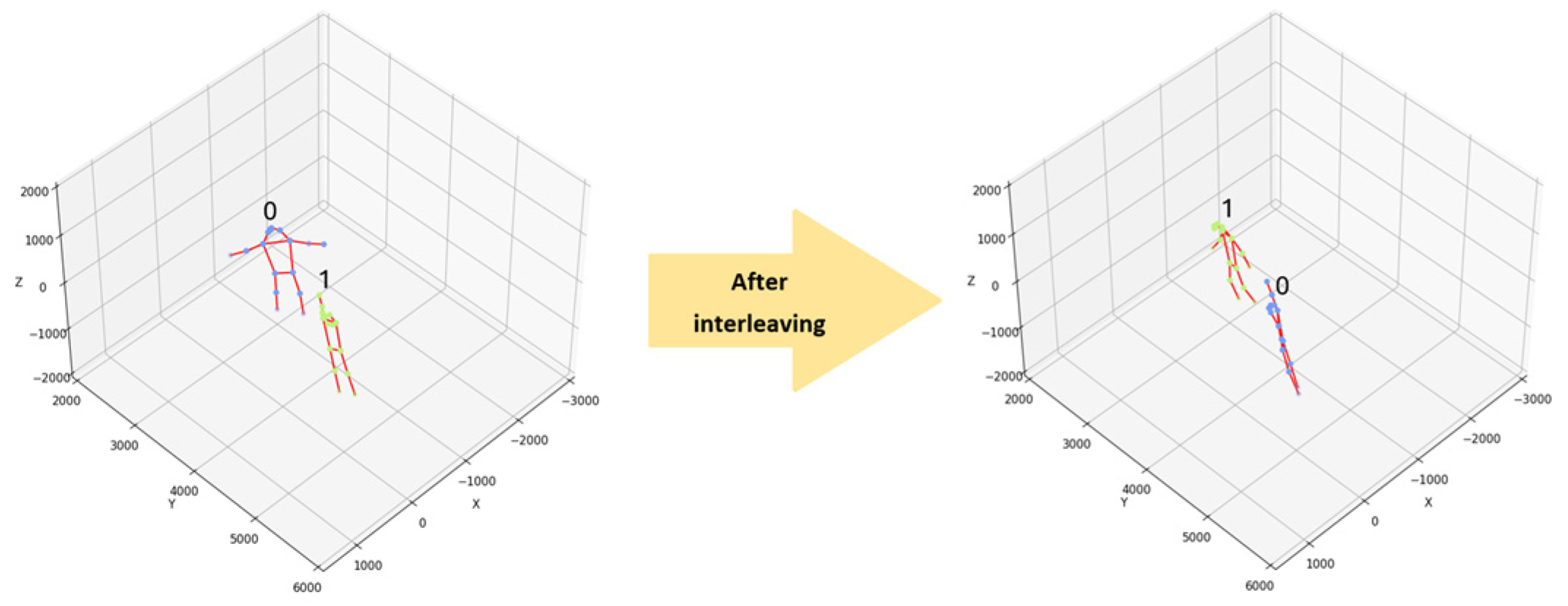
During the tracking process, videos from both viewpoints are played synchronously, and skeleton detection is performed. Then, 3D key point reconstruction technology presents the 3D key point coordinates. The tracking remains effective after the two people cross paths, and no ID switch occurs. This study also conducted single-viewpoint tracking tests on the video of the two-person scene. The test results in
Figure 10 show that after the two people cross paths, the original ID values have switched, resulting in an ID switch problem. However, the test results in
Figure 11 show that the tracking maintains consistent IDs. Therefore, it can be inferred that the dual cameras’ 3D spatial tracking method can have a relatively better continuous monitoring effect than a single camera alone.
3.2.2. Multi-Person Scene Tracking
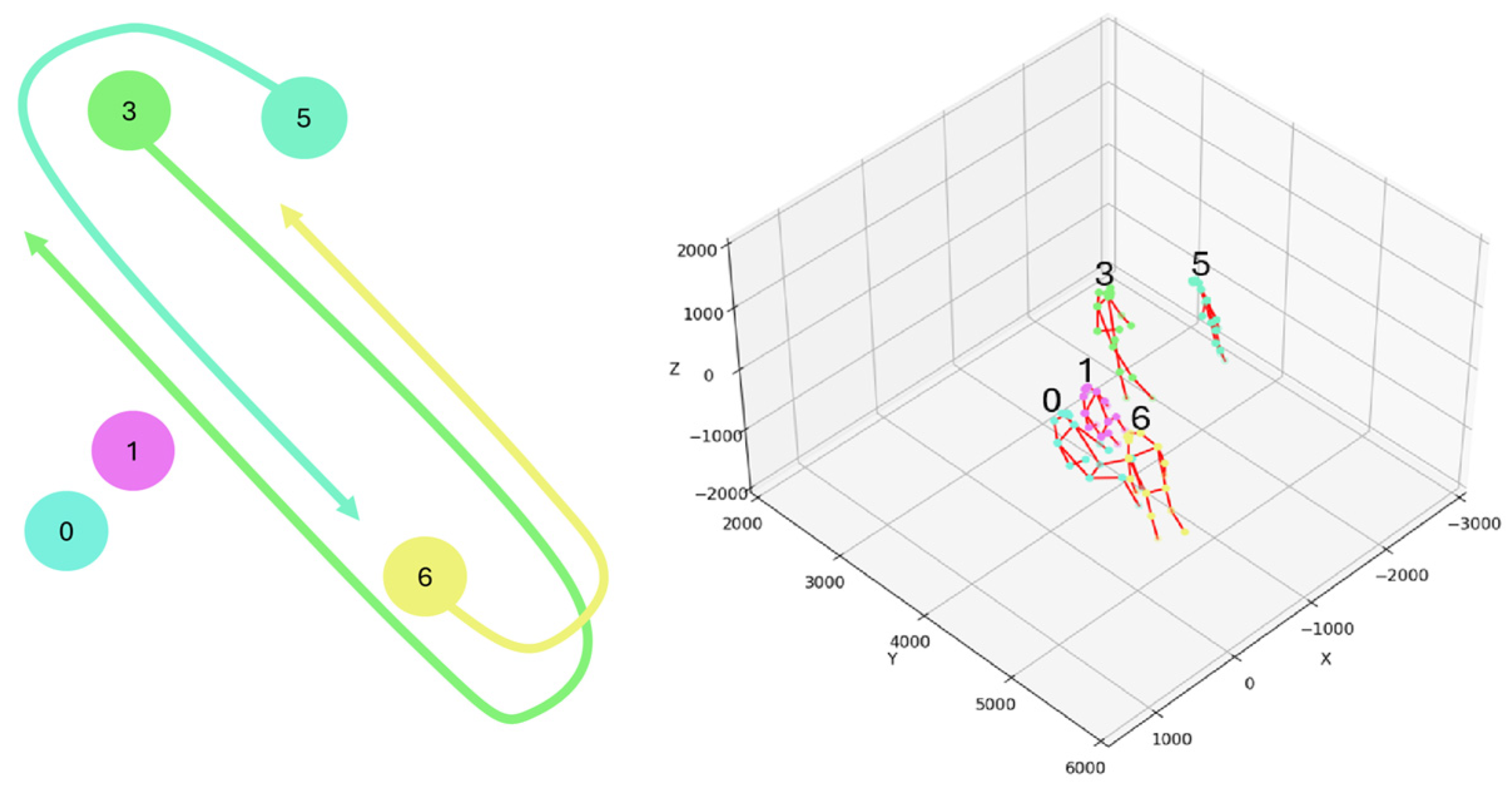
As noted above, we tested the system with videos recording six or more people walking around a laboratory, some stationary, some moving, and others entering and exiting at different times.
Figure 12 gives an example of illustrating the movement paths of six individuals. This scene includes occlusions caused by crossing individuals and occlusions caused by objects.
Compared with the previous experiment, the replication degree of this experiment is relatively high because people may move unpredictably (such as stopping suddenly, turning, or changing speed). If the YOLO system is used, its tracking effect is minimal. This may lead to frequent recognition errors or tracking failures when persons suddenly stop, change direction, or overlap. The same person may have multiple, so-called redundant IDs in this case. Generating these redundant IDs will cause considerable trouble and difficulty in personnel identification. To reduce these redundant IDs, try to group these different IDs with the same person, the so-called Re-ID.
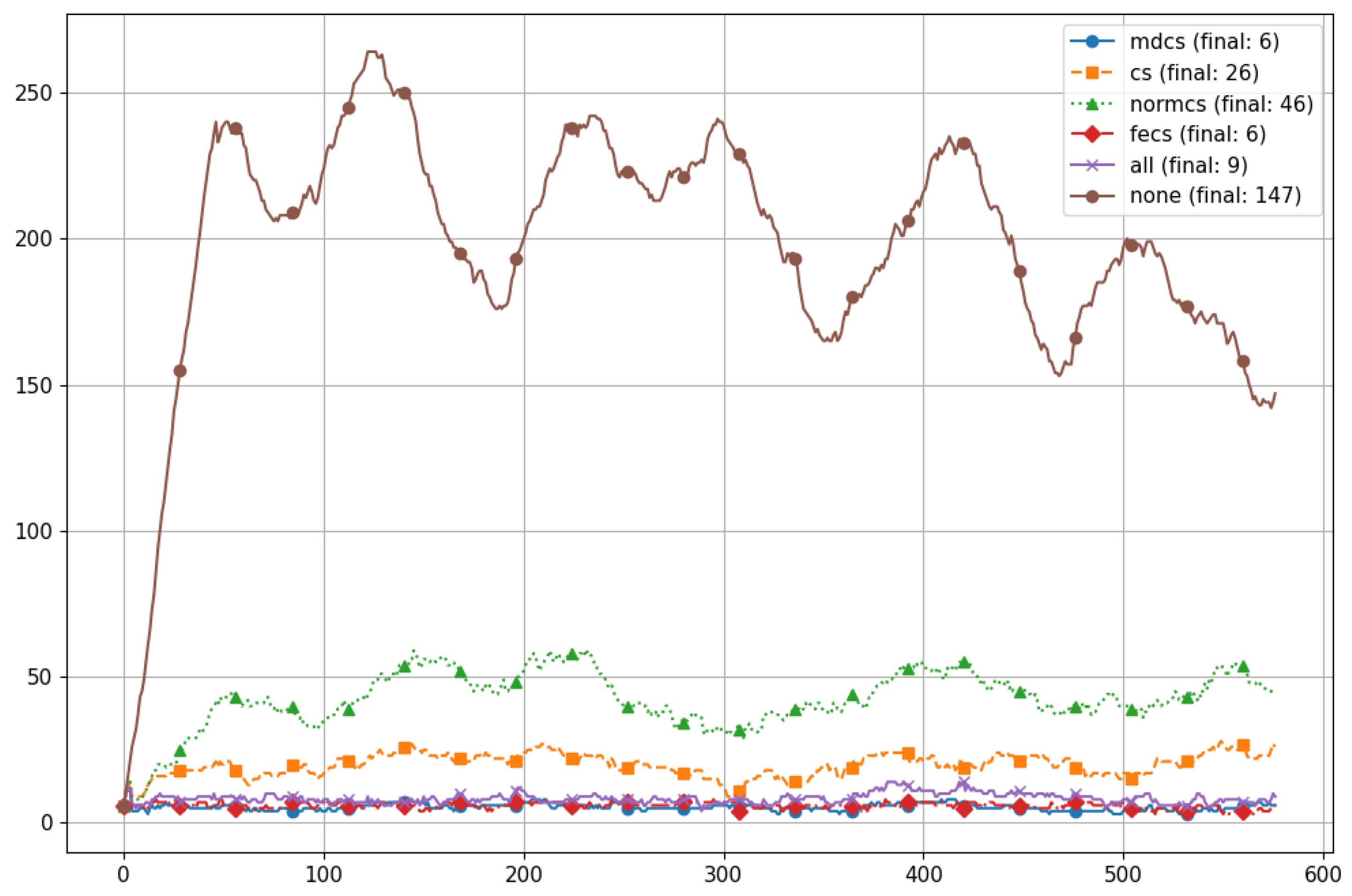
Figure 13 illustrates an example of the change in ID recognitions for a six-person scene with a video length of 575 frames. This result shows that without using any ID re-identification method, a scene with six people, stationary or moving, will generate about 150~250 ID numbers after a short period (about 30 s). When we use any of the four re-identification parameters (MDCS, CS, NORMCS, FECS) alone, the number of IDs is reduced to less than 50. This study further compares these four parameters. The results show that among these four parameters, two (MDCS and FECS) show pretty good results, followed by CS, and NORMCS is unsatisfactory. What is interesting is that when we use these four parameters at the same time, the number of identifications increases from 6 to 9. This result shows that these parameters may conflict due to their different methods. We speculate that the reason behind this is that people’s activities in the laboratory are not only related to body movement but also include other body movements (for example, typing, sitting, discussing, etc. Differences in activity levels will affect 17 key pieces of information. Therefore, specific difficulties exist in using key technologies for re-identification under certain circumstances. There are two possible solutions to this problem. The first is to select key points related to body movement (rather than movement changes) among these 17 key points for tracing. The second is to build a database of different personal activities through large amounts of data collection.
3.3. Summary
Our key finding is that not all plausible measures are equally crucial in multi-view pedestrian tracking. Among these four measures, MDCS and FECS perform better than CS and NORMCS for person tracking because they extract robust and highly discriminative feature representations from motion patterns and visual appearance, two relatively independent dimensions crucial for identity recognition. The stability and discriminability of these two features are further enhanced in multi-view scenarios. MDCS captures the macroscopic motion patterns of pedestrians in three-dimensional space. From a machine learning perspective, this is a high-level, time-continuous feature. It is insensitive to small changes in pose, lighting effects, or slight occlusions in a single frame because it focuses on the overall movement trend. In the three-dimensional space obtained after multi-perspective fusion, the consistency of this motion trajectory is more obvious, providing a very stable and unique clue for distinguishing different individuals. Its relatively low feature dimensionality also makes it less susceptible to excessive effects from noise.
Likewise, FECS is an appearance representation learned by a deep learning model on a large-scale dataset (Market-1501). The design goal of these deep features is to maximize the inter-class differences and minimize the intra-class discrepancies, that is, to make the feature vectors of different people as far apart as possible in the feature space, and the feature vectors of the same person (even under various perspectives, lighting, and slight occlusion) as close as possible. The training process enables FECS to have a certain degree of invariance to changes in perspective, lighting, and even partial occlusion. Therefore, it can effectively capture an individual’s identity information from the visual appearance level.
By contrast, CS and NORMCS mainly rely on instantaneous, low-level geometric information, which is easily disturbed by pose changes and detection noise, resulting in their insufficient stability and discriminability as identity recognition features. If CS measures are used, they are susceptible to subtle changes in posture. Different actions of the same person at various time points (such as swinging arms and turning heads) can cause significant changes in the coordinates of key points, even if the identity remains unchanged. At the same time, the error (noise) of the key point detection model itself will be directly introduced into the similarity calculation. In the high-dimensional keypoint coordinate space, this sensitivity to posture changes and noise makes it difficult for simple metrics such as Euclidean distance to determine whether the identity is consistent, especially when the period is slightly more extended or the posture changes are significant. The specific normalization strategy adopted by NORMCS fails to improve robustness effectively and may even bring adverse effects.
4. Discussions
In this study, we utilized a specially designed laboratory as a research environment to explore some of the challenging questions mentioned above. The limited space of this lab and the placement of objects helped to create occlusion scenes. In addition, the laboratory has two camera setups that serve as direct equipment for multi-view studies. This study uses stereo camera calibration and key point detection to reconstruct the three-dimensional key points of the person being pursued and uses this to perform the tracking task. The results show that the three-dimensional reconstruction of key points in a single-view scene can effectively and stably track the same person.
Secondly, in the same scene, some people may move while others are stationary. It must be emphasized here that a stationary, moving person may exhibit active movements, such as a seated person typing, discussing, etc., and carrying out different activities. These are issues that need to be addressed in more depth than simply tracing the case. This study adopts four ways to evaluate person similarity, which can effectively reduce the unnecessary identity generation of persons. However, using these four methods simultaneously may not produce better results than specific evaluation methods alone.
Finally, since people may enter and exit the same environment at different times, the generation and conversion of person IDs cannot be avoided entirely. To address this problem, the method adopted in this study is to use a dataset to collect the values of 17 key points for the same person and re-identify them using four assessments (MDCS, CS, NORMCS, FECS) when appropriate. Experimental results show that this method effectively collects individually generated ID switches, i.e., forms an ID set representing each person, and can filter erroneous key points from 3D reconstructions. However, the design of this ID collector requires customized standards and combinations for different scenarios. When more information is collected, it can compensate for the limitations of relying solely on individual details and play a complementary role through mutual constraints.
Based on the above discussion, this study hopes to use the individual information of persons to avoid the generation of redundant IDs for each person, which is called a generalization problem. However, when overuse (or emphasis) of generalization shortens the discrimination gap between people, this result will make the system lose the ability to distinguish different persons; that is, it will lack specificity. On the other hand, when we overemphasize specialization, we lose the ability to generalize. Overall, this is a dilemma. Struggling to strike a balance between these two dilemmas is an open issue.
Various challenges must be addressed to enhance person tracking in more complex and realistic scenarios. These scenarios might involve crowded environments, occlusions, multiple camera views, changing lighting conditions, person behavior (e.g., motion patterns), and real-time requirements. Below are several strategies and enhancements that can be implemented to make tracking methods more robust and suitable for such complex environments. These features extracted by YOLO-Pose can help distinguish between individuals even when their bounding boxes overlap. When a person reappears after being occluded, there are two possible solutions. One uses a re-ID system that re-identifies the person based on appearance features extracted from YOLO-Pose. In contrast, the other uses Kalman filters to predict a person’s location during an occlusion.
5. Conclusions
Person tracking is a vital topic that is widely used in various fields. However, person tracking often faces the so-called perspective occlusion problem, which occurs when continuous tracking is affected by object occlusion or person crossing, resulting in monitoring failure or misinterpretation. The solutions and technologies for person tracking across multiple cameras are all-encompassing, including homography and 3D reconstruction, deep learning models for person detection and tracking, graph-based methods, multi-object tracking (MOT) algorithms, sensor data fusion, and detection tracking. Each method and technology has its relative advantages and, of course, its weaknesses. Of course, if these methods and technologies can be reasonably integrated, a fairly complete system can be produced. However, this approach is unimaginably large and complex in terms of time and resource usage complexity. In response to this problem, the general way to deal with it is to limit the problem area to a specific scope and field. In this study, we used a dual-view camera in the laboratory to establish 3D critical point information through binocular camera calibration technology and key point detection in the overlapping area of the shooting range to enhance the tracking effect. In the 3D key point reconstruction process, this study uses a hierarchical clustering algorithm to pair critical points from different angles. It uses direct linear transformation and a singular value decomposition algorithm to reconstruct 3D vital points and use them for person tracking. Identifying the same person or people in different scenes is another problem during tracking.
There is still scope for further development of this research in the future, such as by examining the degree of crowding of persons in the product area, especially when the distance between people is very close. We know that when the degree of overlap between people is high, even with high-confidence detection, each person’s identity may be lost. Another area of research effort is to vary the size of the distance between each camera. Generally speaking, this change will result in considerable differences in the size of persons. Generally speaking, using Yolo to detect persons at a distance may result in detection loss or relatively poor tracking results. This study only uses two cameras and focuses on the overlapping person-tracking process. Other possible future research avenues include increasing the number of cameras and further investigating person tracking from a non-overlapping perspective to address ongoing continuous monitoring in all conditions.
Author Contributions
Conceptualization, J.-C.C. and P.-S.C.; methodology, J.-C.C., P.-S.C. and Y.-M.H.; software, P.-S.C. and Y.-M.H.; validation, J.-C.C. and Y.-M.H.; formal analysis, J.-C.C., P.-S.C. and Y.-M.H.; investigation, J.-C.C., P.-S.C. and Y.-M.H.; resources, P.-S.C. and Y.-M.H.; data curation, P.-S.C. and Y.-M.H.; writing—original draft preparation, J.-C.C. and P.-S.C.; writing—review and editing, J.-C.C.; visualization, J.-C.C. and Y.-M.H.; supervision, J.-C.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki and approved by the Human Research Ethics Committee of the National Cheng Kung University (Approval No.: NCKU HREC-E-114-0169-2, 30 April 2025).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The data presented in this study involves human images and are not publicly available due to ethical restrictions and patient privacy concerns, in accordance with the approval granted by the Institutional Review Board (IRB). The raw data contain potentially identifying information and therefore cannot be shared publicly to protect participant confidentiality.
Conflicts of Interest
The author has no conflicts of interest.
References
- Torres, P.; Marques, H.; Marques, P. Person Detection with LiDAR Technology in Smart-City Deployments–Challenges and Recommendations. Computers 2023, 12, 65. [Google Scholar] [CrossRef]
- Talaoubrid, H.; Vert, M.; Hayat, K.; Magnier, B. Human Tracking in Top-View Fisheye Images: Analysis of Familiar Similarity Measures via HOG and against Various Color Spaces. J. Imaging 2022, 8, 115. [Google Scholar] [CrossRef] [PubMed]
- Du, Y.; Zhao, Z.; Song, Y.; Zhao, Y.; Su, F.; Gong, T.; Meng, H. StrongSORT: Make DeepSORT Great Again. IEEE Trans. Multimed. 2023, 25, 8725–8737. [Google Scholar] [CrossRef]
- Zhu, J.; Chen, S.; Tu, W.; Sun, K. Tracking and Simulating Person Movements at Intersections Using Unmanned Aerial Vehicles. Remote Sens. 2019, 11, 925. [Google Scholar] [CrossRef]
- Razzok, M.; Badri, A.; Mourabit, I.E.; Ruichek, Y.; Sahel, A. Person Detection and Tracking System Based on Deep-SORT, YOLOv5, and New Data Association Metrics. Information 2023, 14, 218. [Google Scholar] [CrossRef]
- Huang, C.; Li, W.; Yang, G.; Yan, J.; Zhou, B.; Li, Y. Cross-Video Person Tracking Algorithm with a Coordinate Constraint. Sensors 2024, 24, 779. [Google Scholar] [CrossRef]
- Wu, Y.-C.; Chen, C.-H.; Chiu, Y.-T.; Chen, P.-W. Cooperative People Tracking by Distributed Cameras Network. Electronics 2021, 10, 1780. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Z.; Luo, H.; Pu, H.; Tan, J. Multi-Person Multi-Camera Tracking for Live Stream Videos Based on Improved Motion Model and Matching Cascade. Neurocomputing 2022, 492, 561–571. [Google Scholar] [CrossRef]
- Gheissari, N.; Sebastian, T.B.; Hartley, R. Person Reidentification Using Spatiotemporal Appearance. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition—Volume 2 (CVPR’06), New York, NY, USA, 21–23 June 2006; Volume 2, pp. 1528–1535. [Google Scholar]
- Temuge, B. Stereo Camera Calibration and Triangulation with OpenCV and Python. Available online: https://temugeb.github.io/opencv/python/2021/02/02/stereo-camera-calibration-and-triangulation.html (accessed on 2 February 2021).
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Ristani, E.; Tomasi, C. Features for multi-target multi-camera tracking and re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6036–6046. [Google Scholar]
- Zhang, S.; Bauckhage, C.; Cremers, A.B. Informed haar-like features improve person detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 947–954. [Google Scholar]
- Nam, W.; Dollár, P.; Han, J.H. Local decorrelation for improved pedestrian detection. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 424–432. [Google Scholar] [CrossRef]
- Hariharan, B.; Malik, J.; Ramanan, D. Discriminative decorrelation for clustering and classification. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 459–472. [Google Scholar]
- Cao, J.; Pang, Y.; Li, X. Learning multilayer channel features for person detection. IEEE Trans. Image Process. 2017, 26, 3210–3220. [Google Scholar] [CrossRef] [PubMed]
- Tesema, F.B.; Wu, H.; Chen, M.; Lin, J.; Zhu, W.; Huang, K. Hybrid channel based person detection. Neurocomputing 2020, 389, 1–8. [Google Scholar] [CrossRef]
- Hu, Q.; Wang, P.; Shen, C.; van den Hengel, A.; Porikli, F. Pushing the limits of deep CNN for person detection. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 1358–1368. [Google Scholar] [CrossRef]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 354–370. [Google Scholar]
- Lin, C.Y.; Xie, H.X.; Zheng, H. PedJointNet: Joint head-shoulder and entire body deep network for person detection. IEEE Access 2019, 7, 47687–47697. [Google Scholar] [CrossRef]
- Wang, S.; Cheng, J.; Liu, H.; Wang, F.; Zhou, H. Person detection via body part semantic and contextual information with DNN. IEEE Trans. Multimed. 2018, 20, 3148–3159. [Google Scholar] [CrossRef]
- Hsu, W.Y.; Lin, W.Y. Ratio-and-scale-aware YOLO for person detection. IEEE Trans. Image Process. 2020, 30, 934–947. [Google Scholar] [CrossRef] [PubMed]
- Manzoor, S.; An, Y.-C.; In, G.-G.; Zhang, Y.; Kim, S.; Kuc, T.-Y. SPT: Single Person Tracking Framework with Re-Identification-Based Learning Using the Siamese Model. Sensors 2023, 23, 4906. [Google Scholar] [CrossRef] [PubMed]
- Borau Bernad, J.; Ramajo-Ballester, Á.; Armingol Moreno, J.M. Three-Dimensional Vehicle Detection and Pose Estimation in Monocular Images for Smart Infrastructures. Mathematics 2024, 12, 2027. [Google Scholar] [CrossRef]
- Maji, D.; Nagori, S.; Mathew, M.; Poddar, D. Yolo-pose: Enhancing yolo for multi-person pose estimation using object keypoint similarity loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2636–2645. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755, ISBN 978-3-319-10602-1. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable Person Re-Identification: A Benchmark. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Huang, H.W.; Yang, C.Y.; Jiang, Z.; Kim, P.K.; Lee, K.; Kim, K.; Ramkumar, S.; Mullapudi, C.; Jang, I.S.; Huang, C.I.; et al. Enhancing Multi-Camera People Tracking with Anchor-Guided Clustering and Spatio-Temporal Consistency ID Re-Assignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5239–5249. [Google Scholar]
- Brunton, S.L.; Kutz, J.N. Singular Value Decomposition (SVD). In Data-Driven Science and Engineering: Machine Learning, Dynamical Systems, and Control; Cambridge University Press: Cambridge, UK, 2019. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}