1. Introduction
Legal text classification falls under the category of text hierarchical multi-label classification tasks. As a subtask within the natural language processing (NLP) field, general text hierarchical multi-label classification aims to assign labels to texts based on a given label hierarchy, where each input text can correspond to multiple different labels structured hierarchically. Multi-label hierarchical text classification plays a significant role in various domains, such as news categorization, legal applications, and document management, owing to its alignment with real-world application requirements [
1,
2]. Unlike traditional flat classification methods, hierarchical multi-label classification tasks require capturing the associations between texts and categories, as well as taking into account the hierarchical relationships and correlations between categories. However, increasing the number of categories and hierarchical levels introduces challenges such as an imbalanced sample distribution and semantic similarity between hierarchical labels [
3,
4], further complicating the task.
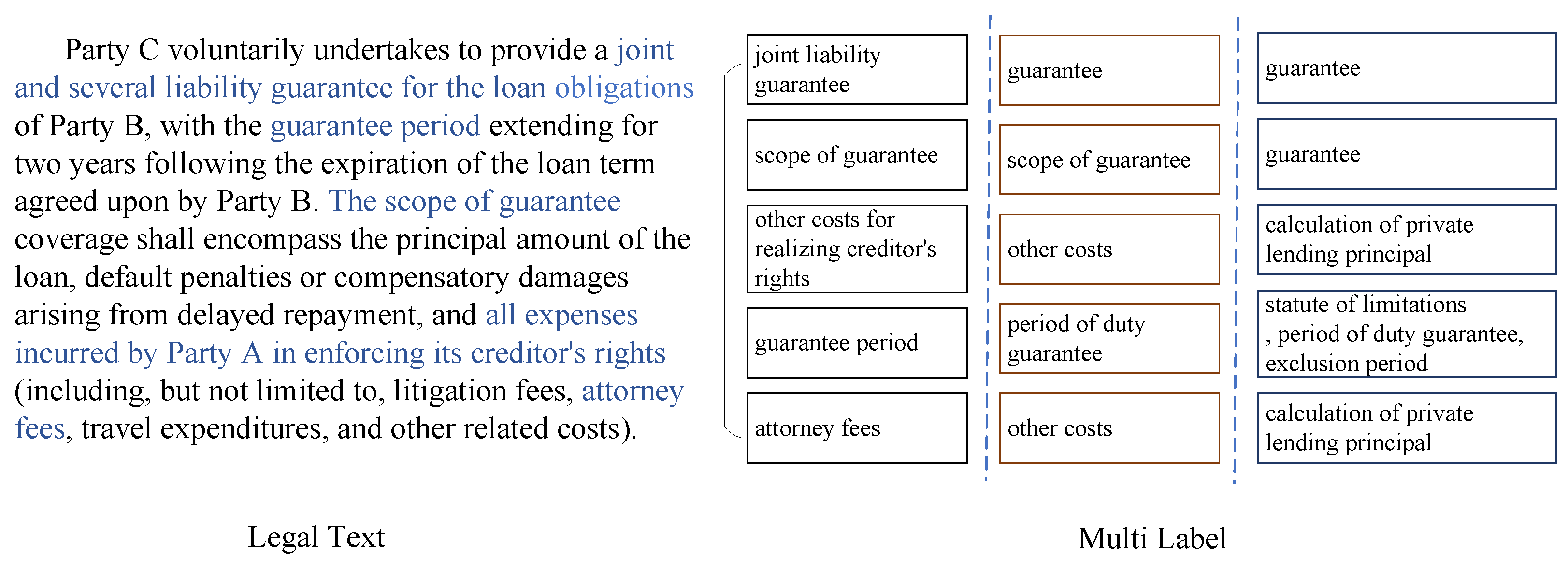
Legal text classification tasks exhibit distinct characteristics compared with traditional multi-label text classification, including stronger semantic reasoning logic embedded in labels and limited labeled samples. Identifying these labels requires contextual semantic analysis combined with factual content and underlying legal logic, further increasing task complexity. An example of a legal text classification task is shown in
Figure 1. For a factual description of a loan relationship case, the deep-level labels (level-3) include “joint liability guarantee, scope of guarantee, other costs for realizing creditor’s rights, guarantee period, attorney fee”. The intermediate-level labels (level-2) are “guarantee, scope of guarantee, other costs, period of duty guarantee, other costs”, while the shallow-level labels (level-1) comprise “guarantee, guarantee, calculation of private lending principal, ’statute of limitations, period of duty guarantee, exclusion period’, calculation of private lending principal”. Here, the level-3 labels “joint liability guarantee” and “scope of guarantee” both fall under the level-1 category “guarantee”, whereas the level-3 label “guarantee period” belongs to the level-1 category “statute of limitations, period of duty guarantee, exclusion period”. Although “joint liability guarantee”, “scope of guarantee”, and “guarantee period” all appear to relate to “guarantee” on the surface, legally, they belong to two distinct categories. Accurate classification requires literal interpretation and precise legal semantic analysis.
Scholars have dedicated efforts to exploring efficient and accurate hierarchical text classification methods to address the aforementioned challenges. Several studies have proposed model design strategies incorporating hierarchical structures to tackle issues such as class imbalance and hierarchical relationship modeling. Zhou et al. [
5] employed directed graphs to represent hierarchical labels and used a hierarchy-sensitive structural encoder to model labels, effectively integrating hierarchical label information into text and label semantics. Chen et al. [
6]’s hierarchy-aware semantics matching network (Hi-Match) performs representation learning on texts and hierarchical labels, using separate text and label encoders to extract semantic features. The model then calculates correlations between text and label embeddings within a joint semantic embedding space to identify multi-label types, defining distinct optimization objectives based on the two representation vectors to enhance hierarchical multi-label text classification performance. However, these methods suffer from insufficient semantic representation of label hierarchies and the inability to resolve imbalanced sample distribution. An increasing number of researchers have recently adopted contrastive learning approaches to optimize hierarchical label semantic representation and address sample distribution imbalance. Zhang et al. [
7] introduced a hierarchy-aware and label balanced model (HALB), which utilizes multi-label negative supervision to push text representations of samples with different labels further apart. In addition, to mitigate label imbalance in hierarchical text classification, asymmetric loss is applied to compute classification loss, enabling the model to focus on learning from difficult samples and balance the contribution of positive and negative labels to the loss function.
Furthermore, scholars have improved classification performance by optimizing multi-label semantic representations [
4], augmenting negative samples [
8], or incorporating external knowledge [
3,
9] to further enhance the accuracy of multi-label recognition. Chen et al. [
3] proposed a few-shot hierarchical multi-label classification framework based on ICL and LLM, leveraging contrastive learning to accurately retrieve text keywords from a retrieval database and improve hierarchical label recognition accuracy. However, these approaches primarily address either imbalanced sample distribution or hierarchical semantic representation issues individually, failing to resolve both challenges synchronously. Zhang et al. [
4] combined multi-label contrastive learning with K-nearest neighbors (MLCL-KNN), enabling text representations of sample pairs with more shared labels to be closer while separating pairs without common labels. Zhou et al. [
5] designed a hierarchical sequence ranking (HiSR) method to generate diverse negative samples that maximize contrastive learning effectiveness, enhancing the ability of the model to distinguish fine-grained labels by emphasizing differences between true labels and generated negatives. Feng et al. [
9] categorized external knowledge into micro-knowledge (basic concepts associated with individual class labels) and macro-knowledge (correlations between class labels), using them to improve discriminative power in text and semantic label representations.
This study addresses these limitations and capitalizes on the advantages of prototype networks in handling imbalanced sample distributions by proposing a multi-label recognition method for legal texts based on hierarchical prototypical networks. In particular, we employ the Sentence-BERT model [
10] to obtain a unified long-text embedding vector representation. A hierarchical prototype network architecture is designed for multi-level label recognition, in which a hierarchical prototype structure is constructed according to the data label levels and relationships. In addition, a hierarchical prototype network loss function is proposed. By integrating inter-layer correlation information between labels and prototypes at different levels, the method achieves unified optimization of cross-level prototype parameters within the prototype network, thereby enhancing the accuracy of multi-level label recognition under conditions of uneven sample distribution.
The main contributions of this article are as follows:
- (1)
We propose a new multi-head hierarchical attention framework suitable for multi-label legal text recognition tasks, which mainly comprises a feature extraction module and a hierarchical module. The feature extraction module is mainly used to extract multi-level semantic representations of the text, while the hierarchical module is used to obtain multi-label category information.
- (2)
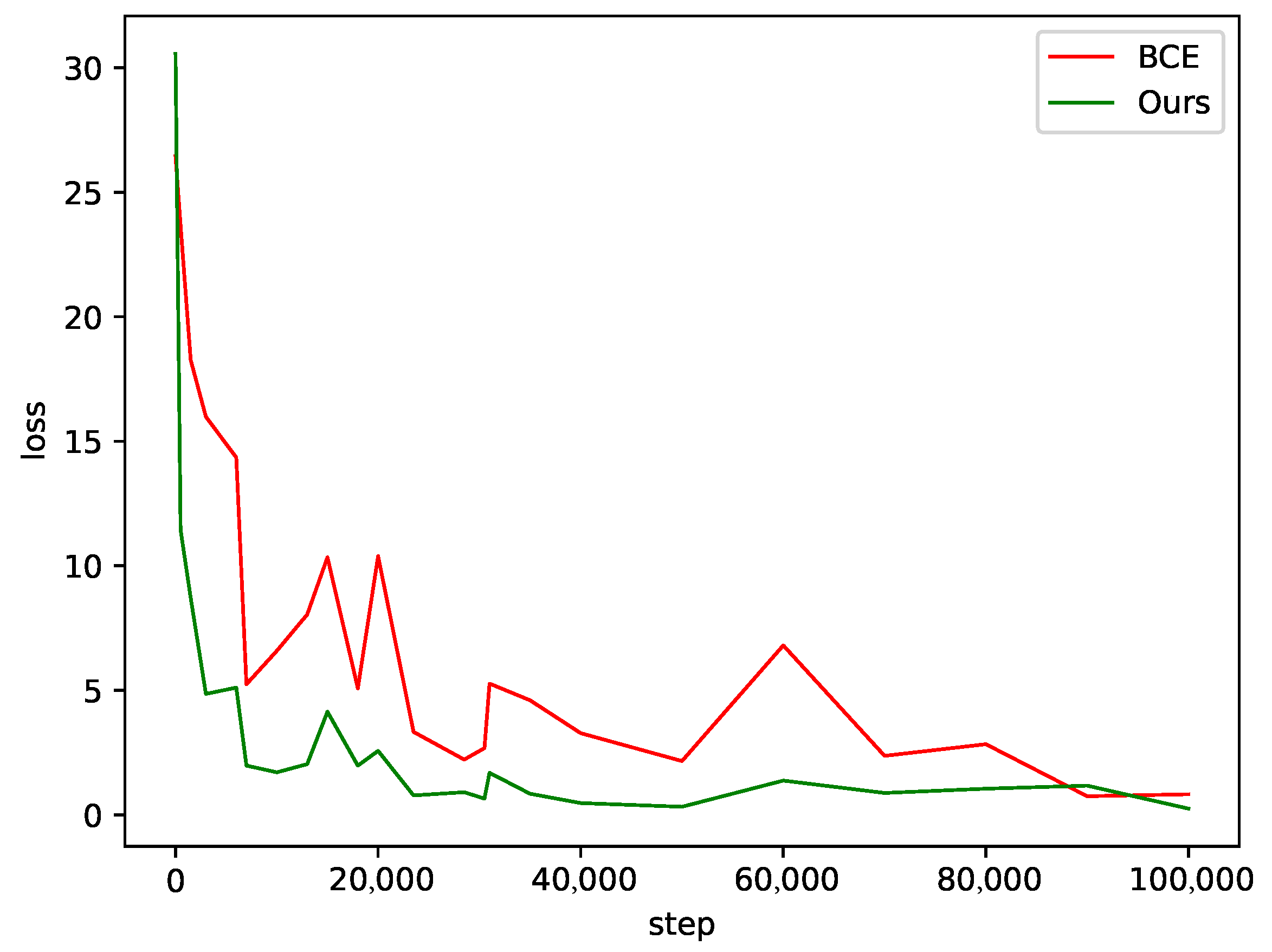
We propose a novel hierarchical learning optimization strategy that considers multi-level semantic representation and multi-label classification information learning requirements through data preprocessing, loss calculation, and weight updating, effectively improving the convergence speed of framework training.
- (3)
We conduct comparative experiments on the legal domain dataset CAIL2021 and the general multi-label recognition datasets AAPD and Web of Science (WOS). The experimental results show that the proposed method is significantly superior to mainstream methods in legal and general scenarios.
3. Methods
3.1. Problem Description
Legal text multi-label recognition falls under hierarchical multi-label classification, where the objective is to identify hierarchically structured legal labels from a given factual description. The set of all multi-labels forms a hierarchical structure, defined as , where H represents the depth of the hierarchical label structure. The classification set of the i-th layer is denoted as , and is the total number of labels at that level. The hierarchical structure T resembles a forest in data structures, where the depth of the label hierarchy corresponds to the depth of trees in the forest, each parent node may correspond to multiple child nodes, and a child node belongs to only one parent node.
The formal definition of the legal text multi-label recognition problem is as follows: Let
D denote the dataset containing
N data samples
where
represents the input legal text comprising
L words:
denotes the corresponding hierarchical multi-label set, where
Let the multi-label recognition model be
, then the legal text multi-label recognition task can be represented as a classification model
learned using the sample set
D and hierarchical structure
T that can predict the multi-label set for legal text
corresponding to the input text.
where
is a parameter of model
.
3.2. Multi-Head Hierarchical Attention Framework
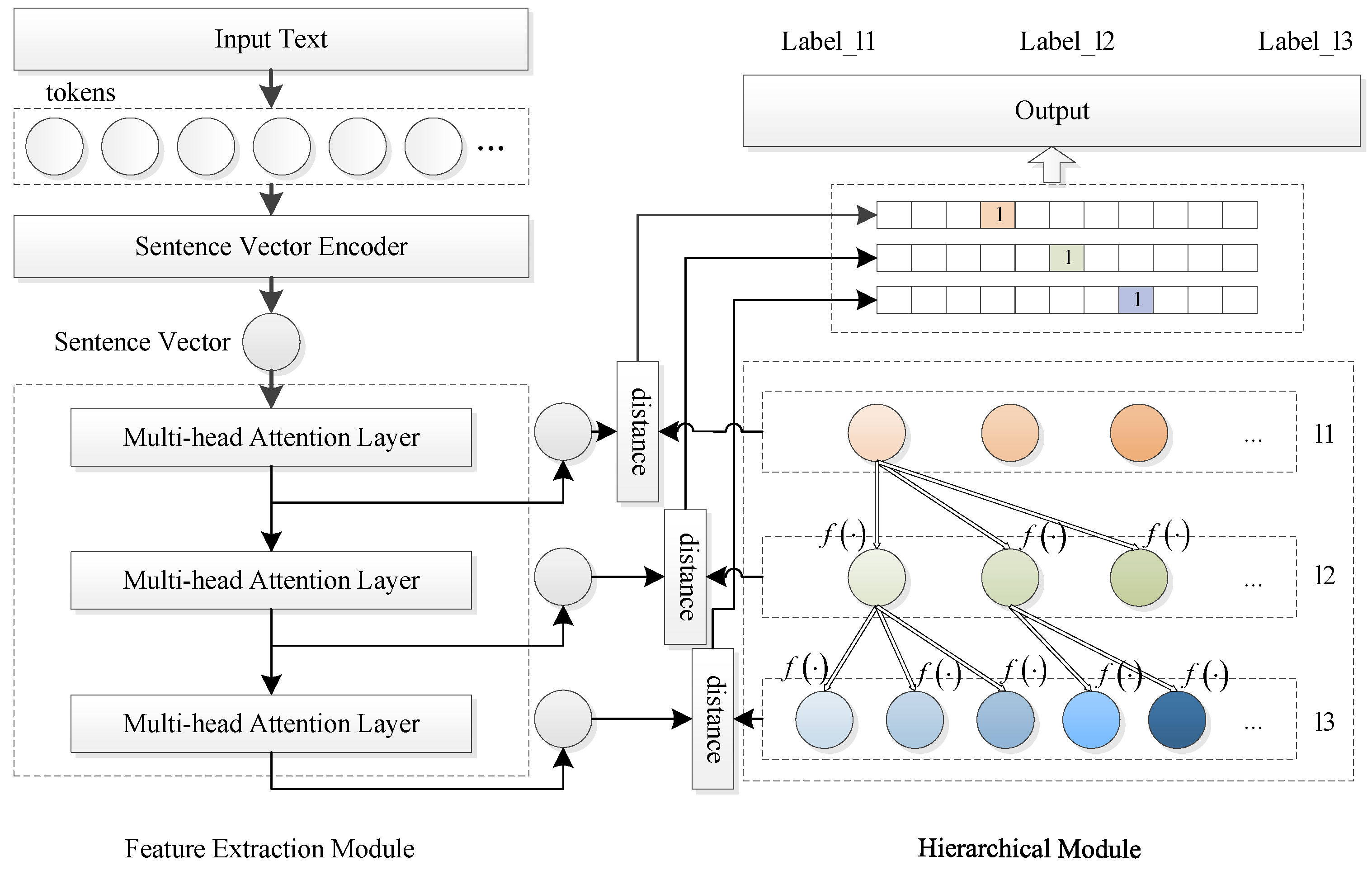
The overall framework of the legal text multi-label recognition model based on the hierarchical prototype neural network proposed in this study is shown in
Figure 2. This framework comprises two parts, the feature extraction module on the left and the hierarchical module on the right. The feature extraction module mainly comprises a vector encoder and a multi-head attention layer. The text sentence vector encoder is responsible for encoding the input text to generate an initial sentence vector, which serves as the semantic representation of the text while preserving contextual dependencies and key semantic features. Subsequently, multiple multi-head attention layers are used to hierarchically represent sentence vectors, enabling the extraction of semantic representations at each level. The hierarchical module calculates the semantic distance between different levels and their corresponding prototype representations for multi-level label recognition.
Figure 2 shows a scenario with three label levels, corresponding to the legal dataset (CAIL2021). The subsequent description of the method is based on this three-layer label structure. The model can be extended to accommodate different depths of hierarchical labels (e.g., 2 layers, 4 layers). Depending on the label hierarchy of the target task, the depth of the feature extraction layer and prototype network in the model can be adjusted accordingly. Model parameters are optimized by calculating the loss function.
3.3. Feature Extraction Module
This study effectively extracts the multi-level semantic representation from the input legal text by utilizing the Sentence-BERT model [
10] to obtain the initial sentence vector
E from the input text
. Sentence-BERT is a supervised sentence embedding model that extends the BERT architecture by incorporating a mean pooling layer, enabling the extraction of fixed-length sentence embeddings. By leveraging a Siamese network architecture, it compares semantic embeddings of input text with manually annotated reference samples, optimizing model parameters using a contrastive learning strategy. This process enhances the semantic representation capacity of sentence vectors.
Multi-head attention mechanisms are utilized to extract hierarchical semantic information at different levels to align with the multi-level label structure [
27]. Each multi-head attention layer captures semantic features at increasing depths, thereby enabling progressive abstraction of textual representations. Given a three-level hierarchical label structure, the multi-level sentence vector representation is computed as follows:
where
,
, and
denote sentence vector representations at three different hierarchical depths while
represents the transformation function applied at each level, implemented using multi-head attention mechanisms.
3.4. Hierarchical Module
Conventional prototype neural networks typically employ a single-layer structure, which fails to capture hierarchical relationships between label classes, leading to suboptimal recognition accuracy. This study overcomes this limitation by proposing a hierarchical prototype neural network model that incorporates a transition matrix to define prototype transitions between adjacent hierarchical levels. The model simultaneously optimizes prototype parameters across all hierarchical levels, ensuring global optimization of multi-label classification.
The hierarchical prototype representations are formally defined as follows:
where
,
, and
correspond to the prototype parameters at three different hierarchical depths,
x,
y, and
z represent the number of prototype labels at each respective level, and
k denotes the number of prototypes under each prototype label.
Let
denote the connection matrix between the prototype parameters of the first and second levels, with a dimensionality of
.
represents the connection between the
i-th prototype parameter in the first level and the
j-th prototype parameter in the second level. If the
j-th prototype parameter in the second level corresponds to the
i-th prototype parameter in the first level, the value is 1; otherwise, it is 0.
denotes the connection matrix between the prototype parameters of the second and third levels, with a dimensionality of
. The equations for calculating the prototypes at different levels are given as follows:
represents the transformation operation between prototypes at different levels. The calculation of prototype parameters is implemented using an attention mechanism layer, and a mean pooling layer is applied to process the parameter calculation results. This stabilizes the distribution of prototype parameters and enables the model to converge quickly.
3.5. Hierarchical Label Classification
Traditional prototype neural networks are primarily designed for single-label classification tasks, where they compute the distance between the feature representation and multiple prototypes and assign the class of the nearest prototype to the input data. The classification process is defined as follows:
is the discriminant function corresponding to the
i-th class:
In addition, can also represent the matching value of sample x to the i-th class.
However, multi-label recognition tasks require assigning zero or more labels to a single sample, making the minimum-distance approach unsuitable as it is inherently limited to single-label classification. Yang et al. [
12] sought to address this by proposing a distance-based prototype neural network for hierarchical multi-label classification. Their method computes distances between hierarchical multi-labels and prototypes, introducing a threshold-based decision mechanism; no label is assigned if the minimum prototype distance of a sample exceeds a pre-defined threshold. However, the sample is assigned all corresponding labels if the distance to at least one prototype falls below the threshold. For a sample
x, which does not correspond to any label,
For a sample
x corresponding to one or more labels, the label set is defined as follows:
Parent–child constraints are applied to ensure hierarchical consistency, enforcing structural dependencies by considering only prototype distances within the same hierarchical parent–child relationships.
3.6. Loss Function
Traditional single-label classification employs loss functions such as DCE [
12] and OVA [
28], which optimize the distance between text embeddings and prototype representations. However, these methods are incompatible with multi-label classification, as they do not account for multi-label assignments. This study introduces a hierarchical cross-entropy loss function that optimizes text embedding representations and prototype parameters to address this limitation, ensuring compliance with the multi-label constraints in Equation (
12).
For an input
, the multi-level text vector representation is computed, followed by confidence-level estimation for each prototype class, as follows:
where
represents the sigmoid function, and
d is the distance function (using cosine similarity). During the calculation, the maximum distance between the text vector representation and the model distance within the same class is taken as its confidence level value with respect to the current class. The loss function for the model output at the current level and its corresponding prototype is defined as follows:
The losses of the model are obtained by summing the three levels of losses as follows:
3.7. Implementation Details
All experiments were conducted on a high-performance computing server running CentOS 7.6. The system specifications include two RTX-TITAN 24 GB GPUs and eight 32 GB memory modules. The experimental environment was set up under the PyTorch 1.7.1 framework, utilizing the transformers model library [
29], with Python version 3.7.6.
For the CAIL2021 dataset, the model employs the three-layer hierarchical structure described above. For the AAPD and WOS datasets, which have label depths of two layers, we modify the feature extraction and hierarchical modules to align with this label hierarchy. In particular, the multi-layer sentence representation is restricted to and , the hierarchical prototype representation is defined as , and the loss function is optimized as .
During the training process, the data in the training samples were first preprocessed. Legal text data typically exhibits strong structural characteristics and considerable length. In our actual training procedure, we processed the data from the training samples of the CAILl2021 dataset as follows: (1) Based on the characteristics of legal data and label types, we segmented the lengthy document data, retaining only key sections such as the trial process, the appellant’s claim, the respondent’s defense, and the court’s findings. In addition, excessively long sentences within the training samples were truncated to improve processing efficiency. (2) Sentences and labels in the factual description section were extracted separately and treated as independent data entries. Finally, we constructed a corresponding label set for the samples according to the number of model labels, thereby obtaining all the required training sample data.
This study employs the AdamW optimizer with weight_decay set to 0.001, a mini-batch size of 8, and an initial learning rate of 1e-8. In addition, a warmup strategy was adopted to adjust the learning rate.
5. Conclusions
This study focuses on the task of multi-label legal text recognition, innovatively constructing a multi-head hierarchical attention framework and supporting a new hierarchical learning optimization strategy. In terms of method construction, the framework achieves precise extraction of multi-level semantic representations of text and effective acquisition of multi-label category information through the collaborative operation of the feature extraction and hierarchical modules. Concurrently, the hierarchical learning optimization strategy successfully breaks the shackles of traditional methods in balancing multi-level semantic and multi-label category information learning, accelerates the convergence speed of framework training, and lays a solid foundation for efficient and accurate multi-label legal text recognition. In the experimental verification phase, the proposed method showed significant advantages compared with mainstream methods on the CAIL2021 legal field dataset and the general multi-label recognition datasets AAPD and WOS. The model can complete tasks more accurately and efficiently, whether it is multi-label recognition of complex legal text in legal scenarios or facing diverse text types in general scenarios. This highlights the strong generalization ability and adaptability of this method. However, the model can be further optimized in terms of cross-level label modeling, such as employing a learnable soft-linked hierarchical label association approach to enhance the robustness and generalizability of the model to real-world legal data. This approach improves the adaptability of the model to challenges such as category interference, label variations, and semantic ambiguity between different labels.
The study findings are expected to be widely applied to the intelligent processing of legal information, such as assisting legal practitioners in quickly searching and classifying massive legal literature, improving the accuracy of intelligent classification of judicial cases, and further promoting the digitalization and intelligence process of the legal industry. Concurrently, this method provides new ideas for related NLP tasks. Future research can explore and expand its potential value to text processing in other professional fields.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}