1. Introduction
Web robots or crawlers have become a major source of network traffic. While some robots (such as those used by search engines) behave well, other robots may perform DDoS [
1,
2] attacks and carry out low-rate threats [
3], posing a serious security threat to websites. Web robots (also known as “Web crawlers”), as a key component supporting data collection and indexing in the modern Internet, are technologically neutral and are thus widely used in building search engine indexes, scanning for network vulnerabilities, and archiving Web content [
4,
5,
6]. According to the latest research [
7], for Web applications with known vulnerabilities, 47.4% of the network traffic is Web robot traffic, with malicious traffic accounting for as much as 63.57%. This trend highlights the urgency of strengthening cybersecurity defenses against such network security events.
Assessing whether a website bot harbors malicious intent is often challenging; it is relatively straightforward to identify such bots only when they display clear danger signals (e.g., frequent access to restricted resources within a short time span or initiating numerous connection requests). However, more covert malicious bots tend to evade detection by mimicking human behavior, spoofing trusted IP addresses, or adhering to typical website navigation structures, thereby posing potential threats to both the ethical and security dimensions of websites and their hosted information [
8]. Currently, the detection of Web robots primarily relies on Web log data to identify and intercept potential malicious activities [
7,
9,
10,
11,
12]. Consequently, extracting effective and comprehensive data representations from Web logs is crucial for reliable Web robot detection. Because these detection models heavily depend on how log data are represented, a lack of high-quality feature extraction and representation can significantly hinder the accurate differentiation between legitimate and malicious access.
Despite notable progress in Web bot detection research, significant limitations persist in feature representation generalizability and temporal modeling capabilities. For instance, methods based on static statistical features (e.g., request frequency and error rate) achieve high detection precision (98.7%) in specific scenarios [
13], yet their reliance on manually defined feature sets fails to capture the temporal semantics of request sequences, resulting in degraded cross-platform generalization performance. To address this limitation, subsequent studies have attempted to integrate multi-source heterogeneous data, such as combining mouse dynamics with request metadata to enhance detection robustness [
12]. However, these approaches heavily depend on manual feature engineering and prior knowledge, making it difficult to handle diverse attack patterns. Recent real-time detection frameworks leveraging multimodal behavioral analysis [
14] have improved temporal modeling by defining 43 browser event features for LSTM classifiers. Nevertheless, their feature design heavily depends on prior knowledge of HTTP protocols, struggles to adapt to emerging communication protocols like WebSocket, and incurs substantial deployment costs due to the requirement for fully annotated event sequences. Notably, semantic-enhanced methods (e.g., LDA2Vec topic feature extraction) that combine Web logs with content data have achieved an F1-score of 96.58% in e-commerce contexts [
7]. However, their session characterization remains confined to static topic distributions and handcrafted statistics, failing to model dynamic contextual relationships in request sequences, which creates detection blind spots for temporally camouflaged bots.
To avoid reliance on manual feature engineering and to better capture cross-request spatiotemporal relationships, this paper proposes an end-to-end session representation method based on multi-instance learning (MIL), termed Session2vec. Under the MIL paradigm [
15], each session is regarded as a bag of multiple request instances, and a comprehensive, scalable session vector representation is constructed through character-level subword embeddings and spatiotemporal clustering. Specifically, we first employ FastText to embed each request URL into a vector. Subsequently, drawing inspiration from the classic VLAD (Vector of Locally Aggregated Descriptors) and Fisher Vector algorithms [
16], we propose two innovative aggregation strategies: SARD and SFAR. SARD extracts spatiotemporal relationships from clustering residuals based on hard assignments, while SFAR captures richer distributional features using soft assignments based on Gaussian Mixture Models (GMMs) [
17]. Compared to traditional manual statistical features or sequence analysis methods, Session2vec focuses more on spatiotemporal associations among requests and the concealed distributional characteristics that malicious activities may exhibit, thereby significantly enhancing Web robot detection performance and robustness. Our five-fold cross-validation results demonstrate that this method achieves optimal performance in terms of both accuracy and F1-score.
In the field of network and information security, multi-instance learning has been widely applied to enhance the representation of unstructured data, such as text and logs. For example, in the threat behavior extraction framework SeqMask, cyberthreat intelligence (CTI) texts are treated as bags of behavioral phrase instances, and a Mask Attention mechanism is employed to mine key behavioral terms, effectively revealing the adversaries’ strategies, tactics, and procedures (TTPs) and achieving excellent classification performance in distant supervision scenarios [
18]. This work demonstrates that under weakly supervised or semi-supervised conditions, semantic aggregation and attention filtering via multi-instance learning can enhance the extraction of critical information while reducing labeling costs. Inspired by this idea, Session2vec extends the multi-instance learning framework to dynamic session behavior modeling: it not only focuses on the content or features of individual requests but also captures the latent associative structures among requests through spatiotemporal distribution modeling, thereby effectively countering complex camouflage attacks.
Furthermore, the MIL-based text representation model BOS proposed by He et al. segments texts into sentence-level instances and employs sentence similarity measures along with an improved KNN algorithm to perform document classification [
19]. This method overcomes the bag-of-words independence assumption inherent in conventional vector space models (VSMs) [
20], thereby preserving to some extent the internal semantic structure of texts. With regard to semantic structure modeling, the syntax-aware entity embedding model developed by He et al. [
19] employs tree-structured neural networks (e.g., Tree-GRU/Tree-LSTM) to represent entity contexts and leverages both sentence-level and entity-level attention mechanisms to enhance the accuracy of distant supervision relation extraction [
21]. Their work indicates that incorporating richer hierarchical structures (such as syntactic trees or graph structures) can provide more refined contextual information for multi-instance learning in complex texts. However, in Web security detection scenarios, request patterns are typically more dynamic and diverse—randomized URL paths, adversarial request fingerprints, and significant quantities of noisy data render static tree structures unsuitable. For this reason, Session2vec does not rely on predefined syntactic trees; rather, it employs FastText [
22] subword embeddings to capture the character-level semantics and structure of request paths, and then applies the SARD and SFAR algorithms to aggregate the entire session sequence, thereby achieving a weakly supervised representation of variable-length request streams.
The main contributions of this work are as follows:
Session representation innovation within the multi-instance learning framework:This research pioneers the systematic application of the MIL paradigm to Web session representation, treating each request as a semantic instance and the entire session as an instance collection. By proposing the SARD algorithm to perform clustering residual encoding on FastText-generated request vectors, we effectively model spatiotemporal behavior patterns within sessions. This approach significantly improves detection accuracy for complex camouflage attacks and provides a novel perspective for session representation in the Web security domain.
Session vectorization and end-to-end detection framework: Traditional Web robot detection typically relies on handcrafted features or synthetic data, which struggle to comprehensively capture real attack scenarios. Session2vec implements cross-request end-to-end detection through session-level vectorization, reducing over-reliance on manual features while naturally integrating contextual information to improve overall malicious behavior recognition. The proposed SARD and SFAR aggregation strategies enable the model to adapt to variable-length sessions while preserving temporal relationships between requests.
Unsupervised embedding and dual aggregation for spatiotemporal modeling: Session2vec addresses the challenges of high annotation costs and data diversity in network security tasks. It combines unsupervised FastText subword embeddings with two complementary aggregation strategies, SARD and SFAR, to achieve efficient spatiotemporal feature capture.
The remainder of this paper is organized as follows: In
Section 2, we review the related work on Web robot detection and session modeling.
Section 3 formulates the problem within a multi-instance learning framework. In
Section 4, we detail our proposed approach, including the request embedding process and the design of the SARD and SFAR aggregation methods for session-level representation.
Section 5 presents the experimental setup, dataset statistics, and performance evaluation.
Section 6 concludes the paper and outlines potential avenues for future research. Finally,
Section 7 discusses future work.
2. Related Work
Recent advancements in Web robot detection have explored diverse methodologies to address the evolving challenges posed by malicious bots. Traditional approaches, such as rule-based systems and classical machine learning algorithms (e.g., KNN, decision trees, and neural networks), have shown limitations in handling variable-length session data and inconsistent feature dimensions, particularly when bots mimic human-like behaviors or employ sophisticated evasion tactics [
13]. For instance, while neural networks achieve high precision in bot detection, their computational overhead and reliance on fixed-dimensional feature vectors hinder scalability.
Semantic-based detection methods leverage content and behavioral patterns to distinguish bots. Studies like [
7,
23] utilize semantic features from Web content or logs, assuming human users exhibit topic-specific interests. However, these methods often neglect the temporal and contextual relationships within session-level requests, limiting their ability to model complex bot behaviors. Similarly, dynamic metadata approaches (e.g., mouse dynamics [
12]) enhance accuracy but focus on biometric traits rather than session-structured log analysis, which is critical for detecting bots operating at scale.
Semi-supervised learning has emerged to address labeled data scarcity. For example, Web-S4AE [
11] employs a stacked sparse autoencoder to exploit unlabeled data, yet its dependency on content–log hybrid features may not fully resolve the challenges of variable request counts within sessions. In contrast, Session2vec introduces a multi-instance learning (MIL) framework coupled with FastText [
22] and miVLAD and miFV algorithms [
16]. This approach uniquely converts individual requests into fixed-dimensional vectors (via FastText) and aggregates them into session-level representations (via miVLAD and miFV), effectively addressing feature inconsistency while capturing temporal and contextual dependencies. Unlike the study [
11], which requires extensive labeled data, MIL reduces annotation costs by treating sessions as bags of instances, aligning with the trend toward weak supervision in bot detection.
Furthermore, while real-time detection methods [
24,
25] prioritize early classification of active sessions, they often overlook the structural heterogeneity of session data. Session2vec bridges this gap by unifying session modeling and representation learning, offering a robust solution for detecting advanced bots with dynamic behavioral patterns.
3. Problem Formulation
In Web behavior analysis, each session can be treated as a “multi-instance” bag composed of multiple requests. Traditional single-instance approaches often focus on the features of individual requests while neglecting the broader temporal and semantic patterns within a session, making it difficult to detect sophisticated malicious bot activities. To address this issue, we model session-level detection as a multi-instance learning problem.
Formally, consider a Web log dataset containing multiple sessions . Each session comprises requests and carries a single label (e.g., “benign” or “malicious”). In the multi-instance setting, each request is treated as an instance, whereas each session is regarded as a bag. Our objective is to make a session-level classification decision to distinguish between human and bot traffic.
Under this framework, we first embed each request into a vector representation. We then deploy an aggregation step that converts all instance vectors within a bag into a fixed-dimensional session vector, which can be fed into supervised or unsupervised methods to uncover potential malicious behaviors. Because the number of requests (instances) per session (bag) can vary, multi-instance learning naturally accommodates this variability, making it highly suitable for our problem setting.
4. Methodology
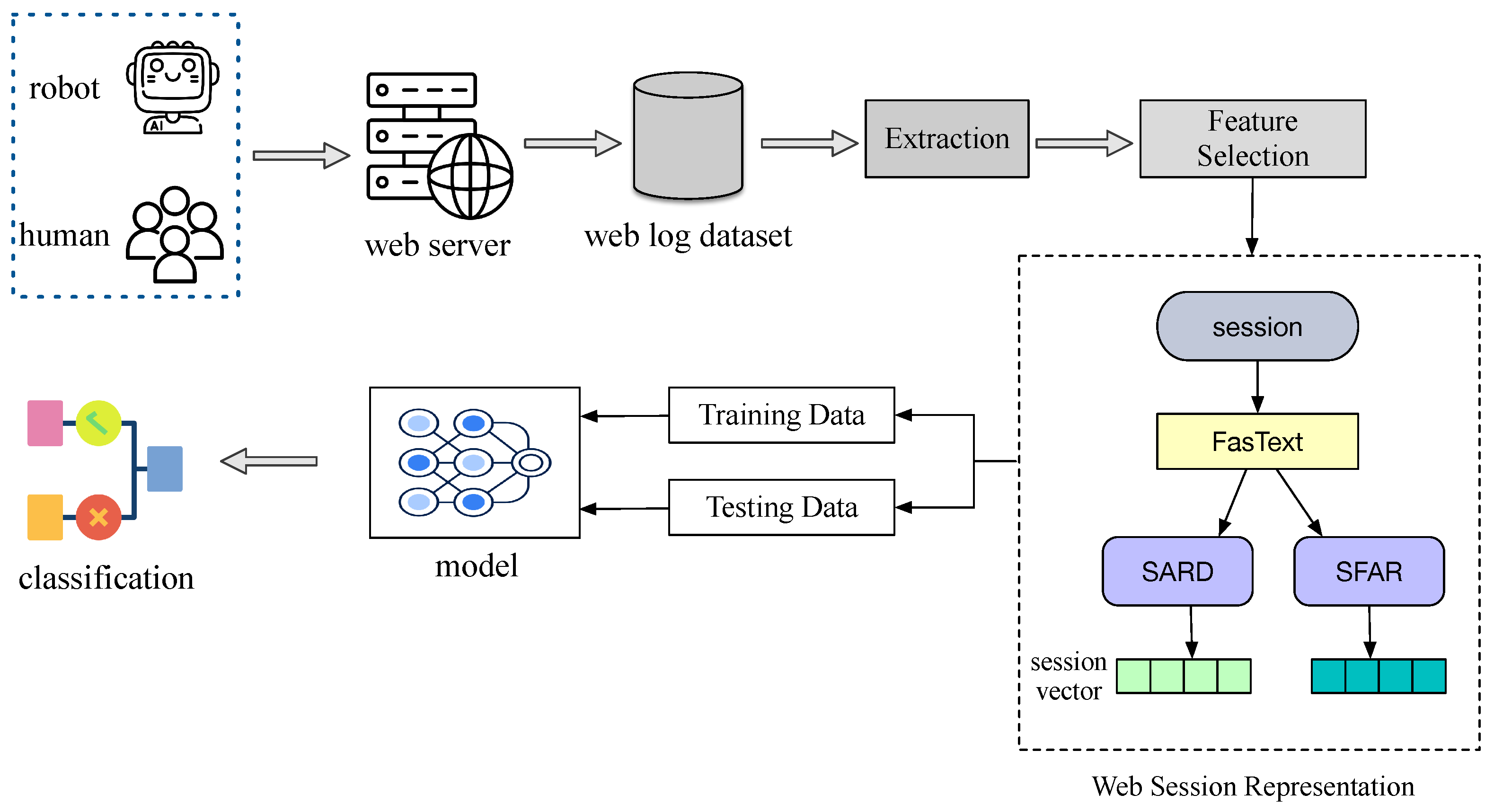
In this study, we propose a structured framework for Web robot detection, illustrated in
Figure 1. First, both human and robot users generate significant numbers of Web logs by interacting with a server. We preprocess these logs, extracting relevant features such as the request URL field. After data filtering and feature extraction, the Session2vec approach is employed to obtain session-level representations.
The representation process involves two stages: (1) Converting each request URL into a fixed-dimensional embedding using a FastText model; (2) Treating all requests within a session as a multi-instance bag, which is subsequently aggregated into a session-level vector through two methods: SARD and SFAR. The resulting vectors can then be fed into a classifier to differentiate between human and robot activities.
4.1. Request Embedding
In this study, we first perform text preprocessing and vectorization on each raw data request to construct a session-level representation. Specifically, the URL path in each request is preprocessed by replacing the forward slash (“/”) with a space, thereby generating a continuous text string. We then apply a pretrained FastText-300 model to convert the text into a 300-dimensional vector representation. Since the model is trained on large-scale corpora, it effectively mitigates issues such as spelling errors and out-of-vocabulary words. The complete process of request embedding generation is detailed in Algorithm 1.
For a single session S, multiple requests are contained within. By stacking the vector of each request in the original chronological order, we obtain an matrix (n is the number of requests), as shown in Algorithm 1. This matrix preserves the local semantic features of each request and simultaneously captures the temporal relationships within the session, laying the foundation for detecting complex behavior patterns.
The following pseudocode illustrates how to build request embeddings using a pretrained FastText-300 model and stack them into matrices grouped by session.
| Algorithm 1 Request embedding generation |
- Require:
Dataset D, where each record contains the fields and ; pretrained FastText model M (with 300-dimensional output). - Ensure:
A vector representation for each request and a request matrix grouped by session. - 1:
for each record do - 2:
Extract the request path: - 3:
Preprocess uri: replace the forward slash with a space to obtain the string - 4:
Use the pretrained FastText model to compute the sentence vector: - 5:
Save the vector v as a new field for the record (e.g., ) - 6:
end for - 7:
for each session s (grouped by ) do - 8:
Collect all request vectors for session s: - 9:
Stack these vectors using to form the matrix - 10:
end for - 11:
Return the collection of request matrices corresponding to all sessions
|
4.2. Session-Level Representations: SARD and SFAR
In this section, we propose two innovative session-level aggregation methods, SARD and SFAR, to build fixed-dimensional session representations from request embeddings. Both methods follow a multi-instance aggregation principle, effectively deriving statistical and distributional features from session requests while maintaining a fixed output dimension.
4.2.1. SARD (Session-Level Aggregated Residual Descriptors)
SARD is inspired by the classical VLAD approach. It utilizes hard assignment to cluster each request vector and accumulates their residuals as the final representation. Let
be the request embedding matrix of session
s, where
n is the number of requests and
d is the embedding dimension (e.g., 300). Assume there is a pretrained KMeans [
26] model
C with
K centroids
For each request vector
in
, we identify its nearest centroid index
via
We then accumulate the residual into the matrix
:
By row-wise flattening
V, we obtain
Finally, we apply power normalization and
normalization:
Algorithm 2 illustrates the complete SARD procedure.
| Algorithm 2 Session embedding—SARD generation |
- Require:
Set of request embeddings , where ; number of clusters K; pretrained KMeans model C. - Ensure:
Fixed-dimensional session representation for each session. - 1:
for the matrix for each session s do - 2:
Initialize the residual matrix - 3:
for each request vector do - 4:
- 5:
- 6:
end for - 7:
Flatten V to obtain - 8:
Apply power normalization and normalization - 9:
Save as the final representation of session s - 10:
end for - 11:
Return
|
4.2.2. SFAR (Session-Level Fisher Aggregated Representation)
Unlike the hard assignment in SARD, SFAR leverages a Gaussian Mixture Model (GMM) to capture the underlying probability distribution of request embeddings. The GMM is parameterized by
where
denotes the prior probability of the
kth component, and
and
are its mean and covariance (often diagonal). For each request vector
, we compute the posterior probability:
We then calculate the first-order and second-order gradients with respect to the GMM parameters:
All these gradients are concatenated to form the Fisher vector
which is then power-normalized and
-normalized to enhance robustness and comparability. Algorithm 3 provides the complete pseudocode for the SFAR approach.
| Algorithm 3 Session embedding—SFAR generation |
- Require:
Set of request embeddings , where ; number of Gaussian components K; pretrained GMM model G. - Ensure:
Fixed-dimensional session representation for each session. - 1:
for the matrix for each session s do - 2:
Initialize the Fisher vector - 3:
for each request vector do - 4:
Compute posterior probabilities for all components k - 5:
Compute gradients and and accumulate them in - 6:
end for - 7:
Apply power normalization and normalization - 8:
Save as the final representation of session s - 9:
end for - 10:
Return
|


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}