2.1. Research Status of 3D Modeling Methods
DT modeling lies at the heart of accurately virtualizing physical entities. Driven by data, DT technology enables monitoring, simulation, prediction, and optimization, supporting a wide range of industrial applications [
5]. Within these applications, the accuracy and reliability of DT models are critical, as they directly influence the overall performance and decision-making capabilities of DT systems in real-world scenarios.
High-precision and high-reliability models not only ensure accuracy in monitoring and forecasting but also provide trustworthy results during optimization and simulation processes. This, in turn, significantly enhances production efficiency, reduces operational costs, and ensures the safety and stability of manufacturing operations [
6].
Geometric modeling, as a traditional 3D modeling approach, typically employs computer-aided design (CAD) tools to construct precise geometric models. These models represent object shapes and features using geometric elements such as points, lines, and surfaces, and are usually stored in the form of polygonal meshes or parameterized surfaces [
7]. The main advantage of geometric modeling lies in its precision and accuracy, making it suitable for modeling industrial components and mechanical equipment that require detailed descriptions [
8]. However, this method often relies heavily on manual operations, making the modeling process time-consuming and costly, and limiting its applicability in dynamic or complex environments [
8]. Moreover, manual modeling lacks flexibility when applied to large-scale or intricate scenarios.
In recent years, diffusion models have achieved remarkable progress in image generation and novel view synthesis. Wu et al. [
9] proposed
ReconFusion, which leverages a diffusion model to regularize the optimization process of Neural Radiance Fields (NeRF), enabling robust 3D reconstruction under sparse-view conditions. Although
ReconFusion demonstrates strong capability in novel view synthesis under limited viewpoints, it primarily relies on regularization in the image space. This strong dependence on image modality introduces high computational costs during reconstruction. Moreover, in industrial workshops populated with a large number of machines and equipment, modeling each unit from 2D images becomes impractical, whereas point cloud data offer a more suitable and efficient alternative.
Point cloud modeling has emerged in recent years as an alternative approach, driven by advances in 3D scanning technologies such as LiDAR and RGB-D cameras [
10]. A point cloud is a data structure composed of numerous points in 3D space, capable of representing the shape and surface features of objects with high fidelity [
11]. Point cloud-based modeling methods typically involve steps such as registration, denoising, segmentation, and reconstruction to generate 3D object models [
12]. The key advantage of this approach is its ability to rapidly acquire 3D environmental or object data, making it well suited for complex and dynamic settings like construction sites and factory workshops [
13]. Nevertheless, point cloud data often suffer from sparsity, incompleteness, and noise, necessitating advanced processing and completion techniques to ensure modeling quality and precision.
In practical applications, the selection of an appropriate modeling method often involves trade-offs among accuracy requirements, modeling speed, and computational resources. In complex industrial and dynamic environments, point cloud modeling is particularly favored due to its capability to rapidly capture 3D geometric information. Compared with traditional geometric modeling, point cloud approaches offer higher automation and better adaptability to intricate environments.
However, the inherent sparsity, incompleteness, and noise of point cloud data remain major obstacles to achieving high modeling accuracy. As a result, recent research has increasingly focused on deep learning-based point cloud registration, segmentation, completion, and reconstruction techniques. The integration of convolutional neural networks (CNNs), generative adversarial networks (GANs), and Transformer-based models has significantly improved the processing capabilities and effectiveness of point cloud analysis. Moving forward, the development of point cloud modeling is likely to focus on improving data processing efficiency and algorithmic robustness, while further optimizing deep learning techniques to meet the high-precision modeling demands of industrial and architectural applications.
2.2. Research Status of Point Cloud Completion Algorithms
With the advancement of 3D scanning technologies—such as RGB-D scanners, laser scanners, and LiDAR—point cloud acquisition has become increasingly efficient and accurate [
14]. These technologies have enabled the widespread collection of 3D spatial data in fields such as industry, architecture, and autonomous driving. However, occlusions, limited sensor resolution, and environmental interference often result in sparse, incomplete point clouds with notable geometric loss [
15].
The inherent incompleteness of point clouds poses major challenges for applications such as analysis, modeling, and object recognition, all of which depend on complete and accurate 3D data for optimal performance. Consequently, completing missing regions in partial point clouds and generating high-quality 3D reconstructions has become a key research focus.
Point cloud completion seeks to algorithmically infer and recover missing geometric structures, reconstructing complete models from partial data. As a core task, it directly influences the performance of downstream applications like classification, reconstruction, and semantic segmentation [
16]. Enhancing its accuracy and robustness is therefore crucial for advancing 3D data processing. Furthermore, accurate point cloud modeling is vital for simulating scheduling optimization in DT systems [
17]. It improves the simulation’s credibility and predictive accuracy, thereby ensuring the reliability of physical system optimization.
To address these challenges, researchers have developed a range of point cloud completion methods. These approaches can be broadly classified into four categories:
The first category includes parametric model-based methods, which complete point clouds by fitting and optimizing geometric parameters. Groueix et al. [
18] introduced a method that generates 3D surfaces by mapping 2D planes onto a set of learnable parametric surface elements. Their approach effectively reconstructs fine surface details on datasets like ShapeNet, addressing common issues in voxel- and point-based methods, such as limited resolution and poor connectivity. However, the reliance on local parameterization can lead to patch seams and discontinuities, impairing global mesh consistency. Moreover, limited local representations hinder the model’s ability to reconstruct complex topologies and detailed geometries.
The second category involves generative adversarial networks (GANs), originally successful in image synthesis and later adapted for point cloud completion to enhance output realism. GANs estimate the distribution of generated point sets via adversarial learning [
19]: a generator produces plausible point clouds by sampling from a prior distribution, while a discriminator distinguishes real from generated data. Zhang et al. [
20] proposed an unsupervised GAN-based framework incorporating inverse mapping to predict missing regions by learning latent encodings from complete shapes. Sarmad et al. [
21] further extended the framework with a reinforcement learning (RL) agent built atop a pre-trained autoencoder and latent-space GAN. While effective in coarse reconstruction, this method struggles with recovering fine local details and suffers from classification bias in complex scenes due to limited semantic discrimination capabilities.
Third, folding-based methods utilize an encoder with graph structures to extract local geometric features and a decoder that continuously “folds” a fixed 2D grid into 3D space to reconstruct object surfaces. This approach significantly reduces decoder parameters and theoretically supports the generation of arbitrary 3D shapes by projecting multi-dimensional point sets onto the original surface [
22]. TopNet [
23] extends this idea with a hierarchical root–tree decoder that organizes points as nested child-node groupings. To enhance structural feature learning, Wen et al. [
24] proposed the skip-attention network, combining skip-attention mechanisms for capturing partial input details with a hierarchical folding decoder to retain geometric information. Building upon this, Zong et al. [
25] developed ASHF-Net, integrating a denoising autoencoder with adaptive sampling and a gated skip-attention-based hierarchical decoder to recover fine-grained structures at multiple resolutions.
Despite their strengths, folding-based methods struggle with complex topologies due to their fixed 2D grid initialization, which limits geometric flexibility.
Finally, Transformer-based point cloud completion methods demonstrate superior capability in modeling long-range dependencies due to self-attention mechanisms. Initially developed for sentence encoding in natural language processing [
26], Transformers were later adopted in 2D computer vision [
27,
28], and subsequently in 3D point cloud processing, with models such as PCT [
29], Pointformer [
30], and PointTransformer [
31] being among the earliest examples.
Yu et al. [
15] formulated point cloud completion as a set-to-set translation task, designing a Transformer-based encoder–decoder that represents unordered point sets with positional embeddings and translates them into complete point clouds via point proxies. SnowflakeNet [
16] progressively densifies point clouds via snowflake point deconvolution (SPD), preserving local structures through a coarse-to-fine refinement approach.
Lin et al. [
32] introduced PCTMA-Net, leveraging attention mechanisms to capture local context and structure for predicting missing shapes. PMP-Net++ [
33], an enhanced version of PMP-Net [
34], incorporates Transformer-based representation learning to improve completion quality. Zhang et al. [
35] proposed a coarse-to-fine Transformer framework featuring a Skeleton-Detail Transformer, which models hierarchical relationships between global skeletons and local geometries via cross-attention. Although effective, this method assumes input completeness and structural coherence, limiting its performance in industrial scenarios with severe occlusions and fragmented distributions.
Tang et al. [
36] proposed CONTRINET, a triple-flow network that robustly fuses multi-scale features by dynamically aggregating modality-specific and complementary cues through a shared encoder and specialized decoders. This structured fusion strategy offers valuable insights for point cloud completion under noisy and incomplete conditions.
Transformer-based point cloud completion methods typically rely on large volumes of annotated data for supervised training. However, such annotations are often scarce and expensive in real-world scenarios. To alleviate this limitation, Cui et al. [
37] proposed P2C, a self-supervised framework that operates on a single incomplete sample. By incorporating local region partitioning, region-aware Chamfer distance, and normal consistency constraints, the model learns structural priors without requiring complete annotations. Building on this, Xu et al. [
38] introduced CP-Net, which decouples point cloud geometry into structural contours and semantic content. This design enhances the model’s focus on semantically relevant regions during reconstruction, improving both representational capacity and transferability. In a related direction, Song and Yang [
39] proposed OGC, an unsupervised segmentation framework that leverages geometry consistency from sequential point clouds to identify object structures without any human annotations, providing further insights into self-supervised point cloud understanding.
These self-supervised strategies not only increase the sensitivity of Transformer-based networks to local geometric features but also offer promising solutions for point cloud completion under limited data conditions. Enhancing local feature perception and exploiting latent geometric cues from unannotated data remain essential directions for future research in this domain.
2.3. Research Status of Transfer Learning
In recent years, transfer learning (TL) has emerged as an effective machine learning technique and has been widely applied in domains where data are scarce or annotations are difficult to obtain. Its core idea is to transfer knowledge from a source domain to a target domain to improve model performance on the target task [
40]. Particularly in 3D point cloud processing, transfer learning effectively alleviates the issues of insufficient data and expensive annotations by reducing the distribution discrepancies between the source and target domains [
41]. As point clouds represent an unstructured form of data—characterized by sparsity, incompleteness, and noise—traditional deep learning methods struggle to handle them, whereas transfer learning offers a novel approach to 3D point cloud processing [
42].
The fundamental idea behind transfer learning is to leverage the knowledge embedded in pre-trained models to address problems of data scarcity or distribution mismatch, especially through techniques such as Domain Adaptation (DA), which reduce the differences in feature distributions between the source and target domains [
40]. In the context of point cloud completion tasks, transfer learning is primarily implemented through several approaches: (1) Feature Transfer: extracting geometric features from source domain data and applying them to the target domain’s point cloud completion tasks to enhance the model’s capability to comprehend and restore incomplete point clouds [
43]; (2) Model Transfer: fine-tuning a pre-trained completion model for the target domain, which can still achieve satisfactory completion performance even with a small dataset [
44]; and (3) Unsupervised Transfer Learning: employing unsupervised adaptive learning to align data from different domains, thereby addressing discrepancies caused by variations in sensors or scenarios in point clouds [
45].
The existing literature demonstrates significant advantages of transfer learning in point cloud completion tasks. For instance, Li et al. proposed a transfer learning-based point cloud completion method that transfers models from large-scale synthetic datasets (e.g., ShapeNet) to small-scale real-world point cloud datasets, achieving efficient recovery of missing point clouds in complex scenarios [
46]. Moreover, research by Chen et al. shows that transfer learning can alleviate overfitting in point cloud completion, particularly when handling high noise and incomplete data, with domain adaptation techniques markedly enhancing model robustness and accuracy [
47].
Despite these advances, several challenges remain. Firstly, the differences in data distributions between the source and target domains—especially regarding 3D structures and geometric shapes—can lead to instability in transfer learning performance [
48]. In manufacturing DT workshops, the high cost of data acquisition and the difficulty of obtaining annotations result in significant discrepancies between the source and target data [
48]. While existing transfer learning methods perform well when abundant annotated data are available, models often exhibit insufficient generalization in industrial scenarios with scarce or unannotated data. Additionally, industrial workshop point clouds are frequently accompanied by noise, occlusions, and data loss—especially in complex equipment structures or during operational processes—which further challenges the effectiveness of domain adaptation techniques [
44]. Thus, how to leverage transfer learning to enhance the accuracy and robustness of point cloud completion under limited industrial data conditions remains an open problem.
Overall, transfer learning opens up new possibilities for point cloud completion by enabling deep learning models to exploit the knowledge acquired during pre-training, even in the face of limited training data. Consequently, further exploration of more robust domain adaptation methods that can improve model adaptability in scenarios with substantial differences in geometric structures between the source and target domains is an important research direction for future transfer learning applications in industrial point cloud completion tasks.
2.4. Research Gaps
In the construction of DT workshops, the generation of accurate models is a critical factor for the successful application of DT scenarios. Despite recent advances in DT, point cloud completion, and transfer learning, key research gaps remain when these approaches are applied to real-world industrial settings.
Firstly, existing large-scale DT modeling approaches for industrial workshops lack an effective and unified framework, resulting in low modeling efficiency and limited accuracy. Secondly, current point cloud completion algorithms underperform when confronted with complex industrial equipment geometries, particularly in recovering fine-grained local structures, thereby affecting the overall quality of the generated models. Lastly, the scarcity and difficulty in acquiring high-quality industrial datasets limit the generalization capability of existing deep learning models, constraining their applicability in practical industrial scenarios.
To address these challenges, the main contributions of this paper are as follows:
- 1.
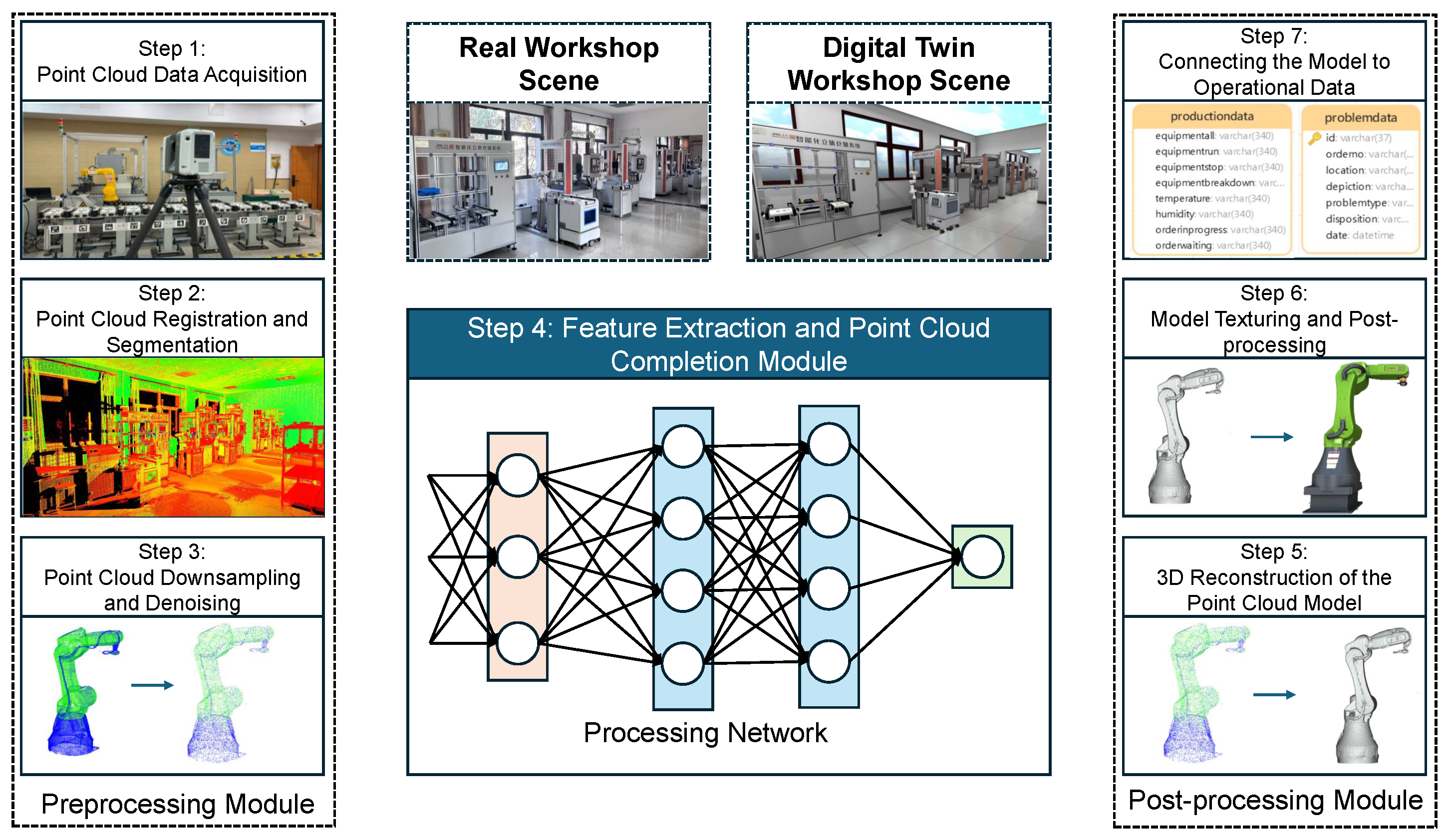
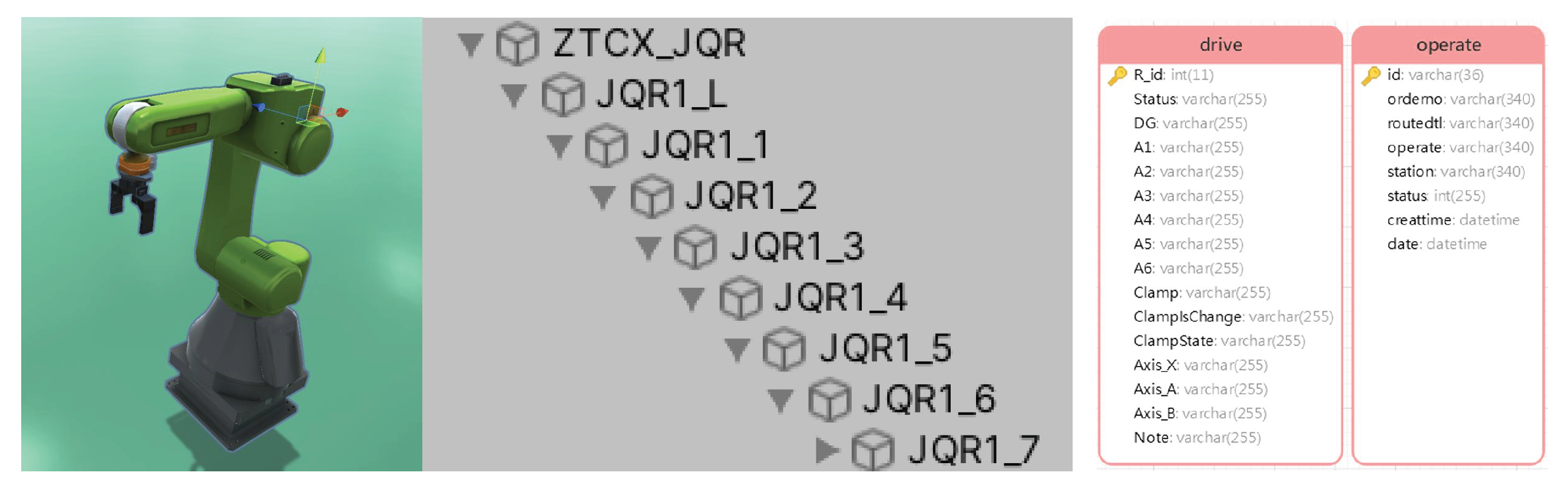
Point Cloud-Based DT Workshop Modeling Framework:
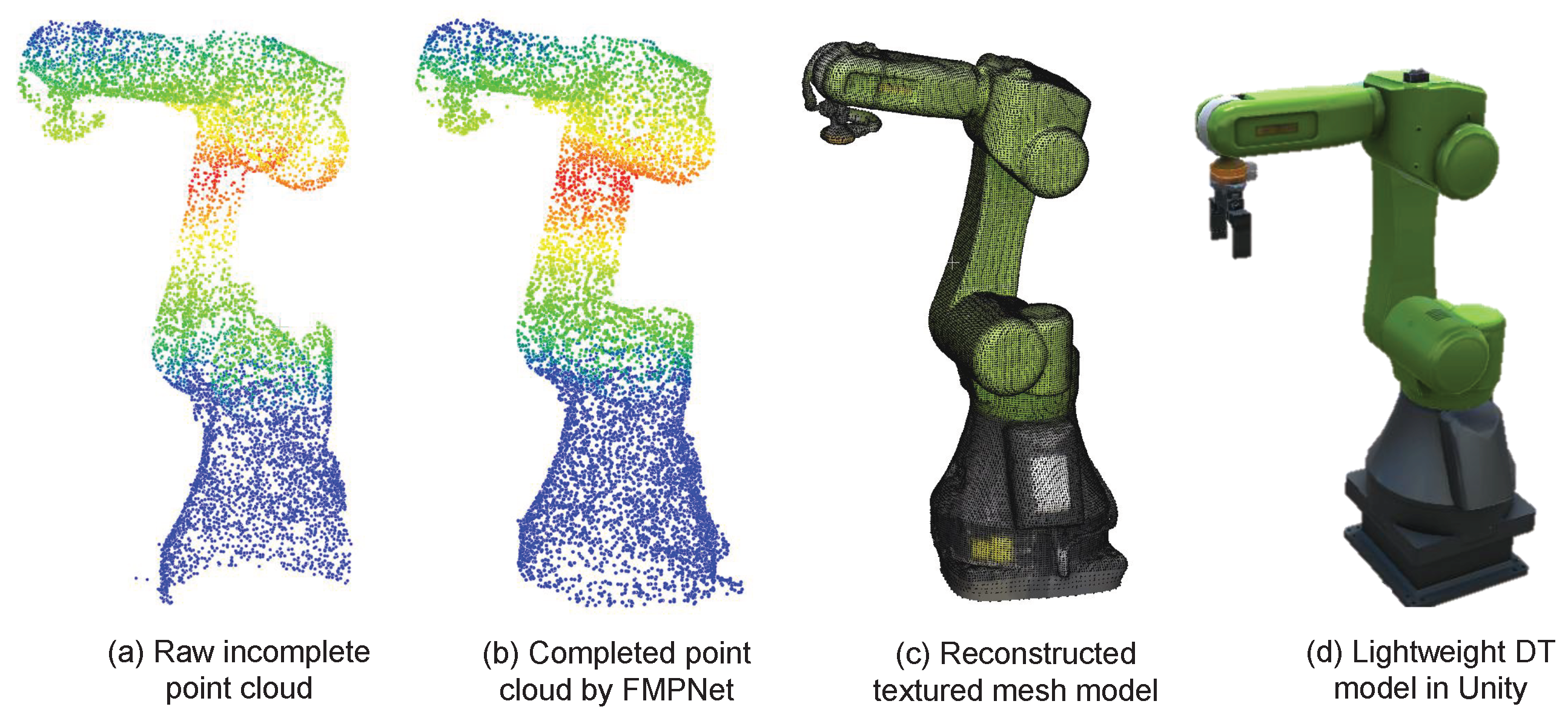
A novel DT workshop modeling framework is introduced, based on point cloud data. By leveraging deep learning techniques, this framework enables automated processing and 3D reconstruction of workshop point clouds. Compared to traditional geometry modeling methods that require substantial manual intervention, our approach significantly reduces labor costs while improving both modeling speed and accuracy. This provides a practical pathway for the efficient construction of DTs in complex industrial environments.
- 2.
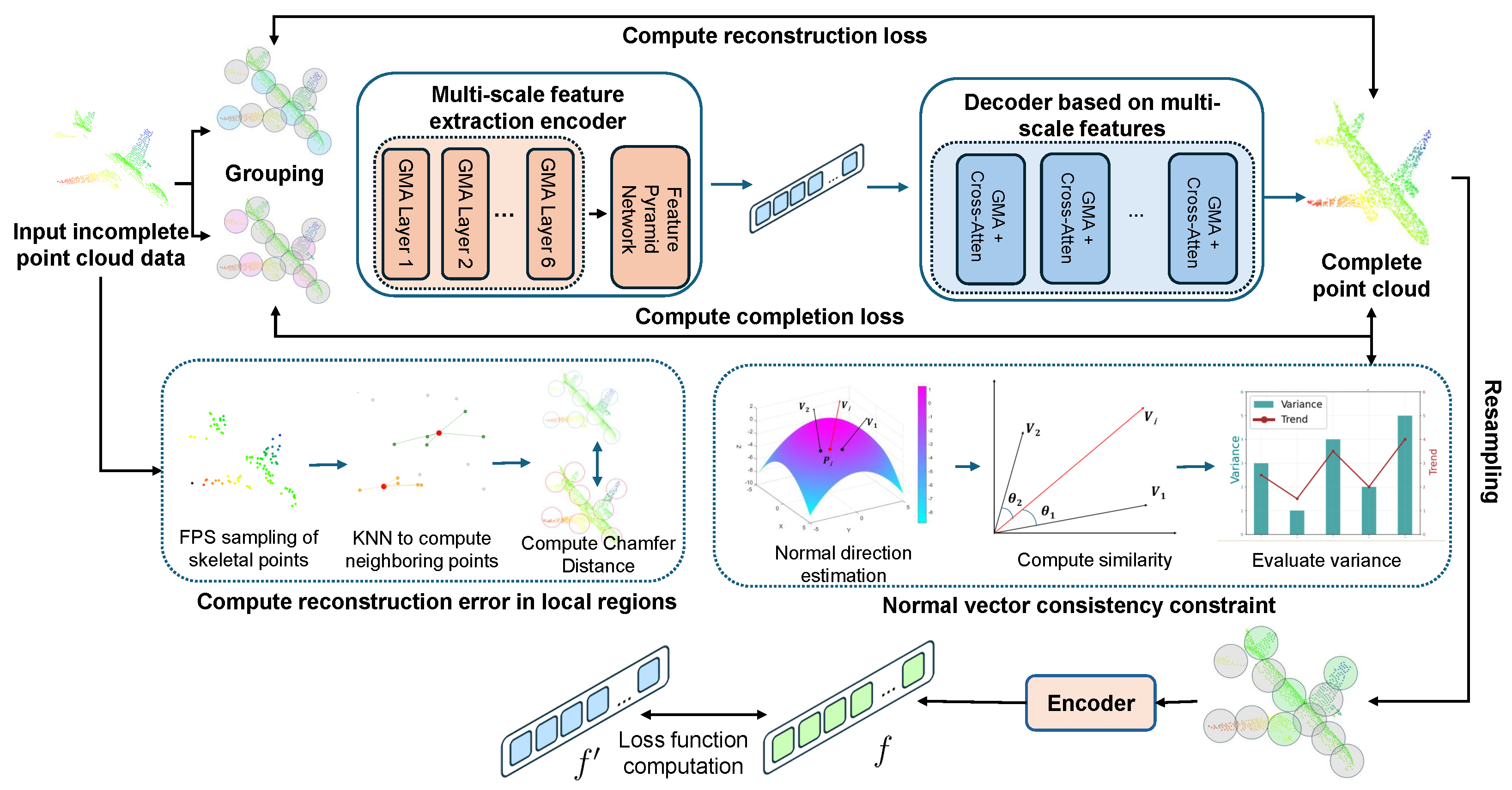
Point Cloud Completion Algorithm:
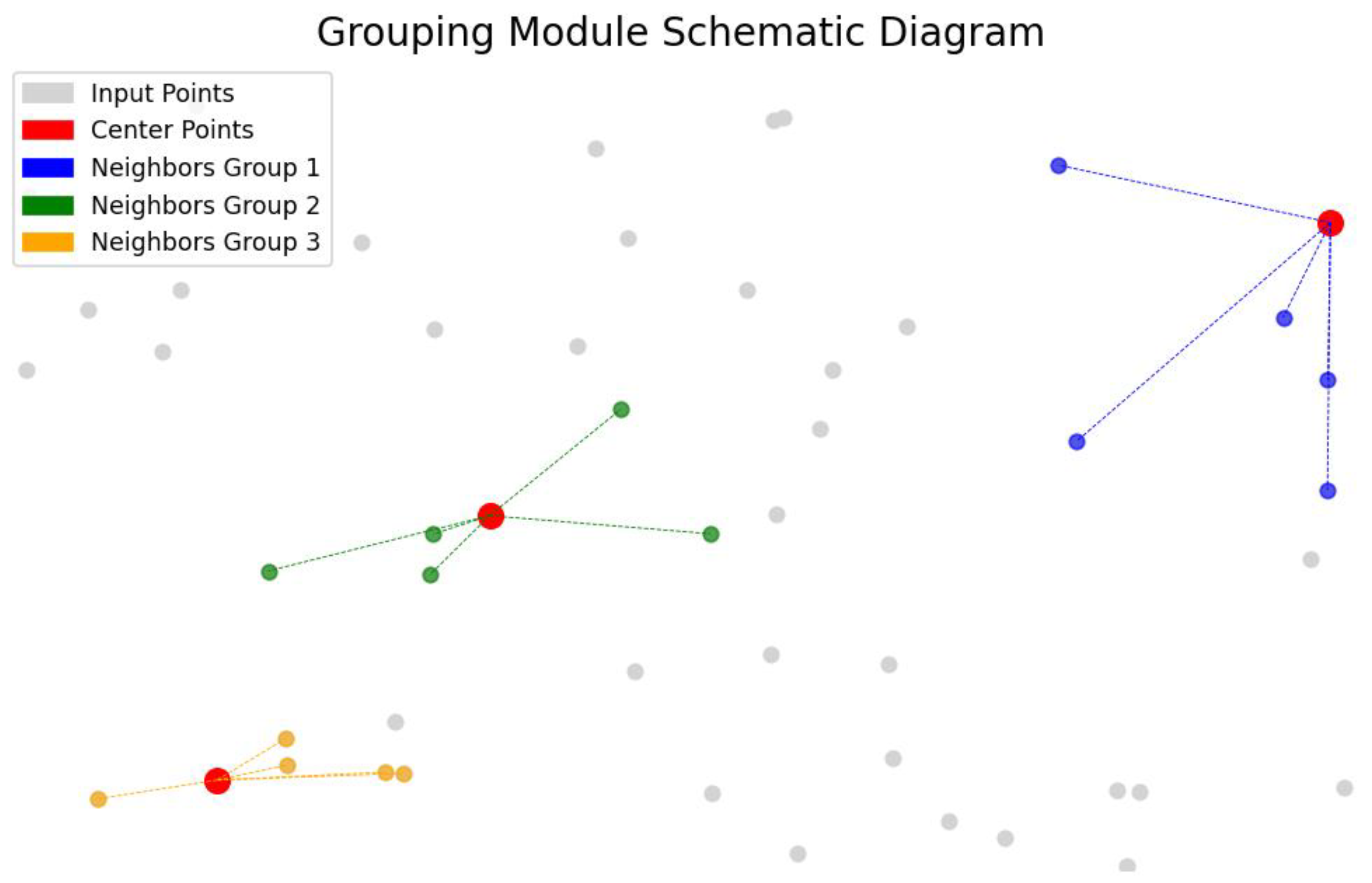
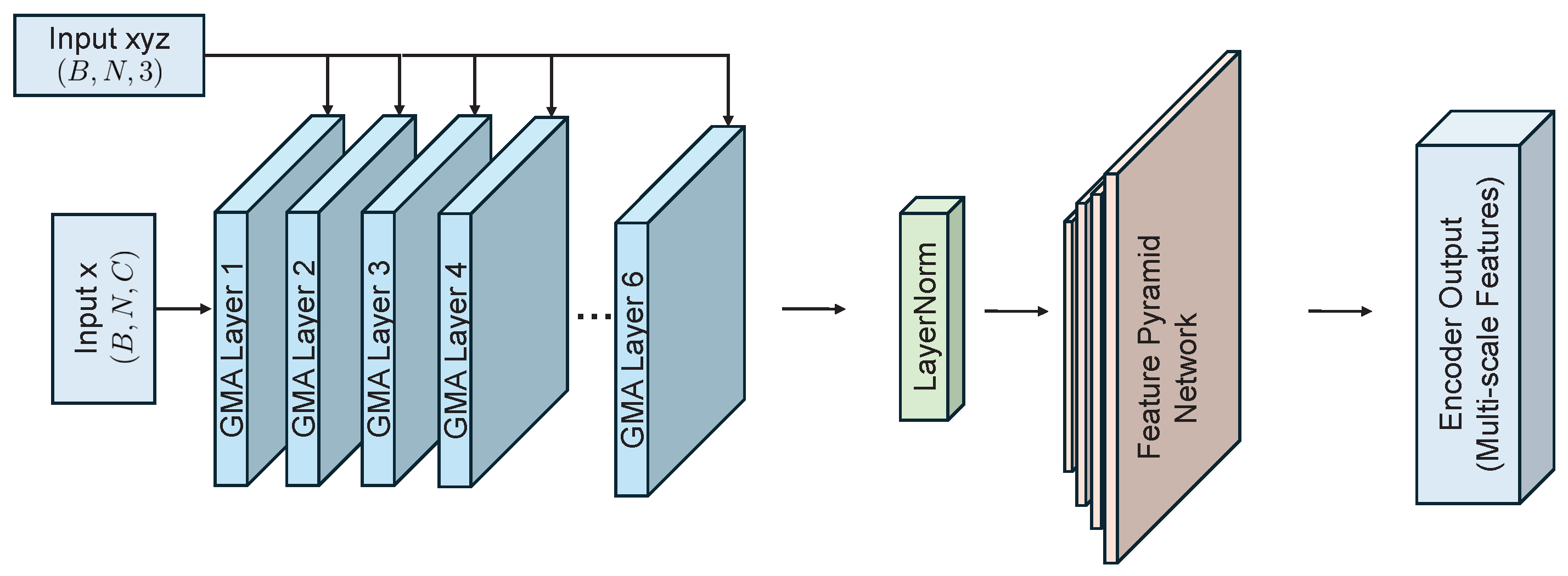
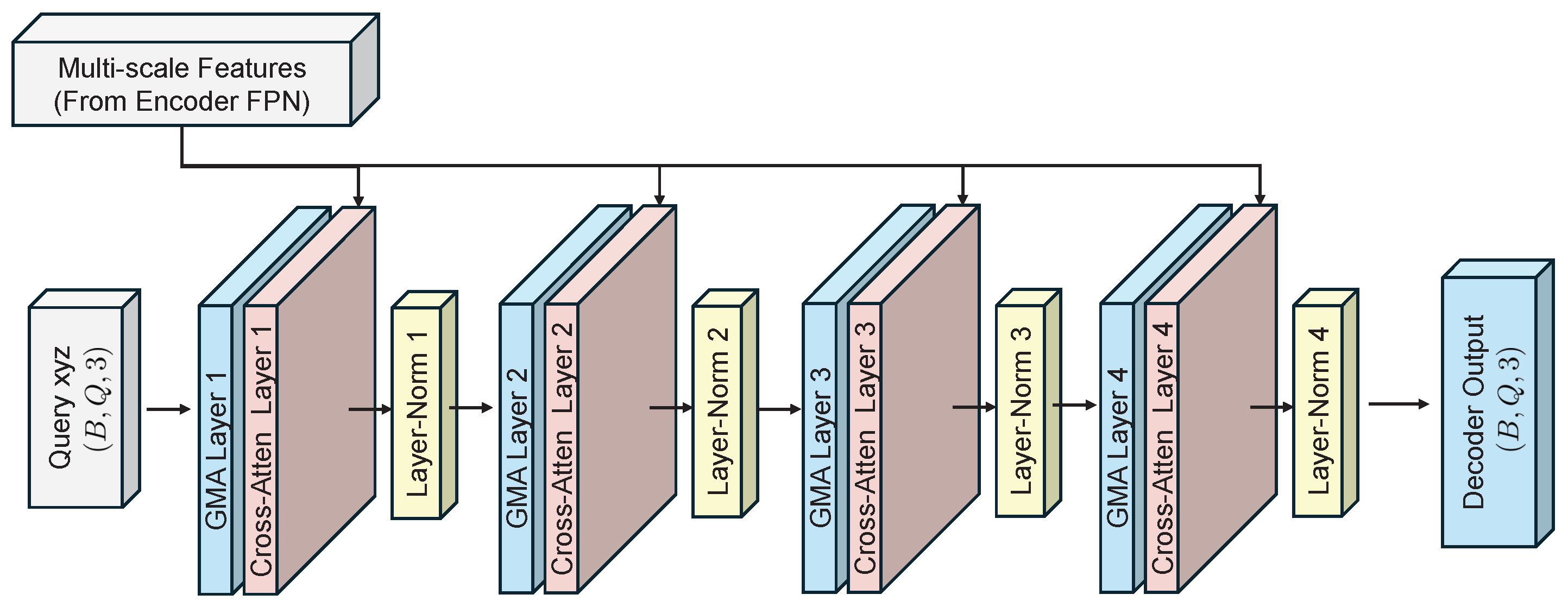
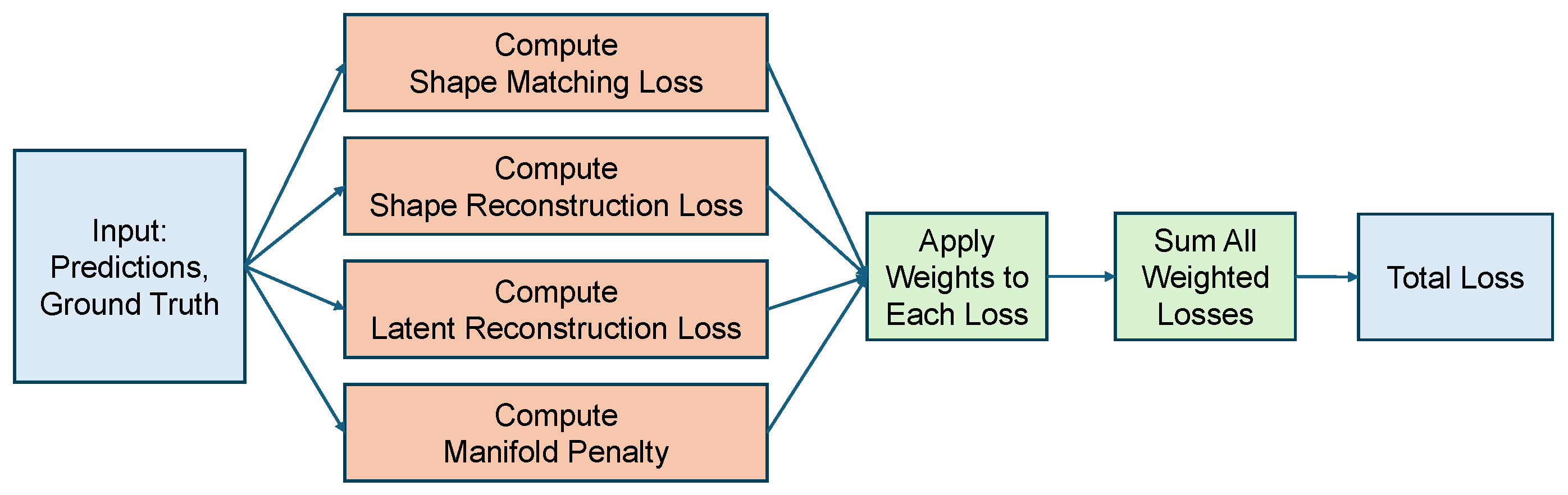
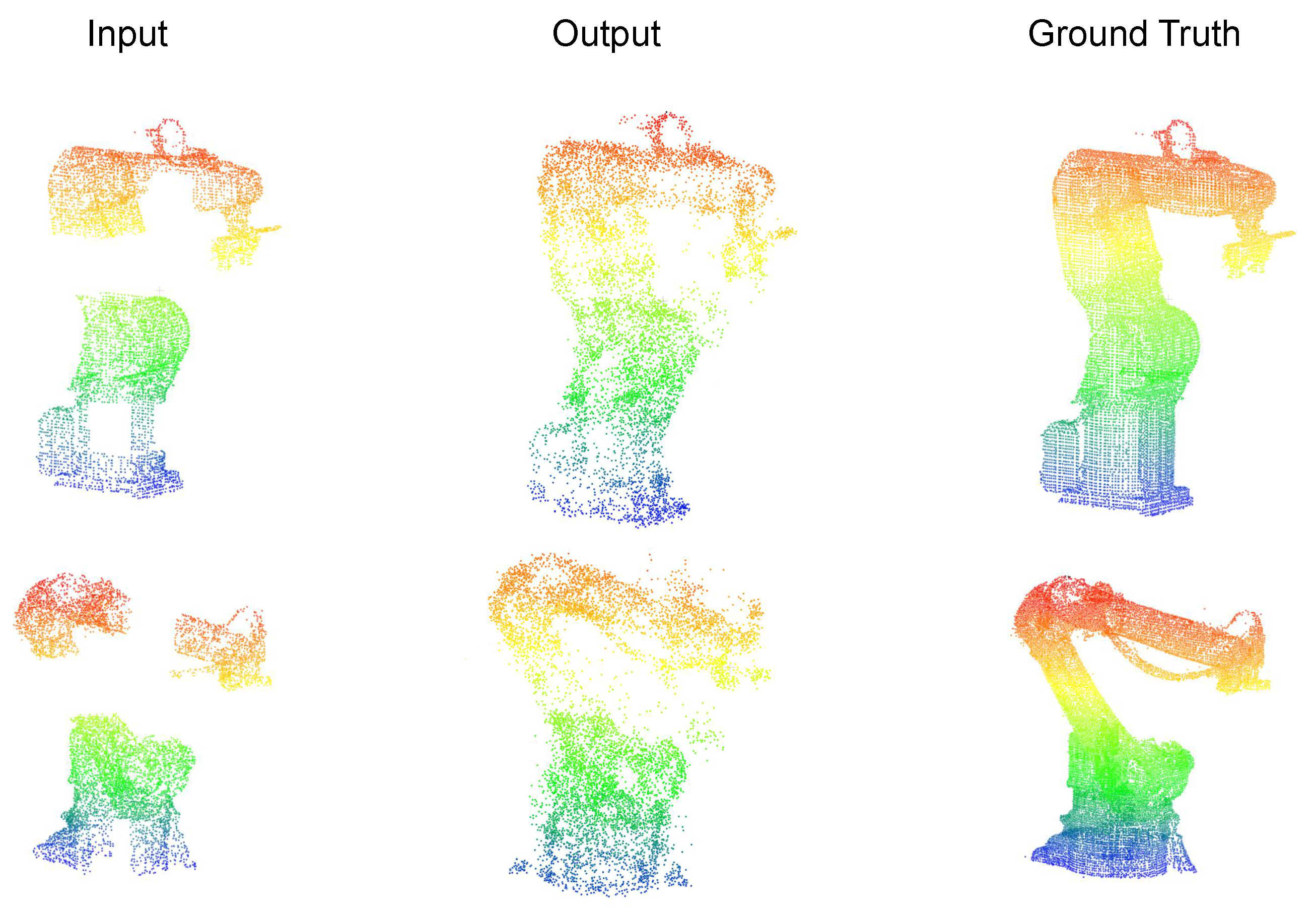
A self-supervised point cloud completion algorithm is introduced, which effectively extracts latent geometric information from incomplete data without requiring large-scale manual annotations. The algorithm integrates multi-scale feature extraction with a cross-attention mechanism, substantially enhancing the ability to capture local geometric features. This ensures high-precision recovery of structural details while maintaining global consistency in the completed point clouds. A multi-objective loss function is further designed to optimize both completeness and local accuracy of the reconstructed data.
- 3.
Application of Transfer Learning in Industrial Scenarios:
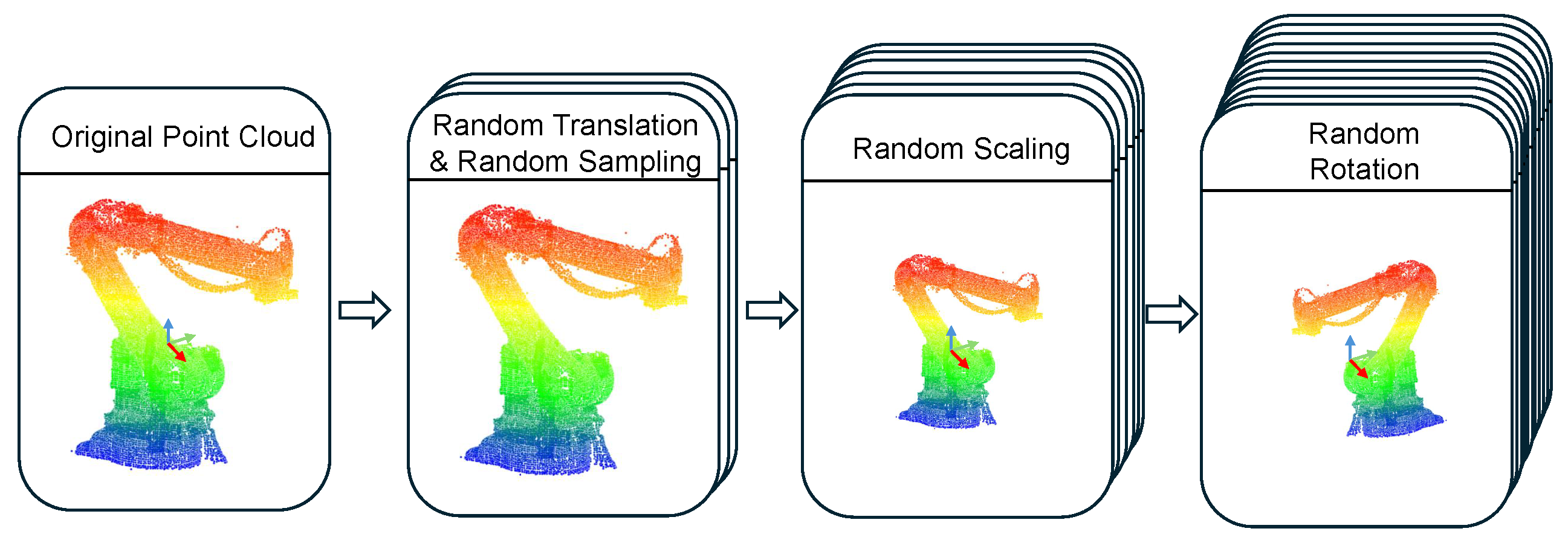
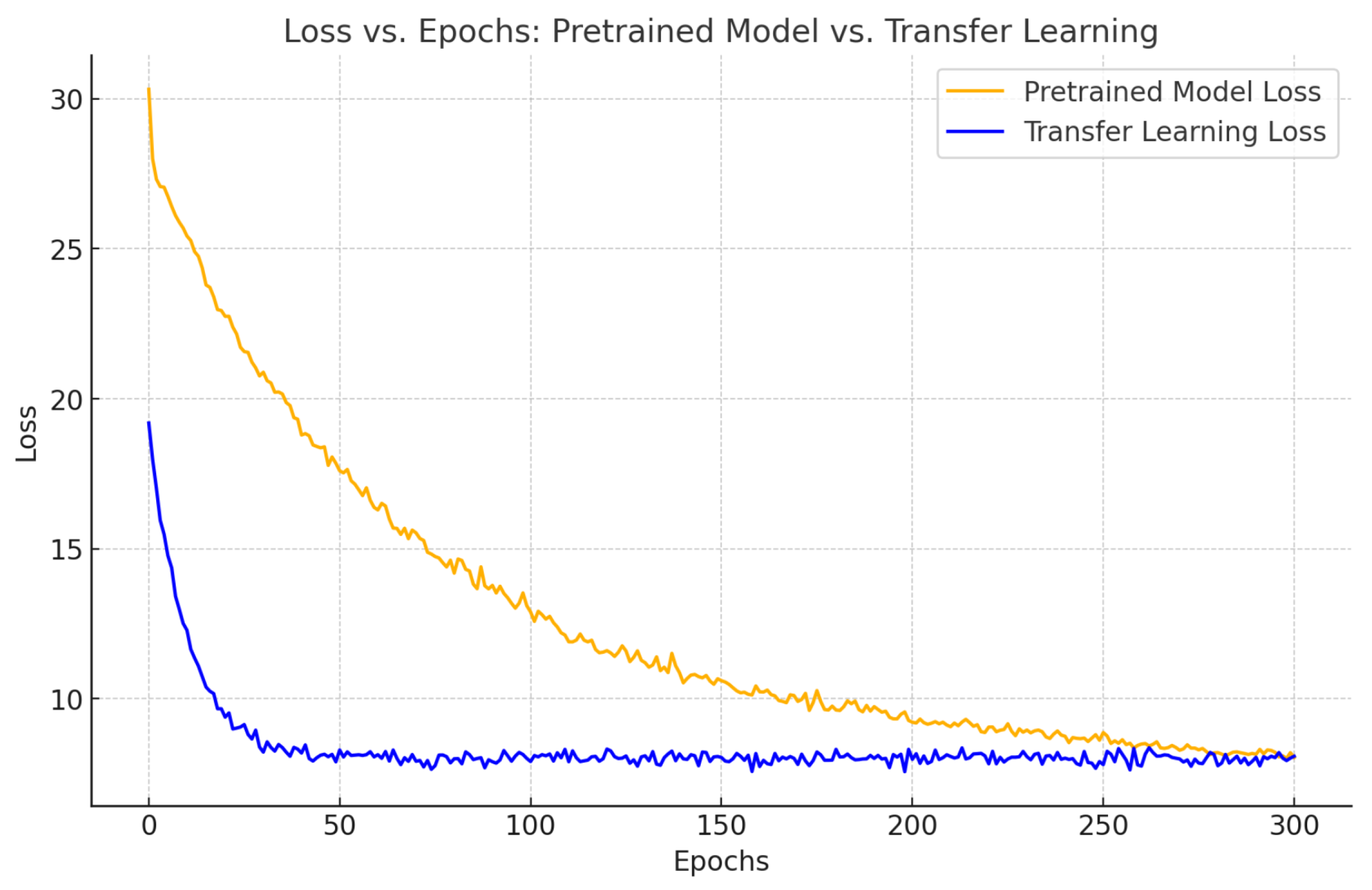
To mitigate the issue of limited industrial datasets, transfer learning techniques are employed to adapt the model from large-scale synthetic datasets to small-scale real-world industrial data. Combined with self-supervised pre-training, transfer learning significantly improves the model’s robustness under noisy and data-scarce conditions and enhances its generalizability across different scenarios. This effectively reduces the reliance on high-quality annotated industrial point clouds.
In summary, this paper addresses key challenges in modeling efficiency, fine-grained structural reconstruction, and data scarcity by proposing a novel DT workshop modeling framework, a self-supervised point cloud completion algorithm, and an integrated transfer learning strategy. Collectively, these contributions provide a comprehensive solution and methodological foundation for advancing the adoption of DT technologies in intelligent manufacturing.







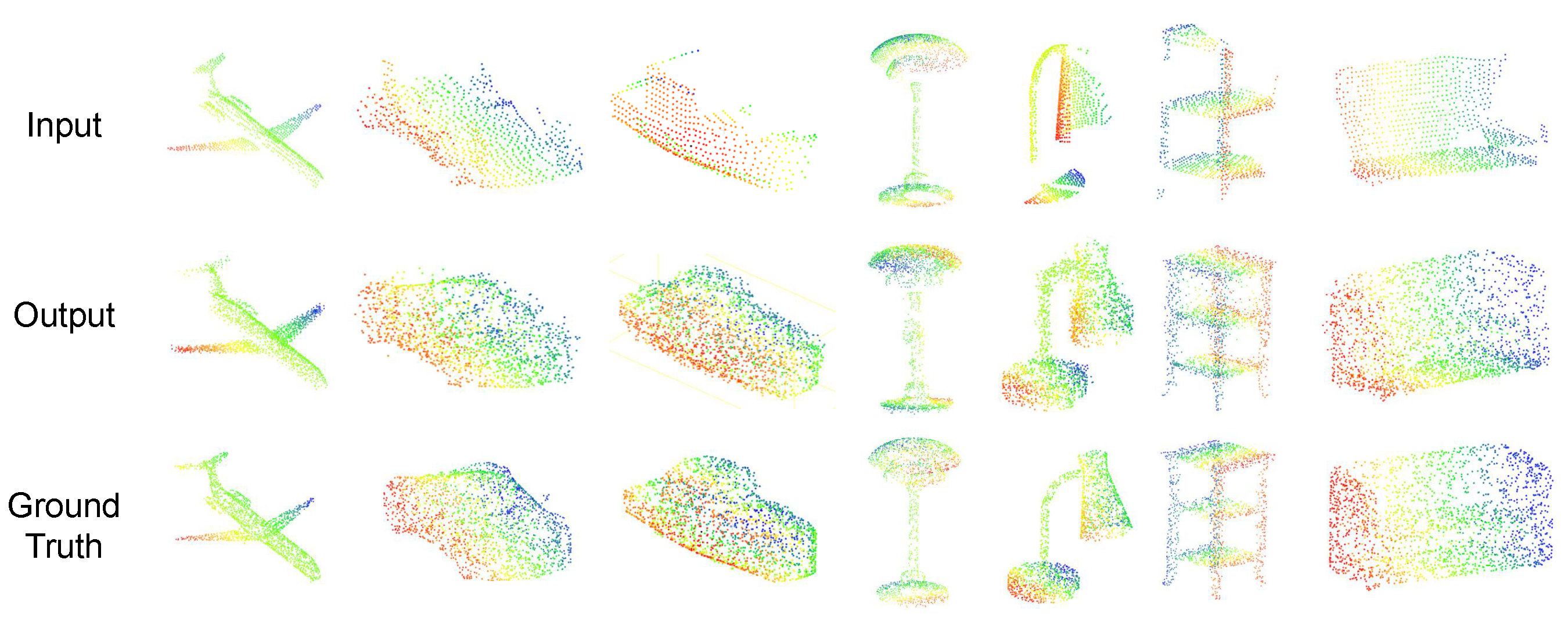

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}