Our approach employs deep learning techniques while relying on minimal prior knowledge of the underlying physics of radio signal propagation. Specifically, we utilize a pretrained neural network and fine-tune it on the available training data, leveraging extensive data augmentation strategies to enhance generalization and mitigate the limitations imposed by data scarcity.
4.1. Data Preprocessing
To ensure consistency and enhance feature representation, a series of systematic preprocessing steps were applied to the dataset. These steps standardize the input data, address variations in geometry and dimensions, and facilitate the integration of additional contextual information relevant to specific tasks. In alignment with the requirements of Tasks 1, 2, and 3, the dataset was prepared as follows:
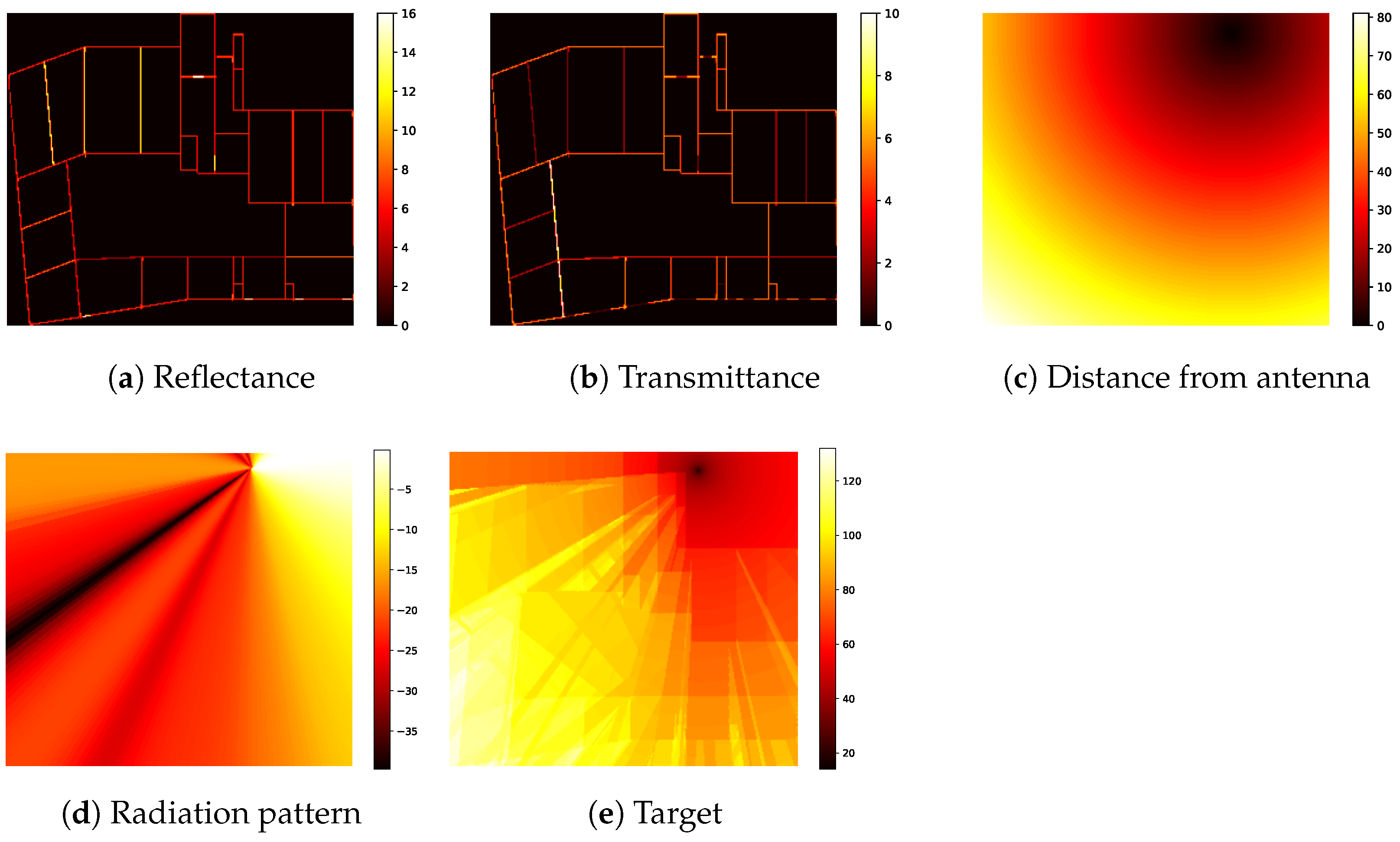
For Task 1, the input data consist of three channels: reflectance, transmittance, and distance. Each input image is padded to form a square and subsequently resized to 518 × 518 pixels. Padding is applied using a value of −1, as the value 0 holds meaningful significance within the dataset. For Tasks 2 and 3, frequency information must also be incorporated. This is encoded as a single additional channel, where each pixel is assigned a uniform value corresponding to the carrier frequency in GHz. In Task 3, antenna configuration must be explicitly represented. To encode the antenna’s radiation pattern, an additional input channel of the same spatial dimensions is introduced. Each pixel value corresponds to the antenna gain at the angle between the respective pixel position and the antenna location. This representation provides a structured visualization of the antenna’s signal coverage, offering spatial context for signal propagation and station placement, as illustrated in
Figure 1d.
4.1.1. Normalization
We conducted an exploratory analysis of the provided dataset to determine the value ranges for each input channel. Based on these observations, we selected channel-specific normalization factors: 25 for reflectance, 20 for transmittance, 200 for distance, 10 for frequency, and 40 for the radiation pattern. Each channel was subsequently normalized by dividing its values by the corresponding factor. The resulting normalized channels serve as the input for the models.
4.1.2. Data Augmentation
We applied a series of data augmentation techniques to enhance the model’s generalization capabilities and robustness to variations in the input data. The following augmentation strategies were employed:
MixUp augmentation: MixUp is a data augmentation technique that generates synthetic training samples by linearly interpolating pairs of input images and their corresponding labels. This method enhances the model’s ability to generalize by encouraging smoother decision boundaries. Additionally, MixUp blends the frequency channels of two inputs, effectively creating intermediate frequency values and enabling the model to generalize to unseen frequencies. In our training pipeline, MixUp was applied to 75% of the training samples, while the remaining 25% were left unchanged. This balanced approach ensures that the model benefits from both augmented and original data, promoting diversity in the learned feature representations while preserving alignment with the original data distribution.
Rotation and flipping: These augmentations introduce variations in the spatial orientation of input samples, improving the model’s invariance to geometric transformations. During training, each input sample is randomly rotated by 0°, 90°, 180°, or 270°, with equal probability. Since no transformation occurs when 0° is selected, rotation is effectively applied to approximately 75% of the training data. Similarly, flipping is applied, where each input sample, along with its corresponding label, is either left unchanged or flipped horizontally and/or vertically. These transformations mitigate overfitting to specific orientations and structural layouts, allowing the model to learn orientation-invariant representations and improve its generalization to unseen data.
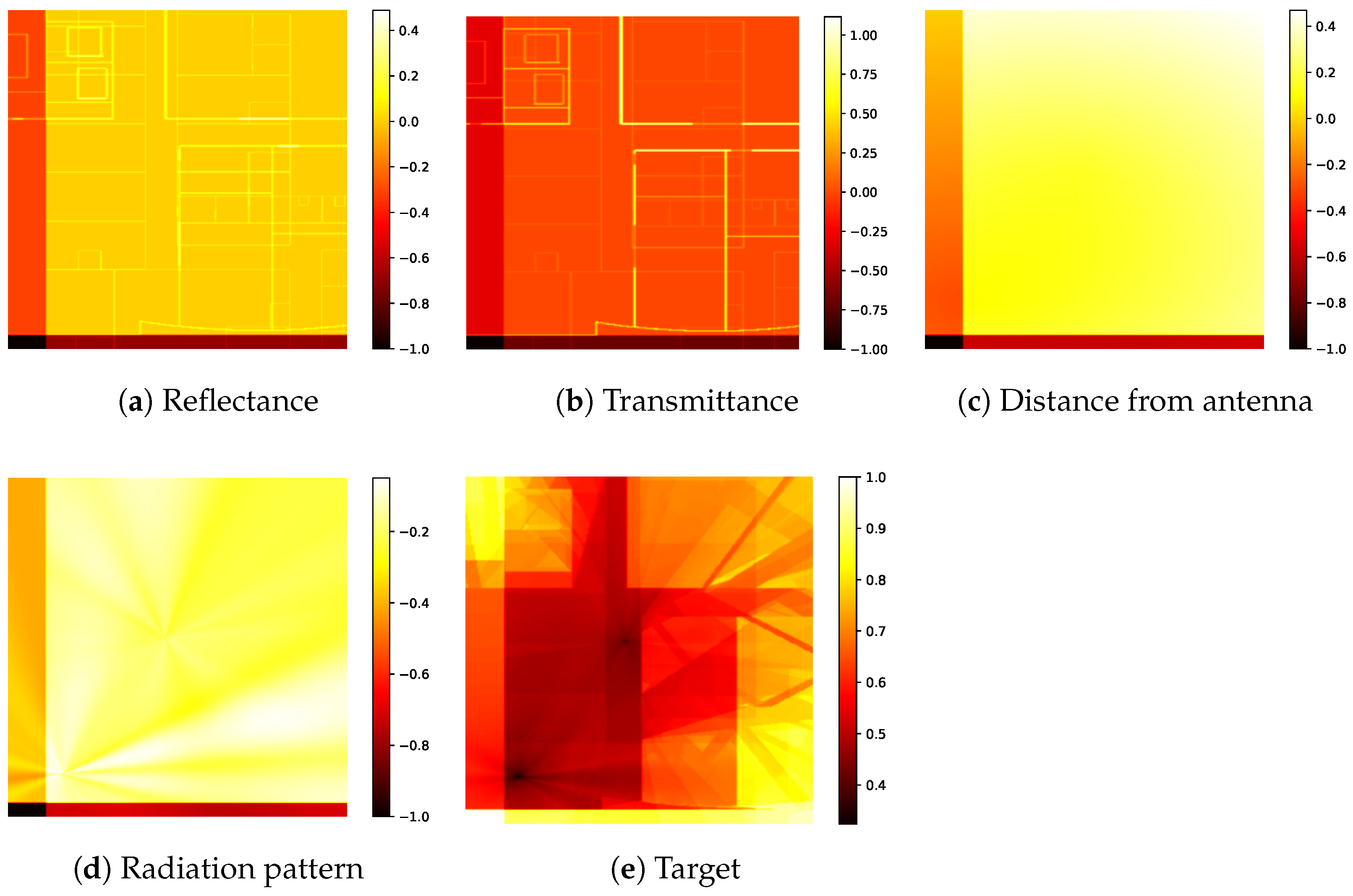
Cropping and resizing: Cropping is used to simulate partial observations of the input data, forcing the model to learn from varying spatial contexts. This augmentation is applied to 75% of the training samples, while the remaining 25% remain unaltered. The crop size is randomly selected within a range between half the size of the input image (259 × 259 pixels) and the full size (518 × 518 pixels). Following cropping, each extracted region is resized to 518 × 518 pixels to maintain consistency in the input dimensions required by the model.
Figure 2 depicts the obtained inputs after applying the aforementioned augmentations.
4.1.3. Training, Validation, and Testing Splits
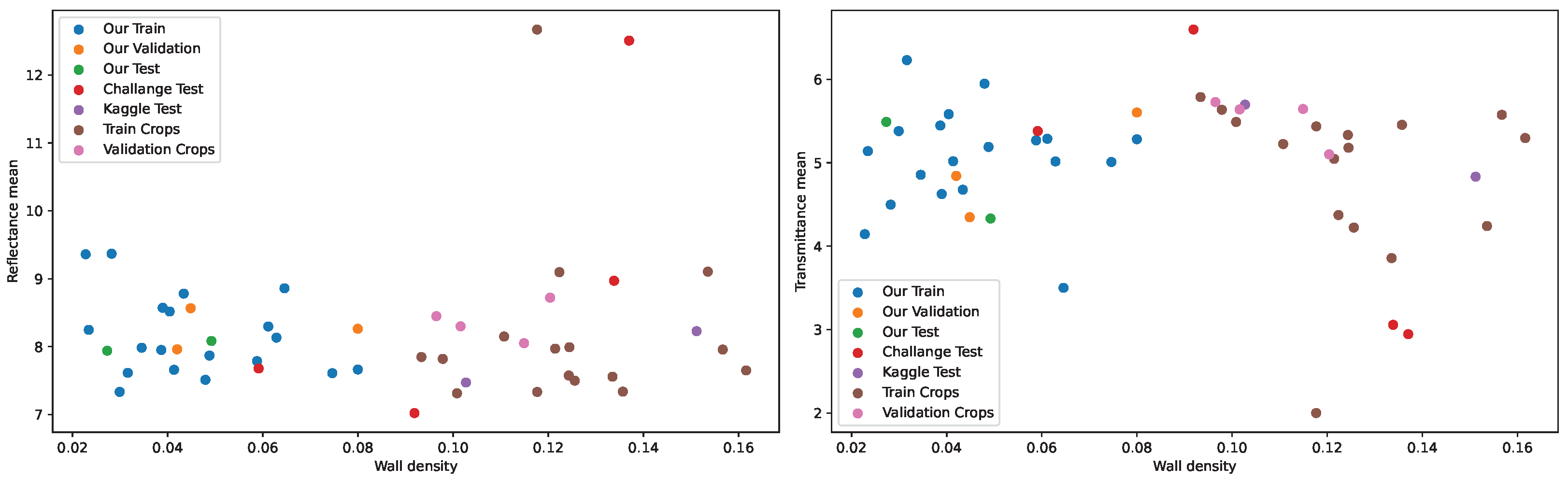
For our experiments, the dataset was partitioned into training, validation, and testing sets according to predefined criteria. Across all tasks, the training set comprises buildings #1 to #19, while buildings #20 to #22 are allocated to the validation set, and buildings #23 to #25 are reserved for testing. For Tasks 2 and 3, the training set includes carrier frequencies of 868 MHz and 3500 MHz, whereas the 1800 MHz frequency is exclusively used for validation and testing. For Task 3, the first three antenna configurations are included in the training set, while configuration #4 is designated for validation, and configuration #5 is held out for testing. As a result, the validation and test sets contain previously unseen buildings across all tasks. Additionally, in Tasks 2 and 3, the validation and test sets include carrier frequencies not present in the training data. In Task 3, the model is further challenged by evaluating its performance on unseen antenna configurations in the validation and test sets.
4.2. Neural Network Design
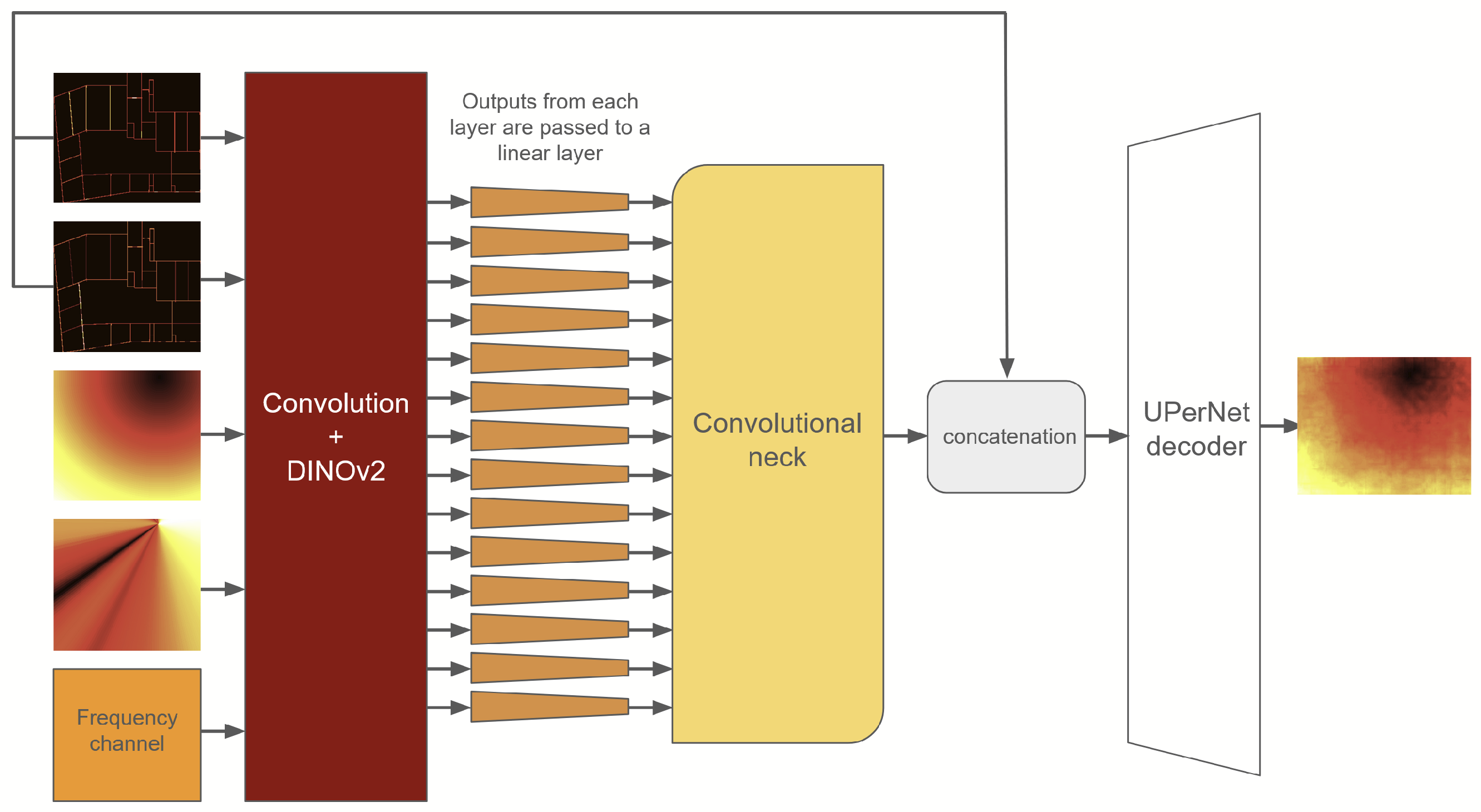
Our neural network consists of three parts: DINOv2 vision transformer [
26], used as an encoder, UPerNet convolutional decoder [
27], and a neck responsible for connecting the ViT-based encoder and the convolutional decoder. We choose the ViT-B/14 version of DINOv2 with pretrained weights. First, the input image is passed through a convolutional layer, which outputs a three-channel image. We do this for compatibility with the DINOv2 input, to be able to leverage the pretrained weights of the network. The resulting image is passed to the encoder to obtain the embeddings of the image. Then, the embeddings from all the 14 layers (the first layer, 12 hidden layers, and the output layer) are passed through a linear layer to decrease the embedding size from 768 to 256 for Task 1, and 512 for Tasks 2 and 3. The low-dimensional embeddings are then reshaped into
squares and fed to the convolutional neck.
The neck consists of a convolutional layer with kernel size 1 that maps the neck input dimension to a predefined depth for each layer, followed up by a bilinear resize operation that scales the image by a predefined factor for each layer, and, finally, another convolutional layer with kernel size 3 that does not alter the depth of the input tensor. Earlier layers use a higher scale factor and smaller depth, while later layers are scaled with a smaller factor, and higher depth. Specifically, the scale factors for each layer are {14, 14, 14, 8, 8, 8, 4, 4, 4, 2, 2, 2, 1, 1}, and the convolution depths are {16, 16, 16, 32, 32, 32, 64, 64, 64, 128, 128, 128, 256, 256} for Task 1, and {32, 32, 32, 64, 64, 64, 128, 128, 128, 256, 256, 512, 512} for Tasks 2 and 3.
The activations are then passed to the UPerNet [
27] decoder to obtain the output. To reinforce the room borders to the network, we also concatenate the reflectance and transmittance channels to the activations obtained from the neck, before feeding it to the decoder. The sigmoid function is then applied to the output, and the result is multiplied by 160 to obtain the final prediction. The model architecture can be seen in
Figure 3.



 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}