1. Introduction
The rapid growth of edge computing and Internet of Things (IoT) devices has intensified the demand for on-device machine learning, particularly for deep learning (DL) inference tasks [
1]. Edge-based inference offers advantages in latency, data privacy, and reduced dependency on network connectivity. However, it also presents substantial challenges in safeguarding model data and user information, particularly on untrusted edge devices. Recent studies have shown that deep neural networks (DNNs) are vulnerable to privacy attacks, including
membership inference attacks (MIAs) [
2], where adversaries can identify if specific data points were part of the model’s training set. These vulnerabilities pose serious privacy risks in sensitive domains such as healthcare and finance.
Traditional methods to secure DNNs, such as homomorphic encryption [
3] and differential privacy [
4], impose high computational costs or reduce model accuracy, making them less suitable for resource-constrained edge devices.
Trusted Execution Environments (TEEs), specifically ARM TrustZone (TZ) [
5], have emerged as viable hardware-based solutions to enhance the security and privacy of edge-based machine learning. TrustZone offers an isolated secure environment, separate from the primary operating system, where sensitive computations can be processed without interference from the normal world. However, the limited memory available in TZ restricts its capacity to protect large DNN models fully, particularly for complex architectures [
6].
Previous methods like
DarkneTZ [
7] addressed these limitations by partitioning DNNs into layers and executing only the most sensitive layers within TZ. Typically, DarkneTZ starts from the final layer and moves backward, securing as many layers as the TZ memory allows. This layer-wise approach protects sensitive outputs that are often targeted by MIAs. However, it also exposes several limitations: (1) for larger models, only a subset of layers can be protected within TZ, leaving other parts exposed; and (2) copying entire layers into TZ incurs significant delays due to data transfer and memory constraints.
To address these challenges, we propose SelTZ, a selective layer protection mechanism that secures only the most sensitive portions of each layer within TZ rather than entire layers. Instead of partitioning feature maps, which would require significant memory overhead, SelTZ partitions model parameters between the normal world and secure world (TZ). This approach leverages the observation that protecting critical parameters can effectively mitigate MIAs while optimizing computational efficiency. By processing sensitive parameters in TZ while handling non-sensitive ones in the normal world, this selective protection reduces memory load in TZ, enables parallel processing across both worlds, and minimizes data-transfer overhead.
The main challenges we address in SelTZ include:
Layer Sensitivity Assessment: Determining which portions of each layer’s computations need to be protected to prevent MIAs while maximizing normal world utilization, SelTZ employs a probabilistic selection strategy that focuses on protecting activation outputs and parameters critical for secure computation.
Efficient Cross-World Data Management: Partitioned computations across worlds introduce data transfer and context-switching overheads. SelTZ addresses this through shared memory management and multi-threaded execution, enabling parallel processing while maintaining security boundaries.
Layer-Specific Processing Strategies: Different layer types require specialized handling due to their unique computational characteristics. Convolutional and fully connected layers use parameter partitioning with secure combining, while normalization layers require complete secure world execution.
We validate SelTZ through extensive experiments, demonstrating significant reductions in MIA success rates and improved computational performance compared to existing methods. Our results show that our probabilistic parameter selection strategy, combined with efficient shared memory management and specialized layer processing techniques, effectively balances privacy protection and efficiency. This approach achieves robust defense against MIAs while requiring substantially less TZ memory than full layer protection methods. The modular design of SelTZ makes it adaptable to various DNN architectures on edge devices while preserving inference accuracy.
The remainder of this paper is organized as follows:
Section 2 provides background on privacy challenges in edge-based deep learning and reviews related work on TrustZone-based protection.
Section 3 details our selective protection approach, including sensitivity assessment, efficient cross-world computation, and layer-specific processing strategies.
Section 4 presents the implementation details of our approach on different neural network architectures.
Section 5 provides comprehensive experimental results comparing SelTZ with DarkneTZ across different architectures and datasets, demonstrating improvements in both privacy protection and resource efficiency.
Section 6 concludes with a discussion of future research directions.
2. Background and Related Work
2.1. Privacy Challenges in Edge-Based Deep Learning
As deep learning (DL) models are increasingly deployed in edge computing and Internet of Things (IoT) applications, significant privacy and security concerns have emerged. Edge devices, by performing data-intensive tasks locally, reduce latency and dependence on cloud resources. However, due to their often untrusted environments, they are highly susceptible to various attacks, including membership inference attacks (MIAs) [
2,
8]. MIAs exploit the ability of an adversary to infer if specific data points were used in training a model, potentially exposing sensitive information, especially in applications involving user-specific data such as medical records or financial transactions. Such attacks take advantage of subtle model behaviors that differ between data it has seen and unseen data, creating a serious privacy vulnerability in edge-deployed models.
A range of techniques has been proposed to defend against MIAs and other privacy risks in DL, including
homomorphic encryption [
3],
secure multi-party computation [
9], and
differential privacy [
4]. Homomorphic encryption enables computations on encrypted data, but it remains computationally prohibitive for resource-limited edge devices. Differential privacy adds noise to model outputs to obscure individual data contributions; yet, this can reduce model accuracy and utility. Consequently, such methods are less practical in latency-sensitive and compute-constrained edge settings. To address these constraints, Trusted Execution Environments (TEEs), specifically ARM TrustZone [
5], have emerged as a promising hardware-based solution. TEEs provide an isolated, secure processing area that operates separately from the primary system, allowing edge devices to run sensitive computations in a secure space protected from tampering or unauthorized access.
2.2. Existing Approaches to Secure Deep Learning with TrustZone
Among TEE-based solutions, DarkneTZ is a significant method that utilizes TrustZone to secure DL models on edge devices [
7]. DarkneTZ partitions deep neural networks (DNNs) at the layer level, prioritizing the protection of layers from the last layer backward, as final layers often contain data most vulnerable to MIAs [
8]. By copying entire layers into TrustZone until the memory limit is reached, DarkneTZ selectively protects as much of the model as TrustZone memory allows. This approach effectively reduces MIA success rates by isolating sensitive layers that contribute most to inference output.
While DarkneTZ addresses TrustZone’s memory constraints, it also presents limitations. First, protecting entire layers restricts DarkneTZ’s ability to secure large models, as TrustZone’s memory can only hold a limited number of layers in full. Consequently, the unprotected layers remain exposed, posing a risk for MIAs and other inference-based attacks [
10,
11,
12]. Additionally, the method of copying entire layers into TrustZone is associated with significant latency, particularly during data transfers. The overhead from this layer-wise copying and execution in TrustZone can compromise real-time inference speeds, limiting the utility of DarkneTZ in latency-sensitive applications.
We select DarkneTZ as our primary baseline for comparative evaluation for several key reasons. First, its implementation is publicly available as open-source software, enabling direct and fair performance comparisons under identical experimental conditions. Second, DarkneTZ was validated on the Raspberry Pi 3B platform, a representative hardware for resource-constrained IoT deployments, allowing for meaningful comparisons in realistic scenarios. Furthermore, as the first comprehensive approach to TrustZone-based neural network protection, its thorough documentation and established performance characteristics provide a robust foundation for demonstrating the advances made by our fine-grained protection strategy.
2.3. SelTZ: Selective Protection Through Fine-Grained Layer Partitioning
To address the limitations in layer-wise protection, we propose SelTZ, a fine-grained protection approach that secures only the most sensitive portions of layer data rather than entire layers. This selective protection strategy is based on the hypothesis that partial protection of critical data elements within each layer is sufficient to defend against MIAs while optimizing computational efficiency. SelTZ splits computations within each layer, processing sensitive data in TrustZone and handling non-sensitive data in the normal world, thus enabling multi-threaded, parallel execution across both environments. This design leverages TrustZone’s secure capabilities without fully occupying its limited memory, thus maximizing both efficiency and security.
The SelTZ design introduces several key technical innovations that enhance privacy protection and reduce computational overhead:
Efficient Data Management and Multi-Threading: By classifying data as either sensitive or non-sensitive, SelTZ minimizes the need to transfer large amounts of data between the normal and secure worlds. Only essential, sensitive data are stored within TrustZone, while non-sensitive data resides in shared memory accessible to both worlds. This selective data management reduces data copying, enables efficient memory use, and supports parallel processing across worlds, significantly decreasing latency compared to layer-wise copying approaches.
Securely Combining Partitioned Computations: SelTZ incorporates zero-padding into partitioned weights and biases in both convolutional and fully connected layers, allowing partial results from each world to be securely combined in TrustZone via summation. For instance, convolutional layers are split by partitioning weights rather than input data, avoiding the need to track and secure large inputs. Zero-padding facilitates secure summation of intermediate results from each world in TrustZone, ensuring robust privacy with minimal data transfer.
Complete Computation of Non-Partitionable Layers: Certain layers, such as Softmax and other normalization layers, require complete access to their input data for accurate computation and thus cannot be partitioned across worlds. SelTZ addresses this by processing such layers fully within TrustZone, ensuring that the outputs remain protected from exposure.
SelTZ represents a major shift from traditional TEE-based solutions by allowing for the fine-grained partitioning of layer computations rather than full layer processing within TZ. Unlike DarkneTZ’s approach, which is limited by TrustZone’s constrained memory, SelTZ dynamically adjusts the level of protection based on data sensitivity within each layer. This selective partitioning enables robust MIA defense with minimal impact on model efficiency, supporting more extensive and complex models on edge devices. Our design demonstrates that a strategic, data-sensitive approach can achieve a balance between privacy protection and computational feasibility on edge hardware.
The next section details the design and implementation of SelTZ, focusing on its partitioning strategy, secure data management, and the computational workflow for parallel processing across TrustZone and the normal world.
3. Design
3.1. Overview of SelTZ’s Approach
SelTZ is a fine-grained data protection mechanism for deep neural networks (DNNs) on edge devices using ARM TrustZone (TZ). Unlike prior methods such as DarkneTZ, which protect entire layers within TZ, SelTZ selectively secures only the most sensitive portions of layer data, leaving non-sensitive data to be processed in the normal world. This approach is based on the hypothesis that targeted protection of sensitive portions is sufficient to defend against membership inference attacks (MIAs), thus optimizing the use of TZ’s limited resources and enhancing overall processing efficiency.
DarkneTZ secures layers by processing them sequentially from the last layer backward within TZ until memory limits are reached, as final layers generally contain data most vulnerable to MIAs. However, this approach restricts protection capabilities with larger models due to the TZ memory constraints and the substantial overhead associated with copying entire layers between normal and secure worlds. SelTZ, instead, partitions layer computations across the secure and normal worlds, allowing more efficient processing by protecting only essential data in TZ while keeping less critical data in the normal world. This division reduces the memory load in TZ, supports concurrent processing in both worlds, and minimizes data-transfer overhead.
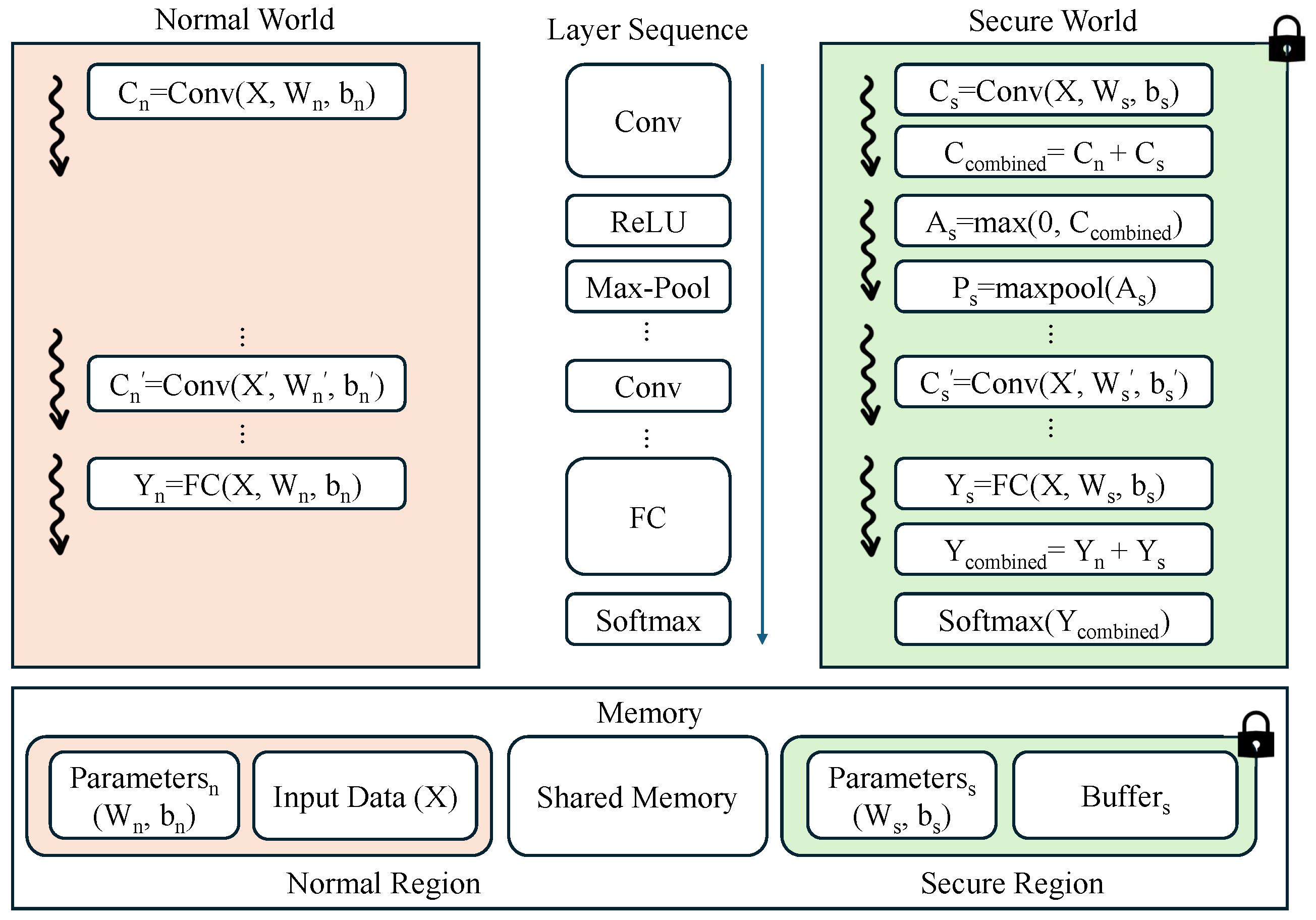
Figure 1 illustrates the overall architecture and data flow of SelTZ. The system processes neural network layers (e.g., Conv, ReLU, Max-Pool, FC, Softmax) by partitioning their computations across normal and secure worlds. Rather than partitioning input data, which would require duplicating large feature maps, SelTZ partitions model parameters (weights
W and biases
b) into two portions: one for normal world processing (denoted with subscript
n) and another for secure world processing (denoted with subscript
s). These partitioned parameters are used to compute partial results in their respective worlds in parallel. The partial results are then combined in the secure world to maintain security. This design ensures that even if an adversary in the normal world has access to the input data, they can only compute partial results using the parameters available in the normal world (
,
), while the secure parameters (
,
) remain protected in TrustZone. Additionally, our design employs a probabilistic parameter selection strategy to determine which portions should be protected, balancing security requirements with computational efficiency. Consequently, the adversary cannot reconstruct the complete computation result without access to the secure world parameters, effectively protecting the model’s sensitive components. The detailed mathematical formulations and security mechanisms for each operation will be elaborated in the following sections. The figure also shows how SelTZ manages memory through dedicated secure/normal regions and a shared memory, enabling efficient data transfer between the two worlds while maintaining security boundaries.
3.2. Challenges and Solutions
The implementation of SelTZ addresses three main challenges. First, we need a systematic approach to assess layer sensitivity and determine optimal partitioning strategies that prevent MIA while maximizing normal world resource utilization. Second, we must efficiently manage data movement and parallel computation across the security boundary while dealing with TrustZone’s memory constraints. Third, each layer type (convolutional, fully connected, and normalization layers) requires specialized handling due to its different computational characteristics and security requirements. In this section, we present our solutions through a combination of randomized parameter partitioning, efficient shared memory management, and layer-specific processing strategies.
3.2.1. Layer Sensitivity Assessment and Partitioning Strategy
The primary objective of SelTZ’s partitioning strategy is to prevent membership inference attacks (MIAs) by ensuring that attack-critical intermediate outputs remain exclusively in the secure world. Specifically, activation outputs (e.g., ReLU outputs) and final layer outputs, which are commonly exploited in MIAs, must be computed and stored only in TrustZone, preventing any possibility of reconstruction or deduction from the normal world. Beyond these critical components, SelTZ aims to maximize the utilization of normal world resources for other computations to optimize overall performance.
Following this strategy, our partitioning approach first allocates memory for essential secure computations:
Activation outputs across all layers
Final layer outputs (e.g., Softmax outputs)
Associated parameters required for computing these secure outputs
If the remaining TrustZone memory permits, additional computations are selectively moved to the secure world based on their sensitivity scores. For a layer
l, we compute its security requirement score
as:
where
is the distance from the output layer and
D is the total network depth. This ensures that layers closer to the output receive higher priority when additional secure memory is available, similar to DarkneTZ’s backward protection strategy.
Given TrustZone’s memory constraint
, the layer selection problem is formulated as:
where
is a binary selection variable indicating whether layer
l is allocated to TrustZone (
) or not (
), and
is the memory requirement of layer
l. The constraint
when
ensures that layers containing critical computations are always allocated to TrustZone. This knapsack-like problem is solved greedily by selecting layers in descending order of their security requirement scores
until the memory constraint is reached.
For the layers selected for protection, weights and biases are then partitioned based on their sensitivity scores. For each selected layer
l, we define a sensitivity score matrix
using a sensitivity assessment function
:
Here,
is a function that evaluates how much each weight parameter contributes to the layer’s output sensitivity, producing values in the range [0, 1]. Theoretically,
Shapley value [
13] could be an ideal choice for this assessment, as it precisely quantifies each weight parameter’s marginal contribution to the network’s outputs by considering all possible parameter combinations. However, computing exact Shapley values requires extensive computational resources and time, making it impractical for real-time applications. Therefore, we propose several efficient yet effective methods to assess parameter importance based on both individual parameter values and their structural relationships within the layer.
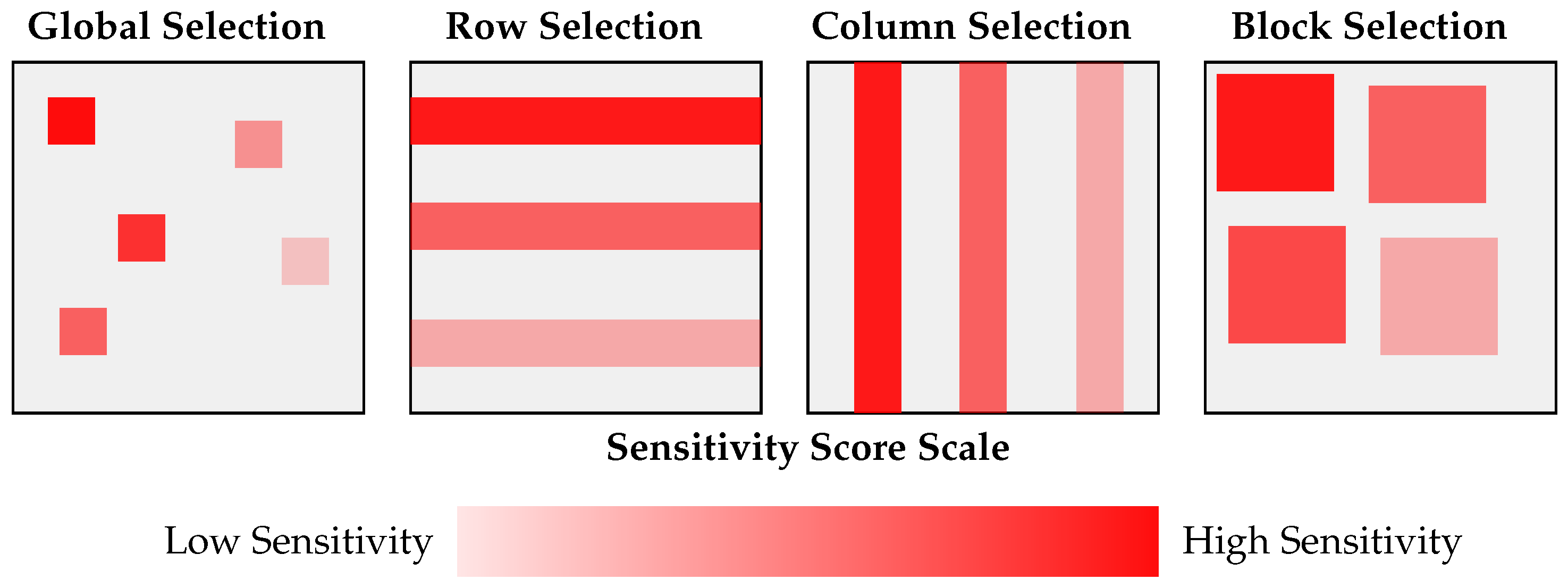
Our parameter selection strategy employs two main approaches, as illustrated in
Figure 2:
Global Importance-based Selection: Parameters are chosen based on their absolute values, reflecting their direct contribution to the layer’s output. For a given protection ratio
:
Structured Pattern Selection: As shown in
Figure 2, we consider the collective importance of structurally related parameters through three distinct patterns. For each pattern type, we compute cumulative importance scores:
where
P represents a specific pattern instance (e.g., a
block or a row of weights). The patterns are selected in descending order of their scores until approximately
fraction of total parameters is covered. Specifically, we consider:
Row/Column patterns: Select entire rows or columns based on their cumulative weight importance
Block patterns (, ): Protect spatially grouped parameters in fixed-size blocks
For any selected pattern instance
P, the sensitivity function assigns:
This weight-based partitioning approach, visualized in
Figure 2, provides two key advantages: memory efficiency through smaller parameter storage requirements and a multiplicative protection effect, where securing critical weights influences multiple output features through partial sum operations. This multiplicative effect of weight protection represents a key advantage in our approach, enabling robust defense against MIAs while maintaining efficient resource utilization. Additionally, since weights remain constant during inference, this approach simplifies the management of sensitive data across world boundaries.
3.2.2. Reducing Inter-World Data Copying Overhead and Multi-Threading
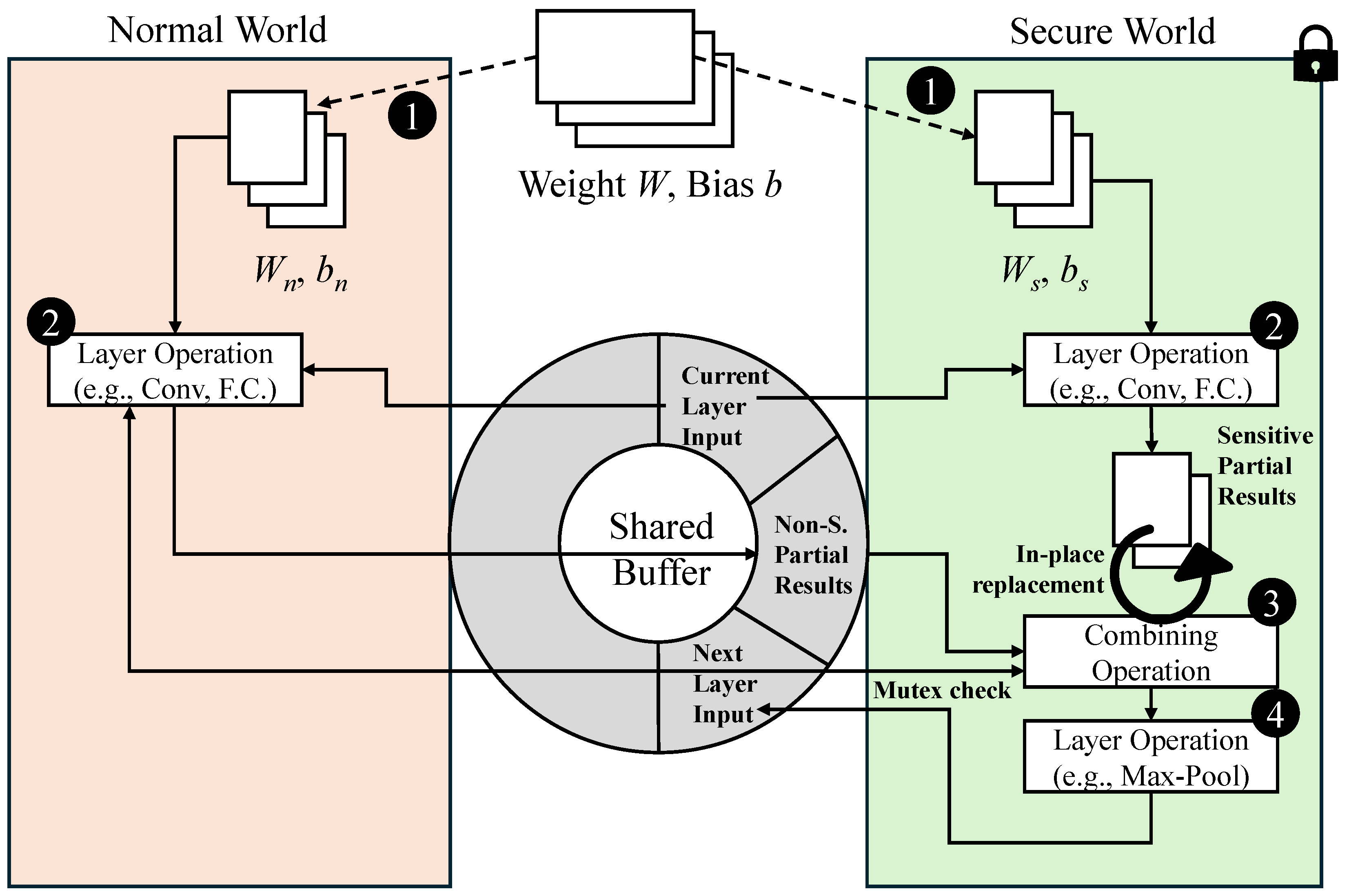
Partitioning layers for dual-world processing introduces frequent data transfers between the normal and secure worlds, which can lead to substantial overhead. To address this, SelTZ classifies data generated in each layer as either sensitive or non-sensitive. Sensitive data, which requires protection, is stored and processed in secure memory, while non-sensitive data resides in a shared memory region accessible to both worlds, reducing the volume of data that must be copied to TZ.
Figure 3 illustrates the processing flow of a representative layer, such as a convolutional or fully connected layer, in our multi-threaded architecture. To efficiently manage data transfer between worlds, SelTZ implements the shared memory region using a circular buffer structure:
Memory Management: The shared buffer is configured as:
where
N blocks of size
B MB are allocated. These parameters (
N and
B) can be adjusted based on the target device platform’s memory capacity. The total shared buffer size (
) should be sufficient to accommodate the largest intermediate result size among all layers. For instance, in AlexNet, the largest layer (fifth convolutional layer) produces intermediate results of 384 channels with 13 × 13 feature maps, requiring approximately 0.25 MB for single-precision floating-point storage. Accordingly, on our test platform, we use
blocks of
MB each. When targeting different network architectures, these parameters should be adjusted based on their maximum intermediate layer size—for example, deeper networks with larger feature maps would require proportionally larger buffer allocations. If the intermediate data exceed the available shared memory space, the computation can be further divided into smaller subsets, processing the data in multiple passes while maintaining the same memory recycling strategy.
Thread Synchronization: When the computational workload is not evenly distributed between worlds (which often occurs due to security requirements), mutex-based synchronization is employed to handle the timing differences in computation completion. This ensures that partial results from the faster thread wait for the slower thread before the combining operation begins in the secure world.
This integrated approach of shared memory and multi-threading minimizes both data transfer and world transition overheads. While TZ handles sensitive operations, the normal world performs non-sensitive computations concurrently, reducing idle time in each environment and optimizing performance. For example, while convolutional operations on sensitive data are executed in the secure world thread, the normal world thread can process non-sensitive portions of the same layer in parallel. This approach also allows larger models to be protected within TZ by limiting the volume of sensitive data managed in secure memory, which is critical given TZ’s constrained memory capacity.
3.2.3. Partitioning and Combining Convolutional Layers
Partitioning computations across worlds requires secure combining of intermediate results from each world. In SelTZ, this challenge is handled by selectively partitioning weights rather than input data for convolutional layers. Partitioning weights reduces the memory overhead that would arise from tracking large input data in both worlds.
For a convolutional layer with input
X, the partitioned weights and biases (
,
for the normal world and
,
for the secure world) are used to compute convolution operations explicitly as
where
K and
L are the kernel dimensions. The zero-padded structure of
and
allows for efficient SIMD processing. Using ARM NEON instructions, we process multiple elements simultaneously by loading four floating-point values into 128-bit NEON registers. The presence of zeros in the padded weights is particularly advantageous as it allows for sparse computation optimization—when a weight block contains zeros due to partitioning, those multiplications can be skipped entirely, further accelerating the convolution operation. This optimization is implemented using NEON’s conditional execution capabilities, effectively reducing the number of required floating-point operations while maintaining the parallel processing advantage.
Partitioned Weight and Convolution Calculation with Zero Padding: The convolution operations are performed in parallel:
Here,
and
represent the partial convolution results based on normal-world and secure-world weights and biases, stored in shared and secure memory, respectively.
Secure Summation of Partitioned Convolution Outputs: Results are combined in TZ using element-wise addition:
This operation is performed within TZ’s secure memory space. Specifically, the secure world process directly accesses
from its secure memory allocation and reads
from the shared memory region. The element-wise addition is performed in-place where
←
+
using NEON SIMD instructions to process multiple elements simultaneously, and this modified
becomes
, avoiding additional memory allocation. Finally, the shared memory region containing
is cleared to prevent potential data leakage. This in-place computation strategy minimizes memory usage within the constrained TZ environment while maintaining security guarantees.
Activation and Pooling within Secure Memory: The activation function
f (typically ReLU) is applied to
in TZ:
For max pooling with window size
and stride
s:
3.2.4. Partitioning and Combining Fully Connected Layers
Fully connected (FC) layers require a modified approach due to their dense connectivity patterns. The weights and biases are partitioned using a block-wise strategy:
Weight Matrix Blocking: For an FC layer with input dimension
and output dimension
, the weight matrix
is divided into blocks:
where each block
is assigned to either
or
based on its sensitivity score.
Partitioned Weight and Bias Computation with Zero Padding: The computations are performed block-wise:
where
and
are the sets of block indices assigned to normal and secure worlds, respectively, and:
The block-wise computation structure enables further performance optimization through NEON SIMD instructions, processing multiple elements simultaneously in both secure and normal worlds, similar to the optimization applied in convolutional layers.
Secure Summation of Partitioned Results: Results are combined in TZ using vector addition:
Activation in Secure Memory: The activation function (typically ReLU) is applied within TZ:
3.2.5. Secure Computation of Normalization Layers
Normalization layers require special handling due to their global dependencies. For Softmax computation:
Complete Computation within the Secure World: The entire Softmax operation is performed in TZ:
Memory Optimization: To reduce memory usage and ensure numerical stability, computation is performed in-place with only two scalar temporary variables (m and s):
Compute maximum: // scalar temporary
Subtract maximum:
Compute exponentials:
Compute sum: // scalar temporary
Normalize:
This implementation requires only two additional scalar values in secure memory, minimizing the memory overhead while maintaining numerical stability.
3.3. Processing Flow Integration
SelTZ processes deep neural networks through a systematic combination of security-driven partitioning and efficient execution strategies. Starting with a sensitivity assessment of each layer, computations are selectively distributed across normal and secure worlds while ensuring that activation outputs and final layer outputs, which are critical for preventing MIAs, remain protected in TrustZone.
The processing flow varies by layer type, reflecting their different security requirements and computational characteristics. Convolutional and fully connected layers leverage parallel processing with partitioned parameters, where normal world results are efficiently transferred through circular shared memory buffers while secure world computations remain isolated. These partial results are then combined securely within TrustZone. In contrast, normalization layers, due to their global dependencies, are processed entirely within the secure world using memory-optimized implementations.
A scheduler coordinates this heterogeneous processing by managing:
Layer dependencies and execution ordering
Transitions between parallel and secure-only processing
Allocation and management of shared memory resources
This integrated approach enables SelTZ to maintain its security guarantees while optimizing performance through efficient resource utilization and parallel processing capabilities.
4. Implementation
4.1. Target Neural Network Models
To comprehensively evaluate the effectiveness of SelTZ, we use three neural network architectures that vary in complexity and depth: AlexNet, VGG-7, and ResNet-20. Each architecture presents unique challenges in terms of memory usage, computational demands, and susceptibility to membership inference attacks (MIAs). While DarkneTZ originally used ResNet-110, we opted for ResNet-20, which extends DarkneTZ’s ResNet-18 implementation with TrustZone-aware operations. This choice allows us to better demonstrate the practical applicability of our approach in resource-constrained TrustZone environments. Additionally, since DarkneTZ is open-source, we conducted all experiments on the same platform under identical conditions, ensuring a fair and direct comparison between SelTZ and DarkneTZ beyond the numbers reported in their paper.
For ease of explanation, we present a detailed breakdown of each model’s layers in
Table 1,
Table 2 and
Table 3. AlexNet has five convolutional layers (with kernel sizes 11, 5, 3, 3, and 3) followed by a fully connected layer and a softmax layer, where the number of neurons for each convolutional layer is 64, 192, 384, 256, and 256, respectively. VGG-7 (The VGG-7 architecture follows the configuration from DarkneTZ (
https://github.com/mofanv/tz_datasets.git (accessed on 29 December 2024))) consists of seven convolutional layers with a uniform kernel size of 3, where the number of neurons progressively increases (64, 64, 124, 124, 124, 124, 124), followed by a fully connected layer and a softmax layer. ResNet-20 introduces residual blocks that enable significantly deeper architectures. It begins with a 7 × 7 convolutional layer with 64 filters and a stride of 2, followed by a 2 × 2 max pooling layer. The network consists of five stages with increasing channel dimensions (64, 128, 256, and 512), where the transitions between stages use strided convolutions for spatial reduction. Each residual block contains two 3 × 3 convolutional layers connected by a skip connection, incorporating TrustZone-aware operations throughout the network.
Our implementation carefully considers the information flow between normal and secure worlds to prevent any potential data leakage. The key insight is that convolutional layers can be safely partitioned between normal and secure worlds when preceded by guarding layers such as max pooling that serve as information-reducing operations. In such cases, the normal world only observes downsampled data for the input, making it impossible to deduce the complete information (i.e., ReLu output). Each table entry specifies the layer type, filter size, output shape, and its partition (world). Following this principle, ReLU and pooling layers after convolution are processed entirely in the secure world to protect sensitive activation outputs. Similarly, when ReLU outputs directly feed into another convolutional layer without intermediate guarding operations, the entire operation must be computed in the secure world.
4.2. Datasets
The experiments use the CIFAR-100 and ImageNet Tiny datasets. CIFAR-100 contains 60,000 images across 100 classes, with 500 training images and 100 test images per class. ImageNet Tiny is a scaled-down version of ImageNet, consisting of 100,000 training images and 10,000 validation images across 200 classes, with images resized to 64 × 64 pixels for edge device deployment.
For membership inference attack (MIA) experiments, we follow DarkneTZ’s methodology for dataset construction. For CIFAR-100, we use 25,000 training set samples as member data and 5000 test set samples as non-member data for attack model training. Evaluation uses 5000 different samples each from training (members) and test sets (non-members). For ImageNet Tiny, we use 50,000 training samples as member data and 5000 validation samples as non-member data for training, with 5000 different samples each from the training and validation sets for evaluation.
4.3. Attack Model
We adopt the same membership inference attack model architecture from DarkneTZ but focus solely on activation outputs. The model employs fully connected network (FCN) components with one ReLU-activated hidden layer and 0.2 dropout to process each target model layer’s activation outputs. These outputs are concatenated and processed by a final encoder for membership prediction. Training uses the Adam optimizer with a 0.0001 learning rate for 200 epochs, selecting the model with the highest testing accuracy. All experiments use a batch size of 64.
5. Experiment Results
5.1. Experimental Setup
The experiments are conducted on a Raspberry Pi 3B platform equipped with ARM Cortex-A53 cores and ARM TrustZone technology. This platform is identical to that used in the DarkneTZ framework, ensuring a fair comparison of TrustZone-related overhead and memory constraints. Being a resource-constrained edge device, the Raspberry Pi 3B provides a realistic testbed for evaluating both the security benefits and performance implications of TrustZone deployment in practical scenarios. OP-TEE is used as the TrustZone operating system, enabling the secure execution of selected layers within TrustZone’s memory. Models are deployed with layers allocated to either the secure world or the normal world based on SelTZ’s selective layer protection strategy.
Our implementation partitions layers where necessary, allowing sensitive portions (such as critical activation outputs and specific parameters) to be processed within the secure world while handling non-sensitive portions in the normal world to optimize resource usage. This fine-grained approach enables efficient use of TrustZone resources while maintaining robust defenses against MIA risks. For the evaluation of membership inference attacks, we assume an adversary who captures activation outputs observable in the normal world during inference on the test platform. These captured outputs are then analyzed offline using pre-trained attack models on a separate machine, reflecting a realistic scenario where the adversary collects exposed intermediate outputs from the edge device before performing computationally intensive analysis on more capable hardware.
5.2. Effectiveness of Weight Protection Strategies
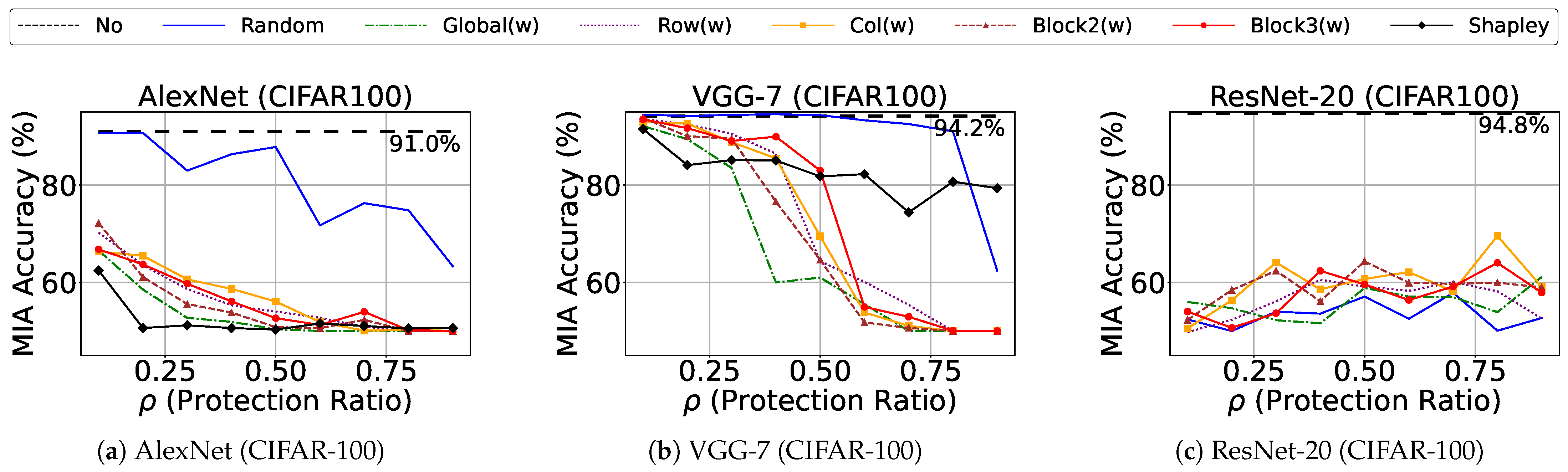
We first evaluate different weight protection strategies against membership inference attacks on CIFAR-100. As shown in
Figure 4a–c, the baseline accuracy without protection reaches 91.0%, 94.2%, and 94.8% for AlexNet, VGG-7, and ResNet-20 respectively, indicating significant privacy risks. All protection strategies described in
Section 3.2.1 demonstrate substantial improvement over this baseline. While Shapley value-based weight selection provides theoretically optimal importance measurement and shows rapid convergence to random guess (50%) in AlexNet (
Figure 4a), its computational overhead becomes prohibitive for more complex architectures. For VGG-7 and ResNet-20, even with 100 Monte Carlo samples, Shapley value computation fails to effectively reduce MIA accuracy regardless of protection ratio (
Figure 4b,c), requiring significantly more samples and computational time to achieve meaningful results.
As a practical alternative, our Global(w) selection strategy based on weight absolute values shows consistently strong performance across different architectures, as evident in
Figure 4. Among the structured pattern selections, Block2(w) outperforms Block3(w), though neither achieves the stability and effectiveness of global importance-based selection. Interestingly, for ResNet-20 (
Figure 4c), even random selection achieves near-random guess accuracy (approximately 50%) with just 10% protection ratio, suggesting that its complex architecture with residual connections may distribute sensitive information more evenly across weights, making random protection surprisingly effective.
We further validate our approach on ImageNet-Tiny, with results shown in
Figure 5. The baseline vulnerabilities are notably lower (72.5%, 60.8%, and 62.4% for AlexNet, VGG-7, and ResNet-20), suggesting that membership inference attacks face greater challenges with larger, more complex datasets. Notably, pattern-based approaches considering locality show superior performance compared to global selection at low protection ratios, as particularly visible in
Figure 5b,c, though the protection patterns remain generally consistent with CIFAR-100 results. Attack accuracy converges to near-random guessing at lower ratios compared to CIFAR-100, suggesting that less secure memory might be needed to achieve adequate protection on ImageNet-Tiny. These results demonstrate our approach’s effectiveness across different dataset complexities and validate the robustness of our protection strategies.
5.3. Performance Analysis
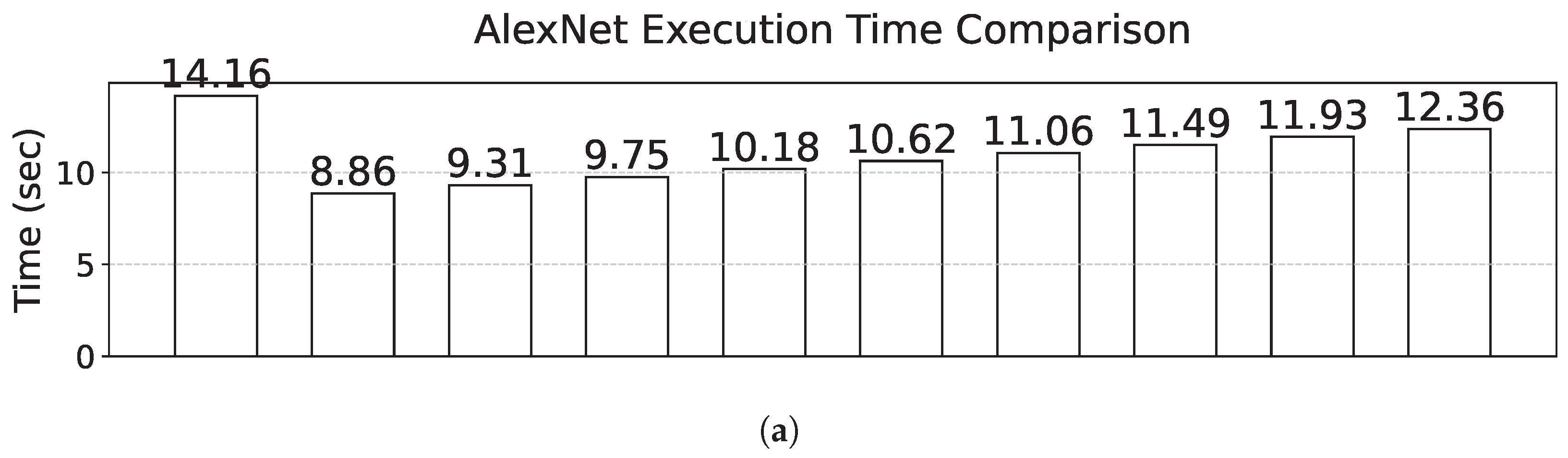
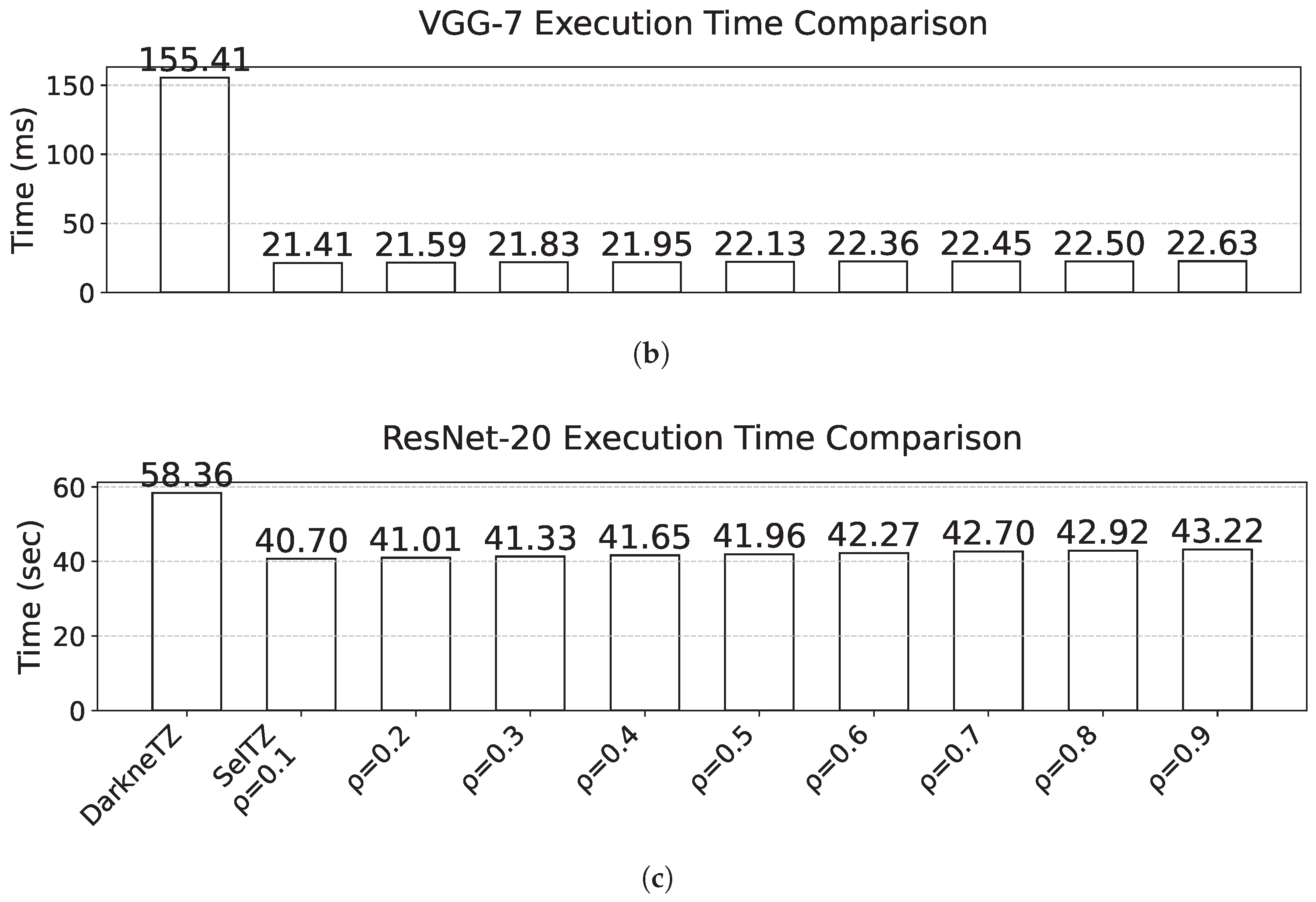
We evaluate SelTZ’s computational efficiency against DarkneTZ across different architectures on our Raspberry Pi 3B testbed. As shown in
Figure 6, all architectures demonstrate significant performance improvements. AlexNet execution time reduces from 14.16 s with DarkneTZ to 8.86 s with SelTZ at
(1.6× speedup). At
, execution time increases to 12.36 s while still maintaining a 1.15× speedup. VGG-7 shows more dramatic improvement, dropping from 155.41 ms to 21.41 ms at
(7.3× speedup), with minimal increase to 22.63 ms at
(6.9× speedup). ResNet-20 follows similar trends, improving from 58.36 s to 40.70 s at
(1.43× speedup) and scaling to 43.22 s at
(1.35× speedup).
The variation in speedup across architectures can be attributed to their different baseline implementations in DarkneTZ. Due to secure world memory constraints, DarkneTZ only protects the last four layers of AlexNet and the last two layers of ResNet-20 in the secure world, while processing the remaining layers in the faster normal world. In contrast, VGG-7’s relatively smaller size allows DarkneTZ to protect all layers in the secure world, resulting in a higher baseline execution time and consequently more dramatic improvements with SelTZ. It is worth noting that SelTZ maintains comprehensive protection for all security-critical layers in the secure world while selectively offloading only those layer computations that can be safely exposed to the normal world, as detailed in
Section 4.1.
These improvements stem from several key optimizations in SelTZ’s design. First, selective weight protection significantly reduces TrustZone resource usage compared to DarkneTZ’s layer-wise approach. Second, our zero-padding strategy for partitioned weights enables efficient use of ARM NEON SIMD instructions with conditional execution. When a weight block contains zeros due to partitioning, those multiplications can be skipped entirely, accelerating both convolution and fully connected layer operations. Third, our block-wise computation structure further optimizes performance through effective memory locality and reduced world-switching overhead. The relationship between execution time and protection ratio across architectures enables predictable performance scaling, allowing system designers to make informed trade-offs between privacy protection and computational efficiency.
5.4. Memory Usage Analysis
TrustZone secure memory usage was measured across all three neural network architectures, comparing DarkneTZ and SelTZ approaches (
Table 4). For a fair comparison in the inference scenario, we modified the original DarkneTZ implementation by removing all training-related memory allocations. Even after these optimizations, DarkneTZ’s memory overhead stems from its need to pre-allocate secure world memory for all protected layers’ data, with each layer requiring sufficient memory for both feature maps and parameters. This approach leads to memory allocation of 1.34 MB for VGG-7, 7.46 MB for AlexNet, and 3.93 MB for ResNet-20. In contrast, SelTZ optimizes memory usage through dynamic allocation based on maximum layer size and in-place operations, requiring only 0.39 MB for VGG-7, 2.80 MB for AlexNet, and 1.96 MB for ResNet-20. This represents substantial memory reductions of 71.13%, 62.41%, and 50.16%, respectively.
The efficiency gains from SelTZ’s approach are particularly evident in memory-constrained environments. While DarkneTZ can only protect up to the last four layers in AlexNet and the last two layers in ResNet-20 due to memory limitations, SelTZ’s optimized allocation strategy enables the protection of significantly more layers. This is achieved by limiting memory demand to the size of the largest layer rather than the cumulative size of all protected layers, while in-place operations further reduce data transfer overhead between normal and secure worlds. These optimizations make SelTZ particularly well-suited for resource-constrained edge devices where memory limitations are a critical concern, while maintaining robust protection against membership inference attacks.
7. Conclusions
In conclusion, this paper presents SelTZ, a novel selective layer protection method that leverages ARM TrustZone to secure deep neural network inference on resource-constrained edge devices. By partitioning layer computations and selectively protecting only the most sensitive data, SelTZ overcomes key limitations of existing solutions that rely on full-layer protection. Our approach achieves significant improvements in both performance and memory efficiency—up to 7.3× speedup and 71% memory reduction compared to DarkneTZ—while maintaining strong privacy guarantees against membership inference attacks. Our experimental results demonstrate that selective protection with global importance-based weight selection provides robust defense against MIAs across different architectures and datasets, reducing attack success rates from over 90% to near random guess (50%). The efficient use of NEON SIMD instructions through zero-padded weight partitioning, combined with parallel processing across security boundaries, enables SelTZ to protect substantially more layers than previous approaches within TrustZone’s limited secure memory. While acknowledging the security limitations discussed earlier, future research should focus on enhancing SelTZ’s capabilities through adaptive protection mechanisms, broader attack coverage, and integration with emerging hardware security features. This will help establish SelTZ as a more comprehensive solution for securing AI deployments on edge devices.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}