

Deep-Learning-Based Neural Distinguisher for Format-Preserving Encryption Schemes FF1 and FF3

Abstract
1. Introduction
1.1. Our Contribution
- The first neural distinguisher for the NIST FPE family: We propose the first neural distinguisher for FF1 and FF3, which are NIST standard format-preserving ciphers. Our neural distinguisher works successfully in the number and lowercase domains and can be effectively utilized for cryptanalysis using differential characteristics.
- Successful verification of two models (single-input difference and multiple-input difference): Our neural distinguisher is divided into an implementation that distinguishes single-input differences and multiple-input differences. When using a single-input difference, the cipher data are distinguished from random data. When multiple-input differences are used, the model can distinguish the input difference used for the input data among multiple-input differences. We adopt both approaches and successfully demonstrate the effectiveness of our model.
- Our neural distinguisher can attack various variants of FF1 and FF3: While format-preserving encryption includes an encryption function, the presence of differential characteristics remains independent of the specific encryption function. Consequently, our neural distinguisher can be effectively employed for distinguisher attacks targeting various variants of FF1, FF3.
1.2. Organization
2. Prerequisites
2.1. Format-Preserving Encryption
2.2. Differential Characteristic
2.3. Neural-Network-Based Distinguisher for Differential Cryptanalysis
3. Neural Distinguisher for FF1 and FF3
| Algorithm 1 ModelOne: Training procedure |
|
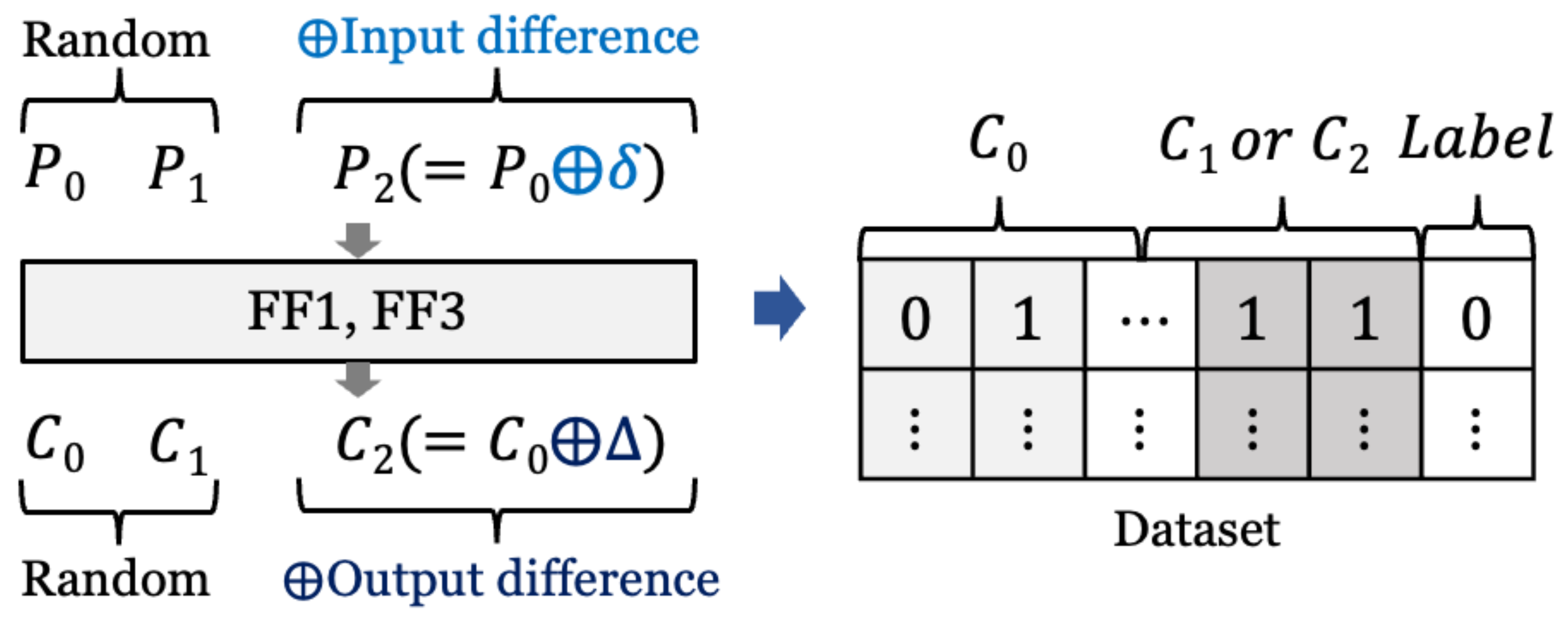
3.1. ModelOne: Single-Input Difference
3.1.1. Dataset
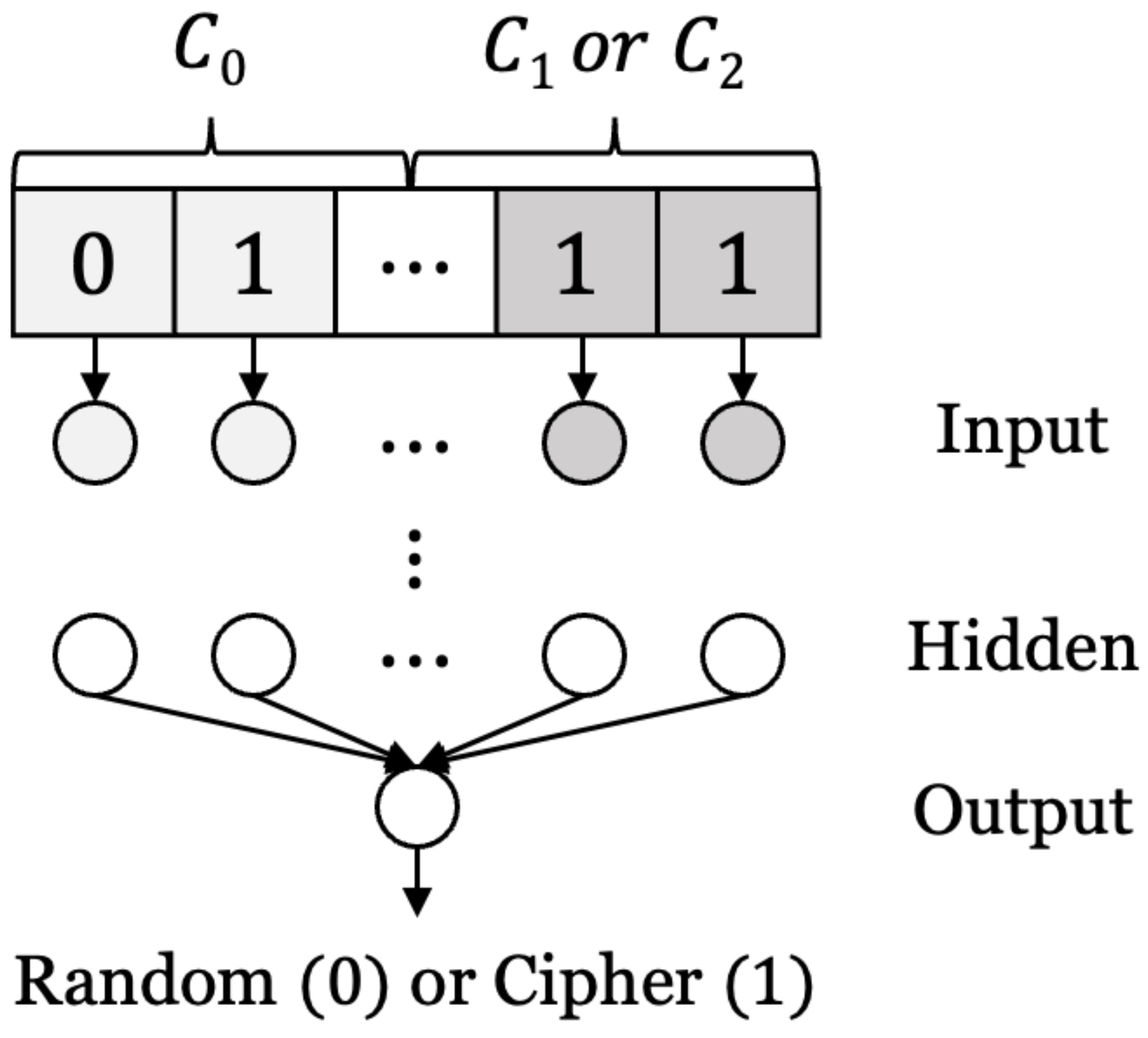
3.1.2. Architecture and Training
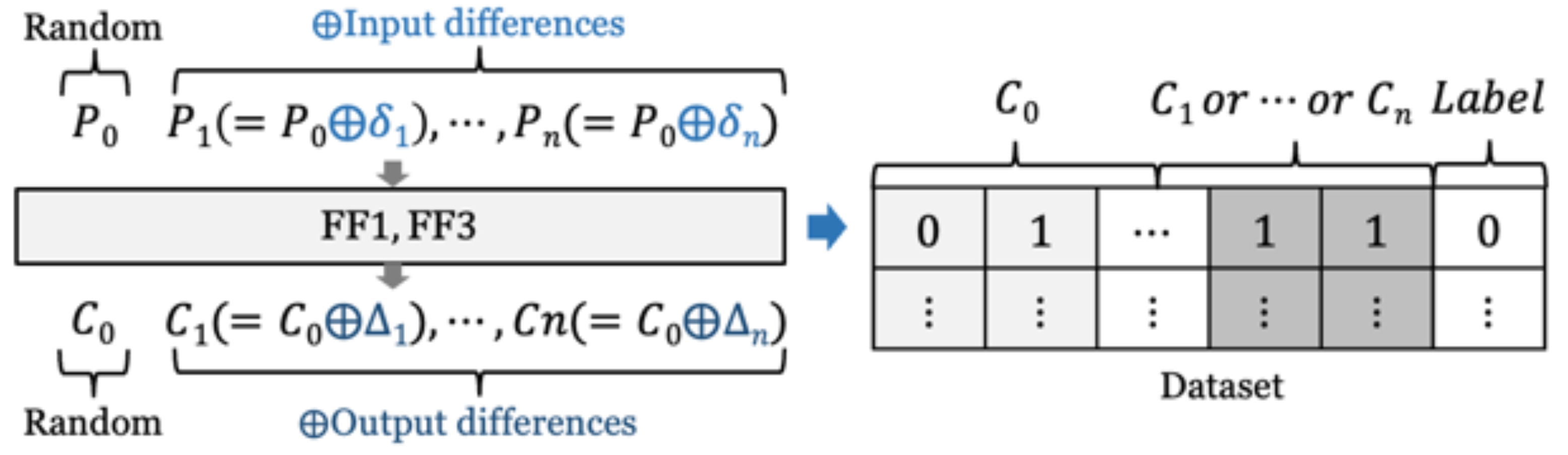
3.2. ModelMul: Multiple-Input Differences
3.2.1. Dataset
3.2.2. Model Architecture and Training
| Algorithm 2 ModelMul: Training procedure |
|
3.3. Hyper-Parameter Tuning
4. Evaluation
4.1. Experimental Environment
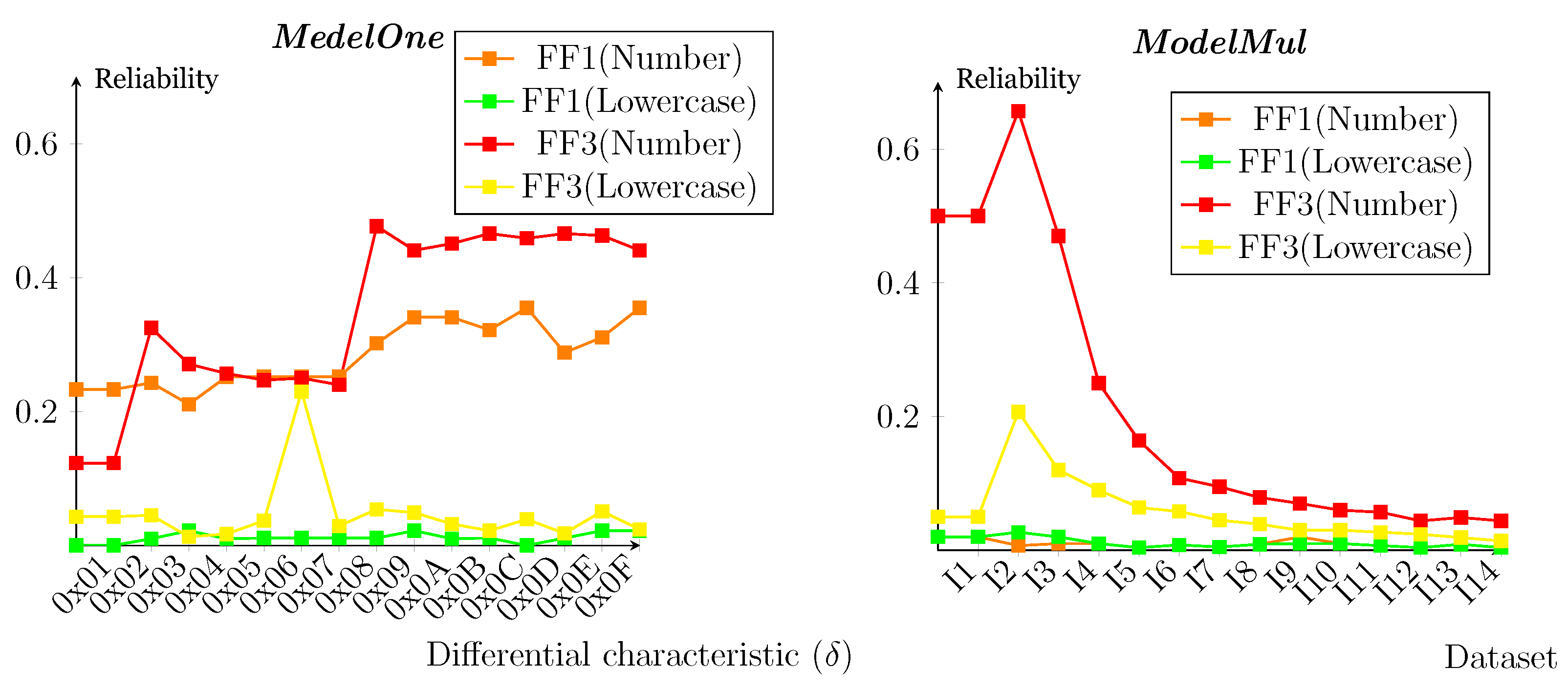
4.2. Result for One-Input Difference
4.3. Result for Multiple-Input Differences
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Heys, H.M. A tutorial on linear and differential cryptanalysis. Cryptologia 2002, 26, 189–221. [Google Scholar] [CrossRef]
- Taye, M.M. Understanding of machine learning with deep learning: Architectures, workflow, applications and future directions. Computers 2023, 12, 91. [Google Scholar] [CrossRef]
- Khaloufi, H.; Abouelmehdi, K.; Beni-Hssane, A.; Rustam, F.; Jurcut, A.D.; Lee, E.; Ashraf, I. Deep learning based early detection framework for preliminary diagnosis of COVID-19 via onboard smartphone sensors. Sensors 2021, 21, 6853. [Google Scholar] [CrossRef] [PubMed]
- Ammer, M.A.; Aldhyani, T.H. Deep learning algorithm to predict cryptocurrency fluctuation prices: Increasing investment awareness. Electronics 2022, 11, 2349. [Google Scholar] [CrossRef]
- Lamothe-Fernández, P.; Alaminos, D.; Lamothe-López, P.; Fernández-Gámez, M.A. Deep learning methods for modeling bitcoin price. Mathematics 2020, 8, 1245. [Google Scholar] [CrossRef]
- Essaid, M.; Ju, H. Deep Learning-Based Community Detection Approach on Bitcoin Network. Systems 2022, 10, 203. [Google Scholar] [CrossRef]
- Zhu, S.; Li, Q.; Zhao, J.; Zhang, C.; Zhao, G.; Li, L.; Chen, Z.; Chen, Y. A Deep-Learning-Based Method for Extracting an Arbitrary Number of Individual Power Lines from UAV-Mounted Laser Scanning Point Clouds. Remote Sens. 2024, 16, 393. [Google Scholar] [CrossRef]
- Lata, K.; Cenkeramaddi, L.R. Deep learning for medical image cryptography: A comprehensive review. Appl. Sci. 2023, 13, 8295. [Google Scholar] [CrossRef]
- Kim, H.; Jang, K.; Lim, S.; Kang, Y.; Kim, W.; Seo, H. Quantum Neural Network Based Distinguisher on SPECK-32/64. Sensors 2023, 23, 5683. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.; Lim, S.; Kang, Y.; Kim, W.; Kim, D.; Yoon, S.; Seo, H. Deep-learning-based cryptanalysis of lightweight block ciphers revisited. Entropy 2023, 25, 986. [Google Scholar] [CrossRef] [PubMed]
- Gohr, A. Improving attacks on round-reduced speck32/64 using deep learning. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 150–179. [Google Scholar]
- Baksi, A. Machine learning-assisted differential distinguishers for lightweight ciphers. In Classical and Physical Security of Symmetric Key Cryptographic Algorithms; Springer: Berlin/Heidelberg, Germany, 2022; pp. 141–162. [Google Scholar]
- Baksi, A.; Breier, J.; Dasu, V.A.; Hou, X.; Kim, H.; Seo, H. New Results on Machine Learning-Based Distinguishers. IEEE Access 2023, 11, 54175–54187. [Google Scholar] [CrossRef]
- Jain, A.; Kohli, V.; Mishra, G. Deep learning based differential distinguisher for lightweight cipher PRESENT. arXiv 2020, arXiv:2112.05061. [Google Scholar]
- Rajan, R.; Roy, R.K.; Sen, D.; Mishra, G. Deep Learning-Based Differential Distinguisher for Lightweight Cipher GIFT-COFB. In Machine Intelligence and Smart Systems: Proceedings of MISS 2021; Springer: Berlin/Heidelberg, Germany, 2022; pp. 397–406. [Google Scholar]
- Mishra, G.; Pal, S.; Krishna Murthy, S.; Prakash, I.; Kumar, A. Deep Learning-Based Differential Distinguisher for Lightweight Ciphers GIFT-64 and PRIDE. In Machine Intelligence and Smart Systems: Proceedings of MISS 2021; Springer: Berlin/Heidelberg, Germany, 2022; pp. 245–257. [Google Scholar]
- Chen, Y.; Yu, H. A New Neural Distinguisher Model Considering Derived Features from Multiple Ciphertext Pairs. IACR Cryptol. ePrint Arch. 2021, 2021, 310. [Google Scholar]
- Benamira, A.; Gerault, D.; Peyrin, T.; Tan, Q.Q. A deeper look at machine learning-based cryptanalysis. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Zagreb, Croatia, 17–21 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 805–835. [Google Scholar]
- Hou, Z.; Ren, J.; Chen, S. Cryptanalysis of round-reduced Simon32 based on deep learning. Cryptol. ePrint Arch. 2021, 2021, 362. [Google Scholar]
- Yadav, T.; Kumar, M. Differential-ml distinguisher: Machine learning based generic extension for differential cryptanalysis. In Proceedings of the International Conference on Cryptology and Information Security in Latin America, Bogotá, Colombia, 6–8 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 191–212. [Google Scholar]
- Yue, X.; Wu, W. Improved Neural Differential Distinguisher Model for Lightweight Cipher Speck. Appl. Sci. 2023, 13, 6994. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks and Learning Machines, 3/E; Pearson Education India: Delhi, India, 2009. [Google Scholar]
- Stallings, W. Format-preserving encryption: Overview and NIST specification. Cryptologia 2017, 41, 137–152. [Google Scholar] [CrossRef]
- Jang, W.; Lee, S.Y. A format-preserving encryption FF1, FF3-1 using lightweight block ciphers LEA and, SPECK. In Proceedings of the 35th Annual ACM Symposium on Applied Computing, Brno, Czech Republic, 30 March–3 April 2020; pp. 369–375. [Google Scholar]
- Kim, H.; Kim, H.; Eum, S.; Kwon, H.; Yang, Y.; Seo, H. Parallel Implementation of PIPO and Its Application for Format Preserving Encryption. IEEE Access 2022, 10, 99963–99972. [Google Scholar] [CrossRef]
- Dunkelman, O.; Kumar, A.; Lambooij, E.; Sanadhya, S.K. Cryptanalysis of Feistel-based format-preserving encryption. Cryptol. ePrint Arch. 2020, 2020, 1311. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | ModelOne | ModelMul |
|---|---|---|
| Schemes | FF1/FF3 | FF1/FF3 |
| Epochs | 20/15 | 20/15 |
| Loss function | Binary cross-entropy | Categorical cross-entropy |
| Optimizer | Adam (0.001 to 0.0001, learning rate decay) | |
| Activation function | ReLu (hidden) | |
| Softmax (output) | Sigomid (output) | |
| Batch size | 32 | |
| Hidden layers | 5/4 hidden layers (with 64/128 units) | |
| Parameters | 173,956/74,497 | 173,956/75,787 |
| 0x | Number (10 Rounds) | Lowercase (2 Rounds) | ||||||
|---|---|---|---|---|---|---|---|---|
| Training | Validation | Test | Reliability | Training | Validation | Test | Reliability | |
| 01 | 0.732 | 0.741 | 0.733 | 0.233 | 0.500 | 0.500 | 0.500 | 0.000 |
| 02 | 0.741 | 0.752 | 0.743 | 0.243 | 0.510 | 0.512 | 0.510 | 0.010 |
| 03 | 0.711 | 0.712 | 0.711 | 0.211 | 0.522 | 0.520 | 0.522 | 0.022 |
| 04 | 0.751 | 0.752 | 0.752 | 0.252 | 0.511 | 0.512 | 0.510 | 0.010 |
| 05 | 0.752 | 0.751 | 0.752 | 0.252 | 0.511 | 0.512 | 0.511 | 0.011 |
| 06 | 0.751 | 0.752 | 0.752 | 0.252 | 0.511 | 0.512 | 0.511 | 0.011 |
| 07 | 0.751 | 0.751 | 0.752 | 0.252 | 0.511 | 0.511 | 0.511 | 0.011 |
| 08 | 0.801 | 0.802 | 0.802 | 0.302 | 0.511 | 0.511 | 0.511 | 0.011 |
| 09 | 0.841 | 0.842 | 0.841 | 0.341 | 0.522 | 0.521 | 0.522 | 0.022 |
| 0A | 0.842 | 0.841 | 0.841 | 0.341 | 0.500 | 0.510 | 0.510 | 0.010 |
| 0B | 0.822 | 0.821 | 0.822 | 0.322 | 0.511 | 0.511 | 0.511 | 0.011 |
| 0C | 0.855 | 0.854 | 0.855 | 0.355 | 0.500 | 0.500 | 0.500 | 0.000 |
| 0D | 0.788 | 0.788 | 0.788 | 0.288 | 0.511 | 0.511 | 0.511 | 0.011 |
| 0E | 0.811 | 0.812 | 0.811 | 0.311 | 0.522 | 0.521 | 0.522 | 0.022 |
| 0F | 0.855 | 0.854 | 0.855 | 0.355 | 0.522 | 0.522 | 0.522 | 0.022 |
| 0x | Number (8 Rounds) | Lowercase (2 Rounds) | ||||||
|---|---|---|---|---|---|---|---|---|
| Training | Validation | Test | Reliability | Training | Validation | Test | Reliability | |
| 01 | 0.629 | 0.624 | 0.623 | 0.123 | 0.545 | 0.544 | 0.543 | 0.043 |
| 02 | 0.829 | 0.825 | 0.825 | 0.325 | 0.552 | 0.548 | 0.545 | 0.045 |
| 03 | 0.783 | 0.769 | 0.771 | 0.271 | 0.52 | 0.514 | 0.513 | 0.013 |
| 04 | 0.761 | 0.756 | 0.757 | 0.257 | 0.523 | 0.52 | 0.517 | 0.017 |
| 05 | 0.773 | 0.752 | 0.747 | 0.247 | 0.539 | 0.538 | 0.537 | 0.037 |
| 06 | 0.758 | 0.748 | 0.75 | 0.25 | 0.523 | 0.519 | 0.523 | 0.023 |
| 07 | 0.756 | 0.739 | 0.74 | 0.24 | 0.532 | 0.529 | 0.529 | 0.029 |
| 08 | 0.987 | 0.976 | 0.977 | 0.477 | 0.556 | 0.554 | 0.554 | 0.054 |
| 09 | 0.962 | 0.942 | 0.941 | 0.441 | 0.547 | 0.543 | 0.549 | 0.049 |
| 0A | 0.969 | 0.953 | 0.951 | 0.451 | 0.538 | 0.534 | 0.532 | 0.032 |
| 0B | 0.97 | 0.965 | 0.966 | 0.466 | 0.53 | 0.526 | 0.522 | 0.022 |
| 0C | 0.97 | 0.959 | 0.959 | 0.459 | 0.538 | 0.536 | 0.539 | 0.039 |
| 0D | 0.968 | 0.965 | 0.966 | 0.466 | 0.532 | 0.524 | 0.518 | 0.018 |
| 0E | 0.964 | 0.963 | 0.963 | 0.463 | 0.549 | 0.549 | 0.551 | 0.051 |
| 0F | 0.965 | 0.939 | 0.941 | 0.441 | 0.528 | 0.524 | 0.524 | 0.024 |
| Dataset | Data Size | Input Difference Pair | Valid Accuracy |
|---|---|---|---|
| I1 | per class | 01, 08 | >0.500 |
| I2 | 01, 02, 08 | >0.333 | |
| I3 | 01∼03, 08 | >0.250 | |
| I4 | 01∼04, 08 | >0.200 | |
| I5 | 01∼05, 08 | >0.166 | |
| I6 | 01∼06, 08 | >0.142 | |
| I7 | 01∼08 | >0.125 | |
| I8 | 01∼09 | >0.111 | |
| I9 | 01∼0A | >0.100 | |
| I10 | 01∼0B | >0.090 | |
| I11 | 01∼0C | >0.083 | |
| I12 | 01∼0D | >0.076 | |
| I13 | 01∼0E | >0.071 | |
| I14 | 01∼0F | >0.066 |
| Dataset | Number (8 Rounds) | Lowercase (2 Rounds) | ||||||
|---|---|---|---|---|---|---|---|---|
| Training | Validation | Test | Reliability | Training | Validation | Test | Reliability | |
| I1 | 0.520 | 0.520 | 0.520 | 0.020 | 0.520 | 0.520 | 0.520 | 0.020 |
| I2 | 0.340 | 0.339 | 0.340 | 0.007 | 0.360 | 0.360 | 0.360 | 0.027 |
| I3 | 0.260 | 0.260 | 0.260 | 0.010 | 0.270 | 0.270 | 0.270 | 0.020 |
| I4 | 0.210 | 0.210 | 0.210 | 0.010 | 0.200 | 0.200 | 0.200 | 0.010 |
| I5 | 0.170 | 0.170 | 0.170 | 0.004 | 0.180 | 0.180 | 0.180 | 0.004 |
| I6 | 0.150 | 0.150 | 0.150 | 0.008 | 0.150 | 0.150 | 0.150 | 0.008 |
| I7 | 0.130 | 0.130 | 0.130 | 0.005 | 0.130 | 0.130 | 0.130 | 0.005 |
| I8 | 0.120 | 0.120 | 0.120 | 0.009 | 0.120 | 0.120 | 0.120 | 0.009 |
| I9 | 0.120 | 0.110 | 0.120 | 0.020 | 0.100 | 0.100 | 0.110 | 0.010 |
| I10 | 0.100 | 0.100 | 0.100 | 0.010 | 0.100 | 0.100 | 0.100 | 0.010 |
| I11 | 0.090 | 0.090 | 0.090 | 0.007 | 0.090 | 0.090 | 0.090 | 0.007 |
| I12 | 0.080 | 0.080 | 0.080 | 0.004 | 0.080 | 0.080 | 0.080 | 0.004 |
| I13 | 0.080 | 0.080 | 0.080 | 0.009 | 0.080 | 0.080 | 0.080 | 0.009 |
| I14 | 0.070 | 0.070 | 0.070 | 0.004 | 0.070 | 0.070 | 0.070 | 0.004 |
| Dataset | Number (8 Rounds) | Lowercase (2 Rounds) | ||||||
|---|---|---|---|---|---|---|---|---|
| Training | Validation | Test | Reliability | Training | Validation | Test | Reliability | |
| I1 | 1.00 | 1.00 | 1.00 | 0.500 | 0.55 | 0.55 | 0.55 | 0.050 |
| I2 | 0.99 | 1.00 | 0.99 | 0.657 | 0.54 | 0.54 | 0.54 | 0.207 |
| I3 | 0.72 | 0.72 | 0.72 | 0.470 | 0.38 | 0.37 | 0.37 | 0.120 |
| I4 | 0.46 | 0.45 | 0.45 | 0.250 | 0.29 | 0.29 | 0.29 | 0.090 |
| I5 | 0.33 | 0.33 | 0.33 | 0.164 | 0.24 | 0.23 | 0.23 | 0.064 |
| I6 | 0.25 | 0.25 | 0.25 | 0.108 | 0.20 | 0.20 | 0.20 | 0.058 |
| I7 | 0.22 | 0.22 | 0.22 | 0.095 | 0.17 | 0.17 | 0.17 | 0.045 |
| I8 | 0.19 | 0.19 | 0.19 | 0.079 | 0.15 | 0.15 | 0.15 | 0.039 |
| I9 | 0.17 | 0.17 | 0.17 | 0.070 | 0.13 | 0.13 | 0.13 | 0.030 |
| I10 | 0.16 | 0.15 | 0.15 | 0.06 | 0.12 | 0.12 | 0.12 | 0.030 |
| I11 | 0.14 | 0.14 | 0.14 | 0.057 | 0.11 | 0.11 | 0.11 | 0.027 |
| I12 | 0.13 | 0.12 | 0.12 | 0.044 | 0.10 | 0.10 | 0.10 | 0.024 |
| I13 | 0.12 | 0.11 | 0.12 | 0.049 | 0.09 | 0.09 | 0.09 | 0.019 |
| I14 | 0.11 | 0.11 | 0.11 | 0.044 | 0.08 | 0.08 | 0.08 | 0.014 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, D.; Kim, H.; Jang, K.; Yoon, S.; Seo, H. Deep-Learning-Based Neural Distinguisher for Format-Preserving Encryption Schemes FF1 and FF3. Electronics 2024, 13, 1196. https://doi.org/10.3390/electronics13071196
Kim D, Kim H, Jang K, Yoon S, Seo H. Deep-Learning-Based Neural Distinguisher for Format-Preserving Encryption Schemes FF1 and FF3. Electronics. 2024; 13(7):1196. https://doi.org/10.3390/electronics13071196
Chicago/Turabian StyleKim, Dukyoung, Hyunji Kim, Kyungbae Jang, Seyoung Yoon, and Hwajeong Seo. 2024. "Deep-Learning-Based Neural Distinguisher for Format-Preserving Encryption Schemes FF1 and FF3" Electronics 13, no. 7: 1196. https://doi.org/10.3390/electronics13071196
APA StyleKim, D., Kim, H., Jang, K., Yoon, S., & Seo, H. (2024). Deep-Learning-Based Neural Distinguisher for Format-Preserving Encryption Schemes FF1 and FF3. Electronics, 13(7), 1196. https://doi.org/10.3390/electronics13071196