MACNet: A More Accurate and Convenient Pest Detection Network


Abstract
1. Introduction
2. Related Work
2.1. YOLO Series Algorithms
2.2. Feature Sampling
2.3. Convolution Operator
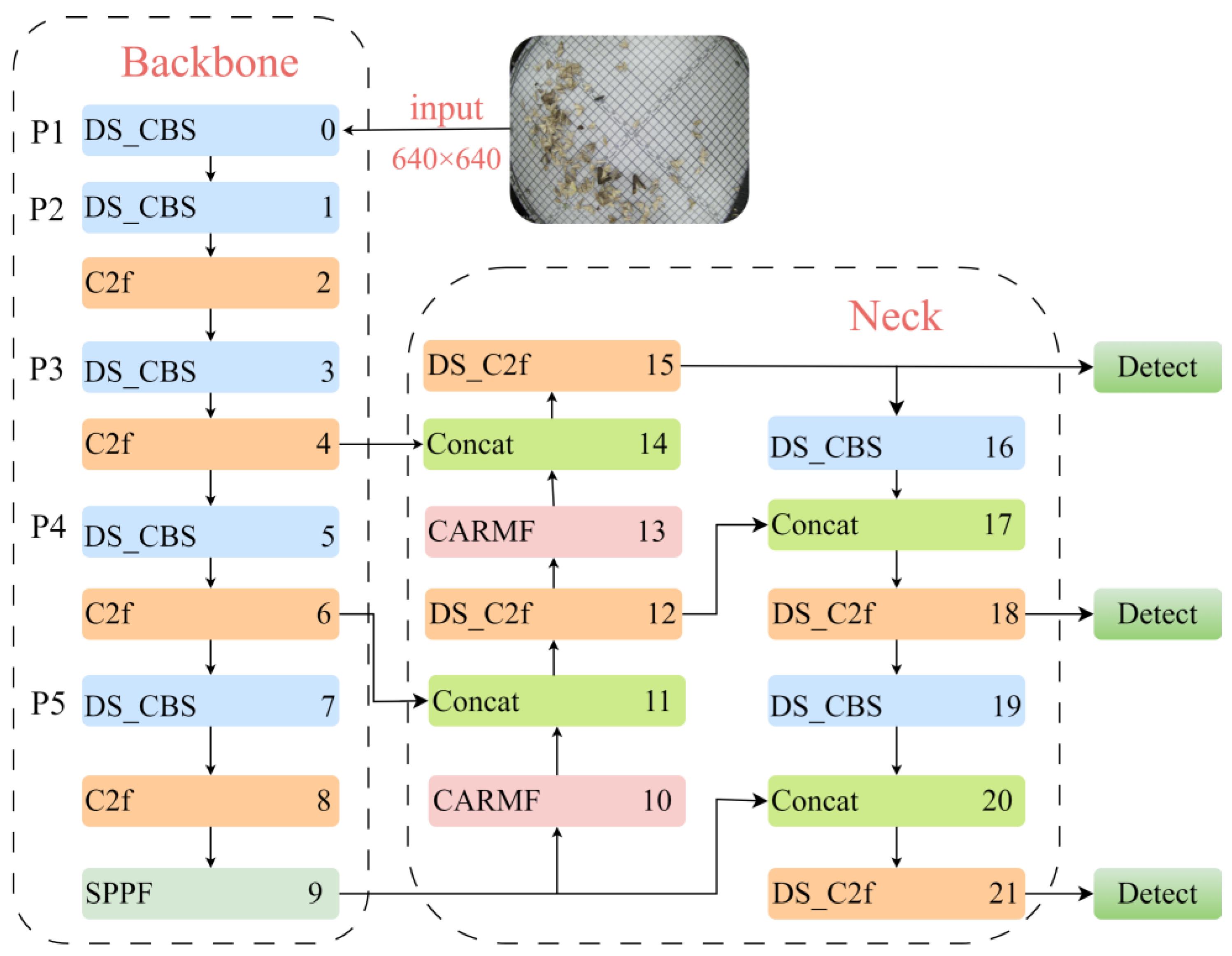
3. Our Approach
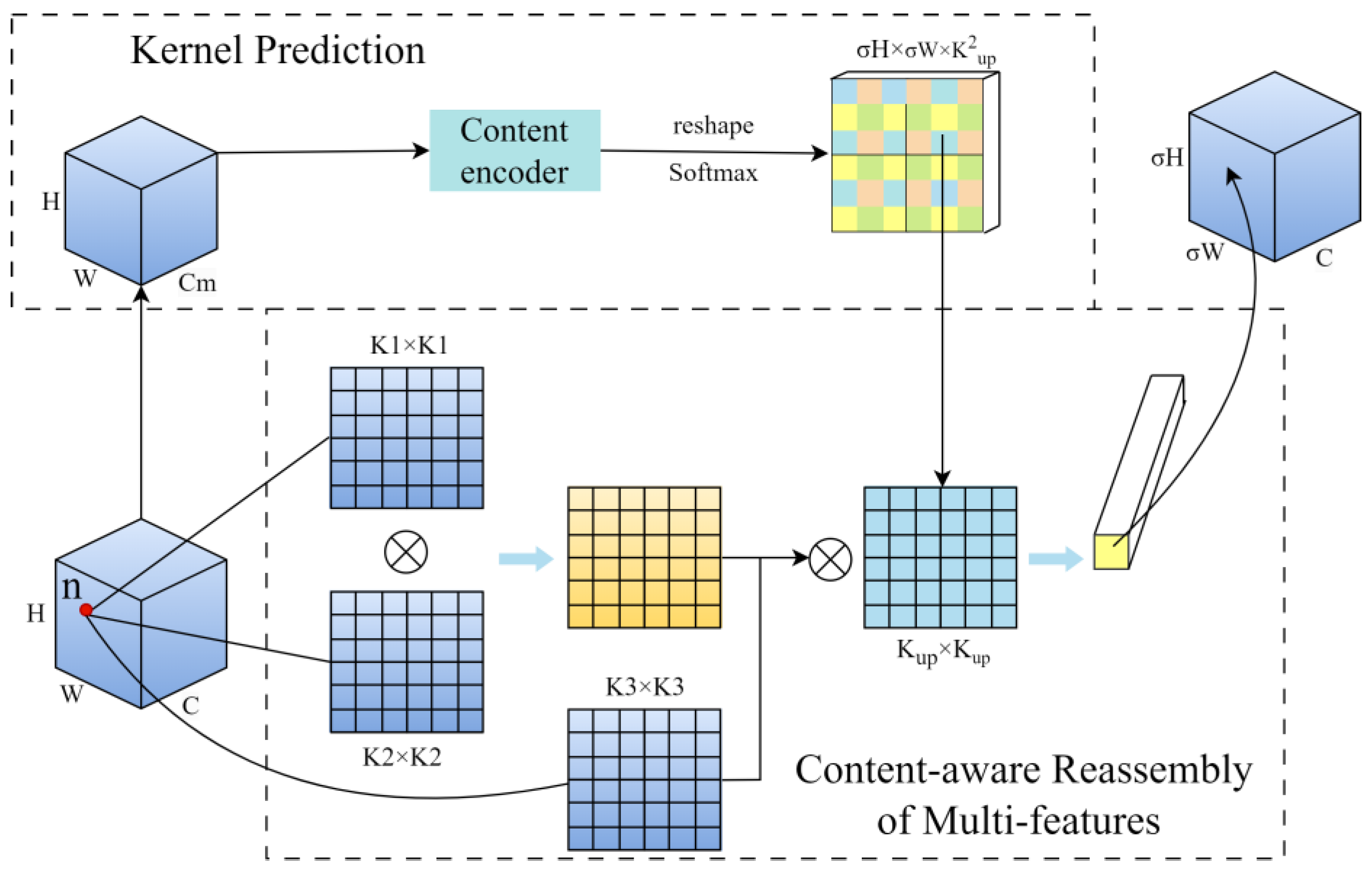
3.1. A More Accurate Upsampling Operator
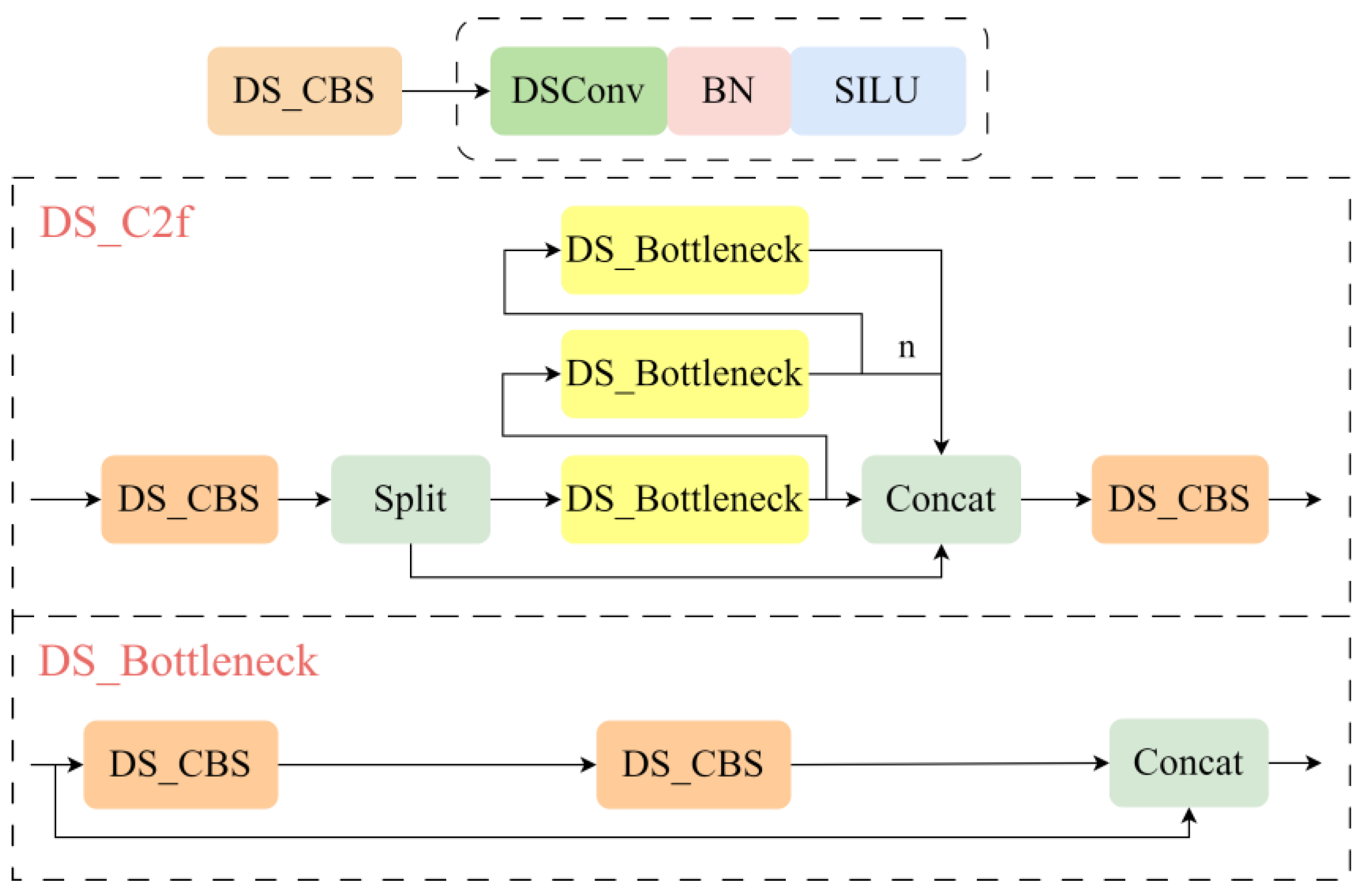
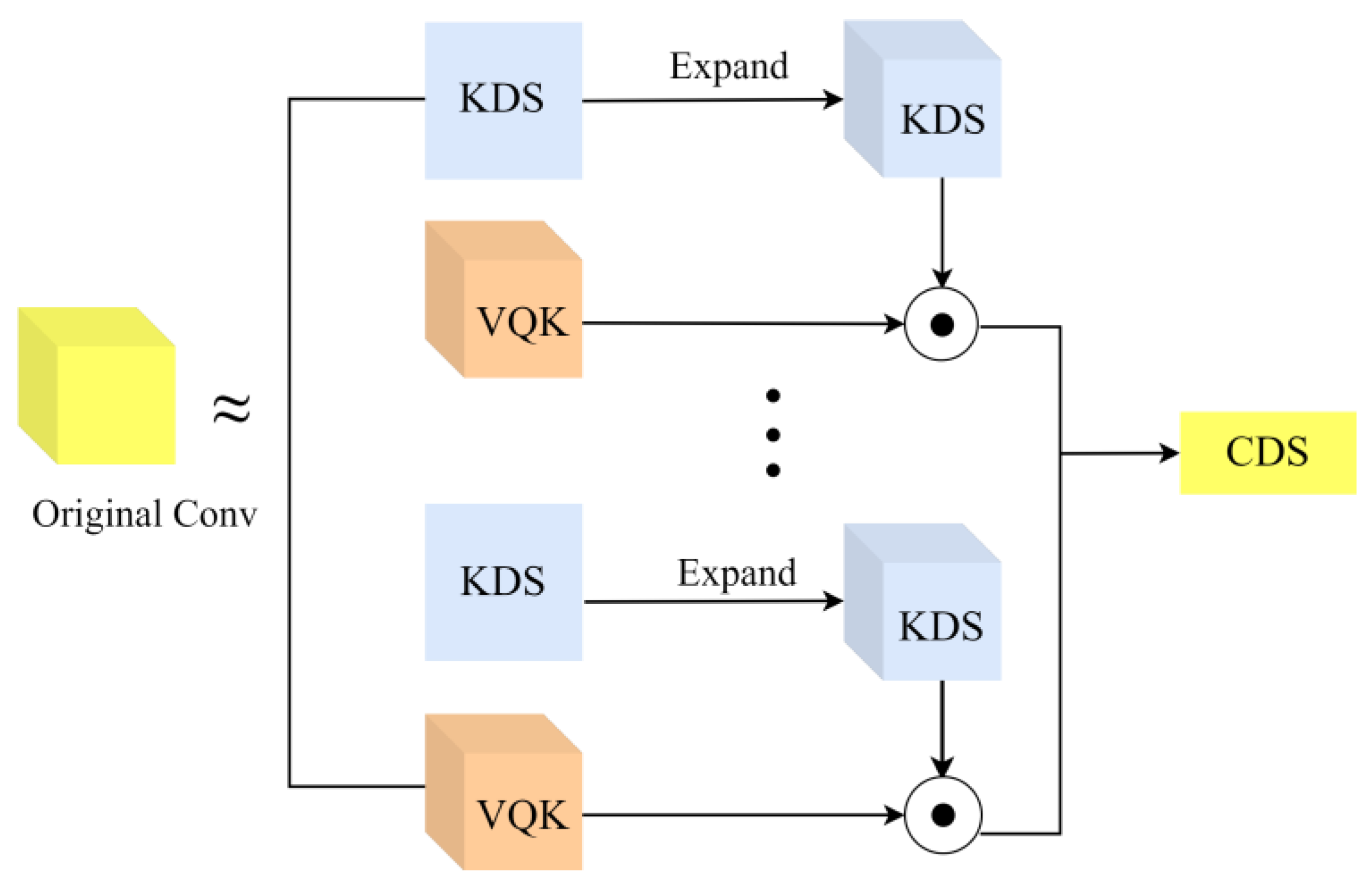
3.2. Faster Convolution
4. Experiment
4.1. Experimental Setting and Evaluation Methods
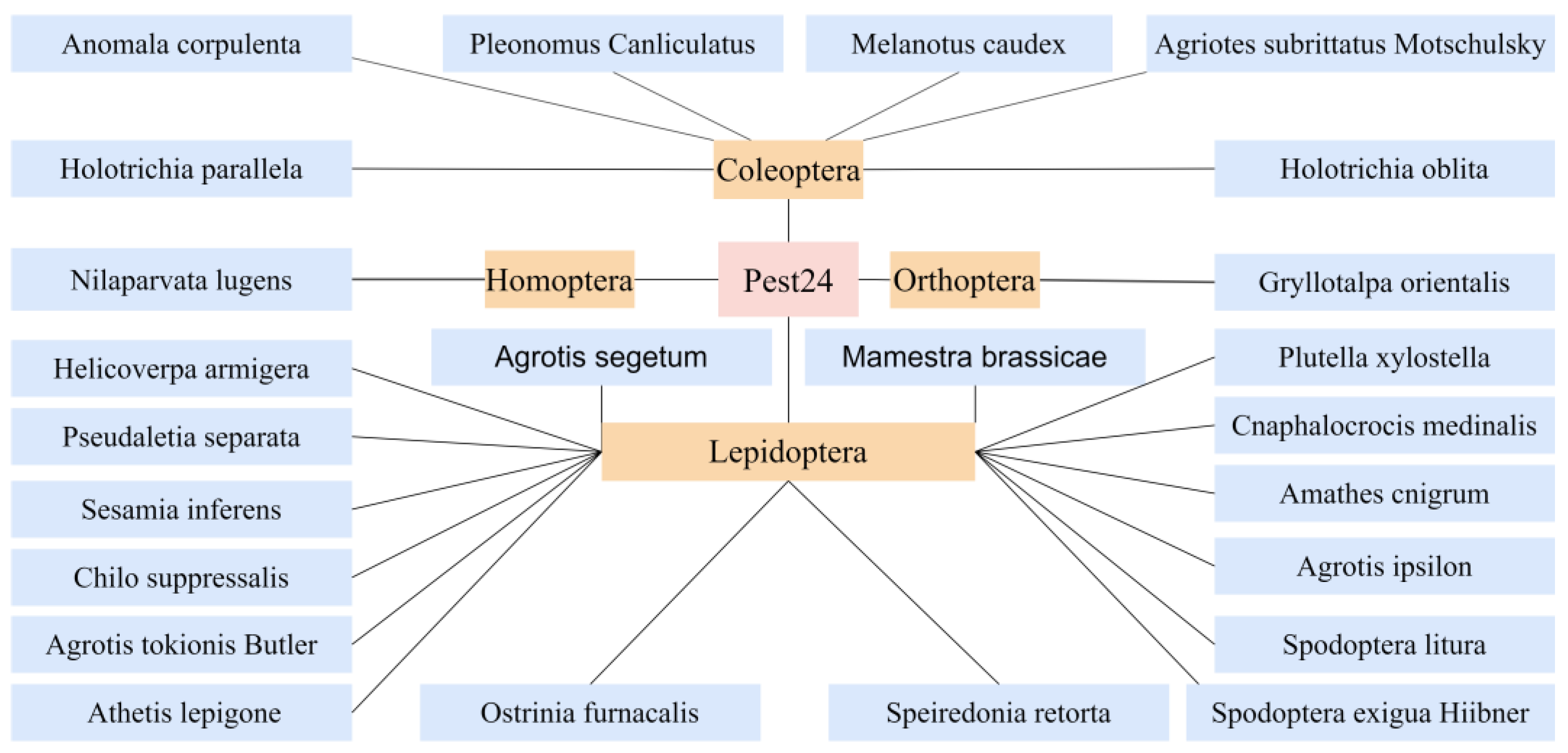
4.2. Pest24 Dataset
4.3. Experimental Results and Analysis
4.3.1. Ablation Experiments
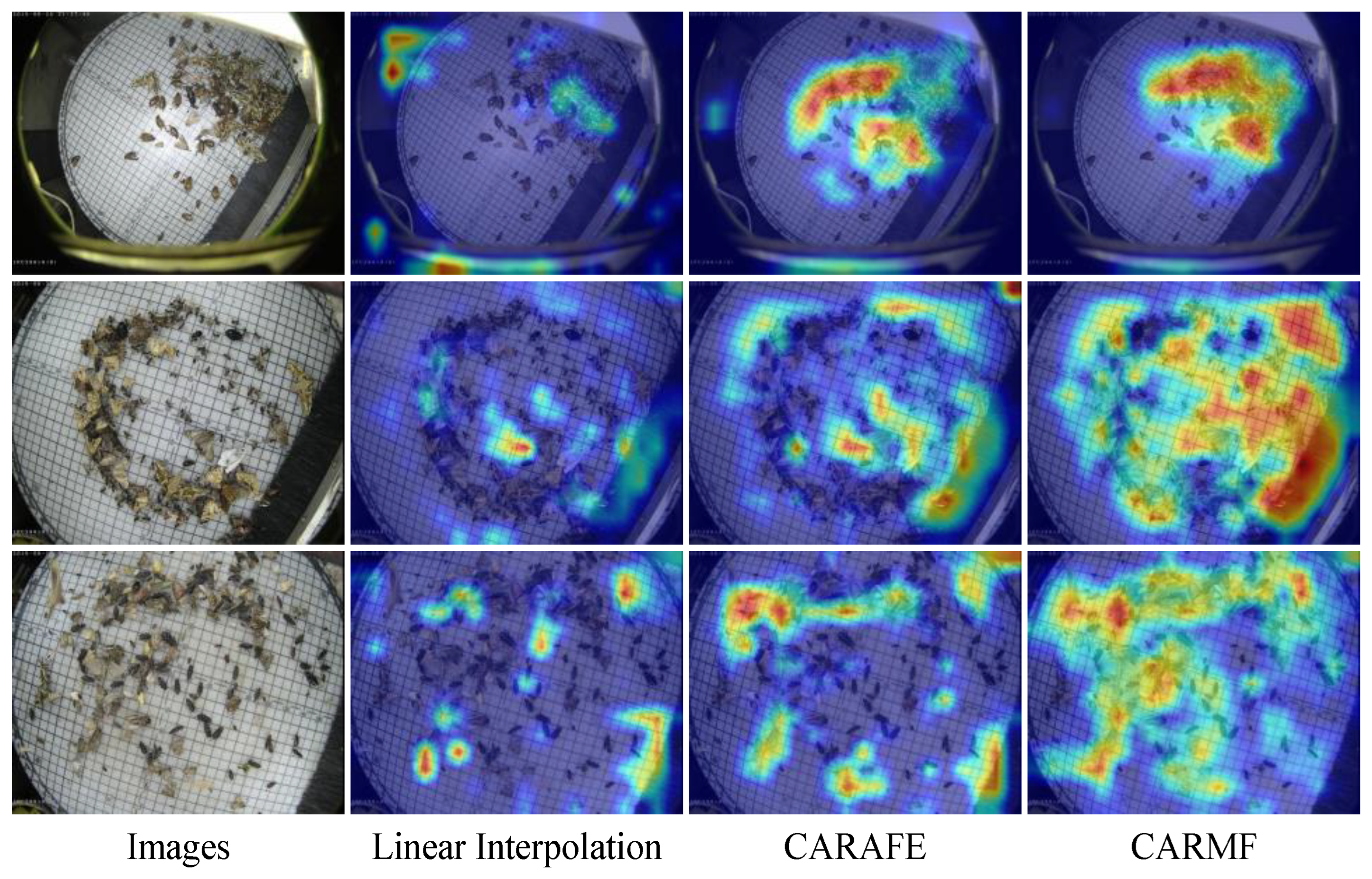
4.3.2. CARMF Module Analysis
4.3.3. Comparison of the CARAFE Method with the CARMF Method
4.3.4. Convolution Comparison Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mateos Fernández, R.; Petek, M.; Gerasymenko, I.; Juteršek, M.; Baebler, Š.; Kallam, K.; Moreno Giménez, E.; Gondolf, J.; Nordmann, A.; Gruden, K.J.P.B.J. Insect pest management in the age of synthetic biology. Plant Biotechnol. J. 2022, 20, 25–36. [Google Scholar] [CrossRef]
- Jiao, L.; Chen, M.; Wang, X.; Du, X.; Dong, D. Monitoring the number and size of pests based on modulated infrared beam sensing technology. Precis. Agric. 2018, 19, 1100–1112. [Google Scholar] [CrossRef]
- Dai, M.; Dorjoy, M.M.H.; Miao, H.; Zhang, S. A New Pest Detection Method Based on Improved YOLOv5m. Insects 2023, 14, 54. [Google Scholar] [CrossRef] [PubMed]
- Deepan, P.; Akila, M. Detection and Classification of Plant Leaf Diseases by using Deep Learning Algorithm. Int. J. Eng. Res. Technol. 2018, 6, 1–5. [Google Scholar]
- Hasan, M.J.; Mahbub, S.; Alom, M.S.; Nasim, M.A. Rice disease identification and classification by integrating support vector machine with deep convolutional neural network. In Proceedings of the 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology (ICASERT), Dhaka, Bangladesh, 3–5 May 2019; pp. 1–6. [Google Scholar]
- Yalcin, H.; Razavi, S. Plant classification using convolutional neural networks. In Proceedings of the 2016 Fifth International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Tianjin, China, 18–20 July 2016; pp. 1–5. [Google Scholar]
- Rong, M.; Wang, Z.; Ban, B.; Guo, X. Pest identification and counting of yellow plate in field based on improved mask r-cnn. Discret. Dyn. Nat. Soc. 2022, 2022, 1–9. [Google Scholar] [CrossRef]
- Wang, Z.; Qiao, L.; Wang, M. Agricultural pest detection algorithm based on improved faster RCNN. In Proceedings of the International Conference on Computer Vision and Pattern Analysis (ICCPA 2021), Guangzhou, China, 19–21 November 2021; pp. 104–109. [Google Scholar]
- Lu, T.; Ji, S.; Jin, W.; Yang, Q.; Luo, Q.; Ren, T.-L. Biocompatible and Long-Term Monitoring Strategies of Wearable, Ingestible and Implantable Biosensors: Reform the Next Generation Healthcare. Sensors 2023, 23, 2991. [Google Scholar] [CrossRef] [PubMed]
- Mirmozaffari, M.; Shadkam, E.; Khalili, S.M.; Yazdani, M. Developing a Novel Integrated Generalised Data Envelopment Analysis (DEA) to Evaluate Hospitals Providing Stroke Care Services. Bioengineering 2021, 8, 207. [Google Scholar] [CrossRef] [PubMed]
- Mirmozaffari, M.; Yazdani, M.; Boskabadi, A.; Ahady Dolatsara, H.; Kabirifar, K.; Amiri Golilarz, N. A Novel Machine Learning Approach Combined with Optimization Models for Eco-efficiency Evaluation. Appl. Sci. 2020, 10, 5210. [Google Scholar] [CrossRef]
- Bui, T.H.; Thangavel, B.; Sharipov, M.; Chen, K.; Shin, J.H. Smartphone-Based Portable Bio-Chemical Sensors: Exploring Recent Advancements. Chemosensors 2023, 11, 468. [Google Scholar] [CrossRef]
- Niranjan, D.; VinayKarthik, B. Deep learning based object detection model for autonomous driving research using carla simulator. In Proceedings of the 2021 2nd International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 7–9 October 2021; pp. 1251–1258. [Google Scholar]
- Han, R.; Liu, X.; Chen, T. Yolo-SG: Salience-Guided Detection of Small Objects in Medical Images. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 4218–4222. [Google Scholar]
- Huang, Q.; Yang, K.; Zhu, Y.; Chen, L.; Cao, L. Knowledge Distillation for Enhancing a Lightweight Magnet Tile Target Detection Model: Leveraging Spatial Attention and Multi-Scale Output Features. Electronics 2023, 12, 4589. [Google Scholar] [CrossRef]
- Benjumea, A.; Teeti, I.; Cuzzolin, F.; Bradley, A. YOLO-Z: Improving small object detection in YOLOv5 for autonomous vehicles. arXiv 2021, arXiv:2112.11798. [Google Scholar]
- Pacal, I.; Karaman, A.; Karaboga, D.; Akay, B.; Basturk, A.; Nalbantoglu, U.; Coskun, S. An efficient real-time colonic polyp detection with YOLO algorithms trained by using negative samples and large datasets. Comput. Biol. Med. 2022, 141, 105031. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Xu, B.; Wu, D.; Zhao, K.; Chen, S.; Lu, M.; Cong, J. A YOLO-GGCNN based grasping framework for mobile robots in unknown environments. Expert Syst. Appl. 2023, 225, 119993. [Google Scholar] [CrossRef]
- Cheng, Z.; Huang, R.; Qian, R.; Dong, W.; Zhu, J.; Liu, M. A lightweight crop pest detection method based on convolutional neural networks. Appl. Sci. 2022, 12, 7378. [Google Scholar] [CrossRef]
- Chu, J.; Li, Y.; Feng, H.; Weng, X.; Ruan, Y. Research on Multi-Scale Pest Detection and Identification Method in Granary Based on Improved YOLOv5. Agriculture 2023, 13, 364. [Google Scholar] [CrossRef]
- Tian, Y.; Wang, S.; Li, E.; Yang, G.; Liang, Z.; Tan, M.J.C.E.A. MD-YOLO: Multi-scale Dense YOLO for small target pest detection. Comput. Electron. Agric. 2023, 213, 108233. [Google Scholar] [CrossRef]
- Akhtar, S.; Hanif, M.; Malih, H. Automatic Urine Sediment Detection and Classification Based on YoloV8. In Proceedings of the International Conference on Computational Science and Its Applications, Athens, Greece, 3–6 July 2023; pp. 269–279. [Google Scholar]
- Wei, Z.; Chang, M.; Zhong, Y. Fruit Freshness Detection Based on YOLOv8 and SE attention Mechanism. Acad. J. Sci. Technol. 2023, 6, 195–197. [Google Scholar] [CrossRef]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A Small-Object-Detection Model Based on Improved YOLOv8 for UAV Aerial Photography Scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef] [PubMed]
- Lou, H.; Duan, X.; Guo, J.; Liu, H.; Gu, J.; Bi, L.; Chen, H. DC-YOLOv8: Small-Size Object Detection Algorithm Based on Camera Sensor. Electronics 2023, 12, 2323. [Google Scholar] [CrossRef]
- Li, Y.; Fan, Q.; Huang, H.; Han, Z.; Gu, Q. A Modified YOLOv8 Detection Network for UAV Aerial Image Recognition. Drones 2023, 7, 304. [Google Scholar] [CrossRef]
- Li, P.; Zheng, J.; Li, P.; Long, H.; Li, M.; Gao, L. Tomato Maturity Detection and Counting Model Based on MHSA-YOLOv8. Sensors 2023, 23, 6701. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VIII 14. pp. 483–499. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Tian, Z.; He, T.; Shen, C.; Yan, Y. Decoders matter for semantic segmentation: Data-dependent decoding enables flexible feature aggregation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 3126–3135. [Google Scholar]
- Hu, X.; Mu, H.; Zhang, X.; Wang, Z.; Tan, T.; Sun, J. Meta-SR: A magnification-arbitrary network for super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 1575–1584. [Google Scholar]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. Carafe: Content-aware reassembly of features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3007–3016. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic convolution: Attention over convolution kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11030–11039. [Google Scholar]
- Nascimento, M.G.d.; Fawcett, R.; Prisacariu, V.A. Dsconv: Efficient convolution operator. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5148–5157. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C. Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 14454–14463. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, Q.-J.; Zhang, S.-Y.; Dong, S.-F.; Zhang, G.-C.; Yang, J.; Li, R.; Wang, H.-Q. Pest24: A large-scale very small object data set of agricultural pests for multi-target detection. Comput. Electron. Agric. 2020, 175, 105585. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. pp. 740–755. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | #Params | GFLOPs | ||||||
|---|---|---|---|---|---|---|---|---|
| YOLOv8s | 11.1 M | 28.7 | 42.6 | 70.9 | 46.8 | 28.5 | 47.8 | 30.7 |
| +DSConv | 10.3 M | 20.0 | 42.6 | 70.6 | 47.4 | 29.3 | 47.9 | 31.6 |
| +CARMF | 11.3 M | 29.0 | 43.2 | 71.2 | 48.1 | 29.3 | 48.3 | 32.5 |
| MACNet | 10.5 M | 20.3 | 43.1 | 71.0 | 48.1 | 29.3 | 48.0 | 32.1 |
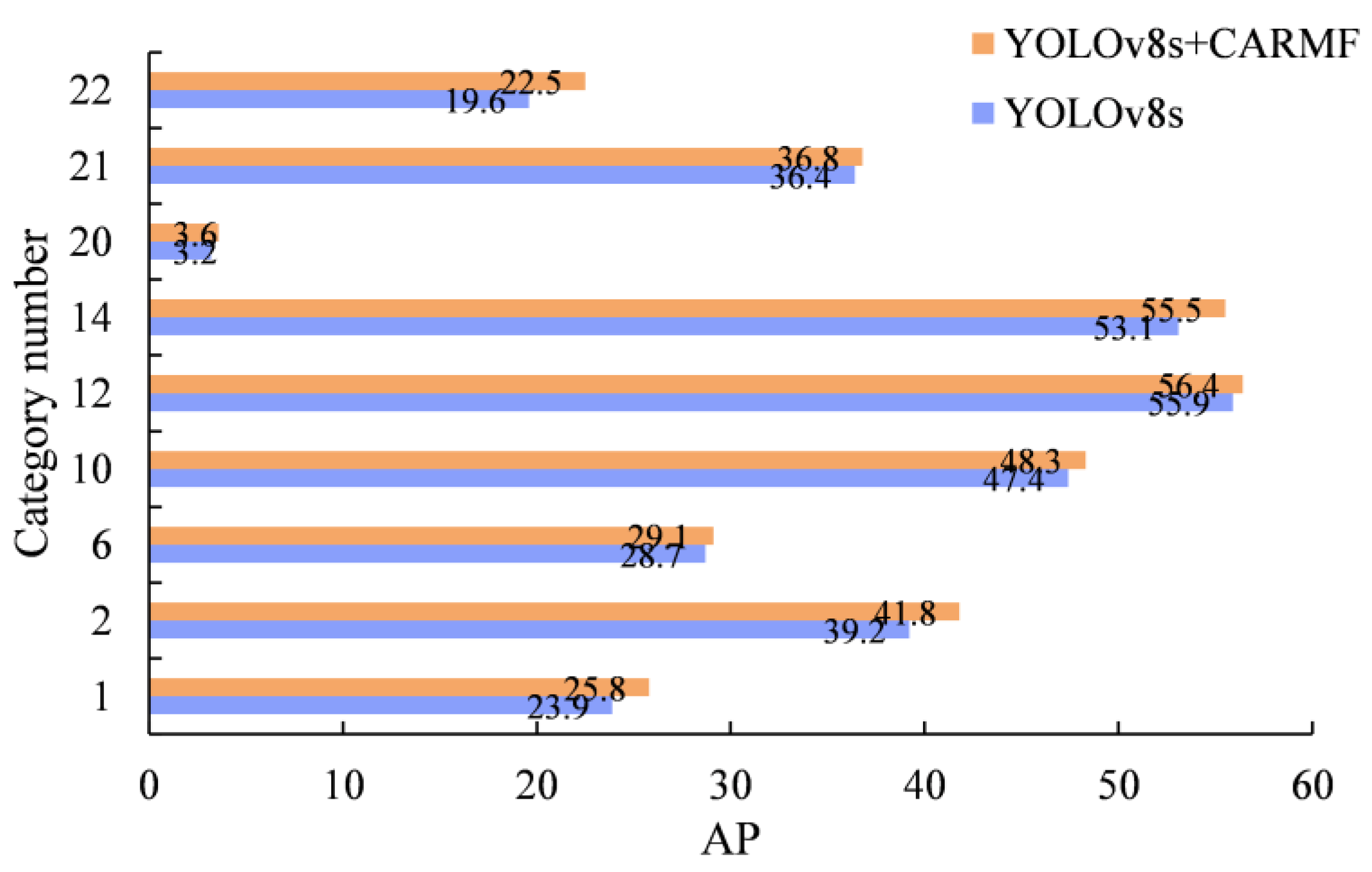
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 23.9 | 39.2 | 55.1 | 43.5 | 53.4 | 28.7 | 1.7 | 64.1 | 60.1 | 47.4 | 58.7 | 55.9 |
| 25.8 | 41.8 | 55.0 | 43.9 | 53.5 | 29.1 | 1.5 | 64.6 | 60.4 | 48.3 | 59.0 | 56.4 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 39.7 | 53.1 | 41.2 | 51.5 | 45.4 | 64.0 | 47.3 | 3.2 | 36.4 | 19.6 | 33.7 | 54.8 |
| 38.6 | 55.5 | 41.5 | 51.9 | 46.6 | 63.6 | 48.7 | 3.6 | 36.8 | 22.5 | 34.6 | 54.0 |
| Method | ] | #Params | GFLOPs | ||||||
|---|---|---|---|---|---|---|---|---|---|
| CARAFE | [3, 3] | 11.2 M | 28.9 | 42.8 | 70.6 | 47.6 | 28.5 | 47.8 | 32.1 |
| [3, 5] | 11.3 M | 29.0 | 42.8 | 70.6 | 47.6 | 28.5 | 47.8 | 32.1 | |
| [3, 7] | 11.4 M | 29.2 | 42.7 | 70.6 | 47.0 | 28.1 | 47.5 | 34.1 | |
| CARMF | [3, 3] | 11.2 M | 28.9 | 42.7 | 70.2 | 47.4 | 28.8 | 48.1 | 33.4 |
| [3, 5] | 11.3 M | 29.0 | 43.2 | 71.2 | 48.1 | 29.3 | 48.3 | 32.5 | |
| [3, 7] | 11.4 M | 29.2 | 42.6 | 70.1 | 47.4 | 28.6 | 47.7 | 33.4 |
| Method | #Params | GFLOPs | ||||||
|---|---|---|---|---|---|---|---|---|
| B1 + B2 | 10.4 M | 19.9 | 41.7 | 69.3 | 46.0 | 27.3 | 46.9 | 30.0 |
| N1 + N2 | 10.3 M | 24.0 | 42.3 | 69.8 | 46.8 | 29.0 | 47.1 | 30.7 |
| B1 + N1 | 11.1 M | 23.8 | 42.4 | 70.0 | 47.0 | 28.0 | 47.7 | 31.6 |
| B2 + N2 | 9.6 M | 15.2 | 41.8 | 69.3 | 46.2 | 27.5 | 47.0 | 29.1 |
| B1 + N1 + N2 | 10.3 M | 20.0 | 42.6 | 70.6 | 47.4 | 29.3 | 47.9 | 31.6 |
| B1 + B2 + N1 | 10.4 M | 19.0 | 41.6 | 69.2 | 45.7 | 27.0 | 46.9 | 32.5 |
| B1 + B2 + N1 + N2 | 9.6 M | 15.2 | 41.5 | 68.7 | 46.2 | 27.8 | 46.7 | 33.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Y.; Wang, Q.; Wang, C.; Qian, Y.; Xue, Y.; Wang, H. MACNet: A More Accurate and Convenient Pest Detection Network. Electronics 2024, 13, 1068. https://doi.org/10.3390/electronics13061068
Hu Y, Wang Q, Wang C, Qian Y, Xue Y, Wang H. MACNet: A More Accurate and Convenient Pest Detection Network. Electronics. 2024; 13(6):1068. https://doi.org/10.3390/electronics13061068
Chicago/Turabian StyleHu, Yating, Qijin Wang, Chao Wang, Yu Qian, Ying Xue, and Hongqiang Wang. 2024. "MACNet: A More Accurate and Convenient Pest Detection Network" Electronics 13, no. 6: 1068. https://doi.org/10.3390/electronics13061068
APA StyleHu, Y., Wang, Q., Wang, C., Qian, Y., Xue, Y., & Wang, H. (2024). MACNet: A More Accurate and Convenient Pest Detection Network. Electronics, 13(6), 1068. https://doi.org/10.3390/electronics13061068