
Prediction Enhancement of Metasurface Absorber Design Using Adaptive Cascaded Deep Learning (ACDL) Model


Abstract
1. Introduction
- Optimal dataset size determination: We thoroughly investigated the requisite dataset size to attain a high level of accepted accuracy in deep neural network (DNN) models for metasurface design. Our numerical experiments reveal that a dataset comprising 4000 samples is adequate to establish a robust DNN model for the rapid design and synthesis of metasurface absorbers with an accuracy greater than 90%.
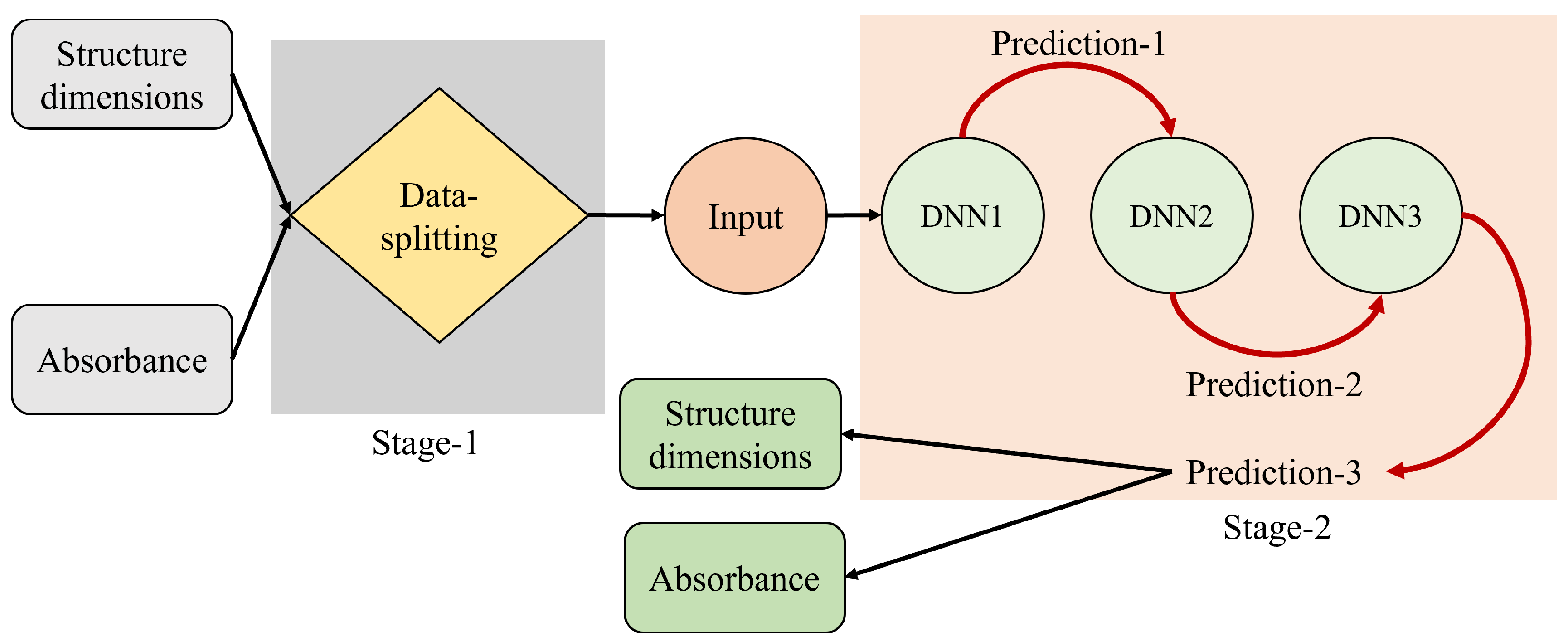
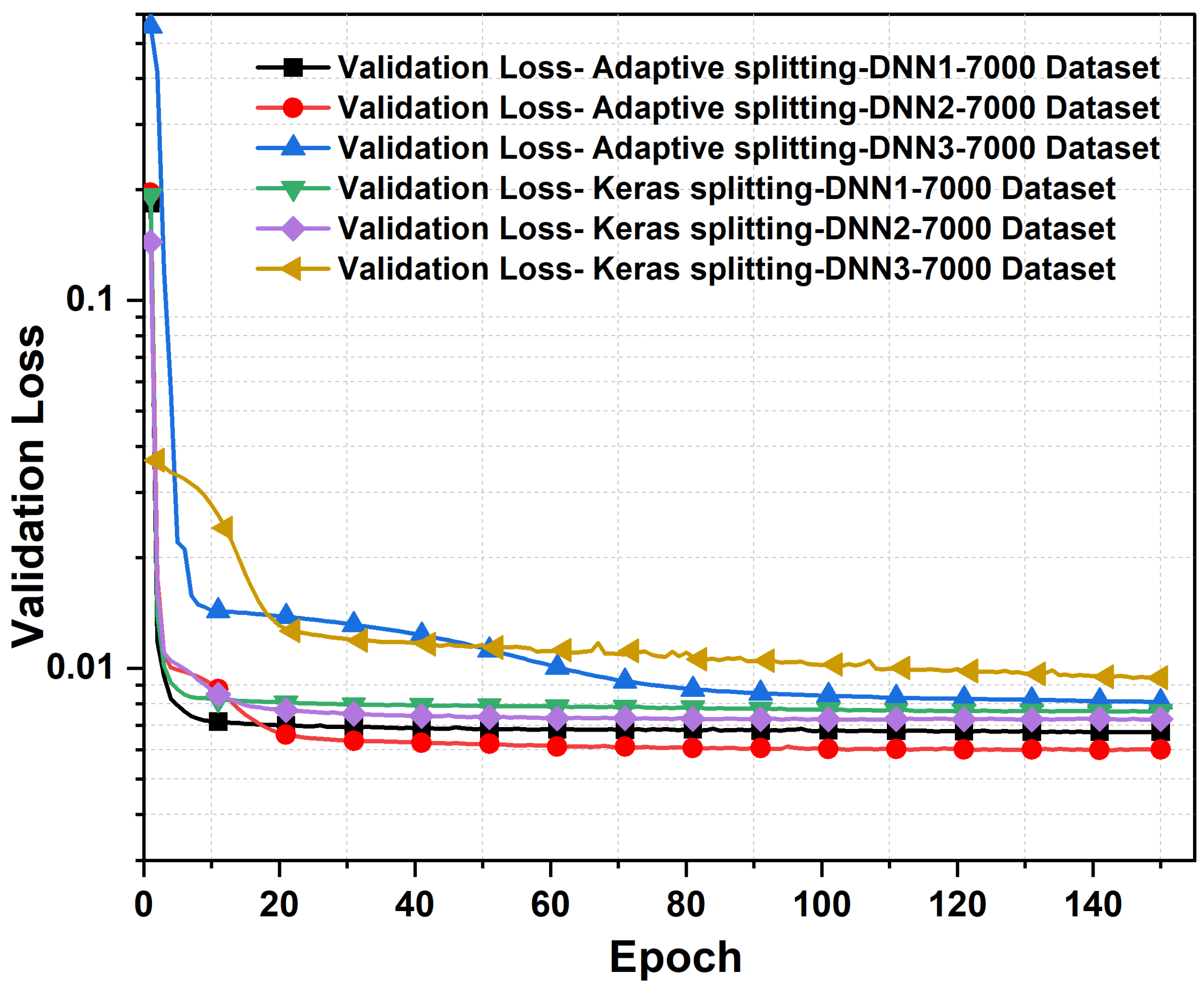
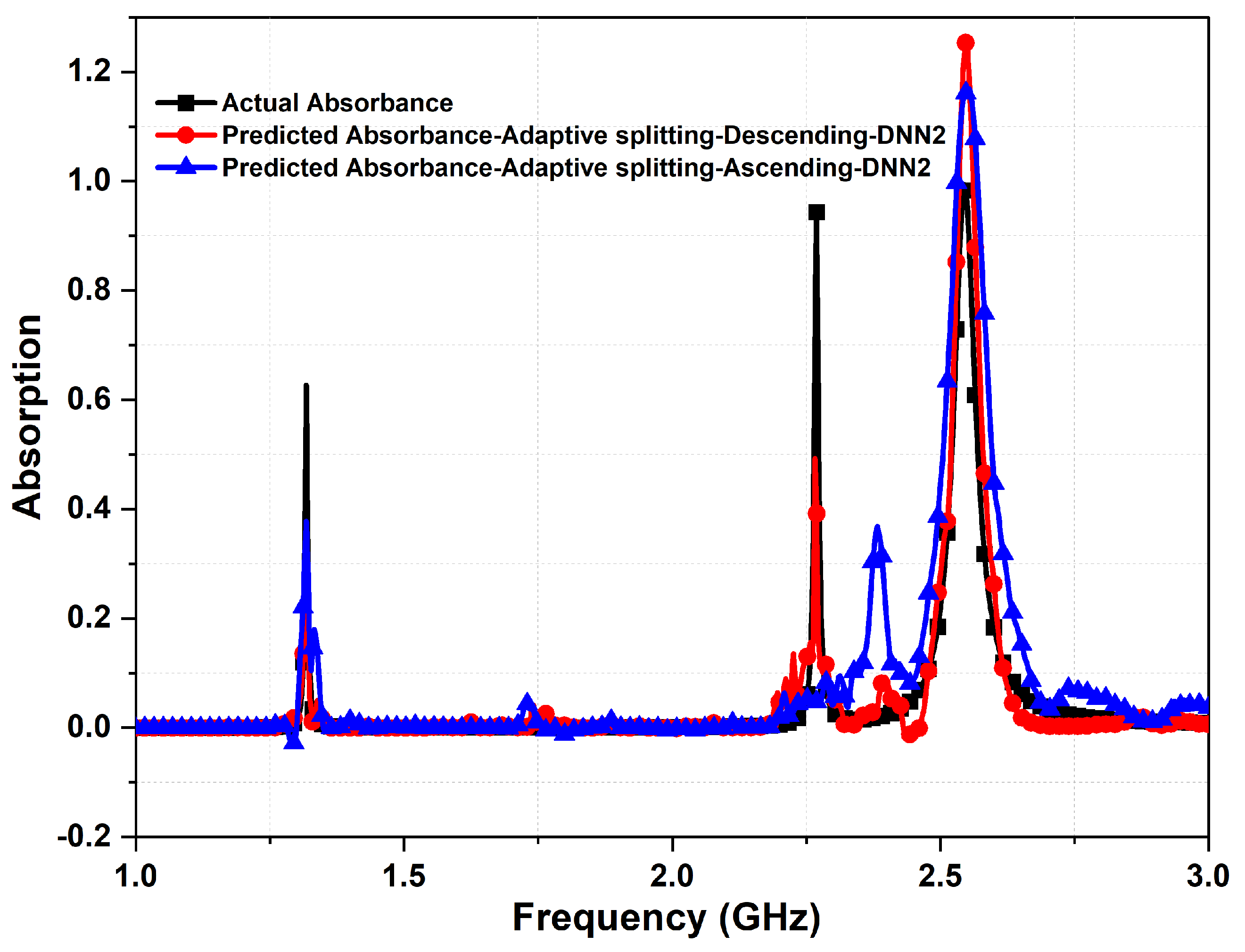
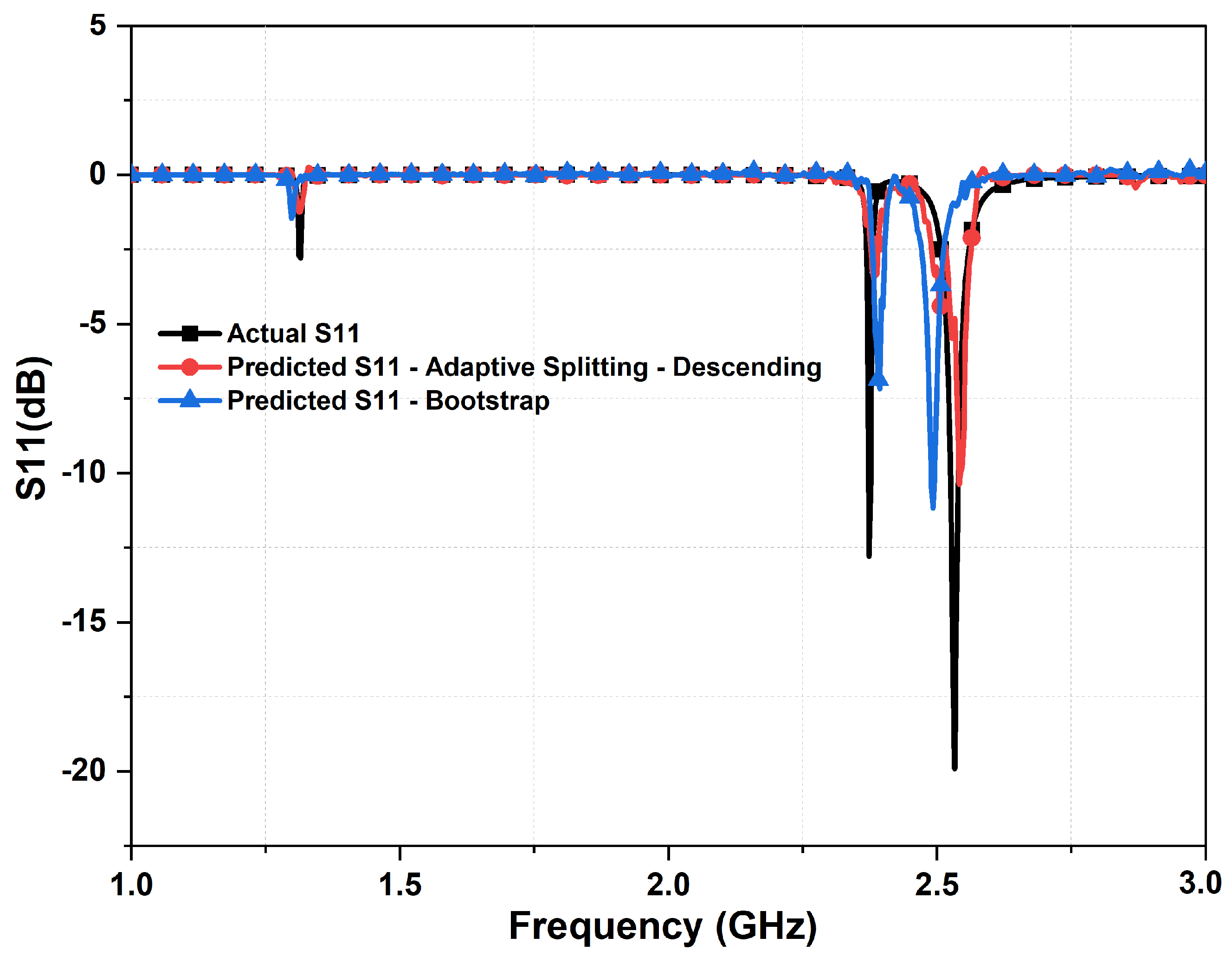
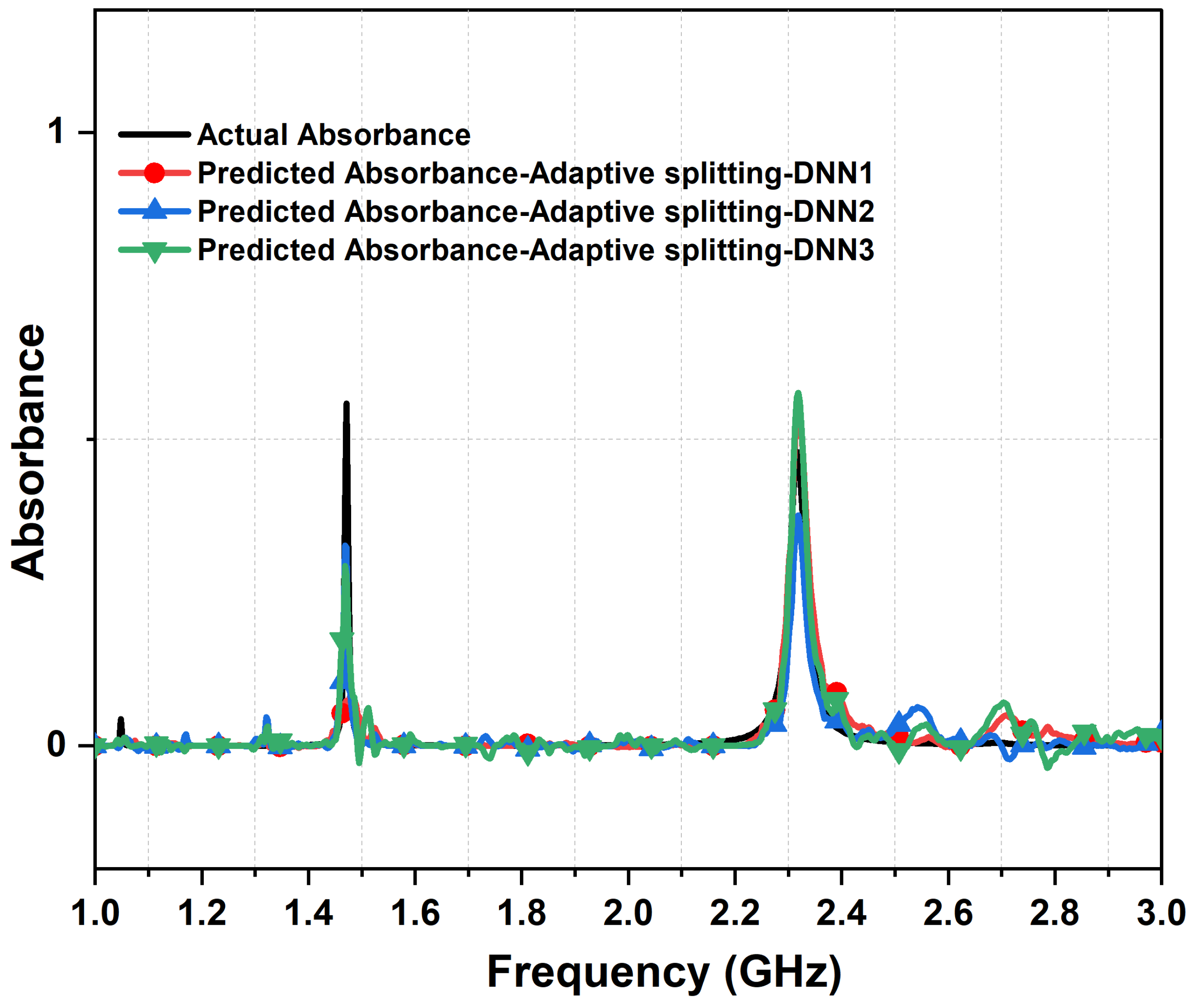
- Sparse data handling with cascaded DNN: We addressed the challenge of handling datasets that are characterized by a high prevalence of sparse data. In addition, we examined the effectiveness of cascaded DNN models in refining prediction values. Our findings indicate that, while cascaded DNNs are effective, careful hyperparameter tuning of the optimizer is essential to mitigate numerical instability. Furthermore, we determined that a two-layer cascaded neural network is sufficient to achieve the desired accuracy in the design of multi-resonant metasurface absorbers. The impacts of two other data sorting and selection techniques, namely the ascending data sorting method and the bootstrap method, were also investigated and compared with the proposed adaptive descending data sorting method.
- Dataset arrangement impact analysis: We conducted a systematic investigation that addressed the impact of different set arrangements on prediction accuracy, which to the best of our knowledge has not been thoroughly explored. Our study demonstrates that there is relatively limited influence on prediction accuracy when datasets are randomly organized or arranged using an alternative method, which we refer to here as the adaptive cascaded DL (ACDL) model. This approach involves aggregating response values for specific cases and subsequently arranging them in descending order, contributing to our understanding of dataset arrangement strategies for metasurface design through AI.
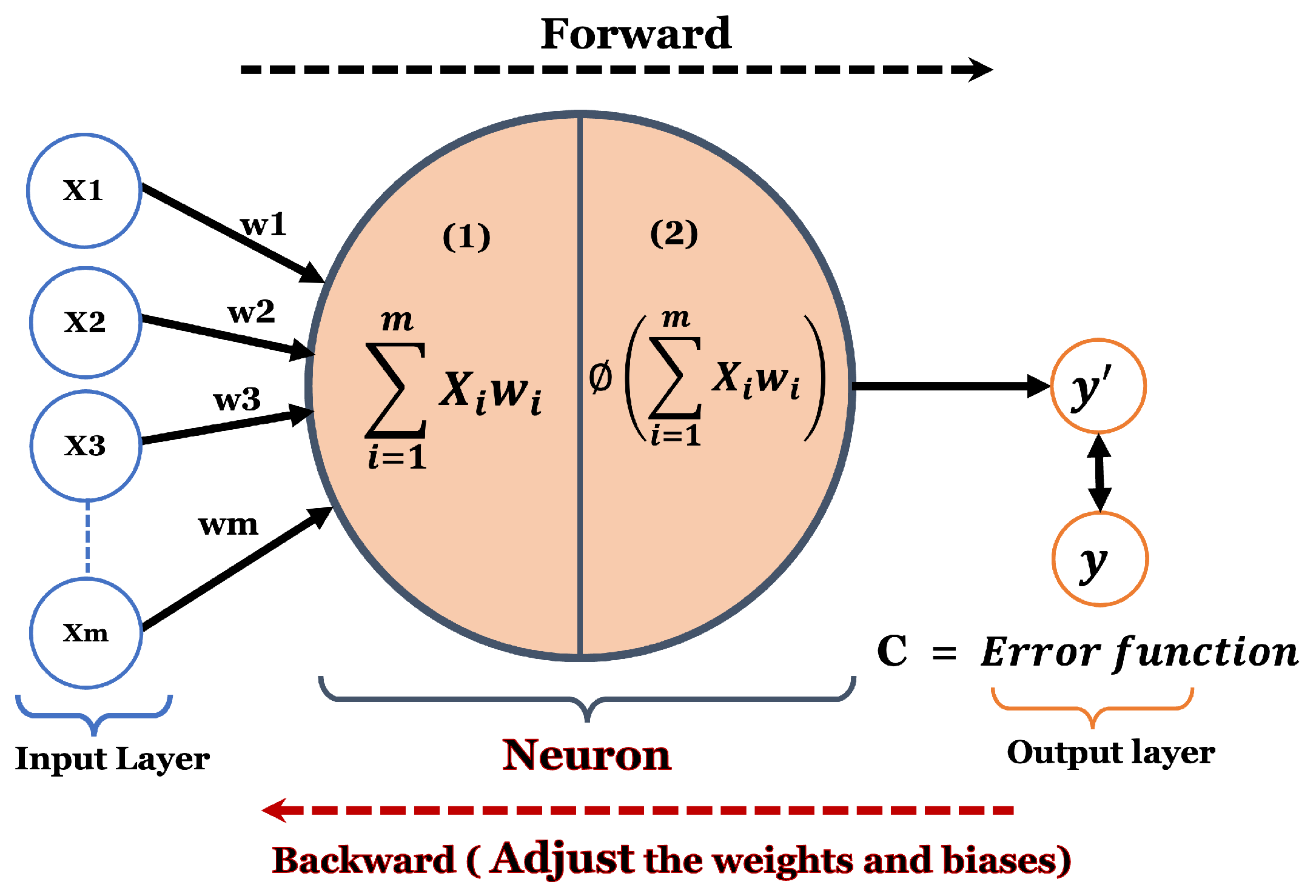
2. Proposed Customized DL Model Methodology
2.1. Model Processing Environment
2.2. Proposed ACDL Model Setting and Training
3. Metasurface Absorber Structure Model
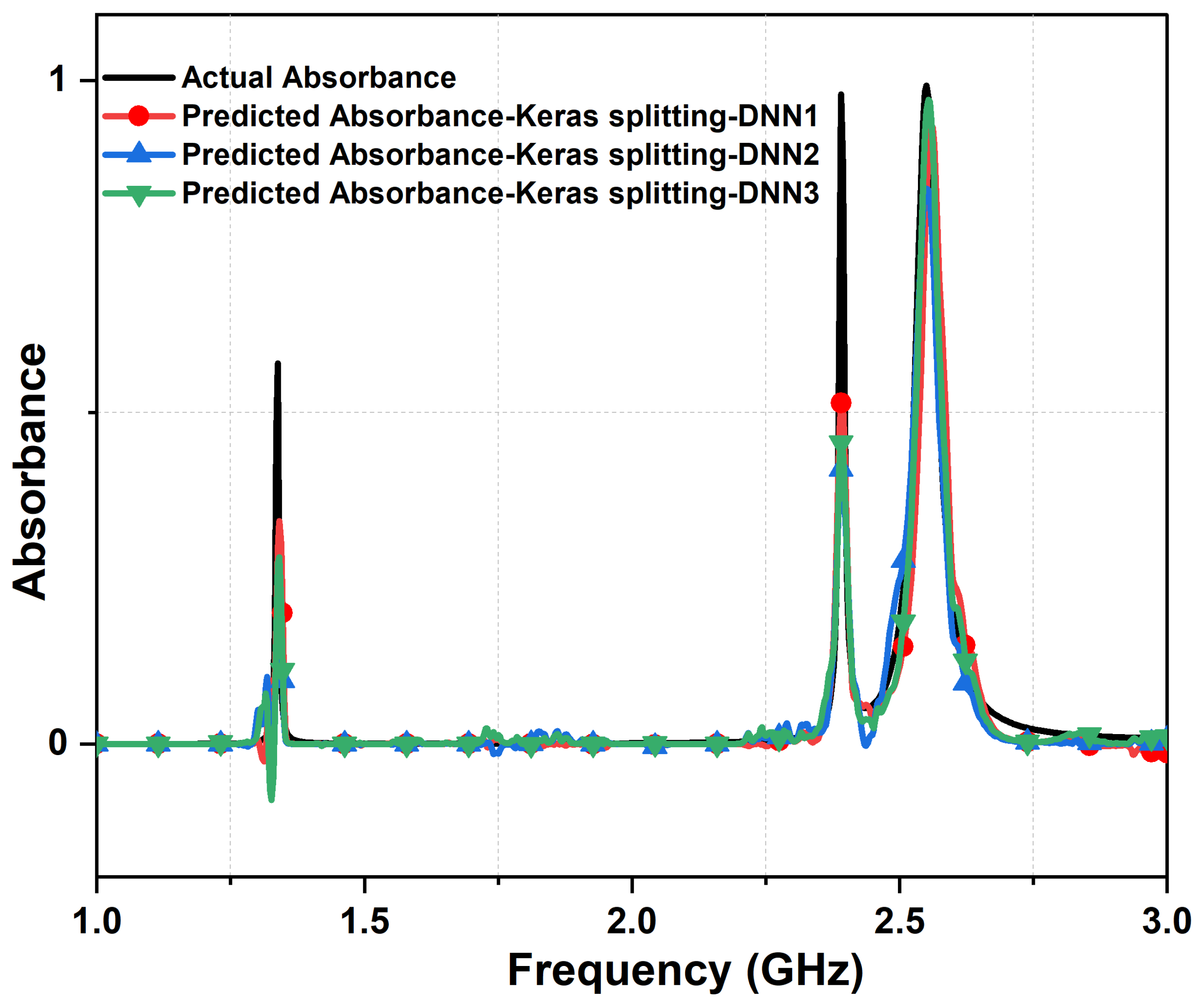
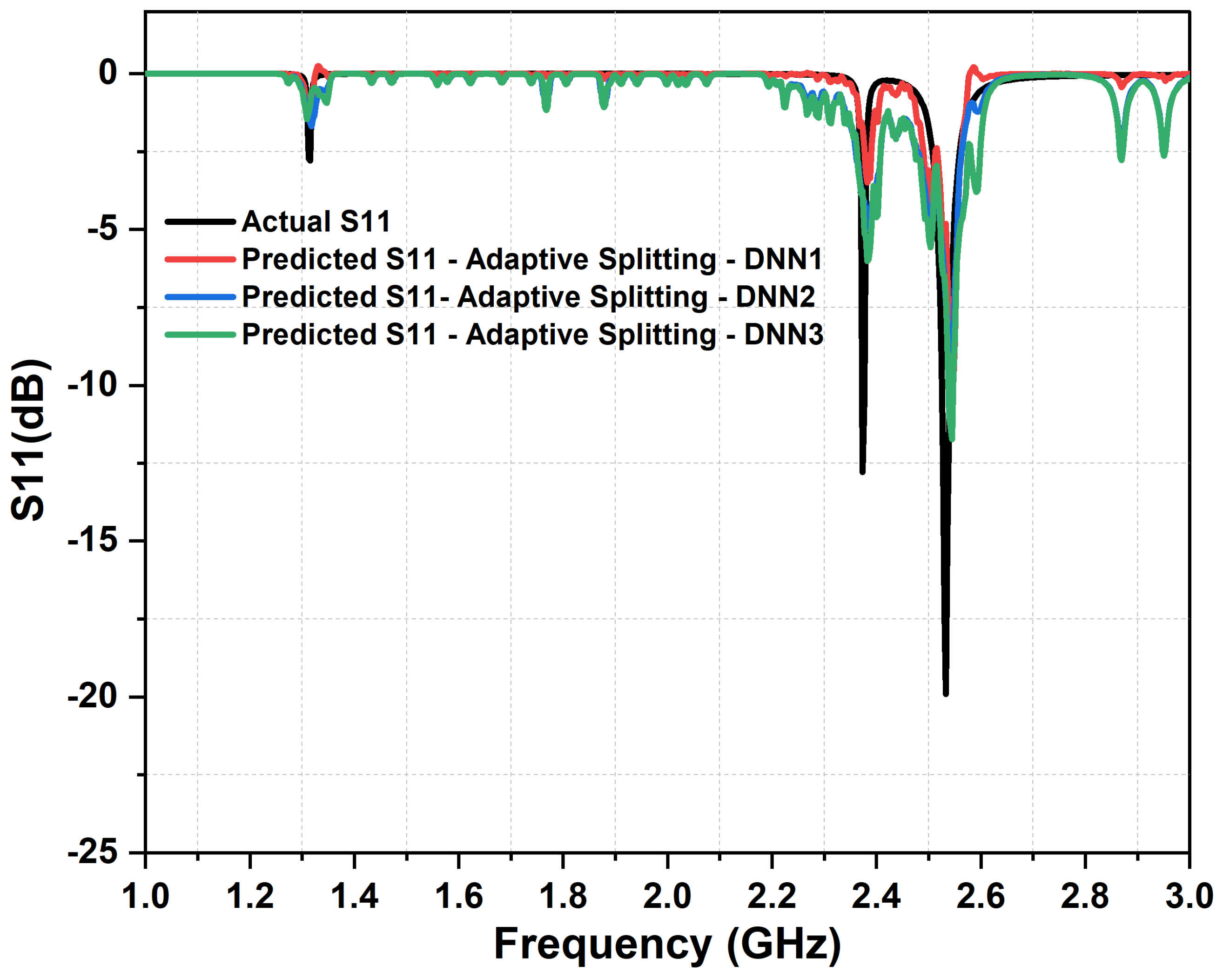
4. Results and Discussions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tan, T.; Yan, Z.; Zou, H.; Ma, K.; Liu, F.; Zhao, L.; Peng, Z.; Zhang, W. Renewable energy harvesting and absorbing via multi-scale metamaterial systems for Internet of things. Appl. Energy 2019, 254, 113717. [Google Scholar] [CrossRef]
- Sabban, A. Wearable circular polarized antennas for health care, 5G, energy harvesting, and IoT systems. Electronics 2022, 11, 427. [Google Scholar] [CrossRef]
- Kjellby, R.A.; Cenkeramaddi, L.R.; Frøytlog, A.; Lozano, B.B.; Soumya, J.; Bhange, M. Long-range & self-powered IoT devices for agriculture & aquaponics based on multi-hop topology. In Proceedings of the 2019 IEEE 5th World Forum on Internet of Things (WF-IoT), Limerick, Ireland, 15–18 April 2019; pp. 545–549. [Google Scholar]
- Ma, W.; Cheng, F.; Liu, Y. Deep-learning-enabled on-demand design of chiral metamaterials. ACS Nano 2018, 12, 6326–6334. [Google Scholar] [CrossRef]
- Malkiel, I.; Mrejen, M.; Nagler, A.; Arieli, U.; Wolf, L.; Suchowski, H. Plasmonic nanostructure design and characterization via deep learning. Light Sci. Appl. 2018, 7, 60. [Google Scholar] [CrossRef] [PubMed]
- Nadell, C.C.; Huang, B.; Malof, J.M.; Padilla, W.J. Deep learning for accelerated all-dielectric metasurface design. Opt. Express 2019, 27, 27523–27535. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J.; Sell, D.; Hoyer, S.; Hickey, J.; Yang, J.; Fan, J.A. Free-form diffractive metagrating design based on generative adversarial networks. ACS Nano 2019, 13, 8872–8878. [Google Scholar] [CrossRef]
- An, S.; Fowler, C.; Zheng, B.; Shalaginov, M.Y.; Tang, H.; Li, H.; Zhou, L.; Ding, J.; Agarwal, A.M.; Rivero-Baleine, C.; et al. A deep learning approach for objective-driven all-dielectric metasurface design. ACS Photonics 2019, 6, 3196–3207. [Google Scholar] [CrossRef]
- Shalaginov, M.Y.; Campbell, S.D.; An, S.; Zhang, Y.; Ríos, C.; Whiting, E.B.; Wu, Y.; Kang, L.; Zheng, B.; Fowler, C.; et al. Design for quality: Reconfigurable flat optics based on active metasurfaces. Nanophotonics 2020, 9, 3505–3534. [Google Scholar] [CrossRef]
- An, S.; Zheng, B.; Tang, H.; Shalaginov, M.Y.; Zhou, L.; Li, H.; Kang, M.; Richardson, K.A.; Gu, T.; Hu, J.; et al. Multifunctional metasurface design with a generative adversarial network. Adv. Opt. Mater. 2021, 9, 2001433. [Google Scholar] [CrossRef]
- Fang, Z.; Zhan, J. Deep physical informed neural networks for metamaterial design. IEEE Access 2019, 8, 24506–24513. [Google Scholar] [CrossRef]
- Zhelyeznyakov, M.V.; Brunton, S.; Majumdar, A. Deep learning to accelerate scatterer-to-field mapping for inverse design of dielectric metasurfaces. ACS Photonics 2021, 8, 481–488. [Google Scholar] [CrossRef]
- Tanriover, I.; Hadibrata, W.; Aydin, K. Physics-based approach for a neural networks enabled design of all-dielectric metasurfaces. ACS Photonics 2020, 7, 1957–1964. [Google Scholar] [CrossRef]
- Ma, W.; Liu, Z.; Kudyshev, Z.A.; Boltasseva, A.; Cai, W.; Liu, Y. Deep learning for the design of photonic structures. Nat. Photonics 2021, 15, 77–90. [Google Scholar] [CrossRef]
- Sajedian, I.; Kim, J.; Rho, J. Finding the optical properties of plasmonic structures by image processing using a combination of convolutional neural networks and recurrent neural networks. Microsyst. Nanoeng. 2019, 5, 27. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, C.; Wan, X.; Zhang, L.; Liu, S.; Yang, Y.; Cui, T.J. Machine-learning designs of anisotropic digital coding metasurfaces. Adv. Theory Simul. 2019, 2, 1800132. [Google Scholar] [CrossRef]
- Ding, W.; Chen, J.; Li, X.M.; Xi, X.; Ye, K.P.; Wu, H.B.; Fan, D.G.; Wu, R.X. Deep learning assisted heat-resistant metamaterial absorber design. In Proceedings of the 2021 International Conference on Microwave and Millimeter Wave Technology (ICMMT), Nanjing, China, 23–26 May 2021; pp. 1–3. [Google Scholar]
- Liu, Z.; Raju, L.; Zhu, D.; Cai, W. A hybrid strategy for the discovery and design of photonic structures. IEEE J. Emerg. Sel. Top. Circuits Syst. 2020, 10, 126–135. [Google Scholar] [CrossRef]
- Donda, K.; Zhu, Y.; Merkel, A.; Fan, S.W.; Cao, L.; Wan, S.; Assouar, B. Ultrathin acoustic absorbing metasurface based on deep learning approach. Smart Mater. Struct. 2021, 30, 085003. [Google Scholar] [CrossRef]
- Qiu, T.; Shi, X.; Wang, J.; Li, Y.; Qu, S.; Cheng, Q.; Cui, T.; Sui, S. Deep learning: A rapid and efficient route to automatic metasurface design. Adv. Sci. 2019, 6, 1900128. [Google Scholar] [CrossRef] [PubMed]
- Ghorbani, F.; Beyraghi, S.; Shabanpour, J.; Oraizi, H.; Soleimani, H.; Soleimani, M. Deep neural network-based automatic metasurface design with a wide frequency range. Sci. Rep. 2021, 11, 7102. [Google Scholar] [CrossRef] [PubMed]
- Niu, C.; Phaneuf, M.; Qiu, T.; Mojabi, P. A deep learning based approach to design metasurfaces from desired far-field specifications. IEEE Open J. Antennas Propag. 2023, 4, 641–653. [Google Scholar] [CrossRef]
- Mansouree, M.; Arbabi, A. Metasurface design using level-set and gradient descent optimization techniques. In Proceedings of the 2019 International Applied Computational Electromagnetics Society Symposium (ACES), Miami, FL, USA, 14–19 April 2019; pp. 1–2. [Google Scholar]
- Campbell, S.D.; Whiting, E.B.; Werner, D.H.; Werner, P.L. High-Performance Metasurfaces Synthesized via Multi-Objective Optimization. In Proceedings of the 2019 International Applied Computational Electromagnetics Society Symposium (ACES), Miami, FL, USA, 14–19 April 2019; pp. 1–2. [Google Scholar]
- Campbell, S.D.; Zhu, D.Z.; Whiting, E.B.; Nagar, J.; Werner, D.H.; Werner, P.L. Advanced multi-objective and surrogate-assisted optimization of topologically diverse metasurface architectures. Metamat. Metadev. Metasyst. 2018, 10719, 43–48. [Google Scholar]
- Elsawy, M.; Gobé, A.; Leroy, G.; Lanteri, S.; Genevet, P. Advanced computational framework for the design of ultimate performance metasurfaces. Smart Photonic Optoelectron. Integr. Circuits 2023, 12425, 34–37. [Google Scholar]
- Adadi, A. A survey on data-efficient algorithms in big data era. J. Big Data 2021, 8, 24. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 506–519. [Google Scholar]
- Jiang, J.; Sell, D.; Hoyer, S.; Hickey, J.; Yang, J.; Fan, J.A. Data-driven metasurface discovery. arXiv 2018, arXiv:1811.12436. [Google Scholar]
- Yoon, G.; Tanaka, T.; Zentgraf, T.; Rho, J. Recent progress on metasurfaces: Applications and fabrication. J. Phys. D Appl. Phys. 2021, 54, 383002. [Google Scholar] [CrossRef]
- Liu, X.; Cheng, G.; Wu, J.X. Noise and uncertainty management in intelligent data modeling. In Proceedings of the Twelfth AAAI National Conference on Artificial Intelligence, Seattle, WA, USA, 31 July–4 August 1994; pp. 263–268. [Google Scholar]
- Garcia, L.P.F.; de Leon Ferreira de Carvalho, A.C.P.; Lorena, A.C. Noise detection in the meta-learning level. Neurocomputing 2016, 176, 14–25. [Google Scholar] [CrossRef]
- Khan, H.; Wang, X.; Liu, H. A study on relationship between prediction uncertainty and robustness to noisy data. Int. J. Syst. Sci. 2023, 54, 1243–1258. [Google Scholar] [CrossRef]
- Karimi, B.; Wai, H.T.; Moulines, É.; Li, P. Minimization by Incremental Stochastic Surrogate Optimization for Large Scale Nonconvex Problems. In Proceedings of the International Conference on Algorithmic Learning Theory, Paris, France, 29 March–1 April 2022. [Google Scholar]
- Al Ajmi, H.; Bait-Suwailam, M.M.; Khriji, L. A Comparison Study of Deep Learning Algorithms for Metasurface Harvester Designs. In Proceedings of the 2023 International Conference on Intelligent Computing, Communication, Networking and Services (ICCNS), Valencia, Spain, 19–22 June 2023; pp. 74–78. [Google Scholar]
- Heaton, J. Ian Goodfellow, Yoshua Bengio, and Aaron Courville: Deep learning: The MIT Press, 2016, 800 pp, ISBN: 0262035618. Genet. Program. Evolvable Mach. 2018, 19, 305–307. [Google Scholar] [CrossRef]
- Ahsan, M.M.; Mahmud, M.P.; Saha, P.K.; Gupta, K.D.; Siddique, Z. Effect of data scaling methods on machine learning algorithms and model performance. Technologies 2021, 9, 52. [Google Scholar] [CrossRef]
- Raju, V.G.; Lakshmi, K.P.; Jain, V.M.; Kalidindi, A.; Padma, V. Study the influence of normalization/transformation process on the accuracy of supervised classification. In Proceedings of the 2020 Third International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20–22 August 2020; pp. 729–735. [Google Scholar]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation functions: Comparison of trends in practice and research for deep learning. arXiv 2018, arXiv:1811.03378. [Google Scholar]
- Dietterich, T.G. Ensemble methods in machine learning. In Proceedings of the International Workshop on Multiple Classifier Systems, Cagliari, Italy, 21–23 June 2000; pp. 1–15. [Google Scholar]
- Apicella, A.; Donnarumma, F.; Isgrò, F.; Prevete, R. A survey on modern trainable activation functions. Neural Netw. 2021, 138, 14–32. [Google Scholar] [CrossRef] [PubMed]
- Sun, S.; Cao, Z.; Zhu, H.; Zhao, J. A survey of optimization methods from a machine learning perspective. IEEE Trans. Cybern. 2019, 50, 3668–3681. [Google Scholar] [CrossRef] [PubMed]
- Fahlman, S. Faster-Learning Variations on Back-Propagation: An Empirical Study. In Proceedings of the 1988 Connectionist Models Summer School. Available online: https://api.semanticscholar.org/CorpusID:238073001 (accessed on 6 January 2024).
- Chauvin, Y.; Rumelhart, D.E. Backpropagation: Theory, Architectures, and Applications; Psychology Press: London, UK, 2013. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Splitting Method | Training Loss | Validation Loss | ||||
|---|---|---|---|---|---|---|
| DNN1 | DNN2 | DNN3 | DNN1 | DNN2 | DNN3 | |
| Keras | 0.031 | 0.033 | 0.032 | 0.049 | 0.044 | 0.046 |
| Adaptive | 0.037 | 0.039 | 0.15 | 0.024 | 0.020 | 0.25 |
| Dataset Splitting Method | Training Loss | Validation Loss | ||||
|---|---|---|---|---|---|---|
| DNN1 | DNN2 | DNN3 | DNN1 | DNN2 | DNN3 | |
| Keras | 0.051 | 0.49 | 0.047 | 0.077 | 0.0073 | 0.0095 |
| Adaptive | 0.049 | 0.045 | 0.05 | 0.0067 | 0.006 | 0.081 |
| Reference | Structure | Machine Learning Model | Accuracy | Model Complexity |
|---|---|---|---|---|
| [18] | Different shapes | GAN | 95% | Complex structure; complex dataset preparation (based on GAN); large dataset requirement |
| [19] | Acoustic metasurface | CNN | - | Complex dataset preparation (based on CNN) |
| [16] | Pexilated metasurface | CNN | 90.5% | Complex structure; complex dataset preparation (based on CNN) |
| [20] | Pexilated metasurface | CNN | 90% | Required significant data preprocessing |
| [21] | Eight-ring-pattern metasurface | CNN | 90% | Complex structure; complex dataset preparation (based on CNN) |
| [22] | Diploe antenna based on metasurfaces | GAN | - | Complex structure; complex dataset preparation (based on GAN) |
| Proposed model | Edge-coupled SRR with automated cut gap position | DNN | 94% (7000-sample dataset) | Straightforward dataset management mechanism; ease of integration with postprocessing data from EM simulators; simple design structure to implement |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ajmi, H.A.; Bait-Suwailam, M.M.; Khriji, L.; Al-Lawati, H. Prediction Enhancement of Metasurface Absorber Design Using Adaptive Cascaded Deep Learning (ACDL) Model. Electronics 2024, 13, 822. https://doi.org/10.3390/electronics13050822
Ajmi HA, Bait-Suwailam MM, Khriji L, Al-Lawati H. Prediction Enhancement of Metasurface Absorber Design Using Adaptive Cascaded Deep Learning (ACDL) Model. Electronics. 2024; 13(5):822. https://doi.org/10.3390/electronics13050822
Chicago/Turabian StyleAjmi, Haitham Al, Mohammed M. Bait-Suwailam, Lazhar Khriji, and Hassan Al-Lawati. 2024. "Prediction Enhancement of Metasurface Absorber Design Using Adaptive Cascaded Deep Learning (ACDL) Model" Electronics 13, no. 5: 822. https://doi.org/10.3390/electronics13050822
APA StyleAjmi, H. A., Bait-Suwailam, M. M., Khriji, L., & Al-Lawati, H. (2024). Prediction Enhancement of Metasurface Absorber Design Using Adaptive Cascaded Deep Learning (ACDL) Model. Electronics, 13(5), 822. https://doi.org/10.3390/electronics13050822