

Resilient Electricity Load Forecasting Network with Collective Intelligence Predictor for Smart Cities †


Abstract
1. Introduction
2. Related Works
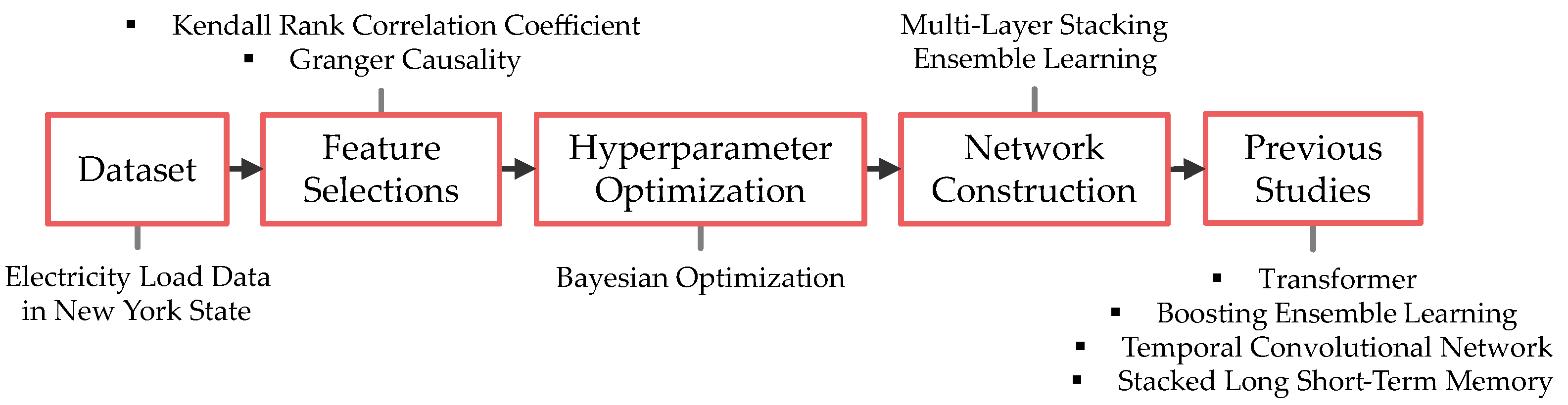
2.1. Overview
2.2. Dataset
2.3. Feature Selections
2.3.1. Kendall Rank Correlation Coefficient
2.3.2. Granger Causality
2.4. Hyperparameter Optimization
2.5. Network Construction
2.6. Previous Studies
- TCN + padding
- Transformer + padding
- Stacked LSTM + padding
- Boosting ensemble learning
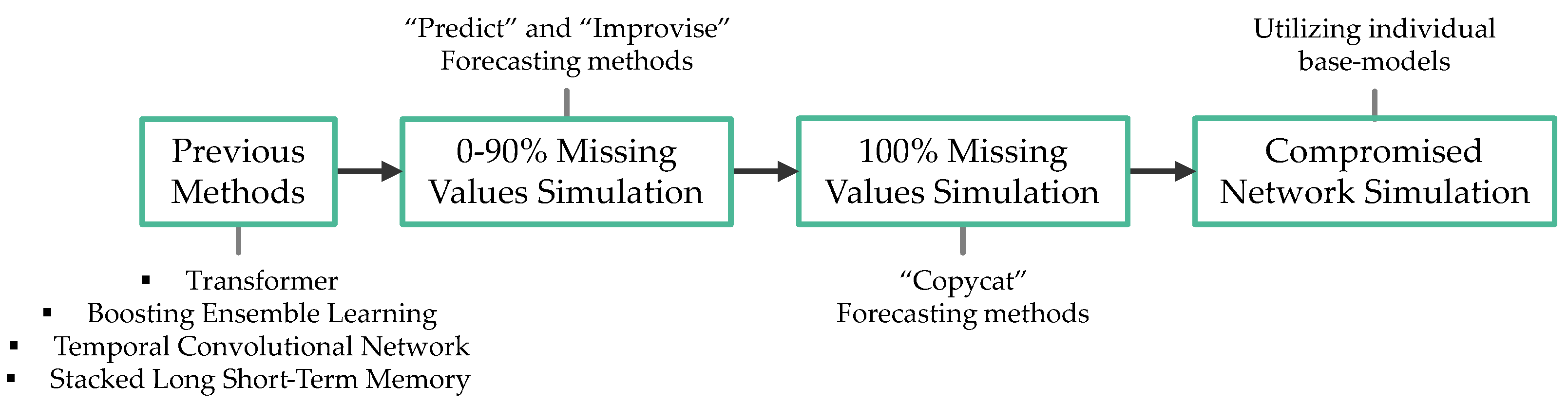
3. Implementation
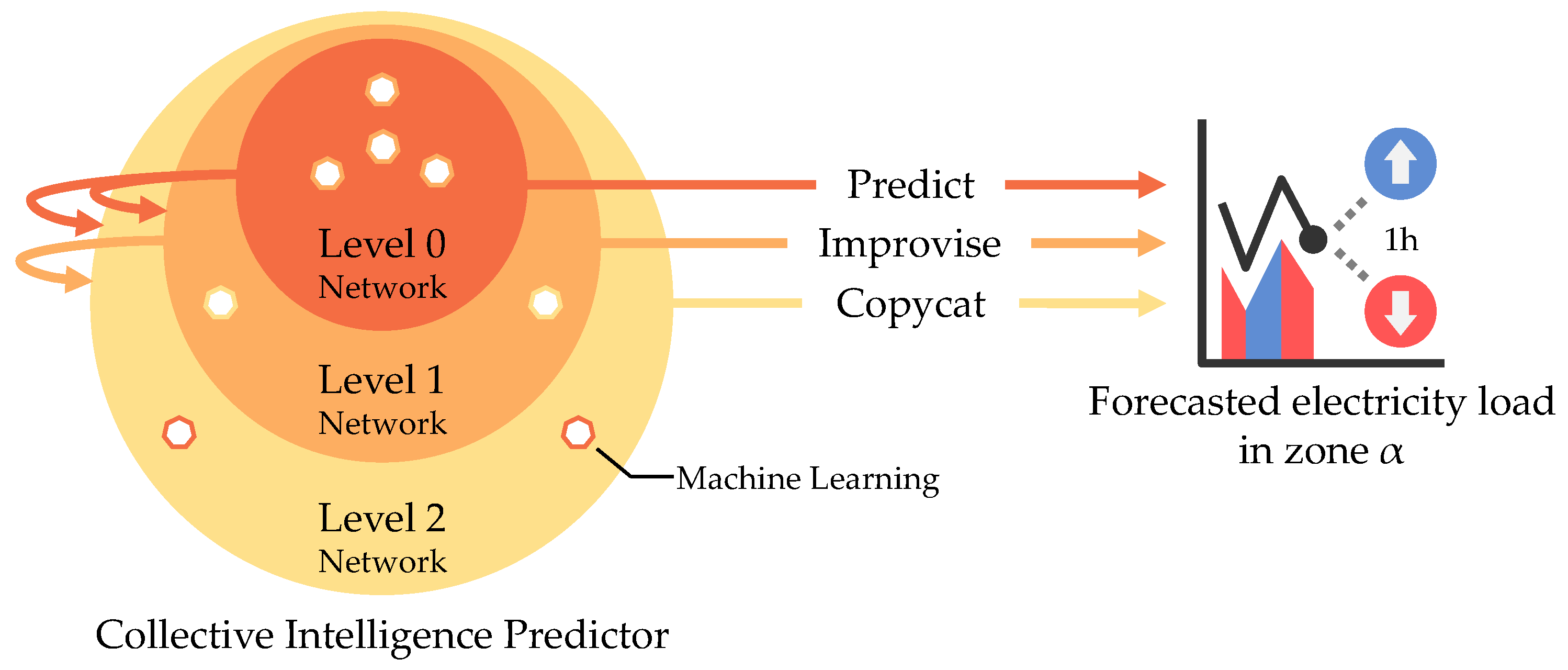
3.1. Overview
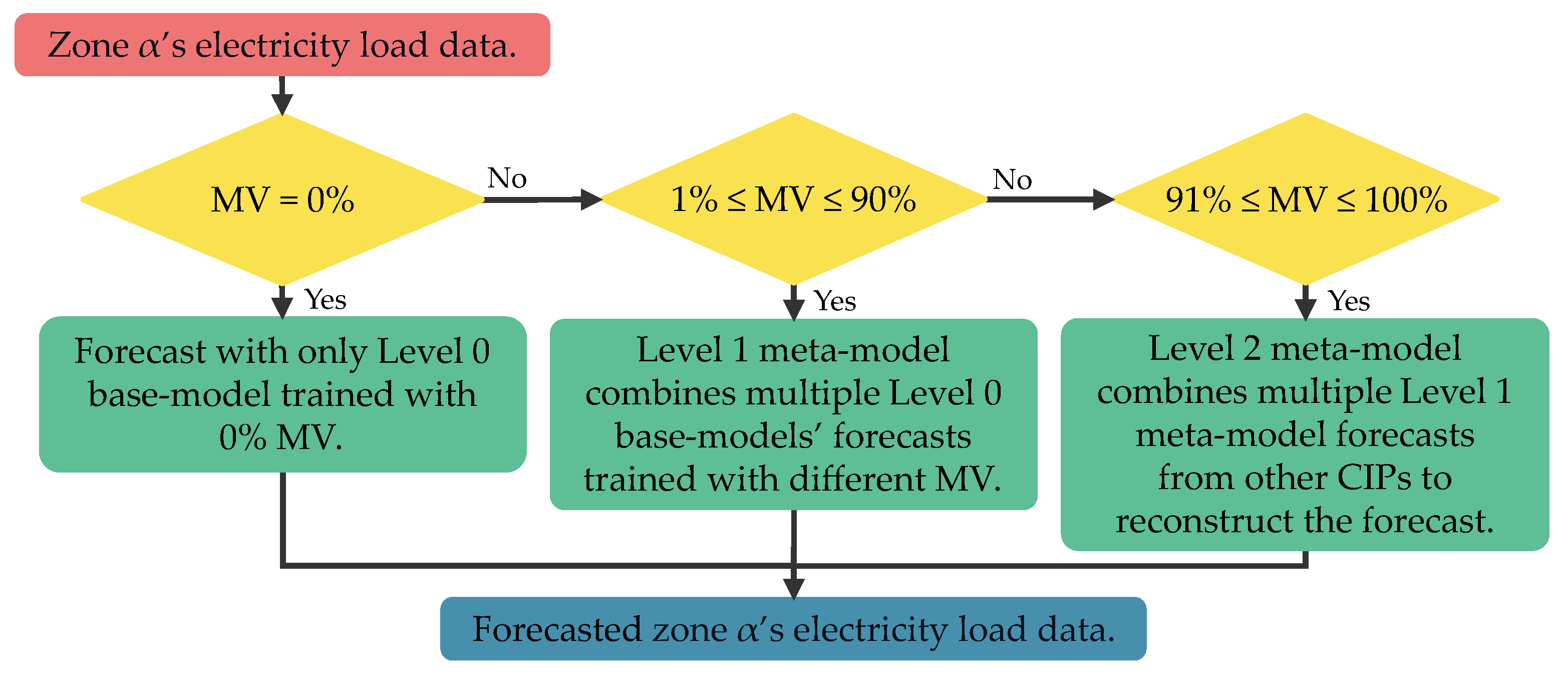
3.2. Concept
| Algorithm 1 Networks activation in . |
| Input: Output:
|
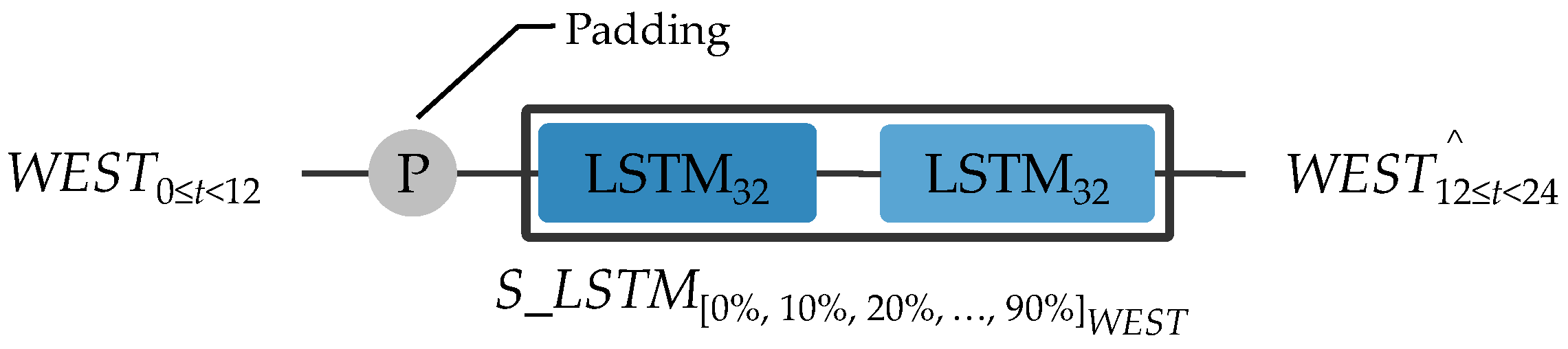
3.2.1. Level 0
| Algorithm 2 Predict() function in . |
| Input: Output:
|
3.2.2. Level 1
| Algorithm 3 Improvise() function in . |
| Input: and Output:
|
3.2.3. Level 2
| Algorithm 4 Copycat() function in . |
| Input: and Output:
|
3.3. Application
3.3.1. Feature Selections
3.3.2. Hyperparameter Optimization
3.4. Training
3.4.1. Level 0
3.4.2. Level 1
3.4.3. Level 2
4. Evaluation
4.1. Overview
4.2. Previous Methods
4.2.1. Transformer
4.2.2. Boosting Ensemble Learning
4.2.3. Temporal Convolutional Network
4.2.4. Stacked Long Short-Term Memory
4.3. 0–90% Missing Values Simulation
4.4. 100% Missing Values Simulation
4.5. Compromised Network Simulation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ML | Machine Learning |
| DDoS | Distributed Denial-of-Service |
| MV | Missing Values |
| ANN | Artificial Neural Networks |
| SPoF | Single Point of Failure |
| CIP | Collective Intelligence Predictor |
| NYISO | New York Independent System Operator |
| RNN | Recurrent Neural Networks |
| LSTM | Long Short-Term Memory |
| GRU | Gated Recurrent Unit |
| TCN | Temporal Convolutional Network |
| LP | Linear Programming |
| MAE | Mean Absolute Error |
| TanH | Hyperbolic Tangent |
| DNN | Deep Neural Networks |
| RMSE | Root-Mean-Square Error |
| MSE | Mean squared Error |
| MLP | Multi-Layer Perceptron |
| XGBoost | eXtreme Gradient Boosting |
| ReLU | Rectified Linear Units |
Appendix A
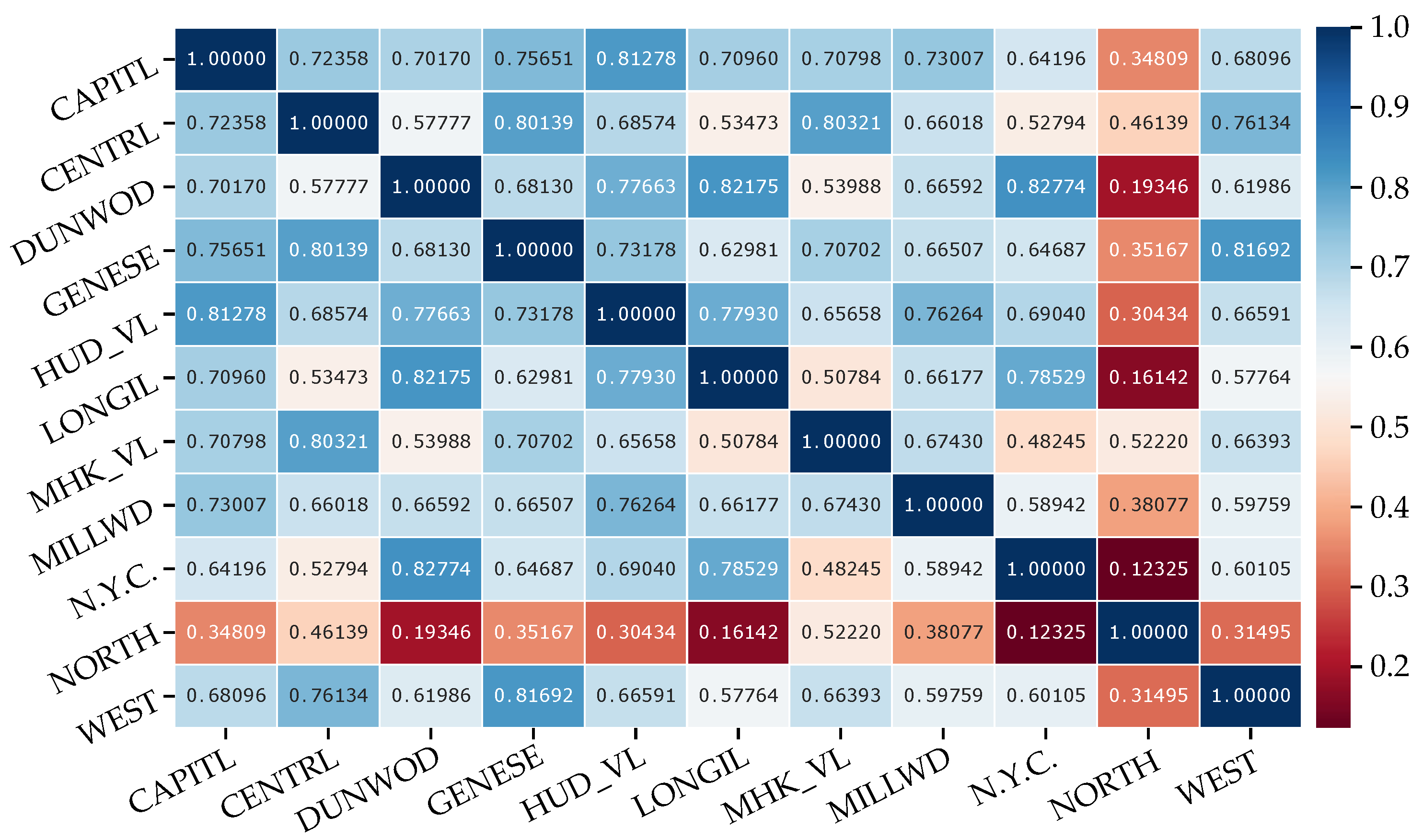

References
- Nti, I.K.; Teimeh, M.; Nyarko-Boateng, O.; Adekoya, A.F. Electricity load forecasting: A systematic review. J. Electr. Syst. Inf. Technol. 2020, 7, 13. [Google Scholar] [CrossRef]
- Kruse, J.; Schäfer, B.; Witthaut, D. Predictability of Power Grid Frequency. IEEE Access 2020, 8, 149435–149446. [Google Scholar] [CrossRef]
- Sweeney, C.; Bessa, R.J.; Browell, J.; Pinson, P. The future of forecasting for renewable energy. WIREs Energy Environ. 2020, 9, e365. [Google Scholar] [CrossRef]
- Klyuev, R.V.; Morgoev, I.D.; Morgoeva, A.D.; Gavrina, O.A.; Martyushev, N.V.; Efremenkov, E.A.; Mengxu, Q. Methods of Forecasting Electric Energy Consumption: A Literature Review. Energies 2022, 15, 8919. [Google Scholar] [CrossRef]
- Sue Wing, I.; Rose, A.Z. Economic consequence analysis of electric power infrastructure disruptions: General equilibrium approaches. Energy Econ. 2020, 89, 104756. [Google Scholar] [CrossRef]
- IBM Security. X-Force Threat Intelligence Index 2023. Available online: https://www.ibm.com/reports/threat-intelligence/ (accessed on 21 November 2023).
- Li, Y.; Liu, Q. A comprehensive review study of cyber-attacks and cyber security; Emerging trends and recent developments. Energy Rep. 2021, 7, 8176–8186. [Google Scholar] [CrossRef]
- Azure Network Security Team. 2022 in Review: DDoS Attack Trends and Insights. Microsoft. Available online: https://www.microsoft.com/en-us/security/blog/2023/02/21/2022-in-review-ddos-attack-trends-and-insights/ (accessed on 10 August 2023).
- Gjesvik, L.; Szulecki, K. Interpreting cyber-energy-security events: Experts, social imaginaries, and policy discourses around the 2016 Ukraine blackout. Eur. Secur. 2023, 32, 104–124. [Google Scholar] [CrossRef]
- Rodrigues, F.; Cardeira, C.; Calado, J.M.F.; Melicio, R. Short-Term Load Forecasting of Electricity Demand for the Residential Sector Based on Modelling Techniques: A Systematic Review. Energies 2023, 16, 4098. [Google Scholar] [CrossRef]
- Wazirali, R.; Yaghoubi, E.; Abujazar, M.S.S.; Ahmad, R.; Vakili, A.H. State-of-the-art review on energy and load forecasting in microgrids using artificial neural networks, machine learning, and deep learning techniques. Electr. Power Syst. Res. 2023, 225, 109792. [Google Scholar] [CrossRef]
- Jung, S.; Moon, J.; Park, S.; Rho, S.; Baik, S.W.; Hwang, E. Bagging Ensemble of Multilayer Perceptrons for Missing Electricity Consumption Data Imputation. Sensors 2020, 20, 1772. [Google Scholar] [CrossRef] [PubMed]
- Rodenburg, F.J.; Sawada, Y.; Hayashi, N. Improving RNN Performance by Modelling Informative Missingness with Combined Indicators. Appl. Sci. 2019, 9, 1623. [Google Scholar] [CrossRef]
- Myllyaho, L.; Raatikainen, M.; Männistö, T.; Nurminen, J.K.; Mikkonen, T. On misbehaviour and fault tolerance in machine learning systems. J. Syst. Softw. 2022, 183, 111096. [Google Scholar] [CrossRef]
- Dehghani, M.; Yazdanparast, Z. From distributed machine to distributed deep learning: A comprehensive survey. J. Big Data 2023, 10, 158. [Google Scholar] [CrossRef]
- Drainakis, G.; Pantazopoulos, P.; Katsaros, K.V.; Sourlas, V.; Amditis, A.; Kaklamani, D.I. From centralized to Federated Learning: Exploring performance and end-to-end resource consumption. Comput. Netw. 2023, 225, 109657. [Google Scholar] [CrossRef]
- Aguilar Madrid, E.; Antonio, N. Short-Term Electricity Load Forecasting with Machine Learning. Information 2021, 12, 50. [Google Scholar] [CrossRef]
- Jiang, W. Deep learning based short-term load forecasting incorporating calendar and weather information. Internet Technol. Lett. 2022, 5, e383. [Google Scholar] [CrossRef]
- New York Independent System Operator. Load Data. Available online: https://www.nyiso.com/load-data/ (accessed on 18 July 2023).
- Puth, M.-T.; Neuhäuser, M.; Ruxton, G.D. Effective use of Spearman’s and Kendall’s correlation coefficients for association between two measured traits. Anim. Behav. 2015, 102, 77–84. [Google Scholar] [CrossRef]
- Makowski, D.; Ben-Shachar, M.S.; Patil, I.; Lüdecke, D. Methods and algorithms for correlation analysis in R. J. Open Source Softw. 2020, 5, 2306. [Google Scholar] [CrossRef]
- Pandas 2.1.3. 2023. Available online: https://pandas.pydata.org (accessed on 18 November 2023).
- Shojaie, A.; Fox, E.B. Granger Causality: A Review and Recent Advances. Annu. Rev. Stat. Its Appl. 2022, 9, 289–319. [Google Scholar] [CrossRef] [PubMed]
- Statsmodels 0.14.0. 2023. Available online: https://www.statsmodels.org (accessed on 17 June 2023).
- Kadhim, Z.S.; Abdullah, H.S.; Ghathwan, K.I. Artificial Neural Network Hyperparameters Optimization: A Survey. Int. J. Online Biomed. Eng. 2022, 18, 59–87. [Google Scholar] [CrossRef]
- Wu, J.; Chen, X.-Y.; Zhang, H.; Xiong, L.-D.; Lei, H.; Deng, S.-H. Hyperparameter Optimization for Machine Learning Models Based on Bayesian Optimization. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar]
- Keras Tuner 1.4.6. 2023. Available online: https://github.com/keras-team/keras-tuner (accessed on 3 December 2023).
- TensorFlow 2.13.1. 2023. Available online: https://www.tensorflow.org (accessed on 4 September 2023).
- Shafieian, S.; Zulkernine, M. Multi-layer stacking ensemble learners for low footprint network intrusion detection. Complex Intell. Syst. 2023, 9, 3787–3799. [Google Scholar] [CrossRef]
- Abumohsen, M.; Owda, A.Y.; Owda, M. Electrical Load Forecasting Using LSTM, GRU, and RNN Algorithms. Energies 2023, 16, 2283. [Google Scholar] [CrossRef]
- Wan, R.; Mei, S.; Wang, J.; Liu, M.; Yang, F. Multivariate Temporal Convolutional Network: A Deep Neural Networks Approach for Multivariate Time Series Forecasting. Electronics 2019, 8, 876. [Google Scholar] [CrossRef]
- Lara-Benítez, P.; Carranza-García, M.; Luna-Romera, J.M.; Riquelme, J.C. Temporal Convolutional Networks Applied to Energy-Related Time Series Forecasting. Appl. Sci. 2020, 10, 2322. [Google Scholar] [CrossRef]
- Zhao, Z.; Xia, C.; Chi, L.; Chang, X.; Li, W.; Yang, T.; Zomaya, A.Y. Short-Term Load Forecasting Based on the Transformer Model. Information 2021, 12, 516. [Google Scholar] [CrossRef]
- L’Heureux, A.; Grolinger, K.; Capretz, M.A.M. Transformer-Based Model for Electrical Load Forecasting. Energies 2022, 15, 4993. [Google Scholar] [CrossRef]
- Stratigakos, A.; Andrianesis, P.; Michiorri, A.; Kariniotakis, G. Towards Resilient Energy Forecasting: A Robust Optimization Approach. IEEE Trans. Smart Grid 2024, 15, 874–885. [Google Scholar] [CrossRef]
- Mienye, I.D.; Sun, Y. A Survey of Ensemble Learning: Concepts, Algorithms, Applications, and Prospects. IEEE Access 2022, 10, 99129–99149. [Google Scholar] [CrossRef]
- Grotmol, G.; Furdal, E.H.; Dalal, N.; Ottesen, A.L.; Rørvik, E.-L.H.; Mølnå, M.; Sizov, G.; Gundersen, O.E. A robust and scalable stacked ensemble for day-ahead forecasting of distribution network losses. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 15503–15511. [Google Scholar]
- Gupta, H.; Agarwal, P.; Gupta, K.; Baliarsingh, S.; Vyas, O.P.; Puliafito, A. FedGrid: A Secure Framework with Federated Learning for Energy Optimization in the Smart Grid. Energies 2023, 16, 8097. [Google Scholar] [CrossRef]
- Shi, B.; Zhou, X.; Li, P.; Ma, W.; Pan, N. An IHPO-WNN-Based Federated Learning System for Area-Wide Power Load Forecasting Considering Data Security Protection. Energies 2023, 16, 6921. [Google Scholar] [CrossRef]
- Shi, Y.; Xu, X. Deep Federated Adaptation: An Adaptative Residential Load Forecasting Approach with Federated Learning. Sensors 2022, 22, 3. [Google Scholar] [CrossRef] [PubMed]
- eXtreme Gradient Boosting 2.0.2. 2023. Available online: https://github.com/dmlc/xgboost (accessed on 19 November 2023).
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef] [PubMed]
- Bin Kamilin, M.H.; Yamaguchi, S.; Bin Ahmadon, M.A. Radian Scaling: A Novel Approach to Preventing Concept Drift in Electricity Load Prediction. In Proceedings of the 2023 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Busan, Republic of Korea, 23–25 October 2023; pp. 1–4. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methodology | Missing Values | Single Point of Failure |
|---|---|---|
| Robust Model [35] | ✓ | × |
| Transformer [33,34] | △ | × |
| Forecasting Network | ✓ | △ |
| Federated Learning [38,39,40] | × | ✓ |
| Boosting Ensemble Learning [36,37] | ✓ | × |
| Temporal Convolutional Network [31,32] | △ | × |
| Recurrent Neural Network Derivatives [30] | △ | × |
| Forecaster | Required Independent Variable | Selected Independent Variables |
|---|---|---|
| , | ||
| , | ||
| , |
| Base Model | First LSTM Layer Units | Second LSTM Layer Units | Adam’s Learning Rate |
|---|---|---|---|
| 192 | 96 | 0.001 | |
| 128 | 128 | 0.001 | |
| 192 | 96 | 0.001 | |
| 192 | 96 | 0.001 |
| MV [%] | CIP | TCN | Boosting | Transformer | Stacked LSTM |
|---|---|---|---|---|---|
| 0 | 0.98831 | 0.98567 | 0.98523 | 0.93445 | 0.98626 |
| 10 | 0.98501 | 0.98465 | 0.98478 | 0.91115 | 0.98579 |
| 20 | 0.98498 | 0.98381 | 0.98392 | 0.89104 | 0.98518 |
| 30 | 0.98492 | 0.98273 | 0.98241 | 0.87363 | 0.98421 |
| 40 | 0.98478 | 0.98159 | 0.97655 | 0.85770 | 0.98311 |
| 50 | 0.98410 | 0.97856 | 0.95719 | 0.36864 | 0.98029 |
| 60 | 0.98214 | 0.97292 | 0.91396 | −1.53278 | 0.97468 |
| 70 | 0.97727 | 0.95687 | 0.75946 | −11.5464 | 0.95892 |
| 80 | 0.96225 | 0.88543 | 0.33560 | −74.1568 | 0.88781 |
| 90 | 0.89345 | 0.65085 | −0.66817 | −296.831 | 0.65736 |
| Average | 0.97272 | 0.93631 | 0.72109 | −37.92314 | 0.93836 |
| MV [%] | CIP | TCN | Boosting | Transformer | Stacked LSTM |
|---|---|---|---|---|---|
| 0 | 0.03137 | 0.03433 | 0.03480 | 0.07452 | 0.03355 |
| 10 | 0.03555 | 0.03557 | 0.03535 | 0.08756 | 0.03413 |
| 20 | 0.03565 | 0.03656 | 0.03637 | 0.09733 | 0.03488 |
| 30 | 0.03573 | 0.03779 | 0.03814 | 0.10501 | 0.03605 |
| 40 | 0.03588 | 0.03903 | 0.04443 | 0.11154 | 0.03733 |
| 50 | 0.03670 | 0.04223 | 0.06089 | 0.23587 | 0.04044 |
| 60 | 0.03899 | 0.04779 | 0.08686 | 0.47234 | 0.04616 |
| 70 | 0.04409 | 0.06083 | 0.14554 | 1.05115 | 0.05935 |
| 80 | 0.05712 | 0.10024 | 0.24196 | 2.57265 | 0.09918 |
| 90 | 0.09663 | 0.17537 | 0.38340 | 5.12129 | 0.17371 |
| Average | 0.04477 | 0.06097 | 0.11077 | 0.99293 | 0.05948 |
| MV [%] | RMSE | |
|---|---|---|
| 0 | 0.81445 | 0.12785 |
| 10 | 0.76918 | 0.14261 |
| 20 | 0.76517 | 0.14385 |
| 30 | 0.76375 | 0.14428 |
| 40 | 0.75983 | 0.14548 |
| 50 | 0.75710 | 0.14630 |
| 60 | 0.75839 | 0.14591 |
| 70 | 0.76295 | 0.14453 |
| 80 | 0.76616 | 0.14354 |
| 90 | 0.74013 | 0.15129 |
| MV [%] | RMSE | |
|---|---|---|
| 0 | 0.98826 | 0.03141 |
| 10 | 0.98739 | 0.03245 |
| 20 | 0.98704 | 0.03294 |
| 30 | 0.98440 | 0.03614 |
| 40 | 0.98409 | 0.03644 |
| 50 | 0.98235 | 0.03846 |
| 60 | 0.97132 | 0.04917 |
| 70 | 0.97086 | 0.04997 |
| 80 | 0.95744 | 0.06045 |
| 90 | 0.88504 | 0.10029 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bin Kamilin, M.H.; Yamaguchi, S. Resilient Electricity Load Forecasting Network with Collective Intelligence Predictor for Smart Cities. Electronics 2024, 13, 718. https://doi.org/10.3390/electronics13040718
Bin Kamilin MH, Yamaguchi S. Resilient Electricity Load Forecasting Network with Collective Intelligence Predictor for Smart Cities. Electronics. 2024; 13(4):718. https://doi.org/10.3390/electronics13040718
Chicago/Turabian StyleBin Kamilin, Mohd Hafizuddin, and Shingo Yamaguchi. 2024. "Resilient Electricity Load Forecasting Network with Collective Intelligence Predictor for Smart Cities" Electronics 13, no. 4: 718. https://doi.org/10.3390/electronics13040718
APA StyleBin Kamilin, M. H., & Yamaguchi, S. (2024). Resilient Electricity Load Forecasting Network with Collective Intelligence Predictor for Smart Cities. Electronics, 13(4), 718. https://doi.org/10.3390/electronics13040718