1. Introduction
In the rapidly evolving digital landscape of the modern digital age, websites are increasingly effective at collecting a wide range of user information and online interactions. This information provides a detailed picture of online behavior that includes personal details, browsing patterns, demographics, and individual preferences. The information collected from contemporary advanced web applications includes, for example, personal identifiers such as names and email addresses, user behavior (including browsing history, click patterns, and time spent on pages), demographic data (age, gender, and geographic location), and preferences (such as product selection, language preferences, and customer settings). As the size and diversity of these data continue to grow, the scientific community is looking for new tools and methods to systematically analyze and utilize this rich information corpus.
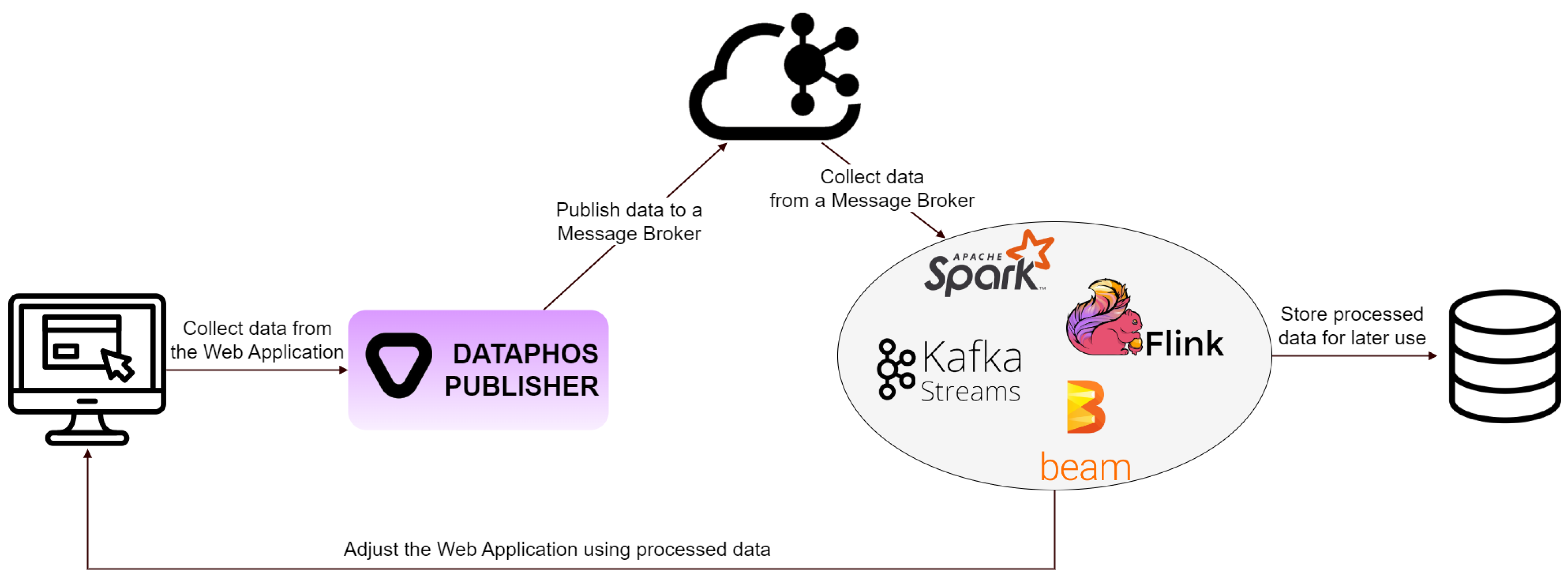
This paper deals with the latest tools and technologies utilized by advanced web applications for data management. It focuses on the process of data collection and publication to the cloud using specialized data ingestion tools. These tools are designed to efficiently collect, categorize, and transfer data while ensuring real-time updates and seamless integration with cloud infrastructures [
1]. Following data collection, the focus shifts to data processing tools. These are crucial for analyzing, refining, and deriving meaningful insights from raw data. They employ algorithms and machine learning techniques to process data and identify patterns, trends, and anomalies. The processed data are then either stored in a database for later use or routed back to the web application. This cyclical flow of data enables the web application to dynamically adapt and personalize the user experience based on real-time data analytics.
The aim of this paper is to explain how advanced web applications work, especially in the area of data engineering, focusing on the importance of data ingestion and processing in today’s data-rich digital environment. First, we introduce the Dataphos Publisher platform, describe its architecture, and experimentally validate its performance advantages over traditional Change Data Capture (CDC) platforms. Also, this paper gives an overview of different data processing tools. This includes a qualitative exploration of their functionalities, strengths, and limitations, providing readers with a clear understanding of the diverse options that are available in the field. Finally, this paper also provides a practical framework for data engineers building advanced web applications and helps select the right tools for data ingestion and processing. This is meant to make it easier for readers to understand and use these technologies when developing web applications.
Figure 1 illustrates an architecture proposed for this comprehensive solution, including a novel tool, Dataphos Publisher, and shows the interrelated roles of data ingestion and processing tools in modern web applications.
The remainder of this paper is organized as follows.
Section 2 provides an in-depth analysis of data ingestion, focusing on specific technologies in web applications such as CDC and Dataphos Publisher, developed by Syntio.
Section 3 explores data processing tools, comparing Apache Spark, Apache Flink, Kafka Streams, and Apache Beam. In
Section 4, practical use cases are provided with a discussion to illustrate the applications of these tools in real-world scenarios. Finally,
Section 5 concludes the paper by summarizing key insights and their implications for advanced web application development.
2. Data Ingestion
Data ingestion is a big data process that involves loading data from one or multiple sources to various destinations that may or may not be in the cloud. As modern systems become increasingly data-oriented, the more data are collected. This is best shown by the fact that 90% of data were collected in the last two years alone, with 2.5 quintillion bytes collected every day [
2], and these numbers will likely grow in the coming years. This requires a robust infrastructure comprising data ingestion, data processing, data storage, etc., that can handle such amounts of data.
This section covers the data ingestion part of the infrastructure, the process of moving different types of data (structured, unstructured, and semi-structured) from one place to another for processing. These data might come from different sources, either internal (e.g., data collected by a company) or external (e.g., publicly available data from social networks such as Twitter/X and Facebook) [
3].
The first subsection covers the state of the art of data ingestion, and we cover some popular data ingestion tools along with Change Data Capture (CDC), a data ingestion concept which is more thoroughly described in the second subsection. The third subsection covers a completely new player in the data ingestion process, Dataphos Publisher. Finaly, the last part of this section contains a comparison between CDC and Dataphos Publisher.
2.1. State of the Art in Data Ingestion Tools
The transition from on-premises to cloud-based environments has emphasized the importance of data ingestion in the world of big data. This transition is particularly challenging for organizations with extensive historical datasets that require efficient and reliable transfer to cloud platforms. To address these challenges, in this section, we examine the main capabilities and commonplace applications of state-of-the-art data ingestion tools, focusing specifically on Apache Kafka Connect (a key component of the Apache Kafka ecosystem), Apache NiFi, and Apache Flume [
4], as well as Airbyte and Meltano [
5]. Finally, we describe Change Data Capture (CDC) in the context of data ingestion. Each of these tools has a number of different features and functions that make the migration and management of large amounts of data in cloud environments more efficient, making them important components of the architecture of modern web applications.
Apache tools are compared in [
4]. In this study, the researchers report that of all the tools compared, none is optimal for all use cases [
4]. A summary of this report can be found in
Table 1. It shows which tools implement a specific functionality (reliability, guaranteed delivery, data type versatility, system requirements complexity, stream ingestion, and processing support) and recommends a tool for this functionality [
4]. The functionality level for each tool was qualitatively evaluated using a three-point scale: fully implemented functionality, partially implemented functionality, and non-implemented functionality. From the table data, Apache NiFi is shown to be the best tool compared to Apache Flume and Apache Kafka Connect due to its more comprehensive coverage of functionality.
Additionally,
Table 2 presents a comparison between commonplace performance indicators of the Apache Flume, Apache NiFi, and Apache Kafka Connect data ingestion tools, with recommendations for optimal tools based on their respective capabilities related to specific performance indicators [
4].
As can be seen in
Table 2, in terms of speed, all three tools (Apache Flume, Apache NiFi, and Apache Kafka Connect) are rated equally with a “Medium” performance level, indicating no significant difference between them in this regard. When it comes to the number of files processed per second, Apache Flume and Kafka Connect both gain a “High” rating, outperforming Apache NiFi, which is rated “Medium”. In terms of scalability, Kafka Connect stands out with a “High” rating, indicating its superior ability to handle larger loads and more complex data processing needs. Flume follows closely behind with a “High” rating, while NiFi follows with a “Medium” rating. Finally, in terms of message durability, Apache Flume and Kafka Connect continue to lead with “High” ratings, demonstrating their robustness in ensuring message persistence and reliability compared to NiFi’s “Low” rating.
These results recommend Flume and Kafka as the best choices for scenarios prioritizing high throughput and message durability, with Kafka being particularly suited for scalability needs.
The other two open-source tools, Airbyte and Meltano, were compared in [
5], where it was found, after an evaluation of data ingestion tools, that Airbyte is more suitable for the problem of data pipeline design for audit analytics. Furthermore, CDC is a process that identifies and captures only changes to data in a database, thereby increasing its efficiency and then delivering those changes in real time to a downstream process or system [
6]. The following section provides more detail about CDC.
2.2. Change Data Capture
Change Data Capture (CDC) is a process that continuously identifies and captures incremental changes in data and data structures from a source such as a production database. The CDC pattern arose two decades ago to help replication software deliver real-time transactions to data warehouses. In these warehouses, data are transformed and then used in analytics applications. CDC enables efficient, low-latency data transfer to operational and analytics users with a low production impact [
7].
An important advantage of CDC is that it can pass data quickly and efficiently to both operational and analytical users without too much disruption to the production environment. It captures changes as they occur and ensures that the data in the target system are up to date and consistent with the source system.
CDC is great for modern cloud architectures because it is a highly efficient way to move data across a wide-area network. It is a method of ETL (Extract, Transform, and Load) in which data are periodically extracted from a source system, transformed to meet the requirements of a target system, and loaded into the target system [
1,
6]. CDC is not only ideal for real-time data movement and an excellent fit to achieve low-latency, reliable, and scalable data replication but also for zero-downtime migrations to the cloud.
There are many use cases for CDC in the overall data integration strategy. They may be moving data into a data warehouse or data lake or creating an operational data store or a replica of source data in real time. CDC helps modernize data environments by enabling faster and more accurate decisions, minimizing disruptions to production, and reducing cloud migration costs, which, all combined, make CDC the preferred method for data ingestion and movement [
6].
CDC is very useful in today’s data systems, especially for big data and real-time analytics. It helps companies quickly understand market trends and customer behavior and determine how well operations are running by continuously providing new data. This is very important for applications that require up-to-date data, such as fraud detection and improving customer service and monitoring operations.
2.3. Dataphos Publisher
When moving data from on-premises systems to the cloud, you are restricted to one of two outcomes: either investing in a very expensive CDC solution for fast, real-time processing or replicating your whole database several times a day, which does not give you the most up-to-date information while also placing a lot of stress on the database itself. Most of the time, these solutions will present the data consumers on your platform with raw data from several sources, and they will first have to process it before it can be used. This process is costly, time-consuming, and can be unsafe. Implementing Publisher with business logic at the source provides a more controlled real-time approach to managing data changes. It helps ensure data quality and consistency before the data are propagated to downstream systems, making it particularly valuable in scenarios in which data integrity and business rule enforcement are critical [
8].
Figure 2 shows Dataphos Publisher’s process, which begins with reading data from an on-premises database. The data are queried and formatted, creating a business object before transferring the data to the cloud. Once the business object is created, the data are serialized, encrypted for security, and sent to a message broker (a mediator between two services able to handle large volumes of data [
9]), where they can be pulled by cloud services. The procedure described allows for a constant flow of ready-to-digest data packages to the cloud, and all at a fraction of the cost. This process (i.e., data ingestion) is integral to the whole system because it sets the foundation for downstream data processing, analysis, and reporting, which are essential for decision making in a timely and accurate manner.
2.4. CDC vs. Dataphos Publisher
Both CDC and Dataphos Publisher in the context of advanced web applications play the same role, which is data ingestion. However, they have different approaches when it comes to the task.
Figure 3 shows the data flow in CDC. There are seven different actors in the diagram. Looking at Dataphos Publisher’s data flow in
Figure 4, it contains only three actors, making the figure not only simpler but also faster. But the main difference between the two is how they carry out the ETL process. While CDC organizes the data right before entering the data warehouse, Publisher does so while the data are still on prem. That means that the data flowing through CDC pipeline are unstructured, while Publisher’s data are presented as a business object ready to use. This also means that there is no need to save the data we derived from the business object in the database because they are never transported to the cloud (in case data are being transferred from an on-prem database).
To show that Dataphos Publisher is faster than CDC, as stated earlier, we performed an experiment in which we compared the performance of Dataphos Publisher and a CDC tool, Debezium [
10], using standardized datasets of different sizes. This experiment compared performance between the Debezium tool and Dataphos Publisher in the context of real-time row detection and message propagation. We focused on measuring the time elapsed from the detection of added rows in the source system to the point at which the corresponding messages arrived at the message broker. The analysis was conducted with four datasets consisting of 1000, 10,000, 50,000, and 150,000 rows, respectively. The experiment was conducted five times for each dataset. The time required to process all rows was recorded for each run and then averaged. The data in the source database were always generated at around 200 rows per second. In the experiment, we utilized the Microsoft Wide World Importers (WWI) database as the dataset (publicly available at [
11]). The WWI database is a sample database developed for use with the SQL Server and Azure SQL Database. It represents a fictional wholesale novelty goods importer and distributor based in the San Francisco Bay Area and serves as a comprehensive platform for learning and demonstrating SQL functionalities in a real-world business context. In the experiment, we used ksqlDB as the processing tool to measure the average time difference from when the message arrived at Apache Kafka to when the row was created in the source. The results of the experiment are provided in
Table 3.
In
Table 3, the first row indicates the throughput in terms of the number of data rows per second. The subsequent rows detail the performance of two different tools: Debezium and Publisher. Specifically, the first row after the throughput row shows the time taken by Debezium to complete the data transfer, while the second row shows the time taken by Publisher.
The analysis revealed distinct performance characteristics between the CDC tool Debezium and Publisher. Specifically, Publisher exhibited at least 2.3 times better results (depending on the number of rows per second) compared to Debezium. These findings may have implications for scenarios in which rapid data propagation and minimal latency are critical factors.
3. Data Processing Tools
In the dynamic landscape of computing and data processing, the efficiency and scalability of tools play critical roles in driving insight and innovation. As scientific institutions, business organizations, and governments grapple with increasingly large and diverse datasets, the choice of data processing tools becomes a critical decision that directly impacts performance, flexibility, and the ability to gain actionable insights.
This chapter explains three sophisticated data processing tools, Apache Spark [
12], Apache Flink [
13], and Kafka Streams [
14], as well as Apache Beam [
15], a tool for creating data pipelines that leverages data processing tools. Each of these tools possesses distinct capabilities that serve specific components of the data processing pipeline. Understanding the functionalities of Apache Spark’s fast and widespread processing abilities, Apache Flink’s exceptional event stream processing, Kafka Streams’ integration into the Apache Kafka ecosystem, and Apache Beam’s unified model for both batch and stream processing is crucial for making well-informed decisions in the current data-driven environment. It is important to note that this chapter is just an overview of some data processing tools available, and any comparisons between them are based on other articles as the authors of this article did not measure the performances of the tools.
Although these four tools specialize in different areas, the problems they solve are similar. Spark, Flink, and Kafka Streams are all tools that process data; however, Spark is more oriented toward batch processing, while Flink and Kafka Streams are stream-oriented [
16,
17]. The difference between Flink and Kafka Streams is that Flink is a more diverse tool and applicable in almost any stream-processing scenario (including scenarios that use the Kafka ecosystem), whereas Kafka Streams is tightly coupled with the Kafka ecosystem [
18]. This makes Kafka Streams perfect for projects that already use Kafka but hardly usable in other cases. Finally, Beam is a different tool compared to the other three. It is not a data processing engine but a unified model that allows users to build pipelines in many popular programming languages and execute those pipelines by specifying the execution engine [
19]. Despite Apache Beam being a unified programming language and not a data processing engine, it is still reviewed with the rest of the tools.
3.1. Apache Spark
Apache Spark [
12,
20] is a multi-language, open-source distributed-data-processing framework that has improved the world of big data analytics by speeding up data processing and being very accessible, allowing developers to seamlessly incorporate it into their pipelines [
21]. Its strengths are its speed, versatility, and ease of use. Each of these strengths helped Spark become an important component in the big data ecosystem. It offers a fast in-memory data processing engine that can handle a wide variety of workloads from batch processing to real-time streaming, machine learning, and graph processing [
16,
20,
22]. Spark is based on a resilient distributed dataset (RDD) abstraction model which is an immutable collection of records partitioned across several nodes [
19,
23,
24].
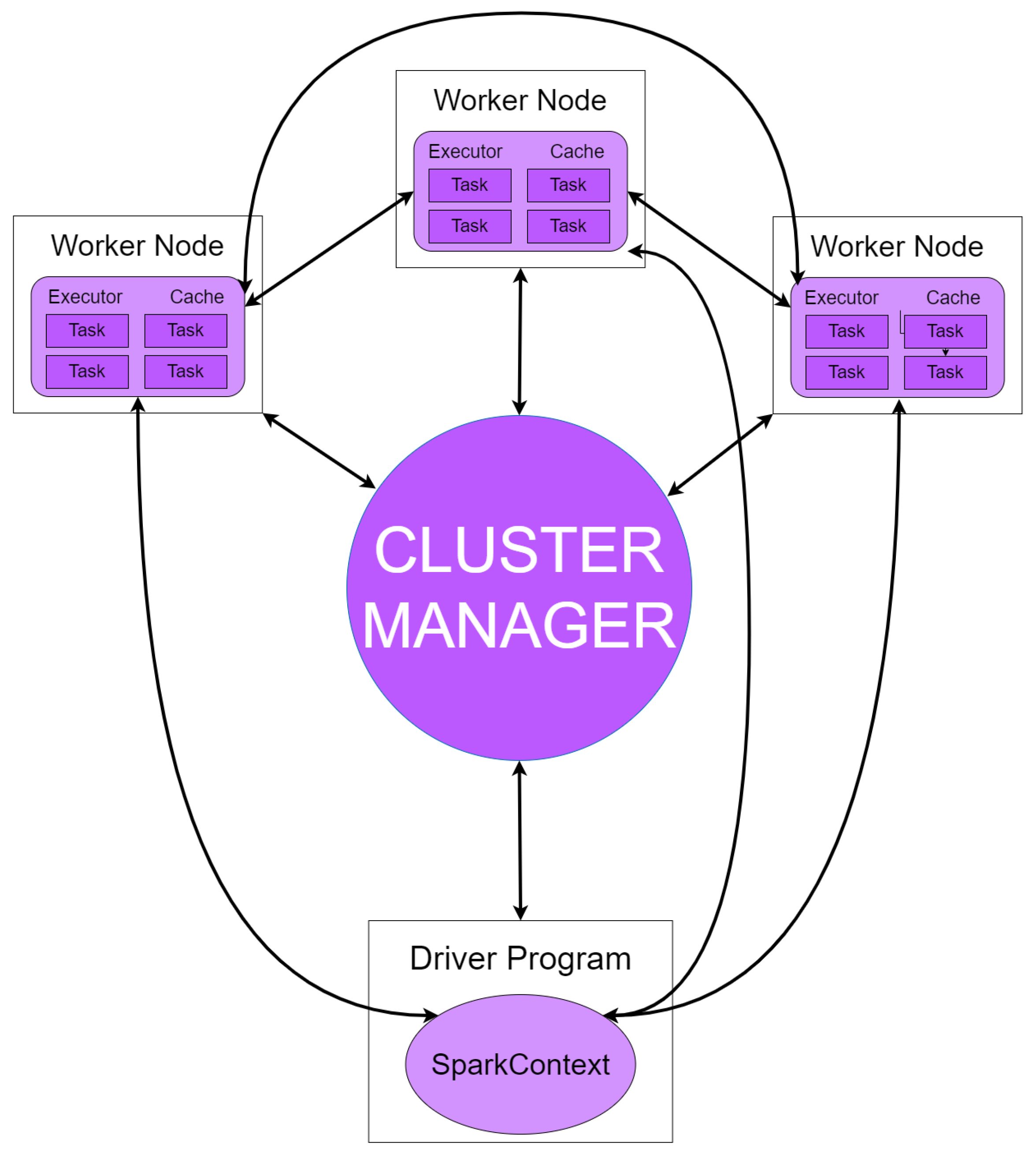
Figure 5 shows the architecture of the Spark cluster. The middle of the diagram is occupied by the Cluster Manager, which is responsible for allocating resources across applications. Spark acquires executors on nodes in the cluster once they are connected which are processes that compute and store data for the application. The application code (JAR or Python files passed to SparkContext on the left) is then sent to the executors. Finally, SparkContext sends tasks to executors to run [
21].
3.1.1. Benefits of Apache Spark
Apache Spark is one of the most popular data processing tools on the market [
16], and that is for a good reason. For example, Spark took Hadoop’s MapReduce and took it to the next level with less expensive shuffles during data processing. What allows it to be so fast is the fact that instead of interacting with a disk (it can interact with a disk as well, but in that case, it is slower), it keeps all its data in memory, or at least it keeps as much of the data in the disk. Spark also supports the lazy evaluation of big data queries, meaning that the values are calculated only before they are used, which optimizes performance.
Given today’s need to process a substantial amount of data in real time, Spark supports streaming data processing in addition to batch processing. It is important to emphasize that streaming data in Spark is not really streaming but processing mini-batches, which is an acceptable solution for many use cases. This allows Spark to be used in a wide variety of use cases ranging from streaming ones, such as finances, telecommunications, and IoT, to batch data ones like ML model training, data analysis, etc. [
27,
28,
29].
Aside from being very fast and versatile, another big factor that influences Spark’s popularity is its support for some of the most popular programming languages in the world, Python, Java, and Scala, by offering corresponding APIs [
24,
30,
31]. Additionally, it offers SQL and DataFrame APIs. The accessibility of Spark does not stop there as there is a very rich ecosystem of libraries, packages, and frameworks surrounding Spark, extending its capabilities and covering even more use cases [
27,
29]. These libraries are written by a very large active and open-source community surrounding Spark, which consequently increases and improves documentation built around Spark, clarifying its processes.
Spark seamlessly integrates with other data processing tools, such as Hadoop, Hive, and HBase, causing effortless merges into existing data infrastructures. With the increasing need to quickly process large amounts of data (not only in big data but also in popular fields such as ML [
30,
32]), Spark turned out to be one of leading data processing tools available. A summary of Spark’s benefits and advantages can be found in
Table 4.
3.1.2. Disadvantages of Apache Spark
In the previous section, we discussed Spark’s assets. However, there are some shortcomings that also must be taken into consideration when choosing the optimal data processing tool. One of the main benefits of Spark is its speed, which is the result of Spark operating in-memory. This high memory consumption causes higher operational costs, scalability limits, and challenges for data-intensive applications. Also, this means that the minimal requirements of a machine running Spark are much higher compared to disk-based applications like Hadoop MapReduce. If there is not enough memory to store a whole dataset, part of it is stored on disk, and that can degrade performance.
Another advantage mentioned in the strengths section was streaming data processing. As previously stated, Spark’s “streaming” supports many use cases but not all, as some applications require near-real-time results. In this regard, Spark is inferior to some of the other solutions currently available on the market. The third issue arises from Spark’s advantage: its steep learning curve. As stated in the previous section, Spark’s ecosystem is wide and varied, which is another double-edged sword. Spark is a “Swiss army knife” of data processing thanks to its wide range of libraries and frameworks, but using it effectively requires a thorough understanding of it, which may be difficult to achieve for some users. A summary of Spark’s disadvantages can be found in
Table 5.
3.1.3. Spark Integration and Managed Services
Apache Spark provides APIs for users to deploy and run on the cloud, making it widely used in various cloud computing platforms and services to power big data and analytics solutions. Several cloud providers offer Spark as a managed service or integrate it into their ecosystems.
Table 6 shows four cloud tools and platforms that use Apache Spark in the background:
These cloud tools and services provide a seamless environment for organizations to leverage the power of Apache Spark without the complexities of managing Spark clusters themselves. Users can scale their Spark workloads up or down, depending on their data processing needs, and take advantage of the cloud provider’s resources and infrastructure.
3.2. Apache Flink
Apache Flink is an open-source, unified stream-processing and batch-processing framework developed by the Apache Software Foundation [
38] for the standardized processing of data streams and batch processes [
30] and a high-level robust and reliable framework for big data analytics on heterogeneous datasets [
19]. It is a distributed streaming data-flow engine written in Java and Scala that executes arbitrary dataflow programs in parallel and in pipelines. Flink provides a high-throughput, low-latency streaming engine with support for event processing and state management. It is fault-tolerant in the event of machine failure and supports exactly-once semantics [
13,
21,
39,
40].
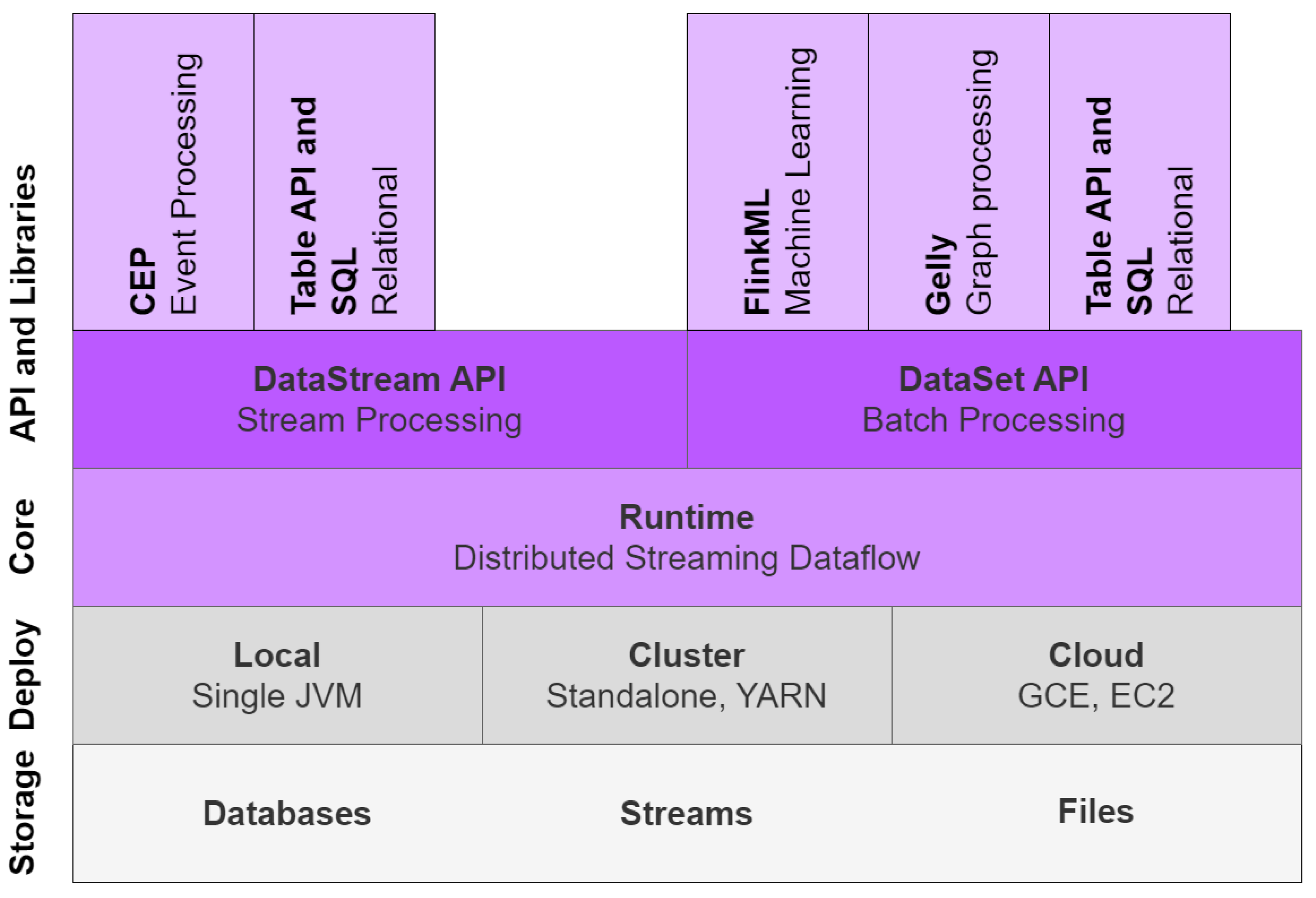
The core of Flink is the distributed dataflow engine which executes dataflow programs. Flink’s runtime program is a DAG of stateful operators connected with data streams. The two core APIs of Flink are the DataSet API, used in batch processing, and the DataStream API, used in stream processing [
32]. The core runtime engine (the green square in
Figure 6) serves as an abstraction layer for the two APIs. On top of the core level, Flink combines both domain-specific libraries and APIs [
13,
41].
Figure 7 shows Flink’s Cluster architecture. The runtime consists of a TaskManager and a JobManager, while the Client is not part of the runtime but is used to send a dataflow to the JobManager and can either be detached or attached later.
The JobManager’s responsibilities are deciding when to schedule the next task (or a set of them), reacting to finished tasks or execution failures, and coordinating checkpoints and recovery following failures, etc. There must always be a JobManager running, and by adding more, the system gains availability. When there are more JobManagers, there is always one that is declared the leader while the others are on standby. A JobManager consists of three components: a ResourceManager, a Dispatcher, and a JobMaster, which will not be discussed in this paper.
The TaskManagers (also called workers) are responsible for dataflow and buffering and exchanging data streams. There must always be at least one TaskManager. Each TaskManager consists of at least one Task Slot, and by adding more, concurrency is increased [
13].
3.2.1. Benefits of Apache Flink
Flink is a powerful tool specified for stream processing. It has high throughput and very low data-processing latency (in nanoseconds). Aside from stream processing, Flink as a secondary mode also supports batch processing, making it versatile and applicable in a wide range of use cases. Flink provides a guarantee for data consistency through exactly-once processing semantics, meaning that the data will be received only once, ensuring it arrives and preventing duplicates. Event time processing allows Flink to be suitable for event-driven applications that process data based on event occurrences as well as event reception.
In its architecture, Flink allows for the duplication of components, increasing the application’s durability and ability to tolerate machine failures. Also, a wide range of libraries and connectors expand Flink’s usages, allowing it to solve machine learning problems (with FlinkML) and complex event problems (with FlinkCEP) and, with the help of many connectors, allows Flink to communicate with various data sources, databases, and messaging systems [
32,
42].
Finally, Flink has a large, growing, and active open-source community built around it, and it is used in many organizations across different industries, which simplifies the process of learning and flattens the learning curve. A summary of Flink’s strengths and benefits can be found in
Table 7.
3.2.2. Disadvantages of Apache Flink
Just like with Spark, Flink also has some downsides, making it inferior to some tools in certain areas. A big issue Flink presents to new users is the complexity of its setup, especially in on-prem or on self-hosted environments. Hardships during deployment might cause developers to step away from Flink before deploying it successfully. Additionally, there is a steep learning curve for new users because of its extensive ecosystem, and mastering it takes a lot of time. Another issue that Flink has compared to some other frameworks is its immature community, which can lead to a smaller selection of third-party tools.
When it comes to processing, Flink blooms with stream processing but lacks other types. Even though support for batch processing exists, it is not nearly as efficient as stream processing, especially with large-scale jobs. Flink also manages resources suboptimally compared to other frameworks, and to optimize it, users need to manually tune the settings for resource allocation [
42]. A summary of Flink’s disadvantages and challenges can be found in
Table 8.
3.3. Kafka Streams
Kafka Streams is an important member of the Kafka ecosystem which allows developers to build applications and microservices using Kafka clusters as inputs and outputs. It is a stream-processing framework used for building streaming microservices in the Kafka ecosystem. Each instance of a stream-processing application is a Java application that uses a lightweight yet powerful Kafka Streams library, which allows it to communicate and coordinate the execution and partitioning of the processing using the Kafka broker [
18,
43,
44]. Though it is not the central point of the ecosystem, it is a valuable addition to it. Before Kafka Streams, developers had two options. The first one was to use producer and consumer APIs and write your own code that would process the data. This solution would become unnecessarily complex once non-trivial operations were included in the stream. This was due to the producer and consumer APIs not having any abstractions to help with such use cases, so the developer would be left to their own devices as soon as they added some more advanced operations to the event stream. The second solution was to incorporate a streaming platform, which added unnecessary complexity to the solution and added unnecessary power [
43]. The Kafka community recognized these problems and added Streams to the Kafka ecosystem which could be seamlessly incorporated into the solution and solve the same problems as the other streaming platforms but use less power [
17].
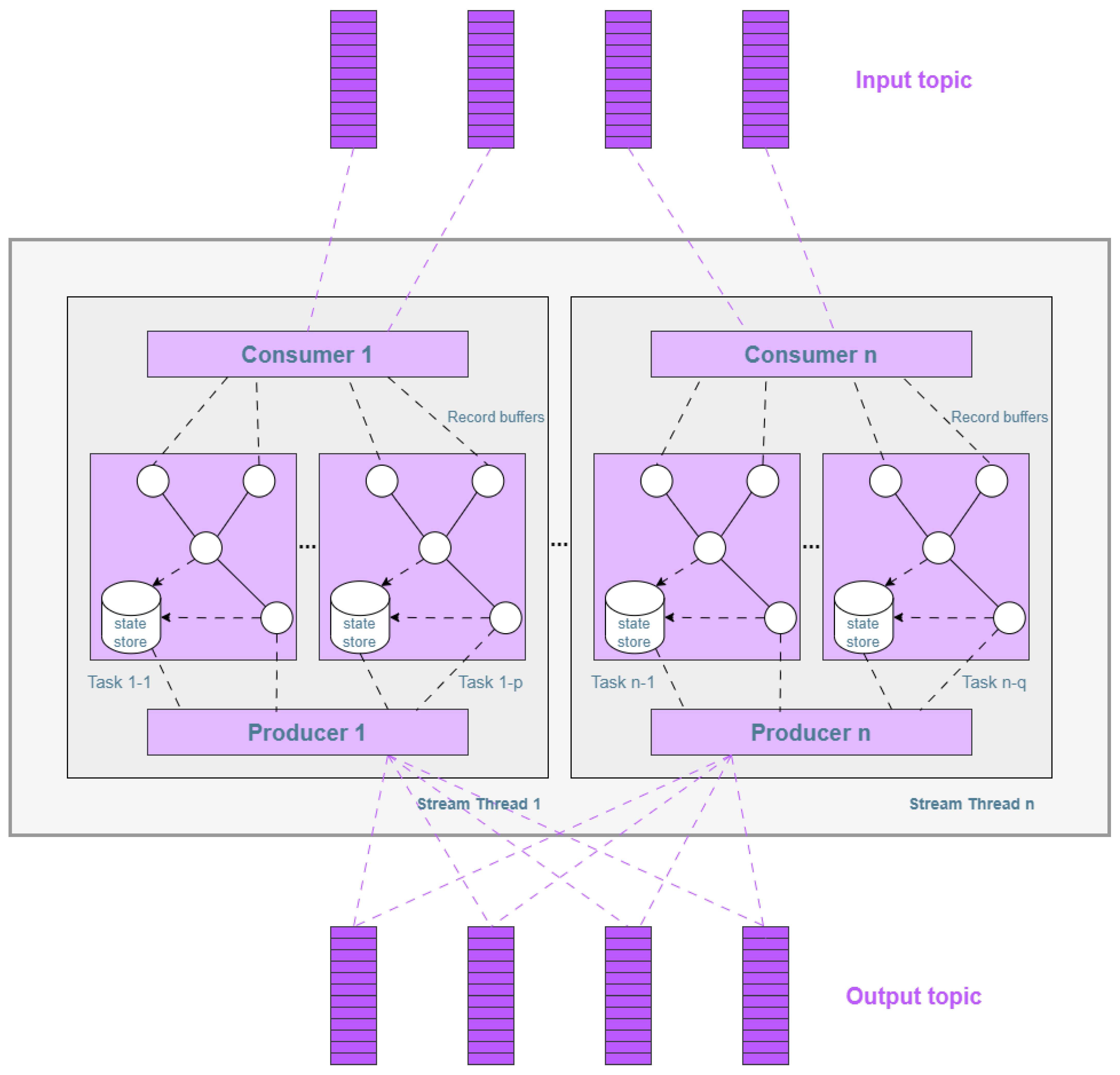
Figure 8 shows the Kafka Streams architecture. Input comes from stream partitions which map to Kafka topic partitions, and data records in the stream map to a message. Each consumer creates a number of tasks that are assigned to a list of partitions to achieve greater parallelism of the application. Every task creates its processor topology according to the assigned partitions. In Kafka Streams, a task is the smallest parallel unit of work. Parallelism is bounded by the number of partitions because the highest possible parallelism occurs when the number of tasks is equal to number of partitions [
14,
17].
3.3.1. Benefits of Kafka Streams
Kafka Streams stands out as a powerful tool for handling real-time data with many advantages, the first one being scalability. Since Kafka Streams is part of the Kafka ecosystem, there are a lot of similarities. Streams work with partitions, and by adding more partitions and consumer groups, Kafka Streams can handle a greater load, thus becoming more scalable. The reliability of Kafka is also transferred to Streams, where one can deploy a Kafka Streams cluster in which all instances are aware of each other. In case one instance fails, the others recognize the fault and automatically start another instance [
17].
Deploying Kafka Streams is also relatively easy. While some other data processing tools require you to build a whole cluster that connects to an existing application, Streams uses the Kafka infrastructure, which requires no extra work if the application already has Kafka [
17]. To add Streams to a system, the user simply adds it to the dependency of their Java project [
43].
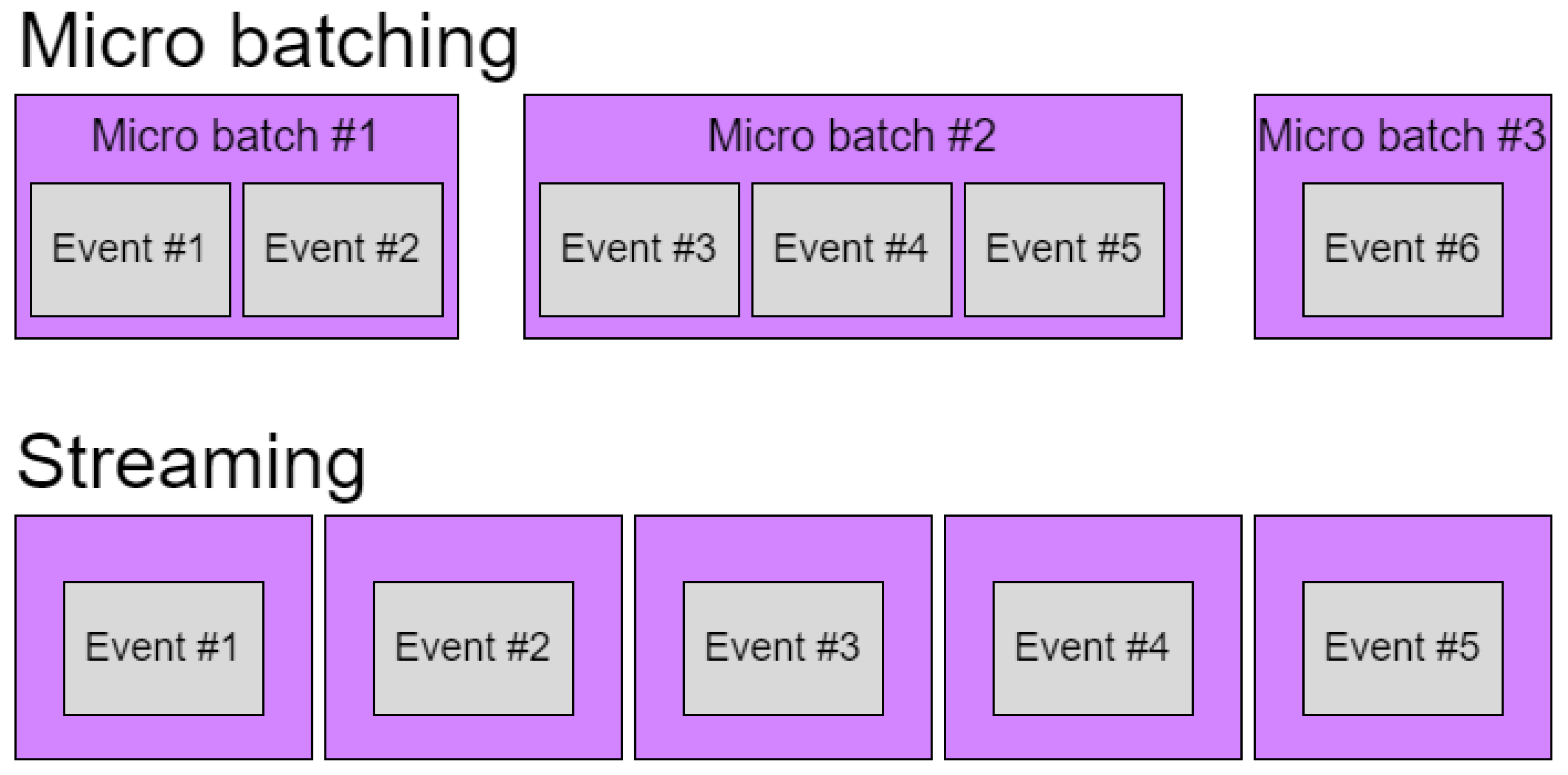
Kafka Streams processes stream data as opposed to some other data processing tools that use micro-batching. You can see the difference in
Figure 9. This makes Streams better for cases in which it is extremely important to have data in real time. The tradeoff here is that with micro-batching, systems achieve close to real time and high throughput, while with streaming, latency is extremely low but throughput is negatively affected. However, thanks to the Kafka architecture, Streams can increase throughput simply by adding another partition, mitigating this issue [
17,
43,
45]. A summary of Kafka Streams’ benefits can be found in
Table 9.
3.3.2. Disadvantages of Kafka Stream
Although Kafka Streams might prove to be a great streaming data processing tool, especially when it comes to systems using Kafka, there are some areas in which Streams does not work as well as its competitors. Mastering Kafka Streams is a long and difficult process. Even though it is easy to start with Kafka Streams, the journey becomes harder later.
When it comes to processing batches, Kafka Streams is not as good as Flink or even Spark because the other two (especially Spark) are more focused on batch streaming [
45,
46]. Also, resource management can be challenging, and users need to adjust the settings to achieve optimal results. A summary of Kafka Streams’ disadvantages can be found in
Table 10.
The final issue is that there are not many third-party tools, reducing flexibility. This is due to the Streams’ immaturity compared to other data processing tools. This also causes a lack of advanced monitoring and debugging capabilities which unnecessarily over-complicate troubleshooting complex topologies.
3.4. Apache Beam
Apache Beam is a unified model for both batch and parallel stream processing. It is not a data processing tool in the traditional sense. Instead, Apache Beam offers a programming model that allows data engineers to develop data processing pipelines in diverse programming languages [
47] that can be executed on various data processing engines, such as Apache Flink, Apache Spark, and Google Cloud Dataflow [
15,
29,
48]. Apache Beam does not process data by itself but rather defines the pipeline, along with the actual data processing engine. The purpose of Apache Beam is to simplify the usage of data processing engines by allowing the user to write pipelines in the programming language of their choice and to switch between these engines in an instant. The main goal of Apache Beam is to streamline the use of data processing engines. This is accomplished by allowing users to write pipelines in their preferred programming language with the flexibility to seamlessly switch between different processing engines as needed.
Apache Beam introduces a few abstractions, the first one being a pipeline. It is a complete description of the ETL job that will be executed, containing a description of the sources, operators, and sinks and the way they are connected. This pipeline is then executed by a Beam Runner. Another abstraction is a PCollection, which is a distributed, potentially unbounded, immutable, homogeneous dataset. Finally, PTransform is a data processing operation in the pipeline. Each PTransform takes data from one or more PCollections and produces zero or more PCollections as output [
15,
29,
41]
The program describing the pipeline is called a Driver program. It first creates a pipeline objective and then creates the initial PCollection from some external source. Then it creates one or more PTransforms which perform operations on this initial PCollection, creating altered PCollections which are potentially used again to derive new PCollections. Finally, using an IO operation, the final PCollection is written to an external source. This whole pipeline is executed using one of Beam’s runners [
29,
41].
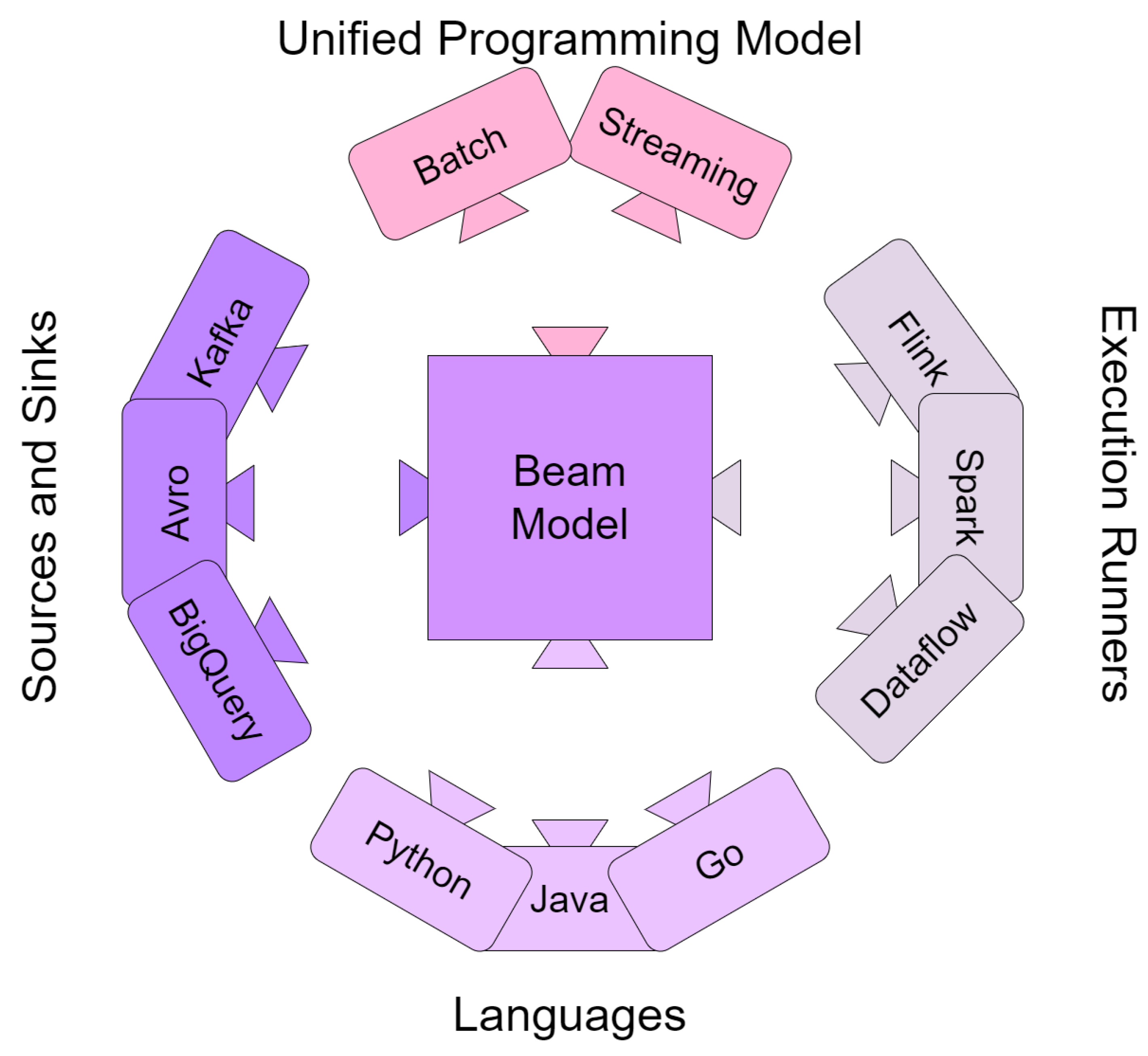
Figure 10 shows the model of Beam. The code for data pipelines can be written in Java, Python, Go, or any other language that supports Beam SDK. The pipeline is specified using the programming language which is passed to the Runner API that converts it into a generic standard language that can be used by the execution languages (Apache Flink, Cloud Dataflow, Apache Spark, etc.). The Fn API then provides language-specific SDK workers that act as a Remote Procedure Call (RPC) interface of User-Defined Functions (UDFs) embedded in the pipeline as a specification of the function. The selected runner finally executes the pipeline [
15,
22,
49].
3.4.1. Benefits of Apache Beam
The main benefit of Apache Beam is in allowing the user to define data processing pipelines in different programming languages (e.g., Python, Java, Go, etc.) as well as their preferred data processing engine. Beam then translates the code into a language the data processing engine understands. This allows the user to quickly switch data processing engines, simplifying testing, which helps the user pick the correct data processing engine. This also means that no matter if the data come in a stream or in batches, Beam supports both because it is not the one performing the processing but rather the tool used to select the processing engine. This is also true for resiliency; Beam inherits the fault tolerance of the processing engine it uses. If the user does not want to use a data processing engine, Beam comes with a built-in engine called Direct Runner, which should be used mainly for testing purposes.
Aside from picking any data processing engine, Beam can also be integrated with many different systems, such as data storage systems and messaging platforms. This further allows users to integrate Beam into almost any ecosystem. Furthermore, Apache Beam requires users to only consider four essential aspects: the nature of the calculated results, specifications for event time, specifications for processing time, and the relationships between result refinements. This streamlined approach enables users to concentrate on the logical composition of their data-processing jobs without studying the details of various runners and implementations. Apache Beam prioritizes ease of learning, emphasizing the logical aspects of data processing over the complexities of physical parallel processing orchestration [
29]. Apache Beam is an open-source project with an active community of contributors, making Beam a well-maintained framework with great support [
51]. A summary of Beam’s strengths and benefits can be found in
Table 11.
3.4.2. Disadvantages of Apache Beam
While Beam is a great tool, it still has some challenges to overcome. The first part is complexity; even though Beam simplifies some things mentioned in
Section 3.4.1., it also complicates the structure when pipelines have both batch and stream processing requirements. Also, mastering Beam’s model takes time and steepens the learning curve.
On one hand, Beam’s flexibility is a great selling point, but on the other hand, some processing engine optimizations might not be fully accessible through Beam. This makes them suboptimal compared to the use of these engines alone. An additional factor that impedes Beam’s application is suboptimal resource management because low-level resource management is abstracted away. Also, the additional layer of abstraction introduced by Beam creates at least some level of overhead, downgrading the system’s performance.
Finally, Beam might not be compatible with the newest version of a processing engine, which prevents Beam users from using the specific version of a processing engine until a new version of Beam that supports that version of the engine is released [
51]. A summary of Beam’s challenges can be found in
Table 12.
4. Discussion
This section discusses different scenarios and provides the preferred solution for developing an advanced web-based application for data processing tasks. When it comes to choosing the best data ingestion tool, Dataphos Publisher outperforms CDC, as demonstrated in
Section 2.3, which is why we believe Publisher is a better overall solution. Also, Apache Beam can be used if the user requires flexibility, such as developing pipelines in their preferred programming language and easily transitioning between data processing engines.
When it comes to selecting the best data processing tool, matters become more complicated because none of the tools we reviewed are best suited to every use case [
32,
41]. In the following two subsections, different use cases will be discussed. The solutions to the problems in the use cases were chosen based on the research conducted in this paper and are, in general, optimal solutions; however, in some use cases, they may be suboptimal in comparison to other solutions.
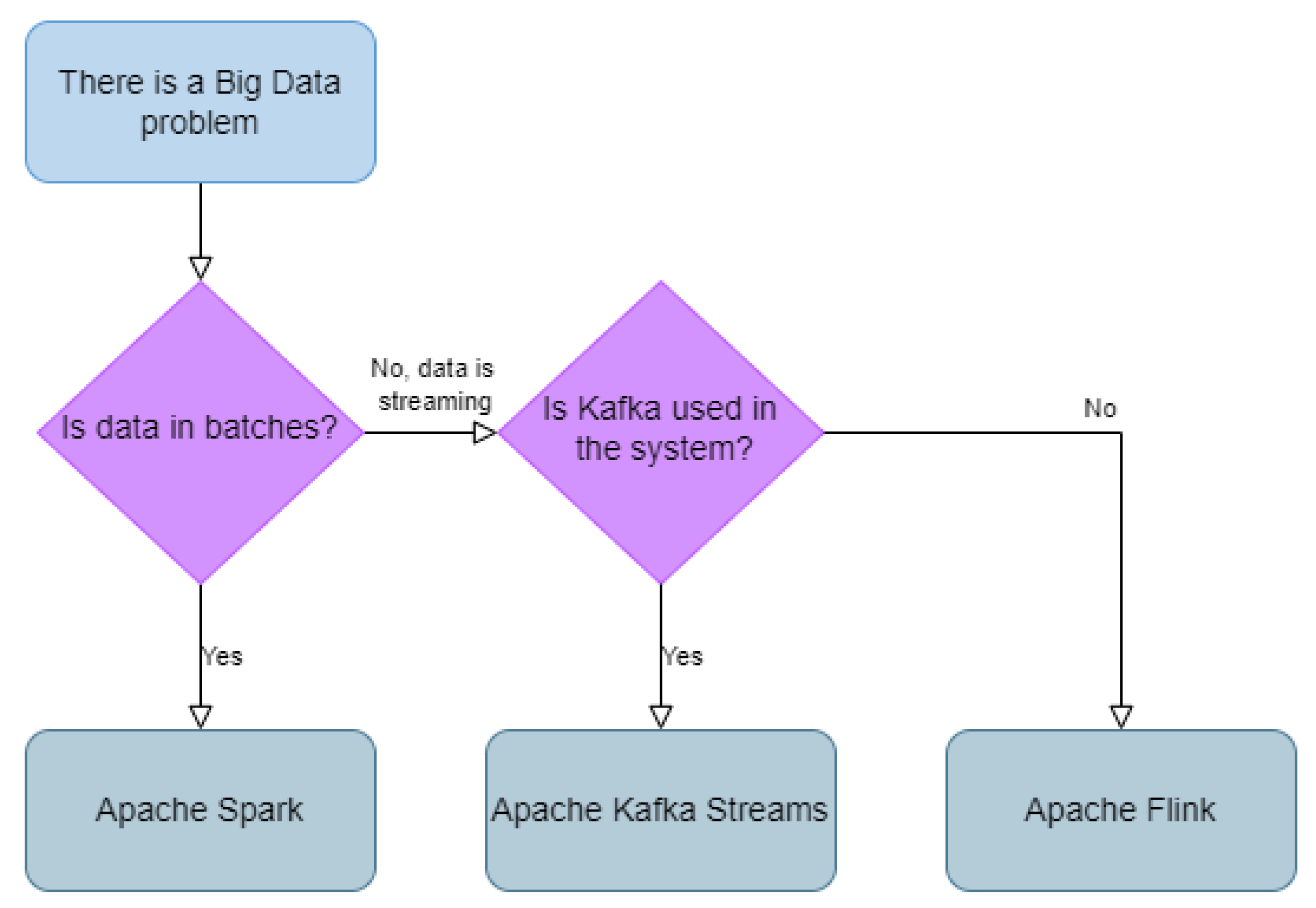
Figure 11 presents a flowchart with general guidelines for selecting the appropriate data processing tool. The following sections provide real-world examples in which a solution to a data processing tool selection dilemma is proposed based on the algorithm shown in
Figure 11.
4.1. Use Case 1
Use case 1 involves a sophisticated fitness application designed to help users set and track their fitness goals. This app synchronizes with a smartwatch and collects important data such as heart rate, exercise duration, and the type of physical activity. As the user exercises, the smartwatch continuously transmits these data to the backend system via a message broker, distinct from Apache Kafka. The backend system processes this information and forwards it back to the user’s smartwatch or smartphone. Using these data, the app performs a customized data analysis and provides a comprehensive set of statistics, including calories burned, remaining sets for goal achievement, and more. Crucially, this entire process occurs in real time, which requires fast data processing.
In this scenario, Apache Flink proves to be the most suitable choice among the data processing tools discussed in our paper. Flink excels in managing streaming data, which aligns perfectly with the application’s need for immediate data processing. While Apache Spark is also a viable option, Flink offers a more direct solution as it processes continuous data streams as opposed to the Spark’s approach, which simulates streams through micro-batching. Kafka Streams is not the ideal solution here due to the absence of Apache Kafka in the application’s message-brokering system. However, if Kafka had been used as a message broker, Kafka Streams would have been the preferred choice for data processing.
4.2. Use Case 2
Use case 2 involves a retail analytics platform that analyzes sales data and dynamically updates product recommendations. This application continuously collects sales data throughout the day. At the end of the day, it processes this information to identify trending products and items that are frequently viewed by the current user. The processed data are then sent back to the app, which can recommend products that the user is likely to like and provide information about product availability in stores or delivery options.
For this scenario, Apache Spark proves to be the optimal choice due to its ability to process large amounts of data. Apache Flink, while also capable, is more tailored to processing streaming data and may not be as efficient in this context. Kafka Streams is not the preferred option here, similar to Flink and additionally due to the lack of integration of the Kafka ecosystem into the application framework. Therefore, Apache Spark, with its robust data processing capabilities, is the most suitable tool to improve the user experience on this retail analytics platform.
5. Conclusions
The objective of this paper is to explain how advanced web applications for data processing work, emphasizing the significance of data ingestion and processing in the contemporary digital environment. Firstly, we have detailed the architecture of Dataphos Publisher and conducted an experimental analysis to compare its performance with traditional CDC platforms. In the experiment, Dataphos Publisher demonstrated superiority over CDC. Secondly, this paper provides a comprehensive overview of various data processing tools. This includes a qualitative exploration of their functionalities, strengths, and limitations, providing the reader with a clear overview of the wide range of available options. Finally, the paper provides practical guidance for data engineers on how to build advanced web applications, including a framework for selecting the most appropriate tools for data ingestion and processing based on the application scenario. The motivation for this was to improve the understanding and use of these technologies and thus facilitate the development of sophisticated and efficient web applications.
Dataphos Publisher follows a “Create–Transform–Publish at source” pattern, utilizing a Relational Database Management System to transform data into structured business objects right there at the source. Data undergo formatting, serialization, compression, and encryption, resulting in a substantial reduction in network traffic. This approach also ensures robust security, making it suitable for use on both public Internet and private networks. In the context of advanced web applications, it serves as a data ingestion tool as it handles huge amounts of data very quickly. When a user interacts with the app, data are collected, and the publisher uploads it to a message broker in the cloud.
Data processing is the second major big data process addressed in this paper after data ingestion. The primary objective of data processing is to handle vast quantities of data, either in real time or in large segments or batches. Each of the data processing tools described in this paper provides distinct advantages and disadvantages, and none of the tools are dominant in all scenarios. This paper provides a comprehensive qualitative examination of three tools: Apache Spark, Apache Flink, and Kafka Streams. Additionally, it explores Apache Beam, a tool specifically designed for constructing data pipelines.
Apache Spark shows its distinct advantages in in-memory processing and closes the gap between batch and real-time data analyses. Its extensive ecosystem of libraries and packages tailored to machine learning, graph processing, and more showed its multifaceted capabilities. Apache Flink proved to be a great tool for real-time data processing characterized by low latency and exactly-once semantics. Its capabilities in processing high-throughput data streams, coupled with stateful processing, made it a formidable force, especially in industries that demand immediate insights and event-driven workflows. Kafka Streams, like Flink, has proven itself as a real-time data processing tool because it is a library that is tightly interwoven with the Kafka ecosystem. It offers seamless event-time processing and exactly-once semantics, making it a must-have player in industries in which data streaming and event-driven applications dominate. Apache Beam introduces a unified model, promising versatility, and portability. With support for multiple languages and compatibility with various processing engines, it has proven to be a great tool that provides a single customizable framework that can orchestrate both batch and streaming data.
The future of web development depends on advanced applications. A robust and scalable backend infrastructure is essential for this development. The use of Dataphos Publisher together with advanced data processing tools is an example of this approach and sets standards for the efficient and dynamic development of advanced web applications. Future work in this area is likely to focus on further improving the efficiency and scalability of data ingestion and processing tools and addressing new challenges related to data security, privacy, and compliance on increasingly interconnected digital platforms.
The integration of artificial intelligence (AI), machine learning (ML), and deep learning (DL) technologies into data processing tools is another area that should be intensively researched. This could lead to more intelligent, predictive, and adaptive web applications that not only respond to users’ needs but also anticipate them. In addition, the development of more sophisticated data processing algorithms and the exploration of new data storage technologies will facilitate the processing of larger amounts of data with greater speed and accuracy.
In terms of practical applications, future research could look at developing more user-friendly interfaces for these complex tools to make advanced data processing accessible for a wider range of users, including those with non-technical backgrounds. In addition, there is a growing need for research in optimizing data processing for different types of networks from high-speed fiber optic networks to 5G telecommunication networks and slower, intermittent connections in remote areas.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}