This section presents the kinds of logs and also the prepared ML tools. The dataset will be based on performance logs (generated by and ).
4.1. Types of Logs
There are various types of logs based on their different scopes of operation, but the principle of operation is common—they are used to report and record events along with timestamps. Server logs record events related to server operation, such as client requests or server errors. In the context of an HTTP server, they contain information about who visited our site (IP address) and what resources (URL addresses) were visited at a given moment. The user-agent is recorded as well—a header identifying the client’s browser and system. Application logs have all the application’s actions recorded in them, such as errors, exceptions, or events related to user handling or processes called by the application. Their main application is to point out the source of the problem in the case of encountering potential errors with the operation of the application. System logs record all events related to the operation of the operating system, such as starting and closing the system, installing and removing packages, changes in configuration files, etc. They contain valuable information for system administrators in case the system is not working properly, e.g., unexpected device shutdown. Network logs are generated by network devices, such as routers, switches, or hardware firewalls. They record events related to network activity, such as network connections, data transfer, or successful network configuration. Security logs are usually a subset of system logs. They record events that could potentially be dangerous to network infrastructure, such as attempts to log into the system without appropriate permissions, network attacks, or attempts to access protected resources. The performance log can log request activities and their min/max/average response time and the number of requests for different time frames or resource loads (the CPU or memory utilization). In summary, monitoring based on log collection is implemented in many solutions that are important for IT designers. It allows for tracking and the analysis of the operation of IT systems, thanks to which we can identify and solve technical problems, monitor the performance of applications, and react to potential security threats through the logs collected. The most characteristic group among the above is application logs. The nature, format, and detail of the generated logs are entirely dependent on the programmers, who can appropriately adjust these features depending on the needs, requirements of the application, and environment in which it is deployed. The prevailing log formats are a text recording in the standard applicable to them: Common Log Format, W3C Extended Log, Syslog, JSON, XML, or CSV.
The stock market system () during the simulation, initiated by the benchmark platform (), generates four performance logs in the CSV format (table data). These are the following, in order:
—logs of the queries performed by the user, e.g., submitting an offer;
—logs of the parameters of consumption of the stock exchange replica—the processor and RAM;
—logs concerning the number of bids/asks submitted;
—logs of the processor and RAM consumption on the traffic generator ().
Performance user query logs carry entries about the queries executed by users and the associated resource parameters (
Table 3). The queries are generated by a load generator (
APP2) based on previously set simulation parameters.
The exchange system is scalable, meaning the number of exchange application containers could be adjusted according to the performance capabilities of the architecture upon which the system operates. Performance replica logs contain information about hardware resource consumption from each predefined exchange application node at regular time intervals (
Table 4).
During the operation of the exchange system, purchase and sale offers of shares are paired and processed by a transaction algorithm. This algorithm determines the feasibility of the transaction finalization in between players trading on the exchange. Also, the transaction algorithm generates performance logs during its operation (
Table 5).
The final type of logs are traffic generator logs of performance, which contain information about the consumption of hardware resources registered on the traffic generator (
). In contrast to the previous logs, the
parameter does not appear here as the traffic generator application operates on a single replica (
Table 6).
The aforementioned logs, generated by the individual components (
and
), have been merged. The purpose of this operation is to facilitate further data analysis and to enable consideration of all features/attributes within the entire system. The only difference between them is that
primarily uses the query log file (
), while
is based on the exchange replica logs (
). This aims to create two datasets of significantly different sizes (
Table 7).
Logs contain a plethora of information, which aids in managing individual systems. Proper implementation of the logging mechanism and its analysis are not only beneficial for software developers but also for IT system administrators and regular users. According to a paper [
24], there are four categories in which the implementation of a logging mechanism in a system will bring tangible benefits: performance, security, prediction, reporting, and profiling. For performance, log analysis might aid in system optimization or debugging when problems arise. Security is another advantage of implementing a logging mechanism. Logs store system security-related information, such as security breach event logs, network flows, user login sessions, etc. The analysis of such logs is based on previously prepared security templates or anomaly detection mechanisms. Predictive models based on generated logs forecast future trends. For example, predictive models developed based on available data can assist in automating or enhancing knowledge about load management, server resource delivery, or system configuration optimization. The final group considered is reporting and profiling. Data collected in system logs are grouped by certain characteristics. For example, websites visited by users in a local network could be divided into categories, thus allowing the profiling of user groups interested in a particular topic. Other applications of log analysis may include system resource profiling in terms of load.
Insights derived from the analysis of active IT system logs could significantly contribute to improving the system’s performance, security, and efficiency in event monitoring. Performance logs are used for the implementation of data feature/attribute classifiers (prediction).
4.2. Log Dataset Analysis
In this section, we present the proposed methods, including the operational methods and types of algorithms, as well as the approach to log analysis of the stock exchange system, which could also be applied in the analysis of logs from other web applications. The described issues include studies of ML techniques (supervised learning algorithms—classification). Before applying the above methods, it is recommended to use EDA to understand the characteristics of the logs, as presented in the article [
2]. This study focuses on classification.
Data classification theory is a field that develops methods and algorithms for assigning objects to specific classes based on their attributes or features. A classification algorithm is a supervised learning technique used to identify the categories of new observations based on training data. The operation of classification involves using a model that has previously been trained (on a training set) to recognize patterns and relationships in data, in order to predict appropriate classes for new, unlabeled data. The output variable of classification is a category (class), which is a designation of a group to which a given observation belongs. In the case of prediction, where the output variable is a numerical value, not a category, we use supervised regression methods. A classifier that predicts only two possibilities is called binary, while one that considers a larger number of possible outcomes is called a multiclass classifier. The general process of data classification can be divided into several steps: data collection, data preparation, model selection, model training, model evaluation, and prediction.
There are many different types of classifiers used in data classification. Classifiers (classification algorithms) could be divided into two categories due to the nature of the model built: linear or nonlinear. Below are examples of algorithms from both of these categories: linear models (linear regression, logistic regression, and support vector machines (SVM)), and nonlinear models (naive Bayes classifier, k-nearest neighbors (KNN) algorithm, decision trees, and neural networks).
Algorithms based on decision trees are popular in the field of machine learning and data analysis. Decision trees generated as a result of the Classification and Regression Trees (CART) algorithms are graphical representations of a hierarchical decision structure. The structure of such a tree consists of nodes (vertices), branches, and leaves. Nodes conduct tests on the values of features/attributes; branches are the outcomes of a given node, e.g., yes/no (binary tree); and leaves represent the results of the classification. Decisions or tests in the decision tree are made based on attributes of a given dataset and feature values. The operation of the CART algorithm is as follows: feature selection, data division, tree construction by recursive data divisions, and ending the tree construction. The built decision tree, as a result of the described steps of the CART algorithm, can be used for the prediction of new data. If the problem we are solving is more complex, it is possible to increase the depth of the generated tree or to use other measures to examine the quality of divisions in the tree. Also, it is possible to modify the existing tree model by pruning branches that negatively affect the final model.
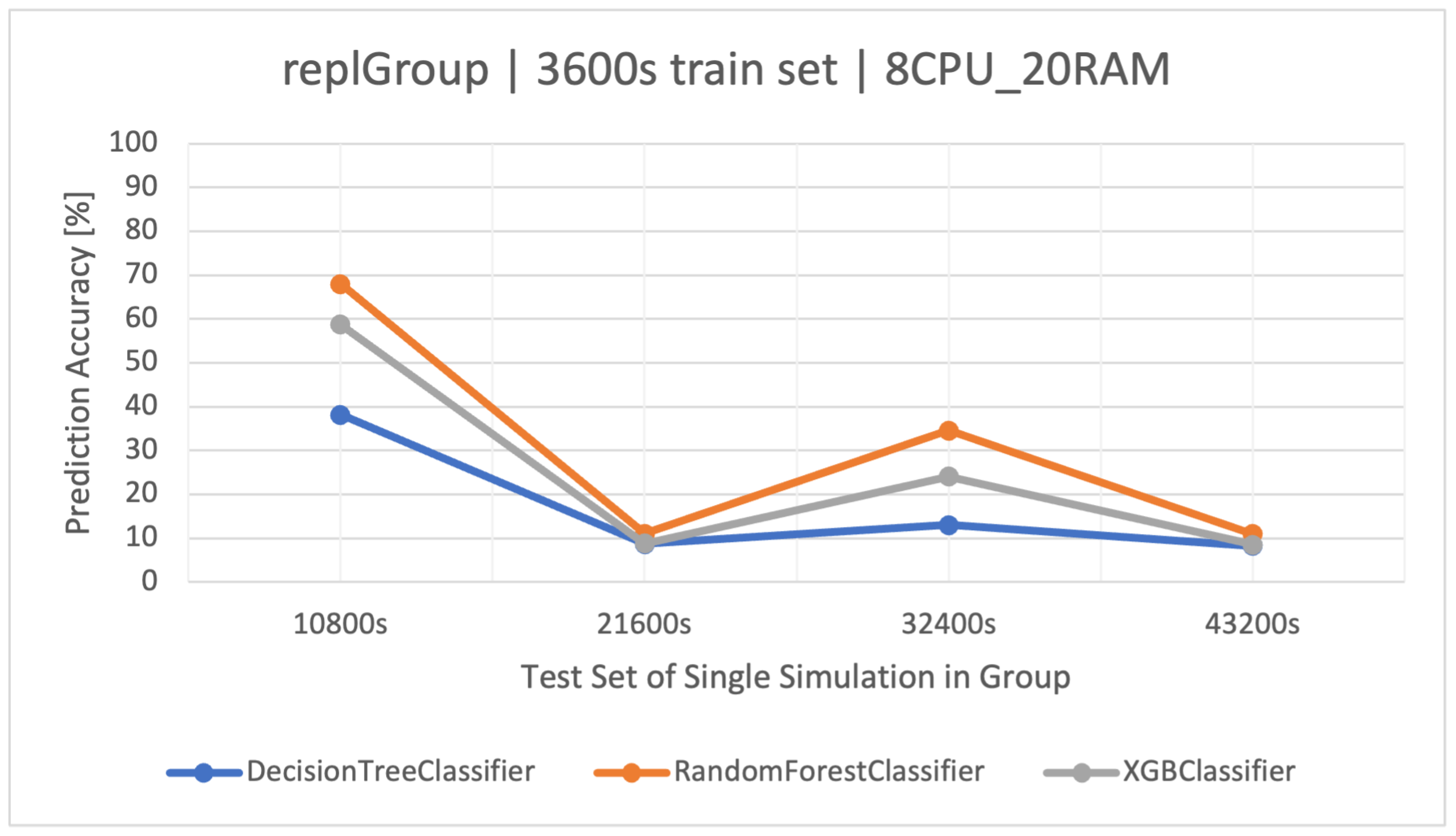
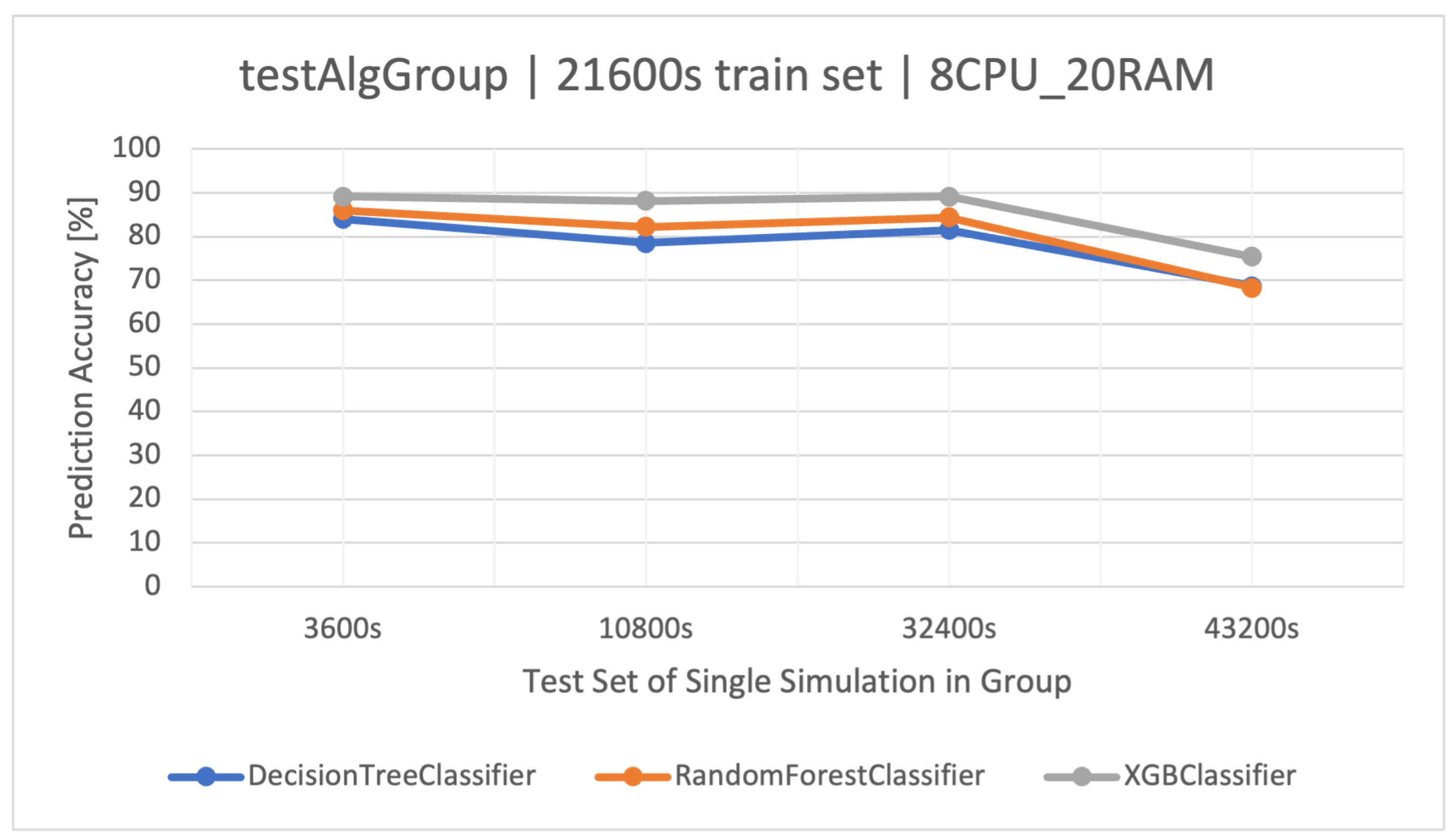
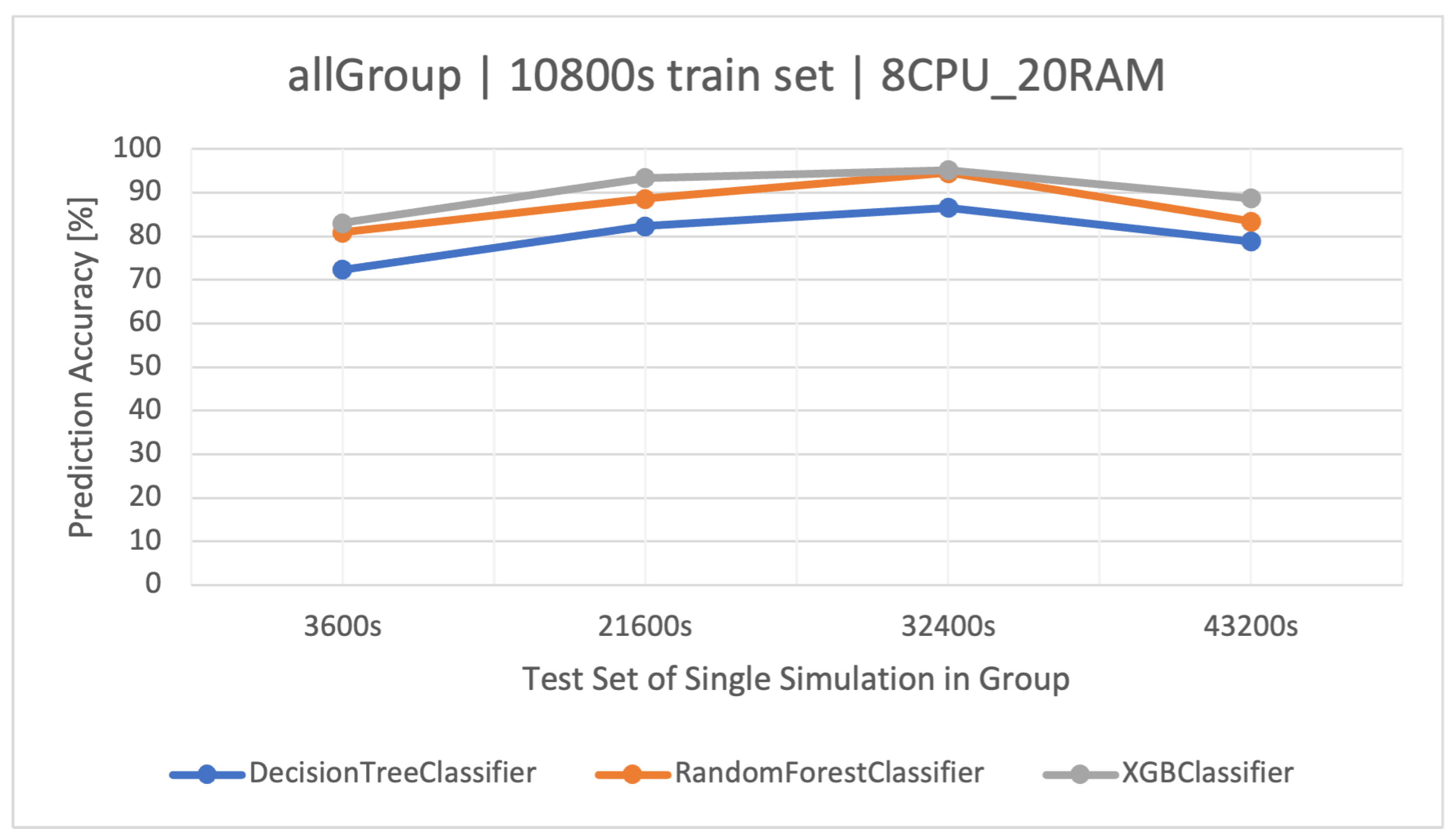
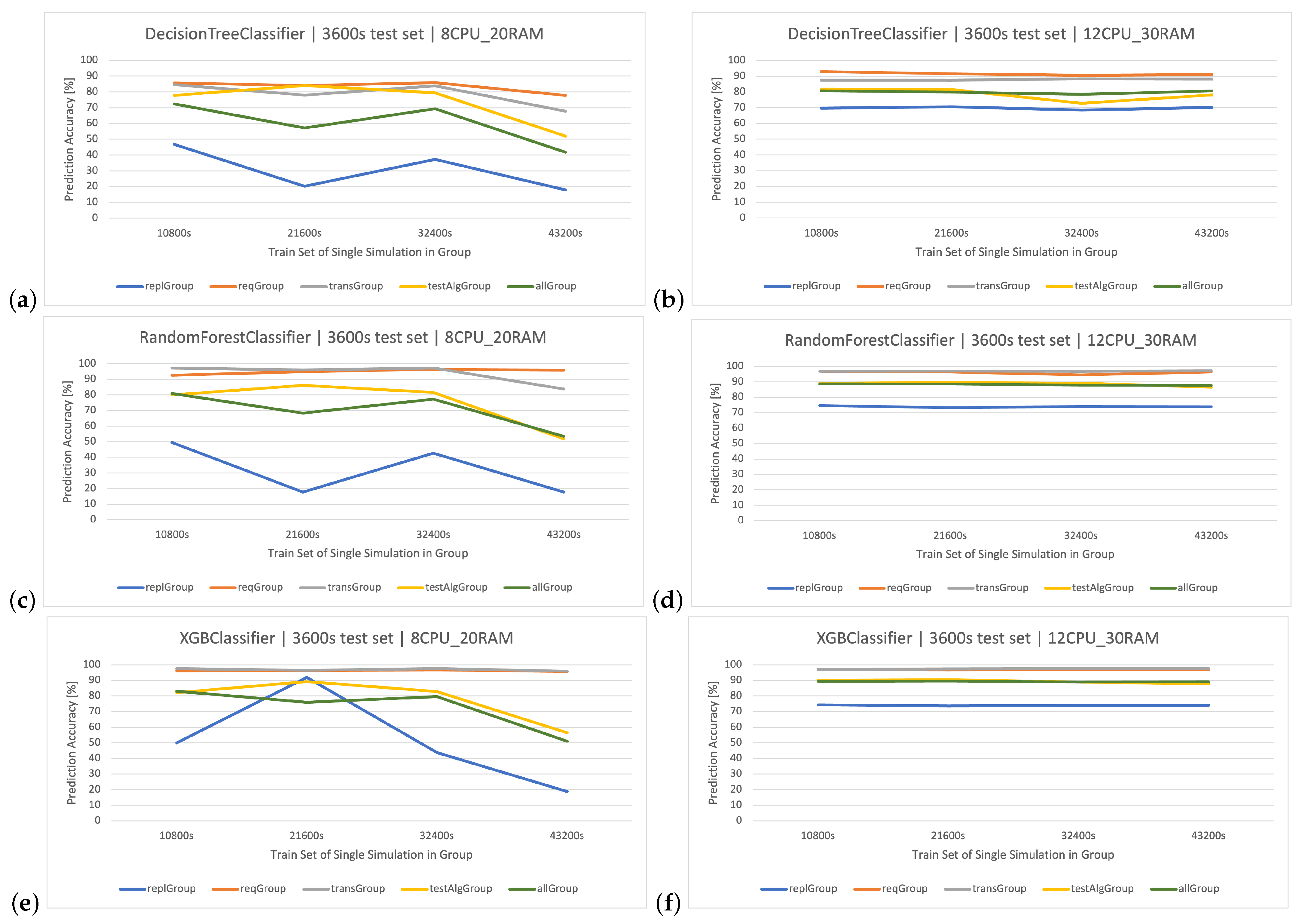
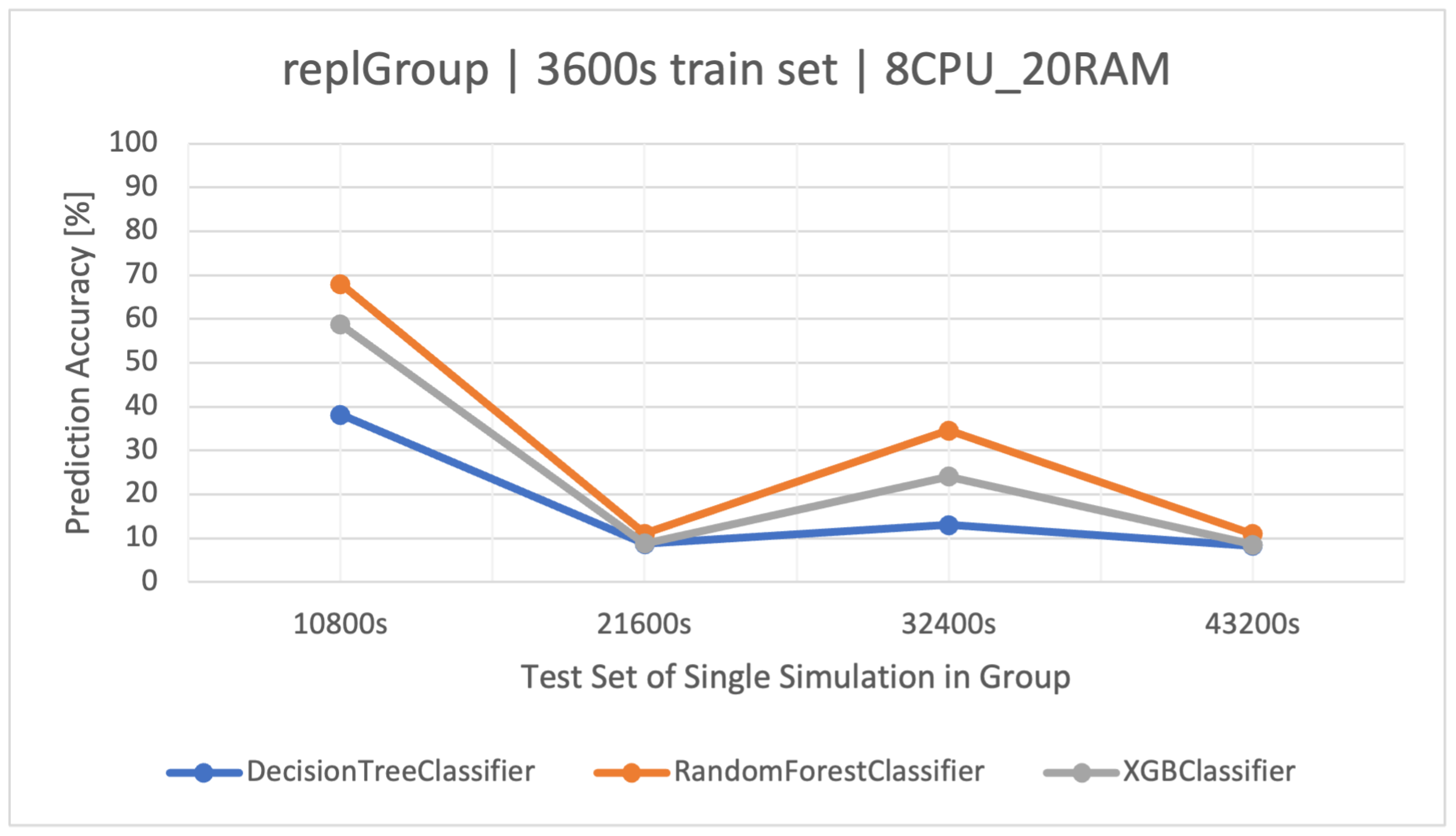
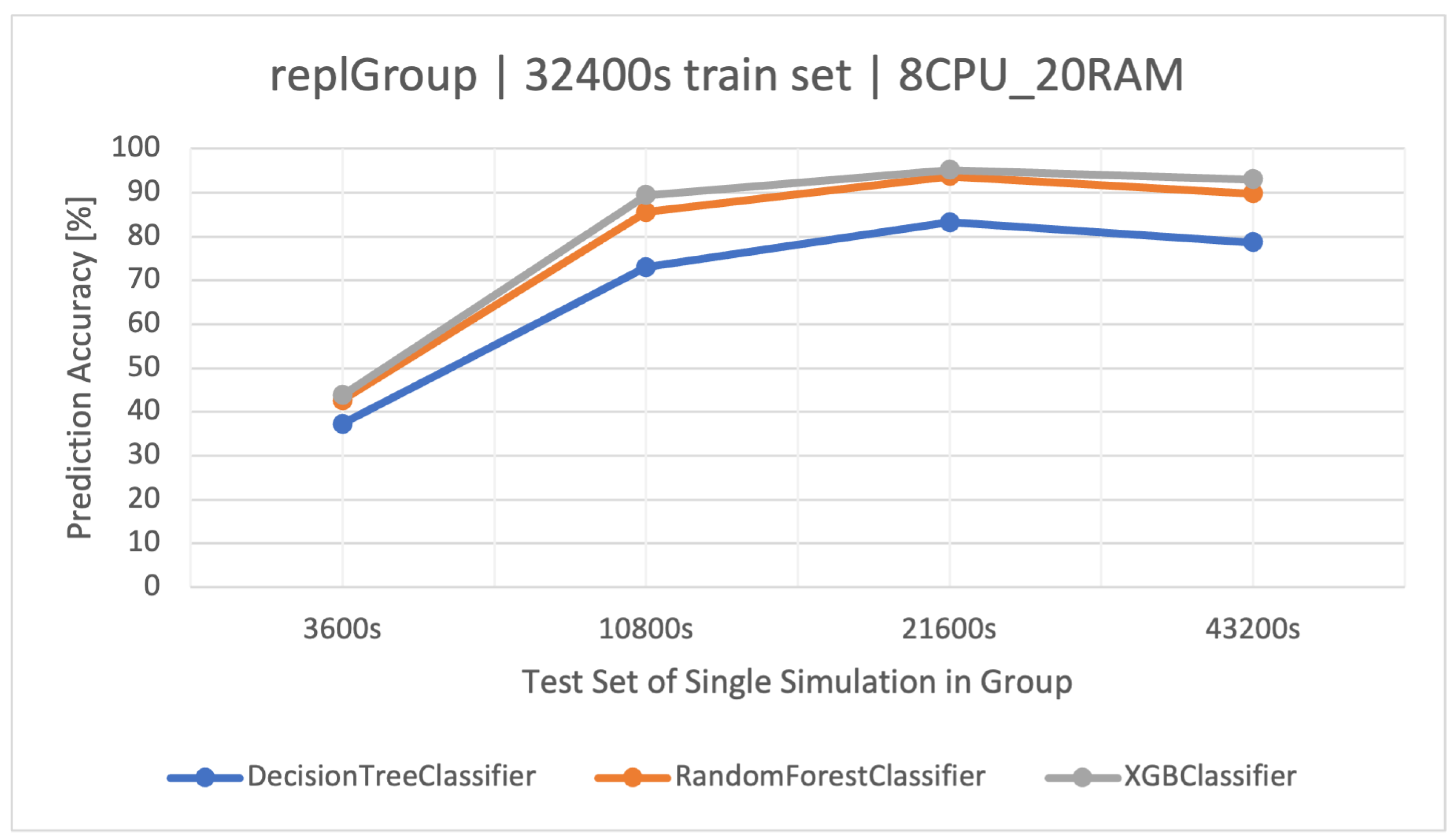
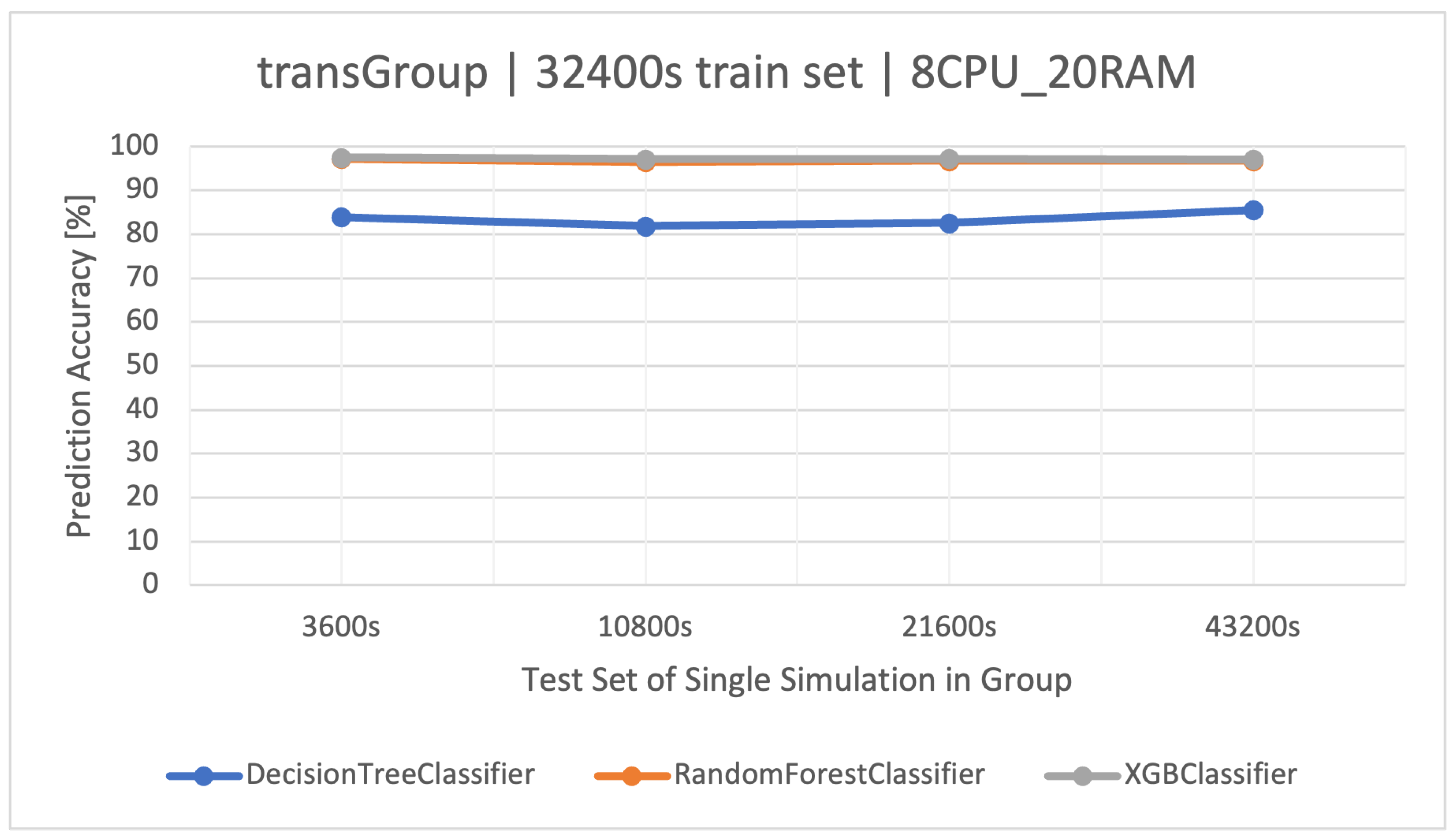
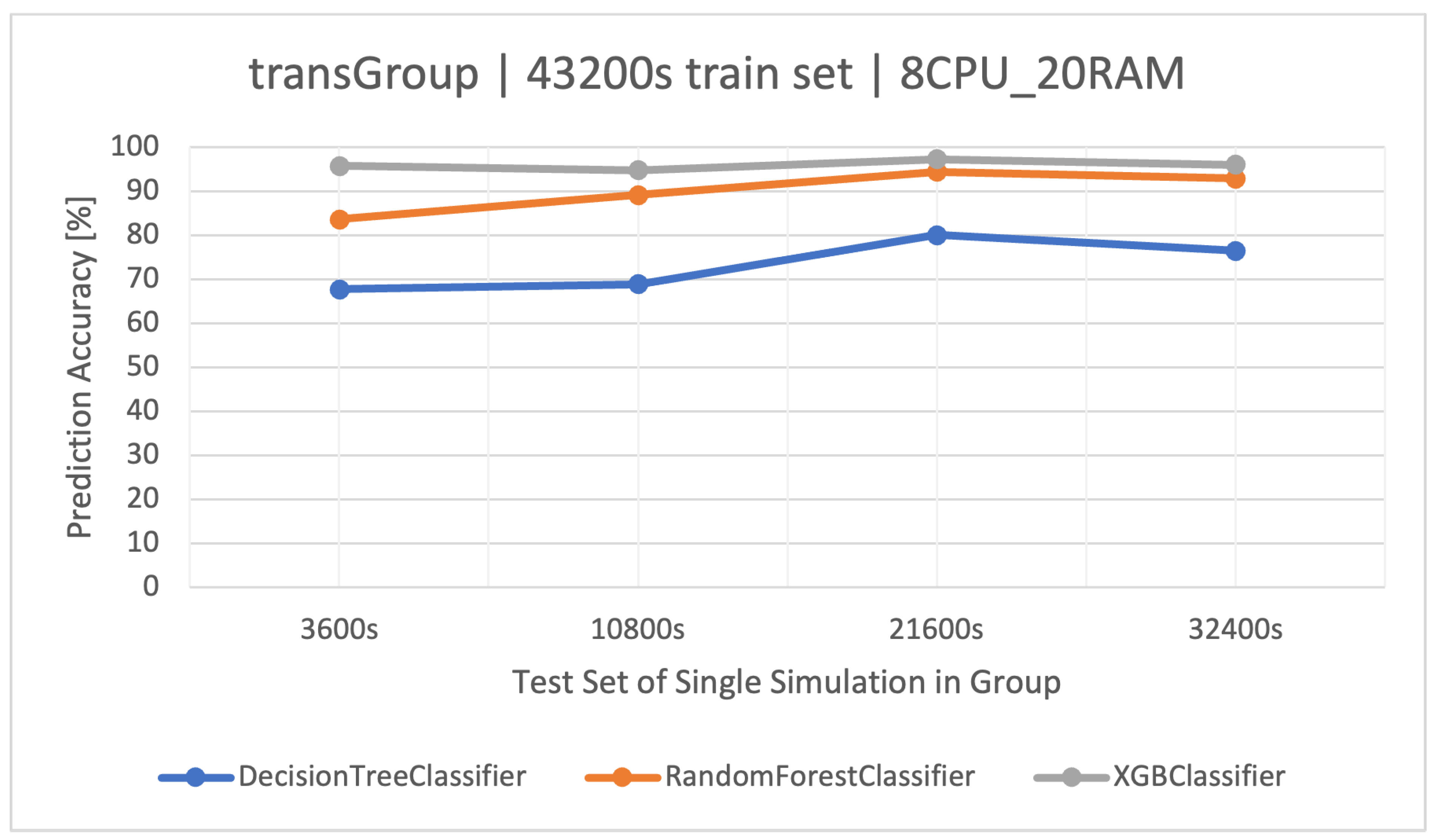
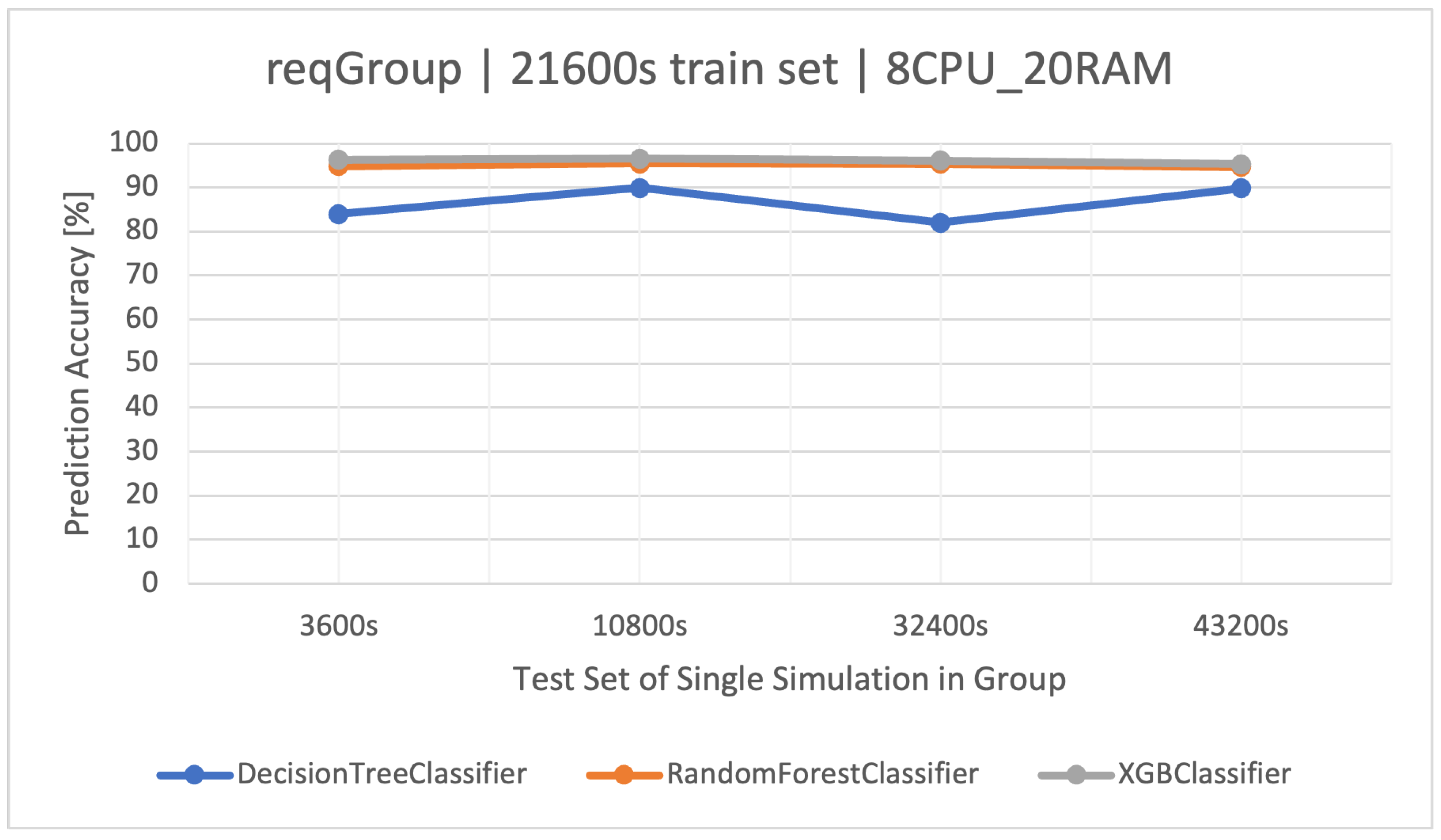
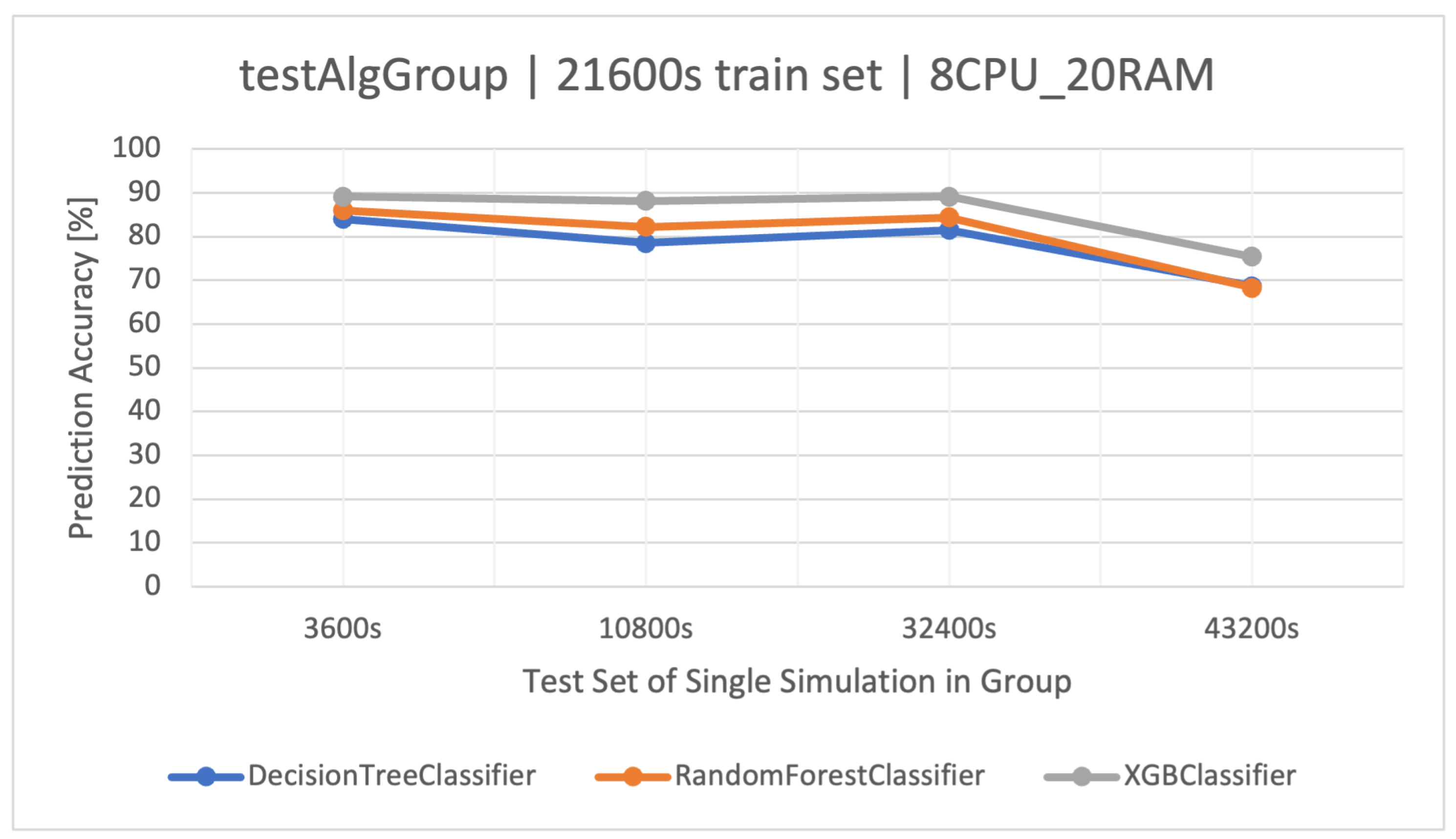
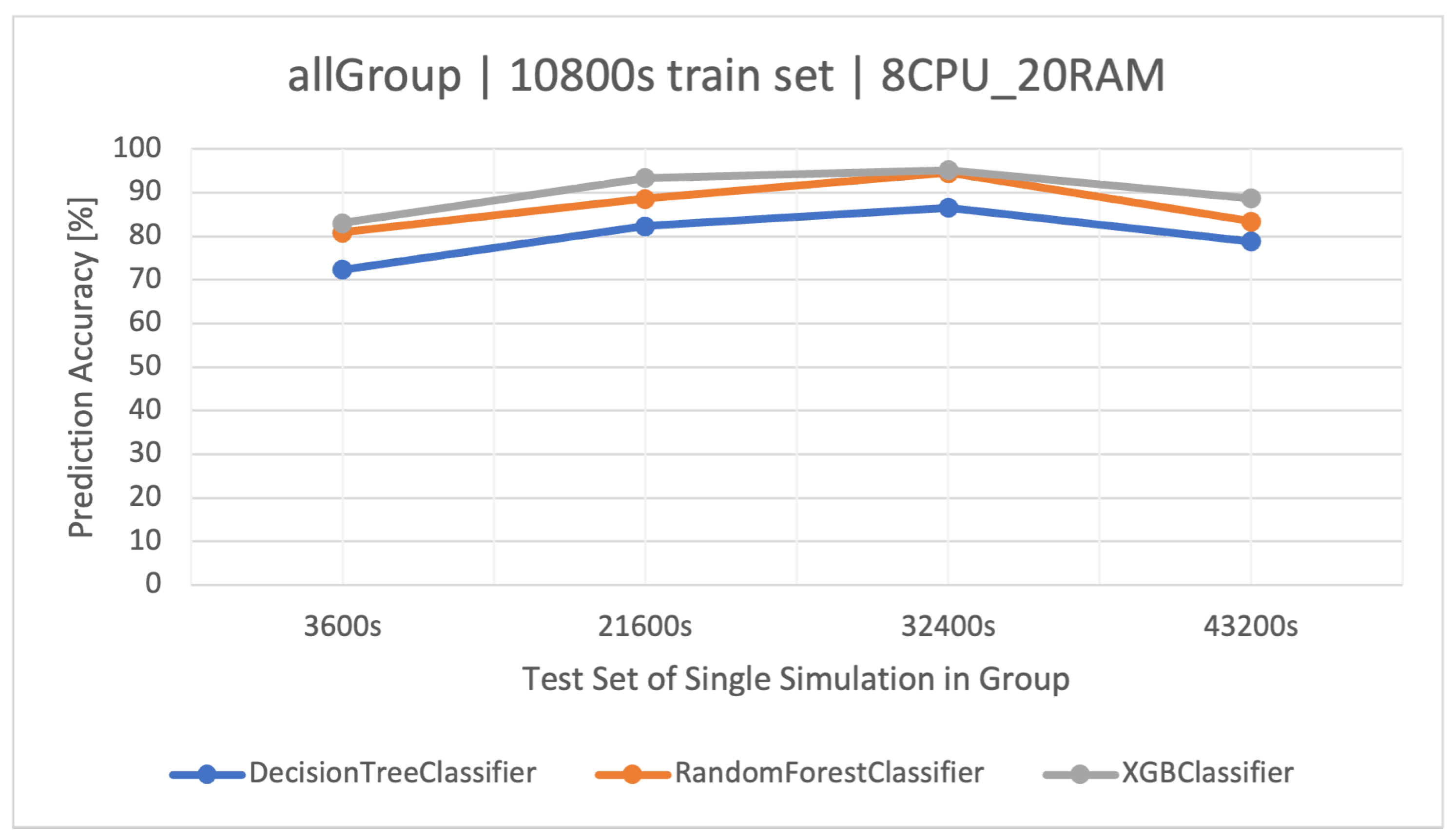
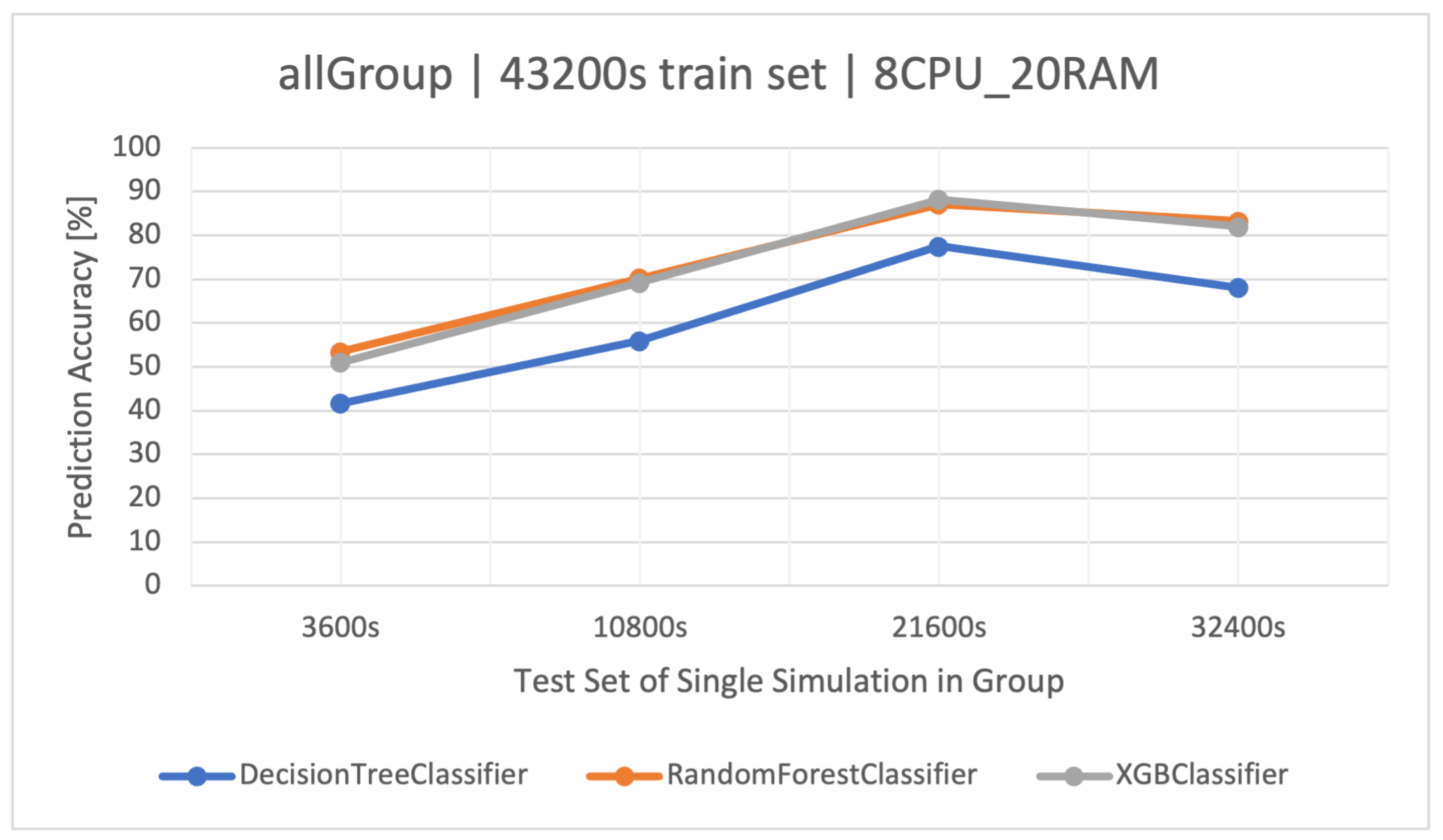
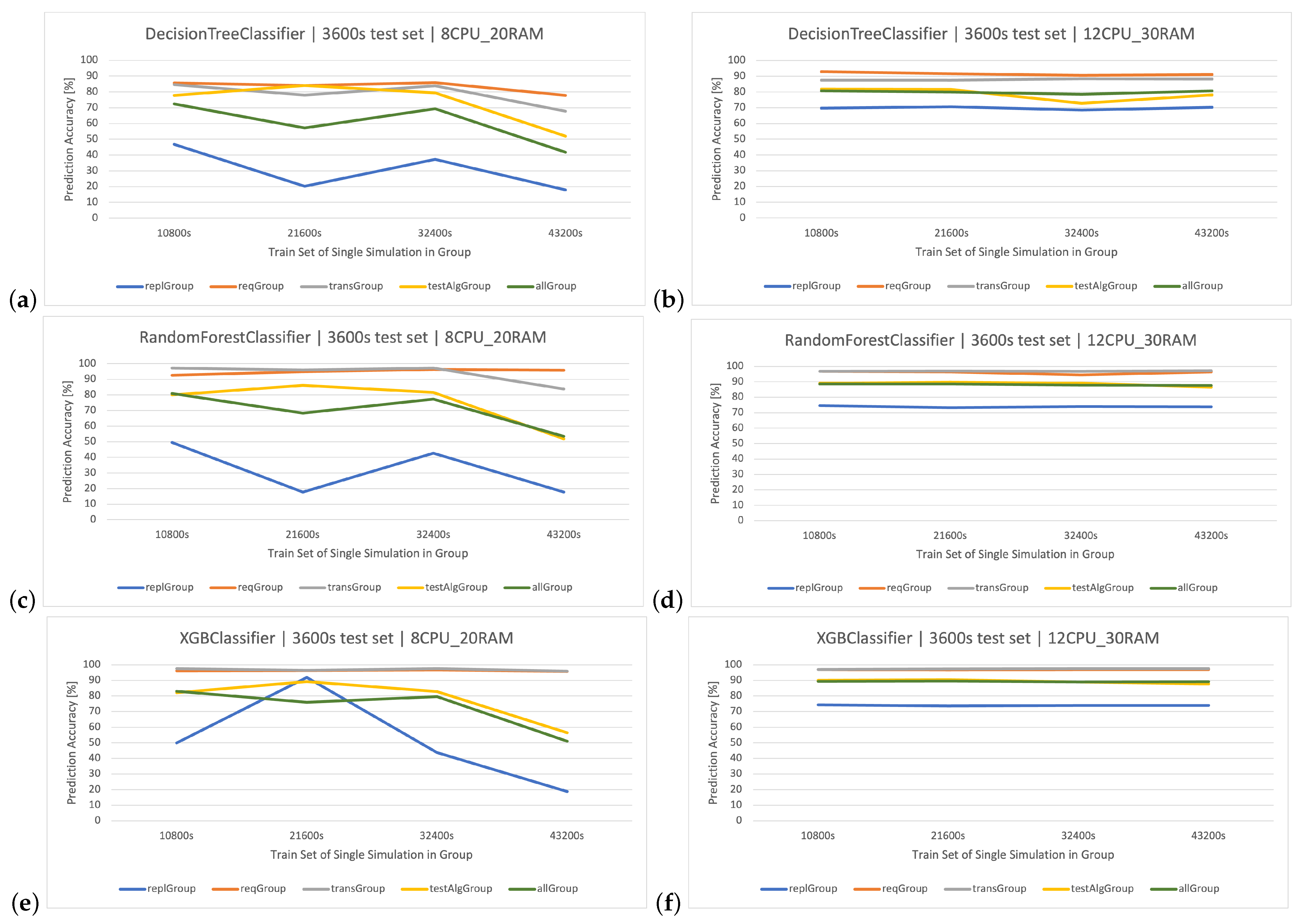
The main goal of this article is to classify user request types in the stock exchange system based on the logs it generates. During the analysis of the stock exchange application logs, three classification methods based on CART were used: Decision Tree (DT), Random Forest (RF), and Extreme Gradient Boosting (XGBoost).
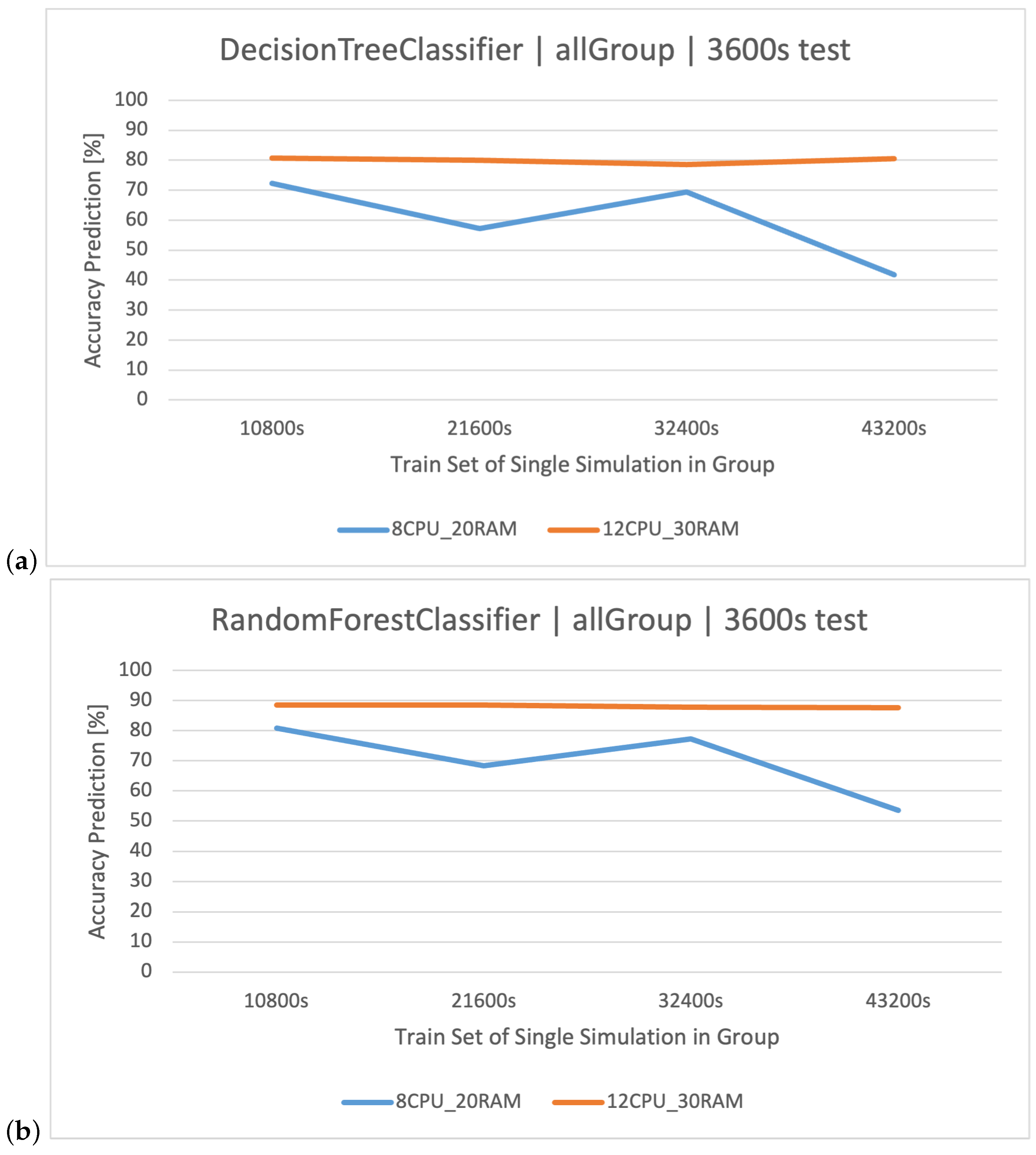
DT is a supervised learning algorithm that utilizes a tree structure to determine outcomes. For each branching point in the tree, the algorithm evaluates an attribute’s value, guiding its path downward until reaching a concluding node or decision. Its main attraction lies in its clear structure and visual interpretability. Within this paper, the was quick to learn owing to its uncomplicated nature. Yet, when contrasted with other classifiers in the simulation environment, it fell short in terms of efficacy.
RF operates as an ensemble technique, amassing multiple decision trees during its training phase. During prediction, it weighs the decisions of all the trees within its “forest" ensemble, finalizing the class label through a majority consensus. Such an approach aids in enhancing precision and mitigating overfitting. As per the discussion in this article, the showcased commendable performance, notably within the , outshining the standalone DT in efficiency.
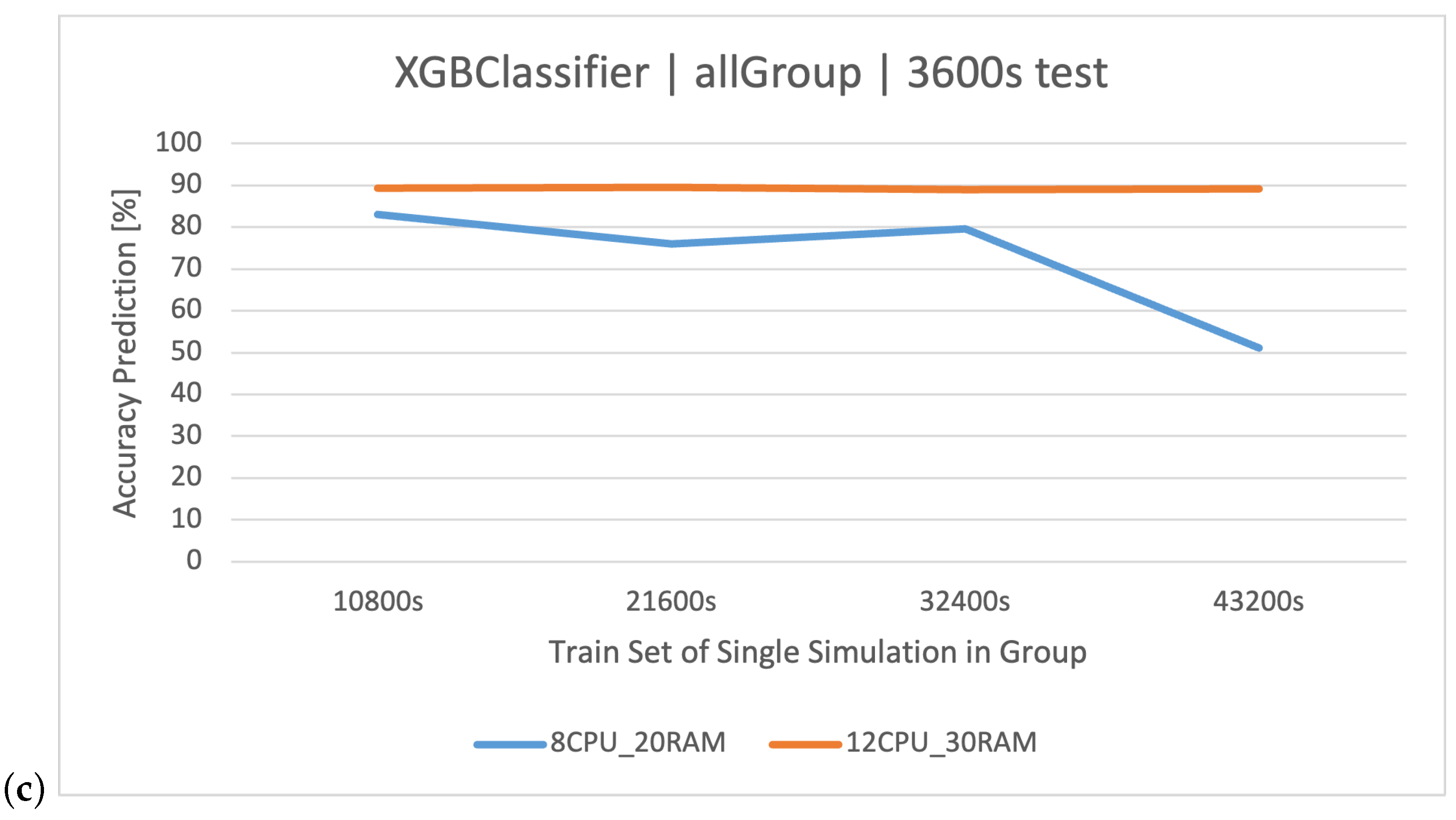
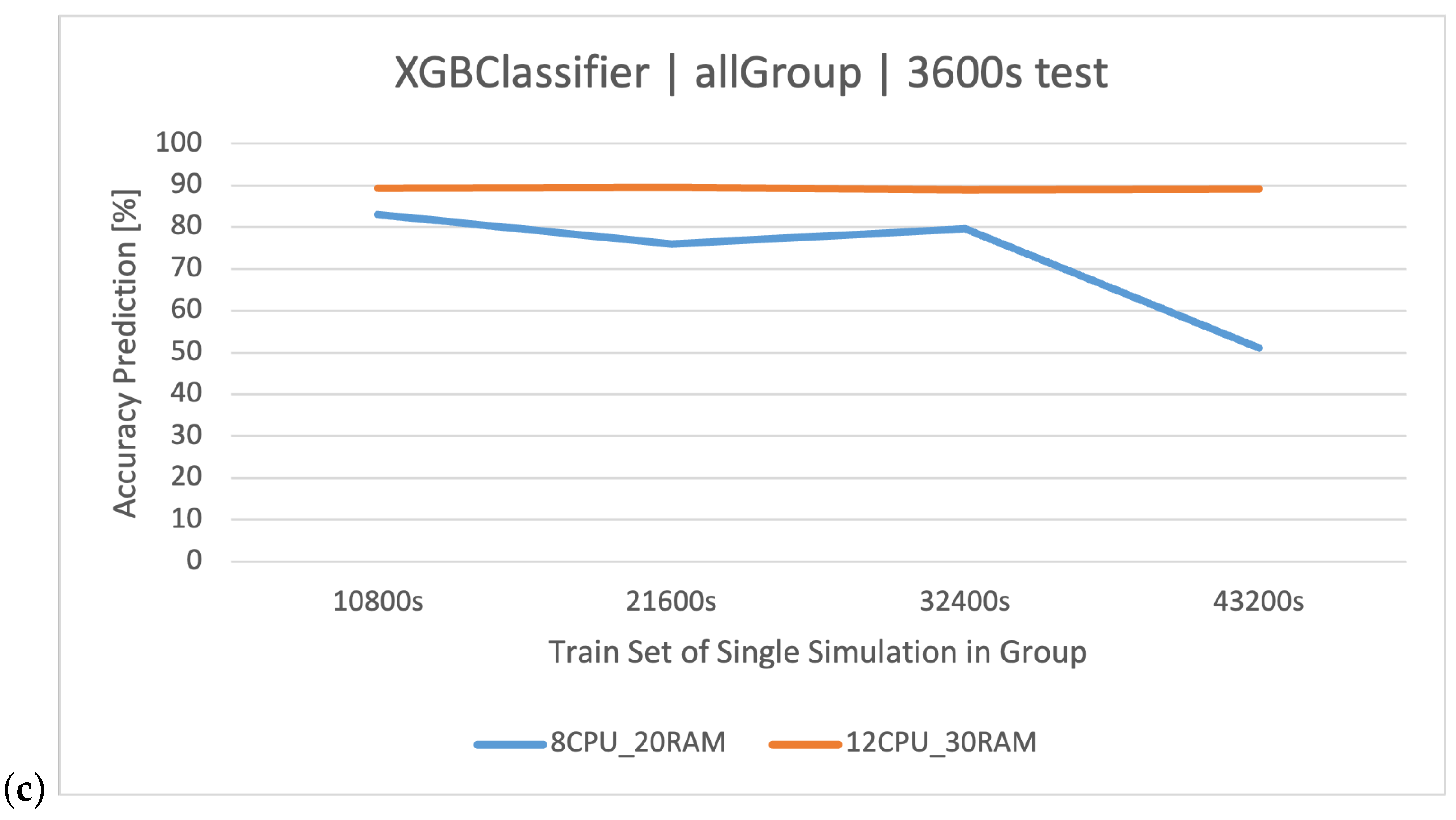
XGBoost refines the gradient-boosting machine learning paradigm. Boosting revolves around the concept of sequentially developing models to rectify the preceding models’ errors. Recognized for its briskness and operational efficiency, XGBoost was perceived to deliver superior results in this study, specifically for the simulation duration of 32400 s, surpassing RF in accuracy metrics and training speed.
The DT algorithm (CART) is a relatively simple (but fast) algorithm, and in the case of a larger dataset, its accuracy may be unsatisfactory. On the other hand, CART can be used in other ensemble learning methods (algorithms) as a solid foundation for advanced algorithms that use the concept of building DTs. One such method is the RF algorithm, which is an extension of CART and is used to improve prediction quality. The RF algorithm involves creating not one, but many DTs based on random subsets of a given set, called the training set. A set of such DTs is called a forest, where each tree is trained on a separate, random subset of training data, and predictions are made based on the voting of all the trees (result confrontation). The operation of the RF algorithm is as follows: creating random subsets, building DTs, and predicting. Another popular algorithm based on the DT concept is XGBoost. This is an advanced ML algorithm based on the Gradient Boosting framework. XGBoost builds predictive models by sequentially adding DTs, each successive tree focusing on correcting the errors of its predecessor. Models are trained in the boosting technique, which means that each subsequent model focuses more on the samples that were incorrectly classified by the previous models. During combination, the cost function is minimized using the method of the straightforward gradient. Classifier models can be added until all elements in the training set are correctly predicted or the maximum number of classifier models is added (a hyperparameter set by the user).
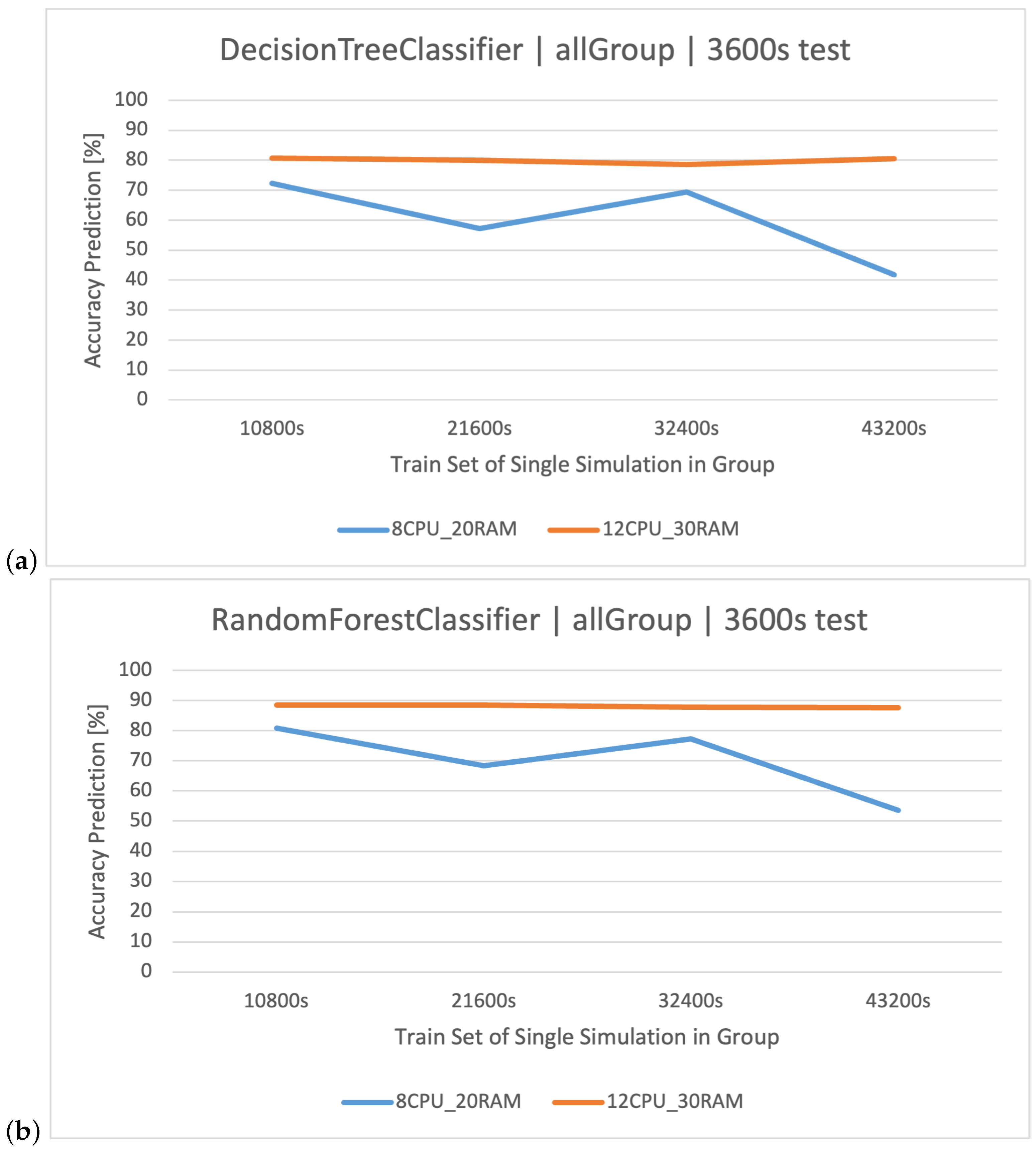
Classification methods can be used to analyze the logs of web applications for various applications: a recommendation/personalization system, identification of attacks and threats, anomaly and error detection, and classification of types of requests and operations. Because web application logs often contain information about different types of requests and operations performed by users, classification methods are used to classify these requests, based on their features such as technical parameters of the request, making it possible to identify and analyze them. This might be useful in system optimization, performance monitoring, and user behavior analysis. In the context of the analyzed stock exchange system and the log dataset related to its operation, specific results are expected through the application of data analysis and machine learning methods. Data classification—the use of data classification methods—will allow for the automatic labeling of stock exchange system log events based on training data. It is expected that the classification will be able to recognize different categories of user queries () generated in the system, based on features, such as the processing time of the query (), the size of the queues ( and ), or the resource consumption of individual components of and ( and ). The created classifiers will be compared to each other in order to select the best method based on the CART algorithms. The impact of the server architecture used ( and ) on the quality of predictions will also be examined.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}