
Task-Level Customized Pruning for Image Classification on Edge Devices †


Abstract
1. Introduction
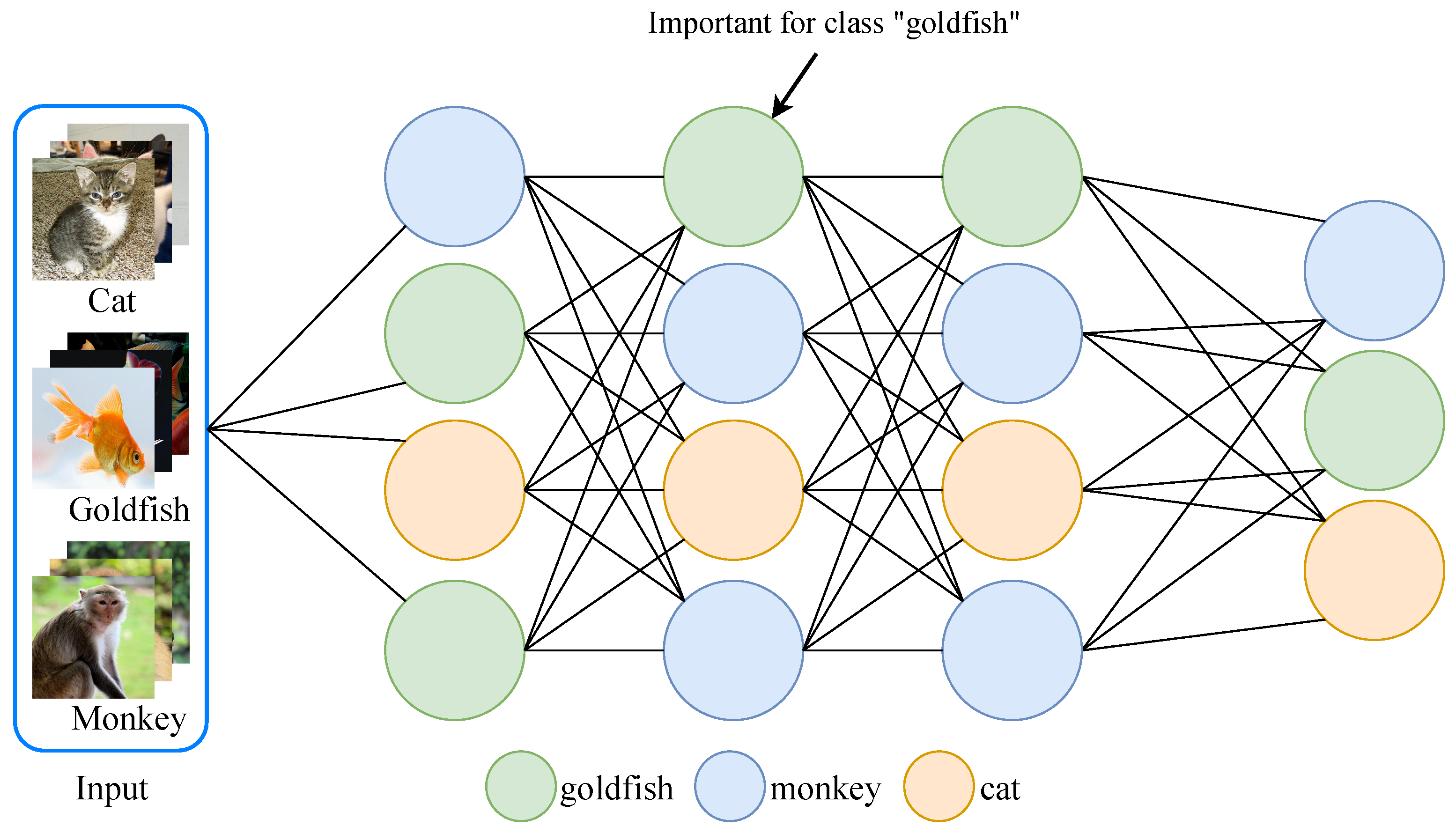
- Observing that edge-side tasks only need to process a subset of classes, we propose a customized pruning method based on the fine-grained information of task, which also conforms to the development trend of wisdom sinking.
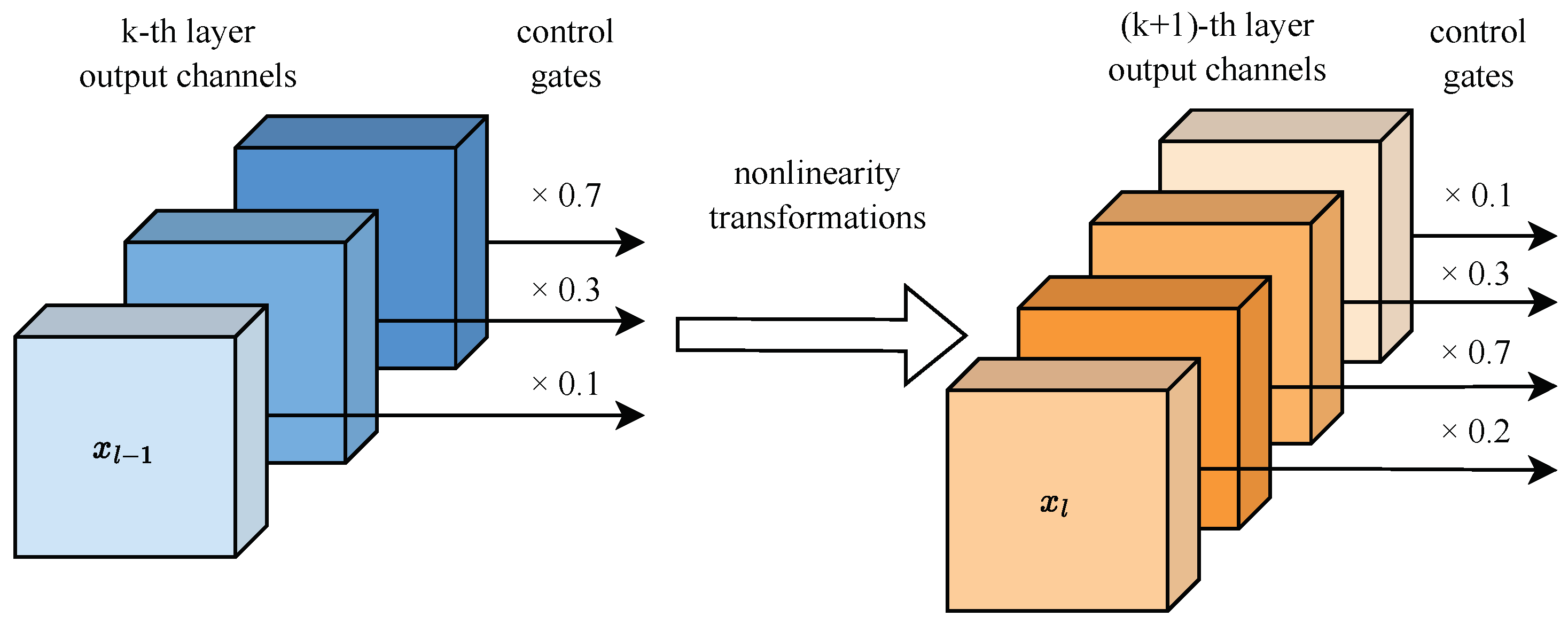
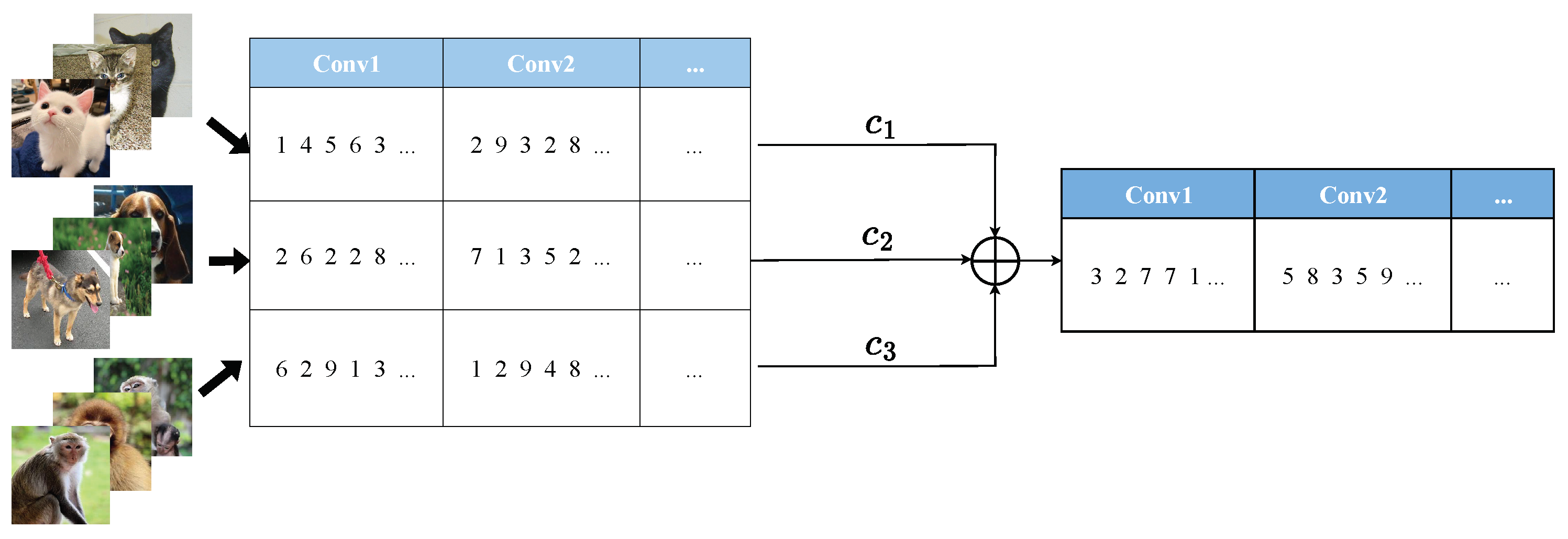
- In this method, we utilize channel-wise control gates to quantify individual channel contributions. Via processing these control gates, e.g., linear combination among different classes, a customized lightweight network is realized.
- Experimental results on three datasets demonstrate the proposed method can significantly decrease the number of network parameters while maintaining nearly identical performance compared to baselines.
2. Related Work
2.1. Tensor Decomposition
2.2. Quantization
2.3. Low-Rank Decomposition
2.4. Pruning
2.4.1. Unstructured Pruning
2.4.2. Structured Pruning
3. Methods
3.1. Class-Level Channel Control Gates
3.2. Class-Level Control Gate Fusion
3.2.1. PSO-Based Control Gate Fusion
| Algorithm 1: PSO-Based Control Gate Fusion |
Input: class-level control gate , number of particles s, mutation rate , inertia weight , cognitive weight , social weight , range of perturbation Output: customized for targeted classes initialize particle population (size = s)  C = compute by Equation (4) |
3.2.2. GA-Based Control Gate Fusion
| Algorithm 2: GA-Based Control Gate Fusion |
Input: class-level control gate , populations, mutation rate , range of perturbation Output: customized for targeted classes generate_population (size = s)  C = compute by Equation (4) |
| Algorithm 3: Task-Level Customized Pruning |
Input: Input image x of targeted classes, original model N Output: Pruned model customized for targeted classes Original prediction class  repeat for each class in targeted classes Algorithm 1/Algorithm 2 Compute by Equation (4) Prune |
4. Results
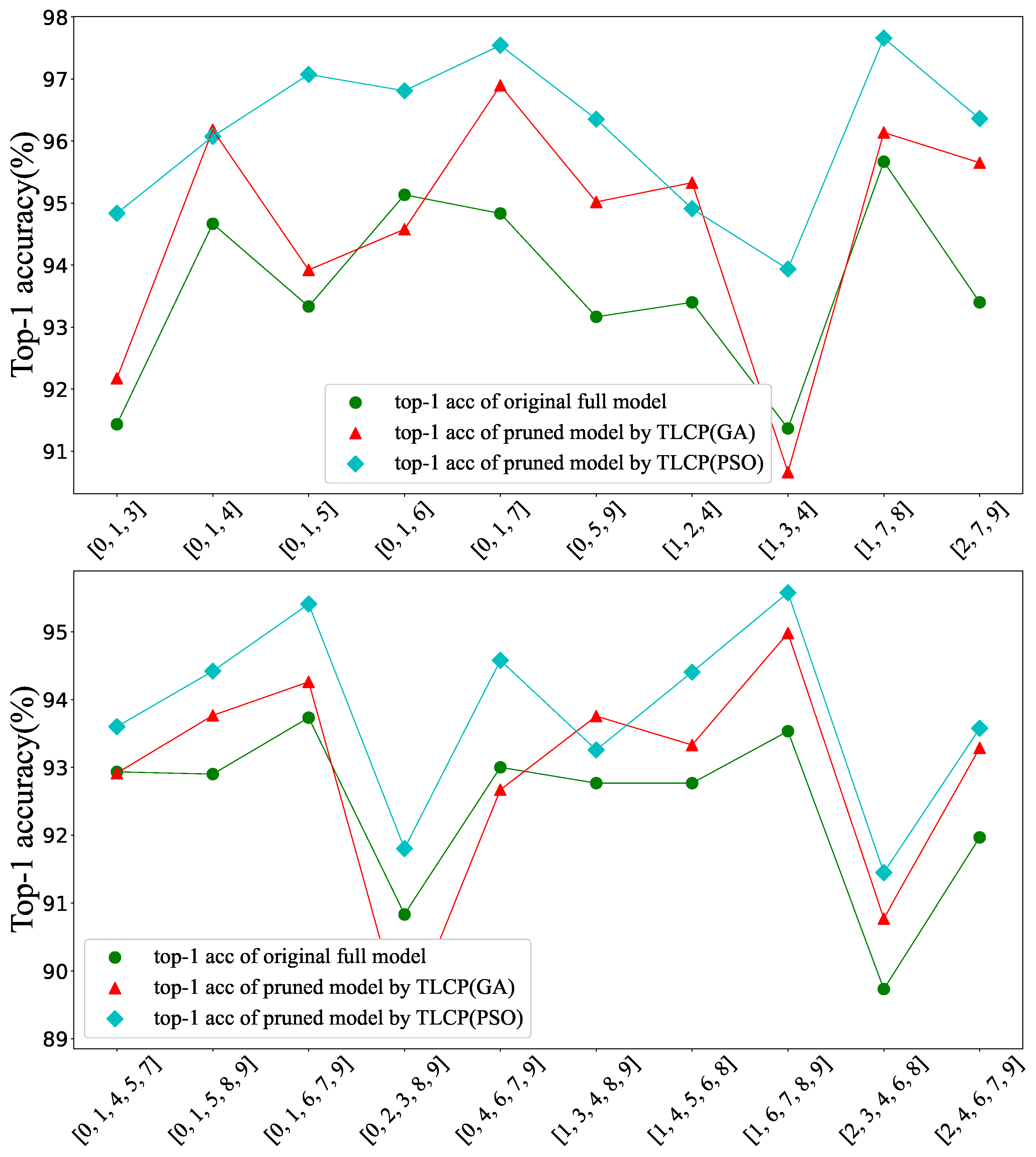
4.1. Performance Comparison
4.2. Choice of PSO or GA
4.3. Effect of Fine-Tuning
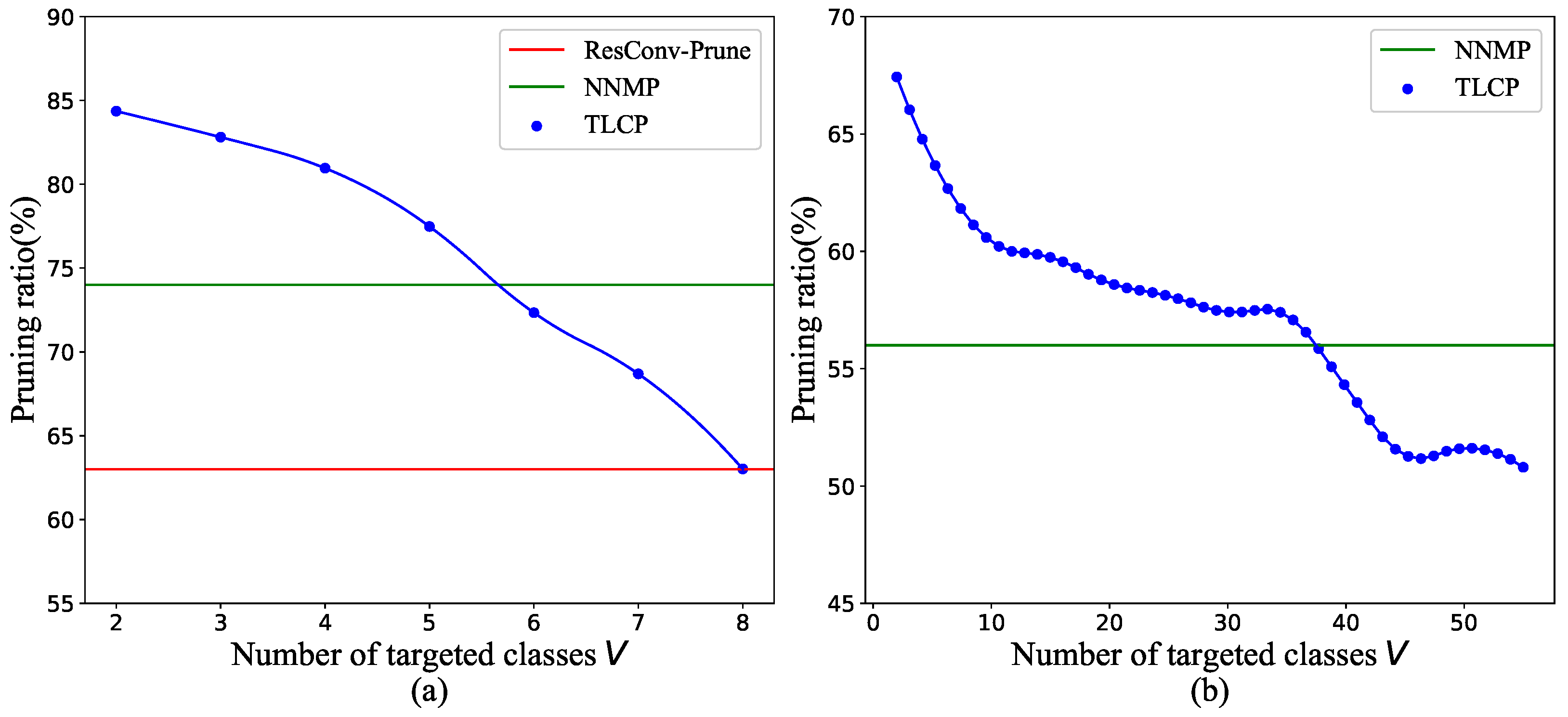
4.4. Relationship between Task and Model
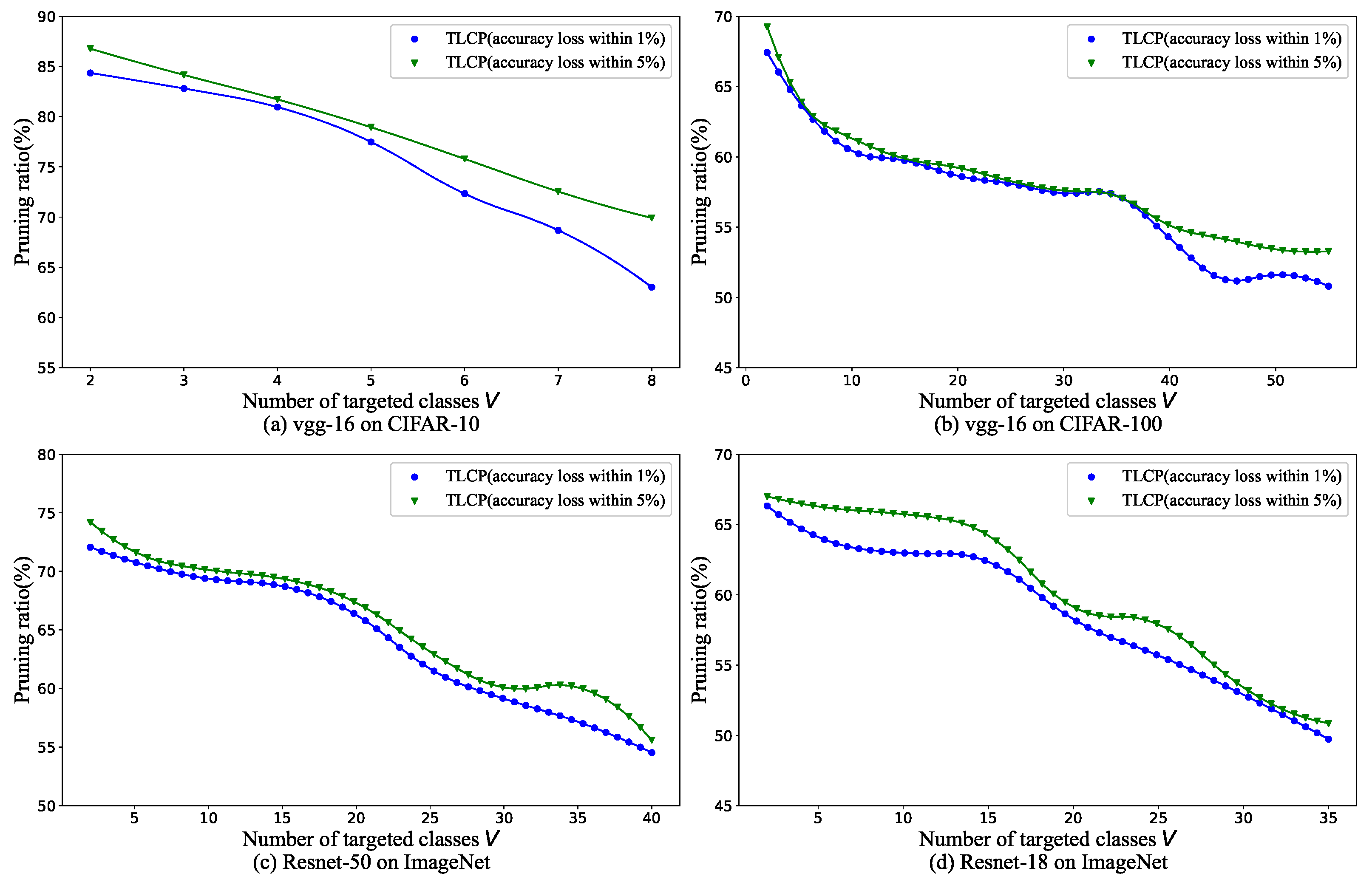
4.5. Trade-Off between Accuracy Loss and Pruning Ratio
4.6. Time and Memory
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Roy, S.K.; Deria, A.; Hong, D.; Rasti, B.; Plaza, A.; Chanussot, J. Multimodal Fusion Transformer for Remote Sensing Image Classification. IEEE Trans. Geosci. 2023, 61, 5515620. [Google Scholar] [CrossRef]
- Han, G.; Huang, S.; Ma, J.; He, Y.; Chang, S.F. Meta faster r-cnn: Towards accurate few-shot object detection with attentive feature alignment. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22February–1 March 2022; Volume 36, pp. 780–789. [Google Scholar]
- Yuan, F.; Zhang, Z.; Fang, Z. An effective CNN and Transformer complementary network for medical image segmentation. Pattern Recognit. 2023, 136, 109228. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Peters, J.; Fournarakis, M.; Nagel, M.; Van Baalen, M.; Blankevoort, T. QBitOpt: Fast and Accurate Bitwidth Reallocation during Training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 1282–1291. [Google Scholar]
- Chauhan, A.; Tiwari, U.; R, V.N. Post Training Mixed Precision Quantization of Neural Networks Using First-Order Information. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 1343–1352. [Google Scholar]
- Yang, G.; Yu, S.; Yang, H.; Nie, Z.; Wang, J. HMC: Hybrid model compression method based on layer sensitivity grouping. PLoS ONE 2023, 18, e0292517. [Google Scholar] [CrossRef]
- Savostianova, D.; Zangrando, E.; Ceruti, G.; Tudisco, F. Robust low-rank training via approximate orthonormal constraints. arXiv 2023, arXiv:2306.01485. [Google Scholar]
- Dai, W.; Fan, J.; Miao, Y.; Hwang, K. Deep Learning Model Compression With Rank Reduction in Tensor Decomposition. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–14. [Google Scholar] [CrossRef]
- Dai, C.; Liu, X.; Cheng, H.; Yang, L.T.; Deen, M.J. Compressing deep model with pruning and tucker decomposition for smart embedded systems. IEEE Internet Things J. 2021, 9, 14490–14500. [Google Scholar] [CrossRef]
- Gabor, M.; Zdunek, R. Compressing convolutional neural networks with hierarchical Tucker-2 decomposition. Appl. Soft Comput. 2023, 132, 109856. [Google Scholar] [CrossRef]
- Lv, X.; Zhang, P.; Li, S.; Gan, G.; Sun, Y. Lightformer: Light-weight transformer using svd-based weight transfer and parameter sharing. In Proceedings of the ACL, Toronto, ON, Canada, 9–14 July 2023; pp. 10323–10335. [Google Scholar]
- Liu, D.; Yang, L.T.; Wang, P.; Zhao, R.; Zhang, Q. TT-TSVD: A multi-modal tensor train decomposition with its application in convolutional neural networks for smart healthcare. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 1–17. [Google Scholar] [CrossRef]
- Xie, Y.; Luo, Y.; She, H.; Xiang, Z. Neural Network Model Pruning without Additional Computation and Structure Requirements. In Proceedings of the 2023 26th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Rio de Janeiro, Brazil, 24–26 May 2023; pp. 1734–1740. [Google Scholar]
- Pietroń, M.; Żurek, D.; Śnieżyński, B. Speedup deep learning models on GPU by taking advantage of efficient unstructured pruning and bit-width reduction. J. Comput. 2023, 67, 101971. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, G.; Grosse, R. Picking winning tickets before training by preserving gradient flow. arXiv 2020, arXiv:2002.07376. [Google Scholar]
- Zheng, Y.J.; Chen, S.B.; Ding, C.H.; Luo, B. Model compression based on differentiable network channel pruning. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 10203–10212. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Freris, N.M. Adaptive filter pruning via sensitivity feedback. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 10996–11008. [Google Scholar] [CrossRef] [PubMed]
- Hanson, E.; Li, S.; Li, H.; Chen, Y. Cascading structured pruning: Enabling high data reuse for sparse dnn accelerators. In Proceedings of the 49th Annual International Symposium on Computer Architecture, New York, NY, USA, 18–22 June 2022; pp. 522–535. [Google Scholar]
- Ma, X.; Yuan, G.; Li, Z.; Gong, Y.; Zhang, T.; Niu, W.; Zhan, Z.; Zhao, P.; Liu, N.; Tang, J.; et al. Blcr: Towards real-time dnn execution with block-based reweighted pruning. In Proceedings of the 2022 23rd International Symposium on Quality Electronic Design (ISQED), Santa Clara, CA, USA, 6–7 April 2022; pp. 1–8. [Google Scholar]
- Guan, Y.; Liu, N.; Zhao, P.; Che, Z.; Bian, K.; Wang, Y.; Tang, J. Dais: Automatic channel pruning via differentiable annealing indicator search. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 9847–9858. [Google Scholar] [CrossRef]
- Tian, G.; Chen, J.; Zeng, X.; Liu, Y. Pruning by training: A novel deep neural network compression framework for image processing. IEEE Signal Process. Lett. 2021, 28, 344–348. [Google Scholar] [CrossRef]
- Lei, Y.; Wang, D.; Yang, S.; Shi, J.; Tian, D.; Min, L. Network Collaborative Pruning Method for Hyperspectral Image Classification Based on Evolutionary Multi-Task Optimization. Remote Sens. 2023, 15, 3084. [Google Scholar] [CrossRef]
- Cong, S.; Zhou, Y. A review of convolutional neural network architectures and their optimizations. Artif. Intell. Rev. 2023, 56, 1905–1969. [Google Scholar] [CrossRef]
- He, Y.; Xiao, L. Structured Pruning for Deep Convolutional Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 2900–2919. [Google Scholar] [CrossRef]
- Dong, Z.; Lin, B.; Xie, F. Optimizing Few-Shot Remote Sensing Scene Classification Based on an Improved Data Augmentation Approach. Remote Sens. 2024, 16, 525. [Google Scholar] [CrossRef]
- Liu, J.; Xiang, J.; Jin, Y.; Liu, R.; Yan, J.; Wang, L. Boost Precision Agriculture with Unmanned Aerial Vehicle Remote Sensing and Edge Intelligence: A Survey. Remote Sens. 2021, 13, 4387. [Google Scholar] [CrossRef]
- Wang, Y.; Li, F.; Zhang, H. TA2P: Task-Aware Adaptive Pruning Method for Image Classification on Edge Devices. In Proceedings of the ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 2580–2584. [Google Scholar]
- Yu, F.; Qin, Z.; Chen, X. Distilling critical paths in convolutional neural networks. arXiv 2018, arXiv:1811.02643. [Google Scholar]
- Wang, Y.; Su, H.; Zhang, B.; Hu, X. Interpret neural networks by identifying critical data routing paths. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8906–8914. [Google Scholar]
- Li, Z.; Li, H.; Meng, L. Model Compression for Deep Neural Networks: A Survey. Computers 2023, 12, 60. [Google Scholar] [CrossRef]
- LeCun, Y.; Denker, J.; Solla, S. Optimal brain damage. Adv. Neural Inf. Process. Syst. 1989, 2, 598–605. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both weights and connections for efficient neural network. arXiv 2014, arXiv:1506.02626. [Google Scholar]
- Luo, J.H.; Wu, J.; Lin, W. Thinet: A filter level pruning method for deep neural network compression. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5058–5066. [Google Scholar]
- Zhang, Y.; Wang, H.; Qin, C.; Fu, Y. Aligned structured sparsity learning for efficient image super-resolution. Adv. Neural Inf. Process. Syst. 2021, 34, 2695–2706. [Google Scholar]
- Fang, G.; Ma, X.; Song, M.; Mi, M.B.; Wang, X. Depgraph: Towards any structural pruning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16091–16101. [Google Scholar]
- Beyer, L.; Zhai, X.; Royer, A.; Markeeva, L.; Anil, R.; Kolesnikov, A. Knowledge Distillation: A Good Teacher Is Patient and Consistent. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10925–10934. [Google Scholar]
- Qiu, Y.; Leng, J.; Guo, C.; Chen, Q.; Li, C.; Guo, M.; Zhu, Y. Adversarial defense through network profiling based path extraction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4777–4786. [Google Scholar]
- Allen-Zhu, Z.; Li, Y.; Liang, Y. Learning and generalization in overparameterized neural networks, going beyond two layers. arXiv 2018, arXiv:1811.04918. [Google Scholar]
- Clerc, M.; Kennedy, J. The particle swarm-explosion, stability, and convergence in a multidimensional complex space. IEEE Trans. Evol. Comput. 2002, 6, 58–73. [Google Scholar] [CrossRef]
- Holland, J.H. Genetic algorithms. Sci. Am. 1992, 267, 66–73. [Google Scholar] [CrossRef]
- Liu, Z.; Sun, M.; Zhou, T.; Huang, G.; Darrell, T. Rethinking the value of network pruning. arXiv 2018, arXiv:1810.05270. [Google Scholar]
- Xu, P.; Cao, J.; Shang, F.; Sun, W.; Li, P. Layer pruning via fusible residual convolutional block for deep neural networks. arXiv 2020, arXiv:2011.14356. [Google Scholar]
- Lin, M.; Ji, R.; Zhang, Y.; Zhang, B.; Wu, Y.; Tian, Y. Channel pruning via automatic structure search. arXiv 2020, arXiv:2001.08565. [Google Scholar]
- Hossain, M.B.; Gong, N.; Shaban, M. A Novel Attention-Based Layer Pruning Approach for Low-Complexity Convolutional Neural Networks. Adv. Intell. Syst. 2024, 2400161. [Google Scholar] [CrossRef]
- Wang, C.; Ning, X.; Sun, L.; Zhang, L.; Li, W.; Bai, X. Learning discriminative features by covering local geometric space for point cloud analysis. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5703215. [Google Scholar] [CrossRef]
- Zhang, H.; Ning, X.; Wang, C.; Ning, E.; Li, L. Deformation depth decoupling network for point cloud domain adaptation. Neural Netw. 2024, 180, 106626. [Google Scholar] [CrossRef]
- Fang, Z.; Li, X.; Li, X.; Buhmann, J.M.; Loy, C.C.; Liu, M. Explore in-context learning for 3d point cloud understanding. arXiv 2023, arXiv:2306.08659. [Google Scholar]
- Cui, Y.; Chen, R.; Chu, W.; Chen, L.; Tian, D.; Li, Y.; Cao, D. Deep learning for image and point cloud fusion in autonomous driving: A review. IEEE Trans. Intell. Transp. Syst. 2021, 23, 722–739. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Number of Targeted Classes | Pruning Ratio (%) | Parameters | Time Reduction (%) |
|---|---|---|---|---|
| Baseline Model | - | - | 17.53 M | - |
| Pruned Model | 2 | 84.36 | 4.04 M | 27.41 |
| Pruned Model | 3 | 82.81 | 4.38 M | 26.10 |
| Pruned Model | 4 | 80.96 | 4.58 M | 26.87 |
| Pruned Model | 5 | 77.48 | 5.08 M | 25.37 |
| Pruned Model | 6 | 72.34 | 6.13 M | 26.09 |
| Pruned Model | 7 | 68.69 | 6.83 M | 25.72 |
| Model | Number of Targeted Classes | Pruning Ratio (%) | Parameters | Time Reduction (%) |
|---|---|---|---|---|
| Baseline Model | - | - | 23.71 M | - |
| Pruned Model | 5 | 70.79 | 8.24 M | 21.93 |
| Pruned Model | 10 | 69.37 | 8.58 M | 19.41 |
| Pruned Model | 15 | 68.74 | 8.73 M | 21.92 |
| Pruned Model | 20 | 66.29 | 8.97 M | 18.76 |
| Pruned Model | 25 | 61.68 | 10.02 M | 20.02 |
| Pruned Model | 30 | 59.13 | 10.91 M | 19.06 |
| Pruned Model | 35 | 57.16 | 11.15 M | 18.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Li, F.; Zhang, H.; Shi, B. Task-Level Customized Pruning for Image Classification on Edge Devices. Electronics 2024, 13, 4029. https://doi.org/10.3390/electronics13204029
Wang Y, Li F, Zhang H, Shi B. Task-Level Customized Pruning for Image Classification on Edge Devices. Electronics. 2024; 13(20):4029. https://doi.org/10.3390/electronics13204029
Chicago/Turabian StyleWang, Yanting, Feng Li, Han Zhang, and Bojie Shi. 2024. "Task-Level Customized Pruning for Image Classification on Edge Devices" Electronics 13, no. 20: 4029. https://doi.org/10.3390/electronics13204029
APA StyleWang, Y., Li, F., Zhang, H., & Shi, B. (2024). Task-Level Customized Pruning for Image Classification on Edge Devices. Electronics, 13(20), 4029. https://doi.org/10.3390/electronics13204029