

Forward Learning of Large Language Models by Consumer Devices


Abstract
1. Introduction
2. The Research Question
- Formulation of PEPITA learning rule for transformers.
- Quantitative analysis of computational complexity and memory needs of PEPITA and MEMPEPITA in contrast with BP on state of the art LLMs such as GPT-3 Small, DistilBERT and AlexaTM.
- Study on the applicability, in terms of memory and latency constraints, of PEPITA and MEMPEPITA on existing hardware for enabling on-device learning of LLMs on edge consumer devices.
3. Background
Transformers and Large Language Models
4. Related Works
4.1. On-Device Learning
4.2. Alternatives to Back-Propagation
4.2.1. PEPITA
4.2.2. MEMPEPITA
5. Pepita Applied to Transformers
| Algorithm 1: PEPITA |
Given: Features(x) and label()
|
6. Quantitative Analysis
6.1. Memory and Computational Complexity
6.2. Methodology
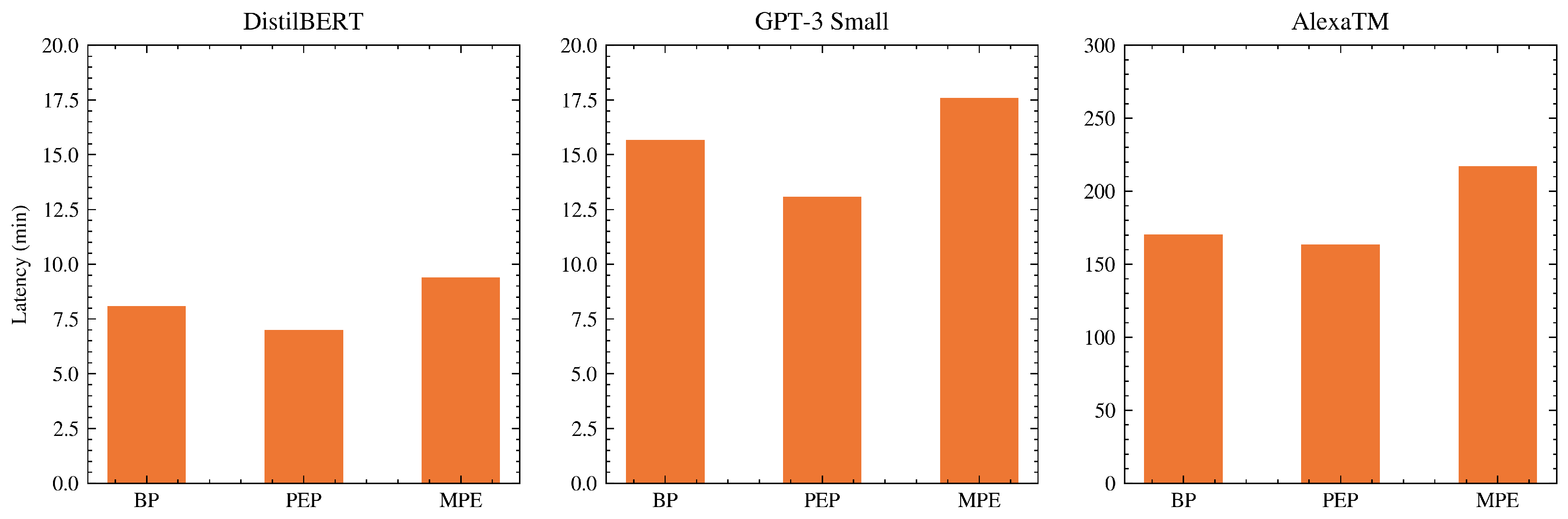
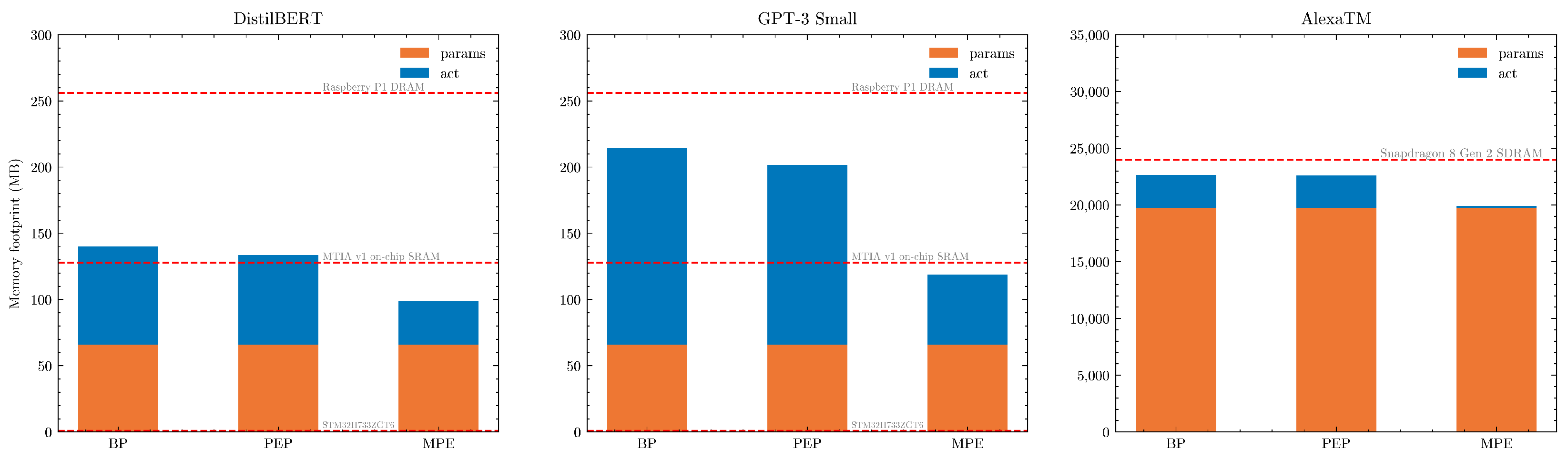
6.3. Results
7. Discussion
8. Applicability to Consumer Edge Devices
9. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Team, N.; Costa-jussà, M.R.; Cross, J.; Çelebi, O.; Elbayad, M.; Heafield, K.; Heffernan, K.; Kalbassi, E.; Lam, J.; Licht, D.; et al. No Language Left Behind: Scaling Human-Centered Machine Translation. arXiv 2022, arXiv:2207.04672. [Google Scholar]
- Zhang, Z.; Yang, J.; Zhao, H. Retrospective Reader for Machine Reading Comprehension. arXiv 2020, arXiv:2001.09694. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv 2020, arXiv:1910.10683. [Google Scholar]
- Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Zhao, T. SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Pittsburgh, PA, USA, 2020. [Google Scholar] [CrossRef]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv 2020, arXiv:1906.08237. [Google Scholar]
- Wang, S.; Fang, H.; Khabsa, M.; Mao, H.; Ma, H. Entailment as Few-Shot Learner. arXiv 2021, arXiv:2104.14690. [Google Scholar]
- Aghajanyan, A.; Shrivastava, A.; Gupta, A.; Goyal, N.; Zettlemoyer, L.; Gupta, S. Better Fine-Tuning by Reducing Representational Collapse. arXiv 2020, arXiv:2008.03156. [Google Scholar]
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling Laws for Neural Language Models. arXiv 2020, arXiv:2001.08361. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Kim, S.; Hooper, C.; Wattanawong, T.; Kang, M.; Yan, R.; Genc, H.; Dinh, G.; Huang, Q.; Keutzer, K.; Mahoney, M.W.; et al. Full Stack Optimization of Transformer Inference: A Survey. arXiv 2023, arXiv:2302.14017. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning Efficient Convolutional Networks through Network Slimming. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22 October 2017. [Google Scholar]
- Wang, K.; Liu, Z.; Lin, Y.; Lin, J.; Han, S. HAQ: Hardware-Aware Automated Quantization with Mixed Precision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Bayram, F.; Ahmed, B.S.; Kassler, A. From Concept Drift to Model Degradation: An Overview on Performance-Aware Drift Detectors. arXiv 2022, arXiv:2203.11070. [Google Scholar] [CrossRef]
- Pau, D.P.; Ambrose, P.K.; Aymone, F.M. A Quantitative Review of Automated Neural Search and On-Device Learning for Tiny Devices. Chips 2023, 2, 130–141. [Google Scholar] [CrossRef]
- Dellaferrera, G.; Kreiman, G. Error-driven Input Modulation: Solving the Credit Assignment Problem without a Backward Pass. arXiv 2022, arXiv:2201.11665. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. In Proceedings of the NeurIPS EMC2 Workshop, Vancouver, BC, Canada, 13 December 2019. [Google Scholar]
- Soltan, S.; Ananthakrishnan, S.; FitzGerald, J.G.M.; Gupta, R.; Hamza, W.; Khan, H.; Peris, C.; Rawls, S.; Rosenbaum, A.; Rumshisky, A.; et al. AlexaTM 20B: Few-shot learning using a large-scale multilingual seq2seq model. arXiv 2022, arXiv:2208.01448. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Pau, D.P.; Aymone, F.M. Suitability of Forward-Forward and PEPITA Learning to MLCommons-Tiny benchmarks. In Proceedings of the 2023 IEEE International Conference on Omni-Layer Intelligent Systems (COINS), Berlin, Germany, 23–25 July 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Ramachandran, P.; Liu, P.J.; Le, Q.V. Unsupervised Pretraining for Sequence to Sequence Learning. arXiv 2016, arXiv:1611.02683. [Google Scholar]
- Dai, A.M.; Le, Q.V. Semi-supervised sequence learning. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural Language Processing (almost) from Scratch. J. Mach. Learn. Res. 2010, 12, 2493–2537. [Google Scholar]
- Peters, M.E.; Ammar, W.; Bhagavatula, C.; Power, R. Semi-supervised sequence tagging with bidirectional language models. arXiv 2017, arXiv:1705.00108. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding with Unsupervised Learning. 2018. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 6 September 2023).
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. PaLM: Scaling Language Modeling with Pathways. arXiv 2022, arXiv:2204.02311. [Google Scholar]
- Barbuto, V.; Savaglio, C.; Chen, M.; Fortino, G. Disclosing Edge Intelligence: A Systematic Meta-Survey. Big Data Cogn. Comput. 2023, 7, 44. [Google Scholar] [CrossRef]
- Yuan, J.; Yang, C.; Cai, D.; Wang, S.; Yuan, X.; Zhang, Z.; Li, X.; Zhang, D.; Mei, H.; Jia, X.; et al. Rethinking Mobile AI Ecosystem in the LLM Era. arXiv 2023, arXiv:2308.1436. [Google Scholar]
- Alizadeh, K.; Mirzadeh, I.; Belenko, D.; Khatamifard, K.; Cho, M.; Mundo, C.C.D.; Rastegari, M.; Farajtabar, M. LLM in a flash: Efficient Large Language Model Inference with Limited Memory. arXiv 2024, arXiv:2312.11514. [Google Scholar]
- Li, T.; Mesbahi, Y.E.; Kobyzev, I.; Rashid, A.; Mahmud, A.; Anchuri, N.; Hajimolahoseini, H.; Liu, Y.; Rezagholizadeh, M. A short study on compressing decoder-based language models. arXiv 2021, arXiv:2110.08460. [Google Scholar]
- Ganesh, P.; Chen, Y.; Lou, X.; Khan, M.A.; Yang, Y.; Sajjad, H.; Nakov, P.; Chen, D.; Winslett, M. Compressing Large-Scale Transformer-Based Models: A Case Study on BERT. Trans. Assoc. Comput. Linguist. 2021, 9, 1061–1080. [Google Scholar] [CrossRef]
- Sun, Z.; Yu, H.; Song, X.; Liu, R.; Yang, Y.; Zhou, D. MobileBERT: A Compact Task-Agnostic BERT for Resource-Limited Devices. arXiv 2020, arXiv:2004.02984. [Google Scholar]
- Jiao, X.; Yin, Y.; Shang, L.; Jiang, X.; Chen, X.; Li, L.; Wang, F.; Liu, Q. TinyBERT: Distilling BERT for Natural Language Understanding. arXiv 2020, arXiv:1909.10351. [Google Scholar]
- Ding, J.; Ma, S.; Dong, L.; Zhang, X.; Huang, S.; Wang, W.; Zheng, N.; Wei, F. LongNet: Scaling Transformers to 1,000,000,000 Tokens. arXiv 2023, arXiv:2307.02486. [Google Scholar]
- Shen, Z.; Zhang, M.; Zhao, H.; Yi, S.; Li, H. Efficient Attention: Attention with Linear Complexities. arXiv 2020, arXiv:1812.01243. [Google Scholar]
- Gómez-Luna, J.; Guo, Y.; Brocard, S.; Legriel, J.; Cimadomo, R.; Oliveira, G.F.; Singh, G.; Mutlu, O. An Experimental Evaluation of Machine Learning Training on a Real Processing-in-Memory System. arXiv 2023, arXiv:2207.07886. [Google Scholar]
- Cai, H.; Gan, C.; Zhu, L.; Han, S. TinyTL: Reduce Memory, Not Parameters for Efficient On-Device Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 11285–11297. [Google Scholar]
- Lin, J.; Zhu, L.; Chen, W.M.; Wang, W.C.; Gan, C.; Han, S. On-Device Training Under 256KB Memory. Adv. Neural Inf. Process. Syst. 2022, 35, 22941–22954. [Google Scholar]
- Chowdhery, A.; Warden, P.; Shlens, J.; Howard, A.; Rhodes, R. Visual Wake Words Dataset. arXiv 2019, arXiv:1906.05721. [Google Scholar]
- Zaken, E.B.; Ravfogel, S.; Goldberg, Y. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. arXiv 2021, arXiv:2106.10199. [Google Scholar]
- Vucetic, D.; Tayaranian, M.; Ziaeefard, M.; Clark, J.J.; Meyer, B.H.; Gross, W.J. Efficient Fine-Tuning of BERT Models on the Edge. In Proceedings of the 2022 IEEE International Symposium on Circuits and Systems (ISCAS), Austin, TX, USA, 27 May 2022–1 June 2022; pp. 1838–1842. [Google Scholar] [CrossRef]
- Warstadt, A.; Singh, A.; Bowman, S.R. Neural Network Acceptability Judgments. arXiv 2018, arXiv:1805.12471. [Google Scholar] [CrossRef]
- Xi, H.; Li, C.; Chen, J.; Zhu, J. Training Transformers with 4-bit Integers. arXiv 2023, arXiv:2306.11987. [Google Scholar]
- Crick, F. The recent excitement about neural networks. Nature 1989, 337, 129–132. [Google Scholar] [CrossRef]
- Lillicrap, T.; Santoro, A.; Marris, L.; Akerman, C.; Hinton, G. Backpropagation and the brain. Nat. Rev. Neurosci. 2020, 21, 335–346. [Google Scholar]
- Lillicrap, T.; Cownden, D.; Tweed, D.; Akerman, C. Random synaptic feedback weights support error backpropagation for deep learning. Nat. Commun. 2016, 7, 13276. [Google Scholar] [CrossRef]
- Nøkland, A. Direct Feedback Alignment Provides Learning in Deep Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 29, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Hinton, G. The Forward-Forward Algorithm: Some Preliminary Investigations. arXiv 2022, arXiv:2212.13345. [Google Scholar]
- Burbank, K.S.; Kreiman, G. Depression-Biased Reverse Plasticity Rule Is Required for Stable Learning at Top-Down Connections. PLoS Comput. Biol. 2012, 8, e1002393. [Google Scholar] [CrossRef]
- Jaderberg, M.; Czarnecki, W.M.; Osindero, S.; Vinyals, O.; Graves, A.; Silver, D.; Kavukcuoglu, K. Decoupled Neural Interfaces using Synthetic Gradients. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 11–15 August 2017; Precup, D., Teh, Y.W., Eds.; PMLR: London, UK, 2017; Volume 70, pp. 1627–1635. [Google Scholar]
- Czarnecki, W.M.; Świrszcz, G.; Jaderberg, M.; Osindero, S.; Vinyals, O.; Kavukcuoglu, K. Understanding Synthetic Gradients and Decoupled Neural Interfaces. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; PMLR: London, UK, 2017; Volume 70, pp. 904–912. [Google Scholar]
- Liao, Q.; Leibo, J.Z.; Poggio, T. How Important is Weight Symmetry in Backpropagation? arXiv 2016, arXiv:1510.05067. [Google Scholar] [CrossRef]
- Banbury, C.; Reddi, V.J.; Torelli, P.; Holleman, J.; Jeffries, N.; Kiraly, C.; Montino, P.; Kanter, D.; Ahmed, S.; Pau, D.; et al. MLCommons Tiny Benchmark. arXiv 2021, arXiv:2106.07597. [Google Scholar]
- Akrout, M.; Wilson, C.; Humphreys, P.C.; Lillicrap, T.; Tweed, D. Deep Learning without Weight Transport. arXiv 2020, arXiv:1904.05391. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Pre-Training Transformers as Energy-Based Cloze Models. arXiv 2020, arXiv:2012.08561. [Google Scholar]
- Pau, D.P.; Aymone, F.M. Mathematical Formulation of Learning and Its Computational Complexity for Transformers’ Layers. Eng. Proc. 2024, 5, 34–50. [Google Scholar] [CrossRef]
- Forward Learning of Large Language Models by Consumer Devices Github Repository. Available online: https://github.com/fabrizioaymone/forward-learning-of-LLMs-to-consumer-devices (accessed on 6 September 2023).
- Laskaridis, S.; Venieris, S.I.; Kouris, A.; Li, R.; Lane, N.D. The Future of Consumer Edge-AI Computing. arXiv 2022, arXiv:2210.10514. [Google Scholar]
- Morra, L.; Mohanty, S.P.; Lamberti, F. Artificial Intelligence in Consumer Electronics. IEEE Consum. Electron. Mag. 2020, 9, 46–47. [Google Scholar] [CrossRef]
- Firoozshahian, A.; Coburn, J.; Levenstein, R.; Nattoji, R.; Kamath, A.; Wu, O.; Grewal, G.; Aepala, H.; Jakka, B.; Dreyer, B.; et al. MTIA: First Generation Silicon Targeting Meta’s Recommendation Systems. In Proceedings of the 50th Annual International Symposium on Computer Architecture, Orlando, FL, USA, 17–21 June 2023; pp. 1–13. [Google Scholar]
- Srinivasan, R.F.; Mignacco, F.; Sorbaro, M.; Refinetti, M.; Cooper, A.; Kreiman, G.; Dellaferrera, G. Forward Learning with Top-Down Feedback: Empirical and Analytical Characterization. arXiv 2023, arXiv:2302.05440. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Learning Methods | BP | PEP | MPE |
|---|---|---|---|
| Forward pass | 1 | 2 | 3 |
| Backward pass | 1 | 0 | 0 |
| Weight update | 1 | 1 | 1 |
| Activations | all | all | current |
| Model | Enc | Dec | # of Heads | # of Parameters | |
|---|---|---|---|---|---|
| GPT-3 Small | 0 | 12 | 12 | 768 | 125 M |
| distilBERT | 6 | 0 | 12 | 768 | 66 M |
| AlexaTM | 46 | 32 | 32 | 4096 | 19.75 B |
| Model | DistilBERT | GPT-3 Small | AlexaTM | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | MACCs | FLOPs | ACT | MACCs | FLOPs | ACT | MACCs | FLOPs | ACT | |||||||||
| PEP | MPE | PEP | MPE | PEP | MPE | PEP | MPE | PEP | MPE | PEP | MPE | PEP | MPE | PEP | MPE | PEP | MPE | |
| 32 | 17% | 56% | 3% | 37% | −0.3% | −51% | 15% | 52% | −0.5% | 33% | −0.3% | −62% | −2% | 31% | −20% | 7% | −0.2% | −94% |
| 128 | 16% | 55% | 2% | 36% | −1% | −52% | 13% | 51% | −1% | 32% | −1% | −62% | −1% | 32% | −20% | 6% | −0.2% | −94% |
| 512 | 6% | 42% | −5% | 26% | −4% | −54% | 3% | 38% | −8% | 22% | −4% | −63% | −1% | 31% | −21% | 5% | −0.6% | −94% |
| 2048 | −48% | −29% | −50% | −32% | −16% | −59% | −50% | −32% | −53% | −36% | −16% | −67% | −14% | 14% | −30% | −6% | −2.5% | −94% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pau, D.P.; Aymone, F.M. Forward Learning of Large Language Models by Consumer Devices. Electronics 2024, 13, 402. https://doi.org/10.3390/electronics13020402
Pau DP, Aymone FM. Forward Learning of Large Language Models by Consumer Devices. Electronics. 2024; 13(2):402. https://doi.org/10.3390/electronics13020402
Chicago/Turabian StylePau, Danilo Pietro, and Fabrizio Maria Aymone. 2024. "Forward Learning of Large Language Models by Consumer Devices" Electronics 13, no. 2: 402. https://doi.org/10.3390/electronics13020402
APA StylePau, D. P., & Aymone, F. M. (2024). Forward Learning of Large Language Models by Consumer Devices. Electronics, 13(2), 402. https://doi.org/10.3390/electronics13020402