
Image–Text Cross-Modal Retrieval with Instance Contrastive Embedding


Abstract
1. Introduction
- Insufficient semantic interaction between image and text. Most existing image–text matching methods follow a dual-tower structure [2,3,7,34,35], where single-modal pre-training models act as encoders to, respectively, extract visual and text features (for instance, CNN and BERT are utilized for image and text feature extraction, correspondingly). However, those methods have limitations: (1) single-modal pre-training models are typically trained as semantic classifiers, overlooking fine-grained visual details in the image, such as color relationships and entity interactions; (2) the encoder simultaneously processes features from multiple modalities without inter-modality correlations, leading to a loss of interaction information between different modalities. Hence, enhancing the feature representation between image and text within the dual-tower structure remains a challenge.
- Feature representation distribution of intra-modality is overlooked. Since each training pair within a batch consists of one image and one text while using the pairwise ranking loss to measure the distance. However, this similarity measure predominantly focuses on inter-modality distance and barely explicitly considers the distribution of intra-modality feature representation. For example, the pairwise ranking loss used in the training phase might not discern subtle differences between semantically similar images, potentially causing the model to retrieve the same sentences. Consequently, addressing the simultaneous regulation of intra- and inter-modality feature distribution poses a challenge.
- We propose a fine-grained cross-modal retrieval method driven by multi-modal pre-training knowledge. Namely, the knowledge from CLIP is transferred to the image–text matching task, addressing the lack of interaction between modalities in the dual-tower structure while bolstering the feature representation capabilities.
- To regulate the feature representation distribution of intra- and inter-modality, we design an instance loss specifically tailored for the “image–text group”, which explicitly considers instance-level classification. Then, integrating this instance loss with a contrastive loss via the two-stage training strategy to bridge the semantic gap between images and text.
- On two widely used public benchmark datasets for image–text cross-modal retrieval, our proposed IConE model is evaluated in comparison to 20 SoTA baseline methods and a series of ablation variants. The results demonstrated significant performance improvements of up to 99.5 and 34.4 on the Rsum metric.
2. Related Work
2.1. Image–Text Cross-Modal Retrieval
2.2. Language-Vision Pre-Training Model
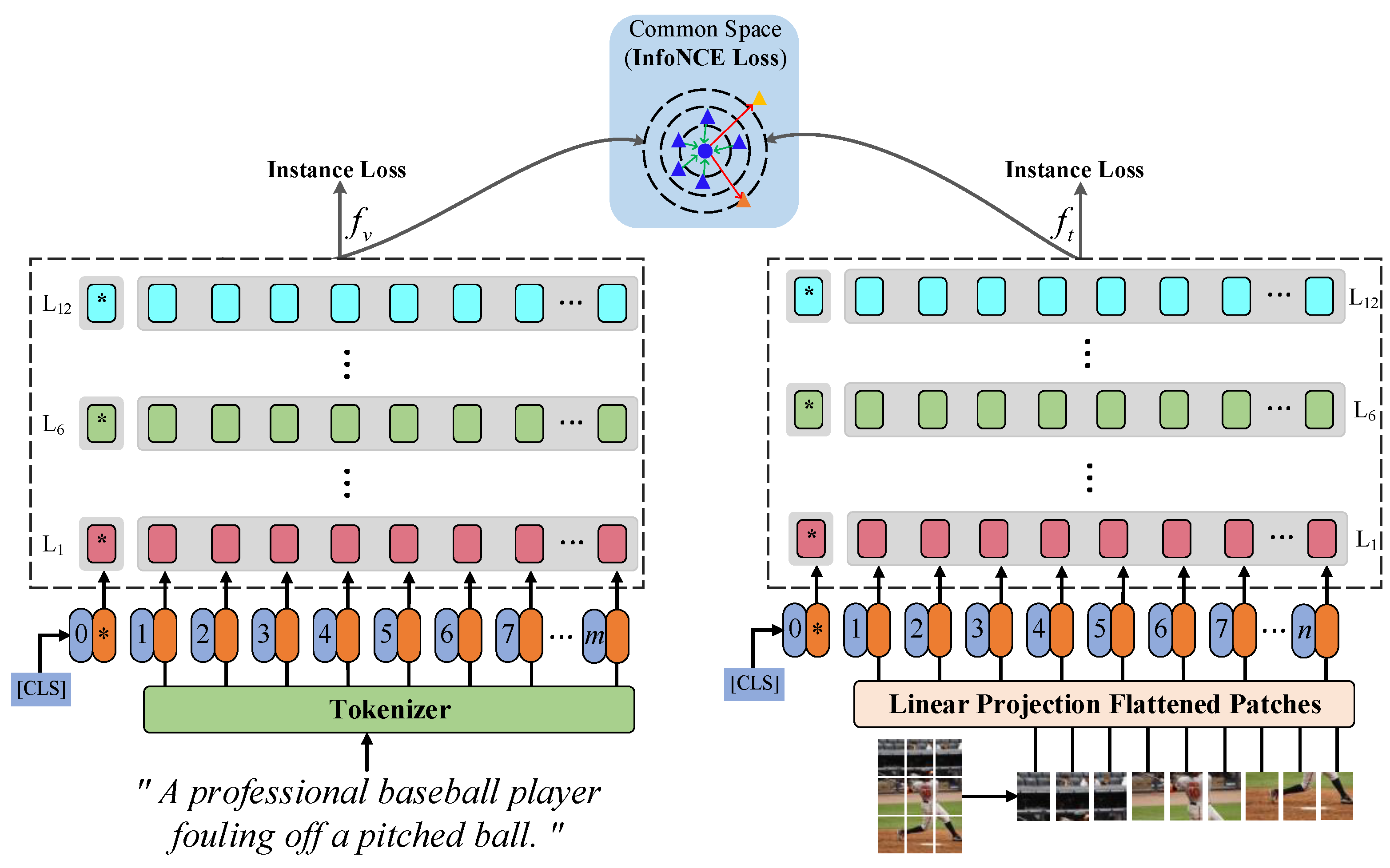
3. Design of the IConE Model
3.1. Image–Text Feature Representation
3.2. Instance Classification Loss
3.3. Contrastive Loss
3.4. Objective Function and Training Strategy
- Stage I: In this stage, the pre-trained image–text cross-modal retrieval of the dual-tower backbone network is employed, namely, fixing the weight parameters of the ViT image encoder and BERT text encoder, and using only the proposed instance loss (i.e., = 1, = 0) to fine-tune the remaining parameters. The purpose of this stage is to thoroughly consider the feature representation distribution of intra-modality, providing a better initialization for the subsequent contrastive loss.
- Stage II: Next, when Stage I has converged, the entire IConE model is fine-tuned end-to-end, i.e., both instance losses and contrast losses are combined (i.e., = 1, = 1). The primary objective of Stage II is to leverage both instance classification and matching ranking, maximizing the benefits of the two loss functions and effectively bridging the semantic gap between image and text.
4. Experimental Settings
4.1. Datasets
4.2. Evaluation Metric
4.3. Implementation Details
4.4. Baselines
5. Experimental Results and Analysis
- RQ1: Does IConE outperform the SoTA baselines overall on two public benchmark datasets?
- RQ2: How does the two-stage training strategy influence the performance of cross-modal retrieval?
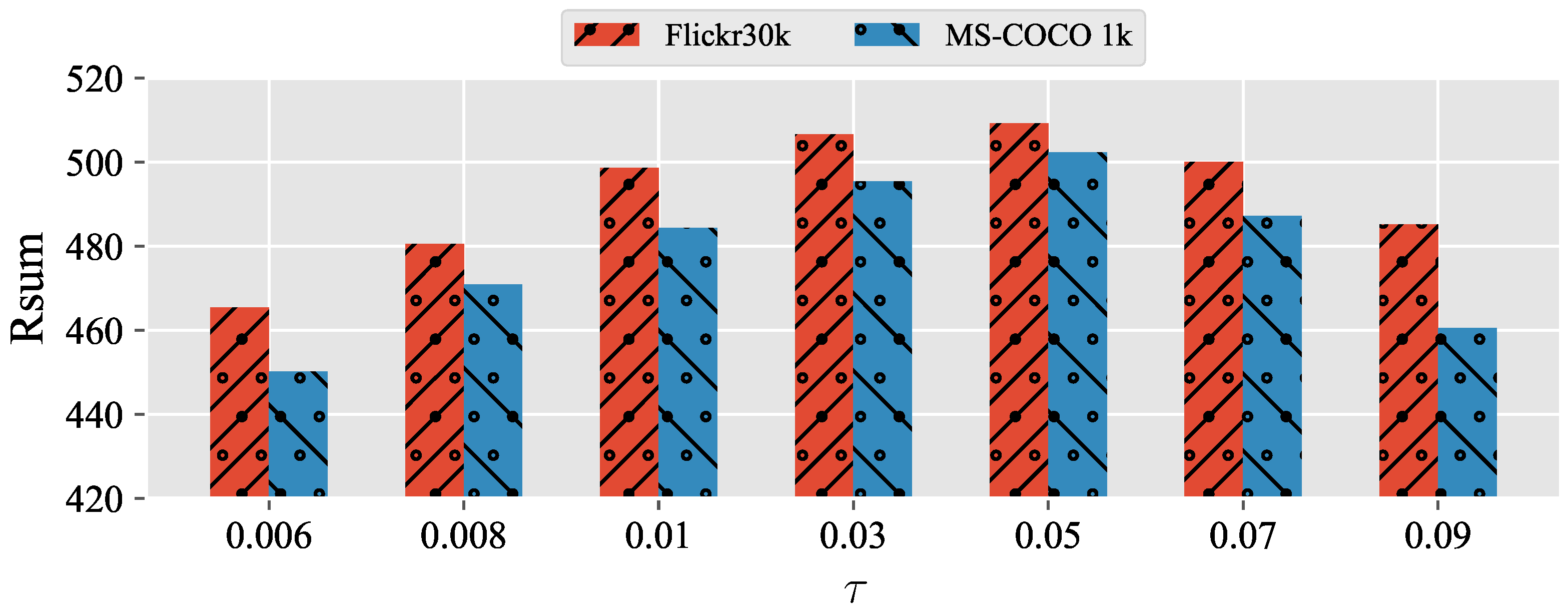
- RQ3: What is the sensitivity of the hyperparameter ?
- RQ4: What is the generalization of the two-stage training strategy?
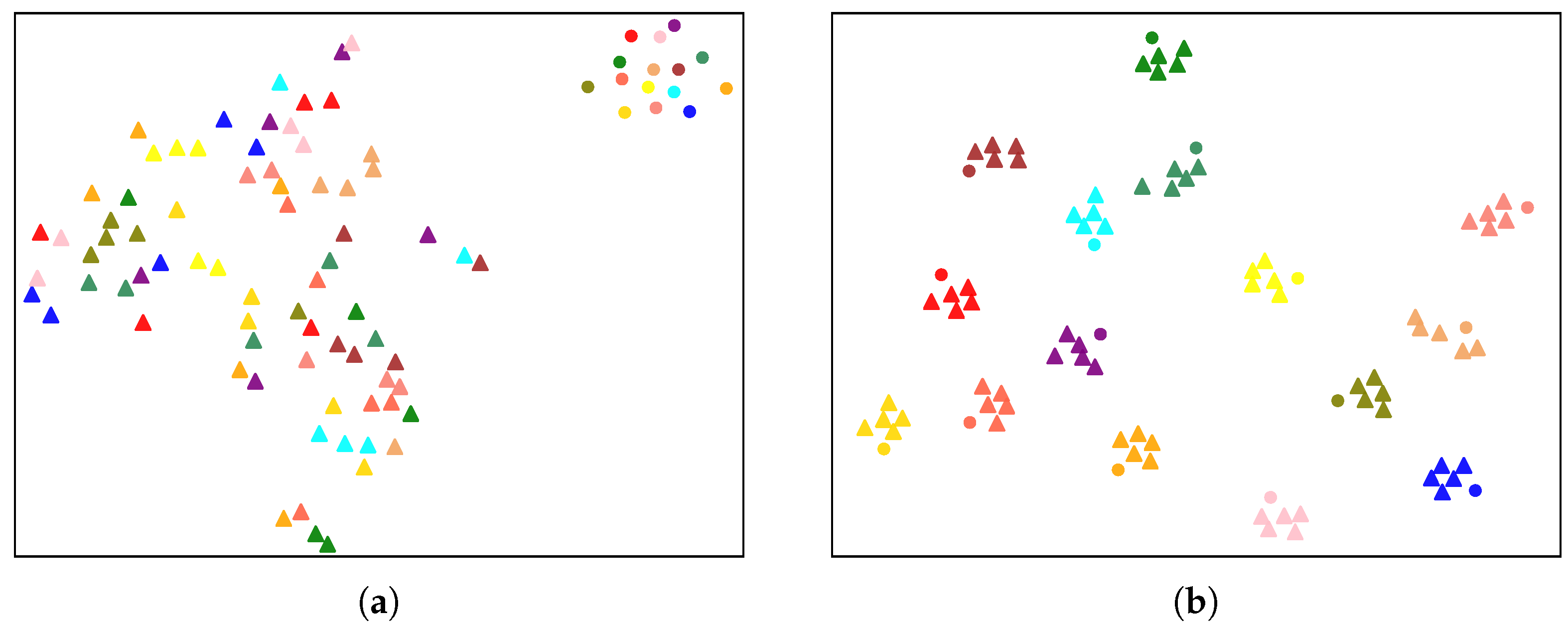
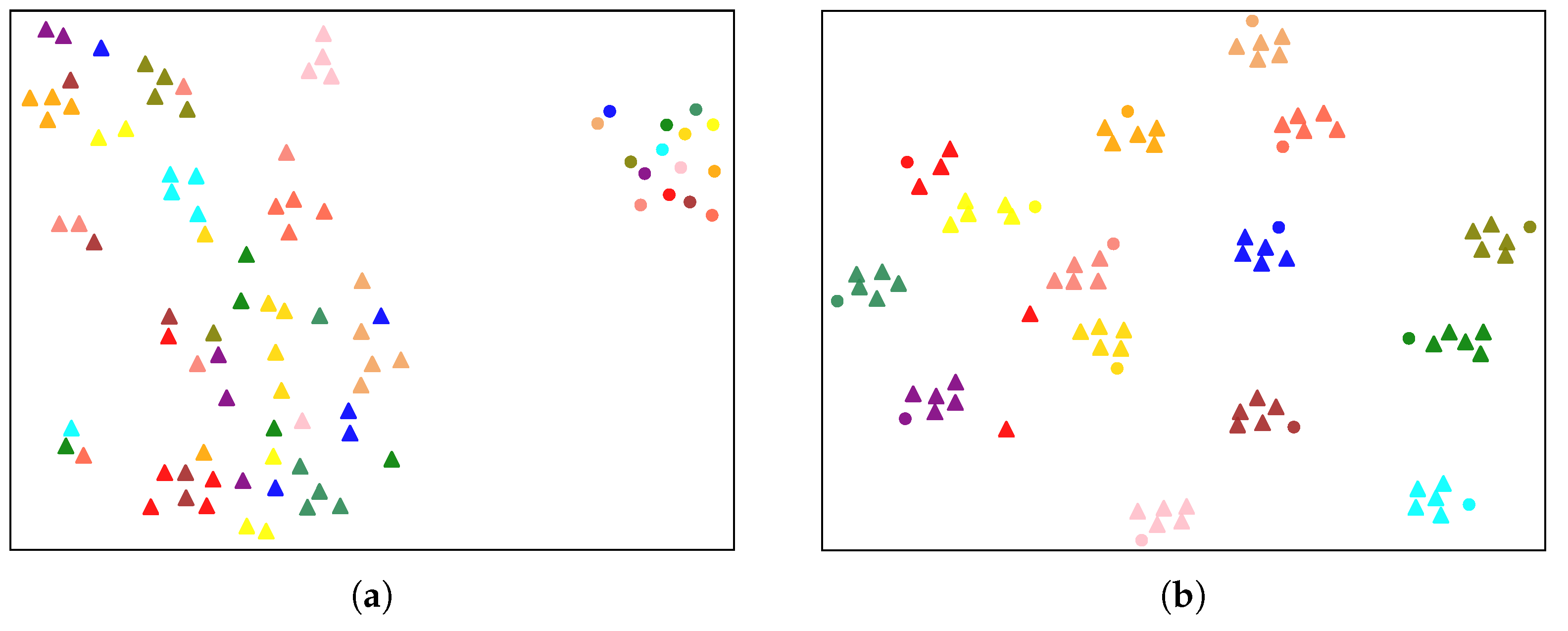
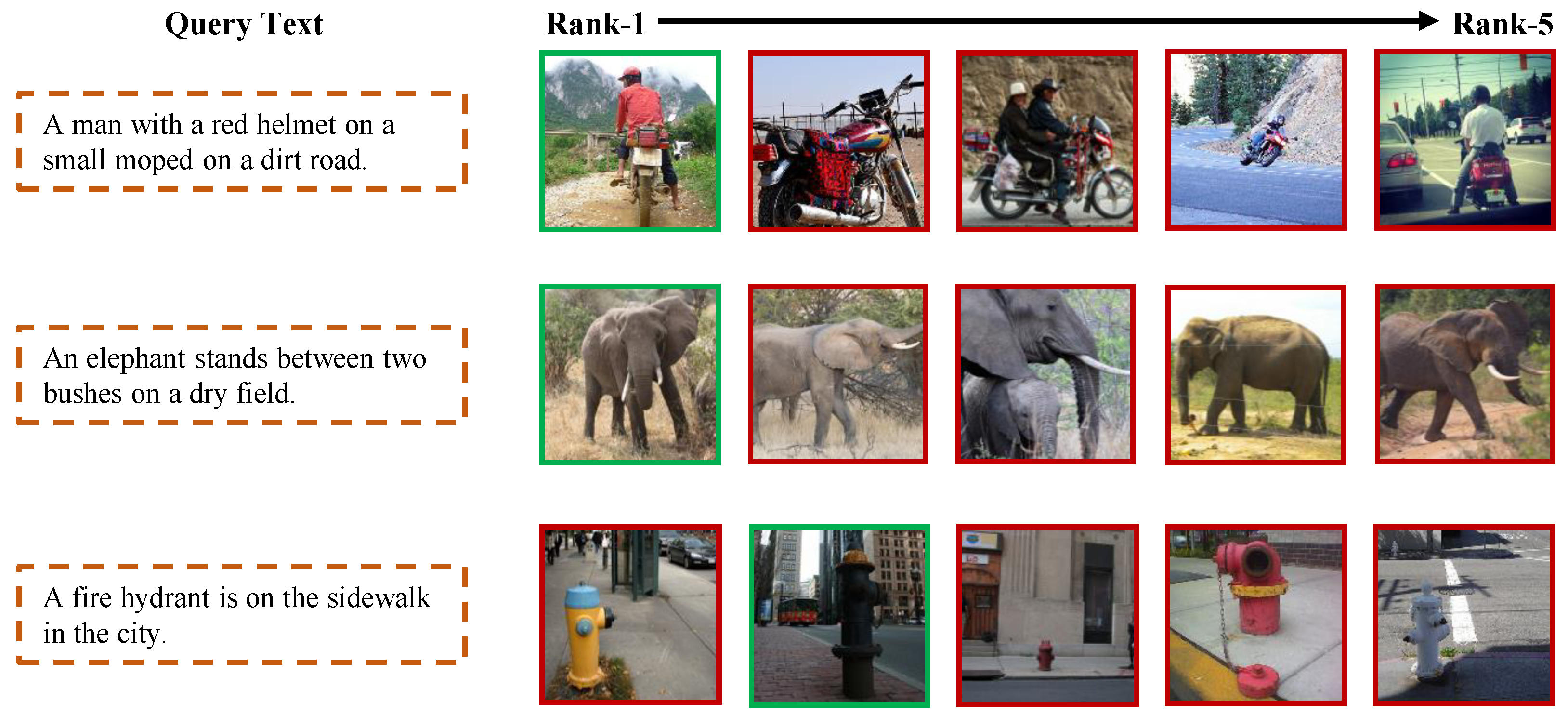
- RQ5: What are the qualitative results for feature representation, cross-modal bi-directional retrieval, and heat map visualization?
5.1. Comparison with SoTA baselines
- Table 1 illustrates the comparison between IConE and SoTA baseline methods on the Flickr30k dataset: (1) IConE surpasses 11 methods based on the graph-free paradigm across all evaluation metrics. Specifically, in comparison to the traditional method VSE++ [6], our IConE can enhance the R@1 index for text retrieval images and image retrieval text by 21.5% and 25.4%, respectively. Moreover, the Rsum index, which reflects the overall retrieval quality, sees a substantial improvement of 99.5 points. Notably, compared to MLMN [13], the representative SoTA method based on the graph-free paradigm, IConE achieves superior results across all indicators, with a relative improvement of 22.9 points in the Rsum indicator. In a departure from MLMN [13], our proposed IConE leverages only one level of feature representation for modality alignment, avoiding the decomposition of image and text data into multiple levels of representation through intricate parsing methods, thereby significantly reducing model complexity and memory consumption. (2) Benefiting from effective graph node modeling and graph reasoning, the performance of graph-based paradigm methods generally exceeds that of graph-free paradigm methods. Our IConE, belonging to the graph-free paradigm, outperforms 9 methods of the graph-based paradigm in most evaluation metrics. Particularly, compared to the earlier SGM [29], IConE can realize the best performance across all indicators, with a remarkable improvement of 30.7 points by the Rsum index. Compared to the representative baseline method, CSCC, IConE achieves sub-optimal results in the R@1 and R@5 indicators for text retrieval images. Similarly, this trend is observed in the HSLM [17], where IConE yields sub-optimal results for R@1 and R@5 in image retrieval text. Despite being lower than some strong baselines in some indicators, IConE consistently maintains superior performance in the Rsum index, which reflects the overall search quality.
- Table 2 provides a comparison between IConE and SoTA baselines on the MS-COCO dataset: IConE showcases superior performance across nearly all metrics. In comparison to the traditional Dual-Path [7], on the 1k test set, the R@1 index for text retrieval images and image retrieval text sees improvements of 10.1% and 8.7%, respectively, and the Rsum is enhanced by 34.4 points. On the 5k test set, the bi-directional retrieval R@1 index improves by 9.6% and 11.1%, respectively, and the Rsum index sees an increase of 56.6 points. While some metrics of IConE on the MS-COCO 1k and MS-COCO 5k test sets are lower than those of the strong baseline GSLS [12] and SGM [29], they remain comparable. Particularly, in comparison to GSLS, competitive results are achieved by IConE, especially notably for the significant 5.4% improvement in the R@1 index for image retrieval text. In contrast to SGM, while IConE may not achieve the best performance in certain bi-directional retrieval metrics, it consistently maintains the most advanced results in Rsum, reflecting the overall search quality.
5.2. Ablation Studies
- The training results in Stage I on both datasets show that the ablation variants with and the one with both achieve promising improvements. Particularly, when is used alone, despite its focus on the feature representation distribution of intra-modality and the limitation in bridging the semantic gap between modalities, it still attains competitive performance. Specifically, compared to the traditional SoTA baseline Dual-Path, it exhibits a 45.4 point improvement by the Rsum indicator on the Flickr30k. On the other hand, , designed to bridge the semantic gap between modalities, achieves superior performance compared to using only .
- By utilizing both losses for joint fine-tuning training in Stage II, the overall performance of the full IConE model significantly improves compared to Stage I. Specifically, the Rsum index on Flickr30k, MS-COCO1k, and MS-COCO 5k reaches 509.3, 502.3, and 394.5, respectively. This underscores that the instance loss in Stage I effectively regularizes the model, providing a better initialization for the contrastive loss. As a result, the model can comprehensively consider both instance classification and matching ranking, effectively bridging the semantic gap in image–text cross-modal retrieval.
5.3. Sensitivity Analysis of the Hyperparameter
5.4. Two-Stage Generalization of Training Strategy
- The performance trends for both the image encoder backbone networks (ResNet-50 and ResNet-152) and text encoder backbone networks (GRU and LSTM) are as we expected: Using the two losses, and , separately in Stage I produces gratifying results and yields more significant improvement than the loss alone. Combining the two losses in Stage II further enhances model performance compared to Stage I, demonstrating the strong generalization of the two-stage training strategy.
- Furthermore, the experimental results in both Table 3 and Table 4 also validate the effectiveness of the CLIP multi-modal pre-training model for cross-modal retrieval tasks. In this paper, the ViT initialized with CLIP is employed as the backbone network for the image encoder. This approach leverages the knowledge from the existing multi-modal pre-training model for the cross-modal retrieval task, enabling the utilization of interactive information between images and text, thereby enhancing the model’s feature representation capabilities. In contrast, ResNet-50 and ResNet-152 are single-modal pre-training models for images, operating independently from text encoders to extract image features without interaction. Consequently, IConE utilizing CLIP-initialized ViT as the image encoder achieves superior performance.
5.5. Qualitative Visualization Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ma, Y.; Xu, G.; Sun, X.; Yan, M.; Zhang, J.; Ji, R. X-CLIP: End-to-end multi-grained contrastive learning for video-text retrieval. In Proceedings of the ACM International Conference on Multimedia, Lisbon, Portugal, 10–14 October 2022; pp. 638–647. [Google Scholar]
- Ma, W.; Chen, Q.; Zhou, T.; Zhao, S.; Cai, Z. Using Multimodal Contrastive Knowledge Distillation for Video-Text Retrieval. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 5486–5497. [Google Scholar] [CrossRef]
- Chen, S.; Zhao, Y.; Jin, Q.; Wu, Q. Fine-grained video-text retrieval with hierarchical graph reasoning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10638–10647. [Google Scholar]
- Ma, W.; Wu, X.; Zhao, S.; Zhou, T.; Guo, D.; Gu, L.; Cai, Z.; Wang, M. FedSH: Towards Privacy-preserving Text-based Person Re-Identification. IEEE Trans. Multimed. 2023; early access. [Google Scholar]
- Wu, X.; Ma, W.; Guo, D.; Tongqing, Z.; Zhao, S.; Cai, Z. Text-based Occluded Person Re-identification via Multi-Granularity Contrastive Consistency Learning. In Proceedings of the AAAI, Vancouver, BC, Canada, 20–27 February 2024. [Google Scholar]
- Faghri, F.; Fleet, D.J.; Kiros, J.R.; Fidler, S. Vse++: Improving visual-semantic embeddings with hard negatives. arXiv 2017, arXiv:1707.05612. [Google Scholar]
- Zheng, Z.; Zheng, L.; Garrett, M.; Yang, Y.; Xu, M.; Shen, Y.D. Dual-path convolutional image-text embeddings with instance loss. ACM Trans. Multimed. Comput. Commun. Appl. 2020, 16, 1–23. [Google Scholar] [CrossRef]
- Li, W.H.; Yang, S.; Wang, Y.; Song, D.; Li, X.Y. Multi-level similarity learning for image-text retrieval. Inf. Process. Manag. 2021, 58, 102432. [Google Scholar] [CrossRef]
- Liu, X.; He, Y.; Cheung, Y.M.; Xu, X.; Wang, N. Learning relationship-enhanced semantic graph for fine-grained image–text matching. IEEE Trans. Cybern. 2022; early access. [Google Scholar]
- Chen, J.; Hu, H.; Wu, H.; Jiang, Y.; Wang, C. Learning the best pooling strategy for visual semantic embedding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 15789–15798. [Google Scholar]
- Xu, X.; Wang, Y.; He, Y.; Yang, Y.; Hanjalic, A.; Shen, H.T. Cross-modal hybrid feature fusion for image-sentence matching. ACM Trans. Multimed. Comput. Commun. Appl. 2021, 17, 1–23. [Google Scholar] [CrossRef]
- Li, Z.; Ling, F.; Zhang, C.; Ma, H. Combining global and local similarity for cross-media retrieval. IEEE Access 2020, 8, 21847–21856. [Google Scholar] [CrossRef]
- Lan, H.; Zhang, P. Learning and integrating multi-level matching features for image-text retrieval. IEEE Signal Process. Lett. 2021, 29, 374–378. [Google Scholar] [CrossRef]
- Li, Z.; Guo, C.; Feng, Z.; Hwang, J.N.; Xue, X. Multi-view visual semantic embedding. In Proceedings of the International Joint Conference on Artificial Intelligence, Vienna, Austria, 23–29 July 2022; pp. 1130–1136. [Google Scholar]
- Zeng, P.; Gao, L.; Lyu, X.; Jing, S.; Song, J. Conceptual and syntactical cross-modal alignment with cross-level consistency for image-text matching. In Proceedings of the ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 2205–2213. [Google Scholar]
- Cheng, Y.; Zhu, X.; Qian, J.; Wen, F.; Liu, P. Cross-modal graph matching network for image-text retrieval. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 1–23. [Google Scholar] [CrossRef]
- Zeng, S.; Liu, C.; Zhou, J.; Chen, Y.; Jiang, A.; Li, H. Learning hierarchical semantic correspondences for cross-modal image-text retrieval. In Proceedings of the International Conference on Multimedia Retrieval, Newark, NJ, USA, 27–30 June 2022; pp. 239–248. [Google Scholar]
- Frome, A.; Corrado, G.S.; Shlens, J.; Bengio, S.; Dean, J.; Ranzato, M.; Mikolov, T. DeViSE: A deep visual-semantic embedding model. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 2121–2129. [Google Scholar]
- Vendrov, I.; Kiros, R.; Fidler, S.; Urtasun, R. Order-embeddings of images and language. arXiv 2015, arXiv:1511.06361. [Google Scholar]
- He, Y.; Xiang, S.; Kang, C.; Wang, J.; Pan, C. Cross-modal retrieval via deep and bidirectional representation learning. IEEE Trans. Multimed. 2016, 18, 1363–1377. [Google Scholar] [CrossRef]
- Lee, K.H.; Chen, X.; Hua, G.; Hu, H.; He, X. Stacked cross attention for image-text matching. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 201–216. [Google Scholar]
- Wang, Z.; Liu, X.; Li, H.; Sheng, L.; Yan, J.; Wang, X.; Shao, J. Camp: Cross-modal adaptive message passing for text-image retrieval. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5764–5773. [Google Scholar]
- Zhang, Q.; Lei, Z.; Zhang, Z.; Li, S.Z. Context-aware attention network for image-text retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3536–3545. [Google Scholar]
- Wang, H.; Zhang, Y.; Ji, Z.; Pang, Y.; Ma, L. Consensus-aware visual-semantic embedding for image-text matching. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 18–34. [Google Scholar]
- Wei, J.; Xu, X.; Wang, Z.; Wang, G. Meta self-paced learning for cross-modal matching. In Proceedings of the ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 3835–3843. [Google Scholar]
- Xu, X.; Wang, T.; Yang, Y.; Zuo, L.; Shen, F.; Shen, H.T. Cross-modal attention with semantic consistence for image-text matching. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 5412–5425. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Liu, H.; Wang, H.; Liu, M. Regularizing visual semantic embedding with contrastive learning for image-text matching. IEEE Signal Process. Lett. 2022, 29, 1332–1336. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Wang, S.; Wang, R.; Yao, Z.; Shan, S.; Chen, X. Cross-modal scene graph matching for relationship-aware image-text retrieval. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1508–1517. [Google Scholar]
- Li, K.; Zhang, Y.; Li, K.; Li, Y.; Fu, Y. Visual semantic reasoning for image-text matching. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4654–4662. [Google Scholar]
- Pei, J.; Zhong, K.; Yu, Z.; Wang, L.; Lakshmanna, K. Scene graph semantic inference for image and text matching. Acm Trans. Asian-Low-Resour. Lang. Inf. Process. 2022, 22, 144. [Google Scholar] [CrossRef]
- Liu, C.; Mao, Z.; Zhang, T.; Xie, H.; Wang, B.; Zhang, Y. Graph structured network for image-text matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10921–10930. [Google Scholar]
- Long, S.; Han, S.C.; Wan, X.; Poon, J. Gradual: Graph-based dual-modal representation for image-text matching. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 3459–3468. [Google Scholar]
- Wang, L.; Li, Y.; Huang, J.; Lazebnik, S. Learning two-branch neural networks for image-text matching tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 394–407. [Google Scholar] [CrossRef] [PubMed]
- Ma, W.; Chen, Q.; Liu, F.; Zhou, T.; Cai, Z. Query-adaptive late fusion for hierarchical fine-grained video-text retrieval. IEEE Trans. Neural Netw. Learn. Syst. 2022; early access. [Google Scholar]
- Huo, Y.; Zhang, M.; Liu, G.; Lu, H.; Gao, Y.; Yang, G.; Wen, J.; Zhang, H.; Xu, B.; Zheng, W.; et al. WenLan: Bridging vision and language by large-scale multi-modal pre-training. arXiv 2021, arXiv:2103.06561. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.T.; Parekh, Z.; Pham, H.; Le, Q.; Sung, Y.H.; Li, Z.; Duerig, T. Scaling up visual and vision-language representation learning with noisy text supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 4904–4916. [Google Scholar]
- Yuan, L.; Chen, D.; Chen, Y.L.; Codella, N.; Dai, X.; Gao, J.; Hu, H.; Huang, X.; Li, B.; Li, C.; et al. Florence: A new foundation model for computer vision. arXiv 2021, arXiv:2111.11432. [Google Scholar]
- Luo, H.; Ji, L.; Zhong, M.; Chen, Y.; Lei, W.; Duan, N.; Li, T. CLIP4Clip: An empirical study of CLIP for end to end video clip retrieval and captioning. Neurocomputing 2022, 508, 293–304. [Google Scholar] [CrossRef]
- Yan, S.; Dong, N.; Zhang, L.; Tang, J. CLIP-driven fine-grained text-image person re-identification. arXiv 2022, arXiv:2210.10276. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Kenton, J.D.M.W.C.; Toutanova, L.K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Young, P.; Lai, A.; Hodosh, M.; Hockenmaier, J. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Trans. Assoc. Comput. Linguist. 2014, 2, 67–78. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Hu, P.; Peng, X.; Zhu, H.; Zhen, L.; Lin, J. Learning cross-modal retrieval with noisy labels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 5403–5413. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ge, R.; Kakade, S.M.; Kidambi, R.; Netrapalli, P. The step decay schedule: A near optimal, geometrically decaying learning rate procedure for least squares. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Text-to-Image | Image-to-Text | Rsum | Parameter Size | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | MedR | MnR | R@1 | R@5 | R@10 | MedR | MnR | ||||
| Graph-free paradigm | VSE++ [6] | 39.6 | 70.1 | 79.5 | 2 | - | 52.9 | 80.5 | 87.2 | 1 | - | 409.8 | - |
| Dual-Path [7] | 39.1 | 69.2 | 80.9 | 2 | - | 55.6 | 81.9 | 89.5 | 1 | - | 416.2 | - | |
| GSLS [12] | 43.4 | 73.5 | 82.5 | 2 | - | 68.2 | 89.1 | 94.5 | 1 | - | 451.2 | - | |
| CMHF [11] | 45.4 | 76.6 | 85.0 | - | - | 63.6 | 88.6 | 94.0 | - | - | 453.2 | - | |
| SCAN [21] | 48.6 | 77.7 | 85.2 | - | - | 67.4 | 90.3 | 95.8 | - | - | 465.0 | - | |
| CAMP [22] | 51.5 | 77.1 | 85.3 | - | - | 68.1 | 89.7 | 95.2 | - | - | 466.9 | - | |
| CASC [26] | 50.2 | 78.3 | 86.3 | - | - | 68.5 | 90.6 | 95.6 | - | - | 469.5 | - | |
| CAAN [23] | 52.8 | 79.0 | 87.9 | - | - | 70.1 | 91.6 | 97.2 | - | - | 478.6 | - | |
| CVSE [24] | 52.9 | 80.4 | 87.8 | - | - | 73.5 | 92.1 | 95.8 | - | - | 482.5 | - | |
| Meta-SPN [25] | 53.3 | 80.2 | 87.2 | - | - | 72.5 | 93.2 | 96.7 | - | - | 483.1 | - | |
| MLMN [13] | 55.3 | 80.2 | 85.6 | - | - | 75.9 | 93.3 | 96.1 | - | - | 486.4 | - | |
| Graph-based paradigm | SGM [29] | 53.5 | 79.6 | 86.5 | 1 | - | 71.8 | 91.7 | 95.5 | 1 | - | 478.6 | - |
| VSRN [30] | 54.7 | 81.8 | 88.2 | - | - | 71.3 | 90.6 | 96.0 | - | - | 482.6 | - | |
| SGSIN [31] | 53.9 | 80.1 | 87.2 | - | - | 73.1 | 93.6 | 96.8 | - | - | 484.7 | - | |
| MLSL [8] | 56.8 | 83.3 | 91.3 | - | - | 72.2 | 92.4 | 98.2 | - | - | 494.2 | - | |
| GSMN [32] | 57.4 | 82.3 | 89.0 | - | - | 76.4 | 94.3 | 97.3 | - | - | 496.7 | - | |
| ReSG [9] | 58.0 | 83.1 | 88.7 | - | - | 77.2 | 94.2 | 98.2 | - | - | 499.4 | - | |
| CGMN [16] | 59.9 | 85.1 | 90.6 | - | - | 77.9 | 93.8 | 96.8 | - | - | 504.1 | - | |
| HSLM [17] | 60.7 | 84.7 | 90.1 | - | - | 79.9 | 95.7 | 97.5 | - | - | 508.6 | - | |
| Our IConE (Graph-free paradigm) | 61.1 | 86.0 | 91.7 | 1 | 6.1 | 78.3 | 94.6 | 97.6 | 1 | 2.6 | 509.3 | 225M | |
| Methods | Text-to-Image | Image-to-Text | Rsum | Parameter Size | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | MedR | MnR | R@1 | R@5 | R@10 | MedR | MnR | |||
| MS-COCO 1k | ||||||||||||
| Dual-Path [7] | 47.1 | 79.9 | 90.0 | 2 | - | 65.6 | 89.8 | 95.5 | 1 | - | 467.9 | - |
| VSE++ [6] | 52.0 | 84.3 | 92.0 | 1 | - | 64.6 | 90.0 | 95.7 | 1 | - | 478.6 | - |
| SCAN [21] | 53.0 | 85.4 | 92.9 | - | - | 67.5 | 92.9 | 97.6 | - | - | 489.3 | - |
| GSLS [12] | 58.6 | 88.2 | 94.9 | 1 | - | 68.9 | 94.1 | 98.0 | 1 | - | 502.7 | - |
| SGM [29] | 57.5 | 87.3 | 94.3 | 1 | - | 73.4 | 93.8 | 97.8 | 1 | - | 504.1 | - |
| Our IConE | 57.2 | 86.2 | 93.5 | 1 | 4.6 | 74.3 | 93.8 | 97.3 | 1 | 2.5 | 502.3 | - |
| MS-COCO 5k | ||||||||||||
| Dual-Path [7] | 25.3 | 53.4 | 66.4 | 5 | - | 41.2 | 70.5 | 81.1 | 2 | - | 337.9 | - |
| VSE++ [6] | 30.3 | 59.4 | 72.4 | 4 | - | 41.3 | 71.1 | 81.2 | 2 | - | 355.7 | - |
| SCAN [21] | 34.4 | 63.7 | 75.7 | - | - | 46.4 | 77.4 | 87.2 | - | - | 384.8 | - |
| CASC [26] | 34.7 | 64.8 | 76.8 | - | - | 47.2 | 78.3 | 87.4 | - | - | 389.2 | - |
| SGM [29] | 35.3 | 64.9 | 76.5 | 3 | - | 50.0 | 79.3 | 87.9 | 2 | - | 393.9 | - |
| Our IConE | 34.9 | 64.4 | 75.7 | 3 | 18.4 | 52.3 | 79.5 | 87.7 | 1 | 7.7 | 394.5 | 225M |
| Methods | Stage | Text-to-Image | Image-to-Text | Rsum | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | MedR | MnR | R@1 | R@5 | R@10 | MedR | MnR | |||
| Flickr30k | ||||||||||||
| Only | I | 48.2 | 76.6 | 84.7 | 2 | 11.6 | 68.3 | 89.9 | 93.9 | 1 | 3.6 | 461.6 |
| Only | I | 52.8 | 81.5 | 88.3 | 1 | 7.5 | 68.8 | 91.1 | 95.5 | 1 | 3.3 | 478.0 |
| Full IConE (with and ) | II | 61.1 | 86.0 | 91.7 | 1 | 6.1 | 78.3 | 94.6 | 97.6 | 1 | 2.6 | 509.3 |
| MS-COCO 1k | ||||||||||||
| Only | I | 41.3 | 75.2 | 86.3 | 2 | 9.1 | 59.2 | 85.4 | 92.9 | 1 | 4.4 | 440.3 |
| Only | I | 49.8 | 81.7 | 91.4 | 1.6 | 5.2 | 60.2 | 87.4 | 94.2 | 1 | 3.8 | 464.7 |
| Full IConE (with and ) | II | 57.2 | 86.2 | 93.5 | 1 | 4.6 | 74.3 | 93.8 | 97.3 | 1 | 2.5 | 502.3 |
| MS-COCO 5k | ||||||||||||
| Only | I | 21.4 | 47.1 | 60.2 | 6 | 40.9 | 35.9 | 64.1 | 74.8 | 3 | 17.9 | 303.5 |
| Only | I | 28.4 | 56.4 | 68.5 | 4 | 21.7 | 36.3 | 65.8 | 77.2 | 3 | 14.1 | 332.6 |
| Full IConE (with and ) | II | 34.9 | 64.4 | 75.7 | 3 | 18.4 | 52.3 | 79.5 | 87.7 | 1 | 7.7 | 394.5 |
| Methods | Stage | Feature Representation | Text-to-Image | Image-to-Text | Rsum | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Image | Text | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |||
| Flickr30k | ||||||||||
| Only | I | ResNet-50 | BERT | 20.7 | 45.9 | 58.4 | 30.5 | 57.5 | 69.2 | 282.2 |
| Only | I | ResNet-50 | BERT | 25.4 | 52.9 | 65.6 | 34.8 | 63.8 | 75.8 | 318.3 |
| Full IConE | II | ResNet-50 | BERT | 32.0 | 59.7 | 70.8 | 46.3 | 72.6 | 81.6 | 363.0 |
| Only | I | ResNet-152 | BERT | 22.3 | 49.2 | 61.5 | 34.8 | 62.4 | 72.8 | 303.0 |
| Only | I | ResNet-152 | BERT | 27.1 | 55.9 | 68.3 | 38.4 | 67.9 | 79.1 | 336.7 |
| Full IConE | II | ResNet-152 | BERT | 36.4 | 65.0 | 75.2 | 51.8 | 77.2 | 84.9 | 390.5 |
| Only | I | ViT | BERT | 48.2 | 76.6 | 84.7 | 68.3 | 89.9 | 93.9 | 461.6 |
| Only | I | ViT | BERT | 52.8 | 81.5 | 88.3 | 68.8 | 91.1 | 95.5 | 478.0 |
| Full IConE | II | ViT | BERT | 61.1 | 86.0 | 91.7 | 78.3 | 94.6 | 97.6 | 509.3 |
| Only | I | ViT | GRU | 46.8 | 78.5 | 86.6 | 69.4 | 90.0 | 94.4 | 465.7 |
| Only | I | ViT | GRU | 51.4 | 80.1 | 87.4 | 69.6 | 89.3 | 94.9 | 472.7 |
| Full IConE | II | ViT | GRU | 52.0 | 80.1 | 87.5 | 70.5 | 89.3 | 94.4 | 473.8 |
| Only | I | ViT | LSTM | 43.7 | 76.1 | 85.4 | 64.6 | 88.6 | 93.3 | 451.7 |
| Only | I | ViT | LSTM | 49.9 | 79.4 | 86.6 | 66.7 | 89.8 | 95.1 | 467.5 |
| Full IConE | II | ViT | LSTM | 66.9 | 90.7 | 95.0 | 50.6 | 79.5 | 87.0 | 469.7 |
| MS-COCO 1k | ||||||||||
| Only | I | ResNet-50 | BERT | 24.2 | 57.4 | 73.0 | 37.4 | 69.2 | 81.8 | 343.0 |
| Only | I | ResNet-50 | BERT | 32.0 | 67.7 | 82.1 | 40.0 | 74.4 | 85.4 | 381.6 |
| Full IConE | II | ResNet-50 | BERT | 37.7 | 72.3 | 84.3 | 54.1 | 83.2 | 90.9 | 422.5 |
| Only | I | ResNet-152 | BERT | 25.4 | 59.9 | 75.1 | 39.1 | 71.1 | 83.8 | 354.4 |
| Only | I | ResNet-152 | BERT | 34.3 | 70.0 | 83.5 | 41.9 | 75.8 | 86.7 | 392.2 |
| Full IConE | II | ResNet-152 | BERT | 43.7 | 78.7 | 89.1 | 60.3 | 86.8 | 93.4 | 452.0 |
| Only | I | ViT | GRU | 49.9 | 83.4 | 92.2 | 68.0 | 91.1 | 96.2 | 480.8 |
| Only | I | ViT | GRU | 53.5 | 85.4 | 93.3 | 67.2 | 91.3 | 96.5 | 487.2 |
| Full IConE | II | ViT | GRU | 54.5 | 85.7 | 93.6 | 68.0 | 91.7 | 96.9 | 490.4 |
| Only | I | ViT | LSTM | 48.9 | 82.5 | 91.8 | 67.4 | 90.9 | 96.4 | 477.9 |
| Only | I | ViT | LSTM | 52.8 | 85.3 | 93.4 | 67.1 | 91.2 | 96.5 | 486.3 |
| Full IConE | II | ViT | LSTM | 53.7 | 85.6 | 93.6 | 66.9 | 91.8 | 96.8 | 488.4 |
| MS-COCO 5k | ||||||||||
| Only | I | ResNet-50 | BERT | 9.7 | 27.7 | 40.3 | 17.0 | 40.2 | 53.4 | 188.3 |
| Only | I | ResNet-50 | BERT | 14.1 | 37.1 | 50.6 | 18.7 | 44.2 | 59.2 | 223.9 |
| Full IConE | II | ResNet-50 | BERT | 18.5 | 43.8 | 57.4 | 31.4 | 60.1 | 72.5 | 283.7 |
| Only | I | ResNet-152 | BERT | 10.2 | 29.5 | 42.6 | 18.4 | 42.6 | 55.9 | 199.2 |
| Only | I | ResNet-152 | BERT | 15.7 | 39.6 | 53.1 | 21.0 | 45.9 | 60.1 | 235.4 |
| Full IConE | II | ResNet-152 | BERT | 23.1 | 50.9 | 64.3 | 37.9 | 66.2 | 77.1 | 319.5 |
| Only | I | ViT | GRU | 28.1 | 57.0 | 70.2 | 44.5 | 73.5 | 83.4 | 356.7 |
| Only | I | ViT | GRU | 31.8 | 60.7 | 73.1 | 43.3 | 71.6 | 82.9 | 363.4 |
| Full IConE | II | ViT | GRU | 32.7 | 61.6 | 73.8 | 43.4 | 73.0 | 83.4 | 367.9 |
| Only | I | ViT | LSTM | 27.2 | 55.9 | 69.5 | 42.8 | 72.4 | 82.6 | 350.4 |
| Only | I | ViT | LSTM | 30.8 | 60.1 | 72.6 | 43.3 | 71.5 | 82.9 | 361.2 |
| Full IConE | II | ViT | LSTM | 31.5 | 61.1 | 73.4 | 43.5 | 72.2 | 83.7 | 365.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, R.; Ma, W.; Wu, X.; Liu, W.; Liu, J. Image–Text Cross-Modal Retrieval with Instance Contrastive Embedding. Electronics 2024, 13, 300. https://doi.org/10.3390/electronics13020300
Zeng R, Ma W, Wu X, Liu W, Liu J. Image–Text Cross-Modal Retrieval with Instance Contrastive Embedding. Electronics. 2024; 13(2):300. https://doi.org/10.3390/electronics13020300
Chicago/Turabian StyleZeng, Ruigeng, Wentao Ma, Xiaoqian Wu, Wei Liu, and Jie Liu. 2024. "Image–Text Cross-Modal Retrieval with Instance Contrastive Embedding" Electronics 13, no. 2: 300. https://doi.org/10.3390/electronics13020300
APA StyleZeng, R., Ma, W., Wu, X., Liu, W., & Liu, J. (2024). Image–Text Cross-Modal Retrieval with Instance Contrastive Embedding. Electronics, 13(2), 300. https://doi.org/10.3390/electronics13020300