
Path Planning in Complex Environments Using Attention-Based Deep Deterministic Policy Gradient


Abstract
1. Introduction
2. Related Works
2.1. Deep Deterministic Policy Gradient (DDPG) Algorithm
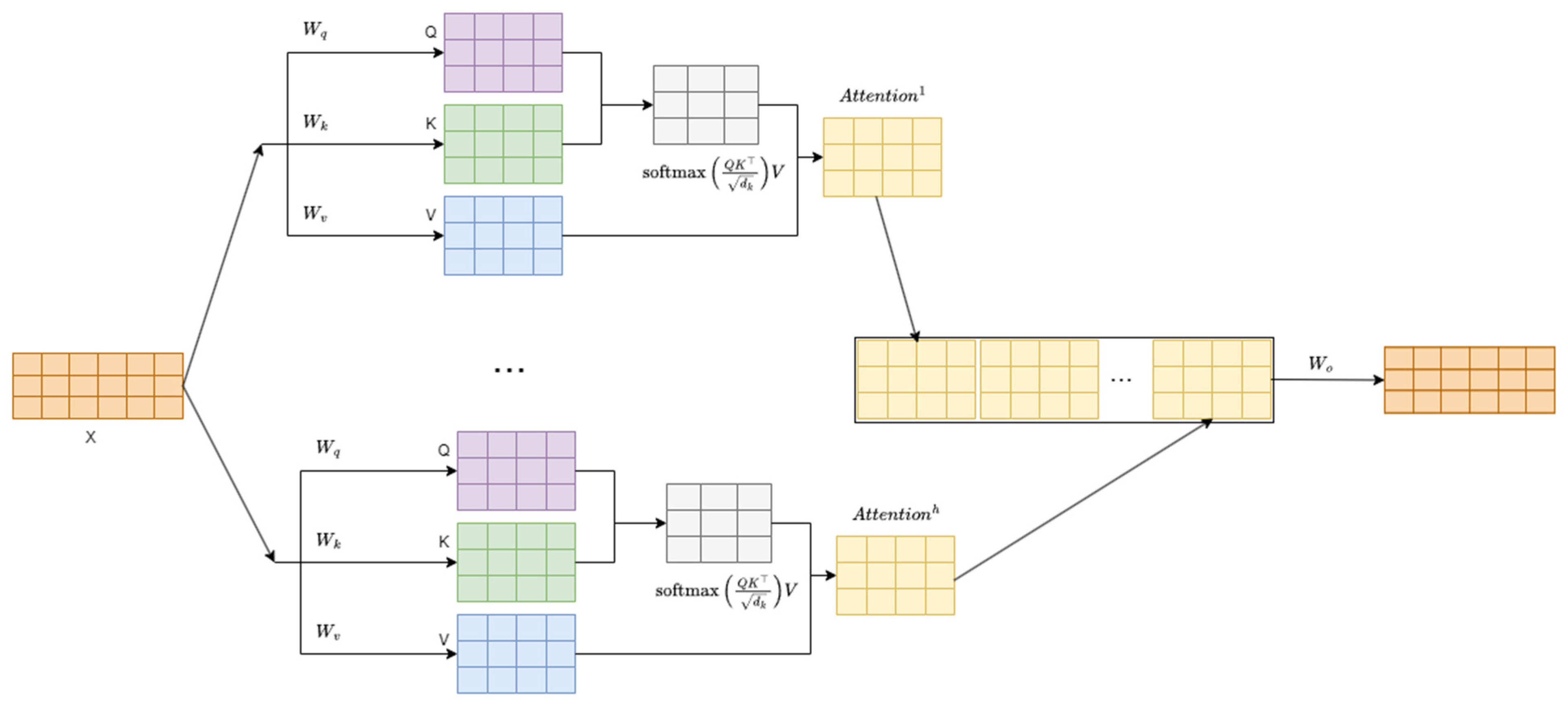
2.2. Attention Mechanism Algorithm
2.3. Prioritized Experience Replay Mechanism
3. Methodology
3.1. Parallel Training across Multiple Complex Environments
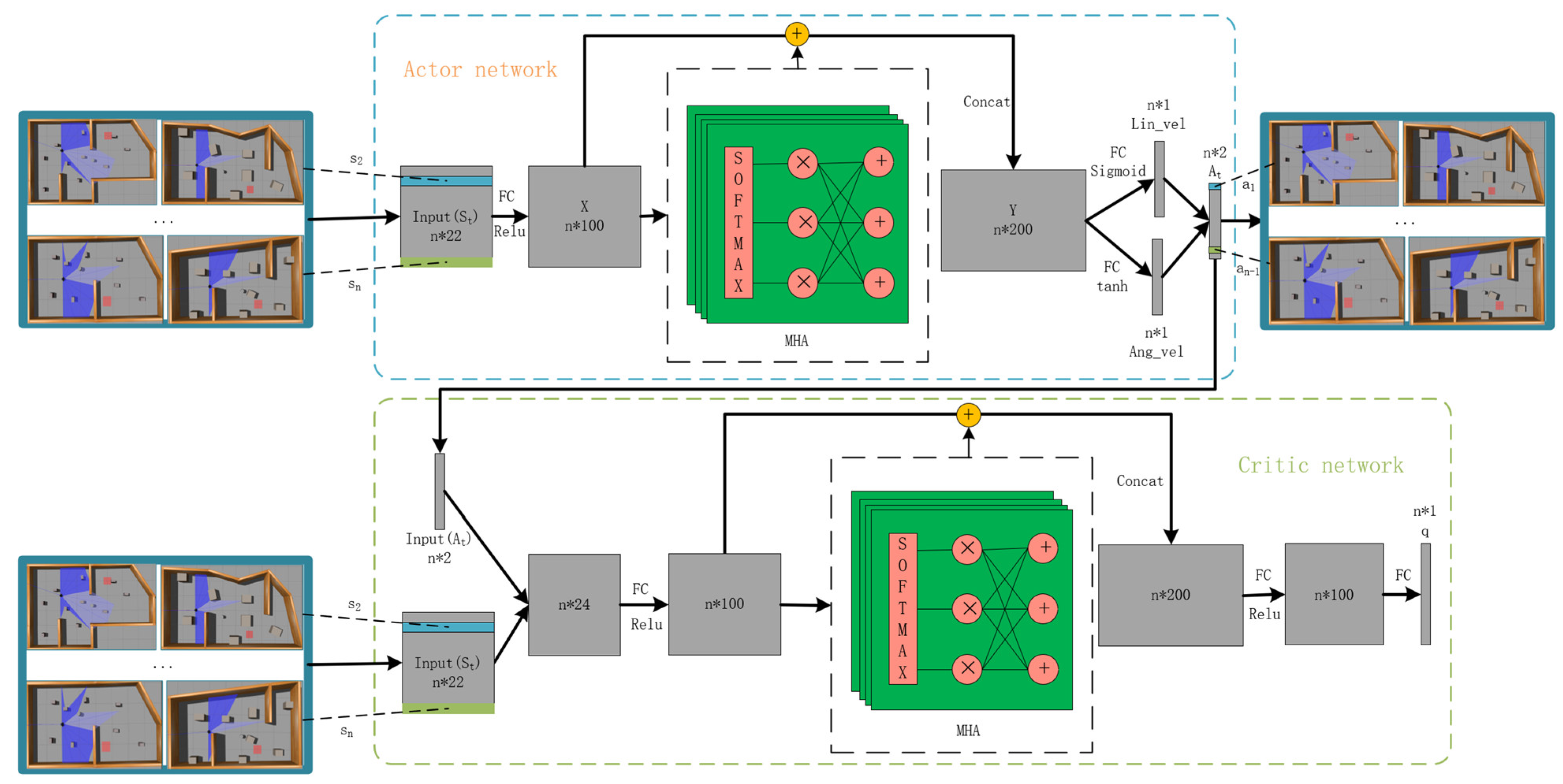
3.2. MAP-DDPG Network Architecture
3.3. Design of the Reward Function
3.3.1. Heading Adjustment Reward
3.3.2. Distance Ratio Reward
3.3.3. Obstacle Penalty
3.3.4. Target Reaching Reward
3.3.5. Collision Penalty
3.3.6. Total Reward
4. Experimental Results and Analysis
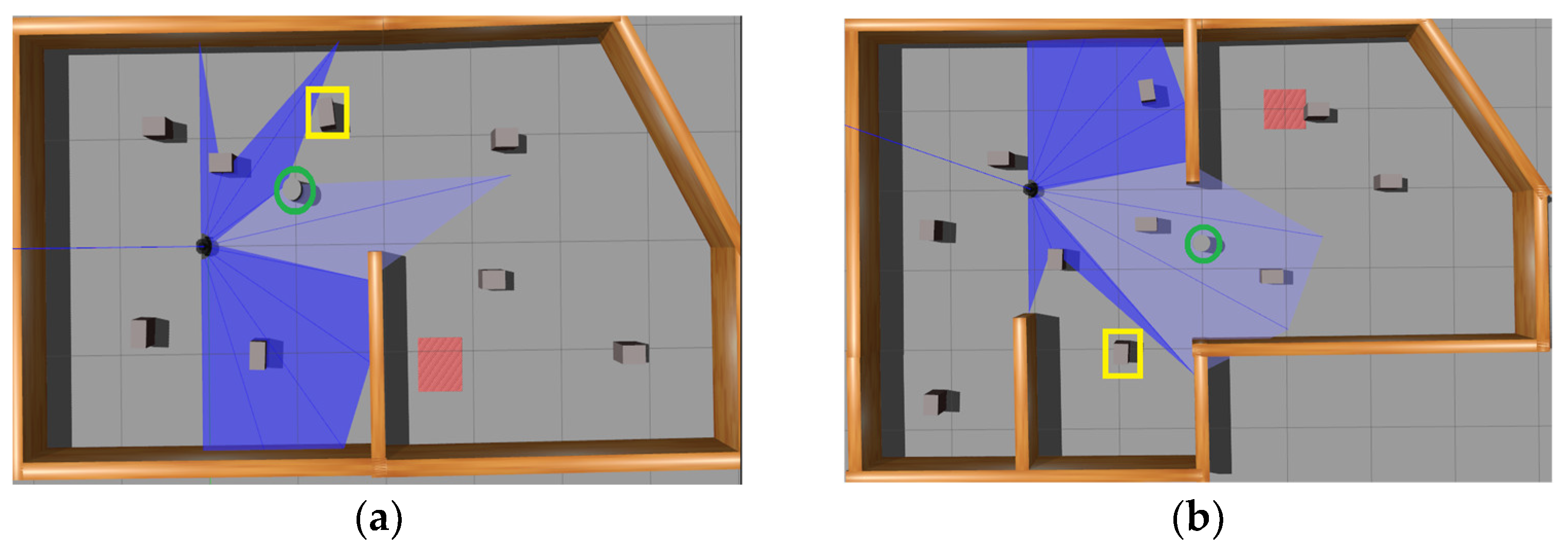
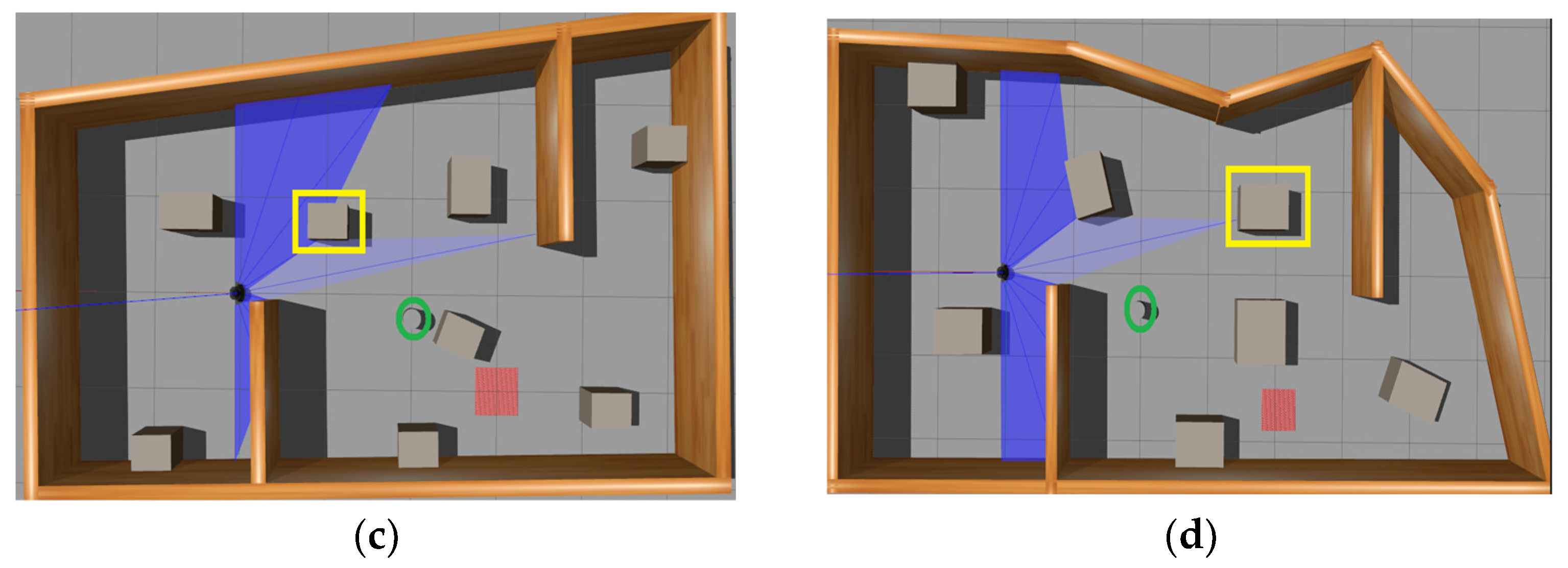
4.1. Simulation Experiment Environment Setup
4.2. Algorithm Performance Analysis
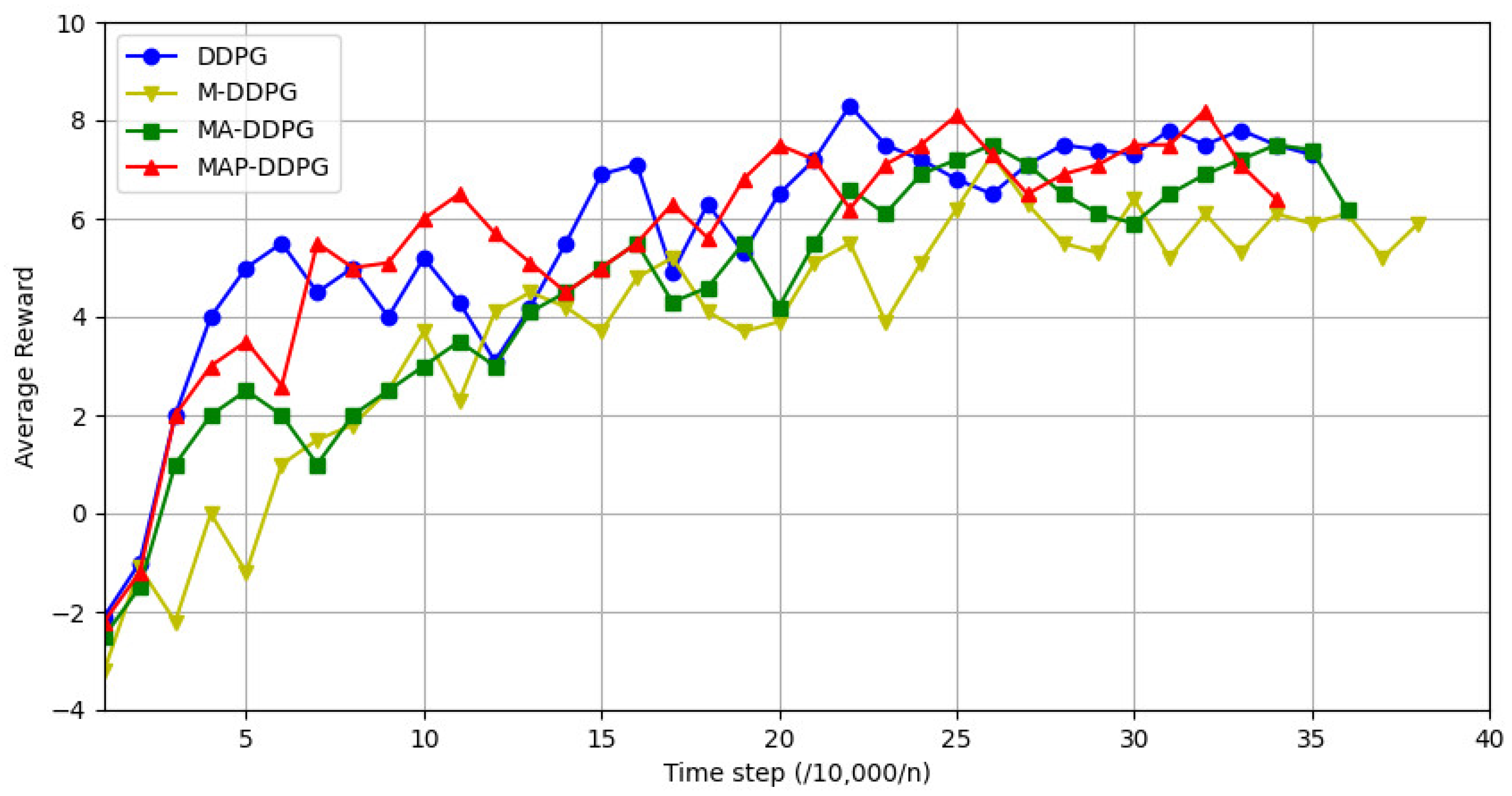
4.3. Comparison and Analysis with Other Algorithms
4.4. Real-World Performance of the Algorithm
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Khan, H.; Iqbal, J.; Baizid, K.; Zielinska, T. Longitudinal and lateral slip control of autonomous wheeled mobile robot for trajectory tracking. Front. Inf. Technol. Electron. Eng. 2015, 16, 166–172. [Google Scholar] [CrossRef]
- Chung, M.A.; Lin, C.W. An Improved Localization of Mobile Robotic System Based on AMCL Algorithm. IEEE Sens. J. 2022, 22, 900–908. [Google Scholar] [CrossRef]
- Guo, G.; Zhao, S.J. 3D Multi-Object Tracking with Adaptive Cubature Kalman Filter for Autonomous Driving. IEEE Trans. Intell. Veh. 2023, 8, 512–519. [Google Scholar] [CrossRef]
- Huang, Y.W.; Shan, T.X.; Chen, F.F.; Englot, B. DiSCo-SLAM: Distributed Scan Context-Enabled Multi-Robot LiDAR SLAM With Two-Stage Global-Local Graph Optimization. IEEE Robot. Autom. Lett. 2022, 7, 1150–1157. [Google Scholar] [CrossRef]
- Saranya, C.; Unnikrishnan, M.; Ali, S.A.; Sheela, D.S.; Lalithambika, V.R. Terrain Based D* Algorithm for Path Planning. In Proceedings of the 4th IFAC Conference on Advances in Control and Optimization of Dynamical Systems (ACODS 2016), Tiruchirappalli, India, 1–5 February 2016; pp. 178–182. [Google Scholar]
- Jeong, I.B.; Lee, S.J.; Kim, J.H. Quick-RRT*: Triangular inequality-based implementation of RRT* with improved initial solution and convergence rate. Expert Syst. Appl. 2019, 123, 82–90. [Google Scholar] [CrossRef]
- Xu, C.; Xu, Z.B.; Xia, M.Y. Obstacle Avoidance in a Three-Dimensional Dynamic Environment Based on Fuzzy Dynamic Windows. Appl. Sci. 2021, 11, 504. [Google Scholar] [CrossRef]
- Wu, J.F.; Ma, X.H.; Peng, T.R.; Wang, H.J. An Improved Timed Elastic Band (TEB) Algorithm of Autonomous Ground Vehicle (AGV) in Complex Environment. Sensors 2021, 21, 8312. [Google Scholar] [CrossRef]
- Bellman, R. A Markovian decision process. J. Math. Mech. 1957, 6, 679–684. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H. Learning from Delayed Rewards. Ph.D. Thesis, King’s College, Cambridge, UK, 1989. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Heess, N.; Hunt, J.J.; Lillicrap, T.P.; Silver, D. Memory-based control with recurrent neural networks. arXiv 2015, arXiv:1512.04455. [Google Scholar]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1587–1596. [Google Scholar]
- Zou, Q.; Xiong, K.; Hou, Y. An end-to-end learning of driving strategies based on DDPG and imitation learning. In Proceedings of the 2020 Chinese Control and Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 3190–3195. [Google Scholar]
- Rao, J.; Wang, J.; Xu, J.; Zhao, S. Optimal control of nonlinear system based on deterministic policy gradient with eligibility traces. Nonlinear Dyn. 2023, 111, 20041–20053. [Google Scholar] [CrossRef]
- Chu, Z.; Wang, F.; Lei, T.; Luo, C. Path planning based on deep reinforcement learning for autonomous underwater vehicles under ocean current disturbance. IEEE Trans. Intell. Veh. 2022, 8, 108–120. [Google Scholar] [CrossRef]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J.; Pieter Abbeel, O.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. Adv. Neural Inf. Process. Syst. 2017, 30, 6382–6393. [Google Scholar]
- Henderson, P.; Islam, R.; Bachman, P.; Pineau, J.; Precup, D.; Meger, D. Deep reinforcement learning that matters. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. Adv. Neural Inf. Process. Syst. 2014, 27, 2204–2212. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28, 2017–2025. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- You, Q.; Jin, H.; Wang, Z.; Fang, C.; Luo, J. Image captioning with semantic attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4651–4659. [Google Scholar]
- Sun, X.; Lu, W. Understanding attention for text classification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3418–3428. [Google Scholar]
- Park, Y.M.; Hassan, S.S.; Tun, Y.K.; Han, Z.; Hong, C.S. Joint trajectory and resource optimization of MEC-assisted UAVs in sub-THz networks: A resources-based multi-agent proximal policy optimization DRL with attention mechanism. IEEE Trans. Veh. Technol. 2023, 73, 2003–2016. [Google Scholar] [CrossRef]
- Peng, Y.; Tan, G.; Si, H.; Li, J. DRL-GAT-SA: Deep reinforcement learning for autonomous driving planning based on graph attention networks and simplex architecture. J. Syst. Archit. 2022, 126, 102505. [Google Scholar] [CrossRef]
- Li, Y.; Long, G.; Shen, T.; Zhou, T.; Yao, L.; Huo, H.; Jiang, J. Self-attention enhanced selective gate with entity-aware embedding for distantly supervised relation extraction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 8269–8276. [Google Scholar]
- Shiri, H.; Seo, H.; Park, J.; Bennis, M. Attention-based communication and control for multi-UAV path planning. IEEE Wirel. Commun. Lett. 2022, 11, 1409–1413. [Google Scholar] [CrossRef]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Wang, G.; Lu, S.; Giannakis, G.; Tesauro, G.; Sun, J. Decentralized TD tracking with linear function approximation and its finite-time analysis. Adv. Neural Inf. Process. Syst. 2020, 33, 13762–13772. [Google Scholar]
- Wu, D.; Dong, X.; Shen, J.; Hoi, S.C. Reducing estimation bias via triplet-average deep deterministic policy gradient. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4933–4945. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Lin, L.; Zhang, T.; Chen, H.; Duan, Q.; Xu, Y.; Wang, X. Enabling robust DRL-driven networking systems via teacher-student learning. IJSAC 2021, 40, 376–392. [Google Scholar] [CrossRef]
- Chen, J.; Xing, H.; Xiao, Z.; Xu, L.; Tao, T. A DRL agent for jointly optimizing computation offloading and resource allocation in MEC. IEEE Internet Things J. 2021, 8, 17508–17524. [Google Scholar] [CrossRef]
- Li, P.; Ding, X.; Sun, H.; Zhao, S.; Cajo, R. Research on dynamic path planning of mobile robot based on improved DDPG algorithm. Mob. Inf. Syst. 2021, 2021, 5169460. [Google Scholar] [CrossRef]
- Gong, H.; Wang, P.; Ni, C.; Cheng, N. Efficient path planning for mobile robot based on deep deterministic policy gradient. Sensors 2022, 22, 3579. [Google Scholar] [CrossRef]
- Zohaib, M.; Pasha, S.M.; Javaid, N.; Salaam, A.; Iqbal, J. An improved algorithm for collision avoidance in environments having U and H shaped obstacles. Stud. Inform. Control. 2014, 23, 97–106. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Sampling batch size | 128 |
| Experience pool size | 100,000 |
| Discount factor | 0.99 |
| Max Learning rate | 0.0001 |
| Network update frequency | 0.001 |
| Number of environments | 4 |
| State dimension | 22 |
| Action dimension | 2 |
| Models | Training Time (h) | |
|---|---|---|
| DDPG | 25.02 | 353,264 |
| M-DDPG | 28.21 | 373,264 |
| MA-DDPG | 27.15 | 362,357 |
| MAP-DDPG | 24.47 | 345,856 |
| Models | Success Rate (100%) | Average Time to Reach Target (s) |
|---|---|---|
| DDPG | 29/50 = 0.58 | 52.3 |
| M-DDPG | 34/50 = 0.68 | 44.1 |
| MA-DDPG | 43/50 = 0.86 | 30.2 |
| MAP-DDPG | 44/50 = 0.88 | 28.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Jiang, Y.; Pan, H.; Yang, M. Path Planning in Complex Environments Using Attention-Based Deep Deterministic Policy Gradient. Electronics 2024, 13, 3746. https://doi.org/10.3390/electronics13183746
Chen J, Jiang Y, Pan H, Yang M. Path Planning in Complex Environments Using Attention-Based Deep Deterministic Policy Gradient. Electronics. 2024; 13(18):3746. https://doi.org/10.3390/electronics13183746
Chicago/Turabian StyleChen, Jinlong, Yun Jiang, Hongren Pan, and Minghao Yang. 2024. "Path Planning in Complex Environments Using Attention-Based Deep Deterministic Policy Gradient" Electronics 13, no. 18: 3746. https://doi.org/10.3390/electronics13183746
APA StyleChen, J., Jiang, Y., Pan, H., & Yang, M. (2024). Path Planning in Complex Environments Using Attention-Based Deep Deterministic Policy Gradient. Electronics, 13(18), 3746. https://doi.org/10.3390/electronics13183746