

A High-Performance and Ultra-Low-Power Accelerator Design for Advanced Deep Learning Algorithms on an FPGA



Abstract
1. Introduction
2. Background
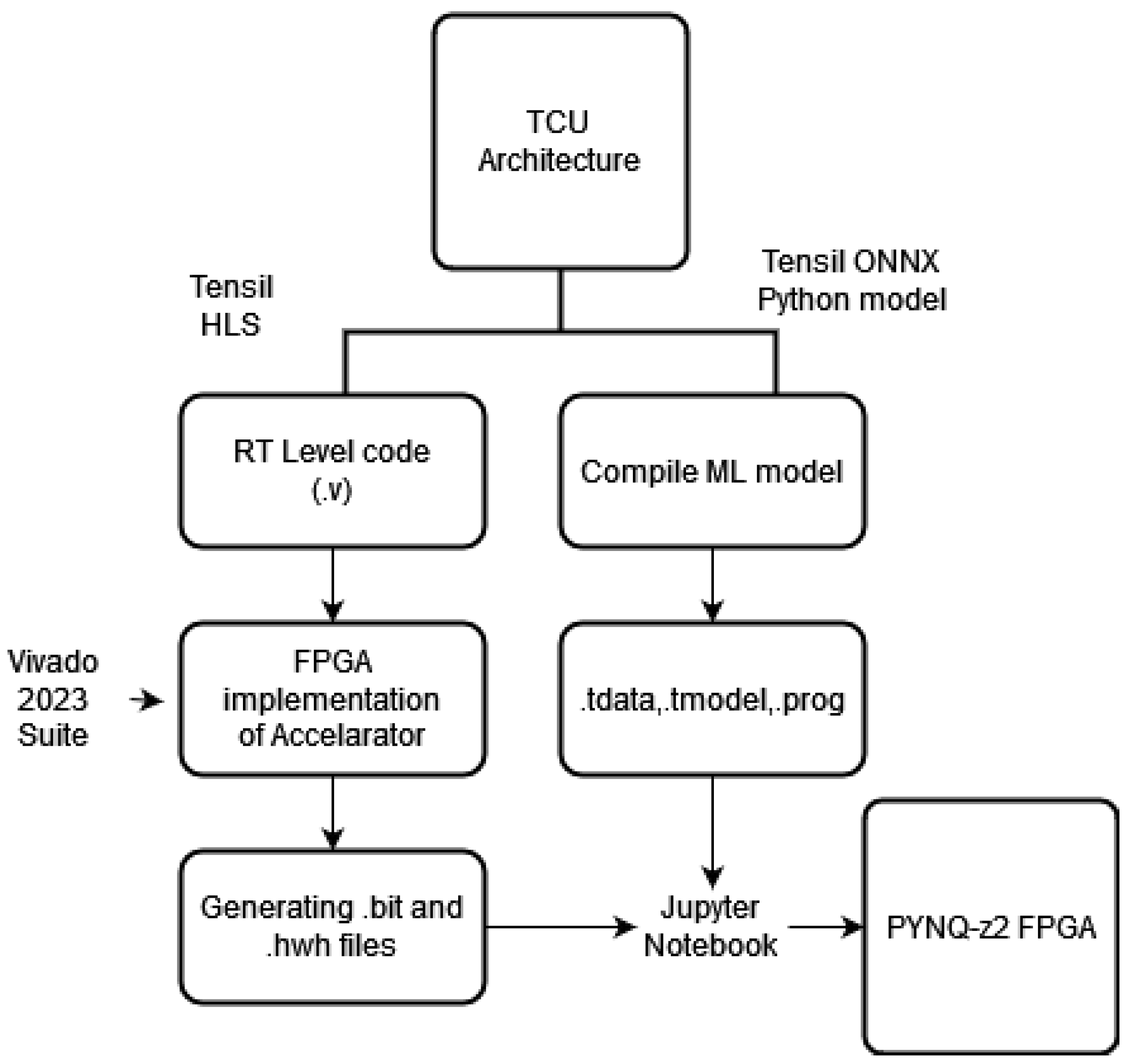
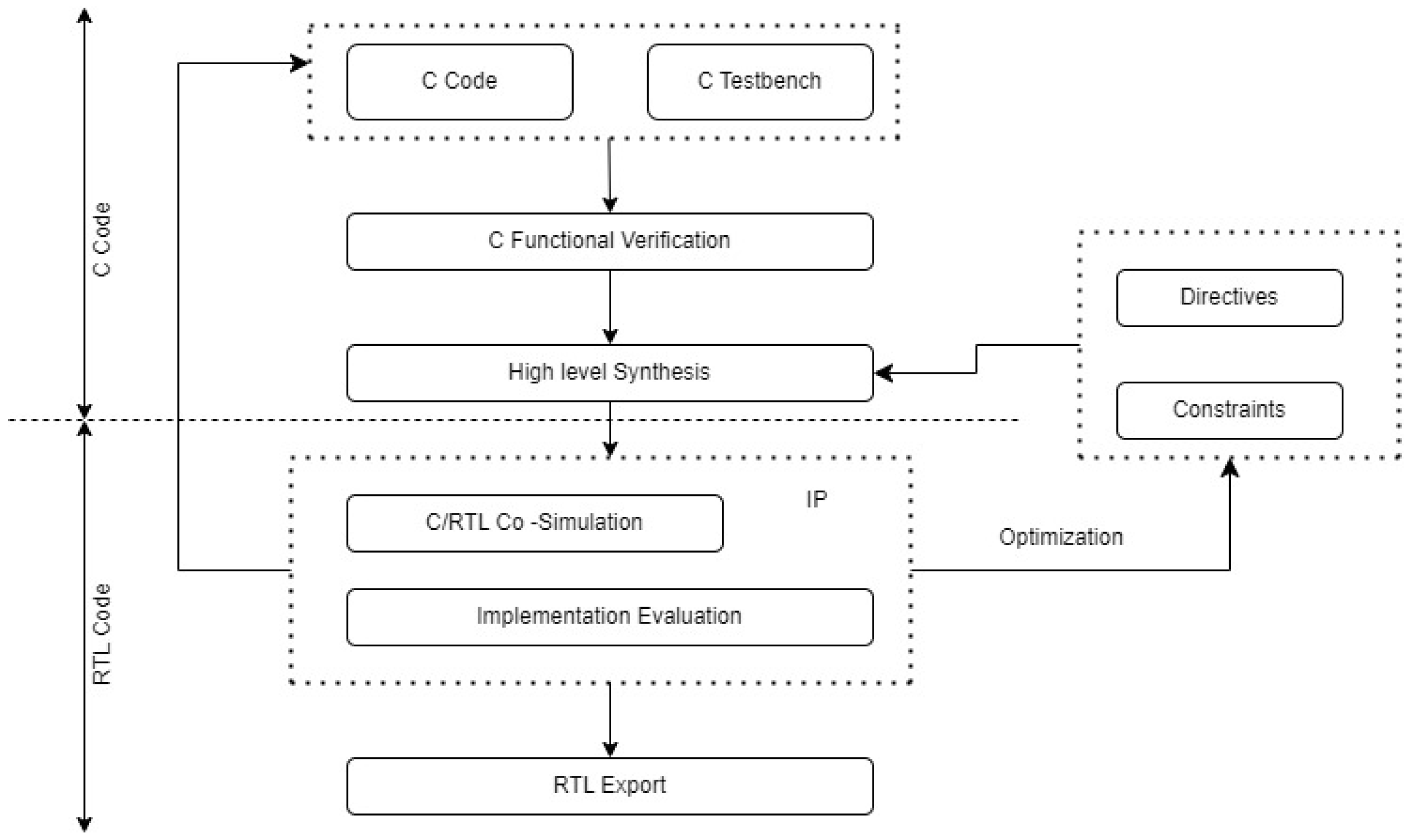
2.1. Design and Tensil Flow for RTL Code
2.2. Clock-Gating Techniques
- Local explicit clock enable (LECE): LECE updates the output on the clock’s rising edge, dependent on a high-enable signal [17]. It allows for precise control of clock-enabled signals, optimizing power consumption in synchronous digital circuits.
- Local explicit clock gating (LECG): LECG optimizes power consumption by updating all the output at once, triggered by a clock-enable signal [17]. It efficiently gates the clock signals to reduce dynamic power consumption in digital circuits.
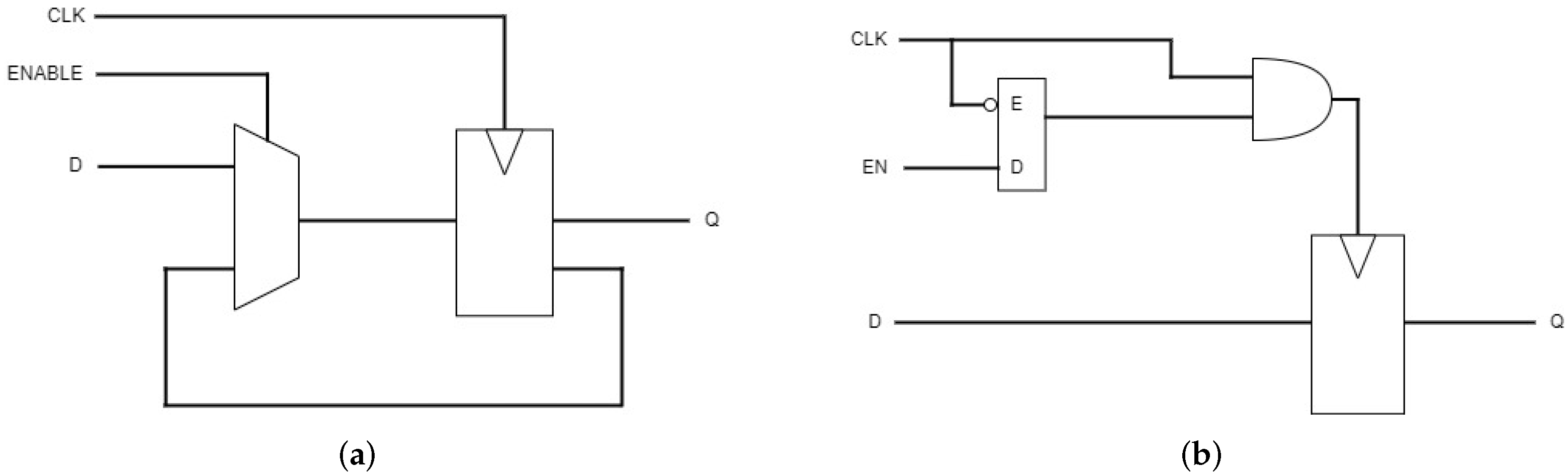
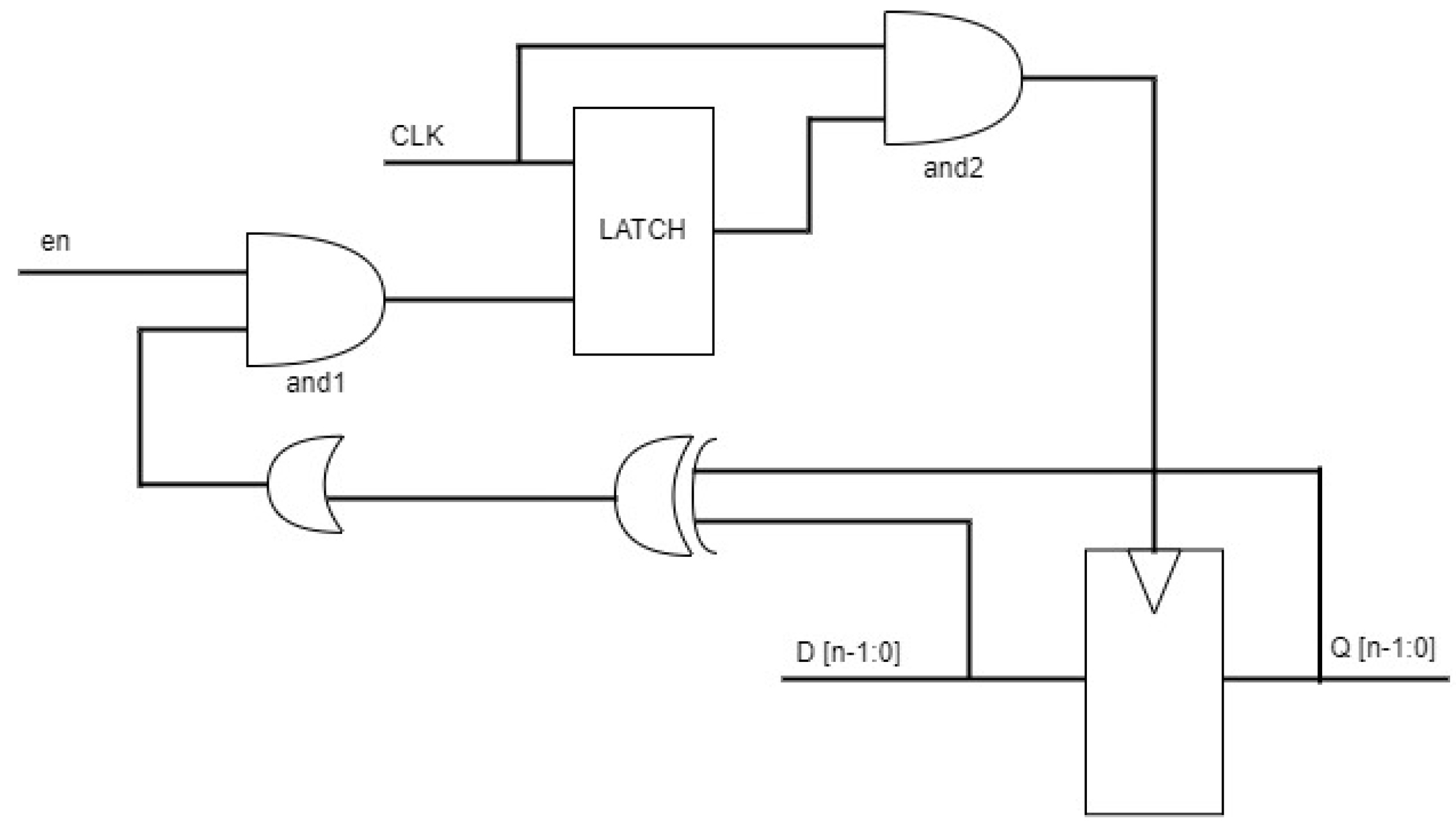
- Enhanced clock gating (ECG): Figure 5 refers to clocking techniques tailored with the XOR gates to control the input clock signal and enable signals when considering multibit I/O data [18]. It optimizes the clock distribution and gating strategies to minimize power consumption while maintaining this structure and the timing requirements.
3. Proposed Design and Optimization
3.1. Implementation of the Original Design
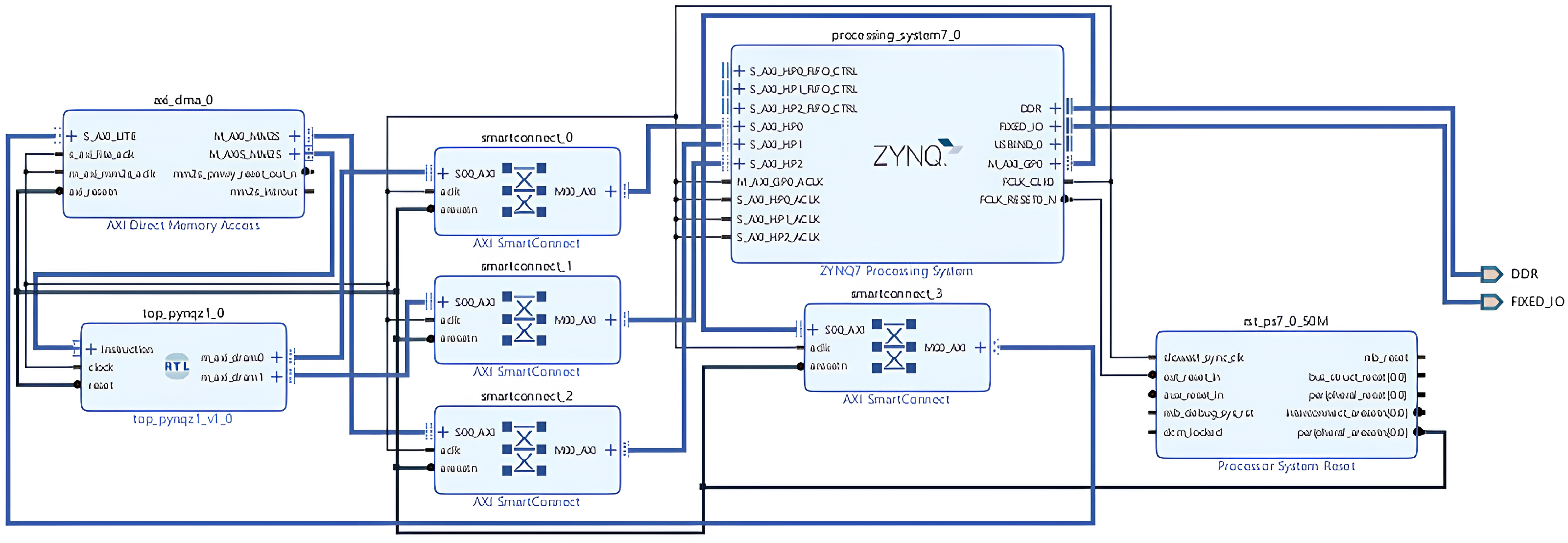
Tensil Clone and Module Integration
3.2. Low-Power Techniques on Original Design
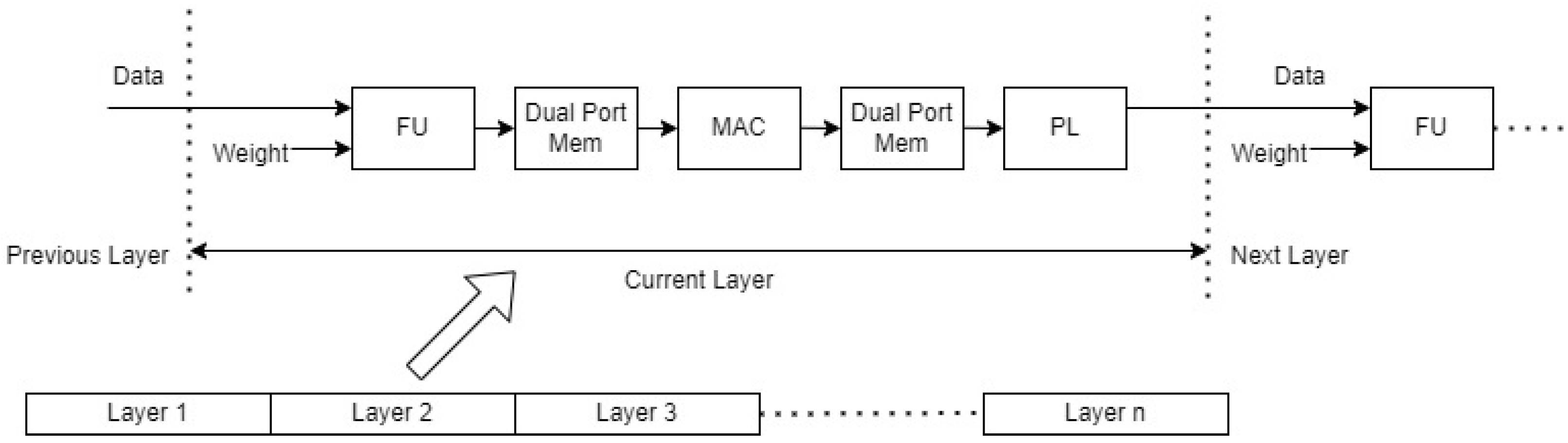
3.3. Proposed Hardware Implementation
Low-Power RTL Design
4. Experiment and Results
4.1. Formality Check
4.2. Power Results
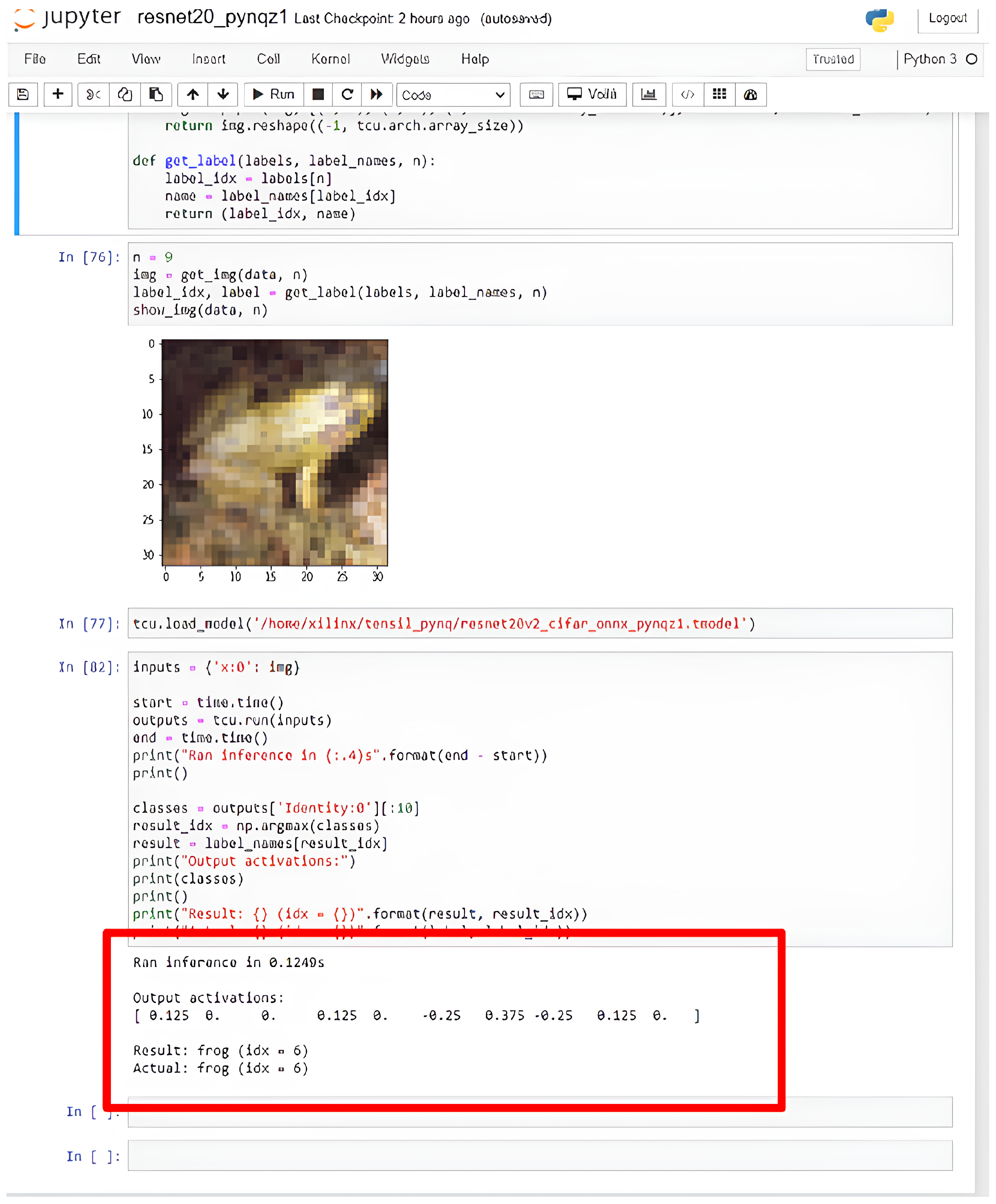
4.3. PYNQ Board Setup
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ECG | Enhanced clock gating |
| LECG | Local explicit clock gating |
| IP | Intellectual Property Blocks |
| BRAM | Block Random Access Memory |
| CONV | Convolution Layer |
| MAC | multiply and accumulate |
| RTL | register transfer level |
| CNN | convolutional neural networks |
| FPGA | field-programmable gate array |
| HLS | high-level synthesis |
| Soc | System-on-Chip |
| ONNX | Open Neural Network Exchange |
References
- Jameil, A.K.; Al-Raweshidy, H. Efficient CNN Architecture on FPGA Using High Level Module for Healthcare Devices. IEEE Access 2022, 10, 60486–60495. [Google Scholar] [CrossRef]
- Zhang, Z.; Mahmud, M.A.P.; Kouzani, A.Z. FitNN: A Low-Resource FPGA-Based CNN Accelerator for Drones. IEEE Internet Things J. 2022, 9, 21357–21369. [Google Scholar] [CrossRef]
- Li, X.; Gong, X.; Wang, D.; Zhang, J.; Baker, T.; Zhou, J.; Lu, T. ABM-SpConv-SIMD: Accelerating Convolutional Neural Network Inference for Industrial IoT Applications on Edge Devices. IEEE Trans. Netw. Sci. Eng. 2023, 10, 3071–3085. [Google Scholar] [CrossRef]
- Nikouei, S.Y.; Chen, Y.; Song, S.; Xu, R.; Choi, B.Y.; Faughnan, T.R. Smart Surveillance as an Edge Network Service: From Harr-Cascade, SVM to a Lightweight CNN. arXiv 2018, arXiv:1805.00331. [Google Scholar]
- Tamimi, S.; Ebrahimi, Z.; Khaleghi, B.; Asadi, H. An Efficient SRAM-Based Reconfigurable Architecture for Embedded Processors. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2019, 38, 466–479. [Google Scholar] [CrossRef]
- Wu, X.; Ma, Y.; Wang, M.; Wang, Z. A Flexible and Efficient FPGA Accelerator for Various Large-Scale and Lightweight CNNs. IEEE Trans. Circuits Syst. Regul. Pap. 2022, 69, 1185–1198. [Google Scholar] [CrossRef]
- Irmak, H.; Ziener, D.; Alachiotis, N. Increasing Flexibility of FPGA-based CNN Accelerators with Dynamic Partial Reconfiguration. In Proceedings of the 2021 31st International Conference on Field-Programmable Logic and Applications (FPL), Dresden, Germany, 30 August–3 September 2021; pp. 306–311. [Google Scholar] [CrossRef]
- Wei, Z.; Arora, A.; Li, R.; John, L. HLSDataset: Open-Source Dataset for ML-Assisted FPGA Design using High Level Synthesis. In Proceedings of the 2023 IEEE 34th International Conference on Application-Specific Systems, Architectures and Processors (ASAP), Porto, Portugal, 19–21 July 2023; pp. 197–204. [Google Scholar] [CrossRef]
- Mohammadi Makrani, H.; Farahmand, F.; Sayadi, H.; Bondi, S.; Pudukotai Dinakarrao, S.M.; Homayoun, H.; Rafatirad, S. Pyramid: Machine Learning Framework to Estimate the Optimal Timing and Resource Usage of a High-Level Synthesis Design. In Proceedings of the 2019 29th International Conference on Field Programmable Logic and Applications (FPL), Barcelona, Spain, 8–12 September 2019; pp. 397–403. [Google Scholar] [CrossRef]
- Ullah, S.; Rehman, S.; Shafique, M.; Kumar, A. High-Performance Accurate and Approximate Multipliers for FPGA-Based Hardware Accelerators. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2022, 41, 211–224. [Google Scholar] [CrossRef]
- Li, S.; Luo, Y.; Sun, K.; Yadav, N.; Choi, K.K. A Novel FPGA Accelerator Design for Real-Time and Ultra-Low Power Deep Convolutional Neural Networks Compared with Titan X GPU. IEEE Access 2020, 8, 105455–105471. [Google Scholar] [CrossRef]
- Yang, C.; Wang, Y.; Zhang, H.; Wang, X.; Geng, L. A Reconfigurable CNN Accelerator using Tile-by-Tile Computing and Dynamic Adaptive Data Truncation. In Proceedings of the 2019 IEEE International Conference on Integrated Circuits, Technologies and Applications (ICTA), Chengdu, China, 13–15 November 2019; pp. 73–74. [Google Scholar] [CrossRef]
- Zhang, X.; Ma, Y.; Xiong, J.; Hwu, W.M.W.; Kindratenko, V.; Chen, D. Exploring HW/SW Co-Design for Video Analysis on CPU-FPGA Heterogeneous Systems. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2022, 41, 1606–1619. [Google Scholar] [CrossRef]
- Tensil. Learn Tensil with ResNet and PYNQ Z1. Available online: https://www.tensil.ai/docs/tutorials/resnet20-pynqz1/ (accessed on 15 December 2022).
- Kim, Y.; Tong, Q.; Choi, K.; Lee, E.; Jang, S.J.; Choi, B.H. System Level Power Reduction for YOLO2 Sub-modules for Object Detection of Future Autonomous Vehicles. In Proceedings of the 2018 International SoC Design Conference (ISOCC), Daegu, Republic of Korea, 12–15 November 2018; pp. 151–155. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, H.; Yadav, N.; Li, S.; Choi, K.K. Low-Power RTL Code Generation for Advanced CNN Algorithms toward Object Detection in Autonomous Vehicles. Electronics 2020, 9, 478. [Google Scholar] [CrossRef]
- Kim, H.; Choi, K. Low Power FPGA-SoC Design Techniques for CNN-based Object Detection Accelerator. In Proceedings of the 2019 IEEE 10th Annual Ubiquitous Computing, Electronics and Mobile Communication Conference (UEMCON), New York, NY, USA, 10–12 October 2019; pp. 1130–1134. [Google Scholar] [CrossRef]
- Kim, V.H.; Choi, K.K. A Reconfigurable CNN-Based Accelerator Design for Fast and Energy-Efficient Object Detection System on Mobile FPGA. IEEE Access 2023, 11, 59438–59445. [Google Scholar] [CrossRef]
- Advanced Micro Devices, Inc. AMD PYNQ-Z2. Available online: https://www.amd.com/en/corporate/university-program/aup-boards/pynq-z2.html (accessed on 19 June 2024).
- Synopsys. End-to-End Verification of Low Power Designs. 2020. Available online: https://www.synopsys.com/content/dam/synopsys/verification/white-papers/verification-e2e-low-power-wp.pdf (accessed on 1 April 2024).
- Zhang, Y.; Tong, Q.; Li, L.; Wang, W.; Choi, K.; Jang, J.; Jung, H.; Ahn, S.Y. Automatic Register Transfer level CAD tool design for advanced clock gating and low power schemes. In Proceedings of the 2012 International SoC Design Conference (ISOCC), Jeju Island, Republic of Korea, 4–7 November 2012; pp. 21–24. [Google Scholar] [CrossRef]
- Gong, L.; Wang, C.; Li, X.; Chen, H.; Zhou, X. MALOC: A Fully Pipelined FPGA Accelerator for Convolutional Neural Networks with All Layers Mapped on Chip. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2018, 37, 2601–2612. [Google Scholar] [CrossRef]
- Bai, L.; Zhao, Y.; Huang, X. A CNN Accelerator on FPGA Using Depthwise Separable Convolution. IEEE Trans. Circuits Syst. II Express Briefs 2018, 65, 1415–1419. [Google Scholar] [CrossRef]
- Qiu, J.; Wang, J.; Yao, S.; Guo, K.; Li, B.; Zhou, E.; Yu, J.; Tang, T.; Xu, N.; Song, S.; et al. Going Deeper with Embedded FPGA Platform for Convolutional Neural Network. In Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, New York, NY, USA, 21–23 February 2016; FPGA ’16. pp. 26–35. [Google Scholar] [CrossRef]
- Geng, T.; Wang, T.; Sanaullah, A.; Yang, C.; Patel, R.; Herbordt, M. A Framework for Acceleration of CNN Training on Deeply-Pipelined FPGA Clusters with Work and Weight Load Balancing. In Proceedings of the 2018 28th International Conference on Field Programmable Logic and Applications (FPL), Dublin, Ireland, 27–31 August 2018; pp. 394–3944. [Google Scholar] [CrossRef]
- Guan, Y.; Liang, H.; Xu, N.; Wang, W.; Shi, S.; Chen, X.; Sun, G.; Zhang, W.; Cong, J. FP-DNN: An Automated Framework for Mapping Deep Neural Networks onto FPGAs with RTL-HLS Hybrid Templates. In Proceedings of the 2017 IEEE 25th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Napa, CA, USA, 30 April–2 May 2017; pp. 152–159. [Google Scholar] [CrossRef]
- Ma, Y.; Cao, Y.; Vrudhula, S.; Seo, J.S. Optimizing the Convolution Operation to Accelerate Deep Neural Networks on FPGA. IEEE Trans. Very Large Scale Integr. Syst. 2018, 26, 1354–1367. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CG Techniques [16] | PYNQ-Z2 Hardware [19] | Original [14] | ECG [18] | LECG and LECE |
|---|---|---|---|---|
| LUTs | 53 k | 14.6 k | 15.6 k | 12.2 k |
| BRAMs (kB) | 630 | 198 | 523 | 198 |
| DSPs | 220 | 73 | 167 | 65 |
| FFs | 85 k | 9.1 k | 41.2 k | 10.45 k |
| Dynamic Power (W) | - | 1.714 | 1.440 | 1.331 |
| Year | 2018 [22] | 2018 [23] | 2018 [24] | 2018 [25] | 2017 [26] | 2018 [27] | 2019 [11] | 2022 [14] | 2022 [18] | 2024 Proposed |
|---|---|---|---|---|---|---|---|---|---|---|
| CNN model | AlexNet | MobileNet V2 | VGG16 | VGG16 | VGG19 | VGG16 | AP2D-Net | ResNet20 | ResNet20 | ResNet20 |
| FPGA | ZYNQ-XCZ7020 | Intel Arria 10-SoC | ZYNQ-XCZ7020 | Virtex-7 VX690t | Stratix V GSMDS | Intel Arria 10 | Ultra96 | PYNQ-Z1 | PYNQ-Z1 | PYNQ-Z2 |
| LUTs | 49.8 k | - | 29.9 k | - | - | - | 54.3 k | 14.6 k | 15.2 k | 12.2 k |
| BRAMs (kB) | 268 | 1844 | 85.5 | 1220 | 919 | 2232 | 162 | 198 | 523 | 198 |
| DSPs | 218 | 1278 | 190 | 2160 | 1036 | 1518 | 287 | 73 | 167 | 65 |
| Precision (W,A) | (16,16) | (16,16) | (8,8) | (16,16) | (16,16) | (16,16) | (8–16,16) | (16,16) | (16,16) | (16,16) |
| Clock (MHz) | 200 | 133 | 214 | 150 | 150 | 200 | 300 | 50 | 50 | 50 |
| Latency (s) | 0.016 | 0.004 | 0.364 | 0.106 | 0.107 | 0.043 | 0.032 | 0.178 | 0.109 | 0.102 |
| Throughput (GOPS) | 80.35 | 170.6 | 84.3 | 290 | 364.4 | 715.9 | 130.2 | 55 | 63.3 | 68.4 |
| Power (W) | 2.21 | - | - | 35 | 25 | - | 5.59 | 1.714 | 1.440 | 1.331 |
| Power Efficiency (GOPS/W) | 36.36 | - | - | 8.28 | 14.57 | - | 23.3 | 28.2 | 43.9 | 51.38 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gundrapally, A.; Shah, Y.A.; Alnatsheh, N.; Choi, K.K. A High-Performance and Ultra-Low-Power Accelerator Design for Advanced Deep Learning Algorithms on an FPGA. Electronics 2024, 13, 2676. https://doi.org/10.3390/electronics13132676
Gundrapally A, Shah YA, Alnatsheh N, Choi KK. A High-Performance and Ultra-Low-Power Accelerator Design for Advanced Deep Learning Algorithms on an FPGA. Electronics. 2024; 13(13):2676. https://doi.org/10.3390/electronics13132676
Chicago/Turabian StyleGundrapally, Achyuth, Yatrik Ashish Shah, Nader Alnatsheh, and Kyuwon Ken Choi. 2024. "A High-Performance and Ultra-Low-Power Accelerator Design for Advanced Deep Learning Algorithms on an FPGA" Electronics 13, no. 13: 2676. https://doi.org/10.3390/electronics13132676
APA StyleGundrapally, A., Shah, Y. A., Alnatsheh, N., & Choi, K. K. (2024). A High-Performance and Ultra-Low-Power Accelerator Design for Advanced Deep Learning Algorithms on an FPGA. Electronics, 13(13), 2676. https://doi.org/10.3390/electronics13132676