Hierarchical Cross-Modal Interaction and Fusion Network Enhanced with Self-Distillation for Emotion Recognition in Conversations

Abstract
1. Introduction
- (1)
- We propose a novel multimodal framework for conversational emotion recognition called HCIFN-SD. It effectively integrates hierarchical cross-modal interaction and a fusion network with self-distillation for learning high-quality multimodal contextual representations, filling the gaps in existing approaches for ERC.
- (2)
- The new GRU structure named MCI-GRU is designed, which not only retains the speaker-dependent cross-modal long-distance conversational context, but also captures local cross-modal conversational context from recent neighboring utterances. The proposed MF-GAT module constructs three directed graphs representing different modality views, which aims to capture both the long-distance conversational context and temporal complementary information from other modalities. In addition, the self-distillation is introduced to minimize the semantic gaps between different modalities for achieving more satisfactory emotion prediction performance.
- (3)
- Experimental results demonstrate that our proposed HCIFN-SD outperforms the existing mainstream ERC models and achieves new state-of-the-art records on the benchmark datasets. Furthermore, extensive ablation studies can systemically demonstrate the importance and the rationality of each component in HCIFN-SD.
2. Related Work
2.1. Emotion Recognition in Conversations
2.2. Multimodal Interaction and Fusion
2.3. Graph Neural Networks
3. Proposed Method
3.1. Problem Formulation
3.2. Unimodal Feature Extraction
3.3. Speaker-Dependent Cross-Modal Context Modeling
3.3.1. Speaker-Dependent Cross-Modal Interactions
3.3.2. Multi-View Cross-Modal-Interaction-Enhanced GRU
3.4. Graph-Attention-Based Multimodal Interaction and Fusion
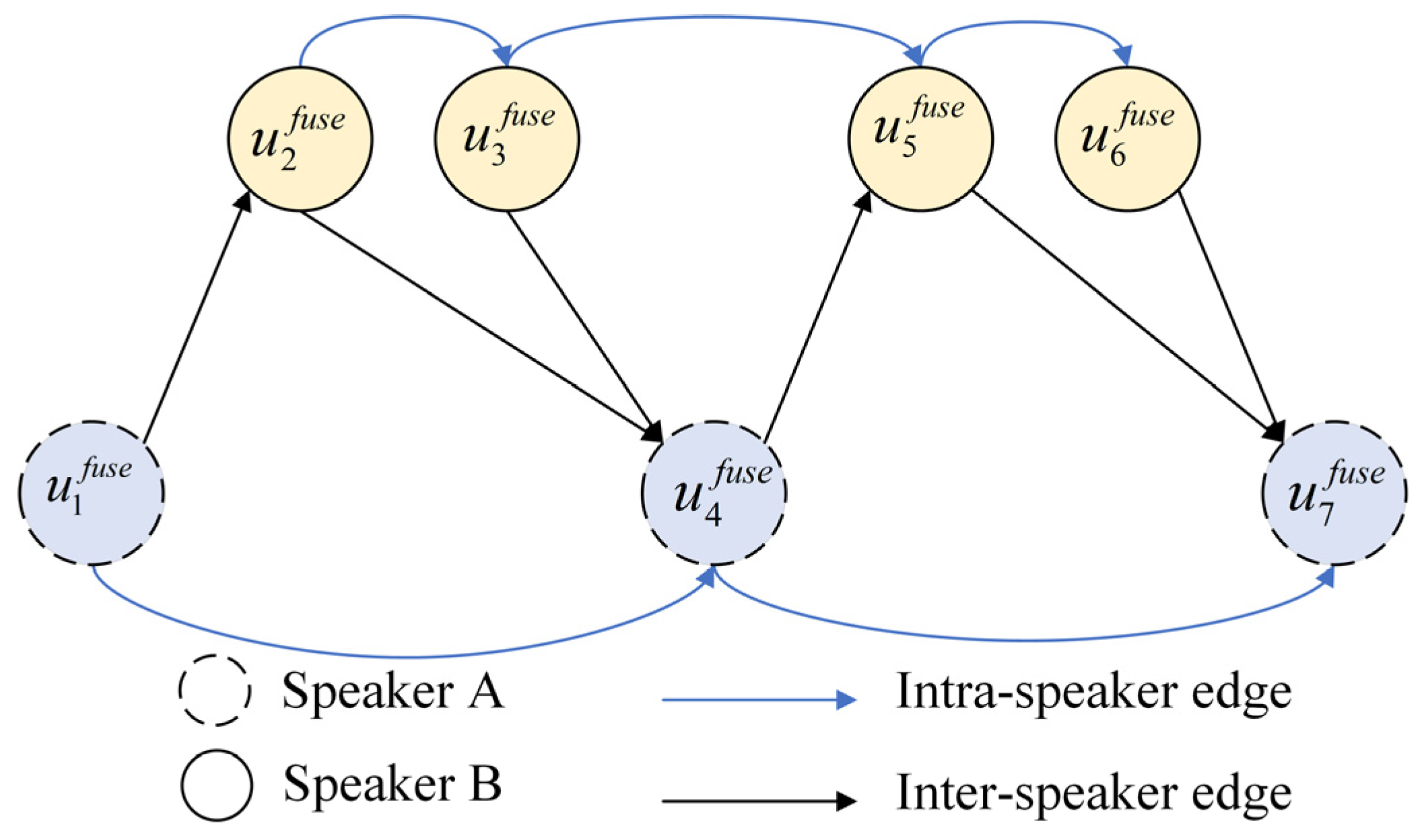
3.4.1. Directed Graph Construction
3.4.2. Graph-Attention-Based Multimodal Fusion
3.5. Self-Distillation-Based Emotion Prediction
4. Experimental Datasets and Setup
4.1. Experimental Datasets and Evaluation Metrics
4.2. Baseline Approaches
- CMN [9] employs two distinct GRUs to explore inter-speaker context dependencies for predicting utterance-level emotions, but it cannot work on multi-party conversation tasks.
- ICON [10], as an improved approach of CMN, employs distinct GRUs to explore both intra- and inter-speaker dependencies for emotion identification, but it still cannot deal with multi-party conversation scenarios.
- BC-LSTM [15] utilizes the bidirectional LSTM architecture to learn conversational context for emotion classification, but it is a speaker-independent model.
- DialogueRNN [6] adopts three distinct GRUs, including Global GRU, Speaker GRU, and Emotion GRU, to capture conversational context, learn speaker identity information, and identify utterance-level emotions, respectively.
- A-DMN [11] is a multimodal sequence-based ERC approach, which utilizes bidirectional LSTM layers to model intra-speaker and inter-speaker influences and then employs the attention mechanism to combine them to update the memory for final emotion prediction.
- DialogueGCN [7] first extracts sequential context based on the Bi-GRU layer, then explores speaker-level dependencies based on the GCN, and finally integrates these two types of context for final emotion recognition. Considering that the original DialogueGCN is a unimodal approach, we implement multimodal DialogueGCN by concatenating features of each modality.
- MMGCN [13] is a multimodal fusion GCN, in which each utterance can be represented by three nodes for distinguishing different modalities to capture both cross-modal dependencies and speaker-dependent dependencies.
- MM-DFN [14] is a graph-based multimodal dynamic fusion approach, which explores the dynamics of conversational context under different modality spaces for the purpose of reducing redundancy and improving complementarity between modalities.
- GraphCFC [20] utilizes multimodal subspace extractors and cross-modal interactions to achieve multimodal fusion. It is a speaker-dependent ERC model.
- GA2MIF [46] is a multimodal fusion approach, involving the textual, acoustic, and visual modalities. It constructs three graphs for modeling intra-modal local and long-distance context as well as cross-modal interactions.
- SMFNM [5] first implements intra-modal interactions based on the semi-supervised strategy, then selects the textual modality as the main modality to guide the cross-modal interaction, and finally explores the conversational context from both multimodal and main-modal perspectives for obtaining more comprehensive context information.
4.3. Implementation Details
5. Results and Discussion
5.1. Comparison with Baseline Models
5.1.1. Comparison of Overall Performance
- (1)
- Our HCIFN-SD is significantly superior to BC-LSTM on both datasets. It is difficult to accurately identify human emotion in a conversation scenario because the emotional state can be easily influenced by the interlocutor’s behaviors [47]; thus, it is quite significant to model the speaker-sensitive dependencies in conversations [11]. However, BC-LSTM is a typical speaker-independent approach. It only depends on LSTM structures to capture conversational context from the surrounding utterances without considering intra-speaker and inter-speaker influences, which leads to the relatively poor performance of BC-LSTM. All the other models take into account speaker-sensitive modeling. For instance, CMN and ICON utilize two distinct GRUs for two speakers to separately explore intra-speaker dependencies and use another GRU for modeling inter-speaker dependencies. The graph-based models (such as DialogueGCN, MMGCN, MM-DFN, GraphCFC, GA2MIF, and SMFNM) utilize the nodes to represent individual utterances and use the edges between nodes to bridge the intra-speaker and inter-speaker influences. Our proposed HCIFN-SD not only explicitly models the intra-speaker and inter-speaker dependencies based on the proposed different mask strategies but also utilizes the different types of edges in the directed graph construction to comprehensively explore speaker-sensitive conversational context.
- (2)
- Our proposed approach significantly succeeds over the multimodal sequence-based approaches (such as CMN, ICON, and A-DMN). It can be observed that these approaches directly concatenate multimodal information without incorporating the cross-modal interaction information. However, lots of multimodal research has demonstrated the importance of exploring cross-modal interaction for enhancing the quality of multimodal fusion representation [5,18,48]. In addition, these recurrence-based models tend to utilize local utterances for conversational context extraction and usually ignore long-term context information. To address these issues, our HCIFN-SD designs the improved GRU structure named MCI-GRU, which utilizes the speaker-sensitive dependency information to participate in the calculation of the update gate to explore speaker-dependent long-distance context. Furthermore, our HCIFN-SD proposes multi-stage cross-modal interactions and fusion and employs the self-distillation strategy to enhance the representation ability of multimodal information.
- (3)
- HCIFN-SD outperforms the multimodal graph-based approaches (such as MMGCN, MM-DFN, GraphCFC, and GA2MIF). It is found that MMGCN and MM-DFN generate three nodes for each utterance to represent different modalities and construct edges for different modality nodes under the same utterance to explore intra-speaker-based complementary information from other modalities. Obviously, this graph construction approach not only results in data redundancy, due to inconsistent data distribution among different modalities, but also fails to extract diverse information in the conversational graph, which all affect the representation ability of the multimodal fusion information. GraphCFC defines different types of edges based on the perspectives of speakers and modalities to extract speaker-dependent cross-modal context information, but it not only fails to capture the sequential information of conversations but also ignores the semantic gaps among modalities. GA2MIF concentrates on cross-modal contextual modeling based on the proposed two modules, but it only depends on the static speaker identity information without considering the in-depth exploration of the speaker-dependent cross-modal context extraction and fusion. To address these issues, our HCIFN-SD proposes the MCI-GRU module to explore speaker-dependent cross-modal context information, utilizes the MF-GAT module to further explore speaker-dependent multimodal interaction and fusion, and finally employs the self-distillation to eliminate the semantic gaps among different modalities.
5.1.2. Comparison for Each Emotion Category
5.2. Ablation Study
5.2.1. Impact of Different Mask Strategies
5.2.2. Impact of Multi-View Cross-Modal-Interaction-Enhanced GRU
5.2.3. Impact of Graph-Attention-Based Multimodal Fusion
5.2.4. Impact of Self-Distillation
5.3. Analysis on Hyperparameters
5.3.1. Analysis of Context Window Size
5.3.2. Analysis of Window Size in LCE
5.3.3. Analysis of Different Number of Graph Layers
5.3.4. Analysis of the Cut-Off Point Selection in Graph Construction
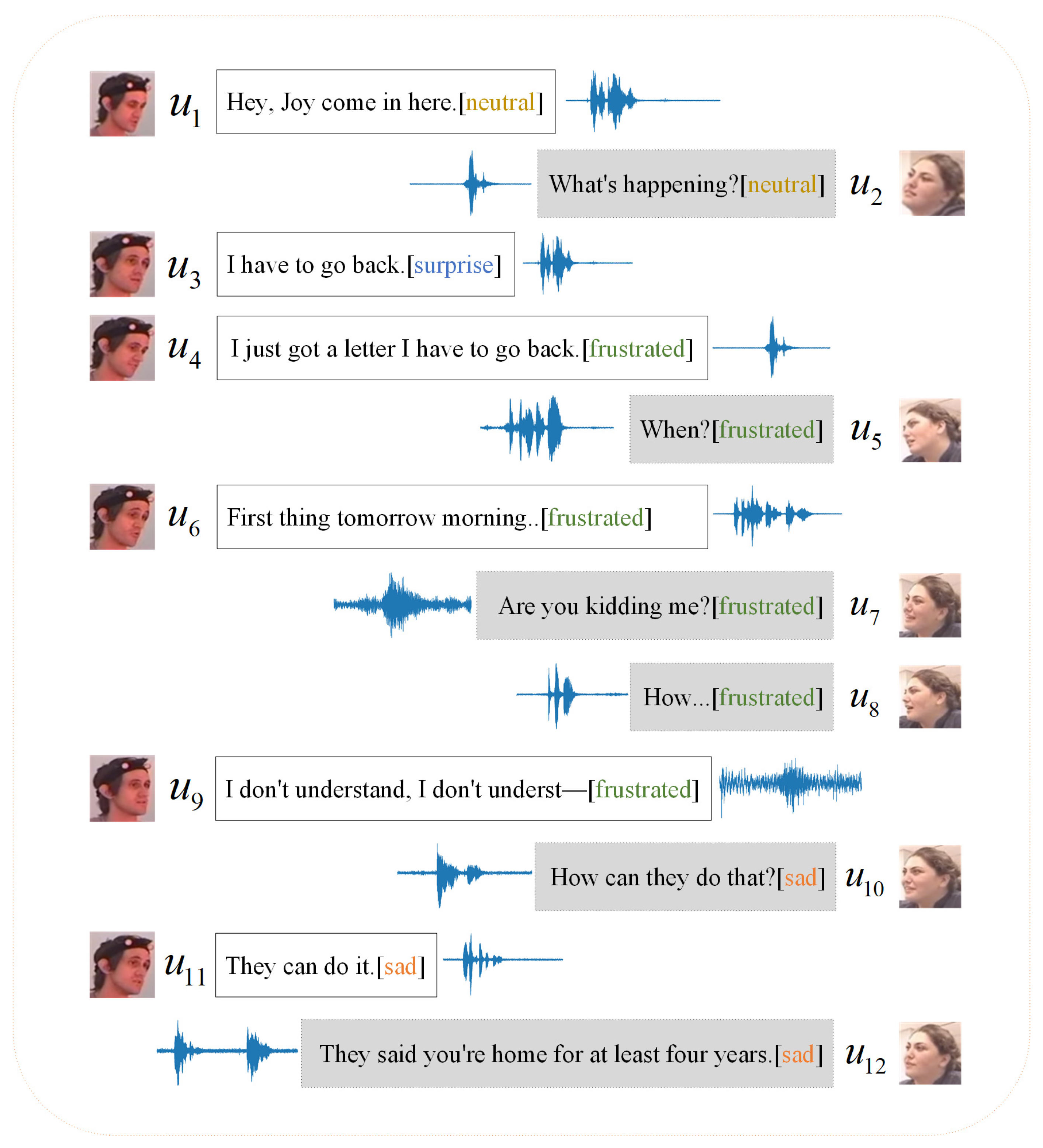
5.4. Case Study
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Van Kleef, G.A.; Côté, S. The social effects of emotions. Annu. Rev. Psychol. 2022, 73, 629–658. [Google Scholar] [CrossRef] [PubMed]
- Li, R.; Wu, Z.; Jia, J.; Bu, Y.; Zhao, S.; Meng, H. Towards discriminative representation learning for speech emotion recognition. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Beijing, China, 10–16 August 2019; pp. 5060–5066. [Google Scholar]
- Ma, Y.; Nguyen, K.L.; Xing, F.Z.; Cambria, E. A survey on empathetic dialogue systems. Inf. Fusion 2020, 64, 50–70. [Google Scholar] [CrossRef]
- Nimmagadda, R.; Arora, K.; Martin, M.V. Emotion recognition models for companion robots. J. Supercomput. 2022, 78, 13710–13727. [Google Scholar] [CrossRef]
- Yang, J.; Dong, X.; Du, X. SMFNM: Semi-supervised multimodal fusion network with main-modal for real-time emotion recognition in conversations. J. King Saud Univ. Comput. Inf. Sci. 2023, 35, 101791. [Google Scholar] [CrossRef]
- Majumder, N.; Poria, S.; Hazarika, D.; Mihalcea, R.; Gelbukh, A.; Cambria, E. DialogueRNN: An Attentive RNN for Emotion Detection in Conversations. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 6818–6825. [Google Scholar]
- Ghosal, D.; Majumder, N.; Poria, S.; Chhaya, N.; Gelbukh, A. Dialoguegcn: A graph convolutional neural network for emotion recognition in conversation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 154–164. [Google Scholar]
- Zou, S.; Huang, X.; Shen, X.; Liu, H. Improving multimodal fusion with Main Modal Transformer for emotion recognition in conversation. Knowl.-Based Syst. 2022, 258, 109978. [Google Scholar] [CrossRef]
- Hazarika, D.; Poria, S.; Zadeh, A.; Cambria, E.; Morency, L.-P.; Zimmermann, R. Conversational Memory Network for Emotion Recognition in Dyadic Dialogue Videos. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1 (Long Papers), pp. 2122–2132. [Google Scholar]
- Hazarika, D.; Poria, S.; Mihalcea, R.; Cambria, E.; Zimmermann, R. Icon: Interactive conversational memory network for multimodal emotion detection. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2594–2604. [Google Scholar]
- Xing, S.; Mai, S.; Hu, H. Adapted Dynamic Memory Network for Emotion Recognition in Conversation. IEEE Trans. Affect. Comput. 2020, 13, 1426–1439. [Google Scholar] [CrossRef]
- Ren, M.; Huang, X.; Shi, X.; Nie, W. Interactive Multimodal Attention Network for Emotion Recognition in Conversation. IEEE Signal Process. Lett. 2021, 28, 1046–1050. [Google Scholar] [CrossRef]
- Hu, J.; Liu, Y.; Zhao, J.; Jin, Q. MMGCN: Multimodal Fusion via Deep Graph Convolution Network for Emotion Recognition in Conversation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th In-ternational Joint Conference on Natural Language Processing, Bangkok, Thailand, 1–6 August 2021; pp. 5666–5675. [Google Scholar]
- Hu, D.; Hou, X.; Wei, L.; Jiang, L.; Mo, Y. MM-DFN: Multimodal Dynamic Fusion Network for Emotion Recognition in Con-versations. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 7037–7041. [Google Scholar]
- Poria, S.; Cambria, E.; Hazarika, D.; Majumder, N.; Zadeh, A.; Morency, L.P. Morency. Context-dependent sentiment analysis in us-er-generated videos. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 873–883. [Google Scholar]
- Ghosal, D.; Akhtar, M.S.; Chauhan, D.; Poria, S.; Ekbal, A.; Bhattacharyya, P. Contextual inter-modal attention for multimodal sentiment analysis. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3454–3466. [Google Scholar]
- Jiao, W.; Lyu, M.; King, I. Real-Time Emotion Recognition via Attention Gated Hierarchical Memory Network. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8002–8009. [Google Scholar]
- Lian, Z.; Liu, B.; Tao, J. CTNet: Conversational Transformer Network for Emotion Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 985–1000. [Google Scholar] [CrossRef]
- Ren, M.; Huang, X.; Li, W.; Song, D.; Nie, W. LR-GCN: Latent Relation-Aware Graph Convolutional Network for Conversational Emotion Recognition. IEEE Trans. Multimed. 2021, 24, 4422–4432. [Google Scholar] [CrossRef]
- Li, J.; Wang, X.; Lv, G.; Zeng, Z. GraphCFC: A Directed Graph Based Cross-Modal Feature Complementation Approach for Multimodal Conversational Emotion Recognition. IEEE Trans. Multimed. 2023, 26, 77–89. [Google Scholar] [CrossRef]
- Joshi, A.; Bhat, A.; Jain, A.; Singh, A.V.; Modi, A. COGMEN: Contextualized GNN based Multimodal Emotion recognition. arXiv 2022, arXiv:2205.02455v1. [Google Scholar]
- Shen, W.; Wu, S.; Yang, Y.; Quan, X. Directed Acyclic Graph Network for Conversational Emotion Recognition. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021; pp. 1551–1560. [Google Scholar]
- Busso, C.; Bulut, M.; Lee, C.-C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Poria, S.; Hazarika, D.; Majumder, N.; Naik, G.; Cambria, E.; Mihalcea, R. Meld: A multimodal multi-party dataset for emotion recognition in conversations. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 527–536. [Google Scholar]
- Picard, R.W. Affective Computing: From Laughter to IEEE. IEEE Trans. Affect. Comput. 2010, 1, 11–17. [Google Scholar] [CrossRef]
- Gross, J.J.; Barrett, L.F. Emotion Generation and Emotion Regulation: One or Two Depends on Your Point of View. Emot. Rev. 2011, 3, 8–16. [Google Scholar] [CrossRef] [PubMed]
- Jiao, W.; Yang, H.; King, I.; Lyu, M.R. HiGRU: Hierarchical gated recurrent units for utterance-level emotion recognition. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Association for Computational Linguistics, Minneapolis, Minnesota, 2–7 June 2019; pp. 397–406. [Google Scholar]
- Ghosal, D.; Majumder, N.; Gelbukh, A.; Mihalcea, R.; Poria, S. COSMIC: Commonsense knowledge for emotion identification in conversations. In Proceedings of the Association for Computational Linguistics: EMNLP 2020, Association for Computational Linguistics, Online, 16–20 November 2020; pp. 2470–2481. [Google Scholar]
- Zhang, D.; Wu, L.; Sun, C.; Li, S.; Zhu, Q.; Zhou, G. Modeling both Context- and Speaker-Sensitive Dependence for Emotion Detection in Multi-speaker Conversations. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence {IJCAI-19}, Macao, China, 10–16 August 2019; pp. 5415–5421. [Google Scholar]
- Shen, W.; Chen, J.; Quan, X.; Xie, Z. DialogXL: All-in-One XLNet for Multi-Party Conversation Emotion Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; pp. 13789–13797. [Google Scholar]
- Lee, J.; Lee, W. CoMPM: Context Modeling with Speaker’s Pre-trained Memory Tracking for Emotion Recognition in Con-versation. arXiv 2022, arXiv:2108.11626v3. [Google Scholar]
- Yang, J.; Du, X.; Hung, J.-L.; Tu, C.-H. Analyzing online discussion data for understanding the student’s critical thinking. Data Technol. Appl. 2021, 56, 303–326. [Google Scholar] [CrossRef]
- Sahoo, S.; Routray, A. Emotion recognition from audio-visual data using rule based decision level fusion. In Proceedings of the 2016 IEEE Students’ Technology Symposium (TechSym), Kharagpur, India, 30 September–2 October 2016; pp. 7–12. [Google Scholar]
- Zhou, Y.; Zheng, H.; Huang, X.; Hao, S.; Li, D.; Zhao, J. Graph Neural Networks: Taxonomy, Advances and Trends. ACM Trans. Intell. Syst. Technol. 2022, 13, 15. [Google Scholar] [CrossRef]
- Li, X.; Sun, L.; Ling, M.; Peng, Y. A survey of graph neural network based recommendation in social networks. Neurocomputing 2023, 549, 126441. [Google Scholar] [CrossRef]
- Lu, G.; Li, J.; Wei, J. Aspect sentiment analysis with heterogeneous graph neural networks. Inf. Process. Manag. 2022, 59, 102953. [Google Scholar] [CrossRef]
- Dai, G.; Wang, X.; Zou, X.; Liu, C.; Cen, S. MRGAT: Multi-Relational Graph Attention Network for knowledge graph completion. Neural Netw. 2022, 154, 234–245. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. In Proceedings of the 34th Conference on Neural Information Processing Systems, Online, 6–12 December 2020; pp. 12449–12460. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1–15. [Google Scholar]
- Brody, S.; Alon, U.; Yahav, E. How attentive are graph attention networks? arXiv 2021, arXiv:2105.14491. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, F.; Ren, X.; Zhang, Z.; Sun, X.; Zou, Y. Rethinking skip connection with layer normalization. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 3586–3598. [Google Scholar]
- Li, J.; Wang, X.; Lv, G.; Zeng, Z. GA2MIF: Graph and Attention Based Two-Stage Multi-Source Information Fusion for Con-versational Emotion Detection. IEEE Trans. Affect. Comput. 2024, 15, 130–143. [Google Scholar] [CrossRef]
- Lee, C.-C.; Busso, C.; Lee, S.; Narayanan, S.S. Modeling mutual influence of interlocutor emotion states in dyadic spoken interactions. In Proceedings of the International Speech Communication Association, Brighton, UK, 6–10 September 2009; pp. 1983–1986. [Google Scholar]
- Yang, J.; Li, Z.; Du, X. Analyzing audio-visual data for understanding user’s emotion in human-computer interaction en-vironment. Data Technol. Appl. 2023, 58, 318–343. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Dialogue Count | Utterance Count | Categories | Speaker per Dialogue | ||||
|---|---|---|---|---|---|---|---|---|
| Train | Valid | Test | Train | Valid | Test | |||
| IEMOCAP | 120 | 31 | 5810 | 1623 | 6 | 2 | ||
| MELD | 1039 | 114 | 280 | 9989 | 1109 | 2610 | 7 | more than 2 |
| Model (& Params) | IEMOCAP | |||||||
|---|---|---|---|---|---|---|---|---|
| Happiness | Sadness | Neutral | Anger | Excitement | Frustration | WAA | WAF1 | |
| CMN (-) | 30.38 | 62.41 | 52.39 | 59.83 | 60.25 | 60.69 | 56.56 | 56.13 |
| ICON (-) | 29.91 | 64.57 | 57.38 | 63.04 | 63.42 | 60.81 | 59.09 | 58.54 |
| BC-LSTM * (-) | 35.60 | 69.20 | 53.50 | 66.30 | 61.10 | 62.40 | 59.80 | 59.10 |
| DialogueRNN * (8.8 M) | 32.90 | 78.00 | 59.10 | 63.30 | 73.60 | 59.40 | 63.40 | 62.80 |
| A-DMN (-) | 50.60 | 77.20 | 63.90 | 60.10 | 77.90 | 63.20 | 64.90 | 64.10 |
| DialogueGCN * (2.7 M) | 36.70 | 81.90 | 65.10 | 64.50 | 68.80 | 65.40 | 66.40 | 65.80 |
| MMGCN (2.6 M) | 45.45 | 77.53 | 61.99 | 66.67 | 72.04 | 64.12 | 65.56 | 65.71 |
| MM-DFN (2.2 M) | 42.22 | 78.98 | 66.42 | 69.77 | 75.56 | 66.33 | 68.21 | 68.18 |
| GraphCFC (5.4 M) | 43.08 | 84.99 | 64.70 | 71.35 | 78.86 | 63.70 | 69.13 | 68.91 |
| GA2MIF (9.3 M) | 41.65 | 84.50 | 68.38 | 70.29 | 75.99 | 66.49 | 69.75 | 70.00 |
| SMFNM (-) | 59.50 | 81.50 | 70.00 | 62.90 | 74.40 | 70.10 | 70.80 | 70.90 |
| HCIFN-SD-small (4 M) | 67.36 | 73.47 | 77.60 | 68.24 | 74.92 | 69.03 | 72.58 | 72.88 |
| HCIFN-SD (12 M) | 68.75 | 75.51 | 77.60 | 69.41 | 72.91 | 70.34 | 73.07 | 73.42 |
| Model (& Params) | MELD | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Neutral | Surprise | Fear | Sadness | Joy | Disgust | Anger | WAA | WAF1 | |
| BC-LSTM * (-) | 76.40 | 48.47 | 0.0 | 15.60 | 49.70 | 0.0 | 44.50 | 58.60 | 56.80 |
| DialogueRNN * (8.8 M) | 73.20 | 51.90 | 0.0 | 24.80 | 53.20 | 0.0 | 45.60 | 58.00 | 57.00 |
| A-DMN (-) | 77.10 | 57.73 | 12.06 | 29.12 | 57.41 | 7.16 | 43.97 | — | 60.45 |
| DialogueGCN * (2.7 M) | 73.30 | 57.00 | 16.50 | 41.10 | 61.80 | 20.10 | 55.30 | 60.20 | 60.40 |
| MMGCN (2.6 M) | 76.96 | 49.63 | 3.64 | 20.39 | 53.76 | 2.82 | 45.23 | 59.31 | 57.82 |
| MM-DFN (2.2 M) | 75.80 | 50.42 | — | 23.72 | 55.48 | — | 48.27 | 62.49 | 59.46 |
| GraphCFC (5.4 M) | 76.98 | 49.36 | — | 26.89 | 51.88 | — | 47.59 | 61.42 | 58.86 |
| SMFNM (-) | 75.00 | 57.50 | 16.80 | 36.80 | 62.30 | 25.00 | 50.30 | 62.60 | 62.40 |
| HCIFN-SD-small (4 M) | 77.55 | 62.28 | 28.00 | 35.10 | 66.17 | 25.00 | 46.96 | 64.41 | 64.05 |
| HCIFN-SD (12 M) | 77.87 | 62.99 | 34.00 | 35.10 | 65.92 | 26.47 | 46.67 | 64.71 | 64.34 |
| Approaches | IEMOCAP | MELD | ||
|---|---|---|---|---|
| WAA | WAF1 | WAA | WAF1 | |
| w/o & mask | 70.36 | 70.57 | 64.13 | 63.96 |
| w/o intra-speaker mask | 72.83 | 73.00 | 64.56 | 64.10 |
| w/o inter-speaker mask | 72.58 | 72.94 | 64.70 | 64.30 |
| w/o local information mask | 71.90 | 72.15 | 64.52 | 64.14 |
| Ours (HCIFN-SD) | 73.07 | 73.42 | 64.71 | 64.34 |
| Approaches | IEMOCAP | MELD | ||
|---|---|---|---|---|
| WAA | WAF1 | WAA | WAF1 | |
| w/o intra-CI | 72.21 | 72.48 | 64.71 | 64.27 |
| w/o inter-CI | 71.41 | 71.77 | 64.64 | 63.88 |
| w/o local-CI | 72.03 | 72.31 | 64.29 | 63.97 |
| w/o MCI-GRU | 71.04 | 70.93 | 64.71 | 64.22 |
| Ours (HCIFN-SD) | 73.07 | 73.42 | 64.71 | 64.34 |
| Approaches | IEMOCAP | MELD | ||
|---|---|---|---|---|
| WAA | WAF1 | WAA | WAF1 | |
| w/o MCI-GRU cell | 72.03 | 72.16 | 64.70 | 64.11 |
| w/o GNN layer | 71.53 | 71.47 | 64.33 | 63.93 |
| Vanilla GAT | 71.53 | 71.47 | 64.21 | 64.03 |
| Ours (HCIFN-SD) | 73.07 | 73.42 | 64.71 | 64.34 |
| IEMOCAP | MELD | ||||
|---|---|---|---|---|---|
| WAA | WAF1 | WAA | WAF1 | ||
| w/o | w/o | 69.38 | 69.53 | 63.87 | 63.75 |
| w | w/o | 70.92 | 71.16 | 64.67 | 64.16 |
| w/o | w | 71.72 | 71.86 | 64.71 | 64.25 |
| Ours (HCIFN-SD) | 73.07 | 73.42 | 64.71 | 64.34 | |
| s | IEMOCAP (6-Way) | |
|---|---|---|
| WAA | WAF1 | |
| 1 | 73.07 | 73.42 |
| 2 | 71.84 | 72.12 |
| 3 | 71.29 | 71.73 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, P.; Yang, J.; Xiao, Y. Hierarchical Cross-Modal Interaction and Fusion Network Enhanced with Self-Distillation for Emotion Recognition in Conversations. Electronics 2024, 13, 2645. https://doi.org/10.3390/electronics13132645
Wei P, Yang J, Xiao Y. Hierarchical Cross-Modal Interaction and Fusion Network Enhanced with Self-Distillation for Emotion Recognition in Conversations. Electronics. 2024; 13(13):2645. https://doi.org/10.3390/electronics13132645
Chicago/Turabian StyleWei, Puling, Juan Yang, and Yali Xiao. 2024. "Hierarchical Cross-Modal Interaction and Fusion Network Enhanced with Self-Distillation for Emotion Recognition in Conversations" Electronics 13, no. 13: 2645. https://doi.org/10.3390/electronics13132645
APA StyleWei, P., Yang, J., & Xiao, Y. (2024). Hierarchical Cross-Modal Interaction and Fusion Network Enhanced with Self-Distillation for Emotion Recognition in Conversations. Electronics, 13(13), 2645. https://doi.org/10.3390/electronics13132645