
HA-Net: A Hybrid Algorithm Model for Underwater Image Color Restoration and Texture Enhancement

Abstract
1. Introduction
- (1)
- We innovatively propose a new method that combines traditional technology with a deep learning network, thus leveraging the advantages of traditional technology and the powerful feature extraction capabilities of deep learning. This method addresses problems such as color cast, low illumination, and turbidity in underwater degraded images, providing reliable and high-quality image support for subsequent machine vision tasks.
- (2)
- In terms of traditional methods, a novel dynamic color correction algorithm is developed based on the widely used gray world algorithm to restore the color of underwater image, which incorporates depth of field estimation. Initially, the depth of field for both the target and the background is estimated by analyzing the color attenuation difference. Subsequently, a dynamic threshold is devised for precise local segmentation. Finally, the degraded image is pretreated with the improved color correction method, thereby reducing the attenuation of underwater image color.
- (3)
- In deep learning networks, we have designed a multi-scale U-Net to increase the depth of convolutional networks and improve their ability to extract deep information from images. Additionally, we have introduced a parallel attention mechanism for adaptive learning of key spatial features, optimizing network parameters, and enhancing learning capabilities. This integration significantly boosts the model’s precision in distinguishing deep semantics, including intricate details and textures.
- (4)
- We propose a global information compensation algorithm to improve the network’s capacity to capture spatial information and enhance image integrity. By combining multiple loss functions, we also improve the network’s robustness and generalization ability for real underwater degraded images.
2. Related Work
2.1. Color Correcion Algorithm Based on Gray World Principle
- (1)
- Direct reference: take half of the maximum value of each channel, that is, k = 128;
- (2)
- , , and , respectively, represent the average values of the three channels of red, green, and blue.
- (a)
- Calculating the average values (, , and ) of the three channels of the image R, G, and B:
- (b)
- The gain coefficients of R, G, and B channels are as follows:
- (c)
- Adjust the pixel value of each R, G, and B channel of the image to an acceptable displayable range (0, 255).
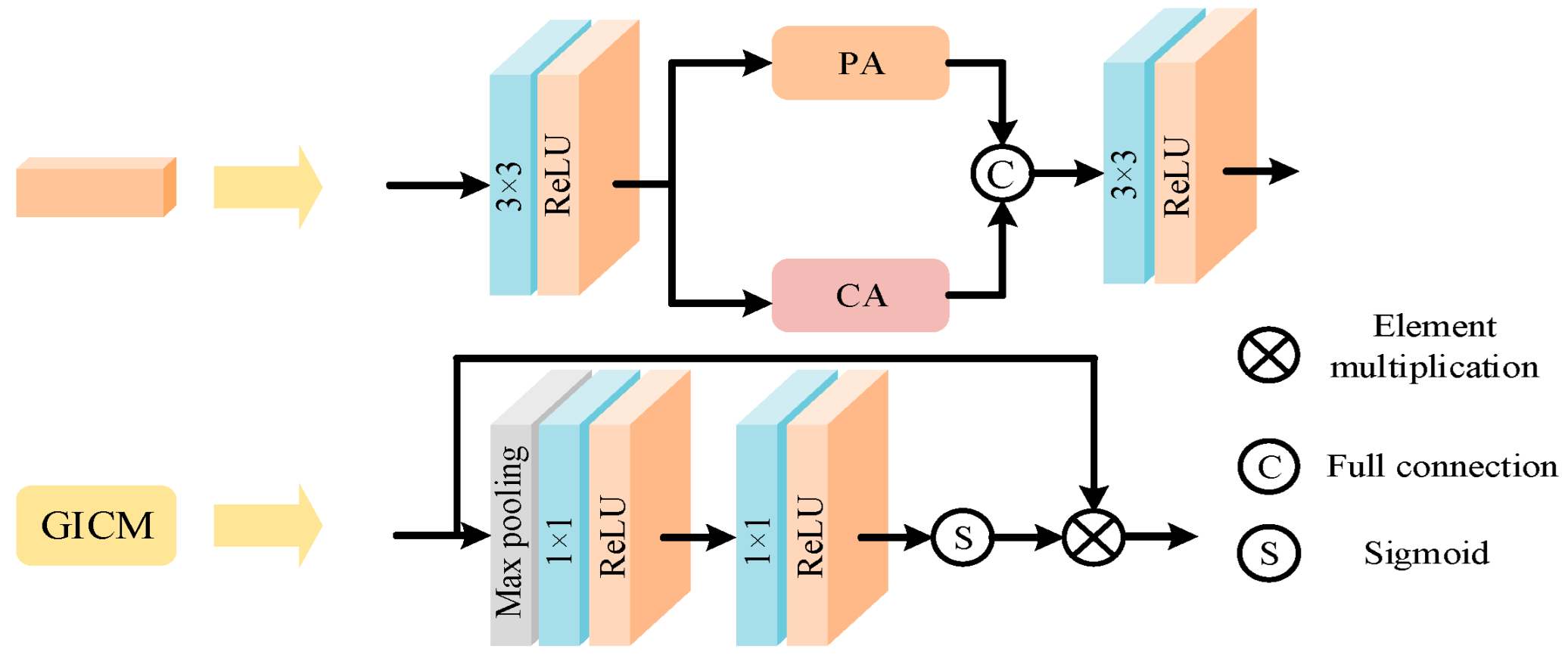
2.2. Channel Attention Mechanism
2.3. Pixel Attention Mechanism
3. Materials and Methods
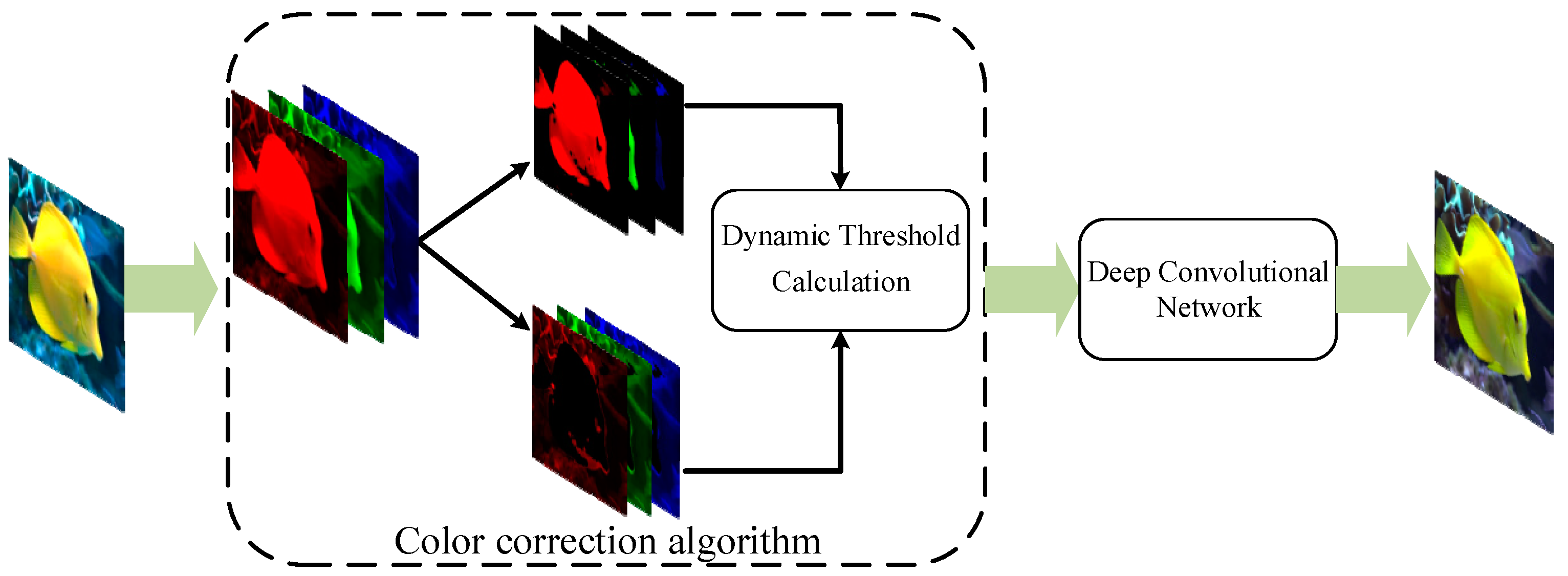
3.1. Color Correction Method
| Algorithm 1 Dynamic threshold calculation |
| Input: R_mean, G_mean, B_mean, R, G, B Output: endpoint1, endpoint2 1: if B_mean ≥G_mean: big = B; mid = G; RAM = 1 else: big = G; mid = B; RAM = 2 2: max = (big-mid).max() 3: min = (big-mid).min() 4: endpoint1 = (max-mid)/2 + min 5: endpoint2 = max return endpoint1, endpoint2 |
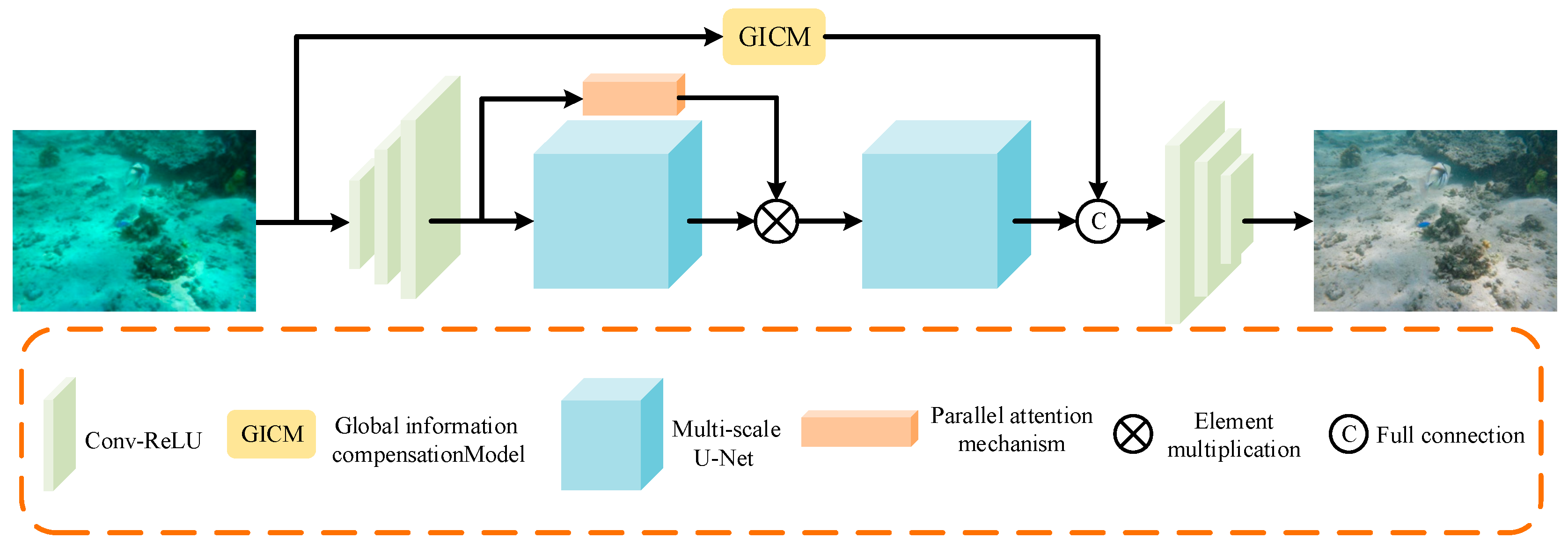
3.2. Deep Learning Network
3.3. Loss Fusion
3.4. Training Details
| Algorithm 2 Threshold calculation strategy |
| Input: J’(x), J(x) Output: model 1: PSNR_max = 0, SSIM_max = 0 2: for i in epoch_max: 3: PSNR = VPSNR(J’(x), J(x)) 4: SSIM = VSSIM(J’(x), J(x)) 5: if SSIM>SSIM_max and PSNR > PSNR_max 6: SSIM_max > SSIM, PSNR_max = PSNR 7: model = model(i) 8: end if 9: end for 10: return model |
4. Experiment and Analysis
4.1. Subjective Evaluation
4.2. Objective Evaluation
4.3. Ablation Study
- (1)
- w/o CCM: the degraded image is directly input to the network for training and testing without using the color correction method for preprocessing.
- (2)
- w/o MSU-Net: instead of using multi-scale U-Net to extract cyberspace information, it is replaced by a six-layer general convolution structure.
- (3)
- w/o GICM: the Global Information Compensation Model is not applicable.
- (4)
- w/o PAM: do not use the parallel attention mechanism.
- (5)
- HA-Net: use the full structure of this paper network.
4.4. Application Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Qian, J.; Li, H.; Zhang, B.; Lin, S.; Xing, X. DRGAN: Dense Residual Generative Adversarial Network for Image Enhancement in an Underwater Autonomous Driving Device. Sensors 2023, 23, 8297. [Google Scholar] [CrossRef] [PubMed]
- Lai, Y. A comparison of traditional machine learning and deep learning in image recognition. J. Phys. Conf. Ser. 2019, 1314, 012148. [Google Scholar] [CrossRef]
- Iqbal, K.; Salam, R.A.; Osman, A.; Talib, A.Z. Underwater Image Enhancement Using an Integrated Colour Model. IAENG Int. J. Comput. Sci. 2007, 34, 239–244. [Google Scholar]
- Ancuti, C.O.; Ancuti, C.; De Vleeschouwer, C.; Bekaert, P. Color balance and fusion for underwater image enhancement. IEEE Trans. Image Process. 2017, 27, 379–393. [Google Scholar] [CrossRef] [PubMed]
- Nomura, K.; Sugimura, D.; Hamamoto, T. Underwater image color correction using exposure-bracketing imaging. IEEE Signal Process. 2018, 25, 893–897. [Google Scholar] [CrossRef]
- Zhang, W.; Pan, X.; Xie, X.; Li, L.; Wang, Z.; Han, C. Color correction and adaptive contrast enhancement for underwater image enhancement. Comput. Electr. Eng. 2021, 91, 106981. [Google Scholar] [CrossRef]
- Zhao, C.; Cai, W.; Dong, C.; Hu, C. Wavelet-based fourier information interaction with frequency diffusion adjustment for underwater image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 8281–8291. [Google Scholar]
- Lu, H.; Li, Y.; Uemura, T.; Kim, H.; Serikawa, S. Low illumination underwater light field images reconstruction using deep convolutional neural networks. Future Gener. Comp. Sy. 2018, 82, 142–148. [Google Scholar] [CrossRef]
- Gangisetty, S.; Rai, R.R. FloodNet: Underwater image restoration based on residual dense learning. Signal Process. Image Commun. 2022, 104, 116647. [Google Scholar] [CrossRef]
- Lu, J.; Yuan, F.; Yang, W.; Cheng, E. An imaging information estimation network for underwater image color restoration. IEEE J. Ocean. Eng. 2021, 46, 1228–1239. [Google Scholar] [CrossRef]
- Yang, M.; Hu, K.; Du, Y.; Wei, Z.; Sheng, Z.; Hu, J. Underwater image enhancement based on conditional generative adversarial network. Signal Process. Image Commun. 2020, 81, 115723. [Google Scholar] [CrossRef]
- Wang, H.; Sun, S.; Chang, L.; Li, H.; Zhang, W.; Frery, A.C.; Ren, P. INSPIRATION: A reinforcement learning-based human visual perception-driven image enhancement paradigm for underwater scenes. Eng. Appl. Artif. Intell. 2024, 133, 108411. [Google Scholar] [CrossRef]
- Wang, G.; Tian, J.; Li, P. Image color correction based on double transmission underwater imaging model. Acta Opt. Sin. 2019, 39, 0901002. [Google Scholar] [CrossRef]
- Zhuang, P.; Li, C.; Wu, J. Bayesian retinex underwater image enhancement. Eng. Appl. Artif. Intell. 2021, 101, 104171. [Google Scholar] [CrossRef]
- Liu, R.; Fan, X.; Zhu, M.; Hou, M.; Luo, Z. Real-world underwater enhancement: Challenges, benchmarks, and solutions under natural light. IEEE Trans. Circuits. Syst. Video Technol. 2020, 30, 4861–4875. [Google Scholar] [CrossRef]
- Liu, X.; Gao, Z.; Chen, B.M. MLFcGAN: Multilevel feature fusion-based conditional GAN for underwater image color correction. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1488–1492. [Google Scholar] [CrossRef]
- Singh, M.; Sharma, D.S. Enhanced color correction using histogram stretching based on modified gray world and white patch algorithms. Int. J. Comput. Sci. Inf. Technol. 2014, 5, 4762–4770. [Google Scholar]
- Pan, B.; Jiang, Z.; Zhang, H.; Luo, X.; Wu, J. Improved gray world color correction method based on weighted gain coefficients. Optoelectron. Imaging Multimed. Technol. III 2014, 9273, 625–631. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11908–11915. [Google Scholar]
- Johnson, O.V.; Chen, X.; Khaw, K.W.; Lee, M.H. ps-CALR: Periodic-Shift Cosine Annealing Learning Rate for Deep Neural Networks. IEEE Access 2023, 11, 11908–11915. [Google Scholar] [CrossRef]
- Mudeng, V.; Kim, M.; Choe, S.W. Prospects of structural similarity index for medical image analysis. Appl. Sci. 2022, 12, 3754. [Google Scholar] [CrossRef]
- Yoo, J.C.; Ahn, C.W. Image matching using peak signal-to-noise ratio-based occlusion detection. IET Image Process. 2012, 6, 483–495. [Google Scholar] [CrossRef]
- Drews, P.; Nascimento, E.; Moraes, F.; Botelho, S.; Campos, M. Transmission estimation in underwater single images. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 2–8 December 2013; pp. 825–830. [Google Scholar]
- Zhang, W.; Wang, Y.; Li, C. Underwater image enhancement by attenuated color channel correction and detail preserved contrast enhancement. IEEE J. Ocean. Eng. 2022, 47, 718–735. [Google Scholar] [CrossRef]
- Hao, Y.; Hou, G.; Tan, L.; Wang, Y.; Zhu, H.; Pan, Z. Texture enhanced underwater image restoration via Laplacian regularization. Appl. Math. Model. 2023, 119, 68–84. [Google Scholar] [CrossRef]
- Pan, P.W.; Yuan, F.; Cheng, E. Underwater image de-scattering and enhancing using dehazenet and HWD. J. Mar. Sci. Technol. 2018, 26, 531–540. [Google Scholar]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast underwater image enhancement for improved visual perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Song, W.; Wang, Y.; Huang, D.; Liotta, A.; Perra, C. Enhancement of underwater images with statistical model of background light and optimization of transmission map. IEEE Trans. Broadcast. 2020, 66, 153–169. [Google Scholar] [CrossRef]
- Huang, S.; Wang, K.; Liu, H.; Chen, J.; Li, Y. Contrastive semi-supervised learning for underwater image restoration via reliable bank. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 18145–18155. [Google Scholar]
- Yang, M.; Sowmya, A. An underwater color image quality evaluation metric. IEEE Trans. Image Process. 2015, 24, 6062–6071. [Google Scholar] [CrossRef] [PubMed]
- Panetta, K.; Gao, C.; Agaian, S. Human-visual-system-inspired underwater image quality measures. IEEE J. Ocean. Eng. 2015, 41, 541–551. [Google Scholar] [CrossRef]
- Hu, K.; Zhang, Y.; Weng, C.; Wang, P.; Deng, Z.; Liu, Y. An underwater image enhancement algorithm based on generative adversarial network and natural image quality evaluation index. J. Mar. Sci. Eng. 2021, 9, 691. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | EUVP | UIEB |
|---|---|---|
| Sun | 3000 | 700 |
| Training set | 2500 | 660 |
| Test set | 500 | 40 |
| SSIM↑ | PSNR↑ | NIQE↓ | UIQM↑ | CEIQ↑ | |
|---|---|---|---|---|---|
| Degraded | 0.75 | 20.10 | 4.58 | 3.67 | 2.85 |
| ICCB | 0.69 | 18.31 | 4.99 | 4.16 | 3.66 |
| BRUE | 0.51 | 13.54 | 5.87 | 5.13 | 3.57 |
| ACDC | 0.60 | 18.71 | 6.51 | 5.14 | 3.47 |
| ULV | 0.71 | 17.95 | 5.98 | 5.84 | 3.14 |
| UDNet | 0.39 | 12.88 | 5.25 | 4.62 | 3.24 |
| FUnIE | 0.71 | 21.51 | 4.87 | 3.54 | 3.36 |
| BLTM | 0.79 | 22.94 | 3.77 | 6.11 | 3.44 |
| UWCNN | 0.73 | 20.58 | 4.95 | 4.97 | 3.54 |
| Semi-Net | 0.81 | 23.37 | 3.84 | 5.17 | 3.12 |
| HA-Net | 0.85 | 23.89 | 3.50 | 5.24 | 3.89 |
| EUVP | UIEBD | |||||
|---|---|---|---|---|---|---|
| NIQE↓ | UIQM↑ | CEIQ↑ | NIQE↓ | UIQM↑ | CEIQ↑ | |
| Degraded | 4.68 | 3.67 | 3.56 | 5.53 | 1.04 | 3.95 |
| ICCB | 6.63 | 4.25 | 3.66 | 6.85 | 1.26 | 3.69 |
| BRUE | 6.44 | 5.13 | 3.47 | 8.07 | 1.58 | 3.47 |
| ACDC | 4.02 | 5.10 | 3.14 | 6.47 | 2.01 | 3.44 |
| ULV | 7.84 | 2.14 | 3.74 | 9.89 | 2.32 | 3.14 |
| UDNet | 4.31 | 4.65 | 3.65 | 6.84 | 1.85 | 3.05 |
| FUnIE | 3.77 | 5.14 | 3.28 | 5.64 | 3.16 | 3.85 |
| BLTM | 4.26 | 4.81 | 3.77 | 6.12 | 3.02 | 3.62 |
| UWCNN | 3.81 | 5.22 | 3.55 | 5.71 | 4.22 | 3.42 |
| Semi-Net | 3.34 | 5.37 | 3.84 | 5.52 | 4.07 | 3.77 |
| HA-Net | 3.11 | 6.01 | 3.88 | 5.00 | 4.16 | 3.83 |
| Method | SSIM↑ | PSNR↑ | NIQE↓ | UIQM↑ |
|---|---|---|---|---|
| w/o CCM | 0.84 | 19.88 | 5.12 | 3.41 |
| w/o MSU-Net | 0.75 | 20.56 | 3.25 | 5.10 |
| w/o GICM | 0.83 | 21.85 | 4.55 | 4.84 |
| w/o PAM | 0.87 | 19.38 | 4.87 | 5.07 |
| HA-Net | 0.95 | 24.89 | 3.47 | 5.31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qian, J.; Li, H.; Zhang, B. HA-Net: A Hybrid Algorithm Model for Underwater Image Color Restoration and Texture Enhancement. Electronics 2024, 13, 2623. https://doi.org/10.3390/electronics13132623
Qian J, Li H, Zhang B. HA-Net: A Hybrid Algorithm Model for Underwater Image Color Restoration and Texture Enhancement. Electronics. 2024; 13(13):2623. https://doi.org/10.3390/electronics13132623
Chicago/Turabian StyleQian, Jin, Hui Li, and Bin Zhang. 2024. "HA-Net: A Hybrid Algorithm Model for Underwater Image Color Restoration and Texture Enhancement" Electronics 13, no. 13: 2623. https://doi.org/10.3390/electronics13132623
APA StyleQian, J., Li, H., & Zhang, B. (2024). HA-Net: A Hybrid Algorithm Model for Underwater Image Color Restoration and Texture Enhancement. Electronics, 13(13), 2623. https://doi.org/10.3390/electronics13132623