1. Introduction
As advancements in hardware and machine learning algorithms continue to unfold, artificial intelligence (AI) is becoming increasingly pervasive in Internet of Things (IoT) applications. One notable trend driving this evolution is the empowerment of IoT devices to conduct local inference tasks. This shift is propelled by two key factors: the remarkable progress in hardware capabilities and the refinement of machine learning algorithms. Modern IoT devices are equipped with increasingly sophisticated processors and specialized neural processing engines, enabling them to process complex AI computations locally with greater efficiency. Concurrently, machine learning algorithms have undergone significant enhancements, becoming more lightweight, efficient, and capable of running on resource-constrained devices. Together, these advancements enable IoT devices to perform real-time data analysis and decision-making at the edge, reducing latency, conserving bandwidth, and enhancing privacy by minimizing data transmission to central servers [
1,
2].
In addition to local inference capabilities, the role of inference task offloading to edge servers remains vital, particularly for tasks with higher computational demands and time-sensitive applications, while local inference is advantageous for quick decision-making and reducing reliance on centralized resources, certain AI tasks may exceed the processing capacity of individual IoT devices. In such scenarios, offloading these tasks to edge servers equipped with more powerful hardware and ample computational resources becomes indispensable. This approach not only alleviates the burden on edge devices but also ensures the timely execution of complex computations, critical for meeting stringent response time requirements in time-sensitive applications [
3].
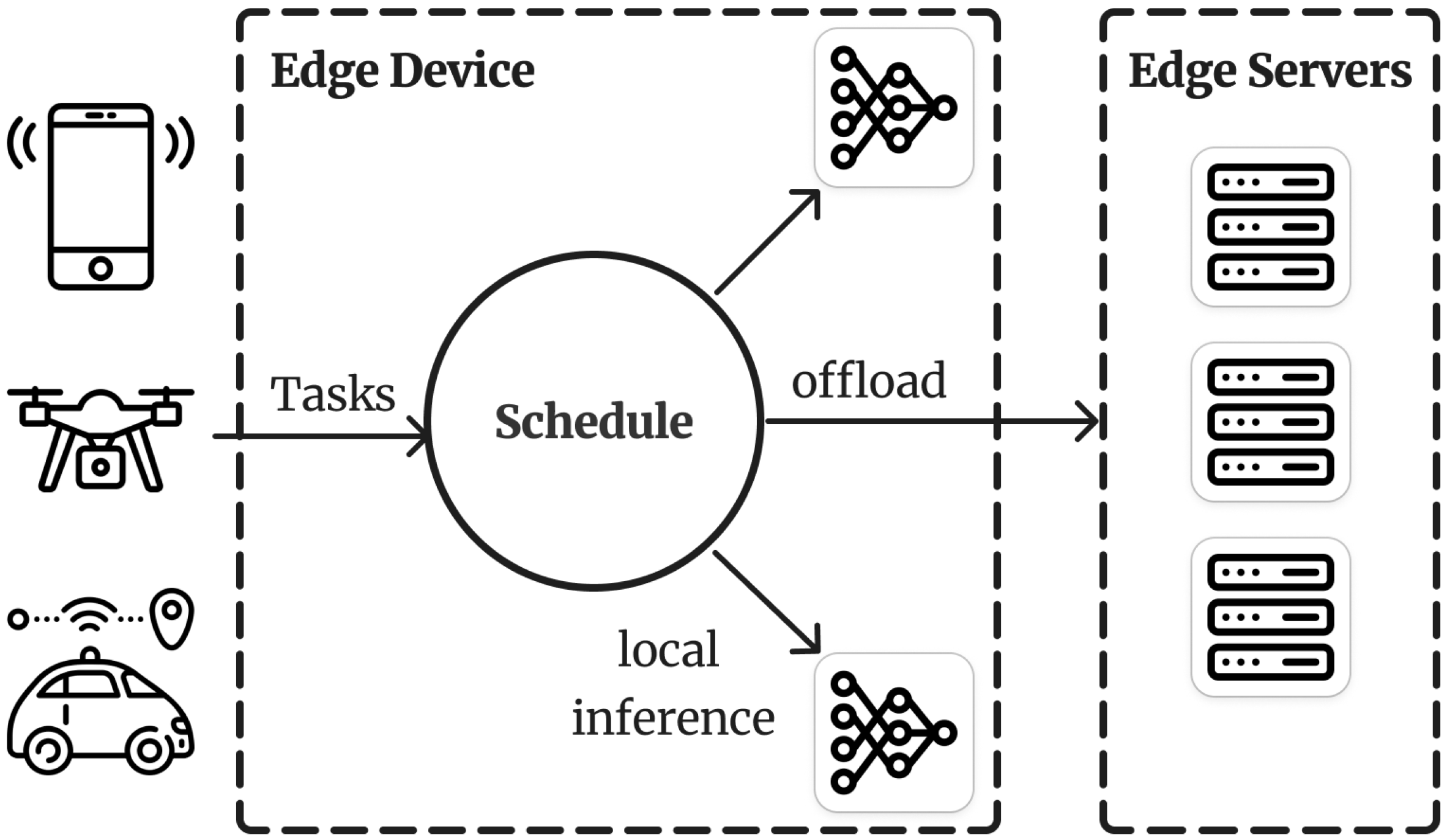
Having multiple local inference models onboard an edge device varying in size and accuracy empowers the system with dynamic adaptability, enabling edge devices to intelligently assign the most suitable model to a task based on various factors such as task properties, device resources, and application parameters (see
Figure 1). This dynamic approach leverages the diverse capabilities of different inference models to optimize performance and efficiency in real-time scenarios. By analyzing task requirements, such as computational complexity, accuracy thresholds, and latency constraints, edge devices can intelligently select the most appropriate model from their repertoire to favor accuracy over energy, for example, or speed over accuracy. Simultaneously, considering device resources, including processing power, memory availability, and energy reserves, ensures optimal utilization of onboard resources without overburdening the device. Additionally, by incorporating application-specific parameters, edge devices can tailor inference model selection to align with application objectives and constraints [
4].
The challenge of assigning local and edge server inference models to tasks under time and energy constraints while maximizing the accuracy is similar in nature to the unbounded multidimensional knapsack problem [
5], which consists of filling a knapsack limited by volume and weight to maximize profit. However, in this case, the aim is to fill a schedule constrained by time and energy with inference models to optimize accuracy. This class of problem falls under the NP-Hard category, lacking any polynomial time solutions. Therefore, in this work, we tackle this complex optimization problem by dividing it into two smaller sub-problems and proposing an edge computing framework for AI-driven edge computing real-time applications, using state-of-the-art deep reinforcement learning methods by leveraging parallel inference between local inference and offloading tasks under time and energy limitations while maximizing inference accuracy.
In real-time IoT applications, such as smart healthcare [
6], autonomous vehicles [
7,
8], and critical resource deployment [
9,
10], timely decision-making is critical for ensuring safety, efficiency, and responsiveness. By efficiently managing inference tasks at the edge, solving this problem enables the seamless integration of AI capabilities into these systems, enhancing their intelligence and autonomy. Moreover, the optimization of inference task allocation contributes to resource conservation, extending the operational lifespan of battery-powered edge devices and reducing overall energy consumption. Beyond IoT, edge computing, and AI integration, solutions to this problem have implications for broader computing paradigms, including cloud-edge orchestration and distributed computing architectures. Therefore, addressing this challenge not only advances the capabilities of edge computing systems but also paves the way for innovative applications that leverage the synergy between AI and edge technologies.
In the literature, there is a notable lack of research on the subject of inference task scheduling and offloading under constraints, primarily attributed to the novelty of the problem under investigation. Few works such as [
11] focus on the decision of whether to process data locally or offload to an edge server based on the probability of the inference resulting in low accuracy while adhering to a given energy constraint. This work represents a smaller subproblem of the more general problem tackled in this work, where their work takes advantage of only a single local inference model with a single-edge server resulting in a binary decision. Moreover, the time aspect is not addressed, which is crucial for real-time applications. On the other hand, the study outlined in [
4] strikes more resemblance to our problem, where multiple inference models within the edge device are considered all while adhering to time constraints. However, their investigation overlooks the energy aspect, which holds significance for battery-powered edge devices. Additionally, their system exclusively allows offloading to a single-edge server. This underscores a research gap wherein the overarching problem necessitates attention, considering both time and energy constraints while maximizing inference accuracy through the allocation of inference models from a set of local and edge server models.
Utilizing deep reinforcement learning (DRL) agents to orchestrate inference task scheduling and offloading in edge computing environments, our work seeks to optimize the allocation of inference models, respecting time and energy constraints while maximizing accuracy, thereby advancing the efficacy and efficiency of AI-driven IoT applications. The main contributions of this paper can be summarized as follows:
We formulate the problem of inference model scheduling between local inference and edge server offloading under time and energy constraints in parallel where we analyze its complexity.
We propose MASITO, a multi-agent deep reinforcement learning (DRL)-based framework for inference task scheduling and offloading for edge computing consisting of cooperating agents for task scheduling and edge server selection.
We perform experiments on the framework and compare its performance against other schemes, such as genetic algorithms (GAs), simulated annealing (SA), and particle swarm optimization (PSO), where we prove its effectiveness and advantages over these schemes.
The rest of this paper is organized as follows.
Section 2 presents the related works and points out the research gap. In
Section 3, we describe the system model. In
Section 4, we propose MASITO and explain the framework components. In
Section 5, we present the experiment setup and results in addition to analysis of the obtained results. Finally, we conclude this work in
Section 6.
2. Related Works
Task offloading in edge computing has attracted significant attention from the research community as a result of its crucial role in optimizing resource utilization and enhancing system performance. Various solutions and architectures have been proposed to address task-offloading problems [
3]. In this section, we focus on the multi-access edge computing (MEC) network architecture in which computing resources are placed at the edge of the network, close to end users. This reduces latency and improves efficiency for data processing and service delivery in applications like IoT and mobile networks [
12,
13,
14,
15].
For instance, works proposed by Yang et al. (2020) [
16], Liu et al. (2019) [
17], and Zhang et al. (2021) [
18] focus on designing offloading decisions based on data characteristics and network conditions, aiming to minimize latency and maximize throughput. Similarly, solutions proposed by Chen et al. (2021) [
19], Li et al. (2020) [
20], and Xu et al. (2020) [
21] examine task-offloading strategies considering energy consumption and device capabilities, developing energy-aware scheduling algorithms. Additionally, studies by Cozzolino et al. (2023) [
22], Abdenacer et al. (2023) [
6], and Younis et al. (2019) [
23] address both energy and latency, aiming to reduce both metrics or find a balance between them. These approaches are often not suitable for real-time applications, which require meeting strict time constraints and tight energy budgets.
A notable scarcity of studies is found in the literature where explicit time and energy constraints are considered, either individually or in combination. For example, works by Li et al. (2021) [
24], Tajallifar et al. (2021) [
25], and Liu et al. (2016) [
26] propose a time-aware task-offloading framework that processes tasks by priority based on given deadlines to dynamically allocate resources for meeting real-time requirements. Similarly, Zhao et al. (2021) [
27] and Jiang et al. (2022) [
28] introduce an energy-aware task-offloading approach optimizing energy consumption by balancing workload distribution across edge devices and servers. Furthermore, Mohammad et al. (2020) [
29], Azizi et al. (2022) [
30], Wang et al. (2019) [
31], and Ben et al. (2024) [
32,
33] tackle the joint optimization of time and energy constraints in task-offloading decisions, using mathematical modeling techniques to formulate the problem as a multi-objective optimization problem. These studies emphasize the necessity of accounting for both time and energy constraints when making task-offloading decisions, underscoring their interdependence and the requirement for comprehensive optimization strategies in edge computing environments.
In the context of inference tasks, accuracy as a task-offloading objective has seen less attention from the research community. With the rise of AI model deployment in IoT, it is becoming an important performance metric. Nikoloska et al. (2020) [
11] propose a data selection scheme based on a confidence metric for edge devices to select the data samples which could lead to poor inference accuracy, in which case they are offloaded to the edge server. Fresa et al. (2021) [
4] propose a task scheduling and offloading scheme based on LP-Relaxation and dynamic programming where all possible cases of scheduling two inference tasks between the edge device and the edge server are considered.
Various optimization methods have been used to tackle the task-offloading problem in edge computing, reflecting the complexity and diversity of the challenges involved. Traditional optimization techniques, such as Mixed Linear Programming (MLP) [
34] and branch and bound [
35], have framed task allocation as a mathematical optimization problem, allowing for exact or near-optimal solutions under certain constraints. Additionally, machine learning methods have gained prominence for their capacity to adaptively learn and optimize task-offloading decisions based on historical data and real-time observations [
36,
37]. Furthermore, metaheuristic algorithms, including genetic algorithms, simulated annealing, and particle swarm optimization, have been employed to address the NP-hard nature of the task-offloading problem by efficiently exploring the solution space and identifying high-quality solutions [
32,
33,
38,
39]. Each method presents unique advantages and trade-offs, depending on the specific problem characteristics and the requirements of the edge computing environment.
Deep reinforcement learning (DRL) approaches stand out as highly adaptive schemes, making them suitable for high-mobility edge computing networks. Additionally, with proper configuration and design, DRL schemes can consistently match and outperform metaheuristic schemes while consuming fewer resources. Chen et al. (2021) [
19] propose a resource allocation scheme for augmented reality (AR) in single and multi-access edge computing (MEC) systems. Using a DRL multi-agent deep deterministic policy gradient (MADDPG) method, their system managed to minimize energy consumption for each user subject to latency requirements and limited resources. Their proposed system uses MEC servers for offload path planning, which incurs a communication overhead while edge devices wait for plans. Additionally, their proposed DRL agent considers a fixed number of MEC servers. Alfakih et al. (2020) [
36] propose a system model consisting of mobile edge computing networks (MECNs) with multiple access points. The edge devices can connect to an MECN through the access points. The edge device uses a state–action–reward–state–action (SARSA) reinforcement learning agent to decide whether to offload the task to the nearest edge server, an adjacent edge server, or the remote cloud. This work relies on networking infrastructure that might not always be available and cost-effective, potentially causing additional delays in real-time applications. Furthermore, the proposed agent has limited actions in terms of deciding which server to offload to, significantly reducing the ability to precisely control the overall task offload latency. Gao et al. (2024) [
40] propose Com-DDPG, an offloading strategy for MEC utilizing multi-agent reinforcement learning to improve offloading performance. Within the Internet of Vehicles (IoV) transmission radius, multiple agents collaborate to learn environmental changes, such as the number of mobile devices and task queues, and develop an offloading strategy for edge servers. The method models task dependency, priority, and resource consumption, and formulates communication among agents. Reinforcement learning determines the offloading strategy, with a Long Short-Term Memory (LSTM) network enhancing internal state predictions and a bidirectional recurrent neural network (BRNN) improving communication features among agents. Li et al. (2024) [
41] propose a Multi-Action and Environment-Adaptive Proximal Policy Optimization algorithm (MEPPO), an enhancement of the conventional PPO algorithm, aimed at optimizing task scheduling and resource allocation in dynamic Vehicular Edge Computing (VEC) environments. The method encompasses three core aspects: generating task-offloading and priority decisions to reduce service request completion time, dynamically allocating transmit power based on expected transmission distances to minimize energy consumption, and adapting scheduling decisions to varying numbers of vehicle tasks by manipulating the state space of the PPO algorithm. This approach ensures efficient and adaptive management of tasks and resources in real-world scenarios.
In summary, a significant gap in the literature is identified, where inference task-offloading decisions are determined by both time and energy constraints while aiming to maximize overall accuracy. Our work stands out by addressing inference task scheduling and offloading with a strong emphasis on accuracy as a key performance metric. Furthermore, our approach directly integrates time and energy constraints to control scheduling and offloading decisions, focusing on parallel task execution. Additionally, deep reinforcement learning enables rapid scheduling and real-time adaptation to network changes.
3. System Model
We consider a sensing system consisting of edge devices equipped with a set of local inference models
. These edge devices have access to a set of edge servers
. Each edge server is equipped with a single inference model. The set of edge server inference models is denoted as
. At each time slot, the edge device receives a set of inference tasks denoted as
. An edge device constructs a selected set of inference models
for each time slot using
and
. This set is then used to assign inference models to tasks. All notations used in this section are presented in
Table 1.
3.1. Inference Accuracy
Edge devices can deploy inference models in several ways. One approach is to use a single tunable model, where adjusting input hyperparameters alters accuracy and inference times. Alternatively, multiple instances of similar models with different internal structures, such as varying layer sizes in Deep Neural Networks (DNNs), can be deployed. Another option is to use diverse types of models with different sizes and top-1 average accuracies. Since the actual top-1 accuracy of each model for a specific inference task is unknown beforehand, we rely on the average accuracy estimated from historical top-1 accuracy measurements. The average top-1 accuracy of model
i is denoted as
. The average top-1 accuracy of models on edge servers is set to be significantly higher than that of local inference models on edge devices [
32].
3.2. Time Delay Model
The average inference time for each model
i denoted as
is estimated using the average historical measured inference times where data pre-processing time is considered part of
. We define
as the average latency of edge server
i estimated from previous measurements.
is continuously updated after every transmission providing an indirect metric to the mobility of edge devices. Let
be the estimated time to offload task
to edge server
i.
can be calculated using the channel bandwidth and the size of task
j denoted as
given by
where
represents the bandwidth of the channel between the edge device and edge server
i. The bandwidth can be estimated from historical transmissions.
Let
be the total time to process a given task
j using model
i including inference and offloading times.
where
represents the average response time from edge server
i given by
where
is a constant representing the response size.
We define
as a binary variable representing the decision whether an inference model
i is assigned to inference task
j. Let
be the total time to process a complete time slot
k. The local inference and offloading are performed in parallel, and therefore we define
as the max between the total local inference time
and the total server time which includes offloading, inference, and response times of all offloaded tasks denoted as
.
is calculated using Algorithm 1.
where
is the total offload, inference, and response times for all tasks offloaded to the edge server with model i.
is a variable to accumulate and track offload times for all edge servers.
is a variable that accumulates and tracks inference times for each edge server with model i.
| Algorithm 1: Steps to calculate |
![Electronics 13 02580 i001]() |
The edge devices, encompassing both standard edge devices and edge servers, are assumed to have two queues as depicted in
Figure 2, one for computation and another for communication. This configuration facilitates parallel processing of inference tasks and offloading or receiving data.
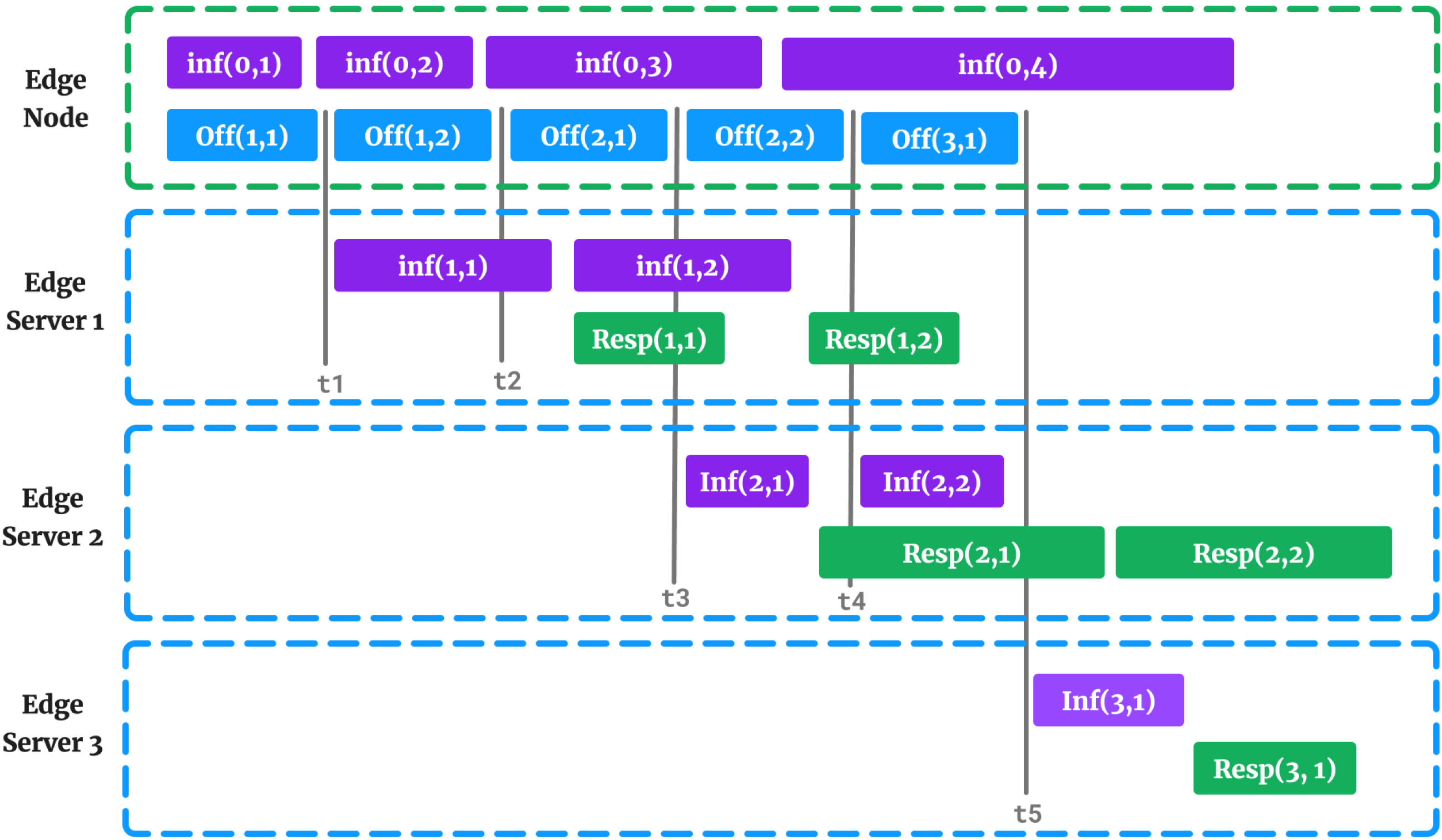
Figure 3 illustrates an example schedule for nine inference tasks, where four tasks are processed using local inference models, and six tasks are offloaded to three different edge servers. At
, the scenario is as follows:
By following the steps outlined in Algorithm 1 and applying them to the example shown in
Figure 3, we obtain the
values presented in
Table 2. The
value is determined as the maximum of all edge server total times. Finally, the total slot time
is calculated by taking the larger value between the total time for local inference
and
.
3.3. Inference Energy
Let be the energy cost of offloading task j to edge server i. depends on the offload time and the average energy cost of transmitting data to edge server i in one time unit. depends on several factors, including the communication medium such as Wi-Fi, Cellular, Bluetooth, or Zigbee, which affects energy consumption. Each medium has different power requirements, data rates, and transmission ranges, which influence the overall energy cost. The transmission power level of the wireless device impacts energy consumption. Higher transmit power levels generally result in greater energy consumption to maintain communication over longer distances or in environments with obstacles or interference. The power consumed by the wireless device when idle or in standby mode also contributes to the overall energy cost. Signal strength and quality impact energy consumption, especially in wireless communication systems that adapt transmission power based on signal conditions. Maintaining reliable communication may require higher power levels in environments with weak or noisy signals, leading to increased energy consumption. Environmental factors such as interference, obstacles, and electromagnetic noise can affect energy consumption by influencing signal propagation and reception quality. Various optimization techniques, such as data compression, packet aggregation, adaptive modulation, and power control algorithms, can help reduce energy consumption during wireless communication by improving spectral efficiency and minimizing transmission overhead.
The energy cost of offloading task
j to edge server
i, denoted as
, depends on the offload time
and
, the average energy cost per time unit for transmitting data to edge server
i. Several factors influence
, including the communication medium (Wi-Fi, Cellular, Bluetooth, or Zigbee), each with distinct power requirements, data rates, and transmission ranges. Higher transmission power levels generally lead to greater energy consumption, especially for maintaining communication over longer distances or in challenging environments. Additionally, the power consumed by the wireless device in idle or standby mode contributes to the overall energy cost. Signal strength and quality also impact energy consumption, as maintaining reliable communication in weak or noisy signal environments may require higher power levels. Environmental factors such as interference, obstacles, and electromagnetic noise can affect energy consumption by influencing signal propagation and reception quality. Furthermore, optimization techniques like data compression, packet aggregation, adaptive modulation, and power control algorithms can reduce energy consumption by improving spectral efficiency and minimizing transmission overhead [
32].
We assume that can be calculated internally by monitoring battery usage and the network adapter’s configurations such as the transmission power. By averaging these measured power usage metrics we can estimate . is given by the following.
We calculate
internally by monitoring battery usage and network adapter configurations, including transmission power levels. By averaging these measured power usage metrics, we can estimate
. The energy cost
of offloading task
j to edge server
i is then given by
Similarly, the energy cost of the inference response denoted by
is given by
Let be the average energy cost of performing the inference of an inference task using model i. The inference energy cost is negligible compared to the offloading energy cost. Therefore it is defined as a constant that can be estimated using the inference time and the maximum power consumption of the edge device’s CPU in the worst case under full load. Let be the total energy cost of processing task j using model i given by the following.
Let
represent the average energy cost of performing inference for a task using model
i. Given that the inference energy cost is minimal compared to the offloading energy cost, it is considered constant. This constant can be estimated using the inference time and the maximum power consumption of the edge device’s CPU under worst-case conditions of full load. Let
denote the total energy cost for processing task
j using model
i, given by:
Finally, we define
as the total energy consumption for slot
k given by
3.4. Problem Formulation
In this section, we identify two optimization problems. First, the problem of assigning inference models to inference tasks while respecting the given time and energy constraints and maximizing the overall accuracy. Secondly, the problem of selecting an optimal subset of available edge servers which maximizes the average accuracy of produced schedules while reducing the scheduling time.
3.4.1. Inference Task Scheduling Problem
The problem can be formulated as follows:
Where
is the total accuracy for a time slot
k. Let
be the total energy consumption of slot
k. Given
E and
T as the energy and time constraints, respectively, Equation (
1) is subject to the following:
Using Equation (
2), we guarantee that each parallel processing time of each slot is respecting the time constraint. Similarly, Equation (
3) ensures energy consumption for a time slot respects the given constraint. Finally, Equation (
4) guarantees each inference task is assigned an inference model that produces a complete solution.
This problem could be thought of as an instance of the well-known classic knapsack problem (KP) in which we are trying to fill our schedule (i.e., a knapsack) with inference models (i.e., pieces) to maximize the accuracy (i.e., profit) while respecting time and energy constraints (i.e., knapsack weight and volume capacities). In this case, the pieces and the knapsack have two dimensions and therefore this problem is an instance of the multi-dimensional KP. Additionally, inference models (i.e., pieces) can be reused to construct a schedule, and therefore the problem becomes an instance of the unbounded multi-dimensional KP (UMdKP). However, since we are considering parallel schedules where inference tasks can be processed locally and in edge servers in parallel, which in UMdKP terms means pieces can be overlapping in the weight dimension (i.e., time) but not in the volume dimension which renders this similarity useless. Alternatively, multiple knapsacks can be considered for each edge server which makes this problem an instance of the multi-knapsack problem (MKP). However, the problem becomes much more difficult to model especially when trying to uphold the time constraint over all knapsacks.
3.4.2. Edge Server Selection Problem
Let be the set of selected edge servers for time slot k. Let be a binary variable representing whether the inference model from edge server j is selected to be part of .
This formulation (Equation (
6)) ensures that each selected edge server contributes its single inference model to the selected subset
. The binary variable
determines the selection of edge servers, and the objective function maximizes the total accuracy obtained from the selected models. Solving this optimization problem provides the optimal or near-optimal solution for selecting the subset
for each time slot
k.
This type of problem is a combinatorial optimization problem known as a subset selection problem, where the goal is to select a subset of elements from a given set while optimizing a certain objective function subject to certain constraints.
In this specific case, we are tasked with selecting a subset of inference models from both local models and models hosted on edge servers to perform inference tasks. The objective is to maximize the total accuracy obtained from the selected models while minimizing the cardinality of (i.e., selecting the fewest number of models necessary to achieve faster scheduling times and higher accuracy).
Such types of optimization problems can be solved using various methods such as greedy algorithms where we select models based on certain criteria (e.g., highest accuracy or best cost–benefit ratio) until the cardinality constraint is met, while greedy algorithms do not guarantee optimal solutions, they can provide fast and efficient solutions in many cases. Moreover, dynamic programming can also be used if the problem exhibits overlapping subproblems and optimal substructure properties. This approach is particularly useful for problems with small problem sizes and a limited number of feasible solutions. Metaheuristic algorithms such as genetic algorithms, simulated annealing, or particle swarm optimization can be used to explore the solution space and find near-optimal solutions.
4. Multi-Agent DRL-Based Selective Inference Task Scheduling and Offloading Framework (MASITO)
Task scheduling and offloading in edge computing systems involve complex decision-making processes due to dynamic network conditions, varying computational loads, time, and energy constraints. Deep reinforcement learning (DRL) is best suited to handling such complexity by enabling agents to learn optimal decision-making policies through interaction with the environment. Task scheduling and offloading decisions in edge computing systems often need to optimize multiple conflicting objectives, such as adhering to time and energy constraints while maximizing accuracy. DRL algorithms can balance these objectives by learning complex trade-offs and generating efficient scheduling and offloading strategies. DRL agents can adapt to such dynamic environments by continuously learning and updating their policies based on real-time feedback.
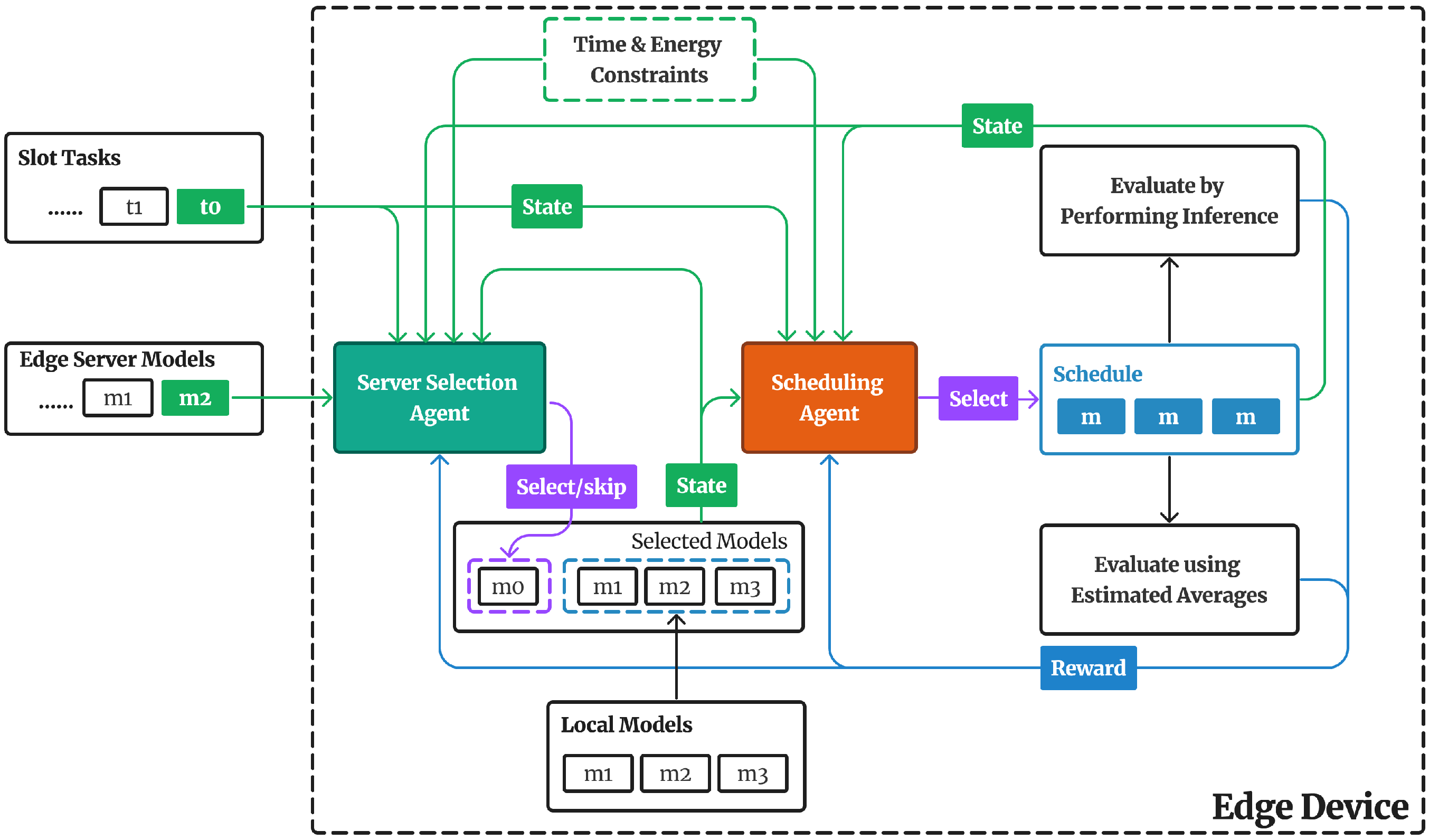
The proposed MASITO framework depicted in
Figure 4 takes advantage of DRL and uses two cooperating reinforcement learning agents, namely edge server selection agent and a scheduling agent. At the beginning of each time slot, the agents have access to information about the received tasks for that time slot. In addition to information about local inference models, available edge server models, given constraints, and network status. Using this information the edge server selection agent selects a single-edge server model for each task to be included in the selected set of inference models along with local inference models. This set is then used by the scheduling agent to assign an inference model for each task.
In the context of edge computing, the system state at a given time slot is often primarily influenced by the decisions made in the previous time slot regarding task scheduling and offloading. This characteristic lends itself well to being modeled as a Markov Decision Process (MDP), where the state transition dynamics satisfy the Markov property, meaning the future state depends only on the current state and the action taken. However, accurately determining the transition probabilities between states, especially in finite-state MDPs, can be challenging due to the dynamic and uncertain nature of the network environment, and while existing works often assume that transfer probabilities can be obtained through offline training, this approach may not accurately reflect the real-world network conditions, which are inherently unknown and subject to change. Therefore, to devise an optimal task scheduling and offloading strategy, reinforcement learning agents, specifically scheduling and server selection agents, are trained using model-free deep reinforcement learning (DRL) algorithms like Double Deep Q-Networks (DDQNs). Model-free DRL algorithms learn directly from interactions with the environment without relying on explicit models of the system dynamics, making them suitable for capturing the complex and dynamic nature of edge computing environments. By leveraging DDQNs, these agents can iteratively learn and update their decision-making policies based on real-time feedback, ultimately enabling more adaptive and effective task scheduling and offloading strategies that maximize system performance under time and energy constraints.
4.1. MASITO Design
For each time slot
k, the edge device receives a set of inference tasks
. For each task, a fixed-size pool of selected inference models
consisting of all the local inference models
in addition to a single slot reserved for a selected edge server model
is constructed.
The design illustrated in
Figure 5 facilitates the operation of DDQNs with fixed inputs and outputs for both agents, enabling them to adapt to the dynamic network of edge servers, which may join and disconnect arbitrarily. The selection of the edge server model
is made based on the current inference task to best adhere to the given time and energy constraints. Subsequently, the set of selected inference models is utilized by the scheduling agent to assign a single model to the ongoing inference task. Initially, the schedule
for time slot
k is initialized with a default local model
where
. Following each scheduling assignment, the model corresponding to the currently processed task is substituted with the selected model. This design approach ensures the availability of a complete schedule before all time slot tasks are completed, facilitating evaluation at each step, and enabling the computation of a reward representing a single action. This design is advantageous for training agents as it necessitates providing a reward for each action, as opposed to multiple actions where the agent selects inference models for all slot tasks and subsequently receives a single reward.
A schedule undergoes evaluation by computing its total time , total energy consumption , and total accuracy . We identify two methods for evaluating a schedule. The first method relies solely on estimated averages, including inference time, inference energy, and accuracy, for each selected model in a schedule. This approach offers benefits for agents as they receive relatively consistent average values, facilitating faster learning. Additionally, multiple agents can run in parallel to produce a single schedule, resulting in significant speed advantages. This is achievable because only cached average values are needed, eliminating the need for real inference after each selection step. However, relying solely on average estimates may lead to incorrect solutions, especially when outliers such as task sizes and network latency deviate significantly from the estimated average values. Hence, we propose a second approach where inference is performed after every selection step. This yields real inference times, energy consumption, and accuracy, as opposed to estimated averages, allowing the agent to adapt its subsequent actions to address previous sub-optimal actions and better handle outlier data, which can cause unexpected time and energy spikes. Consequently, this approach leads to more accurate schedules. Moreover, during training, the second approach benefits from instant and accurate rewards.
4.2. Inference Task Scheduling
In this section, we propose an MDP model for the inference task scheduling problem.
4.2.1. State Space
The state for the scheduling agent is designed such that given a set of selected inference models
, time and energy constraints
T and
E, respectively, and currently processed task
j, it allows it to estimate
,
, and
for time slot
k. As discussed earlier, we initially start with a default schedule
H and start replacing models with selected ones and thus the state is represented as the set of all possible schedules produced from considering all possible actions (i.e., all models in
). A state
for time slot
k and task
j is given by
where
is the id of the inference model
i.
T and
E represent time and energy constraints, respectively.
is the size of task
j.
c is the number of remaining tasks in the schedule which gives the agent an indicator of how to spend the constraints budget according to how many tasks are remaining.
c can be calculated by subtracting
j from the number of tasks per time slot.
,
,
,
,
are estimated from previous schedule values
,
,
,
,
, respectively, passed by previous state
and replacing placeholder default inference model
by model
.
Let
be a binary variable representing whether inference model
is a local model or belongs to an edge server.
All state values except for and c are normalized using a min–max approach where instead of using values from different ranges, we scale all values to a range between 0 and 1.
4.2.2. Action Space
The action space for the scheduling agent consists of the index of the selected inference model. The action space
is given by
4.2.3. Reward Function
After every action, the resulting schedule is evaluated where we calculate
,
, and
; then, using time and energy constraints we define the reward
for time slot
k and task
j is given in Equation (
7). Let
,
, and
be the normalized values of
,
, and
, respectively.
where
and
are normalized values of
T and
E, respectively.
,
, and
are weighting coefficients that determine the relative importance of each term in the reward function.
4.3. Edge Server Selection
In this section, we propose an MDP model for the edge server selection problem.
4.3.1. State Space
The state for the edge server selection agent contains information about the network latency and accuracy about the currently evaluated edge server along with the current task
j and given constraints. This gives the agent enough context to decide whether to use this edge server for offloading or not. Given
as the inference model corresponding to the previously selected edge server, and
as the inference model corresponding to the currently evaluated edge server. We define the state
as follows:
where
T and
E represent time and energy constraints, respectively.
is the size of the currently processed task
j.
4.3.2. Action Space
The action space of the edge server selection agent consists of a binary decision representing whether to use the evaluated edge server
or skip it and keep using the previous one
.
The edge server selection agent receives a similar reward to the scheduling agent since they have a common goal of producing the best schedule given the same constraints.
4.4. DDQN for MASITO
Deep Q-Network (DQN) is a reinforcement learning algorithm that combines deep neural networks with Q-learning to learn optimal policies for decision-making in sequential decision-making tasks. At its core, DQN aims to approximate the optimal action-value function, , which represents the expected cumulative reward when taking action a in state s and then following the optimal policy thereafter. The key innovation of DQN lies in using deep neural networks to approximate the action-value function, enabling it to handle high-dimensional state spaces commonly encountered in real-world applications. DQN learns by iteratively updating the parameters of the neural network to minimize the temporal difference error between the predicted Q-values and the target Q-values. By leveraging experience replay, where past experiences are stored and sampled randomly during training, DQN improves sample efficiency and stability by breaking temporal correlations in the data. Through this process, DQN learns to make optimal decisions by iteratively refining its policy based on feedback received from the environment.
Double Deep Q-Networks (DDQNs) improve upon DQNs by addressing the issue of overestimation bias in action values, which can lead to suboptimal policies. In DDQNs, this bias is mitigated by decoupling action selection from action evaluation through the use of two separate networks, a policy network and a target network (see
Figure 6), and while the policy network selects the best action based on the current state, the target network is used to estimate the value of that action. By periodically updating the parameters of the target network with those of the policy network, a DDQN ensures that the target values used to compute the temporal difference error are more stable and less prone to overestimation. This approach results in more accurate and reliable Q-value estimates, leading to improved convergence and ultimately better performance in reinforcement learning tasks compared to the original DQN algorithm. The target Q-value is calculated according to Equation (
8). The loss function is given by Equation (
9). The target network is updated using Equation (
10).
where
represents the Q-value predicted by the policy network for state
s and action
a with parameters
.
represents the target Q-value for state
s and action
a.
r is the immediate reward obtained after taking action
a in state
s.
is the next state.
is the discount factor determining the importance of future rewards.
represents the parameters of the target network.
is the soft update parameter determining the rate at which the target network parameters are updated.
The deep neural network for the scheduling agent takes an array of size and outputs an array of size , while the deep neural network for the edge server selection agent takes an array of size as input and outputs an array of size 2.
Algorithm 2 describes the steps used to train the DDQN agents. It uses an epsilon-greedy strategy where an agent decides between exploring new actions and exploiting known actions based on a parameter
. Initially,
is set to
and then each episode is reduced by a factor of
until it reaches a minimum value of
. This ensures sufficient exploration to avoid local optima and a gradual shift towards exploitation leveraging accumulated knowledge for better decision-making. Furthermore, Replay memory is used where past experiences (state, action, reward, next state) are stored in a buffer, allowing the agent to randomly sample mini-batches of these experiences during training. This approach breaks the temporal correlations between consecutive experiences, stabilizing the training process and improving learning efficiency. Algorithm 3 presents the main steps of MASITO illustrated in
Figure 5.
| Algorithm 2: DDQN Agent Training Algorithm |
![Electronics 13 02580 i002]() |
| Algorithm 3: MASITO steps |
![Electronics 13 02580 i003]() |
6. Conclusions
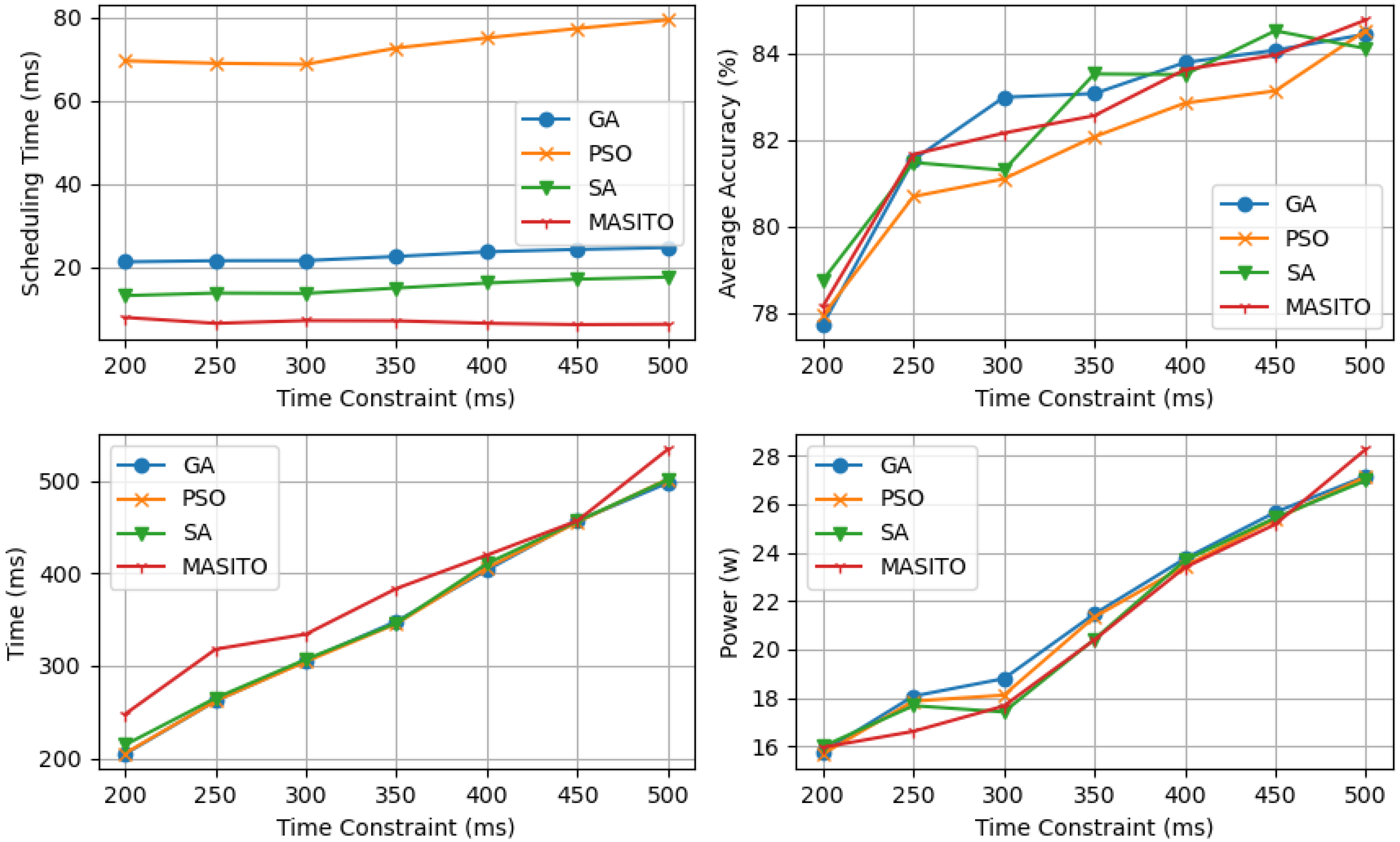
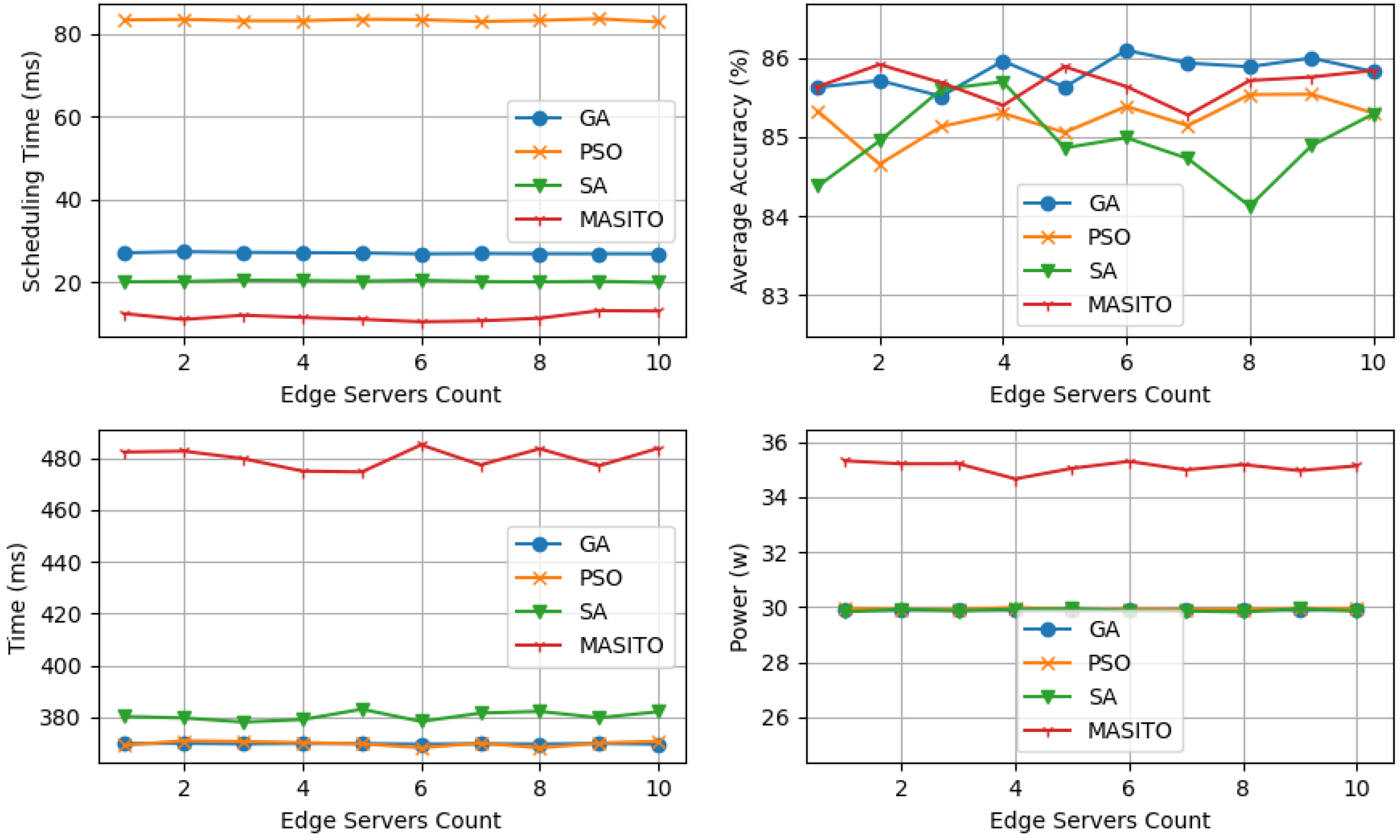
In this study, we address the challenging optimization problem of selective inference task scheduling and offloading under time and energy constraints while prioritizing accuracy maximization. Demonstrated to be strongly NP-Hard, we propose MASITO, a novel framework-leveraging cooperative multi-deep reinforcement learning agents. Our approach involves the deployment of a scheduling DRL agent tasked with allocating inference models to inference tasks, balancing between local inference and offloading to edge servers. Additionally, a complementary DRL agent is devised to select optimal edge servers for each inference task based on specified time and energy constraints. These agents operate synergistically, compensating for each other’s sub-optimal actions, and are seamlessly integrated into MASITO to dynamically adapt to diverse network configurations, facilitating applications in high-mobility edge computing environments. Experimental validation on the ImageNet-mini dataset underscores the efficacy of our framework against genetic algorithms (GAs), particle swarm optimization (PSO), and simulated annealing (SA) which reveal MASITO’s superiority in maintaining consistently lower scheduling times regardless of constraints and the number of edge servers, a critical factor for real-time applications. Moreover, MASITO demonstrates comparable average accuracy in worst-case scenarios and superior accuracy in best-case scenarios. Furthermore, MASITO exhibits the potential for continuous improvement with increased data processing.
Looking ahead, we propose two avenues for future research. Firstly, we advocate for the implementation of a federated learning scheme among edge devices to facilitate the sharing of learned experiences, expediting the convergence to optimal agents. Secondly, we suggest the development of an automated system capable of adapting the reward function coefficients dynamically according to specific application scenarios, enhancing the adaptability and robustness of MASITO in diverse real-world settings.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}