
Advances in Brain-Inspired Deep Neural Networks for Adversarial Defense

 , and
, and
Abstract
1. Introduction
2. Adversarial Attacks and Defenses in Deep Learning
2.1. Adversarial Attacks
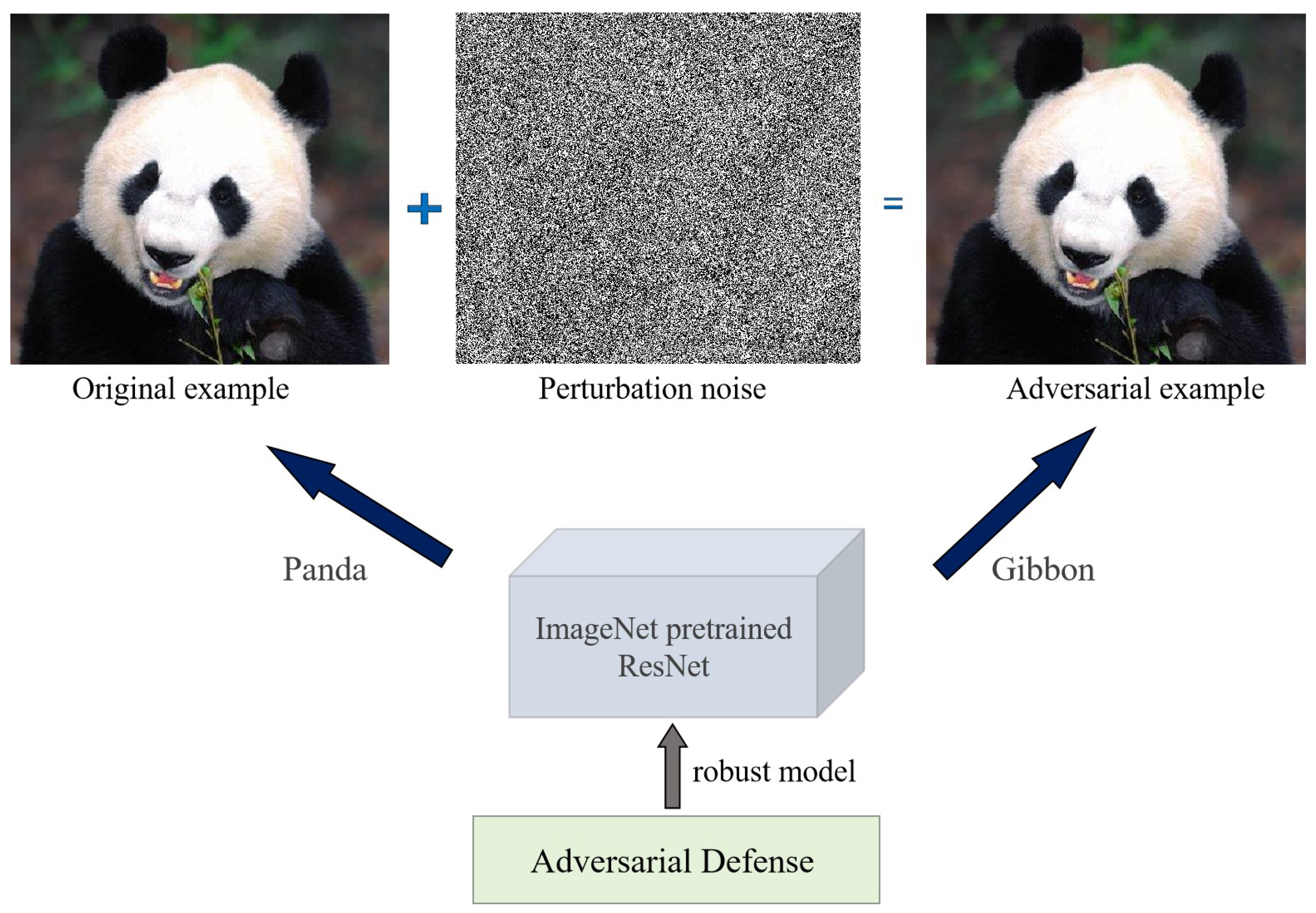
2.1.1. Adversarial Examples
2.1.2. Adversarial Attacks
- (1)
- Optimization-based attack algorithm. Optimization-based attack methods are commonly used techniques in adversarial attacks. They involve searching for the minimal perturbation in the input space that maximally alters the model’s predictions, leading to misclassification of input samples or classification of input samples into incorrect target classes. Szegedy et al. [12] first proposed the Box-constrained L-BFGS algorithm, an optimization algorithm used to solve unconstrained nonlinear optimization problems. It was the first optimization-based adversarial attack algorithm. Another optimization-based adversarial attack algorithm is the C and W (Carlini and Wagner) algorithm [16], an enhanced version of the Box-constrained L-BFGS algorithm. This algorithm introduces a perturbation vector to the input sample that approximates the minimal perturbation, enabling the perturbed sample to deceive the target model. This algorithm successfully bypassed the defense mechanism known as Defensive Distillation proposed by Papernot et al. [17].
- (2)
- Iterative attacks. Iterative attacks are methods used to adversarially attack machine learning models. These methods iteratively adjust the pixels or features of the original input sample to maximize the success rate of the attack on the adversarial samples. Goodfellow et al. [13] proposed the Fast Gradient Sign Method (FGSM) algorithm based on the observation that the linear nature of the local space of the model leads to the generation of adversarial samples. The FGSM algorithm performs the one-step update along the direction (i.e., the sign) of the gradient of the adversarial loss , to increase the loss in the steepest direction, with the goal of causing misclassification by the model. FGSM is a single-step adversarial attack algorithm that generates adversarial samples quickly and exhibits good transferability, but it has a relatively low attack success rate. To improve the success rate of attacks, Kurakin et al. [18] introduced the Basic Iterative Method (BIM), an iterative version of FGSM. BIM performs FGSM with smaller step sizes, generating more powerful adversarial samples, but increases the computational cost significantly. In 2017, Madry et al. [19] proposed the Projected Gradient Descent (PGD) attack algorithm, which is essentially an iterative version of FGSM. Similar to BIM, it serves as one of the benchmark testing algorithms for evaluating model robustness. Moosavi-Dezfooli et al. [20] introduced DeepFool, a method that iteratively computes minimal perturbations. DeepFool is an adversarial attack technique designed to deceive deep neural networks and guide them toward incorrect classifications by minimizing the distance between the input sample and the decision boundary, which exploits the locally linear approximation property of the decision boundaries of neural networks.
- (3)
- Generative neural networks. Attack methods based on generative neural networks leverage the powerful capabilities of generative models to generate high-quality adversarial samples, causing misdirection and deception to the target model. Baluja et al. [21] were the first to utilize generative neural networks to generate adversarial samples and developed the Adversarial Transformation Network (ATN). Adversarial samples generated by the ATN exhibit strong attack potency and have a certain level of interpretability, but their transferability is relatively weak. To address this limitation, Hayes et al. [22] proposed the Universal Adversarial Network (UAN) attack algorithm to enhance the transferability of the ATN. The UAN attack trains a simple deconvolutional neural network to transform randomly sampled noise from a natural distribution into universal adversarial perturbations, which can be applied to various types of input samples. Additionally, Xiao et al. [23] introduced the concept of generative adversarial network (GAN) and proposed the AdvGAN. This network consists of a generator network and a discriminator network, similar to GAN. The generator network is responsible for generating adversarial samples, while the discriminator network is used to distinguish between real samples and adversarial samples.
- (4)
- Practical attacks. Adversarial samples can extend from the digital space to the physical world. For instance, Sharif et al. [24] conducted adversarial attack tests on face recognition systems in real-world scenarios and proposed an attack method using stickers attached to eyeglass frames to achieve their adversarial goals. Hu et al. [25] introduced Adversarial Texture (AdvTexture) to perform multi-angle attacks. AdvTexture can be applied to cover clothing of arbitrary shapes, allowing individuals wearing such clothing to evade human body detectors from various viewpoints, as shown in Figure 2. They also proposed a generative method called Circular Crop-Based Scalable Generation Attack to produce AdvTexture with repetitive structures.
2.2. Adversarial Defenses
2.2.1. Data Preprocessing-Based Methods
- (1)
- Image transformation. Data-level defense, also known as data preprocessing, involves applying data augmentation to images before feeding them into the network, such as random cropping, flipping, and scaling, to reduce or eliminate the impact of adversarial perturbations [15]. Adversarial samples can be mitigated by using JPEG compression to reduce the influence of adversarial perturbations, although the defense provided by this method is limited. To address this issue, Liu et al. [26] redesigned JPEG algorithm and proposed a defense method called feature distillation, which utilizes distributional information of image features to reduce the impact of adversarial perturbations. Bhagoji et al. [27] proposed using Principal Component Analysis (PCA) to compress input data, thereby reducing or eliminating the influence of adversarial perturbations. Jia et al. [28] proposed an image compression network to eliminate adversarial perturbations further and restore clean samples through a reconstruction process. Prakash et al. [29] introduced the pixel deflection method, which randomly selects several pixels and replaces them with randomly chosen pixels to achieve adversarial robustness. They also utilized wavelet denoising to eliminate the noise introduced by pixel replacements. These individual adversarial defense methods are designed for specific attacks. To address this limitation, Raff et al. [30] proposed a comprehensive defense approach that combines multiple preprocessing methods to withstand adversarial sample attacks. Before feeding images into the network, a series of transformations, such as JPEG compression, wavelet denoising, and non-local means filtering, are applied to remove adversarial perturbations from the samples.
- (2)
- Denoising networks. Denoising networks aim to remove adversarial perturbations from input data to mitigate the impact of adversarial attacks. Mustafa et al. [31] proposed a super-resolution defense method that can remap the manifold edge samples to the natural image manifold. This approach does not require modifications to the architecture or training process of the target classification model. Instead, it preprocesses adversarial samples at the input layer, improving the image quality of adversarial samples while maintaining the model’s classification accuracy on original images. Osadchy et al. [32] regarded adversarial perturbations as noise and proposed a pixel-guided denoiser that utilizes filters to eliminate the noise. Liao et al. [33] extended the work above by introducing a high-guided denoiser, which aims to denoise based on high-order representations. This method leverages a U-Net model to learn the noise distribution and the mapping relationship for denoising. After training, adversarial samples are inputted into the U-Net to remove perturbations and restore clean images.
- (3)
- Adversarial training. Adversarial training is to augment the training set with adversarial samples generated through adversarial attacks, aiming to improve the model’s robustness against specific adversarial perturbations. The concept was initially proposed in Ref. [13]. Considering the inefficiency of training with a large number of samples, Kurakin et al. [18] introduced a novel training strategy that expands the training set and applies batch normalization, effectively improving the efficiency of adversarial training. Moosavidezfooli et al. [20] pointed out that adversarial training only enhances the robustness of the model against adversarial samples in the training set, which may affect the model’s performance on original samples. Yang et al. [34] observed that image datasets are generally separable and thus utilized the separability of the dataset to strike a balance between adversarial defense methods and the trade-off between model robustness and accuracy.
2.2.2. Model Robustness Enhancement Methods
2.2.3. Enhancing Model Robustness with Brain-Inspired Deep Neural Networks
3. Models of Bio-Inspired Deep Neural Networks in Adversarial Defense
3.1. Primary Visual Cortex-Inspired Robust Deep Neural Networks
3.2. Neural Signal-Based Robust Deep Neural Networks
3.3. Mechanism-Inspired Robust Deep Neural Networks
3.3.1. Retinal Non-Uniform Sampling and Multi-Receptive Field Mechanism
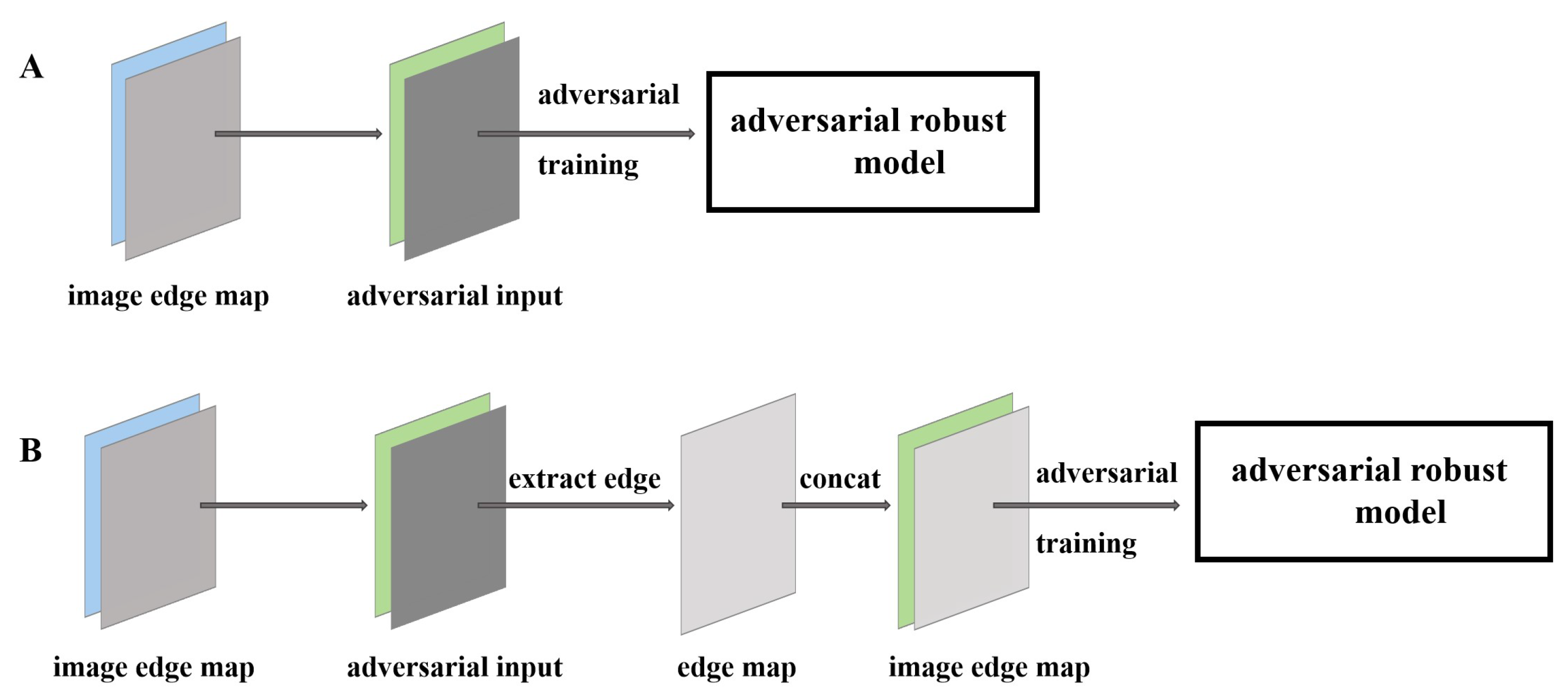
3.3.2. Shape Defense
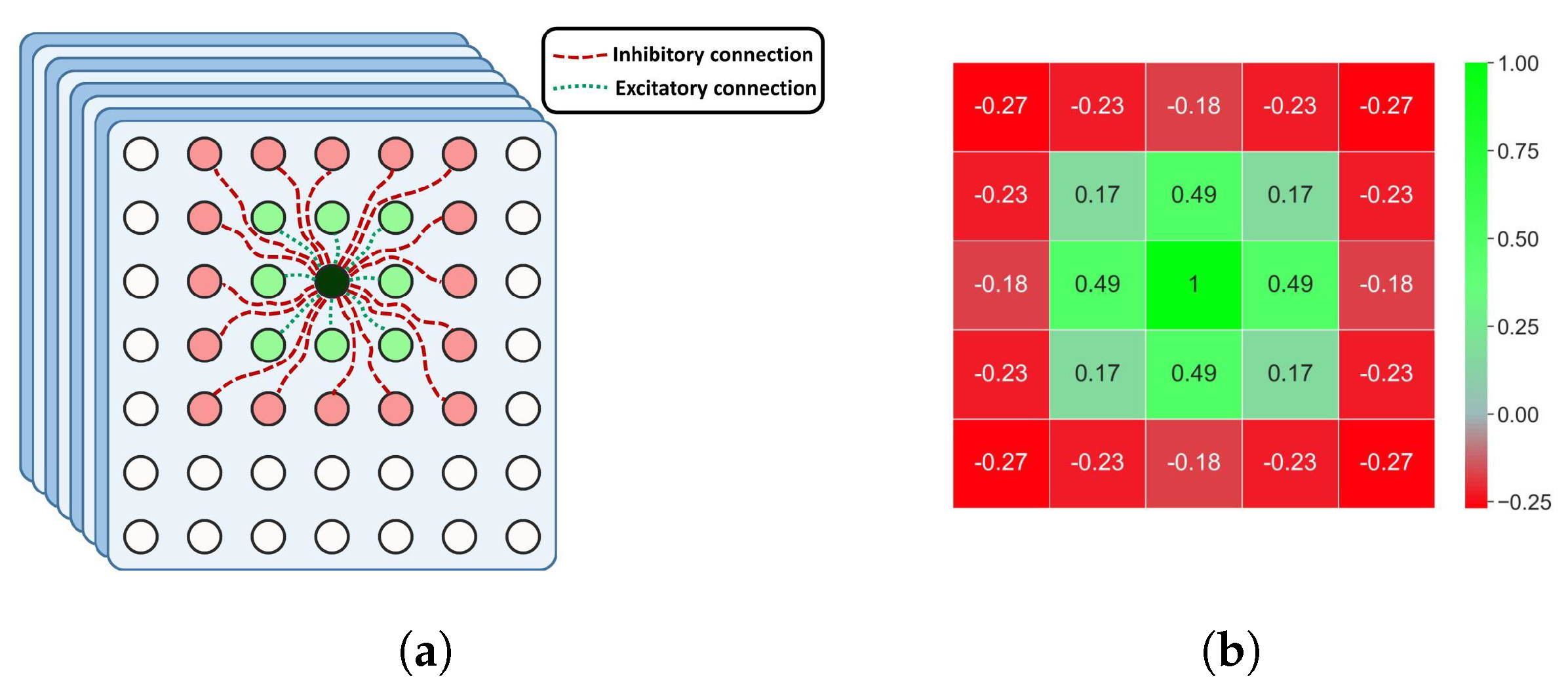
3.3.3. V1 Push–Pull Inhibition-Based Robust Convolutional Model
3.3.4. Surround Modulation-Inspired Neural Network
3.3.5. On–Off-Center-Surround Pathway
4. Discussion
4.1. Advantages of Bio-Inspired Deep Neural Networks
4.2. Main Unresolved Challenges
- (1)
- More complex theoretical foundations. To better understand the contributions of bio-inspired mechanisms to model robustness and why matching biology leads to more robust computer vision models, extensive theoretical foundations and a series of complex mathematical modeling efforts need to be explored. Our understanding of biological neural mechanisms still presents many mysteries, and the lack of clear theoretical guidance can make applying these mechanisms to neural network design challenging. While neuroscience has recently witnessed the emergence of numerous novel neurocomputational models and tools from machine learning, the latest advancements in machine learning and computer vision have primarily been driven by the widespread availability of computational resources and immense computing power. This may result in more time-consuming training and inference processes, requiring higher computational and storage resources, posing challenges for real-time and embedded applications.
- (2)
- Data requirements and model interpretability. Simulating the biological visual perception system requires substantial neural data for reference and training. However, collecting and processing large-scale neural datasets can be challenging and costly in practical implementation. Furthermore, the neural data from primates may exhibit individual variations and complexities, presenting a challenge in handling such differences. Moreover, employing biologically inspired approaches can increase the complexity of the model, rendering it more difficult to interpret and understand. This may restrict the ability to explain model decisions and assess their reliability, which are crucial factors in certain applications, such as medical diagnostics and security domains.
- (3)
- Ethics and privacy issues. Significant amounts of neural data and individual information may be involved when employing methods that simulate biological visual perception. This raises ethical and privacy concerns regarding data collection, storage, and protection, as well as potential misuse and risks. Conducting thorough risk assessments and establishing corresponding regulatory and control measures to prevent abuses and incidents targeting legitimate users are imperative. Additionally, our defense mechanisms may generate false positives, incorrectly labeling legitimate behavior as malicious. This could lead to the wrongful blocking or unfair treatment of legitimate users. Therefore, in designing defense mechanisms, efforts should be made to minimize the possibility of false positives and collateral damage while providing effective mechanisms for appeals and remedies. Finally, introducing models incorporating biological neural mechanisms may have profound societal implications across diverse domains. Ensuring the ethical and social responsibility of developing and deploying these models is essential.
4.3. Bio-Inspirations and Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rinchen, S.; Vaidya, B.; Mouftah, H.T. scalable multi-task learning r-cnn for object detection in autonomous driving. In Proceedings of the IEEE 2023 International Wireless Communications and Mobile Computing, Kuala Lumpur, Malaysia, 4–8 December 2023. [Google Scholar] [CrossRef]
- Cai, J.; Xu, M.; Li, W.; Xiong, Y.; Xia, W.; Tu, Z.; Soatto, S. MeMOT: Multi-object tracking with memory. In Proceedings of the IEEE 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar] [CrossRef]
- Xiao, Z.; Gao, X.; Fu, C.; Dong, Y.; Gao, W.; Zhang, X.; Zhou, J.; Zhu, J. Improving transferability of adversarial patches on face recognition with generative models. In Proceedings of the IEEE 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar] [CrossRef]
- Dapello, J.; Marques, T.; Schrimpf, M.; Geiger, F.; Cox, D.D.; DiCarlo, J.J. Simulating a Primary Visual Cortex at the Front of CNNs Improves Robustness to Image Perturbations. Adv. Neural Inf. Process. Syst. 2020, 33, 13073–13087. [Google Scholar] [CrossRef]
- Liu, X.; Cheng, M.; Zhang, H.; Hsieh, C.J. Towards robust neural networks via random self-ensemble. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 381–397. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef]
- Zhuang, C.; Yan, S.; Nayebi, A.; Schrimpf, M.; Frank, M.C.; DiCarlo, J.J.; Yamins, D.L.K. Unsupervised Neural Network Models of the Ventral Visual Stream. Proc. Natl. Acad. Sci. USA 2020, 118, e2014196118. [Google Scholar] [CrossRef]
- Tuncay, G.S.; Demetriou, S.; Ganju, K.; Gunter, C.A. Resolving the predicament of android custom permissions. In Proceedings of the 2018 Network and Distributed System Security Symposium: Internet Society, NDSS, San Diego, CA, USA, 18–21 February 2018. [Google Scholar] [CrossRef]
- Strisciuglio, N.; Lopez-Antequera, M.; Petkov, N. Enhanced robustness of convolutional networks with a push–pull inhibition layer. Neural Comput. Appl. 2020, 32, 17957–17971. [Google Scholar] [CrossRef]
- Hasani, H.; Soleymani, M.; Aghajan, H. Surround modulation: A bio-inspired connectivity structure for convolutional neural networks. Adv. Neural Inf. Process. Syst. 2019, 32, 1–12. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar] [CrossRef]
- Nguyen, A.; Yosinski, J.; Clune, J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar] [CrossRef]
- Wei, J.; Du, S.; Yu, Z. Review of white-box adversarial attack technologies in image classification. J. Comput. Appl. 2022, 42, 2732–2741. [Google Scholar] [CrossRef]
- Liang, B.; Li, H.; Su, M.; Li, X.; Shi, W.; Wang, X. Summary of the security of image adversarial samples. J. Inf. Secur. Res. 2021, 7, 294–309. [Google Scholar] [CrossRef]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy, San Diego, CA, USA, 22–26 May 2017. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a defense to adversarial perturbations against deep neural networks. In Proceedings of the 2016 IEEE Symposium on Security and Privacy, San Diego, CA, USA, 22–26 May 2016. [Google Scholar] [CrossRef]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial examples in the physical world. arXiv 2016, arXiv:1607.02533. [Google Scholar] [CrossRef]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar] [CrossRef]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. DeepFool: A simple and accurate method to fool deep neural networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Baluja, S.; Fischer, I. Adversarial Transformation Networks: Learning to Generate Adversarial Examples. arXiv 2017, arXiv:1703.09387. [Google Scholar] [CrossRef]
- Hayes, J.; Danezis, G. Learning universal adversarial perturbations with generative models. In Proceedings of the 2018 IEEE Security and Privacy Workshops, San Diego, CA, USA, 24 May 2018. [Google Scholar] [CrossRef]
- Xiao, C.; Li, B.; Zhu, J.Y.; He, W.; Liu, M.; Song, D. Generating Adversarial Examples with Adversarial Networks. arXiv 2018, arXiv:1801.02610. [Google Scholar] [CrossRef]
- Sharif, M.; Bhagavatula, S.; Bauer, L.; Reiter, M.K. Accessorize to a Crime: Real and stealthy attacks on state-of-the-art face recognition. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, CCS’16, Vienna, Austria, 24–28 October 2016. [Google Scholar] [CrossRef]
- Hu, Z.; Huang, S.; Zhu, X.; Sun, F.; Zhang, B.; Hu, X. Adversarial Texture for Fooling Person Detectors in the Physical World. arXiv 2022, arXiv:2203.03373. [Google Scholar] [CrossRef]
- Liu, Z.; Liu, Q.; Liu, T.; Xu, N.; Lin, X.; Wang, Y.; Wen, W. Feature distillation: DNN-oriented JPEG compression against adversarial examples. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Bhagoji, A.N.; Chakraborty, S.; Mittal, P.; Calo, S. Analyzing Federated Learning through an Adversarial Lens. arXiv 2018, arXiv:1811.12470. [Google Scholar] [CrossRef]
- Jia, X.; Wei, X.; Cao, X.; Foroosh, H. ComDefend: An efficient image compression model to defend adversarial examples. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Prakash, A.; Moran, N.; Garber, S.; DiLillo, A.; Storer, J. Deflecting adversarial attacks with pixel deflection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef]
- Raff, E.; Sylvester, J.; Forsyth, S.; McLean, M. Barrage of random transforms for adversarially robust defense. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Mustafa, A.; Khan, S.H.; Hayat, M.; Shen, J.; Shao, L. Image Super-Resolution as a Defense Against Adversarial Attacks. IEEE Trans. Image Process. 2020, 29, 1711–1724. [Google Scholar] [CrossRef] [PubMed]
- Osadchy, M.; Hernandez-Castro, J.; Gibson, S.; Dunkelman, O.; Perez-Cabo, D. No Bot Expects the DeepCAPTCHA! Introducing Immutable Adversarial Examples, with Applications to CAPTCHA Generation. IEEE Trans. Inf. For. Secur. 2017, 12, 2640–2653. [Google Scholar] [CrossRef]
- Liao, F.; Liang, M.; Dong, Y.; Pang, T.; Hu, X.; Zhu, J. Defense against adversarial attacks using high-level representation guided denoiser. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Yang, Y.Y.; Rashtchian, C.; Zhang, H.; Salakhutdinov, R.; Chaudhuri, K. A Closer Look at Accuracy vs. Robustness. arXiv 2020, arXiv:2003.02460. [Google Scholar] [CrossRef]
- Ross, A.S.; Doshi-Velez, F. Improving the Adversarial Robustness and Interpretability of Deep Neural Networks by Regularizing their Input Gradients. arXiv 2017, arXiv:1711.09404. [Google Scholar] [CrossRef]
- Athalye, A.; Carlini, N.; Wagner, D. Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples. arXiv 2018, arXiv:1802.00420. [Google Scholar] [CrossRef]
- Davidson, H.E. Filling the Knowledge Gaps. Consult. Pharm. 2015, 30, 249. [Google Scholar] [CrossRef]
- Ren, K.; Zheng, T.; Qin, Z.; Liu, X. Adversarial Attacks and Defenses in Deep Learning. Engineering 2020, 6, 346–360. [Google Scholar] [CrossRef]
- Lee, H.; Han, S.; Lee, J. Generative Adversarial Trainer: Defense to Adversarial Perturbations with GAN. arXiv 2017, arXiv:1705.03387. [Google Scholar] [CrossRef]
- Lindsay, G.W. Convolutional Neural Networks as a Model of the Visual System: Past, Present, and Future. J. Cogn. Neurosci. 2021, 33, 2017–2031. [Google Scholar] [CrossRef]
- Kerr, D.; Coleman, S.A.; McGinnity, T.M.; Clogenson, M. Biologically inspired intensity and range image feature extraction. In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013. [Google Scholar] [CrossRef]
- Yan, D.; Hu, B. Shared Representation Generator for Relation Extraction With Piecewise-LSTM Convolutional Neural Networks. IEEE Access 2019, 7, 31672–31680. [Google Scholar] [CrossRef]
- Kudithipudi, D.; Aguilar-Simon, M.; Babb, J.; Bazhenov, M.; Blackiston, D.; Bongard, J.; Brna, A.P.; Chakravarthi Raja, S.; Cheney, N.; Clune, J.; et al. Biological underpinnings for lifelong learning machines. Nat. Mach. Intell. 2022, 4, 196–210. [Google Scholar] [CrossRef]
- Khaligh-Razavi, S.M.; Kriegeskorte, N. Deep Supervised, but Not Unsupervised, Models May Explain IT Cortical Representation. PLoS Comput. Biol. 2014, 10, e1003915. [Google Scholar] [CrossRef] [PubMed]
- Cadena, S.A.; Denfield, G.H.; Walker, E.Y.; Gatys, L.A.; Tolias, A.S.; Bethge, M.; Ecker, A.S. Deep convolutional models improve predictions of macaque V1 responses to natural images. PLoS Comput. Biol. 2019, 15, e1006897. [Google Scholar] [CrossRef] [PubMed]
- Schrimpf, M.; Kubilius, J.; Hong, H.; Majaj, N.J.; Rajalingham, R.; Issa, E.B.; Kar, K.; Bashivan, P.; Prescott-Roy, J.; Geiger, F.; et al. Brain-Score: Which Artificial Neural Network for Object Recognition is most Brain-Like? bioRxiv 2018. [Google Scholar] [CrossRef]
- Machiraju, H.; Choung, O.H.; Frossard, P.; Herzog, M.H. Bio-inspired Robustness: A Review. arXiv 2021, arXiv:2103.09265. [Google Scholar] [CrossRef]
- Malhotra, G.; Evans, B.; Bowers, J. Adding biological constraints to CNNs makes image classification more human-like and robust. In Proceedings of the 2019 Conference on Cognitive Computational Neuroscience: Cognitive Computational Neuroscience, CCN, Online, 13–16 September 2019. [Google Scholar] [CrossRef]
- Luan, S.; Chen, C.; Zhang, B.; Han, J.; Liu, J. Gabor Convolutional Networks. IEEE Trans. Image Process. 2018, 27, 4357–4366. [Google Scholar] [CrossRef]
- Baidya, A.; Dapello, J.; DiCarlo, J.J.; Marques, T. Combining Different V1 Brain Model Variants to Improve Robustness to Image Corruptions in CNNs. arXiv 2021, arXiv:2110.10645. [Google Scholar] [CrossRef]
- Safarani, S.; Nix, A.; Willeke, K.; Cadena, S.A.; Restivo, K.; Denfield, G.; Tolias, A.S.; Sinz, F.H. Towards robust vision by multi-task learning on monkey visual cortex. arXiv 2021, arXiv:2107.14344. [Google Scholar] [CrossRef]
- Li, Z.; Brendel, W.; Walker, E.Y.; Cobos, E.; Muhammad, T.; Reimer, J.; Bethge, M.; Sinz, F.H.; Pitkow, X.; Tolias, A.S. Learning From Brains How to Regularize Machines. arXiv 2019, arXiv:1911.05072. [Google Scholar] [CrossRef]
- Reddy, M.V.; Banburski, A.; Pant, N.; Poggio, T. Biologically Inspired Mechanisms for Adversarial Robustness. arXiv 2020, arXiv:2006.16427. [Google Scholar] [CrossRef]
- Freeman, J.; Simoncelli, E.P. Metamers of the ventral stream. Nat. Neurosci. 2011, 14, 1195–1201. [Google Scholar] [CrossRef] [PubMed]
- Han, Y.; Roig, G.; Geiger, G.; Poggio, T. Scale and translation-invariance for novel objects in human vision. Sci. Rep. 2020, 10, 61. [Google Scholar] [CrossRef] [PubMed]
- Kang, X.; Guo, J.; Song, B.; Cai, B.; Sun, H.; Zhang, Z. Interpretability for reliable, efficient, and self-cognitive DNNs: From theories to applications. Neurocomputing 2023, 545, 126267. [Google Scholar] [CrossRef]
- Borji, A. Shape Defense Against Adversarial Attacks. arXiv 2020, arXiv:2008.13336. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar] [CrossRef]
- Su, J.; Vargas, D.V.; Sakurai, K. One Pixel Attack for Fooling Deep Neural Networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef]
- Brendel, W.; Rauber, J.; Bethge, M. Decision-Based Adversarial Attacks: Reliable Attacks Against Black-Box Machine Learning Models. arXiv 2017, arXiv:1712.04248. [Google Scholar] [CrossRef]
- Wang, G.; Lopez-Molina, C.; De Baets, B. Multiscale Edge Detection Using First-Order Derivative of Anisotropic Gaussian Kernels. J. Math. Imaging Vis. 2019, 61, 1096–1111. [Google Scholar] [CrossRef]
- Jing, J.; Liu, S.; Wang, G.; Zhang, W.; Sun, C. Recent advances on image edge detection: A comprehensive review. Neurocomputing 2022, 503, 259–271. [Google Scholar] [CrossRef]
- Babaiee, Z.; Hasani, R.; Lechner, M.; Rus, D.; Grosu, R. On-off center-surround receptive fields for accurate and robust image classification. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Wang, G.; Lopez-Molina, C.; Vidal-Diez de Ulzurrun, G.; De Baets, B. Noise-robust line detection using normalized and adaptive second-order anisotropic Gaussian kernels. Signal Process. 2019, 160, 252–262. [Google Scholar] [CrossRef]
- Wang, G.; Lopez-Molina, C.; De Baets, B. Blob reconstruction using unilateral second order gaussian kernels with application to high-iso long-exposure image denoising. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4817–4825. [Google Scholar]
- Wang, G.; Lopez-Molina, C.; De Baets, B. Automated blob detection using iterative Laplacian of Gaussian filtering and unilateral second-order Gaussian kernels. Digit. Signal Process. 2020, 96, 102592. [Google Scholar] [CrossRef]
- Carandini, M.; Heeger, D.J.; Movshon, J.A. Linearity and normalization in simple cells of the macaque primary visual cortex. J. Neurosci. 1997, 17, 8621–8644. [Google Scholar] [CrossRef]
- Roelfsema, P.R. Cortical algorithms for perceptual grouping. Annu. Rev. Neurosci. 2006, 29, 203–227. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Backbone | Characteristics | |
|---|---|---|---|
| V1-inspired | VOneNet | ResNet50 | VOneblock is an adaptable front-end that is plug-and-play, exhibiting strong transferability in mitigating adversarial attacks and image perturbations. |
| VOneNet variants | ResNet50 | The initial evidence demonstrates that V1-inspired CNN can lead to higher robustness gains through distillation, yet they lack biologically plausible explanations. | |
| Neural signal-based | MTL | VGG-19 | By employing a novel constrained reconstruction analysis technique, this study investigated the changes in feature representations of a brain-trained network as its robustness improved. However, it is worth noting that the training solely relied on neural data from monkey brains, which may introduce specific conditions and limitations to the obtained results, thereby potentially limiting the generalizability of the findings. |
| Mechanism-inspired | Retinal fixations | Standard CNN | By incorporating non-uniform sampling and multiscale receptive fields, CNN exhibits significant improvement in robustness against small adversarial perturbations. However, this enhancement comes at the cost of increased computational overhead, and the performance of these mechanisms on large-scale datasets remains unverified. |
| EAT | Standard CNN | The EAT method, in contrast to utilizing fixed-weight biological filters, still employs adversarial training to enhance edge features. The invariance of edge maps allows the model to exhibit greater robustness against moderate imperceptible perturbations, albeit at a higher training cost. | |
| Push–pull layer | ResNet20 | The introduction of a novel push–pull layer into CNN architectures has demonstrated an improvement in the robustness of existing networks against various types of image corruptions. In the future, it would be beneficial to explore the integration of this mechanism into object detection to enhance the model’s noise robustness. | |
| SM-CNN | Standard CNN | SM-CNN demonstrates superior generalization capabilities when handling challenging visual tasks. However, determining the appropriate connection weights and structural parameters poses a challenging task. Extensive debugging and optimization are required in practical applications to achieve optimal results. | |
| OOCS-SNN | Standard DCNN | The introduction of on-center and off-center filters in OOCS-CNN enables better detection of edge information in images by calculating the variance of on and off kernels through receptive field. This approach enhances the accuracy and robustness of image classification. The robustness to illumination variations offered by this method holds significant potential for improvements in visual perception systems, particularly in autonomous driving. |
| Model | Clean | White Box | Corruption | Mean |
|---|---|---|---|---|
| Base ResNet50 | 75.6 | 16.4 | 38.8 | 27.6 |
| 62.4 | 52.3 | 32.3 | 42.3 | |
| + SIN | 74.1 | 17.3 | 52.6 | 34.9 |
| VOneResNet50 | 71.7 | 51.1 | 40.0 | 45.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, R.; Ke, M.; Dong, Z.; Wang, L.; Zhang, T.; Du, M.; Wang, G. Advances in Brain-Inspired Deep Neural Networks for Adversarial Defense. Electronics 2024, 13, 2566. https://doi.org/10.3390/electronics13132566
Li R, Ke M, Dong Z, Wang L, Zhang T, Du M, Wang G. Advances in Brain-Inspired Deep Neural Networks for Adversarial Defense. Electronics. 2024; 13(13):2566. https://doi.org/10.3390/electronics13132566
Chicago/Turabian StyleLi, Ruyi, Ming Ke, Zhanguo Dong, Lubin Wang, Tielin Zhang, Minghua Du, and Gang Wang. 2024. "Advances in Brain-Inspired Deep Neural Networks for Adversarial Defense" Electronics 13, no. 13: 2566. https://doi.org/10.3390/electronics13132566
APA StyleLi, R., Ke, M., Dong, Z., Wang, L., Zhang, T., Du, M., & Wang, G. (2024). Advances in Brain-Inspired Deep Neural Networks for Adversarial Defense. Electronics, 13(13), 2566. https://doi.org/10.3390/electronics13132566