
A Model for Detecting Abnormal Elevator Passenger Behavior Based on Video Classification



Abstract
1. Introduction
2. Related Work
2.1. Human Behavior Recognition
2.2. Detection of Abnormal Human Behavior in Elevators
3. Methods
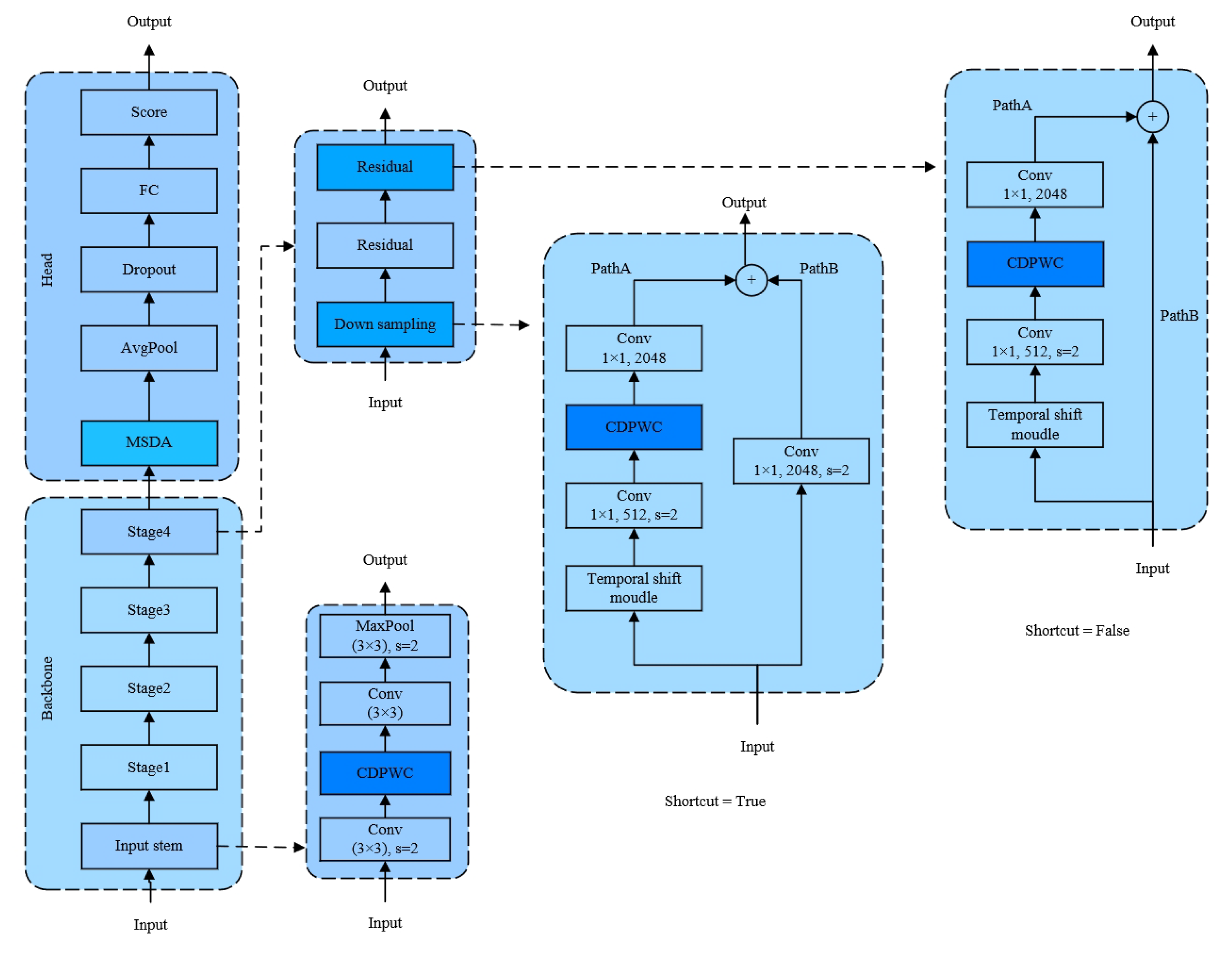
3.1. Overview
| Algorithm 1 TSM-CDPMSDANet Training Pipeline. |
| Input: : the labeled data x means frames of videos; y means the label. Output: Trained TSM-CDPMSDANet model . 1: Initialize TSM-CDPMSDANet. 2: for iter = 1 to max_iter do 3: Feed with D 4: , : features 5: for to 4 do 6: 7: 8: end for 9: 10: 11: 12: 13: 14: 15: Compute Loss. 16: Optimize TSM-CDPMSDANet by minimizing Loss. 17: end for |
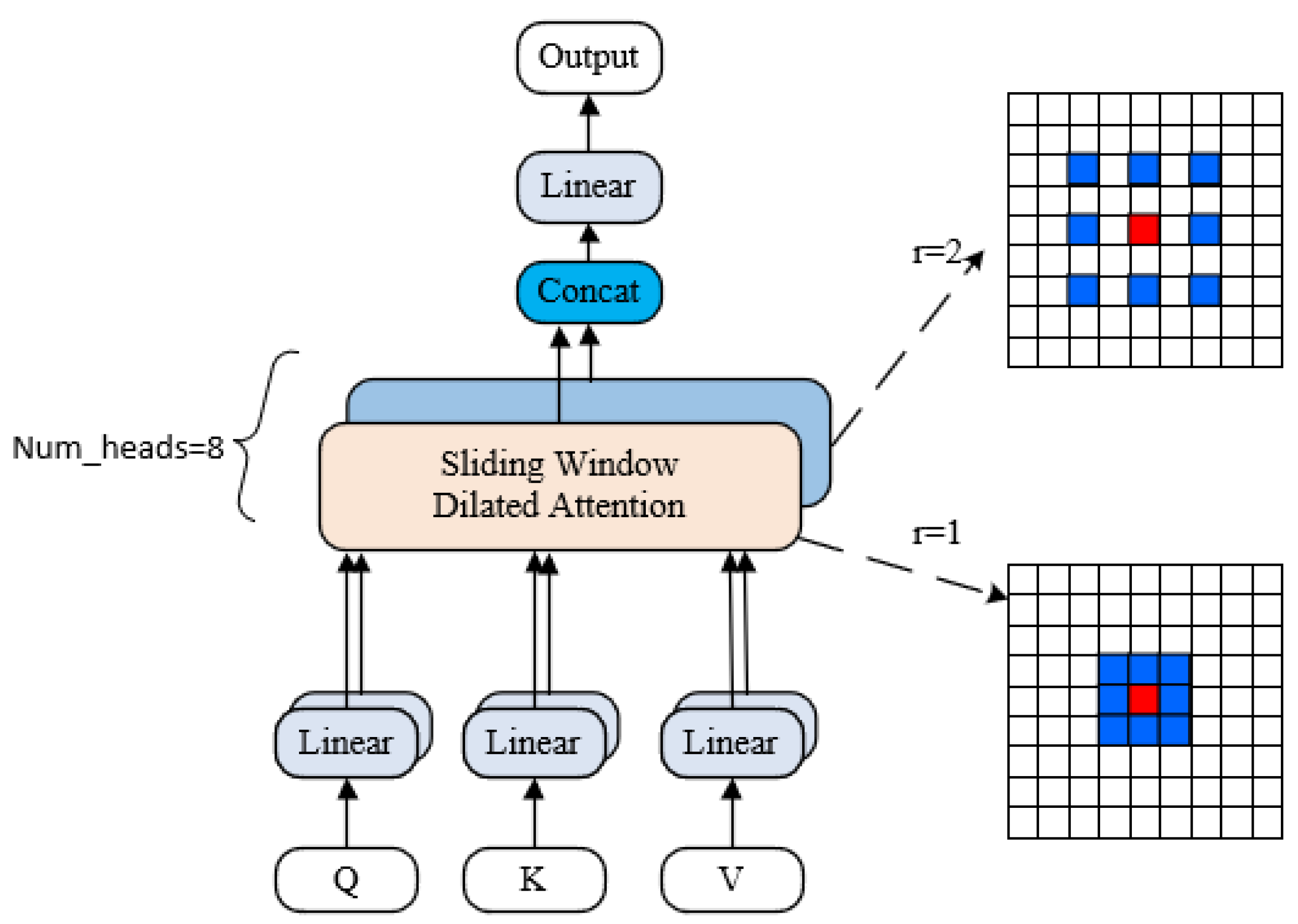
3.2. Multi-Scale Dilated Attention Module (MSDA)
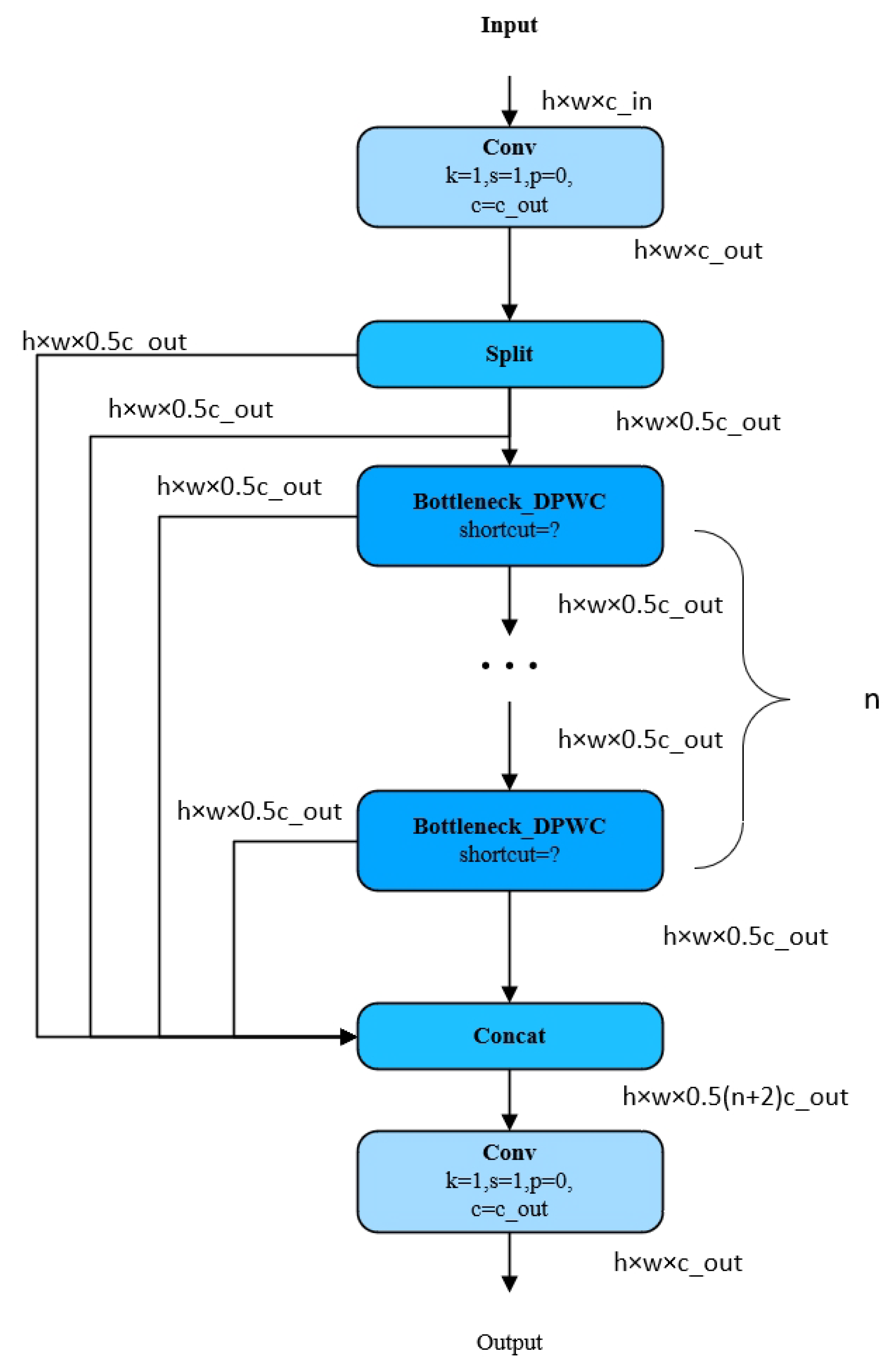
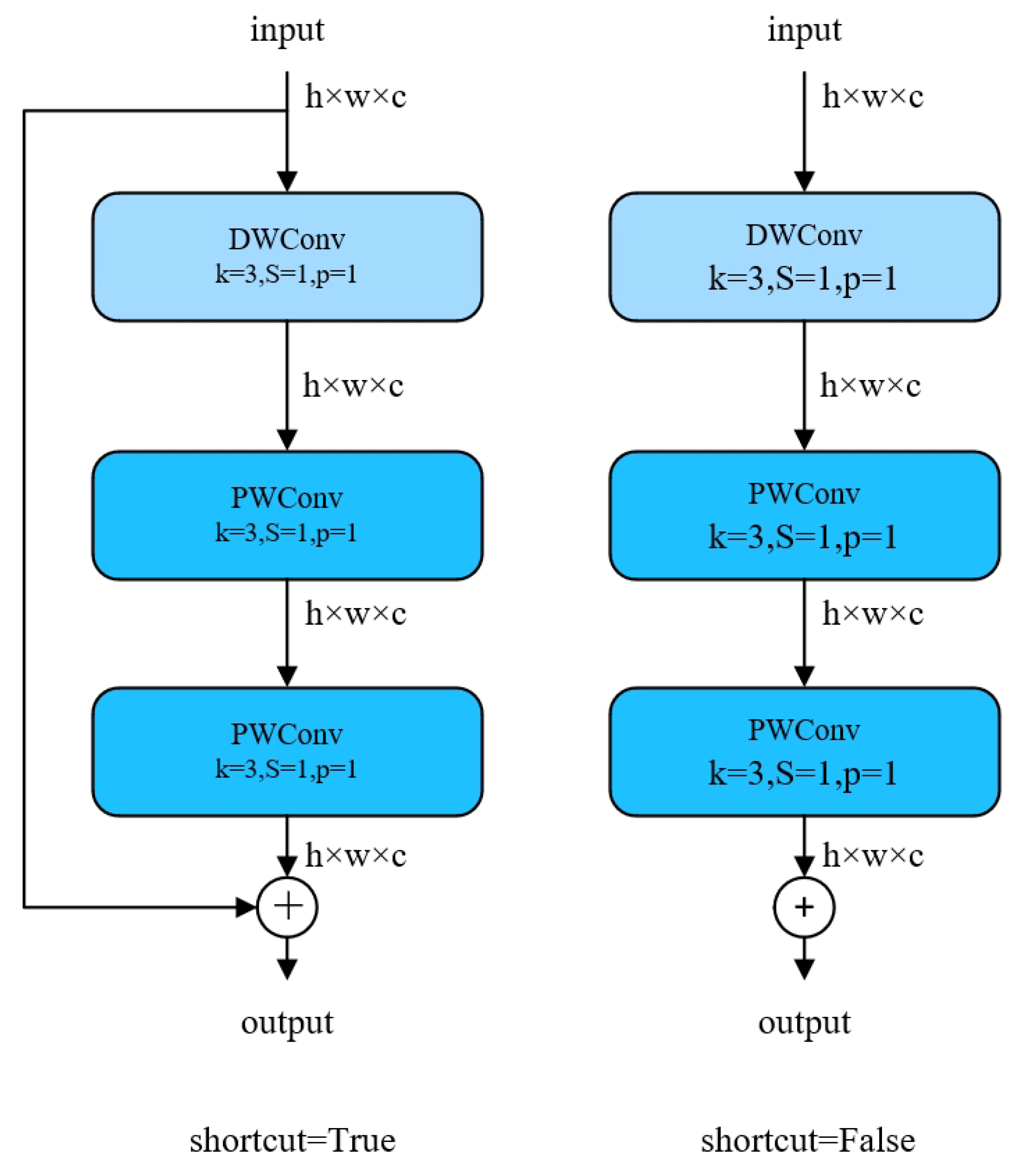
3.3. Gradient Flow Information Aggregation Block Col-Depth-Point Convolution (CDPWC)
4. Experiment
4.1. Experimental Environment and Parameter Settings
4.2. Elevator Passenger Abnormal Behavior Dataset
4.3. Public Behavior Recognition Dataset
- (1)
- UCF101 dataset
- (2)
- UCF24 dataset
- (3)
- hmdb51 dataset
- (4)
- Something-Something-v1 dataset
5. Results and Discussions
5.1. Evaluation Indicators
5.2. Comparative Experiment
5.3. Ablation Experiment
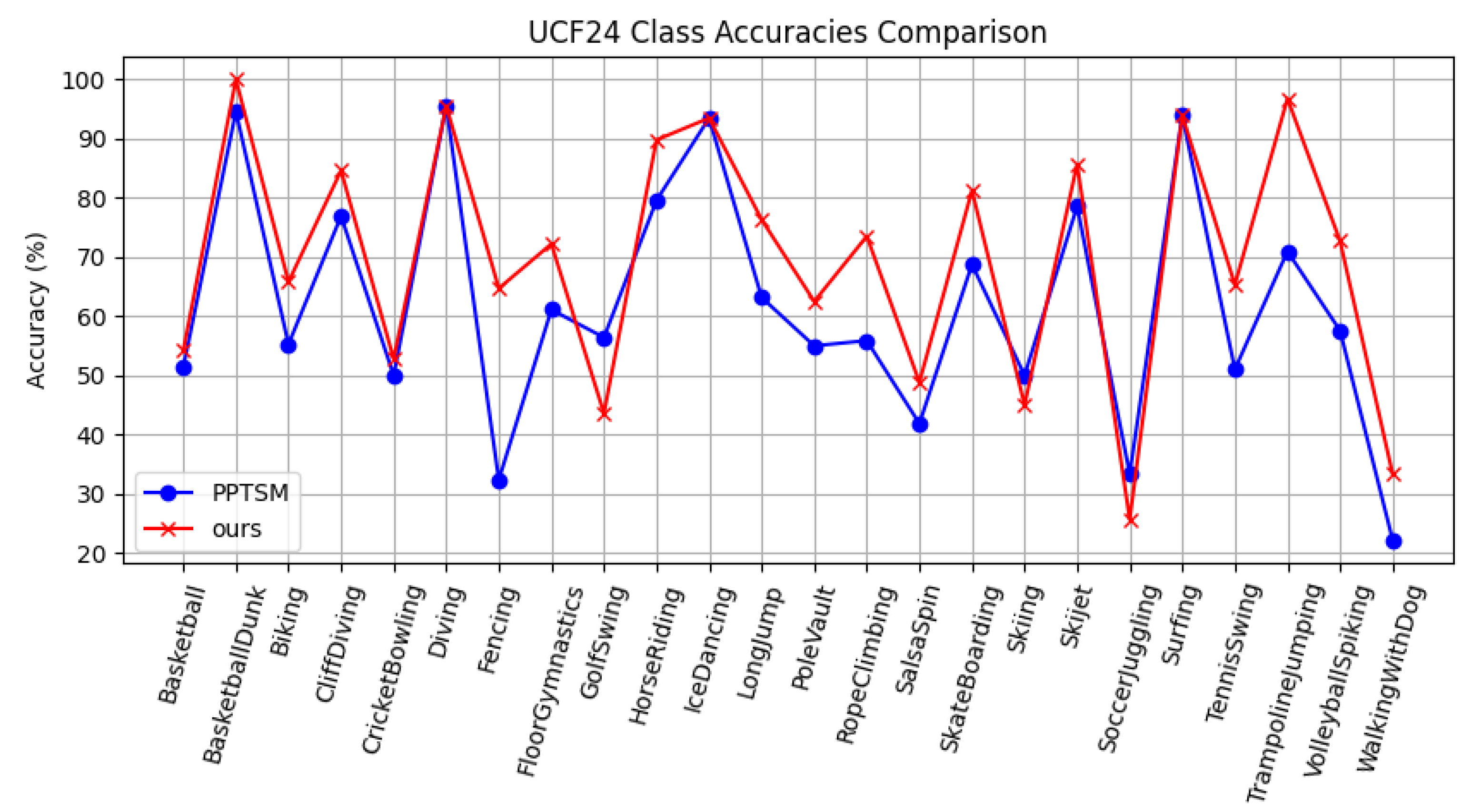
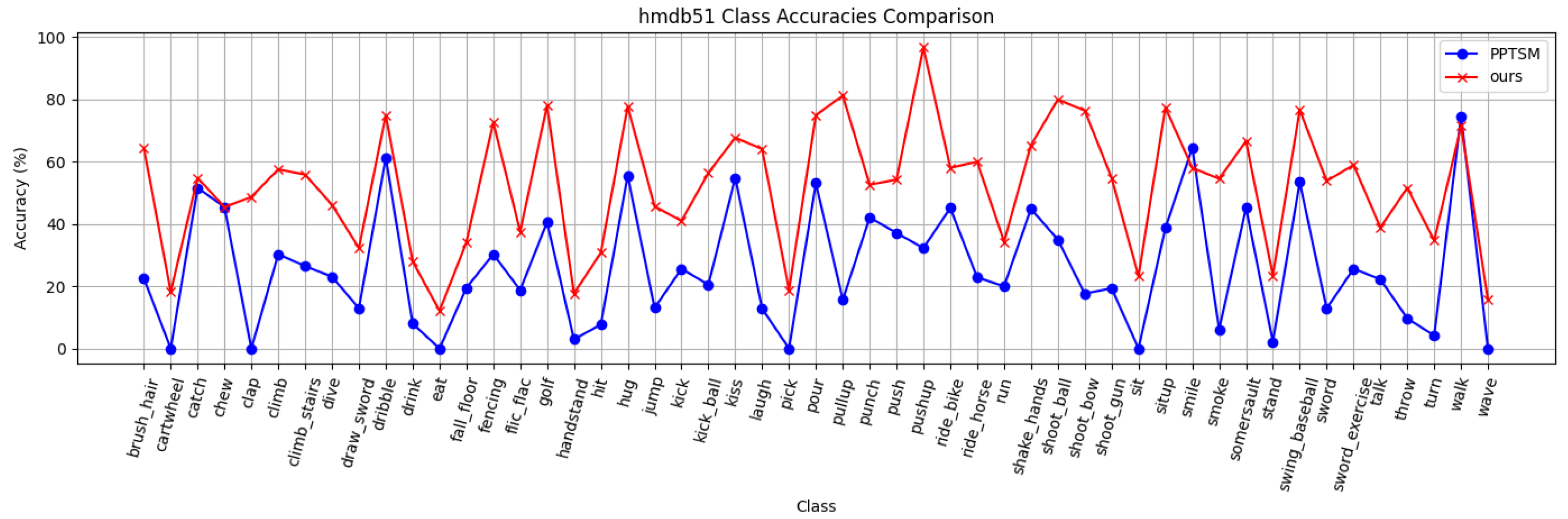
5.4. Visualization
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, H.; Zeng, M.; Xiong, Z.; Yang, F. Finding main causes of elevator accidents via multi-dimensional association rule in edge computing environment. China Commun. 2017, 14, 39–47. [Google Scholar] [CrossRef]
- Lan, S.; Gao, Y.; Jiang, S. Computer vision for system protection of elevators. J. Phys. Conf. Ser. 2021, 1848, 012156. [Google Scholar] [CrossRef]
- Prahlow, J.A.; Ashraf, Z.; Plaza, N.; Rogers, C.; Ferreira, P.; Fowler, D.R.; Blessing, M.M.; Wolf, D.A.; Graham, M.A.; Sandberg, K.; et al. Elevator-related deaths. J. Forensic Sci. 2020, 65, 823–832. [Google Scholar] [CrossRef] [PubMed]
- Prabha, B.; Shanker, N.; Priya, M.; Ganesh, E. A study on human abnormal activity detecting in intelligent video surveillance. In Proceedings of the International Conference on Signal Processing & Communication Engineering, Andhra Pradesh, India, 11–12 June 2021; AIP Publishing: Melville, NY, USA, 2024; Volume 2512. [Google Scholar] [CrossRef]
- Li, N.; Ma, L. Typical Elevator Accident Case: 2002–2016; China Labor and Social Security Publishing House: Beijing, China, 2019; p. 1. [Google Scholar]
- Zhu, Y.; Wang, Z. Real-time abnormal behavior detection in elevator. In Proceedings of the Intelligent Visual Surveillance: 4th Chinese Conference, IVS 2016, Proceedings 4, Beijing, China, 19 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 154–161. [Google Scholar] [CrossRef]
- Sun, Z.; Xu, B.; Wu, D.; Lu, M.; Cong, J. A real-time video surveillance and state detection approach for elevator cabs. In Proceedings of the 2019 International Conference on Control, Automation and Information Sciences (ICCAIS), IEEE, Chengdu, China, 23–26 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Liu, S.; An, Z.; Wang, N.; Bai, D.; Yu, X. Research on elevator passenger fall detection based on machine vision. In Proceedings of the 2021 3rd International Conference on Advances in Civil Engineering, Energy Resources and Environment Engineering, Qingdao, China, 28–30 May 2021; Volume 791, p. 012108. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar] [CrossRef]
- Lan, S.; Jiang, S.; Li, G. An elevator passenger behavior recognition method based on two-stream convolution neural network. In Proceedings of the 2021 4th International Symposium on Big Data and Applied Statistics (ISBDAS 2021), Dali, China, 21–23 May 2021; Volume 1955, p. 012089. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, Q.; Fan, Q.; Huang, X.; Wu, F.; Qi, J. Falling Behavior Detection System for Elevator Passengers Based on Deep Learning and Edge Computing. In Proceedings of the 2nd International Conference on Electronics Technology and Artificial Intelligence (ETAI 2023), Changsha, China, 18–20 August 2023; Volume 2644, p. 012012. [Google Scholar] [CrossRef]
- Shi, Y.; Guo, B.; Xu, Y.; Xu, Z.; Huang, J.; Lu, J.; Yao, D. Recognition of abnormal human behavior in elevators based on CNN. In Proceedings of the 2021 26th International Conference on Automation and Computing (ICAC), IEEE, Portsmouth, UK, 2–4 September 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Lin, J.; Gan, C.; Han, S. Tsm: Temporal shift module for efficient video understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7083–7093. [Google Scholar]
- Jiao, J.; Tang, Y.M.; Lin, K.Y.; Gao, Y.; Ma, A.J.; Wang, Y.; Zheng, W.S. Dilateformer: Multi-scale dilated transformer for visual recognition. IEEE Trans. Multimed. 2023, 25, 8906–8919. [Google Scholar] [CrossRef]
- Gall, J.; Lempitsky, V. Class-specific hough forests for object detection. In Decision Forests for Computer Vision and Medical Image Analysis; Springer: London, UK, 2013; pp. 143–157. [Google Scholar] [CrossRef]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 2014, 27, 568–576. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Ma, C.Y.; Chen, M.H.; Kira, Z.; AlRegib, G. TS-LSTM and temporal-inception: Exploiting spatiotemporal dynamics for activity recognition. Signal Process. Image Commun. 2019, 71, 76–87. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3d residual networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5533–5541. [Google Scholar] [CrossRef]
- Diba, A.; Fayyaz, M.; Sharma, V.; Karami, A.H.; Arzani, M.M.; Yousefzadeh, R.; Van Gool, L. Temporal 3d convnets: New architecture and transfer learning for video classification. arXiv 2017, arXiv:1711.08200. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6202–6211. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference On Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference On Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 12026–12035. [Google Scholar]
- Yin, M.; He, S.; Soomro, T.A.; Yuan, H. Efficient skeleton-based action recognition via multi-stream depthwise separable convolutional neural network. Expert Syst. Appl. 2023, 226, 120080. [Google Scholar] [CrossRef]
- Feng, S.; Niu, K.; Liang, Y.; Ju, Y. Research on elevator intelligent monitoring and grading warning system. In Proceedings of the 2021 IEEE International Conference on Computer Science, Electronic Information Engineering and Intelligent Control Technology (CEI), Fuzhou, China, 24–26 September 2021; pp. 145–148. [Google Scholar] [CrossRef]
- Zhao, J.; Yan, G. Passenger Flow Monitoring of Elevator Video Based on Computer Vision. In Proceedings of the 2019 Chinese Control And Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; pp. 2089–2094. [Google Scholar] [CrossRef]
- Wu, D.; Wu, S.; Zhao, Q.; Zhang, S.; Qi, J.; Hu, J.; Lin, B. Computer vision-based intelligent elevator information system for efficient demand-based operation and optimization. J. Build. Eng. 2024, 81, 108126. [Google Scholar] [CrossRef]
- Qi, Y.; Lou, P.; Yan, J.; Hu, J. Surveillance of abnormal behavior in elevators based on edge computing. In Proceedings of the 2019 International Conference on Image and Video Processing, and Artificial Intelligence, Shanghai, China, 23–25 August 2019; Volume 11321, p. 1132114. [Google Scholar] [CrossRef]
- Shu, G.; Fu, G.; Li, P.; Geng, H. Violent behavior detection based on SVM in the elevator. Int. J. Secur. Appl. 2014, 8, 31–40. [Google Scholar] [CrossRef]
- Jia, C.; Yi, W.; Wu, Y.; Huang, H.; Zhang, L.; Wu, L. Abnormal activity capture from passenger flow of elevator based on unsupervised learning and fine-grained multi-label recognition. arXiv 2020, arXiv:2006.15873. [Google Scholar] [CrossRef]
- Wang, Z.; Shen, Z.; Chen, J.; Li, J.; Wu, W. Recognition of Abnormal Behaviors of Elevator Passengers Based on Temporal Shift and Time Reinforcement Module. In Proceedings of the 2023 8th International Conference on Image, Vision and Computing (ICIVC), Dalian, China, 27–29 July 2023; pp. 670–675. [Google Scholar] [CrossRef]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the IEEE/CVF Conference On Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 558–567. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar] [CrossRef]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the 2011 International Conference on Computer Vision, IEEE, Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar] [CrossRef]
- Goyal, R.; Ebrahimi Kahou, S.; Michalski, V.; Materzynska, J.; Westphal, S.; Kim, H.; Haenel, V.; Fruend, I.; Yianilos, P.; Mueller-Freitag, M.; et al. The “something something” video database for learning and evaluating visual common sense. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5842–5850. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experimental Parameter | Setting |
|---|---|
| Batch size | 2 |
| Epochs | 80 |
| warmup_epochs | 10 |
| warmup_start_lr | 0.002 |
| cosine_base_lr | 0.001 |
| Optimizer | Momentum |
| Momentum | 0.9 |
| weight_decay | L2 |
| Methods | Top1 Acc | Parameter Size (M) | GFLOPs | Model Size (MB) |
|---|---|---|---|---|
| PPTSM | 0.85 | 23.585 | 34.809 | 90.02 |
| MoViNet | 0.63 | 1.907 | 61.029 | 21.73 |
| TSN | 0.8 | 23.571 | 32.876 | 89.73 |
| PP-TSN | 0.9 | 23.591 | 34.809 | 89.81 |
| TSM | 0.65 | 23.571 | 32.876 | 89.73 |
| Ours | 0.95 | 32.857 | 33.852 | 125.40 |
| Dataset | PPTSM | Ours |
|---|---|---|
| UCF24 | 0.6030 | 0.6710 |
| UCF101 (split1) | 0.4970 | 0.5348 |
| UCF101 (split2) | 0.4819 | 0.5302 |
| UCF101 (split3) | 0.4721 | 0.5695 |
| HMDB51 | 0.2778 | 0.4902 |
| Something-Something-v1 | 0.2380 | 0.2776 |
| Methods | Top1 Acc | Parameter Size (M) | GFLOPs | Model Size (MB) |
|---|---|---|---|---|
| baseline | 0.850 | 23.585 M | 34.809 | 90.02 |
| baseline+C2f | 0.900 | 21.070 M | 37.815 | 80.41 |
| baseline+CDPWC | 0.902 | 16.078 M | 27.276 | 61.39 |
| baseline+MSDA | 0.950 | 40.370 M | 41.385 | 154.03 |
| baseline+CDPWC+MSDA | 0.951 | 32.857 M | 33.852 | 125.34 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, J.; Sun, W.; Fang, Y.; Ye, N.; Yang, S.; Wu, J. A Model for Detecting Abnormal Elevator Passenger Behavior Based on Video Classification. Electronics 2024, 13, 2472. https://doi.org/10.3390/electronics13132472
Lei J, Sun W, Fang Y, Ye N, Yang S, Wu J. A Model for Detecting Abnormal Elevator Passenger Behavior Based on Video Classification. Electronics. 2024; 13(13):2472. https://doi.org/10.3390/electronics13132472
Chicago/Turabian StyleLei, Jingsheng, Wanfa Sun, Yuhao Fang, Ning Ye, Shengying Yang, and Jianfeng Wu. 2024. "A Model for Detecting Abnormal Elevator Passenger Behavior Based on Video Classification" Electronics 13, no. 13: 2472. https://doi.org/10.3390/electronics13132472
APA StyleLei, J., Sun, W., Fang, Y., Ye, N., Yang, S., & Wu, J. (2024). A Model for Detecting Abnormal Elevator Passenger Behavior Based on Video Classification. Electronics, 13(13), 2472. https://doi.org/10.3390/electronics13132472