



Intelligent Threat Detection—AI-Driven Analysis of Honeypot Data to Counter Cyber Threats



Abstract
1. Introduction
- Low-Interaction Honeypot: A low-interaction honeypot offers a plain vanilla TCP/IP service without access or with minimal access to the operating system. The adversary would not be able to interact with the honeypot, nor would the honeypots be capable of responding to the attackers in a way that captures their TTPs. The data yield from these honeypots is very low, but it could be easily analyzed to derive attacker information and use it to protect organizations’ critical infrastructure. The quality of the data, especially the intention of attackers, cannot be captured in this type of honeypot [7];
- High-Interaction Honeypot: A high-interaction honeypot is on the other side of the spectrum compared to a low-interaction honeypot. This type of honeypot gives attackers complete root access to the operating system. Instead of merely mimicking specific protocols or services, the attacker is given authentic systems to target, significantly reducing the chances of detecting that they are being redirected or monitored [6]. A High-Interaction honeypot successfully captures the attackers’ intentions and their TTPs. However, the data obtained from this type of honeypot are diverse, and the data analysis takes time to derive actionable insights for protecting organizations’ critical infrastructure;
- Medium-Interaction Honeypot: A medium-interaction honeypot operates between a low-interaction and high-interaction honeypot, sacrificing some operating system authenticity to facilitate easier data analysis [6]. Organizations often resort to medium-interaction honeypots as a compromise, unable to rely on low-interaction honeypots due to their low data quality and unable to timely analyze the wealth of information offered by high-interaction honeypots. However, these honeypots are easily identified by adversaries, leading to a decline in the quality of extracted data.
- Most LLM models today are trained using historical datasets [11]. They can only evaluate a command if the training data references it. Even if the datasets being trained are current, the models do not have a mechanism today to pre-emptively understand the event and classify it as malicious;
- LLM models do not have enough information about attacks within an organization, especially the hosted honeypots, to identify and classify an event as malicious;
- It is also possible to train new LLMs with the organization’s honeypot data. However, significant investments in cost and infrastructure are required to extract the relevant models while the honeypot data are still viable and usable from a security standpoint;
- Lastly, one way to derive a suitable classification of events in critical infrastructure (e.g., malicious, non-malicious) by an LLM is to provide data from the honeypot as a context for an LLM. However, the amount of data coming to the honeypot is significantly high. Providing this context might be impossible for the models where the amount of context exceeds the allowed number of tokens that can be used in a model. Further, as the context increases, the number of input tokens an LLM uses increases, making it cost-prohibitive and computationally expensive to leverage machine learning to identify malicious events.
Novelty of the Current Research
- Develop a novel machine learning model tailored to the security event classification domain. The model aims to efficiently parse data from high-interaction honeypots and accurately identify malicious events in critical infrastructure;
- Investigate the effectiveness of leveraging native data analysis techniques with machine learning algorithms to score realistic events extracted from high-interaction honeypots. The aim is to enhance the accuracy and efficiency of identifying malicious events in critical infrastructure while reducing the time of such detection;
- Design and implement a comprehensive data pipeline integrating various analysis steps, including data parsing from high-interaction honeypots, machine learning-based event classification, and the application of the Retrieval and Augmented Generating (RAG) model to seek out and identify malicious events in critical infrastructure actively. Evaluate the performance and effectiveness of the proposed approach through real-world attack simulations in a cloud-based environment.
2. Related Work
3. Methodology
- Attacker’s IP address;
- Attacker credentials;
- Protocol data;
- Timestamps of each event;
- Adversary commands.
3.1. Attacker IP Address
3.2. Attacker Credentials
3.3. Protocol Data
3.4. Timestamp Data
3.5. Adversary Commands
3.5.1. Command Retrieval Using LLM
3.5.2. Augmentation Using LLM
3.5.3. Generation Using LLM
3.6. Putting Model Together—Creating a Pipeline
3.6.1. Model Algorithm Implementation
3.6.2. Model Infrastructure Implementation
- System Similarity: The underlying honeypot and the critical infrastructure have similar setups. Both the underlying operating systems are Ubuntu 22.04 LTS Jammy Jellyfish. The software installed and the configuration settings are identical between both systems, preventing attackers from differentiating one system from another. Honeypot is configured to allow adversary login as any user and any password. Only one account credential used by critical infrastructure (account name: ubuntu) has a weak password (“abc123”);
- Attracting Adversaries: The AWS cloud hosts a combination of a honeypot network and critical infrastructure that authenticated and organization-approved users should use. Based on prior research, AWS was selected to host the honeypots because adversaries target cloud providers with the highest revenues compared to other cloud providers [19]. The key objective of the research is to maximize the attacks so that correlations to the honeypot data can happen at a shorter frequency;
- High-Interaction Setup: ContainerSSH (version 0.5) is the SSH proxy selected, allowing adversaries and system users to access the honeypot. ContainerSSH offers full SSH functionality to the end users [26] while acting as a proxy to record adversary and user commands. At the same time, the users receive a full-fledged shell into the host and can execute any command to their liking. The ContainerSSH proxy helps log all the SSH protocol-based interactions between adversaries and native infrastructure users;
- Availability Monitoring Detection and Correction: High-interaction honeypots expose the internals of the Operating System to adversaries. Due to the nature of the attacks executed on them, these honeypots are extremely fragile [27]. Therefore, additional infrastructure is needed to protect against service availability concerns. For this reason, Kubernetes service leveraging Kops (version 1.28.4) was selected to host the honeypot containers. Appropriate health checks are configured in Kubernetes to recycle the containers each time the health check results are degraded;
- Concurrent Log Storage: Logs from honeypots and critical infrastructure are quickly transmitted to an offsite S3 bucket (outside the VPC exposed to the users). Every session in both infrastructures is logged in the binary format through the ContainerSSH audit log. This binary format allows for the storage of all the SSH protocol communications and commands executed by the end user. The parity of the logging formats helps cross-correlate data between the two architectures. Further concurrent logging to offsite bucket helps ensure availability of the logs in the event of denial of service on the honeypot;
- Time Window Implementation: The Lambda service automatically parses all the logs from the S3 buckets and extracts the relevant information for the log analysis. The parsed honeypot data are stored in DynamoDB tables with an automated expiration TTL for each record. DynamoDB automatically deletes old records greater than an elapsed TTL value [28]. The current TTL selected for this research is 7 days. Hence, a current log record from critical infrastructure would be matched against honeypot logs from the past seven days;
- Machine Learning Analysis Compute: For the current research, the embedding model selected is “Salesforce/SFR-Embedding-Mistral”, and the LLM selected is “gpt-4-turbo”. The embedding model requires a heavy GPU for execution, and the code snippets need an Nvidia A100 GPU for smooth execution. Since the cost of constantly running the Nvidia A100 GPU 24 × 7 is gigantic, a scheduler is used to launch the servers and code once every 24 h to parse the commands in the timeframe selected. The servers then automatically shut down after the parsing for the day is complete. Since the parsing happens daily, it would take one day to identify any malicious activity in servers using this model. Please note that one can select smaller models instead of “Salesforce/SFR-Embedding-Mistral” for the analysis.
3.6.3. Experimental Setup
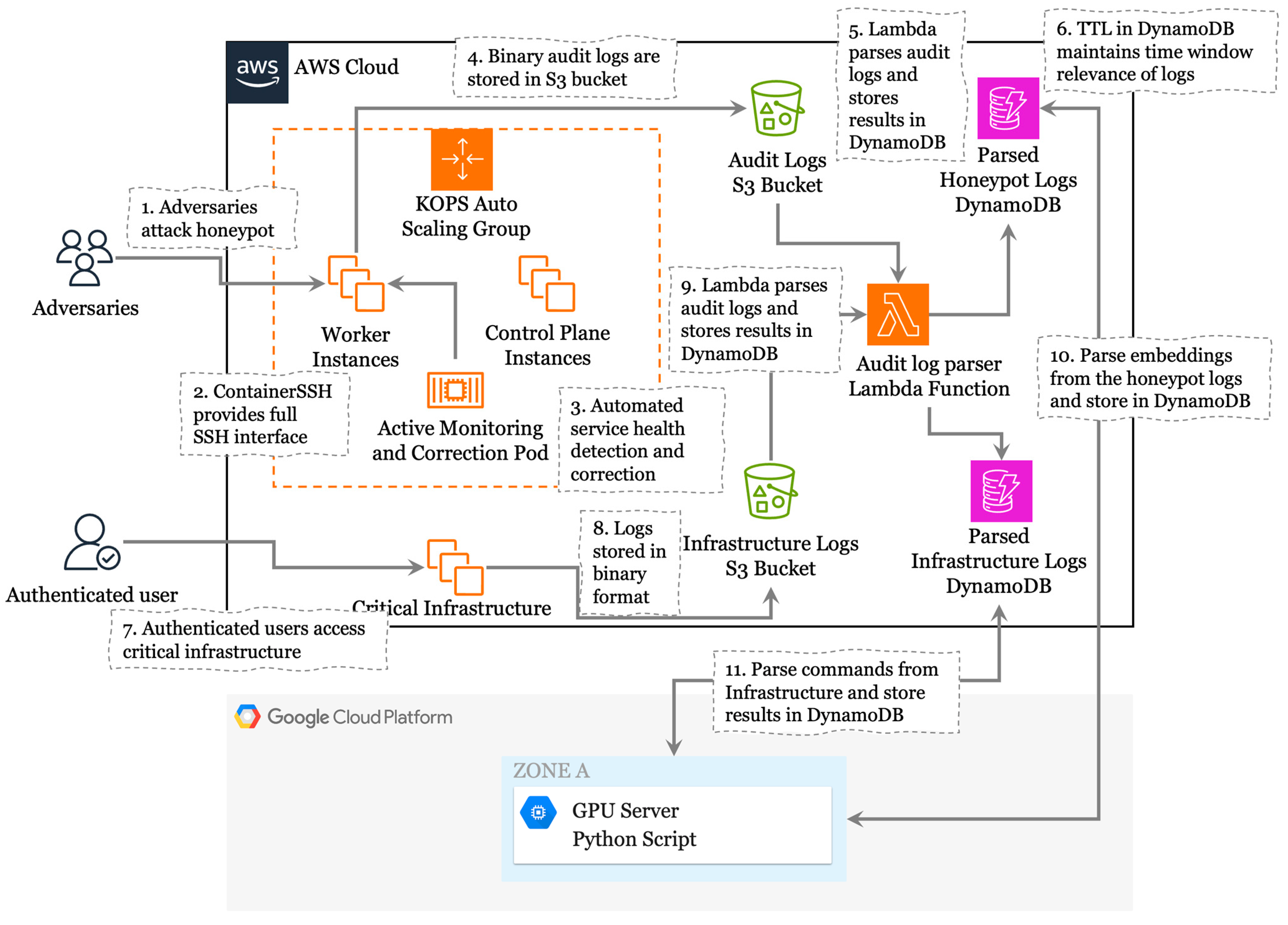
- The experimental setup, depicted in Figure 7, was implemented in both AWS and GCP environments. Kops was employed to automatically create the necessary infrastructure within the AWS account. The Kubernetes API server was configured to be private and accessible only through a bastion host managed by Kops. Kubernetes was deployed on two instances: one dedicated to Kubernetes management and monitoring APIs and the other hosting containers for exploitation purposes. Monitoring capabilities within the Kubernetes service were enhanced using Grafana, Alert Manager, and Prometheus solutions. Alerts were configured to notify administrators if the CPU load on the EC2 instances exceeded 80% for a continuous period of 15 min.
- Kubernetes namespaces were created to host the SSH honeypot solution. The first namespace, named ContainerSSHAdmin, hosted the container SSH solution and its supporting infrastructure. The second namespace, named AdversaryTargets, hosted the target containers for SSH interactions. The containerized SSH service was created using Kubernetes deployment YAML files. Custom code was developed for the authentication service within ContainerSSH, allowing adversaries to access the high-interaction honeypot with any password or private key. The overall solution comprised two containers: one running ContainerSSH code acting as a proxy for SSH connections from adversaries and the other hosting the authentication service that accepted credentials submitted by the adversaries. The authentication service, invoked by ContainerSSH, created a container in the AdversaryTargets namespace for each successful authentication. Each successful SSH connection by an adversary instantiated a new container in the AdversaryTargets namespace, where the adversary obtained root privileges within the SSH session. To mimic critical infrastructure within the organization, Internet access from the SSH session was restricted.
- The ContainerSSH solution required access to S3 buckets, facilitated using an AWS access key and secret key pair securely stored within the ContainerSSH deployment. This setup ensured a robust and monitored environment for experimentation and analysis. Lambda functions were deployed on the AWS accounts to automatically parse logs arriving in the S3 buckets and write them to a new location within the same bucket. GCP servers equipped with A100 GPUs were deployed to analyze the logs and utilize them for LLM analysis. Scripts within Google Colab automatically downloaded parsed logs from the AWS S3 bucket and performed machine learning analysis leveraging the GPUs. Additionally, a Google Colab environment with A100 GPUs was employed for manual analysis and monitoring of the logs. Figure 8 depicts overall dataflow diagram of the setup.
- This comprehensive setup provided a secure and efficient infrastructure for conducting detailed experiments and analyses in a controlled environment. The honeypot and critical infrastructure were kept on the Internet without firewall controls for two weeks between 26 April 2024 and 3 May 2024. The availability of both systems during this time was observed to be 100%.
4. Results and Discussion
4.1. IP Address-Based Analytics
4.2. Credential-Based Analytics
4.3. Session Time-Based Analysis
4.4. Command Analysis
4.5. Identifying Malicious Command Execution in Critical Infrastructure
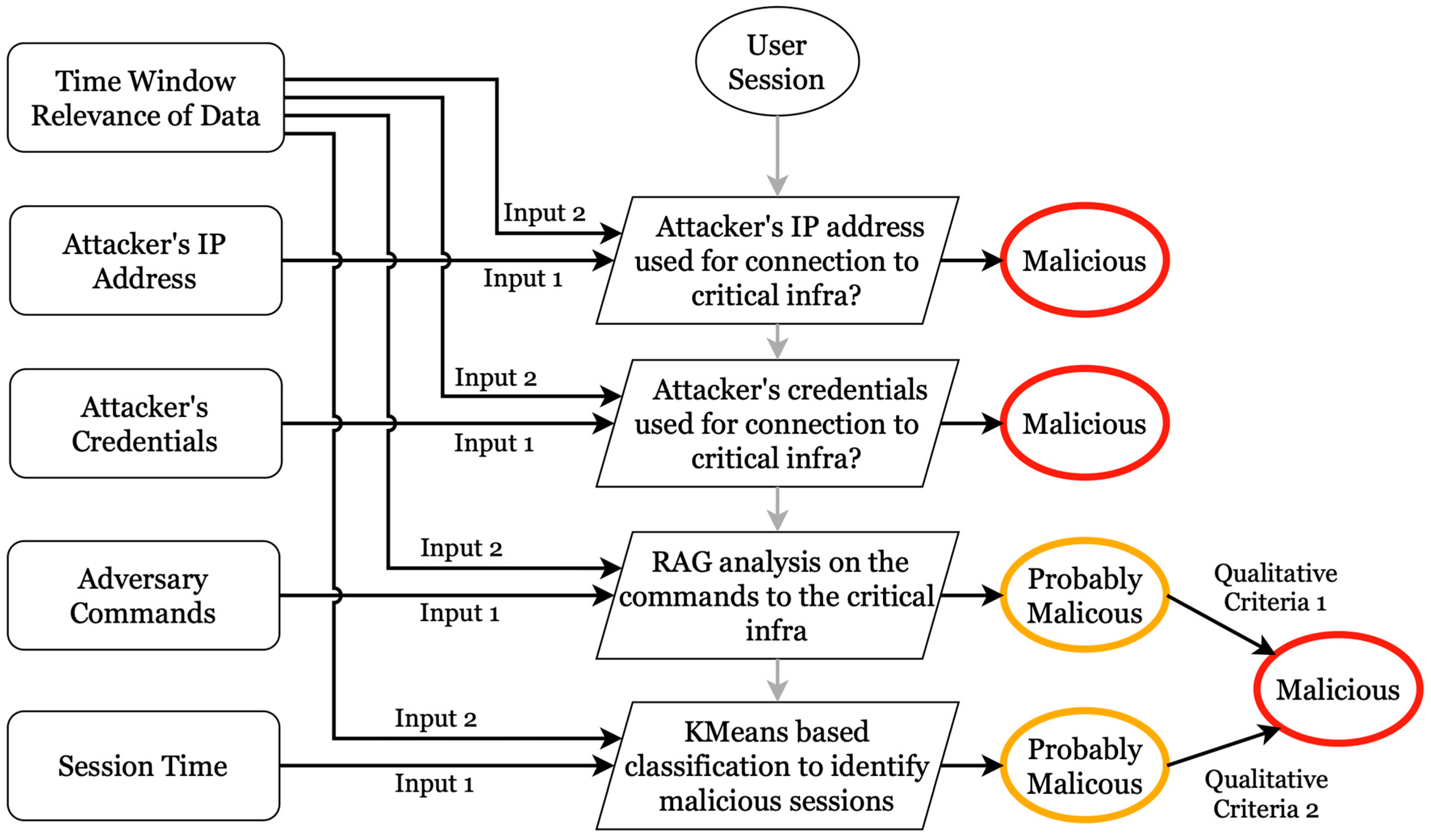
- A successful connection and login to critical infrastructure from a known attacker’s IP address recorded in the honeypot during the observation time window could be deemed malicious;
- A successful login into critical infrastructure leveraging credentials used by adversaries in the honeypot during the observation window could be deemed malicious;
- Table 12 presents the qualitative weights for identifying malicious command execution between session time and command analysis.
5. Remarks and Conclusions
- Two of the parameters, the adversary’s IP address and credentials, are direct indicators of compromise. Essentially, if the connections to the critical infrastructure originate from previously recorded adversary IP addresses or leverage one of the attacker’s compromised credentials, the activity in the critical infrastructure can be deemed malicious;
- K-Means clustering has proven to be an effective method for analyzing session time on honeypot servers and critical infrastructure. Attackers spend minimal time executing commands to gather information and establish persistence in the honeypot [19]. K-Means clustering helps derive clusters that identify honeypot sessions against typical server sessions with an excellent silhouette score and F1 score;
- The Retrieval and Augmented Generation (RAG) method offers a mechanism for identifying if commands executed in critical infrastructure are malicious, leveraging the information from existing commands executed in a honeypot infrastructure. Further, the LLM processing also classifies a command executed in the critical infrastructure into various MITRE ATT&CK categories;
- A qualitative combination of K-Means analysis and RAG analysis using language model-based techniques helps derive another avenue for categorizing events in critical infrastructure as malicious.
Further Research and Next Steps
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rising Cyber Threats Pose Serious Concerns for Financial Stability. Available online: https://www.imf.org/en/Blogs/Articles/2024/04/09/rising-cyber-threats-pose-serious-concerns-for-financial-stability (accessed on 24 April 2024).
- Data Breach Action Guide. Available online: https://www.ibm.com/reports/data-breach-action-guide (accessed on 24 April 2024).
- COVID-19 Continues to Create a Larger Surface Area for Cyberattacks. Available online: https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/docs/vmwcb-report-covid-19-continues-to-create-a-larger-surface-area-for-cyberattacks.pdf (accessed on 24 April 2024).
- Impact of COVID-19 on Cybersecurity. Available online: https://www2.deloitte.com/ch/en/pages/risk/articles/impact-covid-cybersecurity.html (accessed on 24 April 2024).
- What’s the Difference Between a High Interaction Honeypot and a Low Interaction Honeypot? Available online: https://www.akamai.com/blog/security/high-interaction-honeypot-versus-low-interaction-honeypot-comparison (accessed on 24 April 2024).
- High Interaction Honeypot. Available online: https://www.sciencedirect.com/topics/computer-science/high-interaction-honeypot (accessed on 24 April 2024).
- Ilg, N.; Duplys, P.; Sisejkovic, D.; Menth, M. Survey of Contemporary Open-Source Honeypots, frameworks, and tools. J. Netw. Comput. Appl. 2023, 220, 103737. [Google Scholar] [CrossRef]
- 2023 Honeypotting in the Cloud Report: Attackers Discover and Weaponize Exposed Cloud Assets and Secrets in Minutes. Available online: https://orca.security/resources/blog/2023-honeypotting-in-the-cloud-report/ (accessed on 24 April 2024).
- Hacking With GPT-4: Generating Obfuscated Bash Commands. Available online: https://www.linkedin.com/pulse/hacking-gpt-4-generating-obfuscated-bash-commands-jonathan-todd/ (accessed on 24 April 2024).
- Generative AI to Become a $1.3 Trillion Market by 2032, Research Finds. Available online: https://www.bloomberg.com/company/press/generative-ai-to-become-a-1-3-trillion-market-by-2032-research-finds/ (accessed on 24 April 2024).
- Liu, Y.; Cao, J.; Liu, C.; Ding, K.; Jin, L. Datasets for Large Language Models: A Comprehensive Survey. arXiv 2024, arXiv:2402.18041. [Google Scholar] [CrossRef]
- Top Threats You Need to Know to Defend Your Cloud Environment. Available online: https://www.crowdstrike.com/blog/adversaries-increasingly-target-cloud-environments/ (accessed on 24 April 2024).
- No, G.; Lee, Y.; Kang, H.; Kang, P. RAPID: Training-free Retrieval-based Log Anomaly Detection with PLM considering Token-level information. arXiv 2023, arXiv:2311.05160. [Google Scholar] [CrossRef]
- Karlsen, E.; Luo, X.; Zincir-Heywood, N.; Heywood, M. Benchmarking Large Language Models for Log Analysis, Security, and Interpretation. arXiv 2023, arXiv:2311.14519. [Google Scholar] [CrossRef]
- Guu, K.; Lee, K.; Tung, Z.; Pasupat, P.; Chang, M. Retrieval Augmented Language Model Pre-training. In Proceedings of the 37th International Conference on Machine Learning, Vienna, Austria, 13–18 July 2020. [Google Scholar] [CrossRef]
- Yang, X.; Yuan, J.; Yang, H.; Kong, Y.; Zhang, H.; Zhao, J. A Highly Interactive Honeypot-Based Approach to Network Threat Management. Future Internet 2023, 15, 127. [Google Scholar] [CrossRef]
- Szabó, Z.; Bilicki, V. A New Approach to Web Application Security: Utilizing GPT Language Models for Source Code Inspection. Future Internet 2023, 15, 326. [Google Scholar] [CrossRef]
- Wang, B.-X.; Chen, J.-L.; Yu, C.-L. An AI-Powered Network Threat Detection System. IEEE Access 2022, 10, 54029–54037. [Google Scholar] [CrossRef]
- Lanka, P.; Varol, C.; Burns, K.; Shashidhar, N. Magnets to Adversaries—An Analysis of the Attacks on Public Cloud Servers. Electronics 2023, 12, 4493. [Google Scholar] [CrossRef]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.T.; Rocktäschel, T.; et al. Retrieval-augmented Generation for Knowledge-intensive NLP Tasks. Adv. Neural Inf. Process Sys. 2020, 33, 9459–9474. [Google Scholar]
- Amatriain, X. Prompt design and engineering: Introduction and Advanced Methods. arXiv 2024, arXiv:2401.14423. [Google Scholar] [CrossRef]
- Bashlex—Python Parser for Bash. Available online: https://github.com/idank/bashlex (accessed on 24 April 2024).
- Overall MTEB English Leaderboard. Available online: https://huggingface.co/spaces/mteb/leaderboard (accessed on 24 April 2024).
- SFR-Embedding-Mistral: Enhance Text Retrieval with Transfer Learning. Available online: https://blog.salesforceairesearch.com/sfr-embedded-mistral/ (accessed on 24 April 2024).
- Enterprise Matrix. Available online: https://attack.mitre.org/versions/v15/matrices/enterprise/ (accessed on 24 April 2024).
- ContainerSSH: Launch Containers on Demand. Available online: https://containerssh.io/v0.5/getting-started/ (accessed on 24 April 2024).
- Jiang, X.; Wang, X. “Out-of-the-Box” Monitoring of VM-Based High-Interaction Honeypots. Adv. Neural Inf. Process Syst. 2007, 4637, 198–218. [Google Scholar] [CrossRef] [PubMed]
- Amazon DynamoDB Developer Guide—Time to Live (TTL). Available online: https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/TTL.html (accessed on 24 April 2024).
- One Of The 32 Million With A RockYou Account? You May Want To Change All Your Passwords. Like Now. Available online: https://techcrunch.com/2009/12/14/rockyou-hacked/ (accessed on 24 April 2024).
- Touch, S.; Colin, J.-N. A Comparison of an Adaptive Self-Guarded Honeypot with Conventional Honeypots. Appl. Sci. 2022, 12, 5224. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SSH Message Type | Source | Destination | Payload |
|---|---|---|---|
| Connect | Client | Server | {RemoteAddr: “183.81.169.238”, Country: “HK”} Timestamp: 1715108300 |
| Password authentication | Client | Server | Username: “root”, Password: “0” Timestamp: 1715108300 |
| Password authentication successful | Server | Client | Username: “root”, Authenticated: “true” Timestamp: 1715108302 |
| New channel successful | Server | Client | New channel created Timestamp: 1715108302 |
| Execute program | Client | Server | Program: apt update && apt install sudo curl -y && sudo useradd -m -p $(openssl passwd -1 DPdMYqVR) system && sudo usermod -aG sudo system Timestamp: 1715108302 |
| SSH I/O | Server | Client | Program output: WARNING: apt does not have a stable CLI interface. Use with caution in scripts.\n …Timestamp: 1715108310 |
| Execute program | Client | Server | Program: lscpu && echo -e DPdMYqVR\nDPdMYqVR|passwd && curl https://ipinfo.io/org --insecure -s && free -h && apt Timestamp: 1715108310 |
| SSH I/O | Server | Client | Message: Architecture: x86_64\n
…. Timestamp: 1715108322 |
| Disconnect | Client | Server | Client Disconnect Timestamp: 1715108322 |
| Data Field | Type of Data | Fit for Machine Learning | Explanation/Behavior |
|---|---|---|---|
| Attacker IP Address | Identification Data | No | IP addresses in honeypots are used to identify malicious actors from the Internet. |
| Attacker Credentials | Identification Data | No | Credentials from attackers usually represent the dataset these adversaries use to perform brute force attacks and do not provide any benefit for learning. |
| Connection Creation Attempts | Protocol Data | No | Different types of protocols offer different methodologies for connection creation. Connection creation attempts are also influenced by how stable the underlying connection to the honeypot is. These data would not provide any benefit for learning. |
| Commands Executed | Attacker Commands | Yes | Commands executed by the attacker would provide a glimpse into their TTPs. Learning from these data would aid in malicious activity detection. |
| Total Execution Time | Activity Data/Numeric Data | Yes | Attackers are on a constant lookout for externally exposed services and strongly focus on establishing persistence in the cloud [19]. These data can be used for machine learning classification to identify malicious activity. |
| Technique Used | Prompt Additional Instruction |
|---|---|
| Role Playing | You are an advanced Linux bash interpreter. You will be given explicit commands that are executed in a bash shell in a honeypot server. |
| Setting Expectations for Input | These bash shell commands were executed by malicious users. All the bash commands must be assumed to be malicious. |
| Setting Expectations for Input | You would need to interpret the malicious bash commands and identify the tactics used by the malicious user |
| Setting Expectations for Output | The output of your analysis must be list of bullet points that has verbose description of what bash commands are doing. |
| Setting Expectations for Output | The output must be in plain English, showing details of what command does without any reference to the command or its arguments. |
| Teaching Algorithm in Prompt | For example, in cases of sample input “ls/”, the output must be “This command lists the directories and files in the filesystem root of the server in a non-recursive manner. The default implementation of the command does not show the hidden directories and files in the server.” |
| Chain of Thought (CoT) | Take time before you respond. Please proceed step by step and think this through thoroughly for accuracy. |
| Generate Different Options | Please explore multiple potential interpretations and implications of each command to ensure a comprehensive and accurate analysis. |
| Setting Expectations for Output | Please provide no greetings or offer help toward the end. Please provide the responses in bullet list of sentences. |
| Command Used | LLM Output Using Prompt in Table 3 |
|---|---|
| cat/etc/passwd|grep ubuntu |
|
| PASSWDFILE = /etc/passwd; cat $PASSWDFILE|grep ubuntu |
|
| CATCMD = cat; eval “$CATCMD/etc/passwd”|grep ubuntu |
|
| cat../../../../../../../../etc/passwd|grep ubuntu |
|
| echo “$(</etc/passwd)”|grep ubuntu |
|
| Command Used | Identified Entities |
|---|---|
| cat/etc/passwd|grep ubuntu | “/etc/passwd”, “ubuntu” |
| PASSWDFILE = /etc/passwd; cat $PASSWDFILE|grep ubuntu | “/etc/passwd”, “ubuntu” |
| ps aux|grep ld-musl-x86|grep -v grep|grep -v systemd-networkd|grep -v ld-musl-x86_64|grep -v rsyslogd|wc -l | “ld-musl-x86”, “systemd-networkd”, “ld-musl-x86_64”, “rsyslogd” |
| kill -9 $(ps aux|grep zzh|grep -v grep|awk ‘{print $2}’) | “zzh” |
| scp -t/tmp/iy6ii01nig469bn3a5ce66a8t4 | “iy6ii01nig469bn3a5ce66a8t4” |
| echo -e \“C9QXng3P\\nC9QXng3P\”|passwd | “C9QXng3P” |
| curl https://ipinfo.io/org --insecure -s | “ipinfo.io”, “org” |
| Query | Technique Used | Prompt Additional Instruction |
|---|---|---|
| Determine if the user interaction in critical interaction is malicious | Role Playing | You are a security monitoring expert |
| Setting Expectations for Input | You would be given a bulleted list of command descriptions that adversaries have used against our organization’s honeypot. These are called attacker TTPs | |
| Setting Expectations for Output | For a given query, you need to provide output that indicates whether the query command description matches any of the attacker’s TTPs | |
| Teaching Algorithm in Prompt | For example, if the query description matches the attacker TTPs in the description, return with value of True. Otherwise, return with value of False | |
| Setting Expectations for Output | Please provide no greetings or offer help toward the end. Please provide the responses in either True or False | |
| Determine the ATT&CK category | Role Playing | You are a security monitoring expert |
| Setting Expectations for Input | You would be given a bulleted list of command descriptions that adversaries have used against our organization’s honeypot. These are called attacker TTPs | |
| Setting Expectations for Output | For a given query, leverage the provided TTPs and categorize the query into one of the ATT&CK categories—“Reconnaissance”, “Persistence”, “Impact”, “Exfiltration”, and “Command and Control” | |
| Setting Expectations for Output | Please provide no greetings or offer help toward the end. Please provide the responses as a single word with category name |
| Data Field | Honeypot Sessions (Automated) | Infrastructure Sessions (Manual) |
|---|---|---|
| Total number (n) | 345 | 62 |
| Maximum session time (seconds) | 593 | 1498 |
| Maximum commands in session (x) | 552 | 1802 |
| Minimum session time (seconds) | 1 | 224 |
| Minimum commands in session | 1 | 80 |
| Actual Values | |||
|---|---|---|---|
| Positive | Negative | ||
| Predicted Values | Positive | 48 | 3 |
| Negative | 7 | 1899 | |
| Variable Normalized Command Template | Example Command | # Repeats |
|---|---|---|
| echo -e STRING | echo -e “\x6F\x6B” | 27,368 |
| rm -rf .bash_history | rm -rf .bash_history | 4080 |
| kill -9 $(ps aux|grep STRING|grep -v grep|awk ‘{print $2}’) | kill -9 $(ps aux|grep xrx|grep -v grep|awk ‘{print $2}’) | 2832 |
| rm -rf STRING | rm -rf .bash_history | 3060 |
| touch STRING | touch secure | 1700 |
| unset STRING | unset HISTFILE | 1020 |
| uname -a | uname -a | 381 |
| history -n | history -n | 340 |
| nohup sh STRING & | nohup sh/tmp/.ssh/b & | 340 |
| cat > STRING | cat > systemd-net | 318 |
| echo -e STRING | echo -e “\x6F\x6B” | 27,368 |
| rm -rf .bash_history | rm -rf .bash_history | 4080 |
| Commands from Critical Infrastructure | Top 3 Matched Commands | Top 3 Cosine Similarity Scores |
|---|---|---|
| tac/etc/passwd|grep ubuntu | 1. cat/etc/passwd|grep ubuntu | 0.9080 |
| 2. grep ubuntu/etc/passwd | 0.8951 | |
| 3. ul/etc/passwd|grep ubuntu | 0.8661 | |
| pip install requests | 1. apt install sudo curl -y | 0.7136 |
| 2. python -c “print(open(‘/etc/passwd’,‘r’).read())”|grep ubuntu | 0.6556 | |
| 3. curl https://ipinfo.io/org --insecure -s | 0.6404 | |
| id ubuntu | 1. id -u ubuntu | 0.8081 |
| 2. getent passwd ubuntu | 0.7995 | |
| 3. cat/etc/passwd|grep ubuntu | 0.7720 | |
| ps aux | 1. ps|grep ‘[Mm]iner’ | 0.7525 |
| 2. ps -ef|grep ‘[Mm]iner’ | 0.7402 | |
| 3. uname -a | 0.7236 | |
| curl https://virustotal.com/api | 1. curl https://ipinfo.io/org --insecure -s | 0.7507 |
| 2. CATCMD = cat; eval “$CATCMD/etc/passwd | 0.6875 | |
| 3. ./systemd-net --opencl --cuda -o 142.202.242.45:80 -u 43UdTAJHLU2jN3knid9Vq1GB625ZCKhZiZVDZ8Mi PUWQYXbq9QmmAq79BoFhqoLhoygCLsBue6gpoXB kSw5GVW7ZGrXyauv -p xxx -k --tls --tls-fingerprint 420c7850e09b7c0bdcf748a7da9eb3647daf8515718f36d 9ccfdd6b9ff834b14 --donate-level 1 --background | 0.6776 |
| Commands from Critical Infrastructure | Top Matched Commands with Cosine Similarity Score > 0.75 | LLM—Is It Similar to a Malicious One? | LLM—Identify TTP Category |
|---|---|---|---|
| tac/etc/passwd|grep ubuntu | 1. cat/etc/passwd|grep ubuntu 2. grep ubuntu/etc/passwd 3. ul/etc/passwd|grep ubuntu | TRUE | Information Gathering |
| pip install requests | NA | NA (Threshold cosine similarity not met) | NA (Threshold cosine similarity not met) |
| id ubuntu | 1. id -u ubuntu 2. getent passwd ubuntu 3. cat/etc/passwd|grep ubuntu | TRUE | Information Gathering |
| ps aux | 1. ps|grep ‘[Mm]iner’ | TRUE | Information Gathering |
| curl https://virustotal.com/api | 1. curl https://ipinfo.io/org --insecure -s | FALSE | None |
| LLM Command Match | LLM Category | K-Means Analysis | Final Decision |
|---|---|---|---|
| TRUE | Reconnaissance | TRUE | Malicious |
| TRUE | Persistence | TRUE | Malicious |
| TRUE | Impact | TRUE | Malicious |
| TRUE | Exfiltration | TRUE | Malicious |
| TRUE | Command and Control | TRUE | Malicious |
| TRUE | Reconnaissance | FALSE | Benign |
| TRUE | Persistence | FALSE | Benign |
| TRUE | Impact | FALSE | Benign |
| TRUE | Exfiltration | FALSE | Malicious |
| TRUE | Command and Control | FALSE | Malicious |
| FALSE | ANY | TRUE | Benign |
| FALSE | ANY | FALSE | Benign |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lanka, P.; Gupta, K.; Varol, C. Intelligent Threat Detection—AI-Driven Analysis of Honeypot Data to Counter Cyber Threats. Electronics 2024, 13, 2465. https://doi.org/10.3390/electronics13132465
Lanka P, Gupta K, Varol C. Intelligent Threat Detection—AI-Driven Analysis of Honeypot Data to Counter Cyber Threats. Electronics. 2024; 13(13):2465. https://doi.org/10.3390/electronics13132465
Chicago/Turabian StyleLanka, Phani, Khushi Gupta, and Cihan Varol. 2024. "Intelligent Threat Detection—AI-Driven Analysis of Honeypot Data to Counter Cyber Threats" Electronics 13, no. 13: 2465. https://doi.org/10.3390/electronics13132465
APA StyleLanka, P., Gupta, K., & Varol, C. (2024). Intelligent Threat Detection—AI-Driven Analysis of Honeypot Data to Counter Cyber Threats. Electronics, 13(13), 2465. https://doi.org/10.3390/electronics13132465