
Interpretability and Transparency of Machine Learning in File Fragment Analysis with Explainable Artificial Intelligence


Abstract
1. Introduction
- Evaluate the performance and robustness of machine learning models in file fragment classification.
- Improve the transparency and interpretability of these models, ensuring a clear understanding of their decision-making processes.
- Foster greater trust and adoption of machine learning models in critical domains by enhancing their reliability and accountability.
2. Related Work
2.1. General XAI
2.2. XAI in Healthcare
2.3. XAI in Cybersecurity
2.4. XAI in Digital Forensics
2.5. Gap in the Literature
3. Preliminary
3.1. Explainability vs. Interpretability
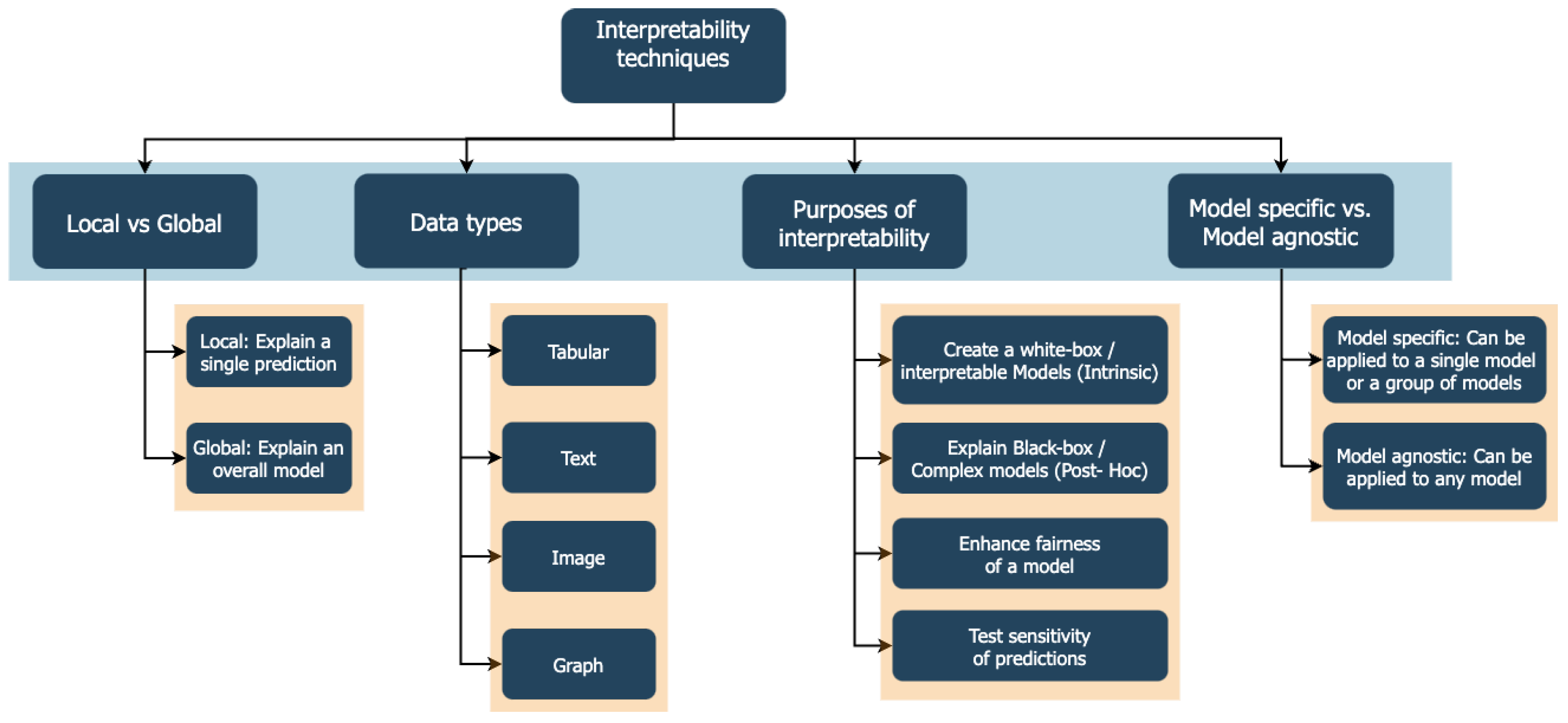
3.2. Interpretability Techniques
- Local interpretation: An interpretation of a single data point is called a local interpretation. For example, why does a model predict that a particular borrower would default? This is an example of a local interpretation.
- Global interpretation: This provides an overall understanding of how a model makes decisions across all instances. It helps to understand the model’s behavior in a broader sense, making it easier to grasp the underlying patterns or features that the model uses for its decisions.
- Intrinsic explanation: This technique involves inherently interpretable models, such as linear regression or decision trees, where the decision-making process is transparent and directly understandable. Hence, there is no need for any post-analysis.
- Post-hoc explanation: This technique explains ML models after training. It is used to interpret complex models like neural networks which are not intrinsically interpretable. It extracts correlations between features and predictions.
- Model-specific: It is tailored to specific types of models, leveraging their unique structures and properties for interpretation, such as feature importance in random forests.
- Model agnostic: Model-agnostic methods can be applied to any machine learning model, regardless of its internal workings, providing flexibility in interpreting various types of models without needing to understand their specifics.
3.3. Limitations of XAI
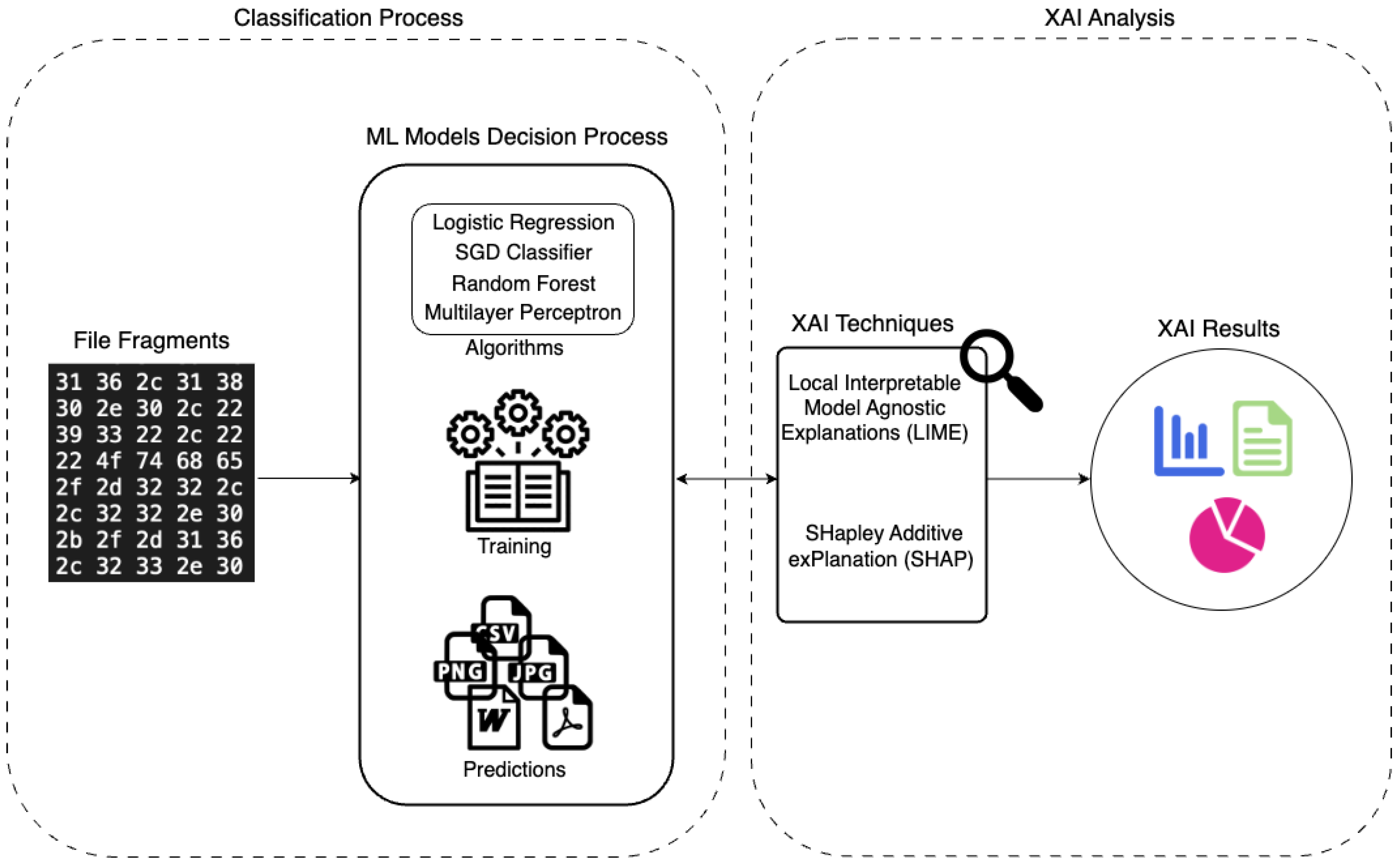
4. Methodology
4.1. Classification Process
4.1.1. Dataset
4.1.2. Machine Learning Models
4.2. XAI Analysis
4.2.1. Local Interpretable Model Agnostic Explanations
4.2.2. SHapley Additive exPlanation
5. Experimental Result and Analysis
5.1. Experimental Setup
5.2. Results
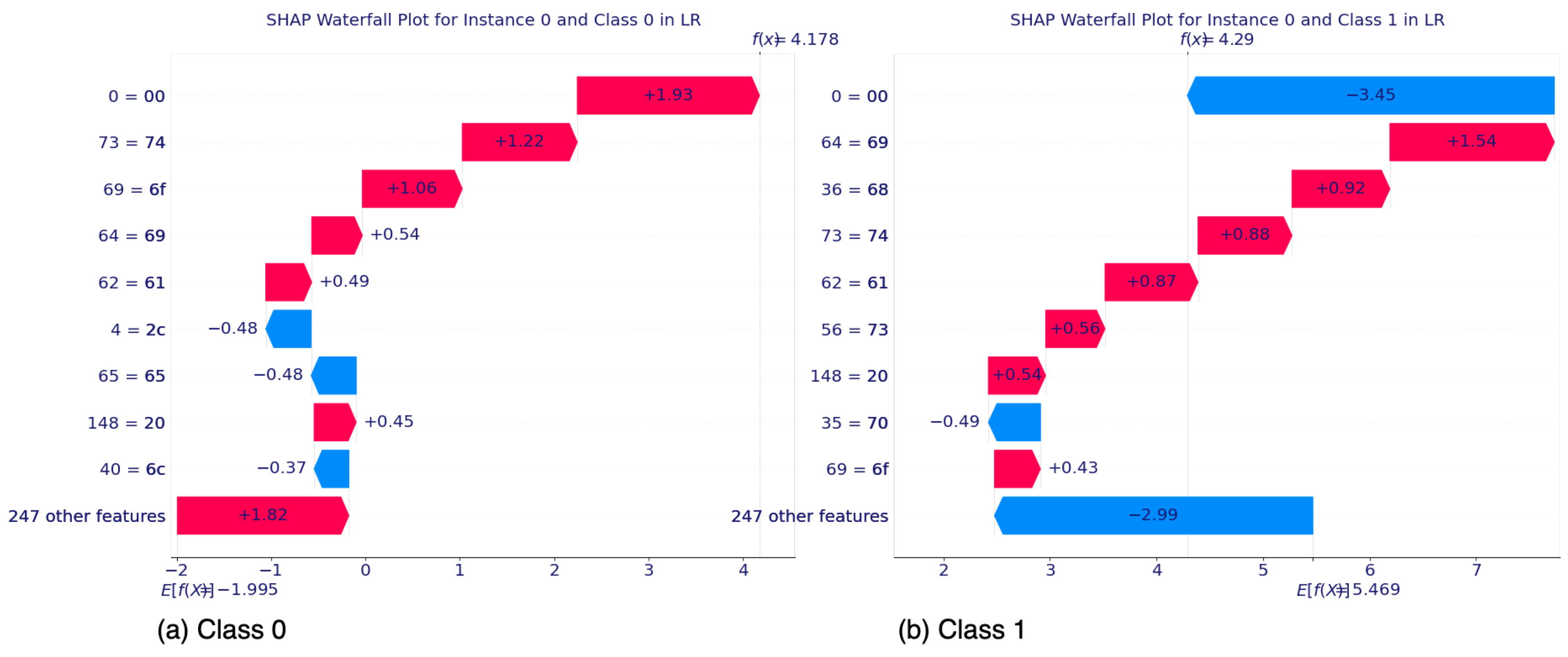
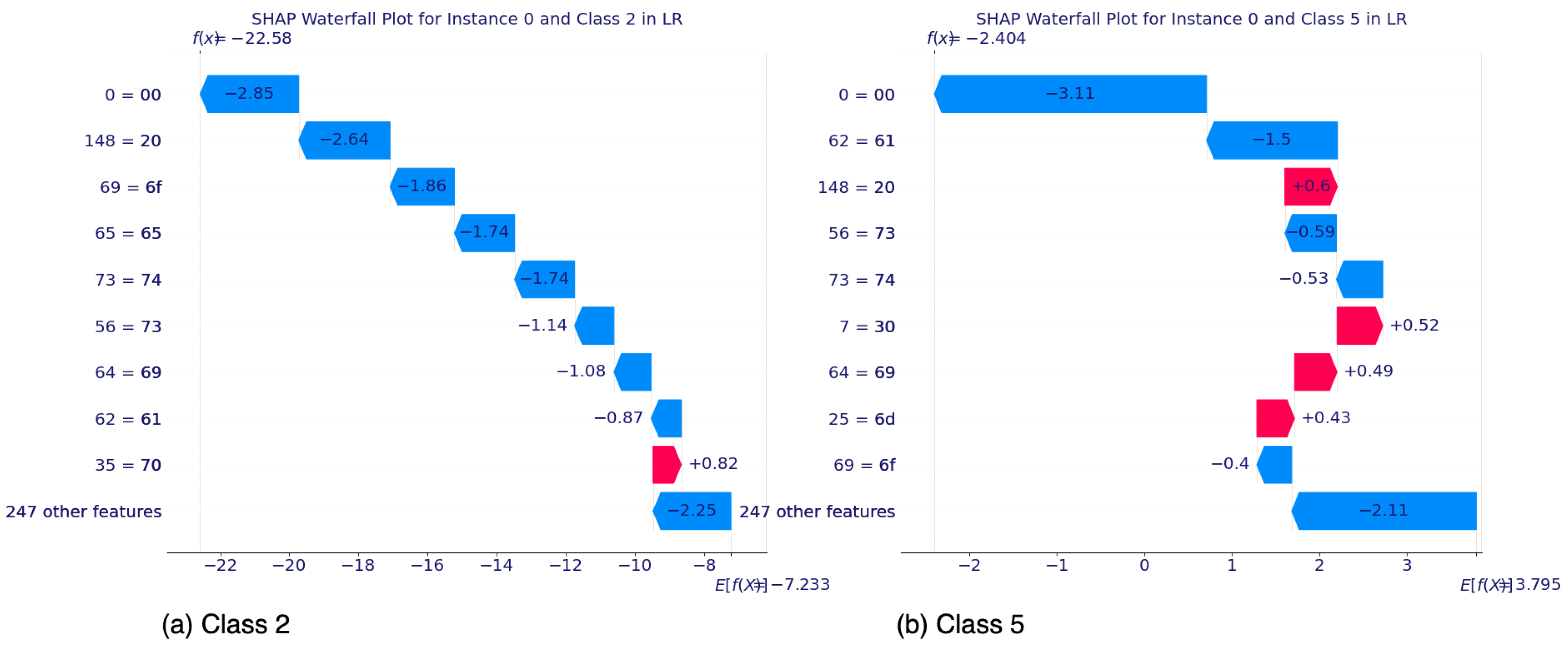
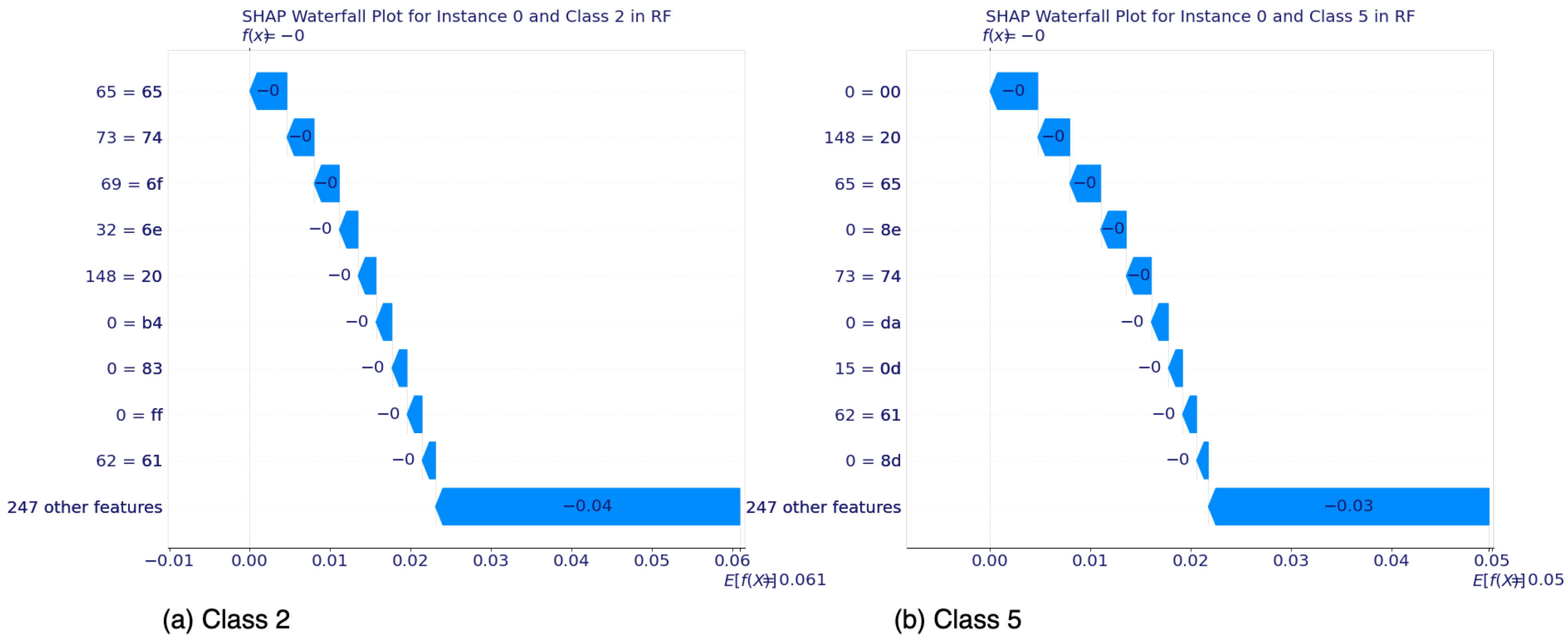
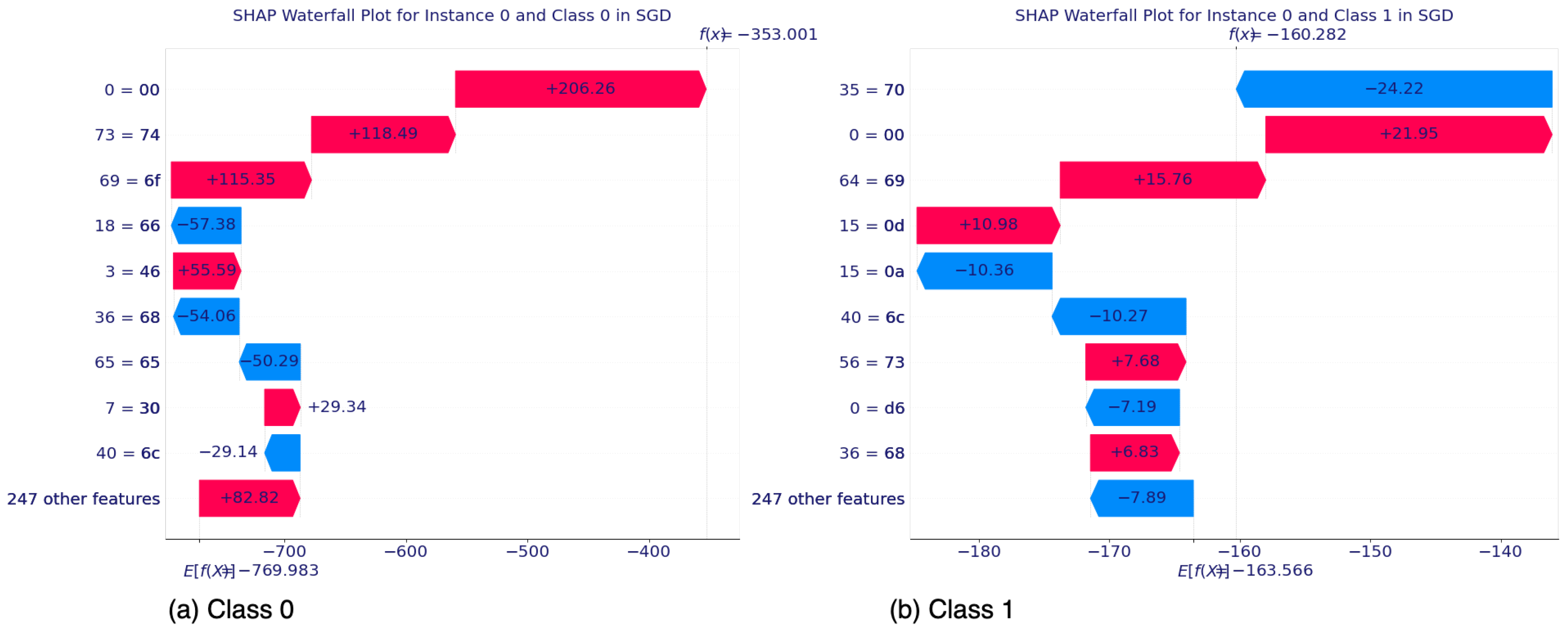
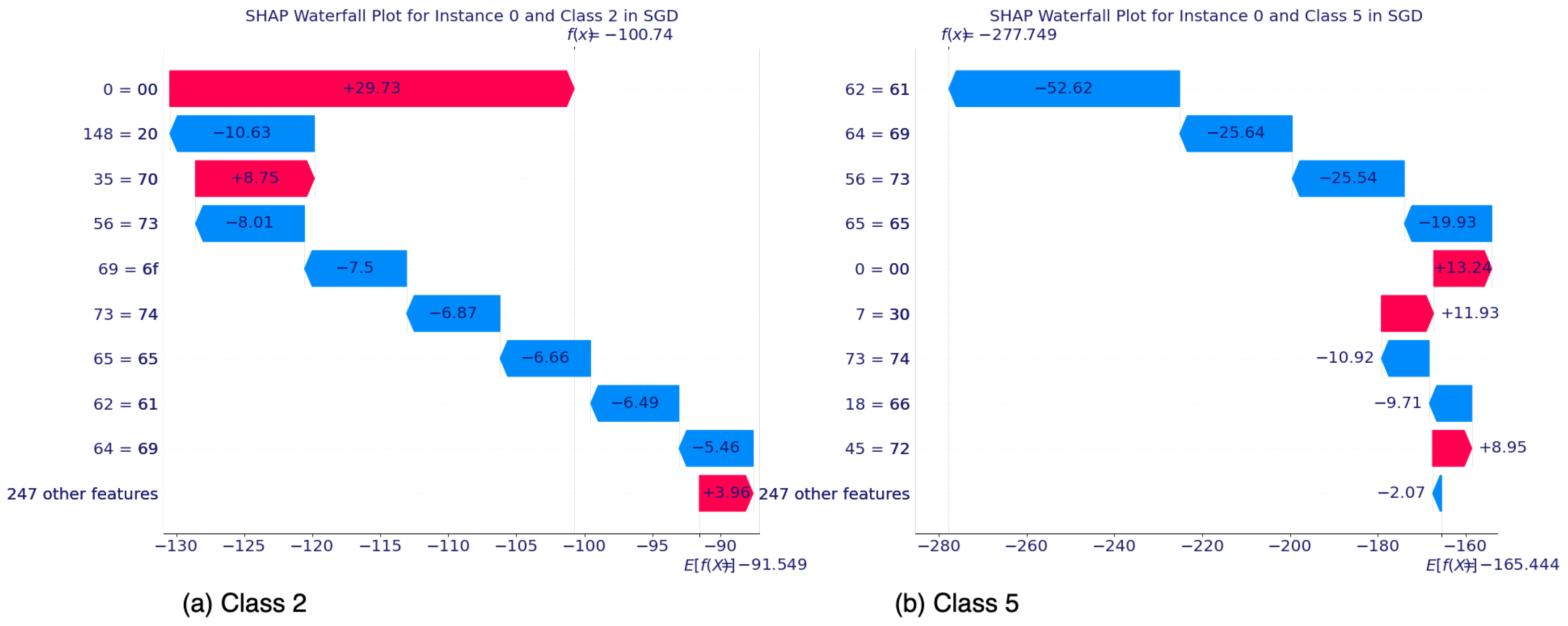
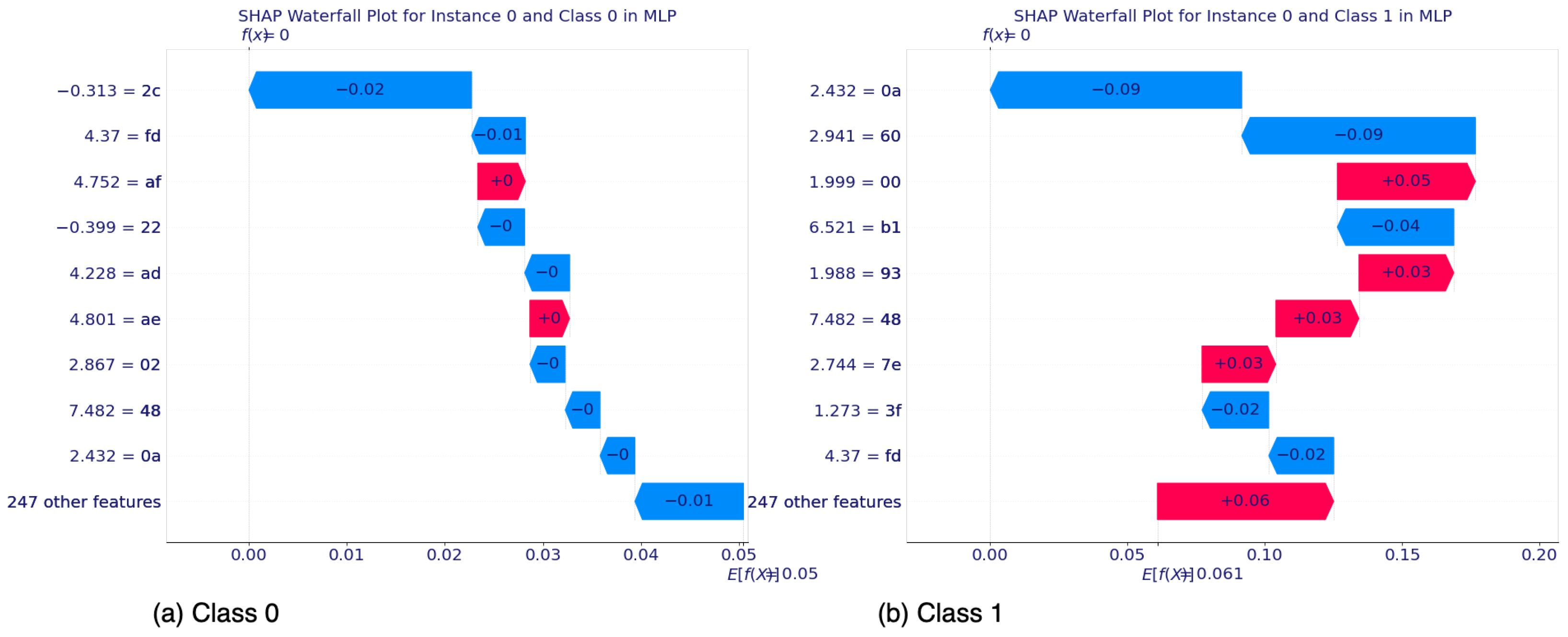
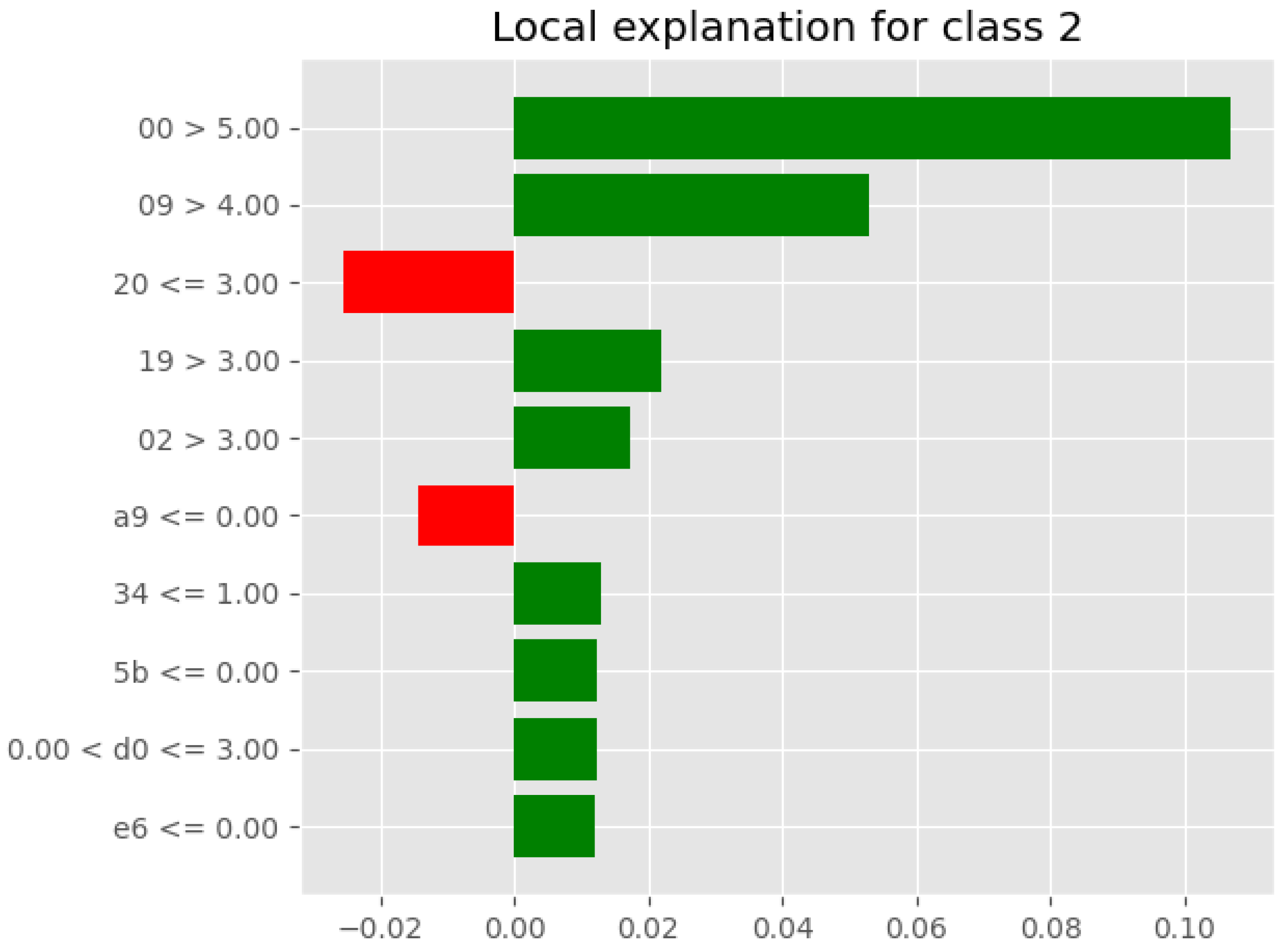
5.2.1. SHAP’s Local Interpretability
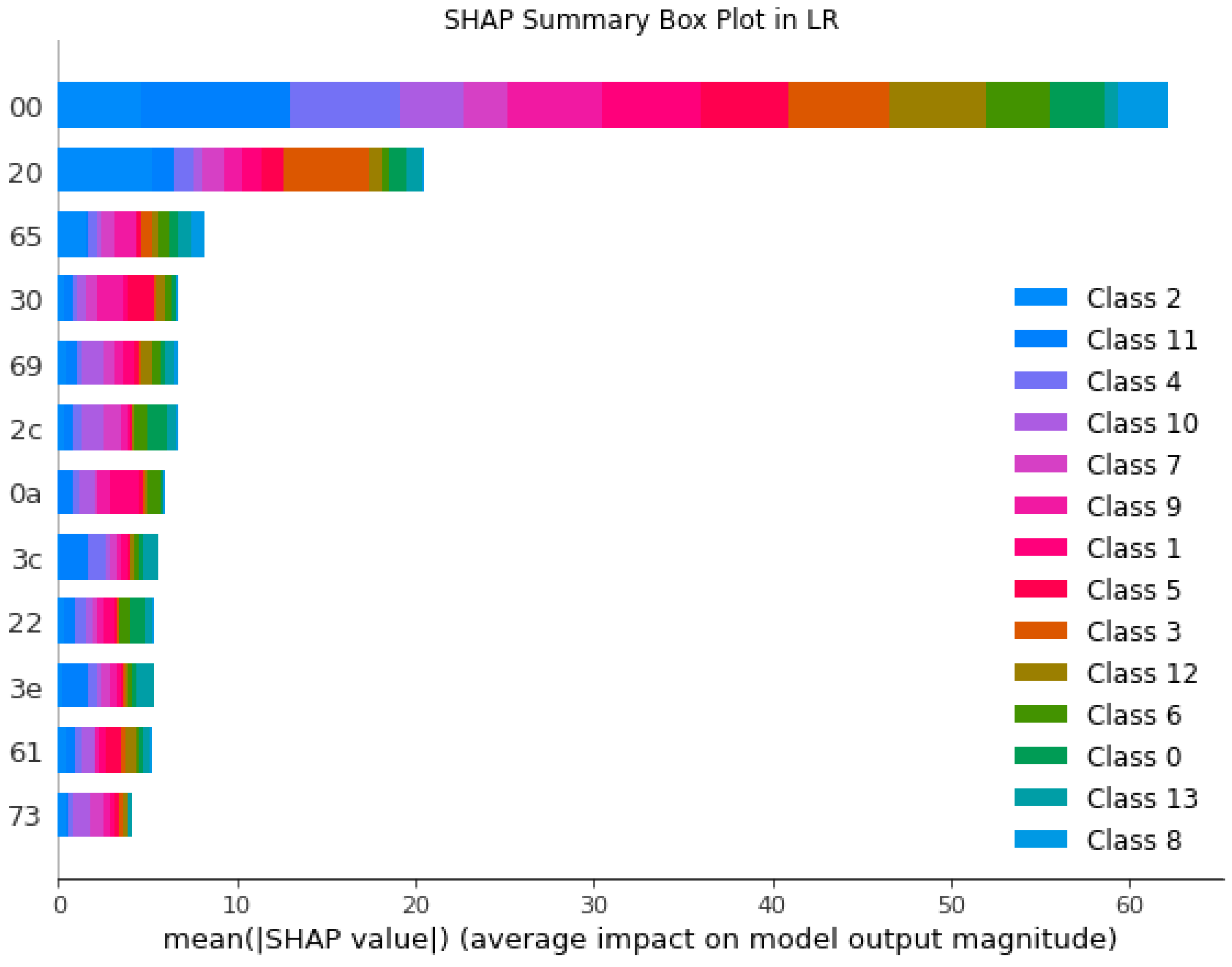
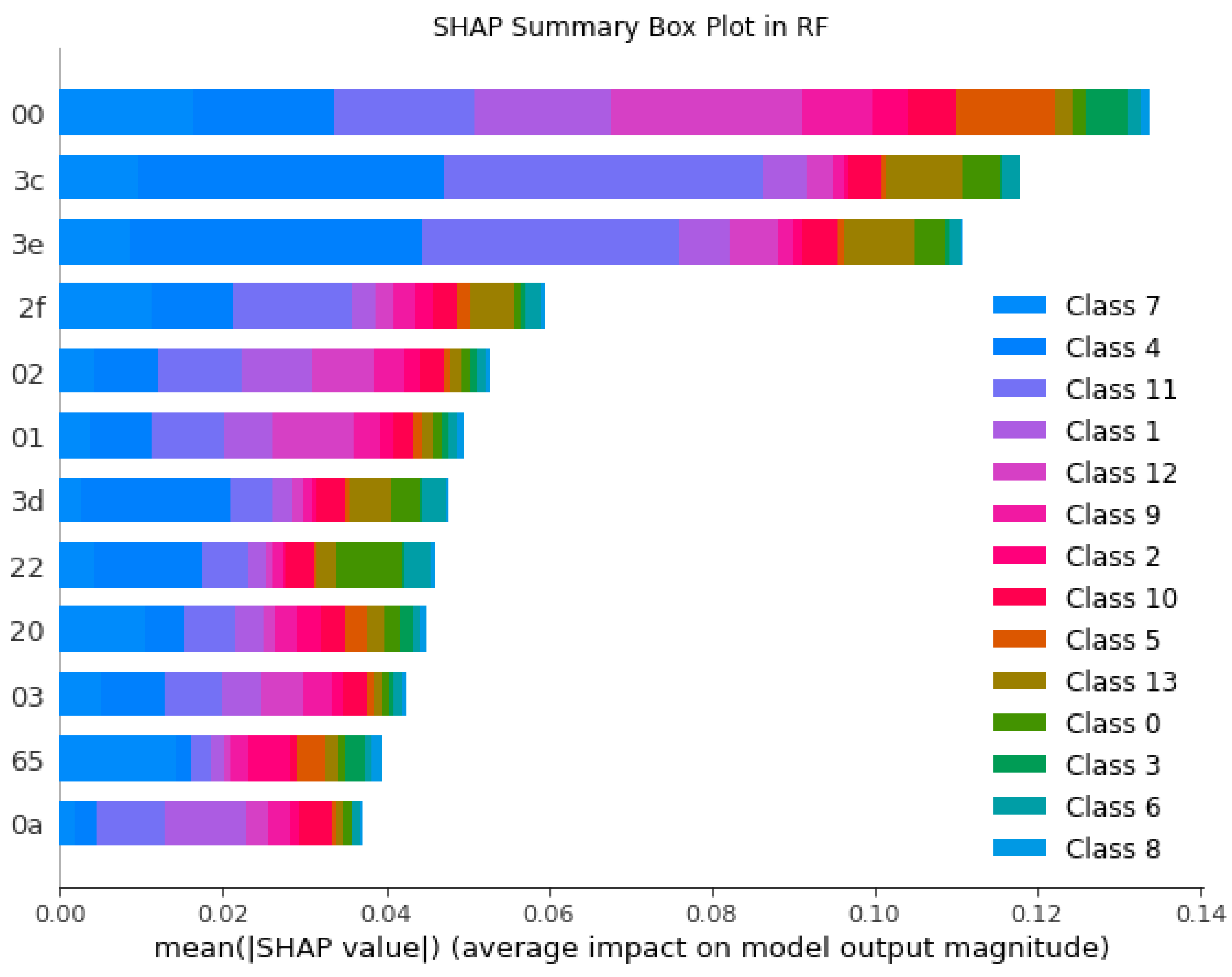
5.2.2. SHAP’s Global Interpretability
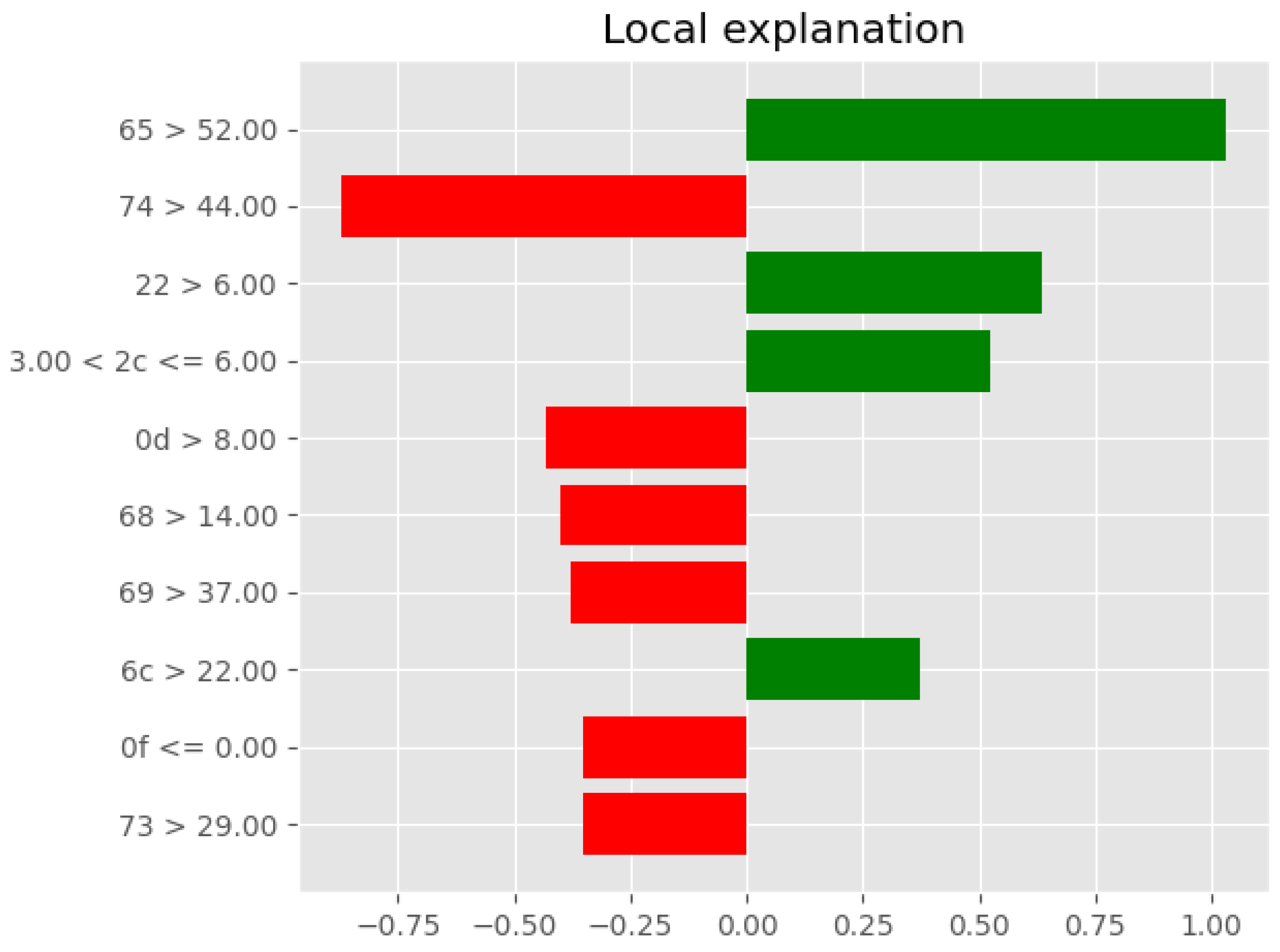
5.2.3. LIME’s Interpretability
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jinad, R.; Islam, A.; Shashidhar, N. File Fragment Analysis Using Machine Learning. In Proceedings of the 2023 IEEE International Conference on Dependable, Autonomic and Secure Computing, International Conference on Pervasive Intelligence and Computing, International Conference on Cloud and Big Data Computing, International Conference on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Abu Dhabi, United Arab Emirates, 14–17 November 2023; pp. 956–962. [Google Scholar] [CrossRef]
- Zhang, S.; Hu, C.; Wang, L.; Mihaljevic, M.J.; Xu, S.; Lan, T. A Malware Detection Approach Based on Deep Learning and Memory Forensics. Symmetry 2023, 15, 758. [Google Scholar] [CrossRef]
- Sivalingam, K.M. Applications of Artificial Intelligence, Machine Learning and related Techniques for Computer Networking Systems. arXiv 2021, arXiv:2105.15103. [Google Scholar]
- Goebel, R.; Chander, A.; Holzinger, K.; Lecue, F.; Akata, Z.; Stumpf, S.; Kieseberg, P.; Holzinger, A. Explainable AI: The new 42? In Proceedings of the Machine Learning and Knowledge Extraction: Second IFIP TC 5, TC 8/WG 8.4, 8.9, TC 12/WG 12.9 International Cross-Domain Conference, CD-MAKE 2018, Hamburg, Germany, 27–30 August 2018; Proceedings 2. Springer: Berlin/Heidelberg, Germany, 2018; pp. 295–303. [Google Scholar]
- Arrieta, A.B.; Diaz-Rodriguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Beddiar, R.; Oussalah, M. Explainability in medical image captioning. In Explainable Deep Learning AI; Elsevier: Amsterdam, The Netherlands, 2023; pp. 239–261. [Google Scholar]
- Gerlings, J.; Shollo, A.; Constantiou, I. Reviewing the need for explainable artificial intelligence (xAI). arXiv 2020, arXiv:2012.01007. [Google Scholar]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining Explanations: An Overview of Interpretability of Machine Learning. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 80–89. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Glasgow, UK, 2017; pp. 4765–4774. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, (KDD ’16), San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Gohel, P.; Singh, P.; Mohanty, M. Explainable AI: Current status and future directions. arXiv 2021, arXiv:2107.07045. [Google Scholar]
- Saeed, W.; Omlin, C. Explainable AI (XAI): A systematic meta-survey of current challenges and future opportunities. Knowl.-Based Syst. 2023, 263, 110273. [Google Scholar] [CrossRef]
- Colley, A.; Väänänen, K.; Häkkilä, J. Tangible Explainable AI-an Initial Conceptual Framework. In Proceedings of the 21st International Conference on Mobile and Ubiquitous Multimedia, Lisbon, Portugal, 27–30 November 2022; pp. 22–27. [Google Scholar]
- Pfeifer, B.; Krzyzinski, M.; Baniecki, H.; Saranti, A.; Holzinger, A.; Biecek, P. Explainable AI with counterfactual paths. arXiv 2023, arXiv:2307.07764. [Google Scholar]
- Liao, Q.V.; Singh, M.; Zhang, Y.; Bellamy, R. Introduction to explainable AI. In Proceedings of the Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–3. [Google Scholar]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Farahani, F.V.; Fiok, K.; Lahijanian, B.; Karwowski, W.; Douglas, P.K. Explainable AI: A review of applications to neuroimaging data. Front. Neurosci. 2022, 16, 906290. [Google Scholar] [CrossRef]
- Qian, J.; Li, H.; Wang, J.; He, L. Recent Advances in Explainable Artificial Intelligence for Magnetic Resonance Imaging. Diagnostics 2023, 13, 1571. [Google Scholar] [CrossRef]
- Van der Velden, B.H.; Kuijf, H.J.; Gilhuijs, K.G.; Viergever, M.A. Explainable artificial intelligence (XAI) in deep learning-based medical image analysis. Med. Image Anal. 2022, 79, 102470. [Google Scholar] [CrossRef]
- Ahmed, S.B.; Solis-Oba, R.; Ilie, L. Explainable-AI in Automated Medical Report Generation Using Chest X-ray Images. Appl. Sci. 2022, 12, 11750. [Google Scholar] [CrossRef]
- Salahuddin, Z.; Woodruff, H.C.; Chatterjee, A.; Lambin, P. Transparency of deep neural networks for medical image analysis: A review of interpretability methods. Comput. Biol. Med. 2022, 140, 105111. [Google Scholar] [CrossRef]
- Moraffah, R.; Karami, M.; Guo, R.; Raglin, A.; Liu, H. Causal interpretability for machine learning-problems, methods and evaluation. ACM SIGKDD Explor. Newsl. 2020, 22, 18–33. [Google Scholar] [CrossRef]
- Rjoub, G.; Bentahar, J.; Wahab, O.A.; Mizouni, R.; Song, A.; Cohen, R.; Otrok, H.; Mourad, A. A Survey on Explainable Artificial Intelligence for Cybersecurity. IEEE Trans. Netw. Serv. Manag. 2023, 20, 5115–5140. [Google Scholar] [CrossRef]
- Srivastava, G.; Jhaveri, R.; Bhattacharya, S.; Pandya, S.; Maddikunta, P.; Yenduri, G.; Hall, J.; Alazab, M.; Gadekallu, T. XAI for Cybersecurity: State of the Art, Challenges, Open Issues and Future Directions. arXiv 2022, arXiv:2206.03585. [Google Scholar]
- Nadeem, A.; Vos, D.; Cao, C.; Pajola, L.; Dieck, S.; Baumgartner, R.; Verwer, S. Sok: Explainable machine learning for computer security applications. In Proceedings of the 2023 IEEE 8th European Symposium on Security and Privacy (EuroS&P), Delft, The Netherlands, 3–7 July 2023; pp. 221–240. [Google Scholar]
- AL-Essa, M.; Andresini, G.; Appice, A.; Malerba, D. XAI to explore robustness of features in adversarial training for cybersecurity. In Proceedings of the International Symposium on Methodologies for Intelligent Systems, Cosenza, Italy, 3–5 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 117–126. [Google Scholar]
- Kuppa, A.; Le-Khac, N.A. Adversarial XAI methods in cybersecurity. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4924–4938. [Google Scholar] [CrossRef]
- Liu, H.; Zhong, C.; Alnusair, A.; Islam, S.R. FAIXID: A framework for enhancing AI explainability of intrusion detection results using data cleaning techniques. J. Netw. Syst. Manag. 2021, 29, 40. [Google Scholar] [CrossRef]
- Suryotrisongko, H.; Musashi, Y.; Tsuneda, A.; Sugitani, K. Robust botnet DGA detection: Blending XAI and OSINT for cyber threat intelligence sharing. IEEE Access 2022, 10, 34613–34624. [Google Scholar] [CrossRef]
- Kundu, P.P.; Truong-Huu, T.; Chen, L.; Zhou, L.; Teo, S.G. Detection and classification of botnet traffic using deep learning with model explanation. IEEE Trans. Dependable Secur. Comput. 2022; Early access. [Google Scholar]
- Alani, M.M. BotStop: Packet-based efficient and explainable IoT botnet detection using machine learning. Comput. Commun. 2022, 193, 53–62. [Google Scholar] [CrossRef]
- Barnard, P.; Marchetti, N.; DaSilva, L.A. Robust network intrusion detection through explainable artificial intelligence (XAI). IEEE Netw. Lett. 2022, 4, 167–171. [Google Scholar] [CrossRef]
- Abou El Houda, Z.; Brik, B.; Khoukhi, L. “Why should i trust your ids?”: An explainable deep learning framework for intrusion detection systems in internet of things networks. IEEE Open J. Commun. Soc. 2022, 3, 1164–1176. [Google Scholar] [CrossRef]
- Sivamohan, S.; Sri, S. KHO-XAI: Krill herd optimization and Explainable Artificial Intelligence framework for Network Intrusion Detection Systems in Industry 4.0. Res. Sq. 2022; preprint. [Google Scholar]
- Mane, S.; Rao, D. Explaining network intrusion detection system using explainable AI framework. arXiv 2021, arXiv:2103.07110. [Google Scholar]
- Wali, S.; Khan, I. Explainable AI and random forest based reliable intrusion detection system. TechRxiv, 2023; preprint. [Google Scholar]
- Zebin, T.; Rezvy, S.; Luo, Y. An explainable AI-based intrusion detection system for DNS over HTTPS (DoH) attacks. IEEE Trans. Inf. Forensics Secur. 2022, 17, 2339–2349. [Google Scholar] [CrossRef]
- Solanke, A.A. Explainable digital forensics AI: Toward mitigating distrust in AI-based digital forensics analysis using interpretable models. Forensic Sci. Int. Digit. Investig. 2022, 42, 301403. [Google Scholar] [CrossRef]
- Gopinath, A.; Kumar, K.P.; Saleem, K.S.; John, J. Explainable IoT Forensics: Investigation on Digital Evidence. In Proceedings of the 2023 IEEE International Conference on Contemporary Computing and Communications (InC4), Bangalore, India, 21–22 April 2023; Volume 1, pp. 1–6. [Google Scholar]
- Hall, S.W.; Sakzad, A.; Minagar, S. A Proof of Concept Implementation of Explainable Artificial Intelligence (XAI) in Digital Forensics. In Proceedings of the International Conference on Network and System Security, Denarau Island, Fiji, 9–12 December 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 66–85. [Google Scholar]
- Kelly, L.; Sachan, S.; Ni, L.; Almaghrabi, F.; Allmendinger, R.; Chen, Y. Explainable artificial intelligence for digital forensics: Opportunities, challenges and a drug testing case study. In Digital Forensic Science; IntechOpen: London, UK, 2020. [Google Scholar]
- Lucic, A.; Srikumar, M.; Bhatt, U.; Xiang, A.; Taly, A.; Liao, Q.V.; de Rijke, M. A multistakeholder approach toward evaluating AI transparency mechanisms. arXiv 2021, arXiv:2103.14976. [Google Scholar]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A review of machine learning interpretability methods. Entropy 2020, 23, 18. [Google Scholar] [CrossRef] [PubMed]
- Doshi-Velez, F.; Kim, B. Toward a rigorous science of interpretable machine learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Garfinkel, S.; Farrell, P.; Roussev, V.; Dinolt, G. Bringing science to digital forensics with standardized forensic corpora. Digit. Investig. 2009, 6, S2–S11. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| File Type | Class Label | Number of Files |
|---|---|---|
| csv | Class 0 | 179 |
| doc | Class 1 | 1102 |
| gif | Class 2 | 424 |
| gz | Class 3 | 127 |
| html | Class 4 | 3839 |
| jpg | Class 5 | 937 |
| log | Class 6 | 110 |
| Class 7 | 3766 | |
| png | Class 8 | 88 |
| ppt | Class 9 | 892 |
| ps | Class 10 | 254 |
| txt | Class 11 | 3224 |
| xls | Class 12 | 667 |
| xml | Class 13 | 188 |
| Precision | Recall | F1-Score | Accuracy | |
|---|---|---|---|---|
| Logistic Regression | 0.63 | 0.40 | 0.44 | 0.40 |
| SGD Classifier | 0.71 | 0.36 | 0.36 | 0.36 |
| Random Forest | 0.59 | 0.51 | 0.46 | 0.51 |
| MultiLayer Perceptron | 0.92 | 0.89 | 0.89 | 0.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jinad, R.; Islam, A.; Shashidhar, N. Interpretability and Transparency of Machine Learning in File Fragment Analysis with Explainable Artificial Intelligence. Electronics 2024, 13, 2438. https://doi.org/10.3390/electronics13132438
Jinad R, Islam A, Shashidhar N. Interpretability and Transparency of Machine Learning in File Fragment Analysis with Explainable Artificial Intelligence. Electronics. 2024; 13(13):2438. https://doi.org/10.3390/electronics13132438
Chicago/Turabian StyleJinad, Razaq, ABM Islam, and Narasimha Shashidhar. 2024. "Interpretability and Transparency of Machine Learning in File Fragment Analysis with Explainable Artificial Intelligence" Electronics 13, no. 13: 2438. https://doi.org/10.3390/electronics13132438
APA StyleJinad, R., Islam, A., & Shashidhar, N. (2024). Interpretability and Transparency of Machine Learning in File Fragment Analysis with Explainable Artificial Intelligence. Electronics, 13(13), 2438. https://doi.org/10.3390/electronics13132438